
Abstract
Text summarization systems often struggle with selecting salient content, avoiding repetition, and handling out-of-vocabulary entities. We address these issues with a two-stage approach: a supervised sentence-ranking head (SRM-head) first selects the top-
Introduction
Text summarization is the task to generate short but refined text from the original article, which not only fully summarizes the information of the original article, but also reducing information overload. At present, the technologies of generating summary can be divided into two types: extractive and abstractive. The extractive methods reconstitute the summary by selecting important sentences or paragraphs in the source text. 1 They can better produce grammatically readable sentences and express the meaning of the original text, but the summaries generated by them may be incoherent summaries with redundant information. In contrast, the abstractive methods are more in line with human thinking, and the generated summary contains some words that never appear in the original text. 2
Because abstractive summary technologies are difficult to implement, most of the early summarization technologies are extractive methods (e.g.3,4), which are usually modeled as sentence ordering problems with length constraints. The neural sequence-to-sequence model has subsequently achieved good results in many text generation tasks (such as Deep Q-Network, 5 Restricted Boltzmann Machine, 6 which makes abstractive summarization techniques feasible (such as7,8). However, the input length of the sequence-to-sequence model is limited, and when it is set too long, the model will be difficult to train and its accuracy will decrease. To solve this problem, the common practice is to delete the part of article which is longer than the set length and use the remaining part as the model input. However, the deleted text may contain important information about the article. As shown in Figure 1, the score of 10 sentences obtained by TextRank is higher than that by original method. And the input text obtained by original method contains only 5 important sentences, which shows that the original method greatly reduces the information of article.

An example of CNN/Daily Mail dataset: The upper of the figure indicates that the first 400 words of the article are directly intercepted as the input of the summary generation model, and the bottom indicates that the article is sorted by TextRank, and selects its top 10 sentences to be the input.
Besides, most of the sequence-to-sequence models are based on RNN.9,10 While RNN is very powerful in encoding sequences, its sequentiality makes the training of network very slowly. Transformer 11 can process all words and symbols in a sequence in parallel. So it is meaningful to research text summarization based on transformer model. However, simply using the transformer to generate summary will generate a lot of oov words and repeated words. Therefore, we use some methods to further to improve the transformer to make it more suitable for generating summary.
In view of the above problems, we divide the summary generation work into two sub-tasks: (1) Calculate the amount of information contained in each sentence in the original text, and then select N sentences with the highest amount of information to represent the original text in the order in which they appear in the original text. (2) Take the text obtained in (1) as the input of the summary generation model, and generate a summary of the original text based on the information carried by the N sentences.
Our contributions in this paper are summarized as follows: We propose a supervised sentences ranking method for articles with titles, which make the text obtained by this method contain more article information. We use the transformer model to generate summary, which only takes 4.15 hours to train for the 32k vocabulary model, while the traditional RNN-based summary generation model
12
usually takes 4.5 days to train. We propose to use the time penalty mechanism and pointer network to improve the transformer model to alleviate the case where the generated summary contains many oov words and repeated words. The time penalty mechanism allows different decoding steps to focus on different parts of the original text, and the pointer network allows the model to choose to extract words from the original text as abstract words.
Based on the literatures in this section, we will briefly introduce the sentences ranking model and summary generation model, and point out how they are related and different from our work.
Sentences ranking model
It involves reordering the original text using relevant indicators. Traditional sentences ranking methods are mainly divided into three types: statistical methods, graph-based methods, and center-based methods. Common statistical indicators are TF-IDF, 13 word frequency, 14 sentence position, 15 and sentence length. 16 Graph-based methods include TextRank, 17 which re-rank sentences following the PageRank algorithm. 18 Zheng and Lapata 19 regards centrality as a feature of sentence importance measures, and centrality refers to a set of words that can represent a series of articles on a topic.
In recent years, neural networks have begun to be used in sentence ranking models. 20 divides the sentence ordering task into a hierarchical regression process, which uses RNN to automatically learn the ranking features of sentences and combines the original features of the sentences to perform hierarchical regression. 21 uses enhanced CNN to capture the prior features of abstracts from variable-length phrases to rank sentences. 22 uses two LSTM to encode article title and paragraphs, then use a logistic regression model to get the similarity between title and paragraphs, and finally sort the article paragraphs based on the similarity. Our work is close to, 22 but we use the self-attention mechanism mentioned in Vaswani et al. 11 to encode title and paragraphes. Besides, we also use the attention mechanism to link the information of title and paragraphes.
Summary generation
Summary generation techniques can be divided into extractive methods and abstractive methods. The extractive methods are to select several important sentences from the original text and combine them into summaries. The commonly used extractive techniques are based on neural networks, which often model the summarization problem as sequence tagging 23 or sentence ordering. 24 The abstractive methods generate summaries through rewriting, and its summary is more refined. Most abstractive technologies are implemented based on a sequence-to-sequence framework. First, the article is encoded using an encoder, and then the decoder generates a summary step by step in an autoregressive manner. The sequence-to-sequence framework was first proposed by 4 in translation task. 25 then began to apply this framework to text summarization, but these models are prone to generate many oov words and duplicate words. Based on this, 26 applied the hybrid pointer generation network and coverage mechanism to the summary generation model, so that it has the ability to copy words from the original text as abstract words, and can suppress the generation of duplicate words.
Our work is close to 26 , but we use the transformer model proposed in Vaswani et al. 11 to generate the summary, and apply a pointer network and a time penalty mechanism between the encoder and decoder. To avoid information redundancy, we use the attention distribution obtained by the last block of the decoder as a pointer of the pointer mechanism.
Our approach
In this section, we mainly describe the overall framework of text summarization model, which is listed in Figure 2. First, we choose a sentence ranking method based on whether the article contains a title. For titled datasets, we use a supervised sentence ordering model to rank them, while using an unsupervised sentence ranking model to rank datasets without titles. Then, we extract the top N sentences that are most relevant to the article topic from the rearranged article as input to the summary generation model to generate summary. In the following sections, we will describe two important components of our model in detail, which can be seen in Figure 3.
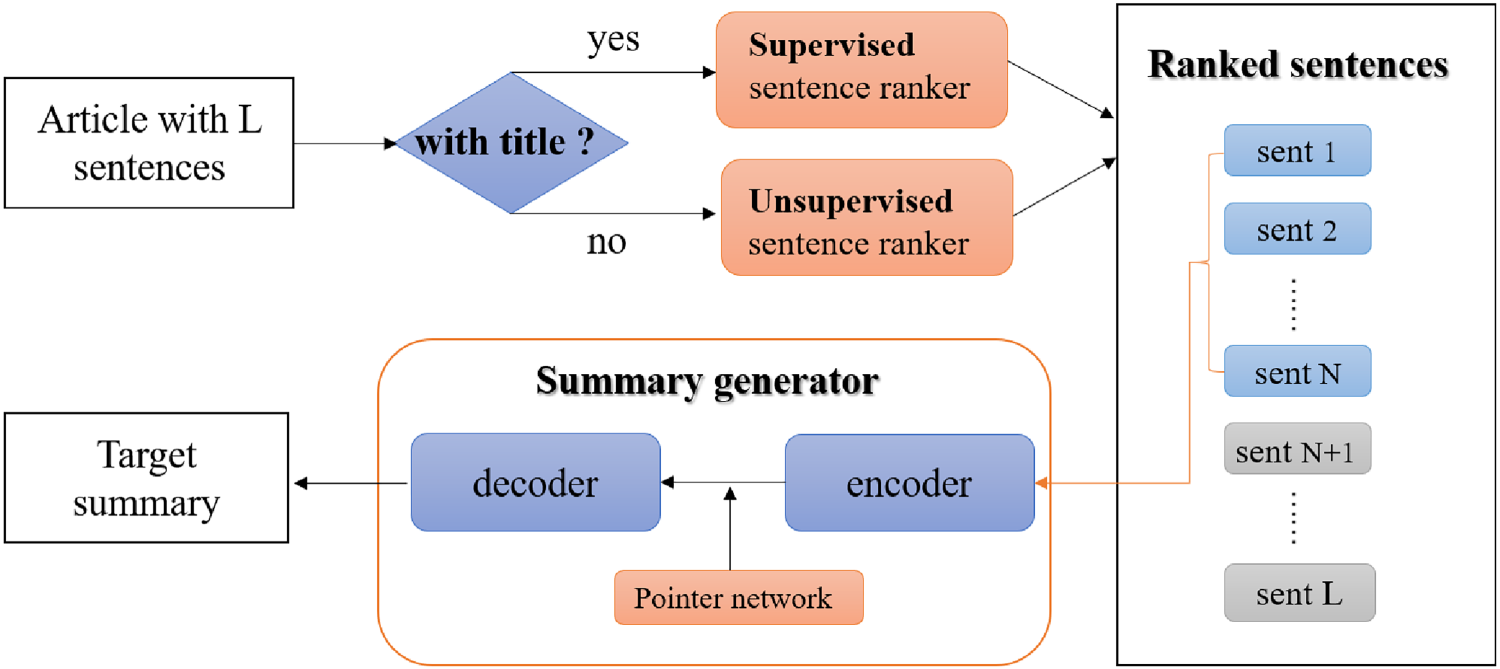
The overall framework.
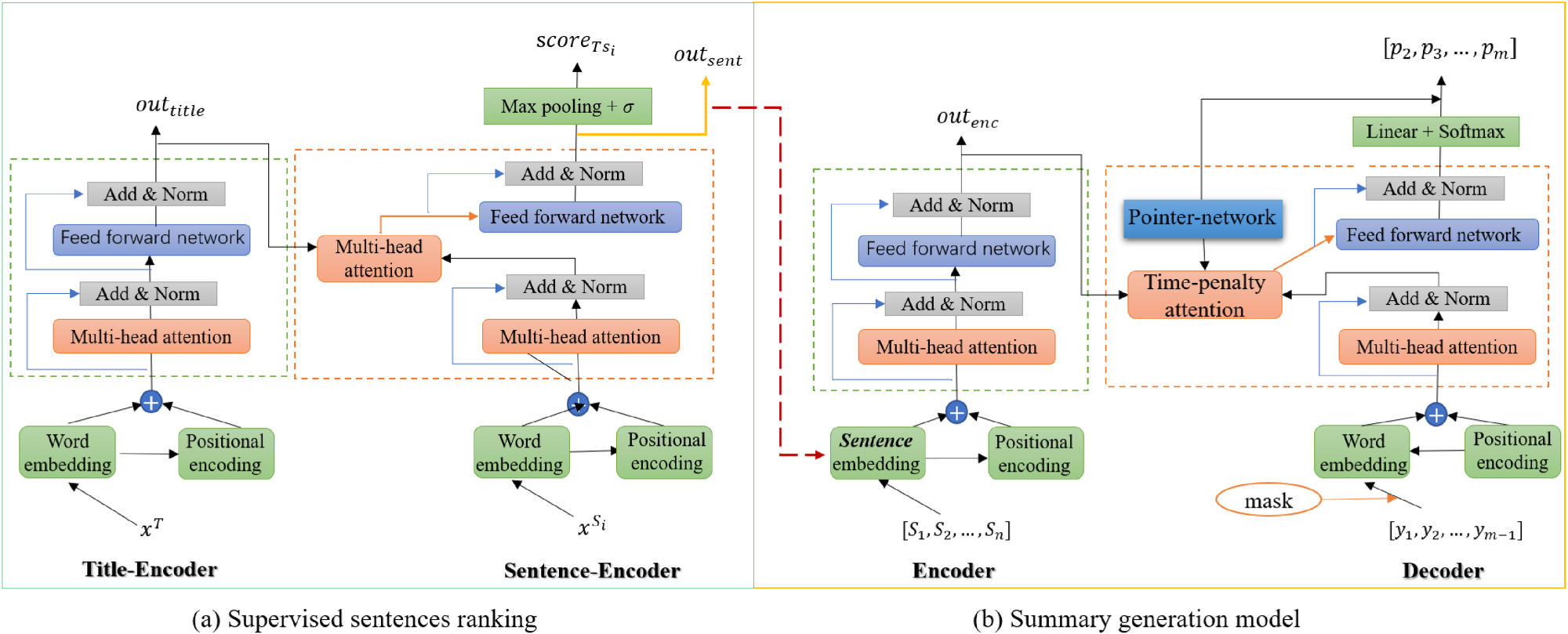
Text summarization model: (a) is used to sort the article, from which the top N sentences are selected as the input of (b), and the encoding result of each sentence-encoder is recorded at the same time
Supervised sentences ranking model: We use two encoders to encode the title and sentences of article, and use the attention mechanism to combine the two encoders. Different from
22
who used LSTM to encode the title and sentence, we chose an encoder based on self-attention mechanism to encode the title T and sentence in source text considering the complexity of calculation and long-term dependence.
The main modules of the sentence-level encoder are the same as that of the title-level encoder, but the semantic information of the title needs to be added to it, so that its final output contains the information of the article.

To calculate the similarity between title and sentence, we use a max-pooling operation on the output of the sentence-level encoder to get the final vector that represents the sentence, and then use a linear mapping and sigmoid activation function to obtain the similarity.

Unsupervised sentences ranking model: For datasets without titles, we use the improved TextRank method to rearrange article. We take each sentence in article as a node in graph, and use the similarity between two sentences to calculate the weight of the edge between two nodes. We use the BERT model
27
to obtain a contextualized sentence representation (BERT-base, uncased; no fine-tuning). The semantic similarity between two sentences is calculated as follows:

Our summary generation model is composed of an encoder and a decoder. The encoder is used to receive the most important sentences obtained by the Sentences Ranking model, and maps each word in the input to a semantic vector
The structure of the encoder is the same as the title-level encoder mentioned in Section 3.1. It contains
The structure of our decoder is similar to the decoder in transformer model, with
Time penalty mechanism: This mechanism calculates the attention distribution to the source text after punishing the information that was concerned in the previous decoding steps, which can reduce the generation of duplicate words.
First, when generating each summary word in the decoder, the way to calculate its attention distribution to the source text is:
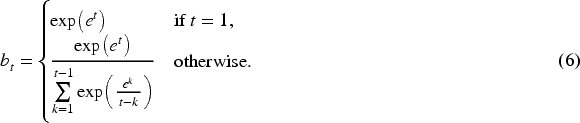
The source text information and the generated summary information are integrated according to the attention distribution obtained in the above manner, and then a context matrix

Finally, the context matrix


When creating the vocabulary table, we set the word with the frequency less than 5 to unk (unknown word), and so some words may be marked as the id of unk when marking the reference abstract. Therefore, when the frequency of real summary word is less than 5, our original model will generate as many unks as possible to achieve low loss, which will make the generated summary less readable. In order to alleviate this problem, we process each sample to get its oov (out-of-vocabulary) table and input id table containing oov information. The oov table is composed of words belonging to the sample but not belonging to the vocabulary table, and the corresponding oov table is different for each sample. The input id table containing oov information is composed of the position in the vocabulary table of each word in the sample sequence, but the id of the word that does not belong to the vocabulary is set to the sum between its position in the oov table and the length of the vocabulary.
Then based on the id table containing oov information, we add the pointer network mentioned in See et al. 26 to our model, so that the model can extract words directly from the source text as abstract words, which is reflected in code is to extract the id of the summary word from the id table containing the oov information.
Pointer network: This mechanism, like the attention mechanism, needs to calculate attention distribution to the source text in each step of decoding and we use the attention distribution calculated by time penalty attention mechanism to be the pointer. It should be noted that the decoder has
We use a soft switch to control the generation ability and extraction ability of our model. The generation ability means that the abstract word is obtained by sampling

Therefore the probability distribution of the abstract word obtained by our model in the extended vocabulary table is:
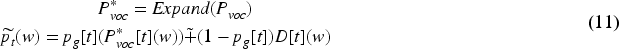
Time penalty mechanism theoretical property: To justify the above design and explain why the time penalty reduces repetition while improving coherence, we formalize the mechanism and present a simple property showing that it diversifies cross-step attention.
Let
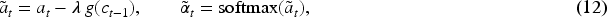

The penalty reduces the logit of source positions that were strongly attended in recent steps, preventing the decoder from fixating and thus curbing near-duplicate token emissions.
Proposition
Let


Since
Complexity
The update of
Datasets and baselines
We use two types of datasets: dataset with titles (WikiHow) and dataset without titles (CNN/Daily Mail).
CNN/Daily Mail includes one million news items, and each piece of news includes one or more manual points, which are combined into its summary. The sizes of the training, validation, and test sets are 286,817, 13,368 and 11,487 respectively. For this dataset, the average article length is about 758 tokens; we build a shared vocabulary with a minimum frequency of 5 (
WikiHow is proposed by Koupaee and Wang
28
and is a collection of articles in the Wikihow knowledge base. Each of these articles consists of a question and numerous solutions, and each of these solutions is a piece of data, and the introduction of the solution is its title. The sizes of training, validation and test sets are 180,000, 10,000 and 20,000 respectively. For this dataset, the average article length is about 460 tokens; the same shared vocabulary (min frequency 5;
Besides, we propose two models, one is a sentences ranking model and the other one is the summary generation model. The sentences ranking model is used to obtain the input of the summary generation model. As follows: SRM-head is our supervised sentences ranking model, which the output of its sentence-level encoder with title information is used to calculate the similarity between the title and the sentence.
To evaluate the performance of our sentences ranking model, we use the following models for comparison:
In addition, we compared our summary generator with various variants of the sequence-to-sequence model to verify its performance.
Implementation details
Data and preprocessing
We build a vocabulary with a minimum frequency threshold of 5 (rare words mapped to
Model configuration
The encoder–decoder follows a standard Transformer: 6 encoder layers and 6 decoder layers, model dimension 768, feed-forward dimension 2048, and 12 attention heads per layer. Dropout is set to 0.1 on attention and feed-forward sublayers. The pointer mechanism uses the cross-attention distribution from the last decoder block; the time penalty is applied in encoder–decoder attention as defined in Section 3.
Optimization and training
We train with Adagrad (learning rate
The effect of the input length
For each article with sentences
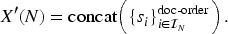
We test the effect of input length of summary generation model on Wikihow dataset and we control the input length by selecting a different number of sentences in the article. As shown in Figure 4, we perform experiments on NN-ABS, PG-coverage, and Trans-Pointer-Time, and their inputs are obtained by selecting sentences from original articles using SRM-head. The number of sentences ranges 1 to 20 with an interval of 2. It can be seen from Figure 4 that it is better to select 10 sentences as the input of some neural generation models than others.
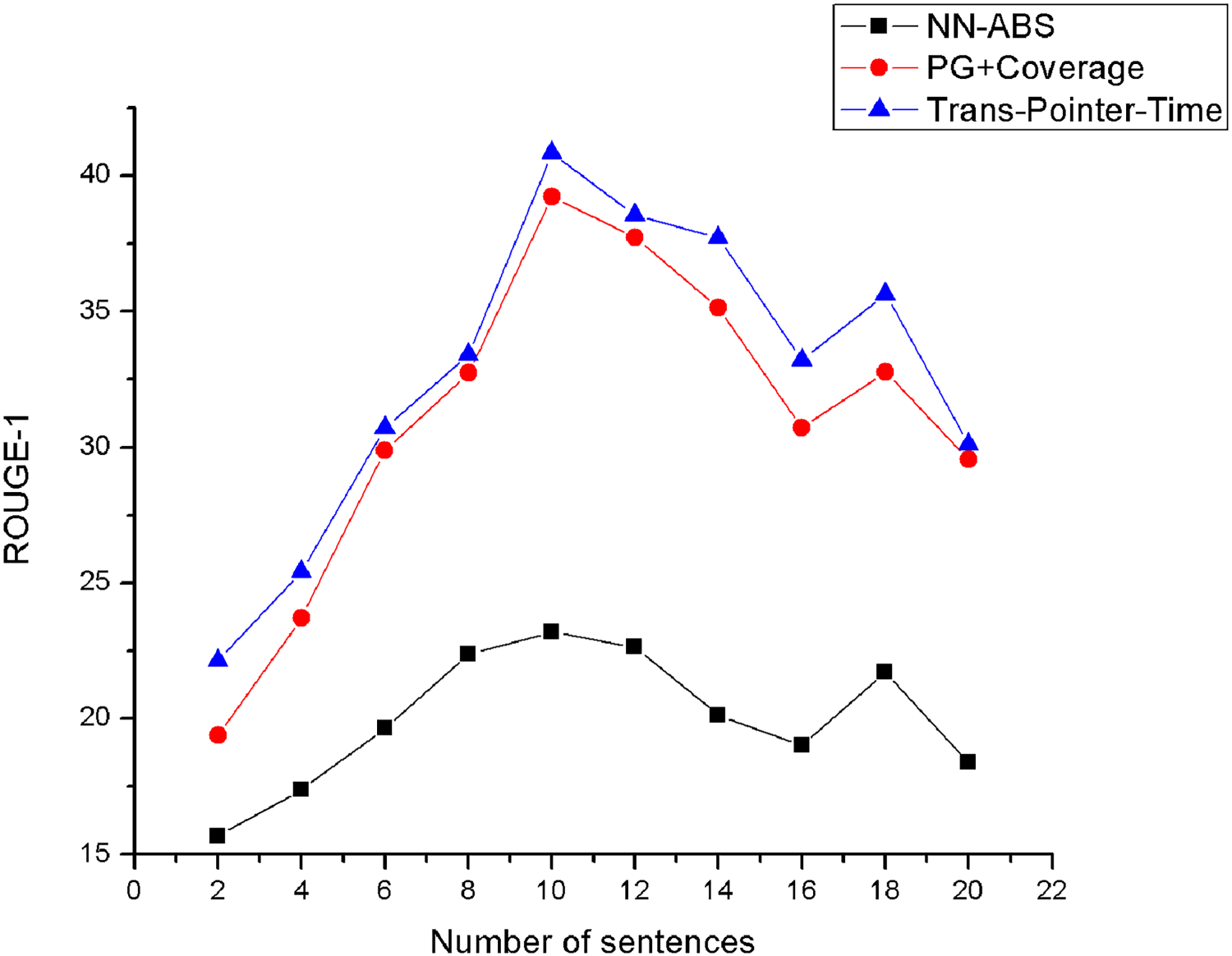
The effect of different number of sentences on the summary generation model(recording ROUGE F1).
In order to evaluate the effectiveness of SRM-head, we apply it to the Wikihow dataset to compare with various other ranking methods. Specifically, we rearrange the article through the sentences ranking method, extracting the top
Comparison results of sentences ranking models on Wikihow dataset(recording the recall score).

Comparison results of sentences ranking models on Wikihow dataset(recording the recall score).
In addition, we calculated the cosine similarity between the top n(lead-n) sentences extracted by the sentences ranking model and the human-written summary, which can represent their semantic similarity. We use this similarity score to evaluate different sentences ranking models. As shown in Figure 5, our SRM-head gets a score of
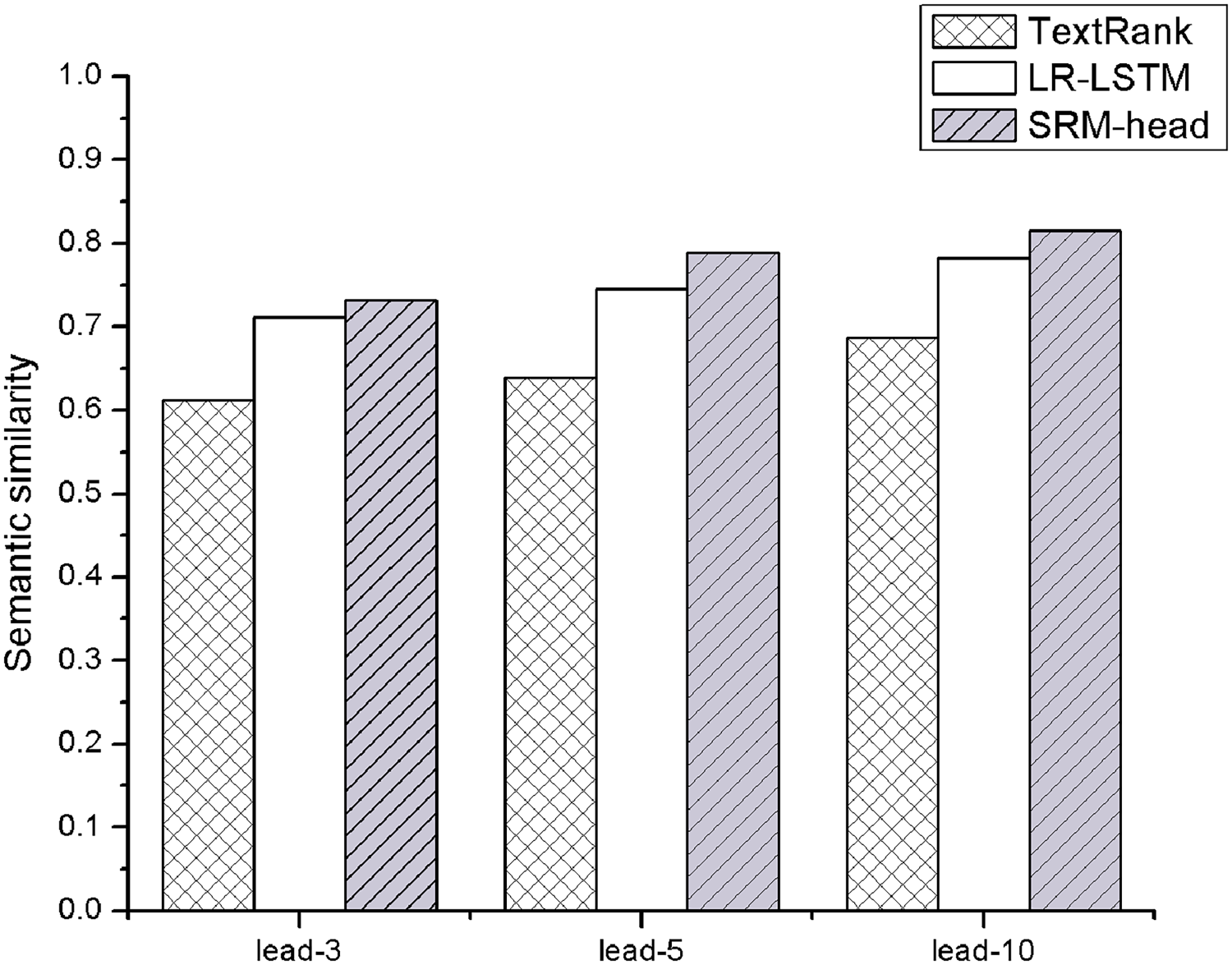
Evaluation of Sentences Ranking Method on WikiHow dataset, which the semantic similarity is obtained by cosine similarity.
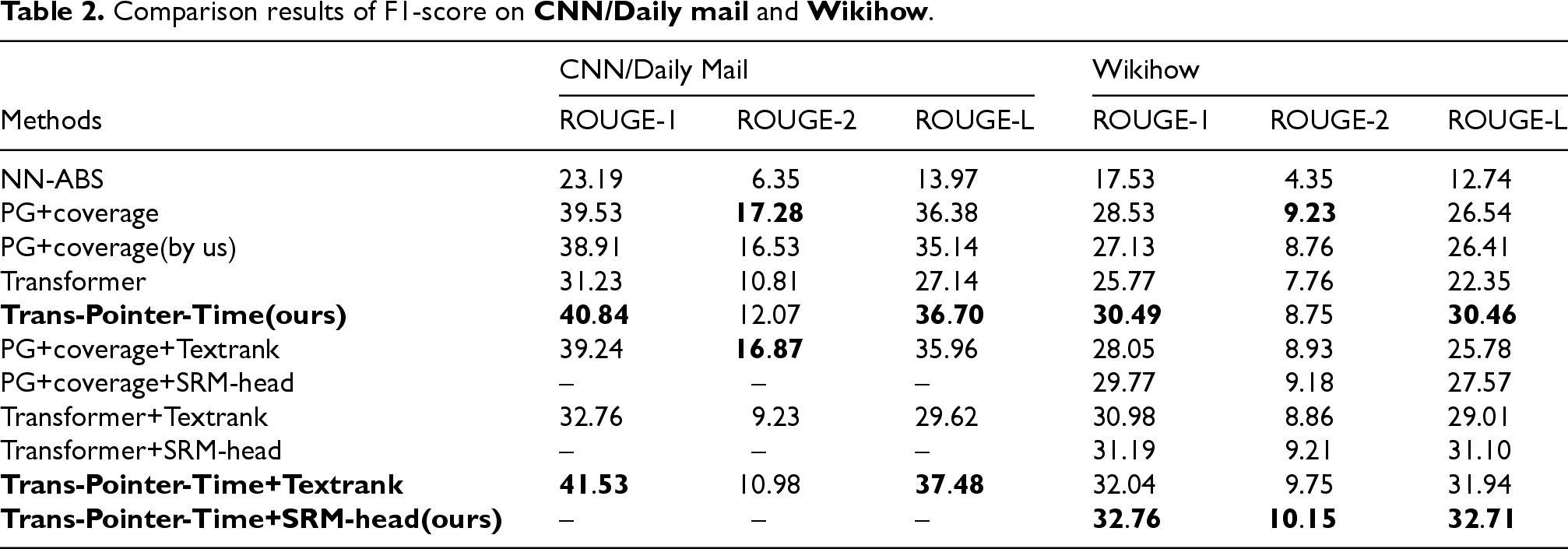
Table 2 is the experimental results of some generators on the CNN/Daily Mail dataset and the Wikihow dataset. The input of the models above the horizontal line in Table 2 is the text in the article that does not exceed the input length set by models. That is, the part of the article that exceeds the set length is directly deleted, and the remaining part is used as the input of the models. The input of models below the horizontal line is the text consisting of the top 10 sentences in rearranged article sorted by TextRank or SRM-head. The scores in row 2 of Table 2 are obtained from 30,31, while the scores in row 3 are obtained by training the models on the Nividia M40 GPU. Although the experimental results we obtained are not as effective as recording in the original article, this has certain reference significance for us and helps us to conduct experimental analysis.
Comparison results of F1-score on CNN/Daily mail and Wikihow .
Comparison results of F1-score on
Figure 6 illustrates the semantic similarity between the summary generated by different summary generation models and the reference summary, and Figure 7 records the proportion of novel words and unks included in the summary generated by different summary generation models, where novel words are the words that appear in the summary but not in the original article and unk represents that a summary word generated by summary generator is out of dictionary.
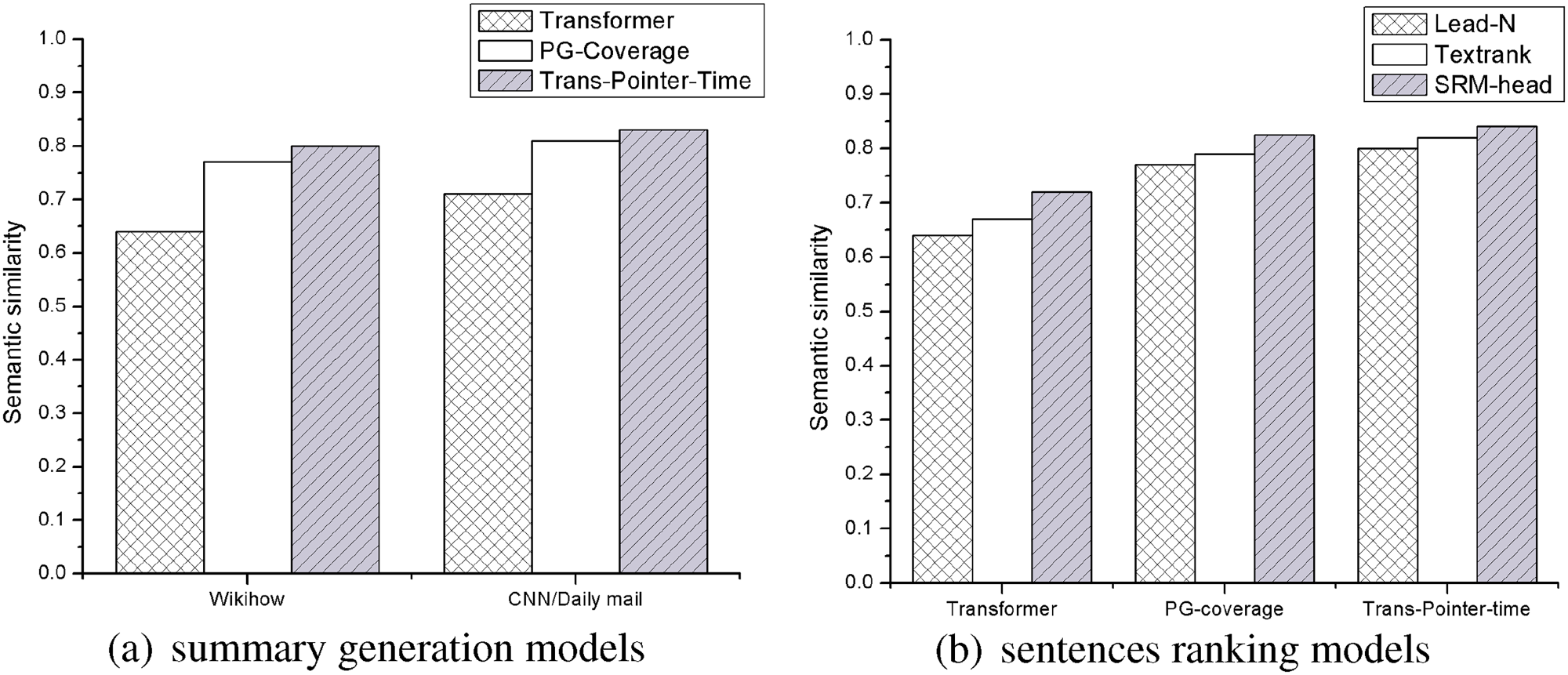
The semantic similarity between the generated summary and reference summary. (a) records the effect of different summary generation models on different datasets. The input of the model is the first
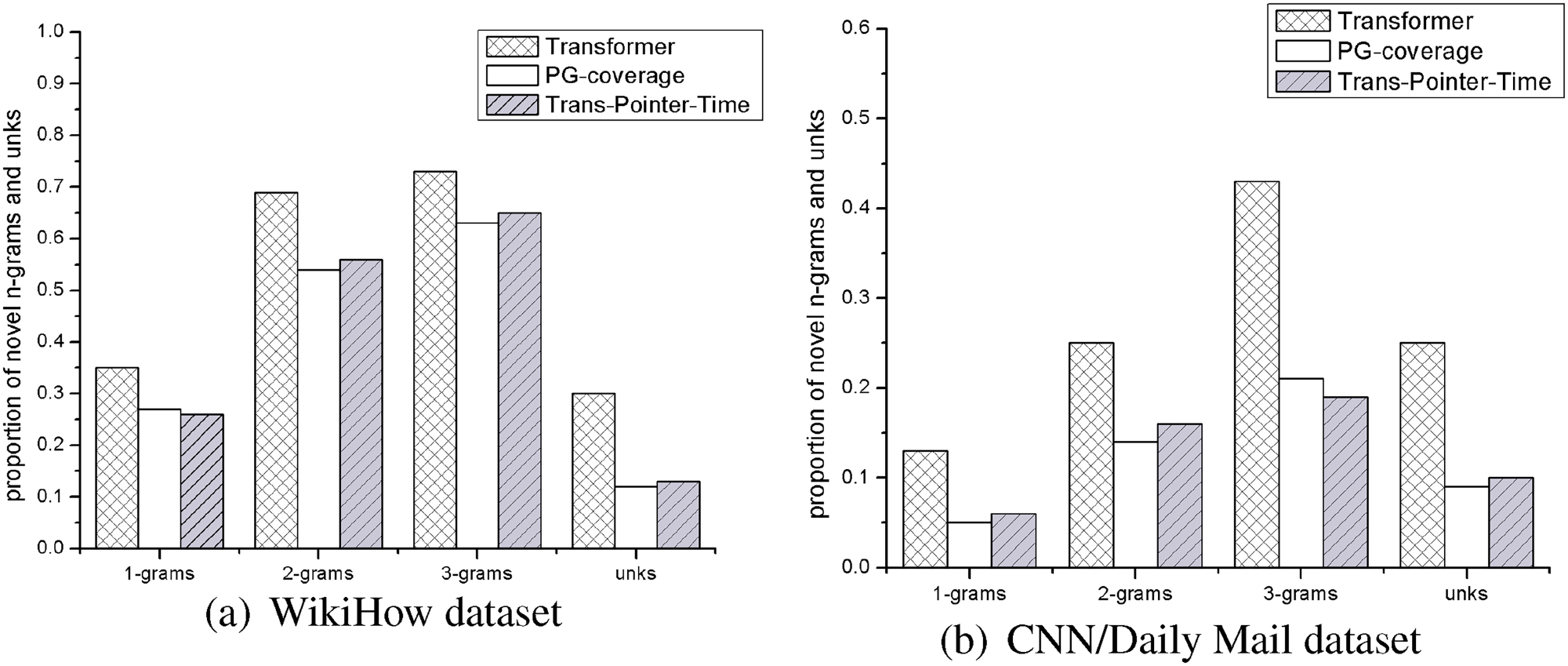
The proportion of novel n-grams and unks in summaries generated by different summary generation models. The proportions of novel words contained in Trans-Pointer-Time and PG-coverage are not high for they sometimes extract words from the source text as summary words.
Comparing the data in the first 4 rows in Table 2, we can see that the result of using Transformer to generate a summary is better than using the traditional sequence to sequence model NN-ABS, but not as effective as the sequence to sequence model with pointer mechanism PG+coverage. From Figures 6(a) and Figure 7, we can see that the semantic similarity between the summary generated by Transformer and the reference summary is not as high as that of PG+coverage, and the summary generated by Transformer contains a lot more unks than PG+coverage. This can indicate that Transformer still has the problem that the generated summary contains many oovs.
Thus we propose Trans-Pointer-Time, which adds a pointer mechanism and a time penalty mechanism to Transformer. From the proportion of unks in Figure 7, the summary generated by Trans-Pointer-Time contains fewer unks, which improves the OOV problem. Meanwhile, you can see from rows 3 to 5 in Table 2 that the scores in ROUGE F1 of Trans-Pointer-Time are
In addition, in order to verify that our supervised sentence ranking model can improve the performance of the summary generation model, we conducted comparison experiments on WikiHow dataset. We preprocess it with TextRank and SRM-head, and then input it to summary generators. The result below the horizontal line in Table 2 shows that SRM-head improves the performance of the summary generation model better than TextRank, and SRM-head improves the F1 in ROUGE-1 of Trans-Pointer-Time by nearly
We isolate the contributions of the time penalty and the pointer mechanism on WikiHow dataset. Under identical training and decoding settings as our main results, we evaluate four variants: (i)
Ablation study on time penalty mechanism and pointer mechanism.

Ablation study on time penalty mechanism and pointer mechanism.
Relative to the plain Transformer, Transformer-Time substantially improves quality, with the largest gain on ROUGE-L (
Time penalty mechanism improves coherence by penalizing consecutive steps that focus on the same source positions, thereby reducing repetition and improving ordering (higher ROUGE-L). The pointer mechanism adds a gated copy distribution from cross-attention, which handles OOV and preserves key entities and phrases, boosting ROUGE-1/2. The two are complementary: Time Penalty guides where to attend over time, while Pointer influences what to emit. Together, they yield the best overall performance on WikiHow.
Table 4 compares our model with recent pretrained summarizers on both CNN/DailyMail and XSum. For BART and PEGASUS, we use the test scores reported in their original papers32,33; for T5 we use its reported CNN/DailyMail score and a widely used public reproduction on XSum
34
. Our model is trained/evaluated on XSum under the same preprocessing, length control, and ROUGE protocol as in CNN/DailyMail, with shorter targets (e.g., 64 tokens) and a smaller SRM-head top-
Comparison with other SOTA models and cross-dataset generalization.

Comparison with other SOTA models and cross-dataset generalization.
On
These outcomes highlight the effectiveness of our design: SRM-head provides explicit content selection, the pointer mechanism preserves lexical fidelity and handles OOV tokens, and the time penalty promotes cross-step attention diversity to curb repetition. Taken together, these lightweight, modular components plug into a standard Transformer and deliver competitive performance without relying on extremely large-scale pretraining.
Let
Incremental cost of our additions: (i) Time penalty keeps a recency footprint
Effect of SRM-head (top-
Both modules are lightweight: they introduce only
Conclusion
We presented a two-stage summarization framework in which a supervised sentence-ranking head (SRM-head) selects the top-
Future work
We plan to (i) extend the pipeline to longer documents via hierarchical selection and long-context/sparse attention, (ii) incorporate structured evidence (tables/knowledge bases) and faithfulness constraints to further improve factual consistency, (iii) complement automatic metrics with targeted human evaluation protocols for fluency, coherence, and relevance, (iv) study domain and language transfer beyond news and how-to articles, and (v) explore joint training of SRM-head and the generator while plugging our modules into large pretrained backbones to combine strong pretraining with our lightweight control mechanisms.
Ethical considerations
This article does not contain any studies with human or animal participants.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work is supported by the National Natural Science Foundation of China (Grant Nos. 62373141, 62302157, 62532005), the Science and Technology Program of Changsha (kh2301011), the Major Science and Technology Research Projects of Hunan Province (Grant Nos. 2024QK2010, 2024QK2009), the Yunnan Provincial Major Science and Technology Special Plan Projects (No. 202502AD080009), the Yunnan Science and Technology Talent and Platform Program (No. 202605AK340003), the open Project Fund of the State Key Laboratory of Cyberspace Security Defense (2024-MS-04).
Declaration of conflicting interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
All data generated or analysed during this study are included in this published article.