
Abstract
In the rapid development of artificial intelligence, multimodal large models (VLM) have led a new wave of technological progress with their revolutionary breakthroughs in the field of natural language processing (NLP). In the wave of artificial intelligence, on-device multimodal large models (On-Device VLM) are becoming the new favourites of technological innovation with their rapid development speed and broad application prospects, and the demand for on-device inference is growing. This study conducts in-depth adaptation and optimization of multimodal large models on the Neural Network Processing Unit (NPU) based on the Qualcomm platform. By adopting the QNN (Qualcomm Neural Network) framework and model compression techniques such as quantization, pruning, knowledge distillation, low-rank factorization, and Lookahead decoding, efficient inference acceleration on Qualcomm NPU is achieved, significantly improving the model’s response speed and decoding efficiency. Experimental results show that the optimized model has significant improvements in first response time and decoding speed, providing a new solution for on-device AI applications.
Keywords
Introduction
In recent years, the rise of multimodal large models has driven innovation and application of AI technology across various fields, making interactions more intelligent and natural. Simultaneously, the rapid development of NPU technology and products has pushed AI technology from the cloud to the edge and devices, enabling more efficient and intelligent multimodal processing and providing strong support for various innovative applications. Under this development trend, the application of multimodal large models on NPUs may establish new interaction paradigms, offering users a more natural, efficient, and personalized interaction experience. Through NPU acceleration, multimodal large models can quickly integrate information such as voice, images, and text upon receiving user input, and provide instant feedback. Multimodal large models can handle various input forms such as speech, visual, and text simultaneously, making human-computer interaction more natural. Leveraging the powerful processing capability of NPUs, these models can analyze user behaviour, habits, and preferences in real time, offering highly personalized interaction experiences. The system can adapt its interaction methods to user needs, making them more aligned with user expectations. Multimodal large models can integrate information from different modalities for more complex understanding and reasoning. For example, in a smart home environment, the system can combine video surveillance, voice commands, and sensor data to make smarter decisions, such as automatically adjusting the indoor environment or identifying emergency situations and notifying users promptly. With the computational advantages of NPUs, multimodal large models in areas like Artificial Intelligence Generated Content (AIGC), virtual reality (VR), augmented reality (AR), and embodied intelligence could bring about entirely new interaction experiences, ensuring highly immersive experiences. Multimodal large models can achieve seamless cross-device and cross-platform interaction with NPU support. For instance, among smartphones, tablets, computers, and smart home devices, users can seamlessly switch and interact with the system through various means like voice, vision, and touch. However, achieving efficient and accurate model inference with limited hardware resources is a significant challenge in current research. This paper explores in-depth the NPU inference optimization on the device side, focusing on the adaptation of multimodal large models for the Qualcomm platform. The main research directions in the field of device-side NPU inference optimization include model compression, hardware acceleration, and algorithm optimization, among others. Existing techniques primarily include quantization, pruning, and low-rank decomposition. In recent years, researchers have achieved significant results in these areas, such as model size reduction and inference speed improvement. Nonetheless, balancing model accuracy and inference efficiency on resource-constrained device-side equipment remains a pressing issue.
In the realm of edge NPU inference optimization, prior research has made significant progress. Here are some representative works along with their strengths and weaknesses: Literature Zhou et al. 1 proposed a quantization-based device-side NPU inference optimization method, significantly enhancing inference speed by reducing the bit-width of model parameters. Its simplicity and applicability to various hardware platforms are its strengths. However, quantization can lead to notable accuracy loss, especially in complex models. Literature Luo et al. 2 used pruning techniques to remove redundant connections in the model, effectively reducing model complexity. While maintaining high accuracy and reducing parameters and computations were beneficial, the complex pruning strategies and poor adaptability to different model architectures were the downsides. Literatures Wang et al., 3 Chen et al. 4 employed low-rank decomposition techniques to optimize model weights, reducing the number of parameters and improving inference efficiency. This method effectively reduced model size but posed a high computational complexity during decomposition, which was not conducive to real-time needs on device-side equipment. Literature Li et al. 5 customized inference optimization for specific hardware platforms, achieving good acceleration effects by fully exploiting hardware characteristics. However, its poor generalizability made it difficult to extend to other platforms. Literatures Gao et al. 6 proposed a device-side NPU inference optimization method based on knowledge distillation, where knowledge from a large model was transferred to a smaller model, reducing model size while maintaining high accuracy. Despite its effectiveness, knowledge distillation required careful design, and small models sometimes struggled to fully inherit knowledge from larger models in complex tasks. Literature Huang et al. 7 explored using hardware-aware compilation technologies to optimize model inference on NPUs, improving inference efficiency through automatic graph adjustment and operator fusion. Its strengths included automated model optimization based on hardware characteristics, but it had limited generalizability and required redesign and adjustment across different hardware platforms and model structures, making the optimization process quite complex for ordinary users to grasp.
Literature Sharma et al. 8 also discussed using Neural Architecture Search (NAS) to automatically design model structures suitable for device-side NPUs, striking a balance between model performance and computational cost while customizing network structures for specific hardware platforms. However, NAS processes were extremely resource-intensive, and the design of the search space heavily influenced the final results, potentially leading to overly complex model structures that hindered efficient inference on actual hardware. Comparing existing research, we find that studies on multimodal large model inference on Qualcomm NPUs are relatively sparse and have gaps. Specifically, optimization strategies for Qualcomm NPUs lack systematization and struggle to balance inference speed and accuracy. Furthermore, current technologies inadequately address energy consumption and real-time requirements on device-side equipment, failing to meet practical application needs.
Based on the above analysis, this study aims to fill the research gap in adapting multimodal large models for the Qualcomm platform and contributes the following innovations and potential benefits: Proposing a device-side inference optimization method suited for multimodal large models on Qualcomm NPUs, balancing inference speed and accuracy.
Combining techniques such as quantization and pruning to improve inference speed while maintaining high accuracy. Comparing the advantages and disadvantages of this method with existing research results, providing new ideas for device-side NPU inference optimization. This paper will elaborate on the above topics, aiming to contribute to the development of the device-side NPU inference optimization field.
The remainder of this paper is structured as follows: Section 2 provides a detailed background on multimodal large models and the challenges associated with their deployment on edge devices. Section 3 delves into the methodology employed for optimizing these models on the Qualcomm NPU, including model compression techniques such as quantization, pruning, and knowledge distillation. Section 4 presents the experimental setup, results, and analysis, showcasing the performance improvements achieved with our optimization strategies. Finally, Section 5 concludes the paper with a summary of our findings, discusses the limitations of the current study, and outlines potential directions for future research.
Research foundation
Multimodal Large Models (Vision-Language Models, VLMs) combine visual and language processing capabilities and can operate on terminal devices such as smartphones, tablets, and smart devices. VLMs demonstrate their powerful capabilities in various application scenarios, including Augmented Reality (AR), Virtual Reality (VR), smart cameras, autonomous driving, smart homes, medical diagnosis, and educational assistance.
Inference Requirements and Challenges on Deploying VLMs on edge devices requires high performance and efficiency while facing several challenges:
Data Synchronization and Fusion: Handling and integrating different modalities of data (such as text, images, audio, and video) necessitate efficient temporal alignment and feature extraction techniques.
Model Compression and Acceleration: Multimodal Large Models are usually very large, requiring compression and acceleration processing when deploying on hardware such as NPUs to reduce memory usage and computational delay.
Hardware Compatibility: NPU hardware architectures are diverse, with varying performance across different models and manufacturers. Optimization for different platforms is necessary.
Real-time and Low Latency: High real-time performance and low latency are essential requirements for many applications, such as voice assistants and AR.
Cross-Platform Consistency: Designing flexible architectures that allow models to migrate across platforms while maintaining consistent user experiences is required.
Data Privacy Protection: Ensuring user privacy when handling multimodal data by implementing local processing and privacy protection algorithms.
Continuous Model Updates: Multimodal models need frequent updates to adapt to new scenarios and user demands, requiring efficient training and updating mechanisms.
NPUs (Neural Processing Units) are specifically designed for neural network processing, offering high throughput, energy efficiency, and scalability. NPUs excel in handling complex AI computation tasks, making them particularly suitable for edge applications requiring real-time responses. Model Compression and Acceleration Techniques: To efficiently run VLMs on NPUs, the following five key model compression and acceleration techniques are discussed:
Quantization: Reducing the precision of model weights and activations to decrease model size. Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT) are applied after and during model training, respectively, to ensure high accuracy after quantization. Model Pruning: Reducing model complexity by removing redundant parameters and structures, including structured pruning and unstructured pruning, which removes entire layers, channels, or individual weights. Knowledge Distillation: Transferring knowledge from a large model to a smaller model. Black-box Distillation (Black-box KD) and White-box Distillation (White-box KD) use the outputs and internal states of the teacher model, respectively, for learning. Low-Rank Decomposition: Breaking down large matrices into smaller matrix products to reduce computational complexity. Common techniques include Singular Value Decomposition (SVD) and optimization methods based on low-rank compensation strategies. Lookahead Decoding: In sequence-to-sequence (seq2seq) model decoding, looking several steps ahead to improve decoding quality. Usually combined with beam search to handle the complexity of processing long sequences.
Role of Hardware Accelerators: Hardware accelerators like GPUs and NPUs are crucial for deploying VLMs on edge devices. NVIDIA’s Tensor Cores and Google’s TPUs provide robust computational power, while FPGAs demonstrate high efficiency through sparse matrix multiplication and quantization techniques. Software and hardware co-design methods, such as quantization-aware training and model compression, further enhance VLM efficiency, enabling deployment from high-power servers to low-power edge devices.
The successful deployment of multimodal large models on edge devices requires systematic optimization and multidisciplinary collaboration. Techniques like quantization, pruning, knowledge distillation, low-rank decomposition, and lookahead decoding enable efficient compression and acceleration of models. Leveraging the powerful computational capabilities of NPUs, these approaches promote intelligent, personalized, and efficient AI interaction experiences.
Methodology
Advanced Model Optimization Techniques and Implementation on Qualcomm NPU
Model Pruning Model pruning9–13 reduces the complexity of neural networks by removing redundant connections and parameters. This is particularly useful for optimizing deep learning models for edge devices with limited computational resources. Types of Pruning: Weight Pruning: Removes model parameters (weights) with minimal contribution to performance. Structured Pruning: Eliminates entire structures such as neurons, filters, or layers. Advantages: Reduces model size and computational overhead. Lowers power consumption, which is highly critical in energy-constrained automotive systems. Speeds up inference for real-time applications like autonomous driving. Implementation on Qualcomm NPU: By using QNN’s pruning tools, filter pruning can streamline convolutional layers, while structural pruning eliminates unnecessary dense connections, maintaining accuracies with low error margins. Pruning Metrics: Complexity is measured as:

Types of PruningWeight Pruning: Removes model parameters (weights) with minimal contribution to performance.Structured Pruning: Eliminates entire structures such as neurons, filters, or layers AdvantagesReduces model size and computational overhead. Lowers power consumption, which is crucial in energy-constrained automotive systems.Speeds up inference for real-time applications like autonomous driving. Implementation on Qualcomm NPU Qualcomm NPU can optimize convolutional layers through filter pruning using QNN’s pruning tools, while structural pruning can eliminate unnecessary dense connections, maintaining accuracy with low error margins. Pruning MetricsThe complexity of the model can be measured using the following formula:
Pruning and Overfitting and Generalization CapabilitiesPruning not only reduces model size and computational overhead but also mitigates the risk of overfitting by reducing the number of model parameters. Overfitting occurs when a model performs well on training data but poorly on unseen data. By pruning, the model becomes more concise, thereby enhancing its generalization capability, which is the model’s ability to perform well on unseen data. In edge device deployment, pruning is particularly important due to the higher risk of overfitting in resource-constrained environments. By pruning, smaller models are created that perform better in resource-limited settings while maintaining high accuracy. Model Optimization: QNN offers a range of model optimization tools, such as quantization, pruning, and knowledge distillation, which significantly improve inference speed and efficiency on edge devices. Hardware Acceleration: QNN is tightly integrated with Qualcomm NPUs, leveraging the hardware’s parallel processing capabilities for efficient model inference. Low Latency: QNN reduces inference latency through optimized model structures and algorithms, making it suitable for real-time applications. Cross-Platform Compatibility: QNN supports various Qualcomm NPU architectures, ensuring that models can run efficiently on different hardware platforms. Ease of Use: QNN provides user-friendly APIs and tools, making it easy for developers to optimize and deploy deep learning models. QNN enhances inference efficiency on edge devices through the following mechanisms: Quantization: By reducing the precision of model weights and activations, QNN decreases model storage and computational requirements, thereby improving inference speed. Pruning: By removing redundant connections and parameters in the model, QNN reduces model complexity, enhancing inference speed. Knowledge Distillation: By transferring knowledge from a large model to a smaller one, QNN maintains model accuracy while reducing complexity. Hardware-Aware Compilation: QNN automatically adjusts model structures and algorithms based on hardware characteristics to achieve optimal inference performance. Low Latency Optimization: QNN optimizes model structures and algorithms to reduce inference latency, making it suitable for real-time applications.Through these mechanisms, QNN significantly improves inference efficiency on edge devices, making them suitable for various real-time applications such as autonomous driving, smart cameras, and voice assistants. The unique advantages of multimodal large models in device-side AI applications:
Enhanced Data Interaction Intelligence: Multimodal large models can simultaneously process and integrate data from different modalities, such as text, images, audio, and video. This capability enables devices to understand and respond to user needs more intelligently, providing more accurate feedback and a more natural interaction experience. Multitasking Capability: Multimodal large models can perform multiple tasks simultaneously, such as image recognition, speech recognition, and natural language processing. This multitasking capability allows devices to handle complex tasks more efficiently, improving overall performance and efficiency. Enhanced User Experience: Through multimodal large models, devices can provide more personalized and enriched user experiences. For example, in a smart home environment, devices can combine video surveillance, voice commands, and sensor data to offer more intelligent services, such as automatically adjusting the indoor environment or identifying emergency situations and promptly notifying users. Reduced Latency and Improved Response Speed: Deploying multimodal large models on the device side can significantly reduce data transmission latency and improve response speed. This is crucial for real-time applications, such as autonomous driving and smart assistants. Improved Data Privacy and Security: Processing data on the device side can reduce the risk of data leakage and enhance data privacy and security. This is particularly important for applications dealing with sensitive information. Reduced Energy Consumption: By optimizing model structures and algorithms, multimodal large models can run efficiently on the device side, reducing energy consumption. This is particularly important for battery-powered devices, such as smartphones and smartwatches. Increased Scalability and Flexibility: Multimodal large models can be easily scaled to different application scenarios and hardware platforms, providing flexible solutions. Through these advantages, multimodal large models demonstrate significant potential in device-side AI applications, offering users more intelligent, efficient, and personalized interaction experiences. The Qualcomm Neural Processing SDK (QNN) framework leverages the hardware support and software toolchain of the Qualcomm NPU to significantly optimize model inference efficiency, achieving notable improvements in energy consumption, latency, and memory usage. Here’s a detailed explanation of how QNN accomplishes these optimizations:
Hardware Acceleration: The QNN framework is tightly integrated with the Qualcomm NPU, fully utilizing the hardware’s parallel processing capabilities. The Qualcomm NPU is designed for deep learning tasks, featuring efficient compute cores and optimized memory access patterns, enabling QNN to accelerate the model inference process. Model Optimization: QNN provides a suite of model optimization tools, such as quantization, pruning, and knowledge distillation. These tools significantly reduce the computational requirements of the model, thereby lowering energy consumption and memory usage. For instance, quantization reduces the precision of model parameters, while pruning removes redundant connections and parameters. Low Latency Optimization: QNN reduces inference latency by optimizing model structures and algorithms. This is crucial for real-time applications like autonomous driving and smart assistants. QNN’s optimization tools ensure that models maintain high accuracy while achieving low-latency inference. Energy Consumption Optimization: By optimizing model structures and algorithms, QNN can lower the energy consumption of the model. This is particularly important for battery-powered devices like smartphones and smartwatches. QNN’s optimization tools ensure that models maintain high accuracy while achieving low-energy inference. Memory Usage Optimization: QNN reduces the memory usage of the model by optimizing model structures and algorithms. This is crucial for devices with limited memory resources, such as embedded systems and IoT devices. QNN’s optimization tools ensure that models maintain high accuracy while achieving low-memory usage inference. Cross-Platform Compatibility: QNN supports various Qualcomm NPU architectures, ensuring that models can run efficiently on different hardware platforms. This allows developers to easily deploy models on different devices without extensive modifications and optimizations. Ease of Use: QNN provides user-friendly APIs and tools, making it easy for developers to optimize and deploy deep learning models. This reduces development costs and improves development efficiency. Through these optimizations, the QNN framework significantly improves model inference efficiency, reduces energy consumption, latency, and memory usage, providing an efficient solution for device-side AI applications. Pruning, quantization, and knowledge distillation are model compression techniques that can be specifically adapted to the Qualcomm NPU to enhance model inference efficiency on the device side. Here’s a detailed description of how these techniques are adapted to the Qualcomm NPU:
Pruning: Pruning reduces model complexity by removing redundant connections and parameters. When adapted to the Qualcomm NPU, pruning can leverage the NPU’s parallel processing capabilities to accelerate the pruning process. Moreover, the pruned model can better utilize the hardware features of the NPU, such as optimized memory access patterns and efficient compute cores, thereby enhancing inference speed. Quantization: Quantization reduces the storage and computational requirements of the model by decreasing the precision of model weights and activations. When adapted to the Qualcomm NPU, quantization can leverage the NPU’s low-precision compute capabilities to accelerate model inference. Additionally, the quantized model can better utilize the NPU’s hardware features, such as optimized memory access patterns and efficient compute cores, further enhancing inference speed. Knowledge Distillation: Knowledge distillation transfers knowledge from a large model to a smaller one, maintaining accuracy while reducing complexity. When adapted to the Qualcomm NPU, knowledge distillation can leverage the NPU’s parallel processing capabilities to accelerate the distillation process. Furthermore, the distilled model can better utilize the NPU’s hardware features, such as optimized memory access patterns and efficient compute cores, thus enhancing inference speed. Motivation for Technique Selection: The choice of pruning, quantization, and knowledge distillation as model compression techniques is driven by their ability to significantly reduce model complexity, thereby improving model inference efficiency on the device side. Moreover, these techniques can better utilize the hardware features of the Qualcomm NPU, such as optimized memory access patterns and efficient compute cores, further enhancing inference speed. Utilization of Hardware Support: The hardware support of the Qualcomm NPU can be leveraged in the following ways: Parallel Processing Capabilities: The Qualcomm NPU features efficient parallel processing capabilities, which can accelerate the model compression processes of pruning, quantization, and knowledge distillation. Optimized Memory Access Patterns: The Qualcomm NPU has optimized memory access patterns, which can accelerate the model inference process. Efficient Compute Cores: The Qualcomm NPU is equipped with efficient compute cores, which can accelerate the model inference process.Through these adaptations, pruning, quantization, and knowledge distillation can be specifically tailored to the Qualcomm NPU, enhancing model inference efficiency on the device side. In discussing the potential issues of computational overhead memory usage and solution: Computational Overhead: Deep learning models typically require significant computational resources, especially during training and inference. This can lead to high computational overhead, affecting device performance and efficiency. For example, in real-time applications like autonomous driving and smart assistants, high computational overhead can result in increased latency, impacting user experience. Memory Usage: Deep learning models often require large amounts of memory to store model parameters and intermediate computation results. This can lead to high memory usage, affecting device performance and efficiency. For example, in memory-constrained devices like embedded systems and IoT devices, high memory usage can lead to slow device operation or crashes. To mitigate these issues, the following measures can be taken:
Hardware-Specific Optimization: By optimizing for specific hardware, computational overhead and memory usage can be significantly reduced. For example, the Qualcomm Neural Processing SDK (QNN) provides hardware-specific optimization tools, such as quantization, pruning, and knowledge distillation, which can significantly reduce the computational requirements of the model, thereby lowering computational overhead and memory usage. Reducing Unnecessary Computational Burden: By optimizing model structures and algorithms, unnecessary computational burden can be reduced. For example, pruning techniques can remove redundant connections and parameters in the model, thereby reducing computational requirements. Additionally, quantization techniques can reduce the precision of model parameters, thereby reducing computational requirements. Memory Management: By optimizing memory management, memory usage can be reduced. For example, memory pooling techniques can be used to pre-allocate memory blocks, avoiding frequent memory allocation and deallocation operations. Additionally, memory compression techniques can be used to reduce memory usage. Parallel Processing: By leveraging the parallel processing capabilities of the hardware, the model inference process can be accelerated. For example, the Qualcomm NPU has efficient parallel processing capabilities, which can accelerate the model inference process. Model Compression: Through model compression techniques, such as pruning, quantization, and knowledge distillation, the computational requirements of the model can be significantly reduced, thereby lowering computational overhead and memory usage.Through these measures, the potential issues of computational overhead and memory usage can be effectively mitigated, enhancing inference efficiency on the device side.
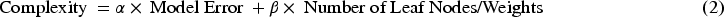
Knowledge distillation14–17 enables the creation of smaller, lightweight models (”students”) by transferring knowledge from larger, pre-trained models (”teachers”).
Core Mechanism: Relies on the teacher model’s output probabilities (soft targets) to guide student models. Additionally, attention or feature maps can be leveraged for deeper representation learning. Advantages: Maintains high accuracy while drastically reducing model size. Ideal for multi-modal applications (e.g., combining vision, LiDAR, and radar data in vehicles) where smaller models are essential for efficient processing. Loss Function: Distillation loss combines both the teacher-student divergence and student loss:
Implementation on Qualcomm NPU: Student models trained using Qualcomm’s SDK can utilize attention-based distillation for feature alignment or probabilistic distillation for diverse AI tasks like speech recognition or object detection.
Brief Explanation of the Working Principle of Knowledge Distillation:
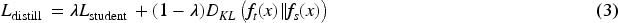
Knowledge Distillation (KD) is a model compression technique that aims to transfer the ”knowledge” from a larger and more complex teacher model to a smaller and more lightweight student model. By doing so, the student model can achieve a comparable level of performance to the teacher model while significantly reducing complexity and storage requirements.
The teacher model is typically a well-trained, high-performing model with a complex architecture, while the student model is a simplified version designed for better inference efficiency. The core idea of knowledge distillation is to train the student model not only on the ground-truth labels (hard labels) from the dataset but also on the output probability distributions (soft labels) generated by the teacher model. These soft labels carry richer information, such as the relative similarities between different classes, which helps the student model learn more effectively.
The objective function in knowledge distillation is often a weighted combination of the standard cross-entropy loss and a distillation loss:
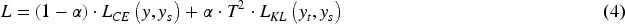
By iteratively optimizing this objective function, the student model can efficiently learn the complex knowledge of the teacher model.
Specific Applications of Knowledge Distillation in Multimodal Model Compression and Optimization
In multimodal model scenarios (e.g., vision-language models, audio-video fusion models), knowledge distillation can significantly enhance efficiency. Below are some specific examples of its application in compressing and optimizing multimodal large models:
Distillation for Multimodal Transformers Multimodal models (e.g., vision-language models) often employ a large number of Transformer modules, which result in high computational and memory demands. Knowledge distillation can optimize such models as follows: The teacher model is a full-sized multimodal Transformer, while the student model is a reduced version with fewer Transformer layers or lower-dimensional parameters (e.g., through pruning or dimensionality reduction). At the input level, the student model learns the interaction attention weights of the teacher model to retain semantic fusion capabilities while reducing computational complexity. Example: For vision-language pre-trained models like CLIP or LXMERT, distilling attention distributions and predictions from the teacher model allows for creating compressed models deployable on edge devices. Modality-specific Distillation For multimodal tasks (e.g., image captioning or video question answering), multimodal models often consist of unimodal encoders (e.g., vision encoder, language encoder) and a fusion module. Knowledge distillation can optimize these models by: Training the student model to learn the teacher model’s feature extraction capabilities within each specific modality. Learning cross-modal interaction information from the teacher model in the fusion module. Example: In video question answering tasks, a student model can distill the teacher model’s visual understanding (e.g., action detection) and language comprehension (e.g., question parsing), significantly compressing the cross-modal reasoning components. Improving Multimodal Inference Efficiency for Edge Devices Multimodal large models often suffer from long inference latency and high energy consumption, making deployment on edge devices challenging. Knowledge distillation can help by: Compressing the original large model into a lightweight student model that retains critical feature extraction modules, optimized for resource-constrained edge devices. Selecting only relevant outputs from the teacher model during distillation to reduce the computational requirements of the student model. Example: In multimodal AI assistants, the attention mechanisms and intermediate features from teacher models can be distilled into compact student models to enable real-time processing on edge hardware. Distillation for Hotspot Classes In multimodal classification tasks, some classes may be more relevant to specific user needs, while others are less frequently used. Knowledge distillation can optimize the model for these ”hotspot classes” by: Training the teacher model comprehensively across all categories but fine-tuning the student model to focus on high-probability classes. Example: For scene detection in edge devices (e.g., smart home cameras), student models can be optimized to efficiently recognize common scenes (e.g., indoor, outdoor) while deprioritizing others. Through knowledge distillation, multimodal models can achieve significant reductions in computational complexity and memory requirements without sacrificing much of their performance. This makes knowledge distillation an essential tool in compressing and optimizing multimodal models for efficient deployment in diverse real-world applications, particularly on resource-constrained edge devices. In future applications, knowledge distillation will continue to be a key technique in enabling high-performance cross-modal understanding and reasoning.
Dynamic Quantization
Dynamic quantization
18
compresses models by reducing the precision of computations, leading to smaller models that run faster during inference.
Key Processes: Floating-point weights and activations are dynamically converted into low-precision representations (e.g., INT8 or INT4). Unlike static quantization, dynamic quantization adapts at runtime to input data properties. Advantages: Reduces computational latency and memory usage. Highly efficient on Qualcomm NPUs optimized for low-bit precision arithmetic. Quantization Workflow: Scale Factor Calculation:
Implementation on Qualcomm NPU: Dynamic quantization integrates seamlessly into layer computation graphs in the QNN framework, ensuring highly accelerated performance on inference workloads.
Detailed Explanation of Qualcomm Hardware’s Specific Features for Supporting Dynamic Quantization
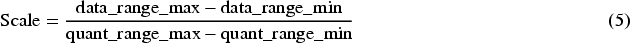


Dynamic quantization is a widely used technique in model compression and optimization, where the precision of weights and activations is dynamically reduced (e.g., from FP32 to INT8 or INT4) during runtime. By employing low-bit precision such as INT8 or INT4, dynamic quantization reduces memory footprint and computational demand, significantly improving inference efficiency without substantial loss of accuracy.
Qualcomm hardware, particularly its NPUs integrated into Snapdragon System-on-Chips (SoCs), offers several unique features that make it highly effective for dynamic quantization. These features include efficient numerical management, specialized hardware acceleration mechanisms, and a robust toolchain, all of which enable high-performance execution of AI models with reduced precision. Below is a detailed explanation of these features and how they enhance the execution efficiency of dynamic quantization.
Efficient Numerical Management on Qualcomm NPUs Qualcomm NPUs are specifically designed to handle low-bit operations, such as INT8 or INT4 and mixed precision calculations, with minimal overhead. This is achieved through hardware-level optimization and precise numerical management strategies:
Support for Mixed Precision ArithmeticQualcomm NPUs natively support mixed-precision computation, allowing models to process weights and activations at reduced precisions (e.g., INT8 or INT4 for most operations) while retaining FP16 or FP32 for specific layers where high precision is necessary for maintaining model accuracy.Dynamic Adaptation: During runtime, Qualcomm NPUs dynamically adjust the precision of computations based on workload characteristics, ensuring optimal trade-offs between speed and accuracy. On-the-Fly CalibrationIn dynamic quantization, input activations are quantized to a lower precision format during runtime. Qualcomm NPUs manage this process efficiently by performing on-the-fly calibration to determine scale and zero-point values, which are critical to preserving the range of numerical representation in low precision.Example: For real-time NLP tasks, such as translating user queries, the NPU dynamically calibrates and scales activations as incoming data varies, ensuring consistency in predictions while maintaining quantization efficiency. Reduced Overhead for Quantization OperationsQualcomm hardware integrates optimized circuits for common quantization operations, such as re-scaling and dequantizing, enabling seamless switching between low and high precision representations.Caching Mechanisms: To improve execution speed, the NPU identifies and caches frequently used quantization parameters (e.g., scale and offset) for model elements like weights, activations, or biases. This reduces computational overhead when reusing quantized operations. Specialized Hardware Acceleration Mechanisms Qualcomm NPUs are equipped with hardware accelerators that are purpose-built for low-precision arithmetic, which dramatically improves the efficiency of dynamic quantization execution. These mechanisms include:
Tensor Accelerators for INT8 or INT4 ComputationQualcomm NPUs are optimized for tensor operations at INT8 or INT4 precision, which is a cornerstone of dynamic quantization. The NPU’s tensor accelerators can process large-scale matrix multiplications–critical to deep learning tasks–with significantly fewer computational cycles compared to FP32 or FP16.Parallel Processing:The NPU maximally parallelizes INT8 or INT4 operations, allowing it to execute multiple matrix multiplications or dot products simultaneously.For example, in Transformer-based models, attention mechanisms (which involve intensive matrix multiplications) can be executed more efficiently using Qualcomm hardware-accelerated INT8 or INT4 processing. Dedicated Quantization KernelsQualcomm NPUs include specialized hardware kernels for quantization and dequantization operations. These kernels speed up processes such as:Quantizing Weights: Mapping FP32-trained weights to INT8 or INT4 format before inference execution.Dequantizing Outputs: Converting low-precision results (e.g., INT8 or INT4) back to higher precision formats like FP32 for final results or further computations.End-to-End Optimization: These kernels are seamlessly integrated into the Qualcomm Neural Processing SDK (QNN), ensuring that every stage of dynamic quantization is optimized during model deployment. Reduced Memory Bandwidth ConsumptionDynamic quantization reduces the precision of activations and weights, leading to significant reductions in the memory bandwidth required to process and store these values.Qualcomm NPUs optimize memory alignment for low bit-width operations, which minimizes bandwidth usage and improves data access efficiency during runtime. How These Features Enhance Dynamic Quantization Execution By leveraging both efficient numerical management and hardware acceleration capabilities, Qualcomm hardware achieves the following benefits for dynamic quantization:
Improved Computational EfficiencyDynamic quantization on Qualcomm NPUs allows models to run faster because INT8 or INT4 computations require fewer cycles than FP32 or FP16 computations:A single INT8 or INT4 multiplication followed by an accumulation (INT8 or INT4-MAC operation) requires less power and computational resources compared to an FP32 equivalent.For multimodal models with heavy tensor operations (e.g., visual-linguistic attention), this approach significantly improves throughput and efficiency. Faster Inference TimeThe reduced precision format (INT8 or INT4) lowers the processing time per operation, shortening the overall inference time for tasks such as real-time object detection or speech-to-text processing.Qualcomm NPUs leverage pipelining and parallelization features to optimize sequential layers. For example, in a convolutional neural network (CNN) deployed on a Qualcomm-powered smartphone, INT8 or INT4 computations accelerate convolutional and fully connected layers, ensuring fast and responsive real-time performance. Memory Efficiency and Reduced Model SizeQuantized models require less memory storage and bandwidth:Weights that are converted from FP32 to INT8 or INT4 consume only one-fourth of the memory.This reduction allows larger models to be deployed on edge devices with limited memory resources, enabling advanced multimodal applications to run on devices like smartphones, wearables, and IoT systems.Qualcomm’s memory compression pipelines ensure efficient data placement and retrieval, further enhancing performance and usability of quantized models. Adaptive and Seamless Quantization for Edge AIQualcomm hardware supports the dynamic adjustment of precision levels based on real-time constraints such as power availability, thermal conditions, or workload complexity:For instance, when running a multimodal AI model in vivid conditions (e.g., AR applications), the NPU dynamically reduces precision to ensure smooth operation without overheating.Similarly, for high-accuracy tasks (e.g., medical image recognition), the NPU may selectively maintain FP16 precision only for critical layers, while quantizing other operations to INT8 or INT4. Practical Examples of Dynamic Quantization on Qualcomm NPUs Example 1: On-Device NLP Applications BERT-like models, which are computationally intensive, can be deployed on edge devices by leveraging dynamic quantization: During runtime, the model’s weights are converted into INT8 or INT4 format, allowing faster matrix multiplications for attention heads. Qualcomm NPUs’ hardware acceleration ensures that the quantized forward pass of the model executes with reduced latency while maintaining high-quality predictions. Example 2: Real-Time Vision Applications Dynamic quantization enhances real-time vision use cases like object detection: Models like MobileNet, which are quantized to INT8 or INT4, achieve both faster inference and smaller memory footprints on Qualcomm hardware. This makes them ideal for tasks like detecting objects in real-time via smart home cameras or augmented reality glasses. Qualcomm hardware offers advanced support for dynamic quantization through its efficient numerical management techniques (e.g., on-the-fly calibration) and specialized hardware acceleration for low-bit operations (e.g., INT8 tensor computations). These features significantly improve computational efficiency, reduce inference time, and optimize memory usage, making Qualcomm NPUs an exceptional choice for deploying compressed AI models on edge devices. By leveraging these distinct capabilities, developers can enable real-time, resource-efficient AI solutions across a wide range of edge applications, from multimodal models to NLP and computer vision tasks.
Low-Rank Decomposition (LRD)
Low-rank decomposition19–22 approximates large matrices within the model using smaller factorized matrices, significantly reducing computation costs.
Techniques: Singular Value Decomposition (SVD). Non-negative Matrix Factorization (NMF). Advantages: Reduces model size while preserving most of the representational power. Ideal for large-scale models used in automotive systems, where memory constraints are strict. Optimization Problem: Matrix factorization minimizes reconstruction error with constraints:
Implementation on Qualcomm NPU: Qualcomm’s SDK incorporates precompiled matrix decomposition modules, enabling seamless integration for sparse and low-rank tensor operations. Low-rank decomposition is an effective model compression technique that can be applied to multimodal models to reduce computational complexity and memory usage. Here are the details of applying low-rank decomposition to multimodal models: Selection of Target Layers or Matrices: In multimodal models, low-rank decomposition is typically applied to layers or matrices with high-dimensional features. These layers or matrices often contain a large amount of redundant information that can be reduced through low-rank decomposition. For example, in convolutional neural networks, low-rank decomposition can be applied to convolutional layers or fully connected layers. Implementation of Low-Rank Decomposition: Low-rank decomposition can be implemented by decomposing high-dimensional matrices into the product of low-dimensional matrices. Specific methods include Singular Value Decomposition (SVD), QR decomposition, and low-rank approximation. These methods decompose high-dimensional matrices into the product of low-dimensional matrices, thereby reducing their complexity. Ensuring Model Performance: While achieving low complexity, it is necessary to ensure the performance of the model. To achieve this goal, the following methods can be adopted: Choosing an Appropriate Decomposition Method: Different decomposition methods have different impacts on model performance. For example, Singular Value Decomposition (SVD) can preserve the main features of the matrix, thereby ensuring the performance of the model. Adjusting Decomposition Parameters: Decomposition parameters, such as the choice of rank, can affect model performance. By adjusting these parameters, the model’s performance can be maintained as much as possible while reducing complexity. Iterative Optimization: Iterative optimization can be used to improve the performance of the model after low-rank decomposition. For example, gradient descent algorithms can be used to optimize the parameters of the decomposed model. Advantages of Low-Rank Decomposition: Low-rank decomposition can significantly reduce the computational complexity and memory usage of the model, thereby improving the inference speed and efficiency of the model. This is particularly important for deploying multimodal models on resource-constrained devices. Through these methods, low-rank decomposition can be effectively applied to multimodal models, reducing their complexity while ensuring the performance of the model.


E. Lookahead Decoding
Lookahead decoding 23 improves sequence generation quality for tasks such as vehicle-to-vehicle communication, speech-to-text systems, or map routing predictions.
The Forward Decoding Technique, is a deep learning approach used in sequence generation tasks. It guides the generation of the current part of a sequence by considering its future parts. Here’s a detailed explanation of its role and importance in sequence generation tasks:
Complete Definition: The Forward Decoding Technique is a sequence generation method that guides the generation of the current part of a sequence by predicting its future parts. This technique is commonly used for generating sequential data such as natural language text, music, and images. It leverages the temporal dependencies in sequential data to improve the quality and coherence of the generated sequences.
Role in Sequence Generation Tasks: The Forward Decoding Technique plays a crucial role in sequence generation tasks. By predicting the future parts of a sequence, it guides the generation of the current part, thereby enhancing the quality and coherence of the generated sequence. For example, in natural language processing, the technique can predict the next word or phrase, improving the fluency and coherence of the text.
Importance: The Forward Decoding Technique is of significant importance in sequence generation tasks. Firstly, it improves the quality and coherence of the generated sequences, enhancing the user experience. Secondly, it reduces uncertainty in the sequence generation process, increasing the accuracy of the generated sequences. Lastly, it reduces the computational complexity in the sequence generation process, improving the efficiency of generating sequences.
Application Examples: The Forward Decoding Technique can be applied to various sequence generation tasks, such as natural language processing, music generation, and image generation. For instance, in natural language processing, it can be used for tasks like text summarization, machine translation, and dialogue generation. In music generation, it can be used to generate melody, chords, and rhythms. In image generation, it can be used for tasks like image captioning, image inpainting, and style transfer.
Through the Forward Decoding Technique, the quality and efficiency of sequence generation tasks can be improved, providing a better user experience.
How it Works: Predicts multiple decoding steps ahead in a sequence generation task. Uses beam search combined with future-context scoring. Steps in Lookahead Decoding: Beam Generation: Maintain multiple hypotheses for decoding steps. Future Probing: Extend predictions over a configurable ”lookahead” window for scoring. Candidate Selection: Choose the most optimal candidates based on cumulative scores. The speedup can be estimated using the following formula:
Advantages: Produces globally coherent predictions. Avoids suboptimal decisions caused by local context limitations. Implementation on Qualcomm NPU: Using cached processing in QNN, Lookahead decoding ensures real-time sequence generation on edge devices with predictive accuracy tailored for tasks like assisted driving or traffic navigation. The Qualcomm NPU’s QNN framework enables seamless integration of these advanced optimization techniques via: Layer Adaptation: Fusion of layers and low-bit quantization for computational efficiency. Technique Combination: Pruning, knowledge distillation, quantization, and decomposition synergize to optimize transformers, convolutional networks, or multi-modal architectures. End-to-End Optimization Workflow: Model optimization is aligned with task-specific inference goals using tools like mixed precision training, automated hyperparameter tuning, and runtime profiling.
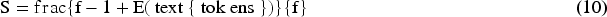
The Qualcomm Neural Processing SDK, when combined with cutting-edge optimization methods like pruning, quantization, and distillation, enables the deployment of efficient, high-performance AI models. By integrating these techniques, especially in automotive frameworks, the Qualcomm NPU platform ensures energy-efficient, real-time inference for AI-driven applications, paving the way for intelligent and sustainable edge computing solutions. These methodologies take AI to new levels of scalability, making advanced machine learning more accessible and effective in modern use cases.
Detailed Discussion on Optimizing Multimodal Models to Enhance User Experience:
Optimizing multimodal models not only improves inference efficiency but also significantly enhances user experience. By combining information from multiple modalities, such as vision, language, and audio, these models enable smarter, more personalized interactions and greatly improve the speed and accuracy of task processing, meeting users’ demands for real-time, high-quality AI services. Below are specific examples of how optimized multimodal models enhance user experience in key scenarios:
Personalized Interaction NPUs Optimized multimodal models allow for highly personalized interactions by efficiently integrating and making sense of multimodal inputs. This capability is critical in the following use cases: Intelligent Voice Assistants: Multimodal models integrated into voice assistants can leverage users’ audio inputs (e.g., tone or emotion) alongside contextual information (e.g., time or location via visual modalities) to provide tailored responses. For example, when a user asks about the weather, the assistant can combine audio queries and location-specific visual data to deliver precise answers. Virtual Avatar Interactions: Within AR/VR applications, optimized multimodal models can process users’ facial expressions (visual modality) and speech (text modality) in real time to enable emotionally aware virtual interactions. Real-time inference optimization ensures smoother, more natural interactions by minimizing latency and avoiding interruptions. Smart Recommendations Optimized multimodal models deliver greater accuracy in recommendation systems by leveraging historical user behaviour and current context to generate more relevant suggestions. This is particularly impactful in the following applications: Personalized E-Commerce Recommendations: An efficient multimodal model can combine user shopping history (text modality, such as reviews or query keywords), clicked images (visual modality), and product videos (audio-visual modality) to recommend items that match a user’s preferences. For example, in a winter clothing search, the system can analyze viewed product images and textual descriptions to fine-tune recommendations while ensuring real-time suggestions are generated. Streaming Content Recommendations: Platforms like music or video streaming services can use optimized multimodal models to analyze users’ watch history (text and visual modalities) and emotional states (audio modality) to recommend content aligned with their preferences. For example, if a user is feeling down, the system can suggest uplifting music or movies based on their activity and sentiment. Real-Time Task Processing The optimization of multimodal models is crucial for tasks that require real-time responses. Enhanced models reduce inference latency while improving their capability to handle complex tasks, as evident in the following scenarios: Autonomous Driving: In autonomous driving systems, optimized multimodal models can efficiently analyze data from cameras (visual modality) and radar sensors (spatial modality) to understand the surrounding environment in real time. This optimization not only improves system response speed but also reduces computational resource consumption, ensuring stability and reliability. For example, vehicles can quickly identify obstacles ahead and combine this with road condition data to generate safe driving decisions. Real-Time Translation and Subtitling: In cross-language communication scenarios (e.g., online meetings or international live streaming), optimized multimodal models can process audio input (text and audio modalities) alongside video data (visual modality) to generate synchronized translated subtitles and emotional feedback. For example, the system can provide accurate real-time subtitles for hearing-impaired viewers while capturing and reflecting the speaker’s emotional cues. Intelligent Surveillance: In smart home or security monitoring systems, optimized multimodal models can efficiently process video streams (visual modality), audio inputs (e.g., unusual sounds), and data from environmental sensors to identify anomalies (e.g., indoor fires or intrusions) in real time. High-speed, high-accuracy inference is critical for ensuring users’ safety by triggering alarms or notifying users through speech. Natural Human-Machine Interaction Optimized multimodal models can significantly improve the naturalness of human-machine interactions by enabling machines to better understand user intent and provide appropriate responses. This is especially evident in the following applications: Customer Service Chatbots: Multimodal interaction-enabled chatbots can analyze user dialogue content (text modality) and emotional states (audio or visual modalities) to deliver more precise and personalized solutions. For example, if a user expresses frustration, the chatbot can adjust its tone and suggest more empathetic and targeted solutions. Accessibility Technologies: For users with special needs (e.g., hearing or vision impairments), optimized multimodal models can combine modalities such as text, speech, and images to generate real-time voice descriptions or textual prompts. For instance, an optimized model can provide detailed image descriptions or recognize facial expressions and integrate these features into assistive devices. Optimizing multimodal models not only increases computational efficiency but also greatly enhances user experience in critical domains such as personalized interaction, smart recommendations, and real-time task processing. These improvements help meet user expectations for smarter, smoother, and more engaging applications and services. Moreover, such advancements provide a solid foundation for the large-scale deployment of multimodal AI models, particularly on resource-constrained edge devices.
Privacy and Security Concerns in Edge-Side Inference:
In the context of edge-side inference, AI models perform computations and predictions directly on user devices (e.g., smartphones, smart home devices, or wearables), without sending data to the cloud for processing. While edge inference offers numerous advantages, such as low latency and real-time responsiveness, it also raises challenges related to data privacy and security. The following outlines key concerns associated with privacy and protection in edge-side inference, along with strategies to mitigate potential risks through technical optimizations.
Privacy Concerns in Edge Environments Local Data Storage Risks: Edge devices typically process user data locally (e.g., visual, audio, or textual inputs), which may include highly sensitive information, such as biometric data, private conversations, or location details. Without robust security measures, locally stored data could be vulnerable to unauthorized access or external attacks. Data Transmission Risks: Although edge inference reduces the need to upload data to the cloud, certain scenarios might still involve cross-device communication, such as collaborative inference between multiple devices or hybrid models relying on both cloud and local computations. Without proper encryption mechanisms, these transmissions may expose data to potential breaches. Model Inversion Attacks: During edge inference, the model generates outputs based on user inputs, and malicious actors may reverse-engineer the model or analyze its outputs in an attempt to reconstruct sensitive user data through a model inversion attack. Offline Inference: A Key Strategy for Enhancing Privacy Offline inference is one of the most effective strategies for protecting user privacy in edge AI systems. Its primary advantage lies in ensuring that models and inference tasks are entirely self-contained on the user’s local device, eliminating the need for data transmission to the cloud. This greatly minimizes the exposure of sensitive information. Fully Localized Processing: All steps of data collection, preprocessing, and inference are performed locally. This eliminates the vulnerabilities associated with transmitting sensitive data over the network. For instance, in speech processing applications, offline inference can directly convert audio inputs into text on the device without sending audio data to the cloud. Independence from Network Connectivity: Offline inference enables devices to perform tasks even in the absence of network connectivity. This not only improves user experience but also eliminates privacy risks stemming from online environments. Model Optimization as a Privacy-Enhancing Technique Optimizing edge models to enhance their efficiency while maintaining accuracy can reduce computational and storage demands and, at the same time, strengthen data privacy protection. Below are several key technical approaches: Model Compression and Quantization: Techniques such as pruning, quantization, and knowledge distillation can significantly reduce model size without sacrificing performance, enabling them to run efficiently on edge devices. Smaller models not only reduce the attack surface for reverse-engineering but also reduce the amount of data they need to store or process. Example: In smart home devices, pruning can retain only the modules relevant to specific tasks while discarding unnecessary components, significantly lowering the risk of exposing sensitive data. Federated Learning Integration: Federated learning enables distributed training of models directly on edge devices without uploading user data to the cloud. Instead, only model updates (e.g., gradients or weights) are shared with the cloud or other devices, minimizing the risk of data leakage. Differential Privacy Techniques: By embedding differential privacy mechanisms into inference or training processes, it is possible to inject statistical noise into the outputs or updates, preventing attackers from deducing sensitive information about individuals. For example, in autonomous driving systems, differential privacy can ensure that video data processed by the model does not reveal identifying details of pedestrians near the vehicle. Secure Multi-Party Computation (SMPC) and Encrypted Inference: Utilizing SMPC or homomorphic encryption allows AI inference tasks to be performed while keeping input data secure and inaccessible. Although these methods are computationally intensive and less suitable for lightweight edge devices, they provide additional safeguards in high-privacy-demand scenarios. Application Scenarios Smart Health Monitoring: In wearable health devices (such as smartwatches), optimized multimodal models process biometric data (e.g., heart rate, activity tracking) to monitor health conditions. By performing inference offline, these devices ensure sensitive health data remains local and is not transmitted to external servers, thereby protecting users’ privacy. Home Security Devices: Smart home cameras equipped with locally optimized multimodal models (combining audio, visual, and contextual data) can analyze indoor activities and detect security risks. By running entirely offline, these privacy-respecting systems keep video footage stored locally, reducing the risk of sensitive content being exposed externally. Personalized Content Recommendation: Edge devices using locally deployed recommendation models can process user behaviour data (e.g., browsing history, voice commands) and generate results directly on the device. This avoids transmitting user behaviour data to external servers and ensures data security during personalized content generation. Edge inference provides significant advantages for protecting user data privacy through its local processing architecture. However, risks remain, particularly due to the limited computational capabilities of edge devices. Strategies such as offline inference to minimize data transmission, the use of model compression and federated learning to localize processing, and the application of differential privacy to prevent data reconstruction attacks can effectively mitigate privacy risks. Optimized multimodal models at the edge not only enhance user experience but also build greater trust by providing robust data privacy in diverse application scenarios.
Expanding the Importance of Edge Computing in AI Inference:
With the rapid development of artificial intelligence, edge computing has become a critical computational paradigm, especially in resource-constrained scenarios. Edge computing brings data processing and inference tasks closer to the source of data generation (e.g., smartphones, smart cameras, wearable devices), addressing many challenges associated with traditional cloud-based computing. By shifting inference tasks from the cloud to the edge, edge computing demonstrates significant advantages in terms of privacy protection, real-time responsiveness, and bandwidth efficiency.
Key Benefits of Shifting Inference Tasks from the Cloud to the Device
Privacy ProtectionIn cloud-based inference systems, user input data is usually transmitted to remote servers for processing, which poses substantial risks of privacy breaches. During data transmission, risks such as man-in-the-middle attacks or unauthorized access may emerge. Additionally, the centralized storage of large amounts of sensitive user data in cloud servers increases the likelihood of data leakage.Edge computing addresses these concerns by performing data processing locally on the device, minimizing the need to upload user data to external servers and reducing the exposure of sensitive information from the outset:Localized Data Processing: Data collected by sensors (e.g., user images, audio, behavioural data) is processed entirely on the local device. For instance, tasks like speech recognition, visual detection, or text generation can be carried out offline, eliminating the need for raw data to be transmitted to the cloud.Compliance with Regulatory Requirements: In industries or regions with strict data privacy regulations (e.g., healthcare, financial sectors, or regions governed by the General Data Protection Regulation [GDPR] in the EU), edge-based inference enables easier compliance by keeping data local and supporting offline inference. Improved Real-Time Performance Real-time responsiveness is critical in many scenarios, such as autonomous driving, industrial robotics, and extended reality applications. Cloud-based inference inherently relies on data transmission between the device and the cloud, making it susceptible to network latency. In contrast, edge computing bypasses this network dependency, significantly enhancing real-time performance.Ultra-Low Latency: For example, in autonomous driving, vehicles must make split-second decisions to avoid collisions. If inference tasks depend on cloud servers, any network fluctuations could lead to unsafe delays. On the edge, optimized AI models process camera and radar data in real-time, ensuring safety.
Challenges in Adapting Qualcomm NPUs and Other Hardware Platforms, and Strategies to Improve Cross-Platform Compa tibility:
The deployment of AI models across diverse hardware platforms, such as Qualcomm NPUs, GPUs, CPUs, and other accelerators, presents significant challenges due to variations in computational architectures, instruction sets, and hardware-specific optimizations. Qualcomm NPUs (Neural Processing Units), designed specifically for efficient AI inference on edge devices, deliver advanced performance but require carefully tailored optimization to fully leverage their capabilities. When adapting to diverse hardware platforms, ensuring compatibility and portability becomes a critical aspect, particularly for multimodal models with high computational complexity.
Below, we discuss the primary challenges in adapting Qualcomm NPUs and other hardware platforms, along with strategies to enhance cross-platform compatibility.
Challenges in Cross-Platform Adaptation
Hardware DiversityDifferent platforms, such as NPUs, GPUs, and CPUs, offer unique computational capabilities and constraints:Qualcomm NPUs are optimized for low power consumption and edge-side inference efficiency, often utilizing specialized instructions for parallel processing and tensor operations.GPUs prioritize high throughput in parallel computing, while CPUs are typically optimized for general-purpose computations.This disparity in capabilities can result in significant performance variances when deploying the same AI model across platforms, necessitating platform-specific optimization. Variation in Precision SupportDifferent hardware platforms support different numerical precision formats, such as FP32, FP16, INT8, or even INT4:Qualcomm NPUs often utilize INT8 quantization for maximal efficiency, but other platforms like GPUs might perform better with FP16.A lack of standardized precision across platforms requires model recalibration, which can introduce implementation complexities and lead to numerical instability across devices. Inconsistent APIs and SDKsEach hardware platform typically provides its own proprietary SDK or API for model deployment and lower-level optimizations:Qualcomm NPUs rely on the Qualcomm Neural Processing SDK (QNN), while GPUs might use libraries like TensorFlow or PyTorch CUDA extensions, and CPUs may rely on MKL or OpenBLAS.This heterogeneity in software stacks adds an extra layer of complexity when developing portable solutions for multimodal models. Compatibility with Multimodal ModelsMultimodal models often involve complex architectures, with interactions across different modalities (e.g., vision and language). This increases the difficulty of achieving optimal hardware utilization on different platforms, as the specific acceleration capabilities for various operations (e.g., attention mechanisms or convolutional layers) may differ significantly across devices. Strategies for Enhancing Cross-Platform Compatibility To address the challenges described above, the following strategies can be employed to improve compatibility and portability across Qualcomm NPUs and other hardware platforms:
Automatic QuantizationQuantization is a key strategy for optimizing models to run efficiently on heterogeneous hardware. Automatic quantization techniques streamline the process of adapting models to distinct precision formats and hardware constraints:Dynamic Quantization: Automatically converts weights and activations to lower precision (e.g., INT8) during runtime while adjusting calculations to maintain accuracy. This is particularly effective for adapting models to Qualcomm NPUs, which are highly optimized for INT8 operations.Post-Training Quantization (PTQ): Involves calibrating pretrained models to lower precision formats, ensuring compatibility with devices that support mixed-precision or low-precision computing. This method allows easy adaptation to NPUs, GPUs, and CPUs without retraining.Quantization-Aware Training (QAT): Models are trained with precision-aware simulations, allowing better generalization across platforms with different precision requirements. For example, a model optimized for Qualcomm NPUs but also deployable on GPUs with minor tweaks. Use of Hardware Abstraction Layers (HALs)Hardware abstraction layers act as intermediaries between the AI model and the underlying hardware, simplifying cross-platform deployments by abstracting hardware-specific details:ONNX Runtime: Open Neural Network Exchange (ONNX) offers portability by allowing models to be deployed across diverse hardware platforms, including Qualcomm NPUs, GPUs, and CPUs.Qualcomm Neural Processing SDK (QNN)**: By leveraging QNN’s integration with ONNX, models can be compiled for Qualcomm NPUs, while alternative backends can handle other hardware platforms.This abstraction reduces the need to rewrite model-specific code for each platform and ensures consistent behaviour across devices. Model Pruning and Layer PartitioningMultimodal models can be modularized by pruning or partitioning their layers to better align with hardware-specific constraints:Layer Partitioning: Computationally intensive layers, such as convolutional or attention layers, can be specifically tailored to target the high-performance capabilities of NPUs, while lighter operations can remain on CPUs or GPUs.Hardware-Aware Pruning: Prune less critical layers based on the hardware device’s compute and memory capabilities, enabling smoother adaptation and lower resource consumption across platforms. Cross-Platform FrameworksAdopting frameworks that inherently support cross-platform adaptation can simplify deployment efforts:TensorFlow Lite: Offers optimized runtimes for a multitude of devices, including Qualcomm NPUs, and facilitates model deployment by automatically adapting to available hardware accelerators.PyTorch Mobile: Supports mobile edge devices and enables efficient deployment across multiple platforms through built-in hardware compatibility layers. Federated OptimizationTo enhance portability, models can gather feedback from real-world performance across diverse hardware and undergo federated optimization:Devices running on specific platforms (e.g., Qualcomm NPUs or GPUs) can collect performance metrics during inference and share them for aggregated analytics to iteratively fine-tune the model for better cross-platform compatibility. Practical Example: Adapting a Multimodal Vision-Language Model
To deploy a vision-language model across Qualcomm NPUs and GPUs:
Use Quantization-Aware Training (QAT) to ensure compatibility with both FP16 on GPUs and INT8 on NPUs. Employ ONNX Runtime to abstract the platform-specific APIs and unify deployment pipelines. Partition the model at the layer level: visual feature extraction layers optimized for NPUs, while lightweight language layers handled on GPUs for multitasking. Apply post-training quantization and calibrate precision layers based on hardware performance.
Adapting AI models for Qualcomm NPUs and diverse hardware platforms involves addressing challenges such as hardware-specific constraints, precision inconsistencies, and software heterogeneity. Strategies like automatic quantization, the use of hardware abstraction layers, model partitioning, and cross-platform frameworks are essential to enhance compatibility and portability. With these approaches, developers can efficiently deploy multimodal models across a wide range of edge devices, harnessing the unique capabilities of different hardware platforms while delivering consistent performance.
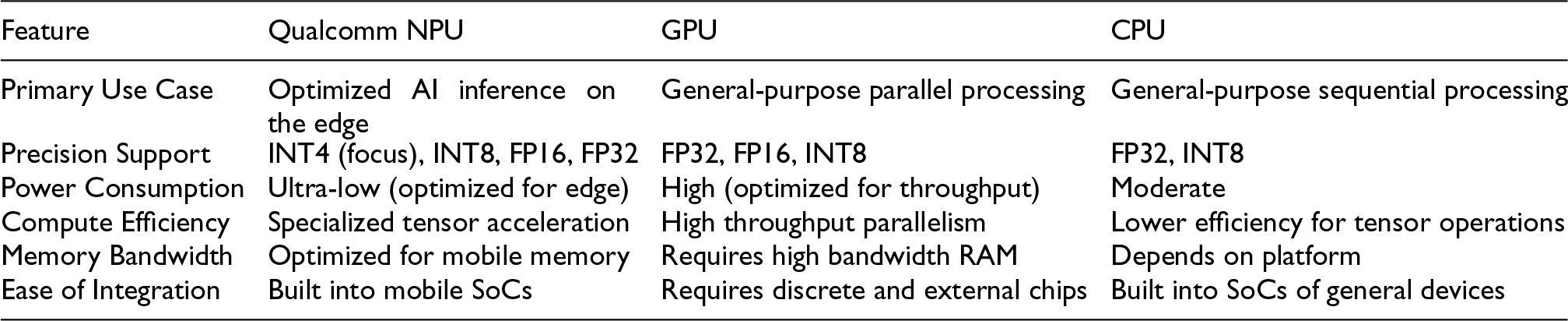
Comparison Between Qualcomm NPUs, GPUs, and CPUs: Unique Advantages of Qualcomm Hardware:
Deploying AI models efficiently on edge devices requires careful selection of hardware platforms, as each has its unique strengths and trade-offs. While GPUs and CPUs are widely used for a variety of workloads, Qualcomm NPUs (Neural Processing Units) offer specialized capabilities that make them particularly suitable for edge AI inference. Below, we provide a comparison of these hardware types and highlight the unique advantages of Qualcomm NPUs in terms of low power consumption, efficient inference, and edge-specific optimizations (Table 1).
Ultra-Low Power Consumption
Examples for test set.
Optimized for Edge Devices: Qualcomm NPUs are integrated within system-on-chip (SoC) architectures developed for mobile and embedded systems. They are specifically engineered to minimize energy consumption during inference, unlike GPUs, which are optimized for throughput-intensive workloads and consume significantly more power.
Example: In mobile AI applications, Qualcomm NPUs can handle complex image recognition tasks with a fraction of the power needed by a GPU, enabling longer operational times on mobile and wearable devices.
High-Efficiency AI InferenceQualcomm NPUs excel at performing inference operations efficiently by utilizing specialized tensor acceleration units and hardware-level optimizations, which are less prominent in general-purpose GPUs and CPUs.INT8 and INT4 Optimization: NPUs are extensively optimized for INT8 and INT4 calculations, which allows for faster and more power-efficient operations compared to FP32 or FP16 calculations, often favoured by GPUs.Dedicated AI Pipelines: Qualcomm NPUs are tailored for AI-specific tasks, such as convolution, matrix multiplication, and attention mechanisms in multimodal models, providing superior efficiency compared to CPUs, which are designed for general-purpose sequential tasks, and GPUs, which may require higher parallelism to achieve similar results.
Real-Time Performance for Edge ApplicationsFor scenarios requiring real-time or low-latency responses, Qualcomm NPUs provide a significant advantage due to their tightly coupled integration into mobile SoCs:Seamless Integration with Sensors: NPUs can process inputs directly from on-device sensors (e.g., cameras, microphones) without the bottleneck of transferring data to an external compute unit like a discrete GPU. This reduces latency and enhances real-time processing.Example: In a smart home security system, a device with a Qualcomm NPU can process video streams from a camera in real time to detect intrusions without sacrificing latency or energy efficiency.
Edge-Optimized Hardware and Software Stack
Qualcomm NPUs are designed specifically for edge environments, offering not only hardware advantages but also a robust software ecosystem that supports efficient AI inference:
Adaptive Hardware Scalability: Qualcomm NPUs are embedded within Snapdragon platforms, allowing them to scale across a wide range of edge devices, from smartphones to IoT devices, without requiring additional hardware like discrete GPUs.
Qualcomm Neural Processing SDK: This software stack enables developers to deploy AI models efficiently, using tools that perform hardware-aware optimizations, such as layer partitioning and memory management. Additionally, it provides support for widely-used formats like ONNX, making it easier to adapt AI models for deployment.
Comparisons to GPUs
While GPUs are well-suited for training and high-throughput parallelism, they face limitations in real-world edge applications:
Power Consumption: GPUs typically demand higher power, making them unsuitable for battery-constrained devices such as smartphones or drones. By contrast, Qualcomm NPUs prioritize energy efficiency and can perform AI tasks without rapidly draining device batteries.
Form Factor: GPUs are often discrete components, requiring additional space and external memory support. Qualcomm NPUs, on the other hand, are integrated into SoC designs, reducing the overall device footprint and enabling compact designs.
Strength Comparison:
GPU for Cloud AI: Training large-scale multimodal models and high-throughput inference in data centers. NPU for Edge AI: Efficient real-time inference for edge applications, particularly in mobile or IoT environments where power is a critical constraint.
Comparisons to CPUs
CPUs, due to their general-purpose design, excel in handling a variety of tasks but are less efficient for AI-specific operations compared to Qualcomm NPUs:
Parallelism vs. Specialization: CPUs are optimized for sequential processing and lack the specialized units for parallel tensor computations present in NPUs, resulting in lower performance for AI tasks like matrix multiplications.
Power Efficiency: CPUs generally consume more power than NPUs when performing the same AI inference tasks, as they are not optimized for the low-bit operations commonly used in edge AI.
Strength Comparison:
CPU for General-Purpose Tasks: Better suited for lightweight or non-AI tasks, such as running background applications or handling simple control logic.
NPU for AI-Specific Tasks: Much faster and more power-efficient for inference tasks in multimodal models (e.g., object detection, language processing).
Case Study: Multimodal AI Applications on Qualcomm NPUs
Let us consider a multimodal AI model that combines vision and language understanding, deployed on an edge device:
On a Qualcomm NPU, INT8-quantized layers for vision processing (e.g., convolutional layers) are computed efficiently with low power usage. Simultaneously, lightweight attention layers for text processing are handled in minimal time due to NPU-specific optimizations.
In comparison, if the same model were deployed on a GPU, power consumption would drastically increase, making real-time inference impractical for battery-powered devices. On a CPU, the inference would become too slow due to limited parallel computing capacity.
Qualcomm NPUs provide a unique blend of low power consumption, high-efficiency inference, and edge-specific optimizations, making them an ideal choice for deploying multimodal AI in resource-constrained environments. While GPUs and CPUs have their advantages in training or general-purpose computing, the tailored architecture of Qualcomm NPUs ensures that they excel in edge AI applications, delivering real-time performance, power efficiency, and scalability across various devices. These strengths position Qualcomm NPUs as a pivotal enabler for the next generation of intelligent, on-device systems.
Clear Definitions of ”Multimodal Large Models” and ”NPU”:
MLMs MLMs refer to AI models capable of processing and integrating information from multiple modalities, such as text, images, audio, video, and structured data. These models are designed to understand and reason across modalities, allowing them to perform complex tasks such as visual question answering, image captioning, video summarization, and voice-based interactions. Key characteristics of MLMs include: Cross-Modal Understanding: The ability to establish semantic links between different modalities (e.g., relating an object in an image to its textual description). Large-Scale Parameters: MLMs often have a high number of parameters due to their complex architectures, such as multimodal Transformers or encoder-decoder frameworks, which require specialized computational resources for inference and training. Data Diversity: These models are trained on diverse and large-scale datasets covering multiple modalities, thus enabling them to handle a wide variety of application scenarios. Examples: Vision-Language Models (e.g., CLIP, LXMERT): Capable of aligning textual and visual information. Audio-Visual Speech Recognition Models: Combine video and audio to improve speech transcription accuracy. Multimodal Recommendation Systems: Leverage user interactions (text), product images (vision), and reviews (text and audio) for personalized recommendations. NPU A NPU is a specialized hardware accelerator designed specifically to perform operations related to AI and machine learning, particularly deep learning inference tasks. Unlike general-purpose processors like CPUs or GPUs, NPUs are architected to achieve high computational efficiency by accelerating tensor operations (e.g., matrix multiplications) that are fundamental to neural networks. Key characteristics of NPUs: Optimized for AI Workloads: Accelerate computations such as convolutions, activations, and attention mechanisms, which are computationally intensive in models like CNNs and Transformers. Low Power Consumption: Designed to handle AI inference on resource-constrained edge devices (e.g., smartphones, IoT devices) with minimal energy consumption. Customized Precision: Often support lower precision formats like INT8, INT4, or FP16 to improve performance without significantly sacrificing model accuracy. Integration in Edge Devices: NPUs are integrated into system-on-chip (SoC) architectures in mobile platforms, enabling on-device AI processing without relying on cloud resources.
Rationale for Selecting Qualcomm’s Platform as the Research Focus
Qualcomm’s platform was chosen as the focus of this research due to its unique strengths in the following areas:
Hardware Optimized for Edge AI Qualcomm’s AI engines, particularly its NPUs integrated into Snapdragon system-on-chips (SoCs), are optimized for edge AI deployment. These engines are designed specifically for low-power operation while delivering high-performance inference, making them particularly well-suited for real-time multimodal AI applications: Efficient Edge Hardware: Qualcomm NPUs excel in processing AI inference locally, avoiding the latency and privacy issues associated with cloud-based inference. Low Power Design: Snapdragon platforms are built to handle AI workloads in a power-efficient manner, which is critical for battery-powered devices such as smartphones, wearables, and IoT systems. Robust Software Toolchain Qualcomm provides a comprehensive software stack, including the Qualcomm Neural Processing SDK (QNN), which offers tools and APIs to optimize AI models for their hardware: Support for Industry Standards: The QNN SDK supports widely used frameworks such as TensorFlow, PyTorch, and ONNX, facilitating easy integration of pretrained models. Model Optimization: Features such as quantization, pruning, and hardware-aware tuning ensure that deploying large multimodal models is feasible and efficient on Qualcomm platforms. Cross-Platform Compatibility: With its layered architecture, the toolchain makes it easier to adapt models for different Snapdragon-powered devices, ranging from smartphones to automotive systems. Suitability for Multimodal Applications Multimodal models, such as those used for vision-language tasks, voice-activated systems, or combined audio-visual processing, require hardware that can efficiently handle computationally intensive operations like attention mechanisms, convolutional layers, and fusion techniques. Qualcomm NPUs offer specialized tensor acceleration capabilities and memory optimizations to handle these workloads efficiently: INT8, INT4 and Mixed Precision Support: Qualcomm’s hardware accelerates multimodal AI by leveraging low-bit arithmetic (e.g., INT8 and INT4), ensuring that models with high computational complexity can run efficiently on device. On-Device Multimodal Fusion: By avoiding cloud dependency, Qualcomm SoCs can process multimodal inputs (e.g., combining visual and textual data in real time) with lower latency and greater privacy safeguards. Alignment with Privacy and Real-Time Requirements Data privacy and low latency are critical for edge-based multimodal applications, particularly in domains like healthcare, automotive, and smart devices. Qualcomm’s platform addresses these challenges effectively: Real-Time Processing: The tightly integrated NPU within Snapdragon SoCs eliminates the need to offload computation to the cloud, ensuring responses are instantaneous and suitable for latency-sensitive applications. Enhanced Privacy: Since computations are performed directly on the device, user data remains local, mitigating the risks of data breaches associated with cloud processing. Scalability and Widespread Adoption Qualcomm’s hardware solutions are widely adopted in the mobile and IoT industries, making their platform an ideal candidate for studying AI model optimizations. The scalability of their SoCs across a diverse range of devices ensures that insights and techniques derived from this research can be applied broadly: Smartphones: Delivering AI-powered photo enhancements and augmented reality effects. Wearable Devices: Supporting health monitoring and real-time activity recognition with limited power budgets. Automotive Systems: Enabling advanced driver assistance systems (ADAS) and in-vehicle infotainment systems that incorporate multimodal AI. MLMs are pivotal for tasks requiring cross-modal understanding and complex reasoning, while NPUs, such as those developed by Qualcomm, offer specialized acceleration for efficient AI inference. Qualcomm’s platform provides an ideal research target due to its highly optimized hardware architecture, robust software ecosystem, and alignment with the growing demand for real-time, privacy-preserving, and resource-efficient AI solutions. By focusing on Qualcomm NPUs, the study not only leverages cutting-edge technology but also lays the groundwork for enabling seamless deployment of multimodal AI across a wide variety of edge devices.
Test Samples This paper conducts experiments using real online user data, covering three scenarios: fatigue driving recognition, car brand and license plate recognition, and child emotion recognition. The test samples are listed in Table 1. Evaluation Method The evaluation was conducted by running the test five times and taking the average value. The same set of test samples was used for each evaluation to ensure consistency. Evaluation Metrics
First Response Time: The time taken from sending a request for inference of a large model to receiving the first token response. Decoding Speed: The rate at which decoded data is processed. NPU Utilization: The computational tasks required for running large model inference applications on the edge device. Memory Usage: The amount of memory resources utilized during the operation of edge-side large model inference applications. CPU Usage: The proportion of CPU resources used during the operation of edge-side large model inference applications. Experimental Results and Analysis The experiments were conducted on Qualcomm’s latest NPU platform for vehicle frameworks, using user datasets from various domains, using user datasets from various fields. The results show that the optimized model significantly improved in both response time and decoding speed, while effectively controlling memory, CPU, and NPU resource usage. The performance comparison of the quantized int4 model in terms of response time and decode speed across various mainstream in-car platforms is illustrated in Figure 1.
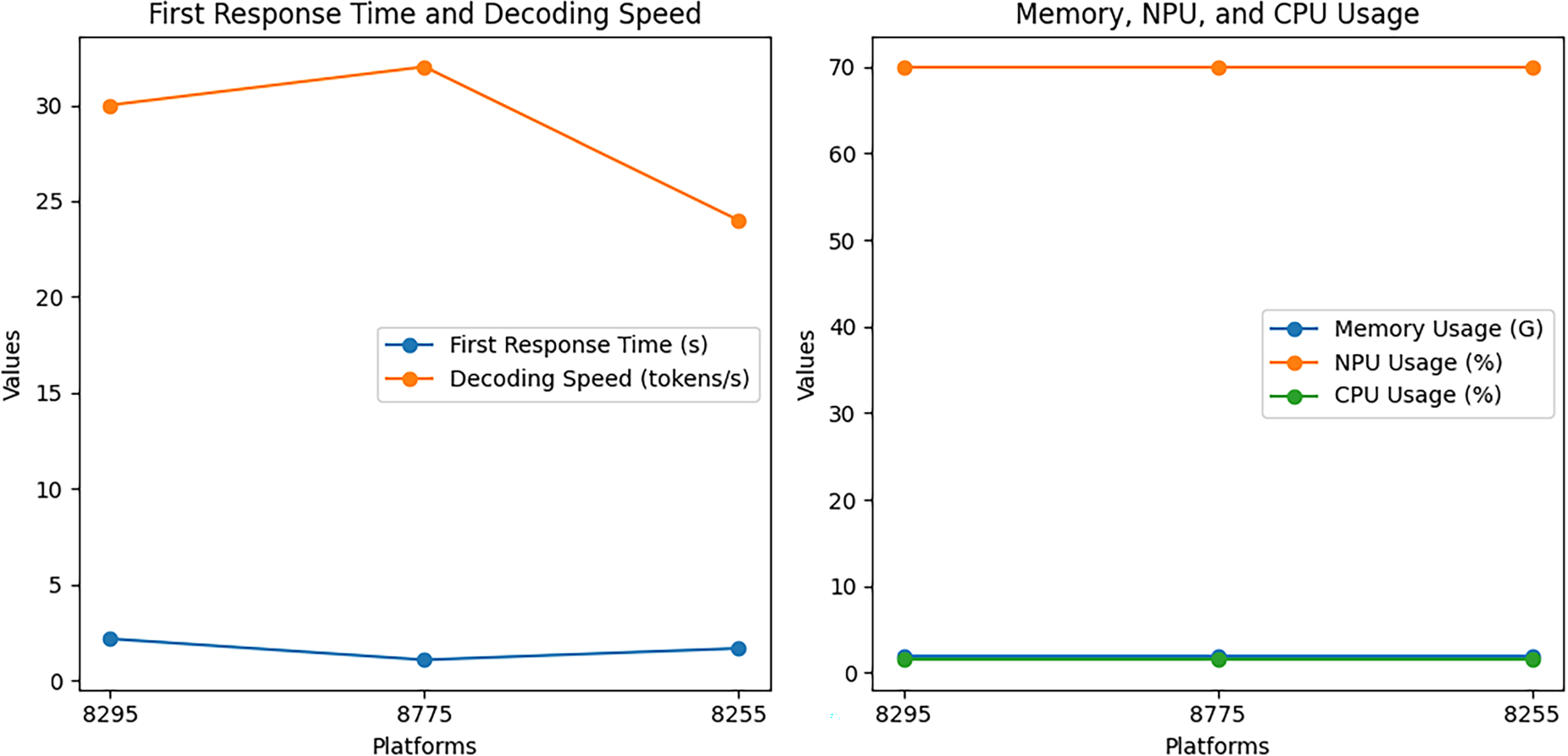
Performance comparison of the quantized int4 model in terms of response time and decode speed across various mainstream in-car platforms.
Tables 2 to 4 provide performance comparison data of the original model, quantized int8 model, and int4 model on various mainstream in-car platforms. The summary analysis of these data is as follows:
The unquantized original 2.xB model cannot run properly on any mainstream in-car platforms. Compared to the unquantized original 2.xB model, the quantized int8 model on various mainstream in-car platforms shows a reduction in model size from 5.3G to 2.4G. Compared to the quantized int8 model, the quantized int4 model on various mainstream in-car platforms shows a reduction in model size from 2.4G to 1.7G, with memory usage of 1.9G, CPU usage of 1.5%, and NPU usage of 70%. The first response times on the mainstream in-car platforms 8295, 8775, and 8255 are 2.2s, 1.1s, and 1.7s respectively, with decoding speeds of 30 tokens/s, 32 tokens/s, and 24 tokens/s.
The original model cannot run properly on various mainstream automotive platforms.

The quantized int8 model is unable to run properly on any mainstream in-car platforms.

Performance comparison of the quantized int4 model on various mainstream automotive platforms.

This study successfully achieved efficient inference of multimodal large models on Qualcomm NPU, marking the beginning of a new chapter in intelligent edge computing. These models enhance data security, reduce latency, and provide a deeply personalized experience, heralding a forthcoming era of personalized, efficient AI, and fundamentally transforming our interactions with technology. However, the study also has some limitations. Currently, the compatibility and performance optimization of the models across different devices still need further improvement. Although significant achievements have been made on Qualcomm NPU, the performance on other hardware platforms needs more verification and optimization. For future prospects, we recommend further exploration and optimization of multimodal large models in a wider range of edge devices and application scenarios. By continually optimizing algorithms and hardware acceleration technologies, we can enhance the adaptability and efficiency of the models. Additionally, bolstering data privacy and security measures is crucial to address the increasingly severe data security challenges. As technology continues to mature, future research can focus on developing smarter, more precise services, enhancing the convenience and quality of user experiences, and laying the foundation for a new era of more intelligent devices.
Footnotes
Authors’ contributions
Yajie Zhu, is responsible for designing the framework, analyzing the performance, validating the results, and writing the article.Hongtao Lu, is responsible for collecting the information required for the framework, provision of software, critical review, and administering the process.
Funding
This paper is supported by NSFC (No. 62176155), Shanghai Municipal Science and Technology Major Project (2021SHZDZX0102).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The data generated and analyzed during the current study are available from the author Yajie Zhu, upon reasonable request but are not yet publicly available due to ongoing research.