
Abstract
Aspect-based dialogue sentiment quadruple analysis (DiaASQ) is a critical task in sentiment analysis, aiming to extract sentiment quadruples (target, aspect, opinion, sentiment polarity) from dialogues. Existing methods primarily focus on single-sentence sentiment analysis, often neglecting the rich contextual information and long-range dependencies in multi-turn dialogues. To address this limitation, we propose a novel memory framework, Memory, which incorporates adaptive contextual memory mechanisms to simulate human-like emotional refinement during conversations. Our framework consists of three key components: a Contextual Knowledge Memorizer to capture token-level syntactic-semantic dependencies, an Utterance-level Sentiment Interactor to model speaker-respondent dynamics, and a Multi-granularity Memory Integrator to fuse token-level and utterance-level information for precise sentiment relationship extraction. Extensive experiments on two benchmark datasets demonstrate the framework’s superiority, achieving 10.14% and 6.03% improvements in Micro-F1, and 13.07% and 5.60% improvements in Iden-F1 on Chinese and English datasets, respectively.
Introduction
Aspect-level dialogue sentiment analysis (DiaASQ)
1
functions as a significant subtask in sentiment analysis. It aims to extract precise sentiment information from multi-turn conversations. Conventional methods often focus on single-sentence classification. As a result, they miss the temporal context and structural complexity of real-world dialogues. Such approaches ignore the long-range dependencies found in conversational data, which reduces their practical value. The primary task involves extracting sentiment quadruples

Example of a dialogue (top) and an emotional quartet (bottom). In the dialogue, different emotional elements are highlighted in various colors. Dotted lines indicate response relationships, and letters in circles represent different spokespersons. In the emotional quartet, the structure and relationships are similarly annotated to illustrate the interactions and emotional dynamics.
Prior studies have sought to tackle these challenges using graph convolutional networks (GCN)2,3 and heterogeneous graphs 4 to improve token- and discourse-level representations. These methods increase cross-layer interaction but often integrate information only at a shallow level, and they do not use memory mechanisms to retain and filter salient content from earlier turns. Methods such as dynamic multi-scale context aggregation (DMCA) 5 show the same limitation: they do not capture long-range dependencies or track topic shifts in multi-turn conversations.
To overcome these limitations, this paper introduces a novel memory network framework (Memory), designed to emulate human-like memory filtering for dialogue sentiment analysis. Our framework is centered on three key components: A contextual knowledge memorizer that captures and filters token-level syntactic-semantic information by leveraging the “thread” structure of dialogues (subtree structures rooted in speaker-reply relationships). An utterance-level sentiment interactor that improves information exchange between speakers and respondents at the discourse level, offering complete structural discourse features. A multi-granularity memory integrator that effectively combines the filtered token-level and discourse-level memory to support accurate sentiment relationship extraction.
The Memory departs from conventional sentiment analysis and models human-like memory through selective storage and retrieval rather than processing each utterance in isolation. Empirical evaluations on multilingual datasets (Chinese and English) support the effectiveness of the framework under standard settings. It yields improvements of 10.14% and 6.03% in Micro-F1, and 13.07% and 5.60% in Iden-F1, respectively. Relative to state-of-the-art baselines, the model reports gains of 1.71% (ZH) and 0.33% (EN) in Micro-F1, and 3.60% (ZH) and 0.21% (EN) in Iden-F1, and it remains effective for long-range dependencies and cross-dialogue sentiment analysis. This work offers four contributions: We present a memory network framework built around a dedicated memory unit that supports selective storage and retrieval across the full dialogue context. It supplies integrated dialogue information to downstream modules in sentiment analysis. A contextual knowledge memorizer and an utterance-level sentiment interactor enrich context and support memory-guided information filtering; this design mitigates limitations in prior methods. A multi-granularity memory integrator that resolves cross-layer memory fusion in the overall architecture. Experiments on the DiaASQ dataset show improvements over strong baselines and establish a performance benchmark for DiaASQ.
Single ABSA tasks
This section reviews single aspect-based sentiment analysis (ABSA) tasks whose objective is to predict one sentiment element only. The four tasks (corresponding to four sentiment elements) are aspect term extraction, aspect category detection, aspect sentiment classification, and opinion term extraction.
Aspect term extraction (ATE) is a core task in ABSA. It identifies aspect-related phrases in text that anchor sentiment. Several methods have been proposed to improve ATE. For example, Yin et al. 6 proposed a syntactic dependency-aware embedding framework (POD), which integrates dependency patterns with positional contextual information, and Wang et al. 7 proposed a progressive self-training method.
Aspect category detection (ACD) identifies the aspect categories discussed in a sentence, where categories come from a predefined, often domain-specific set. Compared with ATE, ACD has two advantages. First, whereas ATE focuses on discrete aspect terms, ACD yields a consolidated representation of opinion targets through aggregated outputs. Second, ACD can detect implicit opinion targets without explicit textual mentions. For instance, in “It is very overpriced and not tasty,” ACD identifies the categories price and food, even though ATE would not apply. Prior studies explore different strategies for category assignment. In Tulkens and van Cranenburgh, 8 category labels are assigned by cosine similarity between sentence embeddings and predefined category vectors. Recent work by Shi et al. 9 proposed a precision-oriented discriminative mapping framework and improved alignment fidelity.
Aspect sentiment classification (ASC), also known as aspect-oriented or context-specific sentiment analysis, predicts the polarity linked to a particular aspect in text. Recent work proposes methods that directly use structural linguistic features. One line employs a graph convolutional network to model syntactic relations. 10 Another line uses dependency parse trees to guide sentiment classification. 11
Opinion term extraction (OTE) detects sentiment expressions associated with given aspects. Because opinion and aspect terms often co-occur, extracting opinion terms in isolation is less informative. OTE is therefore divided into two sub-tasks based on whether an aspect term is provided: (1) aspect-opinion co-extraction (AOCE), which extracts aspect and opinion terms jointly, and (2) target-oriented opinion words extraction (TOWE), which extracts opinion words for a specified aspect term. For instance, Veyseh et al. 12 use syntactic structure, such as dependency-tree distance to the aspect, to aid identification of opinion terms. Mensah et al. 13 empirically evaluate positional embeddings across encoders and report that BiLSTM-based methods have an inductive bias suited to TOWE; they also add a GCN to capture structure, but the gain is small.
Compound ABSA tasks
This section reviews compound ABSA tasks that target multiple sentiment elements. They are often cast as integrated versions of the single-element tasks above. The goal is not only to extract multiple elements but also to link them through prediction of paired (two elements), triplet (three elements), or quad (four elements) structures that encode explicit associations among aspects, opinions, and polarities within a sentence.
Studies on the aspect-opinion co-extraction (AOCE) task often find that extracting aspect and opinion terms can benefit each other. However, AOCE outputs separate sets of aspects and opinions and does not record explicit links between them. The aspect-opinion pair extraction (AOPE) task was proposed to resolve this issue; it jointly extracts aspect–opinion pairs and returns explicit mappings between each opinion target and its expression. 14 Wu et al. 15 presented a grid-based annotation framework (GTS), in which the model classifies word pairs into four types: intra-aspect, intra-opinion, aspect–opinion pairs, or unrelated. This change converts pair extraction into a unified token-classification problem. Later work added syntactic and other linguistic cues and reported improved extraction. 16
End-to-end ABSA (E2E-ABSA) identifies aspect terms and their sentiment polarities as (
Aspect category sentiment analysis (ACSA) jointly detects discussed aspect categories and their sentiment polarities. It resembles E2E-ABSA, but the aspect is a predefined category and may be implicit or explicit in the sentence. This flexibility supports industrial use. Cai et al. 21 proposed a hierarchical GCN method (Hier-GCN): a lower layer models relations among categories, and a higher layer models relations between categories and category-oriented sentiments. Liu et al. 22 used a sequence-to-sequence architecture for ACSA; they use a pretrained generative model and express outputs as natural-language sentences, and the method outperforms prior classification-based models. The approach also uses prior knowledge well and performs strongly in few-shot and zero-shot settings.
The aspect sentiment triplet extraction (ASTE) task
23
identifies (
Compound ABSA seeks fine-grained sentiment at the aspect level, either via pairwise extraction (e.g., AOPE) or triplet extraction (e.g., ASTE). These settings are useful, but a single model that predicts all four sentiment elements in parallel provides a more complete representation. This motivation led to the aspect sentiment quad prediction (ASQP) task, which jointly extracts all four elements as unified quadruples from text. Zhang et al. 26 proposed a paraphrase-based framework that generates sentiment quads with end-to-end learning. They integrate annotated sentiment elements with predefined templates and then reformulate quad prediction as a text-generation problem solved with a sequence-to-sequence architecture. The method makes full use of label semantics (i.e., the contextual meaning of sentiment elements). Subsequent studies extend this line to output opinion trees27,28 or structured schemas 29 and further specify the task design.
Sentiment analysis in conversation
Sentiment analysis in conversation presents unique challenges, including multi-actor interactions, long-range dependencies, and dynamic topic evolution. Traditional approaches to conversation sentiment analysis have primarily focused on coarse-grained sentiment classification, often overlooking the fine-grained sentiment elements that are crucial for understanding complex dialogues. Early methods relied on sequence modeling or graph networks to capture dialogue features, but these approaches struggled to encode the intricate structures of multi-turn conversations. Generative models, while effective in some contexts, often fail to handle the complexity of dialogue structures, and pre-trained models are constrained by input length limitations, making them less effective for long dialogues.
Recent advancements have introduced GCNs2,3 to address these challenges by enabling fusion at multiple granularities. These methods have improved the modeling of token-level and discourse-level interactions, but still face difficulties in handling long dialogues and dialogue intersections. For instance, H2DT 4 introduced heterogeneous graphs to model dialogue structures, but its performance on long dialogues remains suboptimal. Despite these limitations, these studies have laid a solid foundation for addressing the complexities of multi-actor interactions and long-range dependencies in conversations.
This work builds on that line with a Memory model that adds a memory mechanism to capture multi-actor interaction and to cope with long-range dependencies and topic shifts in long dialogues. The model combines token-level and discourse-level information via a multi-granularity memory framework and offers a more complete solution for dialogue sentiment analysis.
Memory-augmented models and long-context modeling
Recent progress in memory-augmented neural networks and long-context mechanisms has reshaped natural language processing. Original memory models relied on external components for data storage and retrieval to support reasoning and question-answering. 30 Modern large language models (LLMs) now extend context windows through specialized attention mechanisms; these systems process tens of thousands of tokens in a single pass. 31
Comprehensive assessments like the HELMET benchmark 32 reveal that current long-context models fail to reliably extract and process data embedded deep within lengthy input sequences. These performance gaps motivated new active memory management frameworks; for example, MemOS 33 organizes memory-augmented generation through a structured, multi-tier approach. Yet, adapting generic long-context methods for multi-turn dialogue sentiment analysis remains difficult due to unique linguistic properties. Standard models often process inputs as uniform, linear sequences. Such simple concatenation ignores the specific structural links found in dialogue, such as speaker dynamics and complex thread-and-reply patterns.
To fill this research gap, the Memory framework moves away from basic flat sequence modeling. The system instead includes an Adaptive Contextual Memory Unit (ACMU) that uses the structural threads of dialogues. Through human-like selective memory and forgetting, our model filters out irrelevant conversational noise. At the same time, it retains long-range sentiment cues across multiple turns. This specialized memory mechanism connects local utterance features with global discourse structures; it provides a more precise and interpretable solution for DiaASQ than earlier memory-based architectures in this field.
Method
Table 1 summarizes the primary mathematical notations and variables used throughout our Memory framework.
Notations and their corresponding descriptions used in the memory framework.
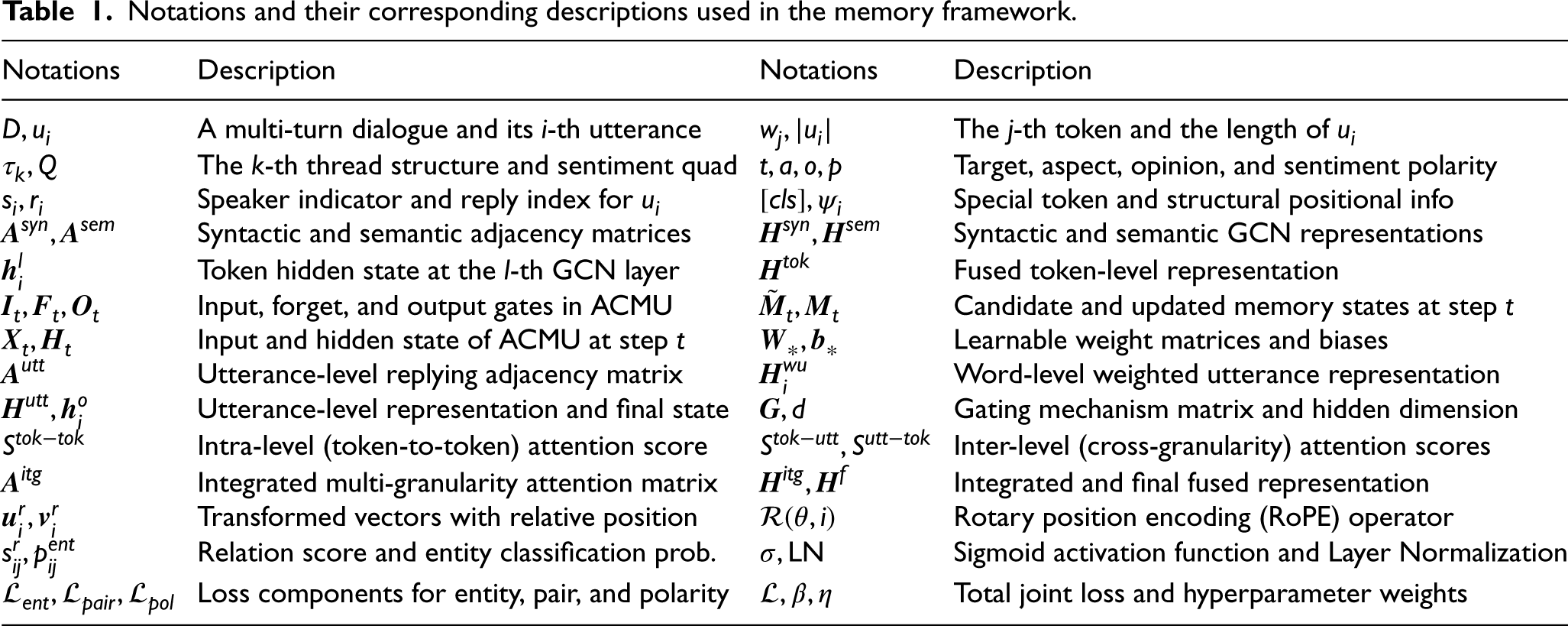
Notations and their corresponding descriptions used in the memory framework.
This section formally defines the DiaASQ task and states the assumptions used in its formulation. The goal is to extract sentiment quadruples (target, aspect, opinion, and sentiment polarity) from multi-turn dialogues. These quadruples encode the sentiment information expressed in a conversational exchange.
Consider a dialogue
Given the dialogue
Each element in the quadruple is a substring of one or more utterances in
In line with the grid annotation framework of Li et al., 1 DiaASQ is decoupled into three joint subtasks: entity boundary detection, entity-pair identification, and sentiment polarity prediction. The entity labels are {tgt, asp, opi} for target, aspect, and opinion. Relations between entities are denoted by {t2t, h2h}. Sentiment polarities are labeled as {pos, neg, other}.
In dialogue sentiment analysis, it is essential to capture long-range dependencies and speaker-specific interactions to track sentiment over a conversation. To improve contextual extraction and handle the length limits of pre-trained language models (PLMs), we adopt a discourse unit–thread architecture. The approach uses the thematic coherence of discourse units within the same conversational thread. Each utterance 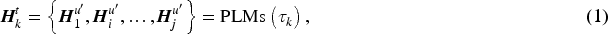

The proposed model Memory consists of four core components. The
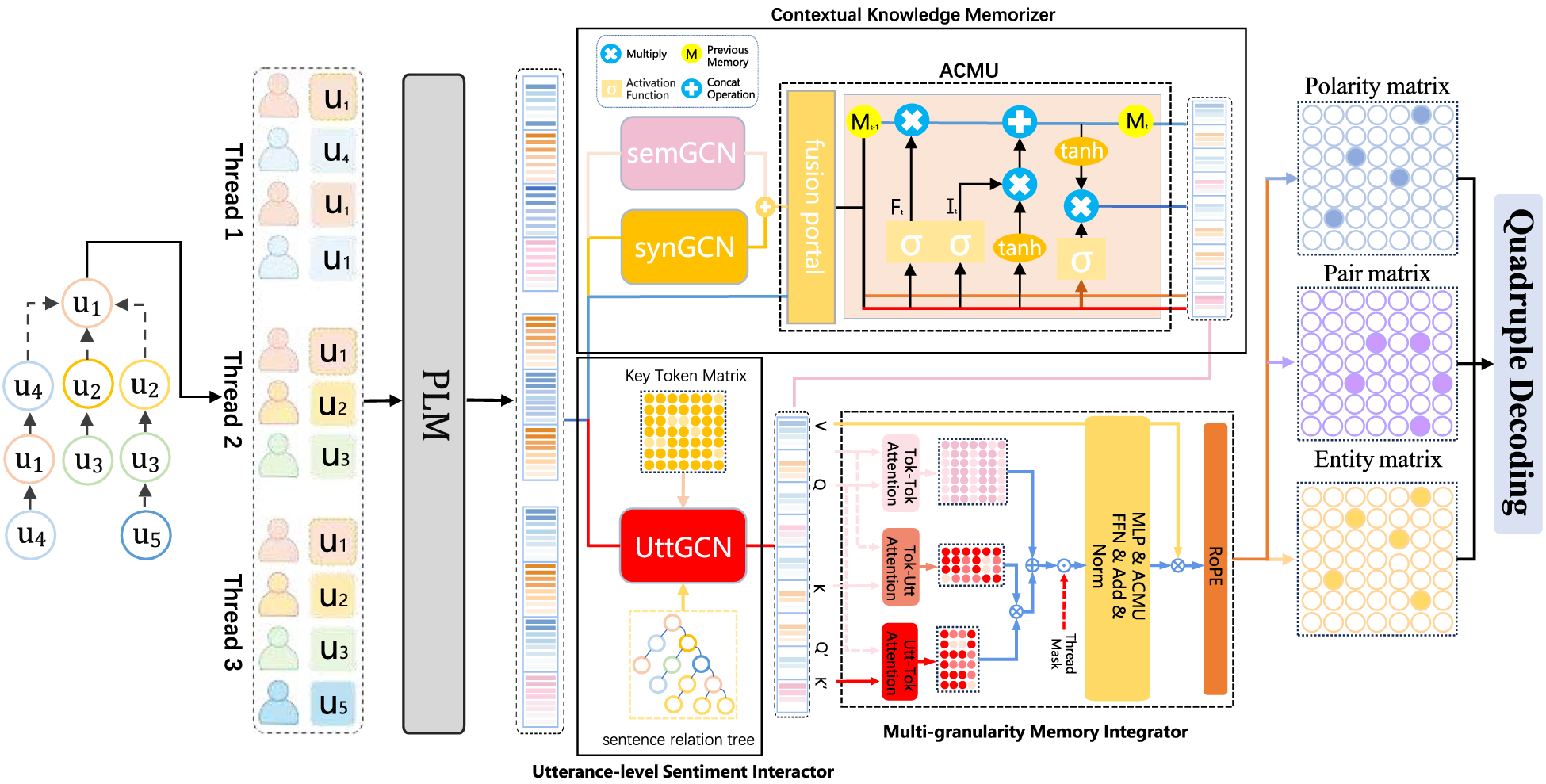
The overall architecture of our proposed Memory.
To improve token-level information extraction in dialogues, the contextual knowledge memorizer adopts a dual-path design that consists of a syntactic parsing module and a semantic module. The syntactic path captures grammatical structure features, and the semantic path captures deep semantic representations, respectively. The two outputs undergo adaptive fusion with the original BERT embeddings through gating mechanisms, and the fused representation is then passed to a memory-augmented network that retains salient information and models long-range dependencies.
Assuming that the graph contains 
To extract syntactic features, we construct a syntactic adjacency matrix for the 


Once the semantic neighborhood matrix
Let
The ACMU begins by computing a fusion score 
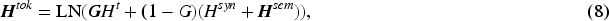
The ACMU employs three gating mechanisms to control the flow of information: the input gate 


The candidate memory 

The hidden state 
This ensures that the hidden state remains within the interval

The utterance-level sentiment interactor has two primary components: a Top-k selector and an utterance GCN. Both components are described below.


The selected tokens are emphasized by weighting them according to their scores. Specifically, we compute the weighted utterance representation as:

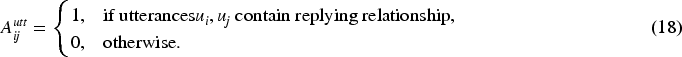

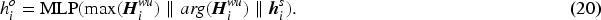

The multi-granularity memory integrator aims to bridge the gap between token-level and utterance-level representations by effectively integrating their contextual information into a unified representation. Given the token-level representations 






Algorithm 3 presents the flow of the multi-granularity memory integrator in detail.

Due to the limitations of the PLM, utterances are necessarily encoded in isolation, which may negatively impact conversational discourse. To address this issue, we integrate rotary position embedding (RoPE)
34
into token representations. RoPE dynamically encodes the global relative distances between utterances at the dialogue level, providing crucial contextual information. Incorporating such distance information enhances discourse understanding.



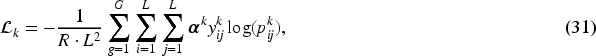


The training of the model involves five essential stages, each playing a role in enhancing the performance of the overall architecture.
Experiment
Data sets and assessment indicators
Our experimental framework is evaluated using two benchmark datasets: the Chinese dataset (denoted as ZH) 1 and the English dataset (EN). 1 Both datasets are sourced from electronic product reviews, each comprising 1,000 dialogues. Each dialogue contains an average of seven discourses and five unique speakers, providing a rich context for sentiment analysis tasks. The ZH consists of 5,742 quadruples, while the EN includes 5,514 quadruples. A notable feature of both datasets is that approximately 22% of the quadruples groups exhibit cross-pronunciation characteristics, indicating a diverse linguistic landscape that challenges traditional monolingual sentiment analysis approaches. A detailed breakdown of dataset statistics refers to Table 2. Consistent with previous studies, we used Micro-F1 score and Iden-F1 as our evaluation metrics. These metrics were used for item detection (T, A, O), pairwise detection (T-A,T-O,A-O), Micro-F1 scores to evaluate the whole quadruple (t,a,o,s), and Iden-F1 to focus only on the triple (t, a, o) without considering affective polarity.
Dataset specifications. “dia”, “utt”, and “spk” stand for dialogue, utterance, and speaker, respectively. “tgt”, “asp”, and “opi” refer to target, aspect, and opinion terms. “intra” and “cross” distinguish between intra-utterance and cross-utterance quadruples, where a quadruple is considered cross-utterance if at least two of its components (target, aspect, or opinion) appear in different utterances.
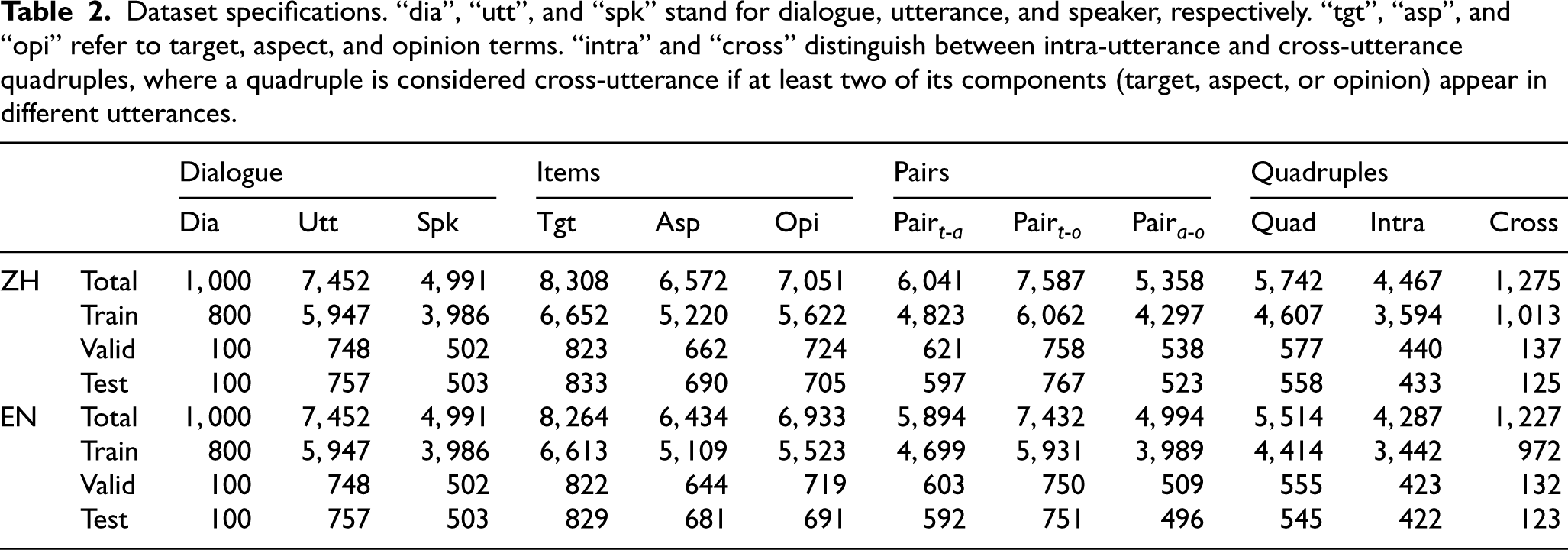
Dataset specifications. “dia”, “utt”, and “spk” stand for dialogue, utterance, and speaker, respectively. “tgt”, “asp”, and “opi” refer to target, aspect, and opinion terms. “intra” and “cross” distinguish between intra-utterance and cross-utterance quadruples, where a quadruple is considered cross-utterance if at least two of its components (target, aspect, or opinion) appear in different utterances.
We evaluated our approach against a suite of baseline models to ensure a thorough and fair comparison. The selected baselines include :
These models were chosen based on their established performance and relevance to sentiment analysis tasks.
Experimental configuration
This study employs two linguistically distinct datasets to validate the proposed method’s cross-linguistic capabilities. The Chinese language component uses Chinese RoBERTa-wwm-ext-base, 39 pretrained on a large-scale corpus of smartphone-related conversational data, including user discussions, product reviews, and technical forums. Its 768-dimensional representation can effectively handle Mandarin’s unique characteristics, particularly the semantic ambiguity of individual characters and word segmentation challenges. The whole-word masking strategy proves essential for maintaining contextual integrity in Chinese, where multi-character compounds often carry meanings distinct from their constituent characters.
For English language modeling, we adopt RoBERTa-Large 40 with 1024-dimensional embeddings, trained primarily on BookCorpus and English Wikipedia with additional domain-specific texts. The increased dimensionality reflects English’s morphological complexity and richer syntactic structures compared to Chinese. Where Mandarin relies on contextual positioning for grammatical relationships, English requires higher-dimensional space to capture its inflectional morphology and grapheme-phoneme variations.
The optimization approach addresses these linguistic differences through tailored learning rates:
Training extends for 40 epochs, determined through validation to balance convergence and efficiency. This accounts for the Chinese dataset’s larger sample size (offsetting shorter average sentence length) and the English data’s deeper syntactic structures. All experiments run on NVIDIA 3090 GPUs with 24GB memory, adequately handling both languages’ sequence length variations without excessive padding. The detailed configuration of the experimental setup is presented in Table 3.
Experimental configuration parameters.
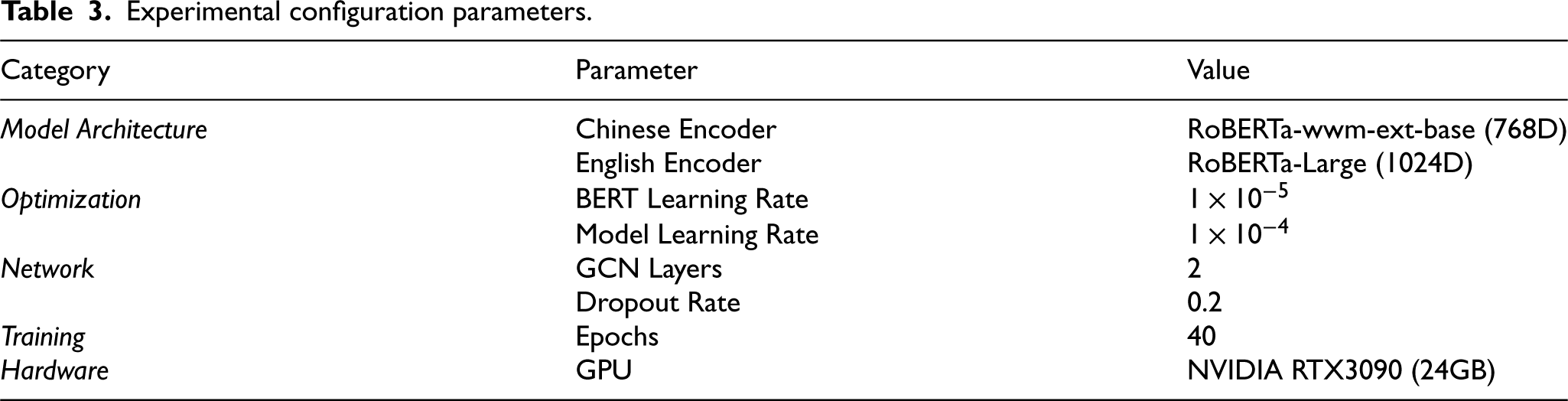
Experimental configuration parameters.
The experimental results on two benchmark datasets, Chinese (ZH) and English (EN), demonstrate our model’s superior performance in sentiment analysis. As shown in Table 4, Figures 3 and 4, our approach achieved impressive improvements over previous baseline models in critical evaluation metrics: Micro F1 and Iden F1. Specifically, we observed a 10.14% and 6.03% increase in Micro F1 scores on the Chinese and English datasets, respectively, and a 13.07% and 5.60% improvement in Iden F1 scores. Even when benchmarked against state-of-the-art models, our methodology outperformed them by 1.71% and 0.33% in Micro F1, and 3.6% and 0.21% in Iden F1 on the respective datasets. These enhancements underscore the model’s robustness and effectiveness across different linguistic contexts. Moreover, our model excelled in cross-dialogue analysis, with a standout performance on the most challenging task, Cross-3. Achieving a score of 22.22%, it nearly doubled the baseline’s 12.50% score. This result highlights the model’s exceptional ability to handle complex, cross-utterance sentiment interactions Table 5.
Different baseline models and the overall performance of our proposed memory, where ‘T/A/O’ stands for target/perspective/viewpoint, respectively.
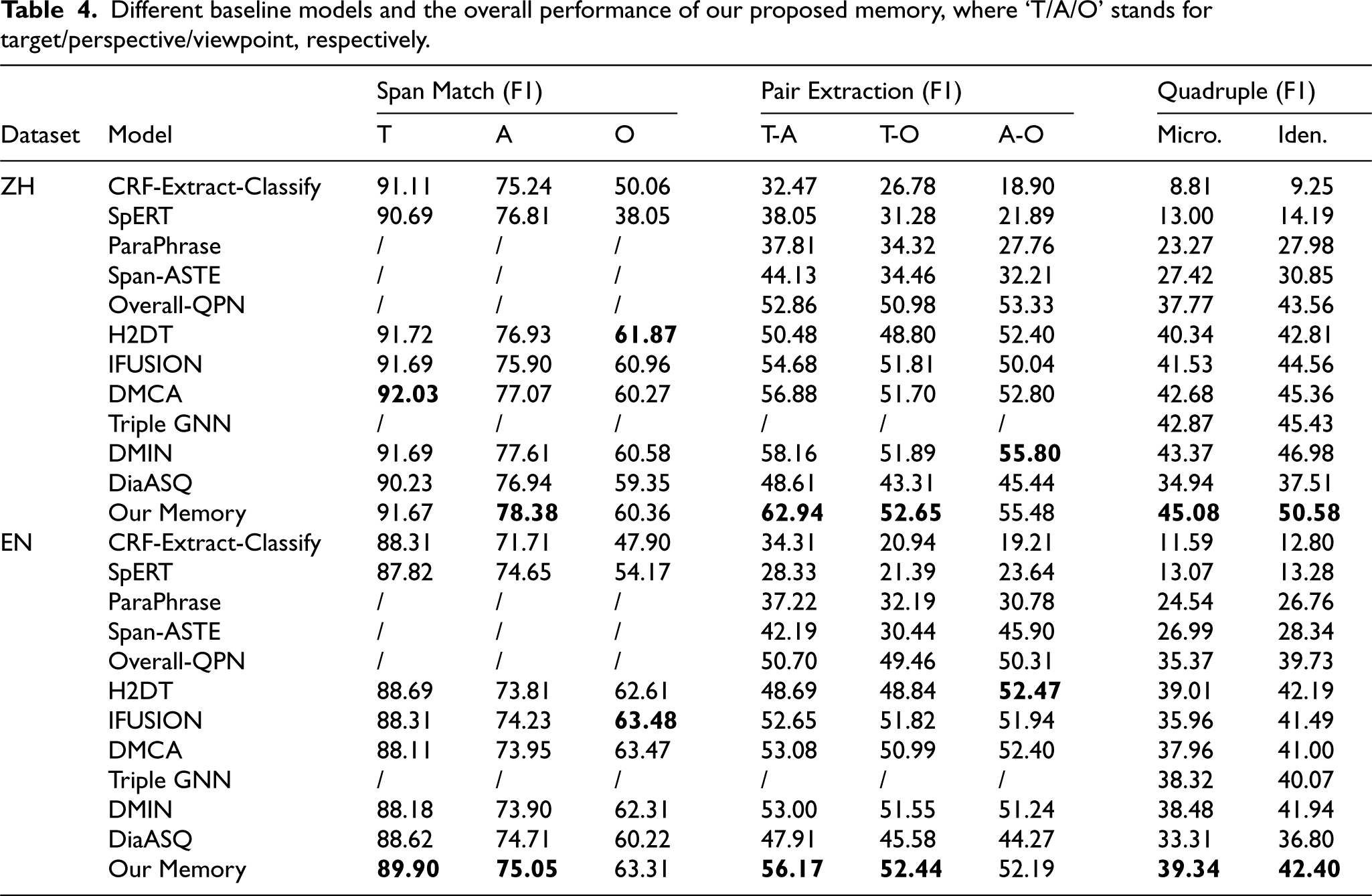
Different baseline models and the overall performance of our proposed memory, where ‘T/A/O’ stands for target/perspective/viewpoint, respectively.
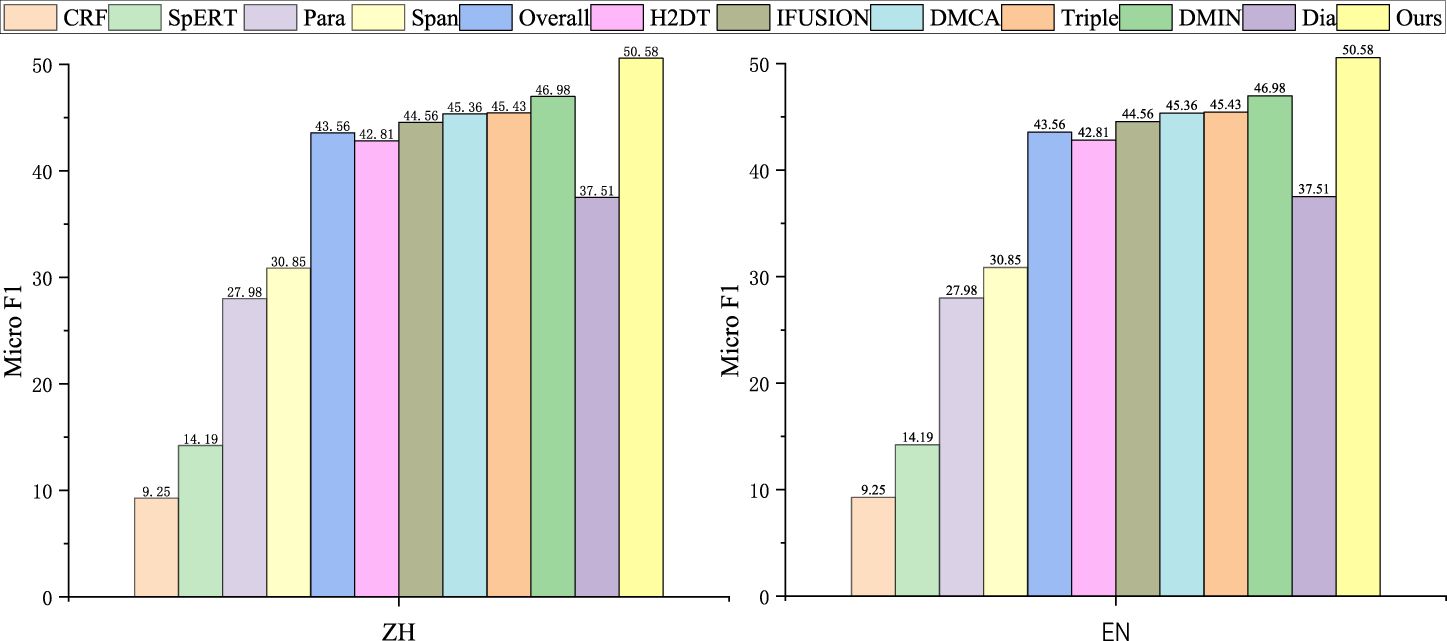
Different baseline models and the overall performance of our proposed Memory.
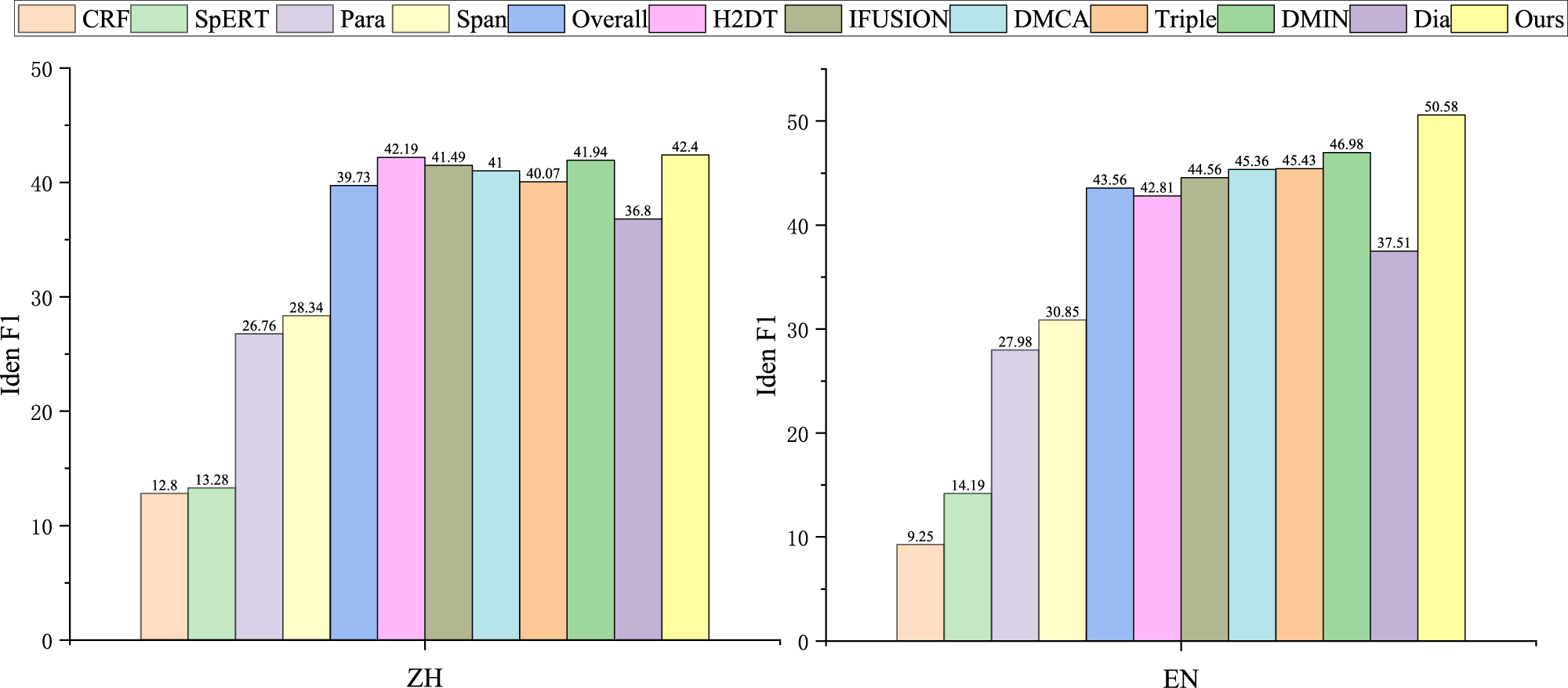
Different baseline models and the overall performance of our proposed Memory.
Results of the ablation study on the dataset. All metrics are micro F1 scores, where “cross-utt” refers to the model’s micro F1 scores on the cross-utt. quaternion.
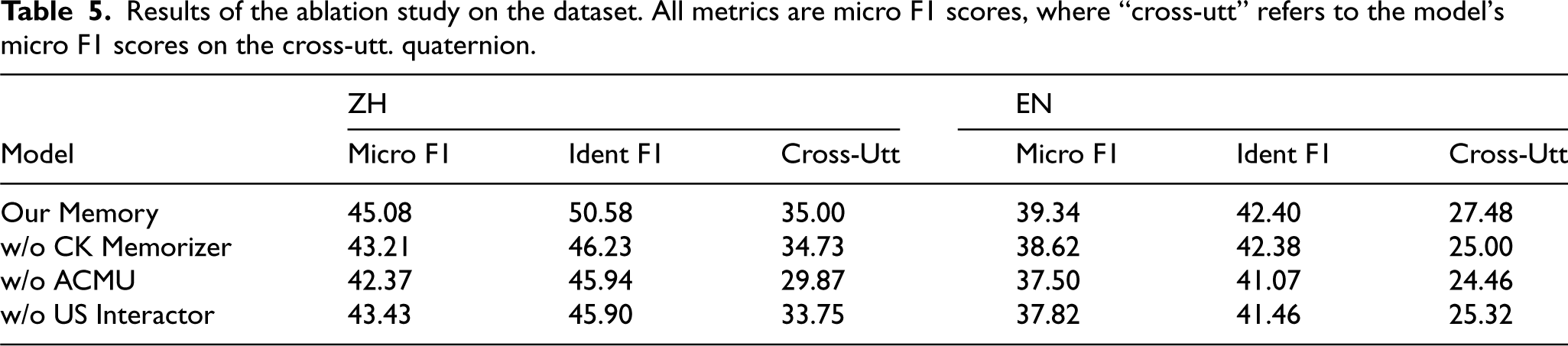
Our ablation study systematically evaluates the contributions of each component in the Memory framework through controlled experiments. The performance variations observed when removing key modules reveal distinct functional roles and validate the architectural design. Comparative analysis between the complete Memory framework and its ablated versions demonstrates several significant patterns that substantiate our design rationale.
Language-specific analysis reveals interesting variations in component importance. The framework shows greater sensitivity to component removal in Chinese processing, particularly regarding the Contextual Knowledge Memorizer and Utterance-level Sentiment Interactor. This aligns with Mandarin’s linguistic properties, including its contextual dependency and use of discourse markers. English processing maintains more consistent performance patterns across ablations. These experimental results support our hypothesis that effective dialogue sentiment analysis requires integrated processing at multiple levels. The Memory framework’s effectiveness stems from the coordinated operation of its components: the Contextual Knowledge Memorizer handling local context, the Utterance-level Sentiment Interactor managing discourse structure, and the ACMU integrating these operations. The system’s consistent performance across languages and dialogue contexts suggests its potential as a robust solution for conversational sentiment analysis.
Cross-utterance quadruple extraction
In this section, we explicitly assess the model’s capacity to resolve complex dialogue structures characterized by long-range dependencies and frequent context shifts. Figure 5 illustrates the performance capability across varying cross-utterance distances, where the red and blue lines represent the proposed Memory framework and the DMIN baseline, respectively.
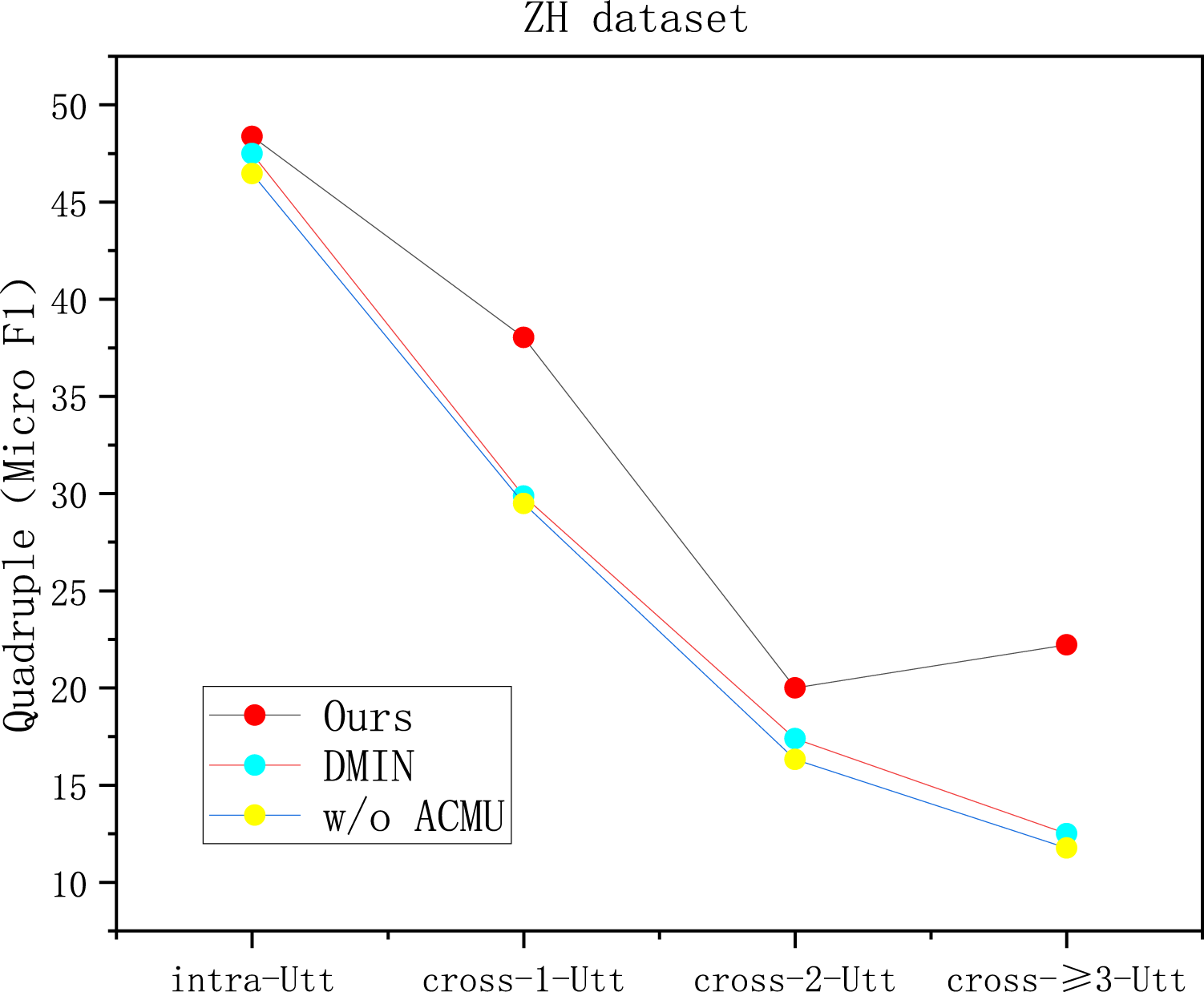
Results Across Various Cross-Utterance Levels.
The “cross-
The impact of our architectural design on solving these complex problems is further evidenced by the yellow line (w/o ACMU). Removing the memory module causes performance on deep cross-utterance samples to drop to 11.76%. This sharp decline confirms that the ACMU is not merely an enhancement but a critical component for overcoming the forgetting problem in complex, multi-turn interactions.
This case study examines the model’s performance in extracting sentiment quadruples from a technical product discussion (Figure 6). The dialogue reveals both the framework’s strengths in contextual memory utilization and its challenges with metaphorical language interpretation.
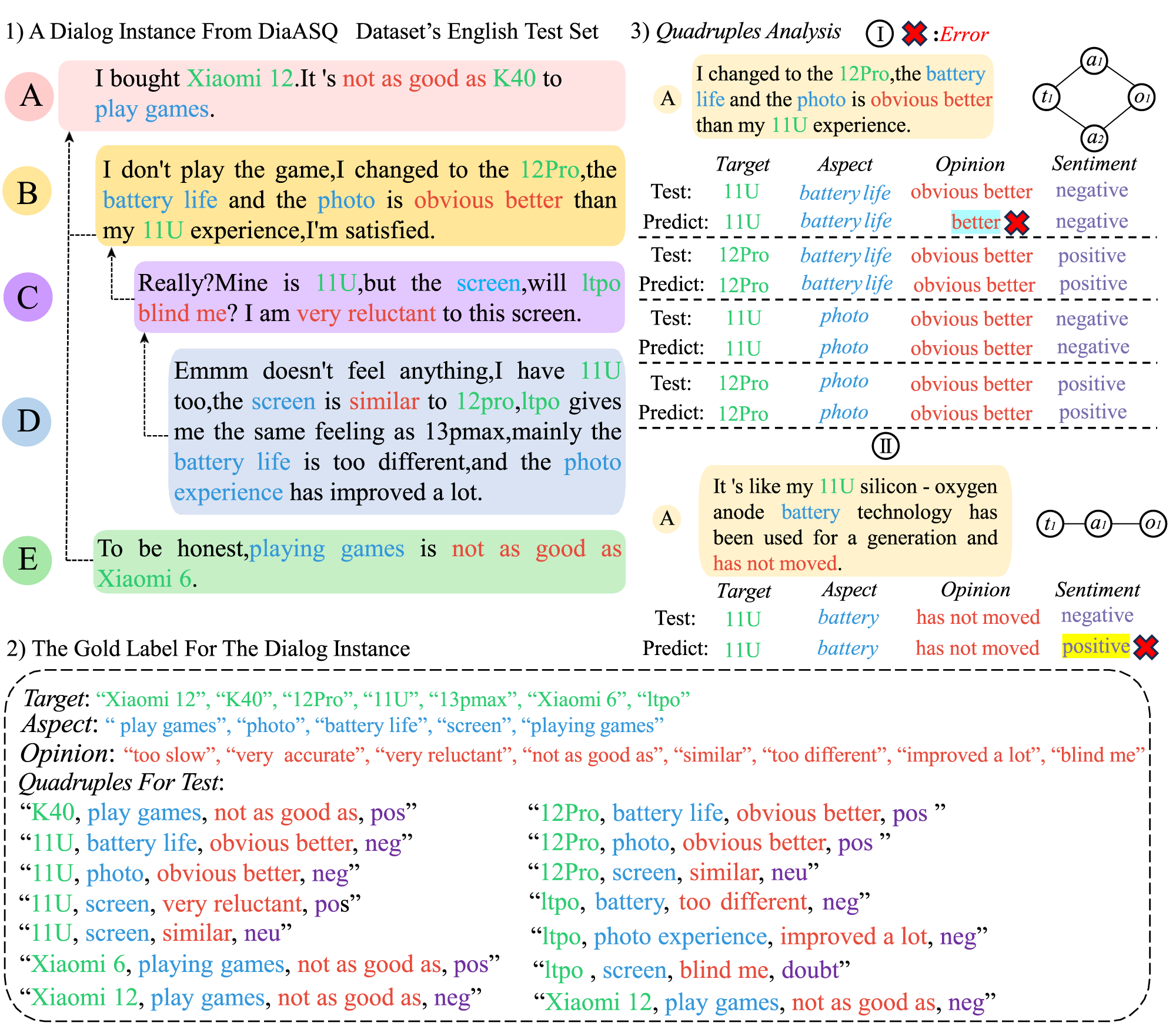
Some examples of detailed dialog in the DiaASQ English dataset.
In the utterance regarding “11U silicon-oxygen battery technology”, the model accurately identifies the target (11U) and aspect (battery) but misclassifies the sentiment polarity of the opinion phrase “has not moved”. While the phrase literally indicates stasis, its contextual meaning conveys technological stagnation - a negative sentiment the model fails to capture. This error stems from the system’s limited metaphorical comprehension, particularly for technical jargon where literal and contextual meanings diverge.
Conversely, the model demonstrates robust contextual understanding in analyzing comparative statements about battery life. Despite only partially capturing the opinion term (“better” instead of “obviously better”), it correctly identifies the negative sentiment toward the 11U’s battery performance. This success highlights the memory mechanism’s effectiveness in compensating for local information gaps through discourse-level context integration.
The contrast between these two cases reveals key insights: the memory architecture successfully maintains sentiment consistency across utterances when analyzing explicit comparisons, but struggles with implicit negative expressions conveyed through technical metaphors. This limitation points to the need for enhanced metaphorical processing capabilities in future iterations, particularly for domain-specific language.
These findings underscore the framework’s advanced contextual reasoning capabilities while identifying technical metaphor interpretation as a critical area for improvement. The case demonstrates how memory-enhanced models can overcome local information deficiencies, yet also illustrates the ongoing challenges in processing nuanced, domain-specific language constructs.
To provide a more interpretable understanding of our memory mechanism’s capabilities and limitations, we conduct a focused analysis based on the specific qualitative cases presented in Table 6 and Figure 6.
A case study comparing the quadruple extraction results between the baseline and our memory framework. The target aspect is implicit in the second clause, requiring contextual reasoning.

A case study comparing the quadruple extraction results between the baseline and our memory framework. The target aspect is
To visually demonstrate the model’s superiority in handling complex linguistic phenomena (e.g., implicit aspects and comparative inference), we analyze a representative case from the test set, as shown in Table 6.
In this example, the user contrasts two phones (“12” vs. “12x”). The aspect “taking photo” is explicitly mentioned for the first entity but is elliptical (implicit) for the second entity (“the 12x didn’t work”). Standard baselines like DMIN often fail to capture this dependency because the aspect is not syntactically connected to “12x”. However, our Memory framework successfully extracts the correct quadruple. This indicates that the Contextual Knowledge Memorizer effectively retained the semantic focus (“taking photo”) from the preceding clause and the Integrator correctly aligned it with the target “12x”, validating the model’s ability to solve complex context-dependent problems.
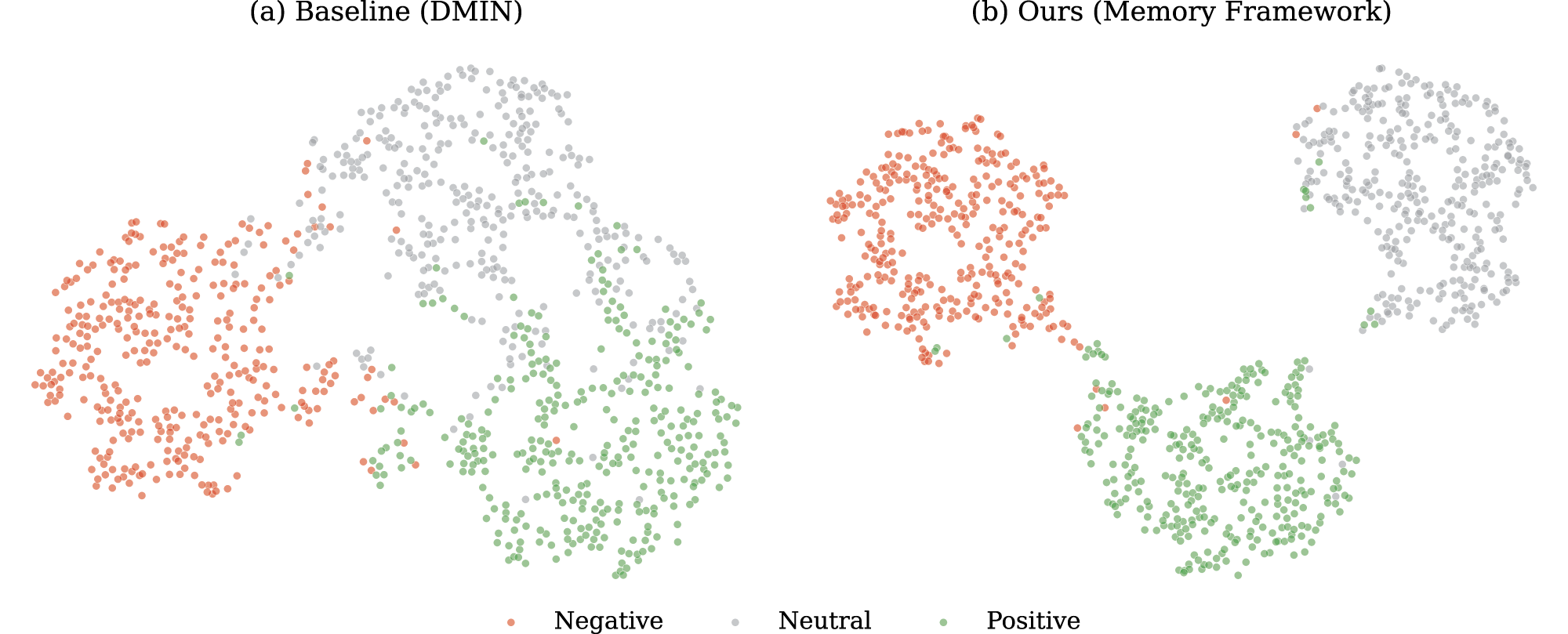
T-SNE visualisation of sentiment representations on the dataset. (a) The baseline DMIN model shows blurred boundaries and overlapping features. (b) Our Memory framework produces well-separated and distinct clusters, indicating superior discriminative power.
To evaluate how our framework learns discriminative features, we map the high-dimensional sentiment representations of the dataset into a two-dimensional space using t-SNE. Figure 7 compares the latent spaces of the state-of-the-art DMIN baseline (Figure 7a) and our Memory framework (Figure 7b).
As shown in Figure 7(a), the baseline model produces separate clusters, yet significant overlap persists between different sentiment categories. This confusion is most evident at the decision boundaries between Neutral and Negative classes. Such results indicate that the baseline model cannot easily separate complex emotional transitions in multi-turn dialogues, which makes the resulting representations sensitive to context noise.
Figure 7(b) shows that the Memory framework learns more stable representations. The Positive, Neutral, and Negative sentiment clusters have higher density and better separation from one another. These clear margins confirm that the Adaptive Contextual Memory mechanism effectively removes irrelevant information. Consequently, the model identifies the essential semantic features needed for accurate sentiment quadruple extraction.
Efficiency analysis
The Memory framework combines several architectural components, including dual GCNs, the ACMU, and an LSTM-based interaction layer. This high level of structural complexity requires a rigorous analysis of its computational efficiency. Our model is compared directly against the DMIN baseline for performance validation. Table 7 lists the total parameter count, average training time per epoch, and GPU memory usage for the ZH dataset.
Efficiency comparison between the strongest baseline (DMIN) and our proposed memory framework on the ZH dataset.

Efficiency comparison between the strongest baseline (DMIN) and our proposed memory framework on the ZH dataset.
Table 7 indicates that the Memory framework adds only a slight computational cost to the base architecture. The total parameter count grows by 6.5 M to a final 134.5 M; this change results from the gating mechanism and the shared LSTM network inside the interaction layer. Likewise, the training time adds 7 seconds per epoch, which shifts the duration from 173s to 180s. GPU memory usage reaches 12.5 GB to store intermediate activations during the process. These costs are justified by substantial performance gains. The framework almost doubles the Micro-F1 score on difficult cross-utterance tasks (Cross-
Our memory framework advances dialogue sentiment analysis through effective integration of multi-granularity sentiment information. The proposed method combines local context modeling with global context understanding via two key components: a Contextual Knowledge Memorizer and an Utterance-level Sentiment Interactor. These components collaboratively capture both fine-grained and broad conversational patterns. A hierarchical attention-based Multi-granularity Memory Integrator further bridges token-level and discourse-level information, enabling more accurate sentiment analysis through the synthesis of local and global contexts.
Experimental results demonstrate consistent performance improvements, with our framework outperforming existing methods across both Chinese and English datasets. This robust performance confirms the framework’s effectiveness in handling complex dialogue sentiment tasks. The integration of cross-level sentiment information significantly advances dialogue sentiment analysis.
Future research directions include optimizing memory utilization efficiency and developing advanced information extraction methods. These enhancements will further strengthen the model’s capabilities for aspect-level sentiment analysis in conversational settings.
Footnotes
Acknowledgment
This work is supported by the National Key R&D Program of China (Grant nos. 2023YFB3308601, 2022YFB3104700), the National Natural Science Foundation (Grant nos. 62576287,62402395), Chengdu “Open bidding for selecting the best candidates” Science and Technology Project (Grant no. 2023-JB00-00020-GX), the Science and Technology Program of Sichuan Province (Grant no. 2023YFS0424), the Science and Technology Service Network Initiative (Grant no. KFJ-STS-QYZD-2021-21-001), and the Talents by Sichuan provincial Party Committee Organization Department, and Chengdu - Chinese Academy of Sciences Science and Technology Cooperation Fund Project (Major Scientific and Technological Innovation Projects).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.