
Abstract
A lot of fake news is published with the help of television and social media. As a consequence, we are affected by the disinformation and misinformation spreading in our community. It is implemented to identify fake news creators to prevent spreading misinformation about the people. Thus, it is published like real news for the reputation and finances of an individual. It is challenging, because that is created by the integration of real and false details, and images are attached like originals to confuse the public. Few fake news detection tools are available to detect fake information. To solve this fake news spreading problem, an effectual multimodal fake news detection system is proposed based on the deep learning technique. In the beginning, the input image and text are gathered from benchmark data sources. Consequently, the deep features are extracted from raw images and text. The dilated Visual Geometry Group 16 (VGG16) is adopted to extract the image features and similarly, the text features are retrieved from the Dilated Text Convolutional Neural Network (DTCNN). After achieving two different features, it is upgraded into weighted fused features, in which the weight is tuned by an Adaptive Controlling Parameter-based Chameleon Swarm Algorithm (ACP-CSA). Finally, the fused features are fed as given to the Dilated Adaptive Deep Temporal Convolution Network with Bi-directional Long Short-Term Memory (DADTCN-Bi-LSTM) for predicting the fake news. The analysis is further performed by tuning the parameters in the model using developed ACP-CSA. The efficiency of the model is investigated and results are conducted. Thus, the analysis of the suggested system shows 95 regarding accuracy, sensitivity, and specificity. The analysis of the F1-score achieves the value of 90 in the developed model. Hence, the findings demonstrate that it achieves a better detection process to evade the existence of misinformation.
Keywords
Introduction
In this modern period, sharing information and connecting with people is a rapid process. Owing to rapid technology development, all users can share details through smartphones, and, social media become a rapid and popular platform for sharing news articles. 1 So, it becomes difficult to identify the exact beginning news spreader article. 2 This possibility and circulating the information easily creates the chance to increase the fake news and give the wrong impression about the ordinary people in the society. 3 Fake news creation intends to appear as reliable information on the social media platform. This is evident owing to the sharing of widespread information every day without the truth of the content. 4 The scope of sharing fake news is to manipulate the opinion of the communal for political gain and financial gain. 5 The fake information also shows the bad effects of an investment in large infrastructure and stock price. 6 Fake information is classified into three types: propagation, creation, and publication. The important reason for the fake news is the frauds. 7 They quickly spread fake information with particular ideas to mislead the people, and also publish false articles in social media. 8 It is complex to determine the value of daily content through these methods for the news shared by various frauds. 9
Fake news creation is mainly obtained with content based on text. 10 Conventional learning techniques for recognizing fake news are classified as learning on the basis of news content and social content. The news content focuses on the article news, style, malign news, etc.., 11 and the social context focuses on the comments, user types, shares, likes, etc. The method based on news content focuses on extracting various contents from the fake information article that includes both style and content. But, the method based on news content mainly focuses on checking the reality present in the news. Moreover, fake information spreaders have an evil plan to publish false information; they require an integration of false and true interesting information and also need the person not present in the story based on true information to make the people responsible. 12 The method based on style focuses on the written styles of the creators and influencers for publishing fake information. These fake news detection methods are not enough to detect the frauds. 13
Nowadays, social media users are always connected to particular groups of people having similar mindsets is termed a user community. 14 They are the main reason to share fake information owing to the common observation about publishing articles. 15 They are groups of people with similar mindsets on social media platforms, where non-paralleled thoughts are disapproved and rejected by the way of checking the majority. For example, on Facebook, many people viewed the comments on the post provided by the user, and some liked the comment as one kind of echo chamber. 16 Some people give bad comments about a person, which may make a bad impression on the particular person. Additionally, on Facebook, the default increases the number of comments regarding the likes and replies received from the friends of the user. 17 Regarding the above-described challenges, we developed the effectual method.
The key components of the implemented multimodal fake detection system are elaborated below.
To propose the multimodal fake news detection model in order to classify the fake news spreaders and misinformation published by the spreader to support the society and an individual. To establish the DTCNN and VGG-16 models are utilized to extract the text features and image features. Thus, these features are optimally selected by the developed ACP-CSA, and also weights of these features are optimized to improve accuracy. To develop the DADTCN-Bi-LSTM model to identify fake news. These parameters are optimized in the developed DTCN-Bi-LSTM model by the developed ACP-CSA to maximize classification accuracy. To execute the operation, the weights are tuned by the designed ACP-CSA algorithm. In the classification process, the parameters tuned by developed ACP-CSA are a count of hidden neurons in DTCN, count of hidden neurons in Bi-LSTM, epoch counts in DTCN, and epoch count in Bi-LSTM to minimize the FPR and increase the sensitivity, accuracy, and F1-score. To estimate the detection process, the developed method is compared with different existing models to give more accuracy and precision.
The flow for the upcoming works is detailed as follows. 2nd section gives the details about the related work. 3rd section has the details for an intelligent model of multimodal fake news detection utilizing optimal weighted integration with dilated adaptive deep learning. 4th section describes the heuristic-based optimal weighted integration for the multimodal fake news detection process. 5th section describes the details of the results and discussion. Finally, the 6th section gives the conclusion.
Literature survey
Related works
In 2021, Jiang et al. 18 have developed three models based on deep learning and five models based on machine learning on real datasets of various scales. To determine the presentation of the model, the authors utilized metrics such as precision, accuracy, F1 score, and recall, and, also the advanced version of McNemar's testing machine was used to calculate the performance of the technique. Then, the developed stacking method attained the best accuracy value in the FDnugget and Information Security and Object Technology (ISOT) dataset. Hence, they recommended that method to detect the fake information.
In 2021, Ni et al. 19 have developed the method of Multi-View Attention Networks (MVAN) based on Neural Networks (NN) for detecting fake information and helping to provide true news on social platforms. The developed MVAN method included the propagation model attention and semantic attention model. These two models helped to capture the real news, clues of the content present in the tweet, and also the fake news spreader. Moreover, these two models, based on attention, could find the keyword obtained in fake information text and doubtful users in a spreading system. The authors analyzed the model by using the real-world dataset, and also the result proved that the MVAN outperformed other models by an average accuracy of 2.5% and produced a sufficient explanation.
In 2020, Dong et al. 20 have recommended a method named Semi-Supervised Learning (SSL) based on deep learning. The developed model has two paths; one lane was for unsupervised learning and the other lane was for the supervised learning. The path of supervised learning had the ability to learn limited labeled data amount, but unsupervised learning learned the greatest unlabeled data amount. Moreover, the two paths of the developed models were tuned to conclude the mechanism of the implemented SSL technique. Furthermore, the authors developed the CNN for extracting the features present in the low range of unlabeled and labeled data. The CNN-based SSL method was analyzed and tested with PHEME and LIAR datasets. The result demonstrated the designed method was able to detect the fake information very effectively with the support of several numbers of labeled data.
In 2021, Song et al. 21 have suggested the fake information recognition method regarding temporal graphs. The developed model fused the structure, temporal news, and content semantics. Particularly, the designed method could design temporal pattern evaluation of the real-world information processed regarding the continued-time dynamic diffusion network. The authors performed effective analyses of real-world datasets. The results displayed the developed technique performed better than other fake information detection methods.
In 2021, Jing et al. 22 have developed Multi-model Progressive Fusion Network (MPFN) for detecting misinformation. The developed MPFN model captured the representative news of every process at various stages and achieved the fusion among the modalities at the different and same stages according to the mixture for establishing the strongest connection among every modality. Particularly, the authors utilized the transformer model, which was very effective based on computer vision approaches, as the visual features extractors progressively sample the feature at various stages and integrated each feature obtained from the text features extractors and the image domain data at various stages to well graining the model. Moreover, the authors designed the fusion task to establish the connections among the modalities, which could enhance the working performances and therefore exceed other network models. The authors conducted effective analyses on the datasets of Twitter and Weibo, and the developed model attained an accuracy of 83.3% in the Twitter dataset, which was 4.3% more than other techniques. The result proved the developed MPFN framework successfully identified the fake information, and also the developed method achieved the improved stage by using the strongest modalities fusion techniques and joining the various stages of news from every modality.
In 2021, Song et al. 23 have suggested the multimodal misinformation recognition model regarding the Cross-modal Attentions Residuals and Multichannel convolution neural Network (CARMN). The developed model effectively extracted the related information relevant to the target modalities from one source to other source modalities when continuing the distinctive news of target modalities. Multichannel Convolution neural Networks (MCN) mitigated the manipulation of the unwanted information that may created by the component of cross-modal fusion by the extraction of textual features from the fused and original textual news simultaneously. The authors conducted different analyses on real-world datasets and proved the developed framework outperformed other conventional models and learned more feature representations.
In 2021, Kaliyar et al. 24 have proposed a model based on social and news content with tensor. The designed framework had various filters in every layer as well as dropouts. The developed task utilized the PolitiFact and BuzzFeed datasets. The detected result proved that the developed Echo-chamber Fake news recognition based on Deep network (Echo-FakeD) task performed better than other current frameworks. The developed model has obtained 92.30% accuracy in fake information detection.
In 2020, Agarwal et al. 25 have constructed a fake news detection model based on a deep learning technique that predicted the article's nature. The developed model was exclusively used in the stage of text processing and was insensible to the credibility and history source of the author. The authors experimented and discussed the suggested model by utilizing the word (GloVe) for processing the text constructed the vector space word, and established the lingual relationships. The developed method had attained the greatest result in predicting fake information with the help of GloVe. Moreover, to confirm the prediction quality, different methods of the parameter were recorded and tuned to provide a better result. By adding the dropout layers between other distinctions, the overfitting problems were reduced in the developed model. The large amount of input feature was trained to provide accurate results which were more than other existing frameworks.
Problem statement
Spreading fake news widely affects the lives of the people; it damages the person's reputation and also affects the potential power. In recent days, the fast growth of social media platforms namely Twitter, Facebook, etc, spread fake news rapidly to the internet, which affects people's judgment and lives. Different models have been developed recently to identify fake news spreaders. Table 1 shows the merits and disadvantages of conventional fake news detecting techniques. The stacking model 18 helps to enhance the isolated performance of the model and also it utilizes an advanced version of McNemar's to determine the accuracy. However, it has a minimum number of fake news data that is only collected for recognizing the fake news. And it has no accepted configurations. MVAN 19 model requires fewer amounts of data to compute. However, it does not consider the reply of the users and it requires more time during operation. CNN-based SSL 20 accelerates the message verification process in a high-speed road traffic circumstance of a vehicle identifier. However, it has a small complexity during implementation, and more consideration is needed to choose the labeled ratio. Temporal Graph Network for Fake News Detection (TGNF) 21 has the ability to handle challenging, structured data. However, TGNF has several difficulties in propagating the information and also the TGNF model can only process limited amount of tweets. MPFN 22 reduces the negative infodemic effects. However, it has some complexity in addressing fake news in some languages. CARMN 6 plays better in reducing noise information. However, the visual information is not applicable in this model. EchoFakeD 23 requires low consumption time. However, temporal information-based analyses are not performed. CNN 24 gives the best extracting features within a short time. However, it does not provide any ratings for creditability depict. To answer all these issues, we implemented a novel strategy for a multimodal fake news detection model.
Features and challenges of existing fake news detecting techniques.
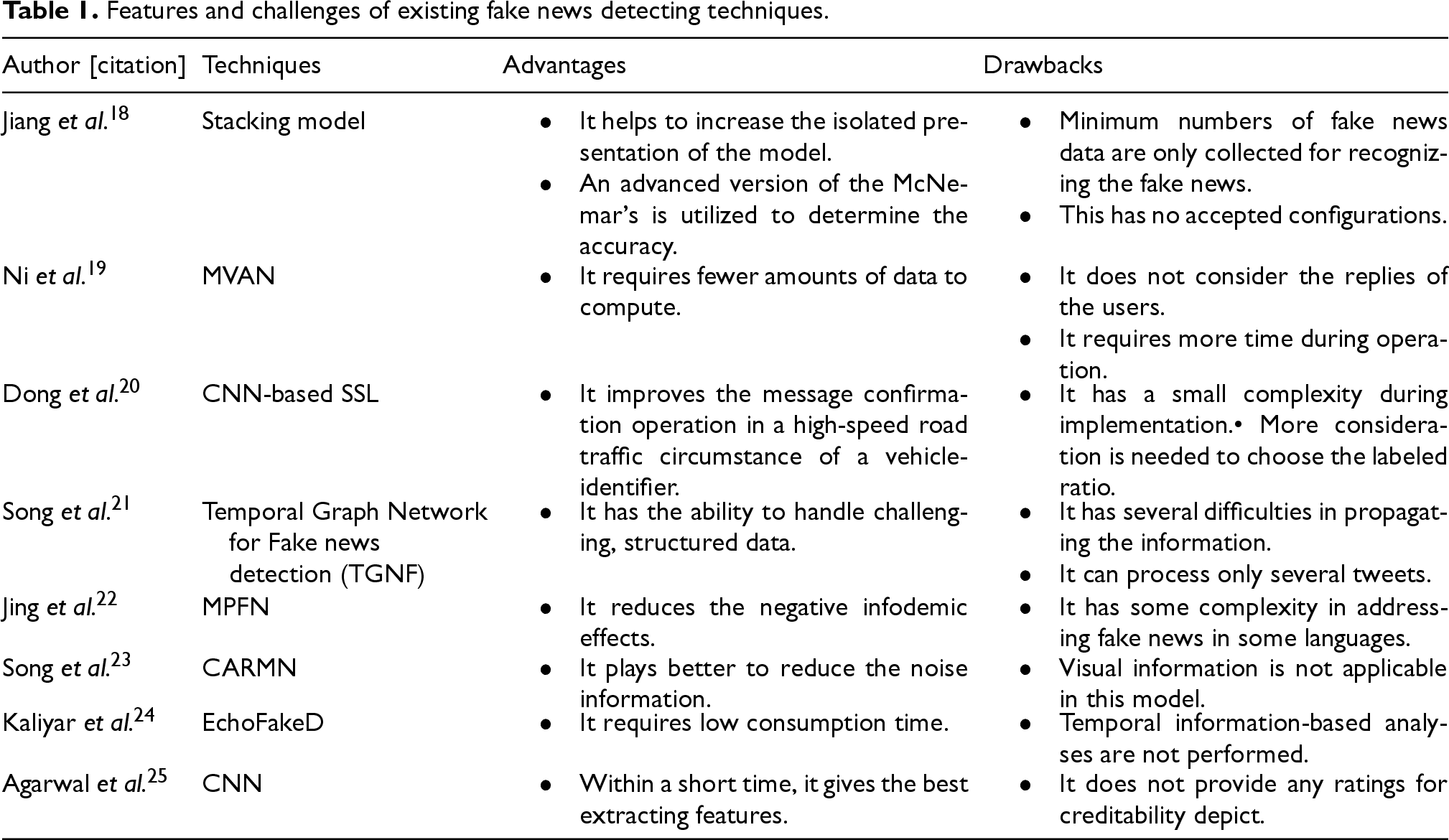
Features and challenges of existing fake news detecting techniques.
Developed multimodal fake news detection model
In this generation, fake news is published through television and social media every day. The misinformation affects the reputation and financial aspects of the people. So, there is efficiency in detecting fake news creators. Several models have been suggested to categorize the wrong information publishers. However, all those models have several challenges while detecting fake news publishers. Fake news is created by the integration of real and false partial details like facts and remaining like wrong. So, the CNN model is implemented to detect fake news. But, it has several limitations and they are, it has a complexity during implementation, it requires more consideration to choose the labeled ratio, and needs more data during implementation. Thus, it is significant to identify the fake news publishers and also misinformation. For these drawbacks, we implemented a new strategy to recognize fake news regarding deep learning approaches. The graphical representation of the developed fake news detection framework is illustrated in Figure 1.
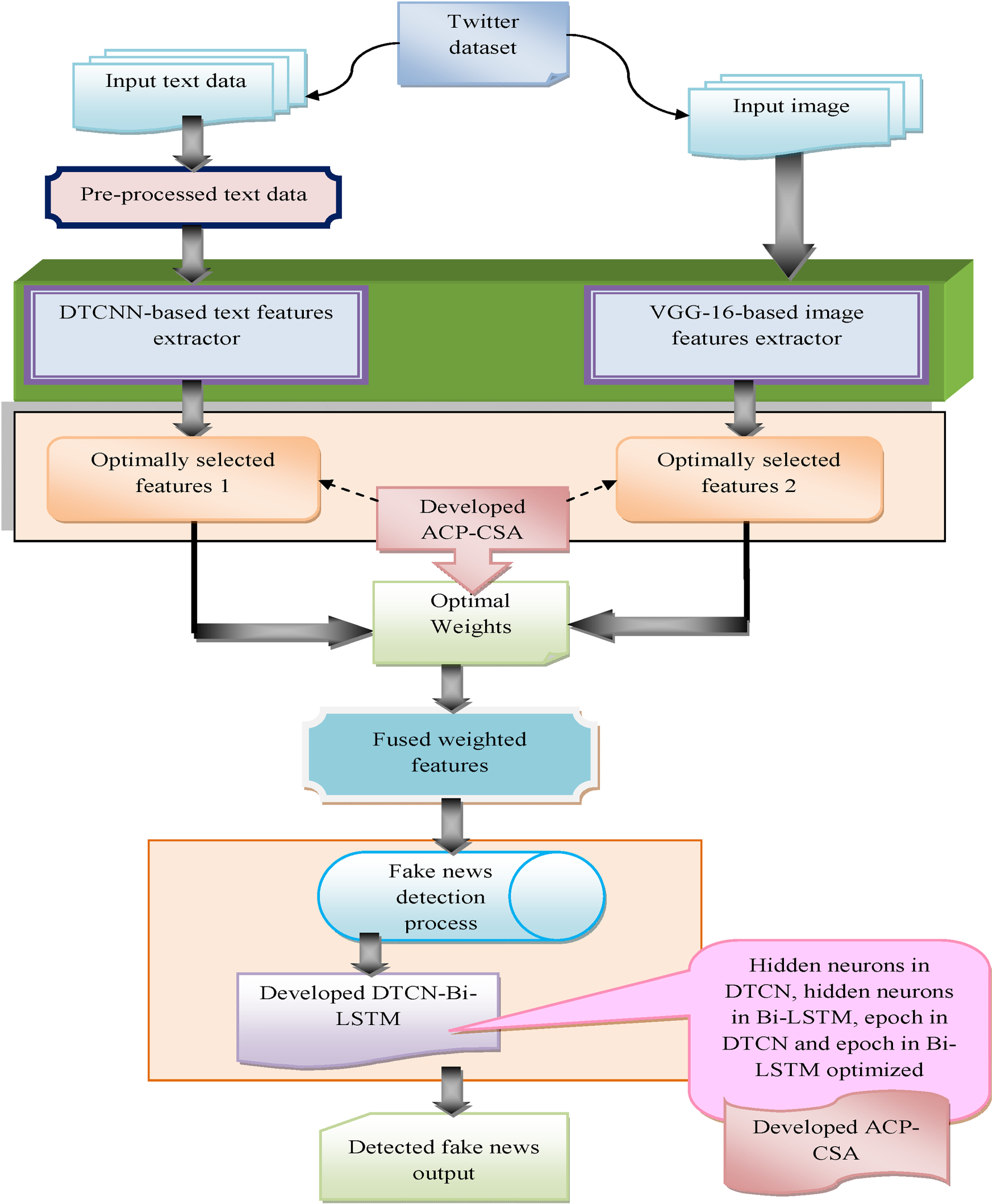
Graphical illustration of the recommended fake news detection framework.
The implemented multimodal fake news detection-based deep learning system is utilized to support people and helps to deliver the facts about the news. The text data is taken from a sufficient dataset. In pre-processing, the text data is progressed as input for further processing. After finishing the procedure, it provides the pre-processed data as the output. The features are fused together with the help of pre-processed data. The VGG-16 and DTCNN techniques are used to extract the image and text features. The extracted text and image features from the DTCNN and VGG-16 models are selected optimally by using the developed ACP-CSA. Similarly, the weights from the VGG-16 and DTCNN models are tuned by utilizing the developed ACP-CSA. Then, the optimally selected features and weights are together integrated. Finally, it offers weighted fused features as the output. Then, these weighted fused features are given into the detection process. In this process, the weighted fused features are processed by the developed DADTCN-Bi-LSTM model. Here, the features are tuned using developed ACP-CSA. The parameters such as hidden neuron count in DTCN, epoch count in DTCN, hidden neuron counts in Bi-LSTM, and epoch count in Bi-LSTM are optimized for enhancing the accuracy, sensitivity, and F1-score and also for reducing the FPR. At last, it provides the classified outcomes by using the averaging process.
The developed multimodal fake news recognition framework gathers the sample text data and images from the Twitter dataset.
Dataset 1 (“Twitter dataset”): The required sample text data and images are taken from the Twitter dataset using the link “https://www.dropbox.com/s/40xl8dsmv4hliip/Twitter_Dataset.zip?dl = 0&file_subpath=%2FTwitter_Dataset%2Ftwitter%2Fpartition: access date: 2023-05-06”. It contains 147 image files and 147 text files.
Dataset 2 (“Fake news”): It is collected from a given link (“https://www.kaggle.com/competitions/fake-news/data?select = train.csv”). In this dataset, several attributes such as title, author, text, label, and ID are considered for training the data. For labeling the data, 0 and 1 are assumed which is considered an unreliable and reliable form.
Dataset 3 (“WELFake”): The WELFake dataset and also it is given in the following link (“https://www.kaggle.com/datasets/saurabhshahane/fake-news-classification”). In total, 72,134 news articles are presented, where the real and fake news consists of 35,028 and 37,106. It contains the serial number, title, text, and label as attributes in this dataset. The sample text data and images are represented as
Proposed ACP-CSA
The developed ACP-CSA algorithm is used for optimization. The parameters optimized by the developed ACP-CSA are hidden neuron count in DTCN; epoch count in DTCN, hidden neuron count in Bi-LSTM, and epoch count in Bi-LSTM for enhancing the accuracy, sensitivity, F1-score and also for reducing the FPR. The CSA algorithm is chosen for having major benefits; it is very effective in solving optimization problems, enhances working ability, and also has generalization and flexibility. But, it has the following drawbacks; implementation quality is low and it requires more memory for updating the velocity. To address these limitations, we developed the ACP-CSA algorithm for tuning. The adaptive concept is introduced in determining different random parameters of CSA using expressions equations (1)–(3).



CSA 26 : The following sections describe the characteristics of a chameleon while pasturing.
Initialization and function evaluation: It works to initialize the tuning process. The population of the chameleons is represented by B. Equation (4) is used to determine the chameleon's position.

The original population of chameleons is generated based on the total count of the chameleons is elaborated in equation (5).

Search for prey: The chameleon's behavior during pasturing is determined using equation (6).
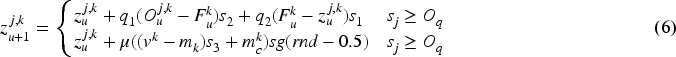

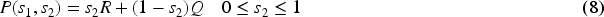

Chameleons’ eye rotation: To recognize the locality of the prey, the chameleons rotate their eyes. Chameleons have the capacity to rotate their eyes at 360. This rotation is mathematically modeled for realizing the behavior of hunting. The chameleons move and rotate their eyes according to the prey's position. Hence, the location of the chameleons can be upgraded from the rotation of the eyes as explained in equation (10).



Hunting prey: Chameleons hunt their prey while the prey is near to the chameleons. Suppose the chameleons get the best prey, that's it optimal position. They utilize their tongue for attaching the prey. Therefore, the position is upgraded as it straightens its tongue fully to attack. The chameleon's tongue velocity is modeled based on equation (13).
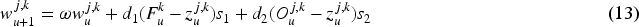


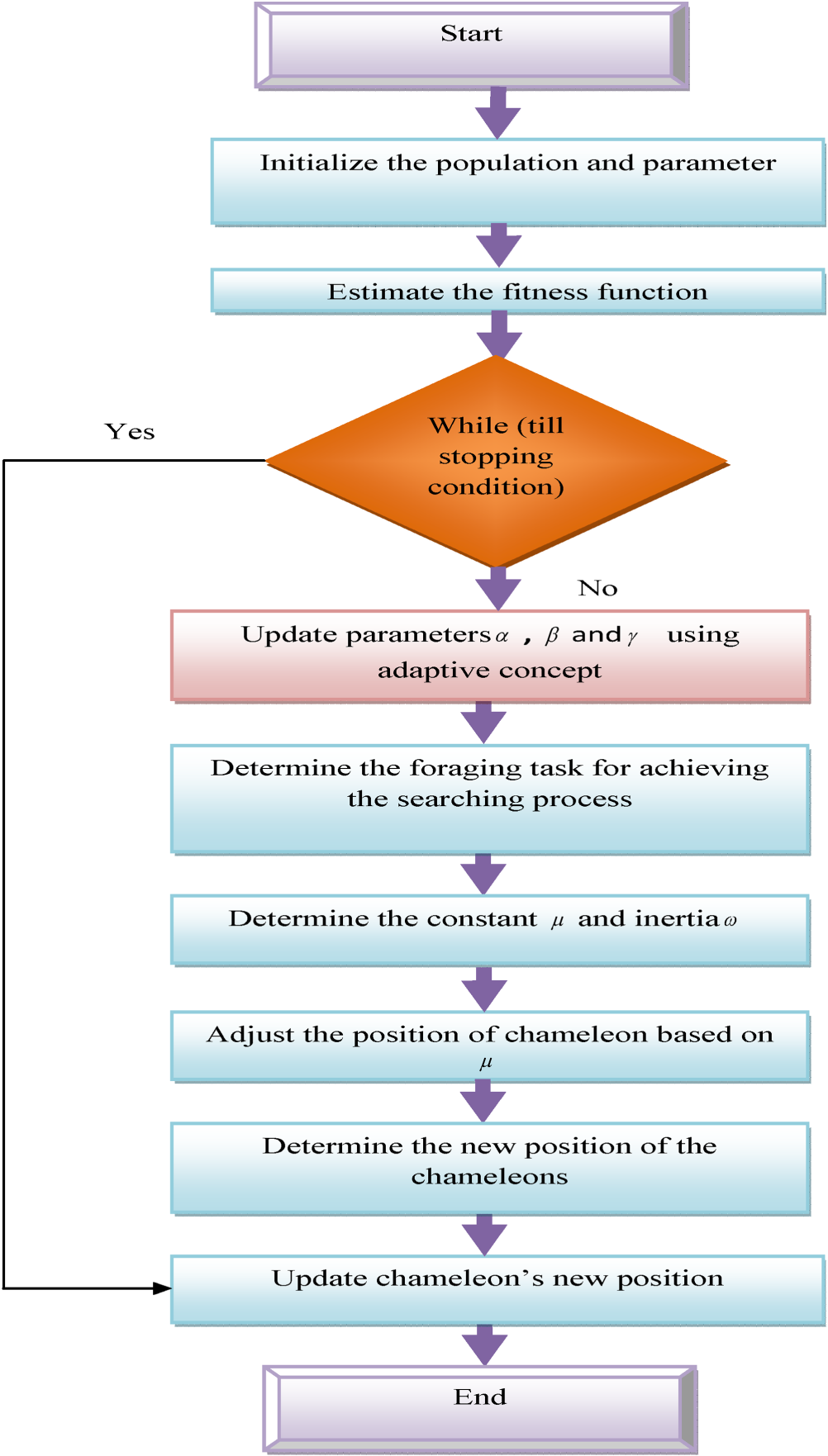
Flowchart of the proposed ACP-CSA.

Pre-processing of data
The text data
Punctuation and stop word removal: This helps to remove conjunctions, adverbs, etc. It used to focus more on the main content by reducing the low-level cases.
Stemming: It is utilized to minimize the meaningless words in the sentence.
After completing these stages, it provides the pre-processed text data as the output and it is represented as
VGG16-based feature extraction
VGG-16
27
model is used to extract the image features and it is described by
DTCNN-based feature extraction
DTCNN
28
architecture is utilized to extract the text features and alternate the input feature
Convolution layer: This layer is applied as the input for creating the feature map and getting classified features. Let's take 

Fully connected layer: This fully concatenated layer has multiple layers, which are connected to the preceding layer. The activation functions of the neurons are determined by using the multiplicative matrix weight added by the value of the offset. Let's take an input as 
Dropout layer: This layer arbitrarily deactivates or activates the extrovert hidden unit at every training phase's output. It is also used to lessen the overfitting problem.
Classification layer: This classification layer is the last layer, which works for the process of classification regarding the extracted features by every preceding layer. This is the modern layer of ANN with the activation functions of sigmoid or softmax.
Loss function: For the binary-class classification task of text, DTCNN is employed to minimize the binary cross entropy using a sigmoid function, is explained in equation (19). The DTCNN is employed to minimize the categorical cross entropy by using the softmax function for multi-class recognition process is explained in equation (20).
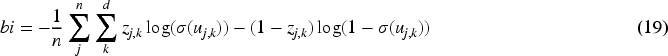
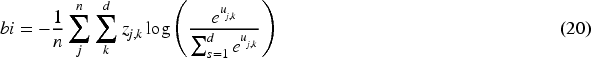
The image features 



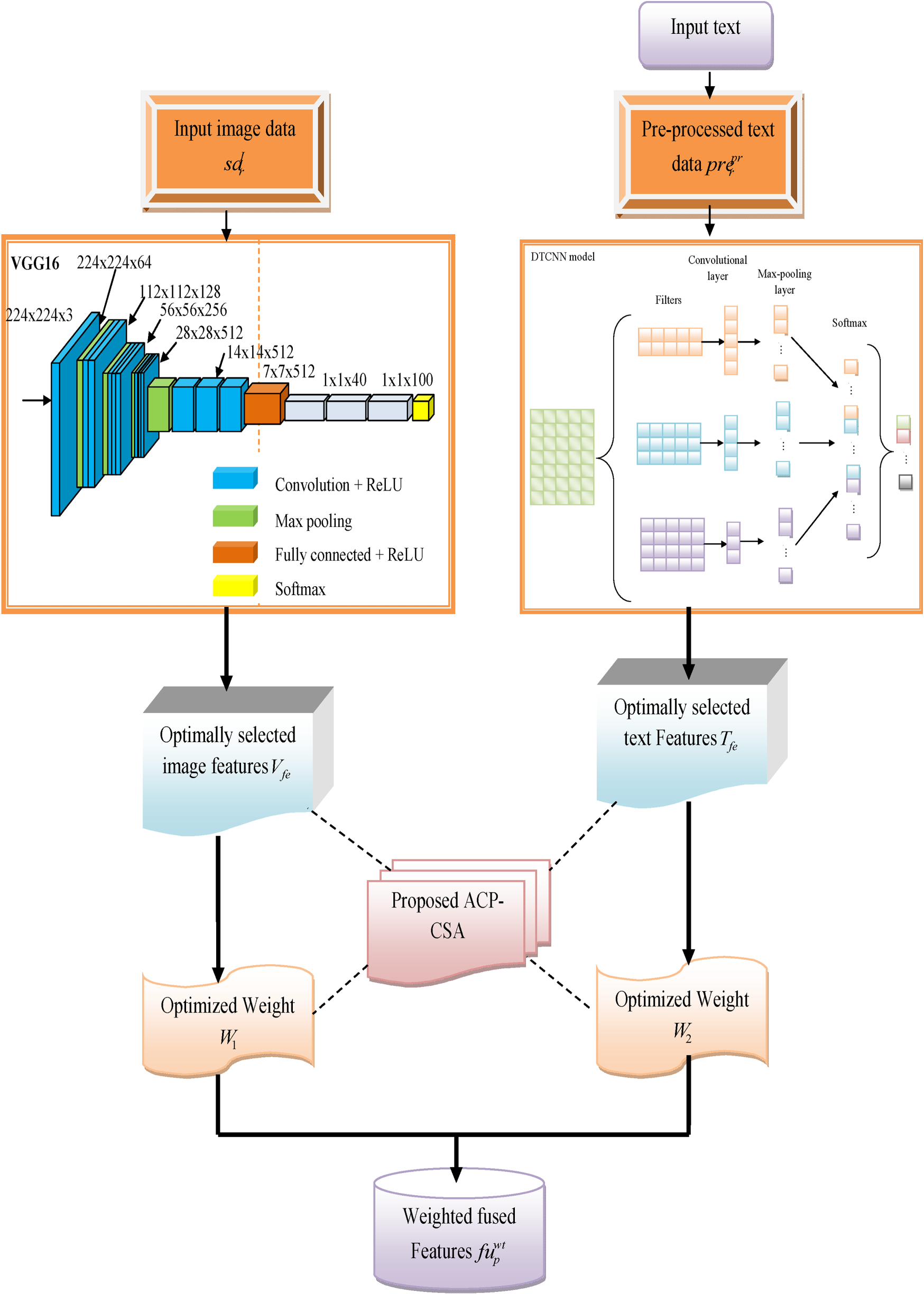
Diagrammatic representation of weighted feature fusion with developed ACP-CSA.
DTCN
DTCN 29 is based on the group of RNNs, and every layer has a 1-D block with dilation. The dilation feature is increased to ensure the appropriate large context to provide the advantages of the speech signals. The waveNet with dilation feature has great success in audio-generating tasks. Stacking dilation convolutions gives a huge receptive field with several layers because the dilation factor increased exponentially. This permits the TCN to take the temporal dependencies of several resolutions with an input series. The TCN develops the temporal chain of command; the top layers can permit the series of long inputs and can learn the representations on a larger scale. The local details from the below layers are propagated via residual connections.
The TCN has two key elements. 1) dilated convolution and 2) residual connection. In the dilated convolution, the following mechanism is described in equation (25).

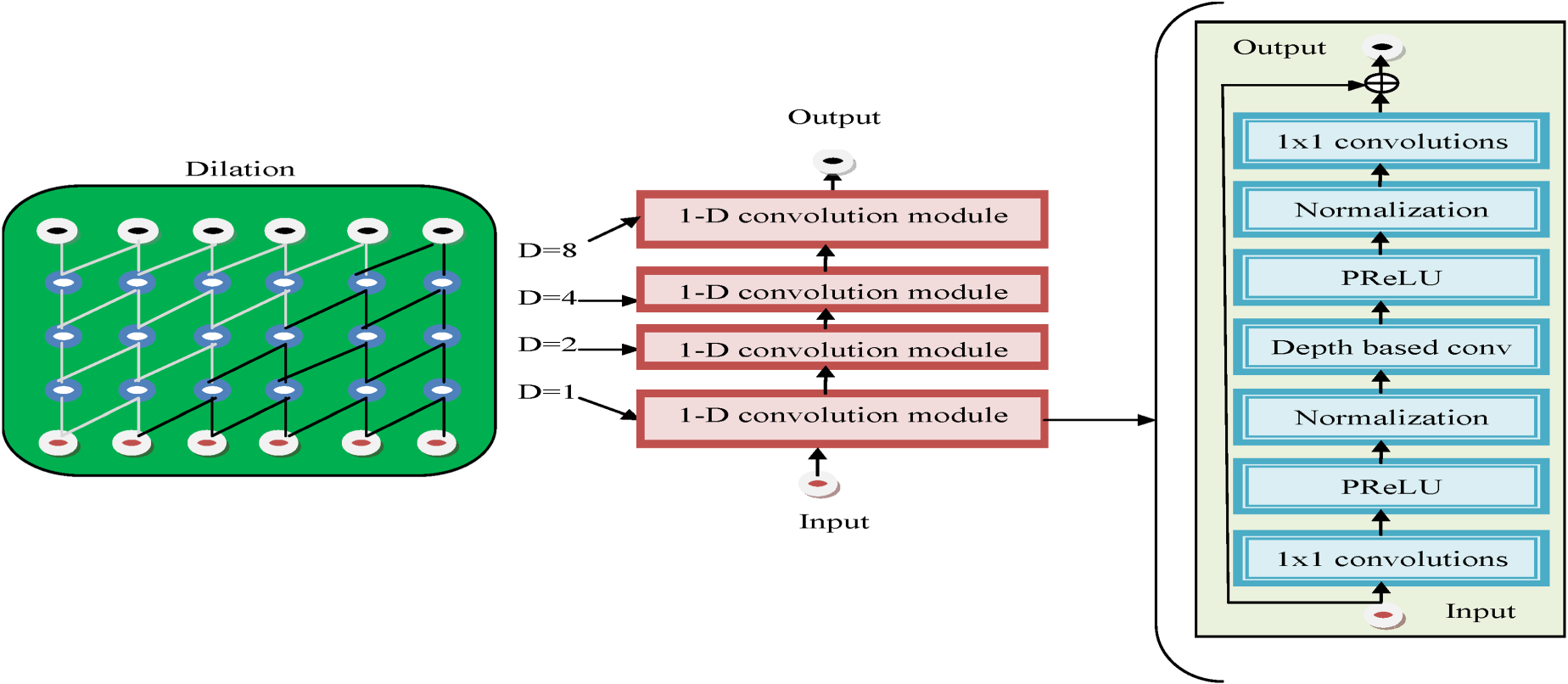
A pictorial illustration of the DADTCN framework.
Bi-LSTM
30
is the series processing technique. It has two LSTMs, the first LSTM taking the text input and the second LSTM processing with a rearward copy in the series. The Bi-LSTM framework has the advantages of the LSTM and CNN model. It has two sections, and they are backward and forward Bi-LSTM. The formulation of Bi-LSTM is provided in equations (26) and (27)



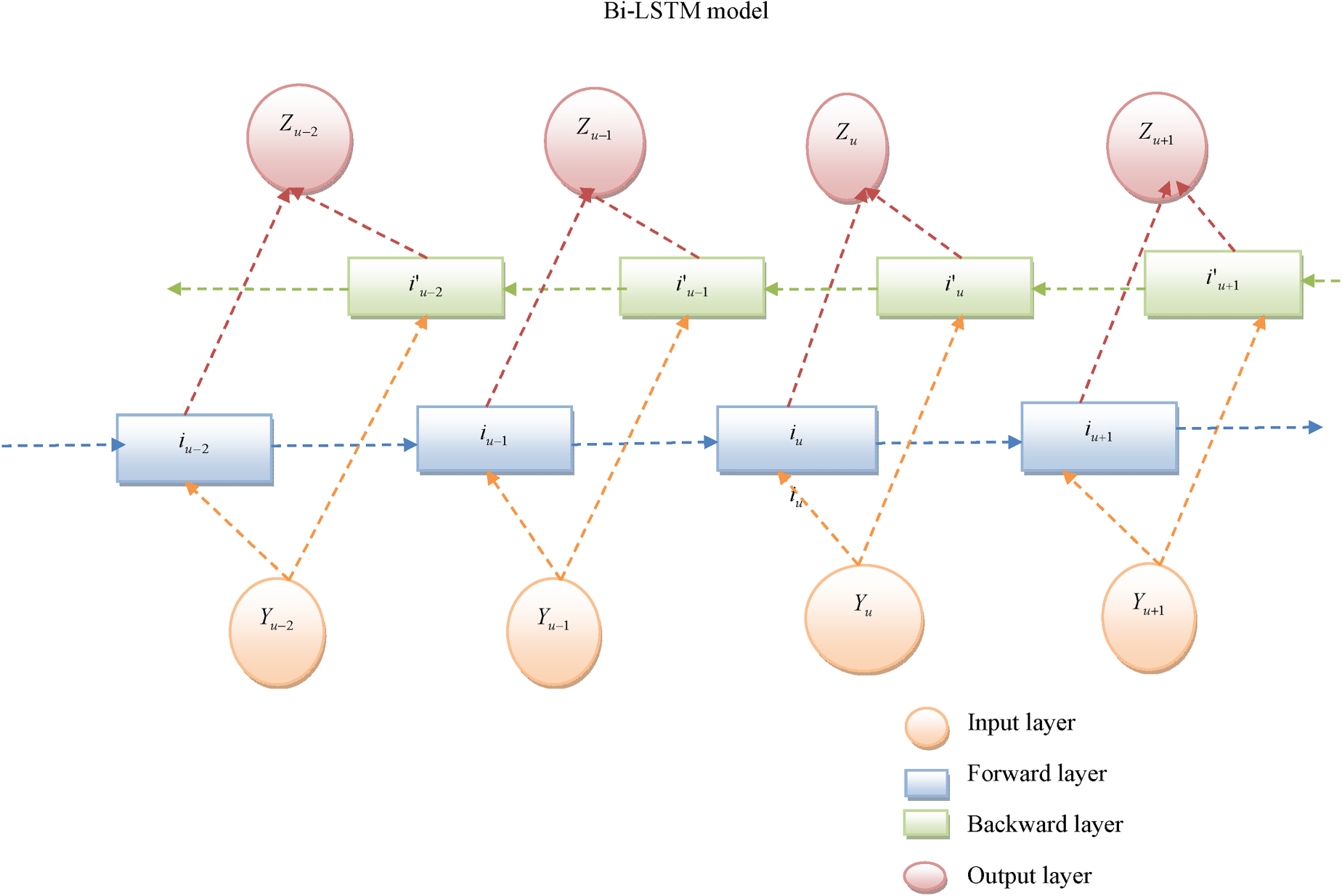
A pictorial illustration of the Bi-LSTM framework.
The weighted fused feature 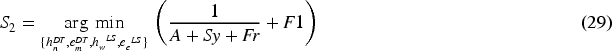




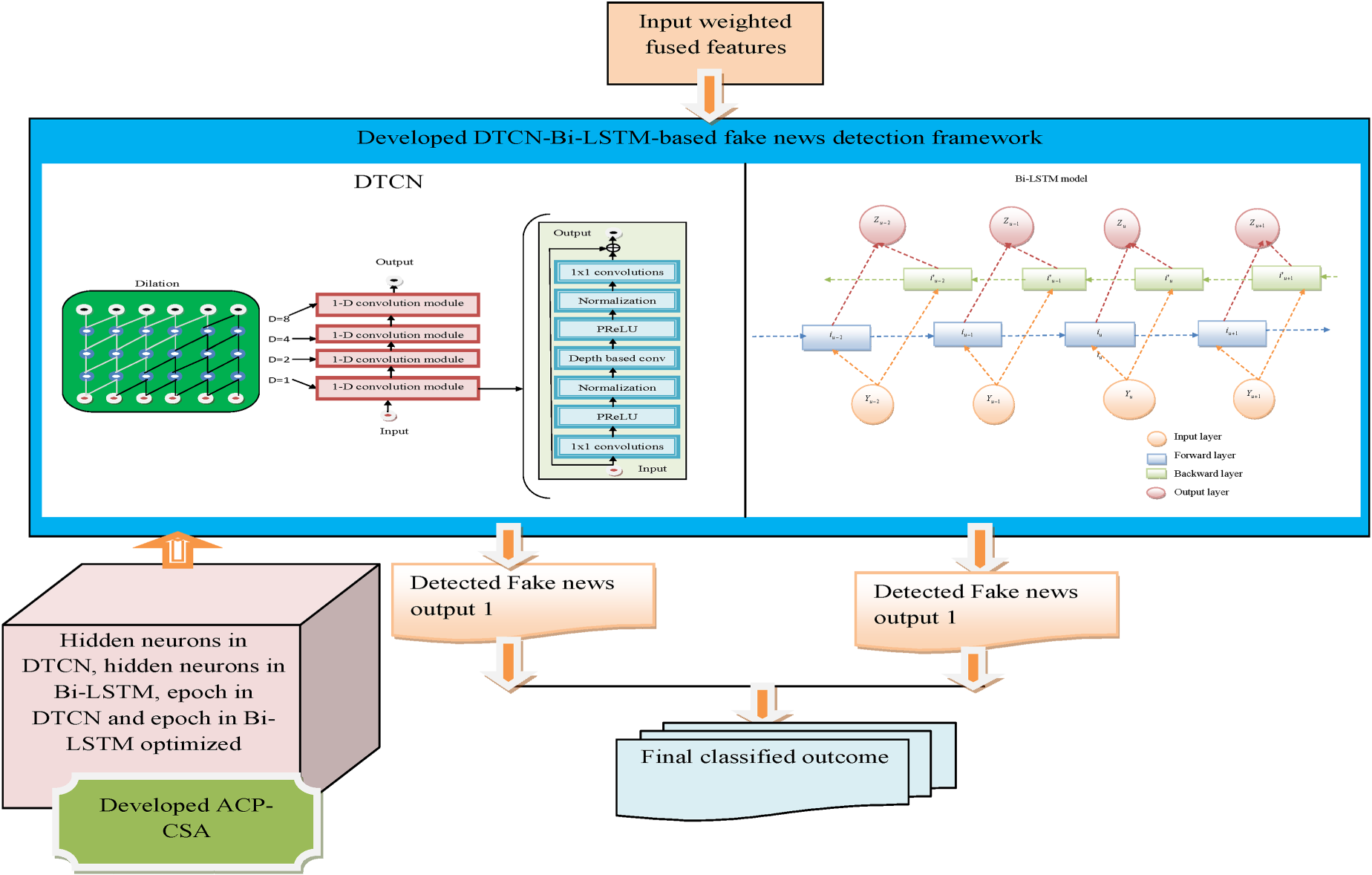
Pictorial representation of DADTCN-Bi-LSTM-based fake news detection model.
Simulation setting
The designed fake news detection process was executed using Python. The implemented system considered the number of populations as 10, and also the maximum iteration was 50. The developed fake news model was compared and analyzed with the classifiers, namely, Autoencoder, 31 DTCN, 29 Bi-LSTM, 30 and DTCN-Bi-LSTM. 31 The algorithms like Dingo Optimizer (DO), 32 Eurasian Oystercatcher Optimizer (EOO), 33 Reptile Search Algorithm (RSA), 34 and Chameleon Swarm Algorithm (CSA) 26 were considered for the validation.
Evaluation metric
The following performance measures are considered to analyze the multimodal fake news identification system.
Precision: It shows the relevant data from the obtained instance which is determined using equation (34).
Negative Predictive Value (NPV): The NPV False Discovery Rate (FDR): FDR measure Specificity: Specificity False Negative Rate (FNR): FNR Mathew's Correlation Coefficient (MCC): MCC





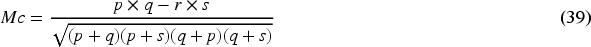
The cost function of the developed fake news classification framework is explained in Figure 7. In Figure 7, the implemented ACP-CSA-DTCN-Bi-LSTM model is 1.48% more than DO-DTCN-Bi-LSTM, 0.99% more than EOO-DTCN-Bi-LSTM, 1.32% enhanced than RSA-DTCN-Bi-LSTM and 2% improved than CSA-DTCN-Bi-LSTM when the maximum iteration at 10. This proved that the efficiency of the implemented method offers enhanced performance.
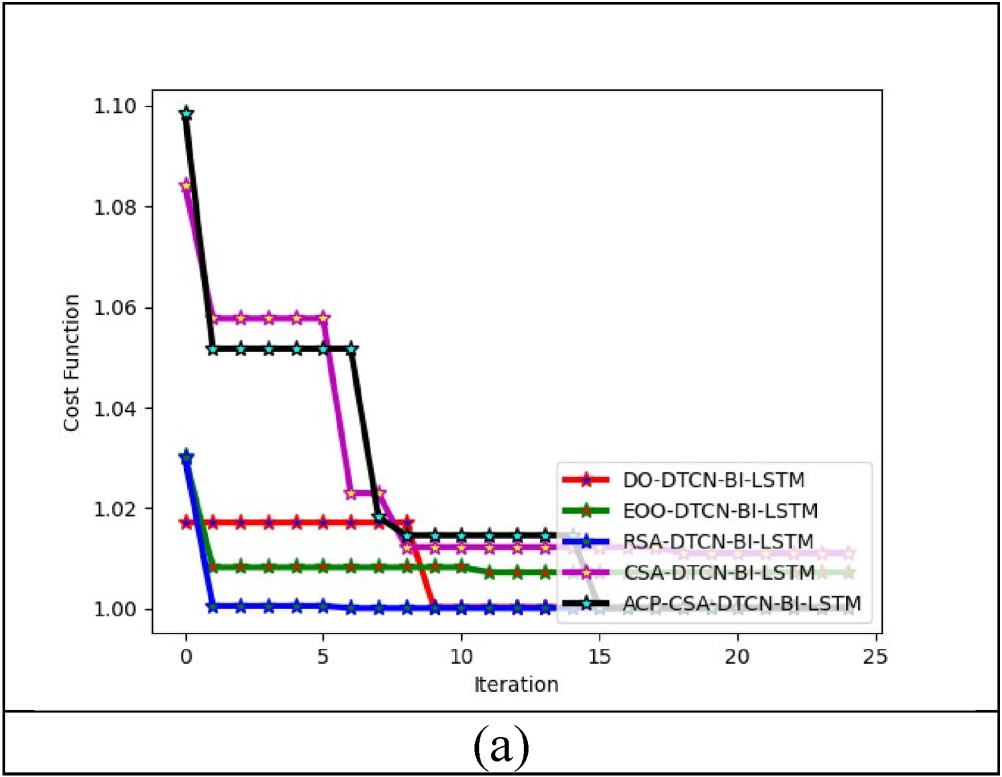
Cost function of the developed model.
The confusion matrix analysis of the implemented fake news model is described in Figure 8. Figure 8 shows the predicted and actual values. The implemented ACP-CSA-DTCN-Bi-LSTM model gives an accuracy value of 97.18% which is better than other existing fake news detecting techniques.
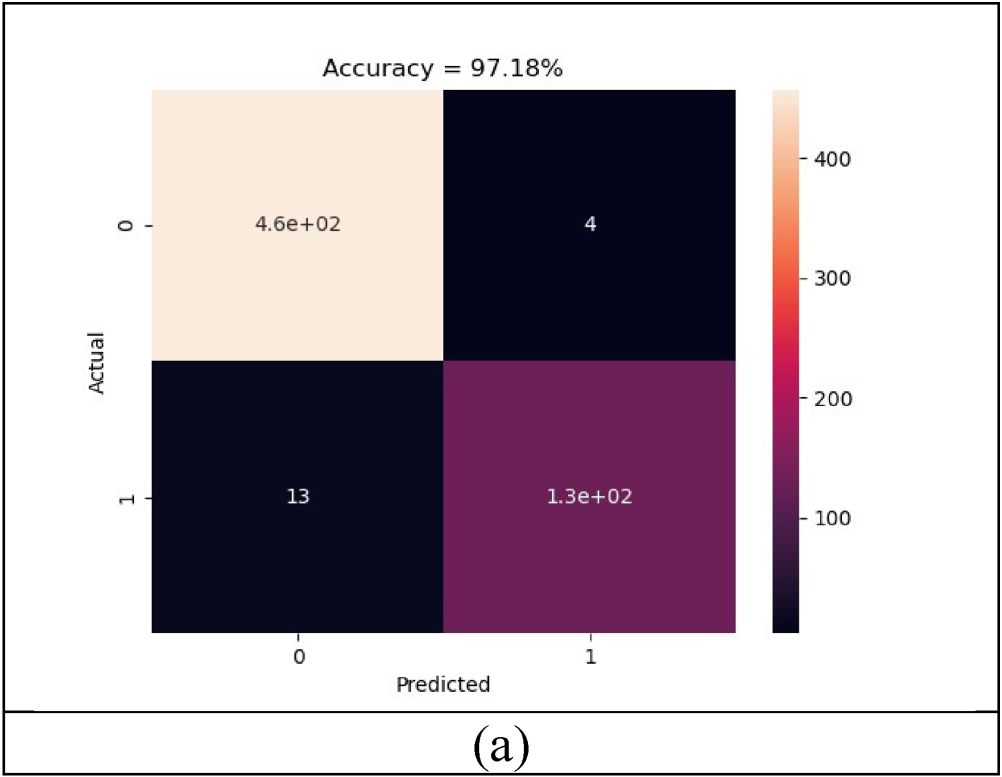
Confusion matrix of the developed model.
The classifier-aided analysis of the implemented fake news recognition process is illustrated in Figure 9. In Figure 9(d), the FNR of the implemented ACP-CSA-DTCN-Bi-LSTM model is 60% improved than Autoencoder, 53.33% more than DTCN, 53.33% higher than Bi-LSTM and 35.38% more than DTCN-Bi-LSTM when the activation function is observed as ReLU. This proved the developed ACP-CSA-DTCN-Bi-LSTM model offers sufficient performance.
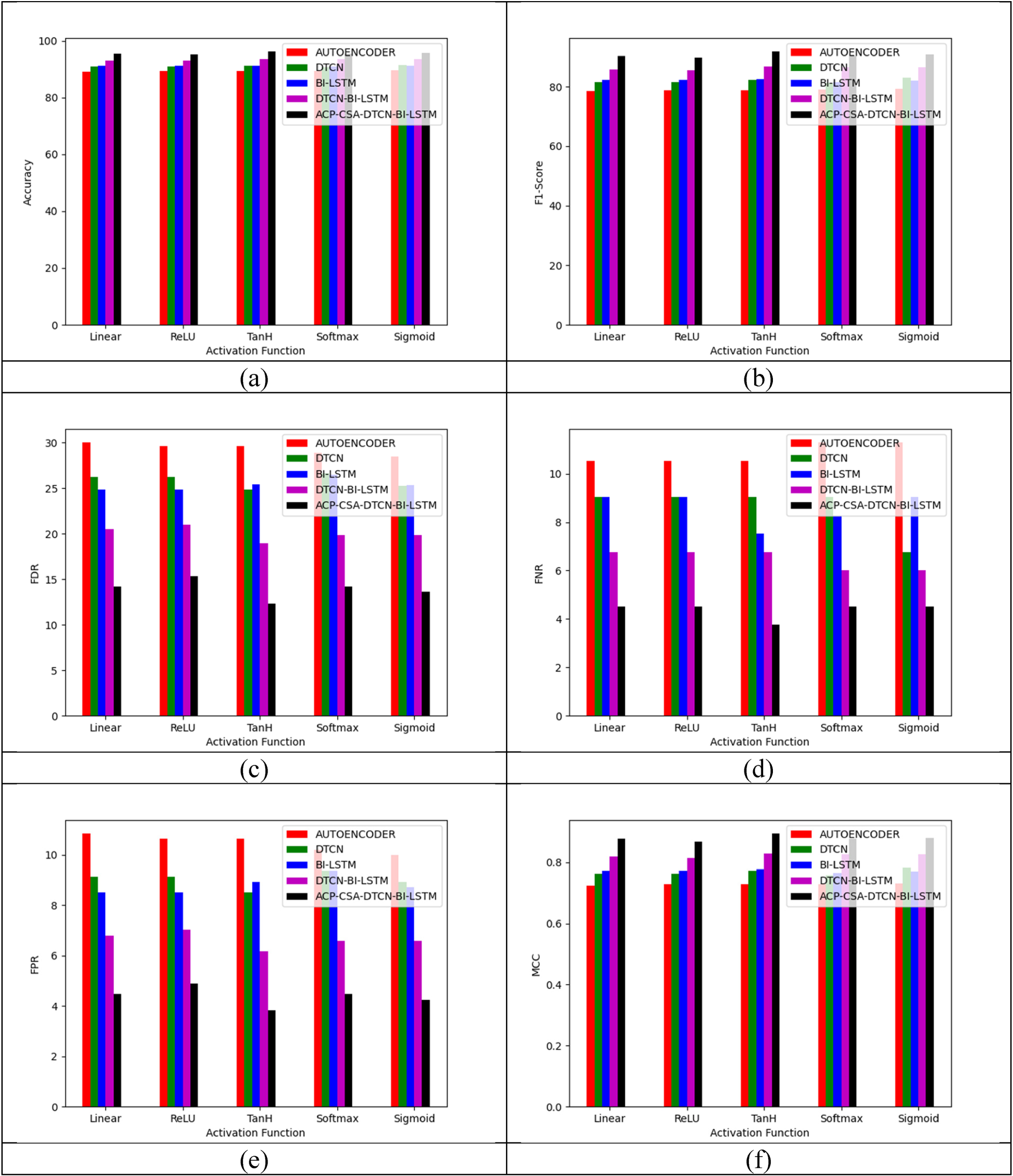
Classifier-based analysis of the implemented fake news detection model regarding “(a) accuracy (b) F1-score (c) FDR (d) FPR (e) FNR (f) MCC (g) NPV (h) precision (i) sensitivity and (j) specificity”.
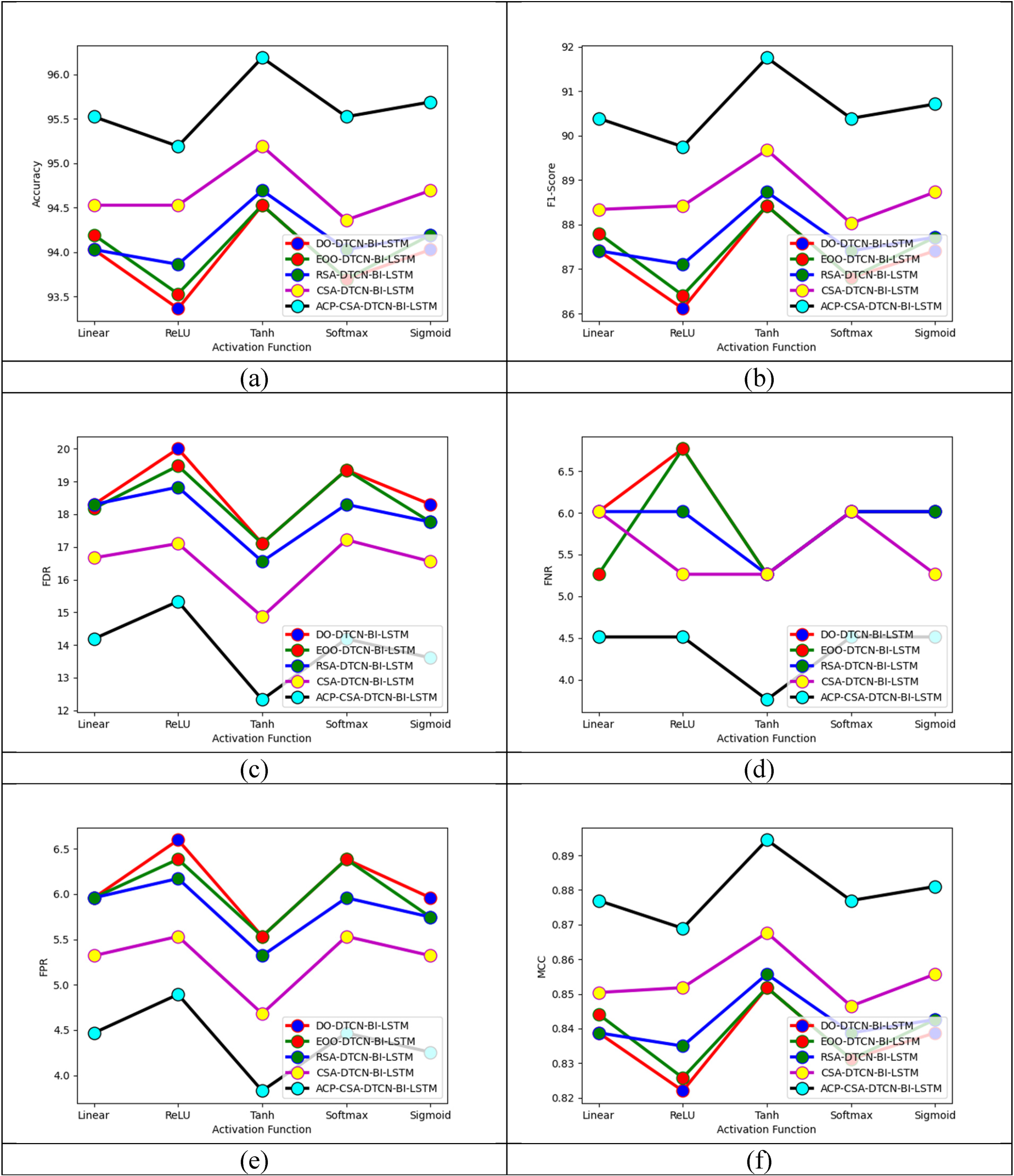
The algorithmic-based analysis of the developed fake news detection process is detailed in Figure 10. In Figure 10(b), the F1-score of the proposed ACP-CSA-DTCN-Bi-LSTM framework is 3.95% improved than DO-ACP-CSA-DTCN-Bi-LSTM, 3.48% enhanced than EOO- ACP-CSA-DTCN-Bi-LSTM, 3.37% more than RSA-ACP-CSA-DTCN-Bi-LSTM and 2.79% higher than CSA- ACP-CSA-DTCN-Bi-LSTM when activation function is TanH. Therefore, this proved the presentation of the designed ACP-CSA-DTCN-Bi-LSTM model is much better than other algorithms.
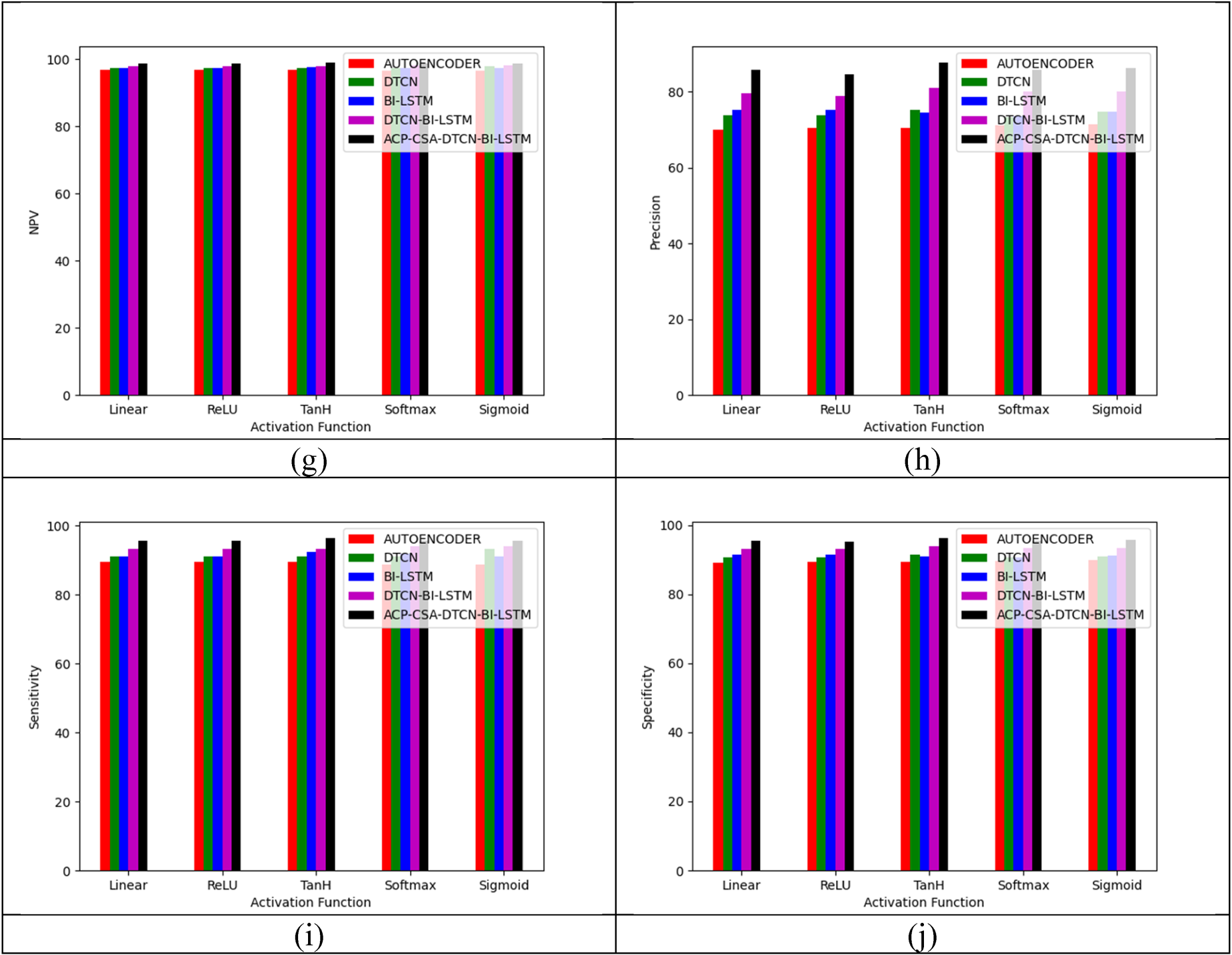
Algorithmic-based analysis of the proposed fake news detection process in terms of “(a) accuracy (b) F1-score (c) FDR (d) FPR (e) FNR (f) MCC (g) NPV (h) precision (i) sensitivity and (j) specificity”.
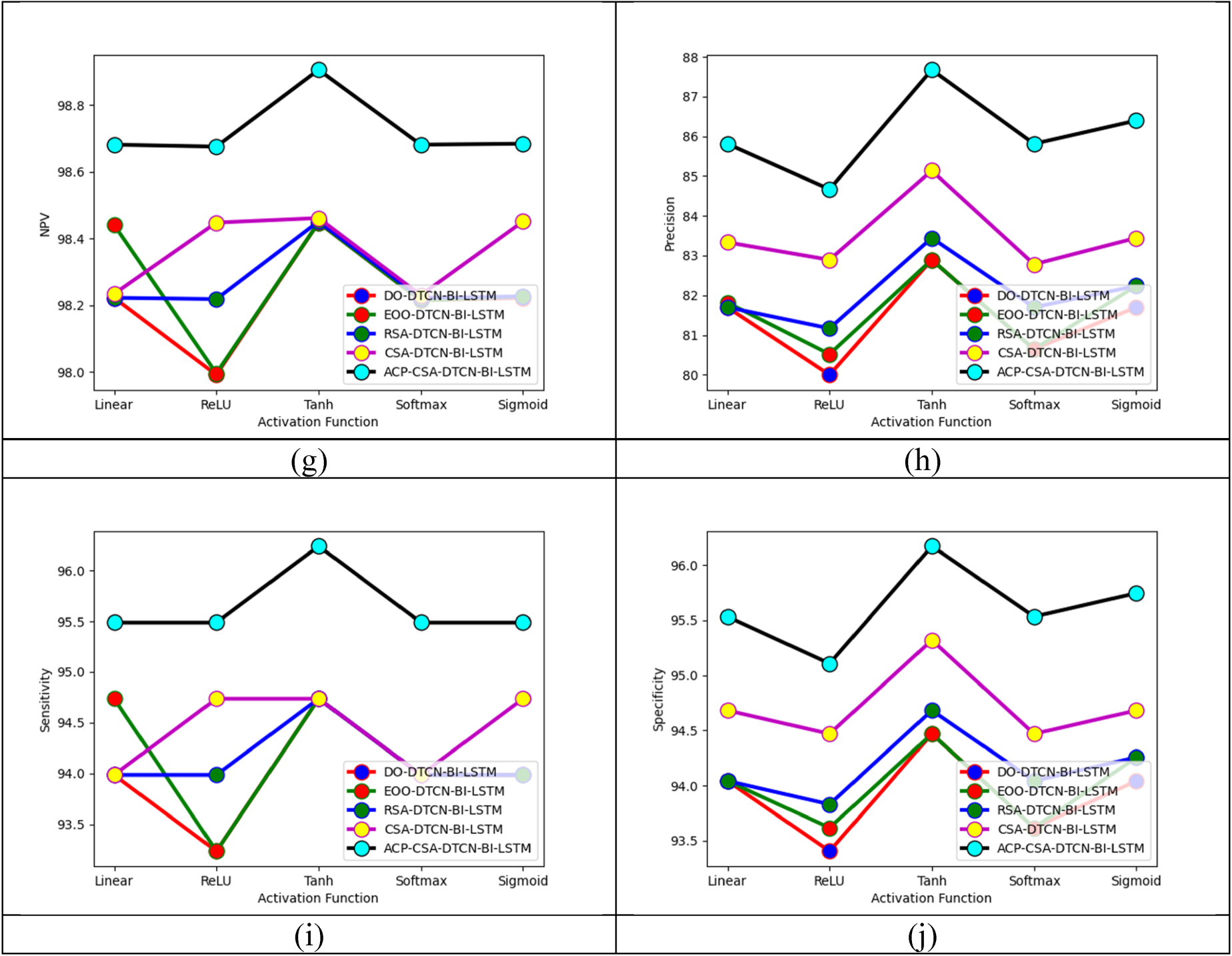
The accuracy-based classifier analysis of the implemented fake news detection framework is detailed in Figure 11. The weighted fused feature accuracy of the designed ACP-CSA-DTCN-Bi-LSTM model is 16.47% more than Autoencoder, 15.11% enhanced than DTCN, 13.79% superior than Bi-LSTM and 12.5% more than DTCN-Bi-LSTM (without optimization). Hence, it showed the developed fake news recognition framework has a significant role in fusing the features. The accuracy-based algorithmic analysis of the implemented fake news recognition process is shown in Figure 11. In Figure 11, the weighted fused feature accuracy of the implemented ACP-CSA-DTCN-Bi-LSTM model is 6.52% more than DO-DTCN-Bi-LSTM, 6.90% improved than EOO-DTCN-Bi-LSTM, 4.25% enhanced than RSA-DTCN-Bi-LSTM and 5.37% more than CSA-DTCN-Bi-LSTM. This ensured that the implemented process has more accuracy while fusing the features.
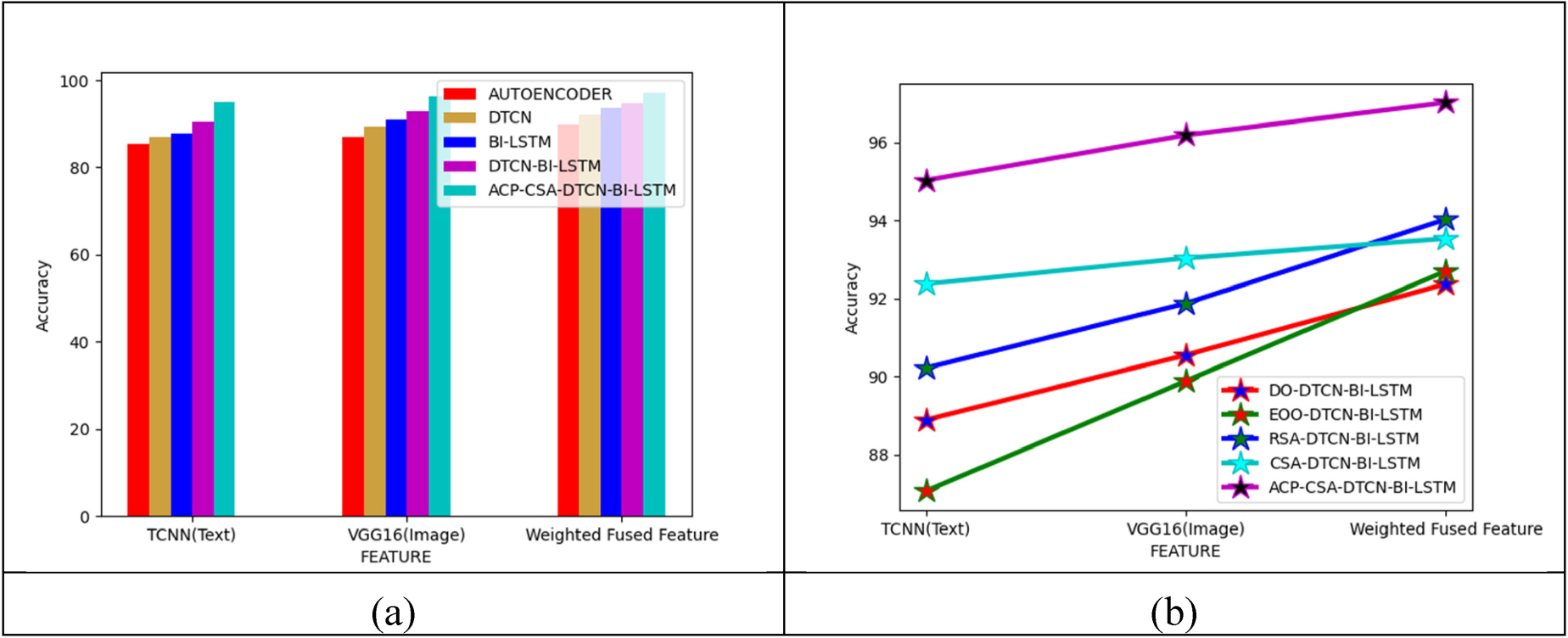
Accuracy-based analysis of the developed fake news detection process in terms of (a) classifiers and (b) algorithms.
The ROC-based analysis of the developed fake news detection process is illustrated in Figure 12. Generally, the ROC curve is determined based on the distinct threshold values of the false positive rate as well as the true positive rate. It demonstrates to show the accurate classification in the fake news process. Hence, the Area under the ROC Curve (AUC) determines the measurement of two dimensional underneath area which holds the entire ROC curve therefore it lies in the interval of 0 to 1. This showed the developed fake news performs more than other existing methods.
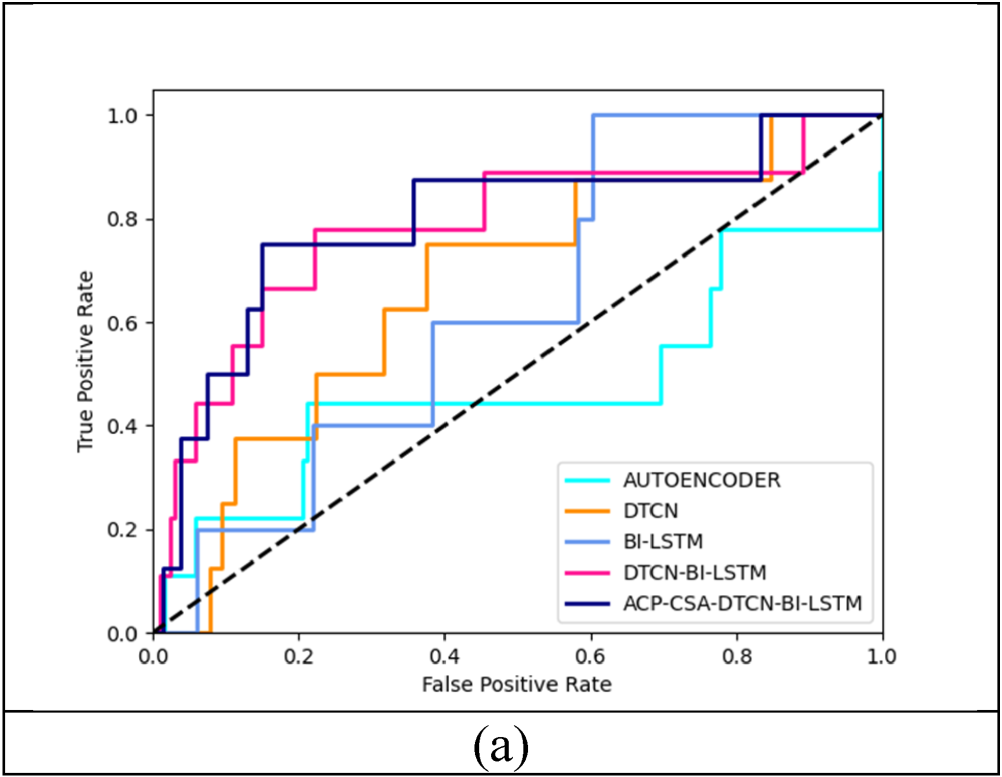
Performance analysis based on ROC using the developed fake news detection framework.
ROC curve: The ROC curve is defined as the true relationship of sensitivity and specificity is provided for each possible cut-off value. The formula for sensitivity is given in equation (31) and also the formula for specificity is shown in equation (32).
The overall classifier investigation of the developed fake news detection process is detailed in Table 2. The overall performance of the developed model is evaluated with diverse conventional methods while considering with standard evaluation metrics. Nowadays, fake news arises in a tremendous manner that's why the implemented process is performed to assist to provide accurate performance in the fake news detection framework. In Table 2, the specificity of the developed ACP-CSA-DTCN-Bi-LSTM method is, 1.80% increased than DO-DTCN-Bi-LSTM, 1.58% more than EOO-DTCN-Bi-LSTM, 1.58% enhanced than RSA-DTCN-Bi-LSTM and 1.12% higher than CSA-DTCN-Bi-LSTM. This showed the developed fake news model has more presentation metrics. In this Table analysis, the implemented process achieves the value of 95 while considering the evaluation measures such as accuracy, sensitivity, and specificity. Due to the increased accuracy value, the error gets reduced while detecting the fake news. Also, the DO-DTCN-Bi-LSTM model attains the value of 18.301 in FDR analysis. The higher error analysis seems to lower the performance of the framework. Hence, the recommended technique proved that it has attained efficient and outsourced performance when compared with the existing approaches.
Overall algorithm-based analysis of the developed fake news detection process.
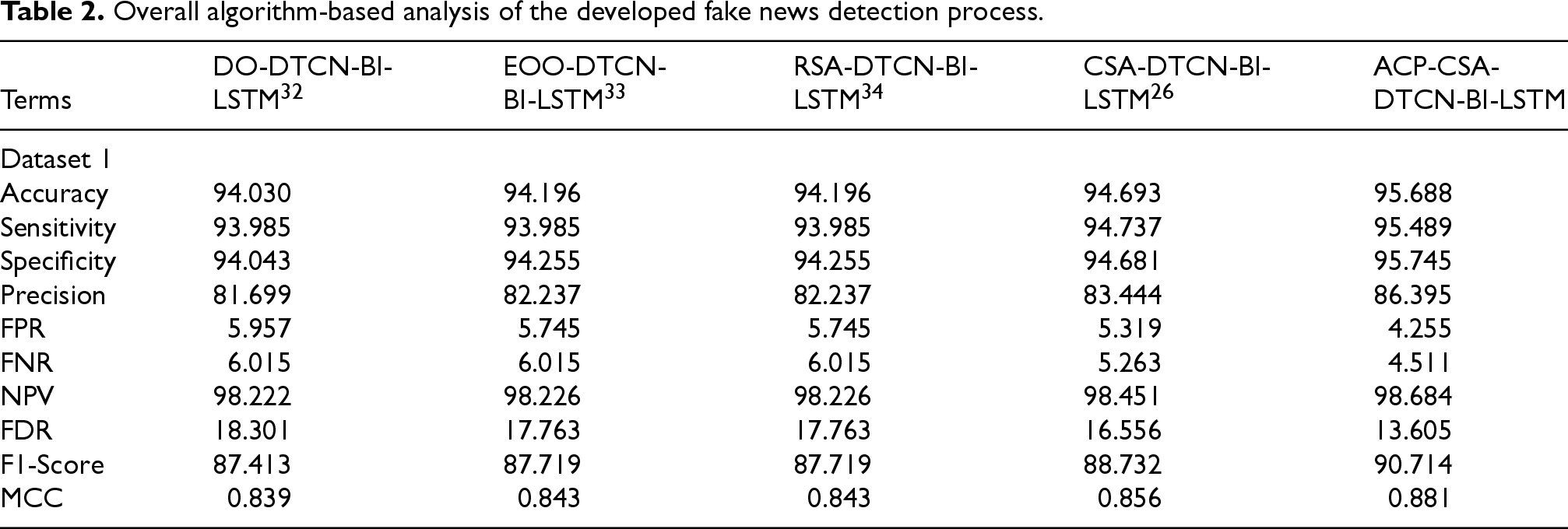
Overall algorithm-based analysis of the developed fake news detection process.
Table 3 illustrates the algorithmic-based analysis of the developed fake news detection model. The analysis is performed with existing techniques where the developed model is suggested to outperform different analyses. Here, the analysis is conducted with positive and negative measures using the developed system. In Table 3, the precision of the developed ACP-CSA-DTCN-Bi-LSTM framework is 20.80% increased to Autoencoder, 15.65% superior to DTCN, 15.69% improved than Bi-LSTM and 7.82% more than DTCN-Bi-LSTM. Accurate fake news is detected where the accuracy of the framework needs to be enhanced. Based on this analysis, the developed ACP-CSA-DTCN-BiLSTM model shows accurate performance. This overall algorithmic-based analysis proved the developed fake news model performs better in all metrics.
Overall classifier-based analysis of the implemented fake news detection process.
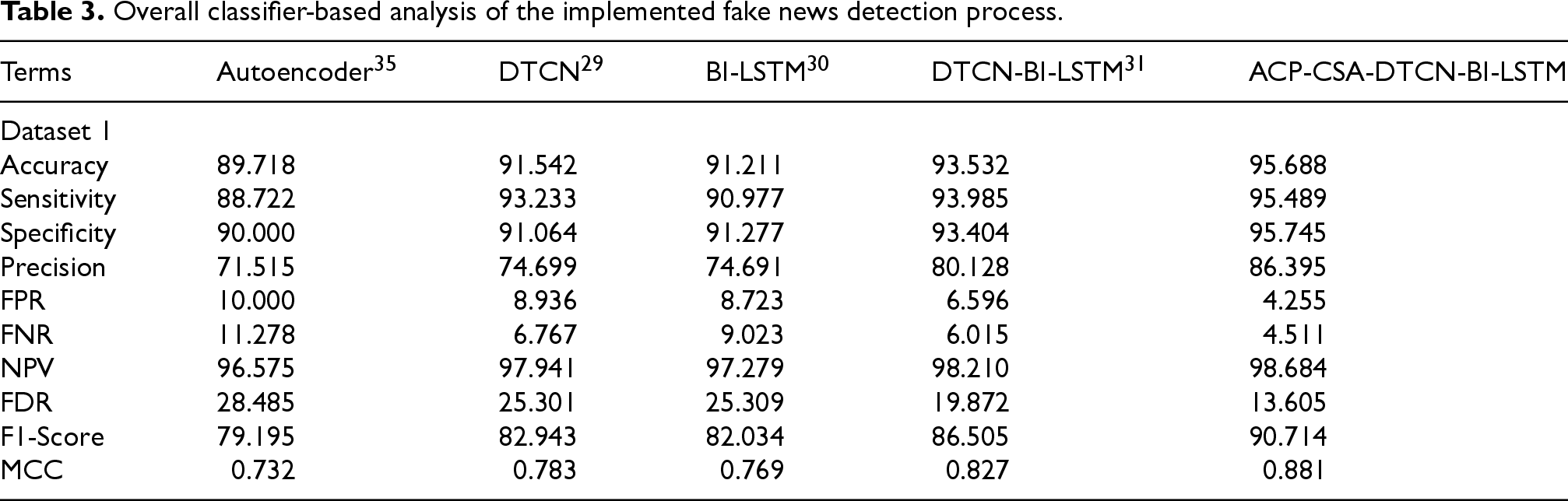
Overall classifier-based analysis of the implemented fake news detection process.
The statistical analysis of the developed fake news detection process is shown in Table 4. The standard evaluation is performed where the developed model is performed with best, worst, mean, median, and standard deviation. Focusing on statistical analysis supports to rectify the problems of gradient vanishing and overfitting issues. This analysis is helpful when the developed model shows better and more accurate performance in the fake news detection process. In Table 4, the mean value of the suggested ACP-CSA-DTCN-Bi-LSTM model is 1.49% increased than DO-DTCN-Bi-LSTM, 1.18% more than EOO-DTCN-Bi-LSTM, 1.19% enhanced than RSA-DTCN-Bi-LSTM and 0.39% higher than CSA-DTCN-Bi-LSTM. This proved that the developed fake news detection model performs better in standard deviation, median, best, mean, and worst.
Statistical analysis of the implemented fake news detection process.
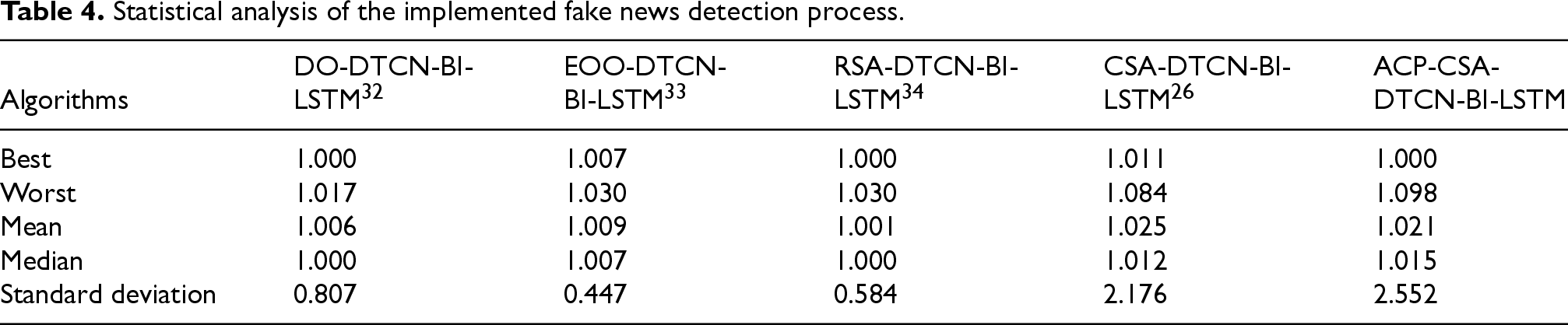
Statistical analysis of the implemented fake news detection process.
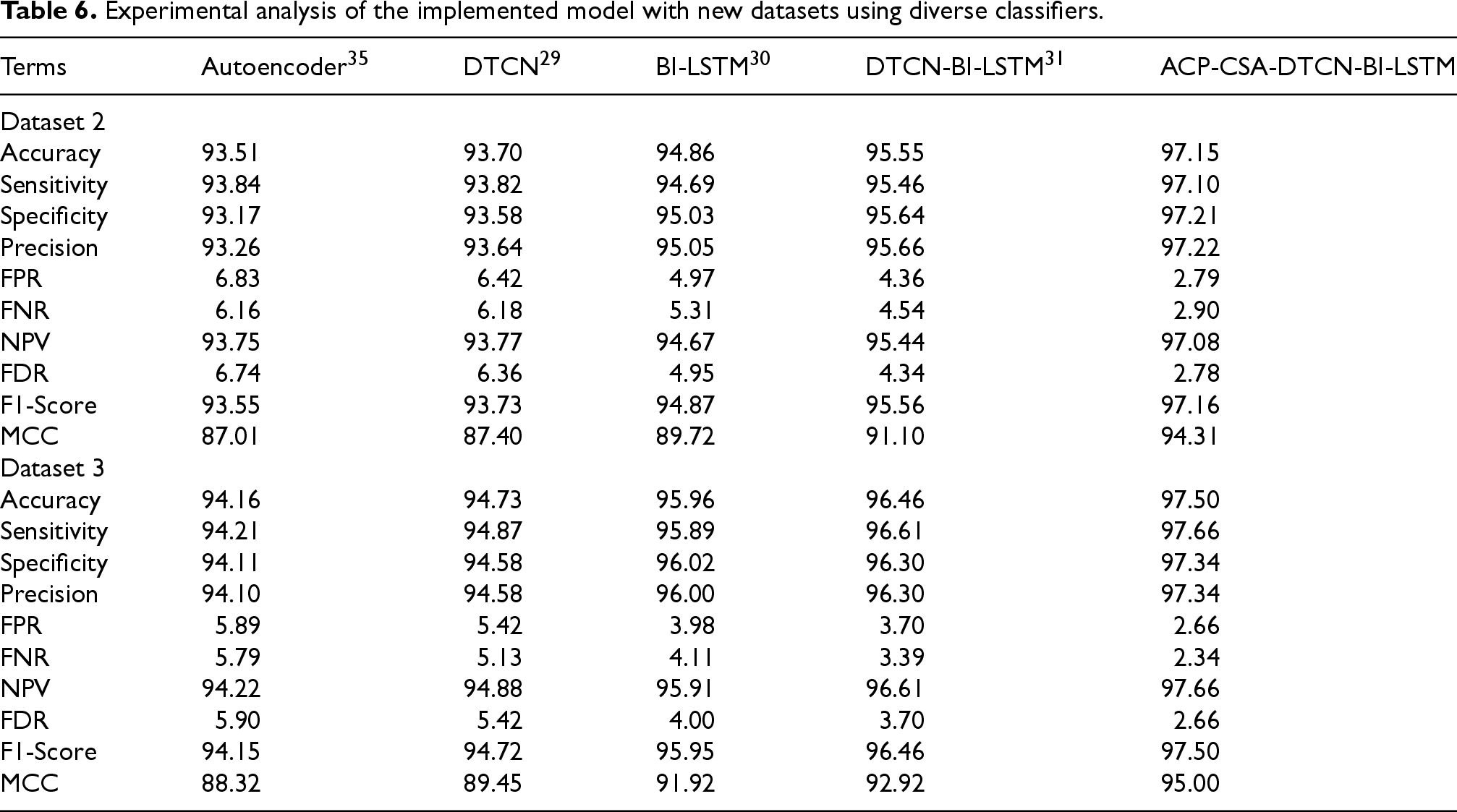
The experimental analysis is contrasted and validated with two experimental datasets for the developed model and also it is shown in Table 5. Also, the implemented process is also compared with diverse classifiers in terms of new datasets which is listed in Table 6. Based on this evaluation, the developed model shows 5.09%, 3.43%, 2.67%, and 1.59% improvements over DO-DTCN-Bi-LSTM, EOO-DTCN-Bi-LSTM, RSA-DTCN-Bi-LSTM, and CSA-DTCN-Bi-LSTM regarding precision metric. It seems that the accuracy of the implemented process is 97% which has the ability to solve complex problems like overfitting. When considering Table 6, the FDR rate in Autoencoder shows the value of 6.74 which is assumed to contain the higher error rate. Hence, the Autoencoder model is not efficient for detecting fake news. While analyzing these results, the developed model proved the accurate outcomes in the fake news detection framework.
Experimental analysis of the implemented model with new datasets using diverse algorithms.
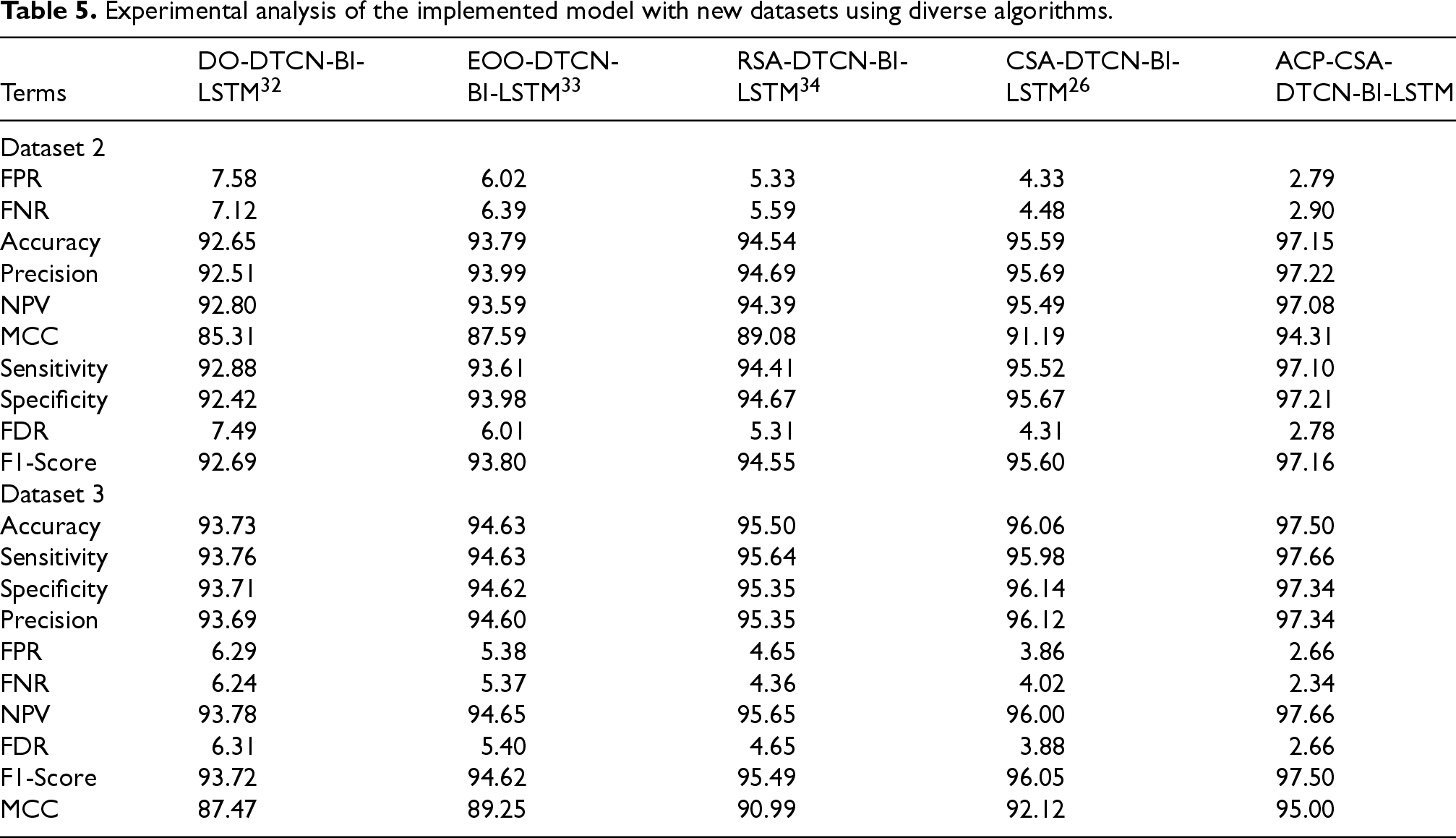
Experimental analysis of the implemented model with new datasets using diverse algorithms.
Experimental analysis of the implemented model with new datasets using diverse classifiers.
The developed multimodal fake news detection model based on deep learning was utilized to detect fake news publishers in society to support the public. The text data were gathered from the Twitter dataset. Those text data were taken to the pre-processing text process. The pre-process was done by stop words-punctuation removal and stemming. Then, those data were provided with the pre-processed text data as the output. Next, the pre-processed text data was carried out to fuse features. In that stage, image data was offered as the input. The VGG-16 model was utilized to extract the image features, and the TCNN model was supported to extract the text features. The features were selected optimally from those two models by the developed ACP-CSA. Moreover, the weights were optimized by the developed ACP-CSA. After that process, that provided the weighted fused features as the outcome. Then, the weighted fused features were taken as the input in the fake news detection process. There, parameters were tuned with the proposed DTCN-Bi-LSTM model by utilizing the developed ACP-CSA. Finally, the implemented fake news detection process provided the classified outcome. The best value of the implemented fake news detection process was 1.5% more than DO-DTCN-Bi-LSTM, 0.79% more than EOO-DTCN-Bi-LSTM, 1.5% improved than RSA-DTCN-Bi-LSTM and 0.29% enhanced than CSA-DTCN-Bi-LSTM. At last, the developed fake news model was performed more to provide the best values in all performances than other fake news detection models. Yet, the developed model suffers from a few complications where it needs to be resolved in the upcoming works. The analysis based on real-time data needs to be considered which is suggested to cope up with the developed model. The validation in real-time data ensures to offer accurate performance in the fake news detection process. In future work, the evaluation based on real-time data using the developed model will be implemented to detect fake news detection framework. Also, the ensemble model will be implemented.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.