
Abstract
Liver cancer survival prediction is challenged by high-dimensional, nonlinear clinical data and censoring effects. To address this, this paper proposes HLPL (Hepatic Evaluation for Life Prediction based on Machine and Deep Learning), an interpretable and scalable framework for accurate survival prediction. The proposed HLPL integrates data preprocessing, Cox-based feature selection, interpretable analysis, and machine learning (ML) and deep learning (DL) modeling. Specifically, the univariate Cox proportional hazards model is used for feature screening, while SHapley Additive exPlanations (Cox-SHAP) is applied solely for interpretability and feature refinement, without being used as a downstream model input. To capture patient heterogeneity, K-means clustering is performed exclusively on the training set, preventing data leakage. Experimental results show that the proposed HLPL framework achieves superior performance compared to conventional methods. The model attains an accuracy of 0.88. Furthermore, clustering analysis reveals distinct survival patterns across patient subgroups, while SHAP analysis identifies key prognostic factors such as tumor stage and treatment modality. These results demonstrate that HLPL provides an accurate, interpretable, and computationally efficient solution for survival prediction in liver cancer.
Introduction
Globally, liver cancer, predominantly hepatocellular carcinoma (HCC), remains one of the leading causes of cancer-related morbidity and mortality worldwide. 1 Its incidence is closely associated with chronic liver diseases, including hepatitis B or C infection, alcohol abuse, and metabolic disorders.2,3 Due to the complex interplay of tumor burden, liver function, and patient-specific conditions, the prognosis of HCC is highly heterogeneous, posing significant challenges for accurate survival prediction and clinical decision-making. 4 Therefore, developing reliable and interpretable prognostic models is of critical importance for personalized treatment planning and outcome optimization.
Traditionally, survival analysis in oncology has been dominated by statistical approaches such as the Cox proportional hazards model.5,6 Although these models provide interpretable risk estimates, they rely on assumptions such as proportional hazards and linear relationships, which may not adequately capture the complex, nonlinear interactions present in high-dimensional clinical data. Extensions such as multivariable Cox regression 7 offer incremental improvements but remain limited in modeling intricate feature dependencies and handling large-scale heterogeneous datasets.
With the rapid advancement of artificial intelligence, ML techniques have emerged as powerful alternatives for cancer prognosis prediction. ML models 8 have demonstrated strong performance in survival analysis,9,10 disease progression prediction, 11 and risk assessment. 12 In liver cancer research, approaches based on Random Forests and Gradient Boosting have shown improved predictive accuracy over conventional clinical scoring systems. 13 However, most ML-based studies rely on single-model architectures and often lack mechanisms to address patient heterogeneity or provide clinically meaningful interpretations.
DL further enhances predictive modeling by leveraging hierarchical feature representations to capture complex patterns in large-scale data. Recent studies have applied DL to dynamic risk prediction,14,15 treatment response modeling,16,17 and survival prediction,16,18,19 achieving promising results across multiple cancer types. Despite these advances, many DL models function as “black boxes,” limiting their interpretability and hindering clinical adoption.
In the literature, studies on liver cancer prognosis prediction have increasingly utilized the combination of ML20–28 and DL9,29,30 techniques to enhance model performance and clinical utility. Wang et al. 20 applied Logistic Regression, Random Forest, and Gradient Boosting to predict postoperative outcomes in HCC. Xie et al. 21 used these modules to predict lymph node metastasis in intrahepatic cholangiocarcinoma, identifying key clinical predictors. However, these methods typically use tree-based models for attribute selection, followed by classification and prediction. The feature selection based on the tree model usually causes the prediction results of the model to tend to the same tree model architecture, thus leading to bias in ML modeling and deficiencies in practical applications.
In addition to supervised approaches, recent research has explored unsupervised and representation learning techniques to uncover latent structures in medical and healthcare data.31–33 These methods aim to identify intrinsic patient subgroups without relying on labeled outcomes, thereby providing insights into disease heterogeneity. However, existing methods are typically designed for clustering or pattern discovery alone and are rarely integrated with downstream survival prediction and interpretability mechanisms, limiting their effectiveness in clinical decision support.
Recent studies have also emphasized the importance of combining predictive performance with model interpretability. For instance, Salehi et al. 34 demonstrated the effectiveness of scalable predictive analytics in healthcare systems, while Kalita et al. 35 highlighted the role of SHAP-based techniques in enhancing model transparency. These developments underscore the growing demand for explainable and clinically trustworthy predictive models.
Another important challenge in clinical prediction modeling is the potential bias and limited representativeness of real-world datasets. Clinical data collected from a single institution may reflect specific demographic distributions, treatment protocols, and prescribing patterns, which could introduce systematic biases into the model. These biases may affect the generalizability of the prediction results across different populations and healthcare settings.
Despite substantial progress, several critical gaps remain in the current literature. First, most existing approaches rely on single models or loosely coupled frameworks, failing to exploit the complementary strengths of ML and DL techniques. Second, patient heterogeneity is insufficiently addressed, which limits the effectiveness of subgroup-specific predictions. Third, interpretability is often overlooked, reducing the clinical applicability of advanced models. Finally, the integration of feature selection, patient stratification, and predictive modeling into a unified framework remains underexplored.
To address the above research gaps, this study introduces a novel ensemble prediction system, named HLPL, designed to improve predictive accuracy, interpretability, and robustness for liver cancer survival analysis. The proposed HLPL integrates ML and DL models through five phases: Data Preprocessing, Feature Engineering, Cox-SHAP Analysis, Pre-clustering, and Model Development and Training (MDT). The Data Preprocessing phase ensures raw data is prepared for analysis by addressing outliers, inputting missing values, normalizing features, and transforming categorical variables into numerical formats. In the Feature Engineering phase, significant predictors are identified using Pearson and Spearman correlations to account for both linear and nonlinear relationships. The Cox-SHAP phase employs the Cox proportional hazards model to compute patient risk scores, and leverages SHAP values to interpret feature contributions, enhancing model explainability. During Pre-clustering, K-means clustering is applied to group patients into similar subpopulations, effectively addressing population heterogeneity. Lastly, the MDT phase utilizes ML and DL models trained on the clustered datasets and combines their outputs through model fusion to boost predictive performance and robustness.
In practical terms, HLPL supports real-world clinical applications by enabling risk stratification, personalized survival prediction, and treatment planning. Its interpretable design allows clinicians to identify high-risk patients, understand key prognostic factors, and compare outcomes under different therapies, thereby facilitating integration into clinical decision-support systems. The proposed HLPL framework provides a structured, interpretable, and powerful approach for liver cancer survival prediction, consistently outperforming existing methods. The main contributions of this paper are summarized as follows:
The remainder of the paper is structured as follows. Section 2 provides a comprehensive overview and comparison of relevant previous studies. Section 3 presents a detailed description of the assumptions, notation definitions, and problem formulation. Section 4 presents a detailed description of the proposed ML and DL mechanisms. Section 5 consists of a simulation and performance evaluation of the proposed method, and section 6 discusses the summary and future work.
This paper reviews the application of ML and DL for prognosis prediction in cancer. It evaluates how ML models have enhanced survival predictions and discusses the advancements brought by DL techniques in analyzing complex clinical data to improve the accuracy of cancer prognostics.
ML in cancer prediction
In the evolving field of ML applications for predicting prognosis in liver cancer, several studies have progressively addressed the complexities of this challenge. Ji et al. 23 set the stage by using a gradient boosting machine (GBM) to predict disease-specific survival for early hepatocellular carcinoma (EHCC) patients, achieving a notable C-statistic over 0.72. Despite its effectiveness, this model's reliance on a single predictive approach raised concerns about its ability to capture diverse patient variations, potentially limiting its broader applicability.
Building on the need for a more nuanced approach, Li et al. 24 developed a machine learning-based prognostic model using lysosome-related genes to predict the prognosis and immune status of HCC patients. The model, which incorporates eight key genes identified through Random Survival Forest (RSF) and Lasso regression, demonstrated superior predictive accuracy with a high C-index. Despite its strengths, the study highlighted the need for further validation of the remaining genes and called for in vivo experiments to explore their roles in HCC. This research emphasizes the potential of integrating various predictive models but also points to the necessity of pre-clustering techniques to enhance generalizability and robustness in clinical settings.
Huang et al. 25 further refined the predictive modeling by employing XGBoost and a comprehensive dataset to analyze recurrence of HCC post-surgery. Their approach demonstrated significant advancements in subpatterns within patient subgroups to further enhance model accuracy. Each of these studies has significantly advanced the field but also left gaps that offer opportunities for further enhancement. The current research aims to bridge these gaps by employing an integrated approach that combines ML and DL techniques. Utilizing a weighted ensemble model, this approach incorporates the strengths of various predictive models, such as those used by Ji et al., Li et al., and Huang et al. Additionally, it introduces pre-clustering to systematically identify and utilize subtle patient subgroup characteristics before model application. This holistic approach is designed to maximize the predictive accuracy and generalizability of survival time prognostics for liver cancer patients, ensuring that all aspects of patient variability are effectively captured and utilized in prognosis prediction.
Deep learning in cancer prediction
In the advancement of predictive modeling for cancer, diverse approaches have demonstrated the potential of deep learning. Huang et al. 26 explored the integration of deep learning models—specifically Cox-nnet, DeepSurv, and AECOX—with the Cox proportional hazards model to enhance the prediction of liver cancer prognosis using RNA-seq data from The Cancer Genome Atlas. Their approach adeptly manages complex, high-dimensional transcriptomic data, highlighting DL's capability in handling such intricacies. However, they noted variability in predictive performance across different datasets, suggesting a need for models that can consistently perform well across diverse clinical scenarios.
Further extending the utility of DL, Bhambhvani et al. 27 advanced the application of deep learning by focusing on pediatric genitourinary rhabdomyosarcoma. They employed deep neural networks (DNNs) to predict 5-year survival rates using data from the SEER database. This demonstrated DL's effectiveness in accurately predicting cancer survival. However, a significant oversight in their study was the lack of external validation, which is crucial for verifying the applicability of their predictive models to broader clinical settings, including different cancer types such as liver cancer. This gap emphasized the critical role that external validations play in ensuring the reliability and generalizability of prognostic models.
Lai et al. 28 implemented a DNN to predict overall survival in non-small cell lung cancer patients by integrating microarray gene expression data with clinical information. Utilizing a systems biology approach, their study identified fifteen prognostic biomarkers that informed the DNN model, demonstrating the model's ability to handle complex, high-dimensional datasets effectively. This integration via bimodal learning highlights the potential of deep learning in enhancing survival predictions through the synergistic use of heterogeneous data types. Despite these advances, the study does not explore pre-clustering techniques that could potentially enhance the identification of intrinsic patient group characteristics before model application. Additionally, the integration of predictions from various models through methodologies such as weighted averaging, which could further stabilize and refine predictive performance across diverse clinical scenarios, is not discussed. These areas represent potential avenues for further research to optimize predictive accuracy and model robustness in the field of cancer prognosis.
Table 1 presents a comparative summary of the proposed HLPL framework and the related studies. The “methodology” column indicates the predictive models employed in each study, while “data type” specifies the nature of the input data used for prognosis prediction. The columns “interpretability,” “patient stratification,” and “model integration” denote whether the corresponding methods consider model explainability, patient subgroup analysis, and the integration of multiple models, respectively. The “limitations” column highlights the main shortcomings of each approach. Compared with the related works, most existing studies rely on single-model architectures and lack mechanisms for interpretability, patient stratification, and comprehensive model integration. In contrast, the proposed HLPL framework integrates ML and DL models through an ensemble strategy, incorporates SHAP-based interpretability, and employs pre-clustering to address patient heterogeneity. These advantages enable HLPL to provide more accurate, robust, and clinically interpretable predictions for liver cancer prognosis.
The comparisons of the proposed HLPL and related work.
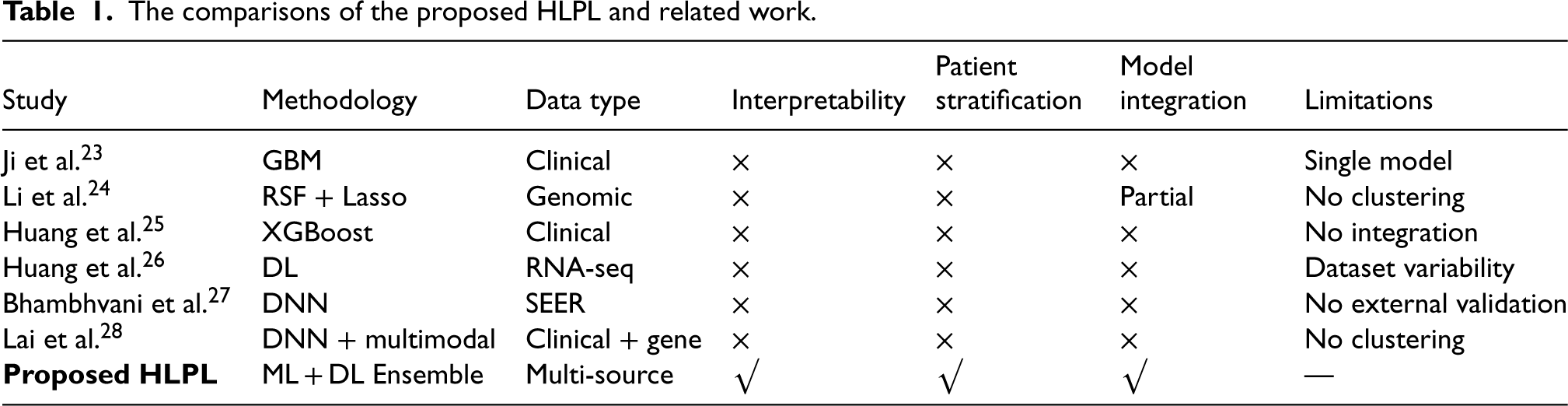
The comparisons of the proposed HLPL and related work.
This section describes the definitions of notations, assumptions, and constraints utilized in this study, along with the formulation of the problem being addressed.
System model and notation definitions
The objective of this study is to analyze and model the determinants of survival duration in liver cancer patients. A dataset of liver cancer patients is denoted as 
In addition to the dataset
Based on the above assumptions, several research hypotheses are formulated to guide the design of the proposed HLPL framework. Specifically, this study hypothesizes that clinical features are significantly associated with survival outcomes, that patient stratification can effectively reduce inter-patient heterogeneity, and that the integration of ML and DL models improves predictive performance. These hypotheses are grounded in prior clinical and methodological studies.
The objective of this study is to analyze and develop the best model, say 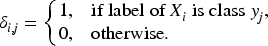
Similarly, let 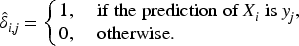
Consider applying the model M to predict the result for an input sample 


Let 


Assume that there are a total of r samples predicted by model M. Let 


Let 


Let 
The proposed HLPL is subject to several important constraints, which are presented as follows.
All features
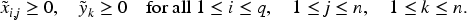
The survival time is categorized into z distinct classes, ensuring that the classification problem is well-defined. The number of classes is constrained to be a positive integer, where 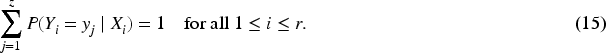
These constraints ensure that the data used in the model is valid and complete, and that the classification model produces interpretable and reliable results.
The primary objective of this study is to develop a predictive model, denoted as
Data preprocessing phase
This phase focuses on transforming the collected dataset to prepare it for model training. Let
The raw input data 
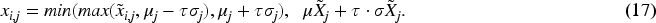
Otherwise, if the row is removed,
Missing values in 
The imputed value replaces the missing value in the dataset. That is,

This process ensures that all missing entries in
To ensure uniformity across features, each feature 
This transformation guarantees that each feature in
Categorical variables in 
Labels 
After applying all these transformations, the dataset
The Feature Engineering phase aims to identify the most relevant features for predicting the survival duration of liver cancer patients. Due to the presence of right-censored observations in survival data, traditional correlation-based metrics (e.g., Pearson or Spearman correlations) are not suitable, as they fail to account for censoring and may lead to biased feature selection. To address this issue, this phase employs univariate Cox proportional hazards regression, which explicitly models time-to-event data and properly incorporates censoring information, enabling a statistically sound assessment of feature relevance.
Following data preprocessing, let
To evaluate the individual prognostic value of each feature, a univariate Cox proportional hazards model
36
is fitted for each feature 
While the hazard function characterizes the relationship between the feature and survival risk, feature selection is performed based on the statistical significance of
After calculating the univariate Cox models for all features, the final set of important features, 
Where
It is important to note that this univariate Cox-based screening step focuses on identifying survival-relevant features rather than modeling complex nonlinear relationships. The modeling of nonlinear effects and higher-order feature interactions is handled in the subsequent ML stage. The resulting feature subset
Till now, the collected dataset has undergone preprocessing, and the most critical features have been identified. The selected feature set is:
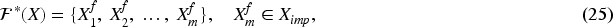
This phase aims to enhance both predictive accuracy and interpretability. Specifically, the Cox proportional hazards model is employed for feature refinement to obtain
Let D denote the output dataset from the Feature Engineering phase. D is a two-dimensional matrix represented as Equation (26).


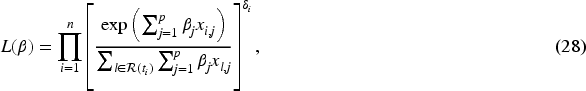

The hazard ratio 
To enhance interpretability, SHAP values
37
are computed for each feature in 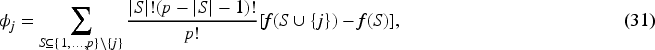
The final output from this phase is the SHAP values for each feature in
The integration of the Feature Engineering phase, Cox proportional hazards model, and SHAP values forms a coherent and interpretable pipeline for survival analysis. The Feature Engineering phase outputs a feature set
This workflow ensures a robust and transparent approach to predicting liver cancer patient survival, where both the statistical significance of features and their individual contributions to the prediction are clear. The combined model not only predicts survival outcomes but also provides insights into which features are most influential, thus supporting clinical decision-making. Thus, the Cox-SHAP module functions as an interpretable feature selection mechanism before model training, rather than a feature transformation step for downstream prediction models.
Unlike conventional clustering used purely for data partitioning, the goal of K-means in this study is to identify latent patient subgroups with distinct clinical characteristics and survival patterns. These clusters may implicitly correspond to clinically meaningful categories, such as differences in tumor stage, treatment modality, or liver function status.
This phase employs the K-means clustering algorithm to group patients based on the Cox-selected feature set
The input feature matrix 

Using these feature vectors, the K-means algorithm partitions the patients into k distinct clusters. The clustering process seeks to minimize the within-cluster sum of squares (WCSS),
38
where the goal is to assign each patient to a cluster such that the total distance between each patient's feature vector and the centroid of their respective cluster is minimized. The WCSS is mathematically expressed as Equation (34).


The K-means algorithm iteratively assigns each patient
Once the clustering process is complete, each patient is assigned a cluster label 
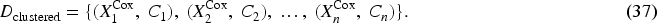
This enriched dataset integrates both the detailed clinical features and the cluster memberships, forming a comprehensive basis for the subsequent modeling phase. By including the cluster information
In the next phase, the predictive model is trained on the clustered dataset
Following the Pre-clustering phase, the dataset
This phase employs specific ML and DL algorithms to predict the survival duration 
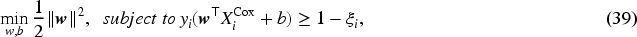
The Random Forest model aggregates predictions from multiple decision trees 
Gradient Boosting iteratively refines predictions by building models sequentially, each correcting the errors of the previous one, described as Equation (41).

The DL algorithm is a fully connected DNN designed to capture non-linear patterns in the high-dimensional clinical data, with activations at layer 

To capitalize on the complementary strengths of the ML and DL models, a model fusion strategy is implemented. The predictions from the ML model 
The dataset is split into training and testing subsets, with
The predictive model 
Upon completion of the training, the model's performance is evaluated by applying
The overall solution workflow of the proposed HLPL mechanism can be summarized in Table 2. This algorithm outlines the order in which equations are applied and the sequence of steps from raw data to final survival prediction.
The algorithm of the proposed HLPL.

The algorithm of the proposed HLPL.
This section focuses on assessing performance improvement of the proposed HLPL compared to traditional ML and DL approaches for liver cancer prediction. Conventional methods, such as Cox proportional hazards models, struggle with the complexities of high-dimensional and heterogeneous data, often leading to suboptimal results in predicting patient survival. Furthermore, while some ML models, such as Random Forest and Gradient Boosting, offer improved accuracy, they lack the robustness needed to address the diverse characteristics present within the patient population. The proposed HLPL leverages both ML and DL techniques synergistically, integrating K-means pre-clustering to account for population heterogeneity. By utilizing pre-clustering, HLPL segments patients into homogeneous groups before predictive modeling, allowing for more targeted and accurate predictions. Additionally, the system's ensemble model combines predictions from Support Vector Machines, Random Forests, and DNNs, leveraging the strengths of each to achieve higher prediction accuracy and reliability. The following sections provide an overview of the simulation environment, evaluation metrics, and a comparative analysis of simulation results between HLPL and baseline methods.
Simulation environmental parameters and dataset
Table 3 summarizes the simulation parameters used throughout this study. The experiment is conducted on a system running Windows 10, with Anaconda as the primary development platform. The hardware includes 16GB of RAM and an NVIDIA GeForce RTX 3060 Laptop GPU with 6GB of memory.
Experimental parameters.

Experimental parameters.
The dataset consists of 673 liver cancer patients collected between 2015 and 2022 from our institutional database. This single-center retrospective cohort includes patients with pathologically confirmed HCC. Inclusion criteria included histologically confirmed HCC, complete clinical and laboratory records, and follow-up ≥1 month. Exclusion criteria included missing survival data, prior liver transplantation, and concurrent malignancies other than HCC. The dataset includes 127 features across several domains. No genomic data was included in this study. Table 4 summarizes patient demographics, tumor characteristics, and survival event rates.
Experimental parameters.

The dataset was randomly split into training (70%), validation (15%), and testing (15%) sets. All preprocessing, feature selection, and K-means clustering were applied only to the training set to avoid data leakage, and learned transformations were applied to the validation and test sets without re-fitting. Five-fold cross-validation was applied on the training set for hyperparameter tuning, while the test set was reserved for final unbiased evaluation. Class imbalance was addressed by applying class weights during training, while the test set remained unchanged.
To evaluate the impact of training dataset size and clustering on model performance, Figures 1, 2, and 3 illustrate the performance of the proposed HLPL framework in terms of Accuracy, Precision, and F1-score by varying the ratio of training data and the number of clusters, respectively. The ratio of training data increases progressively, while the number of clusters is adjusted to evaluate its impact on model performance. As shown in Figures 1–3, all metrics exhibit a consistent upward trend as the training data size increases. This is because a larger training dataset enables the model to learn more comprehensive and representative patterns of patient survival characteristics, thereby improving predictive performance and generalization ability.
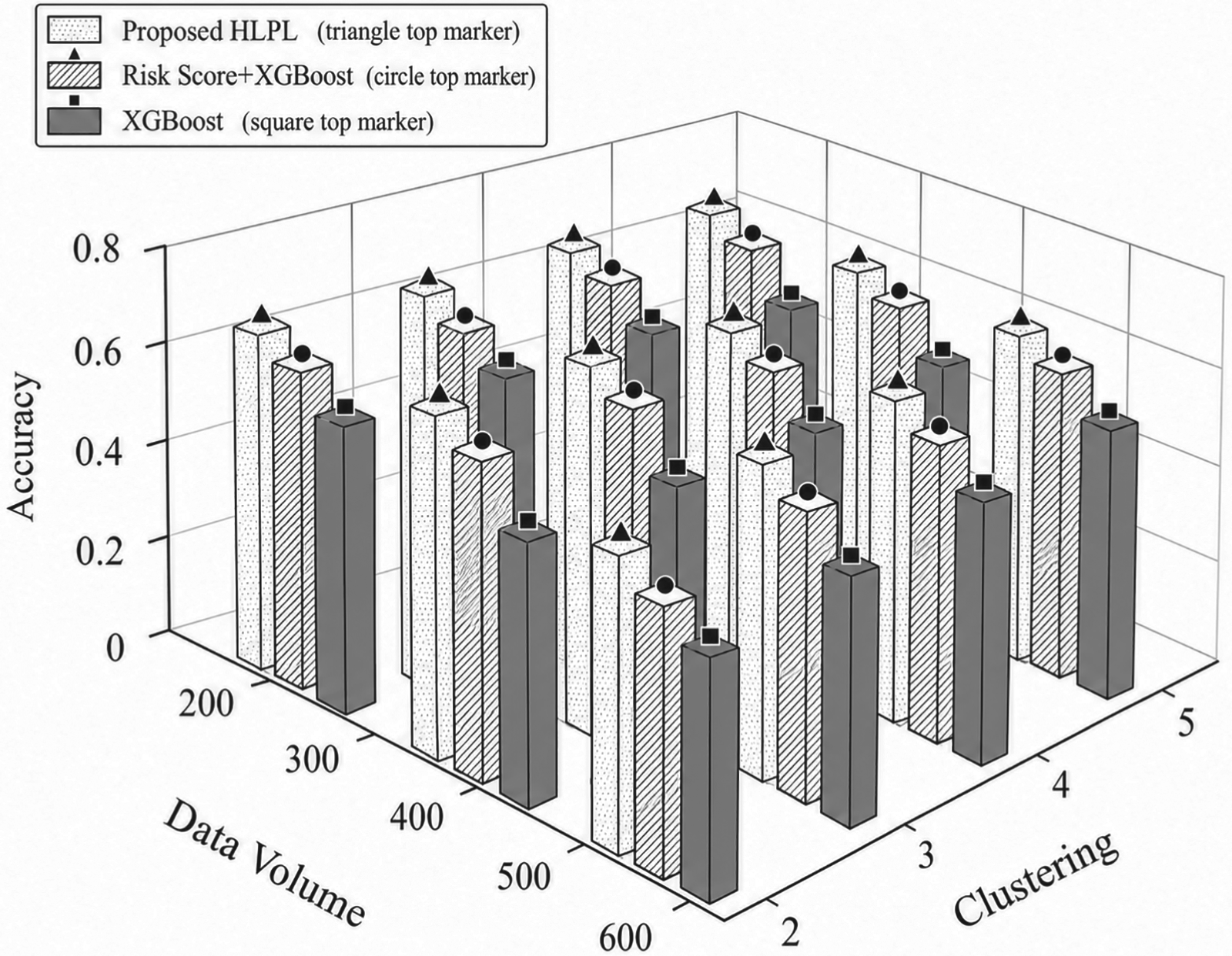
Impact of data volume and clustering on accuracy.
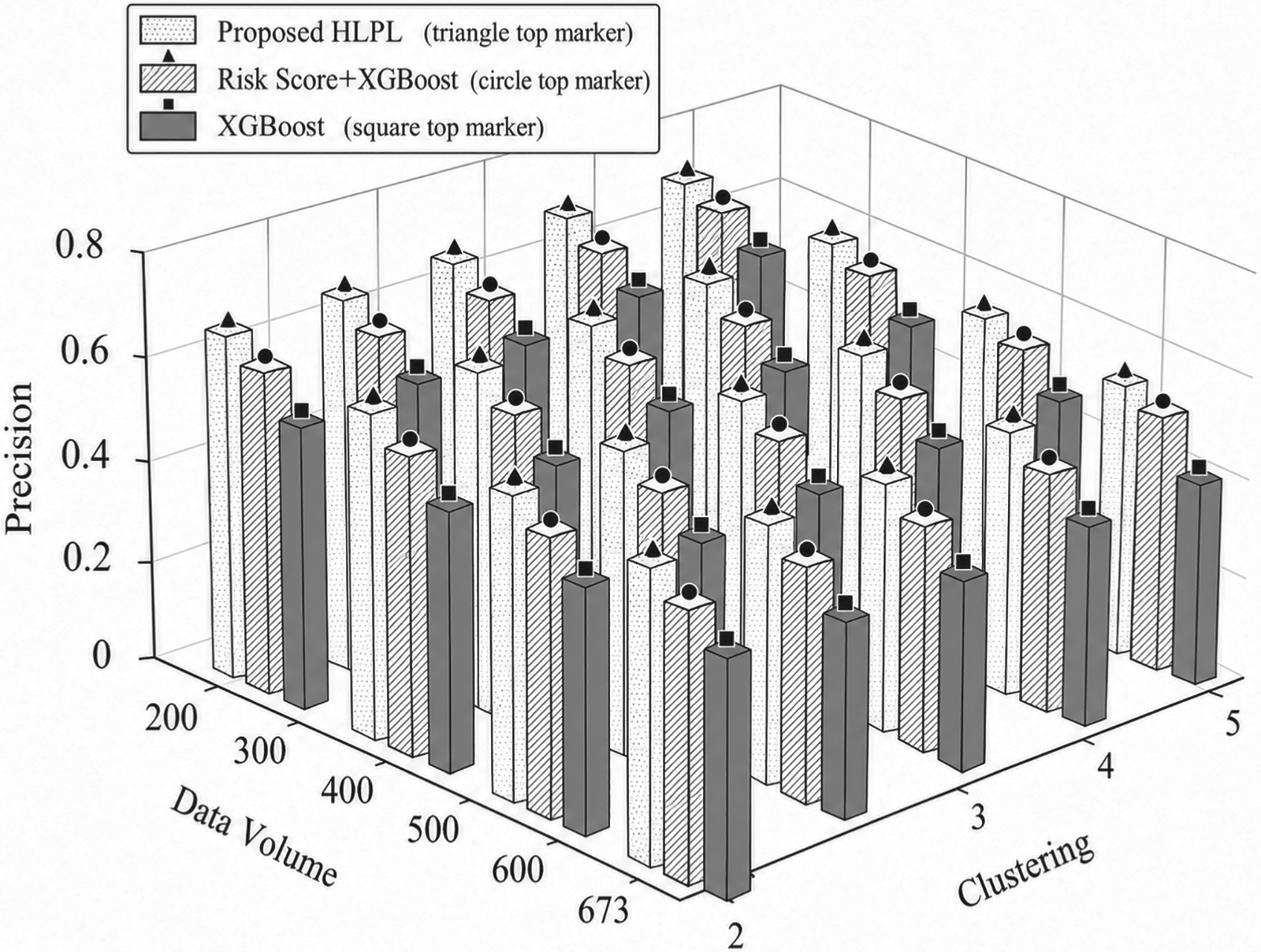
Impact of data volume and clustering on precision.
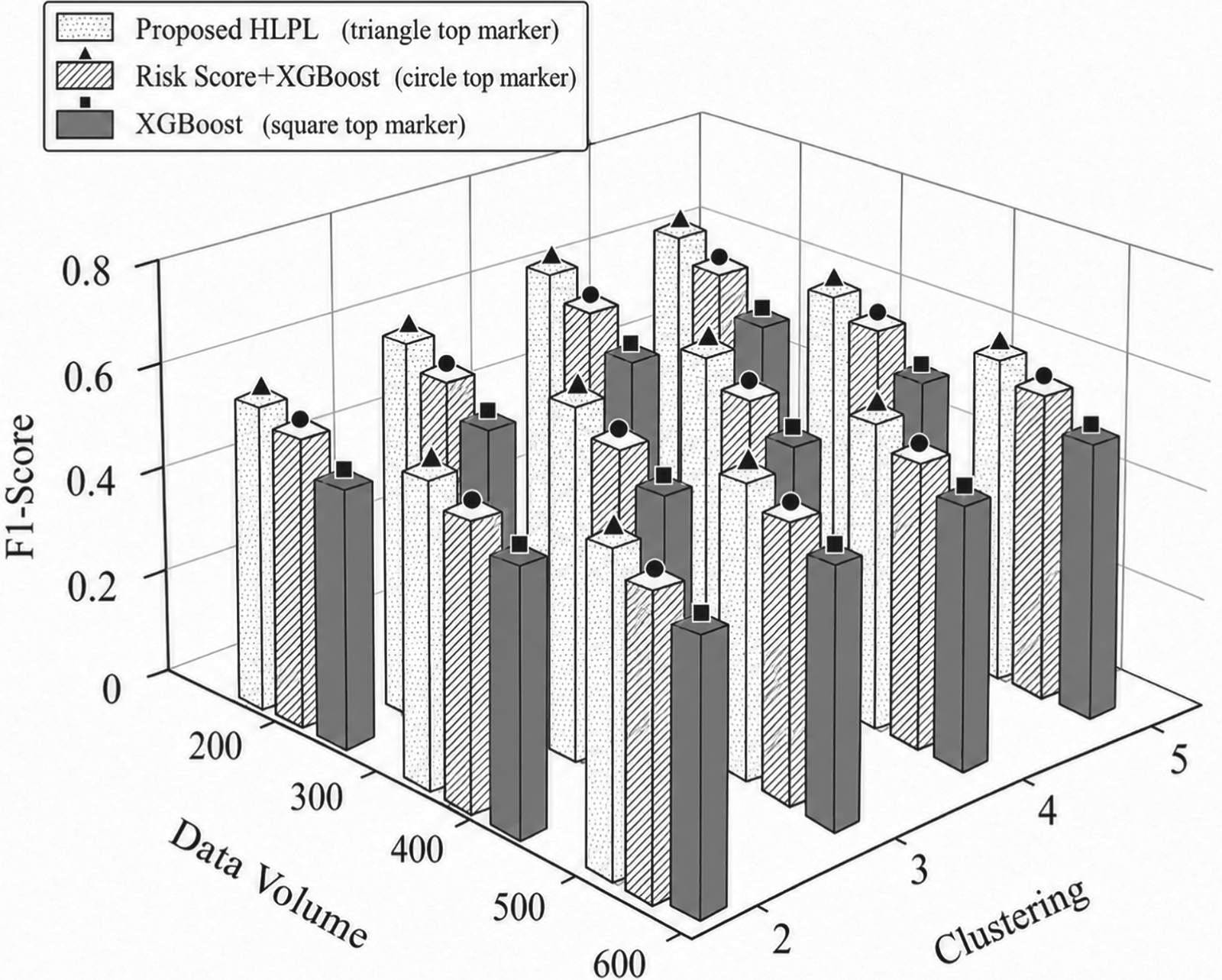
Impact of data volume and clustering on F1-score.
In addition, increasing the number of clusters further enhances Precision and F1-score. The reason is that clustering partitions patients into more homogeneous subgroups, reducing inter-patient heterogeneity and allowing the model to learn subgroup-specific patterns more effectively. This leads to more accurate classification and better balance between precision and recall. Overall, the proposed HLPL framework achieves improved performance across all evaluation metrics under larger data volumes and appropriate clustering settings. This superior performance can be attributed to the integration of clustering and ensemble learning, which jointly enhances the model's ability to capture complex clinical patterns and improve robustness in multi-class survival prediction.
Figures 4, 5, and 6 illustrate the survival distributions of liver cancer patients under different surgical interventions, including no resection, tumor ablation, and resection surgery, respectively. As shown in Figures 4–6, survival outcomes vary significantly across treatment types. Patients without resection show the poorest prognosis, with a large proportion in the shortest survival category, due to the lack of effective tumor control. In contrast, tumor ablation improves short- and mid-term survival, as it can effectively suppress tumor progression in selected patients. Among all groups, resection surgery achieves the best long-term survival outcomes, since complete tumor removal reduces disease burden and improves prognosis. Overall, these results indicate that surgical intervention, particularly resection, plays a critical role in improving survival outcomes, which is consistent with clinical observations.
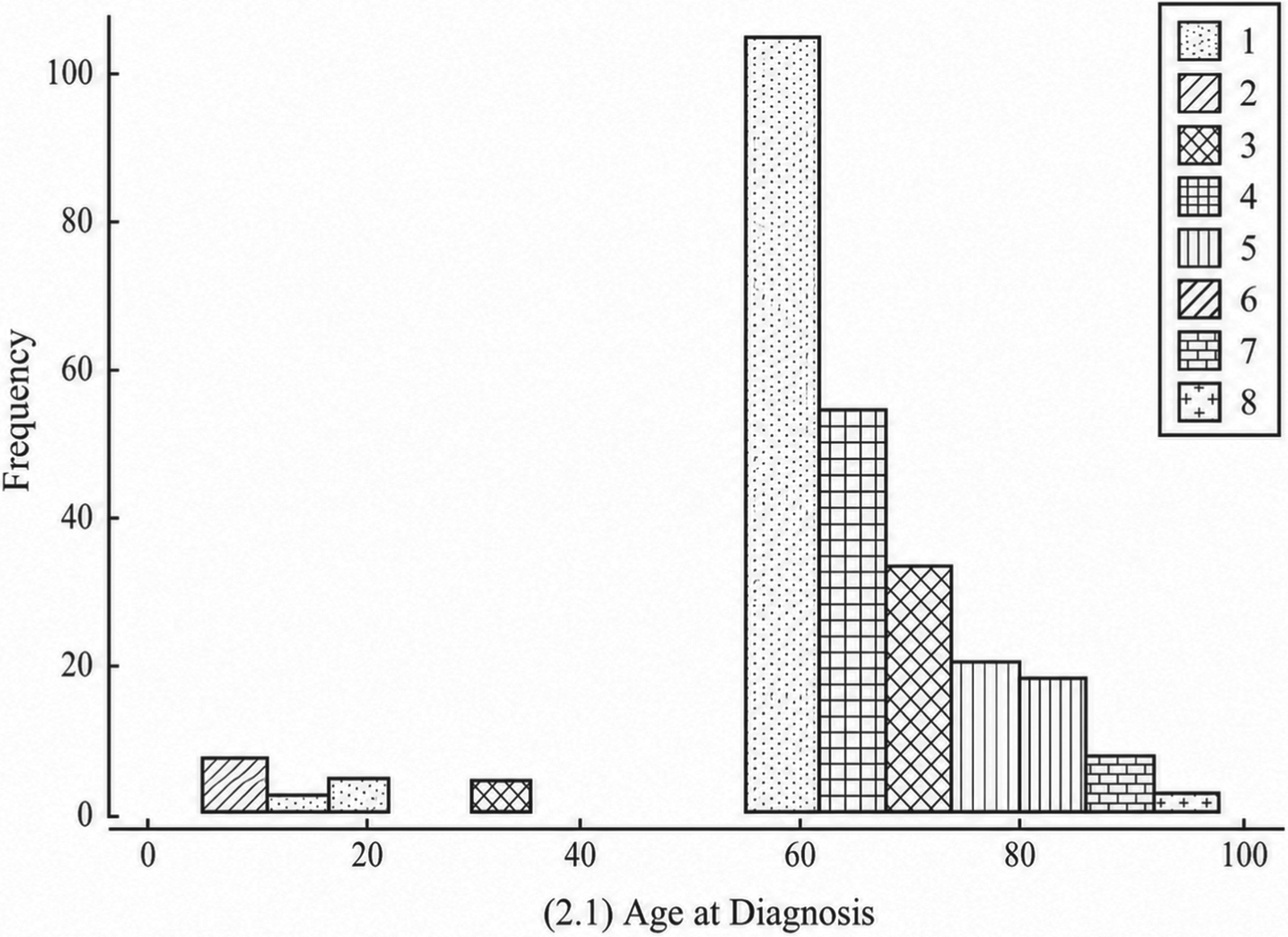
Survival distribution for patients without primary site resection.
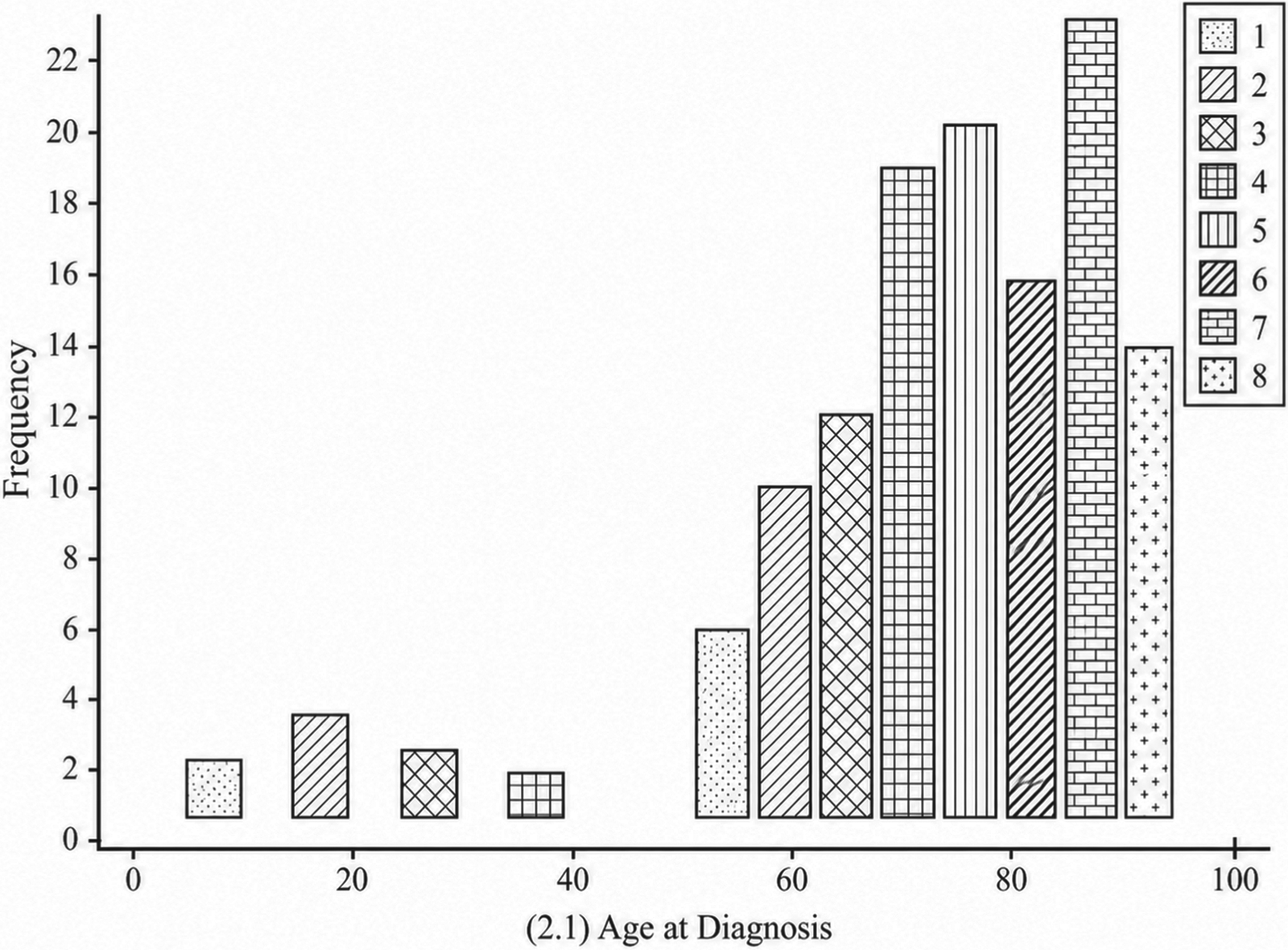
Survival distribution for patients with tumor ablation.
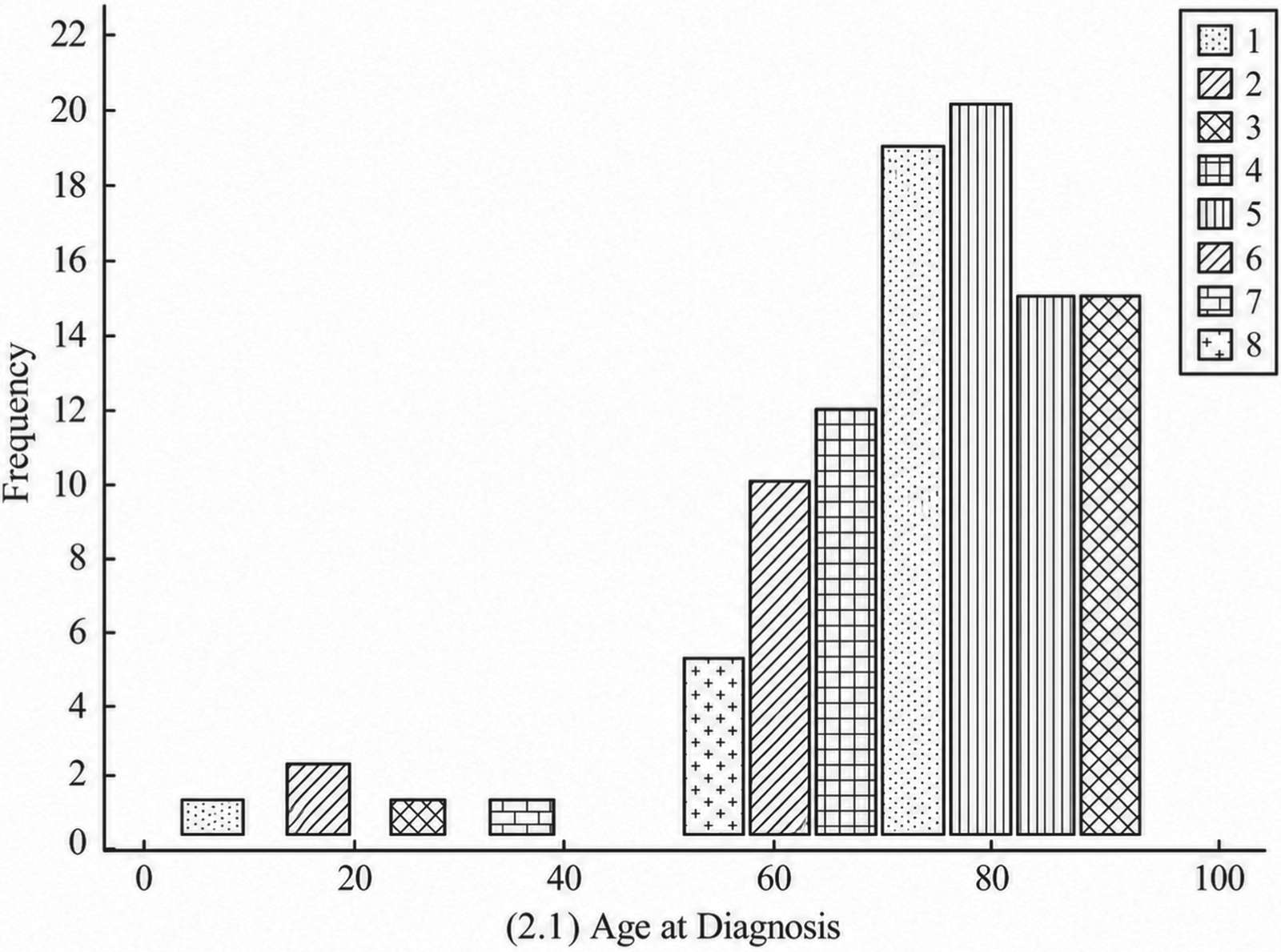
Survival distribution for patients with resection surgery.
Figures 7, 8, and 9 compare the performance of the proposed HLPL framework in terms of Accuracy, Precision, and F1-score by varying the training data size across different surgical groups. As shown in Figures 7–9, all metrics increase with the size of training data, as larger datasets enable the model to learn more representative survival patterns and improve generalization. In addition, performance differs across surgical types, with resection patients achieving the best results, followed by tumor ablation, while non-surgical patients show lower performance. This is because surgical groups exhibit clearer survival patterns, making them easier to model, whereas non-surgical cases are more heterogeneous. Overall, the proposed HLPL framework demonstrates robust performance across different treatment groups, with improved accuracy and balance as data volume increases. This performance gain is attributed to the model's ability to integrate heterogeneous clinical information and leverage both ML and DL techniques, enabling accurate and stable survival prediction across diverse clinical scenarios.
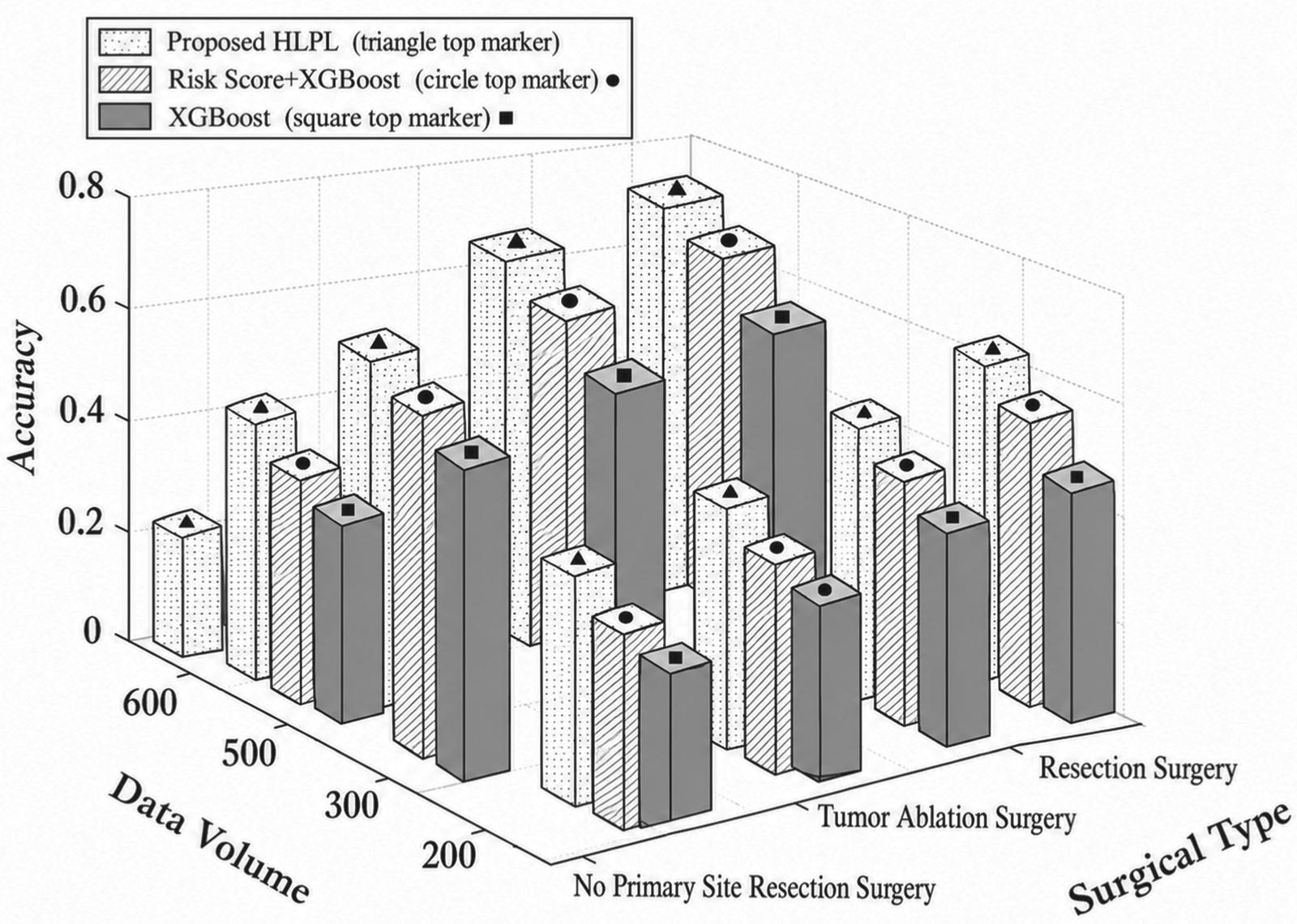
Impact of data volume and surgical type on accuracy.
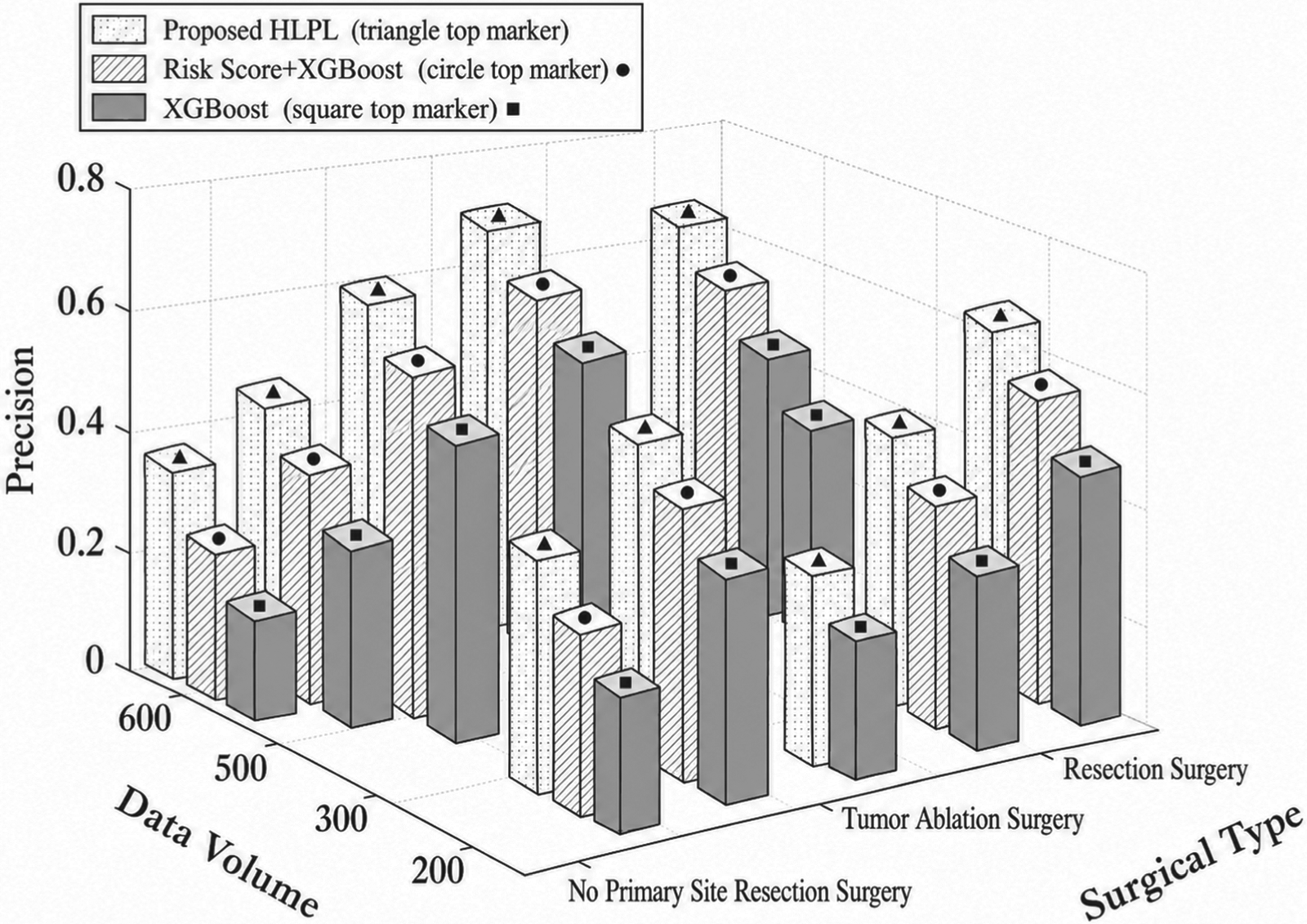
Impact of data volume and surgical type on precision.
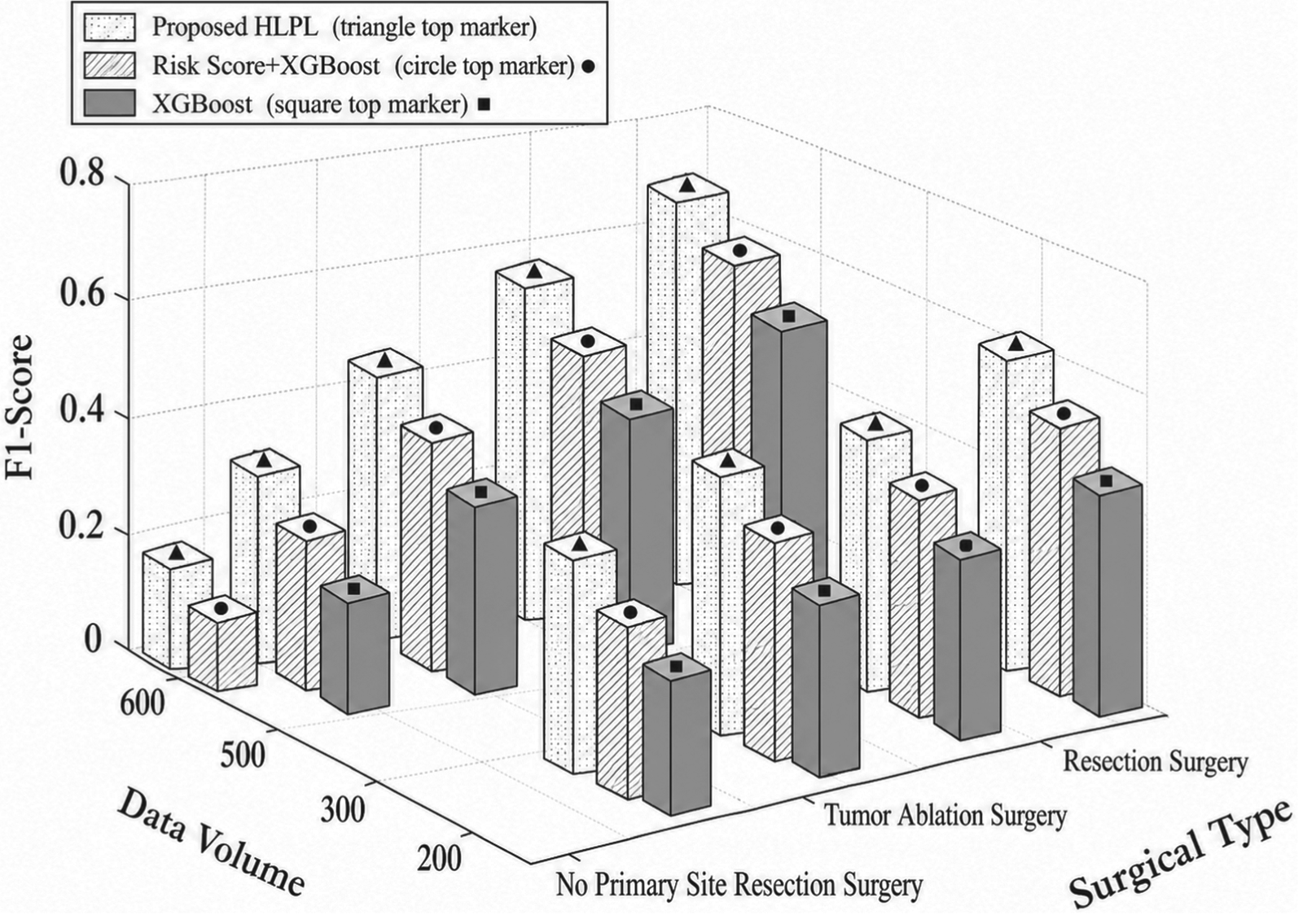
Impact of data volume and surgical type on F1-score.
To validate the clinical relevance of clustering, Figure 10 presents the relationship between the number of clusters and the Silhouette Score, a standard measure of clustering quality. The score stabilizes at four clusters, indicating an optimal balance between intra-cluster cohesion and inter-cluster separation. This clustering strategy improves the model's ability to capture patient heterogeneity by grouping individuals into more homogeneous subpopulations, enabling more accurate and personalized survival predictions. Furthermore, distinct survival trends are observed across clusters, suggesting that the clustering process captures meaningful prognostic stratification rather than merely performing mathematical partitioning.
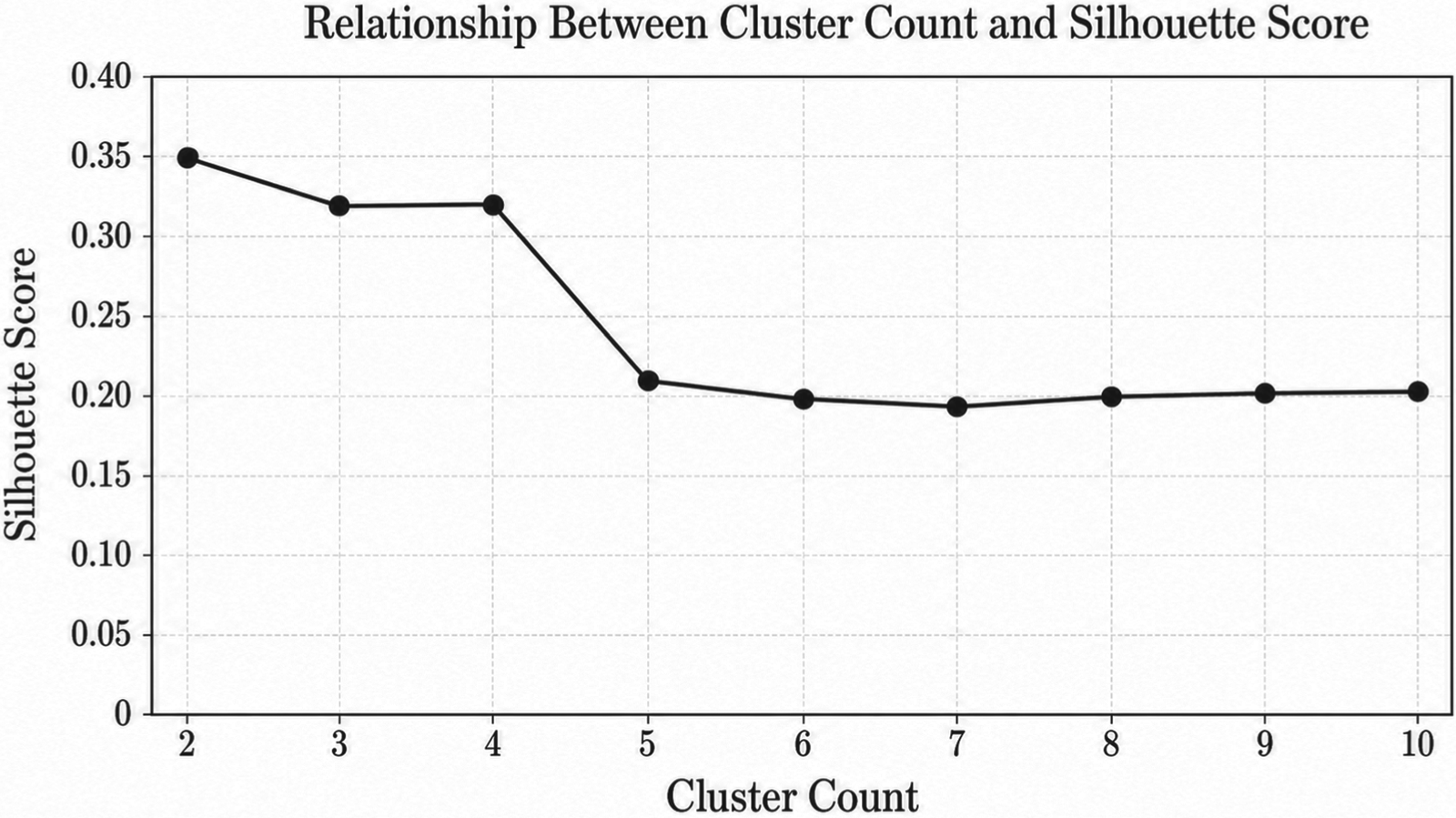
Relationship between cluster count and silhouette score.
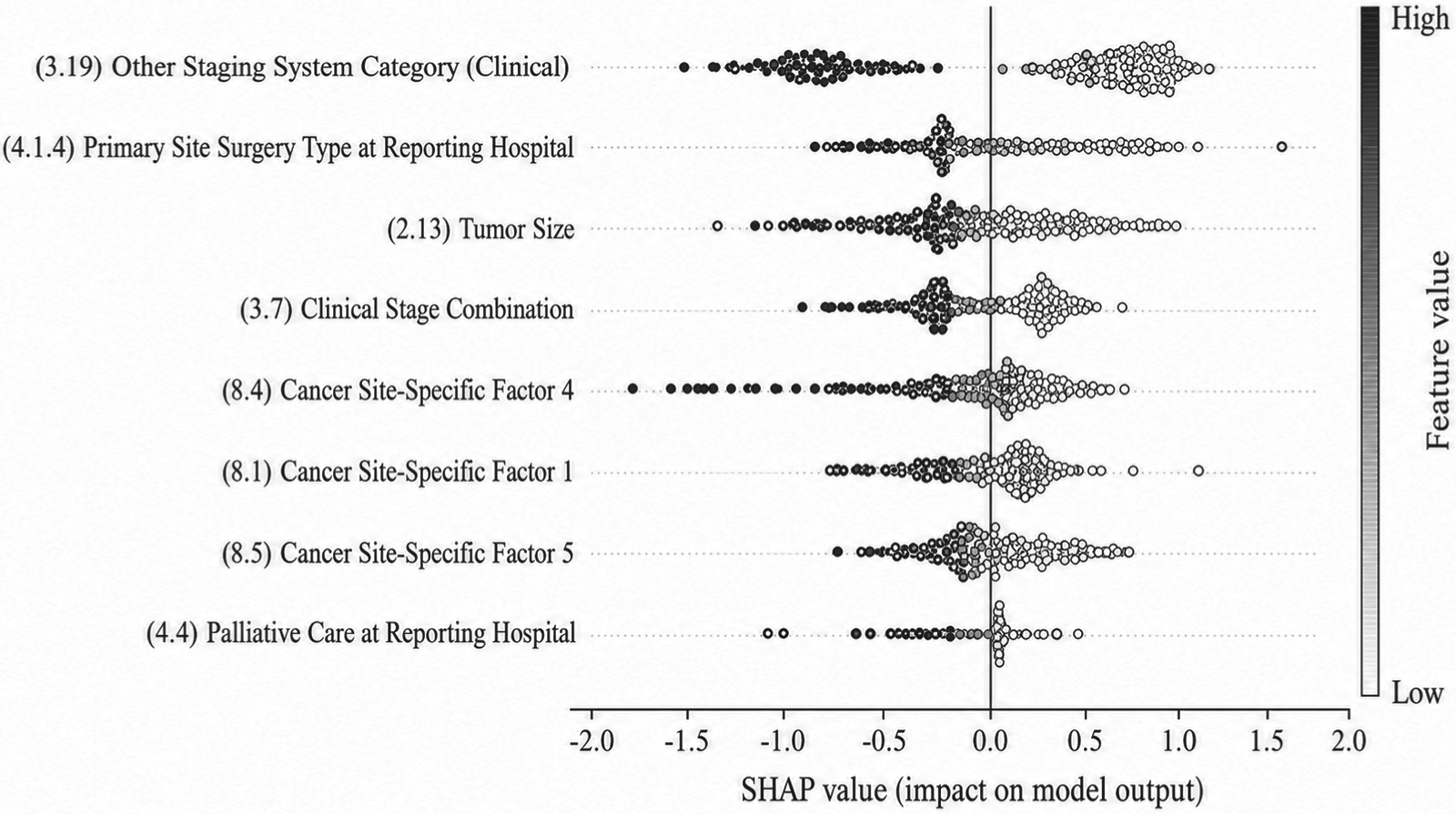
Feature importance analysis using random forest base model.
The significance of clinical features was assessed using SHAP values across three base models: Random Forest, Gradient Boosting, and XGBoost. SHAP values provide an interpretable measure of each feature's contribution to model predictions, enhancing both clinical insight and model transparency. Across all models, clinical cancer stage, primary site surgery type, tumor size, AFP level, and liver function indicators consistently emerged as the most influential predictors. In Figure 11 (Random Forest), clinical cancer stage and primary site surgery ranked highest across patients, indicating strong associations with survival outcomes. Figures 12 and 13 (Gradient Boosting and XGBoost) confirmed these findings, demonstrating the robustness of feature importance across different models. Clinically, these top features correspond to well-established prognostic factors in liver cancer: higher cancer stages are associated with poorer survival; curative surgery improves outcomes; larger tumors and elevated AFP levels indicate higher risk; and abnormal liver function reflects compromised hepatic reserve, which affects both prognosis and treatment tolerance. Moreover, SHAP analysis reveals potential nonlinear effects and interactions among features—for instance, the impact of AFP on survival may depend on tumor size or liver function status. These interpretable insights provide clinicians with actionable information for individualized risk assessment, prognostic refinement, and treatment planning.
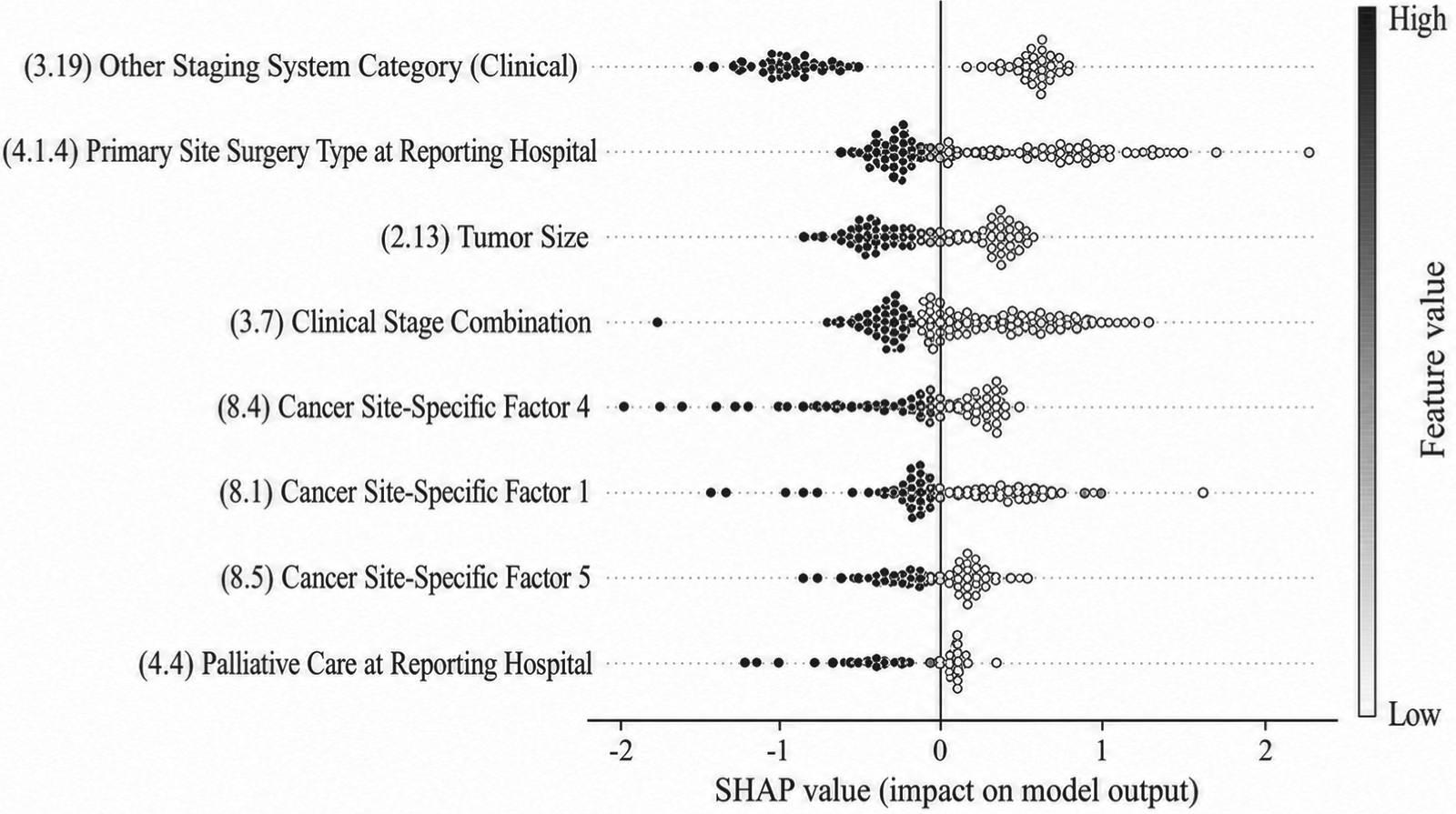
Feature importance analysis using gradient boosting base model.
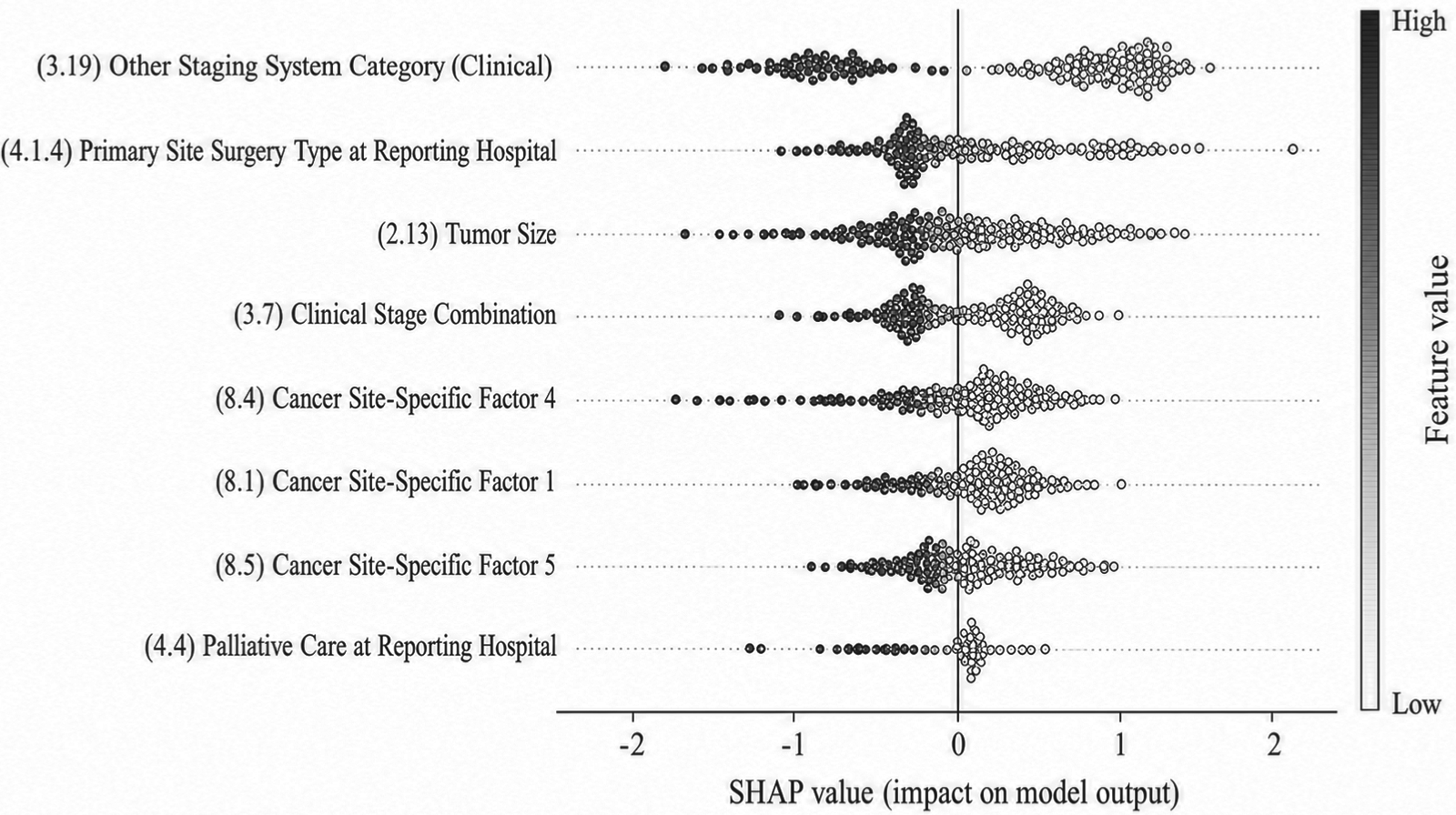
Feature importance analysis using XGBoost base model.
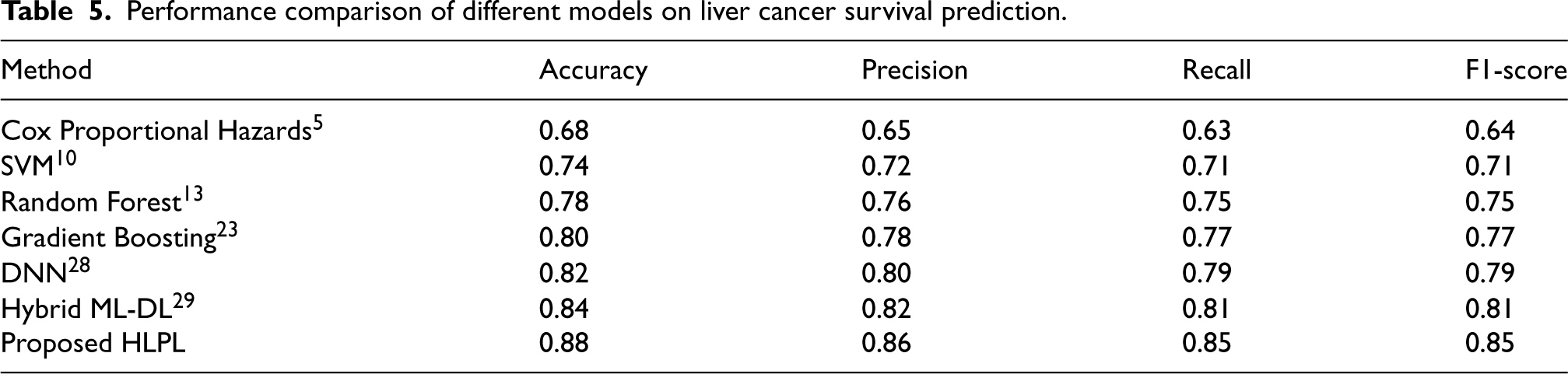
Table 5 compares the performance of the proposed HLPL framework with several baseline methods for liver cancer survival prediction. Traditional statistical models, such as the Cox proportional hazards model, 5 achieve relatively low performance due to assumptions like proportional hazards and limited ability to capture nonlinear relationships. Classical ML methods (SVM, 10 Random Forest 13 ) improve performance, while ensemble methods like Gradient Boosting 23 further enhance results. DNN 28 achieves higher accuracy and F1-score, and the hybrid ML-DL model 29 improves further. Notably, the proposed HLPL framework attains the best performance across all metrics. This superior performance can be attributed to Cox-SHAP feature evaluation, pre-clustering to address patient heterogeneity, and ensemble integration of ML and DL models, which together enhance predictive accuracy and robustness.
Performance comparison of different models on liver cancer survival prediction.
This study presents HLPL, a comprehensive survival analysis framework that accurately predicts the survival duration of liver cancer patients. By combining rigorous data preprocessing and feature engineering, the framework ensures data quality and model robustness. The integration of the Cox proportional hazards model with SHAP value analysis provides interpretable insights into key risk factors, such as tumor stage, liver function, and surgical interventions, linking model predictions directly to underlying physiological and clinical characteristics. K-means clustering captures latent patient subgroups with distinct survival profiles, reflecting the heterogeneity in tumor biology and treatment responses. The combination of ML and DL models achieves high predictive accuracy while maintaining robustness, highlighting the potential of data-driven approaches to complement clinical decision-making.
Despite these promising results, several limitations should be noted. The dataset is derived from a single institution, which may limit population diversity and introduce potential biases related to local clinical practices, thereby affecting model generalizability. In addition, external validation on independent cohorts has not yet been conducted, limiting the assessment of model robustness. Although the HLPL framework is designed to be flexible and extensible, its generalization to other clinical scenarios requires further validation. Additionally, the number of clusters is determined empirically, which may influence model stability, and the current formulation does not fully capture the temporal dynamics of survival processes.
Future work will address these limitations by performing multi-center validation to assess robustness and generalizability, integrating multimodal data such as imaging and genomics to improve predictive performance and interpretability, and developing more advanced survival modeling techniques and real-time clinical decision support systems for practical deployment.
Footnotes
Ethics approval and consent to participate
Not Applicable for the study.
Author contributions
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The datasets generated during the current study are not publicly available but are available from the corresponding author.