
Abstract
The use of qualitative data analysis software (QDAS) has expanded over the last two decades, with new technology allowing researchers to analyze more data, faster, and in more complex ways. However, a review of research articles that mentioned the use of QDAS found that authors often omitted critical details about the value-added of the software. This article seeks to fill that gap. We describe our use of NVivo to analyze qualitative data collected for the comprehensive review preceding the repeal of Don’t Ask, Don’t Tell, the 1994 law banning openly gay individuals from serving in the U.S. military. We describe why we chose this software product, detail the staffing strategies we used for the team-based analysis, and provide examples of the kinds of queries we ran to answer the study questions. We conclude with a brief discussion of “lessons learned” from this quick-tempo, large-scale qualitative project.
Personal computers (PCs) have changed dramatically over the last 20 years, with technological advances making PCs capable of analyzing enormous volumes of data in very complex ways and at lightning speed. As many authors have noted (see, for example, Roberts & Wilson, 2002; Thompson, 2002), for better or for worse, these changes have moved the analysis of qualitative data from paper on the living room floor to electronic forms on PC hard drives. Given the plethora of qualitative data analysis software (QDAS) packages available to researchers, it seems the sky is the limit on how much data researchers can analyze in new and interesting ways.
Woods, Macklin, and Lewis (2015) note, however, that the relationship between researchers and the technology appears to have taken several different forms: First, qualitative methodologists may be taking advantage of the products to conduct their usual analyses in a slightly different way (see also N. G. Fielding & Lee, 2002); second, the software can offer researchers who are trained in qualitative methods ways of exploring the data (e.g., use of query functions) that simply are not possible otherwise; third, and of some concern, the technology itself may be driving the research design and analysis, prompting researchers with little or no training in qualitative methods to collect large volumes of data because the software can handle it, not because the volume is appropriate for answering the research question. This has raised concerns within the field about the technological cart driving the horse, with Lee and Esterhuizen (2000) reporting early on a concern that analysis of large volumes of qualitative data may begin to “mimic survey research” (p. 236).
Despite these concerns, what exactly is happening at the intersection of researcher and technology is not entirely clear. Paulus, Woods, Atkins, and Macklin (2017) found, for example, that in almost 90% of the research articles they reviewed in which the authors note the use of a QDAS product, the descriptions of how the software was used to support the analyses was “minimal” and constituted little more than software “name-dropping.” Were the authors solid qualitative researchers who did not know how to use the software? Were they good qualitative researchers making excellent use of the tool, but who failed to provide more information about their use of it? Or did they have minimal training and hoped that “name-dropping” would somehow add legitimacy to their findings? The authors argued that without adequate descriptions of why a particular product was selected or what features of the product were used in the analysis, these articles “perpetuate misconceptions of who has control over the study—QDAS or the researcher” (page 8).
The goal of this article is to address the information gap identified by these previous authors. In the pages that follow, we provide a detailed description of how we used NVivo (Version 8) 1 to support the analysis of thousands of qualitative data items for one policy study. We describe our reasons for the selection of this particular product and how we organized our team to take full advantage of several of the product’s features, and offer a clear example of how query functions in NVivo contributed to the analysis. We conclude with a summary of project and software management strategies that we hope will be useful to other qualitative researchers.
The Study
In his 2010 State of the Union address, President Obama indicated he would work with Congress and the Department of Defense to repeal Don’t Ask, Don’t Tell (DADT), the 1994 law prohibiting gays and lesbians from openly serving in the U.S. military. In response, the United States Department of Defense (DoD) appointed a Comprehensive Review Working Group (CRWG) to determine the potential impact that a repeal of this law would have on unit cohesion and morale, military effectiveness, military readiness, family readiness, recruitment, and retention. 2 In support of this effort, Westat, a social science research firm based in Rockville, Maryland, was contracted by DoD to obtain the views both of active duty service members and military spouses through qualitative and quantitative data collection efforts. 3 The first step was to conduct two surveys in the summer of 2010. A 103-item web-based survey was fielded between July 7 and August 14, 2010, with a representative sample of 400,000 active duty members of the armed forces, including all five branches of service (Army, Navy, Air Force, Marine Corps, and Coast Guard). Just under 110,000 service members completed the survey, which included one final open-ended question: “If you would like to share other thoughts and opinions about the impacts on you, your family, your immediate unit, or your Service if Don’t Ask, Don’t Tell is repealed, please use the space below.” The qualitative team was tasked with analyzing a purposefully selected sample of 2,000 responses to this question, the criteria for which are described in more detail later in this article.
Second, between August 13 and September 27, 2010, a scannable paper survey was administered to 150,000 military spouses. Slightly more than 44,000 spouses completed and returned this instrument. The spouse survey included two open-ended questions: “Please tell us if you have any other thoughts or comments about how a repeal of Don’t Ask, Don’t Tell will affect your family readiness,” and
As the last question in the survey, we’d like you to tell us about any other thoughts or opinions you have—positive, negative, or neutral—about the implications on family readiness and support or other aspects of military life if the government decides to repeal the Don’t Ask, Don’t Tell law and policy.
The qualitative team analyzed a sample of 1,000 purposefully selected responses to each of these questions (i.e., a total of 2,000 spouse comments). Selection criteria are described later in this article.
In addition to the survey effort, Westat researchers were also tasked with supporting and conducting a variety of in-person discussion groups with active duty service members stationed both in the continental U.S. and in overseas locations, but outside of the combat theater. Focus groups with family members were also conducted at this time. These qualitative data collection activities, which began in April, 2010, included the following:
In addition to these group discussions, Westat was tasked with establishing a confidential communication mechanism through which service members could share their perspectives on the potential impact of repeal. Because DADT was still being enforced at the time of the comprehensive review, a confidential chat mechanism was the one forum where gay or lesbian active duty personnel could have their voices heard without running the risk of being expelled from the military. The qualitative research team analyzed de-identified transcripts from 160 chats, 80 of which were conducted with self-identified gay or lesbian service members.
Finally, DoD established a mechanism by which service members could email their comments about the potential impact of repeal. Ultimately, DoD received more than 70,000 comments, many of these several paragraphs in length. Researchers purposefully selected 1,500 of these comments to include in the qualitative data analysis. Selection criteria included respondent gender (oversampling female respondents) and respondent Service branch. 5
Thus, in total, the Westat qualitative team was responsible for coding and analyzing 4,000 survey comments, notes from 261 discussion groups, 160 transcripts from the confidential chats, and 1,500 inbox comments. This large volume of data was coupled with an extraordinarily tight timeframe: Qualitative data collection commenced in April, 2010, and a final report was submitted to the CRWG in early November, 2010. It is within this context that Westat team leaders made key decisions about the data collection and analysis approach, the topic of the next section.
The Approach
Contract research differs significantly from academic research in that, often, contractors are tasked with collecting large volumes of data (dozens of focus groups, hundreds of cognitive interviews, thousands of surveys) and in a relatively quick timeframe (often only one or two years). Yet even for Westat the number of different data collection activities for this contract, volume of data, and timeframe in which all of activities needed to be completed was unprecedented. The team had to be strategic about how the work would be accomplished. In smaller-scale qualitative studies, data collection, analysis, and reporting are often conducted by the same individual. Indeed, the researcher’s personal observation notes are an additional data source to be considered (Bernard, 2011). The nature of this study was such, however, that organic solidarity had to be the order of the day (Durkheim, 1964) with tasks clearly divided among team members.
The first division of labor in the qualitative team involved the collection of data: One group of data collectors consisted of teams that traveled across the country and overseas to support focus group discussions with service members or spouses. Because a dozen or more groups might be conducted on one military installation over the course of two or three days (and groups might be running simultaneously), each traveling team consisted of four or more Westat research staff who could rotate between moderating a group discussion and taking notes. A second group of qualitative data collectors were the staff who managed and participated in the confidential online dialogues. These staff all worked from Westat’s home office in Rockville, Maryland, in an environment that maximized data security. Although chats occurred in “real time,” staff were prepared to participate in a single dialogue that could last several hours, as the contributor might step away from his or her computer for a time and then come back to add to the discussion. These staff were not responsible for analyzing the online dialogues, but were charged with de-identifying the data before it was sent to the analytic team.
The second major qualitative staffing group consisted of the data analysts. This team was responsible for coding and analyzing all of the qualitative data, including notes from the discussion groups as they were coming in from the field. What was lost for analysis by this division of labor were the moderators’ and note takers’ first-person experiences in the field, observations and impressions that can be important to fully understanding a given social or cultural phenomenon. What was gained, however, was time: Staff were able to code data at the same time that the data collection team was moderating focus groups or confidential online dialogues. Given the importance being placed on service members’ comments, and not the context in which those comments were made, this seemed a methodologically sound trade-off to make.
Finally, and importantly, the Westat qualitative study managers served to maintain the connection between the data collectors and the analysts. These two staff members, both PhD-level cultural anthropologists, developed the discussion group protocols, trained the facilitators, worked with the data analysts to establish a coding scheme, trained staff in how to use the coding scheme, themselves participated in data coding, and wrote the final report for the qualitative components of the comprehensive review.
Decision to Use NVivo
Westat senior qualitative researchers have long promoted the judicious use of digital tools, encouraging staff to understand the epistemology behind qualitative research before incorporating a digital sorcerer’s apprentice into the analytic process. We have also cautioned against letting the software drive the research design, noting that just because a tool can execute a particular function does not mean the function is analytically meaningful (see Roller & Lavrakas, 2015, p. 252 for a brief discussion of this issue). For this study, we believe the decision to use qualitative software was both well-informed and analytically appropriate. First, as often happens in contract research, Westat did not develop the study design: The CRWG had already determined the importance of hearing from as many active duty service members and spouses as possible, and thus had identified the various data collection strategies in advance of the contract. Second, the analytic objectives also had already been determined. The goal of the study was not to ascertain if active duty service members and spouses were in support or not of a repeal of the law, but rather to assess the perceived impact on the armed forces if DADT were repealed. The analytic task presented to Westat researchers was thus fairly straightforward: Here are the types and amounts of data that will be collected, and these are the questions that need to be answered by this date: Can you do the work and, if so, how?
Our answer was, “Yes, using NVivo.” This decision was based on several factors: First, the data were too voluminous (consisting of nearly 6,000 qualitative data items) and the timeframe far too short (eight months) to be able to conduct a reasonable analysis “the old-fashioned way.” If ever there was a time to take advantage of technological advances, this was it. Second, and important to the overall structure of the study team, this product offered an easy approach to team-based coding (see Bourdon, 2002; Wiltshier, 2011). With the proper set-up, several team members could be coding these massive amounts of data, all working side by side. Third, several of the questions being asked of the data by the CRWG were complex and could not have been answered without the use of technology: Did the perceptions about the potential impact of repeal vary by service, for example, did members of the Marine Corps think a repeal would be devastating to unit cohesion, while service members in the Army felt they could fight through the policy change? Did the beliefs vary by gender, that is, were women less concerned about the impact of repeal than their male counterparts? With respect to the survey comments, what were the issues raised by respondents who were uniformly negative about repeal compared to those who were uniformly positive? And how did both groups’ issues compare to the concerns described by respondents whose answers were more ambivalent? Such questions could not have been answered in the required timeframe without the benefit of high-powered software. Finally, our decision to use NVivo was the result both of the features of the software (e.g., matrix queries—discussed in more detail below) and the fact that Westat has long supported this particular digital tool through bulk license purchases as well as annual onsite training in how to use the product. In sum, NVivo was determined to be the right tool for the job.
Though the decision to use NVivo was straightforward, the implementation of that decision was not. Projects dealing with sensitive data, such as this one, require data to be stored and analyzed in what is known as a “data enclave.” This project was hosted in Westat’s DIACAP-compliant (Department of Defense Information Assurance Certification and Accreditation Process) enclave, which met the stringent data security and encryption requirements at the MAC-II level of sensitivity. 6 Westat’s DIACAP enclave also maintains physical security controls, so access is controlled (e.g., keypad entry) and only approved personnel can enter the room. For security reasons, the enclave server does not have an internet connection. Yet, unnoticed by Westat staff until this time, an internet connection was required to launch NVivo so that software updates could be automatically installed. Staff with Westat’s Information Technology (IT) department and QSR, International, the software developer, worked together to develop a solution: A member of Westat’s IT staff downloaded software updates on a USB thumb drive outside of the enclave, and then applied the updates to each workstation within the enclave. Creativity and collaboration allowed the software to fully function in this unique work environment.
How We Used the Software
Team-based coding
As indicated previously, one of the most important aspects of NVivo for the purposes of this project is that it allows for team-based coding. Critical to our effort was understanding the mechanics of the software that allow for group coding and setting up a division of labor accordingly. The first step was to bring in an NVivo consultant who helped develop a database structure that was, from the start, parsimonious and efficient. Working with the consultant was a Westat database manager who was responsible for creating and maintaining the master database. “Maintaining” the master database, however, also meant managing the work of individual coders. Thus the manager was responsible for creating daily working copies of the master for each coder, ensuring that coders knew exactly which sections of the database were their responsibility, and then merging all of the individual copies of the database at the end of each day to create a new working master and backup file. On smaller team-based NVivo projects, the person responsible for managing the database might also be one of the coders; on this project, however, because these databases were so large, the merging process was time-consuming and required careful attention to process and detail. Thus this staff member’s full-time commitment to the study was to manage all aspects of the databases.
The structure of the qualitative research team extended to the coders, many of whose sole responsibility on the study was “simply” to code massive amounts of data. This was no easy task. In addition to the time pressures associated with the project, the data coding and analysis team was required to do all work within the secure environment of the Enclave. Several challenges resulted from this requirement, including the fact that while they were actually doing the coding, staff had no access to their work email or their office phones. Further, because access to the room was restricted, project staff could only be contacted by other Westat employees by calling the Enclave through communication with staff who were coming from or going into the Enclave or when the staff member stepped out for a break. Although most of the coders were dedicated full-time to this project, the altered structure of the work environment was an additional challenge to which each staff member had to adjust.
It’s an ill wind that blows no good, however, and working in the Enclave also brought some unanticipated benefits. For example, because all coders were working in close physical proximity, team members were able to engage in real-time discussions about the coding structure, including which codes needed to be revised, which ones should be removed, and any codes that might need to be added to better capture nuances in the data. In addition, team members were often overwhelmed by the intensity of many of the comments, including those that expressed the writer’s (or speaker’s) negative personal experiences during military service or their explicit contempt for gay men and lesbians. Even though Westat’s role in the review was to be objective, many virulently negative comments could have an adverse emotional effect. Having one or more team members working nearby, however, allowed project staff to talk about their feelings in response to the data and then, just as readily, return to the task of reading and coding.
Development of the coding structure
Because all of the research questions were established at the outset of the project, the Westat team did not use a grounded theory approach to developing the coding structure. Instead, before any coding began, the two qualitative study leads established a provisional coding structure based on the major themes covered in the focus group protocols. 7 They then read through approximately 20 sets of notes from the first set of Information Exchange Forums (IEFs) and focus groups and identified several top-line themes that were emerging in the data. These high-level codes 8 can be found in Table 1.
Summary of Coding Scheme.

These high-level codes were comprehensive and ultimately covered the range of issues raised in the qualitative data. Yet early on in the coding process, the qualitative analysts noted that speakers were invoking the same concepts to express very opposite points of view. Numerous individuals, for example, talked about repeal in terms of civil rights.
9
Below are two examples of comments asserting that repeal was about ensuring that gay and lesbian service members’ civil rights were honored:
This is a violation of the 1st amendment right of freedom of expression. Homosexuals are currently in the military and serving their country with pride. Why should it be up to the DOD to decide if someone can openly serve as a homosexual? I feel that the “don’t ask don’t tell” policy should be repealed because it interferes with gay Service members civil rights. I am a gay Service member and I feel that I have to live a double life.
However, coders were just as likely to come across comments from heterosexual individuals who believed the repeal of DADT would interfere with their civil rights:
If the state favors the demands of the homosexual activists over the First Amendment, it is only a matter of time before the military censors the religious expression of its chaplains and marginalizes denominations that teach what the Bible says about homosexual behavior. You could be infringing on the rights of those who are not comfortable with homosexuality in that they may not want to shower or use heads in front of their homosexual colleagues.
Civil rights was not the only such multifaceted concept. For example, speakers or email writers often stated that a repeal of DADT was consistent with core military values:
I think the repeal of the Don’t Ask Don’t Tell policy is a good move forward for our military service because it allows those who have been serving proudly as Active Duty and Reserves to live up to their respective Core Values.
Those same military values, however, were brought forth to explain why repeal would be detrimental to the armed forces:
Military service is a unique and special profession where members are held to a higher moral standard that the society at large. I respect an individual’s right to choose a gay lifestyle. There is no place for that particular lifestyle in the military.
Developing the coding structure thus required the creation of codes that could accommodate a number of such themes that were viewed from opposite perspectives. Because NVivo and other QDAS products allow for the assignment of multiple codes to the same data, the team’s solution was to create codes that reflected the “valence” of the comment with respect to the impact of repeal. A “Positive” code indicated that the speaker believed repeal of DADT would benefit some aspect of the armed forces, for example, repeal would be consistent with the Constitution or the values endorsed by members of the military. “Negative” was used for those comments that indicated that repeal would have an adverse effect on the concept being discussed, for example, repeal would have a negative effect on a service member’s sense of personal safety. A “Neutral/No effect” code was applied to those sections of text that suggested repealing the law would have no appreciable effect on the issue being discussed (e.g., “Repeal of DADT will not impact our unit’s ability to function.”). And, finally, comments or sections of text that were more questioning than directional were marked “Rhetorical” (e.g., “Will the military change the shower set-up?”). The analysts thus were able to code both the content and directionality of comments and thereby capture important nuances in the data.
Queries
As discussed previously, the CRWG was not interested solely in the overall content or tone of the comments, but if comments and their tone varied by any of a number of important characteristics, such as the speaker’s gender, rank, or branch of service. To answer these questions, the qualitative analysts turned to the “matrix query” function within the software. For readers who are not familiar with NVivo, matrix queries offer the user the ability to create a “cross tabulation” on the data using any of a number of features of the data set. For example, we were able to assess the relative proportion of positive and negative comments regarding privacy concerns by whether the speaker or email sender was male or female. In NVivo, this function had to be done in multistep fashion: The first step was to abstract from the data all of the negative comments regarding individuals’ personal privacy. Using the matrix query function, we first added the code “Privacy Concerns” as a row in the query, as shown in Figure 1. In the second step of this particular query, we used the “Negative” valence code as the column, as indicated in Figure 2.
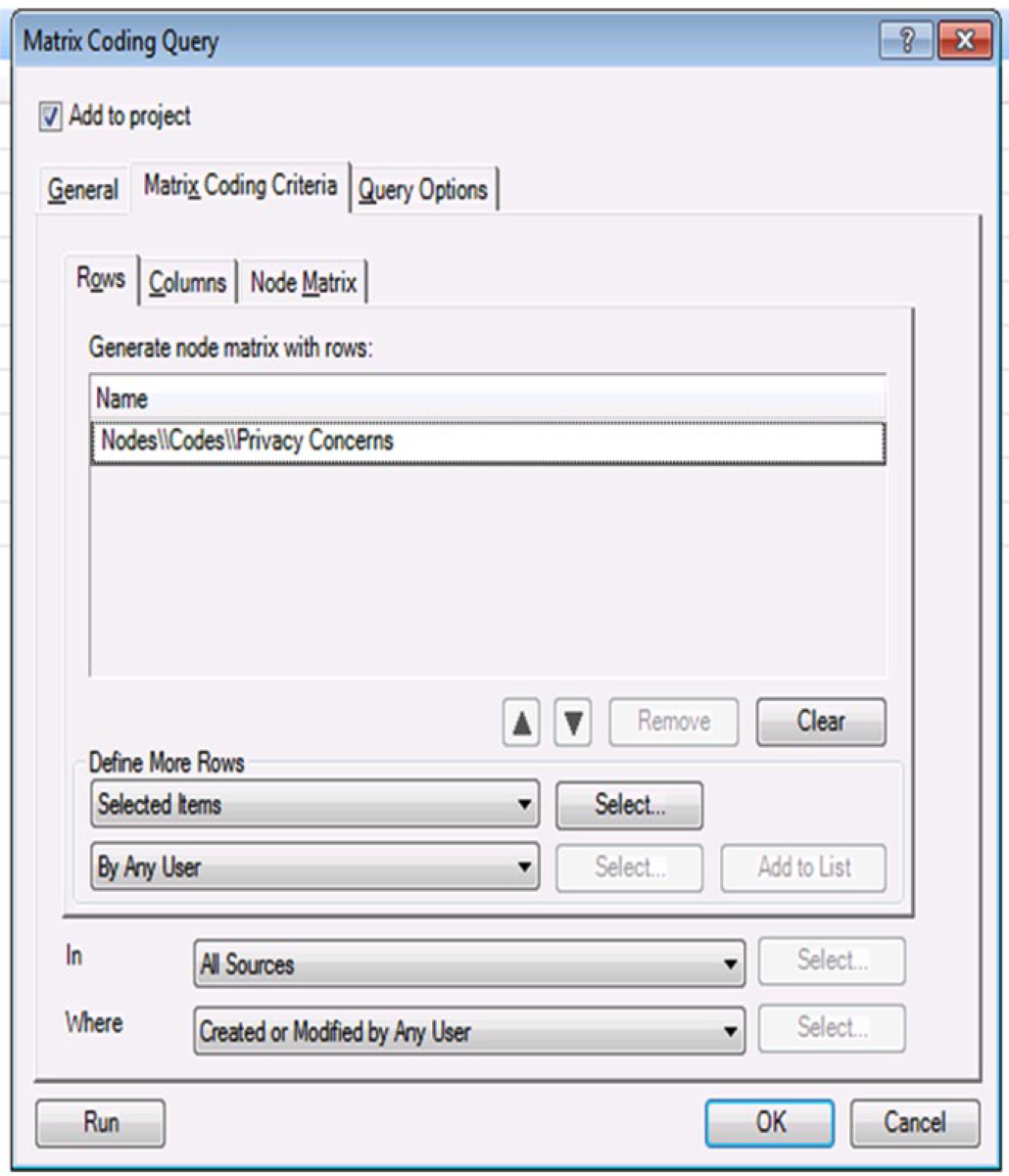
Privacy concerns as row.
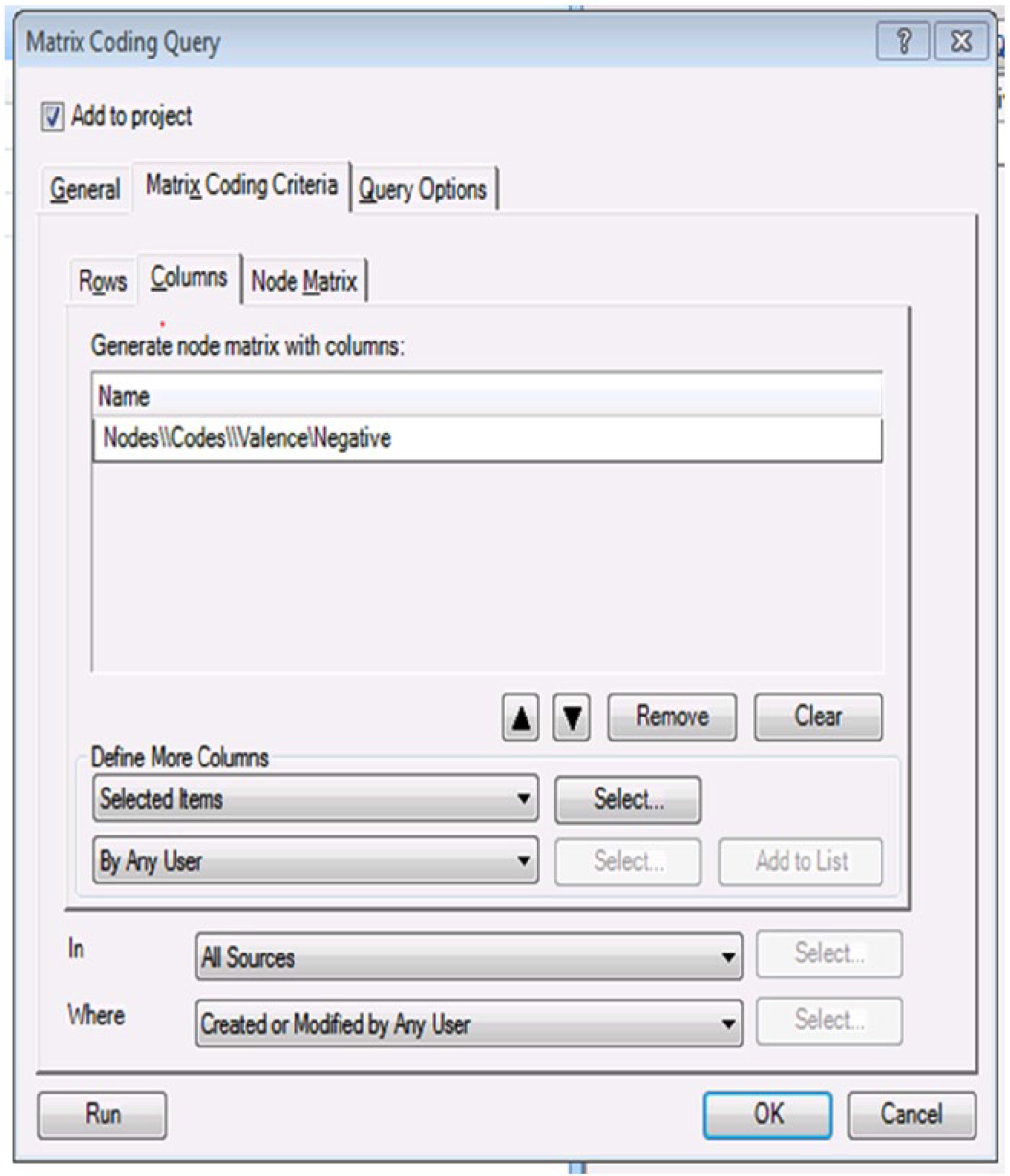
Negative valence as column.
The output of this query is a table (see Figure 3—created solely for the purposes of this article) that displays a count of how many data items indicated the speaker’s personal privacy would be negatively affected by a repeal of the law. In NVivo, the user can simply click on the number in the table and the software generates a list of every item that was coded according to the parameters laid out in the query 10 (e.g., “I would feel violated if I had to shower next to a gay man.”). Finally, this output was saved as a “Result” node so that we were able to use it in subsequent queries (see below).
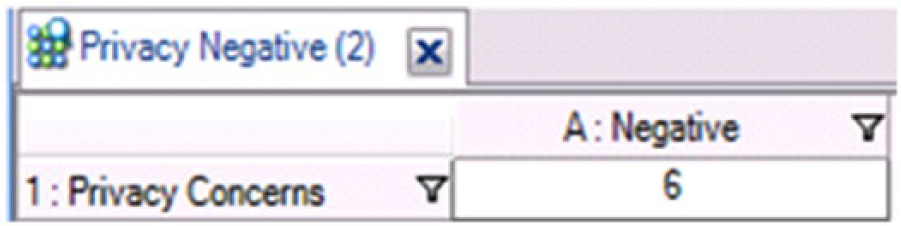
Perceived negative effect on privacy result node.
Next, we ran a similar query to the above, but using the valence code “Positive” as the column entry. That (artificial) tabular output, seen in Figure 4, below, was also saved as a result node.
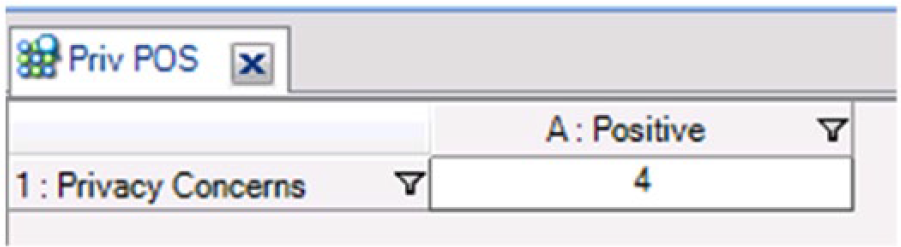
Perceived positive effect on privacy result node.
In the final step of the process, we ran a matrix query using these result nodes as the rows, as illustrated in Figure 5, and respondent gender as the columns in this query (see Figure 6):
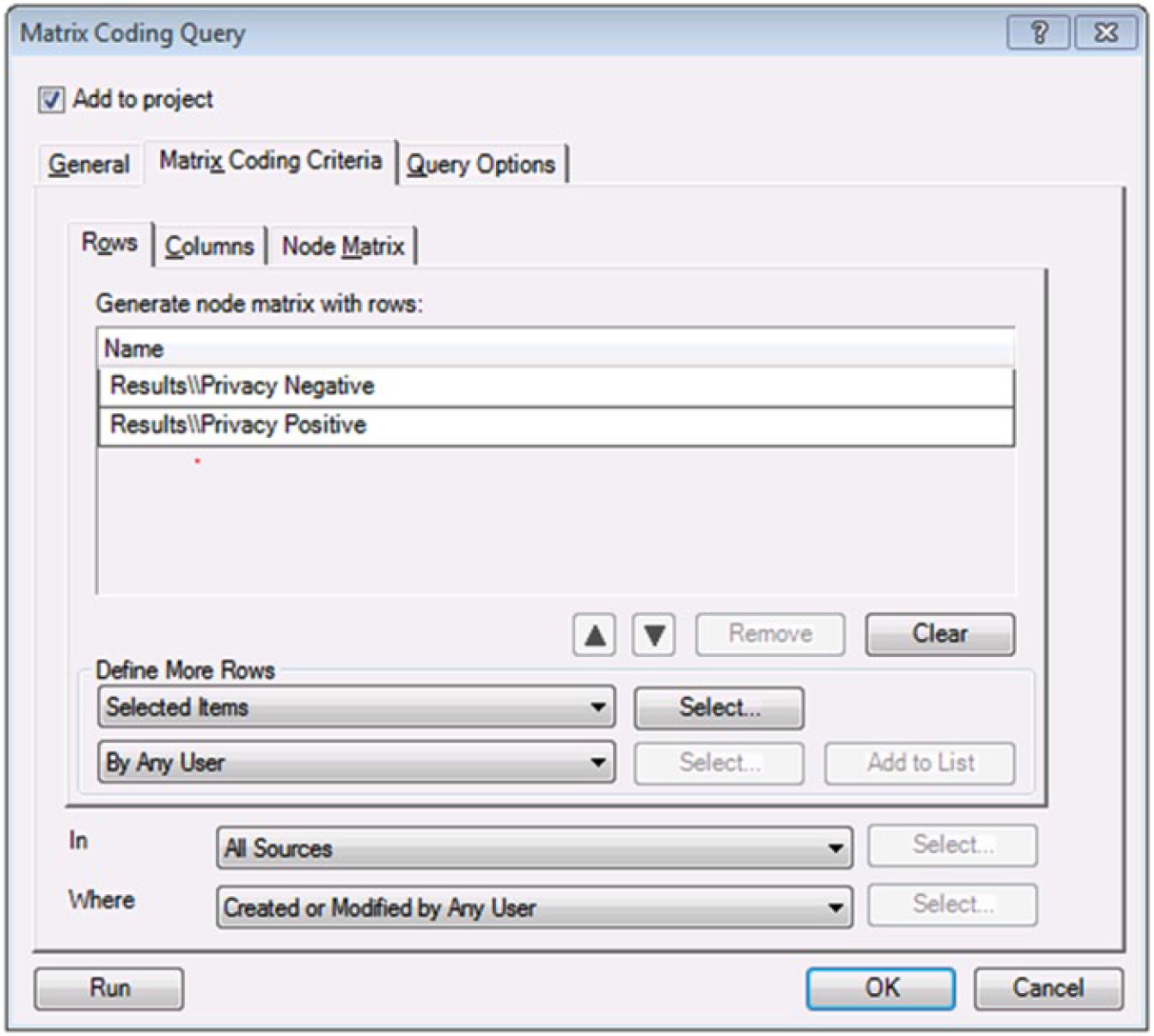
Negative and positive privacy comments as rows in matrix query.
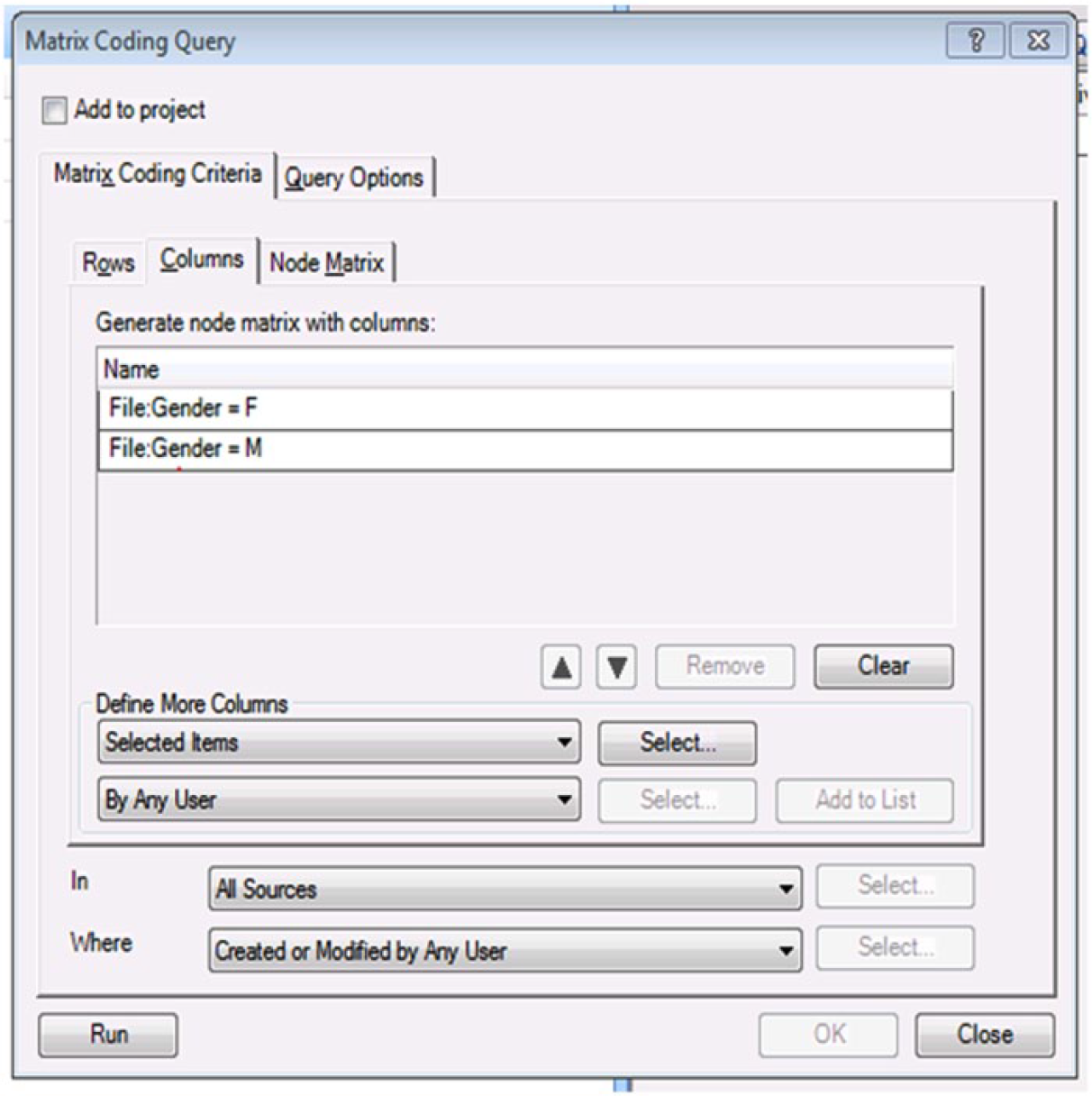
Gender as columns in privacy concerns matrix query.
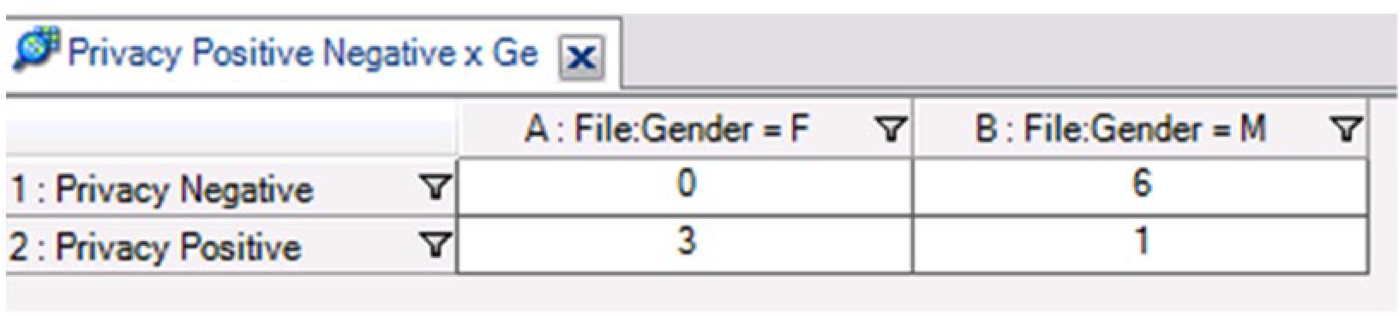
The output was a two-by-two table (see Figure 7), showing how the valence about personal privacy varied by respondent gender:
Privacy concerns by gender result node.
Because the qualitative researchers were not working with a representative sample, we reported the numeric output of such queries in relative proportions rather than absolute numbers. This helped mitigate any attempts by readers to generalize the findings to a larger population. In the above constructed example the team might report,
No female respondents expressed the view that a lift of the ban would have adverse effects on their sense of privacy while showering or in unit sleeping quarters. By contrast, male respondents overwhelmingly expressed such views, although men were not uniformly negative.
Over the course of the analytic process, the team ran hundreds of such queries in order to carefully assess the key issues raised by respondents, the tone with which they raised those issues, and the ways in which those views varied by key demographic factors.
Open-ended survey comments
NVivo also proved critical to our ability to analyze the open-ended comments on both the service member and spouse surveys 11 (see J. Fielding, Fielding, & Hughes, 2013, for a nice discussion of the role of qualitative software in analyzing open-ended comments). For each of these instruments, the survey team identified a set of critical survey items (21 items for the service member survey, eight for the spouse survey). On the basis of their answers to those critical items, the survey analysts grouped respondents into three “classes”: Those who answered “strongly positive” or “positive” to all of the critical items were assigned to the “positive” respondent class; conversely, those who answered “strongly negative” or “negative” to these items were grouped into the “negative” respondent class; and those whose answers varied (i.e., “positive” on some critical items, “negative” or “neutral” on others) were identified as the “mixed” respondent class. Because individuals who had strong positive or negative feelings about the implications of repeal were those whose opinions had been expressed most clearly during the small group discussions and leadership forums, the team opted to oversample the “mixed” respondent class to provide enough data to clarify the meaning of their mixed response. Did their answers to the critical items reflect a “neutral” position about the potential effects of repeal? Or, as a group, were there specific facets of military life that they believed would be adversely affected by repeal, and others that they believed might benefit from a change in policy, that is, their views were truly “mixed”? Of the 2,000 service member comments analyzed, 500 each were randomly selected from the positive and negative respondent classes, and 1,000 members of the mixed respondent class. Proportions were the same when sampling the spouse comments.
Coding of the open-ended comments used the same coding structure developed for the other qualitative data elements in the study; most importantly, coding involved tagging both the content and valence of the statement. The resulting analysis of the service member comments (see Table 2) indicated that, with a few exceptions (and consistent with the group discussion findings), members of the positive respondent class almost uniformly wrote comments on the final question that indicated a belief that repeal of the law would benefit the military. Conversely, those in the negative respondent class mostly wrote comments expressing the belief that repeal would adversely affect the military, although coders did note a large number of neutral comments, and even some positive comments, among this otherwise negative group.
Distribution of Comment Tone by Service Member Respondent Class.
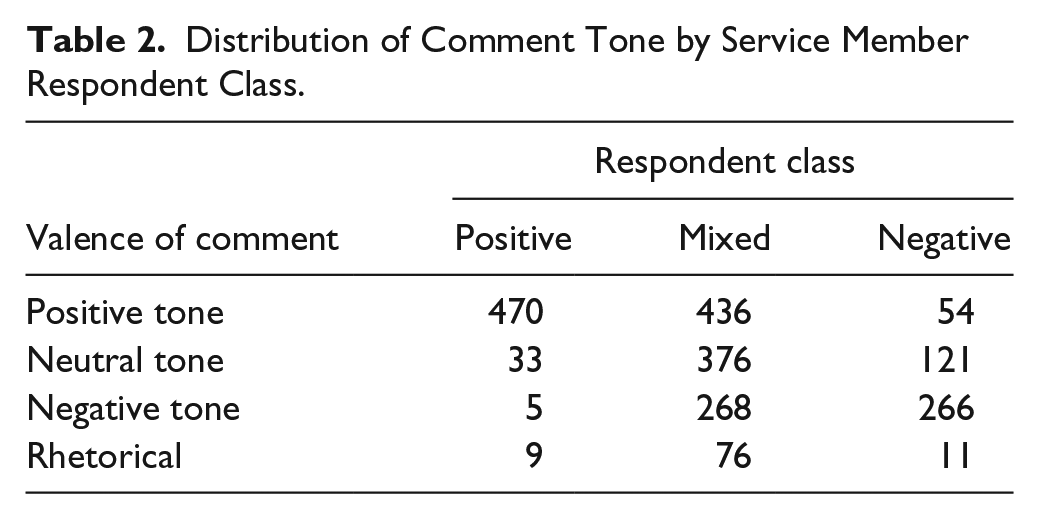
Among service members in the “mixed” class, however, responses to the open-ended item were more broadly distributed among the “valence” codes: More than a third of these service members believed repeal would be a change for the better, approximately one third said that repeal would make no difference at all, and about one quarter wrote comments suggesting that repeal would adversely affect the military. 12 This group also wrote a larger number of rhetorical comments than either the positive or negative groups.
Analysis of the spouse comments revealed a pattern similar to that of their service member counterparts; mixed class respondents were by no means “neutral” on the issue of repeal, but rather offered a wide range of perspectives on how repealing the ban would affect the military. In this way, NVivo allowed us to conduct an analysis that would not have been possible in the absence of the technology. Not only did the software give us the firepower to code 4,000 open-ended comments (a number practically unheard of in the world of qualitative research), but it allowed us to shed light on the views of a group of respondents whose perspectives could not be fully illuminated by survey analysis alone.
Conclusions
Using a digital tool, namely the QDAS product NVivo, proved to be critical to the successful completion of a project that involved an enormous volume of data to be analyzed within an intense timeframe. Yet, as Paulus et al. (2017) note, the success was not the result of the software per se, but a team that included solid qualitative researchers and a management strategy that was able to maximize the tool’s added value. First, the two qualitative study leads were well-trained qualitative researchers who brought their epistemological understanding to the task at hand. The QDAS product thus was brought in as a tool to facilitate the analysis of the data, not to “do” the analysis. Second, staff were structured into teams, each with discrete but related tasks (data collection, data analysis, database management, and project management). In particular, we used an experienced NVivo database manager along with a senior consultant to guide the construction of the databases. This ensured the databases were set up to maximize the software’s capabilities and that coding and analysis could progress while data collection was ongoing. Having an experienced database manager also ensured that changes to the coding structure were identical across all of the databases so that final database merging could occur seamlessly. Third, we strove to use experienced qualitative researchers as analysts and data coders. Because of their expertise, these team members were able to identify the many nuances in the data. Further, because the team had to work side-by-side in the Enclave, they were able to discuss and reach a consensus in real time about any needed changes to the coding structure.
Digital tools offer qualitative researchers analytic capabilities beyond anything we could have dreamed of 30 years ago. However, researchers who have not thought through the rationale for which tool they are using, why, and how, can generate “findings” that make little sense. In this article, we have described the strategy we used in one large-scale project to manage all aspects of the qualitative components of the study, including the staff who were collecting the data, those who were analyzing the data, and the tool that was being used to facilitate the analysis. Such careful planning, we believe, will ensure that qualitative research remains true to its epistemological roots while still benefitting from technological advances.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.