
Abstract
Clinical trials are essential for discovering new treatments and advancing medical knowledge. However, the high uncertainty of carrying out clinical trials often ends with ineffective results. Therefore, the accurate prediction of clinical trial outcomes has become a significant challenge. Numerous publicly accessible clinical trial reports have been discovered to be beneficial in alleviating this challenge but lack necessary annotations to be formal datasets for deep model training. To address the issue, this paper proposes to construct a new clinical trial dataset by extracting publicly available clinical trial reports from ClinicalTrials.gov and PubMed. In addition, a new two-stage method is proposed for the prediction of clinical trial outcomes across all trial phases. Specifically, our method first employs a prompt template combined with each clinical trial report to prompt a large language model to generate a concise summarization text containing essential information related to the clinical trial outcomes. Subsequently, this summarization text is utilized to train a classifier to predict the outcomes. Extensive experiments were conducted on the dataset, and our method was compared with several state-of-the-art classification models. The results showed that our method achieved the best performance in predicting clinical trial outcomes, especially using small amounts of training data under a data imbalance difficulty.
Introduction
Clinical Trial (CT) is an essential procedure in advancing clinical research. It involves the verification of human volunteers or patients who meet the recruitment criteria employed by hospitals or research institutions.1,2 The objective of a CT is to evaluate the safety and efficacy of a new intervention (e.g., a drug or a medical equipment) for a target-specific disease. Conducting clinical trials is highly cost and time consuming. According to statistics, a CT may cost over $2 billion and take more than ten years on average for a new cancer-treatment drug evaluation to complete all trial phases. 3 However, there are uncertainties originating from factors such as drug safety and trial protocol design issues, which significantly increase the risk of loss of these substantial investments.4,5 Hence, preventing trial failures or reducing loss risk are crucial issues in the field of clinical trial research. At the same time, there is a vast amount of clinical data available due to the rapid expansion of clinical trial records and the surge in published scientific literature. This presents an opportunity for machines to learn invaluable clinical insights by effectively leveraging such a wealth of information.
Earlier attempts have been proposed to improve the prediction of clinical success through various machine learning methods that rely on structured data from biomedical, chemical, or drug databases.6,7 With the increasing digitization of clinical trial records and reports over the past decade, many online websites have been established to assist researchers in the clinical field. For instance, ClinicalTrials.gov is a website and online database containing clinical research studies and their outcomes. Similarly, PubMed is a freely accessible search engine that provides a wealth of clinical trial reports. These online data sources offer invaluable text data as summary or description of clinical trials. However, only a small number of studies8,9 have utilized them for modelling and learning. For example, Follett et al. 8 only extract distinctive words that describe trials completed successfully or terminated from ClinicialTrials.gov as supplementary data to assist in quantifying the risk associated with clinical trial termination. This underutilization of abundant online data sources results in missing the opportunity to leverage existing resources for improving clinical trial research.
In recent years, researchers have been exploring leveraging online data as the primary source to improve clinical trial research.1,2,10–12 HINT 1 proposed to utilize structured data from web-based sources (e.g. trial documents, medical codes, etc.), notably data from ClinicalTrials.gov, capturing correlations within interactive networks to enhance the prediction of trial outcomes. Luo et al. 2 extracted publicly available clinical trials from ClinicalTrials.gov to automatically estimate the status of a clinical trial and find out possible failure reasons. While clinical trial data from ClinicalTrials.gov has been widely studied, leveraging clinical trial reports from PubMed to address the clinical trial outcome prediction task has been hardly explored. Compared to the trial information provided by ClinicalTrials.gov, the clinical trial reports provided by PubMed usually offer a more comprehensive range of information. These reports provide details on trial design, implementation, and the interpretation of results. Moreover, clinical trial reports from PubMed have undergone peer review, which ensures that they possess a certain degree of scientific validity and credibility. This starkly contrasts the potential lack of validation and review from other data sources, thereby reducing misleading information.
To bridge the research gap and accelerate the development of predicting clinical trial outcomes, clinical trial records and reports available on two platforms are explored: ClinicalTrials.gov and PubMed. Each clinical trial on ClinicalTrials.gov has a unique identifier, known as ClinicalTrials.gov ID, and a status that tracks current trial stage (e.g., complete, terminated, and withdrawn, etc.). These IDs can serve as keywords to retrieve corresponding clinical trial reports from PubMed, as shown in Figure 1(a). These reports contain detailed information about the clinical trial studies, including objectives, research background, assessment methods, and other relevant details, as shown in Figure 1(b). Intuitively, a learning model having the ability to accurately predict trial outcomes using a large corpus of clinical trial reports can be a significant driving force for clinical trial research. However, the existing data1,2 lacks annotated clinical trial reports, making it difficult to train models that leverage the reports as input to predict clinical trial outcomes. In addition, clinical trial reports are proved to be useful for clinical trial outcome prediction. Therefore, an elaborately annotated clinical trial report dataset to achieve the goal is highly needed.

(a) A simple example. A clinical trial report can be readily located within PubMed using the clinical trial identification (ClinicalTrials.gov ID) acquired from ClinicalTrials.gov. (b) A brief diagram of a clinical trial report. Briefly describe the various components and their roles in clinical trial reports.
To that end, this paper introduces a newly constructed dataset, named POCT (
The main contributions of this work are summarized as follows:
A new clinical trial dataset POCT that associates clinical trial reports and clinical trials is constructed for the first time for model learning. A new method based on a two-stage strategy by leveraging a large language model to assist in fine-tuning a pre-trained model is proposed for predicting clinical trial outcomes. Experiments by comparing with state-of-the-art text classification and summarization baseline methods demonstrate that our two-stage method is effectiveness.
Clinical trial outcome prediction
Clinical trial data analysis and mining is a crucial topic in clinical research, including clinical trial referential search,13,14 clinical trial outcome prediction,15–17 and automatic clinical trial matching.18,19 For the task of clinical trial outcome prediction, early works15–17 predicted the outcome of clinical trials by leveraging expert-crafted features based on machine learning. For example, Wu et al. 17 devised a two-stage classification approach based on SVM to identify genes and genetic lesion statuses from cancer clinical trial documents. Gayvert et al. 15 utilized a random forest model to predict the likelihood of toxicity in clinical trials directly. However, they were primarily focused on patient-level clinical trial outcome prediction rather than offering a comprehensive forecast regarding the overall trial success. To fill the gap, Qi et al. 20 predicted the pharmacokinetics of phase III by modelling subject-level data from phase II trials, employing a residual semi-recurrent neural network. At the same time, Lo et al. 21 utilized statistical machine learning techniques for predicting drug approvals by leveraging drug development and clinical trial data. Unlike previous tasks solely focused on predicting specific clinical phases, the objective of Fu et al. 1 was to utilize drug molecular characteristics and trial protocol information to predict all clinical trial phases. Compared to other data sources lacking effective review, the publication of clinical trial reports experienced peer approval, ensuring a level of validity and credibility. Consequently, utilizing PubMed reports to predict clinical trial outcomes reduced the risk of generating misleading predictions, thus enhancing the reliability of predictions. Nonetheless, none of these prior efforts attempted to leverage clinical trial reports to predict the trial outcomes.
Text classification and summarization
The task objective of text summarization is to generate concise and summarizing content from original text. Text summarization task typically encompasses two categories: extractive and abstractive. Extractive summarization22–24 directly selected important sentences or paragraphs from source text to create a summary. Conversely, abstractive summarization25–27 utilized natural language generation models to create entirely new summaries that were not limited to specific sentences in original text. Benefiting from the rapid development of pre-trained language models, fine-tuned language models specifically designed for the abstractive summarization task28,29 made significant progress. In recent years, these two types of summarization models gained widespread applications in addressing various issues in the medical field, such as medical question answering, 30 electronic health record summarization, 22 and medical fact generation. 31 Katsimpras et al. 11 utilized an extractive summarization model for predicting intervention approval. However, these methods relied on high-quality source text-summary text pairs for training. To address this issue, a method that combined prompt learning with a large language model 32 was adopted to generate abstract summaries. The goal of text classification was to assign text into predefined categories or labels. With the rapid development of pre-trained language models, deep learning methods33,34 based on pre-trained language models (e.g., BERT, 35 RoBERTa 36 ) achieved promising results in short text classification. However, these models had limitations in long text scenarios due to the maximum input text length set during the pre-training stage. This made them unsuitable for direct application in long text classification. To address this challenge, some researchers37,38 truncated inputs in a fixed way to meet the length limitation of model input. Meanwhile, Beltagy et al. 39 proposed to optimize the Transformer 40 by leveraging an attention mechanism that scaled linearly with sequence length. In POCT dataset, the text length of clinical trial reports also has far exceeded the maximum length that the current classification model can handle. Therefore, in order to more effectively address the challenges faced by long text classification, a concise and effective two-stage framework classifier is proposed to address this issue.
The dataset POCT
A new dataset POCT is constructed by associating clinical trial data and clinical trial reports to predict clinical trial outcomes. The construction precedure primarily consists of three steps: 1) Clinical trial selection. All clinical trials are obtained from ClinicalTrials.gov and then filtered by a pre-defined filtering strategy (Section 3.1) to select eligible trials. 2) Clinical trial report filtering. The corresponding reports are retrieved (Section 3.2) from PubMed based on the selected clinical trials by filtering out non-conforming clinical trial reports. 3) Data association and annotation. The collected clinical trials and their corresponding reports are associated by NCT ID (ClinicalTrials.gov ID). The associated trial data is further annotated by referring their outcomes through human verification (Section 3.3). The main steps of the construction of POCT are shown in Figure 2.
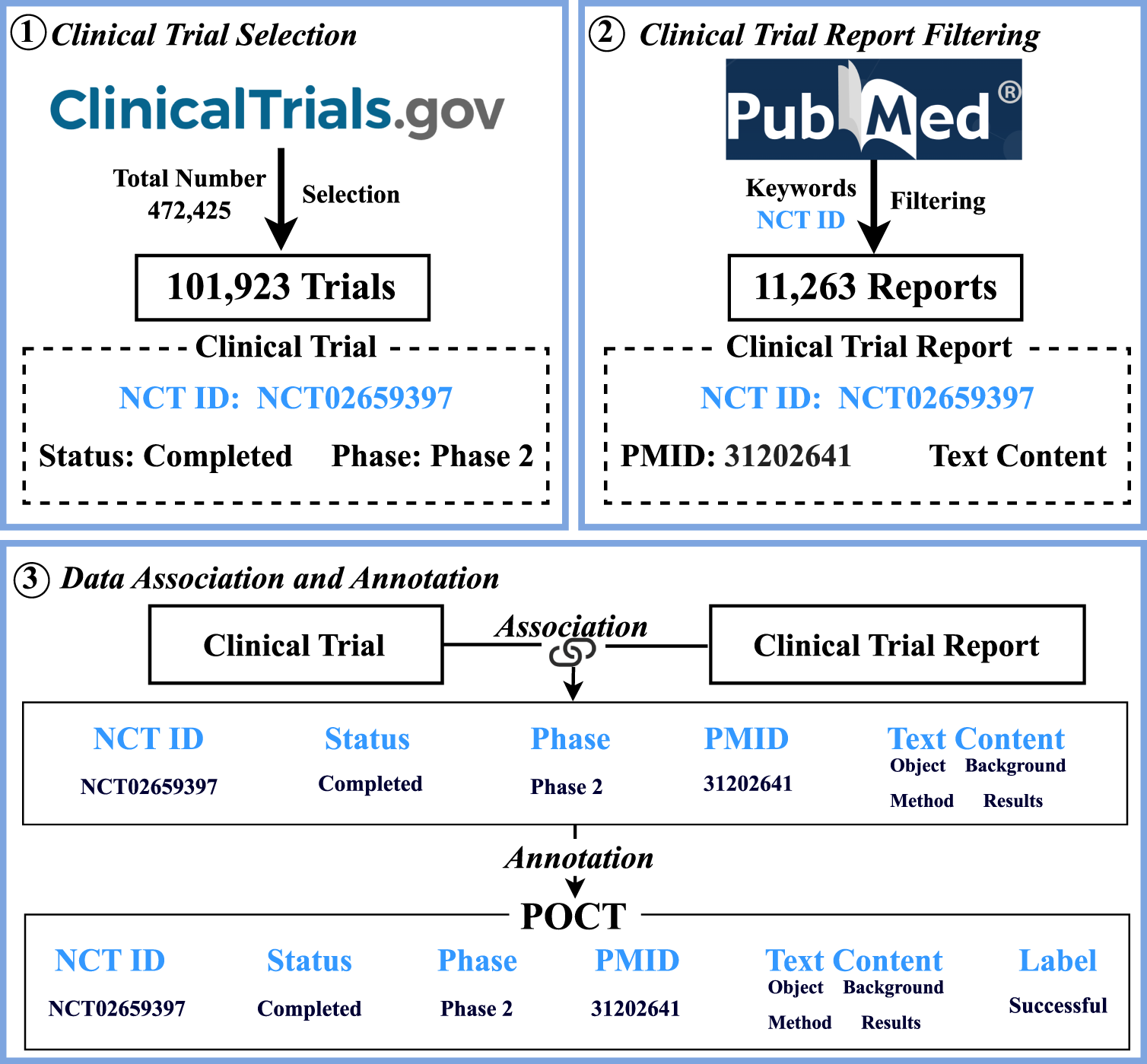
The main procedure of the POCT construction.
Clinical trial documents are initially retrieved from a API (https://classic.clinicaltrials.gov/api/gui) provided by ClinicalTrials.gov, and a series of selection filters are applied to select high-quality trials. To ensure the predictability of trial outcomes, clinical trials of drug interventions are focused on, and trials with the following conditions are selected: 1) explicit trial status and 2) specified trial phase. As shown in Figure 3(a), clinical trials in ClinicalTrials.gov are labeled with various explicit trial statuses, including Completed, Terminated, Suspended, Recruiting, or the other, in which unknown or missing are implicit statuses that are treated as noise. There are also multiple experimental phases, as shown in Figure 3(b), in which unspecified phases, such as unknown or missing are also as noise. To study the trials with outcomes, clinical trials with explicit status as Completed are chosen, meaning that the trial is usually Ended, or Terminated, indicating early stop without resumption. Meanwhile, clinical trials marked as Unknown phase during the trial phase are filtered out. Following these filtering, a preliminary selection of 101,923 trials that meet the requirements has been made from 472,425 candidate clinical trials. Each trial consists of labels of NCT ID (ClinicalTrials.gov ID), status, and phase.
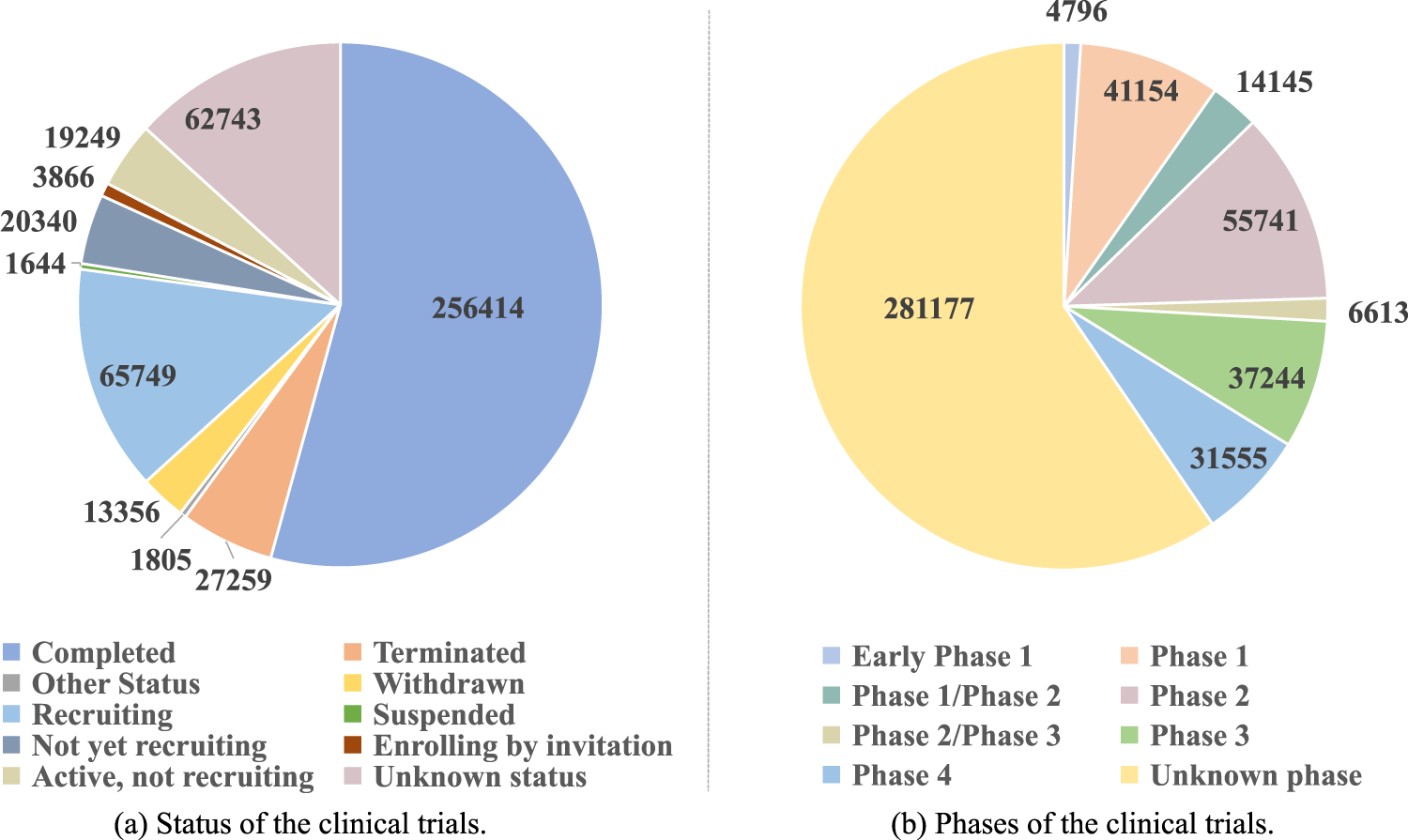
Data analysis of clinical trials.
The clinical trial reports are retrieved from PubMed using the NCT ID of each trial. However, not all clinical trials have clinical trial reports, especially when they are in Terminated status. Additionally, the formats of clinical trial reports may vary dramatically due to different writing styles of clinical trial researchers. Our priority is to find clinical trial reports that have sub-section headings such as Objective, Background, Methods, Results, and Conclusion. Generally, the Conclusion section contains the descriptions of the effectiveness of a clinical trial and thus is kept separately for the verification of clinical trial outcomes. Eventually, a total of 11,263 clinical trial reports are acquired from collected clinical trial reports. Each clinical trial report consists of labels of NCT ID (ClinicalTrials.gov ID), PmID, title, objective, background, methods and results. Table 1 shows the combined criteria for clinical trial selection and clinical trial report filtering.
The criteria for clinical trial selection and clinical trial report filtering.

The criteria for clinical trial selection and clinical trial report filtering.
After collecting eligible clinical trials and clinical trial reports, the two types of data are associated using the common field NCT ID as the linking identifier. Afterwards, each data entry in the dataset consists of the following fields: NCT ID, phase, status, PmID, title, objective, background, methods, and results. After the association, the data annotation approach HINT 1 is adopted to improve the alignment of prediction outcomes with real-world scenarios. Trials with a status of Terminated are labeled as failure. Trials with a status of Completed are divided into two categories: completed trials that achieve the trial objectives are annotated as success, while completed trials that have not achieved expected objectives are annotated as failure. The annotations are further verified by three human experts by referring the conclusion sections of the trial reports to ensure their correctness.
Finally, the resulting dataset POCT consists of 8,466 trials labeled as success and 2,797 trials labeled as failure. The dataset is randomly divided into three parts for training, developing, and testing, with 7,883 trials, 1,690 trials, and 1,690 trials for training, developing, and testing, respectively. Each sub-dataset maintains a balanced ratio of positive to negative trial samples at approximately 3:1. The statistical information and data sample of the POCT dataset are shown in Tables 2 and 3, respectively. Additionally, data from phase I, phase II, and phase III trials are extracted from the POCT dataset to construct three datasets for phase-level clinical trial outcome prediction. The sizes of these datasets are 792, 3202, and 6,195 trials for phase I, II, and III, respectively. The positive to negative sample ratios for these datasets are 4:1, 7:3, and 3.5:1. For the phase-level prediction, the distribution of training, development, and testing data is maintained at approximately 7:1.5:1.5.
The statistical information of the POCT dataset.

The statistical information of the POCT dataset.
A data sample of the POCT dataset.

A two-stage method is proposed for predicting clinical trial outcomes. This method consists of two main modules: 1) a summarization module, which generates concise summarization text for clinical trial reports, and 2) a prediction module, which analyzes the generated summarization text to predict clinical trial outcomes. The overall architecture is illustrated in Figure 4. Firstly, each section of a clinical trial report is formatted into key-value pairs using a linearization layer. Secondly, prompt templates combined with the key-value pairs are input to Gemini-Pro to generate summarization text for the reports. Finally, summarization text is fed into a Longformer-based classifier to predict clinical trial outcomes.

Overview architecture of the proposed method for clinical trial outcome prediction. and  represent frozen and tunable weights during tuning, respectively.
represent frozen and tunable weights during tuning, respectively.
To generate a brief and precise summary for a given clinical trial report, the key challenge is identifying and understanding the critical content in the report. This requires the summarization model to have strong biomedical, commonsense, and numerical reasoning abilities. Additionally, the text length of clinical trial reports surpasses the capacity of most pre-trained language models to handle. To address these challenges, the Large Language Models (LLMs) equipped with the capabilities of powerful reasoning and ultra-long text handling is chosen.
Gemini-Pro 32 is utilized as a summarization model, which is a large language model recently developed by Google. It is employed to generate summarization text for clinical trial reports. Specifically, each trial report is first formatted into key-value pairs. After that, a prompt concatenate with the key-value pairs is used to ask Gemini-Pro to generate a summarization text for an input. The first two steps, including linearization and prompting, are described below:


Given the prompt 
The clinical trial outcome prediction is modelled as a binary classification task. After processing by the summarization module, each clinical trial has a corresponding summarization text. Longformer tokenizer is adopted to convert words of each summarization text into tokens represented as numerical vectors. For each summarization 
Then, the representation of the 
Finally, the classification layer is adopted to process the global representation 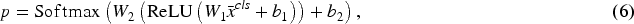
During training, the gradients of Longformer are updated while keeping the parameters of Gemini-Pro frozen. The training objective is to minimize cross-entropy loss is as equation (7),
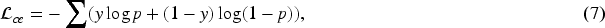
Settings
BERT 35 was based on the Transformer architecture and was capable of unsupervised pre-training on largescale text data.
RoBERTa 36 was built upon BERT by using larger training datasets, longer training times, and dynamic masking strategies, enhancing performance and robustness.
DeBERTa 41 introduced disentangled attention mechanisms and a new decoder architecture on top of BERT for improving model performance and generalization capabilities.
Due to the limited input length of the above models, it is infeasible to input the entire clinical trial report into the models at once. To tackle this, a block processing approach has been adopted that considers the characteristics of clinical trial reports. The clinical trial reports are firstly split into several sub-reports, in which each sub-report is fed to the models to produce feature representations. Finally, the feature representations of each sub-report are concatenated to predict trial outcome.
Longformer 39 introduced an attention mechanism that scaled linearly with sequence length, making it easy to process documents of thousands of tokens or longer.
BART 28 was a transformer encoder-decoder model with a bidirectional encoder and an autoregressive decoder. It introduced a denoising autoencoder to pre-train sequence-to-sequence models. For generation tasks, the noising function was text infilling, which used single mask tokens to mask randomly sampled text spans.
Pegasus 42 was a sequence-to-sequence model with the same encoder-decoder model architecture as BART. It employed gap-sentences generation as a pre-training objective tailored for abstractive text summarization.
Gemini-Pro 32 was built on an enhanced Transformer decoder, employing an efficient attention mechanism that supported context lengths of up to 32 K . Zero-shot testing of Gemini-Pro was conducted on the POCT dataset with a provided prompt, as depicted in Figure 5.

Zero-shot Gemini-Pro prompt.
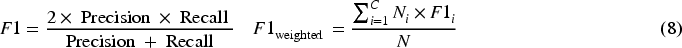
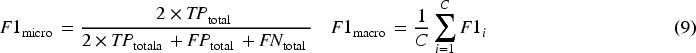
Precision is calculated as the ratio of true positive predictions to the sum of true positive and false positive predictions, while Recall is calculated as the ratio of true positive predictions to the sum of true positive predictions and false negative predictions.
For BART or Pegasus, a two-stage training strategy is employed by combining them with Longformer. Firstly, BART or Pegasus generates a summarization text for the trial report. During training, evaluation metrics such as ROUGE-1, ROUGE-2, and ROUGE-L are used to determine the quality of the generated summary texts. To ensure consistency between the training and prediction stages, a cross-validation strategy is utilized to generate text summaries for all data in the dataset. The generated summary texts are input into the Longformer model for outcome prediction.
The performance comparison of our method and the baseline methods is presented in Table 4. Our method demonstrates the best performance on most of the evaluation metrics. Compared to Gemini-Pro, our method improved with an average performance increase of 1.24% on 3 out of 4 metrics. Specifically, our method improves Weight F1 by 0.93%, Micro F1 by 2.19%, and F1 by 2.13% compared to Gemini-Pro, indicating its robust classification capabilities. Longformer, which excels in handling long sequences, achieves better performance than other one-stage models like BERT, RoBERTa, and DeBERTa. However, our method still outperforms Longformer on all metrics, achieving an average improvement of 0.55%. This demonstrates that Longformer is adept at capturing long-range dependencies, while our method effectively leverages both the summarization strengths of Gemini-Pro and the contextual reasoning capabilities of Longformer. Furthermore, in comparison to other models utilizing two-stage training strategies, such as BART+Longformer and Pegasus+Longformer, our method exhibits substantial performance increase, with a maximum average improvement of 5.73%. This significant enhancement emphasizes ability of our model to synergize the summarization prowess of generative models with the detailed reasoning capability of transformer-based models, leading to state-of-the-art results in predicting clinical trial outcomes. The results clearly indicate that our proposed method not only achieves the best performance on the POCT dataset but also sets a new benchmark by effectively integrating the strengths of both summarization and reasoning techniques.
The performance comparison of the methods on the POCT dataset.
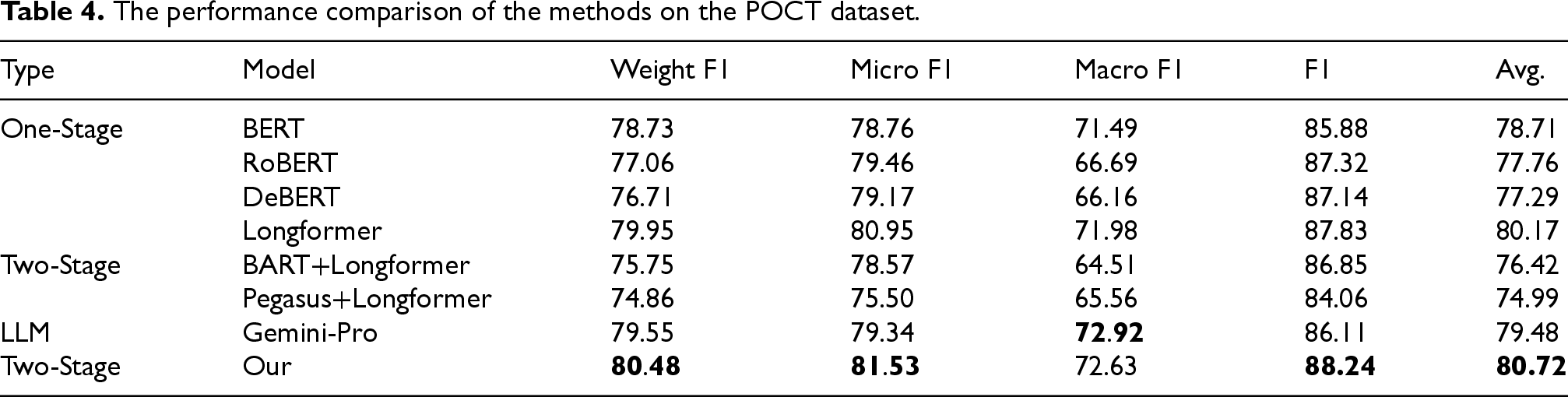
The performance comparison of the methods on the POCT dataset.
In the POCT dataset, clinical trial reports consist of four main sections: objective, background, methods, and results. Notably, the methods and results sections occupy a significant portion of the content. Experiments are conducted to investigate the importance of methods and results sections in clinical trial outcome prediction. Specifically, experiments are carried out by removing them one by one to observe the impact of changes on overall performance. The model trained with all sections (as ALL) serves as the baseline. The results and methods sections are denoted as
The ablation study on the POCT dataset.

The ablation study on the POCT dataset.
Clinical trials are required to be divided into multiple trial phases, and predicting the success of a trial at the earliest phase has significant meaning for clinical research. To test the effectiveness of our method in different phases, separate models are trained using training instances from corresponding phases. Our method is compared with several baseline methods, and the results are shown in Table 6. Our method exceeds all baseline methods on phase-level trial outcome prediction. When comparing performance across all phases, our method improves by 1.45%, 3.17%, and 11.87% compared to Gemini-Pro, Longformer, and BERT, respectively. Our method outperforms other baseline models during phase I and II trials. Compared to the suboptimal model Gemini Pro, our method improves by 1.60%, 1.19%, and 1.54% in phase I, II, and III trials, respectively. This demonstrates that leveraging data generated by LLMs to assist in fine-tuning pre-trained language models can achieve better performance, particularly in scenarios with limited training data and class imbalance.
Performance on phase level outcome prediction of various approaches.
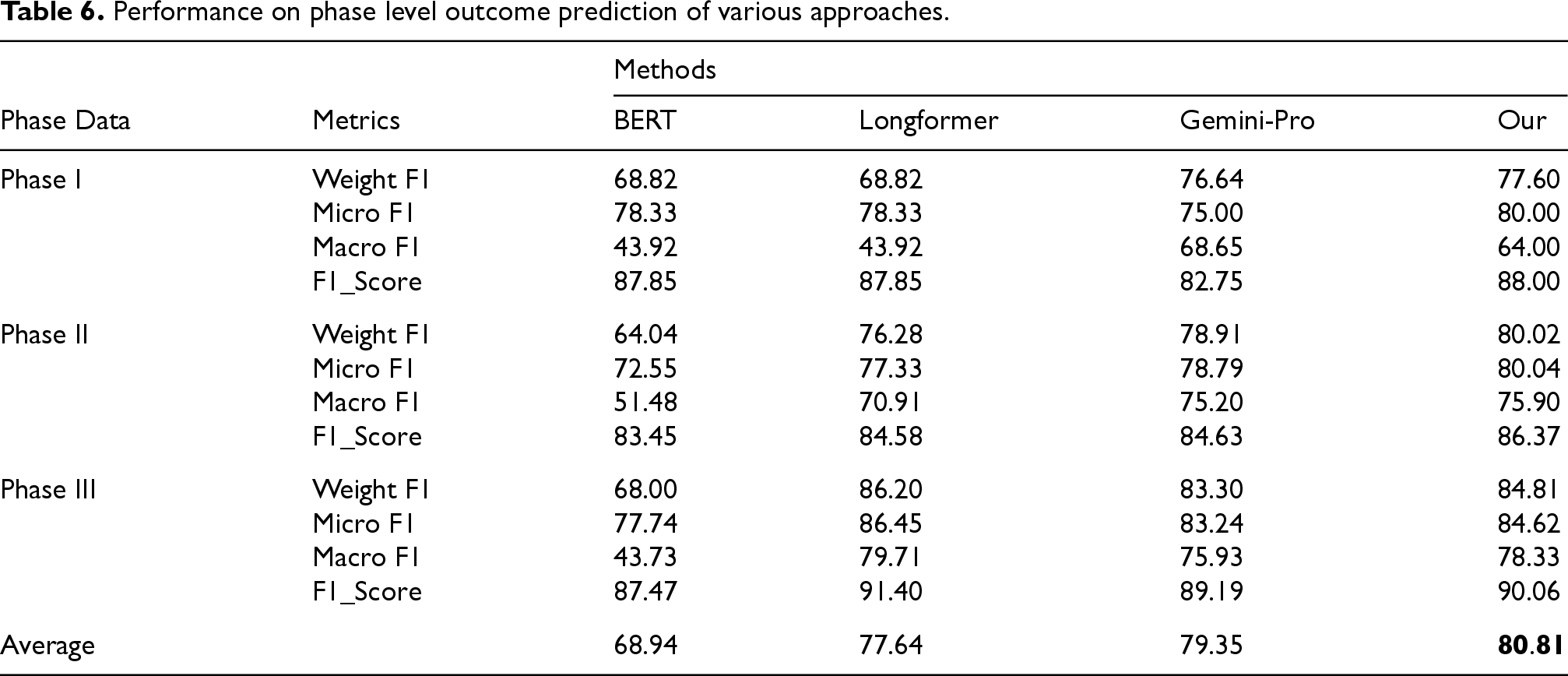
Performance on phase level outcome prediction of various approaches.
Clinical trials are conducted in phases, and each phase builds on the previous one. Therefore, the transfer ability of our method across phases is required to be systematically evaluated. At each transition, only the data from the previous phase is used for training. For example, when moving from phase I to phase II, only the data from phase I is used. The performance of the cross-phase transfers is shown in Figure 6. The result indicates that our model has certain degree of transfer capability. Compared to transition from phase I to phase III, transition from phase II to phase III improves by 1.91%, 0.22%, and 4.89% in Weight F1, Micro F1, and Macro F1, respectively. Considering the limited training data utilized in the cross-phase tasks, these experimental results should be regarded as indicative of our method.
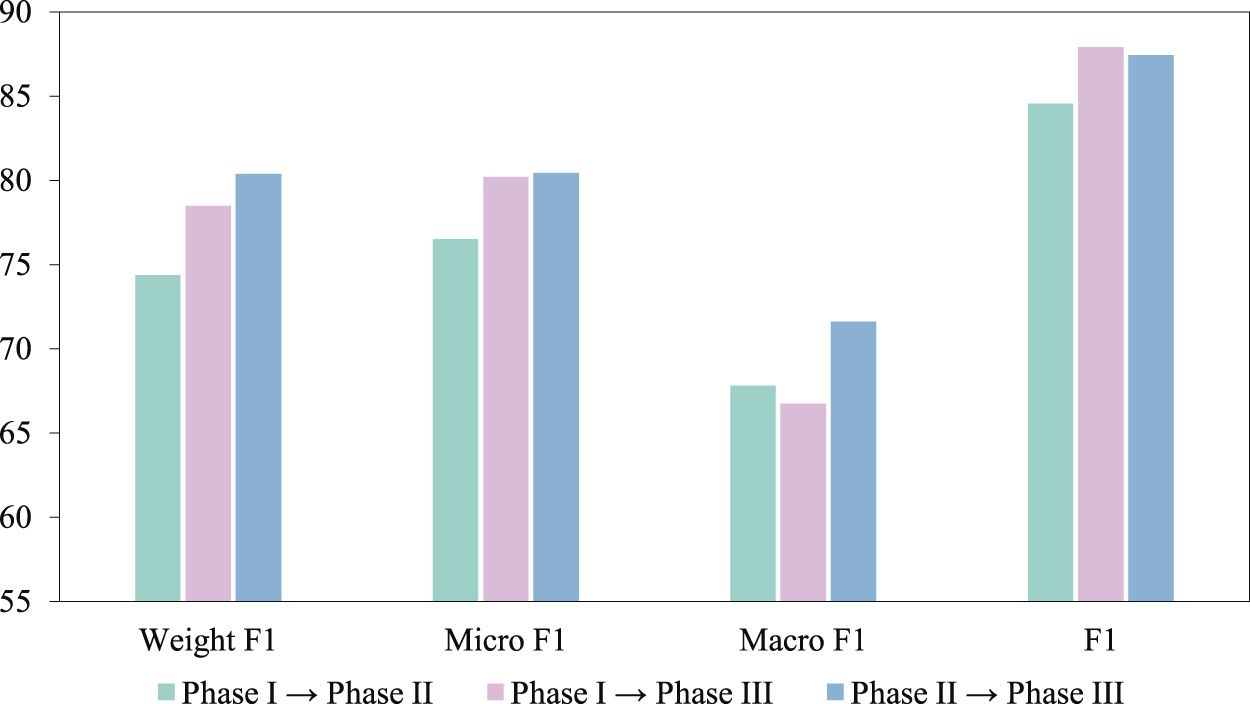
The performance of our method in predicting cross-phase transfer.
To enhance the trust and understanding of clinical researchers in the model prediction results, we employ SHAP values to elucidate the decision-making process of our method. The explanatory result is shown in Figure 7, where the text marked in red increases the probability of our method predicting the clinical trial outcome as successful, while the text marked in blue decreases this probability. By highlighting the key factors that influence prediction outcomes, the understanding of our method among clinical researchers can be deepened, while also strengthening their trust in its decision-making process.

Decision making process.
Case study comparing our method and zero-shot Gemini-Pro using the POCT dataset is presented in Table 7. The case includes the NCT ID, the clinical trial report, the outcome label, the prediction outcome of zero-shot Gemini-pro, the generated summarization text by Gemini-Pro, and the prediction outcome of our method. The clinical trial does not meet its primary endpoint. However, most of the content in the clinical trial report indicates that higher dose losmapimod reduced vascular inflammation in the most severely affected areas. This may cause challenges for Gemini-Pro in predicting this clinical trial outcome, leading to incorrect judgments. In contrast, our method filters out irrelevant information from clinical reports during summarization, thereby increasing the proportion of crucial information for predicting clinical trial outcomes. This allows our method to make accurate predictions, demonstrating its effectiveness in predicting clinical trial outcomes.
A case study for our method and zero-shot gemini-pro on dataset POCT.
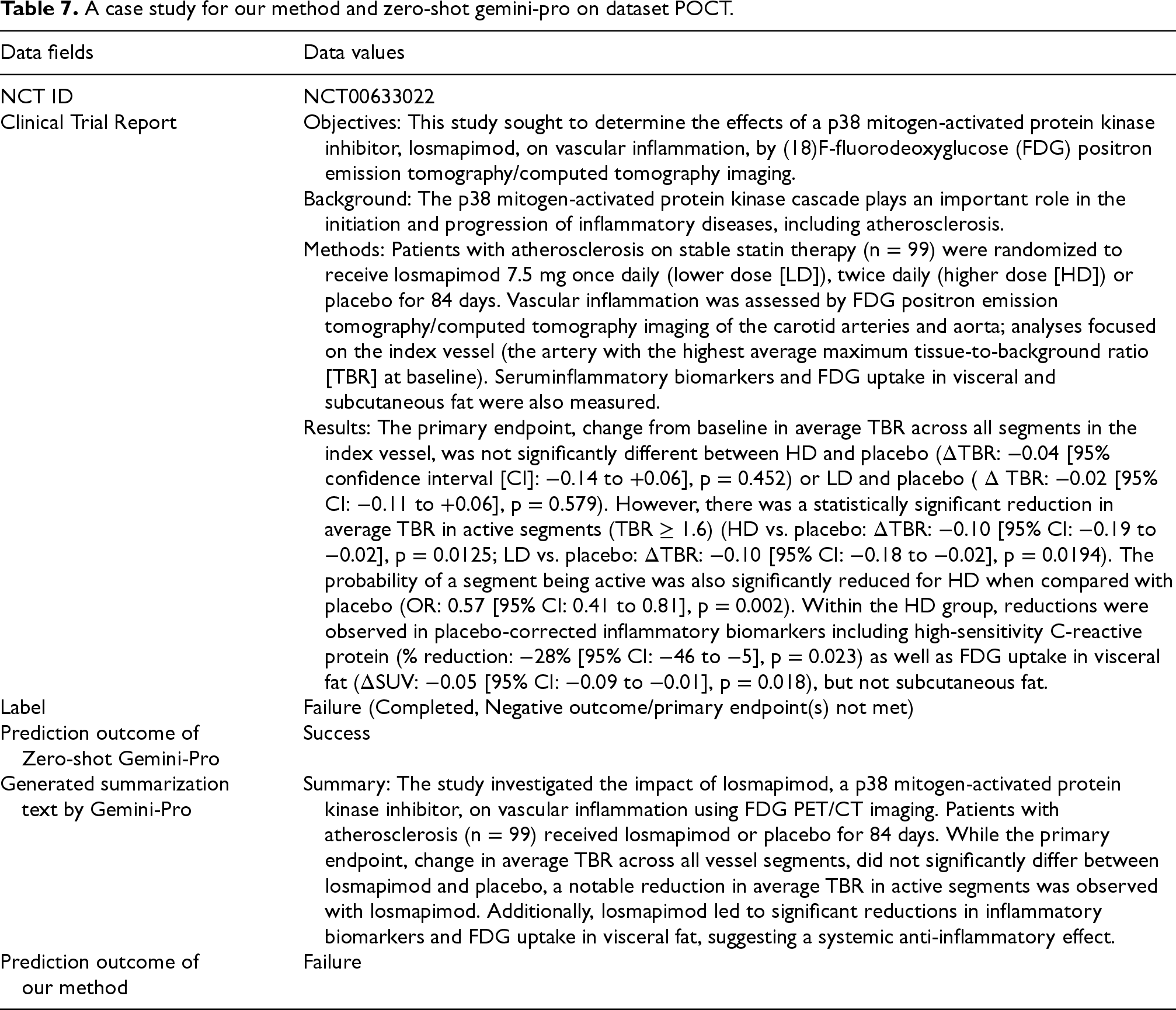
A case study for our method and zero-shot gemini-pro on dataset POCT.
Predicting clinical trial outcomes effectively has become increasingly challenging in clinical research. To address this issue, clinical trial reports are explored by associating with clinical trials to build a new dataset POCT. In addition, a method based on two-stage strategy is newly proposed for predicting clinical trial outcomes. The method utilizes large language models to summarize clinical trial reports and trains classifiers with the generated summaries to achieve full-phase clinical trial outcome prediction. Our method was evaluated by comparing it to other baseline models, and the results illustrate the best performance in predicting general clinical trial outcomes, particularly when dealing with a small amount of training data under a data imbalance situation. While our research demonstrates certain advantages, further refinements are possible. Clinical trial reports contain a wealth of intricate medical terminology, which present significant challenges for model comprehension. Therefore, future research could benefit from integrating specialized medical knowledge bases to enhance understanding and performance.
Footnotes
Acknowledgements
The work is supported by grants from National Natural Science Foundation of China (No. 62372189).
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.