
Abstract
Neural constitutive models have recently emerged as powerful tools for data-driven continuum mechanics, yet their integration into higher-order theories remains largely empirical and often lacks structural guarantees. In this work, we develop a rigorous variational framework for invariant neural representations of stored energy densities in strain-gradient continuum models. The energy is expressed as a neural mapping of isotropic invariants of the infinitesimal strain tensor and its gradient, thereby enforcing objectivity and isotropy at the representation level. We prove thermodynamic admissibility through potential structure, establish coercivity in
Keywords
1. Introduction
Higher-order continuum theories—including second-gradient (strain-gradient) elasticity, Cosserat–micropolar continua, micromorphic media, and related generalized continuum frameworks—provide a mathematically rigorous and physically consistent methodology for incorporating intrinsic length scales, microstructural interactions, curvature effects, and nonclassical boundary phenomena into continuum mechanics. Their importance is now well established in situations where classical Cauchy elasticity becomes insufficient, singular, or incapable of capturing experimentally observed responses. This includes, in particular: (1) size-dependent behavior in microstructured and nanostructured solids, (2) strain localization and the regularization of softening-induced ill-posedness, (3) energetic descriptions of microstructural rearrangements and curvature-dependent mechanisms, and (4) boundary layer effects associated with higher-order tractions, moments, and double forces [1–8]. In contrast to classical local theories, higher-order continua naturally introduce additional energetic penalties on gradients of deformation or microstructural descriptors, thereby providing both enhanced mathematical regularity and improved physical fidelity in heterogeneous materials.
Discrete microstructured systems such as pantographic lattices, articulated beam networks, modular truss assemblies, and architected metamaterials provide concrete mechanical realizations of media whose effective macroscopic behavior inherently involves higher-gradient effects and internal characteristic lengths. In these systems, the underlying geometry and connectivity of the microstructure generate nonlocal interactions and curvature-dependent responses that cannot be adequately represented within standard first-gradient elasticity. Early foundational work demonstrated that modular truss-beam systems may possess deformation energies depending explicitly on higher displacement gradients, thereby furnishing a discrete mechanical justification for second-gradient continuum theories and related generalized elastic models [9].
Among such systems, pantographic lattices and beam-based metamaterials have emerged as particularly important experimental and numerical platforms for studying the emergence of higher-order kinematics at the continuum scale. Through heuristic homogenization procedures, large-deformation experiments, and detailed numerical simulations, these structures have been shown to exhibit equilibrium configurations, bending-dominated responses, and wave propagation phenomena that are accurately described by strain-gradient and second-gradient continuum models [10,11]. These results provide strong evidence that generalized continuum theories are not merely abstract mathematical extensions of classical elasticity, but rather effective macroscopic descriptions of physically realizable microstructured media.
Recent theoretical developments have further clarified the continuum mechanics of three-dimensional pantographic lattices within the framework of second-gradient elasticity. In particular, rigorous formulations have been developed to characterize their nonlinear equilibrium behavior, stability properties, and higher-order constitutive structure, thereby strengthening the connection between discrete architected systems and generalized continuum theories [12]. Such developments reinforce the interpretation of higher-gradient elasticity as an effective continuum limit of mechanically rich lattice-type microstructures possessing complex internal kinematics.
More broadly, articulated mechanisms and zigzagged lattice geometries also exhibit highly nontrivial deformation patterns involving rotational couplings, constrained motions, and geometric compatibility effects whose effective macroscopic description frequently requires additional kinematical fields or higher-order deformation measures [13]. These examples further motivate the development of mathematically robust generalized continuum frameworks capable of capturing the interplay between geometry, microstructure, and nonlocal mechanical interactions in modern metamaterials and architected solids.
From a variational viewpoint, the introduction of strain-gradient terms yields coercivity in
In parallel, the last decade has seen rapid growth of data-driven and machine-learning–based constitutive modeling in computational mechanics. Neural networks and related regressors have been used to approximate stress–strain responses, discover constitutive operators, and build fast surrogates for multiscale simulations [16,17]. Physics-informed learning has further emphasized embedding differential constraints into training, improving extrapolation and physical consistency [18]. Despite their empirical success, however, many neural constitutive models remain “black-box” mappings from kinematic inputs to stresses (or tangent moduli) and therefore lack structural guarantees that are routine in classical mechanics: material frame indifference (objectivity), thermodynamic admissibility (existence of a potential and satisfaction of the dissipation inequality), and well-posedness of the induced boundary value problem. When such models are inserted into finite element solvers, even small violations of these structural constraints can manifest as nonintegrable stress fields, loss of symmetry, spurious mesh dependence, or catastrophic loss of robustness under Newton iterations.
This work addresses this structural gap by embedding neural constitutive representations into a rigorous variational and functional-analytic framework tailored to higher-order continua. The central idea is conceptually simple but mathematically decisive: instead of learning stresses directly, we represent the stored energy density and derive the stress measures as variational derivatives, thereby inheriting thermodynamic consistency and compatibility with the calculus of variations. Concretely, in the small-strain second-gradient setting, one considers a displacement field

over an admissible space
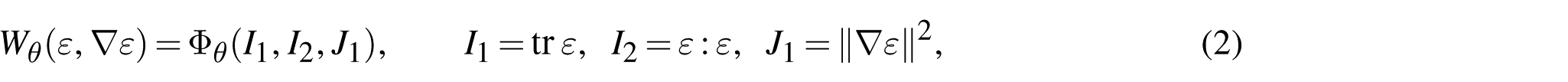
so that objectivity and isotropy are enforced structurally by representation theory, independently of the parametrization of the scalar map
The motivation for enforcing a variational structure is multifold:
Objectivity and isotropy without penalties. Frame indifference is a structural requirement: for superposed rigid motions
Thermodynamic admissibility by potential structure. In an isothermal elastic setting, defining stresses via
Well-posedness and existence of minimizers. For generalized continua, the natural weak formulation lives in
Stability: strong ellipticity and localization control. A constitutive model is not useful in computation if it is prone to spurious instabilities. Local stability in elasticity is governed by the Legendre–Hadamard condition, equivalently the positive definiteness of the acoustic tensor
Beyond convexity: polyconvex neural energies. While convexity in
We introduce a structure-preserving invariant neural representation of strain-gradient energies, in which material symmetry and objectivity are enforced at the representation level through dependence on scalar isotropic invariants.
We formulate the associated variational problem in
We derive a detailed Legendre–Hadamard stability analysis for the invariant neural energy, obtaining explicit sufficient conditions for strong ellipticity expressed directly in invariant space.
We clarify the distinction between convexity, rank-one convexity, quasiconvexity, and polyconvexity within the present framework and propose a polyconvex neural extension suitable for finite-strain elasticity.
These contributions collectively establish a mathematically controlled foundation for data-driven higher-order continuum modeling that preserves invariance, thermodynamic admissibility, existence, and stability.
Outline of the paper
Section 2 introduces the kinematics of second-gradient continua, including the displacement space
Section 3 develops the invariant neural energy representation
Section 4 embeds the neural energy into continuum thermodynamics. The Clausius–Duhem inequality is verified in the purely elastic case, energetic conjugacy is established, and admissible extensions to inelastic internal-variable formulations are discussed.
Section 5 establishes the existence of minimizers for the variational problem in
Section 6 provides a detailed Legendre–Hadamard analysis of the invariant neural energy, deriving sufficient conditions for strong ellipticity expressed directly in invariant space and characterizing stability at and near the reference configuration.
Section 7 introduces polyconvex neural energy representations for finite-strain elasticity. Convex neural architectures (including input convex neural network (ICNN)-based constructions and positive-semidefinite Hessian parametrizations) are shown to enforce polyconvexity structurally and guarantee the existence of minimizers in
Section 8 translates the functional-analytic stability and convexity conditions into explicit neural architectural constraints, demonstrating how ellipticity, convexity, and coercive growth can be enforced independently of training data.
Section 9 clarifies the hierarchy between convexity, polyconvexity, quasiconvexity, rank-one convexity, and Legendre–Hadamard ellipticity and analyzes the regularizing role of second-gradient contributions in preventing fine-scale microstructure formation.
Section 10 discusses the mathematical implications, limitations, and scope of the framework, highlighting the distinction between local ellipticity and global variational well-posedness.
Section 11 concludes by summarizing the structural integration of neural parametrizations into generalized continuum mechanics and outlining open problems, including sharper ellipticity criteria and finite-strain gradient extensions.
2. Kinematics of second-gradient continua
Let
2.1. Displacement field and strain measures
We consider small deformations described by a displacement field

The infinitesimal strain tensor is defined by

In a second-gradient theory, the higher-order kinematical measure is

a third-order tensor belonging to
2.2. Admissible function space
Let

The admissible displacement space is

The
2.3. Energy functional
Let

be the stored energy density.
The total potential energy is defined by

where ℓ is a bounded linear functional on
2.4. Variational problem
We consider the minimization problem:

The second-gradient contribution provides coercivity in the

then the functional is coercive in
2.5. Euler–Lagrange equations
Formally, the first variation yields
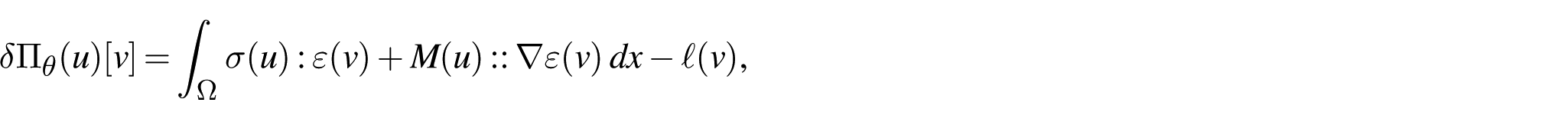
where the stress measures are defined by

Integration by parts leads to fourth-order equilibrium equations with classical and higher-order boundary terms. This highlights the structural role of second gradients in regularizing strain localization.
3. Invariant neural energy representation
We introduce a structure-preserving representation of the stored energy based on isotropic invariants. The objective is to embed the neural parametrization into a representation-theoretic framework that enforces material frame indifference and isotropy at the structural level.
3.1. Representation-theoretic framework
Let

Similarly, the third-order tensor

A scalar function

is objective if

By classical representation theory of isotropic tensor functions, a scalar isotropic function of tensor arguments must depend only on scalar invariants generated by contraction operations. We therefore construct the neural energy through invariant arguments.
3.2. Restricted invariant modeling class
We restrict attention to stored energy densities that depend on the strain tensor through the quadratic invariants

and on its gradient through

Accordingly, we consider the modeling class

where

is twice continuously differentiable.
This restriction is intentional: it provides a minimal yet structurally consistent function class suitable for neural parametrization while remaining compatible with existence and ellipticity analysis.
3.3. Invariance of the generating set

and

since the Euclidean tensor norms are invariant under orthogonal maps. □
3.4. Neural invariant Ansatz
We define the stored energy density as

with
The parameter vector θ represents internal coefficients (e.g., weights in a neural network). Although
3.5. Objectivity and isotropy

By the preceding lemma, the scalar invariants remain unchanged. Therefore

3.6. Scope of the representation
The above ansatz characterizes the class of quadratic-invariant isotropic small-strain energies. More general isotropic energies may depend on additional invariants of ε and on mixed invariants involving ε and
3.7. Regularity
The assumption

ensuring the existence of first and second variations. This regularity is required for the derivation of Euler–Lagrange equations and for the Legendre–Hadamard analysis performed in section 6.
3.8. Extension to anisotropy
Anisotropic models can be obtained by introducing structural tensors. Let

The invariant neural framework therefore extends naturally to transversely isotropic or orthotropic materials by augmenting the invariant argument list.
4. Thermodynamic structure and dissipation inequality
We now embed the invariant neural energy representation into the framework of continuum thermodynamics for second-gradient media.
4.1. Balance laws
Let
The balance of linear momentum reads

where
σ is the Cauchy stress tensor,
M is the third-order hyperstress tensor,
b denotes the body forces,
The associated virtual power identity is
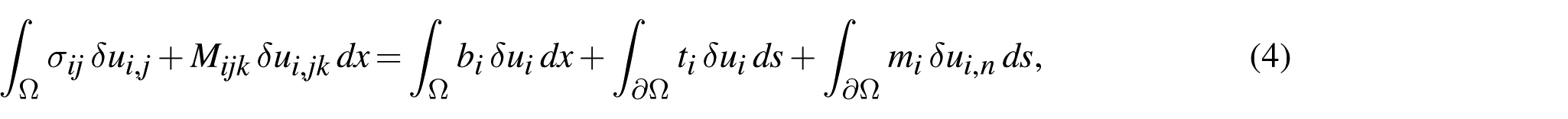
4.2. Free-energy density
We assume the Helmholtz free-energy density

with

We define constitutive relations through energetic conjugacy:

4.3. Local dissipation inequality
The local form of the Clausius–Duhem inequality under isothermal conditions is

4.4. Elastic case

Then, the local dissipation inequality is satisfied identically, i.e.,


Substituting the constitutive relations yields

Hence

4.5. Energetic conjugacy and boundary contributions
Integrating the local inequality over

After integration by parts,
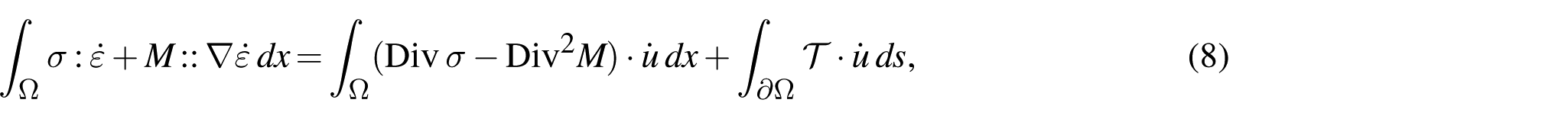
where
Thus, the energetic formulation is fully consistent with the balance equations.
4.6. Extension to inelastic internal variables
Let the free energy depend additionally on an internal variable α:

Define thermodynamic force

The dissipation becomes
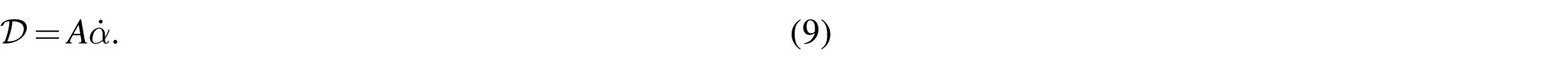

where

4.7. Structural implications for neural parametrizations
Thermodynamic admissibility is not an auxiliary modeling preference but a structural requirement dictated by continuum thermodynamics. Within the present invariant neural framework, admissibility must hold independently of the training data and therefore be enforced at the representation level. In the isothermal setting considered here, this translates into the following constitutive requirements:

must be symmetric, reflecting the balance of angular momentum. Because the energy depends only on the symmetric strain tensor and is derived from a scalar potential, this symmetry follows automatically.

must arise from the same free-energy density. This ensures integrability of the constitutive response, compatibility with the principle of virtual power, and exact satisfaction of the local Clausius–Duhem inequality in the purely elastic case.
These conditions collectively ensure that the neural parametrization remains embedded within a thermodynamically consistent constitutive class, rather than merely approximating stress responses in a data-driven manner. These conditions can be enforced at the level of neural parametrization by ensuring smooth activation functions and convex architectures when modeling inelastic processes.
5. Existence of minimizers in
We establish the existence of minimizers for the second-gradient neural energy functional using the direct method of the calculus of variations.
5.1. Variational setting
Let
Define the admissible space

The total potential energy is

where ℓ is a bounded linear functional on
The minimization problem reads:

5.2. Structural assumptions
We assume:


Assumption (A2) provides second-gradient coercivity, while (A3)–(A4) ensure weak lower semicontinuity.
5.3. Second-order Korn inequality

5.4. Coercivity

Since ℓ is continuous in

Applying the second-order Korn inequality yields

which implies coercivity. □
5.5. Weak lower semicontinuity

Convexity in
5.6. Existence of minimizers

Weak lower semicontinuity yields

so u is a minimizer. □
5.7. Remarks
6. Strong ellipticity and the Legendre–Hadamard condition
We analyze stability of the invariant neural energy representation through the Legendre–Hadamard condition, which characterizes strong ellipticity of the second variation.
6.1. Second variation and tangent operator
Consider the strain-dependent part of the stored energy

with invariants

We define the fourth-order tangent tensor

The derivatives of the invariants are

and

Applying the chain rule yields
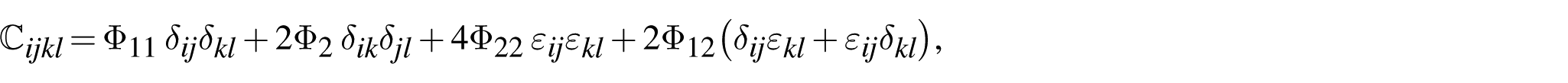
where subscripts denote the partial derivatives of
6.2. Legendre–Hadamard condition

Equivalently, defining the acoustic tensor

strong ellipticity is equivalent to positive definiteness of
6.3. Ellipticity at the reference configuration
At the reference configuration

This has the standard isotropic elasticity structure. The corresponding acoustic tensor is

The eigenvalues of
Longitudinal mode:

Shear modes (multiplicity two):


then the Legendre–Hadamard condition holds at
6.4. Local preservation of ellipticity

Then there exists
6.5. Interpretation in invariant space
The above result shows that the ellipticity at the reference state is governed entirely by the invariant derivatives
7. Polyconvex neural energy representations
Convexity of
7.1. Polyconvexity in finite strain
Let

such that

Polyconvexity implies quasiconvexity, and hence weak lower semicontinuity of the functional

under suitable growth conditions. Classical existence results are due to Ball.
7.2. Neural polyconvex ansatz
We define a neural polyconvex energy as

where

is convex with respect to all its arguments.
This construction enforces polyconvexity structurally, independently of parameter identification.
7.3. Existence result in finite strain
We impose the following growth condition: there exist constants


admits at least one minimizer in

7.4. Relation to strong ellipticity
Polyconvexity implies rank-one convexity. For
The converse is false: strong ellipticity does not imply polyconvexity. Therefore, polyconvexity constitutes a strictly stronger, global stability requirement.
7.5. Neural implementation strategies
In order to embed neural constitutive parametrizations into a mathematically admissible class, convexity (or polyconvexity) must be enforced at the architectural level rather than learned empirically.
We describe three structurally controlled constructions.
1. ICNN
Let

with output

subject to the structural constraint

If the activation functions
Thus, the convexity of
2. Positive-semidefinite Hessian parametrization
An alternative approach is to parametrize the Hessian of
Let

where
Integrating the Hessian twice (with suitable boundary conditions) produces a convex potential.
This construction is particularly useful when convexity is required only in selected arguments (e.g.,
3. Convex anchor and convex residual decomposition
A structurally robust strategy is to decompose

where
For instance,
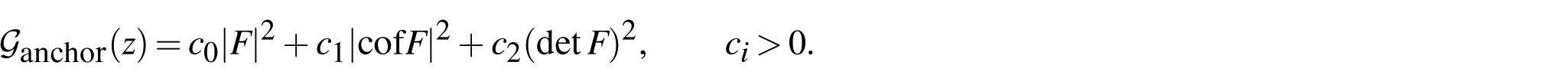
This decomposition ensures:
Existence of minimizers via coercivity,
Stability under parameter updates,
Independence of convexity from training data.
Relation to polyconvexity
In the finite-strain setting, polyconvexity requires convexity in the extended variable

If

is polyconvex.
Thus, architectural convexity in the invariant space provides a direct mechanism to enforce polyconvexity at the constitutive level.
8. Neural architecture constraints and structural enforcement
The previous sections derived existence and stability conditions in terms of derivatives of the invariant scalar map
8.1. Invariant input encoding
The neural energy is represented as

Because
8.2. Ellipticity constraints in invariant space
From the Legendre–Hadamard analysis, strong ellipticity at the reference configuration requires:

These conditions depend only on derivatives of
For example:
Parametrize
Parametrize
Use positive-definite Hessian parametrization via Cholesky factors.
Thus, the ellipticity constraints become algebraic constraints on neural outputs.
8.3. Convexity enforcement
A central requirement for the existence of minimizers in the second-gradient setting is weak sequential lower semicontinuity of the functional in
To make this requirement explicit at the level of neural parametrization, we consider a separable invariant representation
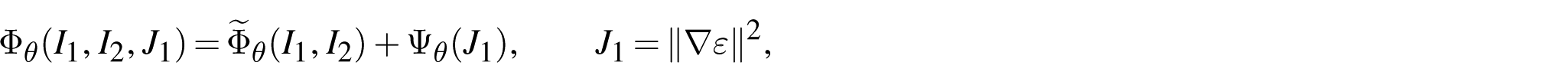
where the higher-order contribution
Convexity of
Importantly, the convexity of
These constructions convert an abstract functional-analytic condition (convexity in
8.4. Coercive growth control
A central requirement for the existence of minimizers in
From a neural modeling perspective, such growth cannot be left to empirical training alone. Neural parametrizations identified from finite datasets may exhibit flat regions, subquadratic growth, or even local degeneracy outside the data manifold, thereby compromising coercivity of the total functional.
To enforce this property at the architectural level, we augment the invariant neural representation by a strictly positive quadratic anchor in the gradient invariant:

Because

for suitable
Importantly, this coercive anchor is not a numerical regularization term but a structural component of the hypothesis class. It ensures that the admissible neural energy remains within a variationally well-posed class throughout training and inference. Moreover, it prevents degeneracy in regions of sparse or extrapolated data, where purely data-driven models may otherwise lose stability.
8.5. Comparison with unconstrained neural stress models
Many data-driven constitutive approaches approximate the stress response directly by a neural mapping

While such formulations may reproduce observed stress–strain relations within a training regime, they generally lack structural guarantees.
In particular, stress-driven neural models:
do not guarantee the existence of an underlying potential and therefore may violate integrability conditions;
may fail to produce a symmetric consistent tangent operator, leading to loss of variational structure and difficulties in Newton-type solvers;
can destroy strong ellipticity or acoustic tensor positivity, since no invariant-based convexity constraints are enforced;
provide no existence guarantees for the associated boundary value problem, as weak lower semicontinuity and coercivity are not structurally controlled.
These deficiencies are not merely theoretical. In computational practice, they may manifest as mesh dependence, nonconvergent iterations, spurious localization, or lack of robustness under extrapolation.
In contrast, the present energy-based invariant framework begins with a stored energy density defined on scalar invariant space. Admissibility conditions—objectivity, thermodynamic consistency, coercive growth, and ellipticity—are enforced structurally through architectural constraints on the scalar mapping
9. Relation to convexity, rank-one convexity, and quasiconvexity
Convexity plays a central role in existence theory for variational problems. However, in nonlinear elasticity and generalized continua, full convexity is often too restrictive. We therefore clarify the hierarchy of convexity notions and their implications for the present neural framework.
9.1. Convexity and weak lower semicontinuity
A central question in the calculus of variations is whether the energy functional

is weakly lower semicontinuous in the natural function space. Weak lower semicontinuity is the key structural property required for the direct method to yield the existence of minimizers.
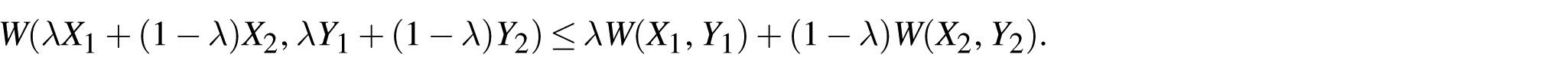
If W is convex and satisfies suitable growth conditions, then
However, full convexity is extremely restrictive from a physical standpoint. Most nonlinear elastic energies—especially those capable of describing instabilities, phase transitions, or strain softening—fail to be convex. Thus, weaker notions of convexity are required.
9.2. Rank-one convexity and the Legendre–Hadamard condition
A first relaxation of convexity is rank-one convexity, which is closely tied to stability against simple laminates.

is convex for all
For twice differentiable energies, rank-one convexity is equivalent to the Legendre–Hadamard condition

where ℂ is the fourth-order tangent tensor. This is precisely the condition of strong ellipticity in elasticity theory.
Thus, strong ellipticity represents a local form of rank-one convexity. It ensures local stability of homogeneous states with respect to plane-wave perturbations, but it does not guarantee global variational well-posedness.
9.3. Quasiconvexity
The correct structural condition for weak lower semicontinuity in nonlinear elasticity is quasiconvexity.

Quasiconvexity characterizes weak lower semicontinuity of integral functionals in
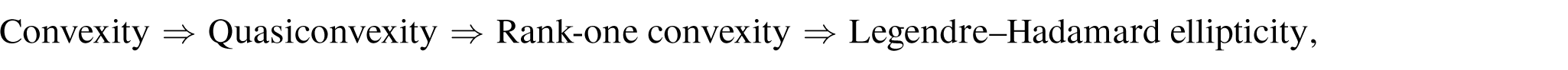
and the converses generally fail.
Hence, strong ellipticity alone is insufficient to guarantee the existence of minimizers. Additional structure—either convexity or higher-order regularization—is required.
9.4. Second-gradient regularization
Consider now an energy of the form

Suppose that
The second-gradient term alters the second variation:

The additional term is coercive in

Then, for sufficiently large

By interpolation and second-order Korn-type inequalities, this term dominates any bounded negative contribution arising from the first-gradient part, provided ℓ is sufficiently large. □
Thus, higher-order regularization does not restore classical strong ellipticity, but it restores variational coercivity and prevents unbounded oscillations.
9.5. Implications for neural energy representations
Consider neural strain-gradient energies of separable form

Assume:
Higher-order coercivity


Combined with a second-order Korn inequality, this ensures coercivity of the total functional in
Regularization of localization
Let

be the first-gradient tangent tensor. Loss of positive definiteness of
The higher-order contribution generates the bilinear form

which penalizes high-frequency strain fluctuations. Even if
Suppression of fine-scale microstructure
Let

is uniformly bounded. The Rellich compactness then prevents arbitrarily fine oscillations. Thus, the neural gradient term acts as a curvature penalty that suppresses pathological microstructure formation.
Ellipticity versus well-posedness
It is crucial to distinguish:
Local strong ellipticity of the first-gradient tensor.
Global coercivity and the existence of minimizers of the full functional.
Second-gradient regularization does not restore classical ellipticity of
9.6. Microstructure and relaxation
In classical first-gradient elasticity, loss of quasiconvexity of the strain energy density
The introduction of a second-gradient contribution modifies this picture fundamentally. Consider an energy of the form

The higher-order term penalizes spatial variations of the strain field through a curvature-type energetic cost. In particular, if
Within the present neural strain-gradient framework, this regularization mechanism is not introduced a posteriori, but is embedded directly at the level of the energy representation. The neural mapping
9.7. Summary of the stability hierarchy
The various notions of convexity that arise in nonlinear elasticity form a strict hierarchy, reflecting progressively weaker structural requirements while retaining different levels of stability and variational control. In the classical setting, one has the chain of implications
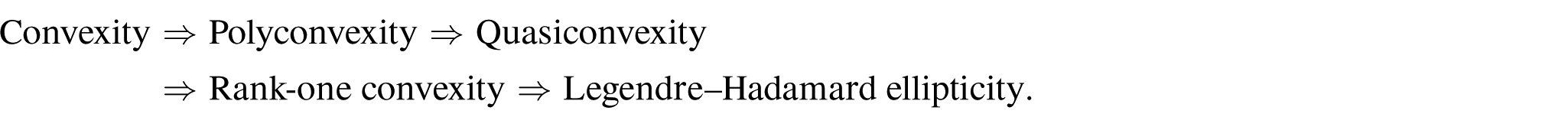
Each implication is strict in general. Convexity is sufficient for weak lower semicontinuity and therefore guarantees the existence of minimizers by the direct method, but it is often too restrictive for physically realistic elastic energies. Polyconvexity relaxes convexity by enlarging the argument space (e.g., to
Within the present invariant neural framework, these concepts acquire a clear structural interpretation:
Convex neural parametrizations (e.g., convex architectures in invariant space) guarantee weak lower semicontinuity and thus the existence of minimizers directly.
Polyconvex neural energies provide existence results under weaker structural assumptions, particularly in finite-strain settings, while remaining compatible with nonlinear kinematics.
Legendre–Hadamard conditions, expressed explicitly in terms of derivatives of the invariant scalar map
Second-gradient regularization does not restore classical ellipticity of the first-gradient part, but it enforces global coercivity in
This layered structure embeds neural constitutive modeling into a mathematically controlled stability hierarchy. Rather than relying on empirical regularization alone, the framework makes explicit which architectural constraints correspond to which level of variational stability. In this way, expressive neural parametrizations can be reconciled with the fundamental analytical requirements of existence, ellipticity, and localization control in generalized continuum mechanics.
10. Discussion
The results established in the previous sections provide a coherent variational and stability framework for invariant neural energy representations in higher-order continua. We summarize the principal structural properties and discuss their mathematical implications.
10.1. Objectivity and representation
A foundational requirement in continuum mechanics is the material frame indifference. In classical constitutive theory, this constraint is not optional but structural: the stored energy must remain invariant under superposed rigid body motions. In the present framework, this requirement is enforced at the level of representation by constructing the stored energy density exclusively from isotropic scalar invariants of the infinitesimal strain tensor ε and its gradient
More precisely, the energy is written as

where
This structural enforcement sharply contrasts with generic tensor-to-tensor neural mappings
From the viewpoint of invariant theory, the constitutive modeling problem is reduced to the construction of a scalar function defined on a low-dimensional invariant space. This reduction not only simplifies the mathematical analysis but also clarifies the connection between neural parametrization and classical isotropic elasticity. In particular, classical quadratic elasticity emerges as a special case corresponding to quadratic forms in
10.2. Variational structure
A central feature of the proposed framework is the preservation of potential structure. Rather than learning stresses directly, the model learns a stored energy density from which stress and hyperstress fields are derived as variational derivatives:

This energetic construction yields several decisive consequences:
The Clausius–Duhem inequality is satisfied identically in the purely elastic case, since dissipation vanishes by construction.
The equilibrium problem admits a weak formulation in
The existence of minimizers follows from coercivity and weak lower semicontinuity via the direct method of the calculus of variations.
In contrast, black-box neural constitutive models typically regress stress tensors directly. Such models need not admit an underlying potential and therefore may violate integrability conditions, destroy symmetry of the tangent operator, or produce ill-posed equilibrium problems. The absence of a variational structure can lead to nonconservative stress fields, loss of ellipticity, and severe computational instability in Newton-type solvers.
The present framework eliminates these failure modes by embedding neural parametrizations within the classical energetic structure of continuum mechanics.
10.3. Stability and ellipticity
Local stability of elastic materials is governed by the Legendre–Hadamard condition. A key result of this work is that strong ellipticity of the first-gradient part can be characterized directly in terms of derivatives of the invariant scalar map
The chain-rule expansion of the tangent operator shows that the acoustic tensor depends explicitly on the Hessian of
This establishes a precise link between scalar convexity properties in invariant space and tensorial stability conditions in physical space. Consequently, ellipticity constraints can be enforced directly at the level of neural parametrization, without explicit manipulation of the fourth-order elasticity tensor.
It is important to emphasize that the derived conditions are sufficient but not necessary. A complete invariant characterization of global ellipticity would require a refined analysis of coupling terms arising in the chain-rule expansion of
10.4. Polyconvex extensions
While convexity in
By representing the energy as

with
From a modeling perspective, this allows the incorporation of nonlinear geometric effects, volumetric changes, and large deformations while retaining analytical well-posedness. This extension is particularly relevant for applications involving microstructural instabilities, buckling, or softening phenomena at finite strain.
10.5. Functional-analytic perspective
The framework embeds neural constitutive modeling into the classical functional setting of Sobolev spaces. The second-gradient contribution ensures coercivity in
As a result, the equilibrium problem is well-posed in the sense of the direct method of the calculus of variations. Minimizing sequences are bounded, compactness is available, and existence follows rigorously. Neural parametrizations therefore operate within the same analytical framework as classical second-gradient elasticity.
This functional-analytic embedding distinguishes the present approach from purely empirical data-driven models, which typically lack existence guarantees or PDE-level stability analysis.
10.6. Numerical implementation strategies and computational outlook
The analytical framework developed in this work naturally calls for a carefully structured computational realization. Because the governing equations are fourth-order and the constitutive response is parametrized through invariant neural mappings, numerical implementation must preserve both variational structure and architectural constraints at the discrete level. We outline below a research program for the robust computational deployment of invariant neural higher-order energies.
Invariant evaluation at quadrature level
At the element level, the primary kinematic quantities are

are computed locally and passed to the neural scalar map
This invariant preprocessing layer guarantees that objectivity and isotropy are preserved exactly at the discrete level. Since the neural model only receives invariant inputs, no rotational augmentation or symmetrization is required in training or inference. This dramatically reduces the dimensionality of the learning problem and improves numerical conditioning.
Consistent linearization and automatic differentiation
Robust nonlinear finite element implementation requires the consistent tangent operator. Because stresses are defined as

the element residual and stiffness matrix must incorporate the full second variation of the energy.
Automatic differentiation (AD) provides a natural tool for this task. By implementing
First derivatives for stress and hyperstress evaluation.
Second derivatives for construction of the fourth-order tangent tensor.
Guaranteed symmetry of the consistent stiffness matrix.
Preserving symmetry is crucial for quadratic convergence of Newton-type solvers and for compatibility with symmetric linear algebra routines. In contrast, stress-driven neural regressors may yield nonsymmetric or inconsistent tangents, leading to solver breakdown.
Discretization of fourth-order problems
Second-gradient elasticity leads to fourth-order PDEs. Several discretization strategies are possible:
The choice of discretization influences the stability of the numerical solution and the computational cost. Systematic comparison of these approaches for neural higher-order energies constitutes a natural extension of the present work.
Architectural enforcement of stability at training time
The analytical results show that ellipticity and coercivity conditions can be expressed in terms of invariant derivatives of
Positive-definite Hessian parametrizations via Cholesky factors.
ICNN architectures.
Convex anchor decompositions with guaranteed quadratic growth.
Barrier or projection methods enforcing
Training under such structural constraints ensures that the learned model remains within the admissible class throughout optimization, preventing the emergence of unstable parameter regimes.
Data-driven calibration with variational consistency
Parameter identification may proceed via minimization of an objective functional measuring discrepancy between experimental and predicted responses. A variationally consistent training procedure can be constructed as:

subject to structural constraints on
Because stresses derive from a potential, gradient-based optimization is stable and fully differentiable. Moreover, PDE-constrained training can be incorporated, where equilibrium equations are enforced at the field level rather than only at the material point level.
Multiscale and homogenization extensions
Invariant neural energies provide a natural interface with computational homogenization. At the microscale, high-fidelity simulations can generate energy data as functions of invariant measures. The neural model then serves as a reduced-order surrogate for the homogenized energy density.
Future work will investigate:
Learning effective strain-gradient moduli from microstructure.
Scale-bridging between discrete lattice models and continuum higher-order representations.
Solver robustness and conditioning
Second-gradient terms introduce additional stiffness and length-scale parameters. Numerical conditioning depends strongly on the relative magnitude of the gradient contribution. Preconditioning strategies, block factorization methods, and operator-splitting techniques will be investigated to ensure scalability in large-scale simulations.
Particular attention must be paid to:
Spectral properties of the discrete fourth-order operator.
Interaction between neural nonlinearities and Newton updates.
Sensitivity of solutions near ellipticity boundaries.
Verification and benchmark problems
To validate the computational framework, a hierarchy of benchmark problems will be considered:
Patch tests for objectivity verification.
Acoustic tensor tests for ellipticity preservation.
Strain localization under softening.
Size-effect simulations in bending or indentation.
Finite-strain large-deformation tests for polyconvex models.
Such verification is essential to demonstrate that architectural constraints indeed translate into discrete stability and robustness.
Analytical versus computational reproducibility
The present work primarily addresses reproducibility at the analytical level. All assumptions, constitutive structures, variational settings, and stability conditions are stated explicitly and can be independently verified within the framework of generalized continuum mechanics and the calculus of variations. In this sense, the mathematical results are reproducible in the classical analytical sense. By contrast, computational reproducibility of trained neural constitutive models requires additional implementation-specific components, including discretization choices for fourth-order PDEs, AD strategies for stress and tangent operators, optimizer selection, training protocols, benchmark datasets, and finite-element implementations compatible with higher-order continua. More broadly, the numerical realization of invariant neural higher-order energies requires the integration of differentiable programming, advanced finite-element technology, and structurally constrained optimization procedures. The analytical guarantees established in this work provide the mathematical and variational foundation for such developments. A systematic computational investigation, including reproducible training pipelines and large-scale numerical benchmarks, constitutes an important direction for future research and will complete the bridge between mathematical admissibility and data-driven computational mechanics.
Local versus global stability
The Legendre–Hadamard conditions derived in the present work provide local sufficient conditions for strong ellipticity near the reference configuration. Such conditions characterize infinitesimal stability with respect to rank-one perturbations, but they do not by themselves guarantee global variational well-posedness for arbitrary strain states. Global existence and stability generally require stronger structural assumptions such as quasiconvexity or polyconvexity together with suitable coercive growth conditions. The present framework therefore distinguishes carefully between local ellipticity, global coercivity, and stronger nonlinear stability notions arising in the calculus of variations.
10.7. Limitations and open problems
Several open questions remain:
The analysis was carried out primarily in the small-strain regime. Extension to geometrically nonlinear higher-order continua requires a systematic treatment of polyconvexity in extended variable spaces.
The sufficient ellipticity conditions may be conservative. Sharper criteria relating invariant convexity and rank-one convexity remain to be derived.
Quasiconvexity for second-gradient neural energies is not fully characterized and constitutes a challenging open problem.
Despite these limitations, the present framework demonstrates that neural parametrizations can be integrated into generalized continuum mechanics without sacrificing invariance, stability, or variational consistency. It provides a mathematically controlled alternative to purely empirical constitutive learning and establishes a rigorous bridge between machine learning and higher-order continuum theory.
11. Conclusion
This work has developed a rigorous variational framework for invariant neural representations of stored energy densities in higher-order continuum models. By expressing the energy as a neural mapping of isotropic invariants of the strain tensor and its gradient, objectivity and isotropy are enforced structurally rather than through penalization or data augmentation procedures. The associated stress and hyperstress fields are derived as variational derivatives of a stored-energy potential, thereby guaranteeing thermodynamic admissibility, energetic conjugacy, and compatibility with the principle of virtual power.
From a functional-analytic perspective, we established explicit growth, regularity, and convexity-type assumptions under which the total potential energy is coercive in
The present framework demonstrates that neural constitutive modeling need not be incompatible with the analytical structure of continuum mechanics. Rather than replacing classical constitutive theory, neural parametrizations can be embedded within admissible variational classes that preserve invariance, the existence of minimizers, thermodynamic consistency, and PDE-level stability. In this sense, the neural architecture becomes part of the constitutive structure itself, rather than a purely empirical regression mechanism. This establishes a mathematically controlled pathway toward data-driven generalized continua compatible with variational principles, ellipticity constraints, and modern computational mechanics.
An important aspect of the present contribution is that the analytical results are reproducible in the classical mathematical sense. All assumptions are stated explicitly, the variational setting is fully specified, and the proofs follow standard principles from higher-order continuum mechanics and the calculus of variations. The framework is therefore independently verifiable by readers familiar with second-gradient elasticity and nonlinear variational analysis.
At the same time, the present study is intentionally theoretical in scope and does not yet constitute a complete computational implementation framework. Although Sections 7, 8, and 10.6 provide explicit architectural prescriptions for enforcing convexity, coercivity, polyconvexity, and ellipticity at the neural-design level, the manuscript does not include training datasets, benchmark finite-element simulations, optimizer studies, or large-scale numerical experiments. Consequently, while the variational and thermodynamic structure is fully reproducible, practical reproducibility of trained neural constitutive models will require additional computational developments involving: (1) standardized datasets, (2) reproducible training protocols, (3) automatic-differentiation-based consistent tangent operators, (4) robust discretizations of fourth-order PDEs, and (5) open computational implementations integrated with finite-element solvers.
Several open mathematical and computational problems therefore remain. A complete characterization of global ellipticity in invariant coordinates, sharper quasiconvexity criteria for strain-gradient neural energies, and extensions to finite-strain gradient plasticity, damage, and dissipative generalized continua constitute natural analytical directions. From the computational viewpoint, systematic implementation studies, reproducible numerical benchmarks, and PDE-constrained training strategies for invariant neural higher-order energies remain to be developed.
The framework proposed here provides the analytical foundation necessary for such future investigations and establishes a rigorous bridge between machine learning, the calculus of variations, and the mathematical theory of generalized continuum mechanics.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.