
Abstract
Semantic segmentation in urban scenes is an important task in computer vision. However, urban road scenes still present many challenges, such as category imbalance and complex backgrounds. These problems lead to unclear edge segmentation and inaccurate classification of occluded objects in existing semantic segmentation methods for urban scenes, which limits their accuracy and robustness in practical applications. In this paper, we propose a model that recursively enhances edge feature representation while incorporating local spatial context. To address the problem of unclear edge segmentation, we introduce Multi-scale Central Difference Convolution (MS-CDC) to fuse multi-scale edge features. The feature pyramid-based FeedBack Connection (FBC) module fuses multi-scale features while recursively enhancing the original network, thereby improving the robustness of the model to occluded objects. Meanwhile, we design a Local Feature Extraction (LFE) module to capture pixel-wise relationships by constructing local pixel graphs and center pixel graphs. It can learn local contextual information to extract finer-grained pixel features. Experimental results on the Cityscapes and Mapillary Vista datasets validate the effectiveness of the proposed model. Our model achieves 80.67% and 45.5% mIoU on the validation sets of Cityscapes and Mapillary Vista, respectively. We open-source our code at https://github.com/sanmanaa/segmentation-autodriving-graph-centralconv.
Introduction
Semantic segmentation is a fundamental task in computer vision that aims to assign a category label to each pixel in an image. It plays a crucial role in urban scene understanding for autonomous driving. In urban road scenes, semantic segmentation techniques can be used to identify key object categories, such as vehicles, drivable areas, and traffic signals. Beyond scene parsing itself, reliable understanding of road environments can also support safety-oriented downstream tasks, such as crash risk assessment based on road images. 1 However, urban road scenes often involve highly complex visual relationships, including mutual occlusion among multiple objects, ambiguous category boundaries, and unclear object edges. These challenges greatly increase the difficulty of visual understanding in urban road scenes.
Early semantic segmentation methods usually relied on hand-crafted features. 2 However, the performance of these methods was far from satisfactory. In the past few years, with the remarkable development of deep learning,3,4 Deep Convolutional Neural Networks (DCNNs)5–7 have been successfully applied to semantic segmentation. Fully Convolutional Network (FCN) 8 is a pioneering work to employ DCNNs in semantic segmentation, which replaces fully connected layers with convolutional layers in the final stage of a typical CNN architecture to obtain better results.
Although these methods have achieved impressive results, as shown in Figure 1, two key problems still remain in urban road scenes: (I) unclear edge segmentation and (II) ambiguous classification of occluded objects. For example, some parts of the “pole” (i.e., row (I) of Figure 1) are missing in the segmentation mask, and some regions involving multiple mutually occluded targets (i.e., row (II) and row (III) of Figure 1) are misclassified. We find that unclear edge segmentation arises because ordinary convolution is unable to capture sufficient edge features, making it difficult to accurately locate object boundaries. In addition, the misclassification of multiple occluded targets is caused by insufficient spatial details in high-level feature maps.
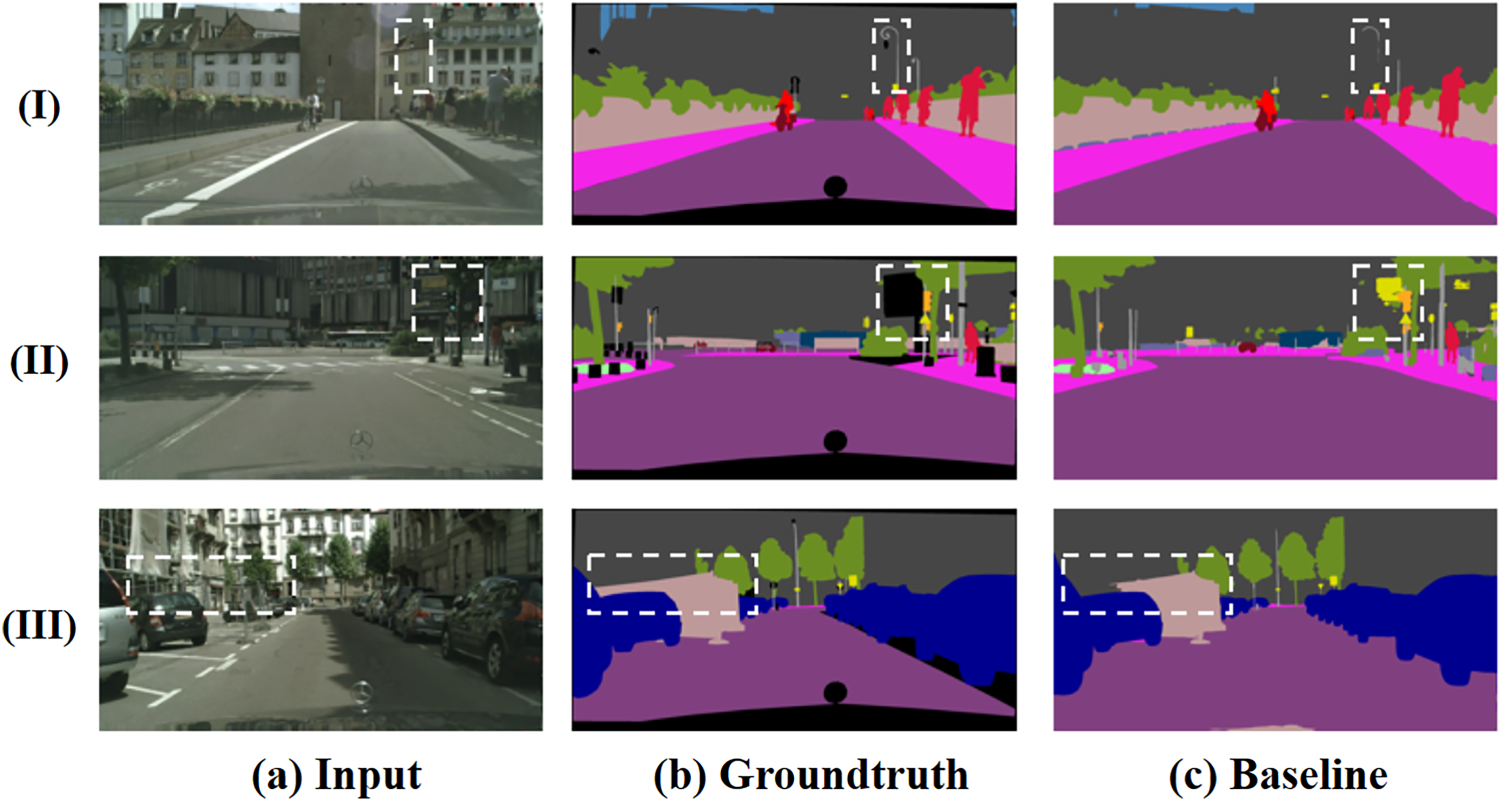
Two basic problems in our baseline, which are unclear edge segmentation and blurred classification of occluded objects. Samples are from the val set of the Cityscapes dataset.
To address these problems, the DeepLabv3+ 9 introduces a spatial pyramid pooling module to better understand the differences between large and small targets. Li et al. 2 model the body and edges of the target object to obtain new body features and residual edge features. U-Net 10 adopts an encoder-decoder architecture to improve the semantic segmentation performance. It adds skip connections between the encoder and decoder, which can recover fine-grained details in the semantic prediction. Feature pyramid networks (FPNs) 11 use the structure of U-Net 10 to make predictions from each level of the feature pyramid. FFS-Net 12 designs a multiscale channel attention module to balance the low-level fine information and high-level semantic features. These methods show that handling asymmetries between deep and shallow features contributes to improved segmentation performance; however, they do not consider extracting multi-scale edge features and contextual detail information for feature fusion. This information not only helps to localize the edge locations but also helps to improve the segmentation accuracy of mutually occluded targets.
In order to improve the accuracy of segmentation, several pioneering approaches have been proposed to utilize local spatial contextual visual information. Ding et al. 13 introduce a context converter for embedding contextual information in contextual branches and selectively projecting it onto local features. Fang et al. 14 propose a contextual representation enhancement network (CRENet) to enhance global context (GC) and local context (LC) modeling in high-level features. Combining local contextual information to re-model the relationships between objects has been shown to be effective in improving the accuracy of semantic segmentation.
In this work, we propose a semantic segmentation model for urban road scenes that integrates multi-scale edge-aware extraction, recursive feature fusion, and local relational modeling to jointly alleviate unclear boundary delineation and occlusion-induced misclassification. Specifically, the Multi-scale Central Difference Convolution (MS-CDC) module is introduced to enhance multi-scale edge and texture feature extraction, the pyramid-based FeedBack Connection (FBC) module is designed to improve recursive feature fusion and the robustness to occluded objects, and the Local Feature Extraction (LFE) module is employed to model local pixel-wise relationships while reducing irrelevant global interactions. Through the complementary integration of these modules, the proposed model enhances boundary representation, occlusion-aware feature interaction, and local structural modeling in complex urban road scenes.
The main contributions of this paper are summarized as follows: We propose a semantic segmentation model for urban road scenes that integrates multi-scale edge-aware extraction, recursive feature fusion, and local relational modeling to jointly address boundary ambiguity and occlusion-induced misclassification. We design a Multi-scale Central Difference Convolution (MS-CDC) module and a pyramid-based FeedBack Connection (FBC) module to enhance multi-scale edge perception and recursive feature fusion, respectively, thereby improving boundary delineation and the robustness of occluded object classification. We introduce a Local Feature Extraction (LFE) module to model local pixel-wise relationships by leveraging local pixel graphs and center pixel graphs, which enhances local structural representation while reducing irrelevant global interactions. Extensive experiments on the Cityscapes and Mapillary Vista datasets demonstrate the effectiveness of the proposed model and show its competitiveness against several representative semantic segmentation methods.
We have extensively surveyed recent advances in semantic segmentation, with a particular focus on urban-scene understanding for autonomous driving. In recent years, research in this field has evolved from conventional convolution-based dense prediction toward multi-scale representation learning, context modeling, and Transformer-based semantic segmentation. In the following, we review representative studies from the perspectives of semantic segmentation, Transformer-based urban-scene segmentation, multi-scale feature fusion, context modeling, and convolution operator design, and further discuss their relevance to boundary delineation, occlusion handling, and efficient feature modeling in complex road scenes.
Semantic segmentation
Semantic segmentation has attracted extensive research attention in recent years,9,14–21 where the Full Convolutional Network (FCN) 8 is one of the most representative early architectures and many subsequent methods are built upon this dense prediction paradigm.15,19,22 A central challenge in semantic segmentation is to maintain high-resolution representations while preserving sufficient semantic and contextual information. To address this issue, existing methods can generally be categorized into two groups: methods designed to maintain high-resolution representations23,24 and methods intended to capture broader contextual information.9,22,25 To preserve fine spatial details, a widely adopted strategy is to fuse low-level feature maps with high-level semantic feature maps before the final prediction,9,24 thereby enhancing the spatial resolution of the resulting representations.
These methods are designed to balance high-resolution representations with rich semantic and contextual information. Nevertheless, their multi-level feature maps are often directly upsampled and fused only at the final stage, which may cause information loss, since simple upsampling operations are unable to fully recover the fine structural details and accurate spatial information preserved in low-level features. In urban-scene segmentation, this limitation becomes more evident when the model needs to parse thin structures, small traffic-related objects, and mutually occluded categories. Therefore, beyond improving global semantic understanding, accurately preserving local structures and boundary details remains an important issue in autonomous-driving scene segmentation.
Transformer-based semantic segmentation for urban scenes
Transformer-based methods have become an important branch of semantic segmentation because they model long-range dependencies and global context more effectively. Representative methods such as Segmenter, 26 MaskFormer, 27 and StructToken 28 introduce token-based decoding, mask classification, or structural priors into dense prediction and achieve competitive performance. Recent studies further extend this line to urban-scene understanding and large-scale pre-trained models. CMFormer 29 enhances mask attention with content-aware multi-resolution cues for urban-scene segmentation, while Rein 30 shows that vision foundation models can be adapted to semantic segmentation with only a small number of trainable parameters. EoMT 31 further suggests that large pre-trained ViTs can support simpler segmentation architectures, while ALGM 32 improves plain Vision Transformer-based segmentation through adaptive local-to-global token merging. In addition, CCASeg 33 further improves semantic segmentation by decoding multi-scale context with convolutional cross-attention.
Despite their strong global modeling ability, these methods still encounter difficulties in complex autonomous-driving scenes. Fine boundary recovery, recognition of small traffic-related objects, and discrimination between locally occluded categories remain challenging. Therefore, in urban-scene segmentation, global context modeling alone is not sufficient, and explicit enhancement of edge representation and local structural interaction is still necessary. This is also the motivation for introducing multi-scale edge enhancement, recursive feature fusion, and local pixel-wise relational modeling in our framework.
Multi-scale feature fusion
Multi-scale feature fusion is a popular direction in computer vision. FPN 11 combines top-down paths to sequentially combine features at different scales, PANet 34 adds another bottom-up path on top of FPN, and STDL 35 proposes to exploit cross-scale features through a scale transformation module. HRNet 24 connects in parallel from high to low convolutional streams so that it can maintain a high resolution representation throughout the process. BFMNet 36 uses a parallel architecture and dilated convolution strategy to perceive multi-scale features. MFFTNet 37 proposes multi-scale strip convolution to refine the information present within both deep and low-level feature sets.
These methods improve the model’s ability to perceive multi-scale targets and complex scenes by integrating multi-scale feature information. However, since multi-scale fusion mainly focuses on the overall scene features, it ignores the local features of individual objects in the occluded region. Therefore, they may have difficulty in accurately segmenting individual objects when multiple objects are occluded.
Context for segmentation
Pyramid pooling techniques focus on a fixed square context region, as pooling and scaling are typically used in a symmetric manner. Relational context approaches build context by focusing on the relationships between pixels and are not limited to square regions. Such techniques can construct more suitable contexts for non-square semantic regions, such as long trains or slender lamp posts. OCRNet 38 constructs better contexts by aggregating the representation of context pixels, where the context consists of all pixels. MCRNet 39 captures spatial details for high resolutions and semantic encoding for low resolutions. It effectively solves the image blurring problem caused by downsampling operations. Tian et al. 40 propose a context-aware classifier to use additional contextual hints, decently adapting to different latent distributions.
The core idea of these methods is to capture richer contextual information by considering the relationships between pixels. However, since they need to consider the relationship between pixels in the whole image, their computational complexity is usually high, which may lead to slower training and inference.
Convolution operator
Convolution operators are commonly used to extract basic visual features in deep learning frameworks. However, convolution operators compute the kernel response to each local patch of the input feature map and are not good at modeling the boundary information. To address this problem, the local binary convolution (LBC) 41 uses a series of predefined binary filters instead of learnable kernels in convolution. Yu et al. 42 introduce the central difference convolutional network (CDCN) to extract intrinsic deception patterns by aggregating intensity and gradient information. Compared to traditional convolution, CDCN can provide a more robust modeling capability. Chen et al. 43 propose DEConv, which employs Difference Convolution (DC) to integrate both low-frequency and high-frequency information. However, it struggles in capturing boundary details. On the other hand, Tan et al. 44 introduced Semantic Difference Convolution (SDC), which leverages semantic similarity to guide CDC. Nevertheless, it lacks perceptual awareness across different scales.
These methods share a commonality in their pursuit of improving feature extraction through diverse convolution operators, aimed at capturing more comprehensive contextual information. However, they face a common limitation: they have a suboptimal capability to accurately capture boundary information. This shortcoming in boundary perception may impair their overall performance in tasks that demand precise boundary delineation.
Methodology
Figure 2 illustrates the overall design of the proposed model for integrating multi-scale features with local spatial context. The model consists of three key components: the Multi-scale Central Difference Convolution (MS-CDC) module, the FeedBack Connection (FBC) module, and the Local Feature Extraction (LFE) module. The input image is first fed into the network. Whenever a lower-resolution feature map is generated in the backbone, the MS-CDC module is applied to extract multi-scale edge and contextual features. Based on these features, the LFE module is then employed to model local pixel-wise relationships and aggregate local structural information. During the fusion of feature maps from different levels, the FBC module is introduced to improve the robustness of the network in classifying occluded regions. In this way, MS-CDC, FBC, and LFE function as complementary mechanisms rather than isolated modifications: MS-CDC enhances edge-aware representation, FBC improves occlusion-aware feature interaction, and LFE strengthens local structural modeling. Their joint integration enables the proposed model to better address boundary ambiguity, occlusion-induced confusion, and insufficient local detail representation in complex urban scenes. Finally, hierarchical multi-scale attention 45 is introduced outside the backbone to further improve segmentation accuracy.
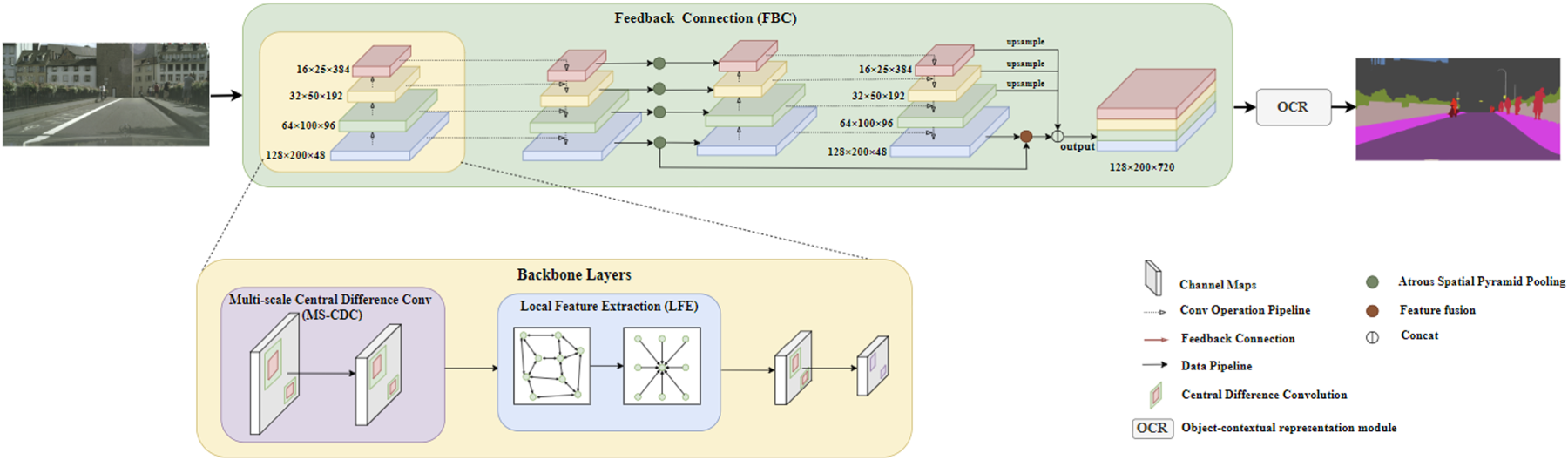
Overview of the proposed semantic segmentation model for integrating multi-scale features with local spatial context. The model incorporates the MS-CDC, FBC, and LFE modules to enhance edge-aware representation, multi-level feature interaction, and local structural modeling. Specifically, the MS-CDC module extracts multi-scale edge and contextual features at different resolution levels, the FBC module performs recursive multi-scale feature fusion, and the LFE module models pixel correlations and aggregates local structural information. In addition, the OCR (Object-Contextual Representation) module 38 is employed to further enhance feature representation with contextual information.
For the input images, HRNet
24
produces high-resolution feature representations, achieving state-of-the-art performance in many semantic segmentation datasets. However,
In this paper, we design a new multi-scale central difference convolution module to efficiently extract multi-scale edge features on urban roads. Intensity-level semantic information and gradient-level details are crucial for distinguishing the boundaries of urban roads, which suggests that combining ordinary convolution with center difference is a more feasible way to provide more robust modeling capabilities. Central difference convolution
42
enhances the representation and generalization capabilities of ordinary convolution by aggregating the central gradients of the sampled values. At each resolution level, we use the multi-scale central difference convolution to extract more consistent patterns and biologically motivated features, so that it can capture some fine-grained invariant information. The output feature map
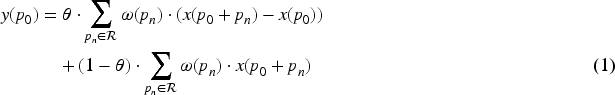
More robust and biologically motivated features can be captured through the use of central difference convolutional layers at different scales. As shown in Figure 3, we deploy small
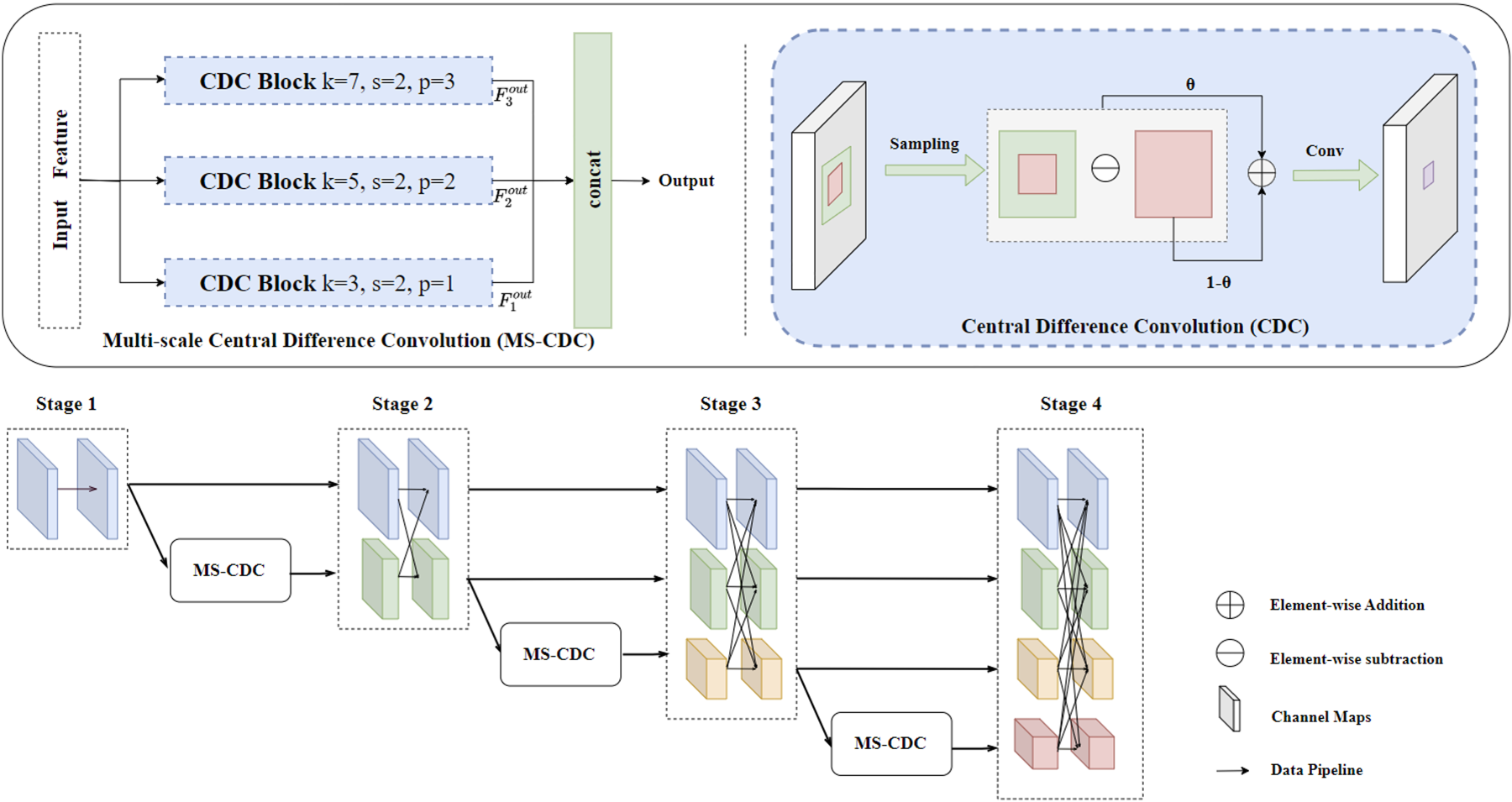
The left one is the pipeline of the MS-CDC module, in which k; s; p denote kernel size, stride and padding. Right one is the architecture of the Central Difference Convolution. The bottom one shows the location of the MS-CDC in the network.
Although HRNet 24 performs well in handling multi-scale targets and preserves multi-scale features effectively, it still struggles to clearly distinguish adjacent targets under occlusion. This limitation leads to ambiguous and inaccurate segmentation results.
To address this challenge, we introduce the FBC module to alleviate the difficulties caused by multi-target occlusion. Human visual perception can selectively enhance or suppress neuronal responses by exploiting high-level semantic information through feedback connections. Inspired by this mechanism, similar feedback strategies have been introduced in computer vision to refine feature representations by re-evaluating information. Based on this idea, the proposed Feedback Connection (FBC) module incorporates feedback from the bottom-up feature pyramid into the backbone layers. Let
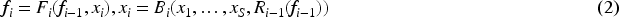
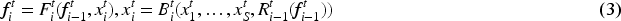
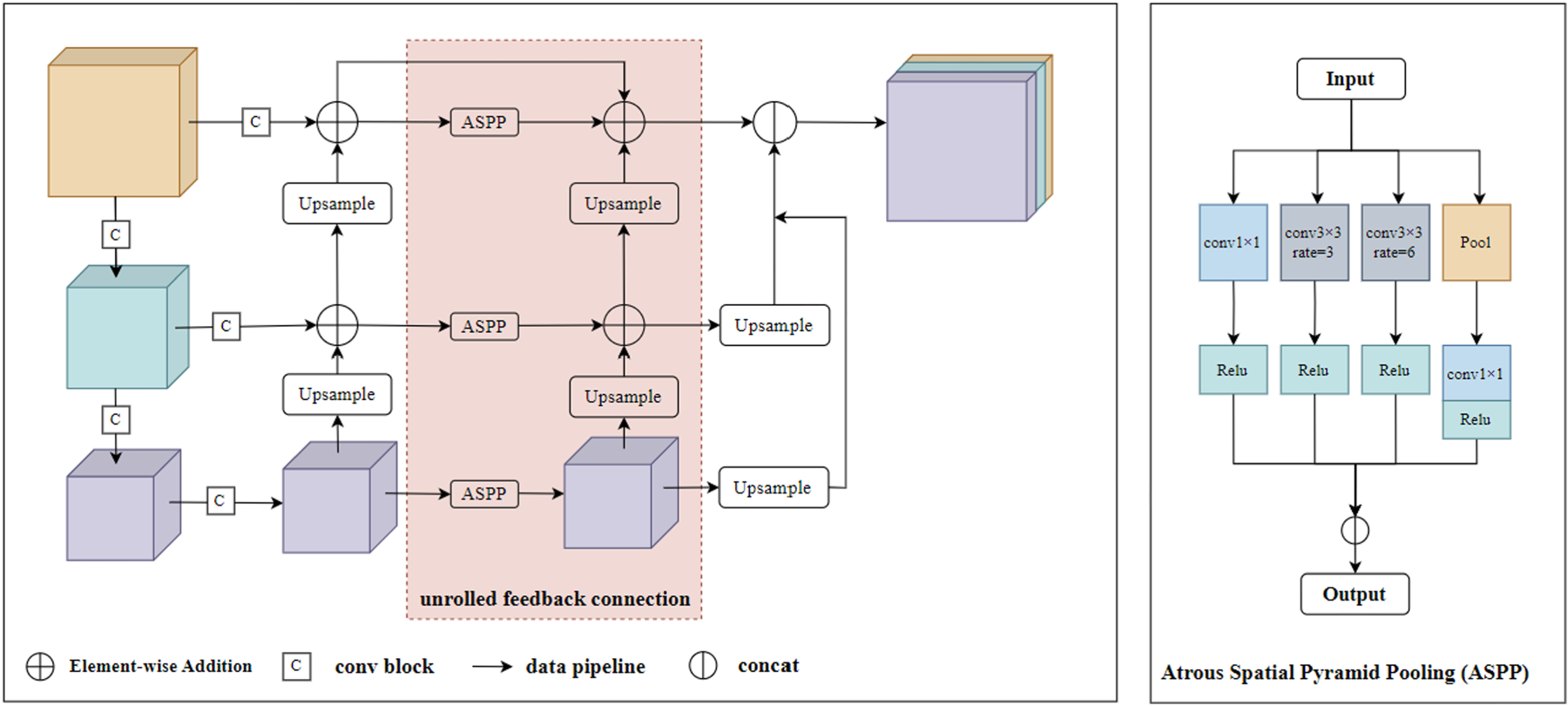
The feedback connection based on the feature pyramid unfolds as a two-step sequential network, which is shown in the figure for the case S = 3. The pink block is the specific structure of unrolled feedback connection.
In complex urban scenes, considering relationships between all pixels may introduce irrelevant information, possibly degrading model performance and adding unnecessary complexity. Additionally, neglecting local relationships may hinder capturing vital local details, impacting performance in intricate scenarios. Therefore, LFE module is introduced to effectively extract and utilize local detail information.



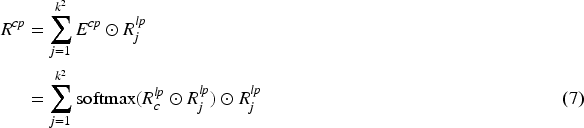
In summary, we obtain improved features from the proposed local pixel graph and central pixel graph. First, we refine each local patch by using pixel-level information. Then we obtain the final features by aggregating the local patch features to its central pixel. Compared with traditional non-local modules, our method has less computational overhead and can effectively utilize the local structure information in the image.
Dataset and evaluation metrics
In all the experiments on Cityscapes validation set and Mapillary Vistas validation set, we train our models using finely annotated training set for 200K iterations with a total batch size of 2 and a crop size of 1024

For each class


All experiments were conducted on a workstation running Ubuntu 22.04.2 LTS, equipped with one NVIDIA RTX A6000 GPU (48 GB memory) and an AMD Ryzen 5 5600 6-Core Processor. The implementation was based on Python 3.8.16, using PyTorch 1.13.0, torchvision 0.14.0, and torchaudio 0.13.0. The software environment was built with CUDA 11.7 and cuDNN 8.5.0. Mixed-precision training and synchronized batch normalization were adopted to improve computational efficiency.
For data augmentation, Gaussian blur, color augmentation, random horizontal flipping, and random scaling (
Comparisons with the state-of-the-art methods
In this section, we make result comparisons between our proposed model and the state-of-the-art approaches quantitatively and qualitatively.
Quantitative benchmarks of applying the proposed method to some segmentation methods with different backbone networks , while testing on the whole image. SI: sidewalk; BU: building; TL: traffic light; TS: traffic sign; VE: vegetation; TE: terrain; PE: person; MO: motorcycle; BI: bicycle.

Quantitative benchmarks of applying the proposed method to some segmentation methods with different backbone networks , while testing on the whole image. SI: sidewalk; BU: building; TL: traffic light; TS: traffic sign; VE: vegetation; TE: terrain; PE: person; MO: motorcycle; BI: bicycle.
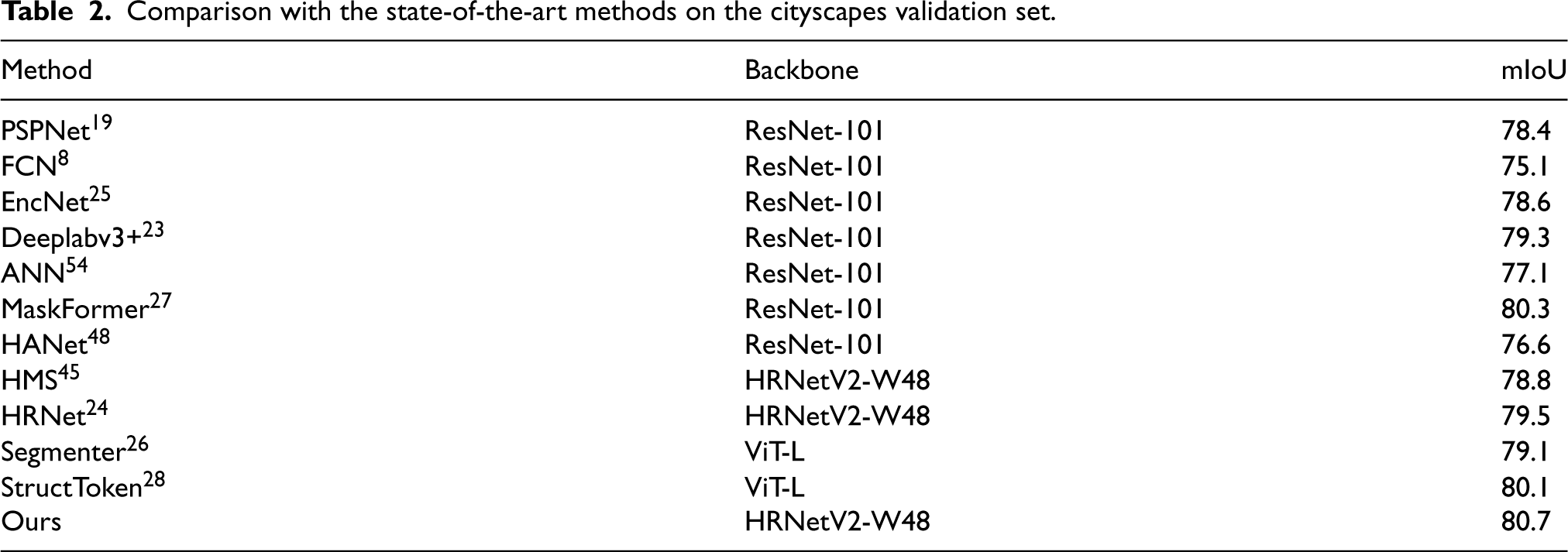
To demonstrate the effectiveness of the proposed model, we compare it against existing state-of-the-art semantic segmentation approaches on the val set of Cityscapes. Table 2 shows the results of our model and other methods8,19,23–26,45,48 on the Cityscapes val set. Compared to methods using ResNet-101 as the backbone, such as MaskFormer
27
and HANet,
48
our model achieves a 0.3%–5.6% mIoU improvement. In particular, our best obtained result reaches an mIoU of 80.7, which is slightly higher than the 80.3 reported by MaskFormer.
27
Repeated experiments under the same implementation setting further show that our method achieves 80.5
Comparison with the state-of-the-art methods on the cityscapes validation set.
Comparison with the state-of-the-art methods on the mapillary vista validation set.


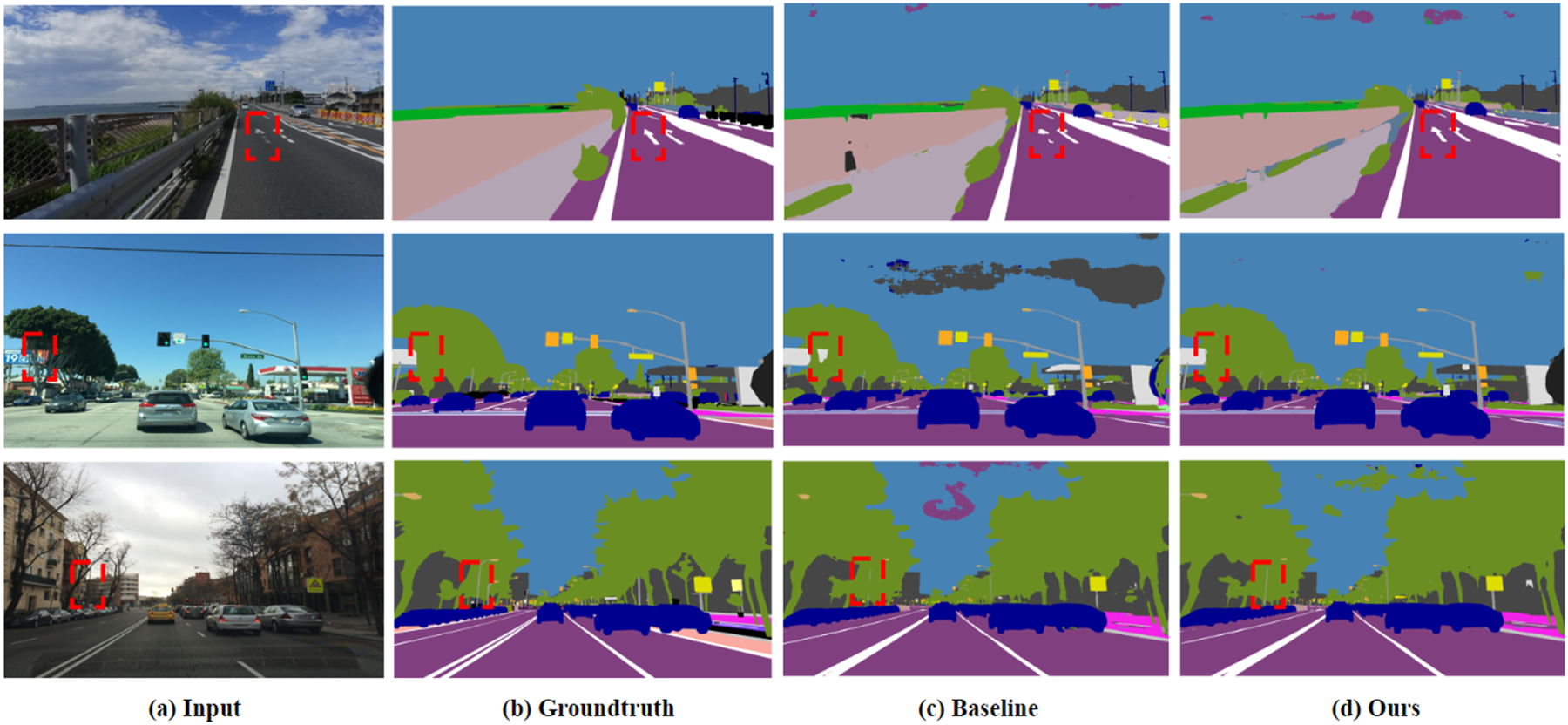
Qualitative visualization of the input images, ground truth, baseline results, and our results. The examples are selected from the Cityscapes dataset. Compared with the baseline, our model reduces unclear edge segmentation and errors caused by multiple-object occlusion, as highlighted in the white boxes.
Qualitative visualization of the input images, ground truth, baseline results, and our results. The examples are selected from the Mapillary Vista dataset. Compared with the baseline, our model reduces unclear edge segmentation and errors caused by multiple-object occlusion, as highlighted in the red boxes.
Our ablation study aims to investigate the effectiveness of the Multi-scale Center Difference Convolution (MS-CDC) module, the feature pyramid-based FeedBack Connection (FBC) module, the Local Feature Extraction (LFE) module, and their combinations for semantic segmentation. For this purpose, we conduct a series of experiments on the validation set of Cityscapes. Table 4 shows the experimental results compared with the baseline. The results are reported in terms of mIoU, PixAcc, model parameters, GFLOPs, and FPS for comparison. Among them, mIoU and PixAcc are used to evaluate segmentation accuracy, while model parameters, GFLOPs, and FPS are provided as supplementary indicators for computational cost and inference efficiency.
Ablation study and efficiency comparison on the Cityscapes
49
val set. FPS is measured on a single NVIDIA RTX A6000 GPU with input size
under the same inference setting.
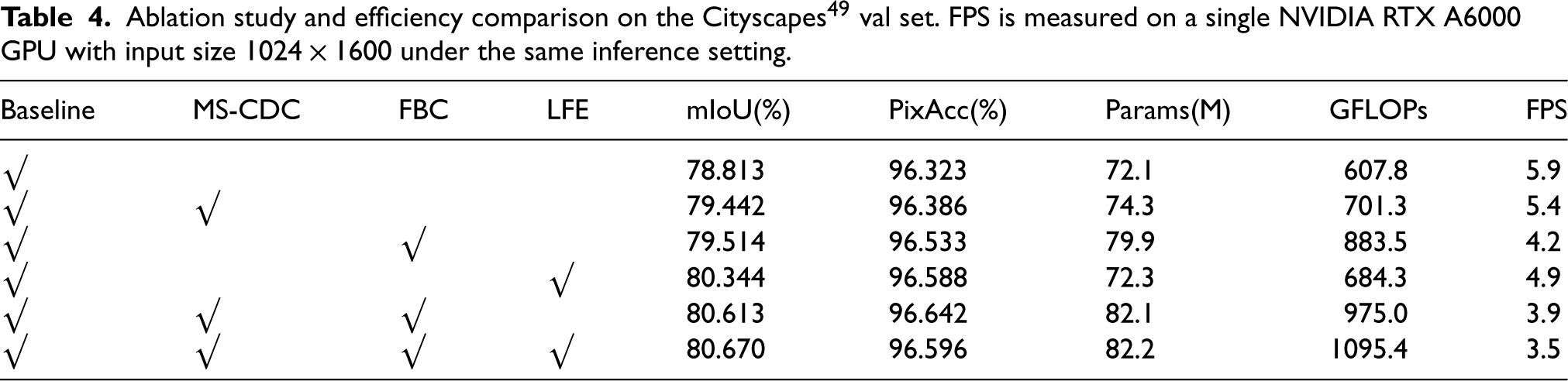
Ablation study and efficiency comparison on the Cityscapes
49
val set. FPS is measured on a single NVIDIA RTX A6000 GPU with input size
Although the proposed model improves the overall segmentation performance, several challenging cases still remain, as shown in Figure 7. In particular, the remaining errors are more likely to occur on distant small objects, such as traffic signs, and on highly co-occurring category pairs, such as rider and bicycle.
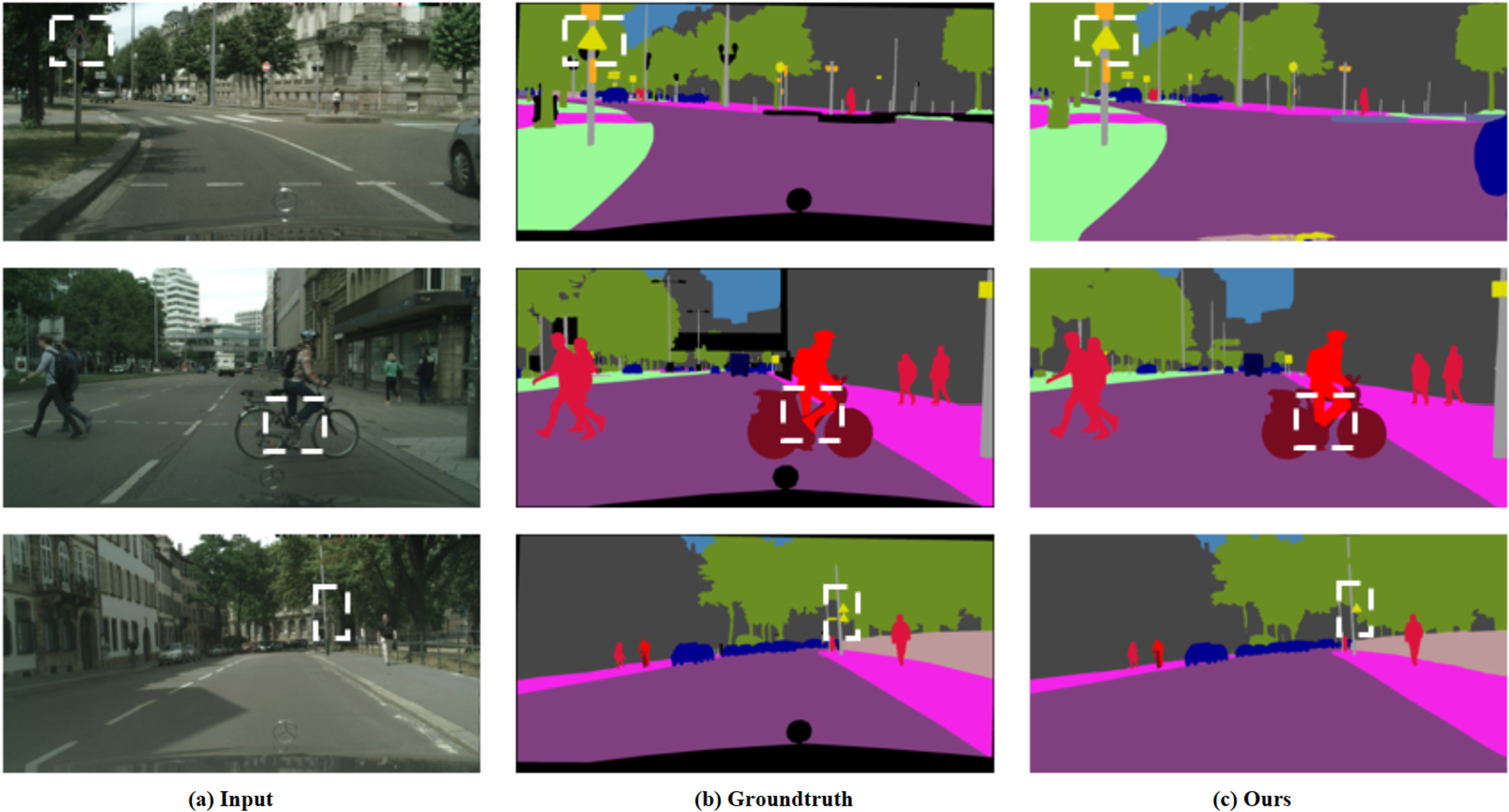
The failure cases on the val set of Cityscapes. The white dashed frames highlight the failed areas predicted by our model.
For traffic signs, the failure is not merely caused by insufficient resolution representation, but is more closely related to the intrinsic difficulty of distant small objects in urban scenes. In many cases, traffic signs occupy only a very limited number of pixels and are located far from the camera, which makes their fine structures and boundaries highly sensitive to repeated downsampling and feature aggregation. As a result, their predicted regions may become incomplete or fragmented in difficult scenes.
For the rider-bicycle pair, the difficulty mainly arises from strong spatial co-occurrence and boundary coupling. In many street scenes, rider and bicycle frequently appear adjacent to each other or partially overlap, which increases the risk of mutual confusion near ambiguous boundaries. To quantitatively analyze this phenomenon, we divide the validation images into co-occurring and non-co-occurring subsets based on the ground-truth semantic labels. An image is regarded as a co-occurring case if both rider and bicycle are present in its annotation. For each category, we then compare its IoU in co-occurring images with its IoU in images where the paired category is absent. Specifically, for rider, the non-co-occurring subset contains images with rider but without bicycle; for bicycle, it contains images with bicycle but without rider, as summarized in Table 5. The results show that both categories obtain lower IoU scores in co-occurring scenes, suggesting that their frequent spatial adjacency and partial overlap increase the difficulty of fine-grained category separation.
Segmentation performance of rider and bicycle in images with and without co-occurrence. For rider, the non-co-occurring subset contains images with rider but without bicycle; for bicycle, it contains images with bicycle but without rider.

Overall, these failure cases do not contradict the effectiveness of the proposed framework for urban scene segmentation. Instead, they indicate that, despite the improvements brought by the proposed modules, there is still room for improvement in handling distant small objects and strongly co-occurring categories.
In future work, these limitations may be alleviated by enhancing small-object representation and by designing more explicit feature decoupling mechanisms for highly correlated category pairs.
We introduce a novel network for semantic segmentation that achieves multi-scale feature fusion, edge feature extraction, and local feature aggregation through three key components, namely MS-CDC, FBC, and LFE. The proposed model jointly addresses challenges such as unclear edge segmentation and ambiguous classification of occluded objects in urban scenes. Experimental results on the challenging Cityscapes and Mapillary Vista datasets validate the effectiveness of the proposed network.
Our model demonstrates strong performance in semantic segmentation. However, it still faces several challenges, such as the potential increase in computational complexity caused by higher-resolution representations and the co-occurrence problem between foreground and background regions. Nevertheless, the network shows promise in handling multi-scale, occlusion, and fine-detail issues in urban environments. In future work, we plan to further improve computational efficiency, incorporate additional multimodal information (e.g., text and supplementary images) into segmentation, and enhance the model’s ability to handle more complex scenarios, such as dynamic objects, varying illumination, and diverse environmental conditions.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key R&D Program of China (No. 2021ZD0111902) and the National Natural Science Foundation of China (Nos. 62472014, U21B2038).
Declaration of conflicting interests
The authors declare no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data and code availability
The datasets and code supporting the findings of this study are available as follows:
The accession number for the code is included in the provided DOI. For any materials that must be obtained through a Material Transfer Agreement (MTA), please contact the corresponding author for further details.