
Abstract
Digital twins (DTs) enhance structural health monitoring (SHM) through accurate simulation and automation. Deep learning (DL) can boost DTs performance, but it relies on both healthy and damaged data, the latter being often scarce. Finite-element modeling (FEM) can supplement this, though aligning simulated data with real-world conditions is key. This paper presents a novel hybrid framework that bridges the gap between simulated and real-world SHM data through a convolutional domain expansion (CDE) technique. A hybrid database integrating FEM simulation data with real accelerometer signals is developed to address the scarcity of damage-state data. Furthermore, a decentralized single-channel deep neural network (SC-DNN) architecture is introduced for multi-damage identification, enhancing flexibility and domain adaptability. Experimental validations on scaled wind turbine structures show that the proposed system achieves over 96% classification accuracy, even under previously unseen damage scenarios. The proposed CDE method increases the cosine similarity between synthetic and real-damaged data from 0.4 to 0.7, demonstrating improved domain transferability. This integrated approach significantly improves generalizability in SHM applications and offers scalable potential for deployment in large civil infrastructures.
Keywords
1. Introduction
Structural health monitoring (SHM) traditionally follows the four-stage paradigm of operational evaluation, data acquisition, feature extraction, and statistical modeling (Avci et al., 2018; Cheng et al., 2024). Recent SHM advances increasingly target domain mismatch, where models trained on one structure or environment falter in new, unseen settings (Gardner et al., 2021; Giglioni et al., 2024; Wang et al., 2024). To bridge this gap, domain adaptation (DA) and domain generalization (DG) have emerged as pivotal methodologies (Li et al., 2024b; Xiangyu et al., 2023).
Early DA studies introduced CNN-based feature alignment with maximum mean discrepancy (MMD) loss, enabling label-free transfer of damage-sensitive features between structures (Gardner et al., 2020; Giglioni et al., 2024). Subsequent research simplified alignment via statistical alignment (SA), matching mean and variance for robust yet efficient cross-domain performance (Poole et al., 2023).
Meanwhile, generative approaches have flourished. Cycle-consistent GANs (CycleGANs) translate undamaged signals into synthetic damaged counterparts, alleviating the scarcity of damaged-state data (Li et al., 2024a; Luleci et al., 2023). More recent physics-informed GANs integrate finite-element simulations with real measurements, further narrowing the simulation-to-reality gap (Cavanni et al., 2024; Ge and Sadhu, 2024; Zhang et al., 2024b). Further extending these generative capabilities to zero-shot scenarios, advanced frameworks employ GANs with spectral mapping and multi-source aggregation to enable diagnosis without target labels (Soleimani-Babakamali et al., 2023; Soleimani-Babakamali et al., 2025). Conversely, alternative strategies adopt a reverse trajectory, utilizing target-to-source mapping to reconstruct features for alignment with source-domain classifiers (Heravi et al., 2026).
Supporting research demonstrates that integrating convolutional neural networks with correlation alignment (CORAL) loss delivers robust unsupervised domain adaptation capabilities, even when facing significant environmental variations (Cavanni et al., 2024; Qian et al., 2023; Qiu et al., 2024; Zhang et al., 2024a). Beyond Domain adaptation, domain generalization strategies that embed digital twin surrogates or employ knowledge distillation have demonstrated robust out-of-distribution performance while reducing the need for extensive labeled data (Li et al., 2024b; Liu et al., 2024; Wang et al., 2025). However, these approaches face limitations in few-shot scenarios. Statistical alignment (e.g., CORAL, MMD) becomes unstable as data scarcity hinders accurate covariance estimation, while generative models (e.g., CycleGAN) are prone to mode collapse or physical artifacts without substantial training distributions. Consequently, a method capable of bridging the domain gap without relying on unstable statistics or extensive datasets is urgently needed.
Digital twins (DTs) technology integrates high-accuracy numerical simulations with real-time sensor data to create a dynamic, cyber-physical model that continuously represents the state of engineering systems (Lai et al., 2023; Qin et al., 2023; Zhang et al., 2024c). When integrated with SHM, DTs can predict structural responses, validate them with in-service measurements, and enable condition-based maintenance. However, deployment is hindered by a simulation-to-reality gap: FEM cannot fully capture operational uncertainties, and field data seldom cover the range of damage states needed for robust data-driven diagnosis. Bridging this gap requires enriching limited sensor data while transferring simulated knowledge into the domain used for learning-based assessment.
In this study, we propose convolution domain expansion (CDE) to bridge the simulation-to-reality gap by generating hybrid samples via convolution between finite-element (FEM) and real accelerometer (ACC) signals. CDE produces a hybrid database that expands and diversifies the training set while embedding characteristics from both domains. We also introduce a lightweight, decentralized single-channel deep neural network (SC-DNN) for multi-damage classification under data scarcity and edge-compute constraints.
The contributions are threefold: (i) Convolution domain expansion (CDE) algorithm that narrows the domain gap and substantially improves generalization between simulated and real data; (ii) hybrid-database pipeline that automatically generates and labels large synthetic datasets from limited seeds; and (iii) validation of a single-channel deep neural network (SC-DNN) that delivers high accuracy at markedly lower computational cost, enabling real-time damage detection on resource-constrained edge devices. This combined approach mitigates domain mismatch in SHM, enabling scalable, accurate systems suitable for real-world deployment.
2. Methods
2.1. Operational modal analysis: Data foundation for deep-learning-based SHM
Operational modal analysis (OMA) provides the physical backbone of our method by converting raw vibration records into damage-sensitive modal information without requiring measured input forces. Assuming the external excitation
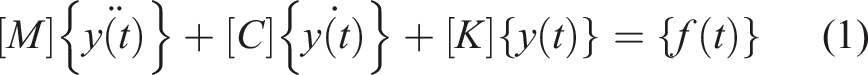
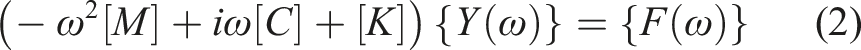
which can be rewritten as
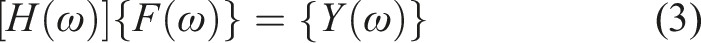
The transfer matrix
In our framework, the estimated Schematic of the proposed deep-learning framework for SHM: (a) Internal calculation process of the neural network; (b) overall system workflow from signal input to structural state output.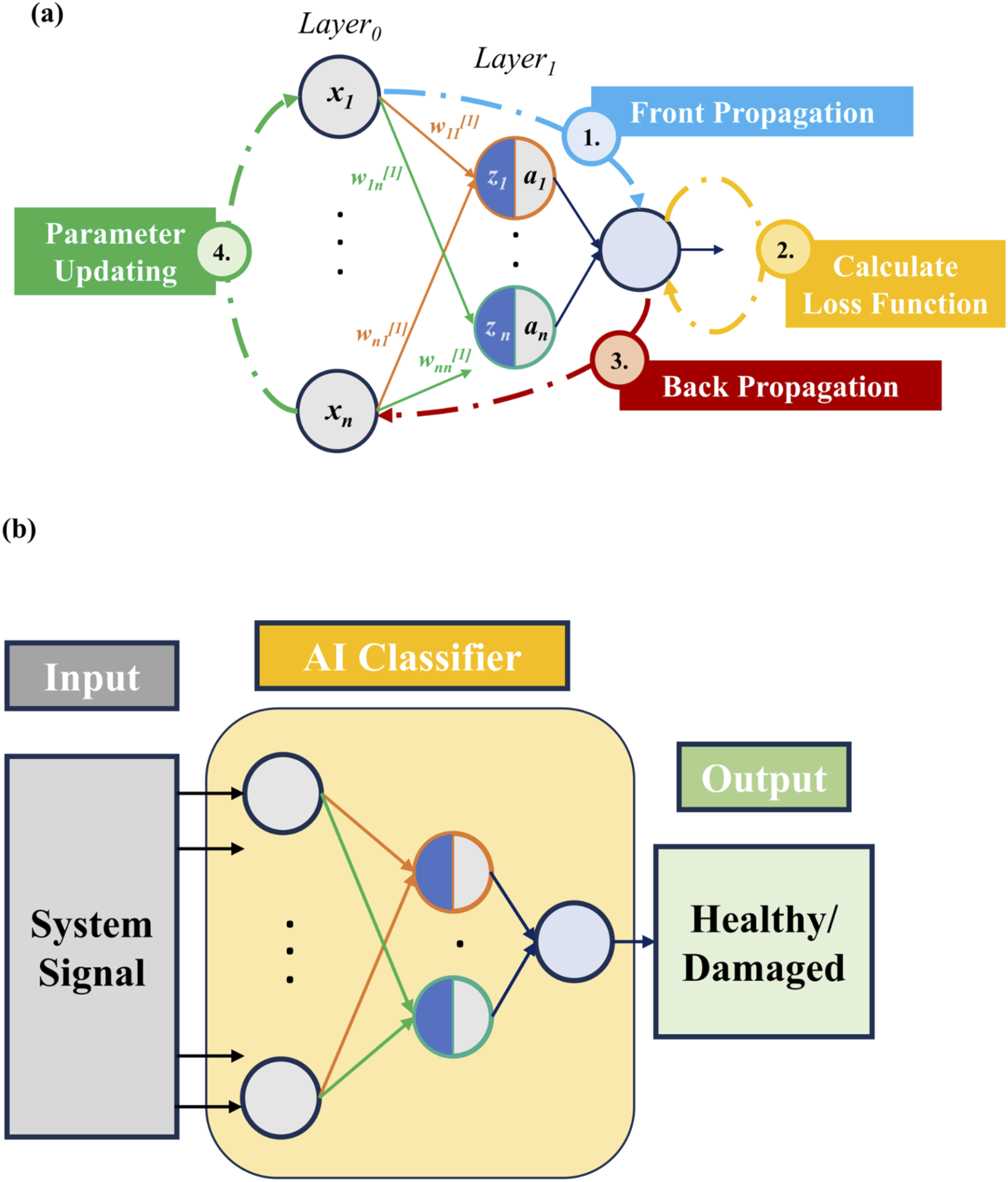
2.2. Hybrid database
To supply the neural network (NN) with both accelerometer and finite-element method data, we constructed a hybrid database that integrates the two sources. Figure 2 illustrates the laboratory-scaled acrylic model (Cheng et al., 2024): the upper section represents the tower of a wind turbine, whereas the lower section represents the submerged portion. The mass density, Young’s modulus, and Poisson’s ratio of the acrylic material are assumed 1190 Experimental setup comparison: (a) Physical acrylic model with sensor locations P1–P4; (b) corresponding finite-element model (FEM) built in COMSOL.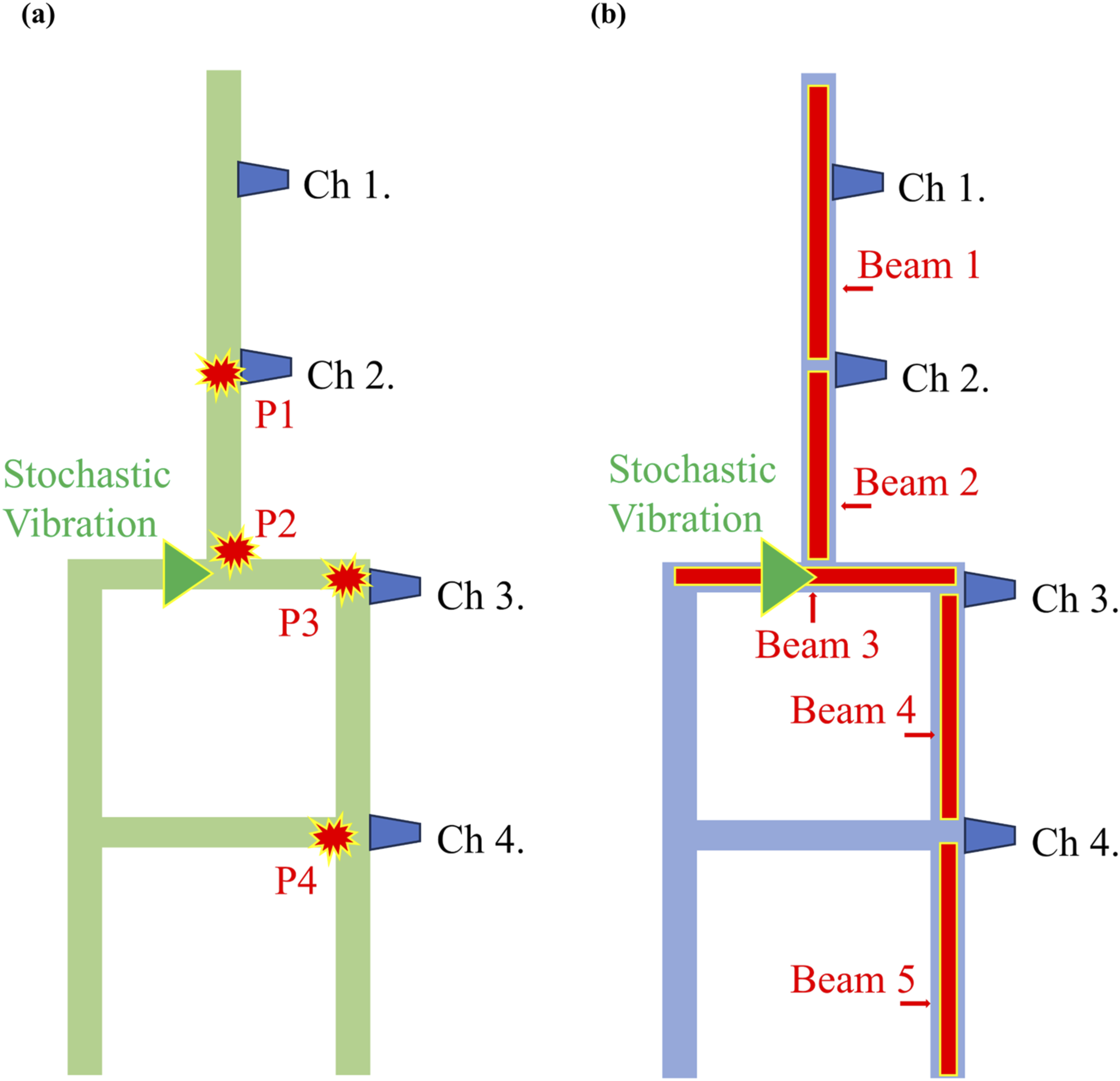
A double pendulum at mid-height (P2) excites broadband vibrations. Four accelerometers on the physical model and its digital twin record data; both sets of responses are transformed into discrete Fourier-transform (DFT) spectra and stored as NumPy arrays. All four channels from the healthy state train the model, while each damage case keeps only the channels nearest the damage.
To reduce memory and accelerate neural network (NN) training, the finite-element (FEM) solver exported only 300 samples per record, eliminating downstream downsampling and enabling rapid synthesis of large time-series datasets. The same FT-based feature extraction was applied to both FEM and accelerometer signals over the 1–15 Hz band, so that simulated and measured data share an identical representation. For each of six structural states (one healthy and five damaged), examples were saved to separate .npy files. We then concatenated each FEM feature vector with its corresponding accelerometer feature vector to form a hybrid yet domain-segregated database. The remaining preprocessing steps—normalization, shuffling, and train/validation/test splitting, yielding a fully shuffled training set.
2.3. Convolutional domain expansion
Domain adaptation methods such as CORAL, MMD-based alignment and style-transfer networks aim to reduce the discrepancy between simulated and measured data, but they typically operate in the latent feature space and require additional loss terms, hyperparameters, or even adversarial training. Expanding field datasets directly is also costly in practice.
Convolution, in its classical signal-processing sense, expresses the response of a linear, time-invariant (LTI) system to an arbitrary excitation by folding one waveform over another and integrating their point-wise products. Convolution is attractive because, by the convolution theorem, it is equivalent to a point-wise product in the complementary domain, granting both physical interpretability and computational efficiency via the fast Fourier transform. In structural-health-monitoring practice, however, the two operands seldom correspond to a neat input and impulse response. Instead, engineers face a chronic distribution mismatch: plentiful, noise-free finite-element simulations describe an idealized structure, whereas sparse, noisy sensor records capture the same structure under uncontrolled boundary conditions. Directly training a classifier on either source creates a covariate-shift problem that erodes generalization.
Convolutional domain expansion (CDE) repurposes convolution as a symmetric, data-level fusion operator that embeds both simulated and measured spectra into a joint manifold while retaining their respective physical meanings. Unlike feature-space methods (e.g., CORAL, MMD) that align distributions after feature extraction, CDE operates directly on raw inputs to construct a hybrid domain without requiring auxiliary networks or regularization losses. While systematic benchmarking against or integration with these statistical methods offers promising avenues for future research, this study focuses on establishing CDE as a standalone, physics-guided augmentation framework.
Let
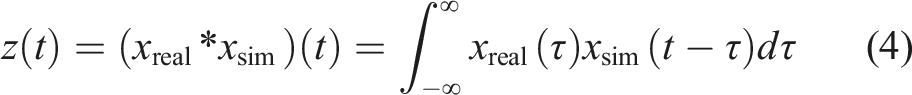
whose discrete form is
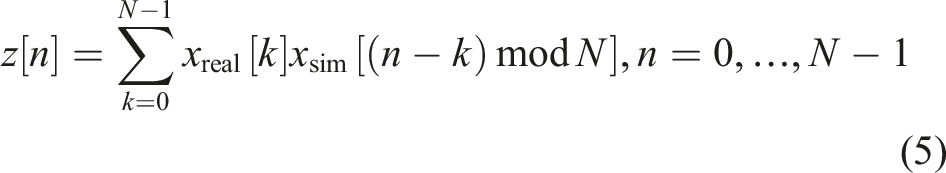
Applying the Fourier transform gives
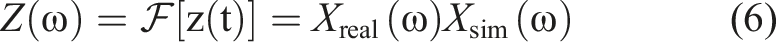
Each hybrid
The hybrid spectrum combines simulated modal peaks with the stochastic background of measurements, modulating weak bands rather than suppressing them and narrowing the inter-domain feature gap. Convolving each measured spectrum with multiple FEM counterparts yields thousands of label-consistent hybrids, effectively synthesizing rare cases seldom captured in field campaigns. CDE is a data-level alignment: raw samples are embedded in a shared manifold directly, avoiding the complexity of adversarial training or explicit statistical-matching losses often found in feature-based adaptation.
For reliable evaluation, the development and test sets must reflect the distribution that the deployed model will face, but new damage variants are scarce. As Figure 3(a) shows, a network that usually converges with ∼10 k labeled samples may receive only 1.8 k for a new class; a 70/15/15 split would leave dev-and-test pools badly under-sampled. Injecting CDE hybrids restores class balance in every split, curbs over-fitting, and ensures that training, validation, and testing draw from a joint distribution statistically indistinguishable from deployment data. Conceptual framework of the proposed method: (a) Illustration of the domain mismatch problem caused by data imbalance; (b) the convolutional domain expansion (CDE) process projecting data onto a shared feature manifold.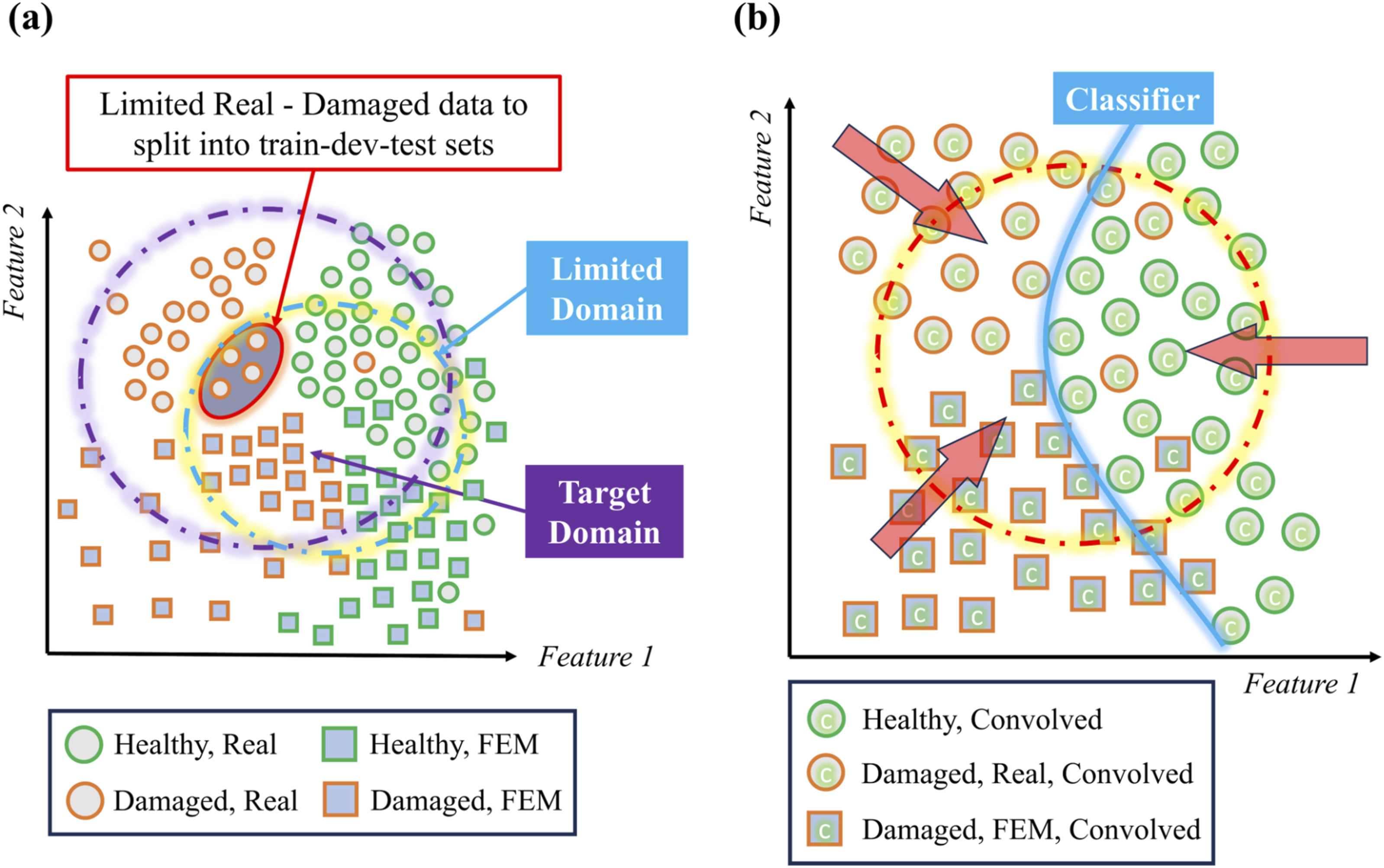
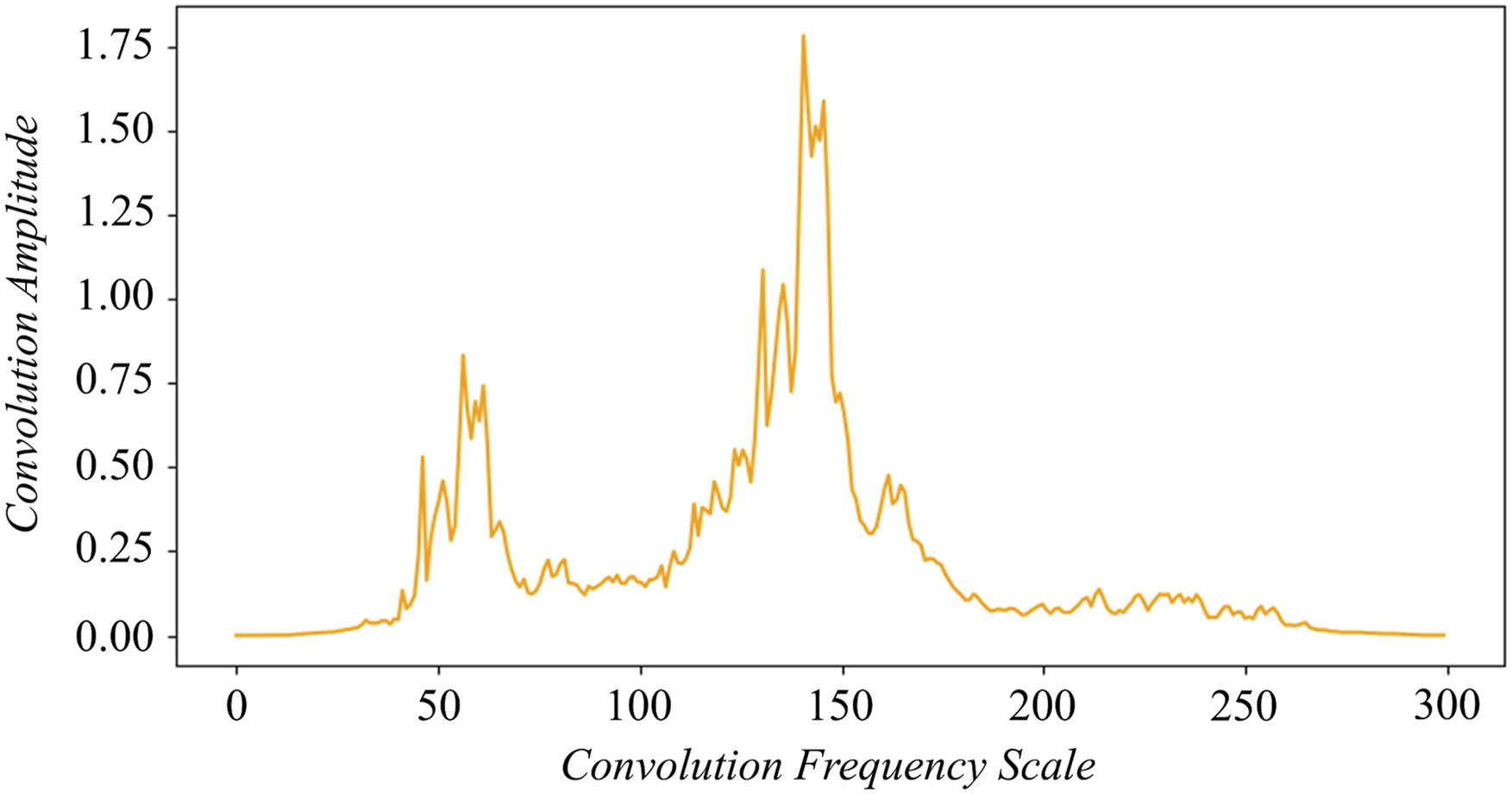
Convolution is intuitive: the output inherits the characteristics of its filter. In this study, the accelerometer spectrum in Figure 4(a) serves as a filter sliding over the FEM spectrum in Figure 4(b), producing a new signal shown in Figure 5 that blends features from both domains. This convolutional fusion generates a dense and continuous manifold that interpolates between simulated and measured distributions. The resulting spectrum preserves salient modal signatures from both sources and provides the neural-network classifier with enriched input representations. This domain expansion promotes learning of more generalizable representations, curbing over-fitting and improving robustness at deployment. Unlike a dot product, convolution redistributes rather than cancels energy, thereby retaining low-frequency content. (a) Spectrum of a randomly selected accelerometer signal, normalized to the 1 Hz to 15 Hz band and sampled at 30 Hz. (b) Spectrum of a corresponding FEM-generated signal after the same normalization. Spectrum of the convolutional signal obtained by combining the two normalized spectra. The absolute frequency scale has no physical meaning for the deep neural network analysis and is kept only for consistency of input format.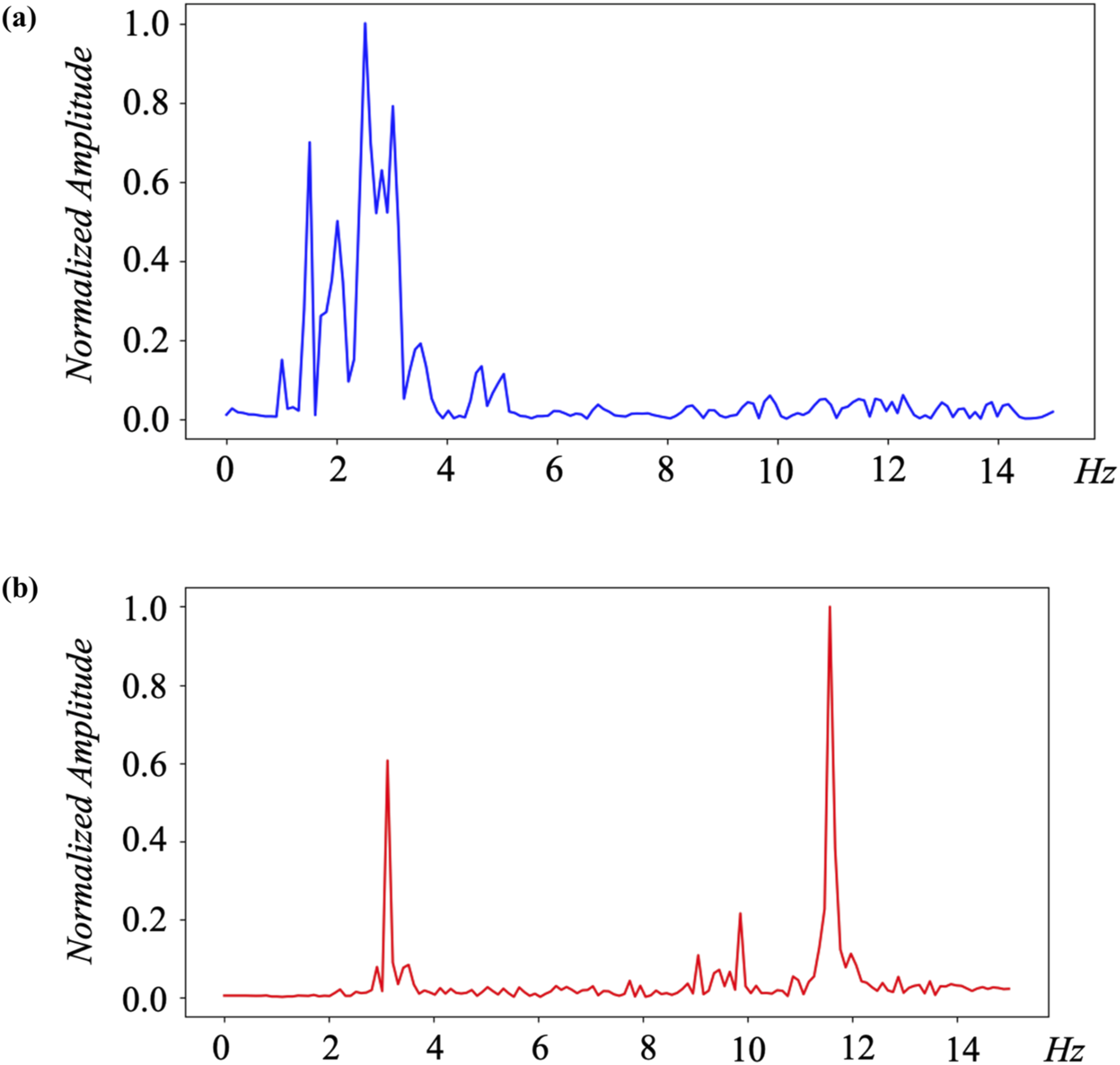
2.4. Simplified single-channel model
As illustrated in Figure 6 (Left), a centralized deep-learning framework, every sensor location is treated as a class, enabling the neural network to detect single-joint faults but leaving it blind to simultaneous ones—it simply selects the most probable joint. Enumerating all multi-location combinations would blow up the label space and data requirements, which is infeasible given scarce real-damage data, while synthetic multi-damage signals remain unreliable because of nonlinear interactions. Schematic comparison of damage detection frameworks. Left: The centralized multi-channel architecture. Right: The proposed decentralized single-channel (SC) architecture.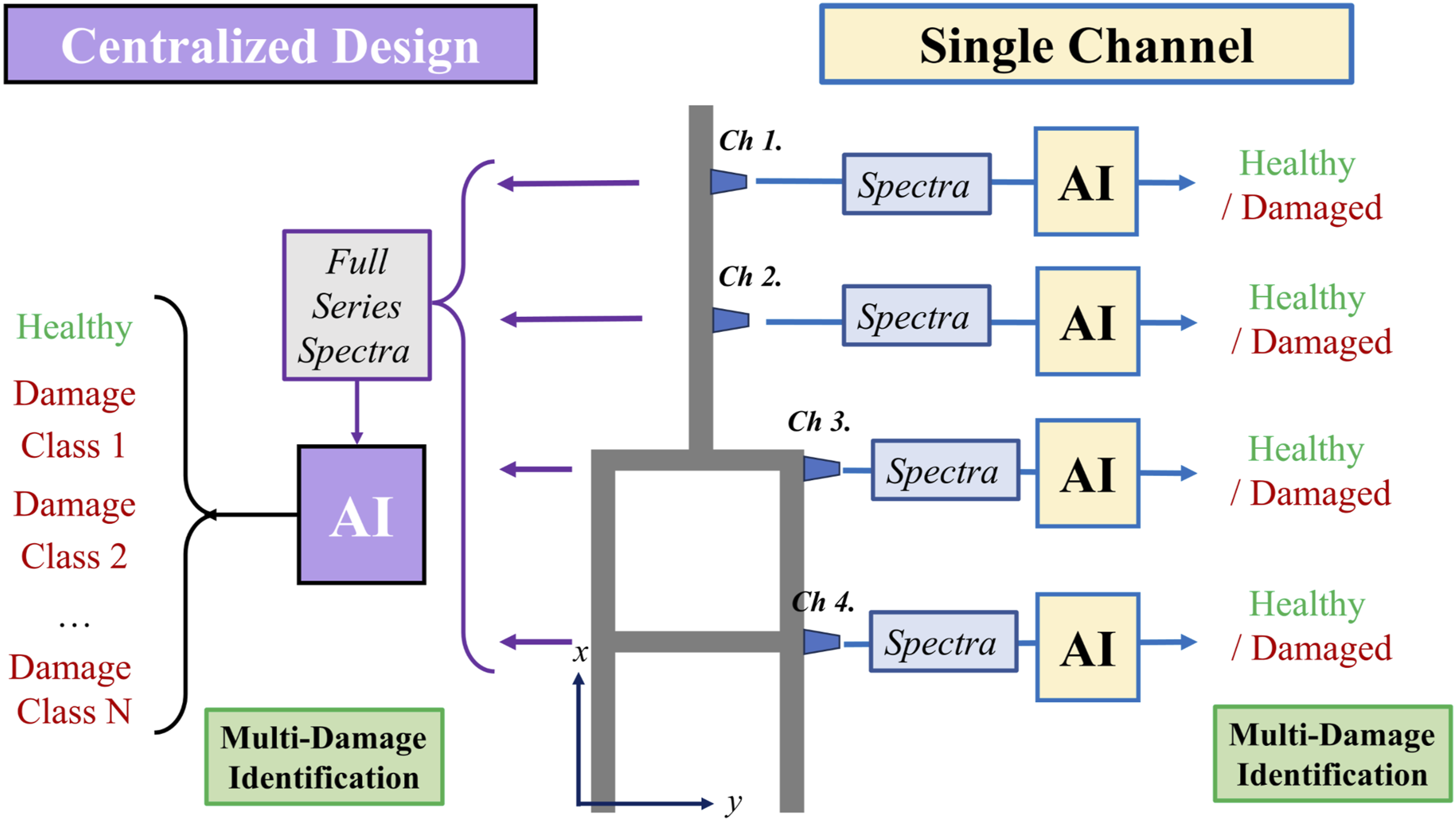
The single-channel, decentralized architecture in Figure 6 (Right)—adapted from Onur Avci (Avci et al., 2018)—sidesteps the earlier drawbacks. Each accelerometer stream is fed to its own neural network, which performs a binary task: healthy or damaged. By decoupling damage location from class labels, this approach cuts model complexity and data requirements. Restructuring the database lets channels share information, further enlarging the training pool, and a failed sensor no longer jeopardizes coverage at other points. When applied carefully, this scheme also strengthens domain adaptation, as later results show.
A further advantage of a decentralized single-channel (SC) architecture is consistent handling of physical data sources. Accelerometer channels often exhibit non-operational noise from differences in installation position and orientation. Training each channel on its own stream prevents the model from confounding local mechanical-field or boundary-condition effects with damage features, reducing classification ambiguity.
When data are scarce, pairing the SC approach with CDE is especially effective. Treat each (channel, damage-variant) pair as an independent subtask to enlarge the training set. With weight sharing and online knowledge distillation across channels, the network transfers features efficiently. This strategy mitigates the paucity of damaged-state data and enables model lightweighting, making the system well-suited for edge deployment.
To mitigate over-fitting given limited real-damage data, we adopted a strict evaluation protocol throughout this study. The training, validation, and test sets were kept disjoint, and all preprocessing statistics were computed using the training set only. For CDE-based augmentation, hybrid samples were generated exclusively from the training pool, and no test sample or derived feature was used in hybrid construction, preventing correlation leakage across splits. Model training was regularized using dropout and early stopping based on validation loss, such that generalization performance (rather than training accuracy) governed model selection.
3. Results and discussion
3.1. Convolution domain expansion results
Convolution serves as a data-augmentation and domain-alignment tool in convolutional domain expansion (CDE). Starting from a small set of finite-element (FEM) spectra and an abundant pool of real-healthy spectra, each FEM spectrum is convolved with randomly selected real-healthy spectra (Figure 7), turning FEM’s virtually unlimited supply into hybrid signals that better approximate the statistics of the real domain. In this study we denote hybrids created from FEM-healthy and real-healthy spectra as “CONV-Healthy” and hybrids created from FEM-damage and real-healthy spectra as “CONV-Damage.” These terms are used consistently in the subsequent figures. (a) Workflow of Convolution Domain Expansion. (b) Cosine similarity for 1000 randomly selected pairs before and after CDE.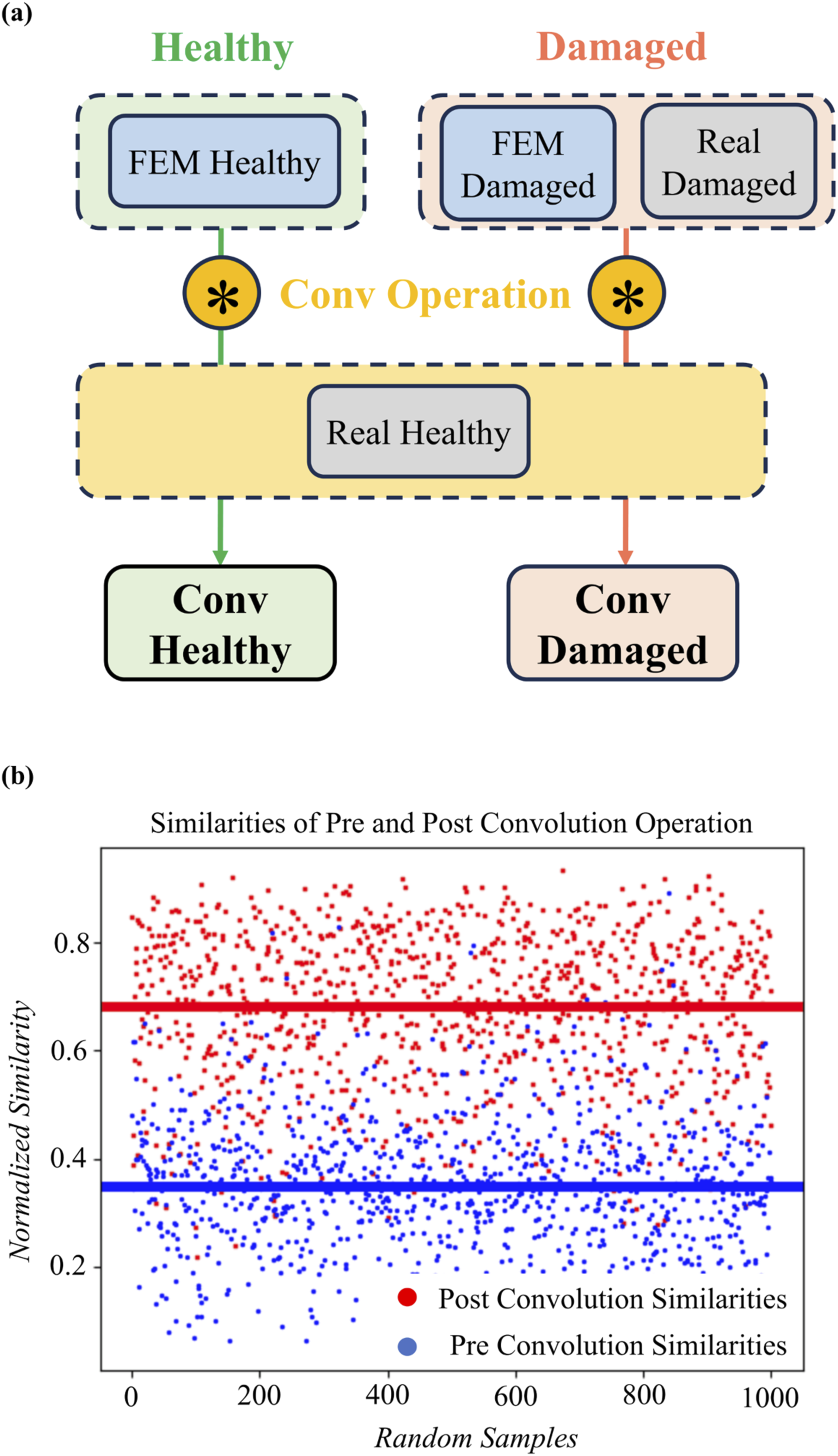
The proposed method utilizes a base dataset of 3,500 FEM and 2,000 real spectra per class. Through the CDE process, these baselines are expanded into a massive hybrid database, theoretically offering up to 7 million synthetic combinations (FH–RH, FD–RH) and 4 million real-hybrid pairings (RD–RH). Unlike masking or perturbing a single spectrum, this convolutional pairing produces genuinely new combinations of modal peaks and background noise, substantially enriching database variability with minimal extra data collection. It is important to note that CDE does not eliminate the need for real-damaged data; instead, it amplifies the information contained in a limited set of labeled damaged examples by combinatorially pairing them with healthy spectra (Figure 8). Conceptual illustration of the SC decision boundary and the domain mismatch between real and FEM spectra.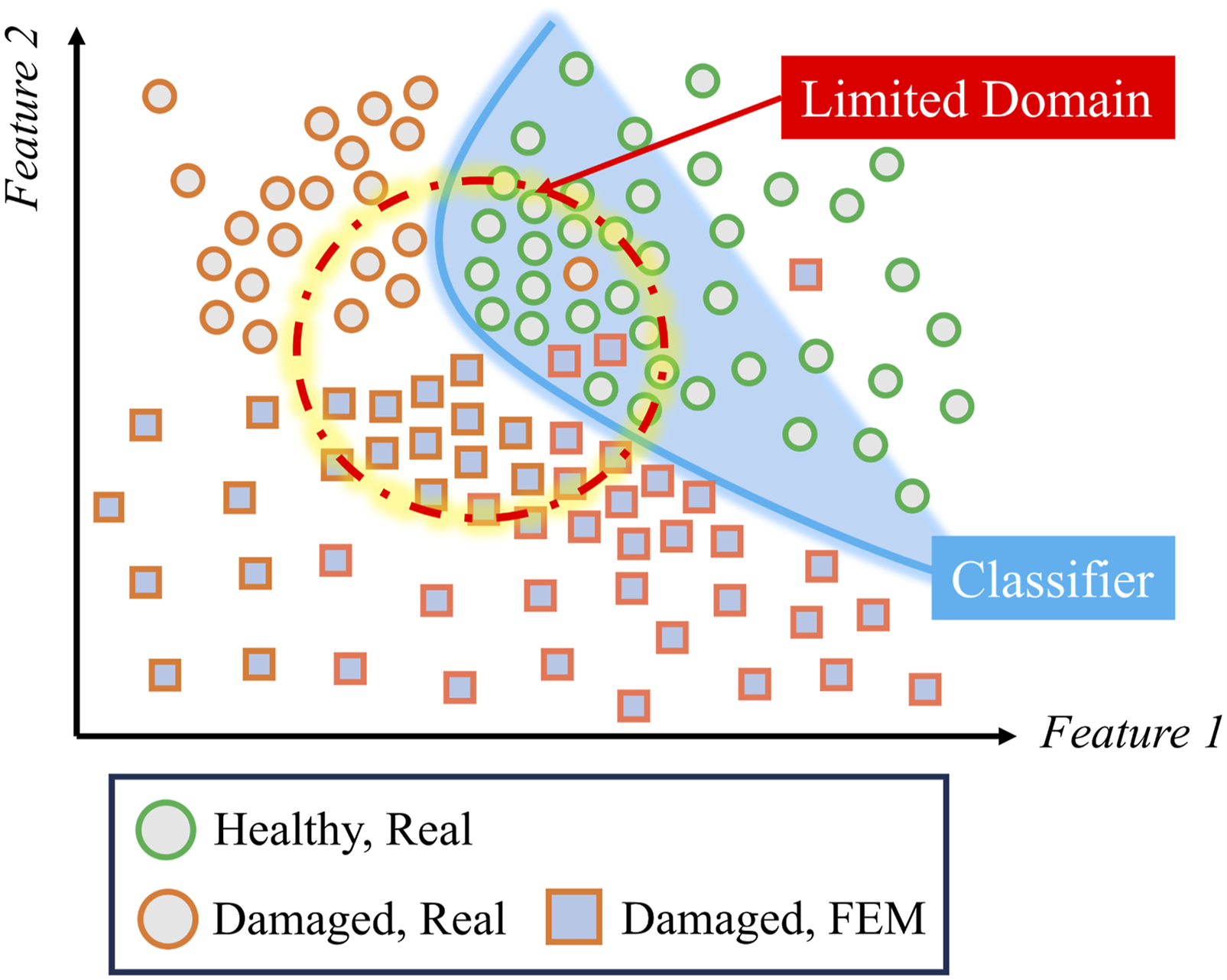
To quantify how CDE reduces the simulation–reality gap, we compute cosine similarity at the input-spectrum level. Specifically, for a feature vector
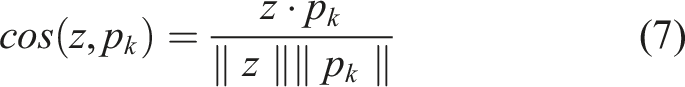
Each sample is then assigned to the class whose prototype attains the highest cosine similarity. CDE boosts average cosine similarity between finite-element and real spectra from ∼0.35 to 0.70 across 1000 samples, sharply reducing the simulation–reality gap.
3.2. Single-channel results
In a decentralized single-channel (SC) architecture, each joint is monitored by an independent neural network. Because the class label no longer encodes the damage location, the network can, in principle, detect previously unseen combinations of faults using only binary labels—healthy versus damaged. Reformulating the multi-damage problem as a binary classification task broadens the model’s applicability while simplifying training. An SC network that returns a healthy/damaged decision for each channel can focus on accurately identifying the healthy state and treat any deviation as damage, a strategy that may improve accuracy and enhance robustness to domain shifts.
The hybrid database augments scarce accelerometer damage data with spectra synthesized by finite-element method (FEM) simulations. The training set (57,600 examples) comprises 50% real-healthy, 45% FEM-damaged, and 5% real-damaged data; in contrast, the validation and test sets (7,200 examples each) contain 50% real-healthy, 25% FEM-damaged, and 25% real-damaged data. Figures 9 and 10 depict a deliberately minimalist neural network: the simplest architecture that meets performance targets is chosen. Training uses the ADAM optimizer with early stopping at ≈30 epochs, yielding 99.9 % training accuracy and 96.9 % validation accuracy in just over 1 minute. Early stopping (patience = 5) led the single-channel model to 99.99 % training accuracy and 96.96 % validation accuracy. (a) Architecture of the single-channel model. (b) Confusion matrix on the test set.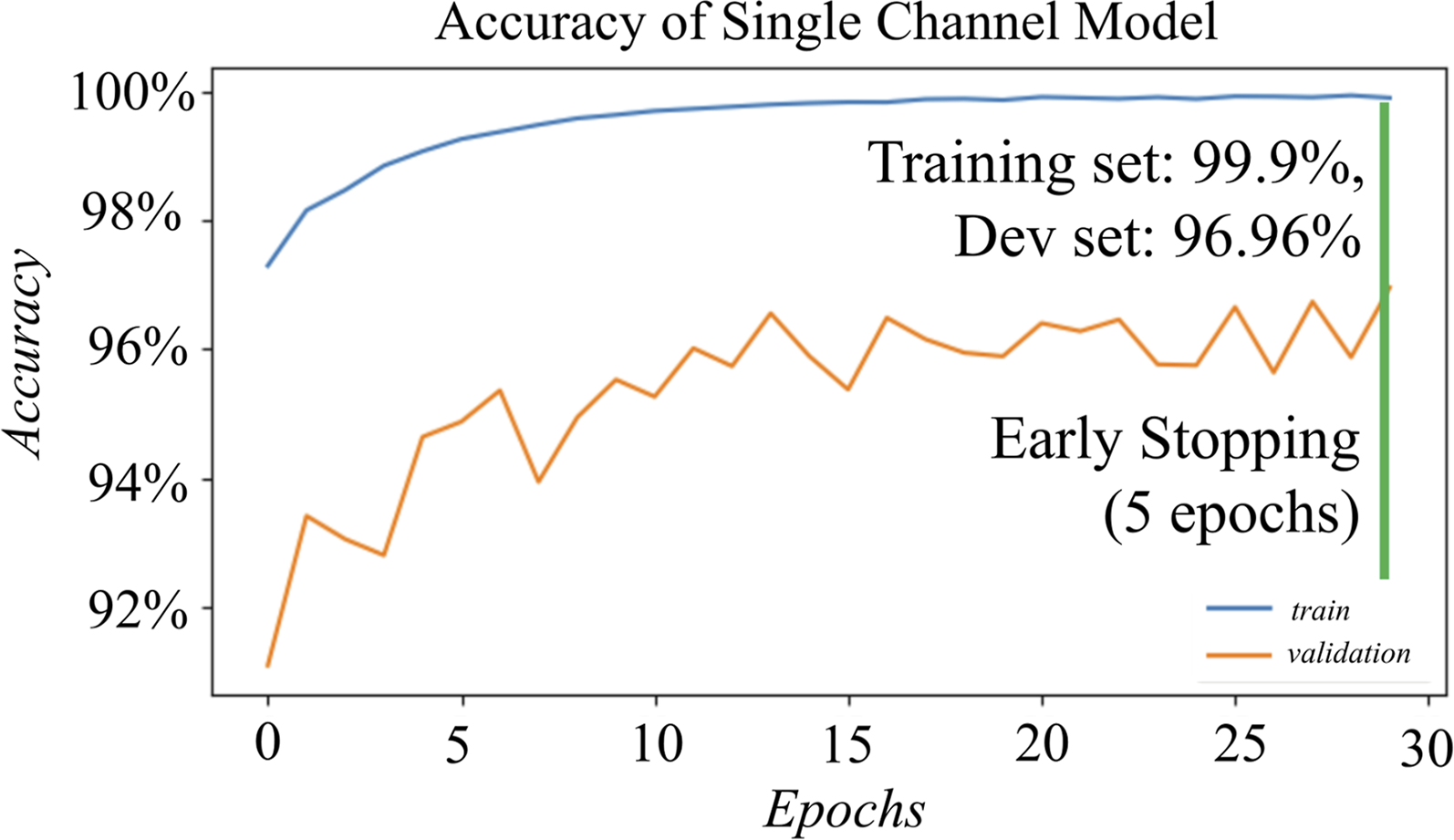
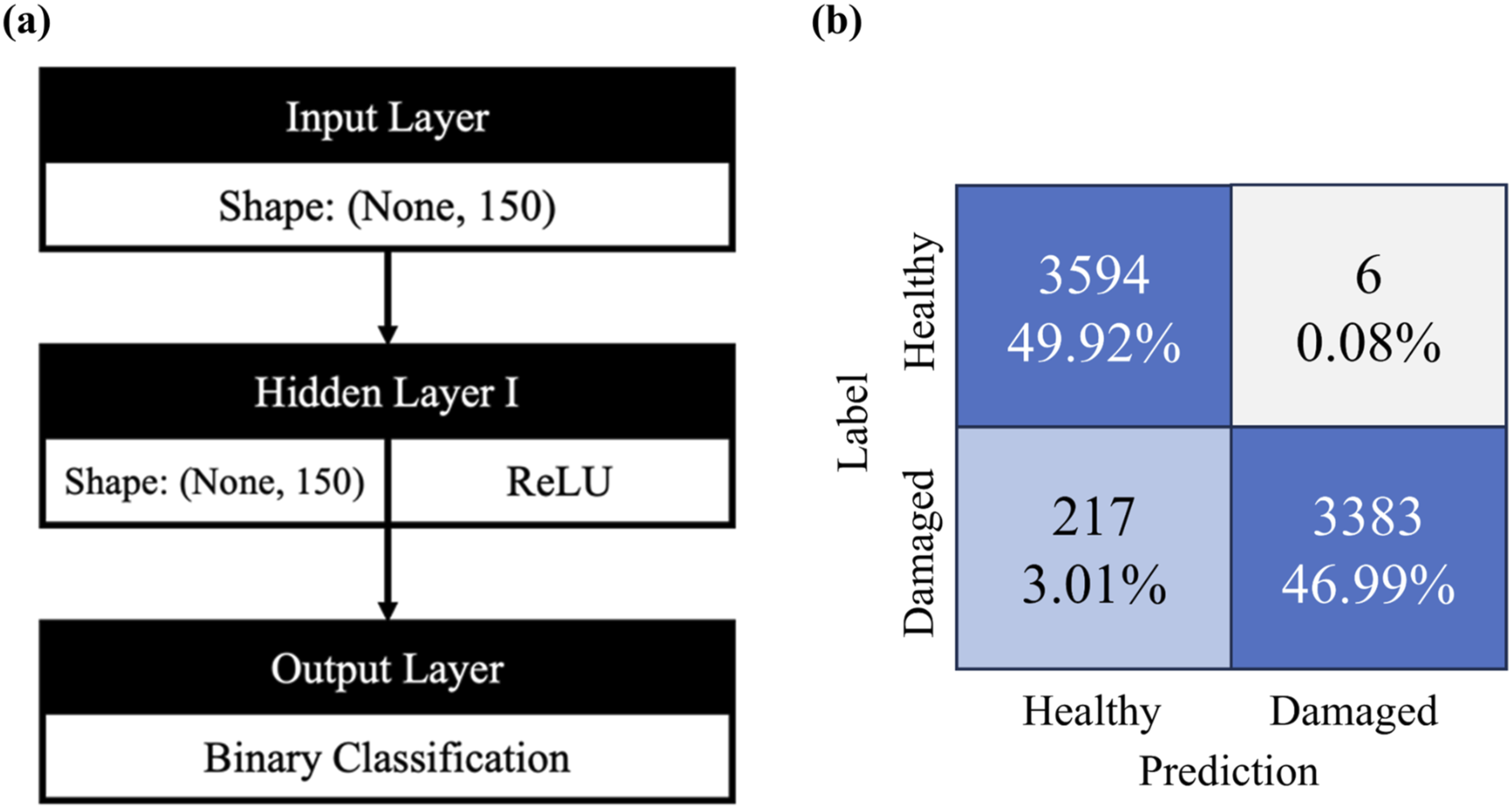
On the test set the model also attains 96.9 % accuracy. It mislabels only six healthy spectra as damaged (0.08 %) but misses 217 damaged spectra (3.01 %), roughly 75–80 % of which come from the limited real-damage subset. Even so, the network generalizes well to previously unseen cases, and the long-term risk of misdiagnosis remains low.
3.3. CDE and SC results
This section merges CDE with the SC design to create a monitor more relevant to real-world use. Raw samples from the 'Convolution domain expansion results' section are randomly paired and convolved as in Figure 7, enlarging the training set while keeping the earlier class balance. The training set (273,600 examples) comprises 50% FHRH, 45% FDRH, and 5% RDRH; conversely, the Development and Test sets (7,200 examples each) balance the damaged class with 50% FHRH, 25% FDRH, and 25% RDRH. The tailored network in Figure 11(a) accommodates the added complexity, using dropout in its third hidden layer to curb over-fitting and ADAM for optimization. Architecture of the CDE-SC model.
Standard neural-network optimization kept training and validation accuracy high. As Figure 12(a) shows, once their gap widened at epoch 150, we set the learning rate to one-tenth. The model then reached 97.5 % training accuracy and 96.3 % validation accuracy. Although this required a larger network, a bigger dataset, and more epochs, it produced a steadier model with much less over-fitting. (a) Accuracy curves after fine-tuning for 150 epochs: with the learning rate reduced to one-tenth of its initial value. (b) Confusion matrix of the CDE-SC model.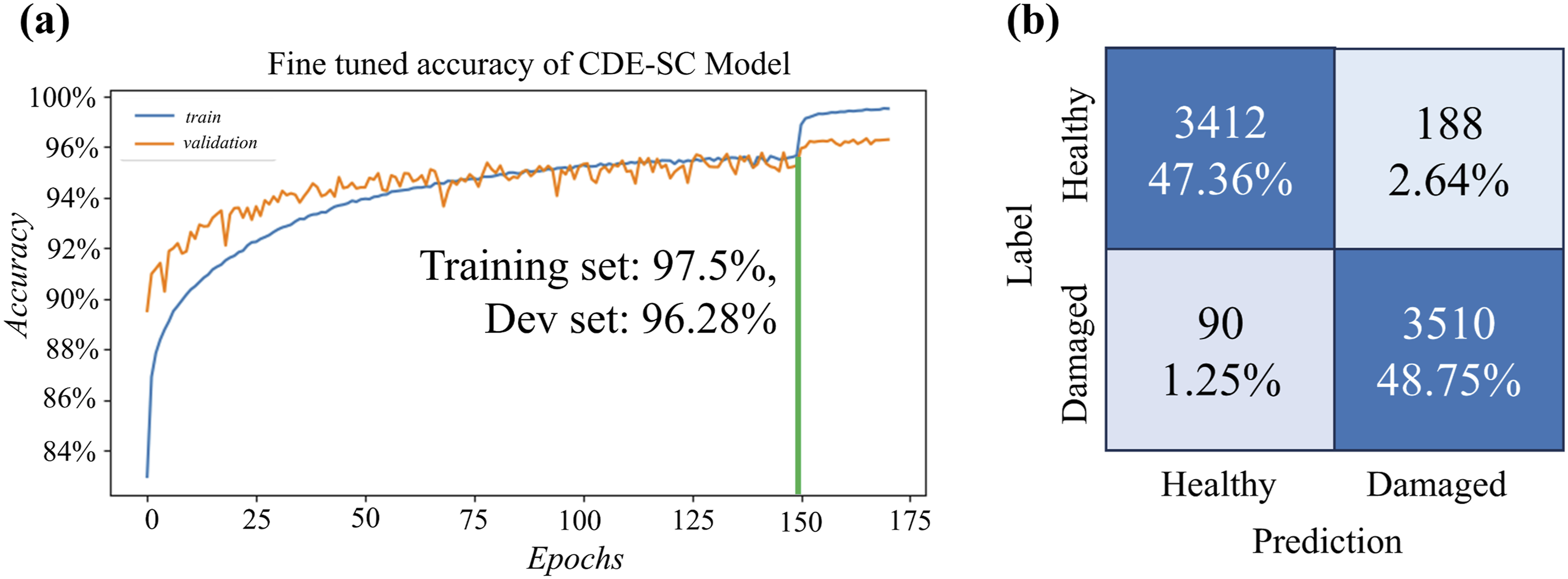
On the 3600-sample test set, the CDE-SC model reached 96.14 % accuracy. It mislabeled 188 healthy spectra as damaged (false positives) and missed only 90 of the 1 800 damaged spectra (5 % false negatives)—substantially fewer than the single-channel baseline, as confirmed by the confusion matrix in Figure 12(b). The extra false positives likely stem from convolving damaged spectra with real-healthy ones, which makes some healthy signals appear faulty. Nevertheless, the smaller train-validation gap shows the model generalizes better than the SC baseline while reliably detecting true damage.
3.4. Hybrid monitoring task with CDE-SC model
To assess the channel-wise independence of damage detection in the CDE-SC architecture, the eyeball test set was split into two channels, each with 48 samples (total duration 480 s). In Channel 1, accelerometer data were ordered as 12 healthy followed by 12 damaged samples; the same sequence was then repeated with visual-inspection signals (12 healthy, 12 damaged). Channel 2 used the identical arrangement. This balanced design equalizes healthy and damaged counts within each sensing modality, enabling an unbiased evaluation of the SC classifier.
In Channel 2, the sequence is: 12 healthy accelerometer samples, 12 healthy visual-inspection samples, 12 damaged accelerometer samples, and 12 damaged visual-inspection samples (see Figure 13). Because the damage sequences in Channels 1 and 2 are independent, the trained model must detect them despite not having seen this exact cross-modal ordering during training. The monitored structure is the same as the one used to collect the training data. Timeline of the hybrid monitoring task for Channel 2 and Channel 4, showing the alternating sequences of healthy and damaged states from different data sources.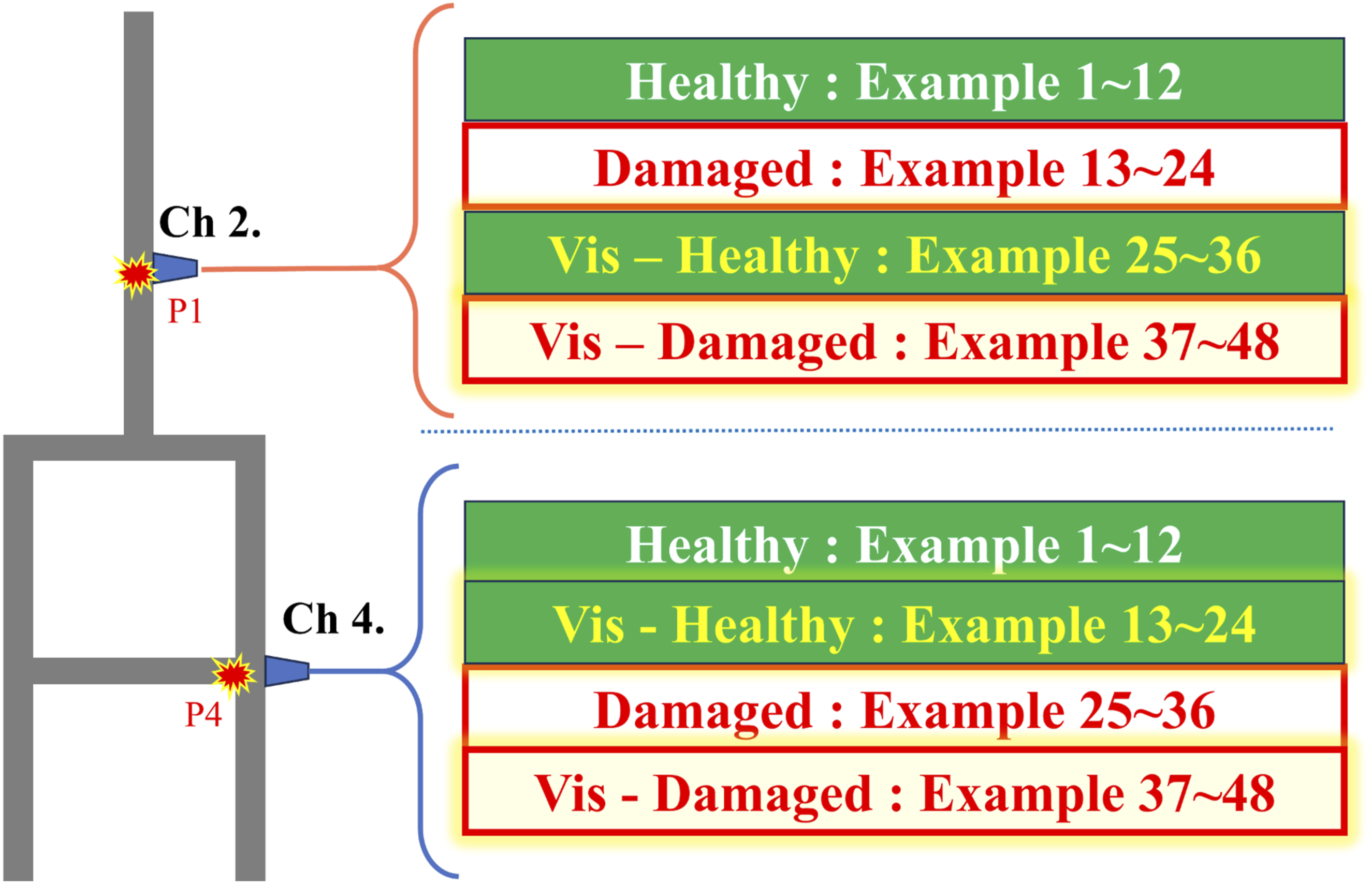
For visual inspection, vibration data were extracted with the optical-tracking code developed by Cheng et al. (2024). The algorithm tracks predefined points on the structure in each video frame and outputs their displacements. The monitoring results appear in Figure 14. Overall, the model correctly identifies the alternating patterns of healthy and damaged states. In the second, third, and fourth segments of the result chart, it recognizes multiple damage combinations even as the stage changes over time. The classifier shows high sensitivity: every damaged sample is detected. However, this heightened sensitivity also raises the false positive rate, as more healthy samples are misclassified as damaged. Channel-wise monitoring results of the CDE-SC model. Channel 2 achieves 94% accuracy and Channel 4 achieves 90% accuracy; most errors occur in the vision-derived healthy subset.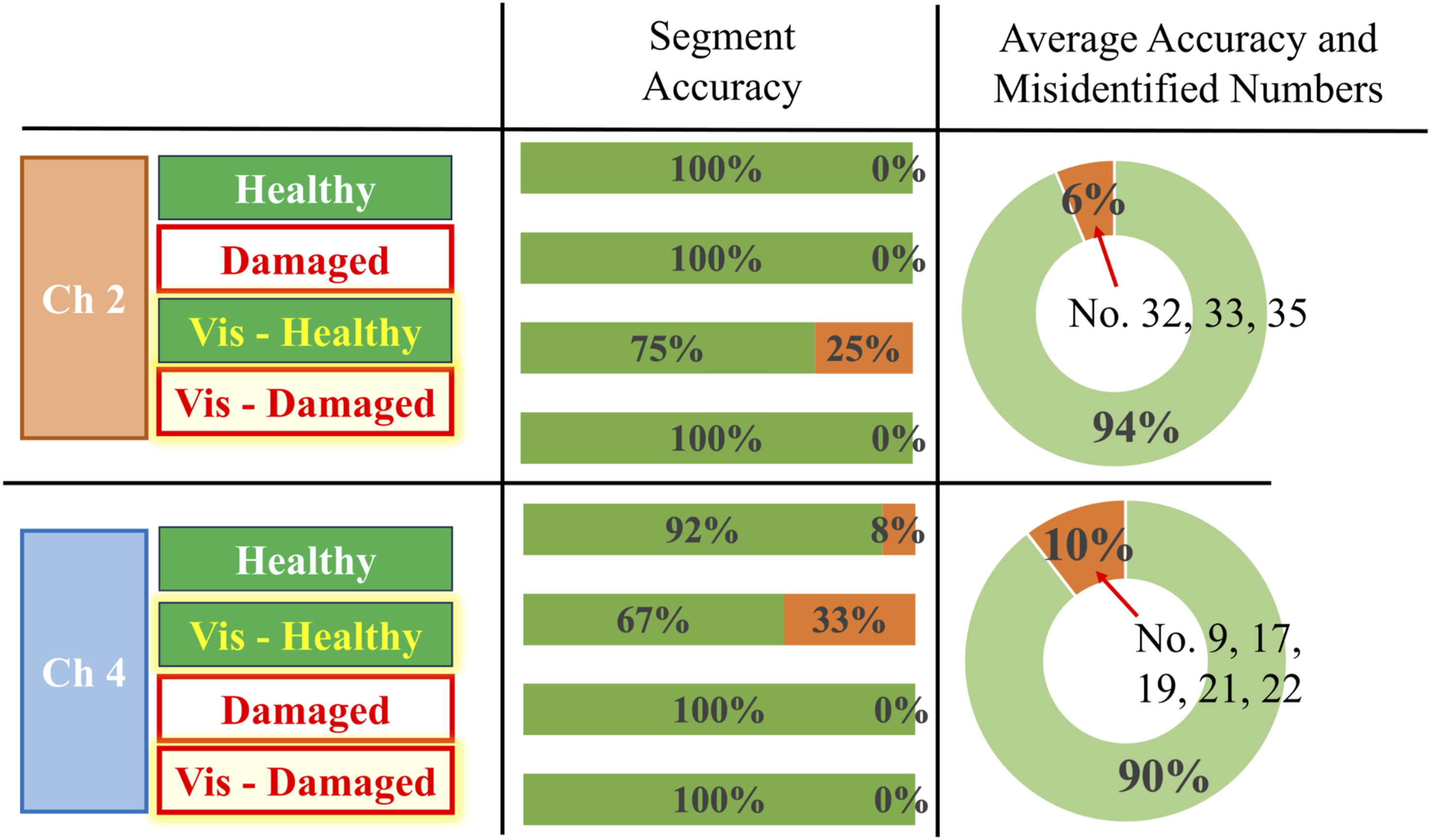
To assess practical applicability, we evaluated the SC-DNN’s complexity. The model is highly lightweight, containing only 1.0 × 104 and 2.3 × 104 parameters, which facilitates deployment on edge devices. Training on a standard CPU was completed in just 42.6 s. While sparse visual data currently accounts for most misclassifications, the network otherwise ensures precise multi-joint identification. With a sub-10 ms inference time, the framework is effectively primed for real-time streaming detection.
4. Conclusion
In this study, we applied deep-learning techniques to SHM and obtained results that merit further investigation—especially for large-scale civil structures. The key findings are: [1] The propose DNN approach classifies complex structural states in the frequency domain with an overall accuracy of 96 %. [2] Convolutional domain expansion (CDE) increases the cosine similarity between simulated finite-element spectra and real-world measurements from 0.40 to 0.70, providing a more reliable supplement of damage cases. [3] By combining CDE with a decentralized DNN architecture, the model adapts effectively to multiple data sources and remains flexible when confronted with previously unseen damage scenarios.
Training the SC-DNN with real spectra, FEM spectra, and CDE-generated hybrids mitigates class imbalance and the simulation-to-reality mismatch, improving generalization in our laboratory validation. CDE is a mathematically explicit and low-cost, physics-guided operation: convolving FEM simulations with limited measurements produces label-consistent hybrids that enrich the training distribution while preserving key spectral characteristics from both domains. This makes the approach promising for scalable SHM settings where comprehensive instrumentation and large new field campaigns are impractical (e.g., transmission towers, bridges, and building frames).
Two practical extensions of potential future work are: (i) post-event screening scenarios (e.g., after earthquakes or typhoons) under realistic environmental/operational variability, and (ii) cross-structure transfer learning where models trained on one configuration serve as priors for related assets. In addition, CDE creates large label-consistent repositories (e.g., CONV-Healthy and CONV-Damage) that may support retrieval-based decision support, but whether retrieval can complement or reduce explicit fine-tuning requires dedicated validation. Finally, the current study is limited to a laboratory-scale frame with sparse instrumentation and controlled damage scenarios; performance may depend on FEM fidelity, boundary-condition consistency, and the diversity of the healthy reference pool. We use fixed-band magnitude spectra as inputs, and robustness under long-term variability is untested. A controlled benchmark against feature-space DA baselines (e.g., CORAL/MMD) under the same backbone and split, together with field-scale and long-term validation on more complex and progressive damage mechanisms, remains our main research agenda.
Supplemental material
Supplemental material - Convolutional domain expansion technique for hybrid databases applied in DNNs on multi-damage structural health monitoring
Supplemental material for Convolutional domain expansion technique for hybrid databases applied in DNNs on multi-damage structural health monitoring by Wei-Hsuan Chiang, Yu-Han Chiang, Hsin-Haou Huang in Journal of Vibration and Control
Footnotes
Author contributions
Conceptualization, funding acquisition, resources, and supervision: Hsin-Haou Huang; methodology: Wei-Hsuan Chiang, Yu-Han Chiang, and Hsin-Haou Huang; formal analysis and investigation and writing—original draft preparation: Wei-Hsuan Chiang and Yu-Han Chiang; writing—review and editing: Wei-Hsuan Chiang and Hsin-Haou Huang.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Science and Technology Council (NSTC), Taiwan [Grant No. 113-2221-E-002-084-MY3].
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.