
Abstract
In recent years, Transformer-based models have dominated the field of long-term time series forecasting. However, the quadratic complexity of attention mechanisms makes both training and inference computationally expensive. The SOFTS model has emerged as an efficient alternative, replacing attention mechanisms with the STAR module to preserve linear complexity while achieving performance comparable to or better than competing approaches. The SOFTS model builds on the iTransformer architecture, which marked a significant advancement in long-term time series forecasting. Although neither iTransformer nor SOFTS incorporates positional embeddings, our analysis revealed a clear opportunity to improve forecasting accuracy by introducing them. However, the straightforward inclusion of positional embeddings leads to convergence and generalization issues. To address this, we propose a simple yet effective technique: during training, positional embeddings are randomly omitted in certain forward passes, which reduces instability and helps the model generalize better. We refer to this novel form of using positional embeddings as Learnable Stochastic Positional Embedding. Additionally, we incorporate multiple dropout layers to mitigate overfitting and improve accuracy. These modifications result in SOFTS++, a fast and accurate model that achieves the best performance on at least 10 out of 12 standard benchmark datasets. By maintaining linear complexity and requiring minimal computational resources, SOFTS++ stands out as a capable and resource-efficient method for multivariate long-term forecasting tasks.
Keywords
Introduction
Multivariate time series forecasting has traditionally relied on statistical methods such as ARIMA and Exponential Smoothing.1–3 However, with the exponential growth of data and advances in computational power, deep learning models, particularly those based on the Transformer architecture, have begun to dominate this field.4–6 Transformers have proven particularly effective due to their ability to capture long-range temporal dependencies and have found applications not only in forecasting, but also in classification, imputation, and anomaly detection tasks.7–9
Despite their success, the quadratic complexity of the attention mechanism poses a significant computational bottleneck, 10 especially for long input sequences. While early Transformer models such as Informer and Autoformer brought notable improvements,11,12 studies have shown that even simple linear models can achieve comparable or better performance with significantly lower computational costs. 13 This has led to a re-evaluation of architectural choices and a renewed interest in designing lightweight models that do not rely on self-attention.
One such advancement is the SOFTS model, 14 which replaces the attention mechanism with the STAR (STar Aggregate-Redistribute) module, reducing complexity to a linear scale while maintaining strong performance. STAR aggregates information into a central representation and applies stochastic pooling, 15 striking a balance between efficiency and accuracy.
In this paper, we build upon the SOFTS architecture and propose SOFTS++, a fast and accurate model designed for multivariate long-term forecasting. Although the original SOFTS and its predecessor iTransformer omit positional embeddings, we identify that their careful inclusion can lead to further performance gains. However, naively adding positional embeddings introduces convergence issues.
To address this, SOFTS++ employs a simple yet effective technique where positional embeddings are selectively applied during training, improving generalization and stability. Furthermore, we introduce multiple dropout layers to mitigate overfitting. With these modifications, SOFTS++ achieves state-of-the-art performance on 10 out of 12 benchmark datasets, while preserving linear complexity and requiring minimal computational overhead. This work complements our previous study about HASPFormer model, where we investigated attention-based architectures for time series forecasting. In contrast, the current study focuses on lightweight linear models, aiming to assess their efficiency, robustness, and performance in long-term forecasting tasks.
In this paper, we first review the most relevant papers in the field of multivariate time series forecasting in Section 2. In Section 3, we provide the theoretical background by outlining the fundamental components and techniques underlying the models and experiments in this study. In Section 4, we detail the structure and innovations of the original STAR and proposed STAR++ module, emphasizing improvements in robustness and generalization. Section 5 presents extensive experimental results on 12 benchmark datasets, comparing SOFTS++ with competitive baselines in terms of accuracy and robustness. Finally, Section 6 concludes the paper and outlines directions for future research.
Related work
Time series forecasting has evolved significantly in recent years. It began with traditional statistical models such as ARIMA and Exponential Smoothing, followed by various deep learning approaches, especially recurrent neural networks (RNNs) like LSTM 16 and GRU, 17 and more recently, Transformer-based models have become increasingly prominent. Statistical models offer efficiency and interpretability, 18 but their performance in complex patterns is limited due to strong assumptions about the data generation process, the dependence on linear formulations and the limited capacity to learn from the data,19,20 while machine learning approaches can capture non-linear dynamics more effectively. Transformer models initially generated enthusiasm due to their success in natural language processing,21,22 but early versions, such as the vanilla Transformer, were later found to be inefficient for time series tasks due to high computational cost and poor scalability.
To address these limitations, numerous specialized Transformer variants have been proposed. Informer 12 introduced ProbSparse self-attention to reduce complexity and improve long-sequence forecasting. Autoformer 11 tackled periodicity via a decomposition block and auto-correlation mechanism. PatchTST 6 leveraged subseries-level patching and channel independence to extend receptive fields without increasing computation. Crossformer 23 extended forecasting capabilities by modelling both temporal and inter-variable dependencies using DSW embeddings and Two-Stage Attention. A different approach came with TSMixer, 24 which used simple MLPs to outperform attention-based models in some cases, reviving interest in linear architectures.
Further innovation came with iTransformer, 5 which restructured the attention mechanism by embedding entire time series into tokens. It demonstrated improved efficiency and generalization in multivariate forecasting. Similarly, SOFTS 14 introduced the STAR module, centralizing information aggregation across channels to reduce complexity while maintaining performance.
FEDformer 25 combines seasonal-trend decomposition with attention in the frequency domain, using a compact set of Fourier components to capture key patterns efficiently. This design improves accuracy and scalability for long-sequence forecasting. DLinear and NLinear 13 renewed interest in linear modelling by demonstrating that simple channel-independent linear projections can match or even outperform attention-based architectures in long-horizon time series forecasting. In addition, KAN-based approaches 26 have proven to be to be effective for multivariate time series forecasting, 27 as demonstrated through extensive experiments and visualizations.
Theoretical background
In this section, we outline the mathematical and theoretical foundations of the main components of SOFTS++, focusing on stochastic pooling, dropout layers, and various positional embedding mechanisms (Figures 1 and 2). The embeddings include the classical fixed sinusoidal formulation, the proposed learnable stochastic variant, as well as rotary, relative, and hybrid approaches, which are considered for comparative evaluation in our experiments.
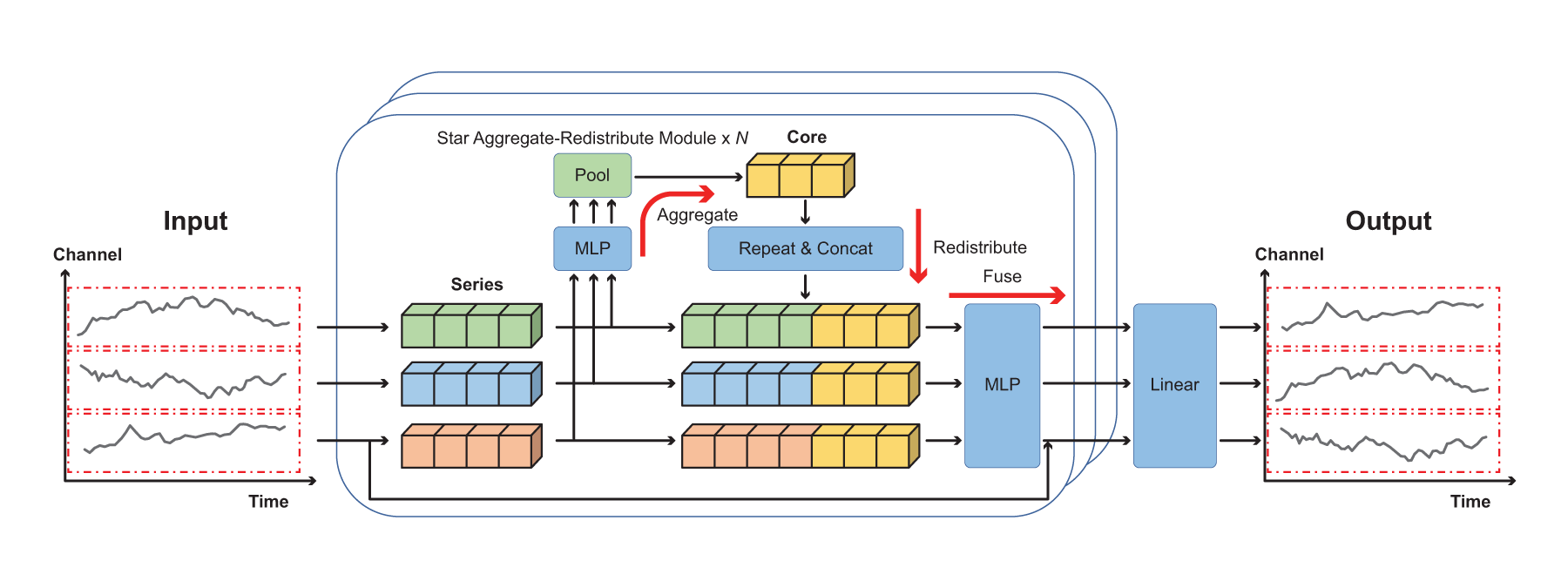
Original STAR module architecture. Image re-drawn from original paper. 14
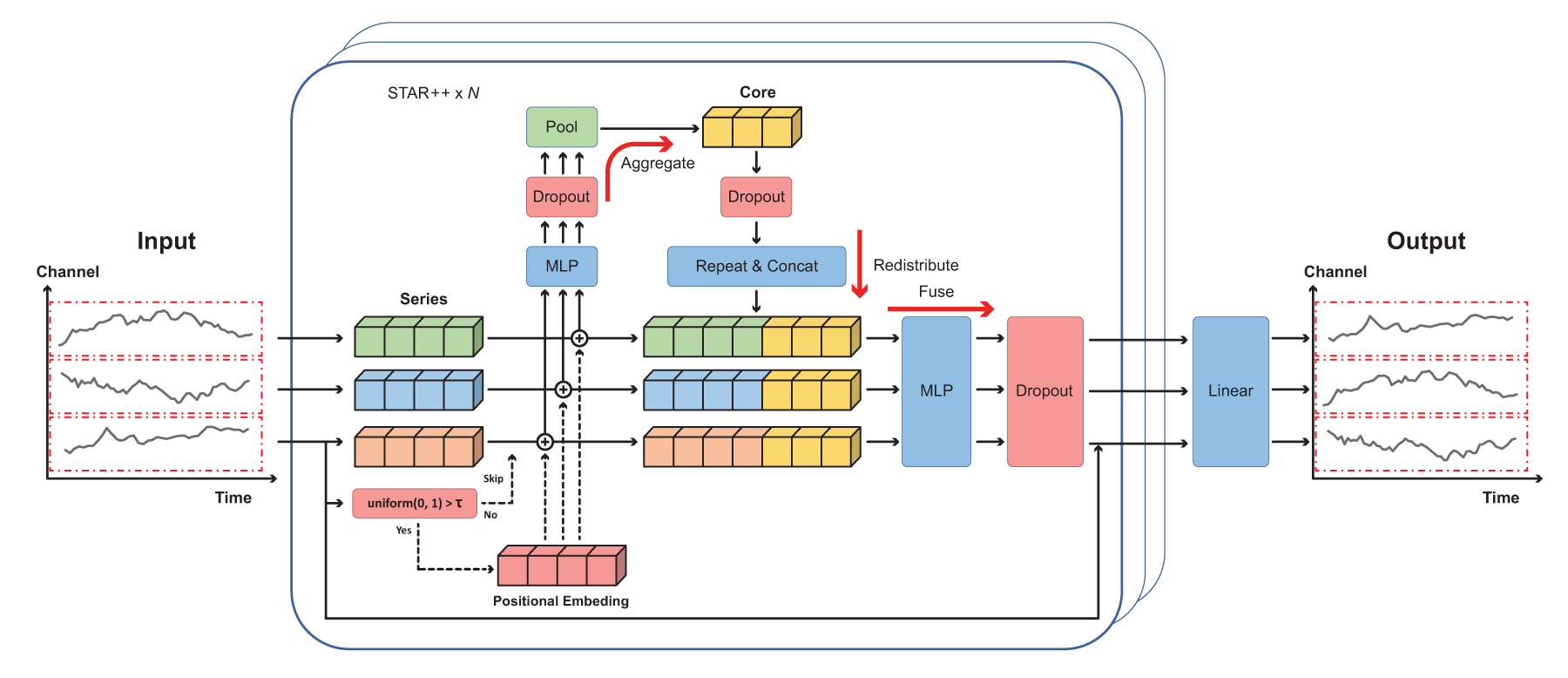
Architecture of the proposed STAR++ module. If the learnable threshold (
Stochastic pooling 15 is employed as an alternative to the attention mechanism whenever the learnable threshold guides the model towards local generalization. The implementation here follows the approach described in Han et al. 14 Unlike pooling strategies that combine maximum and average values, stochastic pooling selects a single activation from each pooling region at random, with a bias towards higher values. The selection probabilities are obtained by applying a softmax over the activations, introducing controlled randomness that makes larger activations more likely to be chosen.
Formally, for a pooling region

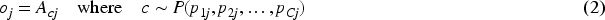

Transformers, unlike recurrent architectures, do not inherently encode sequence order. To introduce positional information,
This positional encoding enables the model to represent both absolute and relative positions, which is crucial for capturing temporal dependencies in time series forecasting.
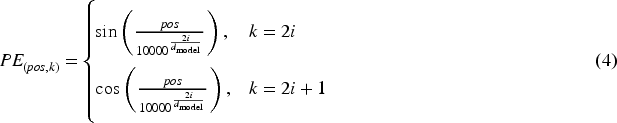
Relative positional embedding (RPE) encodes the relative distances between positions rather than their absolute indices, enabling better generalization to sequences longer than those seen during training. This technique modifies the attention score computation by adding distance-dependent biases, reducing the reliance on fixed sequence length and improving performance in tasks requiring variable-length context modelling. In experiments, we adapt relative positional embedding by adding distance-dependent representations directly to the input features, without modifying attention scores, providing a simplified mechanism to incorporate relative position information. Rotary positional embedding (RoPE) incorporates rotations in the complex plane for each pair of dimension of the feature, multiplying the positional information in the attention of the dot product. 30 In this paper, we reformulate Rotary Positional Embedding (RoPE) as a direct rotation of feature dimension pairs using sinusoidal functions, since our architecture does not employ attention mechanisms. Learnable positional embedding treats position indices as regular embedding vectors that are learned during training, without relying on predefined functional forms. 31 The advantage is flexibility and potential adaptation to specific data distributions.
Presented module
In this section, we build upon the SOFTS model, 14 which introduced the STAR module as a lightweight and effective alternative to traditional attention mechanisms for multivariate time series forecasting. The STAR module replaces costly pairwise channel interactions with a centralized aggregation-redistribution strategy, significantly reducing complexity while improving robustness in noisy settings.
To lay the groundwork for our proposed improvements, we first revisit the original STAR module in detail, explaining its architectural design and advantages. We then introduce STAR++, our enhanced version that forms the core of the SOFTS++ architecture. STAR++ builds on the foundational concepts of STAR, introducing several novel mechanisms, including learnable positional embedding control and multiple dropout layer, that together further improve generalization and efficiency.
Through this progression, we aim to demonstrate how centralized interaction mechanisms can be incrementally enhanced to deliver state-of-the-art performance on challenging long-term forecasting benchmarks, without compromising computational scalability.
STAR Module: STar Aggregate-Redistribute
A core contribution of the SOFTS architecture is the integration of the STAR module (

Centralized interaction via global core. The STAR module operates by first aggregating representations across all input channels to construct a shared latent representation referred to as the core. This core serves as a central bottleneck that captures global context and facilitates indirect communication between channels. Formally, given input series representations 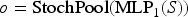
Fusion of core and local representations. Once the core is computed, it is repeated and concatenated with each channel’s local representation to form a fused tensor:
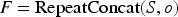
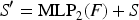
Advantages over distributed mechanisms. The key benefit of STAR’s centralized topology is its
STAR++ Module: Enhanced STar Aggregate-Redistribute
To further improve the original STAR module’s accuracy, we propose an enhanced version named
Stochastic learnable positional embedding. While the original STAR module omits positional embeddings, STAR++ optionally integrates sinusoidal (i.e., sine and cosine-based) positional embeddings. To avoid convergence issues associated with fixed positional embeddings, we introduce a learnable scalar threshold
Core construction. Similar to STAR, we first project each channel’s representation using:
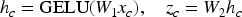
Fusion and regularization. The core representation is concatenated with each input channel and processed as:
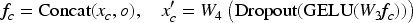

Summary of improvements. STAR++ enhances the original STAR module by: Introducing a learnable threshold to regulate positional embedding injection, Applying multi-stage dropout for better regularization, Preserving linear computational complexity, Improving robustness to anomalies and generalization across datasets.
These architectural improvements enable SOFTS++ to consistently outperform baseline models while maintaining efficiency and scalability. The final structure of the STAR++ is described in Algorithm 2.
Occasional activation as regularization. The design of STAR++ draws inspiration from our previous work on HASPFormer, where a learnable threshold decides whether to apply self-attention or fallback to stochastic pooling. This conditional mechanism proved effective not only for improving accuracy, but also as a form of regularization. Similarly, in STAR++, the stochastic activation of positional embeddings introduces controlled variability during training, helping the model generalize better. More broadly, such selective activation strategies may represent a promising new class of regularization techniques, particularly in the context of large models where full self-attention at every layer is computationally expensive. By occasionally invoking complex operations like attention only when needed, models can reduce training time and resource usage without sacrificing performance.
Computational complexity. SOFTS has linear complexity in both time and memory. 33 The SOFTS++ model preserves the linear time and memory complexity of SOFTS. Both dropout layers and learnable stochastic positional embeddings introduce only element-wise operations and simple additive terms, which scale proportionally with the input size. As a result, these modifications do not alter the asymptotic complexity, and SOFTS++ remains a linear-complexity model with respect to the number of channels and sequence length.
Random omission of positional embeddings. During training, STAR++ applies positional embeddings with probability 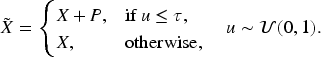
Experiments and results
To evaluate the effectiveness of SOFTS++, we carried out a comprehensive set of experiments across 12 widely used multivariate long-term forecasting benchmarks. We retained the same core size, encoder depth, and other architectural hyperparameters as proposed in the original SOFTS implementation
14
to ensure a fair comparison. All models were trained using the Adam optimizer with a learning rate of
Datasets and methodology
The datasets used in this study are adopted from Han et al., 14 which provides a comprehensive overview of time-series benchmarks relevant to forecasting and predictive modelling. Each dataset originates from a specific domain, including energy, transportation, and weather. For example, the ETT (Electricity Transformer Temperature) dataset contains hourly and 15-minute measurements of transformer temperatures from 2016 to 2018, along with seven features related to oil and load conditions.
The Traffic dataset includes hourly road occupancy rates on San Francisco freeways from 2015 to 2016. The Electricity dataset records hourly power usage for 321 clients between 2012 and 2014. The Weather dataset provides 21 weather indicators, such as air temperature and humidity, sampled every 10 minutes throughout 2020 in Germany. The Solar-Energy dataset includes 10-minute solar production data from 137 photovoltaic plants collected in 2006. Finally, the PEMS dataset offers 5-minute traffic data from sensor networks in California, commonly used for short-term traffic forecasting. Detailed attributes for each dataset, including the number of channels, sampling rate, prediction length, and train/validation/test splits, are provided in Table 1.
Detailed dataset descriptions.
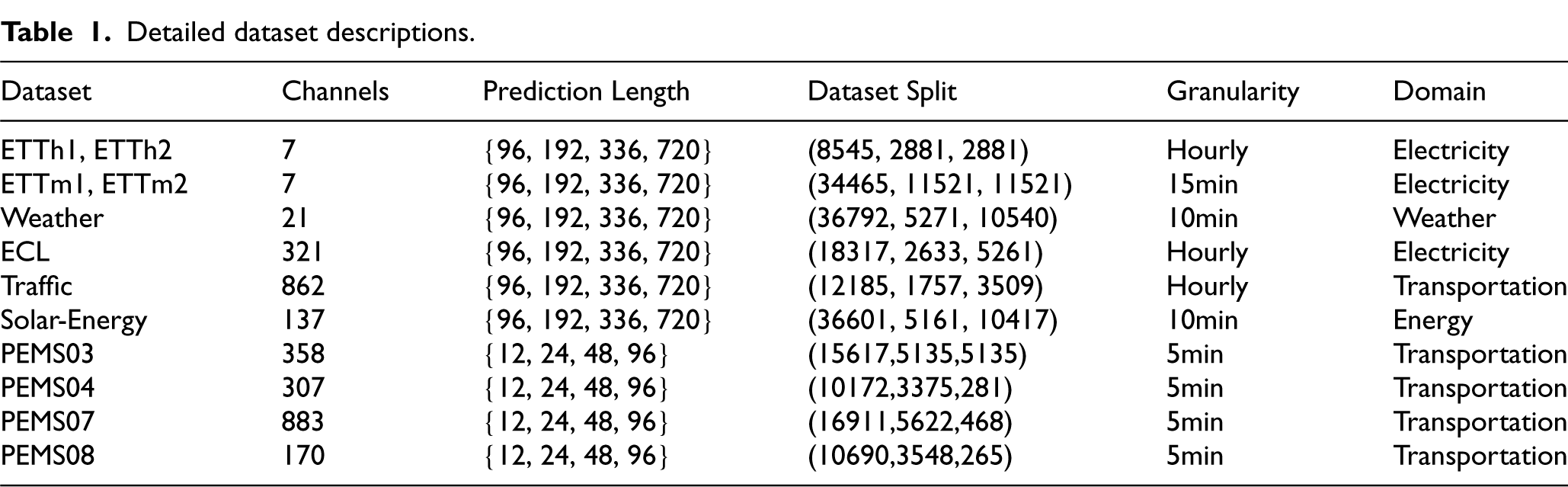
Detailed dataset descriptions.
Ablation study. Table 2 presents the results of the ablation study conducted on the SOFTS++ architecture, which was extended with LSPE (Learnable Stochastic Positional Embedding) and three dropout layers. The objective of this experiment was to assess the contribution of each component to the overall performance. When only the third dropout layer was removed (w/o D3), the results remained very close to the full model, suggesting that a single dropout layer does not have a dramatic impact on its own, but still contributes to model performance. Removing dropout layers 2 and 3 (w/o D2-3), or all three dropout layers (w/o D1-3), leads to a more noticeable degradation, indicating that the combined effect of dropout layers is essential for improved stability and generalization.
Ablation results for full model and its variants across all datasets with fixed lookback window length
. Results are averaged over prediction horizons.
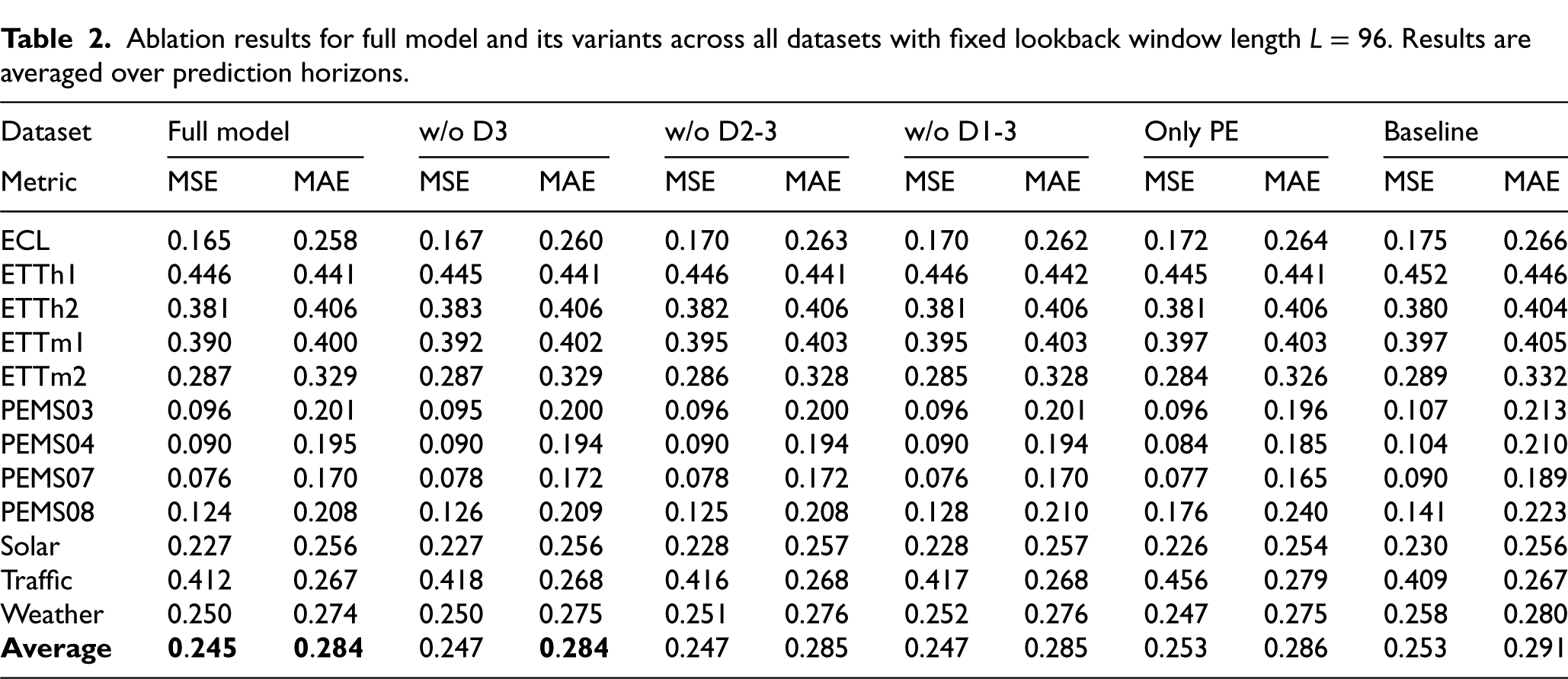
Ablation results for full model and its variants across all datasets with fixed lookback window length
Furthermore, when the LSPE component was removed and only the fixed positional embedding (PE) was retained (Only PE), performance degradation became evident across nearly all datasets. The effect was particularly severe on the Traffic dataset, where the MSE increased from 0.409 (baseline SOFTS) to 0.456 with fixed PE, demonstrating that traditional positional encodings are insufficient to capture the complex temporal patterns present in traffic data. Although LSPE does not outperform the baseline across all datasets, it substantially mitigates this issue by bringing the error very close to the original value (0.412 on Traffic), thereby confirming its role in providing more adaptive and stable temporal representations.
In comparison to the baseline model (SOFTS++ without LSPE and dropouts - plain SOFTS), it is evident that each added component has a clear justification: dropout layers provide regularization and prevent overfitting, while LSPE enhances the adaptability of positional information. The final integrated model achieves the best overall performance (0.245 MSE and 0.284 MAE on average), demonstrating that the combination of all components yields the most consistent and robust improvements across datasets. All experiments were conducted with five different random seeds, and the reported results are averaged values.
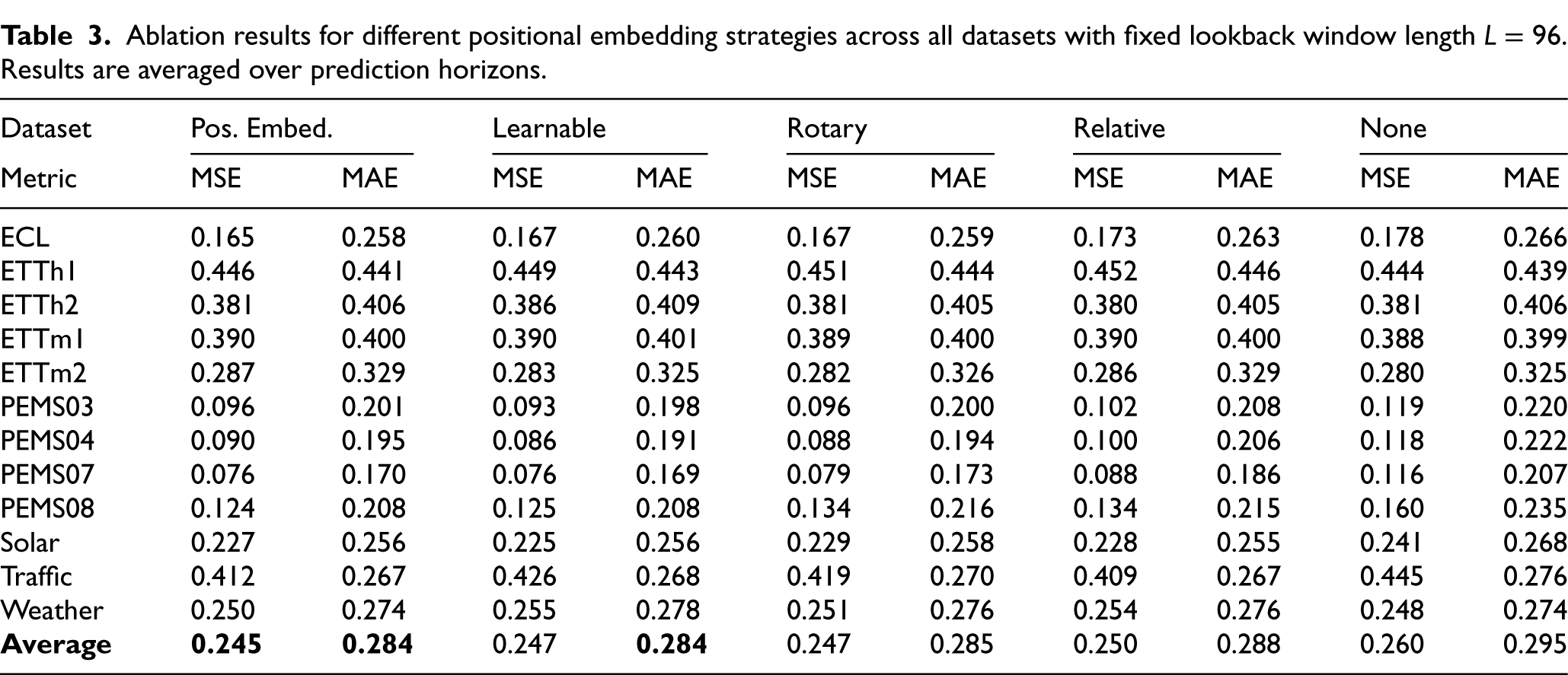
Positional embedding strategies. Tables 3 and 4 reports the ablation study of different positional embedding strategies within the full model configuration, where the dropout rate was fixed to 0.1 and LSPE was employed as the baseline approach. Five different embedding variants were evaluated across 12 datasets, and all experiments were conducted with five random seeds, with results averaged over prediction horizons. The first configuration, which uses the classical positional embedding that was initially adopted in our design, consistently achieves the best performance across datasets, yielding the lowest average error (0.245 MSE and 0.284 MAE). This validates our initial choice, as it provides the most stable and robust temporal representations compared to the alternatives.
Ablation results for different positional embedding strategies across all datasets with fixed lookback window length
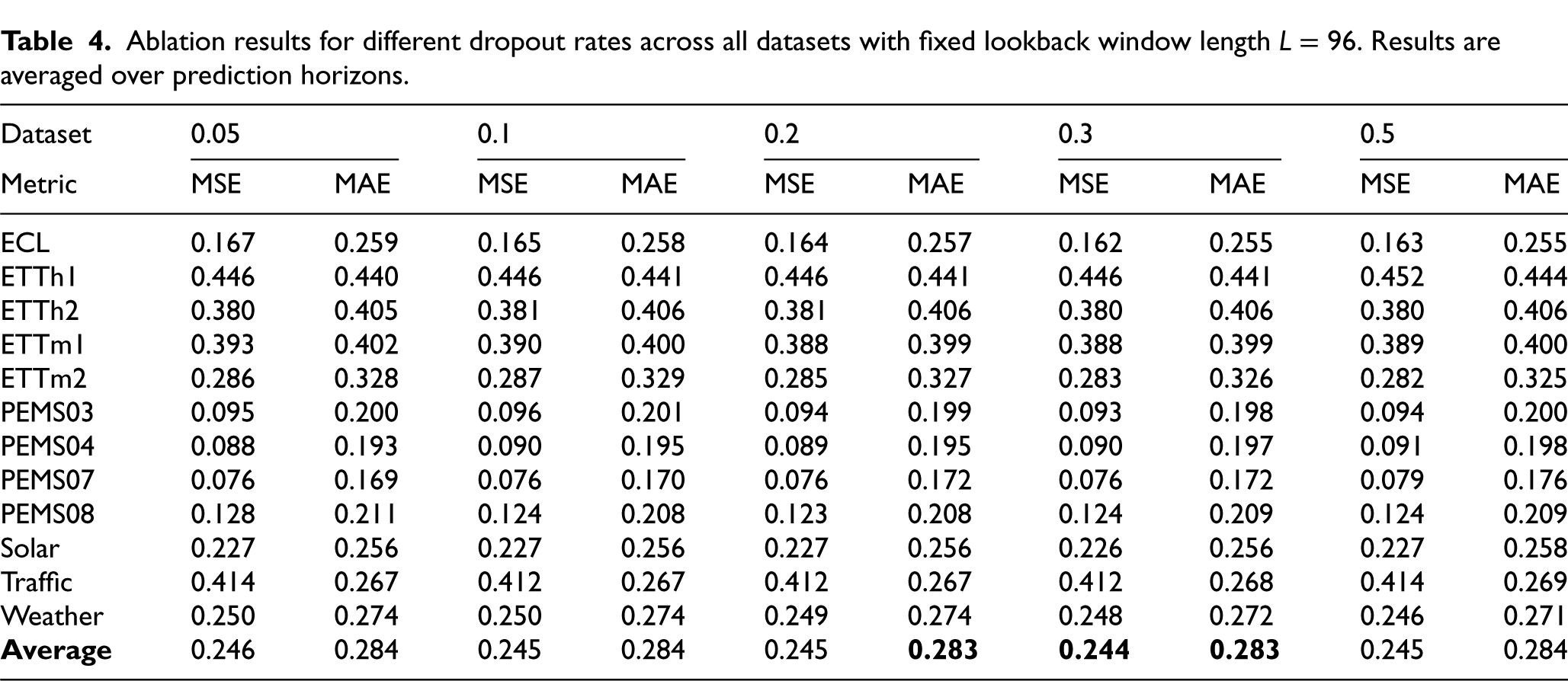
Ablation results for different dropout rates across all datasets with fixed lookback window length
Replacing the classical embedding with a learnable embedding (Learnable) results in a slight degradation of performance, although the difference is not large (average MSE
Finally, the removal of LSPE entirely (None) was included as a control to demonstrate the contribution of positional encoding itself. The results show a clear deterioration in performance (average MSE
Sensitivity to dropout rate. After confirming the importance of all model components and establishing that the classical positional embedding is the most suitable choice, we further examined the sensitivity of the model to different dropout strengths before running the main experiments. The same dropout rate was applied uniformly across all three dropout layers. Results are presented in Table 4, averaged over 12 datasets and five random seeds. The comparison shows that very low dropout (0.05) and very high dropout (0.5) yield weaker results, as they either fail to provide sufficient regularization or remove too much information. Intermediate settings between 0.1 and 0.3 perform more consistently, with the rate of 0.3 achieving the best overall average performance (0.244 MSE and 0.283 MAE). Based on these findings, a dropout strength of 0.3 was selected for the subsequent main experiments.
We evaluated SOFTS++ on 12 standard long-term forecasting datasets and compared it against ten competitive baselines, including SOFTS, iTransformer, PatchTST, TSMixer, Crossformer, TiDE, 35 TimesNet, 36 DLinear, and SCINet. 37 Since SOFTS++ builds directly upon the SOFTS model, ensuring a fair and consistent comparison between these two architectures was of particular importance. For this reason, we did not reuse the SOFTS results reported in their paper, but instead re-ran the experiments for both SOFTS++ and SOFTS under identical conditions. This was necessary because the original experiments used different random seeds, which could introduce discrepancies. While the differences in average metrics are minimal and do not impact the summary table (Table 5), some variations are observed in the full results provided in the appendix (Table 7). Across both MSE and MAE metrics, SOFTS++ achieved the best average performance overall, with an average MSE of 0.245 and MAE of 0.284, outperforming all other models in the majority of datasets.
Multivariate forecasting results with prediction lengths
for PEMS and
for others and fixed lookback window length
. Results are averaged from all prediction horizons. Full results are listed in table 7.
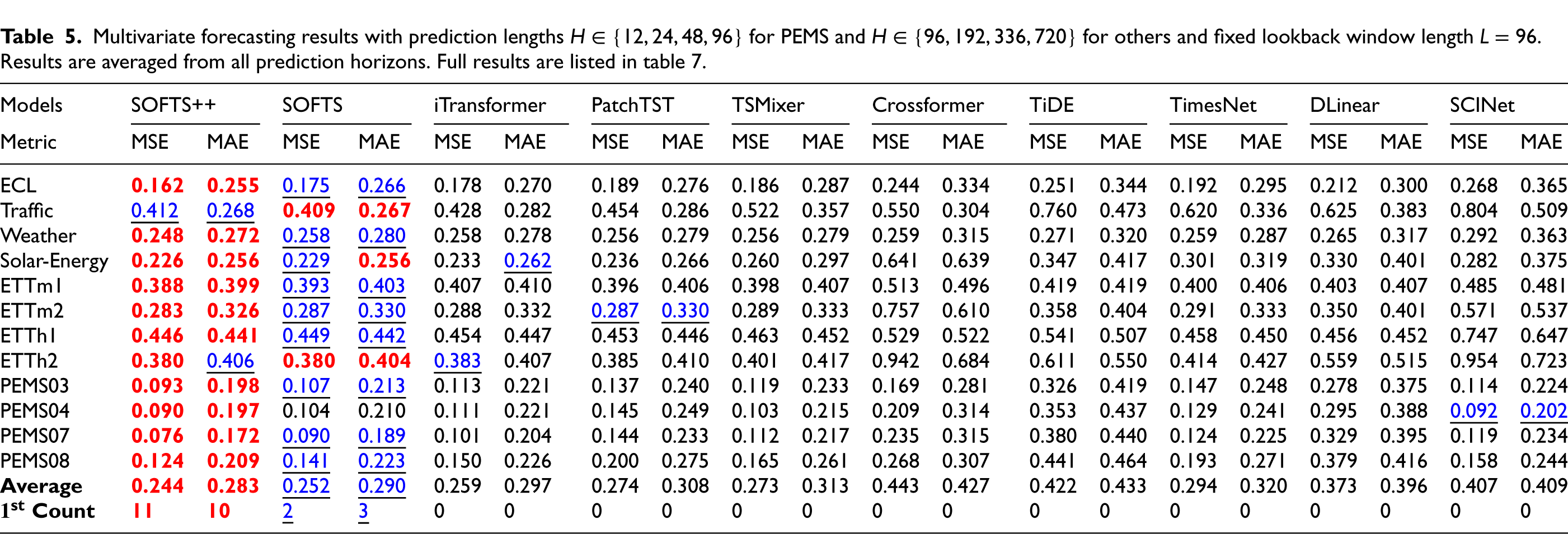
Multivariate forecasting results with prediction lengths
SOFTS++ obtained the best results (lowest MSE and/or MAE) on 10 out of 12 datasets in MSE and 11 out of 12 in MAE. It showed particularly strong improvements on high-frequency traffic datasets (PEMS03, PEMS04, PEMS07, PEMS08), where the model consistently achieved significantly lower error values compared to all baselines. This suggests that SOFTS++ is especially effective in capturing fine-grained temporal dependencies in transportation data.
In contrast, the performance on datasets such as ETTh1 and ETTh2 was slightly below that of the SOFTS baseline, though the difference was marginal and did not substantially impact the overall average. Notably, the use of robust data embedding and regularization mechanisms in SOFTS++ contributed to its increased robustness across diverse domains and forecasting horizons. The strong and consistent performance of SOFTS++ confirms its state-of-the-art effectiveness for multivariate long-range time series forecasting.
To evaluate the robustness of STAR++, we compared its forecasting performance with the original STAR module across six benchmark datasets and four prediction horizons. Table 6 presents the results averaged over five random seeds, reporting both the mean and standard deviation for MSE and MAE metrics. Overall, STAR++ consistently achieves a lower forecasting error than STAR across most datasets and horizons. However, when it comes to robustness, which refers to the consistency of results across different random seeds, the situation is more complex.
Comparison of the robustness of the STAR++ module with the baseline (STAR) module.
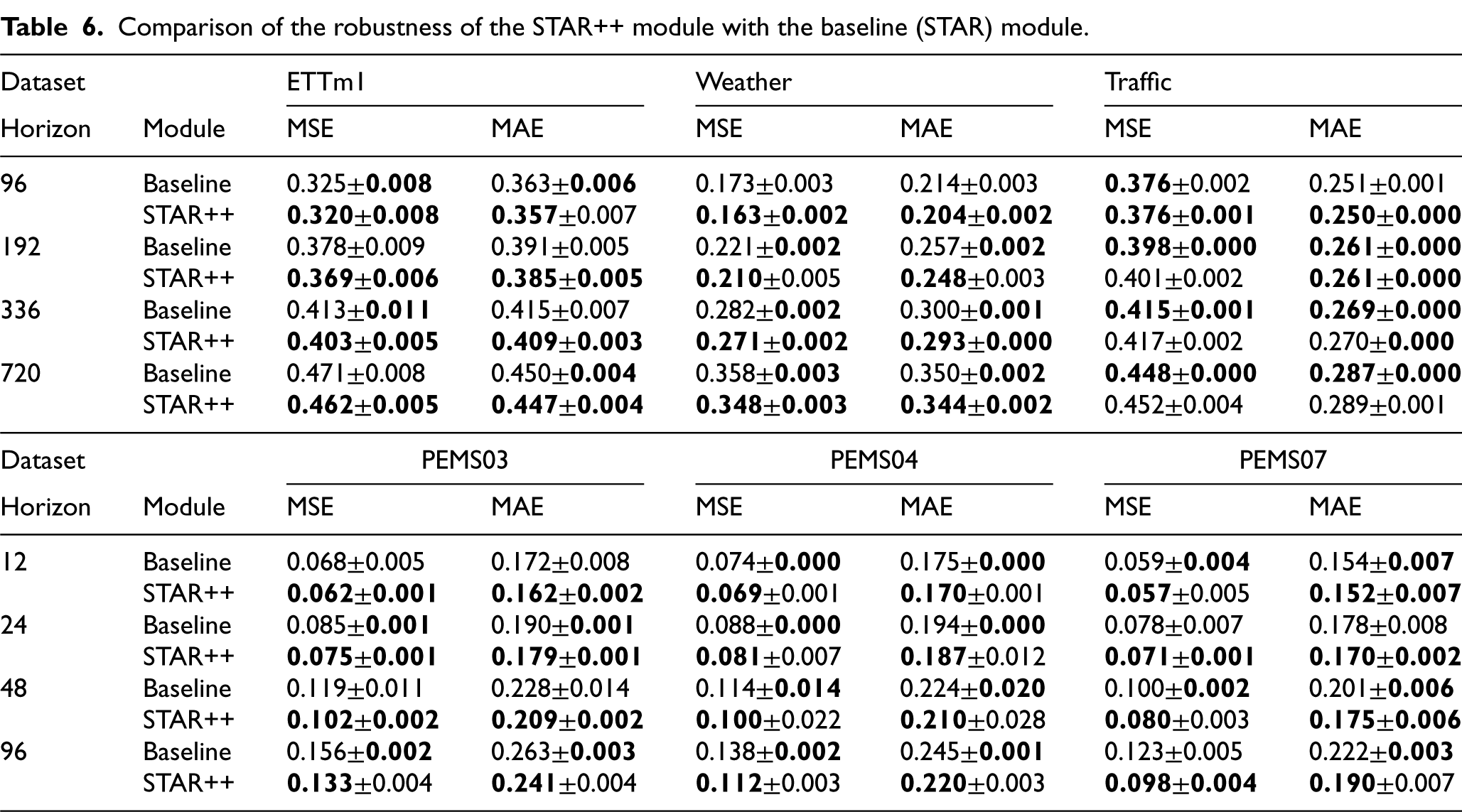
Comparison of the robustness of the STAR++ module with the baseline (STAR) module.
Multivariate forecasting results with prediction lengths
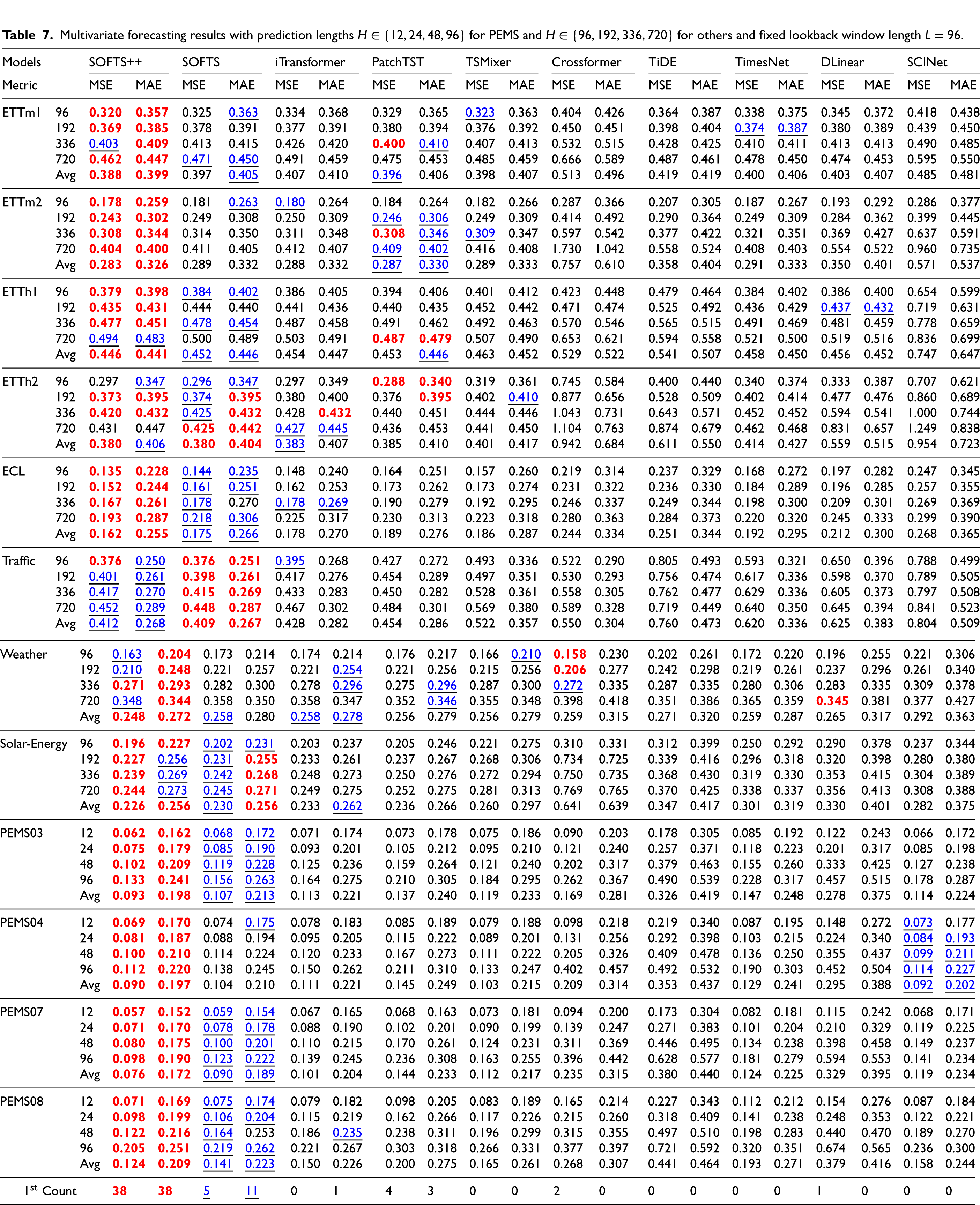
A quantitative comparison between SOFTS and SOFTS++ shows that the differences are relatively small but highlight meaningful trends. On average, SOFTS achieves slightly lower mean values (0.04 for both MSE and MAE) compared to SOFTS++ (0.05 for both metrics), suggesting marginally higher robustness in terms of mean performance. However, when considering the median, which better reflects typical behaviour by reducing the impact of outliers, SOFTS++ demonstrates a clear advantage: for MSE the median is equal to SOFTS (0.03), but for MAE it improves to 0.02 compared to SOFTS’s 0.03, indicating more consistent gains in standard use cases.
Looking at variability across datasets, SOFTS again shows slightly better stability, with lower standard deviations (MSE: 0.004462, MAE: 0.004063) than SOFTS++ (MSE: 0.006361, MAE: 0.006391). Taken together, these findings suggest that while SOFTS can be considered more robust due to its lower variability and mean values, SOFTS++ provides consistent improvements in median performance, which indicates stronger results in typical real-world scenarios. This makes it a more practical choice for applications, even though SOFTS still has a slight advantage in overall robustness.
In this paper, we present SOFTS++, an enhanced linear model for multivariate long-term time-series forecasting that builds on the SOFTS architecture. By integrating selectively applied positional embeddings, multiple dropout layers, and a robust variant of the STAR module (STAR++), our approach improves predictive accuracy across a wide range of benchmark datasets while maintaining linear complexity and low computational overhead.
Extensive experiments conducted on twelve standard datasets show that SOFTS++ outperforms competitive baselines, achieving the best average performance on 10 out of 12 datasets in MAE and 11 out of 12 in MSE. SOFTS++ achieves notably strong results on high-frequency traffic datasets (PEMS03–08), which are challenging due to their large number of channels and short sampling intervals. It consistently outperforms competing models such as iTransformer and PatchTST, especially at longer forecasting horizons. This advantage stems from the centralized STAR++ module, which reduces noise sensitivity and overfitting, while stochastic positional embeddings enhance generalization. The linear complexity of the model proves to be highly effective in handling datasets with many input channels, where traditional attention-based architectures struggle to scale.
Although SOFTS++ demonstrates improved accuracy, robustness analysis revealed non-consistent behaviour: while the model often maintains lower average errors, it occasionally exhibits higher variance across random seeds in specific configurations. A detailed study across all 48 forecasting setups showed a clear trade-off: SOFTS has lower variance, but SOFTS++ consistently achieves higher average accuracy. This indicates that SOFTS++ favours performance at the cost of slightly higher variability, which is an important aspect for practitioners to consider depending on their application.
Beyond accuracy and robustness, a key strength of SOFTS++ is its efficiency: the model retains linear complexity and was trained on a single GPU with modest runtime. This makes it suitable for resource-constrained settings such as edge devices and real-time traffic monitoring. Finally, our most significant finding is that positional embeddings need not be applied at every step; when used selectively, they yield superior results.
Future work. Our primary goal is to further improve the robustness of SOFTS++ without compromising efficiency. While the model achieves strong average performance, some datasets and horizons reveal higher variability across random seeds, making variance reduction an important next step. Future research will therefore explore new regularization methods, improved initialization, and alternative pooling mechanisms that could lower variance while preserving the linear-time and low-memory advantages of SOFTS++. Equally important is interpretability: although SOFTS++ is lightweight and scalable, understanding how individual inputs influence predictions is crucial in sensitive domains. Integrating the STAR++ module with tools such as SHAP 38 could provide fine-grained feature attributions and enhance transparency, which is valuable not only in energy forecasting and anomaly detection but also in traffic management, healthcare, and smart city applications.
Copyright
Copyright © 2016 SAGE Publications Ltd, 1 Oliver’s Yard, 55 City Road, London, EC1Y 1SP, UK. All rights reserved.
Footnotes
Acknowledgements
We gratefully acknowledge the support of the HR-ZOO project for providing access to NVIDIA A100 GPUs, which significantly contributed to the computational resources used in this work.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.