
Abstract
RGBT target tracking is a significant downstream task in the field of object tracking. However, compared to visible light target tracking, RGBT target tracking faces the challenge of smaller datasets, making it difficult to achieve performance levels comparable to those achieved in visible light target tracking. To address how to effectively combine the complementary characteristics of visible and thermal modalities, as well as how to fully leverage the superior performance of models trained on visible light target tracking tasks, while also aiming for lower computational costs and higher tracking effectiveness, a dual-prompt complementary fusion strategy for an RGBT tracking network is proposed. Drawing on the concept of prompt learning, this network aims to extend the efficient performance of visible light target tracking to the RGBT target tracking domain. In its implementation, the prompt module inputs both visible and thermal modality information as dual prompts into the backbone network, where the network utilizes these prompts to generate new, enriched prompt information at each layer. Subsequently, an information enhancement fusion module enhances the acquired prompt information and refeeds it into the backbone network, aiming to improve the tracking accuracy and robustness. Experimental results on GTOT, RGBT234 and LasHeR datasets show that the tracking accuracy (PR) and success rate (SR) of the network reach 93.1%/76.8%, 84.4%/62.4% and 66.8%/53.8%, respectively, which is improved compared with the current mainstream RGBT target tracking network, which verifies the effectiveness of the network.
Introduction
Visual target tracking constitutes a foundational task within the realm of computer vision, with visible and thermal infrared target tracking (RGBT target tracking) representing a crucial extension of this domain. In real-world applications, tracking based solely on visible light imagery often struggles under complex environmental conditions such as fog, rain, and extreme lighting scenarios. Conversely, thermal infrared imagery excels under these circumstances due to its insensitivity to light variations and its capability to penetrate smoke. The advent of advanced visible light and thermal infrared camera technologies in recent years has propelled RGBT target tracking to the forefront of research, finding extensive application across video surveillance, robotics, and autonomous driving, among others. The pivotal challenge in RGBT target tracking lies in effectively harnessing both visible light and thermal infrared modalities to exploit their complementary strengths.
At present, the mainstream RGBT object tracking algorithm adopts the method of multi-domain learning and the structure of siamese network. 1 The aspect ratio of the candidate box region obtained by the RGBT tracking method based on multi-domain learning is fixed. And it only contains local features, which cannot flexibly adapt to changes in the shape of the target. At the same time, because it contains an online update module, its real-time performance is poor. The RGBT tracking algorithm based on the siamese network needs a large amount of data for offline training in order to obtain a robust model. At present, the RGBT object tracking dataset is still small in terms of data volume compared to the visible object tracking dataset. Therefore, the RGBT object tracking algorithm based on the siamese network often fails to achieve the desired performance level. Transformer 2 was originally applied to the field of natural language processing, but due to its powerful sequence modeling capabilities and attention mechanism, researchers began to expand it to the field of computer vision. In the field of object tracking, Wang et al. 3 proposed TMT, which is the first time that Transformer has been applied to a target tracking task. Subsequently, Transformer was widely used in the field of single-target tracking, and a series of effective trackers appeared, such as TransT, 4 Stark, 5 and OSTrack. 6 The use of Transformer for target tracking is conducive to extracting the global features of the object.
Prompt learning, propelled by the rapid evolution of large-scale models, has gained prominence in natural language processing. This led Jia et al. to introduce Visual Prompt Tuning (VPT), 7 bringing the concept of prompt learning into computer vision. This approach enables the application of large models to downstream tasks via prompt information. Given that RGBT target tracking is a derivative task of visible light target tracking, large models pre-trained on the latter can be adeptly applied to RGBT target tracking challenges. ProTrack 8 first implemented this concept within RGBT tracking, utilizing a simple color transformation on thermal infrared images as a prompt. This method combines the visible light image with prompt information to form a novel three-channel input for network processing. Similarly, ViPT 9 adopted a comparable strategy by integrating multiple lightweight modal complementary prompters into the foundational model, with thermal modal information serving as the prompt. Prompt learning achieves noteworthy outcomes with minimal parameter augmentation. Unlike comprehensive fine-tuning, prompt learning freezes the backbone network’s parameters, focusing fine-tuning efforts solely on the prompt module. This approach significantly curtails computational resource and time requirements, offering a more streamlined solution. However, these algorithms typically employ a single modality as prompt information, which can lead to inaccuracies in tracking outcomes if the prompt modality is compromised or absent. Additionally, this overlooks the complementary nature of the two modalities, potentially limiting tracking performance in complex scenes due to the underutilization of available complementary information.
Given the potential for thermal infrared images to exhibit low resolution or missing modes in practical applications, and the fact that visible light images, despite their higher resolution, can suffer from degraded quality in scenarios marked by lighting fluctuations, relying solely on a single modality for prompt information could compromise tracking accuracy. To address this, this paper introduces a Dual-Prompt Complementary Fusion Network for RGBT Tracking (DPCFT). This network features a dual-prompt information structure that fuses interaction information from both visible and thermal modalities as dual prompts. These fused prompts are then integrated into the backbone network, with subsequent enhancement and reintegration facilitated by an information fusion enhancement module. This interactive fusion within the prompt module maximizes the complementary attributes of both modalities, thereby refining tracking accuracy with only a minor increase in parameter count.
The principal contributions of this work are outlined as follows:
The introduction of a dual-prompt complementary fusion tracking network that leverages dual prompt messages to mitigate the tracking accuracy issues associated with poor-quality single modalities. The development of an information enhancement fusion module that applies spatial and channel attention mechanisms to augment and amalgamate prompt information, optimally harnessing the modalities’ beneficial characteristics. The demonstration of the algorithm’s superior performance across multiple benchmark datasets, affirming its efficacy and potential in enhancing RGBT target tracking capabilities.
Related work
RGBT target tracking
RGBT target tracking is a downstream task of visual target tracking, which currently contains three main paradigms. The first one is the RGBT tracking algorithm based on multi-domain learning. This method is based on extracting candidate frame regions, then fusing features from candidate frame regions of different modalities, and finally obtaining the tracking results of the current target through binary classification and bounding box regression. MANet 10 extracts modality-specific features, modality-shared features, and instance-aware features, respectively, by designing three different adapters in order to better exploit the complementary properties of the visible and thermal infrared modalities. MFGNet 11 uses a dynamic modality-aware generation module to enhance the information interaction between the visible and thermal infrared modalities by adaptively adjusting the convolution sum based on different input images during the tracking process. APFNet 12 designs an attribute-based progressive fusion network with five challenge branches designed to adaptively aggregate attribute-specific fusion features to improve the fusion capability. This multi-domain learning-based approach obtains candidate frame regions with fixed aspect ratios and contains only local features that cannot flexibly adapt to changes in the target shape.
Then comes the Siamese-based RGBT tracking algorithm, which involves designing two same branches of the network to extract features for visible and thermal infrared modalities respectively. The extracted features of both modalities are then fused using a fusion module, and the fused features are fed into the header for classification regression. SiamFT 13 extends SiamFC 14 by designing a feature fusion branch to fuse visible and thermal modal features. DSiamFT 15 uses a channel attention mechanism to fuse the features of the template frame, while keeping the search frame unchanged. The Siamese-based RGBT tracking method is able to achieve high speed because it does not require online updates, but it requires a large amount of data for training to obtain robust results.
Finally, Transformer-based RGBT tracking algorithms have also attracted a lot of attention due to the wide application and good results of Transformer 2 in the field of visual target tracking. Since the Transformer structure is able to capture global features, it is more effective in acquiring global features compared to the two previous paradigms using CNN structure. ViPT 9 adopts prompt learning based on OsTrack, 6 and inputs the thermal infrared features as prompt information into the backbone network. It freezes the backbone network parameters and only fine-tuning the prompt module to obtain good tracking results with fewer parameters trained. TBSI 16 extended the ViT 17 backbone network into a dual-stream structure to extract the features of visible and thermal infrared modalities respectively. In order to make full use of the complementary nature of the two, a template-bridging interaction fusion module was designed for cross-modal interactions, and good results were achieved.
Prompt learning
The “pre-training, prompt” paradigm first appeared in the field of natural language processing and gradually replaced the “pre-training, fine-tuning” paradigm as the mainstream. This paradigm allows the base model to adapt to different types of tasks by adding prompts to the model’s input. Compared to the popular fine-tuning paradigm, the prompt paradigm can update only the parameters of the prompt part while freezing the parameters of the backbone network, which significantly reduces the consumption of computational resources and time. In addition, the prompt paradigm is able to achieve performance comparable to fine-tuning while significantly reducing memory footprint. Due to the prompt’s promising results in the field of natural language processing, researchers have started to investigate its application to the field of computer vision. VPT 7 applies prompt to the vision Transformer, adapting a large-scale pretrained model to a variety of downstream tasks by fine-tuning a very small number of learnable parameters. DualPrompt, 18 on the other hand, employs a dual-prompt approach, where one set of prompts is used to encode task-invariant instructions and the other set of prompts is used to encode task-specific instructions, enabling the model to adapt to new categories while retaining the memory of the old ones. In the field of RGBT target tracking, algorithms such as ProTrack 8 and ViPT 9 have introduced prompt learning to the field with good results.
Method
In this section, our proposed RGB-T tracking model DPCFT is described in detail, as shown in Figure 1. It mainly consists of ViT backbone network, multi-prompt complementary fusion (MPCF) branch and a localization head. The multi-prompt complementary fusion branch includes Prompt (P) module and Information Enhancement Fusion (IEF) module.
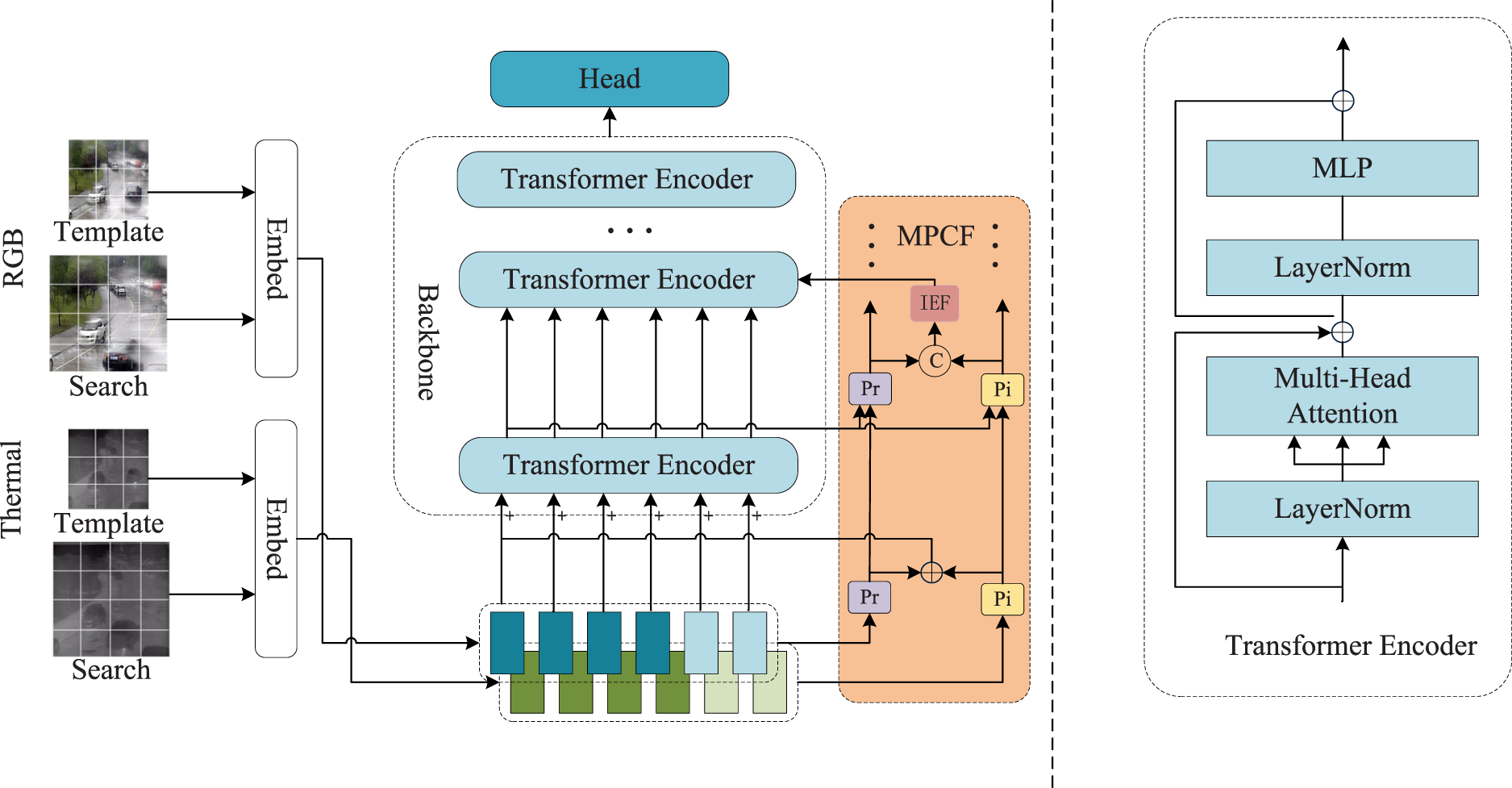
Overview architecture of our proposed.
Firstly the input visible and thermal infrared images are segmented and flattened into a patch sequence. Subsequently, two pieces of prompt information are obtained through the initial prompt module, and these two pieces of information, along with the visible light patches, are fed into the Vision Transformer (ViT) backbone network. The output from each layer of the backbone network goes through a multi-prompt complementary fusion branch. Within this branch, the output from each layer of the backbone network and the two pieces of prompt information from the previous layer of the prompt module are processed through the prompt module again to generate new sets of two prompt information. These new prompt information are then passed through an information enhancement fusion module, producing prompt information for the next layer. This prompt information is added to the output of the previous layer of the backbone network before being input into the subsequent network layer. Finally, the features obtained from the backbone network are fed into the tracking localization head to predict the current state of the target. For the tracking localization head the design is similar to OSTrack. 6
ViT backbone
With the development of Transformer, Vision Transformer has been widely used in computer vision-related tasks, including image classification,
17
image denoising,
19
remote sensing image processing
20
and other fields. In this paper, the ViT used in image classification is used as the backbone network. The input initial visible and thermal infrared video frames are used as template images

The backbone network is composed of The overall architecture of prompt module.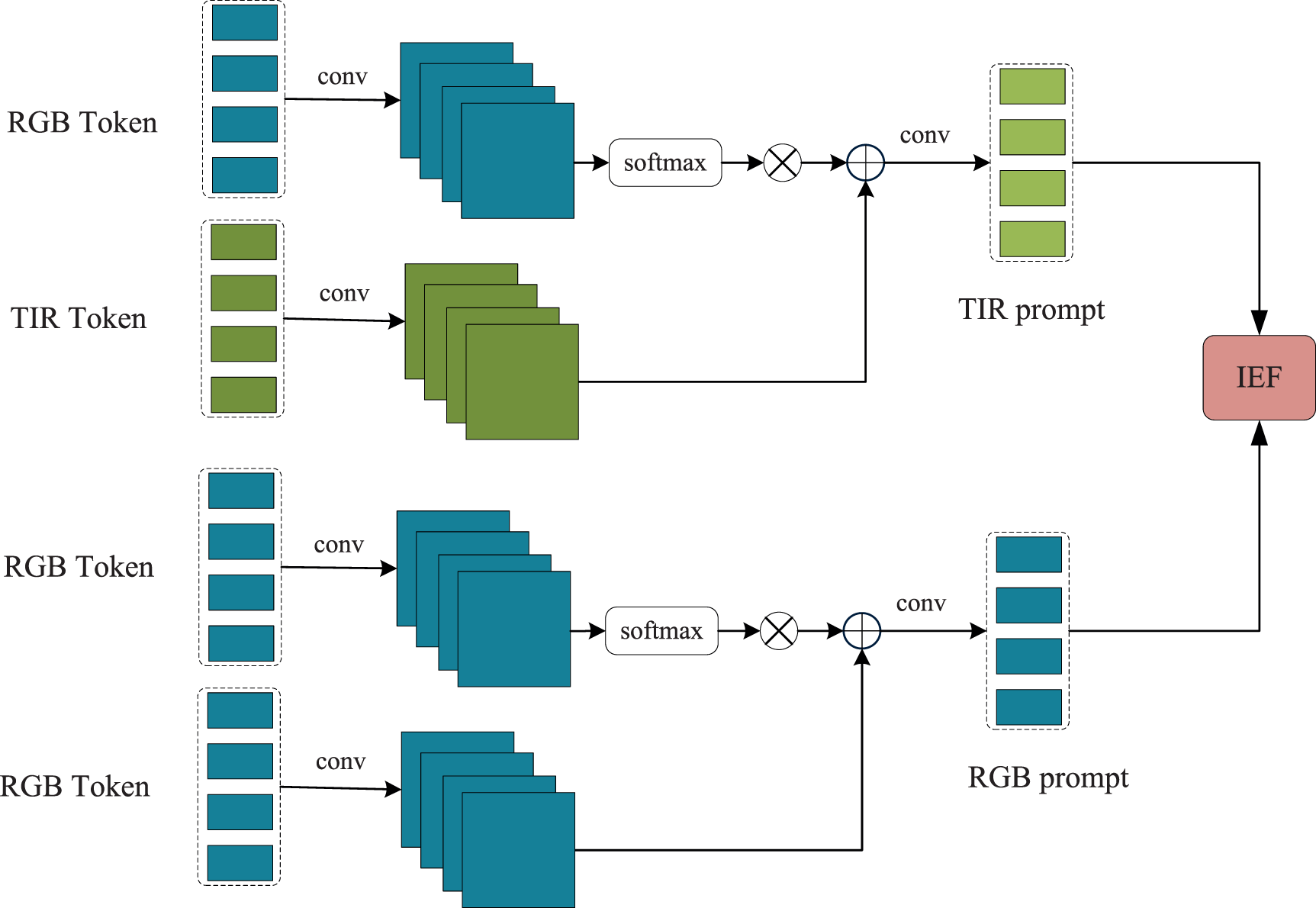
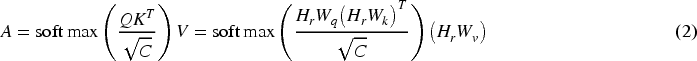
Prompt module
Inspired by ViPT,
9
the prompt module generates two types of prompt information: visible light self-enhancement prompt information and thermal infrared prompt information that fuses with visible light features. This allows base models pre-trained on large-scale RGB datasets to adapt to downstream RGBT target tracking tasks. Specifically, the visible light prompt is used to enhance visible light features, while the thermal infrared prompt is employed for cross-modal interaction, facilitating partial fusion between visible light and thermal infrared modalities. The design of the prompter is shown in Figure 2, with its generation process as follows:

The prompt module performs identical operations on both the template and search sequences, exemplified here by the generation of thermal infrared information for the search sequence. For simplicity, superscripts are omitted. Initially, the prompter module employs a
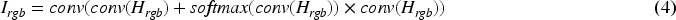
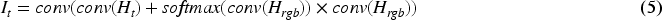
In the initial prompt module, the variables
To better utilize the effective information from the two prompt messages generated by the prompt module, inspired by the CBAM
21
attention mechanism, this paper employs both spatial and channel attention mechanisms to enhance the model’s focus on important features. Channel attention assigns different weights to each channel, suppressing redundant channels. Spatial attention weights the spatial positions of the feature map to highlight the areas that contribute most to the tracking task. These two types of attention are complementary to each other. Using both channels and spatial attention can further improve model performance. It has proved its effectiveness in multiple image processing tasks, such as image rain removal,
22
image classification,
23
etc. The information enhancement fusion module is illustrated in Figure 3. Initially, through a channel attention module as shown in Figure 3(a), global average pooling is performed on the feature map of each channel. Then, the relationships between channels are obtained through a fully connected layer, generating a weight vector to weight the features of each channel. Subsequently, through a spatial attention module as depicted in Figure 3(b), global average pooling is conducted on the feature map of each spatial position, and the relationships between spatial positions are derived through a fully connected layer, generating a weight vector to weight the features of each spatial position. Finally, the features processed by the channel and spatial attention modules are added together to obtain the enhanced and fused prompt information. For the channel attention module, the input features are first processed through both global average pooling and max pooling separately, then treated by a shared fully connected layer. The output features from these processes are then added together and normalized to obtain the channel attention weights. As for the spatial attention module, the input features undergo global average pooling and max pooling respectively, after which the obtained features are concatenated. This concatenated feature is then passed through a convolutional layer, and finally, spatial attention weights are obtained through a normalization operation. The specific formulas are as follows:
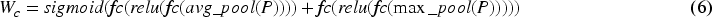
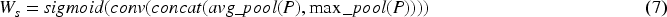
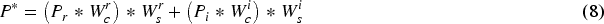
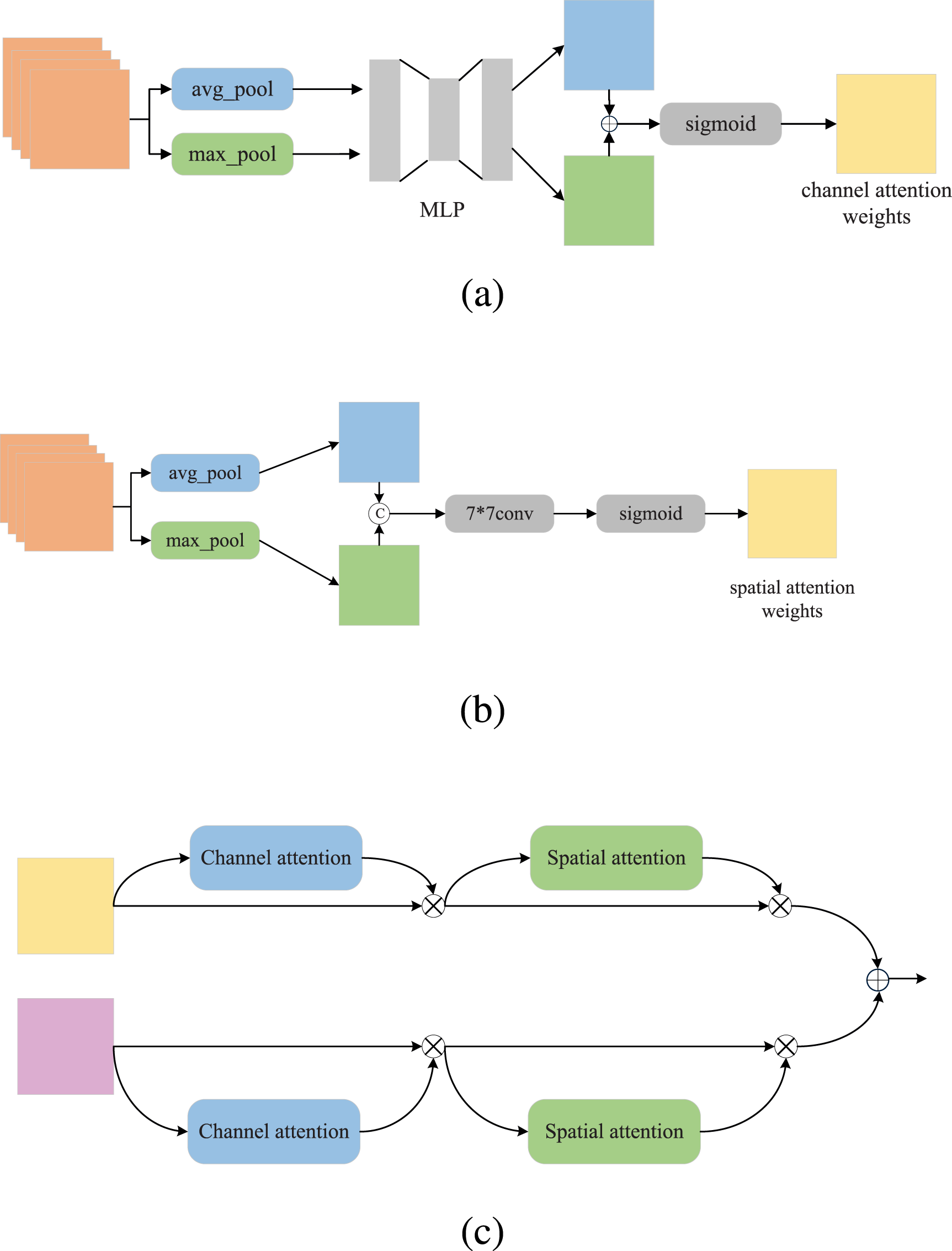
The overall architecture of Information enhancement fusion module, (a) is the process of generating channel attention weights, (b) is the process of generating spatial attention weights, (c) is the overall pipeline.
Integrating channel attention mechanisms and spatial attention mechanisms allows the model to more effectively focus on important channel and spatial information within the input feature maps, thereby enhancing the model’s performance and generalization ability.
The loss function adopted in this paper is consistent with that of OSTrack,
6
employing weighted focal loss
24
for classification and utilizing L1 loss and generalized IoU loss
25
for bounding box regression. The overall loss function is presented as follows:

This section mainly introduces the specific implementation method of DPCFT, evaluates its performance on multiple datasets, and conducts ablation experiments on the involved modules to verify its effectiveness.
Implementation details
The models in this paper were implemented using PyTorch, trained on two NVIDIA RTX2080Ti. The training set of LasHeR
26
was used to train the network in the experiments, a total of 120 epochs were trained, the batch size was set to 16, and each epoch contained 60,000 sample pairs. During model training, the parameters of the backbone network and classification header were frozen and only the parameters of the multi-prompt interactive fusion branch were updated. The frozen parameters were initialised using the baseline model OSTrack,
6
while the other parameters were initialised using the xavier uniform initialisation scheme.
27
The optimiser uses AdamW
28
with the weight decay set to 0.0001, and the learning rate set to 0.0004. The input search regions are resized to
Evaluation on LasHeR dataset
The LasHeR dataset 26 is a large-scale short-term RGBT tracking dataset containing a total of 1224 pairs of visible and thermal infrared video sequences with 730K frames of images. Its test set contains 245 visible and thermal infrared image sequences. Nine other state-of-the-art trackers are used to compare with the tracker DCPFT proposed in this paper, mainly containing MANet, 10 mfDiMP, 29 MaCNet, 30 CAT, 31 MANet++, 32 DMCNet, 33 APFNet, 12 ProTrack, 8 and ViPT. 9 The results are reported in Figure 4. From the figure, it can be seen that the DCPFT outperforms the state-of-the-art tracker ViPT by 1.7% and 1.3% in PR and SR, respectively. The performance of DCPFT also dominates over other trackers, which fully demonstrates the effectiveness of the DCPFT proposed in this paper.
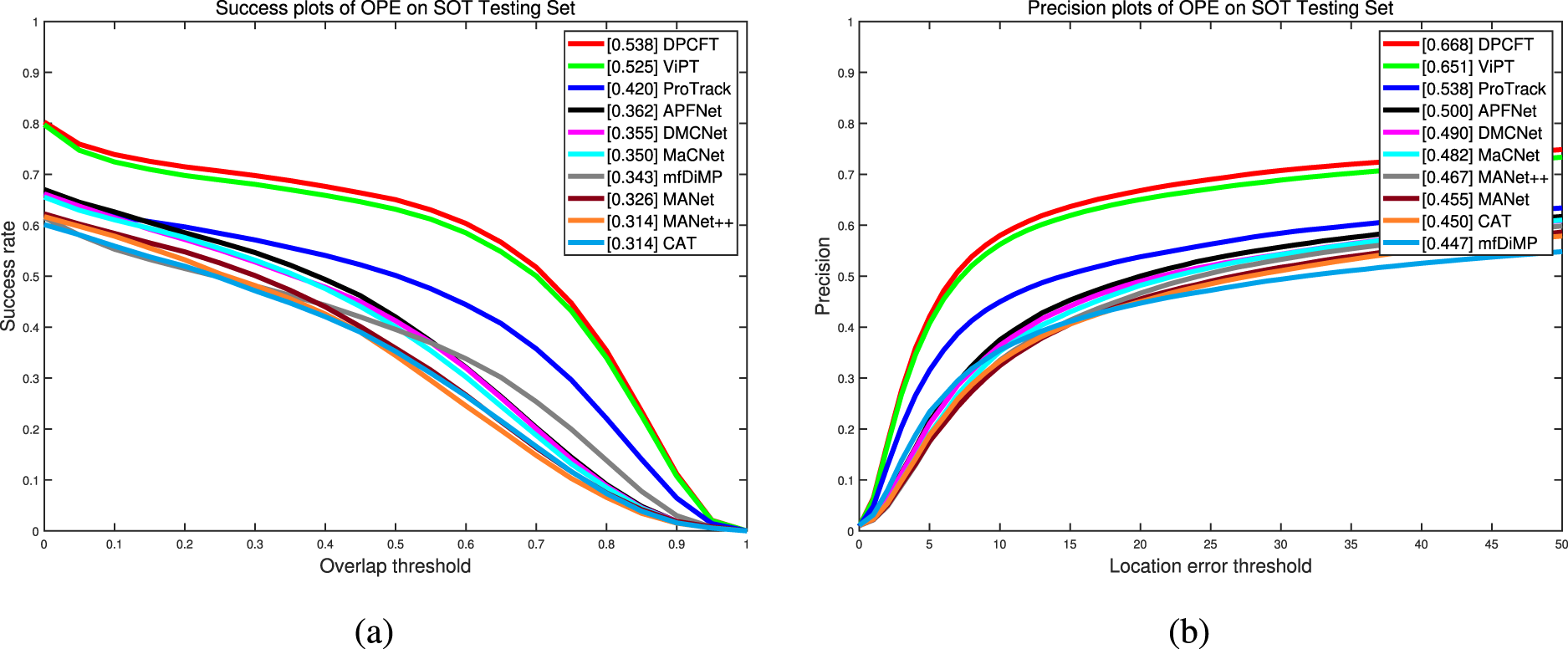
Overall performance on LasHeR test set.
In order to evaluate the effectiveness of the algorithm proposed in this paper more comprehensively, the challenge attributes were evaluated on the test set of LasHeR. The LasHeR dataset contains 19 challenge attributes, including Background Clutter (BC), Camera Moving (CM), Fast Motion (FM), Motion Blur (MB), Deformation (DEF), Scale Variation (SV), Heavy Occlusion (HO), Total Occlusion (TO), No Occlusion (NO), Partial Occlusion (PO), Out-of-view (OV), Low Illumination (LI), High Illumination (HI), Abrupt Illumination Variation, AIV), Low Resolution (LR), Thermal Crossover (TC), Similar Appearance (SA), Frame Lost(FL), and Aspect Ratio Change (ARC).
The experimental results are shown in Table 1, and seven algorithms which are better in the above results are selected for further comparative analysis. From the table, it can be seen that DCPFT outperforms other trackers in most of the challenging scenarios, and especially for the challenging scenarios with light changes, such as HI, LI, and AIV, the algorithms in this paper show excellent performance. This further illustrates the effectiveness of the dual-prompt complementary fusion idea proposed in this paper, which can effectively solve the situation of extreme illumination in visible target tracking and give full play to the advantages of both visible and thermal infrared modalities. Meanwhile, for occlusion-type challenging scenarios such as HO, TO, and PO, the algorithm in this paper also demonstrates better performance.
Attribute-based evaluation on LasHeR dataset. Bold for the best results, italic for the second-best results.
Attribute-based evaluation on LasHeR dataset. Bold for the best results, italic for the second-best results.
The RGBT234 dataset 34 contains 234 pairs of visible and thermal infrared image sequences, totaling 234K frames of images. The comparison results of DCPFT with other 10 algorithms are shown in Table 2. From the table, it can be seen that the PR and SR of DCPFT are improved by 0.9% and 0.7%, respectively, compared to ViPT, and also compared to other tracking algorithms.
Overall performance on RGBT234 dataset. Bold for the best results, italic for the second-best results.
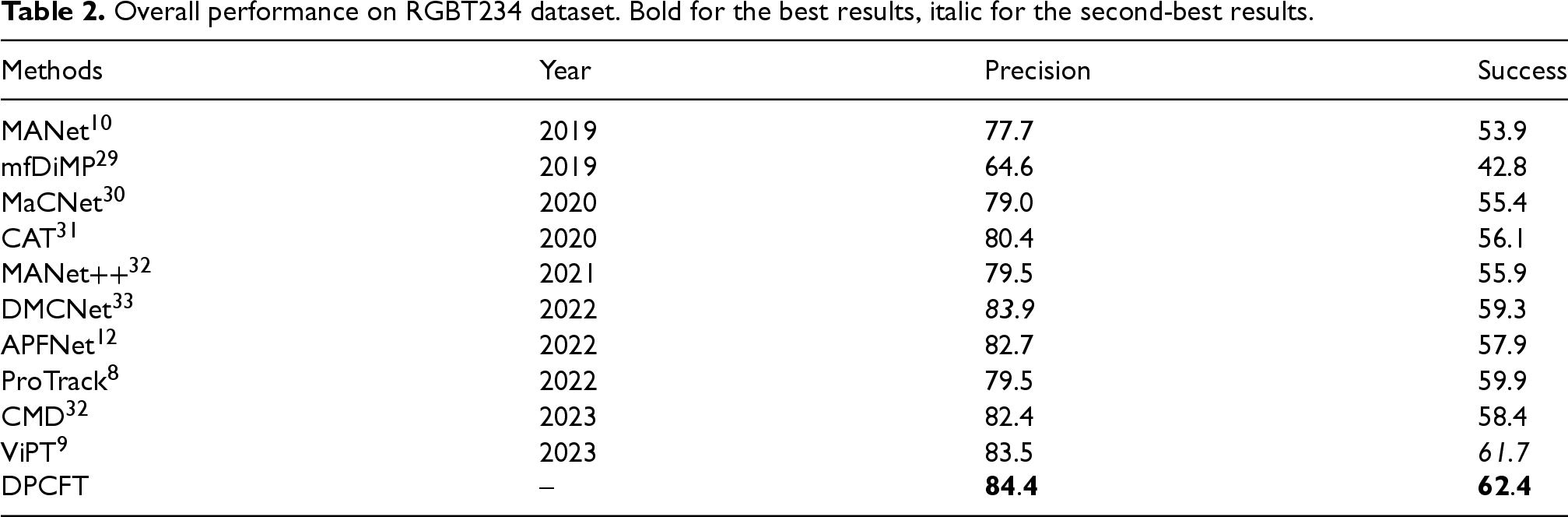
Overall performance on RGBT234 dataset. Bold for the best results, italic for the second-best results.
The GTOT dataset 35 contains 50 pairs of visible and thermal infrared image sequences and is a small RGBT target tracking dataset. The comparison results of DCPFT with other 9 algorithms are shown in Table 3. From the table, it can be seen that the performance of DCPFT is improved compared to the other tracking algorithms, which illustrates the effectiveness of our algorithm DCPFT.
Overall performance on GTOT dataset. Bold for the best results, italic for the second-best results.
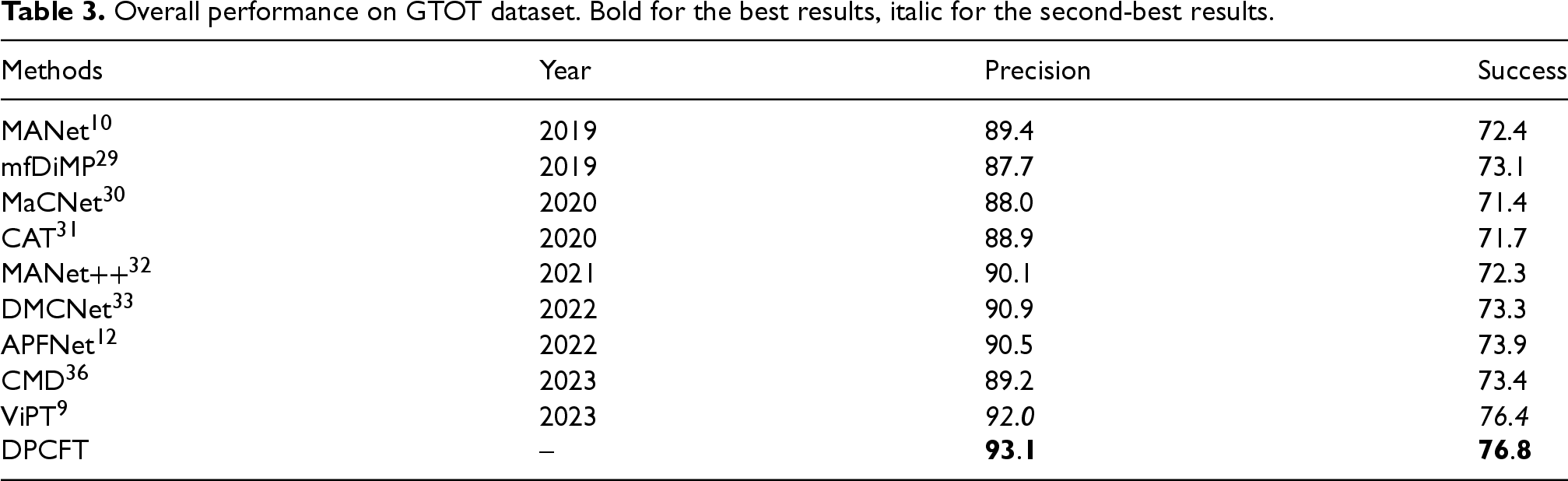
Overall performance on GTOT dataset. Bold for the best results, italic for the second-best results.
In order to further analyze the practical application effect of the algorithm proposed in this chapter, a parameter analysis is carried out, and the results are shown in Table 4. In order to effectively alleviate the problem of large number of parameters, the prompt learning method is adopted, and the parameters of the backbone network are frozen during training, so as to effectively reduce the resource consumption during training. It can be effectively applied to real-world scenarios that require a balance between computing resources and accuracy.
Parametric analysis. Bold for the best results, italic for the second-best results.
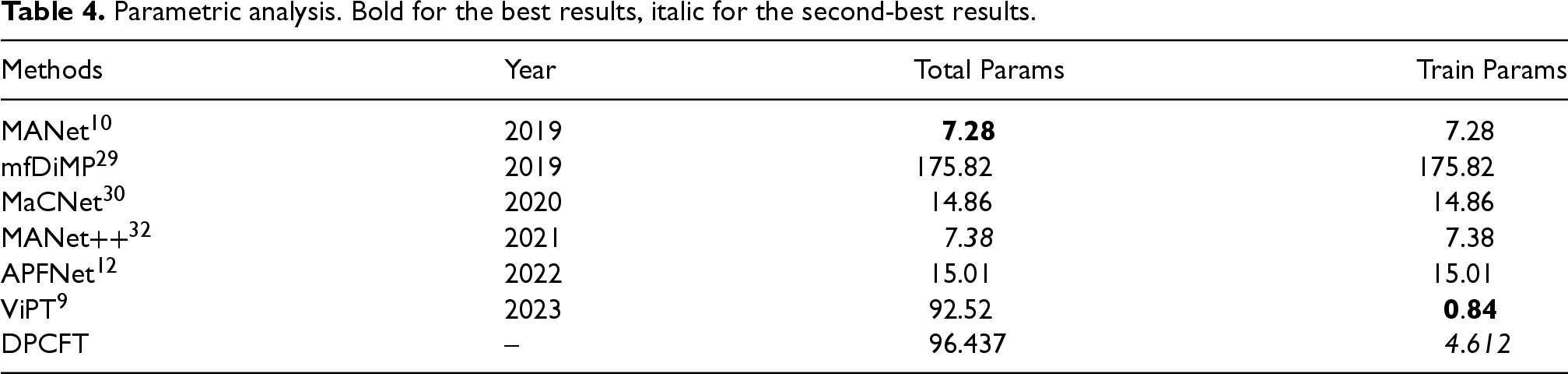
Parametric analysis. Bold for the best results, italic for the second-best results.
Variants comparison
In order to verify the effectiveness of the individual modules of the proposed model, ablation experiments are performed on the test set of LasHeR. Three different models are compared: model 1 represents a single-branch RGB tracker containing a backbone network and a classification header, model 2 represents a baseline tracker with a prompt (P) module added to it, and DCPFT represents the tracker proposed in this paper.Model 3 and model 4 represent the CA module and SA module in the IEF module, respectively. The experimental results are shown in Table 5.
From the table, it can be seen that with the addition of the Prompt module, the accuracy and success rate are improved by 14.7% and 12.2%, respectively, compared to the baseline network, which indicates that the design of the prompt module is effective for both visible and thermal infrared modalities. From the experimental results of model 3 and model 4, it can be seen that the tracking performance is reduced when only the CA or SA module is used, which further illustrates the effectiveness of the IEF module. The performance is further improved with the addition of the information-enhanced fusion module, indicating the effectiveness of the module. Thus, the results of the ablation experiments show that the modules of our proposed algorithm are effective.
Ablation studies on LasHeR test set. Bold for the best results.

Ablation studies on LasHeR test set. Bold for the best results.
For different prompter designs, it has a large impact on the effect of the final model. In this paper, we analyse the effects of three kinds of prompters, whose designs are shown in Figure 5, and the experimental results are shown in Table 6. Model a is shown in Figure 5(a), which uses only thermal modality as the prompt information. Model b is shown in Figure 5(b), using visible and thermal modalities as the two prompt information, where each prompt information is designed using the interaction of the two modalities. Model c, shown in Figure 5(c), employs the prompter design method proposed in this paper, where one of the prompts employs two modal interactions while the other employs self-interaction enhancement of visible light features. From the experimental results, it can be seen that the prompter design method adopted by our algorithm is more effective compared to the other two methods.
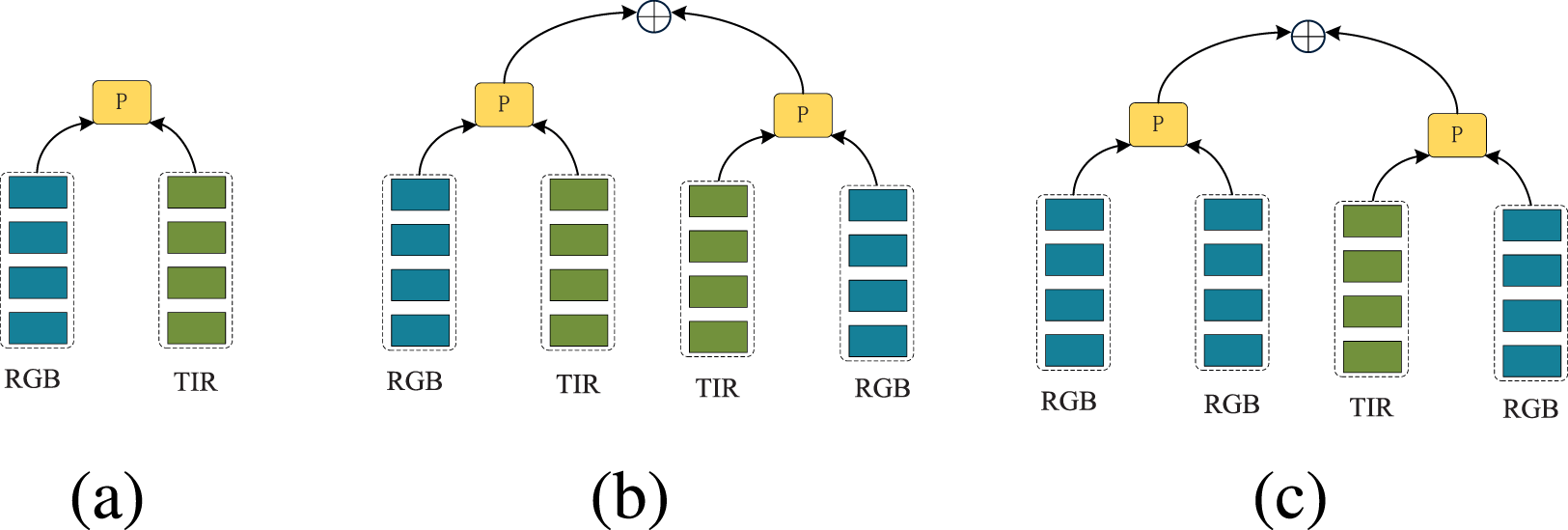
Design drawings of different prompters.
Quantitative comparison between different variants of prompter on the LasHeR dataset. Bold for the best results.

To better verify the effectiveness of the proposed DPCFT algorithm, tracking results were visualized on several representative tracking sequences, as shown in Figure 6(a) shows the visualization results for the sequence 10runone, demonstrating that, in the event of severe occlusions, other trackers exhibited various degrees of deviation, whereas DPCFT was still able to accurately track the target. Figure 6(b) presents the visualization results for the sequence small-gai, where the target is a transparent object with other objects in the background, the other two algorithms were more likely to focus on background features, yet the algorithm discussed in this paper was still able to effectively track the target. Figure 6(c) displays the visualization results for the sequence truckgonorth, where there were low and high illumination changes in the scene, the other two algorithms experienced varying degrees of deviation due to illumination changes, whereas the algorithm proposed in this paper was still able to track the target well. The analysis of the visualization tracking results shows that the DPCFT algorithm possesses good robustness and effectiveness.
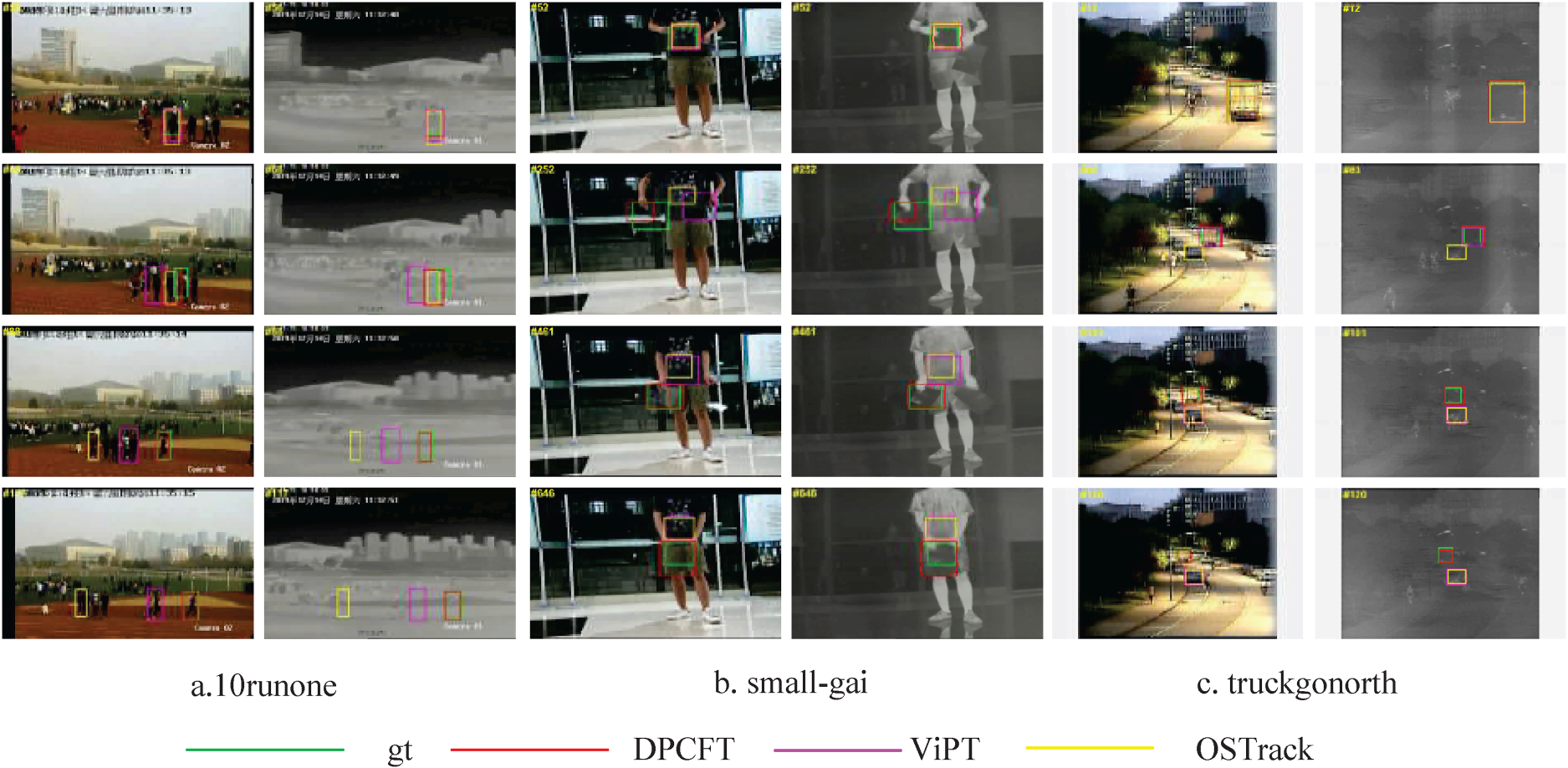
Visualize the tracking results. Green bounding boxes represent the true boundaries, red bounding boxes represent DPCFT, purple bounding boxes represent ViPT, and yellow bounding boxes represent OSTrack.
Figure 7 depicts cases of tracking failure. In the figure, green bounding boxes represent the true positions of the objects, while red bounding boxes depict the predictions made by the method proposed in this paper. As shown in Figure 7(a), for the sequence boytakingbasketballfollowing, the tracker performs well under normal conditions. However, when sudden camera movement causes image blur, and the target is severely obscured by trees before re-emerging into extreme lighting conditions, the tracker loses the target. Subsequently, the target exits and re-enters the field of view, appearing very small upon re-entry. Under such complex scenarios involving multiple challenges, the method presented in this chapter struggles to maintain effective tracking. As illustrated in Figure 7(b), for the sequence boyunder2baskets when there is simultaneous extreme lighting and thermal crossover, along with the presence of multiple similar objects, the method fails to accurately track the target. This failure is primarily due to the reduced reliability of both modalities under these conditions and the distraction caused by multiple similar objects, leading to easy deviation of the tracker.

Failure Cases. Green bounding boxes represent the true boundaries, red bounding boxes represent DPCFT. (a) boytakingbasketballfollowing; (b) boyunder2baskets.
In this paper, a double-prompt complementary fusion RGBT tracking network is proposed. It effectively solves the problem of inaccurate tracking results due to the absence of a single modality in practical applications. The network makes full use of the complementary properties of visible and thermal modes, and by introducing a dual-prompt design, the accuracy of the tracking results can still be ensured in the absence of one of the modes. In addition, an information enhancement fusion module is introduced, which can effectively enhance the expressive ability of the prompt information, thus improving the network’s ability to effectively integrate information from different modalities. Meanwhile, the strategy of cue learning is adopted to enable the pre-trained base model for visible light tracking to be migrated to RGBT target tracking. The excellent performance of the visible light target tracking model is fully utilised, and the computational resources and time consumption are greatly reduced. Through experimental validation on several benchmark datasets, compared with several existing RGBT target tracking algorithms, the method proposed in this paper shows good performance in coping with scenarios with varying illumination such as high illumination and low illumination, as well as the presence of various kinds of occlusions, and has good practicality and promotion value. However, from the case of tracking failure, it can be seen that the tracking accuracy of this paper is low for scenes with multiple complex challenges at the same time, and we consider further increasing the processing of lighting changes and tracking of small target objects in the future work to further improve the algorithm.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China under Grants 52374155, Anhui Provincial Natural Science Foundation under Grant No. 2308085MF218, Natural Science Research Project of Colleges and Universities in Anhui Province under Grant No. 2022AH040113.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.