
Abstract
Fault prognostics and health management (PHM) is essential for ensuring the high reliability and extending the lifespan of extra-large-scale bearings. Within the PHM of extra-large-scale bearing, signal de-noising is the top priority due to the presence of weak fault characteristic, which is almost submerged by the strong background noise. Under the premise of accurate signal de-noising, the next critical aspect of PHM depends on remaining useful life (RUL) prediction, which provides guidance for the operation and maintenance of extra-large-scale bearing. In view of these two aspects, a new signal de-noising method is proposed through the combination of complete ensemble robust local mean decomposition with adaptive noise with kernel principle component analysis (CERLMDAN-KPCA). Subsequently, the implementation of RUL prediction is conducted using multi-layer kernel extreme learning machine based auto-encoder (MLKELM-AE). During the processes of signal de-noising and RUL prediction, parameter optimization is carried out to enhance signal decomposition ability and prediction performance. Experimental results demonstrate that MLKELM-AE, combined with CERLMDAN-KPCA-based signal de-noising, achieves superior RUL prediction accuracy for extra-large-scale bearing.
1. Introduction
Fault prognostics and health management (PHM) has been extensively employed to guarantee the safety and reliability of mechanical equipment. Given the critical role of extra-large-scale bearings as transmission components that endure low-speed heavy-load operation, the implementation of PHM for extra-large-scale bearing is imperative. A typical PHM system involves four fundamental steps: (i) data acquisition, (ii) feature extraction, (iii) the construction of health indicator, and (iv) remaining useful life (RUL) prediction (Zio 2022). The first three steps support RUL prediction to enhance prediction accuracy, which can guide the operation and maintenance of extra-large-scale bearing (Ferreira and Gonçalves, 2022). However, the operating condition under low speed and heavy load generates vibration signals contaminated with significant background noise (Liu et al., 2020). Consequently, the primary challenge within the PHM system lies in executing effective weak signal de-noising (Pan et al., 2021).
The extra-large-scale bearing consists of several rotating machinery and components, including cage, balls, ring, and outer and inner rings. Therefore, the faults of extra-large-scale bearing often manifest as multi-mode coupling, with various components interacting and causing non-linear and non-stationary vibration signals (Caesarendra and Tjahjowidodo, 2017). To address these complicated signals, multi-scale adaptive decomposition methods, such as empirical mode decomposition (EMD), ensemble EMD (EEMD), local mean decomposition (LMD), and robust LMD (RLMD), are highly suitable due to their purely digital-driven nature (Han et al., 2021; Huynh et al., 2021; Jia et al., 2023; Sarmadi et al., 2020). However, these methods are plagued by mode mixing and reconstruction errors (Zheng et al., 2014). By incorporating a noise-assisted approach, which involves adding adaptive Gaussian white noise at each decomposition stage, these issues can be mitigated (Zhao et al., 2024). Besides, it should be noted that noise amplitude and ensemble trials are crucial factors in noise-assisted methods, yet there is no standardized criterion for determining these hyperparameters (Zhan et al., 2019). Therefore, combining the noise-assisted approach with a parameter optimization method is the optimal choice for enhancing decomposition accuracy. Furthermore, considering that LMD-related functions are more proficient at preserving the amplitude and frequency variations within the raw vibration signal compared with EMD-related functions (Ali et al., 2023), a new self-adaptive signal decomposition method, named complete ensemble robust local mean decomposition with adaptive noise (CERLMDAN) along with parameter optimization, is introduced to handle the non-linearity and non-stationarity of extra-large-scale bearing vibration signals. After adaptive decomposition, another challenge in signal de-noising lies in selecting the appropriate low-frequency fault components owning to the low-speed operation condition. To the best of our knowledge, existing research primarily focuses on extracting fault components from short-term vibration signals for de-noising, which is better suited for signals with high rotational speeds and high-energy impact components (Lu et al., 2025; Peng et al., 2022). However, the energy of low-frequency fault components in extra-large-scale bearings is extremely low, making it challenging to identify and select those using traditional methods (Pan et al., 2024). To address this limitation, a novel fault component selection strategy is introduced, tailored to the trend of fault degradation in extra-large-scale bearings.
In addition to accurate signal de-noising, another critical aspect of PHM depends on RUL prediction, which can guide the operation and maintenance of extra-large-scale bearing. Both deep learning (DL) and machine learning (ML) have demonstrated promising results in the field of bearing RUL prediction (Bai et al., 2023; Schwendemann et al., 2021). Compared with ML, the primary core advantage of DL lies in its capacity to automatically learn high-level features from data through multi-layer neural networks (Dargan et al., 2020). However, the multi-layer structure necessitates the training of all hidden layers, leading to a greedy iterative adjustment of all parameters layer by layer (Wang et al., 2025). To address these drawbacks, Kasun et al. proposed an unsupervised learning algorithm named extreme learning machine based auto-encoder (ELM-AE), which combines strong feature expression capabilities of AE with efficient model training of ELM (Kasun et al., 2013). With the aid of layer-by-layer DL structure, a multi-layer ELM-AE can achieve feature expression without resorting to greedy learning and time-consuming calculation (Zhang et al., 2020). However, the main shortcomings of ELM include poor stability, poor robustness, and prone to overfitting. Through the replacement of the random mapping in ELM by stable kernel mapping, Huang et al. proposed kernel ELM (KELM) by the introduction of a kernel function (Huang 2014). This enhancement improved the stability and robustness compared with ELM (Liu et al., 2023). Building on this, a new RUL prediction method of extra-large-scale bearing is proposed based on multi-layer KELM-AE (MLKELM-AE). However, the randomness of kernel parameter and penalty coefficient can lead to insufficient stability and poor generalization in the MLKELM-AE model (Li et al., 2022). Similar to adaptive decomposition, parameter optimization is implemented for the enhancement of prediction ability.
Given the aforementioned challenges, a hybrid prognostic approach for extra-large-scale bearings is proposed, which leverages an enhanced CERLMDAN-KPCA and MLKELM-AE. CERLMDAN-KPCA-based signal de-noising is suited for weak low-frequency fault component extraction, especially in extra-large-scale bearing. After that, MLKELM-AE is then utilized to establish RUL prediction model. Additionally, the optimization of hyper parameters in CERLMDAN-KPCA and MLKELM-AE is carried out to enhance signal de-noising and RUL prediction accuracy. Experimental results demonstrate that RUL prediction using improved MLKELM-AE exhibits high accuracy, making it a suitable choice for extra-large-scale bearing prediction analysis.
The remainder of the paper is organized as follows: Section 2 provides an overview of the systematic approach. The signal de-noising, RUL prediction, parameter optimization, and the procedure of proposed method are shown in Section 3. In Section 4, the proposed method is verified using life-cycle experimental signals. The paper concludes with remarks and suggestions for future research directions in Section 5.
2. Methodology
2.1. CERLMDAN
By integrating the noise-assisted approach with RLMD to bolster its resistance to mode mixing and refine its decomposition outcomes, the new CERLMDAN method is introduced. The steps involved in the decomposition process of CERLMDAN are outlined as below: Step 1: I times of Gaussian white noise Step 2: Perform RLMD on all preprocessed x
i
to obtain the first PFi1 and take their average value as the PF1 obtained by CERLMDAN, thus obtain the first residual sequence u1. Step 3: Add Gaussian white noise into the residual sequence u1 to construct I new sequences Step 4: Conduct I times RLMD on Step 5: Repeat the above steps until residual sequence is either devoid of oscillations or constant, and the expression of the sequence x after CERLMDAN decomposition is as follows:
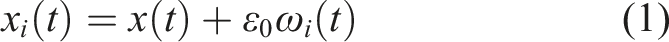
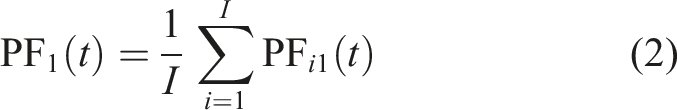
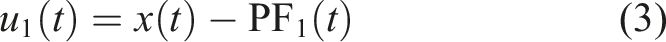
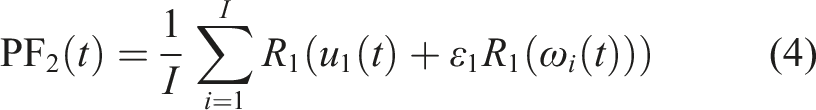
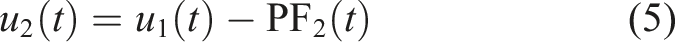
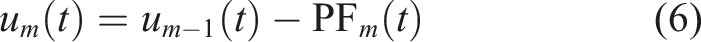
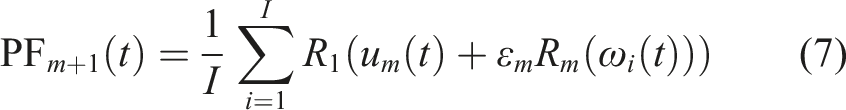
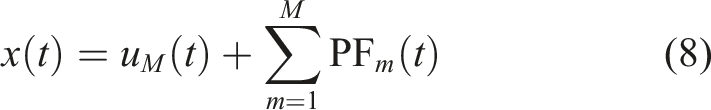
2.2. KPCA
In the realm of fault detection, squared prediction error (SPE) statistic in KPCA quantifies the discrepancy between each sample and the statistical model in terms of change trends, functioning as an indicator of external data alterations within the model. The formula for SPE is given as below:
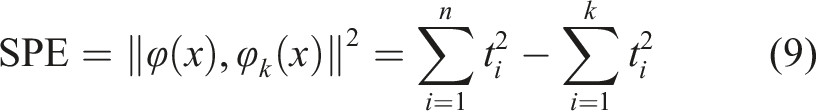
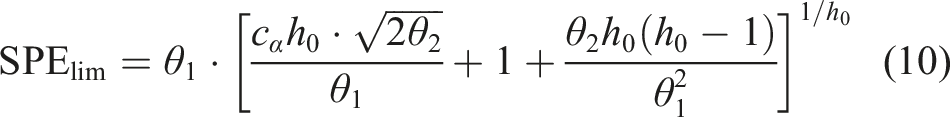
2.3. KELM
Given N training samples, denoted as {(
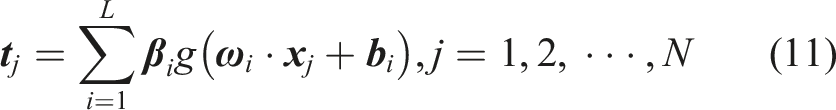


In KELM, a kernel matrix
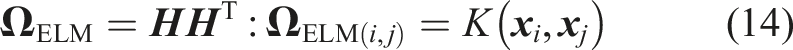
The kernel function is denoted as K (
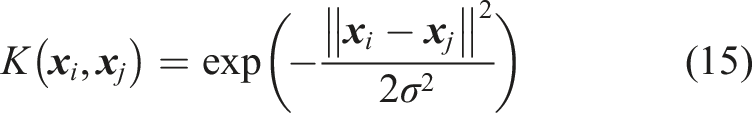
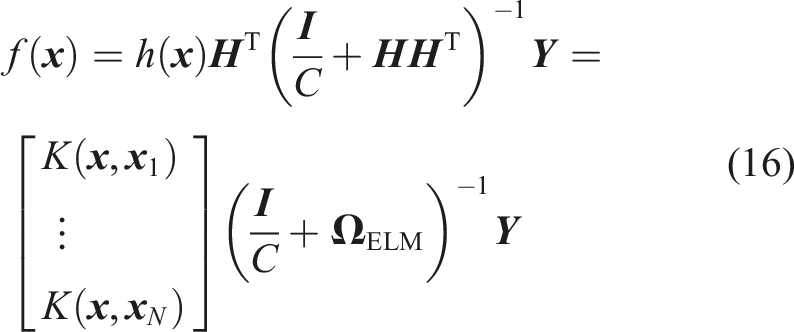
2.4. AE
AE is a neural network model that consists of an encoder and a decoder (Wang et al., 2016). The process of AE can be divided into the following two steps: Encoder and Decoder. The primary objective of AE is to reduce the reconstruction error to the greatest extent possible, which can learn a compact and efficient representation of the input data.
2.5. MFO
Moth-flame optimization (MFO) is a novel optimization approach based on swarm intelligence, inspired by the lateral orientation behavior exhibited by nocturnal moths (Mirjalili 2015). Since the MFO algorithm is a population-based algorithm, the set of moths and flames is represented in a matrix
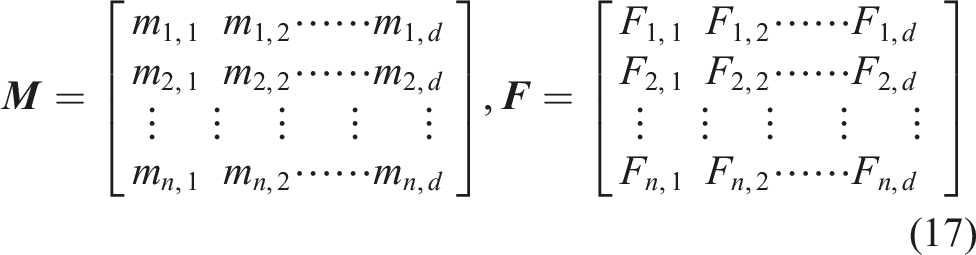
To accurately replicate the behavior of moths, the position update of each moth corresponding to the flame can be defined as below:

The main updating mechanism of moths is logarithmic spiral shown as below:
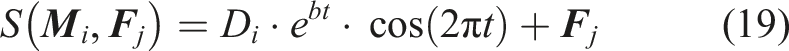
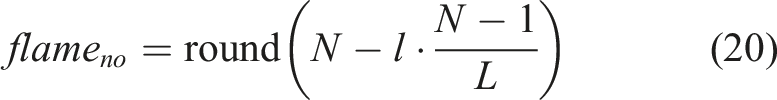
3. Hybrid prognostic approach using enhanced CERLMDAN-KPCA and MLKELM-AE
3.1. CERLMDAN-KPCA
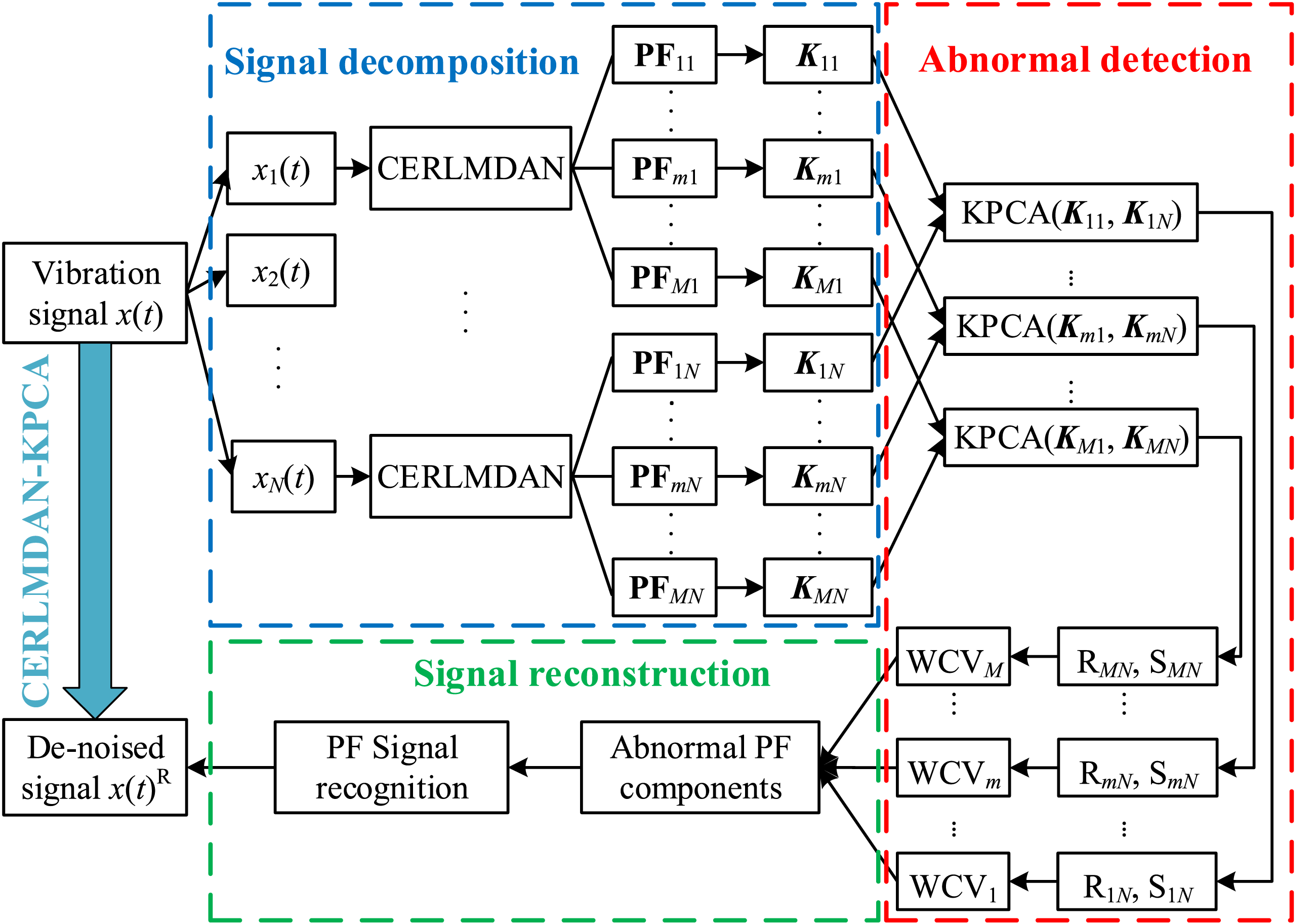
Through signal decomposition by CERLMDAN, vibration signals of extra-large-scale bearing can be divided into several PFs ordered from high frequency to low frequency. Following this decomposition, a new strategy for selecting fault-related components is introduced, leveraging statistical detection through KPCA. The energy of low-frequency components occupied by fault characteristics tends to increase over time, while that of high-frequency components associated with background noise remains constant. In view of this point, the new selection strategy evaluates the trend of each decomposed functions throughout the entire operation life rather than focusing on short-term signals. The detailed CERLMDAN-KPCA procedure is outlined as below: Step 1: Collect entire life vibration signal x
n
(t) (n = 1, 2, N). The first segment x1(t) represents the normal working signal without faults. Step 2: Decompose each segment into M PFs through CERLMDAN, and set PF
mn
as the mth (m = 1, 2, M) PF of x
n
(t). Step 3: Divide each PF
mn
into a matrix K
mn
. Step 4: Km1 is regarded as the normal KPCA model, and project K
mn
into Km1 to obtain SPE
mn
. Calculate the root mean square of SPE
mn
, R
mn
, and take S
mn
(S
mn
= R
mn
–Rm1) as evaluation indicator of change trend. Step 5: Define the weighted cumulative value (WCV) of S
hk
as a choice criteria aimed at bringing to light the general trend of each PF. Step 6: Choose fault-related PFs with lager WCV, and then reconstruct entire life-cycle vibration signals x(t)R. Figure 1 demonstrates the detailed signal de-noising procedure.
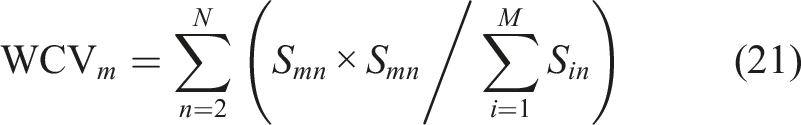
3.2. Parameter optimization of CERLMDAN
How to balance the ensemble trials I and noise amplitude ε in CERLMDAN affects both the decomposition precision and decomposition efficiency. A smaller ε may fail to alter the extreme point distribution, leading to an uneven scale of extreme point. Conversely, a larger ε can result in an increased decomposition number and heightened computational complexity. Besides, the larger the number of ensemble trials I is, the better the decomposition effect will be, but causing the computational complexity. As a result, an enhanced CERLMDAN methodology is proposed using MFO to improve its adaptive decomposition capability. Step 1: Initialize parameters of MFO, such as number of moth, maximum iteration times, and logarithmic spiral shape constant. Step 2: Utilize the adaptive mechanism in equation (20) to decrease the number of flames. Step 3: Fitness function is designated using the mean envelope spectrum entropy (MESE), as outlined in equation (22), and utilize MFO to optimize the parameters ε and I. Evaluate the MESE for each moth to determine the optimal one that exhibits the best performance, which is referred to as the flame. Flow chart of proposed CERLMDAN-KPCA.
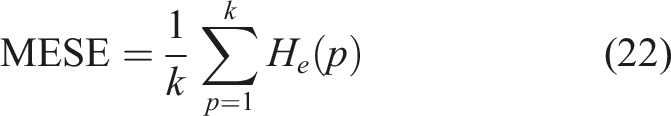
The calculation formula of envelope spectrum entropy H
e
of decomposed PF is as follows: Step 4: Adjust the moth position using equation (19) and subsequently obtain its corresponding fitness value. Then, reorganize the sequence of flames based on the optimal solution identified. Step 5: Repeat Steps 2∼4 to initiate the next generation, continuing this process until the iteration count satisfies the algorithm criteria or the fitness function fails to improve beyond the global optimum. Step 6: Find the optimal set of (ε, I) and construct the signal decomposition CERLMDAN accordingly.
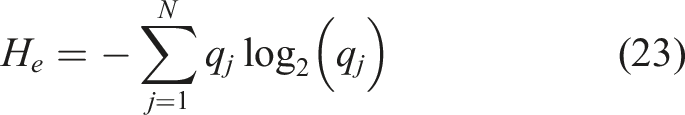
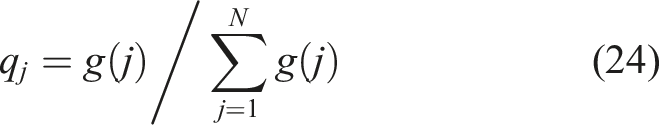
3.3. MLKELM-AE
Through integrating KELM with AE, the reconstruction of input signals is accomplished by KELM-AE, as illustrated in Figure 2(a). Hidden layer output can generate encoded representation input. By stacking multiple KELM-AE layers, the multi-layer structure is capable of extracting high-level representations from the input features. Consequently, a novel RUL prediction model, termed MLKELM-AE, is introduced. This model consists of multi-layer KELM-AE, followed by a prediction layer utilizing KELM. Figure 2(b) shows the detailed structure diagram of MLKELM-AE. Structure diagram: (a) KELM-AE and (b) MLKELM-AE.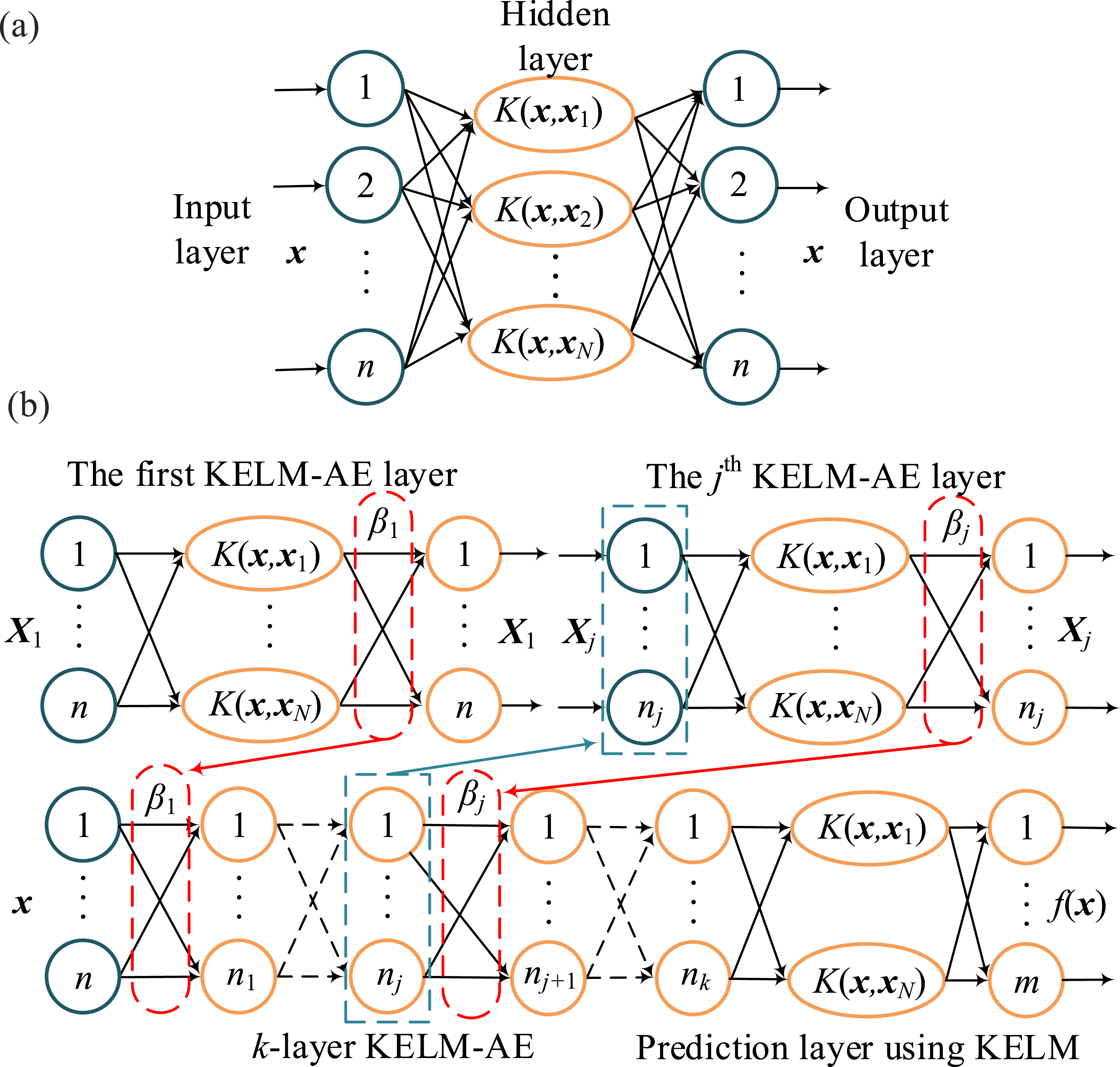
For KELM-AE with k layers, the jth layer weight output is presented as below: Step 1: Parameter initialization: this includes penalty coefficient and kernel parameter. Step 2: Multi-layer feature extraction: this calculates the hidden layer weights and outputs of KELM-AE layer by layer, and determines all network weights in the multi-layer model. Step 3: RUL prediction: this sets the last layer output of KELM-AE as the input for prediction layer KELM and output RUL.
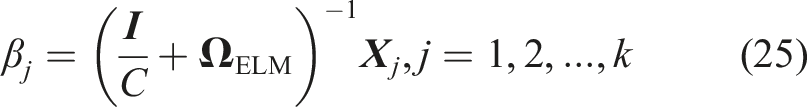
The training process of traditional deep learning involves unsupervised pre-training and supervised fine-tuning, requiring the simultaneous training of all hidden layers through a layer-by-layer greedy iterative adjustment of all parameters. This approach not only exhibits high time complexity but also allows for the layer-wise propagation of systematic bias. In contrast, the proposed MLKELM-AE is composed of multiple independent KELM-AE layers. In a single KELM-AE, the weights and output are solely dependent on its input, thus eliminating the need for fine-tuning. Furthermore, the multi-layer KELM-AE architecture mitigates the random fluctuations in model output caused by the random matrix H in ELM-AE. Consequently, the MLKELM-AE model proposed in this study for extra-large-scale bearing RUL prediction enhances the mapping capability for nonlinear features while offering superior efficiency and speed.
3.4. Parameter optimization of MLKELM-AE
The uncertainty of kernel parameter σ and penalty coefficient C in MLKELM-AE leads to a prediction model with reduced generalization performance and unsatisfactory stability. A smaller σ value makes the RBF kernel behave similarly to a polynomial kernel, while a larger σ value causes it to resemble a linear kernel. A larger C value placing a greater emphasis on empirical risk minimization. Consequently, σ and C significantly influence the capability of RUL prediction model. To tackle this challenge, we propose an enhanced MLKELM-AE methodology using the MFO algorithm. Similar to MFO-CERLMDAN, the updated process of MFO-MLKELM-AE can be generalized as outlined below: (1) Update the Step 3 of MFO-CERLMDAN: Fitness function is designated using the mean squared error. (2) Update the Step 6 of MFO-CERLMDAN: Find the optimal set of (σ, C) and construct the RUL prediction model MLKELM-AE accordingly.
3.5. The procedure of hybrid prognostic approach
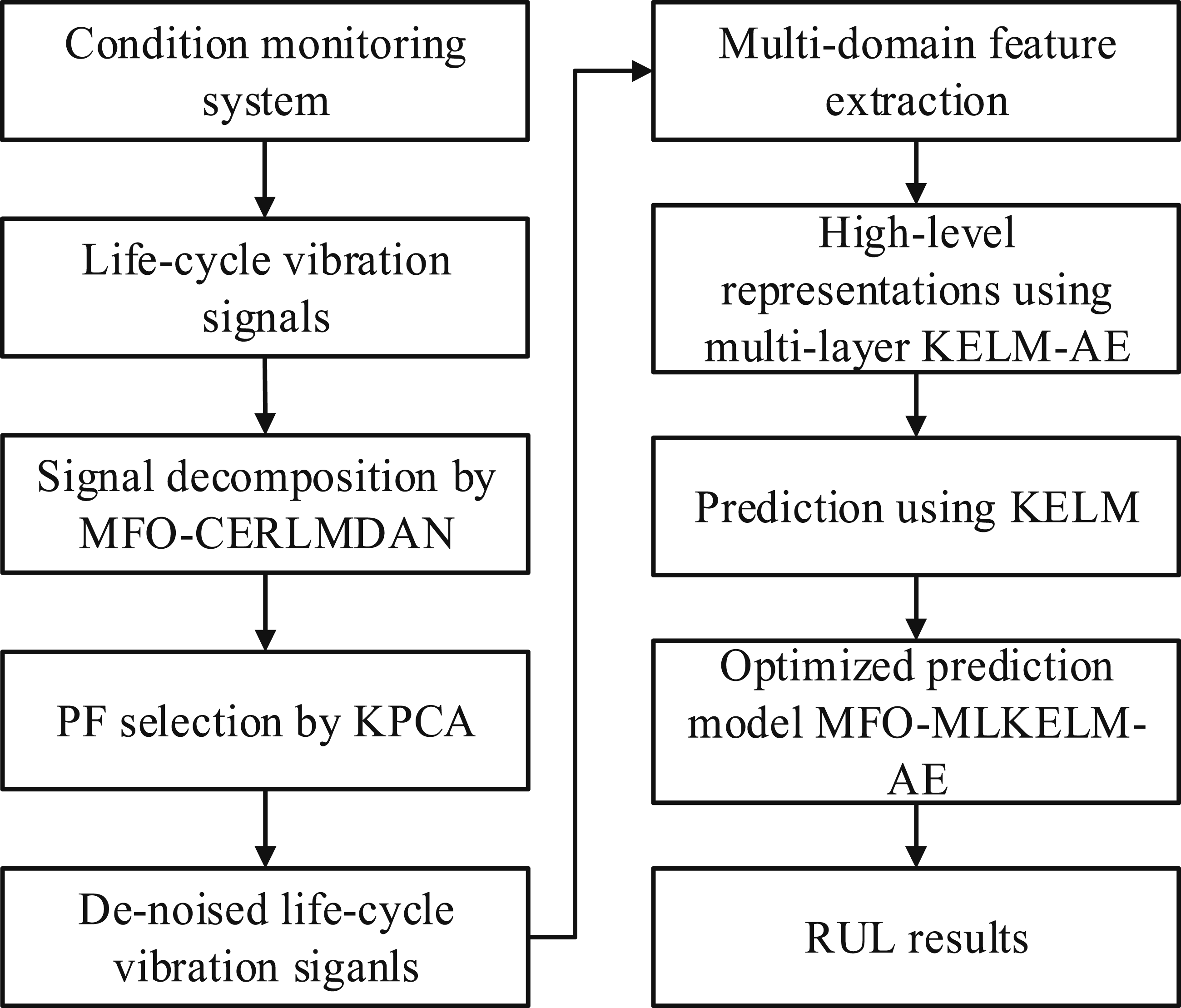
The proposed method comprises two essential steps. Initially, MFO-CERLMDAN-KPCA-based signal de-noising is implemented to enhance the fault characteristic information of extra-large-scale bearing. Subsequently, MFO-MLKELM-AE is utilized to predict RUL. The step-by-step executive process is detailed as follows: Step 1: Gather entire life vibration signals from the extra-large-scale bearing. Step 2: Implement signal de-noising by MFO-CERLMDAN-KPCA to the entire vibration signals. Step 3: Extract multi-domain features, followed by normalizing the entire dataset and dividing it into training and testing sets. Step 4: The training set is used to train the MFO-MLKELM-AE model, with the extracted multi-domain features serving as input. Then output the optimal MLKELM-AE extra-large-scale bearing RUL prediction. Step 5: Utilize the trained MFO-MLKELM-AE model to predict the RUL. The procedure depicting the proposed method is presented in Figure 3.
4. Experimental verification and analysis
4.1. Extra-large-scale bearing test rig
As shown in Figure 4, the extra-large-scale bearing test rig employs three bidirectional hydraulic cylinders, namely, Cylinder 1, Cylinder 2, and Cylinder 3, for loading. Among them, Cylinder 1 and Cylinder 2 apply loads in opposite directions with different magnitudes, achieving the application of axial force and overturning moment. Cylinder 3, on the other hand, applies radial load to the tested bearing through a top flange. The tested extra-large-scale bearing is rotated by the accompanied bearing, driven by hydraulic motor Cylinder 4. Test rig for extra-large-scale bearing. Procedure of the proposed RUL prediction method.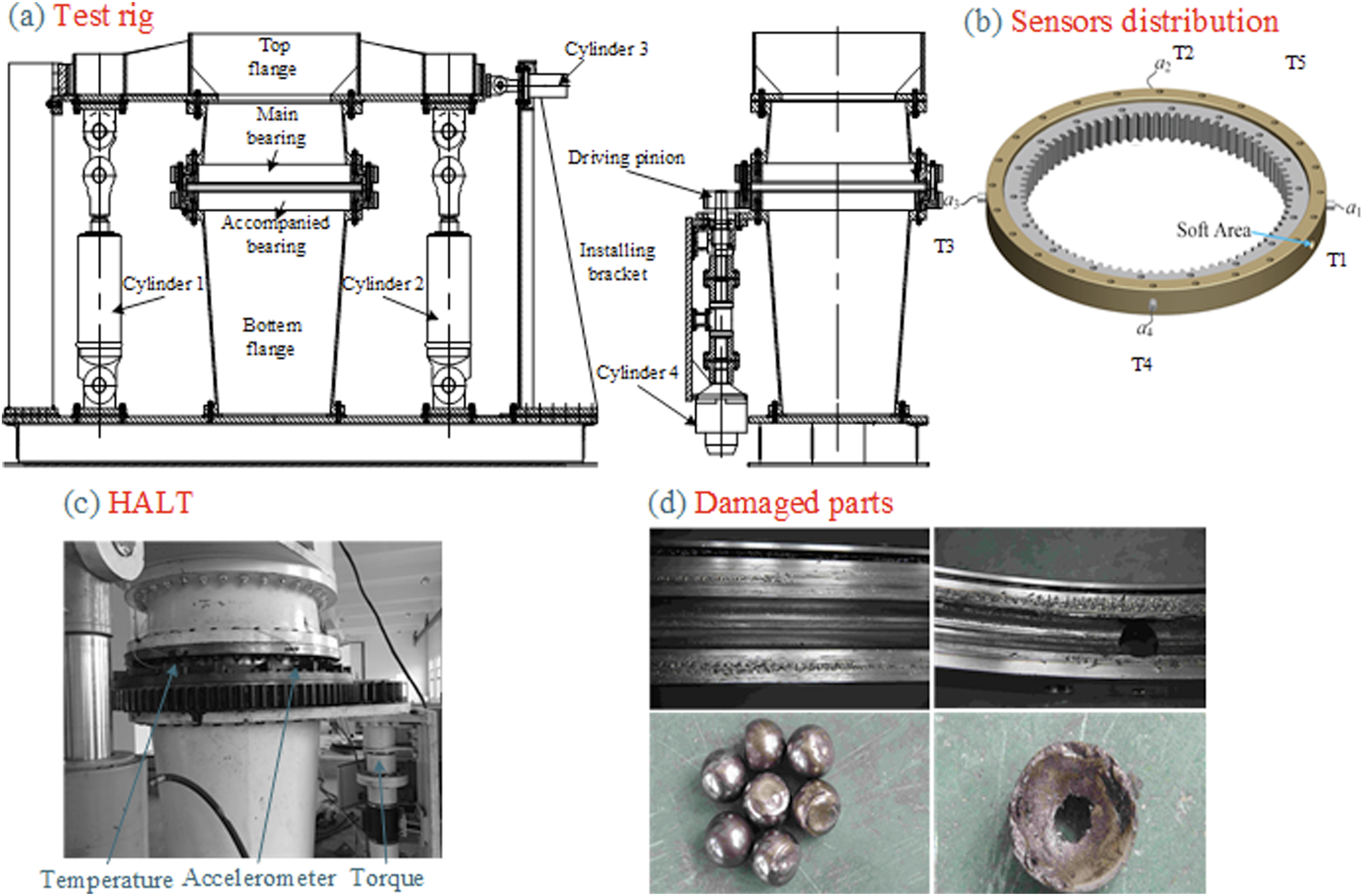
The QNA-730-22 extra-large-scale bearing is chosen for this test, classified as single-row internal-tooth four-point contact bearing. Considering the different characteristics of signals, the sample rate of vibration signal is set at 2048 Hz, and the rest is set at 10 Hz. The accelerated life test, illustrated in Figure 4, lasted for 11 days in total. At the conclusion of the test, the tested extra-large-scale bearing had undergone severe failure, causing it to seize. The outer ring raceway exhibited extensive fatigue spalling and wear. Additionally, some of the balls suffered fatigue fractures, while the inner ring raceway displayed severe pitting corrosion, as illustrated in Figure 4.
To demonstrate the process of deterioration, Figure 5 presents the vibration signal throughout extra-large-scale bearing lifecycle. From Figure 5, it is evident that vibration signal progressively intensifies as faults initiate and worsen. Therefore, the vibration signal serves as an indicator of the extra-large-scale bearing health status throughout its entire lifecycle. However, the presence of significant background noise obscures the subtle fault characteristics. Life-cycle vibration signal.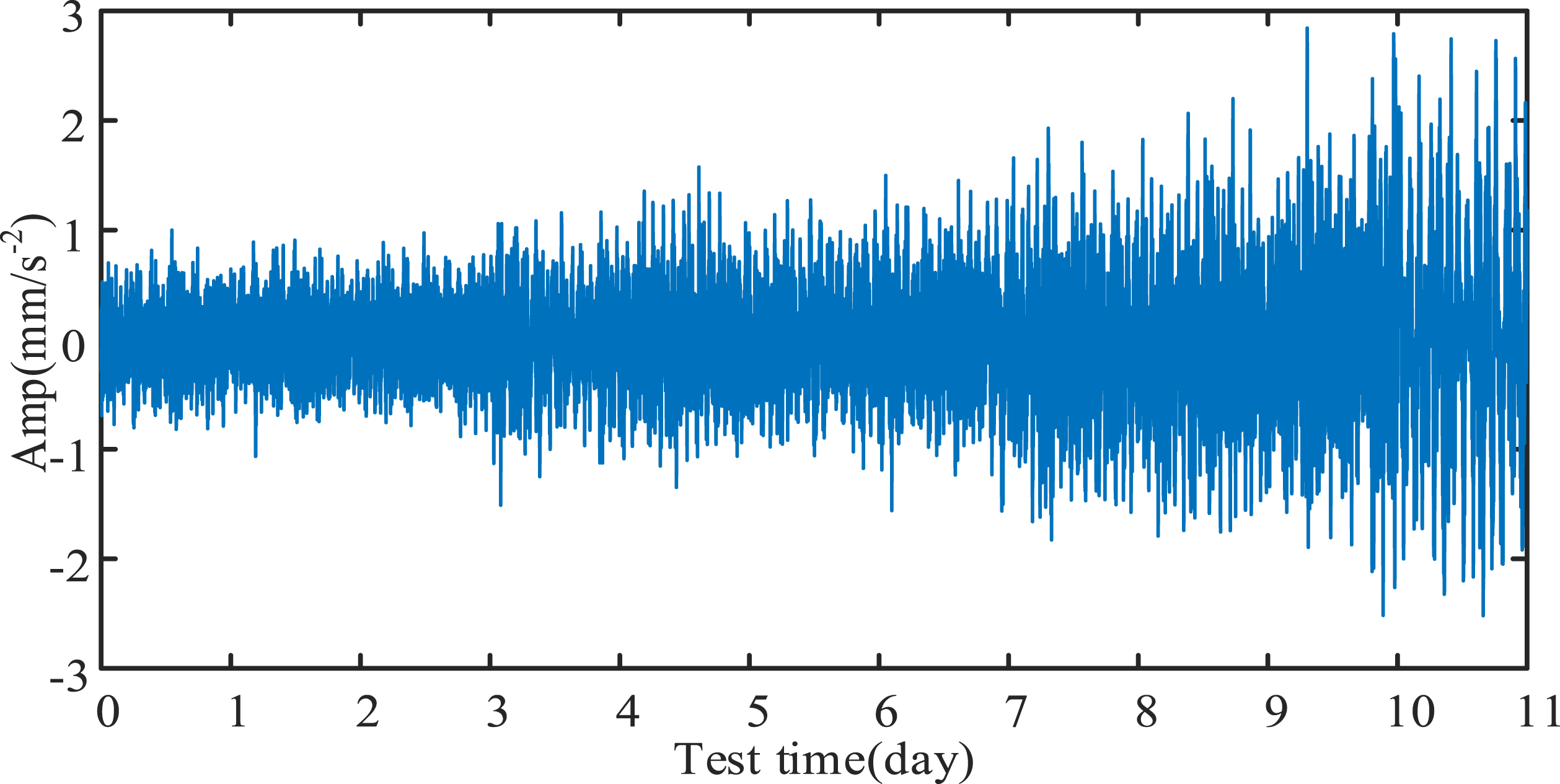
As depicted in Figure 6, the graph showcases the entire life-cycle trend of alterations in grease temperature and driving torque. It can be noted that the change tendencies of the two are essentially in accord. Hence, the characteristic curves of temperature and driving torque can also indicate the process of performance deterioration of extra-large-scale bearing. Life-cycle characteristic signals: (a) temperature and (b) driving torque.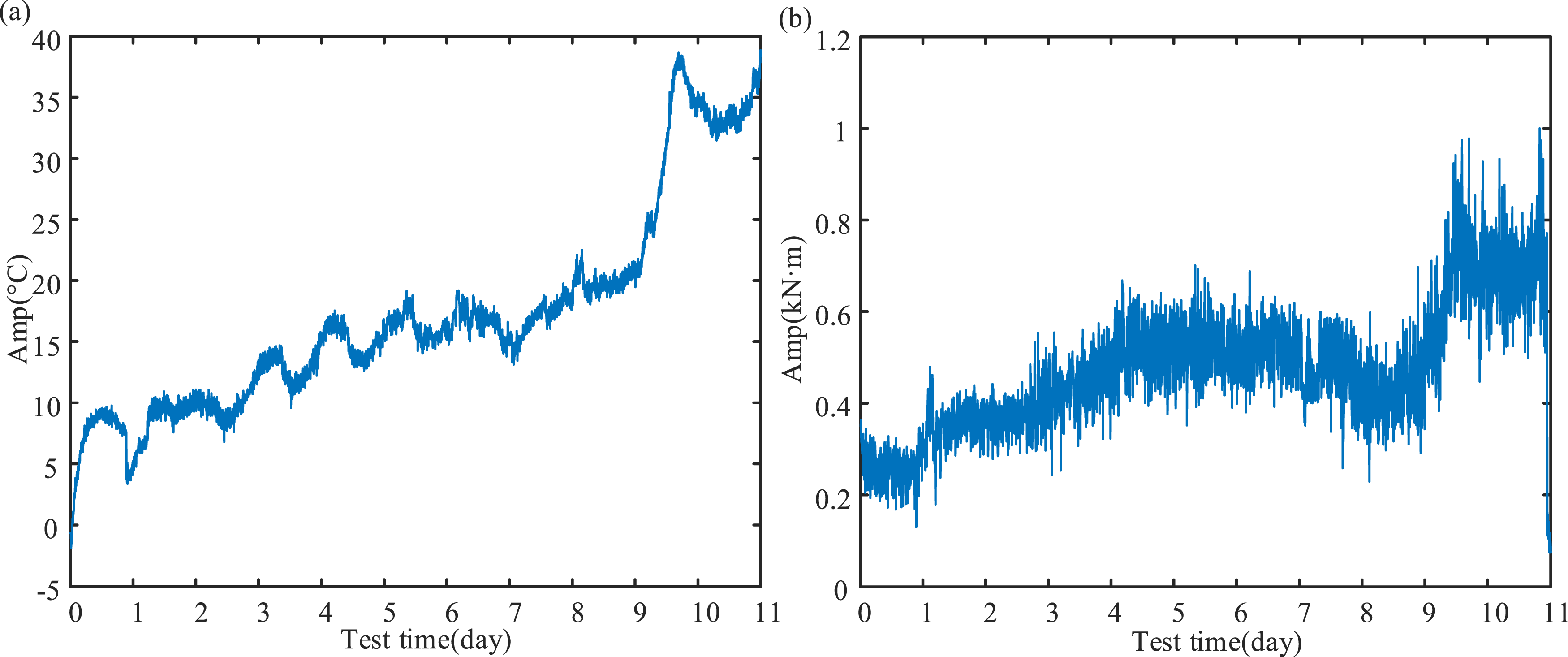
Additionally, it is worth noting that vibration signals are more sensitive to faults compared with temperature and torque signals. Nevertheless, the advent of large data volumes, variability, and diversity brings new opportunities for advancing signal processing techniques. Consequently, data fusion emerges as a viable option for enhancing RUL prediction, and its superiority will be demonstrated in the following sections.
4.2. Signal de-noising
Firstly, the procedure commences by segmenting the raw signal into 11 parts based on the test duration, followed by computing the corresponding PFs through MFO-CERLMDAN. Next, divide each PF into a matrix with multiple dimensions, with the normal matrix functioning as the reference for the healthy state in the KPCA model. The SPE statistics are derived through the projection of the multi-dimensional matrix into the healthy state KPCA model. Subsequently, calculate the WCV of decomposed PFs, and PFs with larger WCV are selected. Finally, reconstruct the life-cycle signals by utilizing the selected PFs. Figure 7(a) depicts the de-noised effect obtained through the application of MFO-CERLMDAN-KPCA. De-noised life-cycle vibration signal: (a) MFO-CERLMDAN-KPCA and (b) CERLMDAN-KPCA.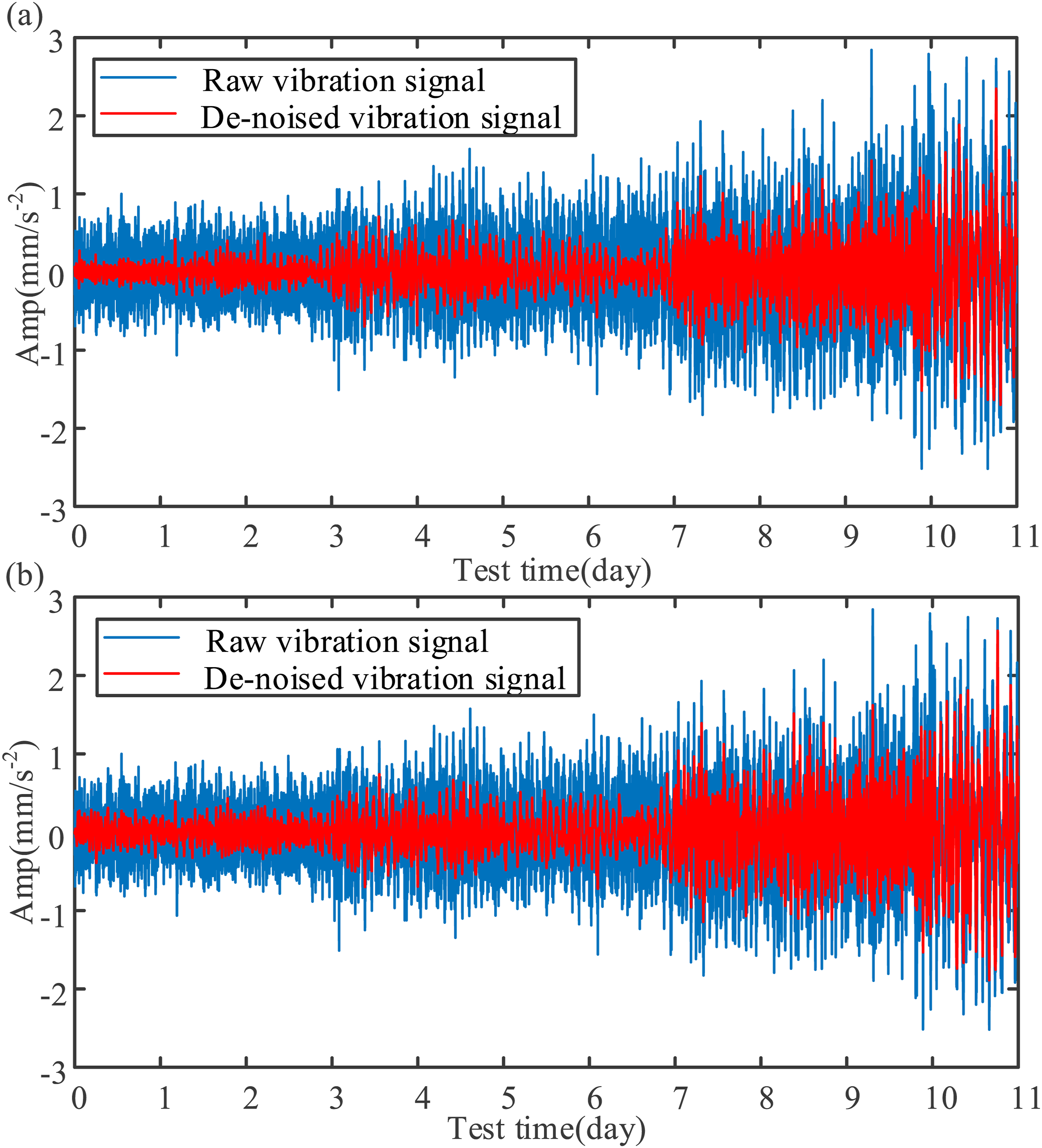
To verify the effectiveness of parameter optimization, we utilize CERLMDAN-KPCA with empirical value (ε = 0.2 and I = 100) as a benchmark for comparison. Figure 7(b) depicts the de-noised results obtained using CERLMDAN-KPCA. From Figure 7, the following insights can be derived: (1) Both MFO-CERLMDAN-KPCA and CERLMDAN-KPCA effectively eliminate considerable white noise contamination in life-cycle vibration signals. (2) Compared with CERLMDAN-KPCA, MFO-CERLMDAN-KPCA significantly reduces reconstruction errors with suitable decomposition parameters, making fault characteristics clearer from an overall trend observation. Therefore, MFO-CERLMDAN-KPCA stands as the optimal method for signal de-noising of extra-large-scale bearing.
4.3. RUL prediction
The performance degradation of large-size, low-speed extra-large-scale bearings, from normal operation to failure, can span months or even years. While feature extraction allows for the monitoring of this temporal degradation, different features exhibit varying sensitivities to specific faults during distinct stages (Bhavsar et al., 2022). Furthermore, the efficacy of analytical methods often varies across different operational phases. To maximize the preservation of fault information, this study extracts comprehensive features from both the time domain and time-frequency domain to holistically reflect the health condition of the bearing.
Time-domain features are primarily categorized into dimensional and dimensionless indicators. Dimensional features (e.g., kurtosis, mean, variance, and root mean square) characterize the impact energy of the vibration signal. In contrast, dimensionless features (e.g., waveform index, peak index, margin index, and skewness) are widely utilized for condition monitoring and fault recognition in rotary equipment, as they are independent of signal amplitude. Consequently, eight representative time-domain features are selected. To mitigate information loss under non-stationary conditions, time-frequency analysis is employed to map one-dimensional time-domain signals into a two-dimensional time-frequency representation. As a representative time-frequency method, wavelet packet transform (WPT) decomposes signals into various frequency bands with adaptive time-frequency resolution. In this paper, WPT is utilized to divide the vibration signal into eight frequency bands and calculate the energy spectrum of each band, yielding eight time-frequency domain features.
After feature extraction, these different domain features are used as the input vector of the prediction model at time t and the corresponding real RUL as model output. The aim is to build the relationship between the features and RUL of extra-large-scale bearing. The entire life-cycle multi-domain features are divided into 660 samples, with the training and testing dataset allocated at a ratio of 2:1. Based on preliminary experiments conducted in our lab, we set the number of layers in the KELM-AE to 2, resulting in satisfactory prediction performance with the involved methods. For parameter optimization, MFO is employed, with the C and σ for MLKELM-AE optimized within ranges of 0.1 to 1000.0 and 0.01 to 100.00, respectively.
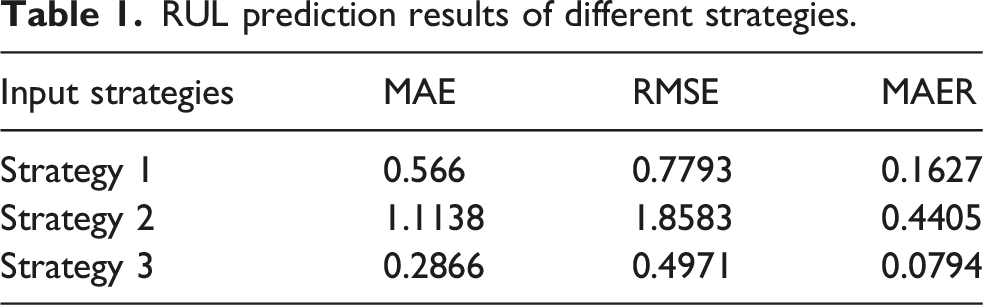
To quantitatively assess the impact of feature extraction within the MLKELM-AE, three strategies for combining features are employed in RUL prediction: (i) Strategy 1: time-domain features; (ii) Strategy 2: time-frequency domain features; and (iii) Strategy 3: time-domain and time-frequency domain features. Figure 8 presents the RUL prediction results obtained from testing datasets using Strategies 1, 2, and 3. To quantitatively evaluate the performance of each method in RUL prediction, the mean absolute error (MAE), root mean square error (RMSE), and mean absolute error ratio (MAER) are calculated for comparative analysis. These indicators provide a comprehensive view of prediction accuracy from different perspectives. However, their similarities lie in that the smaller RMSE, MAE, and MAER are, the lower predicted error is, signifying a more robust prediction capability. The mathematical formulations for RMSE, MAE, and MAER are provided below: RUL prediction results of different strategies: (a) Strategy 1, (b) Strategy 2, and (c) Strategy 3.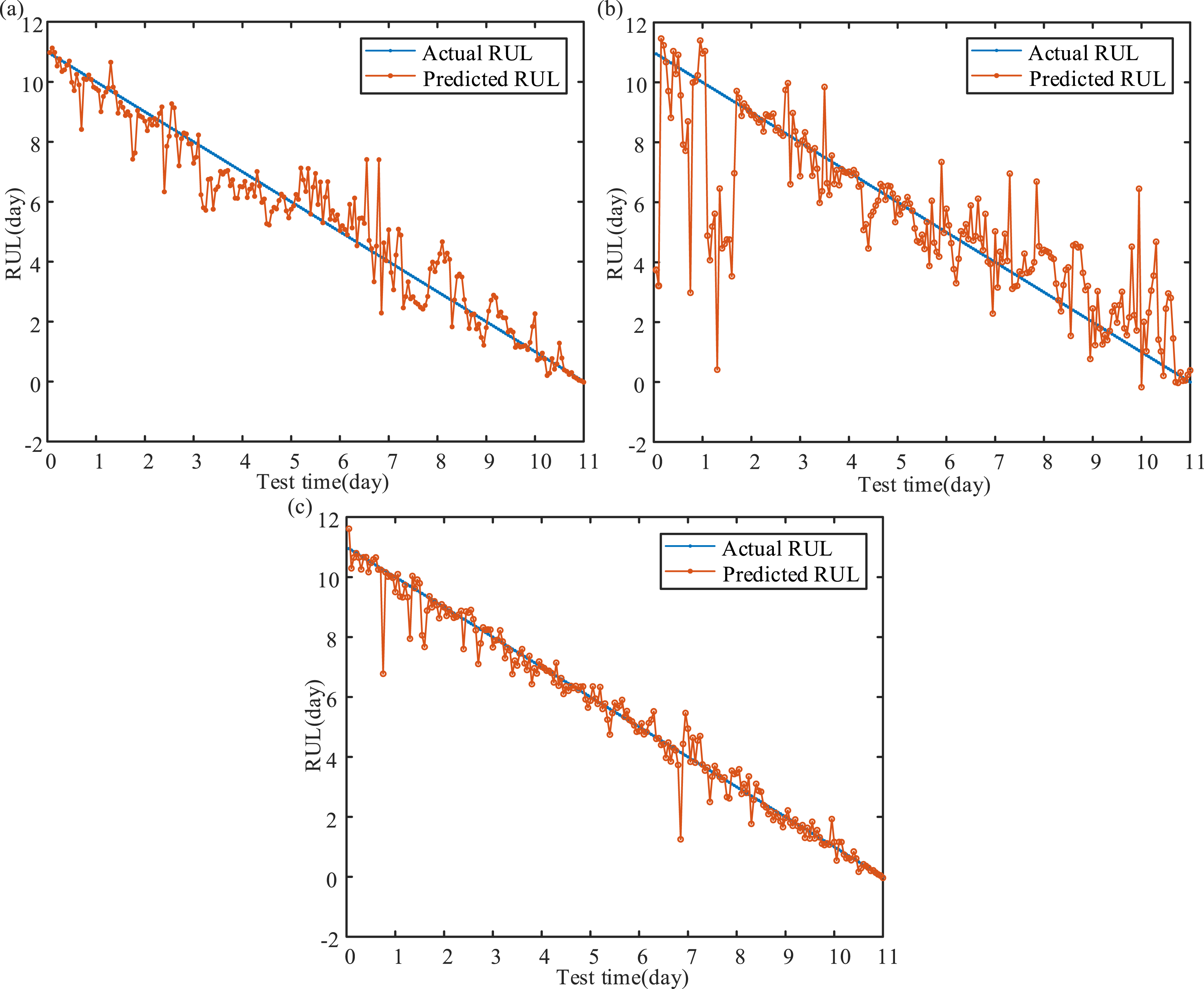
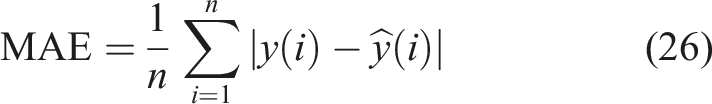
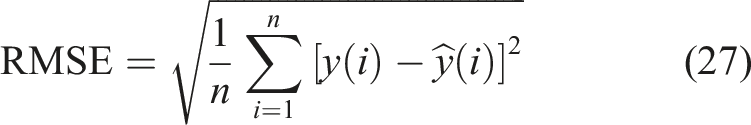
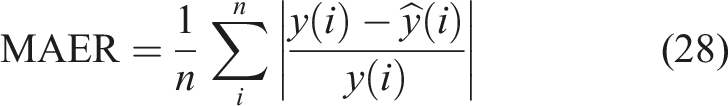
RUL prediction results of different strategies.
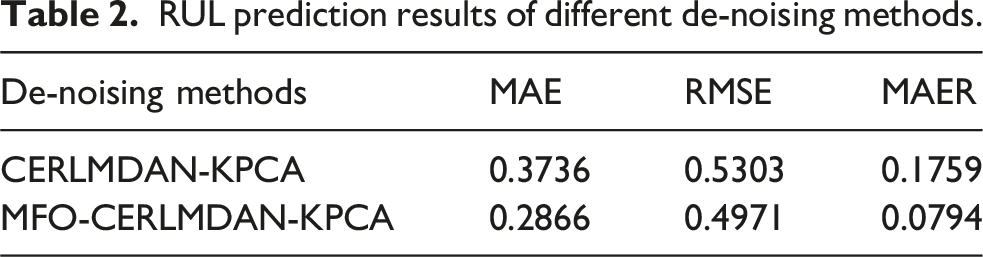
To further demonstrate the effectiveness of parameter optimization for signal de-noising, we calculate the RUL prediction results using de-noised vibration signals processed by both MFO-CERLMDAN-KPCA and CERLMDAN-KPCA. For simplicity, only Strategy 3 is selected as the input feature. Figure 9 and Table 2 illustrate the prediction results. Prediction results based on CERLMDAN-KPCA perform worse than those using MFO-CERLMDAN-KPCA. Therefore, through both visualization analysis (Figure 9) and quantitative analysis (Table 2), the proposed parameter optimization for signal decomposition is essential for RUL prediction on such low signal-to-noise ratio vibration signals. RUL prediction results of different de-noising methods: (a) CERLMDAN-KPCA and (b) MFO-CERLMDAN-KPCA. RUL prediction results of different de-noising methods.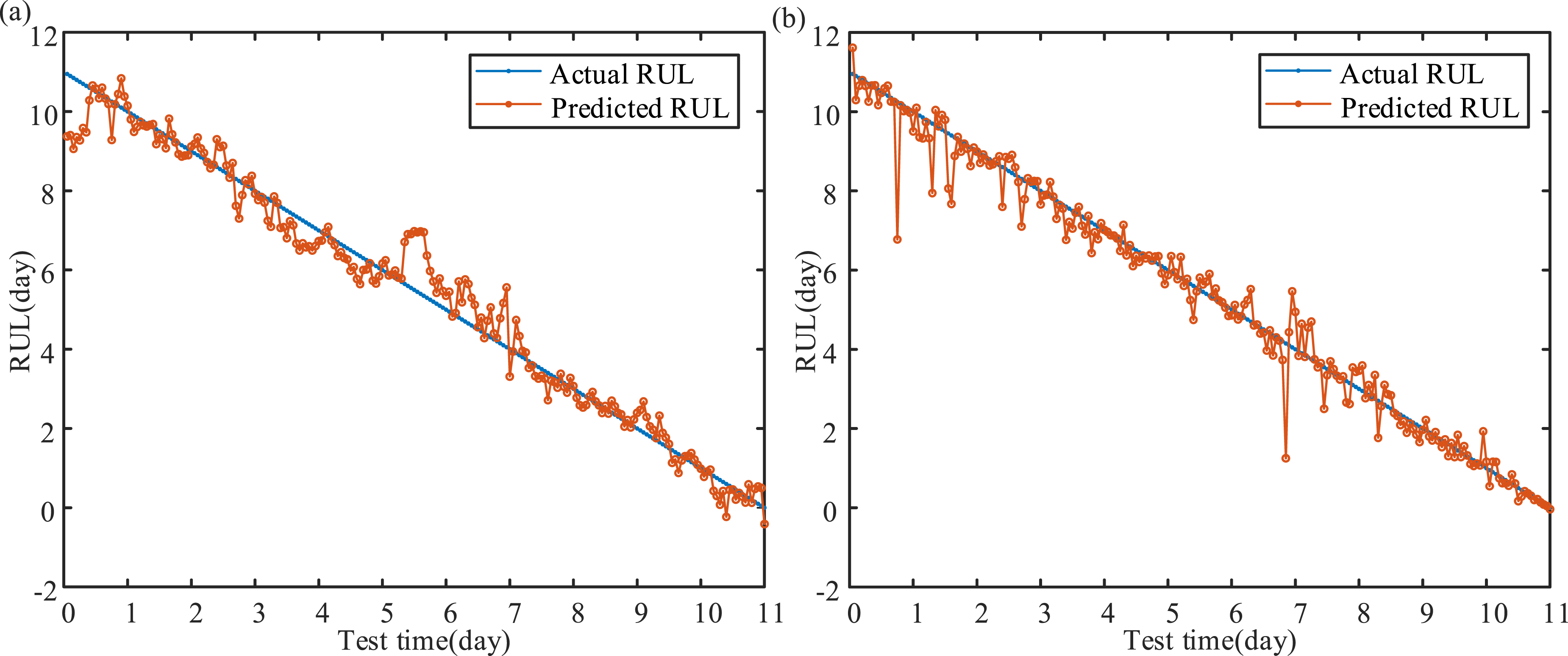
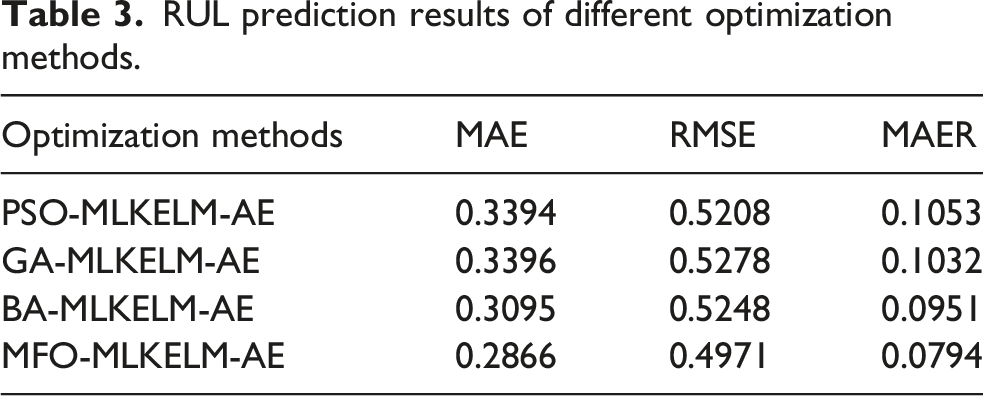
To explore the parameter optimization performance of MFO proposed in this research, particle swarm optimization (PSO), genetic algorithm (GA), and bat algorithm (BA) are employed as comparison algorithms. Figure 10 and Table 3 depict the RUL prediction results of four models. The prediction accuracy of MFO-MLKELM-AE is superior to that of other optimization models. Therefore, the proposed MFO method can achieve the optimal fitness value with ensuring the prediction accuracy, demonstrating superior stability and robustness. Furthermore, to verify the effectiveness of parameter optimization, random values are assigned to C and σ. The RUL prediction accuracy is shown in Figure 11 and Table 4. RUL prediction accuracy based on MFO-MLKELM-AE significantly surpasses that utilizing non-optimized MLKELM-AE. Consequently, the combined values of C and σ exert a notable influence on the capability of MLKELM-AE, verifying the necessity of using swarm intelligence algorithms to optimize the hyperparameters. RUL prediction results of different optimization methods: (a) PSO, (b) GA, (c) BA, and (d) MFO. RUL prediction results of different optimization methods. RUL prediction results without parameter optimization: (a) Strategy 1, (b) Strategy 2, and (c) Strategy 3. RUL prediction results without parameter optimization.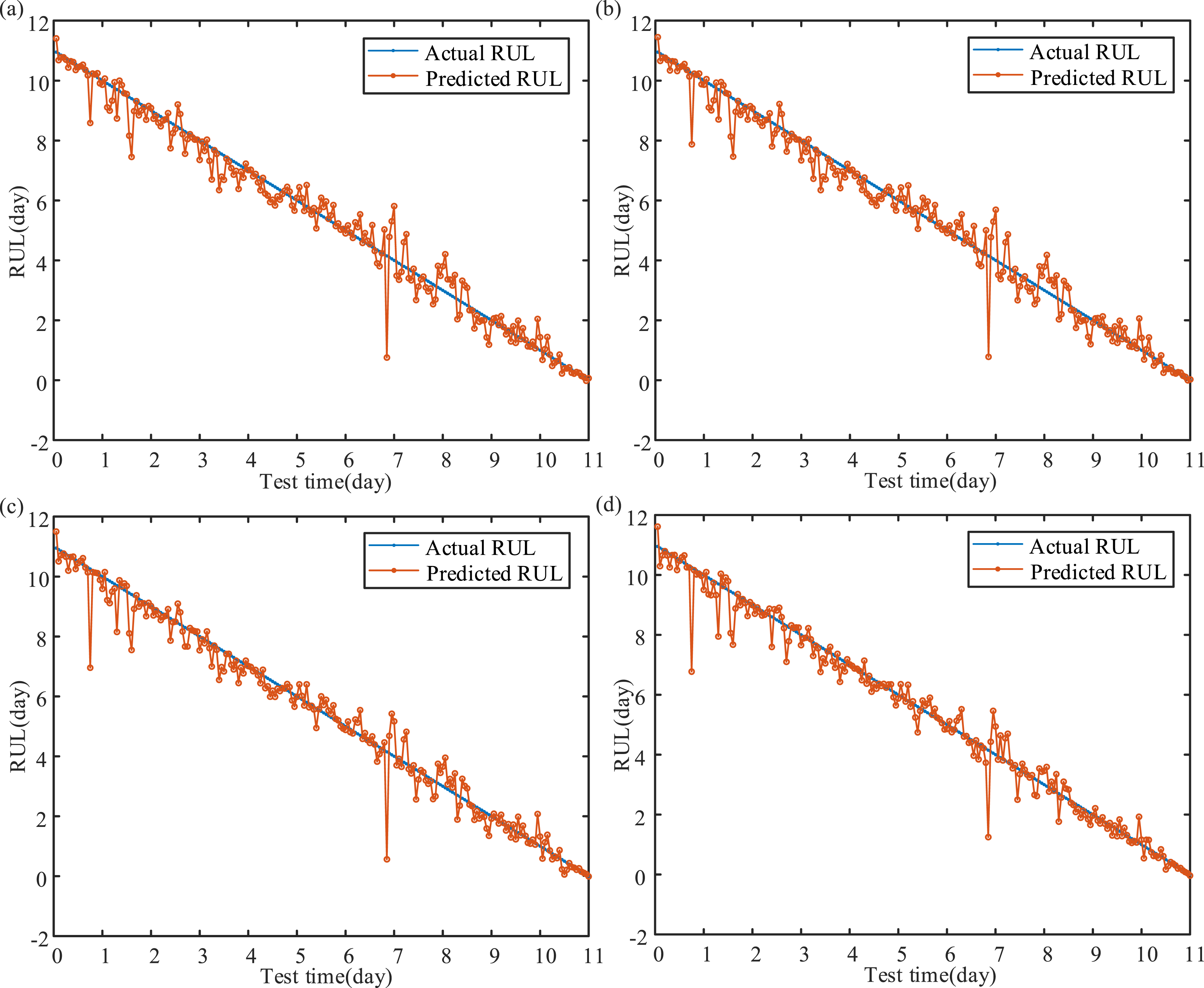
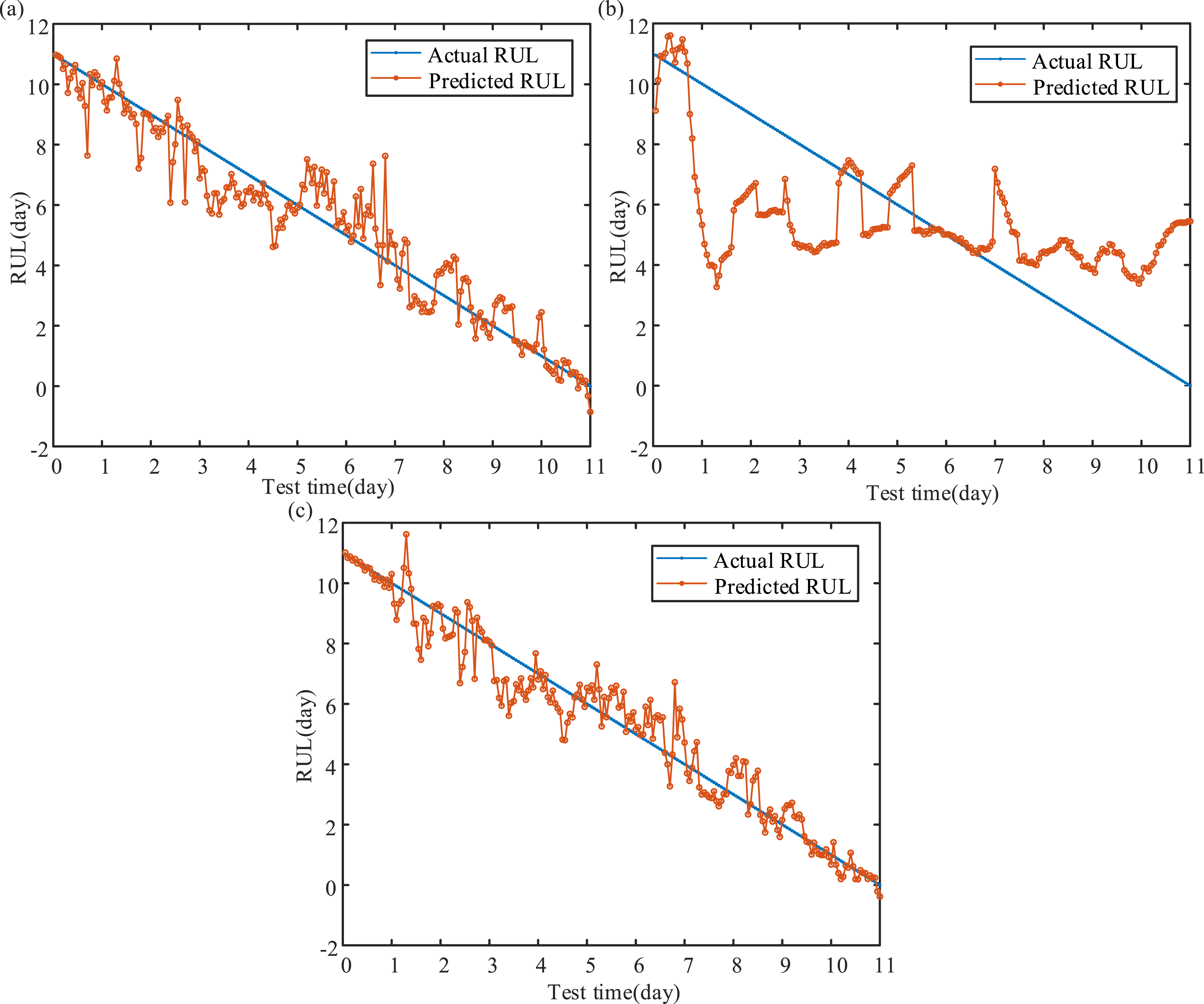

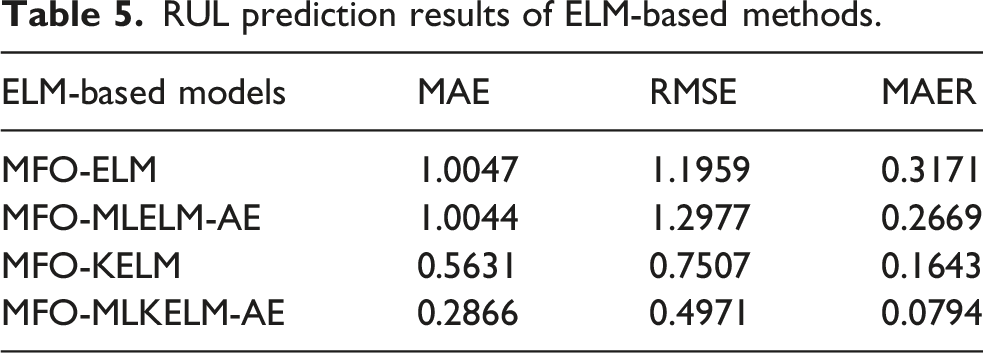
According to Section 3.3 mentioned above, the development of MLKELM-AE is rooted in ELM-based theory, particularly in its multi-layer structure and kernel mapping. Furthermore, we evaluate the effectiveness of MLKELM-AE by comparing it with the multi-layer extreme learning machine based auto-encoder (MLELM-AE), single-layer ELM, and KELM models. The MLELM-AE consists of multiple ELM-AE layers followed by a prediction layer ELM. To ensure a fair comparison, MFO is employed to optimize the weights, biases in both MLELM-AE and ELM, as well as the kernel parameter and penalty coefficient in KELM. The results, displayed in Figure 12 and Table 5, demonstrate that the proposed MFO-MLKELM-AE demonstrates superior prediction accuracy compared with the other three traditional models. Obviously, the multi-layer structure boosts the accuracy of MFO-MLELM-AE and MFO-MLKELM-AE compared with MFO-KELM and MFO-ELM. Additionally, incorporating the kernel function in KELM improves the prediction accuracy of MFO-MLKELM-AE and MFO-KELM over MFO-MLELM-AE and MFO-ELM, respectively. In conclusion, the combination of multi-layer structure and kernel mapping enhances the ability of MFO-MLKELM-AE model to extract multi-dimension nonlinear features, leading to better generalization and robustness. RUL prediction results of ELM-based methods: (a) MFO-ELM, (b) MFO-MLELM-AE, (c) MFO-KELM, an d (d) MFO-MLKELM-AE. RUL prediction results of ELM-based methods.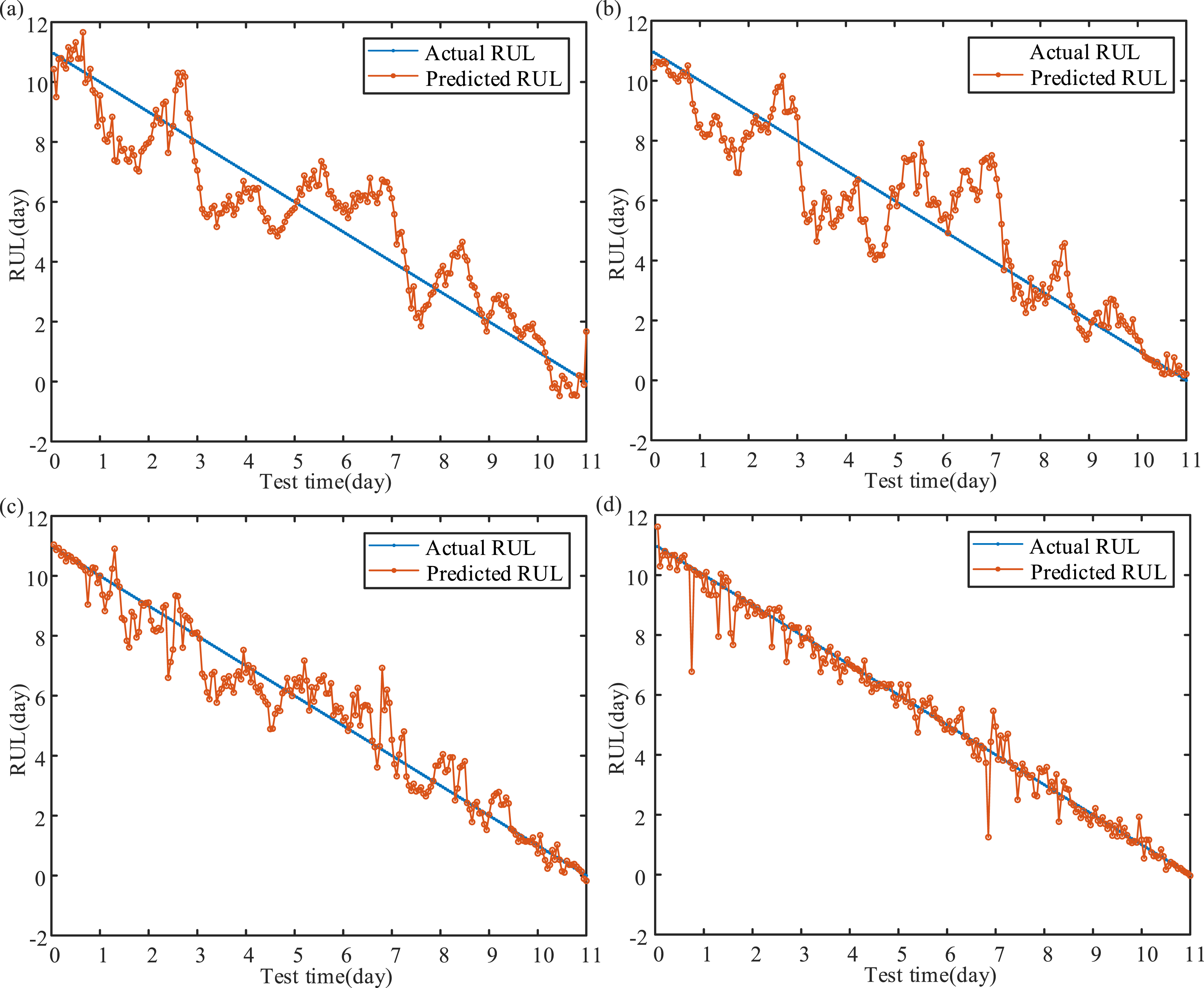
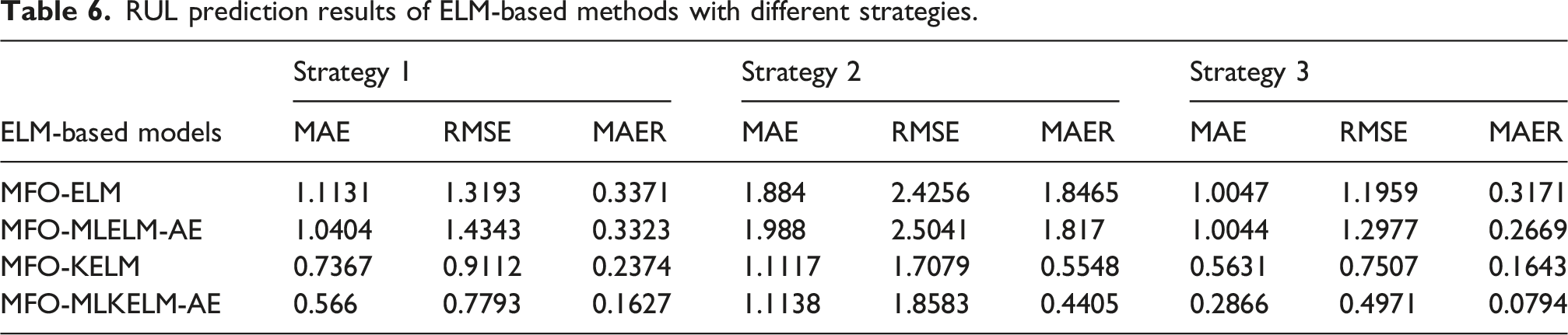
RUL prediction results of ELM-based methods with different strategies.
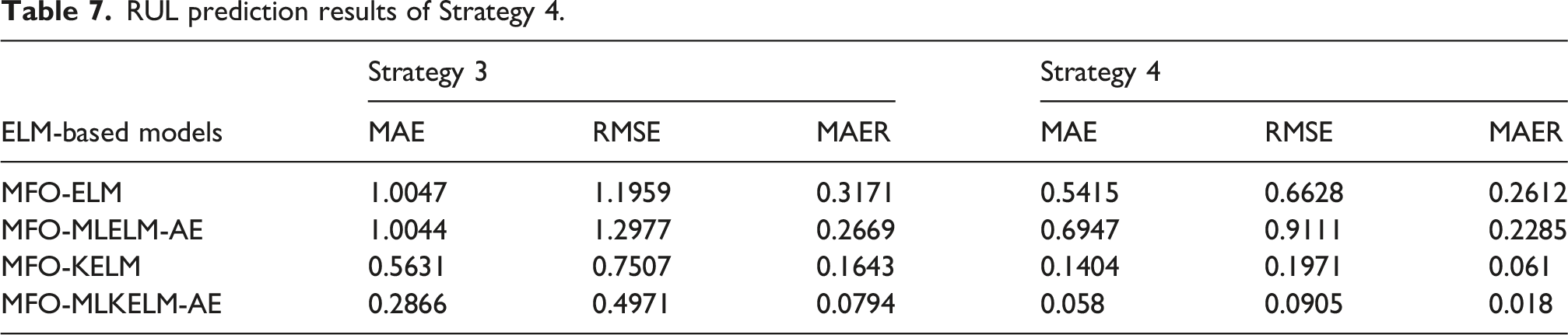
Apart from vibration signals, damage to extra-large-scale bearings can manifest through other characteristic signals such as grease temperature and driving torque. To fulfill the requirement for signal diversity in RUL prediction and leverage multi-sensor information effectively, multiple characteristic indicators are integrated to comprehensively reflect the operational status of extra-large-scale bearing. A RUL prediction model is established using 16-dimensional vibration features combined with 2-dimensional auxiliary parameters as model input (Strategy 4). The RUL prediction results, illustrated in Figure 13 and Table 7, demonstrate that the inclusion of auxiliary parameters enhances the prediction outcomes for all four ELM-related prediction models. This indicates that the auxiliary parameters contribute additional characteristics of extra-large-scale bearing from various perspectives, ultimately improving the accuracy of RUL prediction model. RUL prediction results utilizing Strategy 4: (a) MFO-ELM, (b) MFO-MLELM-AE, (c) MFO-KELM, and (d) MFO-MLKELM-AE. RUL prediction results of Strategy 4.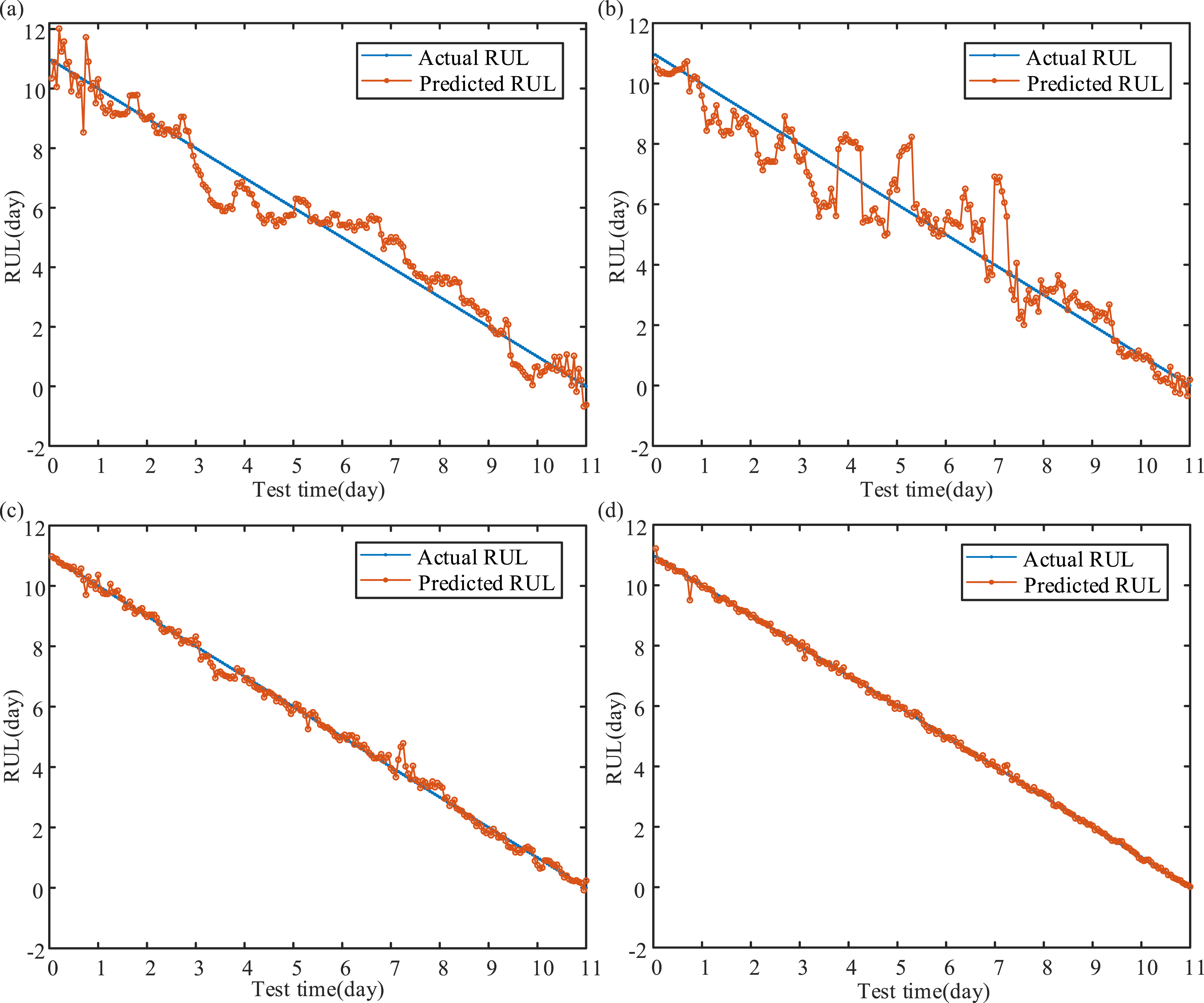
4.4. Evaluation of different models
Merely comparing ELM-related models may not be sufficient to conclusively demonstrate their superiority in RUL prediction. Therefore, it is imperative to take into account classical ML techniques such as back propagation (BP), least squares support vector regression (LSSVR), and DL methods like deep belief network (DBN). For a fair comparison, DBN along with two-layer restricted Boltzmann machine is utilized for feature representation (Pan et al., 2023). Following this, DBN-ELM and DBN-KELM, which incorporate prediction layers such as ELM and KELM, are selected. Additionally, kernel parameter and penalty coefficient of LSSVR, weights, and basis of BP are optimized using MFO. Hence, MFO is employed to determine the parameters of ELM and KELM within the DBN-ELM and DBN-KELM models. The prediction results are presented in Figures 14 and 15 and Tables 8 and 9. Four key conclusions can be drawn: (1) Notably, models employing Strategy 4 exhibit superior prediction accuracy compared with those using Strategy 3. (2) LSSVR demonstrates superior prediction ability compared with BP in both Strategy 3 and Strategy 4. Compared with MLKELM-AE, LSSVR appears visually significant deviations in the later stages of the service life. (3) DBN-ELM falls behind DBN-KELM in RUL prediction. Moreover, the feature representation via DBN fails to enhance prediction performance compared with KELM-AE structure with the same layer. (4) MLKELM-AE stands out as the most accurate model among the ones evaluated. The primary reason for the outstanding capability of proposed method is attributed to MLKELM-AE, which effectively captures the fault information during the extra-large-scale bearing degradation process. Meanwhile, data fusion plays a crucial role in retaining sufficient fault information. RUL prediction results of ML algorithms: (a) MFO-BP+Strategy 3, (b) MFO-BP+Strategy 4, (c) MFO-LSSVR+Strategy 3, and (d) MFO-LSSVR+Strategy 4. RUL prediction results of DL algorithms: (a) DBN-ELM+Strategy 3, (b) DBN-ELM+Strategy 4, (c) DBN-KELM+Strategy 3, and (d) DBN-KELM+Strategy 4. RUL prediction results of ML algorithms. RUL prediction results of DL algorithms.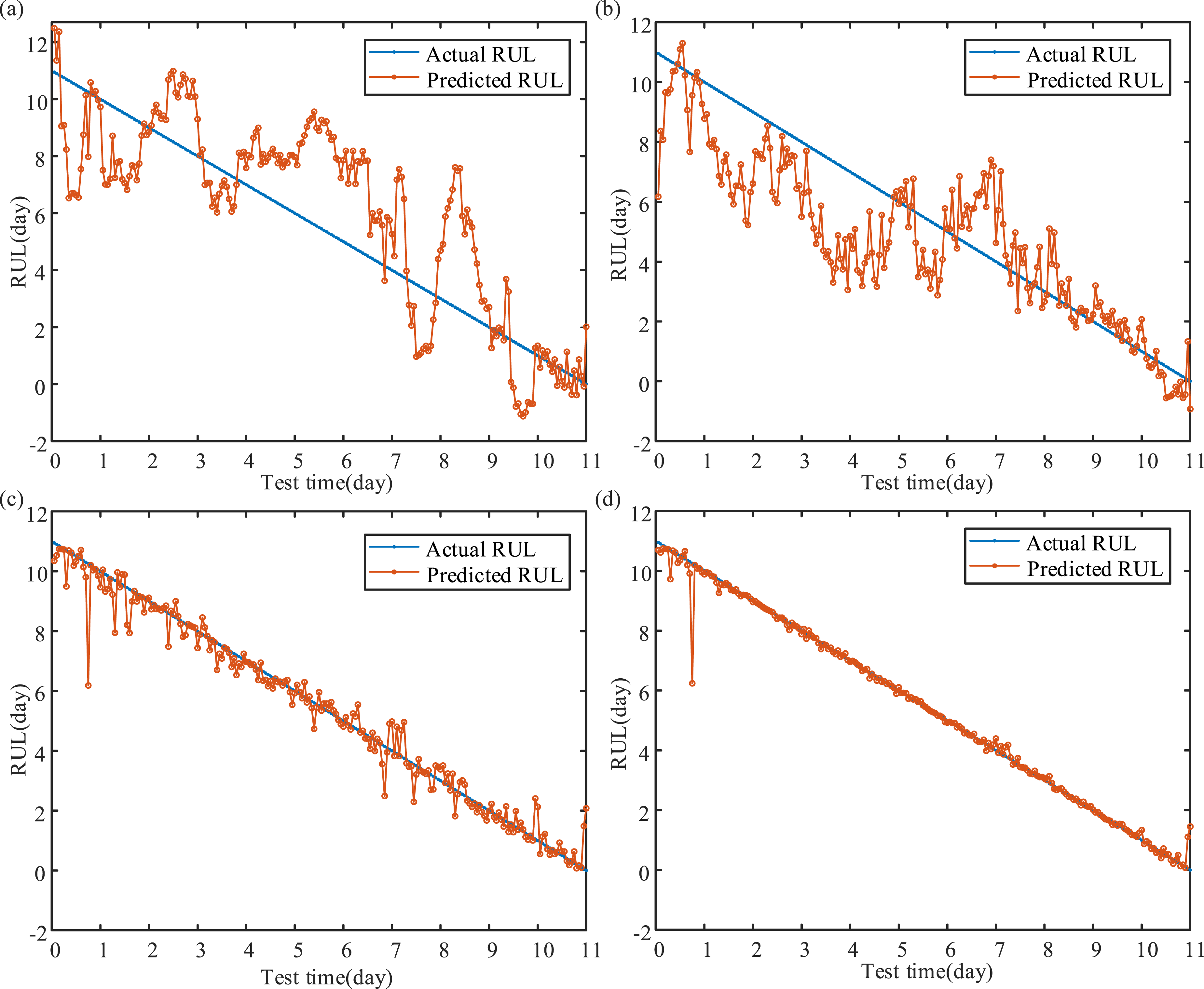
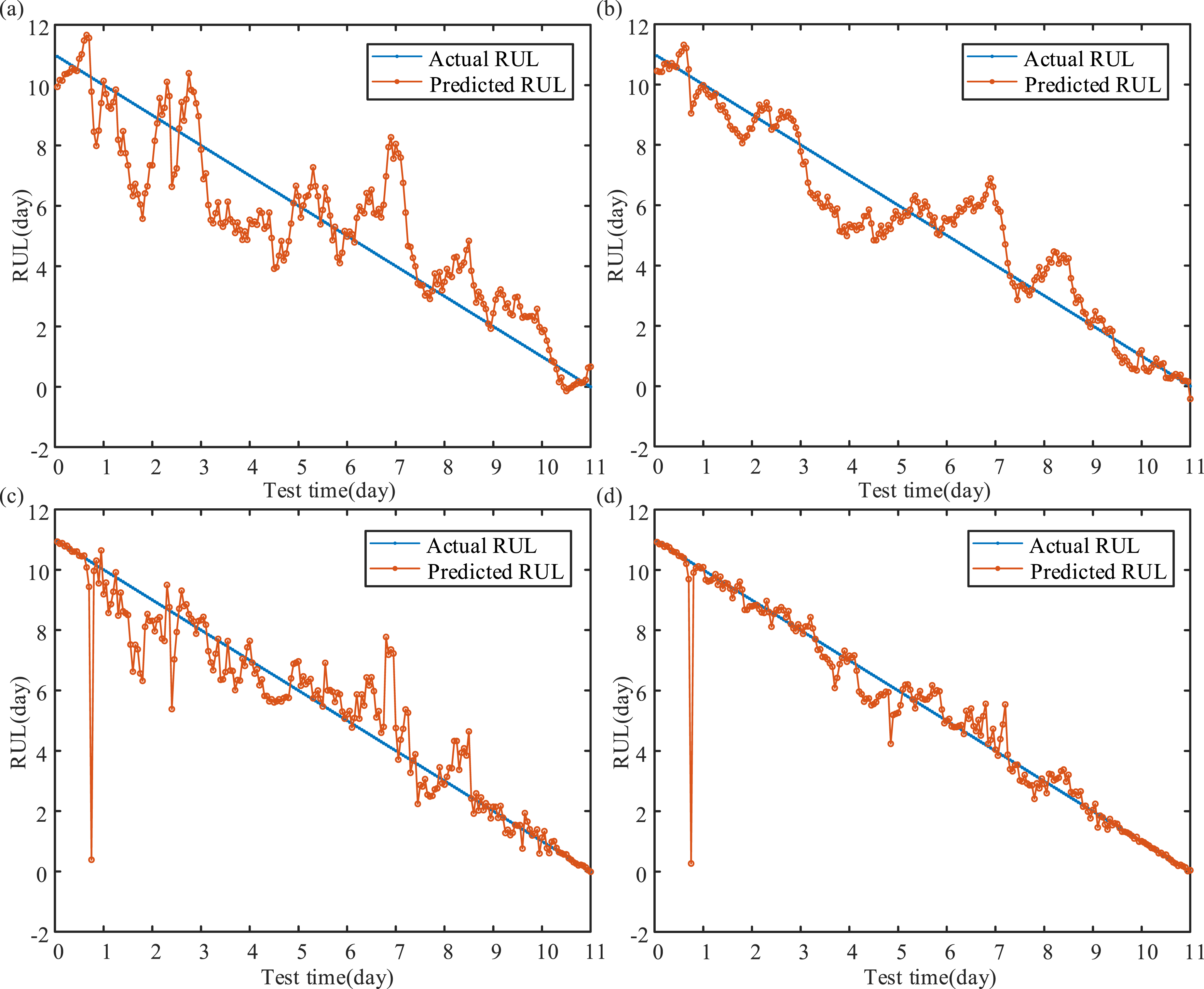


In summary, the primary areas of analysis in the hybrid prognostic approach encompass the following aspects: (1) Data-Centric Prognostic Approach: The model input holds paramount importance in data-driven prediction. By utilizing a combination of CERLMDAN-KPCA for signal de-noising and multi-domain feature extraction, it is capable of gathering as much fault information as feasible, thus guaranteeing superior model data input quality. (2) Model-Centric Prognostic Approach: The multi-layer structure of KELM-AE, equipped with a prediction layer, allows for the consideration of both high-level feature representation and prediction accuracy.
Therefore, the integration of an effective data-centric approach with a model-centric prediction method underscores the high performance of this methodology, making it particularly suited for the prognostic analysis of extra-large-scale bearing.
5. Summary and conclusion
This paper presents a hybrid prognostic approach for extra-large-scale bearing using enhanced CERLMDAN-KPCA and MLKELM-AE. MFO-CERLMDAN-KPCA-based signal de-noising, coupled with multi-domain feature extraction, effectively characterizes the life degradation process of extra-large-scale bearing, outperforming CERLMDAN-KPCA and single-domain features. Additionally, auxiliary parameters such as grease temperature and driving torque enhance model accuracy, providing deeper insights into operation condition of extra-large-scale bearing. Four ELM-related models—ELM, MLELM-AE, KELM, and MLKELM-AE—are analyzed in this study. Experimental results demonstrate that the proposed MLKELM-AE, with its multi-layer structure and kernel mapping, surpasses the other three models. In terms of parameter optimization effect, MFO-MLKELM-AE performs better than BA-MLKELM-AE, GA-MLKELM-AE, and PSO-MLKELM-AE, especially better than non-optimization MLKELM-AE. When compared with other DL techniques like DBN-ELM and DBN-KELM, as well as ML methods such as BP and LSSVR, MLKELM-AE exhibits superior RUL prediction capabilities.
Future work will extend the proposed framework to diverse network architectures to evaluate its generalizability across various deep learning paradigms. Additionally, comparative analyses will be conducted to investigate the method adaptability to other rotating machinery, accounting for variations in dynamics, load conditions, and measurement sensitivity. These efforts will further validate the generalization capability of the proposed approach. Ultimately, the development of an online monitoring system is planned to deploy this methodology in real-world scenarios, thereby advancing proactive maintenance capabilities for extra-large equipment.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by funding from the National Natural Science Foundation of China (52205106) and Natural Science Foundation of Jiangsu Province (BK20210547).
Declaration of conflicting interests
The authors declared no conflicts of interest in relation to the research, authorship, and/or publication of this article.