
Abstract
Biomedical review articles are important for education, evidence synthesis, and clinical decision-making. Large language models such as ChatGPT may contribute to a surge in the number of AI-written reviews, raising concerns about the quality and reliability of scientific content. We searched PubMed for open-access reviews in inflammatory bowel disease (IBD) published before ChatGPT (period 1), during the first year after ChatGPT’s release (period 2, 2023–2024), and the year after (period 3, 2024–2025), and randomly selected 60 articles for analysis from each period. Using an AI text detector, no articles were identified as AI-written in period 1, versus 1.7% and 6.7% in periods 2 and 3, respectively. None of the potentially AI-written articles disclosed AI use. None of them had an IBD expert as the first author; only one article from period 2 and one from period 3 had an IBD expert among the authors. While the absolute number of AI-written reviews remains relatively low at present, the growing trend is a cause for concern regarding the potential decline of the quality and trustworthiness of biomedical review articles. Safeguards should be established to maintain the values of review articles.
Keywords
Introduction
Scientific publishing can now be categorized as before and after large language models. Large language models have changed the landscape and enabled AI-assisted writing, introducing new challenges. 1
Review articles are important in shaping the synthesis of evidence and informing the development of clinical practice guidelines. However, the rise of large language models, such as ChatGPT or DeepSeek, may facilitate an increase in AI-generated review articles. This threatens scholarly integrity and promotes redundancy and reduced critical analysis.1–3
Here, we assessed trends in the likelihood of AI-generated review articles in inflammatory bowel disease (IBD), an area of our expertise, before and after the release of ChatGPT. IBD was selected as a case example because it represents a highly active research field with a large volume of review literature, rapidly evolving therapeutic paradigms, and frequent reliance on reviews to inform clinical practice guidelines. These characteristics make IBD particularly vulnerable to the potential impact of AI-assisted review writing, while also underscoring the importance of subject-matter expertise in evidence synthesis.
Methods
PubMed was searched for English-language, open-access review articles using the following title terms: “inflammatory bowel disease,”“ulcerative colitis,” or “Crohn’s.” The selection of open-access articles was to ensure homogeneity, reproducibility, and accessibility of the articles. The searches were performed across three periods: (a) before ChatGPT (November 1, 2021–November 1, 2022), (b) immediately after ChatGPT (March 1, 2023–March 1, 2024), and (c) the subsequent year (March 2, 2024–March 1, 2025). This search resulted in 565, 726, and 653 review articles, respectively. From each period, 60 articles were selected with a computerized random number generator with simple random sampling without replacement.
The full texts of the review articles were analyzed on June 19, 2025, with GPTZero (https://gptzero.me/). Analysis was performed on a single day to avoid confounding from model updates and detection rates. GPTZero calculates AI probability by evaluating linguistic features, such as perplexity (a measure of the predictability of a text), burstiness (sentence length and construction), and pattern recognition (resembling AI output). GPTZero has an estimated specificity of approximately 0.90 in detecting AI-generated text. In validation tests, it has identified >90% of AI-generated papers.4,5 It provides both a categorical classification (human, mixed, or AI-generated) and an associated AI probability score. The categorical label is determined by a classifier that considers multiple parameters simultaneously, not just whether a score crosses the ≥50% probability threshold. For each period, we calculated the proportion of articles with AI probability thresholds of ≥10%, ≥20%, and ≥50%. Classification was based on the internal thresholds of GPTZero calibrated to minimize false positives. We also reported the categorical classification of the included articles. The means of the AI probability scores were also calculated, allowing for the characterization of the overall distribution in AI-generated text likelihood across the sampled articles.
Results
A total of 180 articles were analyzed (60 per period). When examining probability thresholds, no articles before ChatGPT exceeded the ≥10% cutoff, whereas 21.7% (13 of 60) and 41.7% (25 of 60) exceeded this threshold in the first and second post-ChatGPT years, respectively. At the ≥20% threshold, 6.7% (4 of 60) exceeded the threshold in 2023–2024, and 25.0% (15 of 60) exceeded the threshold in 2024–2025; at ≥50%, 1.7% (1 of 60) exceeded the threshold in 2023–2024 and 11.7% (7 of 60) in 2024–2025 (Figure 1). Across the three periods, an upward shift in the overall distribution of AI probability scores was also recognized (Figure 2).
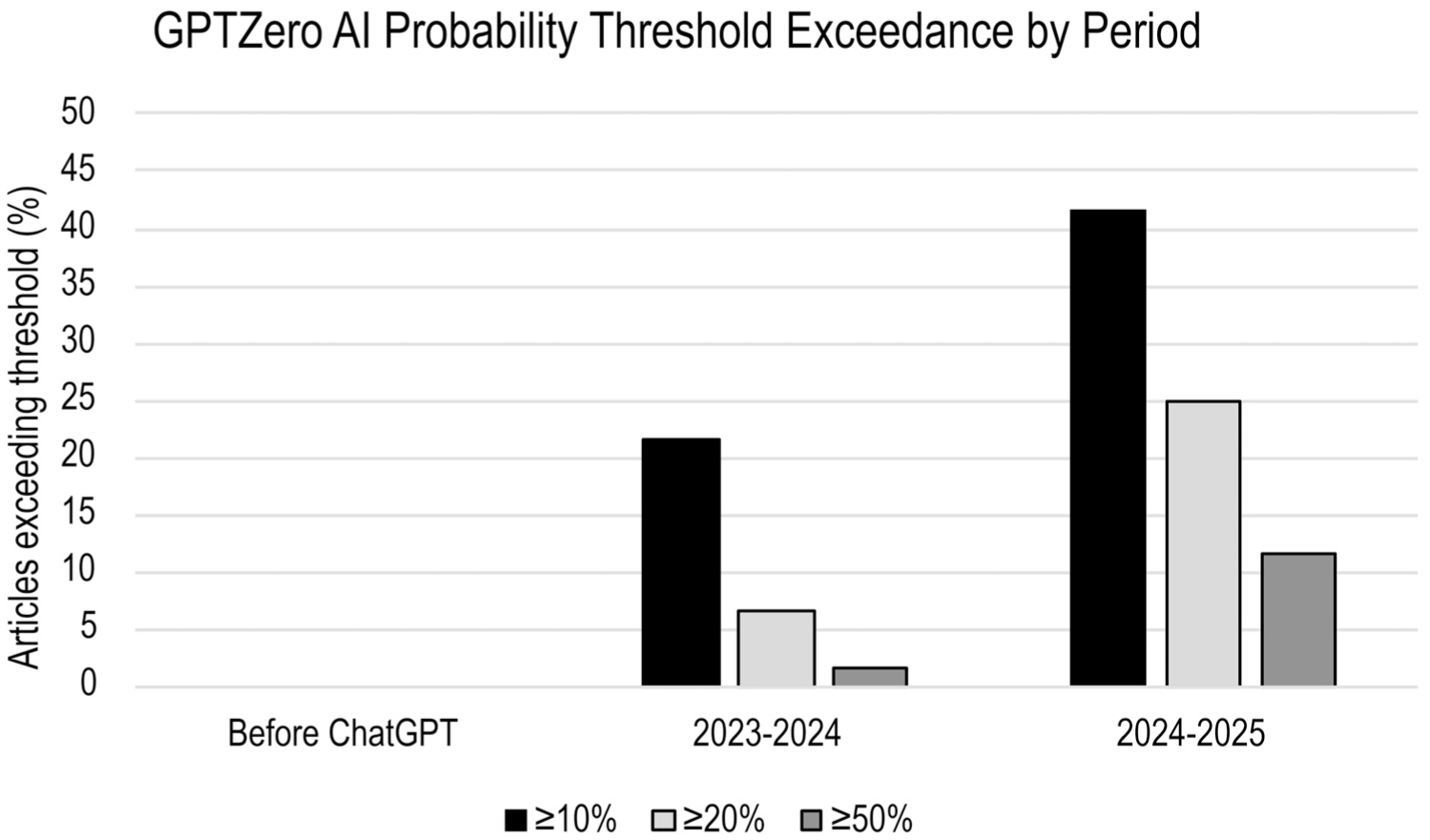
Proportion of review articles exceeding GPTZero AI probability thresholds before and after the release of ChatGPT.
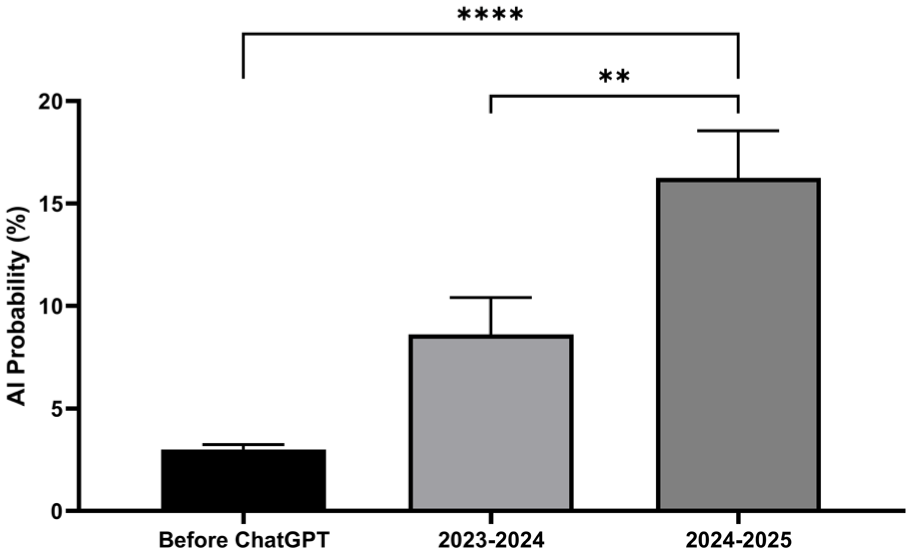
Trends in AI probability (%) of the selected review articles before and after ChatGPT.
Before ChatGPT, no reviews were classified as AI-generated, per categorical classification. In the first year after ChatGPT’s release, 1 of 60 (1.7%) articles was classified as AI-generated. This increased to 4 of 60 (6.7%) in the subsequent year. None of the potentially AI-generated articles acknowledged the use of large language models and none of them had an IBD expert as the first author. The AI-labeled article in the first year after ChatGPT had an IBD researcher as a coauthor. In the second year, only one out of four had a gastroenterologist/IBD expert among the authors. The impact factor of the journals that published these articles ranged between 1 and 4.8. Authors represented diverse geographic regions and institutional affiliations.
Across all three periods, most articles were narrative reviews (pre-ChatGPT: 58/60; 2023–2024: 54/60; 2024–2025: 54/60), with systematic reviews and meta-analyses comprising a smaller proportion across periods. Two of four articles which were labeled as AI-generated during 2024–2025 were systematic reviews.
Discussion
In this study, we observed a chronological increase in the likelihood of AI-generated content within review articles on IBD published in the years following the release of ChatGPT. Some of the AI-labeled articles did not have an IBD expert among the authors.
Our findings agree with recent reports showing an increase in AI-generated text among scientific abstracts, peer reviews, and academic manuscripts. Howard and colleagues showed an increase in AI-generated content in abstracts submitted to the American Society of Clinical Oncology meeting in 2023 compared with earlier years. 6 Spinellis investigated the extent of AI-generated content in a journal where a fabricated article was falsely attributed to him; of the 53 examined articles, at least 48 seemed to be AI-generated. 7 Another study by Pesante et al. on 577 abstracts published in 2024 in five orthopedic journals showed AI-generated text in 28 (4.8%) of abstracts. Only 1 abstract disclosed the use of AI-generated text. 8 Schnieder et al. 9 analyzed 100 randomly selected manuscripts (2023–2024) in high-impact neurosurgery journals; 1 in 5 manuscripts contained sections flagged as AI-generated. Kobak et al. 10 studied more than 15 million PubMed-indexed biomedical abstracts from 2010 to 2024 and showed that at least 13.5% of 2024 abstracts were processed with large language models. These studies, together with our data on IBD reviews, suggest that the academic community is entering a new era in which AI-written scholarship will become increasingly common.
We know that review articles play a central role in synthesizing evidence, informing guideline development, and educating trainees and clinicians. Reviews written by AI models may lack critical judgment, promote redundancy, or reinforce low-quality studies. As observed in other analyses, large language model-generated writing is often fluent but may produce superficial or fabricated content. 11 The incremental increase in AI probability scores we observed raises concerns that the intellectual rigor traditionally expected of review articles may be diluted if AI involvement is not transparently disclosed and appropriately managed.
The employment of AI text “humanizers,” which modify sentence construction to appear less AI-generated, will be another challenge to detecting AI-written content. 12 The growing volume of AI-generated review articles risks overwhelming both reviewers and editors, while also flooding literature databases with concepts that are difficult to validate and may eventually get beyond control. To address this, new tools will be needed to better distinguish “fact from fiction.” Such challenges could even influence patient compliance if questionable material makes its way onto the internet and social media. Furthermore, the surge in large database analyses of anecdotal hypotheses and associations, sometimes undertaken by authors with limited subject expertise, carries additional risks. These hypotheses themselves could be AI-generated, intensifying the problem.
Therefore, with respect to review articles, the implementation of safeguards is urgently needed:
Journals should require authors to disclose any use of AI tools during manuscript preparation. Several journals have already adopted such policies.
Although current AI-detection tools have variable sensitivity and specificity, they may still serve as a useful assistant in the editorial screening process.
Journals may need to consider prioritizing invited reviews authored by recognized experts with substantial original contributions or clinical experience in the field. For systematic reviews and meta-analyses on clinical topics, collaboration with clinicians specializing in the condition under discussion would enhance both accuracy and clinical relevance. Notably, we must always bear in mind that statistical significance does not necessarily equate to clinical significance.
Articles written by junior trainees must be carefully reviewed by senior authors to ensure accuracy.
This study has limitations. First, we analyzed only open-access IBD review articles indexed in PubMed, which may not fully represent all review literature. Second, detection accuracy is dependent on the performance of a single tool and may misclassify highly edited AI text or human writing that mimics machine-generated features. Third, the modest sample size precludes precise estimates of prevalence, although our random sampling approach reduces bias.
Conclusions
Although the absolute number of review articles written by AI remains moderate, there has been an increasing trend since the release of ChatGPT. If precautions are not taken, the growing use of AI in review articles could lead to a lack of critical analysis, repetitive or low-quality content, and eventually weaken the trust and value of these articles. Although AI tools may be valuable in supporting the synthesis of research, drafting assistance, and language editing, they may not serve as a replacement for expert authorship. It is important that the credibility and educational value of review literature are maintained through the exercise of selectivity and transparency. If, at some point, AI reaches the judgment and knowledge of human experts, the role of traditional review articles, as well as their value as scholarly activities, may need to be redefined.
Footnotes
Author contributions
Armin Bashashati: Analyzing the data, Critical revision of manuscript, Drafting manuscript, Literature review.
Anagha Samoath: Critical revision of manuscript, Drafting manuscript, Literature review.
Deepal Agrawal: Critical revision of manuscript, Designing the study.
Mohammad Bashashati: Critical revision of manuscript, Designing the study.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.