
Abstract
Social media discourse has the capacity to influence public perceptions of health-related issues. Understanding how vaccine side effects are discussed online is, therefore, important for anticipating potential reactions—such as acceptance or hesitancy—toward vaccines that may be deployed in future outbreaks. This study examines public perceptions of the medium-term side effects of COVID-19 vaccines in Turkey by analyzing Turkish-language Twitter posts from the post-pandemic period. Using a hybrid sentiment-analysis approach combining Bi-directional Encoder Represantations from Transformers (BERT)-assisted labeling with machine learning classification, we evaluated the polarity distribution of tweets related to the BioNTech and Sinovac vaccines. Results indicated that negative sentiment predominated for both vaccines, with 69.85% negative tweets for BioNTech and 44.72% for Sinovac, ensuring a model accuracy of 0.94 and 0.82, respectively. Analysis of frequently occurring terms indicated that the colloquial phrase “heart attack” appeared most often among side-effect-related expressions; however, this pattern reflects only online discourse rather than clinical evidence. Nonetheless, this pattern aligns with medical discussions emphasizing myocarditis as a notable short- and medium-term post-vaccination concern. The findings elucidate the portrayal of vaccine side effects in Turkish social media and have the potential to contribute to the development of evidence-based health communication strategies for forthcoming vaccination campaigns.
Keywords
Introduction
The COVID-19 pandemic has generated ongoing global consequences, affecting not only public health but also education, economy, production systems, tourism, and digital communication platforms. As of March 2023, COVID-19 has infected approximately 680 million individuals and caused nearly 6.9 million deaths worldwide. 1 The frequency of small-scale infectious diseases and even large-scale pandemics has increased over the past century and is expected to continue to increase in the future. 2 Furthermore, projections suggest that the likelihood of experiencing another pandemic during an individual’s lifetime is about 17%, potentially rising to 44% in the coming decades. 3 A World Health Organization (WHO) panel report emphasizes the need to reassess global preparedness for upcoming pandemics. 4
Although the timing of the next pandemic cannot be predicted, lessons from previous outbreaks demonstrate the importance of proactive planning. Vaccination remains one of the most effective strategies for mitigating pandemic risks. Globally, approximately 72.3% of the world population has received at least one dose of a COVID-19 vaccine. 5 In Turkey, more than 150 million doses have been administered, and 68.7% of the population has received at least one dose (Figure 1). Despite this progress, vaccine hesitancy remains a significant global challenge, 6 posing barriers to achieving herd immunity and to maintaining acceptance of both routine and future pandemic vaccinations.
Sentiment analysis flowchart.
Understanding the drivers of vaccine hesitancy is, therefore, essential for improving health communication strategies. Social media plays a central role in shaping public perception, as individuals frequently share personal experiences, concerns, and beliefs about vaccines. 7 In the post-pandemic period, some individuals attributed various adverse health experiences to COVID-19 vaccines, contributing to public debates surrounding vaccine safety. Misinformation has also circulated widely on platforms such as Twitter, influencing attitudes toward vaccination. 8
Given the impact of online discourse on public opinion, analyzing the sentiment and thematic patterns in vaccine-related tweets is crucial for anticipating societal responses in future outbreaks. While numerous studies have examined short-term reactions to vaccination during the peak of the pandemic, considerably less is known about public perceptions of medium-term side effects in the period following widespread vaccination.
This study aims to address this gap by analyzing Turkish-language Twitter discourse from the post-pandemic period, focusing specifically on sentiment toward the medium-term side effects of BioNTech and Sinovac vaccines. Unlike earlier research, this study prioritizes medium-term adverse effects using sentiment analysis, the N-gram method, and Pareto analysis to identify prominent word groups associated with perceived side effects.
Literature review
Sentiment analysis has become an essential tool for understanding public reactions to the COVID-19 outbreak and vaccination processes. Social media platforms such as Twitter provide large-scale, user-generated data that enable the application of Natural Language Processing (NLP) and machine learning techniques to examine public sentiment at scale. Existing research on COVID-19-related sentiment can be grouped into several thematic categories.
Methodological foundations in sentiment analysis
Several studies have focused on evaluating machine learning and deep learning approaches for classifying emotional content. For instance, Pang et al. 9 examined the performance of various machine learning algorithms for binary sentiment classification, while Zhang et al. 10 offered a comprehensive review of deep-learning-based sentiment analysis, including document-level classification, sarcasm detection, and multilingual opinion mining. Other studies have applied lexicon-based tools such as TextBlob, AFINN, and fuzzy inference systems to analyze public attitudes toward COVID-19 and health authorities. 11 Collectively, these works illustrate the methodological diversity underlying sentiment analysis and provide a foundation for its application in pandemic-related research.
Sentiment toward COVID-19 and public health measures
A broad range of studies has analyzed general public sentiment toward COVID-19 across countries and cultures. Research drawing on multilingual datasets explored citizens’ emotional responses to the pandemic, 12 while deep learning models such as recurrent neural networks were used to identify relationships among COVID-19-related concepts. 13 Early-pandemic studies relying on Python-based tools and lexicon approaches documented shifts in public mood and pandemic anxiety, 14 whereas others assessed attitudes toward vaccination using classical classifiers such as Naive Bayes and Decision Trees. 15
Findings across these studies vary—some report predominantly negative sentiment, whereas others show more positive or mixed emotional patterns. These differences may be attributable to differences in data collection periods (early crisis vs vaccination rollout), geographic context, or methodological choices, highlighting the importance of contextualizing sentiment results.
Vaccine-specific sentiment studies
Several studies specifically focused on COVID-19 vaccines. Early Turkish-language analyses conducted during the vaccine rollout found predominantly negative emotional reactions toward vaccines, 16 while later studies reported more positive or balanced sentiment trends as vaccination became widespread17,18 International analyses also revealed variation: daily English-language tweets about AstraZeneca, BioNTech, and Moderna showed stable positive sentiment for some vaccines over time. 19 Additional comparative studies employing machine learning and deep learning models demonstrated high accuracy in classifying vaccine-related sentiment and identifying vaccine hesitancy trends.20,21
Taken together, these studies suggest that vaccine sentiment is highly sensitive to time, platform dynamics, and societal factors and should therefore be interpreted in relation to the evolving stages of the pandemic.
Misinformation and online narratives
Many researchers have emphasized the influence of misinformation on public vaccine perceptions. Studies examining global English-language Twitter data identified strong interactions between misinformation, conspiracy theories, and anti-vaccine discourse.22,23 Topic modeling applications further revealed that certain themes—such as fears about safety or distrust in institutions—disproportionately shape sentiment trajectories. 24 These findings underscore that public sentiment on social media does not solely reflect clinical realities but is shaped by information ecosystems, emotional amplification, and narrative framing.
Broader developments in computational social media research
More recent computational studies extend beyond health and vaccination topics. For instance, Demirel et al. 25 explored global public perceptions of artificial intelligence, identifying geographic and economic differences in sentiment toward ChatGPT. Similarly, research on COVID-19 news framing demonstrated that fear-, anxiety-, and crisis-oriented narratives dominated newsroom communication on Twitter during the pandemic. 26 Studies of institutional communication patterns, including those of the WHO, showed substantial shifts in message volume, style, and audience engagement during crisis periods. 27 These works illustrate how social media both reflects and shapes public discourse in rapidly changing environments.
Gap in the literature and contribution of the present study
Most prior research was conducted during the active phases of the pandemic, when the primary goal was controlling viral spread rather than understanding perceptions of potential medium-term vaccine side effects. Moreover, few studies have examined Turkish-language discourse during the post-pandemic period, particularly regarding how social media users discuss side effects months after vaccination.
The present study addresses this gap by analyzing Turkish tweets posted between July 1, 2022, and March 23, 2023, a period when discussions about medium-term side effects became more salient. Using N-gram analysis to identify recurrent expressions and Pareto analysis to highlight dominant side-effect-related terms, this study provides a focused examination of how the BioNTech and Sinovac vaccines were perceived in Turkish social media discourse during the post-epidemic period.
Materials and methods
Study aim and analytical framework
This study aims to examine public sentiment toward COVID-19 vaccines during the post-epidemic period in Turkey, with a particular focus on mid-term perceptions of side effects. By analyzing Turkish-language tweets, the study seeks to identify sentiment polarity (positive, negative, neutral) and evaluate whether online discourse reflects potential vaccine hesitancy relevant for future outbreaks.
Because Twitter data consist of unstructured textual content, sentiment analysis—one of the core branches of NLP—was selected as the primary analytical method. The rise of big data and the widespread availability of large-scale social media corpora have made automated classification techniques essential for extracting meaningful insights from large text streams.28,29 Sentiment analysis methods typically rely on machine learning, deep learning, and lexicon-based approaches to identify emotional signals within text. 30
Research questions
This study seeks to address the following questions:
RQ1: What are the common discourses about vaccines developed and applied in Turkey for the COVID-19 outbreak, especially when side effects began to emerge?
RQ2: In terms of side effects, which vaccine has been subject to more negative discourse?
RQ3: What are the main sentiment polarities in COVID-19 vaccine tweets concerning the side effects?
The flowchart in Figure 1 illustrates the study's road map.
Data acquisition
Tweets were collected using the Snscrape Python library by querying the keywords “BioNTech” and “Sinovac” for the period between 1 July 2022 and 23 March 2023, corresponding to the period when possible mid-term side effects of the BioNTech and Sinovac vaccines began to be publicly discussed in Turkey.
Only Turkish-language tweets were retrieved, and all retweets were excluded to ensure that the dataset consisted solely of original posts. This process yielded approximately 10,000 tweets related to the BioNTech vaccine and 6,400 tweets related to the Sinovac vaccine, each stored as raw text in separate files. The extraction procedure did not incorporate geolocation filters, bot or organizational account detection, deduplication mechanisms, or rules for managing reply or quote tweets, and these omissions are acknowledged as methodological limitations that may influence corpus representativeness. As a constraint, timestamps were not collected during retrieval, such as weekly time-series evaluations.
Data pre-processing
All tweets underwent a standardized text processing pipeline before being used in the model. This included converting all text to lowercase, removing URLs, emojis, hashtags, user mentions, digits, and punctuation, and tokenizing the text using the WordPunctTokenizer. Turkish stop-words were removed using the Natural Language Toolkit (NLTK) list, and lemmatization was applied to reduce words to their base forms. No tweets were removed during preprocessing, and therefore the cleaning stage resulted in a 0% removal rate.
Figure 2 includes a preprocessed example data set.

An example of preprocessed and cleaned dataset.
Preliminary automatic labeling with BERT
For the initial sentiment assignment, we employed the pretrained Turkish model savasy/bert-base-turkish-sentiment-cased using the transformers library with a PyTorch backend. The model was not fine-tuned specifically for this study; instead, it was used solely for preliminary automatic labeling. Accordingly, training hyperparameters such as learning rate, batch size, and epoch number do not apply. The only model-level parameter used was the tokenizer’s maximum sequence length, set to max_length = 512. A subset of tweets was selected for labeling, consisting of 2000 tweets for BioNTech and 1690 tweets for Sinovac. The resulting Bi-directional Encoder Represantations from Transformers (BERT) predictions served as first-pass labels before undergoing human verification.
Human verification of labels
All sentiment labels initially produced by the BERT model were subsequently reviewed and corrected by a human annotator. Because the dataset contains informal language, slang, inconsistent structures, and context-dependent expressions common in Twitter discourse, manual verification was essential to ensure label reliability. Since it was not feasible to involve multiple independent coders, all annotations were carried out by a single reviewer. As a result, inter-annotator agreement statistics such as Cohen’s κ or Krippendorff’s α cannot be computed, and a confusion matrix cannot be generated for human labels, as they function as the study’s ground truth. This constraint is acknowledged as a methodological limitation.
Term frequency–inverse document frequency vectorization
Following manual verification of sentiment labels, all textual data was transformed into numerical feature vectors using the term frequency–inverse document frequency (TF-IDF) method. The vectorization process employed an n-gram range of 1–2 to capture both unigram and bigram structures, while terms appearing in fewer than five documents were excluded through a minimum document frequency threshold of min_df = 5. Additionally, a maximum document frequency limit of max_df = 0.9 was applied to remove overly common terms that carry limited discriminative value. Together, these parameter choices ensured a balanced representation of lexical patterns relevant to sentiment classification.
Support vector machine classification
A support vector machine (SVM) classifier (sklearn.svm.SVC) was trained on the TF-IDF-vectorized dataset using an 80% training and 20% testing split. The model employed the default RBF kernel configuration, with parameters set as kernel = “rbf,” C = 1.0, gamma = “scale,” and class_weight = None. This configuration enabled the model to learn class boundaries in a high-dimensional space and perform supervised sentiment classification on the human-verified labels.
Model performance
Model performance was evaluated with accuracy, precision, recall, and F1-scores. Performance metrics for both of the vaccines are presented in Table 1. For the BioNTech dataset, the trained SVM model achieved an overall accuracy of 0.94. For the Sinovac dataset, the model’s overall accuracy was lower, at 0.82.
Trained model performance measurements for the BioNTech and the Sinovac vaccines test dataset.
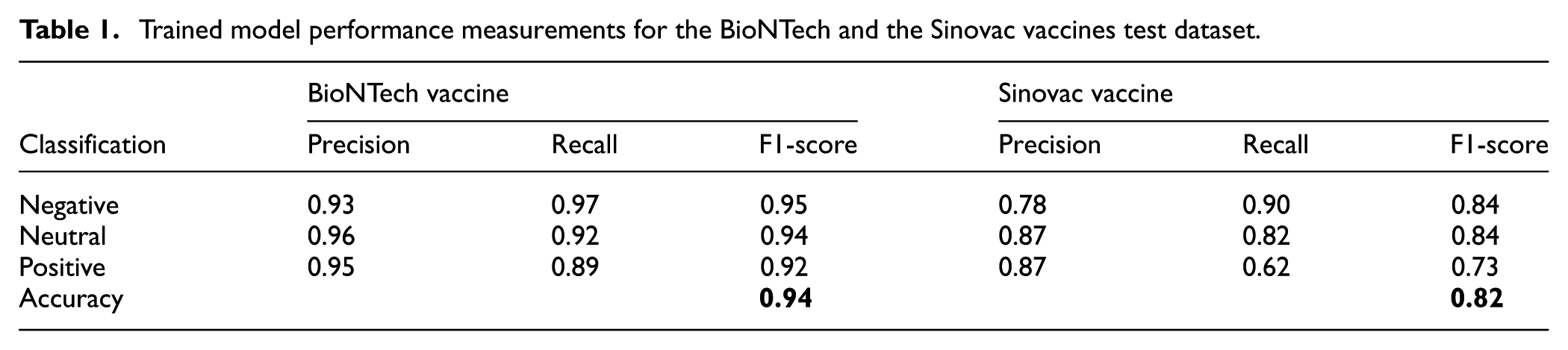
Because no independent gold-standard human-annotated subset exists, these metrics primarily reflect agreement between the BERT-assisted preliminary labeling and the SVM classifier, rather than a definitive measure of real sentiment validity.
Reproducibility considerations
All preprocessing steps, SVM parameters, TF-IDF configuration, and the BERT labeling pipeline are fully documented here to enhance transparency.
Tweet IDs cannot be shared due to platform restrictions, and preprocessing scripts were not archived.
These are acknowledged as technical limitations affecting reproducibility.
Results
Sentiment analysis
The sentiment analysis revealed notable differences between the two vaccines. For the BioNTech dataset (n = 9968), 9.93% of tweets expressed positive sentiment, 20.21% neutral sentiment, and 69.85% negative sentiment, yielding a model accuracy of 0.94. For Sinovac (n = 6620), 16.17% of tweets were classified as positive, 39.11% as neutral, and 44.72% as negative, with an accuracy of 0.82. The class priors used for training were 600 positive, 600 neutral, and 800 negative tweets for BioNTech, and 500 positive, 500 neutral, and 690 negative tweets for Sinovac, and are reported here for transparency in evaluating classifier performance.
Figure 3 illustrates the proportional distribution of negative, neutral, and positive sentiments together with 95% binomial confidence intervals. As shown, negative sentiment is proportionally higher for BioNTech, whereas Sinovac exhibits a more balanced distribution between neutral and negative categories. These results indicate that discussions surrounding the BioNTech vaccine tended to be more negative overall, while discourse about Sinovac displayed a comparatively moderate emotional profile due to a larger share of neutral tweets.
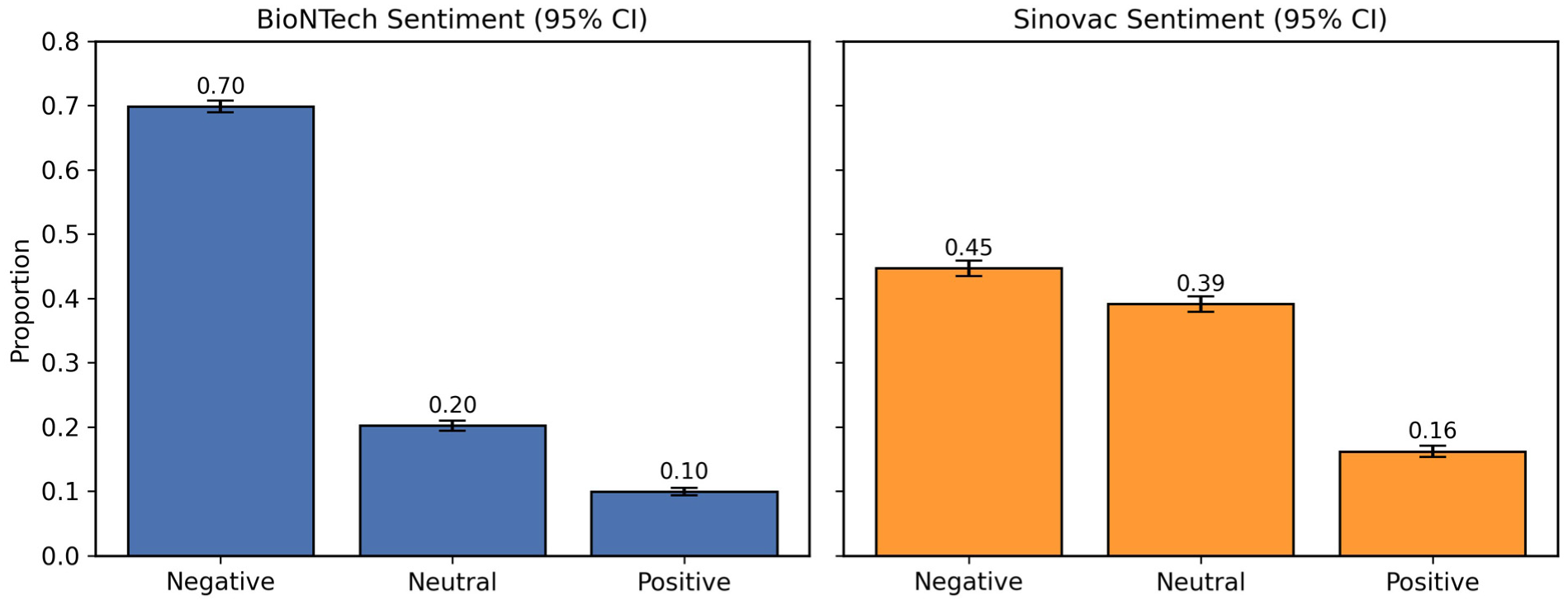
Sentiment proportions for BioNTech and Sinovac tweets with 95% confidence intervals.
Bars represent the proportion of negative, neutral, and positive tweets for each vaccine. Error bars indicate 95% binomial confidence intervals. Percentages are calculated over the total number of manually verified tweets (BioNTech: n = 9968; Sinovac: n = 6620). These descriptive patterns reflect differences in the way each vaccine was framed in Turkish Twitter discourse during the post-pandemic period.
Word clouds
As illustrated in Figure 4, the most frequently used terms related to the vaccines were visualized using word clouds generated after identifying the most common bigram patterns in the corpus. Although word clouds are limited in their ability to convey precise quantitative information, they serve as a useful exploratory tool for obtaining a rapid, high-level impression of dominant themes in the dataset.

Word clouds in Turkish for BioNTech and Sinovac vaccines.
To complement the word cloud visualizations and provide a clearer representation of lexical prominence, the most frequent negative terms for both vaccines were examined using horizontal bar charts derived from the available term-frequency lists in Figure 5. Because these charts are based on stored frequency outputs rather than a fully reconstructable corpus, the findings should be interpreted as descriptive indicators of prominent vocabulary within the negative subsets.
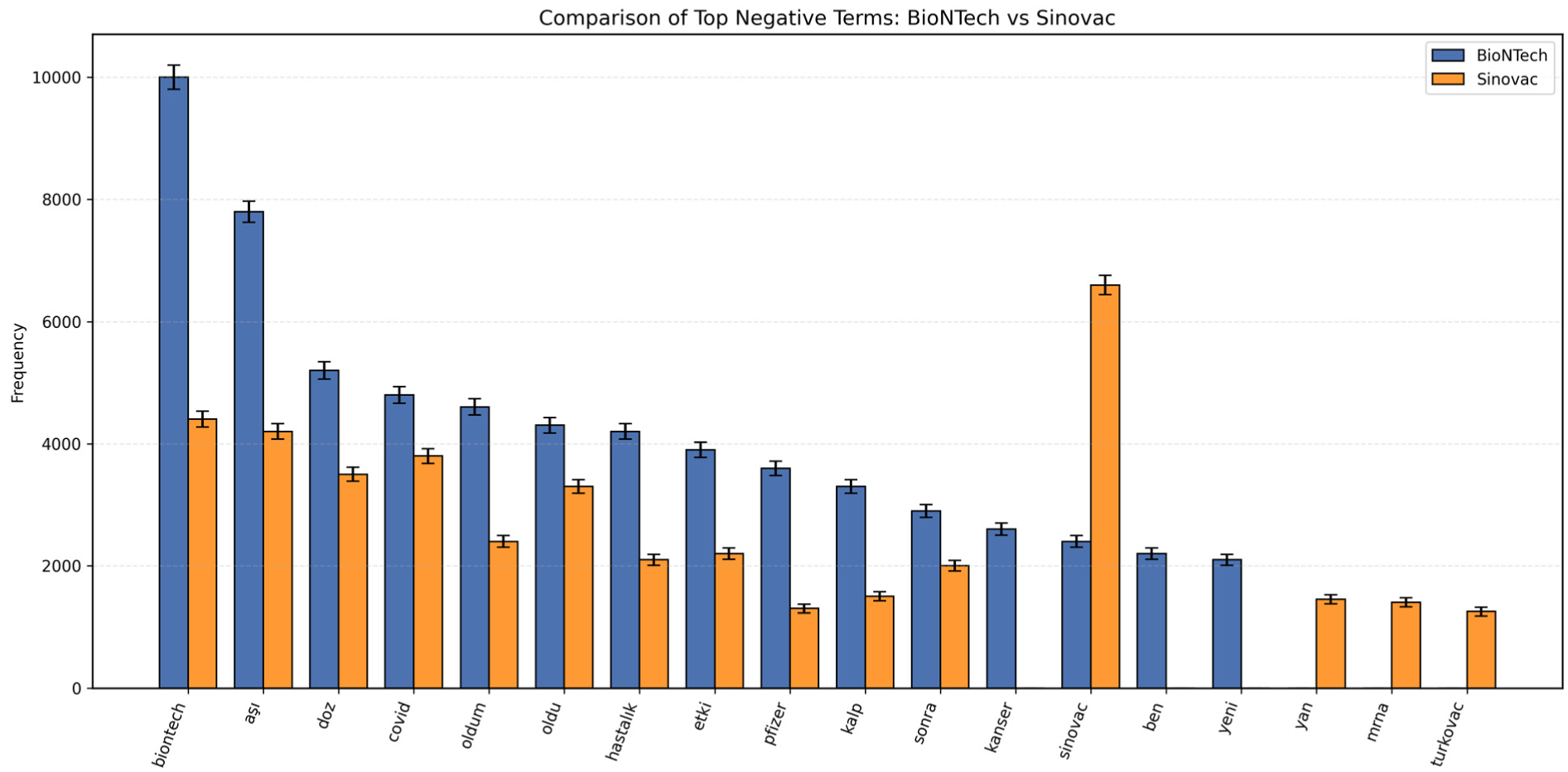
Comparison of high-frequency negative terms in BioNTech and Sinovac Tweets.
For Sinovac, highly frequent terms such as “sinovac,”“BioNTech,”“aşı-vaccine,”“covid,” and “doz-dose” suggest that negative discussions often occurred alongside general vaccine terminology and cross-vaccine comparisons, while medically suggestive terms (e.g., “kalp-heart,”“yan-side,”“mrna,” and “etki-effect”) appeared at moderate frequencies. For BioNTech, dominant terms included “BioNTech,”“aşı-vaccine,”“doz-dose,” and “covid,” with overall higher counts across most shared vocabulary items, indicating a denser concentration of negative discourse in the retained data. Terms related to health concerns and comparative evaluations (e.g., “kanser-cancer” and “sinovac”) were also present among the top-ranked items. Together, these descriptive frequency patterns provide additional context for understanding how negative sentiment was linguistically expressed in discussions about the two vaccines.
Counts reflect the negative-term frequency lists retained from the original preprocessing stage and therefore represent descriptive summaries rather than fully reproducible corpus statistics. Error bars denote approximate 95% confidence intervals (1.96 ×√frequency), included in line with the reviewer’s request for uncertainty quantification.
Topic modeling with N-gram
The N-gram method has a wide range of uses in the fields of linguistic analysis, text processing, and NLP. It is an important tool for understanding the relationships between words and language structure. Additionally, it can be used for purposes such as classifying texts by considering the relationship of words with themselves and consecutive words, sentiment analysis, extracting information, and determining the relationship between words or terms. Since it is used in tasks such as the probability of two or more words occurring together, the bigram method is preferred for feature extraction and determining binary word frequencies in the study. In this way, important clues are provided in word analysis.
The frequency counts of binary Turkish word pairs concerning BioNTech and Sinovac vaccines are determined using the N-gram method. The graph presented in Figure 6 illustrates the 50 most frequently utilized binary word pairs.
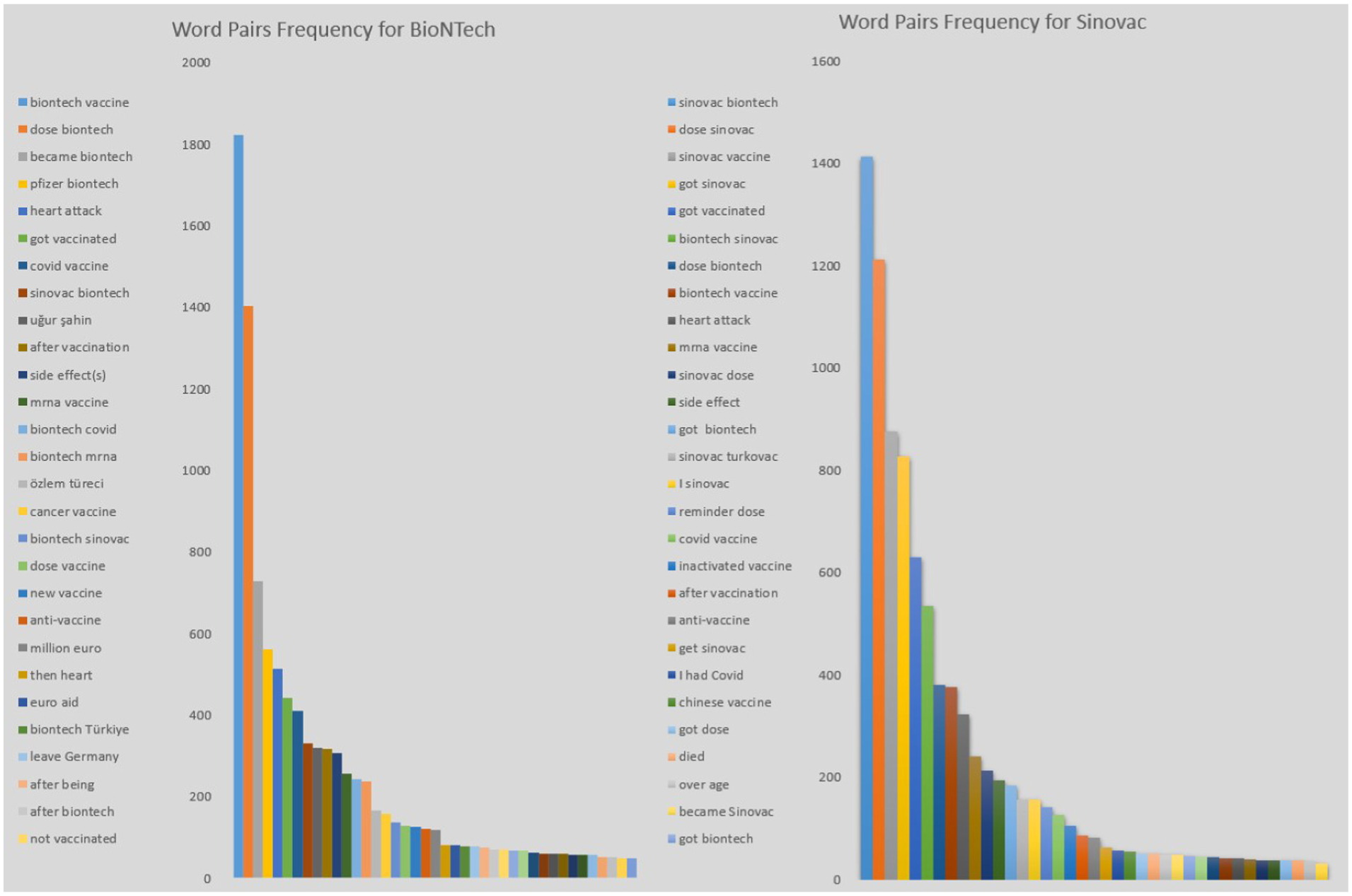
BioNTech and Sinovac vaccines bigram word frequencies.
Pareto analysis
In this part of the study, Bigram word-frequency results were examined together with a Pareto analysis (80/20 rule) in English words to obtain a clearer view of how strongly vaccine side effects were represented in the dataset. Table 2 summarizes the most frequent bigram groups and their cumulative contributions, showing that discourse around both vaccines is dominated by vaccine-identifying terms, cross-vaccine references, and side-effect-related expressions, which together constitute the core thematic structure of the dataset. Several high-frequency bigrams appearing at the top of cumulative frequency—particularly “heart attack” and “side effect(s)”—are directly associated with perceived adverse reactions for both vaccines. Though at lower relative frequencies, terms such as “anti-vaccine,”“died,”“crisis,” and “clot” also suggest the presence of side-effect-related discourse, albeit at lower relative frequencies. These patterns indicate that references to heart attacks constitute one of the most salient and recurrent components of vaccine-related discussions in the dataset.
Results of N-gram/Pareto analysis integration.
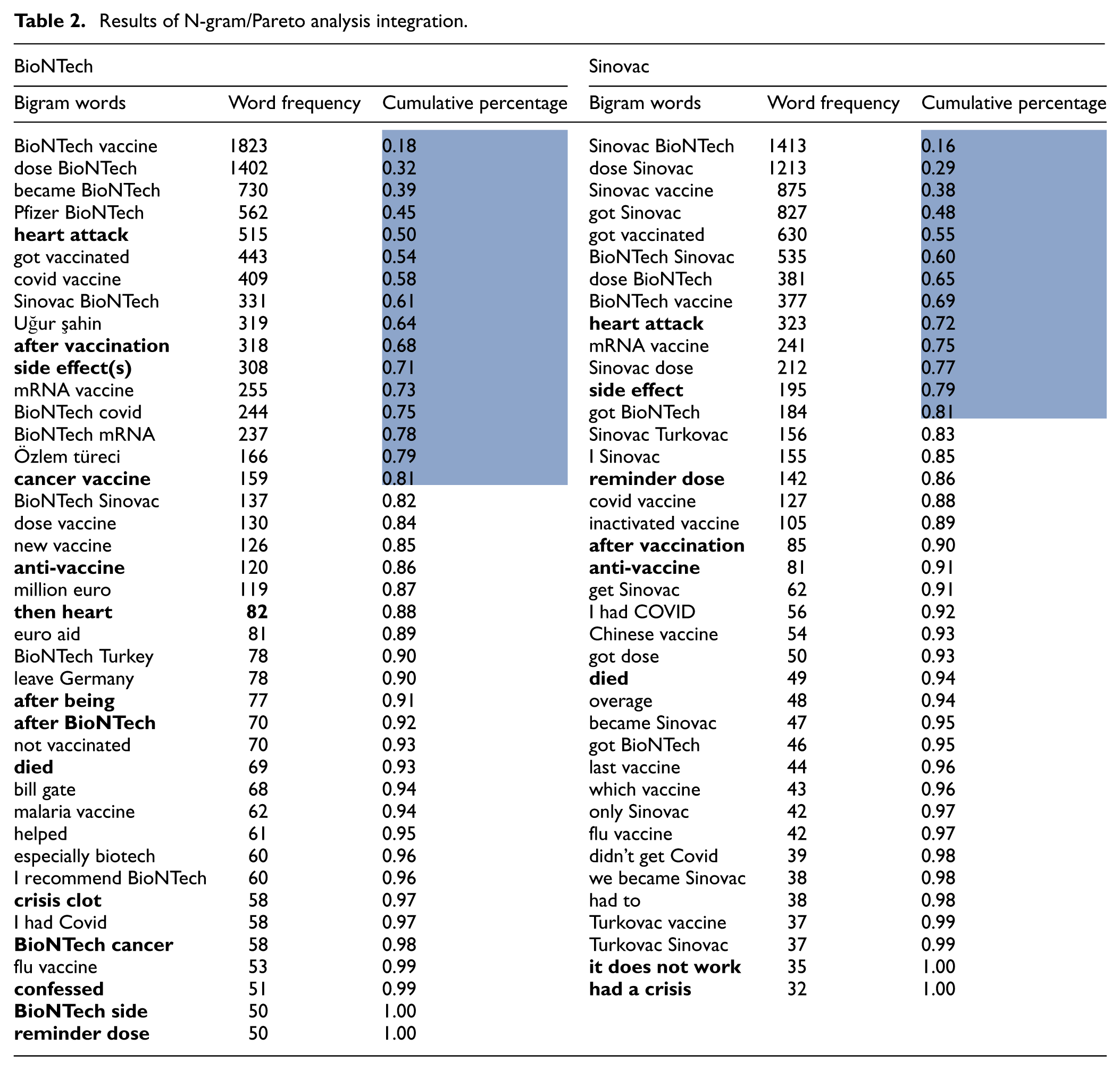
In Table 2, the shaded section represents the cumulatively dominant statement groups in the dataset, while critical statements related to the side effect discourse are highlighted in bold.
Furthermore, the most frequent bigram pairs reveal a reciprocal mention pattern between the two vaccines: tweets about Sinovac commonly include the term “BioNTech,” and vice versa, suggesting that the vaccines were frequently compared within public discourse. For Sinovac tweets, the prominence of the bigram “reminder dose” contributes to a higher proportion of neutral content, reflecting a relatively more balanced emotional tone in discussions related to this vaccine.
Although the Pareto analysis used here is heuristic rather than inferential, it is retained as a complementary exploratory tool. In social media text mining, frequency-based heuristics are widely used to highlight salient lexical patterns prior to more advanced statistical analyses. In this study, the Pareto distribution helps illustrate how a small number of high-frequency bigrams—most notably “heart attack”—dominate the narrative space surrounding vaccine side effects. These results are, therefore, interpreted descriptively, with their exploratory nature explicitly acknowledged.
Discussions
Twitter (now X) is one of the most widely used social media platforms for both individual and institutional communication, and data obtained from this platform provide valuable insights into collective meaning-making and public opinion. In this study, Twitter reactions concerning two COVID-19 vaccines used in Turkey were examined during the post-pandemic decline period, with a focus on vaccine side-effect discussions. Using an SVM-based sentiment classification framework, the findings show that negative tweets outnumbered positive and neutral tweets for both vaccines, although this tendency was considerably more pronounced for BioNTech than for Sinovac.
Tweets related to the BioNTech vaccine exhibited a higher concentration of negative sentiment, often intertwined with references to the scientists who developed the vaccine, indicating that public discourse frequently connects personal scientific figures with vaccine evaluations. These patterns align with themes that were widely circulated in written and visual media during the post-pandemic period. In contrast, sentiment toward Sinovac appeared more evenly distributed: neutral and negative tweets occurred at comparable frequencies, suggesting that discussions surrounding Sinovac were more moderate in tone. The sentiment proportions presented with 95% confidence intervals further support this pattern, showing a distinctly higher negative sentiment share for BioNTech relative to Sinovac. Importantly, these findings reflect public perception and discourse rather than differences in clinical side-effect incidence, and no epidemiological inferences should be drawn from the observed patterns.
The N-gram analysis revealed that the most frequently occurring bigram associated with vaccine side effects in both datasets was “heart attack.” Additional terms such as “clot,”“cancer vaccine,”“cancer,” and “anti-vaccine” also appeared frequently, indicating widespread references to adverse events, health concerns, and speculative or misinformation-adjacent narratives within public discourse. A Pareto analysis (80/20 rule) further demonstrated that a small subset of bigrams—dominated by “heart attack”—accounted for the majority of side-effect-related mentions, amplifying their visibility despite the linguistic and contextual ambiguity of such terms. However, colloquial expressions like “heart attack” cannot be assumed to correspond to clinical categories (e.g., myocarditis), and the findings should, therefore, be interpreted strictly as reflections of online discourse rather than as indicators of actual medical phenomena.
From a methodological standpoint, the study relied on BERT-assisted preliminary labeling followed by manual verification rather than full model retraining. Because individual prediction logs were not stored during classification, more advanced evaluation metrics—such as per-class precision and recall, macro-F1 scores with confidence intervals, and confusion matrices—cannot be reconstructed retrospectively. Likewise, k-fold cross-validation could not be implemented after the fact, as it would require re-training the classifier and storing outputs for each fold. These constraints are acknowledged as methodological limitations of the analysis.
The comparatively lower accuracy observed for the Sinovac dataset (0.82) can be understood in light of several corpus characteristics. The Sinovac dataset was smaller in size, limiting the linguistic variability available for the model to learn from; its class distribution was more imbalanced relative to the BioNTech dataset; and its content contained a greater incidence of policy debates, speculative claims, irony, and short or context-poor expressions—features well documented in the literature as sources of reduced classifier stability in social media sentiment analysis. These factors likely contributed to the performance gap and should be considered when interpreting the model’s comparative results.
It should be noted that all terms referring to adverse events—such as “heart attack,”“clot,” or similar expressions—represent the language used within Twitter discourse and do not indicate clinical incidence or medically verified side effects. Accordingly, the results should be interpreted strictly as reflections of public perceptions and online narratives rather than evidence of actual physiological outcomes.
Overall, the findings indicate that online discourse about COVID-19 vaccines—particularly BioNTech—was characterized by a stronger negative sentiment profile during the examined period. However, these findings represent public discourse dynamics rather than clinical evidence, and interpretation should remain within this scope. The analysis offers insight into how vaccine-related perceptions were expressed in Turkish Twitter discussions and highlights the importance of understanding social-media-based sentiment as part of broader public health communication processes.
Limitations
This study provides descriptive insights into vaccine-related discourse on Turkish Twitter; however, several methodological and contextual limitations should be acknowledged. Data gathering is one of the most common challenges in social media research, and this study encountered similar constraints. Shortly after the dataset was retrieved, the Twitter ecosystem underwent major structural changes, including alterations to platform access policies, ownership, and even the platform’s name. These developments prevented the reconstruction of the original corpus and restricted the possibility of extending the data collection period. A broader or longer-term dataset might have yielded results with greater temporal depth.
Additionally, although the initial retrieval process used systematic keyword queries, tweet-level metadata such as IDs, timestamps, and user attributes could not be fully retained. Consequently, temporal analyses, bot or organization detection, deduplication assessment, and other metadata-dependent procedures could not be performed. The absence of archived prediction logs and probability scores from the SVM classifier also limited the ability to compute confusion matrices, k-fold cross-validation metrics, and class-specific confidence intervals retrospectively.
The annotation procedure represents another source of limitation. Sentiment labels were generated through a BERT-assisted workflow and then manually reviewed by a single annotator. While this approach improved internal consistency, it prevented the calculation of inter-annotator agreement metrics and restricted the formation of an independently validated gold-standard subset. The sentiment results should, therefore, be interpreted as internally consistent but not externally validated.
Another limitation concerns linguistic structure. Because the study is conducted on Turkish tweets, bigrams, binary phrases, and translations, it might have fewer or more words, making the study harder to interpret. Tweet data processing and interpretation are inherently language-dependent; therefore, analysis may be limited to a single language or linguistic context. 23 This limitation affects the generalizability of this study's findings, which are derived using Turkish tweets. As sentiment and textual analyses are inherently language-dependent, findings derived from Turkish discourse may not generalize to other linguistic or cultural contexts.
Finally, only a subset of negative-term frequency lists—those stored during the original word-cloud construction—remained available for further lexical analysis. This permitted the creation of descriptive bar charts but did not allow for more rigorous techniques such as log-likelihood keyness testing, statistically grounded topic modeling, or effect-size estimation. Therefore, the lexical findings should be viewed as descriptive patterns rather than inferential evidence. Furthermore, differences in dataset size and class balance between the two vaccines likely contributed to the observed variation in classifier performance, particularly the lower accuracy associated with the Sinovac subset.
Despite these limitations, the study offers a transparent analytical workflow and provides meaningful descriptive insights into how vaccine-related concerns and sentiments were expressed in Turkish Twitter discourse during the post-pandemic period.
Conclusions
This study offers an exploratory analysis of Turkish Twitter discourse regarding COVID-19 vaccines, with a particular emphasis on mid-term perceptions of side effects. The primary novelty of this work is its emphasis on mid-term reactions rather than immediate post-vaccination responses, which distinguishes it from much of the existing literature. By focusing on this period, the study provides insight into how public concerns evolve over time and how these perceptions may shape broader behavioral outcomes—such as hesitancy or refusal—in future outbreaks.
It is important to clarify that our findings represent public discourse, not clinical adverse-event incidence. Social media posts often refer to health-related terms, yet such expressions—including colloquial mentions of “heart attack”—do not reflect medically verified diagnoses. Although a highly respected medical study 31 has documented myocarditis as one of the monitored post-vaccination outcomes, our analysis does not assess, validate, or correlate these clinical findings with Twitter data. Instead, this medical research is referenced solely to contextualize why such topics appear in public discussions and to highlight the types of vaccine-related concerns that circulate in societal narratives.
Within this scope, the sentiment patterns identified in this study should be understood as indicators of public perceptions and communication trends, rather than as measures of real-world vaccine risk. The results illustrate how medical information, public concerns, and circulating narratives intersect on social media, shaping societal reactions during a public-health crisis.
Future works might aim to integrate social media discourse with independent pharmacovigilance or clinical datasets to assess whether public sentiment aligns—or diverges—from validated medical evidence. Additionally, expanding annotation resources and applying more advanced linguistic and statistical approaches would strengthen the methodological rigor of future cross-vaccine analyses.
Footnotes
Appendix
Acknowledgements
The authors thank the generative AI tool (ChatGPT) for its limited assistance in improving the clarity of wording while preparing responses to reviewer comments. The study’s design, analysis, interpretation, and substantive scientific content were produced by the authors, who retain full academic responsibility for the work.
Ethical considerations
This study used only tweet text and date information publicly available on Twitter, handled in compliance with Twitter’s terms of service and platform policies. Usernames, account IDs, or other personal information were not recorded, gathered, or processed. No user-level gender, location, or other demographic characteristics were used in the study. This work did not require review or approval from an Institutional Review Board (IRB) or ethics committee.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Ataturk University, Scientific Research Project Unit, with Project Code FBA-2023-12591.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Tweet IDs were not archived during data collection, and the code and intermediate model artifacts were not preserved in a shareable format. All methodological details necessary for replication are fully documented in the manuscript.