
Abstract
Chatter vibration in cold rolling significantly affects productivity and product quality. Accurate prediction of the speed at which that chatter vibration occurs is crucial for vibration control, leading to high-speed, high-quality, and stable rolling. This study proposes a multi-fidelity transfer learning (MFTL) approach to predict the critical chatter speed in a two-stand cold rolling mill, utilizing process information and machine learning (ML). Recognizing the limited availability of high-fidelity data, a two-stage training strategy is employed. First, a low-fidelity dataset generated from a physics-informed model is used for initial training. This model, derived using response surface methodology (RSM), efficiently approximates the computationally expensive analytical rolling process model, enabling the generation of a large and diverse dataset. Subsequently, the network is fine-tuned using a smaller, high-fidelity dataset. Results demonstrate that using MFTL approach outperforms a model trained solely on high-fidelity data and can effectively predict the critical chatter speed based on process data, reducing the need for time-consuming and costly trial-and-error approaches to determine maximum allowable speeds. This assists the vibration control unit in preventing chatter, leading to improved quality and enhanced rolling process efficiency.
Keywords
1. Introduction
Rolling mills are one of the most important equipment in the steel industry. One of the main problems of the rolling mills is a phenomenon called chatter (Niroomand et al., 2019). Chatter is a kind of self-excited vibration that occurs during the rolling of high-strength, thin, and high-speed steels. The occurrence of chatter can lead to improper conditions such as unacceptable sheet folds, surface defects, damage to mills, and undesirable noise in the work environment (Mehrabi et al., 2015). Chatter has three predominant types: torsional, third octave and fifth octave. Third octave chatter is the most serious type of chatter characterized by a very sudden occurrence and it happens at a frequency between 100 and 250 Hz (Niroomand et al., 2012). This type of chatter occurs suddenly and can lead to oscillations in strip thickness or even strip rupture (Mehrabi et al., 2015). Chatter is typically controlled by reducing the rolling speed, which leads to a decrease in plant productivity. Considering the high cost of rolling mills and the reduction in production rates aimed at controlling chatter, this phenomenon holds significant importance from both technical and economic perspectives. Therefore, preventing chatter is important for a high-speed and stable rolling process (Lu et al., 2020). Research on rolling mill vibrations is categorized into two domains: modeling of the chatter phenomenon and detection and prediction of chatter.
In studies that have modeled the chatter phenomenon, the focus has generally been on examining the effect of various rolling process parameters on the critical chatter speed. In the study by Yun et al. (1998), a review of existing mathematical models of the mill structural, the rolling process, and chatter models, which result from the interaction between the structural dynamics of the mill stand and the dynamics of the rolling process, is presented. Kimura et al. (2003) established a mathematical model to simulate the vibration behavior of a five-stand rolling mill and investigated the fundamental mechanism of chatter and the relationship between rolling conditions and the stability of mill vibrations. Heidari and Forouzan (2013) optimized the rolling process using a genetic algorithm by employing simulation data and developing a statistical model that describes the relationship between the system’s tendency to chatter and rolling parameters. Mehrabi et al. (2015) have developed the stand structure model as a mass-spring-damper system and the rolling process model using the finite element method (FEM). By combining the two models, they investigated the effects of rolling speed, reduction, input thickness to the stand, and friction coefficient on the chatter phenomenon. Heidari et al. (2018) proposed a chatter model for a two-stand cold rolling mill under unsteady lubrication conditions. The results obtained from the developed model were compared with simple friction models and experimental results in terms of chatter critical speed, frequency range, rolling force, and torque.
Rolling mills are highly complex systems, and therefore, several assumptions have been made in developing their models. Nonetheless, these models are suitable for analyzing the impact of parameters influencing chatter. Studies have demonstrated that the parameters of speed, friction coefficient, reduction, and exit thickness from the stand have the most significant effect on chatter (Mehrabi et al., 2015; Heidari et al., 2018).
One of the new methods for studying the chatter phenomenon is the integration of a control unit with structure-process mathematical model. In the study by Gao et al. (2020), by applying the Routh–Hurwitz stability criterion to the process-structure-control model, a model for calculating the rolling speed threshold has been obtained and the effects of reduction, friction coefficient, and control parameters on stability and instability have been investigated. Subsequently, Gao et al. (2021) optimized the reduction parameter for each stand and the inter-stand tensions to increase rolling speed and the stability range.
In some studies, using data collected from real rolling process, the chatter phenomenon has been investigated or solutions for detecting it have been proposed. Niroomand et al. (2012) placed accelerometer sensors on various components of the rolling mill to investigate the sensitivity of different points to the chatter phenomenon. Through the analysis of the obtained acceleration signals, they concluded that the most sensitive points belong to the second stand, in the following order: upper backup roll, top housing, upper work roll, and lower work roll. In another study, Niroomand et al. (2019) investigated the chatter phenomenon from both vibration and sound perspectives. It was shown that there is a 0.15-s delay from the onset of vibration amplitude growth and the hearing of the chatter sound. In the invention by Nagai and Nohara (2023), it is stated that small vibrations occur before intense vibrations lead to noise. By detecting such small vibrations as an indication of chatter, the problems caused by chatter can be prevented. Another approach used for detecting the chatter phenomenon is the application of signal processing techniques and artificial intelligence. Lu et al. (2020) used data from a five-stand cold rolling mill and various regression models to predict the amplitude of vibrations in the stable rolling process. Finally, chatter detection was carried out based on the difference between the actual vibration amplitude and predicted value. Wang et al. (2023) proposed a cold rolling chatter monitoring and early warning method based on a combination of Functional Data Analysis and a General Autoregressive Model (GAM). In the GAM, various ML models are employed to predict the vibration energy using rolling process data. Ultimately, the optimal model is selected based on the criterion of maximum prediction step.
In recent years, deep neural network (DNN) models have been increasingly employed in problems where multiple interacting factors jointly determine the final outcome, with the aim of improving accuracy and reducing the computational cost of numerical simulations (Kocabıçak et al., 2025; Guo et al., 2025). Classical numerical methods such as the FEM rely on the discretization of partial differential equations, and their accuracy strongly depends on mesh quality. To overcome these limitations, Physics-Informed Neural Networks have been introduced (An Khang et al., 2025). Large datasets enable ML to approximate any mapping relationship well; they are highly misleading on smaller target datasets (Zhang et al., 2024). It is usually difficult to collect abundant high-fidelity training data for the expensive problems (Li et al., 2022). One of the promising solutions to this problem is TL where a pre-trained model on a large dataset is used (Pattnaik et al., 2020). High-fidelity data are highly accurate and detailed data that closely represent reality. Low-fidelity data are less accurate, simpler data that can be generated faster and at lower cost and only approximate reality. In the study by Liu et al. (2022), a DNN is first trained using the low-fidelity data. Then, TL is employed to transfer the knowledge of the composition/structure property relationship learned from the low-fidelity data to the model training with high-fidelity data. Noh et al. (2023) propose a multi-fidelity approach that combines low-fidelity and high-fidelity data to estimate Remaining Useful Life (RUL). Liang et al. (2023) used a vehicle-track-coupled analytical model and a 3D FEM to calculate train-induced ground vibration data under various condition variables. These data were then used to pre-train a DNN model. Additionally, a large number of vibrations were measured and used to fine-tune the DNN using TL strategies. Shi et al. (2024) utilized the low-fidelity data and the medium-fidelity data to generate a large amount of data for pre-training, and for fine-tuning, high-fidelity data from experiments was employed. Zhang et al. (2024) combined auto-encoders and a multi-channel TL strategy, enabling the network model to comprehend the relationship between the low-fidelity and high-fidelity models in both explicit and implicit manners. Luan and Zhang (2024) have introduced a novel MFTL framework designed to predict the complex bund overtopping fraction in catastrophic tank failure scenarios. This framework addresses the challenge of differing input dimensions between low-fidelity and high-fidelity datasets. Zhang et al. (2025), for fault diagnosis, proposed a TL model with a local sparse structure based on a parallel multi-channel convolutional neural network and a long short-term memory. Hou et al. (2025) proposed a deep learning (DL) framework for the multi-component fault diagnosis of bearings and gears. The one-dimensional mill vibration data were transformed into two-dimensional images, and TL was employed to accelerate model convergence and enhance the training efficiency. Given that numerous studies have been conducted on modeling the chatter in cold rolling mill in recent years, there is potential to leverage these models for generating low-fidelity data and to integrate multi-fidelity data utilization methods.
Research on chatter detection in cold rolling mills has focused on understanding the phenomenon and developing real-time detection methods. The number of studies conducted on chatter prediction in cold rolling mills is limited, and these studies have primarily focused on predicting vibration amplitudes or vibration energy using intelligent models and rolling parameters. Lu et al. (2020) used a limited number of data points (Lu et al., 2020; Wang et al., 2023), the performance has been evaluated only on data from normal conditions, and has not been investigated in situations where chatter occurred. The aim of previous studies in the field of chatter prediction has been to prevent the occurrence of chatter in real-time. This involves the operator of the rolling mill having to rely on trial and error to achieve the highest allowable speed. In this study, with the aim of achieving the highest rolling speed and preventing chatter, the prediction of chatter occurrence speed is carried out using rolling parameters and intelligent models. High-fidelity dataset has been extracted from a two-stand cold rolling mill based on the speeds at which chatter may occur. A low-fidelity dataset has been generated using an analytical model developed in previous studies for the rolling mill under investigation. Finally, the predictive performance of the MFTL approach is compared with that of a model trained solely on high-fidelity data.
2. Rolling mill and high-fidelity dataset
The rolling mill under study is a two-stand reversing cold rolling mill. The strips entering this rolling mill typically have an initial thickness of 2 mm. Each strip passes through two four-high stands in three passes and achieves the desired thickness. The minimum output thickness of this mill is 198 μm. A view of this mill is shown in Figure 1(a). (a) Two-stand tandem mill unit; (b) The placement of the accelerometer sensor.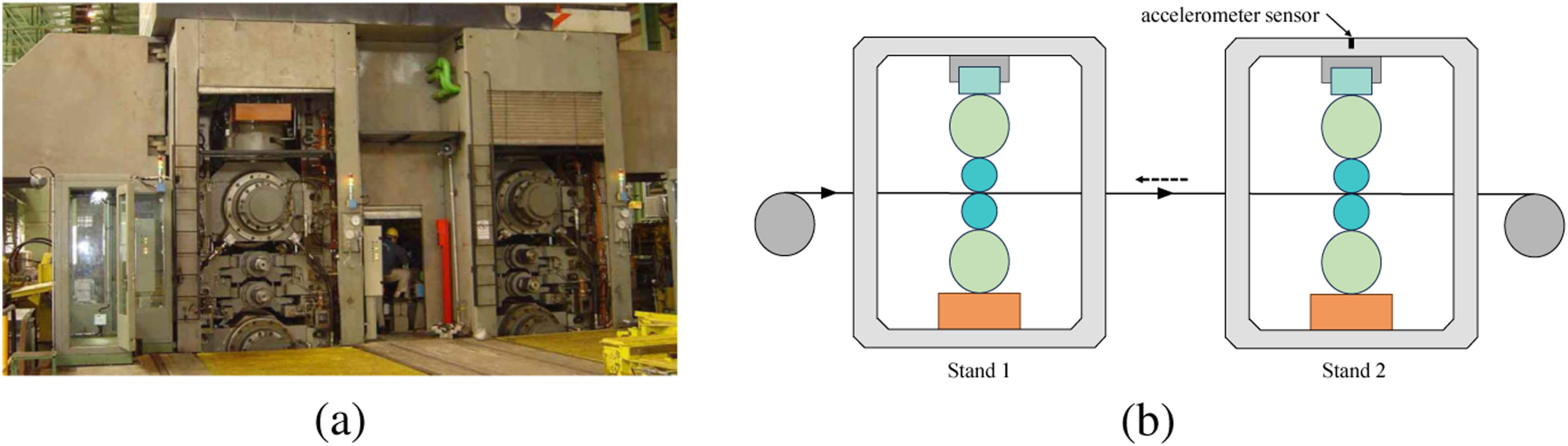
To achieve the maximum possible rolling speed and prevent strip rupture and equipment damage, a chatter detection system is employed. The chatter detection system employs data from the accelerometer sensor mounted on the top housing of the second stand. In Figure 1(b), the placement of the accelerometer sensor is illustrated.
The data acquisition frequency of the employed sensor is 5120 Hz. The vibration data is filtered within the frequency range of 70–140 Hz. The operation of the detection system is such that two levels of warning and alarm are calculated. If the root mean square (RMS) of the vibrations over the past 2 seconds exceeds the alarm level, and simultaneously, the RMS of the vibrations is increasing or a sudden increase in the RMS of the vibrations is detected, an alarm signal is issued. A warning signal is issued when the RMS of the vibrations over the past 2 seconds exceeds the warning level. The alarm level and the warning level are obtained according to equation (1).
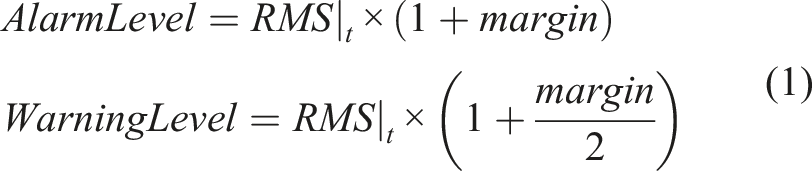
RMS|
t
represents the RMS of vibrations over the past t seconds. The margin is determined experimentally based on four parameters: strip thickness, strip width, work roll mileage (measured in kilometers), and rolling speed. For determine the alarm level under constant speed conditions, the RMS value of vibrations over the past 10 seconds is used and in conditions of increasing speed, and for up to 2 seconds afterward, the RMS value of vibrations over the past 4 seconds is used to avoid false alarms. The warning level is determined in a similar manner to the alarm level, with the exception that it is determined using half of the calculated margin for the alarm level. Figure 2 illustrates the functionality of the chatter detection system in the third pass of the rolling process of a coil. Functionality of the chatter detection system: (a) Variations of the linear speed for the second stand, and moments at the warning and alarm signals were issued; (b) Variations in the RMS values of vibrations, warning level, and alarm level.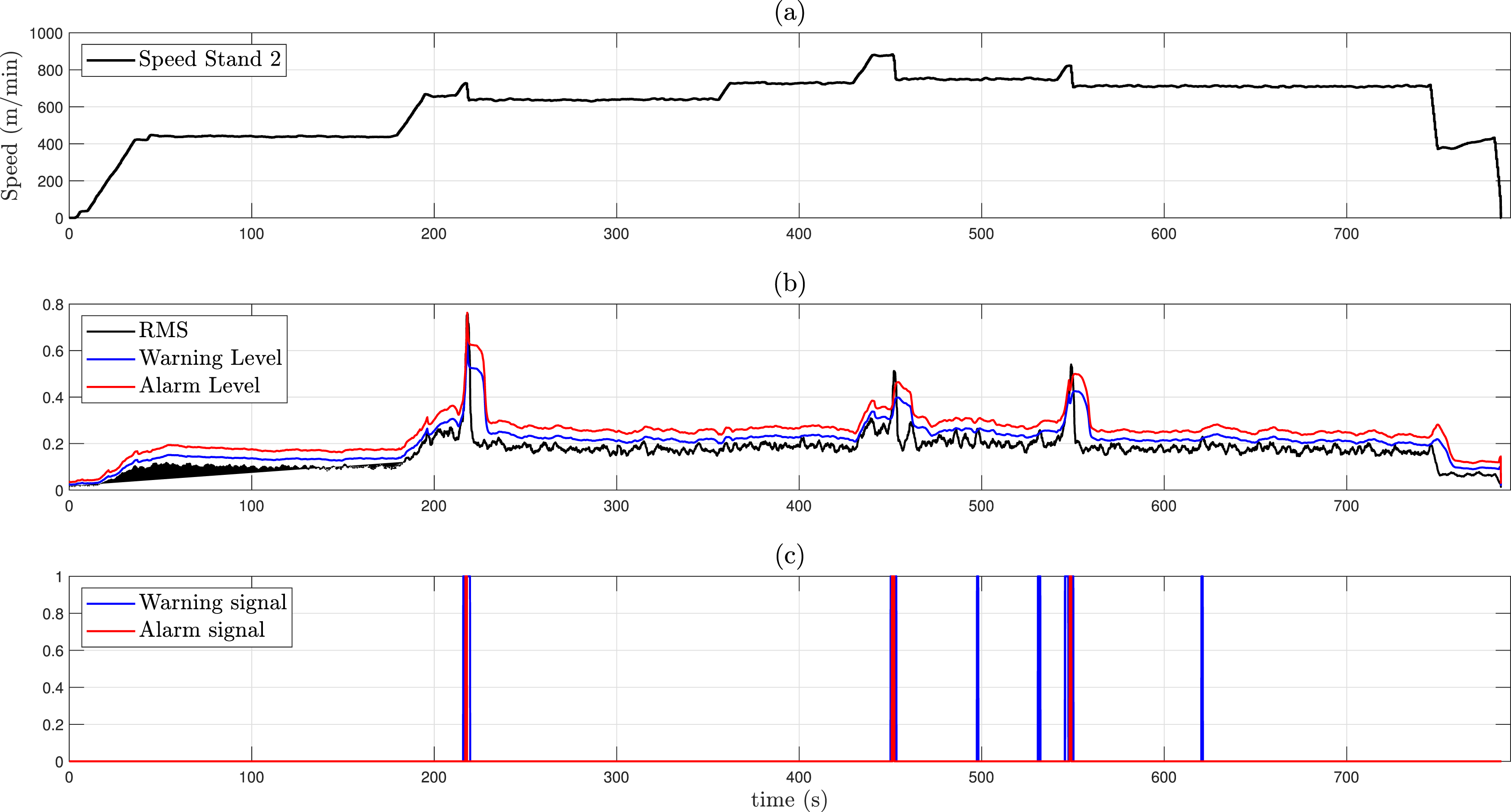
In this study, archived data from 188 various coils were utilized, which were acquired using a data acquisition system equipped with a hardware-level anti-aliasing filter to attenuate high-frequency components and prevent aliasing in the sampled signals. Since chatter occurs at high speeds and in thin strips, this study only utilizes data from the third rolling pass of strips having an output thickness less than 304 μm. Figure 3 illustrates the histogram of the output strip thickness from the second stand in the third rolling pass for all coils. In Table 1, the variation ranges of some rolling parameters in the available data are shown. In previous studies, the effects of these parameters on chatter occurrence speed have been investigated using mathematical and FEM (Kimura et al., 2003; Mehrabi et al., 2015). Analyzing the impact of these parameters on chatter occurrence speed was not an objective of the present study. The histogram of the output strip thickness from the second stand in the third rolling pass. Range of variations of rolling parameters in available data.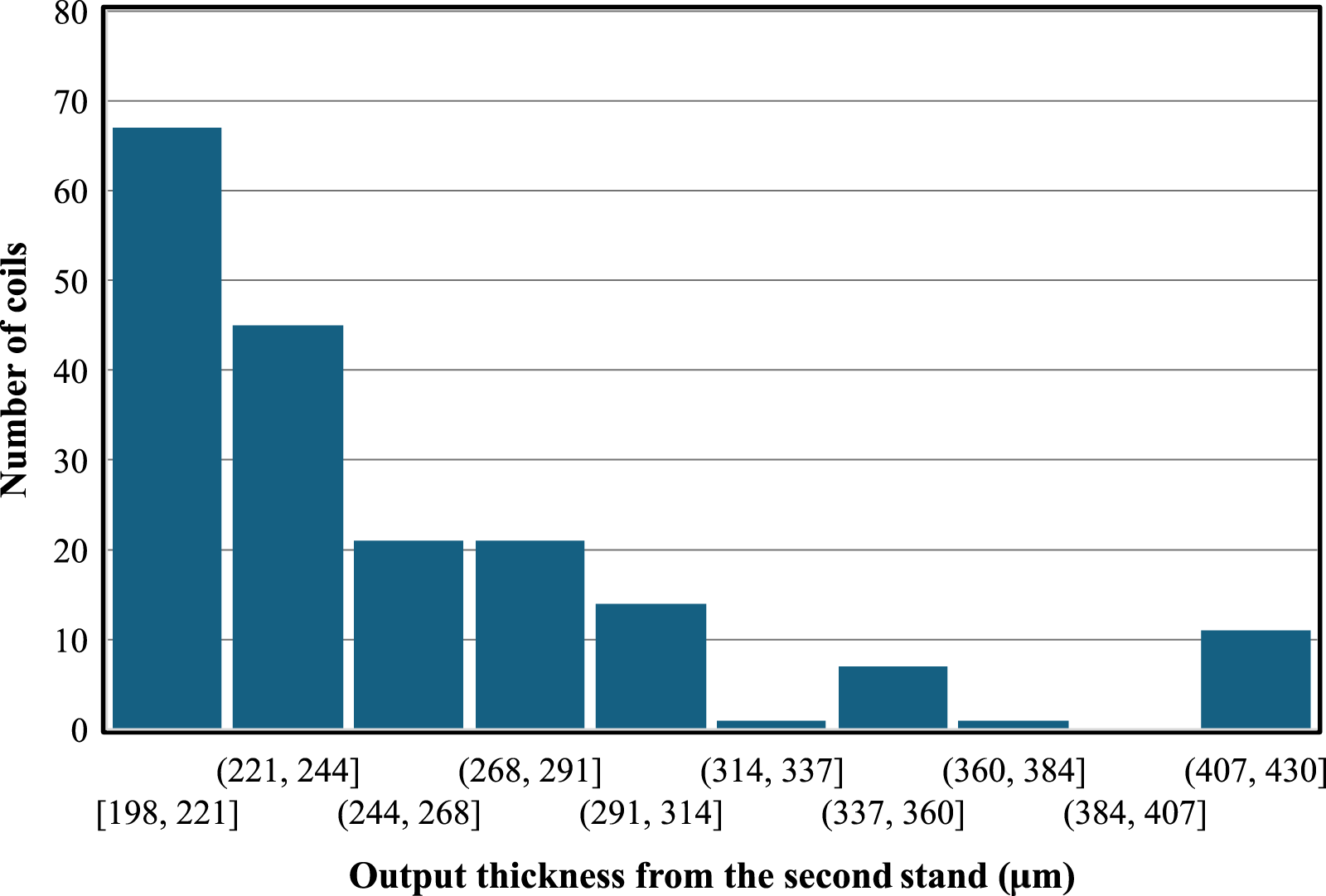

The proposed chatter detection system may issue alarm signals at very low speeds, and for this reason, it is assumed that if the rolling speed at the time of alarm is less than 300 m per minute, the alarm signal is a false alarm. In the chatter detection system, if the RMS value of the vibrations exceeds either the warning or alarm level, a warning or alarm signal is issued every 0.1 seconds, leading to the registration of multiple signals during the occurrence of chatter. For this reason, it is assumed that if the time between the issuing of two consecutive warning or alarm signals is less than 0.5 seconds, only the signal corresponding to the higher rolling speed is considered. If the time exceeds 0.5 seconds, two separate warning or alarm signals are considered. It is expected that with the issuance of the first alarm signal at a speed, the rolling speed should not be further increased to prevent chatter. To investigate this matter, the value of γ, defined as the ratio of the speed at which the alarm signal is issued to the maximum speed at which a coil has been rolled, was calculated. The closer γ is to 1, it indicates that the operator has not increased the machine speed after the issuance of the alarm signal. In Figure 4(a), the histogram of the number of alarm signals at values of γ for all coils is illustrated. It can be observed from Figure 4(a) that in many cases, despite the issuance of an alarm signal, the rolling speed has increased significantly. The histogram of (a) Number of alarm signals at values of γ for all coils; (b) Critical speeds of the second stand in the high-fidelity dataset created using γ = 0.6.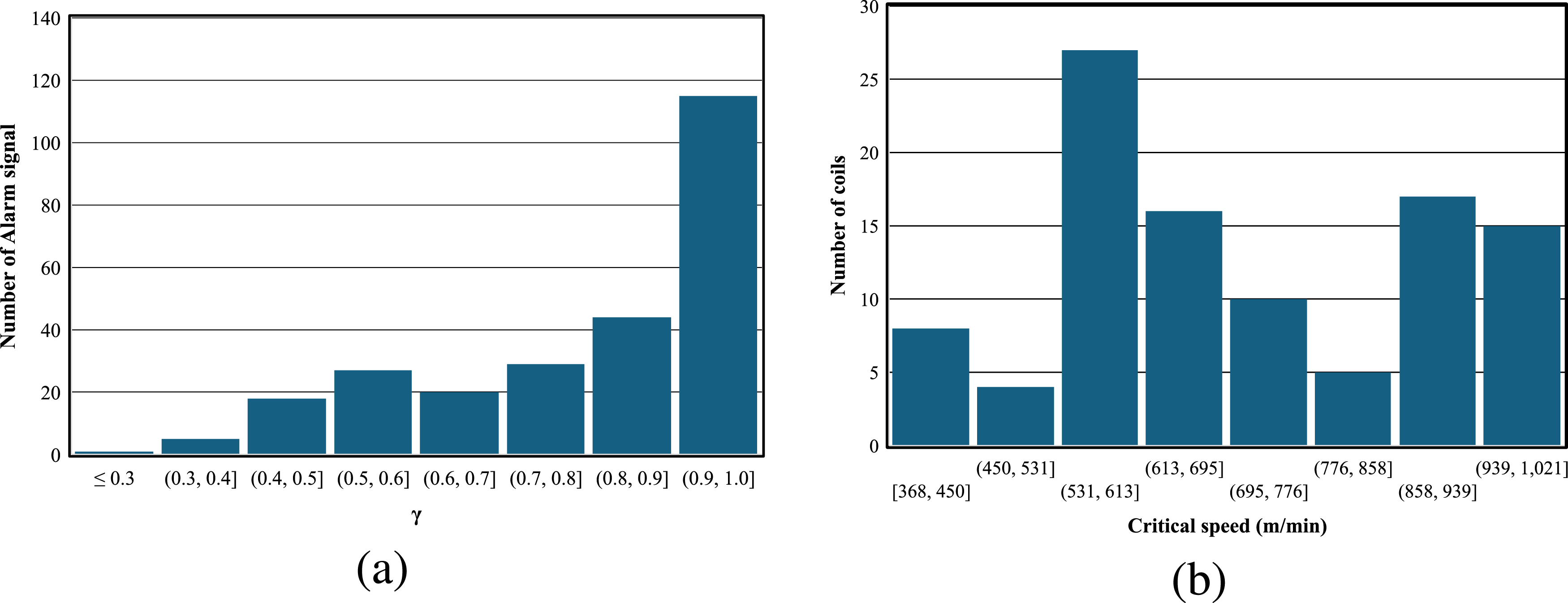
The chatter detection system may issue several alarm signals during the rolling of each coil. To prevent damage to the strip, a conservative approach is to consider the first alarm given by the chatter detection system as the occurrence of chatter. The problem with using this method is that the detection system may issue an alarm signal at speeds lower than those typically used for rolling. For this reason, to create a dataset, it is assumed that if γ for a coil is greater than 0.6, the minimum speed at which the alarm signal is issued is considered as the critical speed, whereas if γ is less than 0.6, the coil is not considered in the dataset. The reason for selecting a value of 0.6 is that if the operator determines that, despite receiving an alarm signal at a certain speed, the rolling speed can be increased to more than twice the speed at which the alarm signal was issued, it is likely that the signal was a false alarm and can be disregarded. Coils without an alarm signal are also excluded from the dataset. The histogram of critical speeds for the high-fidelity dataset created using the value of 0.6 is shown in Figure 4(b). The total number of high-fidelity data points is 102.
3. The low-fidelity dataset extracted from the rolling process simulation
In this section, the analytical model employed for simulating the rolling process is first introduced, and then the RSM and its application are explained.
3.1. The analytical model for simulating the rolling process
In this study, the analytical model of the two-stand cold rolling mill introduced in Section 2, has been utilized. This model was developed in the Simulink environment of MATLAB software in the study by Heidari et al. (2018). This model includes the payoff reel, dynamic model of first and second stands, and pickup reel. In the payoff reel and pickup reel models, the variations in the tension behind the first stand and in front of the second stand are considered. In the dynamic models of the first and second stands, the inter-stand tension, the stand structure model, and the rolling process model with Coulomb damping are considered.
The analytical model has been used to determine the critical speed at different values of the rolling parameters. The model is executed for different speeds at specific values of the rolling parameters, and the speed at which the vibration amplitude remains constant over time is considered the critical rolling speed. In each model execution, a 5-s segment of the rolling process is simulated. The 5-s duration was determined based on our parametric simulations at different time horizons, in conjunction with the reference plots reported by Heidari et al. (2018).
In Figure 5, the variations in the amplitude of oscillations of the second stand at different speeds are shown. The simulated vibrations of the second stand in the model for (a) At speeds lower than the critical speed, and (b) At speeds higher than the critical speed.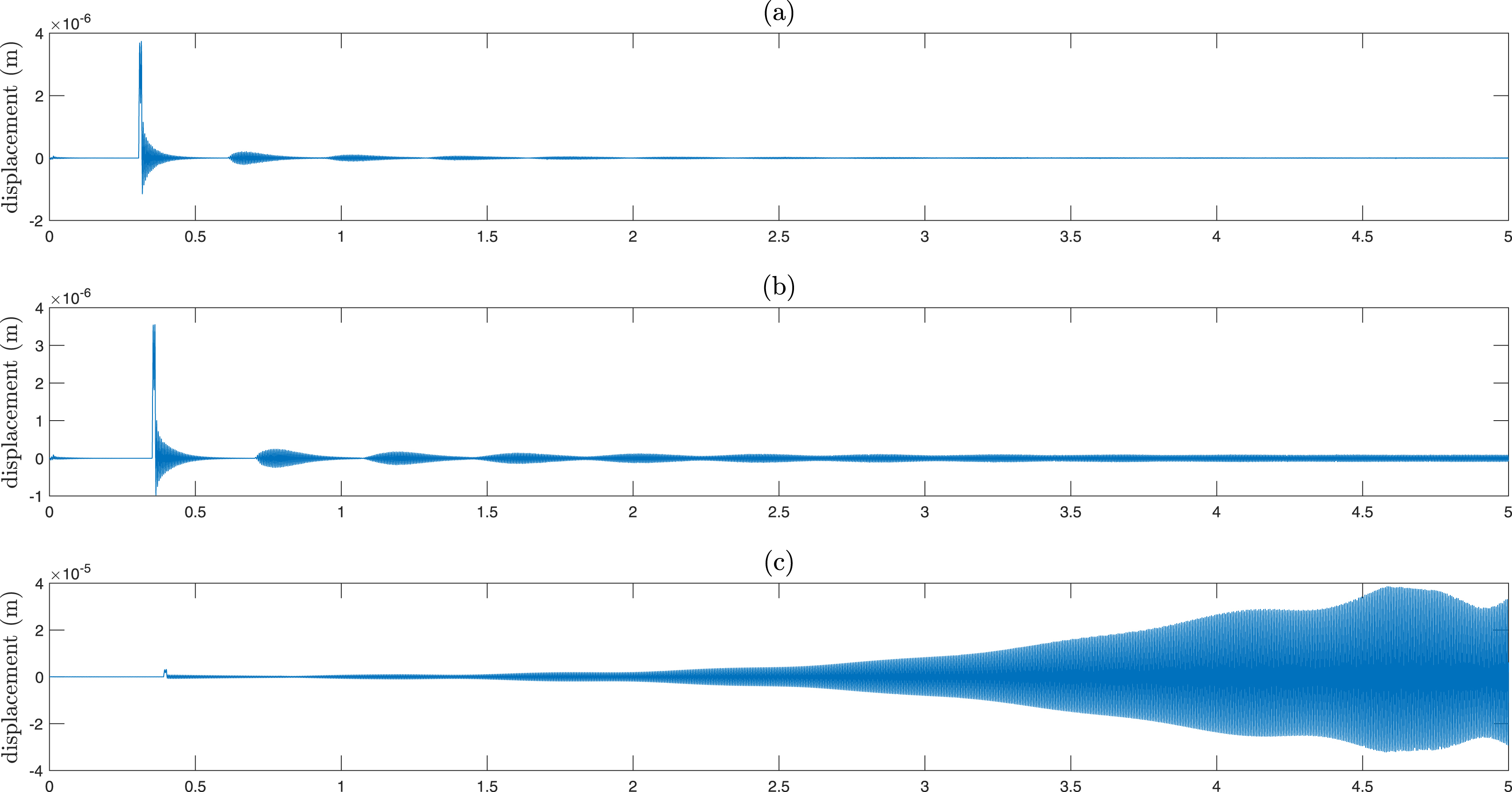
Each simulation of the rolling process for a duration of 5 seconds takes more than 90 minutes. Due to the time-consuming process of generating a dataset from the analytical model, the RSM was employed to establish a regression model that relates the input parameters of the model and the critical speed. This regression model is used to generate a large number of low-fidelity data points.
3.2. Response surface methodology
RSM is a collection of statistical and mathematical techniques useful for developing, improving, and optimizing processes. The most extensive applications of RSM are in the industry, particularly in situations where several input variables potentially influence performance measures or quality characteristics of the product or process (Myers et al., 2016).
In the RSM, it is assumed that the process, or system involves a response y that depends on the controllable input variables x1, x2, …, x
k
. The relationship between the input variables and the output is expressed as equation (2).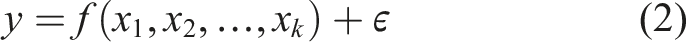
f is the unknown response function, and ϵ includes effects such as measurement errors, sources of instability, and others on the response. ϵ is considered as a statistical error and is often assumed to follow a normal distribution with a zero mean and variance σ2. Because the response function f is unknown, it is approximated. In many cases, a first-order or second-order model is used. In this study, a second-order model was used. The second-order model is given by equation (3) (Myers et al., 2016).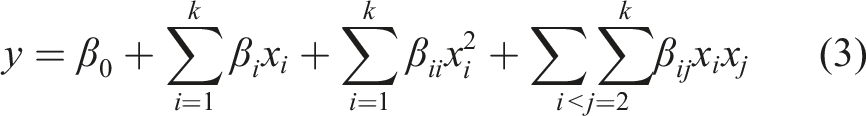
Due to the fact that determining the critical speed using the analytical model is a trial-and-error and time-consuming process, the RSM is used to establish a relationship between the rolling parameters and the critical speed of the analytical model. The RSM was implemented in Minitab software within the range of actual data variations. The parameters of the analytical model, including the reduction in the first stand, the output thickness from the second stand, the friction coefficients for the first and second stands, the back tension of the first stand, the front tension of the first stand, and the front tension of the second stand are considered as input variables. The critical speed is considered as the output or response. In Table 1, the ranges of the input variables are provided. The friction coefficients for all coils have been calculated using the analytical model. The coefficient of friction is determined by selecting the value that makes the force of the analytical model equal to the actual force. By averaging over all coils, the total reduction in third pass, strip width and the work roll radius of the first and second stands are found to be 48%, 782 mm, 236 mm, and 230 mm, respectively.
Using the CCD for 7 input variables, 143 experiments are required based on the n2 + 2 × n + 1 formula. The critical speed of 143 experiments was obtained through trial and error of the analytical model at different speeds.
4. The proposed method for predicting the chatter critical speed
This section presents the neural networks trained using low-fidelity and high-fidelity data, as well as the neural network architecture employed for TL. In Figure 6, the schematic diagram of TL and direct DL is presented. In TL, Model A is first trained using low-fidelity data. Although Model A exhibits low accuracy, it is capable of learning the fundamental features and general patterns within the data. Model A is used as a pre-trained neural network, and through fine-tuning with high-fidelity data, Model B is obtained. Model C, is trained directly using high-fidelity data. Schematic diagram of TL and direct DL.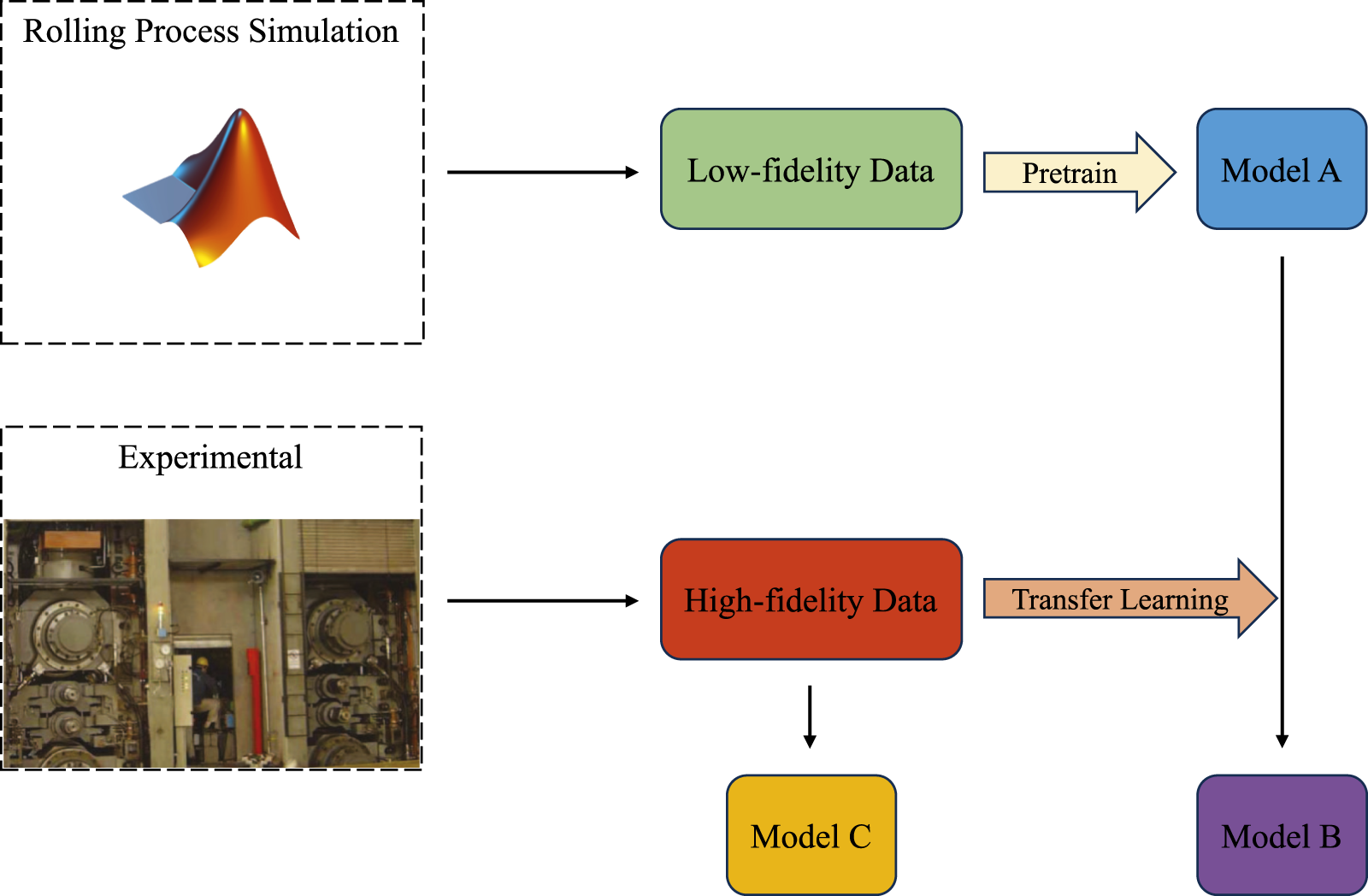
TL in ML refers to a technique where a model leverages knowledge gained from one or more source tasks to improve learning performance on a target task. An important aspect of the benefits of TL is in simulation technology (Yang et al., 2020). TL, when dealing with different levels of data fidelity, is an essential step to adapt to many situations that are not encountered in the simulated environment.
The TL network architecture used consists of two interconnected neural networks, NNL and NNH. This structure is illustrated in Figure 7. NNL is the same as Model A, responsible for processing low-fidelity data. The output of this network, QL, encapsulates the overall behavior of the low-fidelity data and serves as the input to the NNH network. The fine-tuning strategy is such that the trainability of certain layers in the NNL section is deactivated, and the remaining layers are trained using high-fidelity data. Architecture of the transfer learning network (Model B): integration of low-fidelity (NNL) and high-fidelity (NNH) models.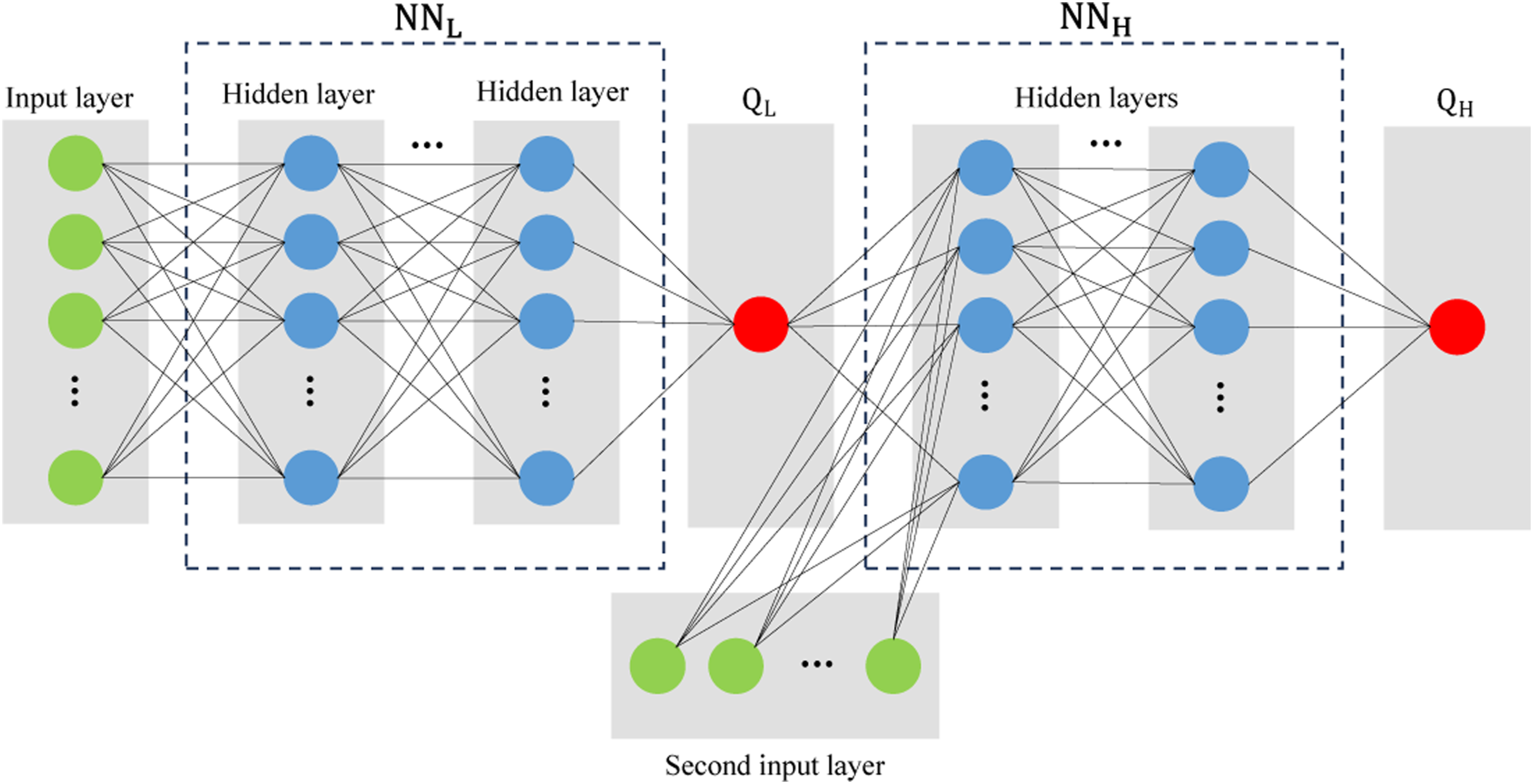
NNH takes QL and some other parameters from the high-fidelity data as input and generates QH as the output. Adding the second input allows for capturing more complexities, while still leveraging the patterns identified from the low-fidelity data. As discussed in Section 1, rolling mills are complex systems, and various parameters influence the chatter phenomenon. The simplifications made in the development of simulation models result in not all influential parameters of the chatter phenomenon being considered, or some important parameters being regarded as dependent variables. Therefore, it is necessary to incorporate the important parameters that influence the occurrence of the chatter phenomenon and are not included in the first input, through the second input to the model.
In all models, Mean Squared Error (MSE) is used as the loss function, and the Stochastic Gradient Descent (SGD) optimizer with a momentum of 0.9 is employed. Regularization techniques and the EarlyStopping callback are employed to prevent overfitting.
5. Results and discussion
To evaluate the prediction performance of the regression models, the following metrics were used: the coefficient of determination (R2), the adjusted R2, and the Root Mean Square Error (RMSE). The coefficient of variation (CV) was used to assess stability and sensitivity to data partitioning, while confidence intervals (CI) were employed to quantify uncertainty in the estimated performance metrics. The R2 indicates the percentage of the variation in the dependent variable that is explained by the independent variables. The R2 is obtained from equation (4).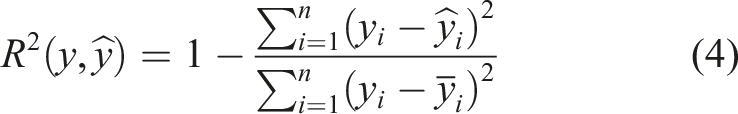
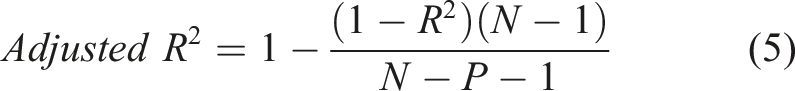
N represents the total number of data points, and P represents the number of independent variables.
RMSE is a way to measure the average magnitude of the differences between predicted values and observed values. Basically it’s quantifies how well a model is performing in predicting numeric outcomes. The value of the RMSE is obtained from equation (6).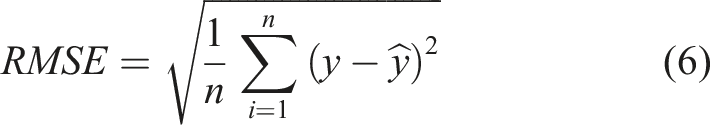
The CV is defined as the ratio of the standard deviation to the mean. A p-CI is defined as an interval that includes the true performance of the model with (at least, if being conservative) probability p in identical repetitions of the analysis with new datasets from the same data distribution (Paraschakis et al., 2024). The CI was estimated using the percentile bootstrap method. In percentile bootstrap, the percentiles of the bootstrap sampling distribution are used to create a confidence interval, where the lower and upper bounds are taken from the 2.5% and 97.5% percentiles of the bootstrap distribution. Further details are presented by (Flowers-Cano et al., 2018).
5.1. The nonlinear regression developed for generating low-fidelity data
The coefficient of determination values of the regression model.
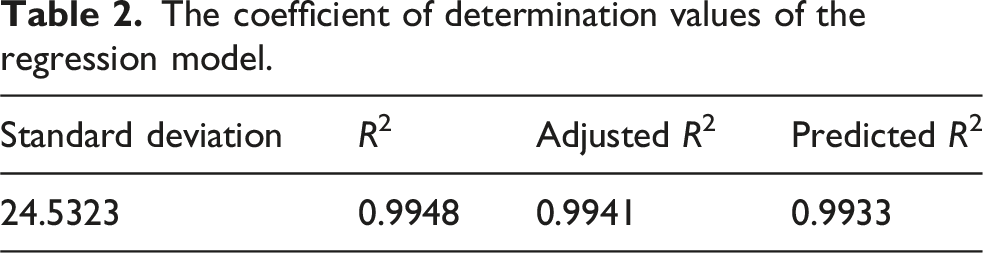
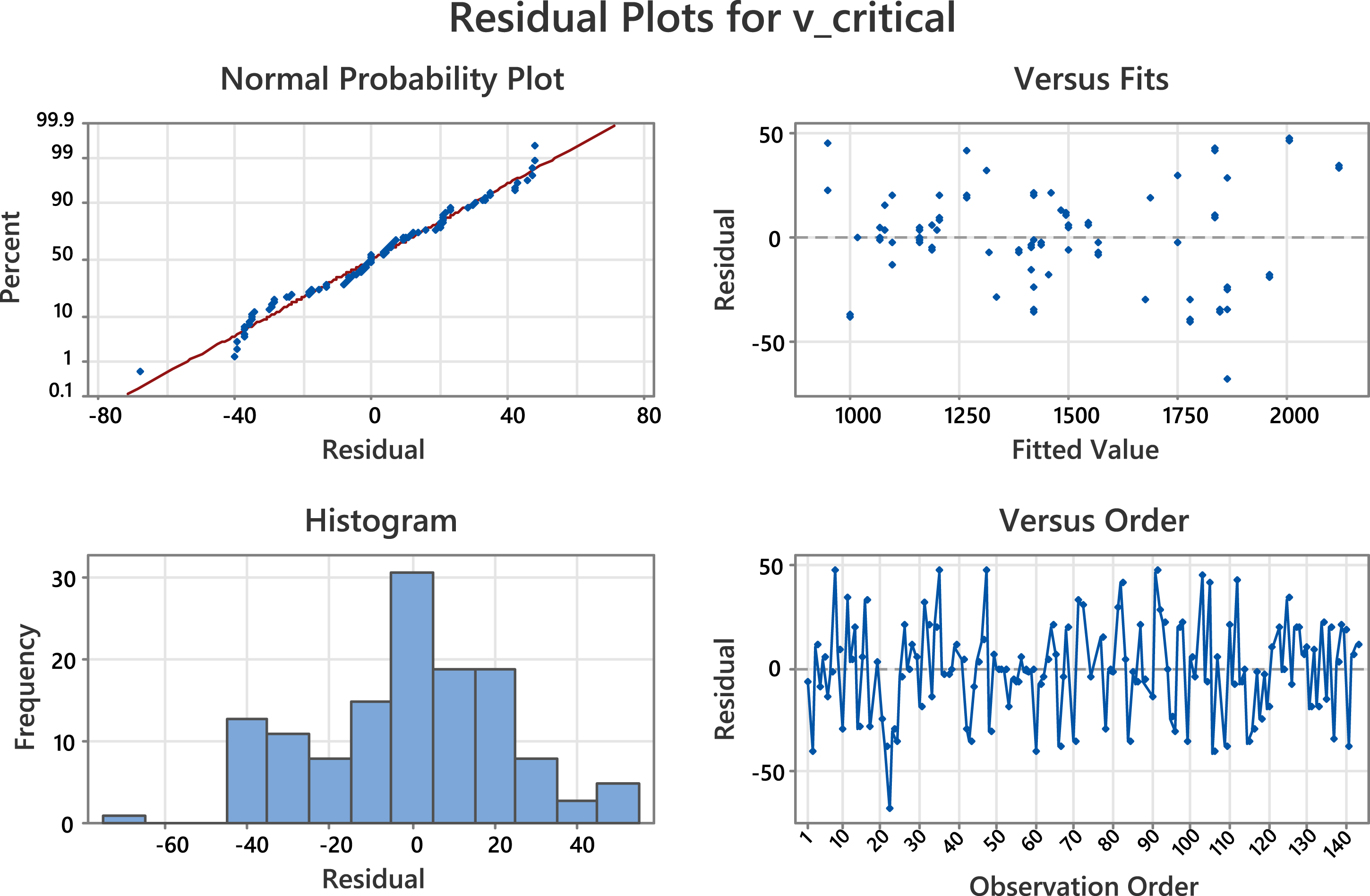
Residual plots for the regression model generated by the RSM.
The regression equation generated by the RSM is given in equation (7). The variables in this equation have been scaled to the range of −1 to +1.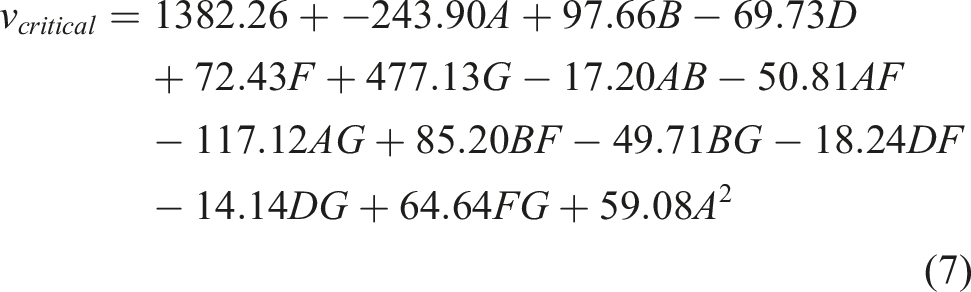
In order to compare the critical speed obtained from the analytical model with the rolling speed of real data, data from 20 coils have been used. For each coil, the average value of each rolling parameter was calculated, and then the analytical model was run using these values to determine the obtained critical speed. Furthermore, the speeds predicted by the regression model are also calculated using these average values. The RMSE value for these data was obtained as 92.4. In Figure 9, the critical speeds obtained from both the analytical and regression models, as well as the maximum speed at which each coil was rolled are shown. As mentioned in section 2, high-fidelity data was obtained using the γ = 0.6. This leads to larger difference between the critical speeds of the low-fidelity data and the actual chatter speed in high-fidelity data, compared to the difference shown in Figure 9. Therefore, to reduce the difference between the critical speeds of low-fidelity data and high-fidelity data, the critical speeds calculated from the regression model are divided by the correction factor. The correction factor is calculated as follows: for high-fidelity data. The critical speed is determined using the regression equation. The ratio of the critical speed of regression model to the critical speed of the high-fidelity data is then computed, and the average of this ratio is taken across all the data. The correction factor for the high-fidelity data created with γ = 0.6 is 1.8878. Comparison of the critical speed obtained from the analytical model and regression model with the maximum rolling speed for 20 different coils.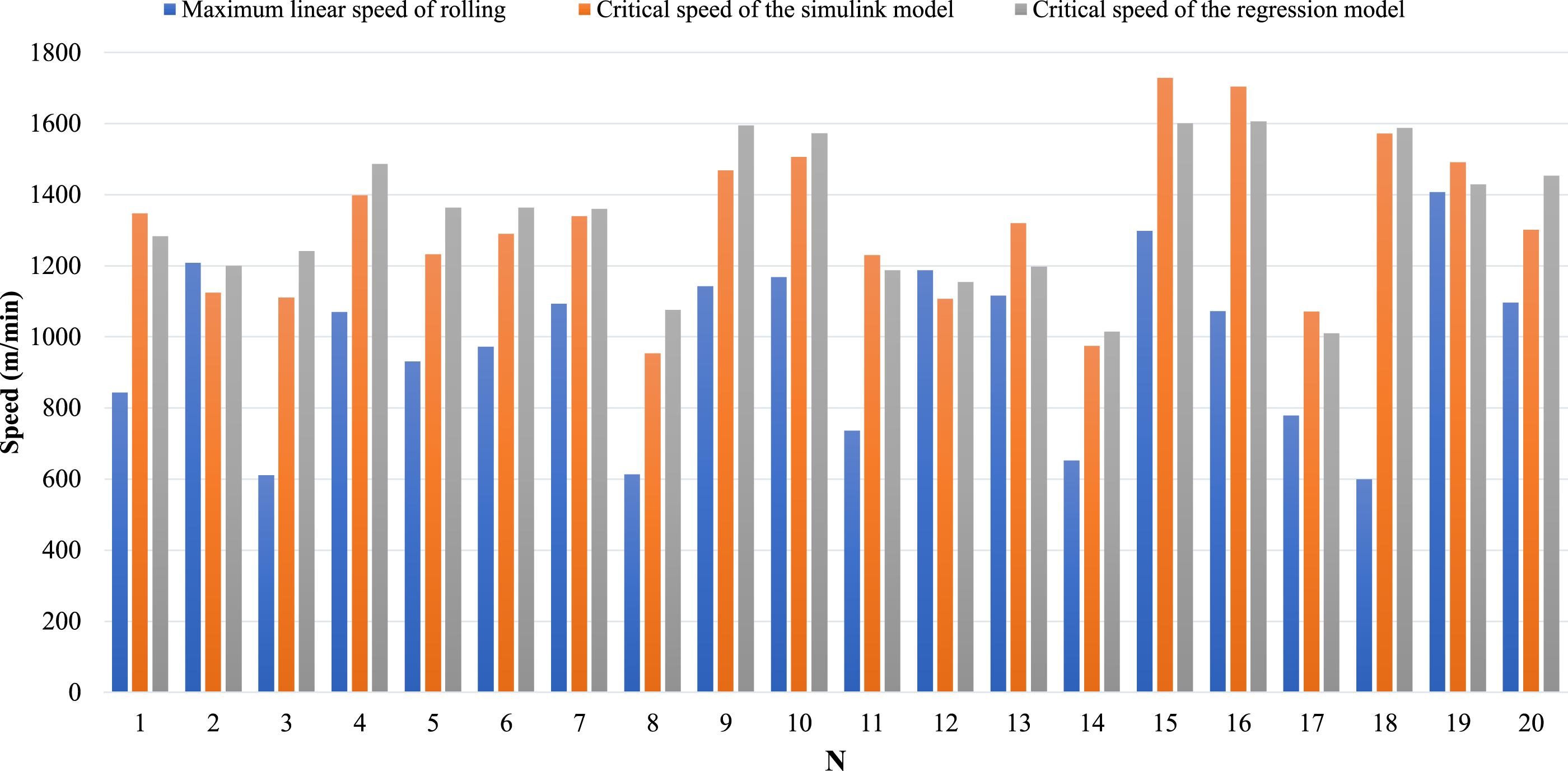
5.2. Prediction performance of direct DL (Model C) and TL (Model B) on high-fidelity dataset
A low-fidelity dataset is generated using the regression model developed between the input parameters and the output of the analytical model. Seven levels are selected within the range of input parameters (Table 1), which affect the calculation of the critical speed equation (7) and a low-fidelity dataset is generated using the full factorial design. The critical speeds for this dataset are calculated using the regression equation developed. Model A consists of three layers, with 16, 8, and 4 neurons in each layer, respectively. This model employs the LeakyReLU activation function with a negative slope of 0.1, Dropout with a rate of 0.2, and L2 regularization with a value of 0.0001. Model A is trained using 80% of the low-fidelity dataset and tested on the remaining 20%. The results indicate that the Model A has a R2 of 0.999 on both the training and testing datasets.
Hyperparameter ranges for Model B and Model C for random search optimization.

The second input layer in Model B includes the second stand torque, the work roll mileage of the second stand, which is equivalent to the roll surface roughness, the slip at the front of the second stand roll, the gap distance between the rolls of the second stand, front tension of the second stand, rolled length of strip, reduction in the second stand, and output thickness from the second stand. The input layer in Model C includes all the input parameters of Model B, except that instead of the friction coefficients for the first and second stands, the forces of the first and second stands are used. Additionally, between the parameters reduction in the first and second stand, only the reduction in the first stand is used.
For Model B, the best results for the hidden layers of the NNH section have been obtained with neuron counts of 6 and 4, dropout rates of 0.1 and 0.15, and negative slopes of 0.15 and 0.1 in the LeakyReLU activation function. The learning rate and the number of frozen layers have been determined to be 8 × 10−6 and 5, respectively. In Figure 10(a), the cross-validation results of Model B have been presented. For this model, the average R2 and the average RMSE for the training data are 0.745 and 93.5, respectively, while for the validation data, they are 0.734 and 89.8, respectively, with CV of 10% for R2 and 16% for RMSE. The evaluation results of the (a) Model B, and (b) Model C using coefficient of determination, and root mean squared error.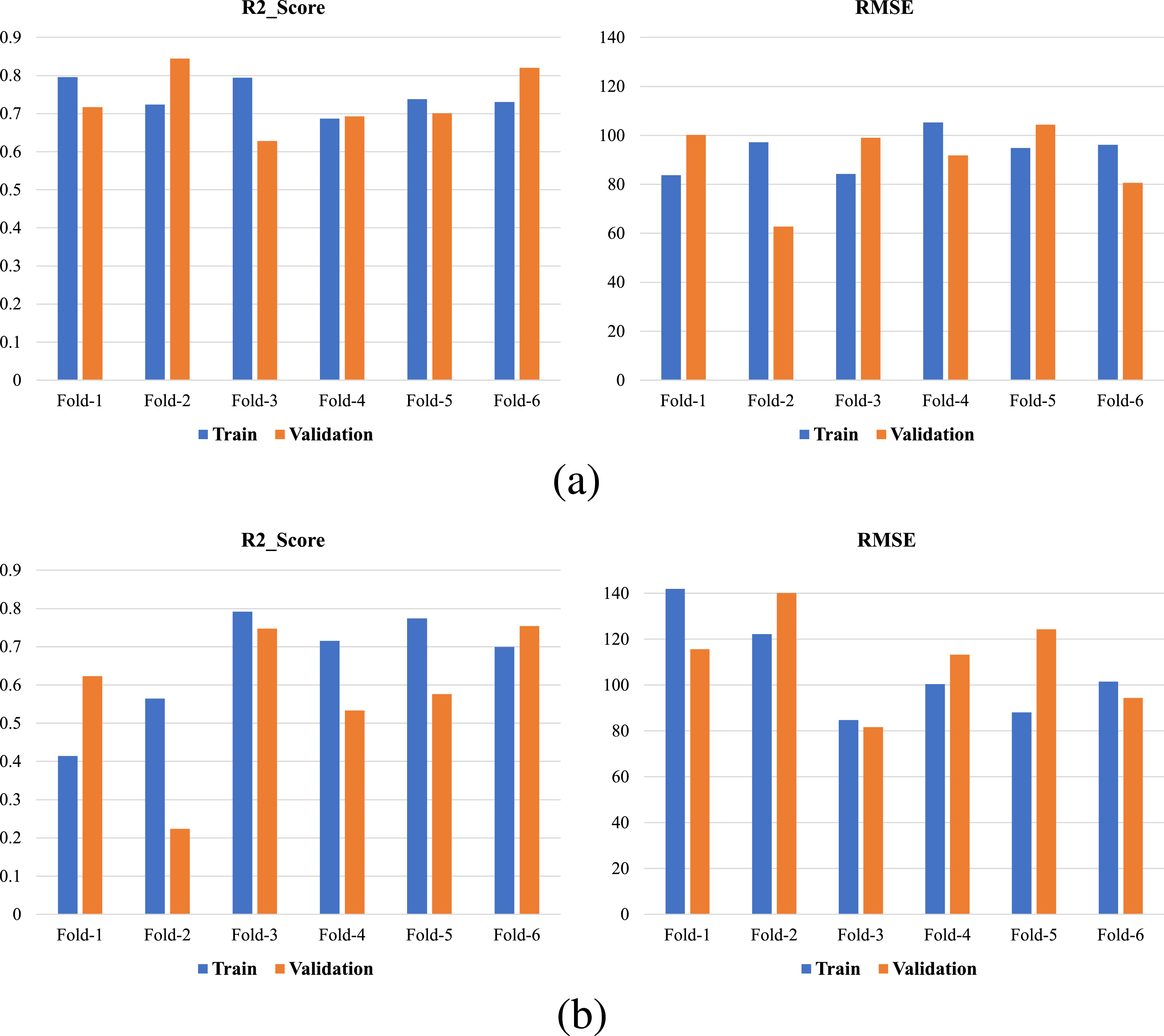
For Model C, the best results have been obtained with neuron counts of 4 and 4, dropout rates of 0.05 and 0.15, and negative slopes of 0.0 and 0.2 in the LeakyReLU activation function. The learning rate has also been determined to be 1 × 10−5. In Figure 10(b), the cross-validation results of Model C have been presented. For this model, the average R2 and the average RMSE for the training data are 0.656 and 106.4, respectively, while for the validation data, they are 0.576 and 111.5, respectively, with CV of 30% for R2 and 17% for RMSE. Comparison of the CV values of Models B and C shows that Model B is less sensitive to the training/test split.
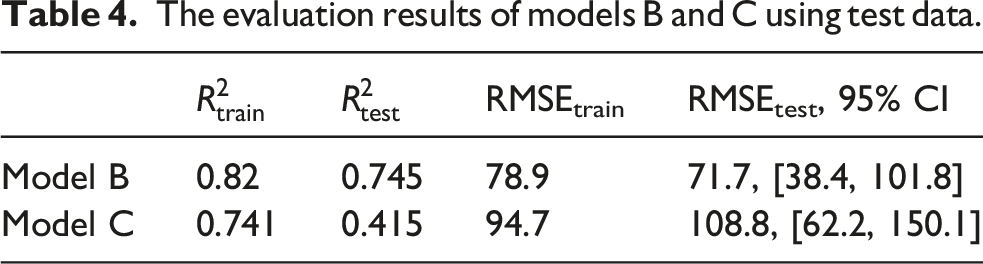
The evaluation results of models B and C using test data.
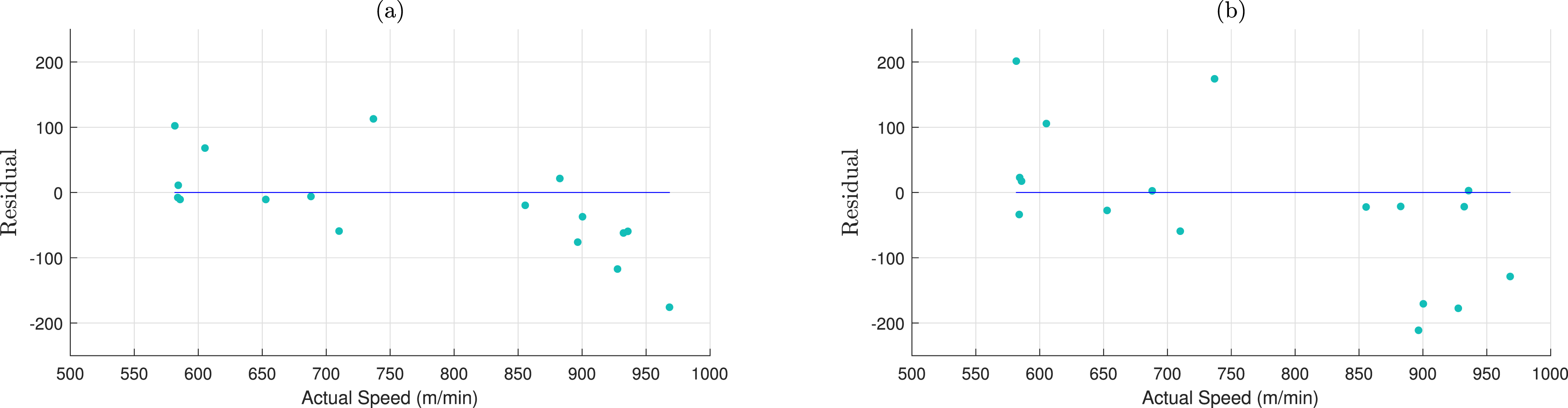
Residual plots against the actual speed values of test data for (a) Model B, and (b) Model C.
6. Conclusion
In order to perform high-speed and stable rolling, the critical chatter speed was predicted using MFTL. An analytical model developed in previous studies was used to generate the low-fidelity dataset. Due to the time-consuming nature of generating a dataset using the analytical model, the RSM was employed to establish a relationship between the input and output parameters of the model. Using this established relationship, a low-fidelity dataset has been generated, and used for initial model pre-training. High-fidelity dataset was created from the available real data based on the speeds at which the alarm signal occurred. Model B was developed using the TL approach, while Model C was created solely based on high-fidelity data. The results indicated that Model B and Model C achieved a R2 of 0.74 and 0.41, respectively, on the test data. Thus, Model B demonstrated superior performance. The training time required for Model B is greater than that for Model C. However, because acquiring a sufficiently large dataset is a highly costly and time-consuming process, and industrial plants typically cannot provide such extensive data, a multi-fidelity framework was adopted to improve performance metrics and enhance result stability.
Footnotes
Acknowledgments
The authors express their gratitude for the cooperation of the experts in the cold rolling mill unit at MSC.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Mobarakeh Steel Company (No. 48557056). The National Research Foundation of Korea(NRF) grant funded by the Korea government(MSIT) (No. RS-2025-25435356).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.