
Abstract
Knowledge graph-based question answering (KGQA) systems face several challenges. These include the need for detailed training data, difficulty in handling complex multi-hop queries, and dense knowledge gap interactions. The model needs training on annotated entities and relations, which requires significant human effort and time. We developed methodologies that improve end-to-end question answering with knowledge graphs, eliminating the need for pre-annotated entities (gold entities). Our approach incorporates language models—Text-to-Text Transformer (T5) and Longformer—and employs a named entity disambiguation technique. We reduced the dependency on gold entities by first removing explicit entity annotations from the training data and then augmenting this data with relevant knowledge base facts. In this paper, we explored two different methodologies: (1) training T5 and Longformer on this augmented dataset to answer factoid questions using inferred knowledge graph entities, and (2) applying transfer learning with SPARQL-based supervision to improve generalization. The experimental results demonstrate that the proposed models are efficient and offer effective strategies for addressing complex questions while significantly reducing the need for manual annotation of training data.
Introduction
Knowledge graph-based question answering wystem
Knowledge graphs (KGs) are graphical representations of knowledge bases (KBs) that serve as structured storage systems for abstracting data and integrating information from diverse sources. Knowledge graphs play a vital role in machine learning techniques by providing a target representation of the extracted knowledge. The proposed approaches leverage the essence of KGs, which are structured as directed labeled graphs. In these graphs, nodes represent entities, and edges represent relations between them, which are stored as triples <entity1, relation, entity2>. Knowledge graph-based question answering systems (KGQA) traverse this graphical structure through hops between entities. Traditional Knowledge Graph Question Answering (KGQA) approaches consist of several loosely connected components. These include entity resolution, which identifies entities within the question, and semantic parsing, which creates structured representations of the questions. These representations can then be processed using a knowledge graph, enabling the system to retrieve answers effectively.
The system processes natural language queries by applying various preprocessing techniques. These techniques include tokenization, which breaks down the query into individual words or tokens, and named entity recognition, which identifies specific entities mentioned in the query. The system then performs a process called entity disambiguation. This involves linking identified mentions to correct entities in the knowledge graph. The system uses the semantic structure of the question to develop formal queries, such as SPARQL. These queries are executed on the knowledge graph to retrieve relevant facts. The retrieved facts were extracted as structured triples. These triples can be passed through a language model to generate fluent and human-readable answers.
Challenges
Obtaining training data for individual components in Knowledge Graph Question Answering (KGQA) is challenging due to the need for diverse and comprehensive data. The complexities involved include ensuring the representation of varied entities and complex semantic structures. Current KGQA methods face challenges, especially in entity resolution (ER), which are often overlooked in end-to-end learning. This is because entity resolution requires labeled data, which can be difficult to obtain. The proposed approaches uniquely avoid the necessity for labeled ER data for training. The models can efficiently integrate entity resolution (ER) and directly address ambiguities related to entities, thereby affecting the confidence in provided answers. Our models require only question text and answer entities for training, which enables end-to-end learning.
Existing question-answering models achieve high performance on simple questions that require retrieving only a single fact from the knowledge base. However, it’s essential to develop models that can effectively handle complex questions, which necessitate the extraction of multiple facts and the application of logical reasoning to them. The model aims to handle complex questions involving multi-hop reasoning and comparisons for thorough answers. For instance, consider a question like, “Which city experienced a greater population increase, New York or Los Angeles?” The process requires the model to compare population statistics for both cities, highlighting the difficulty of handling more complex questions beyond simple fact-checking.
To improve efficiency, QA systems start by narrowing the search scope to a set of facts expected to include all relevant answers and cues. A common method is to use named entity disambiguation (NED) on the question and retrieve relevant information from the knowledge base for the identified entities.1,2 NED techniques link tokens (mentions) in questions to entities in a knowledge base. This helps the question-answering system focus on facts related to these entities. However, standard NED tools have some drawbacks. The tools are not designed to be effective for question-answering systems, fail to recognize non-named entities, and offer only the top single entity for each term, ignoring other possibly relevant choices.3,4 To address these challenges, we employed an NED 5 method that is both time-efficient and memory-efficient. This method traverses all items in the knowledge base to generate leading candidates for entities, types, concepts, and predicates.
Contributions
The current datasets include manual annotation of entities and relations, ensuring a rich representation of structured information. It includes relevant topic entities within questions and specifies the relevant relations for querying. State-of-the-art solutions that leverage these gold entities and relations achieve exceptionally high accuracy. However, when these annotations are not utilized, model accuracy substantially decreases. The primary objective of this paper is to improve the model’s accuracy without relying on these manually provided entities and relations, aiming to improve overall scores and reduce dependency on annotated information. The significant contributions of the work are summarized as follows:
This work presents approaches that utilize language models and transfer learning techniques to answer complex questions. The models developed are trained to answer complex multi-hop questions without using gold entities and relations. A comprehensive evaluation of the proposed models demonstrated superior performance as compared to the existing alternatives on the MINTAKA dataset. Specifically, the MINTAKA dataset without gold entities is prepared for training the proposed models. The creation of the MINTAKA dataset without gold entities establishes a basis for training the proposed models and promoting research in this area. The proposed methods focus on effectively integrating NED technique, reducing the search space by allowing for the precise retrieval of disambiguated entities associated with questions and relevant knowledge base facts.
The following sections explore related work and methodologies, highlighting entity extraction, effective language model usage, and strategic application of transfer learning. These elements collectively enhance the performance of the Knowledge Graph Question Answering (KGQA) system.
Related work
There has been a lot of progress in enhancing the domain of question-answering systems using knowledge graphs. A knowledge graph is a semantic network that illustrates the relationships between related real-world entities, which can be objects, events, situations, concepts, or thoughts. These are implemented through graph databases, and their schema is represented using triples and ontologies. The task of answering questions using these graphs is modeling our knowledge in a way that we can efficiently and accurately retrieve it. 6 used the pre-trained transformers to answer simple questions using the knowledge graph, suggesting that this issue is largely resolved. The authors focused on addressing 1-hop and factoid questions within the framework of knowledge graphs. While the developed model demonstrates strong performance in handling simple 1-hop questions, there is an opportunity for further enhancement when dealing with more complex questions. To optimize the performance of the system, it is imperative to train it using a dataset that have complex questions. Including diverse questions in the training process ensures that the model faces a range of challenging scenarios. This broad exposure helps the model develop the depth and skills needed to effectively handle real-world complexities. Therefore, the training dataset should include a wide variety of question types, such as those that require multi-hop reasoning, comparative analysis, and complex queries involving set intersections. Recent studies have also highlighted the growing role of artificial intelligence and data-driven analytical models in extracting complex knowledge from large datasets and supporting intelligent decision-making systems. 7
Existing question-answering datasets face limitations in striking a balance between simplicity and complexity. Large datasets often focus on straightforward questions, while smaller ones tackle more complex queries, hindering comprehensive model evaluation. Additionally, datasets with automatically generated questions, such as KQA Pro 8 and GrailQA, 9 may produce less natural queries, posing challenges in real-world applicability. The absence of diversity in current datasets also leads to a discrepancy between the training data and real-world situations. To tackle these disparities, MINTAKA, 10 a large, complex, naturally elicited dataset, has been released, aiming to overcome the shortcomings of existing datasets and provide a more comprehensive and diverse benchmark for evaluating question-answering models.
LC-QuAD 2.0 11 is a comprehensive KGQA dataset with 30K questions, featuring multi-hop queries and leveraging the latest Wikidata and DBpedia knowledge graphs. The dataset includes the annotated Wikidata entities with the SPARQL queries. The predominant technique used in KGQA is the generation of SPARQL queries that can be used to query the knowledge graph to acquire the answer entity. Most KGQA datasets come with annotated gold entities and/or relations. These are the topic entities and relations that the question refers to, and using them as part of the input makes generating the SPARQL query significantly easier. On the other hand, generating queries without having the gold entities and relations is a more realistic task with much lower state-of-the-art scores, as seen in Table 1.
Existing models on LcQuAD 2.0 without using the gold entities.

Existing models on LcQuAD 2.0 without using the gold entities.
Mintaka
Mintaka is a multilingual dataset with complex and natural questions created specifically for evaluating end-to-end QA models. 10 The dataset consists of 20,000 question-answer pairs gathered in English, enriched with Wikidata entities, and subsequently translated into eight other languages. Table 2 provides a comprehensive summary of the MINTAKA dataset characteristics.
MINTAKA dataset summary.

MINTAKA dataset summary.
The dataset encompasses eight types of complex queries, including multi-hop, comparative, intersection, superlative, count, ordinal, difference, and yes/no questions, which were naturally elicited from crowd workers. Notably, the majority of questions require multi-hop reasoning, where the answer cannot be derived from a single knowledge base triple but requires chaining multiple relations. A path connecting question and answer entities exists within one hop for 62% of questions and within two hops for 97% of questions, indicating that most questions are theoretically answerable using Wikidata. Table 3 shows examples of question-answer pairs from MINTAKA.
Examples of questions and answers from the MINTAKA dataset.
The primary dataset being used for training the proposed model with the transfer learning approach is LcQuAD 2.0. It is a large question-answering dataset with 30,000 pairs of questions and their corresponding SPARQL queries. 11 The target knowledge bases are Wikidata and DBpedia. The dataset characteristics are shown in Table 4.
Characteristics of the LcQuAD dataset.

Characteristics of the LcQuAD dataset.
The QALD (Question Answering over Linked Data) dataset is a collection designed for evaluating the QA models over linked data. 14 It features questions expressed in natural language and targets knowledge graphs represented in Resource Description Framework (RDF) format. The dataset encompasses diverse topics and covers multiple languages. Each question is associated with a corresponding SPARQL query, facilitating the assessment of a system’s ability to convert natural language queries into executable queries on linked data.
The GrailQA is a comprehensive dataset designed for evaluating QA systems in the context of open-domain and multi-hop reasoning. 9 It features questions that necessitate complex reasoning and an understanding of diverse knowledge sources. Questions in GrailQA are diverse, covering various topics, and often require the integration of information from multiple documents or passages to arrive at a coherent answer. The dataset aims to assess the ability of question-answering models to perform advanced reasoning across a wide range of domains, making it a valuable resource for advancing research on various NLP tasks.
The QALD and the Grail dataset are utilized for the transfer learning approach. We trained the T5 and longformer models with semantic SPARQL queries using the LC-QuAD2 and QALD datasets and expanded the training dataset to include the Grail QA dataset.
Proposed techniques
This section describes the techniques used and is organized into three parts. The first part explains how relevant facts are extracted from the knowledge base based on the entities identified in the question. The following two parts outline the process of generating answers using the extracted information. The proposed techniques utilize a combination of methods, including Named Entity Disambiguation (NED) and the CLOCQ method, 5 to reduce the answer space of the knowledge base. Additionally, language models such as T5 (Text-to-Text Transfer Transformer) 15 and Longformer (a long-document transformer) are employed.
Model Overview: The methodology used involves a structured approach to preparing the dataset for training the KGQA model, excluding the gold entities. We preprocessed the MINTAKA dataset 10 and removed all the question IDs from it. We created answer contexts from questions in the MINTAKA dataset, systematically incorporating knowledge base facts to provide accurate model training. The use of Named Entity Disambiguation (NED) allowed the retrieval of exact disambiguated entities connected with the queries and pertinent knowledge base facts. Furthermore, the CLOCQ approach is implemented to restrict the search space, resulting in an ordered list of items in the knowledge base. The technique gave scores based on lexical similarity, relevance, item coherence, and knowledge graph connectivities. Through dataset augmentation, extracted facts are seamlessly integrated into the MINTAKA dataset, enriching the context for training the model. Figure 1 depicts the architecture of answer generation using the proposed approaches.
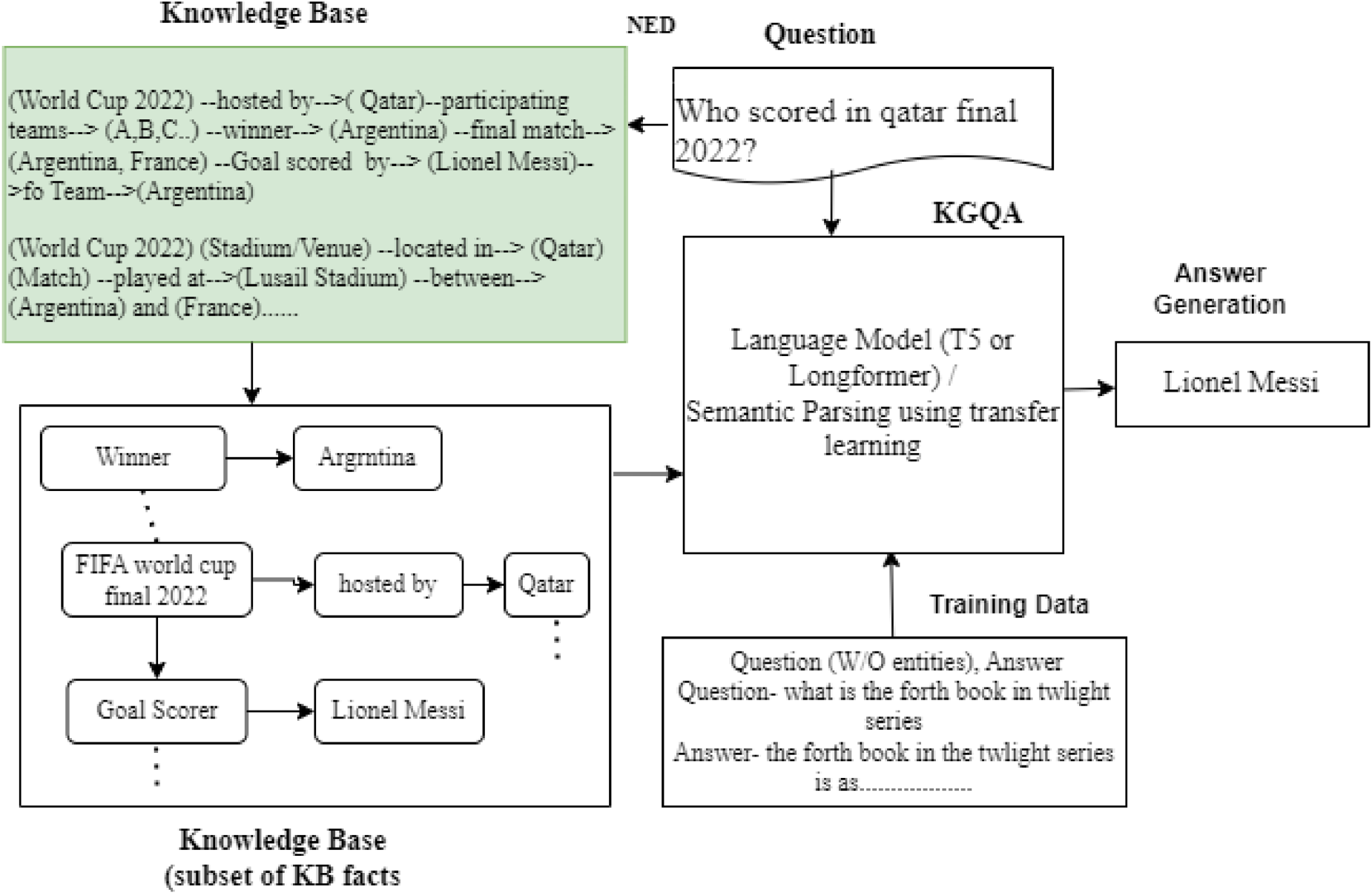
Proposed models architecture for answer generation.
We used advanced models, T5 and Longformer, to improve our language modeling approach. The T5 model was used for inference, providing accurate answers to questions based on their related context, even when there were no specific entities provided. The Longformer model helps manage long text inputs. It improves understanding of complex questions by processing large amounts of text and providing better context. To improve performance, we used transfer learning techniques. We enhanced our models’ training by incorporating knowledge graph information from other datasets like LC-QuAD2 11 and QALD. 14 This allowed models to better understand and respond to complex queries.
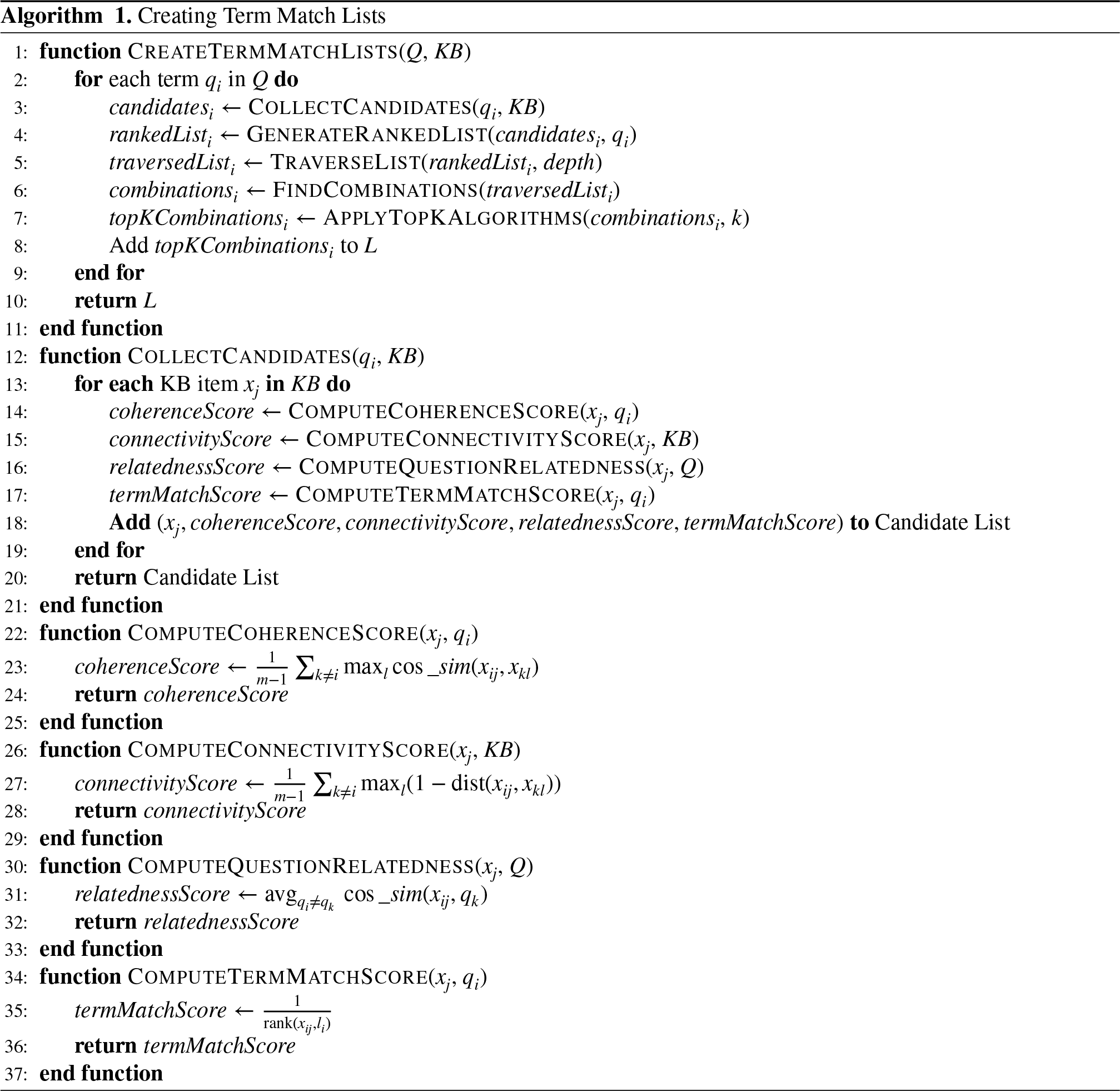
Knowledge base fact extraction is the process of creating lists of matching terms. This helps to clarify keywords or phrases in a question by connecting them to entries in a knowledge base (KB). Candidates from the KB are selected using a lexical matching score for each question phrase. These candidates are sorted lists of KB items based on the degree of similarity between question tokens and KB items. The highest-ranked items in each list are chosen as relevant KB candidates for further processing.
To calculate the relevance score for each item, we create several lists for each question token. Each list has its own unique relevance score. Each item is assessed for relevance based on four criteria: coherence, connectedness, question-relatedness, and term matching. These indications help identify the most relevant knowledge base items for the question. Top-k algorithms are applied to sorted lists of relevant KB candidates to determine the optimal combinations of KB items that closely fit the query. The final set of knowledge base items creates the search area for the question answering system. A pruning threshold is used to prevent including all details of particularly frequently searched KB objects in the search area.
Adaptive Top-k Selection: Unlike traditional NED systems that apply a fixed top-k threshold uniformly across all question terms, the CLOCQ framework employs an adaptive candidate selection mechanism. Top-k algorithms are applied to sorted lists of relevant KB candidates to determine the optimal combinations of KB items that closely fit the query. The number of candidates selected per term is determined heuristically based on the estimated ambiguity of that term—more ambiguous terms yield larger candidate sets (higher
Pruning Threshold: A pruning threshold
The algorithm “Creating Term Match Lists” (Algorithm ??), describes the methodology for extracting candidate KB items pertinent to a provided input question
KGQA using language modeling
T5 model
The Text-to-Text Transfer Transformer (T5) model utilizes a transformer-based encoder-decoder architecture that follows a text-to-text approach. The proposed approach involves the T5-base model, which contains 220 million parameters. Additionally, the XL version of the T5 model is employed to predict answers to questions.
We divided the answer context for a given question into sequences that fit within the token limit of the T5 model. Given that the T5 base model has an input sequence length of 512 tokens, batches of 512 tokens are created for each question. For each batch, a ground-truth answer to the question is specified. This ground truth depends on whether the required answer to the question, corresponding to the original dataset, is present in the 512-token context segment in that tuple (question, context, and answer pairs). If the answer is present in the context, then that is designated as the ground truth answer for that tuple. If the original answer is not present in the context, the answer is designated to be NO_ANSWER. During the model training phase, the model navigates through all tuples for a given question, selecting the most likely answer as the prediction. In cases where the most probable answer is NO_ANSWER, the second most likely answer is chosen as the prediction. This approach allows the model to comprehensively explore all contexts and facts within the knowledge graph when answering a question, thereby enhancing the probability of generating accurate responses.
Longformer
Each input question generates hundreds, or even thousands, of predicted facts because of the varying hyperparameters. However, the T5 model struggles with the complexity of long input sequences, making it unable to process them all at once. Therefore, we need to break down the sequences into smaller parts. This creates the challenge of getting several answers to the same question. The main task is to rank these answers.
The Longformer, known as the Long-Document Transformer, 16 offers a solution to this issue by introducing innovative strategies to handle longer input sequences. Unlike regular transformer models that exhibit quadratic scaling with sequence length, rendering longer sequences non-trainable, the Longformer implements three distinct attention approaches that scale linearly with sequence length. This linear scaling is a noteworthy advancement, allowing for a significant speed-up in model training. One significant advantage of the Longformer is its ability to handle sequences of considerable lengths, surpassing the constraints of traditional models like BERT and T5, which have a maximum sequence length of 512 tokens. In contrast, Longformer can effectively process sequences of lengths 4096, 8192, or even 16384, showcasing its versatility in managing extensive textual inputs.
By applying a combination of attention patterns, the Longformer efficiently addresses challenges associated with handling extended input sequences. A dilated sliding window (local attention) is employed, utilizing dilated attention to expand the receptive field without a proportional increase in computational complexity. Global attention (full self-attention) is incorporated to capture broader contextual relationships, allowing each token to attend to the entire sequence. This strategic use of attention mechanisms in the Longformer addresses the limitations of extended input sequences, ensuring efficient and effective handling of knowledge graph information throughout the model’s learning process.
KGQA using semantic parsing
The Mintaka dataset presents a unique challenge while utilizing the semantic parsing approach for the proposed model. Unlike standard semantic parsing datasets, Mintaka does not provide gold queries for training. To address this constraint, we use alternative datasets such as LC-QuAD2 and QALD to build a model that can read questions and generate SPARQL queries.
The subsequent application of this trained model to the Mintaka dataset produces SPARQL queries containing entity and relation IDs specific to the knowledge graph (KG). To render these queries more interpretable, we replace the IDs with their corresponding labels, resulting in what we term a “labeled SPARQL query.” The modified dataset, which includes labeled SPARQL queries, serves as the foundation for training our T5 model. T5 begins to generate labeled SPARQL queries in the form of phrases such as:
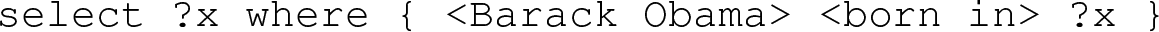
To operationalize these queries, we employ a text search mechanism to map entities like “Barack Obama” to an entity ID and “born in” to a relation ID, thereby constructing a proper SPARQL query.
Our experiments encompass two distinct scenarios:
Train the T5 model with semantic SPARQL queries on the LC-QuAD2 and QALD datasets. Apply a transfer learning approach to adapt the model to the Mintaka dataset.
Expand the training dataset to include the GrailQA dataset along with LC-QuAD2 and QALD. Train the T5 model with semantic SPARQL queries on this augmented dataset. Employ a transfer learning approach to fine-tune the model for optimal performance on the Mintaka dataset.
These experiments with several datasets attempt to evaluate the T5 model’s transferability and adaptability, revealing insight on its efficacy in semantic parsing tasks when confronted with distinct knowledge graphs represented by different datasets.
This section provides a detailed explanation of the experimental approach used, the evaluation metrics, and a comparative analysis of the results. This comprehensive evaluation aims to explain the breadth of the tests conducted and provide insights into the reliability and accuracy of our results.
Dataset and evaluation metrics
We conducted our experiments on the MINTAKA dataset, specifically focusing on complex questions. The dataset includes recent benchmarks for complex questions, providing a challenging testbed for evaluating model performance. We utilized the “Hit@1” metric to assess the effectiveness of the proposed models.
Dataset preparation for KGQA tasks
We prepared data utilizing the Mintaka dataset according to our requirements for the task. The primary objective was to train the models without reliance on gold entities. To achieve this, we systematically excluded Wikidata-ids from questions lacking associated entities. Our resultant dataset comprises tuples structured as (question, context, and answer pairs), with each question being associated with a sequence of such tuples. An example of the prepared dataset is provided in Table 5. The key steps involved in dataset preparation are as follows:
Prepared dataset example.
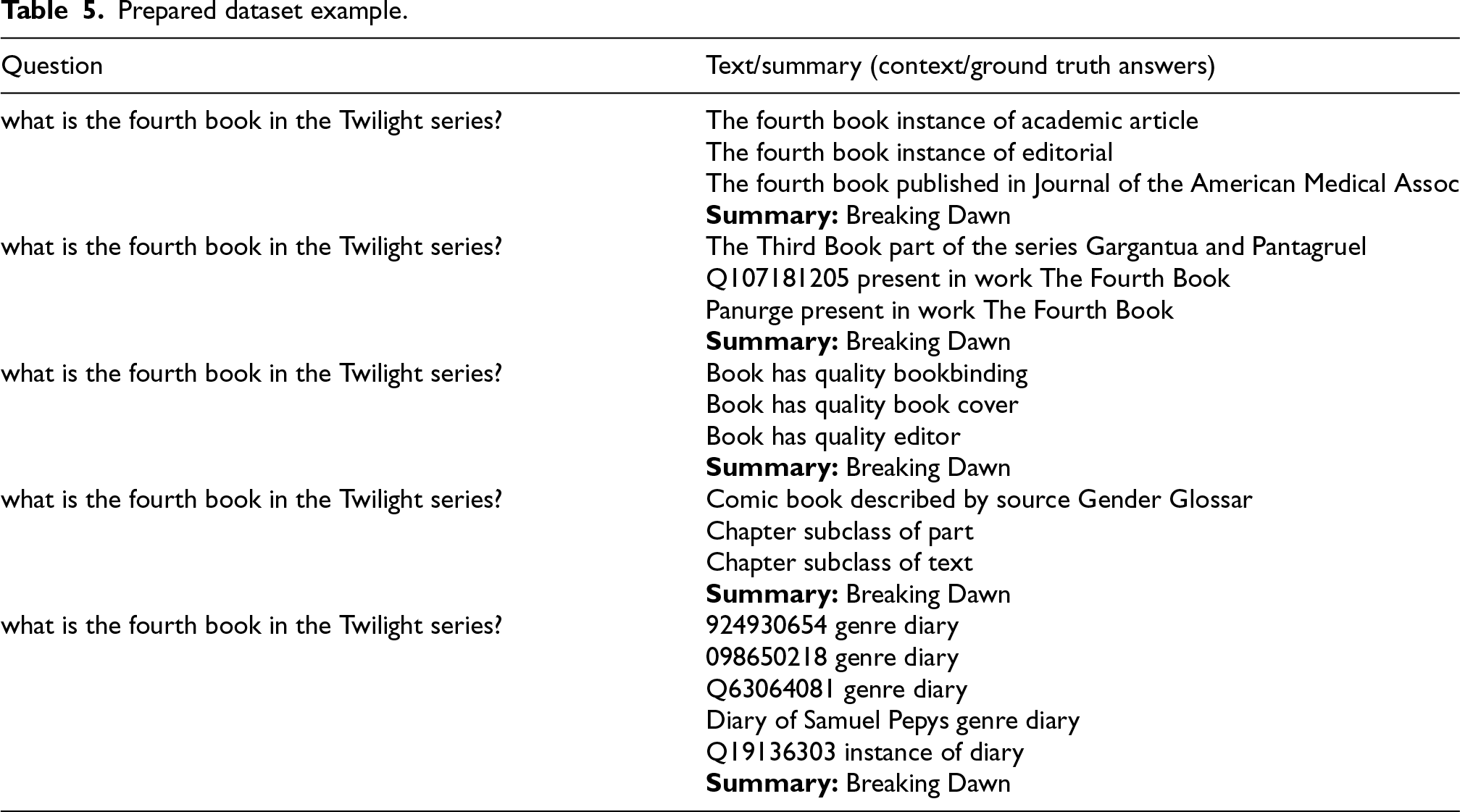
Prepared dataset example.
Data source: The training of the proposed model utilized questions from the MINTAKA dataset. Removing gold entities: We removed the Wikidata IDs from the question for training without the gold entities. Context formation: We built our answers by using clear and accurate facts to provide the right context for each question. We used the NED system to find specific entities, which helped in reducing the search space and assigning scores based on different factors.
The preprocessing involves dividing the context for a question into batches of 512 tokens. Each batch is assigned a ground-truth answer based on whether the required answer is present in the context segment. During training, the model selects the most likely answer from all tuples for a question. If the most probable answer is NO_ANSWER, the second most likely answer is chosen, allowing for a thorough exploration of context and improving response accuracy. Table 6 provides a summary of the dataset statistics that were obtained. The table shows the progression of the question count in the training, testing, and development sets and gives a summary of the dataset created for the task. Each question is paired with multiple 512-token context batches retrieved from the knowledge base, creating several (question, context, answer) tuples per question. For example, Table 5 shows a single question generating 5 distinct training instances.
Prepared dataset size for the KGQA.

We employed several evaluation metrics to evaluate the performance of the proposed methods in different scenarios. Given that the MINTAKA benchmark only defines and reports Hit@1, which is essentially the same as Exact Match (EM), we selected Hit@1 as our main metric for comparison with all baselines. Furthermore, we present Hit@5, Mean Reciprocal Rank (MRR), and F1-score to provide a more comprehensive perspective of model performance. The metrics are defined as follows:
Hit@k Metric
Hit@k measures whether the correct answer appears within the top-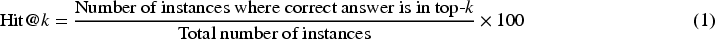
Mean Reciprocal Rank (MRR)
Mean Reciprocal Rank evaluates ranking quality by considering the position of the first correct answer, as shown in equation (2).

F1-Score
We computed the token-level F1-score (as shown in equation (3)) to measure the overlap between predicted and ground truth answers. This metric captures partial correctness and is particularly valuable for multi-token answers.

All models were implemented using the Hugging Face Transformers library and trained using PyTorch. The T5-base and Longformer models were fine-tuned on the augmented MINTAKA dataset. The Longformer model was employed to handle extended input sequences that exceed the 512-token limit of T5. For the transfer learning experiments, models were first trained on LC-QuAD 2.0, QALD, and GrailQA datasets and subsequently fine-tuned on MINTAKA. Table 7 summarizes the key hyperparameters used across all model configurations. For the transfer learning configurations, the same hyperparameters were applied during both the pretraining phase (on LC-QuAD 2.0, QALD, and GrailQA) and the fine-tuning phase (on MINTAKA).
Hyperparameters.
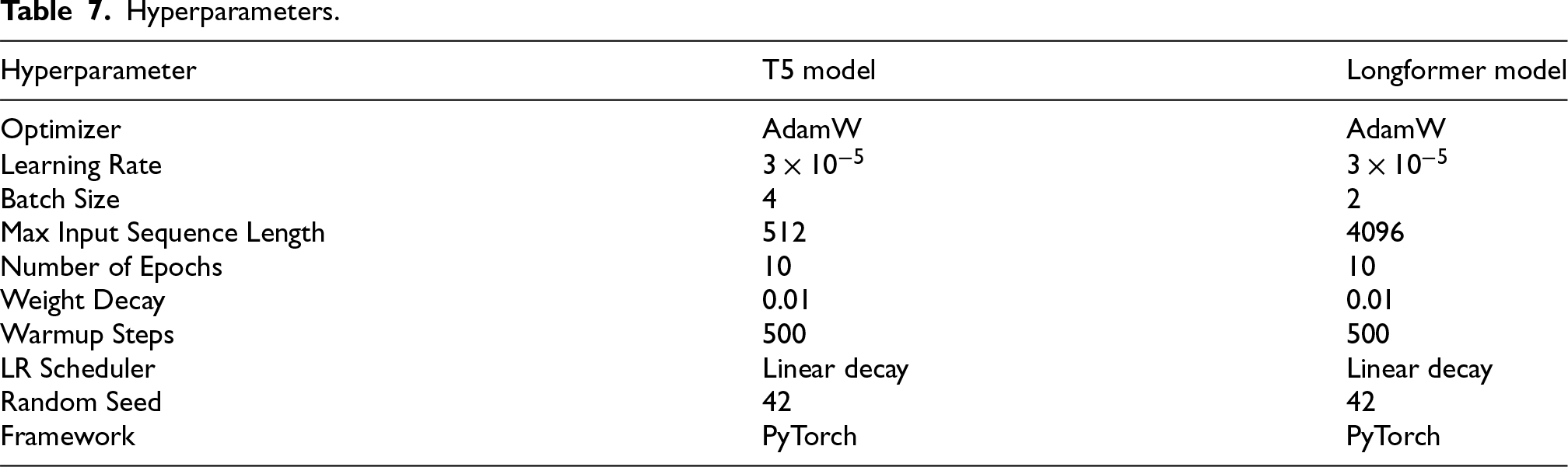
Hyperparameters.
We evaluated the language and semantic parsing models on the MINTAKA dataset, using the answers provided by crowd workers as the ground truth. The results, summarized in Table 8, present a detailed comparison of our proposed models with the baseline models, showing the “Hit@1” scores for each. It is important to note that the results for all baseline models were derived using gold entities, whereas our proposed approaches produce results without relying on them.
Comparison of proposed models with baselines, showing “Hit@1” scores.

Comparison of proposed models with baselines, showing “Hit@1” scores.
For language model baselines, we compared with T5 base and T5 for Closed-Book Question Answering (CBQA). 17 The evaluation of the CBQA baseline was performed under two conditions: (i) zero-shot performance utilizing a model that was pre-trained on the Natural Questions dataset, and (ii) fine-tuning on MINTAKA for a duration of 10,000 steps. For knowledge graph-based baselines, we compared with three existing approaches, KVMenet, EmbedKGQA and Rigel. Key-Value Memory Networks (KVMemNet) 18 store knowledge graph triples in structured memory using a key-value format. Given a query, the system identifies relevant keys, retrieves corresponding values, and generates answers. 19 EmbedKGQA 20 incorporates pre-trained knowledge graph embeddings into the question answering pipeline, using separate modules for knowledge graph, question, and answer embeddings to score and rank candidate answer entities. Rigel21,22 employs a learning-based encoder-decoder architecture built on RoBERTa, generating answers by computing a probability distribution over all relations in the knowledge graph. Finally, Dense Passage Retrieval (DPR) 23 follows a two-stage retriever-reader approach where a dense retriever first identifies relevant passages from Wikipedia, and a reader model subsequently extracts answer spans from the retrieved passages.
Table 8 presents the Hit@1 scores for all models evaluated. Our proposed approach achieves a Hit@1 score of 0.18 using the T5-base model without gold entity annotations, which is competitive with EmbedKGQA (0.18), a model that utilizes gold entities, and is close to the performance of Rigel (0.20), which also depends on gold entity annotations. The Longformer-based variant also achieves a Hit@1 of 0.20, matching Rigel’s performance despite forgoing gold entities. Longformer achieves modest improvement over T5-base (Hit@1: 0.20 vs. 0.18) due to its extended context window (4096 vs. 512 tokens). This advantage is most apparent for complex questions generating extensive KB fact retrieval, where Longformer processes context holistically while T5-base must partition into multiple segments. For simpler questions with limited context, both models perform comparably. The performance gain comes at 2x computational cost, requiring selection based on complexity-resource trade-offs. Furthermore, the transfer learning approach provides significant improvements over the base models. When pre-trained on the LC-QuAD 2.0 and QALD datasets and then fine-tuning on MINTAKA, our model attains a Hit@1 score of 0.28, which is equivalent to the T5 baseline that uses gold entities. The optimal configuration, which leverages transfer learning from the LC-QuAD 2.0, QALD, and GrailQA datasets, achieves a Hit@1 of 0.36, nearing the performance of the T5 CBQA fine-tuned model (0.38) while retaining the advantage of not requiring manual entity annotation.
To provide a more comprehensive evaluation beyond Hit@1, we present additional metrics, including Hit@5, Mean Reciprocal Rank (MRR), and F1-score, as shown in Table 9. Given that T5 and Longformer are generative models that produce a single response per question rather than ranked candidate lists, the metrics for Hit@1, Hit@5, and MRR exhibit identical values for our proposed models. F1-scores are calculated based on token-level overlap between predicted and gold answers, allowing for partial credit for responses that contain correct information but do not strictly match the exact format of the gold answer. We found that F1 consistently outperformed Hit@1, highlighting the model’s capability to generate partially correct answers that include relevant entities or information, even if they introduce additional context or deviate from exact formatting.
Comprehensive evaluation of proposed models on the MINTAKA dataset.

To assess the statistical reliability of the observed performance improvements, we conducted bootstrap resampling analysis with 10,000 iterations, treating test set predictions as binomial outcomes. The 95% bootstrap confidence intervals demonstrate non-overlapping ranges between our best model and key baselines: our model achieves 0.360 [0.343, 0.377] compared to Rigel’s 0.200 [0.185, 0.216], T5 baseline’s 0.280 [0.263, 0.297], and EmbedKGQA’s 0.180 [0.165, 0.195]. Two proportion z-tests confirm statistical significance: our model vs. Rigel (
To contextualize the computational requirements of our approach, we discuss inference time and memory consumption based on standard benchmarks for comparable architectures. Our T5-base models (220M parameters) typically achieve inference speeds of 50–80 ms per question on modern GPUs, while Longformer requires 120–160 ms due to its extended attention mechanism.16,17 The CLOCQ-based entity disambiguation and fact retrieval component adds overhead estimated at 0.4-0.5 seconds per question based on similar KGQA configurations. 5 However, this overhead is justified by the substantial performance gain it provides. Regarding memory consumption, T5 base requires approximately 2-3 GB GPU memory for inference, while Longformer requires 3-5 GB due to its extended context window,16,17 making both configurations deployable on consumer-grade GPUs. Importantly, our approach uses T5-base (220M parameters) compared to the MINTAKA baseline’s T5-XL (3B parameters), achieving competitive performance.
To measure the contribution of each component in our proposed method, we performed an ablation study using the MINTAKA test set. Table 10 shows the Hit@1 performance for different model configurations, both with and without the CLOCQ-based fact extraction and transfer learning.
Ablation results.

Ablation results.
The results indicate that the CLOCQ-based approach for named entity recognition improves performance by adaptively selecting relevant candidate facts. The multi-signal scoring strategy helps narrow down the search space by identifying the most relevant entities. In addition, the Longformer architecture provides a small improvement by allowing the model to process longer input contexts more effectively. Transfer learning provides the most effective results, showing that pre-training on SPARQL-annotated datasets (LC-QuAD 2.0, QALD, GrailQA) enables the model to generalize more effectively to complex multi-hop questions in MINTAKA. These ablations demonstrate that all three components—CLOCQ, Longformer, and transfer learning—make complementary contributions to the final model performance.
We also performed the error analysis to explore the limitations of the proposed approaches. The identified failure cases are categorized in Table 11. We specifically focused on factoid questions, adjusting ground truth answers for boolean, count, and comparative types. All the experiments were performed on the prepared dataset having 22,000 training, 5,000 validation, and 3,000 test instances. Through manual inspection of a representative sample of incorrect predictions, we categorized errors into three primary types based on question characteristics and analyzed their distribution across the test set. Boolean questions requiring yes/no answers are the most frequent error type, with counting questions and comparative questions following in frequency. Together, these three categories comprise most prediction failures.
Categories of failure cases.

Examples of partially correct predictions.
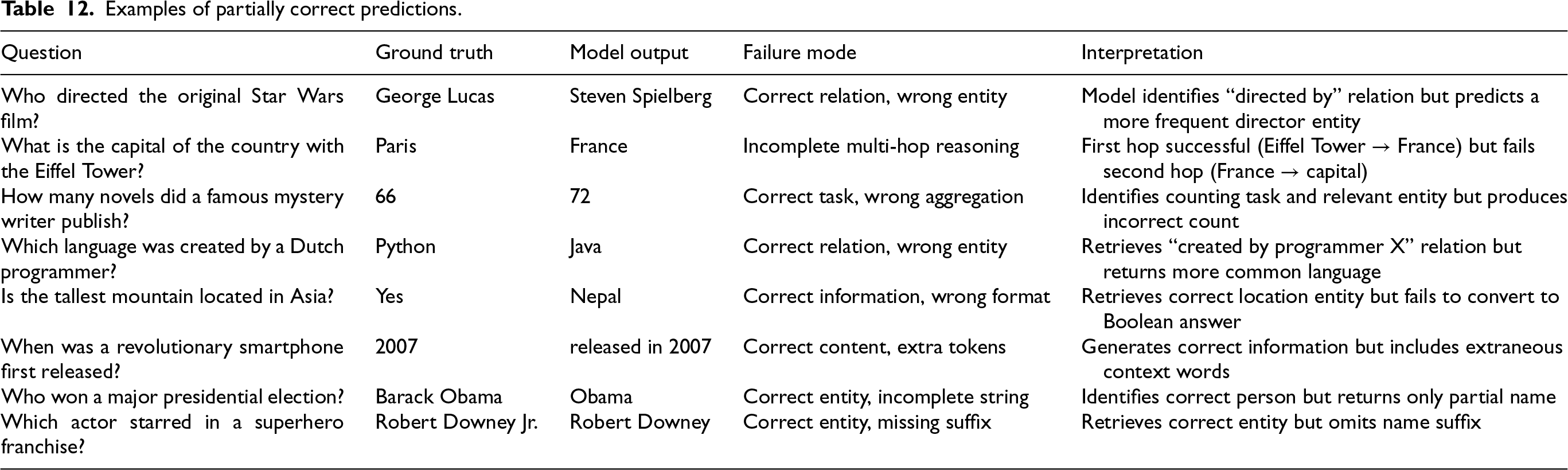
We observed that the model is not able to perform reasoning with true or false questions. The main challenge is that Boolean answers often require inferring the absence of information—for example, finding the response to the question “Is city X NOT located in city Y?” when no location relation exists in the retrieved knowledge base context. Since T5 and Longformer are generative models trained to generate answers from the given context, they are unable to generate answers when information is not present in the context. Counting questions pose different problems: while the models retrieve relevant entities, they fail at accurate counting. The model often extracts relevant entities, but due to duplicate triples, and difficulty in distinguishing between distinct entities from multiple mentions of the same entity, it does not count them accurately. Comparative errors occur mainly because of direct comparison relations (e.g., “older than”) are few in knowledge bases, requires the model to retrieve attributes for both entities (e.g., birth dates) and perform implicit comparison, which requires multi-hop reasoning. Additionally, we have identified cases of partial correctness—predictions where the responses are classified as incorrect under strict exact-match evaluation yet retain considerable accurate information. Table 12 shows examples of Partially Correct Predictions
From the examples, four common types of failures can be observed. First, entity popularity bias: the model predicts frequently occurring entities from the training data even when less common entities are correct, suggesting that entity frequency in the knowledge base influences predictions as compared to contextual relevance. Second, multi-hop incompleteness: the model successfully executes initial reasoning steps but fails to chain subsequent hops, returning intermediate results instead of final answers. Third, answer type mismatch: the model sometimes produces the correct information but in the wrong format, especially for Boolean and numerical questions. This suggests the need for explicit answer-type classification. Fourth, incomplete entity strings: the model finds the correct entities but returns a shortened or incomplete form because of tokenization or missing labels. The observed gap between Hit@1 (0.36) and F1 (0.47) provides quantitative support for these patterns: approximately 11% of predictions contain correct information or entities but fail exact-match evaluation due to formatting differences, extraneous context, or incomplete strings. This suggests that post-processing steps to standardize answer formats and extract core entities could yield improvements without requiring model retraining.
The proposed approach enhances the effectiveness of end-to-end knowledge graph–based question answering systems for complex queries. Many existing approaches depend on training datasets that contain manually annotated gold entities, which requires considerable human effort and time to prepare. In contrast, the proposed model is created to function without the need for such gold entity annotations, thereby eliminating the dependency on manually labeled data. The proposed framework combines named entity disambiguation with transformer-based language models, including T5 and Longformer. The experiments on the MINTAKA dataset show that the proposed approaches perform comparably with existing baseline models without using the gold entities. In addition, the error analysis identifies specific areas that require further improvement—first, adding specialized reasoning, such as handling negation and performing mathematical computation, to improve the model’s performance on Boolean, counting, and comparative questions, and second, reducing the computational overhead by exploring a more efficient entity disambiguation method. Third, integration of large language models (LLMs) to improve the multi-hop reasoning and support for more complex logical inference. Future work will also include re-implementing baseline methods on the MINTAKA dataset to allow direct comparison of computational efficiency. In addition, a comprehensive multilingual evaluation will be conducted to examine how well the model generalizes across the nine languages supported by the dataset.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article.