
Abstract
Information leakage and model attacks pose risks in the analysis and exchange of medical data, as the language models used to process medical records may retain training data. Traditional models, on the other hand, are often too complicated and use old ineffectual methods for removing personal data. This can compromise the data’s integrity and quality, making it less useful for future tasks, especially when combined with other language models. This paper introduces the Self-Decoded Model of Medical De-identification (SDM-M-DID). The model employs a secure BERT-based encoder to paraphrase sensitive data, ensuring HIPAA compliance. Unlike traditional models that only mask sensitive tokens, the SDM-M-DID decodes its own embeddings to generate an internal representations of these tokens. Then, it integrates this representations with the pre-trained BERT dictionary to rephrase tokens, preserving their semantic role while altering grammar to prevent re-identification. Compared to existing large language models, our model achieves a score of 0.8416 F1 BERTscore, striking an optimal balance between the variability and similarity of deidentified tokens. We conducted experiments on two medical datasets to demonstrate the effectiveness of the model. Metrics show that there is only a
Keywords
Introduction
Healthcare data, as an exceptionally sensitive form of information encompassing detailed particulars regarding an individual’s health status, including medical records, diagnostic outcomes, therapeutic protocols, and laboratory results, has consistently been subject to stringent protection and regulation. With the ascendance of digitization and big data within the healthcare sector, the challenges concerning the confidentiality and security of healthcare data have grown increasingly intricate and urgent. Breaches involving healthcare data may precipitate severe ramifications, such as identity theft, infringement of personal privacy, and perpetration of healthcare fraud. As highlighted by Vakili et al., 1 nearly twenty percent of incidents involving the unauthorized disclosure of sensitive information pertain to Protected Health Information (PHI). Consequently, safeguarding the privacy of healthcare data has emerged as a critical challenge within the realm of global healthcare information management and research.
Large Language Models (LLMs) are capable of performing a variety of tasks related to Natural Language Processing (NLP), significantly enhancing the efficiency and quality of work for medical professionals in the field of medical data handling. However, due to the sensitive nature and privacy concerns associated with healthcare data, the application of publicly accessible language models can lead to significant issues. These models may inadvertently expose sensitive information by retaining data on which they were trained, even after training is complete. Data generated within one medical institution must be de-identified before being transferred to any other institution, ensuring the removal of all sensitive information that could reveal the identities of personnel or patients. At the same time, the data must retain its value, as overly aggressive or improper anonymization could compromise the integrity of the data.
S.M. Meystre et al. 2 analysed 18 systems for automated text de-identification and proposed a method for automated personal data deletion based on machine learning. They addressed key issues such as anonymisation, adequate performance and ’over-cleansing’, but their solutions lack the capacity to learn. In a review of methods for disclosing and de-anonymising sensitive information in medical records submitted in Grouin et al. 3 found that the de-identification system must consider access to the hospital’s information system in order to call on information in more than one document and medical knowledge of medical coding to re-identify the patient. Neurolinguistic models, namely LSTM (Long Short-Term Memory) and GPT-2, were employed to generate synthetic medical data text with annotations 4 in order to achieve the objective of preserving the privacy of medical data. Furthermore, the models were used in conjunction with real data to enhance the recall rate.
As differential privacy may be unable to safeguard sensitive data by reducing the accuracy of the model, thereby potentially increasing the probability of disclosing sensitive data, Seyedi et al. 5 utilized an LSTM-based free text recognition algorithm to ascertain the likelihood of divulging identifying information about subjects. Larbi et al. 6 employed data corresponding to five distinct datasets, each representing a different NLP task. They investigated the impact of various anonymisation techniques on the performance of ML models and confirmed that overly robust anonymisation techniques result in a notable decline accuracy in system performance.
These de-identification techniques primarily rely on masking strategies, which protect personal privacy by replacing sensitive information with symbols or synthetic data, such as “patient name,” “doctor’s name,” and “healthcare facility name.” However, there is a paucity of research exploring methods that involve interpreting specific sensitive tokens to leverage smaller and more secure language models, thereby enhancing the quality and usability of anonymized data.
In summary, we propose a relatively small and secure language model specifically designed for the de-identification of sensitive information in medical records, named SDM-M-DID (Self-decoded Model for Medical - De-identification). The key feature of this model is its ability to decode its own embeddings, thereby enhancing the training quality of all the layers of the decoder and the encoder. This feature enables the model to be re-trained for almost any type of sensitive information within medical records using a relatively small dataset and with minimal training time. Given that the structure of a classic transformer allows for the replacement of model blocks for situational adjustments, this experiment will test four different versions of the BERT encoder model. Each model has a unique training approach and was developed for specific tasks, which can be advantageous for the de-identification task due to their contextual embeddings, enabling precise contextual understanding in a wide range of texts. These models will be evaluated on two datasets with different structures.
We conducted a comprehensive analysis of reports addressing the vulnerabilities of language models in retaining and potentially exposing training data. Based on these findings, we propose a novel de-identification model that leverages the BERT model architecture as an encoder for analyzing and generating embeddings from medical records. Additionally, modified transformer blocks are integrated as decoders, aiding in the training and fine-tuning of the model for handling domain-specific medical data. This study introduces a new training approach for the proposed model using Multi-Task Learning techniques. In this approach, the model simultaneously performs multiple auxiliary tasks that sequentially contribute to the success of the primary de-identification task. The core objective is to decode its own embeddings to enhance contextual understanding of the processed tokens.
Contextual and medical embeddings: An overview
To comprehend the general process of model development in NLP, it is essential to begin with traditional word-level vector representations, such as word2vec 7 and GloVe. 8 These representations encapsulate all possible meanings of a word into a single vector, yet they are unable to resolve ambiguities and inconsistencies that arise from the surrounding context. Over time, models such as BERT 9 and ELMo 10 have introduced robust solutions that provide contextualized word representations, achieved through extensive pre-training on vast amounts of high-quality data. These models, due to their dual-phase training process – comprising both pre-training and fine-tuning – are exceptionally well-suited for integration into a wide range of tasks, even those with low convergence. Although these architectures are now over five years old, research continues to show significant interest, leading to the ongoing development of numerous NLP models based on the BERT encoder.
Privacy concerns and data extraction in language models
The medical field heavily relies on continuous advancements based on language model encoders, as AI tools are invaluable and highly effective in performing routine tasks that involve analyzing vast amounts of data. However, the use of these tools is accompanied by significant risks, including the potential for data leakage and declassification. For instance, Vakili et al. explored the vulnerability of language models to attacks by adversaries, specifically investigating data extraction from GPT-2 models. 1 These models were capable of decoding entire passages from IRC logs 11 demonstrating a serious risk of sensitive information exposure. Nakamura et al. 12 conducted a similar attack aimed at re-predicting pseudo-anonymized information. To achieve this, they trained a BERT model on the MIMIC-III corpus, which contains surrogate values, and subsequently re-masked all sensitive entities within the dataset. They then attempted to recover the original names but were unsuccessful, demonstrating that the BERT encoder is better at protecting sensitive information during such attacks.
Multi-task learning
Multi-task learning (MTL) has emerged as a powerful approach to machine learning and natural language processing (NLP) to improve model generalization and performance across multiple related tasks. In MTL, a single model is trained simultaneously on several tasks, allowing it to leverage shared representations and learn complementary information from diverse datasets. This approach is particularly effective in transformer-based models, such as BERT, which have been designed to handle a wide range of NLP tasks through a unified architecture. Recent studies, such as the one conducted by Liu et al., 13 have demonstrated that MTL with transformer models can significantly enhance performance by sharing knowledge across tasks, reducing overfitting, and improving data efficiency.
For instance, BERT has been extended to perform MTL by training on tasks like masked language modeling (MLM) and next sentence prediction (NSP) simultaneously during its pre-training phase. This allows BERT to learn both token-level and sentence-level representations, which are beneficial for downstream tasks such as text classification, question answering, and named entity recognition. Furthermore, more recent works 14 in the T5 model have demonstrated that unifying multiple NLP tasks into a single model framework can lead to substantial gains in performance by leveraging a shared encoder-decoder architecture.
The proposed model builds on this MTL framework by training the decoder for two distinct tasks concurrently, aiding the main decoder in generating more accurate outputs. This design allows the model to benefit from auxiliary tasks, which provide additional context and help refine the decoder’s ability to produce correct predictions. Recent developments in transformer models indicate that MTL strategies not only improve individual task performance but also contribute to more robust and versatile language models. 15
Model training parameters
The process of de-identification in Natural Language Processing (NLP) involves anonymising sensitive information in textual data while maintaining the usability of the data, but one of the difficulties is how to identify specific tokens that can be replaced by parses that retain the original semantics without revealing potentially sensitive information, such as names, locations or other personal identifiers. One fundamental problem in this context is accurately comparing two tokens that are syntactically different but semantically identical, especially when using paraphrasing techniques. Paraphrasing involves generating alternative expressions of text that convey the same meaning as the original. 16 In the process of de-identification, it maintains the integrity of the text context by replacing sensitive information with appropriate words. Traditional string-matching methods are inadequate, as they rely only on exact token comparisons, failing to account for synonymous or contextually equivalent terms that differ in their surface forms.
To address this issue, a solution leveraging cosine similarity between vector representations of tokens has been proposed. Cosine similarity is a metric that quantifies the similarity between two vectors in a multi-dimensional space by measuring the cosine of the angle between them. 7 In the context of NLP and deidentification, tokens or paraphrases are embedded into continuous vector spaces using pre-trained word embeddings or contextual embeddings from models like Word2Vec, GloVe, or transformers. 17 The cosine similarity between these vectors provides a robust measure of their semantic similarity, regardless of their syntactic differences.
Mathematically, the cosine similarity
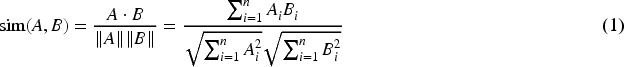
Protected Health Information (PHI) includes any data that can identify an individual and pertains to their health, healthcare, or payment for services (HIPAA, 2019). Common PHI Figures 1 and 2 in medical records includes names, social security numbers, addresses, and birth dates. 18 Protecting the confidentiality of PHI while allowing its use for research is a significant challenge, requiring effective de-identification methods.
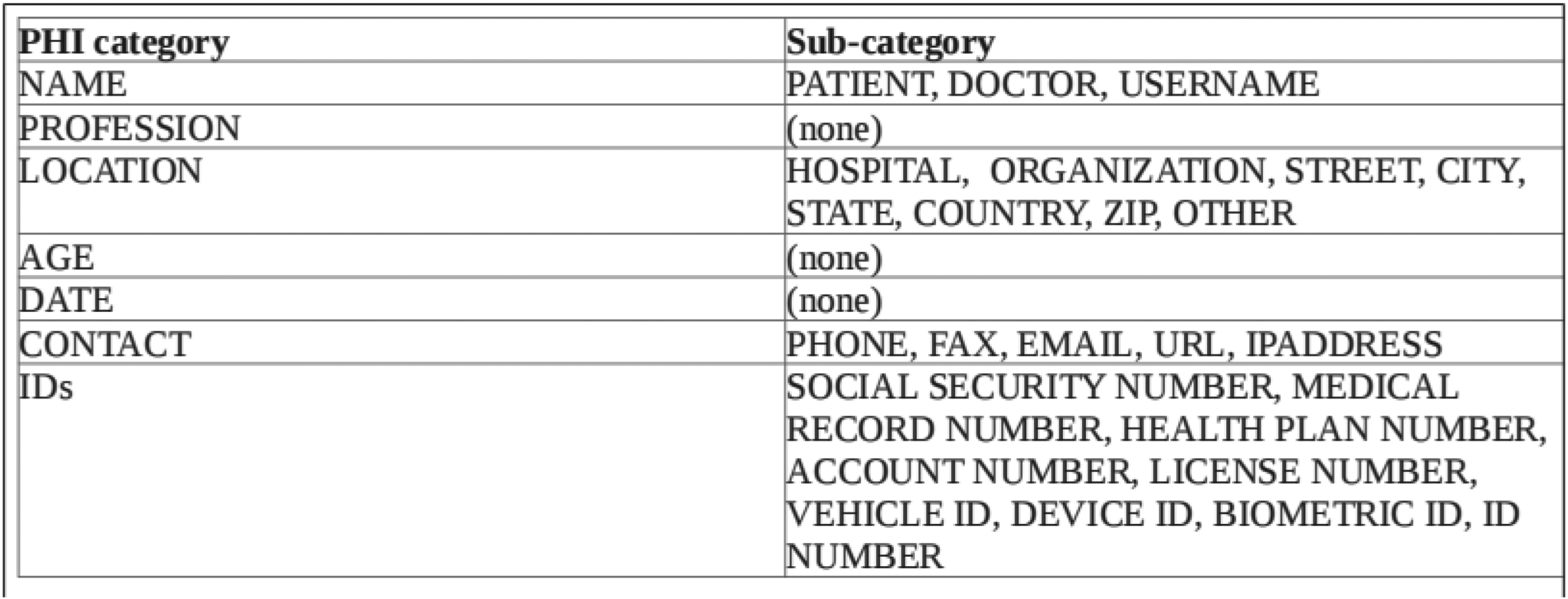
Classification of protected health information.
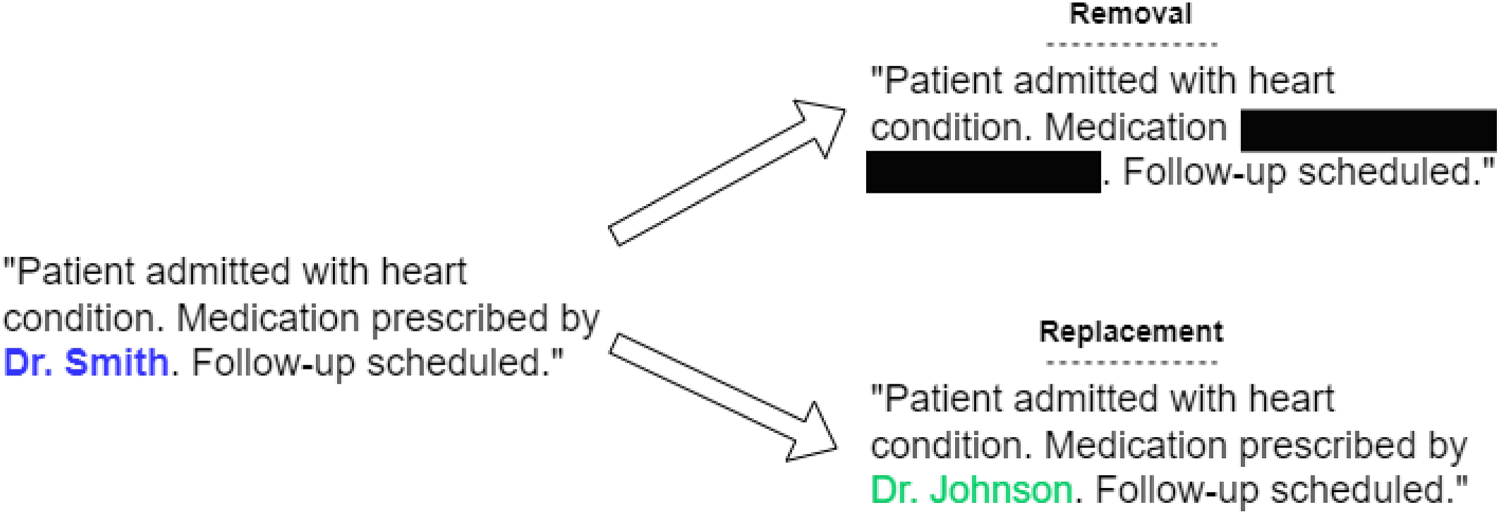
De-Identification method.
De-identification removes or obscures identifiers to protect privacy. Techniques include suppression, generalization, and data masking, with pseudo-replacement and paraphrasing emerging as promising approaches.
These methods substitute identifiable data with realistic but fictitious alternatives, maintaining semantic context and utility for downstream tasks. 19 For example, patient names or addresses can be replaced with similar fictitious ones, preserving syntactic and semantic properties critical for tasks like NLP-based diagnostics. Unlike suppression or generalization, which can remove important information, pseudo-replacement and paraphrasing retain contextual integrity, allowing meaningful analysis while minimizing re-identification risk. Paraphrasing, using advanced NLP models, ensures de-identified data remains representative of the original. 20
Research has demonstrated that these methods effectively safeguard privacy while preserving the utility of data. Transformer-based models, particularly through paraphrasing, maintain the semantic structure of the text and outperform traditional techniques by retaining readability and coherence. Therefore, pseudo-replacement and paraphrasing strike an ideal balance between protecting sensitive information and ensuring the usability of medical data, making them indispensable for future research where patient confidentiality must be maintained without compromising the quality of the datasets.
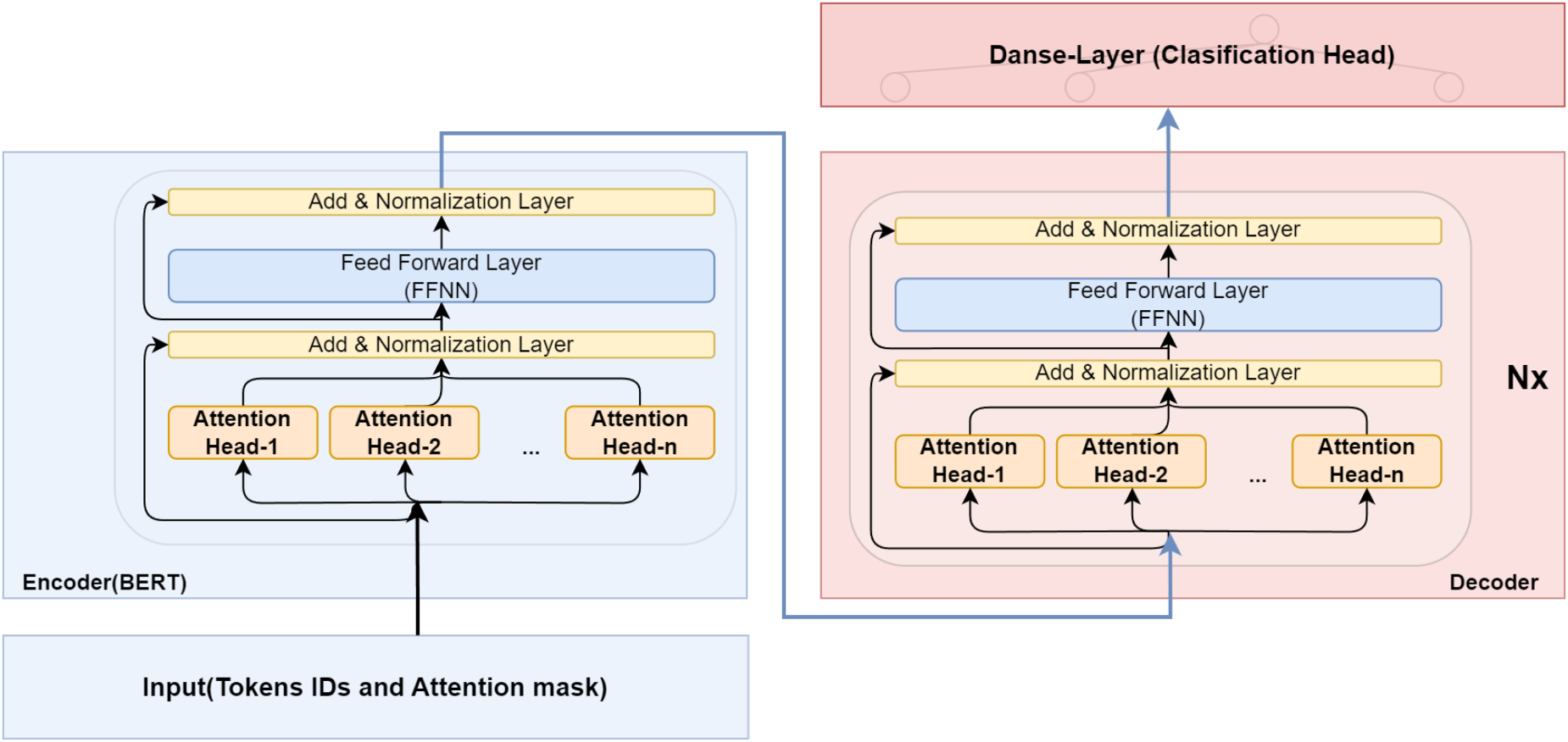
We divide the proposed model, as depicted in Figures 3 and 4, into the following components: the encoder block, transformer-decoder block, matrix of trainable parameters, and classification head.
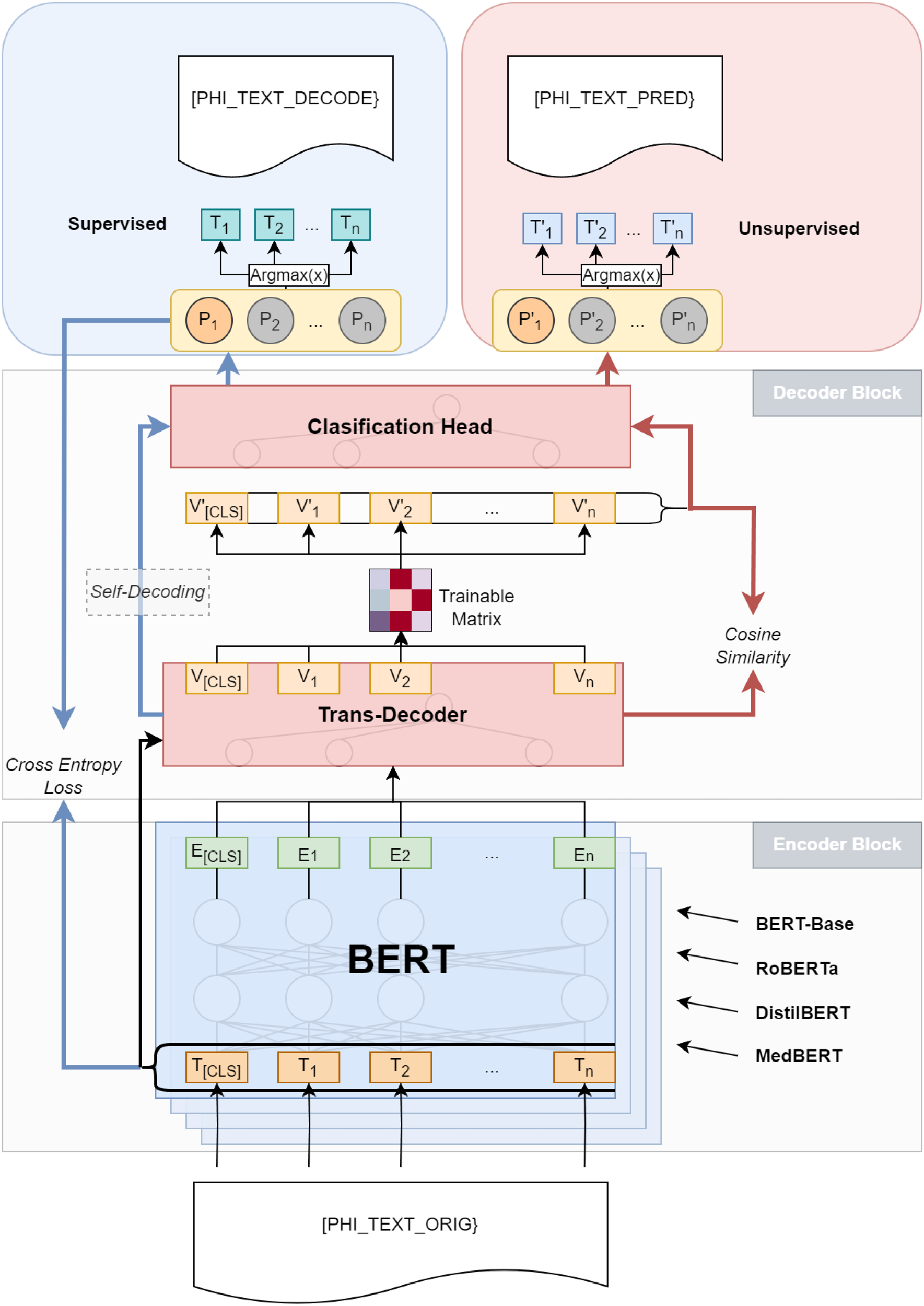
Overview of SDM-M-DID model.
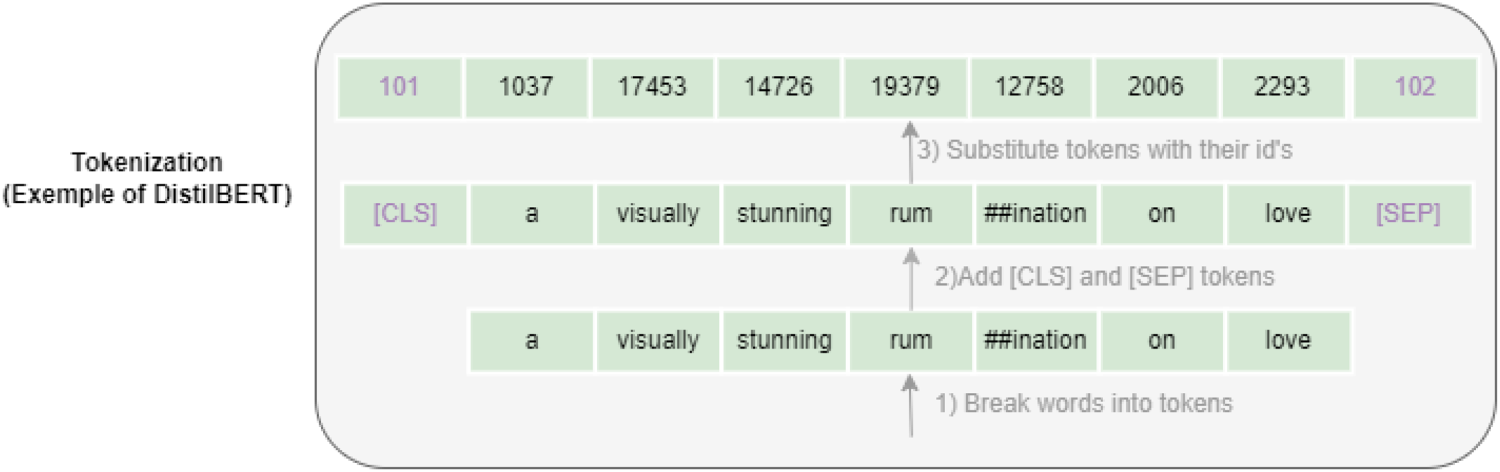
Tokenization process.
During decoder training, an auxiliary task of decoding its embeddings is performed, bypassing the trainable matrix, with embeddings directly fed into the classification head. Now we will take a closer look at each component of the model.
The model’s encoder utilizes the full BERT architecture, which involves several key steps in processing the input text.
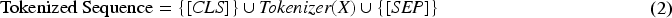


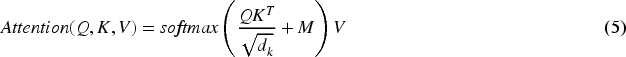
The logical structure of the encoder closely aligns with the classic transformer model’s description. The model’s input undergoes multiple layers of attention, followed by normalization, resulting in the generation of a vector for each token.
The decoder block of the proposed model represents a modified version of the original transformer architecture. A notable distinction is that our decoder does not accept additional tokens as input (as shown in Figure 5 at the bottom) like the original version; instead, it only processes the embeddings generated by the BERT encoder (depicted on the left). Furthermore, unlike the original transformer, which generates tokens sequentially, our decoder outputs the complete sequence directly through the Classification Head based on the embeddings received from the encoder.
Decoder logic overview.
The Classification Head of the model is a single full dense layer that takes one vector per token as input, multiplies it by the weights, adds a bias, and outputs it as a dictionary-sized vector where each digit is the score of the word. A dense layer (also known as a fully connected layer) is a fundamental building block in neural networks, particularly in multilayer perceptrons (MLPs). It is used to create connections between input and output data. In a Dense layer, each neuron in the current layer is connected to every neuron in the previous layer. The connections between neurons are represented by weights, which are learned during the training process.
Let

The proposed de-identification model is based on a modified transformer architecture designed to effectively anonymize sensitive information in text data. Traditional transformer models, such as the ones used in various natural language processing (NLP) applications, consist of an encoder-decoder structure with multiple attention heads and feed-forward layers that capture complex patterns and dependencies within the data. However, for the specific task of de-identification, where the goal is to replace sensitive information with suitable pseudonyms or paraphrases while preserving the overall semantic content, additional architectural modifications are necessary to enhance model performance (Figure 6).
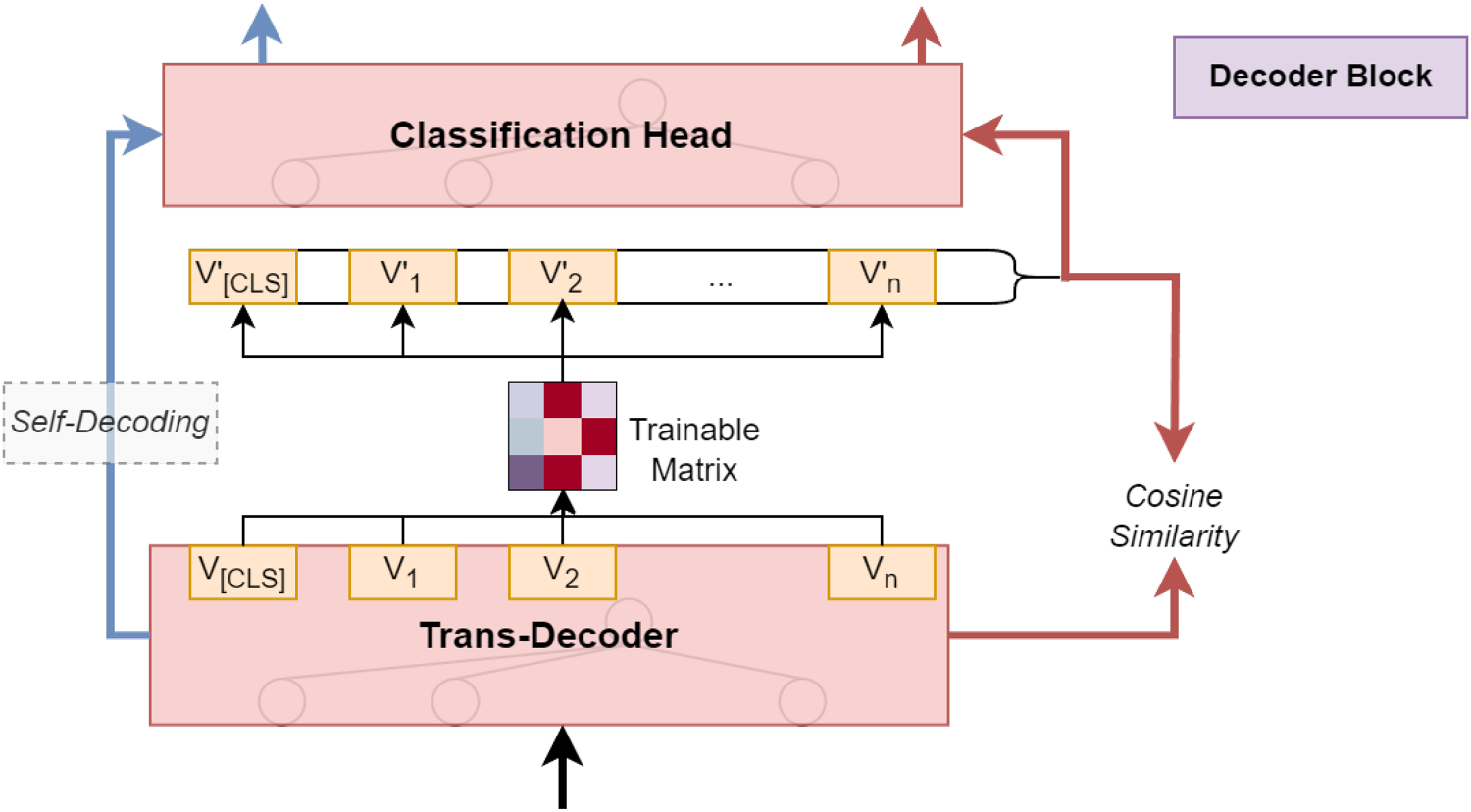
Decoder and matrix of trainable parameters.
We change the classical transformer by adding an extra layer between the classification head and the decoder. This layer, called the parameter matrix layer, takes one output – the embedding from the decoder – and modifies it for the paraphrase task. As a result, this matrix provides a new task for our model, where the model predicts tokens without the presence of original labels, similar to unsupervised learning.
Mathematically, let

As an additional task, the model performs “self-decoding.” The task involves passing the embeddings generated by the decoder directly through the classification head, without using the matrix of trained parameters, to predict the same sequence of tokens

In the de-identification task of the proposed SDM-M-DID model, it is essential to replace sensitive information with paraphrased tokens that maintain the same meaning but differ in form, thus protecting personal or institutional details. To achieve this, the primary task of token replacement is divided into two parallel subtasks, each contributing to the overall training objective.
The first subtask involves decoding the model’s own embeddings by following the classical transformer approach to token prediction. The loss function for this process is based on cross-entropy, where the predicted token is compared to the actual token. This is formalized as:
In the context of training transformer-based models, cross-entropy loss is a critical component used to optimize the model’s performance. Cross-entropy loss measures the dissimilarity between the predicted probability distribution and the true probability distribution of the target labels. It is particularly effective in classification tasks where the model predicts a probability distribution over a set of classes. For a batch of

Cross-entropy loss quantifies how well the predicted probabilities align with the actual class labels, guiding the optimization process during model training. By minimizing this loss function, the model adjusts its parameters to increase the likelihood of correctly predicting the true labels, thereby improving its performance on classification tasks (Figure 7).
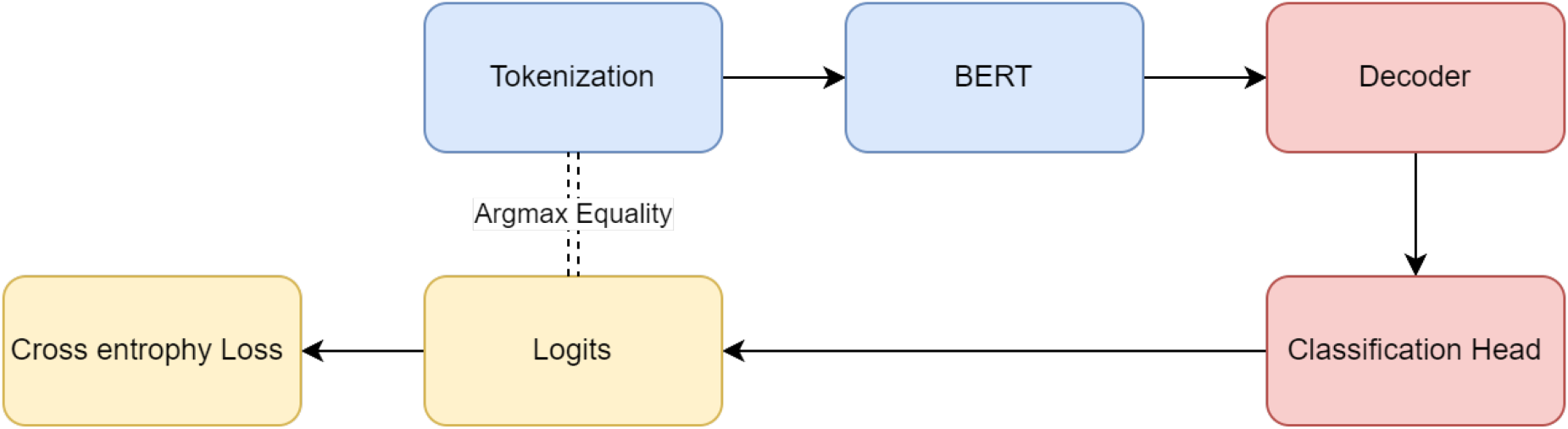
Flow chart oF self-decoding.
The second subtask addresses the challenge of replacing the sensitive token without directly providing the target label to the model. Instead, it relies on an additional parameter matrix layer, where the cosine similarity between vectors is used as the learning metric. The model incorporates cosine similarity to enforce a target similarity of
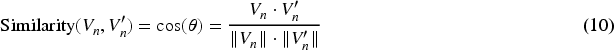
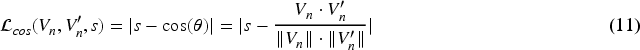
The total loss combines cross-entropy loss with cosine similarity loss to guide the model in both predicting tokens and ensuring that the replacements are semantically similar to the original:

Together, these parallel processes form the overall training objective. The model compares input tokens, converted into vectors via the BERT encoder, and generates anonymized counterparts based on vector similarity. This dual-loss approach ensures that the sensitive tokens are replaced effectively while retaining their contextual relevance. Additionally, the training process of the proposed model is demonstrated using Algorithm 1.

We build the model using components from transformer architectures that have demonstrated excellent protection against information leakage. The model will be trained using a multi-task learning method that includes two auxiliary tasks that support the main task of replacing sensitive tokens. Two datasets will be used to train the model, one small dataset and one large dataset. We will evaluate the model against the latest state-of-the-art large language models as a baseline in a similar de-identification task. Additionally, we propose a method that compares our de-identified dataset with the original dataset by processing it through two other BERT models. Furthermore, we add comparison results with previous studies using the provided script, in which the models perform an entity recognition task (NER).
Data analysis and processing
The de-identification model proposed in this study utilizes two primary datasets, both of which focus on sensitive patient information extracted from medical records. The datasets used for training and evaluation of the model are a combination of real-world and synthetic data, allowing for a robust demonstration of the model’s capabilities in anonymizing sensitive information in healthcare contexts.
The first dataset is a Natural Language Processing (NLP) research dataset, deidentification and heart disease, 21 curated by the Harvard Biomedical Informatics Department (DBMI) division. It comprises unstructured medical records from the Patient Research Data Registry (Partners Healthcare), which was initially developed during the i2b2 initiative. This dataset has been used in multiple challenges, including the n2c2 (National Clinical Challenges in NLP) series, which are designed to push forward advancements in medical NLP. Tasks in these challenges often include information extraction, text classification, and de-identification of clinical records.
For the purposes of this study, the dataset comprises 1,035 unique medical records, containing a variety of sensitive data points such as DATE, PATIENT, MEDICAL RECORD, AGE, DOCTOR, HOSPITAL, COUNTRY, STREET, CITY, STATE, ZIP, USERNAME, PHONE, ORGANIZATION, PROFESSION, LOCATION-OTHER, DEVICE, FAX, and EMAIL. The goal of de-identification is to anonymize such personal information while maintaining the semantic integrity of the medical records.
In this experiment, the focus was placed on two key types of sensitive data: PATIENT and DOCTOR, specifically targeting all possible names within the dataset. Names are considered among the most sensitive and challenging information to anonymize due to their strong identifying potential. After pre-processing the dataset and filtering for uniqueness, 3,040 name samples were extracted for tokenization, as illustrated in Tables 1 and 2. This dataset represents a real-world challenge for the de-identification model, providing a smaller, more complex test case that mirrors few-shot learning scenarios, where the model must perform well with limited and intricate data.
Characteristics of selected entities from datasets.

Characteristics of selected entities from datasets.
Token and length abbreviations.

The second dataset is a synthetic alternative, titled the Healthcare Dataset - Dummy Data with Multi-Category Classification Problem. This open dataset was created for educational purposes to help data science, machine learning, and data analytics practitioners develop skills in healthcare-related data manipulation and analysis. It consists of 10,000 synthetic patient healthcare records with attributes that mimic real-world medical data, such as patient demographics, medical conditions, and admission details. Importantly, this dataset is entirely synthetic and does not contain any real patient information, making it suitable for non-commercial and research purposes.
In total, this synthetic dataset contains 49,992 unique values, from which the de-identification model selects names as the primary focus, similar to the real-world dataset. After processing and filtering for uniqueness, 71,197 unique names were identified and extracted for de-identification.
The rationale behind using these two datasets with distinct characteristics is to demonstrate the model’s flexibility and performance under different conditions. In the first case, the real-world dataset with a smaller, more complex set of samples highlights the model’s ability to generalize and learn effectively in a few-shot learning context. In contrast, the synthetic dataset, which contains a larger number of samples, allows for a demonstration of the model’s scalability and efficiency in processing large amounts of data with fewer training epochs.
We implemented the BERT as encoder for the input sequence into the model. Four BERT-based models were used for the experiment: BERT base 9 - as the most standard general model without precise directions, RoBERTa 22 as an improved version, DistilBERT 23 as a simplified version for fast training and tuning with minimal performance loss, and MedBERT 24 as a version specially trained for working with medical data. They are used for overall performance comparison on a single de-identification task and to show the flexibility of the proposed framework in tuning to different data (Figure 8).
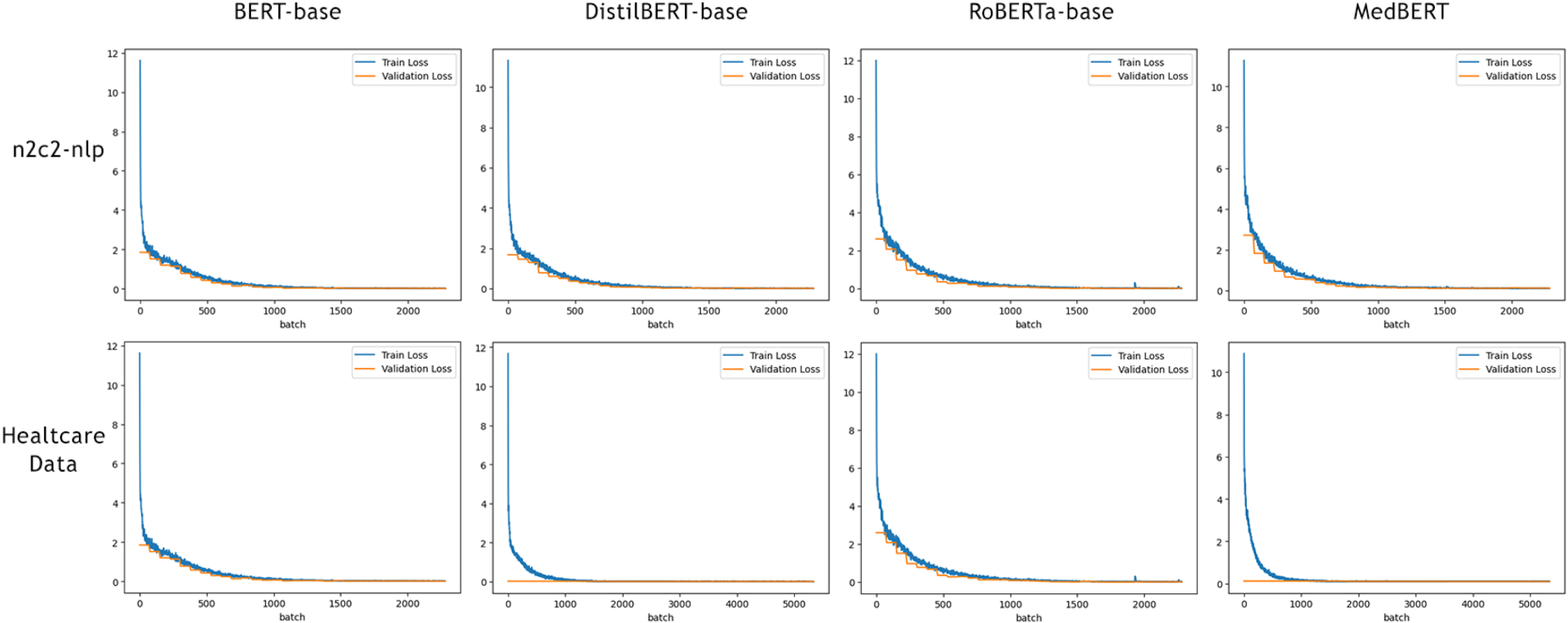
Train loss and validation loss.
The label embedding process in our model utilizes BERT architecture. The input data is tokenized using a maximum token length of 16, followed by padding to the same length. The input tensor is processed through a custom encoder-decoder structure based on a Transformer architecture with the default number of encoder layers from the original papers and 6 decoder layers with 8 attention heads. The model incorporates cosine similarity to enforce a target similarity of 0.7 between the original and modified hidden states. We trained the model for 30 epochs for n2c2 NLP Research Data Sets
21
dataset and 3 epochs for the Synthetic Medical Dataset
25
using the AdamW
26
optimizer with a learning rate of
To evaluate the encoders of the de-identification model, several metrics are employed, each targeting different aspects of token prediction accuracy. The first metric is Original length, which measures the length of the original sensitive token in characters, followed by Prediction length, which captures the length of the predicted replacement token generated by the model. Levenshtein distance is used to quantify the difference between the original and predicted tokens by counting the minimum number of single-character edits (insertions, deletions, or substitutions) required to transform one string into the other. 27 This metric is paired with the Levenshtein ratio, which normalizes the distance by dividing it by the length of the longest token, providing a proportionate view of token similarity.
Additionally, Bigram and Trigram metrics, traditionally used to compare sequences of two or three words, are adapted in this report to evaluate letter sequences instead, assessing how closely the predicted token matches the original on a character-level basis. 28 When comparing encoders, these trigrams assess the similarity of words. When comparing new large language models, they also assess diversity, that is, how much predicted words differ from each other within a single model output, indicating the diversity in the output of a language model.
The report also tracks failure cases: “Empty” tokens indicate instances where the model fails to generate any prediction, “Same” refers to cases where the model mistakenly predicts the original token, a critical error in de-identification, and “Out of dictionary” highlights situations where the model lacks the capability to predict a token due to the absence of the required vocabulary in its pre-trained dictionary. Also, to compare the model’s performance, classical NLP metrics like Precision, Recall, and F1 score 13 will be applied to evaluate how effectively the SDM-M-DID model anonymizes sensitive information (PHI) and its impact on the overall dataset.

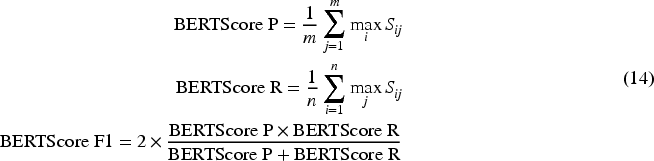
The variance in these metrics, applied to the anonymized dataset and to the new large and popular language models, will illustrate the influence of the proposed model on the performance of other models in related tasks when tested on the n2c2 dataset. These metrics together provide a comprehensive evaluation of the model’s performance across various aspects of token prediction and substitution.
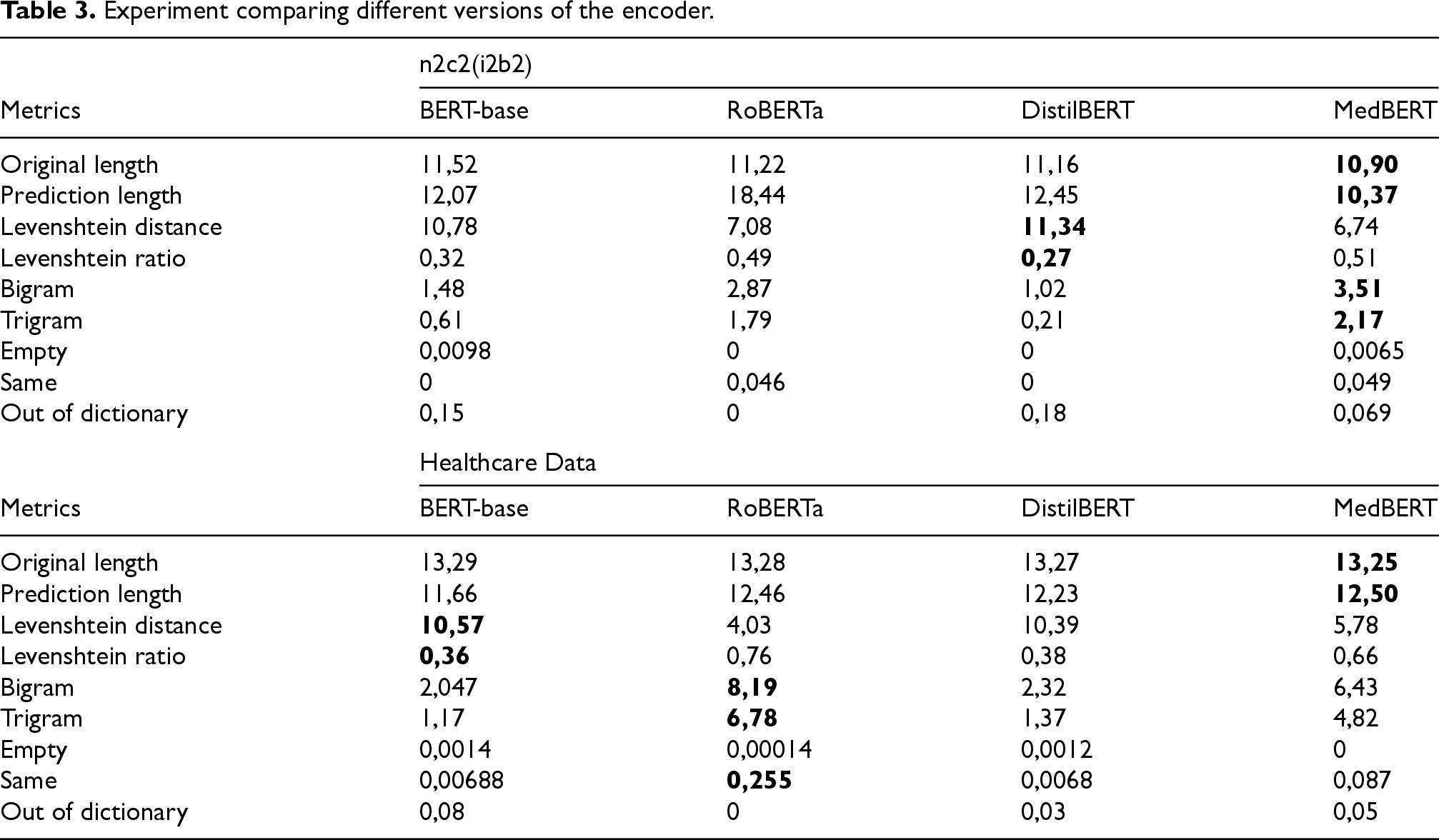
This section of the report presents the results of training the model utilizing four distinct encoder versions. The outcomes for each sensitive label are meticulously evaluated using the metrics previously discussed, with a focus on analyzing modifications at both the token and sequence levels.
The results shown in Table 3 indicate that for decoding the model’s own embedding to understand the context of a de-identified token or sequence, the difference between Original length and Prediction length should ideally be minimal. All models perform comparably well, except for RoBERTa, which displayed a higher difference on the small n2c2 dataset, signalling an error. However, when trained on a larger dataset like Healthcare Data, this difference aligns with the other encoders. MedBERT shows near-perfect accuracy in decoding its tokens.
Experiment comparing different versions of the encoder.
Experiment comparing different versions of the encoder.
The Levenshtein distance metric, which measures the minimal edits needed to transform one string into another, and the Levenshtein ratio, a normalized version expressing similarity from 0% (completely different) to 100% (identical), also warrant attention. In this metric, BERT and DistilBERT achieved good results, with around 30% similarity indicating significant changes in the strings.
Metrics like Bigram and Trigram, which measure how much the string changed after de-identification by analyzing letter sequences, show strong performance by MedBERT on small datasets and RoBERTa on larger datasets.
The remaining metrics, such as “Empty” and “Same,” help identify encoder errors and vocabulary limitations, demonstrating that RoBERTa stands out on the large dataset. Additionally, “Out of Dictionary” is almost negligible for all models, indicating their vocabularies are sufficiently comprehensive for the task.
The Tables 4 and 5 presents a comparison of our model, SDM-M-DID, with prominent large language models. We selected the SDM-M-DID version based on the MedBERT encoder from our experiments. For baselines, we chose well-known language models: Mistral 7B, developed by a “Mistral AI” company specializing in open-source language models; Llama 2 7B, created by Meta (formerly Facebook) as part of the LLaMA family for research and commercial use; TinyLlama 1.1B, an unofficial optimization project supported by communities like Hugging Face; and Phi 3.5 Mini, officially released by Microsoft.
Comparison of the proposed model with new large language models.

Medical named entity recognition using BERT and ALBERT.

Each model was tasked with de-identification through replacing sensitive sequences, as described in Table 6 (“Decoded-Predicted”). The input for all models consisted solely of a list of original sequences extracted from the n2c2 (i2b2) dataset with the system prompt: “You are a helpful assistant that communicates using JSON.” and the prompt template: “Generate a new completely different name using this example:{}.” All these large language models are quantized to 4 bits in GGUF format. 30 This allows saving computational resources, reducing memory requirements and increasing processing speed, while maintaining acceptable model accuracy.
Model output from the experiment.

This analysis demonstrates that, according to the BERTscore metrics (Precision, Recall, and F1), our model ranks among the leaders with an F1 score of 0.8416, followed by TinyLlama 1.1B with an F1 score of 0.8781. While these results may seem promising and even superior, particularly when considering only these metrics, the Same metric, which measures how often the model incorrectly predicts a sequence identical to the original, reveals a significant discrepancy. TinyLlama 1.1B shows a high error rate of 0.1579, whereas SDM-M-DID achieves a substantially lower error rate of 0.0493, and some other models even produce a result of 0.
Consequently, the 3-gram Similarity metric, which indicates the similarity of the predicted token to the original, also shows a concerning high value for TinyLlama at 0.4076, signalling a problem. In contrast, the SDM-M-DID model yields a much lower score of 0.1519, and Mistral 7B achieves an even smaller score of 0.0168.
Finally, the 3-gram Diversity metric, which evaluates the diversity in token predictions, reveals that our proposed model provides the greatest diversity, with a score of 0.9958. This means that each predicted token by the model is distinct from all other tokens predicted within the same output, demonstrating a high degree of variation and effectiveness in handling the de-identification task.
Furthermore, we will introduce a method for evaluating datasets through the application of two separately trained models, BERT and ALBERT, specifically targeting the task of Named Entity Recognition (NER). This approach allows for a comprehensive assessment of the models’ performance in recognizing entities within the modified datasets.
In Table 5, we compare the performance metrics of two models, BERT and ALBERT, on the de-identified n2c2 dataset using a pre-specified script. The key metrics evaluated are recall, precision, and the F1-measure, which serve as the primary performance indicators. The script was originally designed for research on BioELECTRA
31
and deep learning language models applied to Named Entity Recognition (NER) tasks in medical informatics. This highlights that the dataset de-identified by the proposed SDM-M-DID architecture introduces minimal changes in accuracy and overall model quality. Interestingly, the results indicate that, in certain instances, the accuracy of the model improves post-de-identification. For example, when comparing the accuracy metrics on the de-identified dataset, the BERT model demonstrated a
This variation in performance may stem from the model’s capacity to understand and process the tokens required for classification Table 6, particularly individual words or phrases. When sensitive tokens are replaced, the model may select substitute tokens that are easier to classify, utilizing a paraphrasing-like method. This could explain why pretrained models, such as BERT, occasionally perform better on the de-identified dataset. The official script with report used to make this metrics comparison is: https://github.com/a-darsh/Medical-Named-Entity-Recognition.
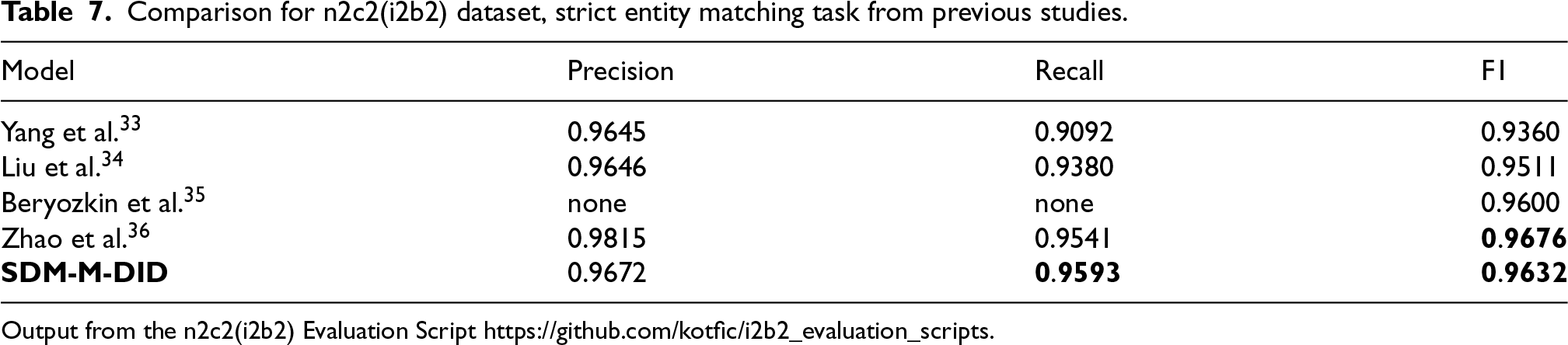
We present additional results of our model in comparative Table 7, which includes four prior studies focused on the de-identification task. The evaluation metrics used are Precision (P), Recall (R), and F1-measure (F1), as defined in equation (13). Precision measures the accuracy of positive predictions, reflecting the proportion of correctly identified sensitive entities. Recall evaluates the model’s ability to detect all actual sensitive entities. The F1-measure harmonizes these metrics, providing a single score that balances precision and recall. The primary metric, the entity-level strictly matched F1 score, requires exact alignment of entity start, end, and category with the i2b2 standards, ensuring rigorous evaluation. An official evaluation script, provided by the organizers, calculates these scores to maintain comparability across experiments. All reported results adhere to this standardized methodology, facilitating benchmarking with existing baselines in Kotfic et al. 32
Comparison for n2c2(i2b2) dataset, strict entity matching task from previous studies.
Comparison for n2c2(i2b2) dataset, strict entity matching task from previous studies.
Output from the n2c2(i2b2) Evaluation Script https://github.com/kotfic/i2b2_evaluation_scripts.
Yang et al., 33 the winners of the 2014 i2b2 de-identification challenge, utilized a combination of rule-based methods for certain types of Protected Health Information (PHI) and Conditional Random Fields (CRFs) for others. Liu et al. 34 provided a representative study on ensemble learning, comprising three models: CRF, LSTM-CRF. Beryozkin et al. 35 introduced a state-of-the-art solution for the 2014 i2b2 dataset, employing a BiRNN-CRF model with character-level RNNs, achieving an F1 score of 96.00%.
Additionally, Zhao et al. 36 combined rule-based models and were among the few to suggest using BERT-based models for de-identification tasks in future research. The comparison of previously proposed hybrid complex systems is essential for fully understanding the effectiveness of our newly proposed model, as the data is derived from the official n2c2 (i2b2) script, specifically designed to evaluate de-identification models on the dataset described earlier. The comparison indicates that our model demonstrates excellent results with an F1 score of 0.9632, only slightly behind the latest model by Zhao et al. 36 However, Zhao’s model exhibits a significant 0.3 imbalance between Precision and Recall, which, while boosting the F1 score to state-of-the-art levels, could potentially increase sensitivity-related errors. In contrast, the SDM-M-DID model achieves a nearly ideal balance of 0.96.
Furthermore, our model surpasses Beryozkin et al. 35 in F1 score by 0.032, suggesting relatively higher Precision and Recall, though these specific values were not reported by the authors. It is also important to note that, based on the original studies of the precision, recall, and F1 metrics, any value above 0.9 is considered acceptable. Given that most models demonstrate results above 0.95, and ours achieves 0.96, we can conclude that the proposed model successfully handles the de-identification task while employing more advanced and resource-efficient methods.
Our model currently masks sensitive tokens at the word level, making its performance heavily dependent on the dictionary size of the chosen encoder, which may introduce errors. All experiments were conducted exclusively on English data, leaving its effectiveness in other languages unknown. Additionally, this study did not aim to develop a new NER algorithm. Lastly, like many machine learning models, there is limited transparency regarding which components enhance task performance after training and which should remain unchanged to prevent potential performance degradation.
A future direction of this work is to extend the research by exploring more complex methods for assessing the accuracy of paraphrasing and enhancing the model through the testing of newer, relatively secure encoders. These advancements aim to unlock the potential of paraphrasing sensitive information at the sentence level. We are also exploring the integration of explainable artificial intelligence (XAI) techniques, leveraging our model’s self-decoding mechanism. This approach aims to enhance our understanding of how specific model components contribute to improved contextual comprehension. One potential XAI method involves visualizing embeddings through PCA 2 compression algorithms, offering insights into model behavior during training.
Conclusion
This study presents a self-decoding model for medical de-identification (SDM-M-DID) Figure 3, based on a method of identical replacement of sensitive entities, analogous to paraphrasing, using BERT as an encoder and a modified decoder for the self-decoding subtask. The integration of a decoding method with its own embeddings plays a crucial role, as it allows the model to create a separate contextual representation of the token sequence (sensitive information) without the need for training on large datasets, complex additional NLP algorithm adjustments, or a feedback loop, as seen in other large language models.
The developed mechanisms enable fine-tuning of the model for various types of sensitive information, relying on pre-trained dictionaries of replaceable encoders and parameter settings for cosine similarity, equation (11), between original and output tokens, transformed into vectors. Rigorous experiments designed to obtain precise data on the modification of each sequence (Table 3), direct comparison with new large language models (Table 4) and direct comparisons between the new anonymized dataset and the original on entity recognition tasks in Table 5, demonstrate the substantial potential of the proposed model. The results show that the model’s impact on the quality of the anonymized dataset is minimal, and in some cases, accuracy can even increase by 1-2%, as observed in the experiment with the basic BERT model.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article.
Conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The large dataset “Healthcare Data” used to train the model can be found at the following URL: https://www.kaggle.com/datasets/prasad22/healthcare-dataset. The n2c2(i2b2) dataset is not publicly available as it requires registration on the official website ![]() . To generate the n2c2 de-identified version, an algorithm must be applied to systematically replace sensitive entities in the original labeled n2c2 dataset with the corresponding outputs generated by the SDM-M-DID model.
. To generate the n2c2 de-identified version, an algorithm must be applied to systematically replace sensitive entities in the original labeled n2c2 dataset with the corresponding outputs generated by the SDM-M-DID model.
The official script for metrics comparison and models source page :