
Abstract
With the rapid development of maritime commerce, the complexity of ship operation environments continues to grow, so that it is crutial for ship designers to make accurate forecasting of ship performance under various sea conditions. However, there exist the following challenges in ship performance evaluation and optimization. The first challenge is the computational overhead and slow response of numerical simulations based on Computational Fluid Dynamics (CFD), and the second is the inability of traditional machine learning to achieve the computational accuracy of numerical simulations. To address these issues, this paper proposes an online surrogate model, called Increformer, for ship performance prediction. The Increformer leverages continuous self-attention mechanisms to explore the temporal dependencies between feature variables and employs continuous normalization mechanisms to handle non-stationary data issues. In addition, in order to improve prediction accuracy by the model, we employ an incremental training strategy based on elastic weight consolidation to acquire new knowledge from data streams. Experiments are conducted by using historical performance data from various types of vessels including KCS, Wigley-III, and C60. The results demonstrate that the Increformer model effectively captures the temporal information and inter-dimensional correlations in the data, with the accuracy of ship performance prediction enhanced significantly. Furthermore, ablation experiments are also carried out to assess the effectiveness and necessity of the continuous normalization mechanism, continuous attention mechanism, and incremental training strategy for the Increformer model. The findings validate the accuracy and universality of the proposed model. It is also shown that the Increformer model adeptly captures trends and fluctuations in ship sequence data and thus provides a reliable solution for ship performance prediction.
Introduction
With the continuous development of computing technology, simulation-based design (SBD)1,2 become the mainstream method for optimal design of ships. It effectively combine numerical methods of computational fluid dynamics (CFD) with hull geometry reconstruction techniques, aiming to achieve optimal sailing performance under given constraints. As such, SBD has essetntially promoted the development of modern ship hull optimization methods, driving the transition of ship design methodologies from traditional experience-based approaches to data-driven intelligent design methods.
CFD technology is the main tool in the SBD method. However, when used for actual optimal ship hull design, it also encounters problem of high computational costs, which thus are detrimental to ship design work. Therefore, it is of great significance to ship design to develope methods of ship performance prediction and evaluation with lower computational requirements and higher efficiency, based on physical experimental data and CFD simulation data. To this end, many scholars have introduced surrogate modeling methods to replace CFD methods.
A surrogate model refers to a fast and non-linear response model built based on existing ship performance data. It can effectively reduce the computational costs required for CFD numerical simulations during ship hull design and performance test. 1 By employing suitable machine learning models, a surrogate model with high prediction efficiency and accuracy can be constructed to precisely predict various sub-performances and the overall performance of a ship during the design process, and thus can provide a objective function for ship performance optimization.2–5
It is certainly helpful for for efficient ship design to employ machine learning-based surrogate models to predict ship performance. However, traditional machine learning or deep learning models are generally used for static scenarios and cannot adapt or expand their peridction capabilities over time. Since ship type data is often not obtained and imported to the model all at once, the model should be iterated based on the already trained model with newly acquired data. Besides, due to the limitation of storage and computation capacities, the iterative updating of the model generally does not involve old data.6–9 Hence, incremental learning methods10–12 can be employed for updating the surrogate model data streams and thus can enable the model to perform ship performance prediction based on new ship data. This is especially important for evaluating ship hydrodynamic performance, because it is not only related to the ship's inherent characteristics but also is influenced by the continuous flow of external information during navigation. Thus, the surrogate model needs to learn and remember relevant knowledge from the dynamic data distribution so that ship performance can be effectively predicted. Taking ship rolling motion as an example, the effectiveness of ship anti-rolling devices typically depends on the ship's current motion state. If short-term predictions of future rolling angles and other motion states can be achieved, this predicted information can be used to optimize the control strategy of the ship's anti-rolling devices. By adjusting the anti-rolling devices in advance, the ship's rolling amplitude can be controlled more precisely, effectively reducing rolling during navigation and thus improving the ship's seaworthiness and safety.
In summary, traditional physical ship model testing involves a complex design process and yields limited data, while CFD numerical simulation methods are computationally intensive and inefficient, and cannot provide timely responses. Furthermore, traditional machine learning methods used to build surrogate models fail to dynamically adapt to real-world scenarios for real-time prediction of ship performance. Therefore, it is of great significance to develop efficient and effective intelligent surrogate models for ship performance prediction by using incremental learning methods. However, there are no such kind of researches in this area.
This work aims to construct an incremental learning based on surrogated model for accurat and real-time ship hydrodynamic performance prediction. To this end, we design an online time series prediction model called Increformer and employ an incremental learning for model training . The novelty of our method is that its combines an improved EWC incremental learning algorithm and the Transformer deep learning framework, aiming to provide more accurate hydrodynamic performance predictions during ship navigation. Sepcificaly, the novelty and the contributions of this work are as follows.
First, the Increformer model, inspired by the encoder-decoder structure of the Transformer model, is an architecture that has achieved tremendous success in the field of natural language processing. However, we have made significant improvements on this model, particularly in the attention mechanism and the normalization methods of the network layers. With these improvements, the Increformer model can not only handle long-range dependencies in ship navigation data but also can adapt to constantly changing marine environments and ship operating conditions, thereby enabling effective incremental learning.
Second, in terms of the attention mechanism, we adopt a continuous multi-head attention mechanism to enable the model to dynamically adjust its focus based on the characteristics of the input data. This allows Increformer to accurately capture the motion state of the ship, which is measured by key performance indicators such as roll, pitch, and heave, regardless of whether the sea conditions are calm or rough. Simultaneously, the model can also predict the resistance encountered by the ship in waves, which is crucial for evaluating the ship's energy efficiency and structural safety.
Third, to further improve the model's performance, we also optimize the normalization method of the network layers. Normalization is a common technique in deep learning, which helps to accelerate training speed and improve the model's generalization ability. In our model, the improved normalization method ensures that the model maintains a stable learning speed and prediction accuracy when new data continuously receives.
Fourth, we incorporate Increformer with an improved Elastic Weight Consolidation algorithm to enable effective incremental training, so that the model is allowed to continuously update and maintain prediction accuracy as new data arrives.
Finally, we conduct experiments on historical performance data of various ship types, including container ships, cargo ships, and tankers. And through comparative analysis with other incremental learning and deep learning baseline models, we verify the effectiveness and practical application value of the Increformer model to ship hydrodynamic performance prediction.
Related work
Batch learning methods
With the rapid development of artificial intelligence technology, machine learning methods, such as neural networks and support vector machines, have shown promising applications prospects in ship performance forecasting. Recently, researchers have begun to explore applying surrogate models based on m-achine learning in the optimization design of ship types. In order to address the high cost of CFD (Computational Fluid Dynamics) calculations, Peri 1 studied the application of surrogate models, such as response surface models, variable precision models, Kriging models, and radial basis function models, in the optimization design of ship types. Pedersen et al. 2 used a neural network model to predict propulsive power based on actual ship data. In addition, there has been extensive research on performance prediction of ships in waves, for example, forecast of the rolling motion and trajectory of ships during navigation. Hamid et al. 3 optimized the underwater profile parameters of hydrofoils by using neural networks and response surface methods. Petersen et al. 4 established a functional relationship between ship types and actual ship performance by using artificial neural networks and Gaussian process models. Babadi et al. 5 employed a BP (Backpropagation) neural network to investigate the impact of the waterline face coefficient on seakeeping performance. Wang et al. 6 proposed a ship heading time series prediction method based on the structure and algorithm of the backpropagation wavelet neural network. Tang et al., 7 to address the issue of decreased control performance due to time delays in wave compensation control systems, studied time series analysis modeling methods such as AR (Autoregressive), ARMA (Autoregressive Moving Average), and ARIMA (Autoregressive Integrated Moving Average). Ferrandis et al. 8 trained a recurrent neural network (RNN) to predict the pitch, heave, and roll motions of ships. Li et al. 9 proposed a short-term roll motion prediction model based on the convolutional long short-term memory network and attention mechanism. Xu et al. 13 proposed an online prediction method based on the automatically moving grid search least squares support vector machine. Guan et al. 14 proposed a ship roll motion prediction method based on the extreme learning machine. In, 15 Yin et al. combined the discrete wavelet transform method with the variable structure radial basis function network for the prediction of ship roll motion. Hou et al. 16 used a non-parametric identification method combined with the random decrement technique and support vector regression to predict the nonlinear roll motion of ships at sea. Wei et al. 17 proposed an integrated multi-step forecasting model composed of adaptive quadratic decomposition, multi-input multi-output strategy deep belief network, multi-objective optimization, and adaptive error correction.
Incremental learning methods
The different models and methods in the above-mentioned work are modeled and trained through a large amount of historical data to achieve higher prediction accuracy. However, these studies have focused on the setting of batch learning, which requires the whole training dataset to be a priori. This means that the relationship between input and output always remains static. However, when the data stream gradually arrives, the data distribution may change over time and thus the model's prediction accuracy decreases. Training a model from scratch can be time-consuming, and historical data can be difficult to obtain due to issues such as privacy and security. Therefore, it is particularly important to employ incremental learning to update the model in real time. However, the problem of catastrophic forgetting can easily occur in this case. In other words, training the model on a new data set can cause the model's performance on the old dataset to deteriorate significantly. The solution to this problem may fall into the “stability-plasticity” dilemma, that is, how to learn the knowledge of new data while maintaining the prediction accuracy of old data. There are three main paradigms to overcome this problem in the field of incremental learning: regularization, replay, and parameter isolation. For example, elastic weight consolidation (EWC) 10 algorithm is a regularization method; experience replay (ER) 11 and dark experience replay (DER++) 12 are based on the replay mechanism; Packnet is a representative parameter isolation 18 algorithm. However, current research on incremental learning mainly focuses on incremental tasks, and there is a lack of in-depth research in the field of regression prediction.
Wang 19 proposed to combine extreme learning machine (ELM) with incremental training methods to achieve integrated online learning. In this method, extreme learning machine with kernels(ELMK) is used as a base model. In, 20 an incremental learning algorithm with dynamically weighting ensemble learning(DWE-IL) was proposed. This algorithm dynamically updates the weights of the model parameters, making the model have better generalization performance. However, the differences between the errors of different models in the ensemble may increase over time. In addition to ensemble learning, some researchers proposed to modify the network structure of the deep learning models to adapt the models to online learning scenarios. Wang. 21 proposed an incremental ensemble LSTM model (IncLSTM), which achieves incremental prediction by optimizing the LSTM network structure. Woo 22 used the temporal convolutional network (TCN) as the backbone and proposed an online-TCN model, which can maintain the prediction accuracy of time series data while performing incremental updates. Huang 23 employed Bayesian estimation to improve the transformer model, making the model more suitable for processing streaming data.
Recent studies on time series forecasting have mainly focused on improving model architectures and representation learning for long sequences. Chen et al. 24 provide a comprehensive survey of deep learning methods for long-sequence forecasting, highlighting the trend toward attention-based and transformer-style models. Wang et al. 25 further benchmark a wide range of deep time series models, showing that scalability and generalization remain key challenges. Zeng et al. 26 systematically analyze the effectiveness of transformers for time series forecasting, indicating that architectural inductive bias is often more critical than model complexity. Qiu et al. 27 propose a dual clustering framework to enhance multivariate forecasting, reflecting a recent trend of exploiting latent structure and correlations across variables. In parallel, incremental and continual learning methods have gained attention to handle evolving data distributions. Lopez-Paz & Ranzato 28 propose Gradient Episodic Memory (GEM), which leverages episodic memory to maintain performance on past tasks. Chaudhry et al. 29 introduce A-GEM, an efficient approach for lifelong learning that reduces forgetting via gradient projection. Zeng et al. 30 explore context-dependent continual learning in neural networks, highlighting mechanisms to preserve previously learned knowledge while adapting to new tasks.
Time series forecasting is increasingly applied through diverse and adaptive architectures to address distribution shifts and complex temporal dependencies. 31 At the same time, multimodal integration and large pre-trained models enable applications that jointly process time series and textual data, supporting more flexible and intelligent analysis. 32 Additionally, hybrid models combined with transfer learning demonstrate strong effectiveness in real-time prediction tasks within complex systems. 33 Overall, these developments highlight the broad applicability of time series forecasting in handling dynamic, multimodal, and real-world scenarios. However, there are no reported studies on the application of incremental learning to surrogate models for ship performance prediction.
Methodology
In this work, we propose a method of ship hydrodynamic prediction based on an Incremental Transformer (Increformer). Increformer is a time-series prediction framework that combines deep learning with incremental learning. The model is based on the Transformer. The input encoding module is used to extract temporal features and obtain the input vector of the encoder. The encoder and decoder use a continuous attention mechanism that is more suitable for incremental scenarios. At the same time, the continuous normalization mechanism replaces layer normalization. The encoder extracts features from the input time series, and the decoder uses the extracted feature information to predict the time-series data, which are then fed into a linear fully connected layer to obtain the final prediction output. In addition, the training framework updates the model through an improved elastic weight consolidation algorithm called TS-EWC, enabling the model to continuously learn new knowledge and enhance forecasting accuracy. The framework of the Increformer for time series data forecasting is shown in Figure 1.
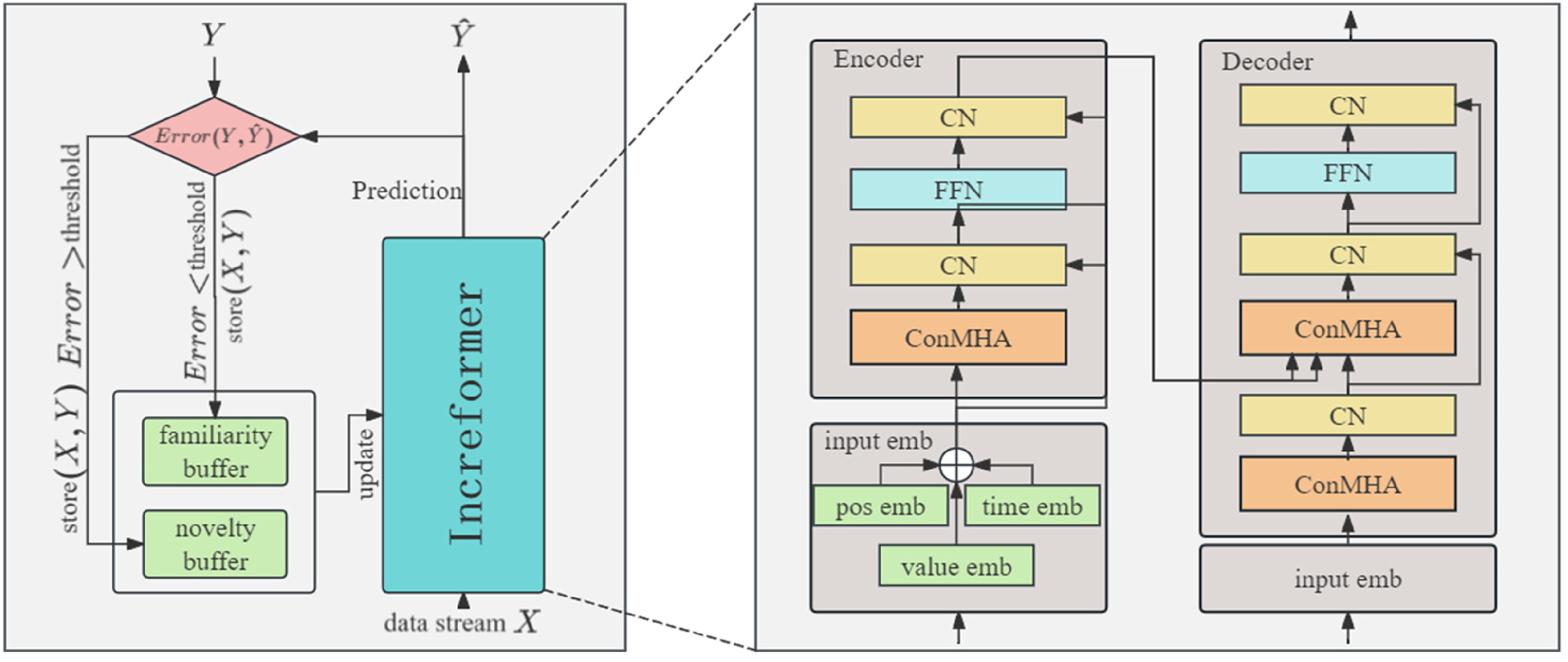
The model structure of increformer.
The overall workflow of the proposed framework can be summarized as follows. The input embedding module maps raw hydrodynamic variables and timestamp information into a common feature space. The encoder-decoder backbone then models temporal dependencies and cross-variable interactions through continual multi-head attention. Continual normalization stabilizes hidden representations when the statistics of the incoming stream change, and TS-EWC constrains parameter updates when the novelty buffer triggers online retraining. In this way, feature extraction, statistical stabilization, and knowledge retention are handled within one unified online framework.
The input embedding in the model use settings like Informer,
34
and it includes three parts: data embedding, positional embedding and timestamp embedding. A one-dimensional convolutional network with a convolution kernel of 3 is used to map sequence
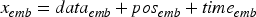
The encoder of Increformer consists of multiple same layers tack composition, and each layer includes three sublayers, respectively, i.e., Continual Multi-Head Attention (ConMHA), feed-forward neural network(FFN) and continuous normalization mechanism (CN). The original input sequence
The decoder of Increformer, similar to the encoder, is composed of multiple identical layers. However, in the sublayers, a new group has been added with Mask attention module, which assign different weights to the intermediate result Q of the decoder according to the outputs K and V of the encoder to calculate the degree of correlation between K and Q. The decoder also uses continuous normalization (CN) to process the data between the sub-layers of the network model. The input vector to the decoder is:
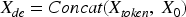
The self-attention mechanism in the Transformer can model relationships among data points and retain important interactions between elements. The self-attention mechanism uses query-key-value(QKV), by which the similarity between each element and other elements is calculated to extract temporal dependencies:

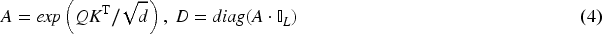
However, conventional multi-head attention is primarily designed for static or offline settings, where the data distribution is assumed to remain relatively stable. In streaming and incremental scenarios, newly arriving data often exhibit evolving patterns and distribution shifts, which cannot be effectively captured by standard attention mechanisms. Moreover, directly applying conventional multi-head attention may lead to an overemphasis on historical information while lacking sufficient adaptability to recent changes. Motivated by these limitations, we propose a continual multi-head attention mechanism that explicitly accounts for temporal dynamics, enabling the model to continuously adapt to new data while preserving previously learned representations.
For online time-series forecasting, Increformer calculates through step-by-step continuous update to adapt to the sequential arrival of the data stream. At each time step,
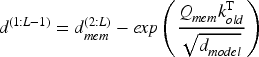

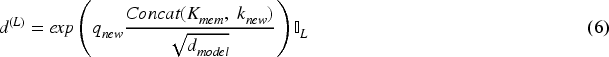
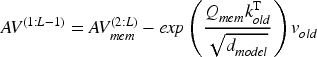

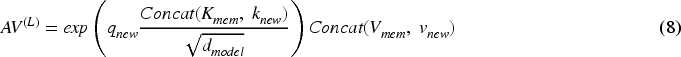
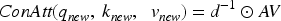
It can be seen that the time complexity and space complexity of the improved continual attention are both
In the actual operation process, under the multi-head attention mechanism, multiple different and V are input and projected to different subspaces respectively. Such a mechanism can enhance the ability of the network model to capture the dependencies between different dimensions of the sequence. Given a new set of queries-key-values-values, the continual multi-head attention mechanism (ConMHA) can be described as:


Transformer uses layer normalization (LN), which is suitable for processing sequence data with varying lengths. It operates on different features of a single sample and normalizes each dimension of a single sample. Group normalization (GN)
35
normalizes different features of a single sample by grouping them together, and LN is essentially the GN when the group number is 1. Batch normalization (BN)
36
normalizes the same feature across different samples, which helps the network training converge faster and achieve better performance. The standard normalization is implemented as follows:
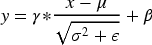
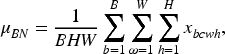
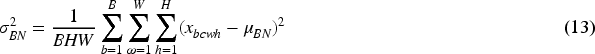

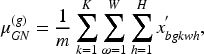

For time-series scenarios, BNs can easily disrupt the correlations in the temporal dimension. Thus, in this work, the advantages of GN and BN are combined to propose a continual normalization (CN), which is suitable for data incremental scenarios. It works as follows. First, spatial normalization is performed on the feature map using KNN, and the features are then further normalized through BN. The calculation of CN can be described as follows:
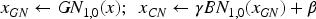
In the scenarios of incremental learning, since data arrives in sequence, CN replaces the mini-batch mean and variance involved in Equation (17) with estimated global values from the training process. It can be described as follows:
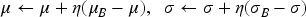
The EWC incremental learning algorithm is a method of selective regularization of network parameters. It uses the Fisher information matrix to determine the directions in parameter space that are critical for performing the learning task. By keeping important parameters close to their historical values, it identifies weights that are particularly important for a given task, and correspondingly reduces their learning rates. Therefore, parameters in other directions can be updated more freely without forgetting the directions of the learned task.
Based on Bayes’ rule, assuming that the input data set is D. With the obtained conditional probability
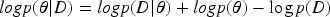
If the parameters are given, then its log probability can be defined as a negative loss function. Assume that the data is divided into two parts that are independent of each other, denoted by
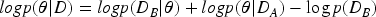
In incremental learning scenarios, the left side of Equation (19) describes the posterior probability of the parameters for the entire dataset, while the right side depends solely on the loss function of Task B. All the information from Task A must be absorbed into the posterior distribution
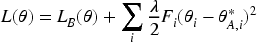
In the Increformer framework, the model update method and triggering conditions play a crucial role. Due to the high noise and non-stationary characteristics of ship motion data, the model needs to incrementally learn knowledge from new data when the data distribution changes. For online time series forecasting tasks, we improved and optimized the EWC algorithm and propose in this work a time series elastic weight consolidation algorithm TS-EWC). Specifically, every time when the data distribution changes, the new data is treated as a new task for learning. Over time, EWC maintains a penalty term for each historical task generated by the data stream. The number of penalties increases linearly with the number of tasks, thus resulting in significant computational overhead. Each new task is derived by applying a penalty term to the previous task. Therefore, when updating the model, we only need to maintain the previous penalty term and perform a weighted summation of the Fisher matrices generated from the preceding historical tasks. The loss function in TS-EWC is given by:
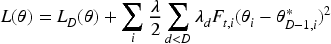
To comprehensively evaluate the ability of the model proposed in this study to forecast ship performance under wave conditions, experiments were conducted on three different ship navigation time-series datasets. The selected ship types include the widely recognized Wigley-III model ship in the shipbuilding field, the KCS container ship, and the C60 cargo ship. The hydrodynamic performance data for the Wigley-III and C60 ship types originate from physical model experiments conducted at the Iowa Institute of Hydraulic Research (IIHR). In contrast, data for the KCS ship type were obtained through simulation. Initially, a three-dimensional model was created in the Maxsurf simulation software to acquire detailed ship parameters and lines drawings. Subsequently, these ship data were imported into the CFD simulation software Fluent for motion simulation and drag calculation of the ship in oblique waves. The experiment collected time-series data of the ship under oblique wave navigation conditions, including ship parameters and environmental factors such as wind speed, wave height, and wave period, with a data collection frequency set to once every 5 s, over a continuous duration of 10 h. Based on this historical data, the model is capable of predicting key performance indicators of the ship in ocean waves, such as the roll angle, pitch angle, heave value, and total drag coefficient. Taking the KCS as an example, the KCS is a 3600 TEU (Twenty-foot Equivalent Unit) container ship, which is a standard ship type commonly used internationally. The geometric model of the ship's hull is depicted in Figure 2. Table 1 lists the main dimensional parameters of the KCS ship type. Through these experiments, the aim is to validate the model's capability to effectively predict ship performance in complex marine environments.

Geometric schematic of the KCS container ship.
Main Dimensions of the KCS Container Ship.

To eliminate the influence of different units of measurement across the various feature dimensions of the data, the sequential data were standardized. The dataset was divided into those for warm-up phase, validation phase, and online prediction phases in a ratio of 2:1:7. The model was pre-trained during the warm-up and validation phases, while during the online prediction phase, the dataset is sequentially input into the model to simulate a continuously growing data stream. The review window length was set to 60, and the prediction window was set with a prediction step of 12. After each round of prediction, the actual values were compared with the predicted values. The experimental model was built and calculated on an Nvidia Tesla T4 GPU. The Increformer consists of an encoder with N = 2 and a decoder with M = 1. An Adam optimizer with a learning rate of 0.0001 was used during the warm-up phase, and the mean squared error (MSE) was chosen as the loss function. During the online prediction phase, the TS-EWC algorithm is used to compute the loss function and perform incremental updates.
In regression tasks and time series forecasting, the following evaluation metrics are commonly used. Mean Squared Error (MSE) is a statistical measure that assesses the accuracy of predictions. It is calculated as the average of the squares of the differences between observed and predicted values. Minimizing MSE enhances the precision and reliability of forecasts, so it is a crucial metric for evaluating a model's predictive performance. The MSE is given by:
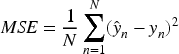
Mean Absolute Error (MAE), also referred to as the L1 norm loss, is a widely utilized metric for measuring the error in regression prediction. It evaluates the model's predictive performance by averaging the absolute differences between the actual and predicted values. The MAE is given by:
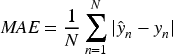
The smaller the values of the evaluation metrics MAE and MSE, the smaller the difference between the predicted and actual values, indicating that the model's predictive results are more accurate.
To validate the effectiveness of the method proposed in this paper, a comparative analysis was conducted on time-series datasets of ship navigation in ocean waves for three types of ship models: the Wigley-III, KCS container ship, and C60 cargo ship. Several mainstream deep learning and incremental learning prediction methods were selected for comparative analysis in the context of ship performance prediction. Historical data, including the main dimensions of the ship and external environmental conditions during navigation, were selected as input sequences for the model to predict the roll angle, pitch angle, heave displacement, and total resistance coefficient of the ship during its oscillatory motion in waves.
In this section of the experiment, we employed a variety of advanced deep learning methods for comparison to evaluate the performance of the proposed model. These methods include: LSTM, which effectively addresses long-term dependency issues with its gated mechanism, preventing gradient disappearance or explosion; TCN, which utilizes a causal convolutional structure to capture local patterns, ensuring that predicted future data is based solely on past information; and Transformer, which employs an encoder-decoder architecture and attention mechanism to capture global dependency relationships, using masks during the decoding process to prevent information leakage. Additionally, several ensemble incremental learning methods were also tested, such as IncLSTM and DWE-IL, which enhance the accuracy and computational efficiency of predictions by integrating multiple models. IncLSTM is based on LSTM and employs the Tradaboost method for ensemble learning, while DWE-IL is based on ELMK and utilizes an RBF Kernel as the kernel function. These methods are capable of continuously updating the model during the online prediction phase to adapt to changes in new data. Lastly, ER and DER++ incremental learning methods based on the replay mechanism were also employed. To ensure the robustness of the experimental results, 20 independent prediction experiments were conducted for each model, and the mean values of MSE and MAE metrics were calculated.
In the experimental setup, we selected appropriate loss functions and optimizers, and configured suitable network structures and parameters for each model. For instance, the LSTM model was configured with 50 hidden layer units and a ReLU activation function, while the TCN consisted of residual modules and a fully connected layer, with the number of filters and the size of the convolutional kernel carefully chosen. To compare with the algorithms presented above, the ER and DER++ methods used in the experiment both employs Transformer as the backbone network for online prediction. Both methods maintain the same memory buffer size as Increformer to review old samples. This design helps the model to retain previously learned knowledge while continuously receiving new data.
During the online prediction phase, the accuracy of different models for ship performance prediction was compared. These models include not only traditional LSTM, TCN, and Transformer but also ensemble incremental learning methods such as IncLSTM and DWE-IL, as well as online learning baseline models ER and DER++. These methods handle and forecast the hydrodynamic performance of ships under wave conditions through different mechanisms, providing us with a comprehensive benchmark for comparison. The specific experimental results of the aforementioned models for ship performance forecasting are shown in Tables 2–4.
Comparative experimental results on wigley-III.
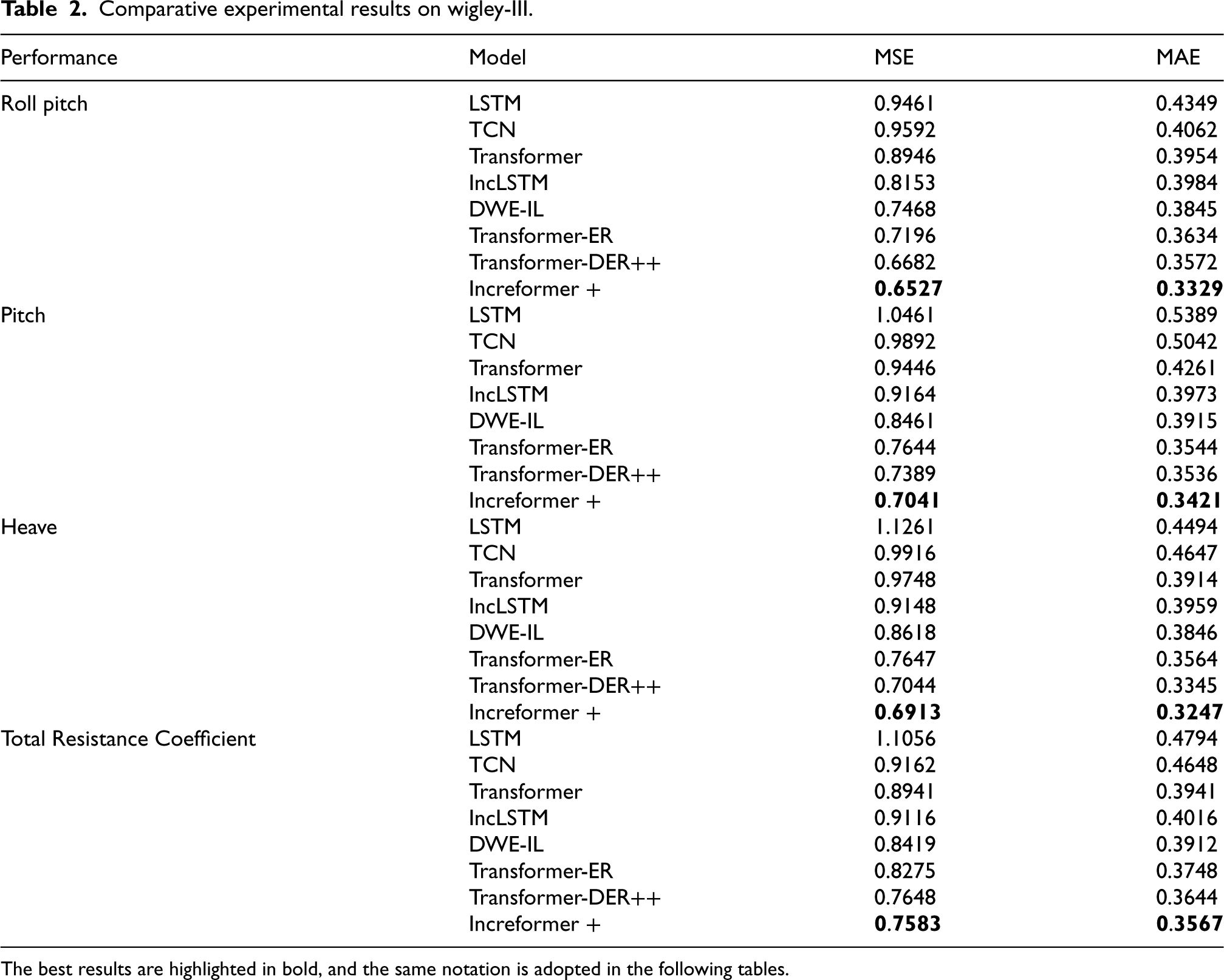
Comparative experimental results on wigley-III.
The best results are highlighted in bold, and the same notation is adopted in the following tables.
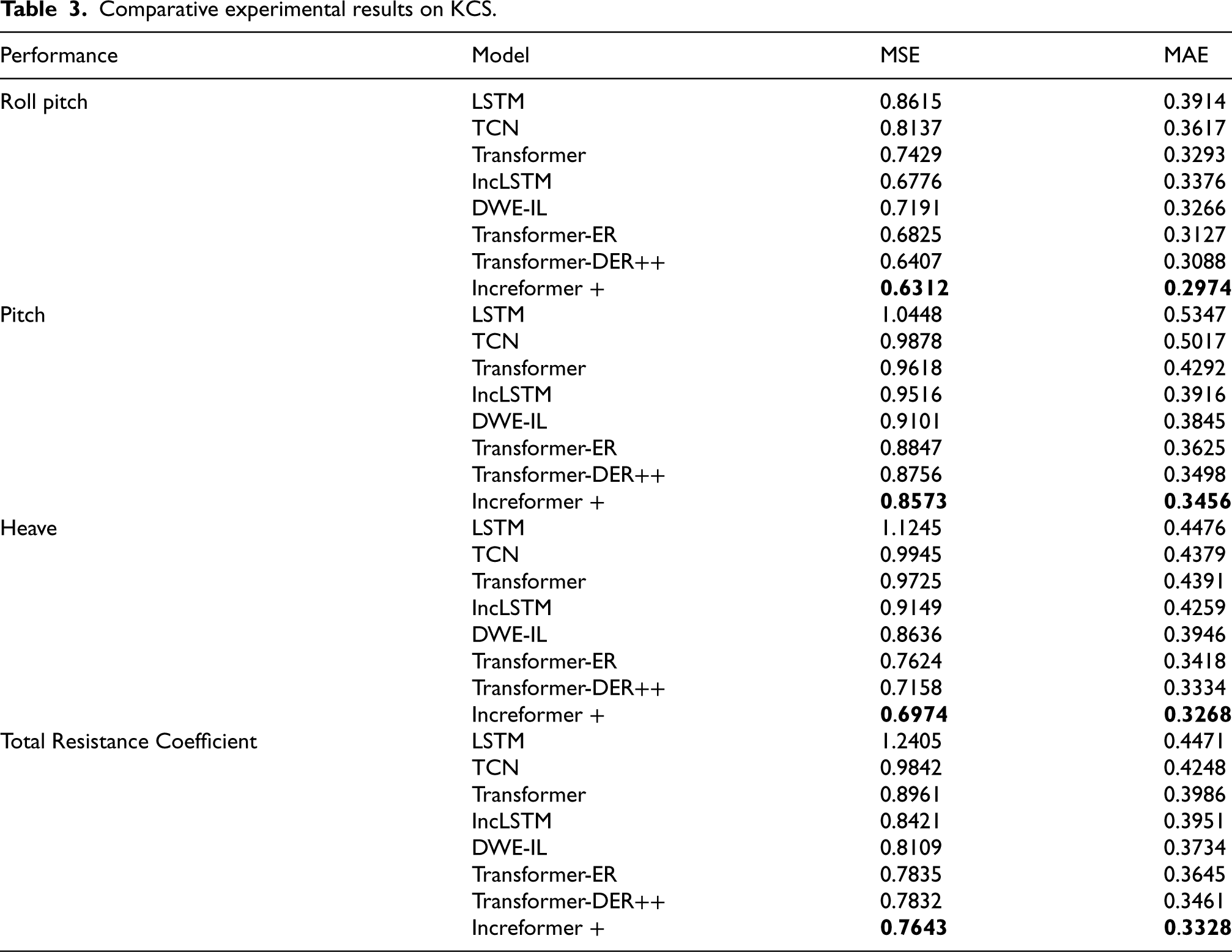
Comparative experimental results on KCS.
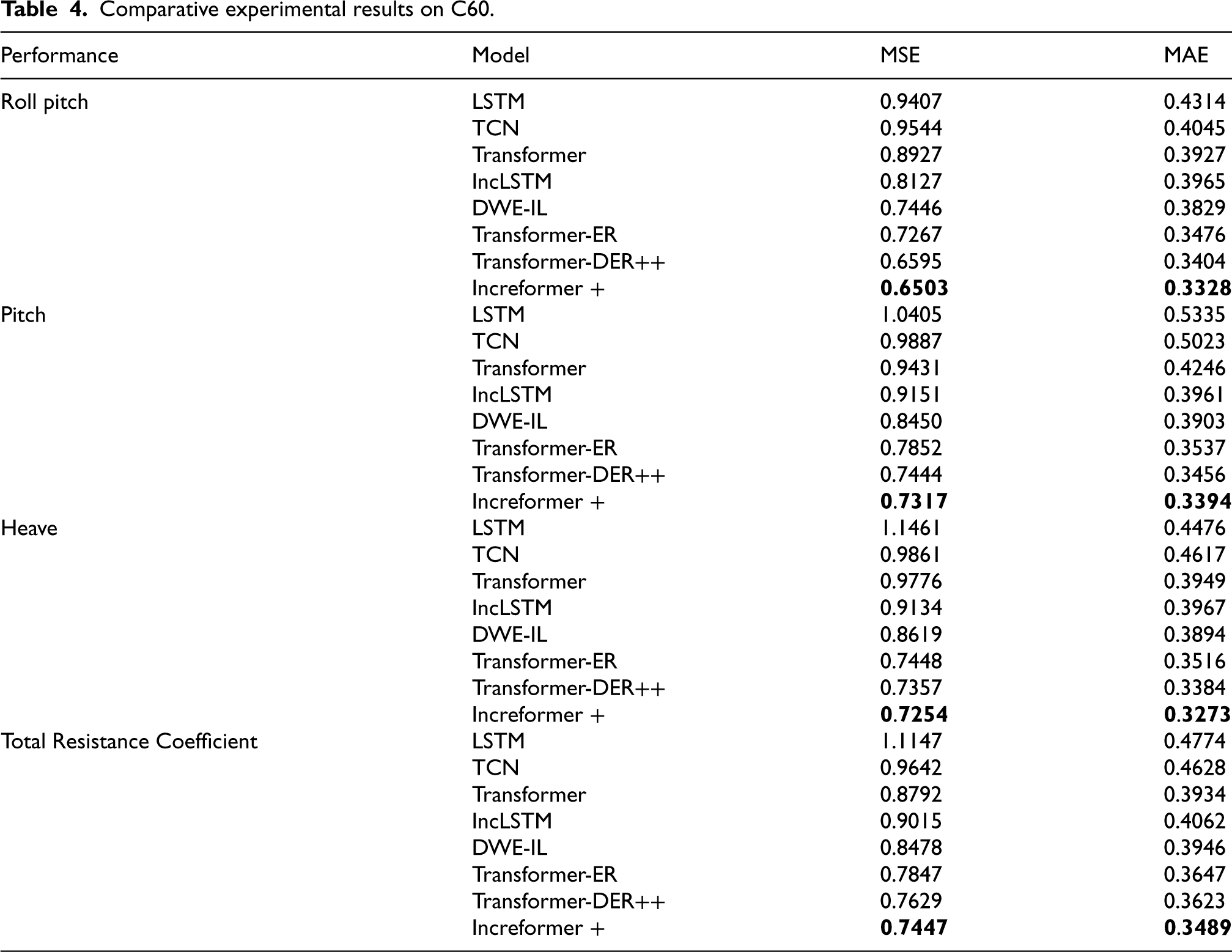
Comparative experimental results on C60.
Based on the experimental results illustrated in Table 2, it can be observed that on the Wigley-III ship model dataset, the proposed Increformer model has demonstrated significant performance enhancements in predicting key parameters of ship motion—roll angle, pitch angle, heave value, and total resistance coefficient—compared to the other tested models. Specifically, compared to the ER model, the Increformer showed reductions of 9.2%, 7.8%, 9.5%, and 8.3% in the MSE metric, respectively. These improvements significantly highlight the role of the continuous normalization mechanism in facilitating stable model learning. The continuous attention mechanism of the Increformer model enables rapid adaptation to new data during the online prediction phase, while the TS-EWC method ensures the long-term consolidation and memory of new knowledge, effectively addressing the characteristics of time-series data and thus performing admirably in ship performance forecasting. When compared with the DER++ method, the Increformer also exhibited superiority in the MSE metric on the Wigley-III ship model dataset, with reductions of 2.3%, 4.8%, 1.8%, and 0.8%, respectively. The performance of the Increformer was particularly outstanding in predicting the roll angle and total resistance coefficient. This indicates that the incremental learning strategy of the Increformer is more effective overall, especially in the prediction of roll motion, where the continuous attention mechanism effectively captures short-term data fluctuations and extracts temporal dependencies, achieving precise forecasting of roll motion. Additionally, in terms of rapid ship performance forecasting, the model can effectively extract features of new data, predict the long-term trend of the total resistance coefficient, and demonstrate better predictive performance.
Furthermore, the Increformer model, by integrating the Transformer architecture and the EWC (Elastic Weight Consolidation) method, has further enhanced its capability to process time-series data. The introduction of the continuous attention mechanism and continuous normalization mechanism allows the model to more effectively capture trends and periodicity in time-series data related to ship performance. The application of the time-series Elastic Weight Consolidation algorithm, TS-EWC, an improvement based on EWC, enables the model to better balance the learning of new and old knowledge during the incremental learning process, dynamically adjust model weights, and efficiently and accurately forecast the hydrodynamic performance of ships. These advantages have increased the efficiency and accuracy of the Increformer model in ship performance forecasting tasks.
Based on the results in Table 3, it can be observed that on the KCS ship model dataset, the proposed Increformer model achieved superior results in predicting ship motion in waves, including key performance indicators such as the roll angle, pitch angle, heave value, and total resistance coefficient. Compared with the benchmark Transformer model, the Increformer model demonstrated significant improvements in the MSE metric, with reductions of 15%, 10.8%, 28.2%, and 14.7%, respectively. These results reflect the effectiveness of the incremental learning strategy.
Furthermore, the Increformer model demonstrated more significant performance prediction capabilities for the KCS ship type. This is attributed to the bulbous bow structure of the KCS, which effectively mitigates the impact of waves on the hull, leading to more stable resistance fluctuations. At the same time, due to the anti-rolling devices such as the bilge keel, the amplitude of the rolling motion is also smaller compared to the Wigley-III type. Therefore, the periodicity of the ship's hull shape data is more pronounced, the data noise is smaller, and the model can extract features more effectively. The Models based on the Transformer framework outperformed those based on LSTM and TCN frameworks in terms of predictive performance. This is because the Transformer's attention mechanism has superior feature extraction capabilities for time series data, effectively capturing both long-term trends and short-term fluctuations. On the KCS dataset, due to the high stability of the data, the difference in performance prediction between incremental learning methods and traditional deep learning methods is not significant. This may be because, with limited data in the new mode, the advantages of the incremental learning strategy have not yet been fully demonstrated. However, overall, models based on incremental learning strategies still outperform traditional deep learning models in terms of prediction performance.
As shown in Table 4, the Increformer model has a significant advantage over the Transformer baseline model. Other incremental learning models based on the Transformer architecture, such as ER and DER++, also performed well, indicating that Transformer-based models are more effective than TCN for time-series forecasting. The proposed model effectively leverages the representation capability of the Transformer and integrates incremental learning strategies to enhance the ability to capture dependencies within sequential data, continuously absorbing new trends and fluctuation patterns from incoming data. On the C60 ship model dataset, Increformer achieved the best forecasting accuracy across all evaluated metrics.
Figure 3 displays the roll motion prediction results of the proposed model and the comparative models on the KCS ship model. It can be observed that deep learning methods performed poorly when predicting new data with different distributions, sometimes showing opposite trends or large fluctuations at inflection points. In contrast, incremental learning methods can improve model weights and structure through timely learning, leading to better predictions for new patterns. Among them, the Increformer shows the best curve fitting effect, with predictions closest to the actual values and better fits than those of the other models.
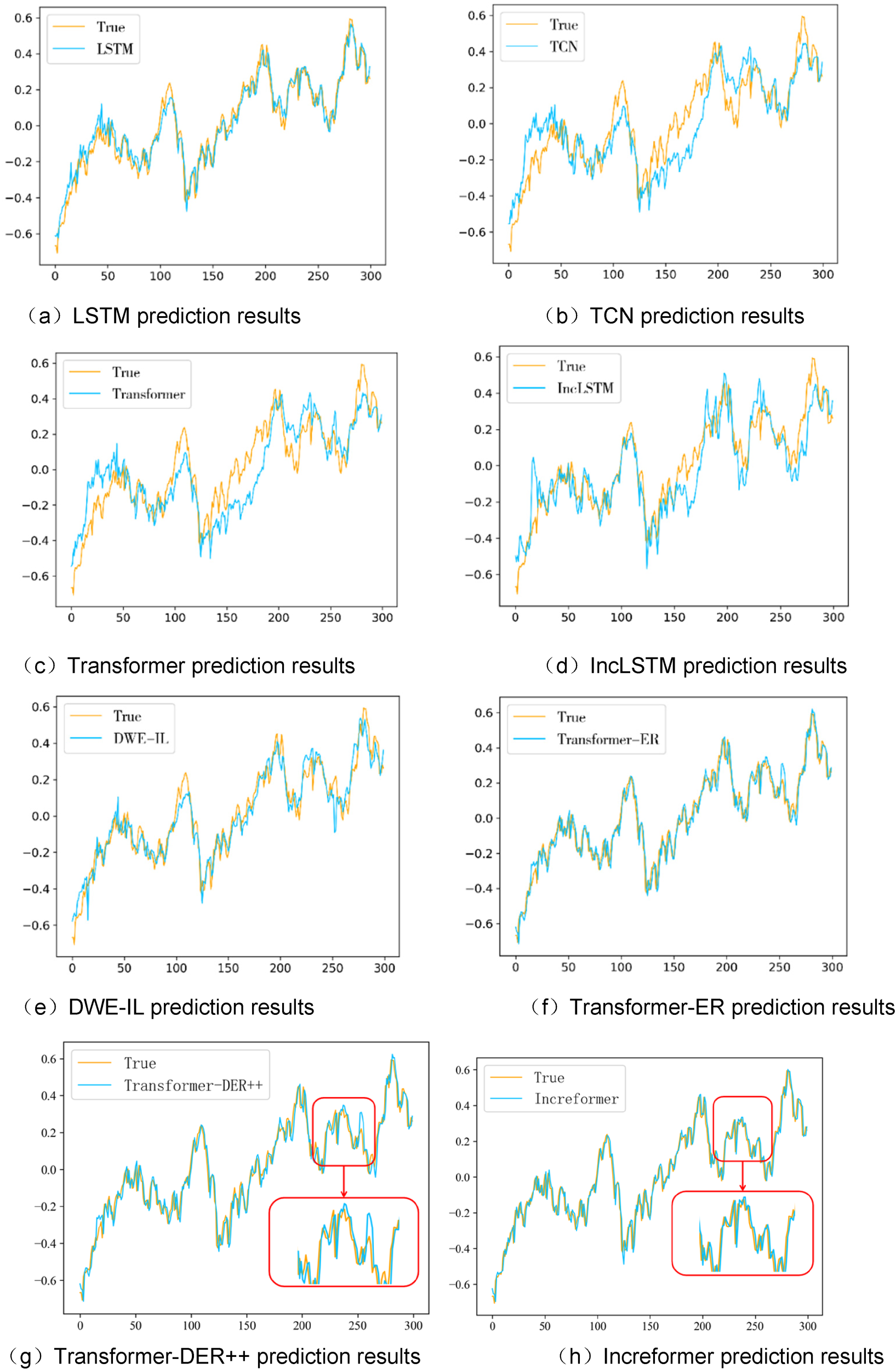
Prediction results of ship roll motion on the KCS dataset.
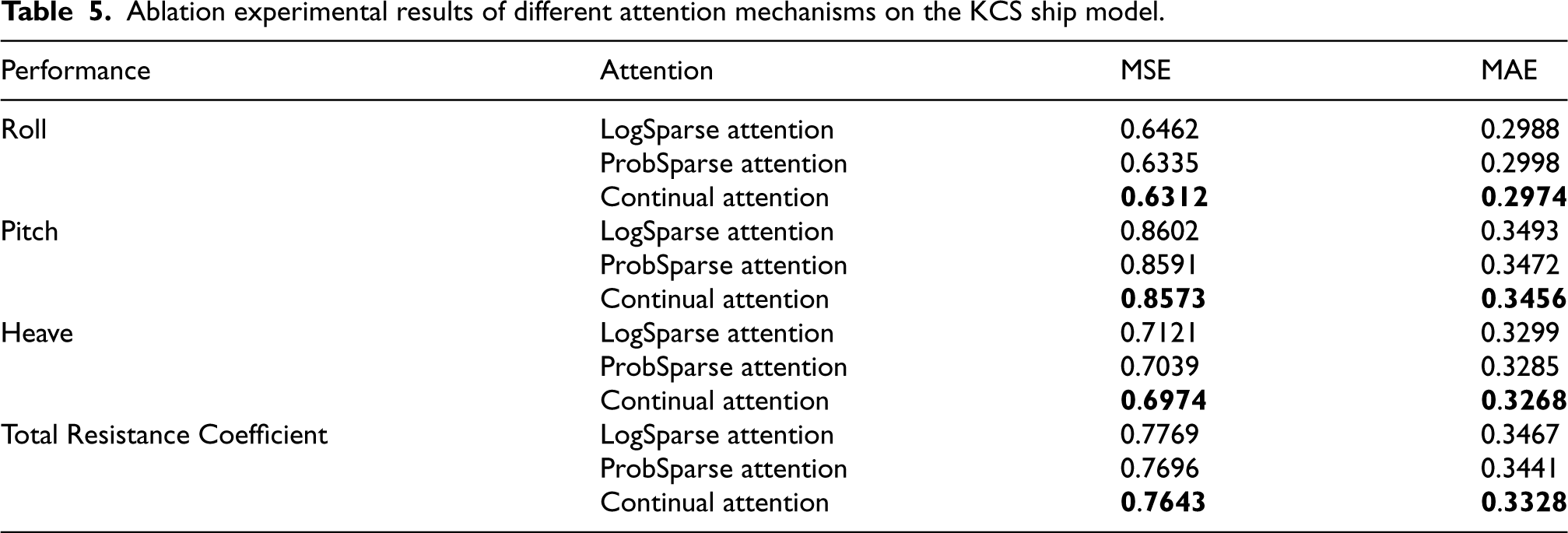
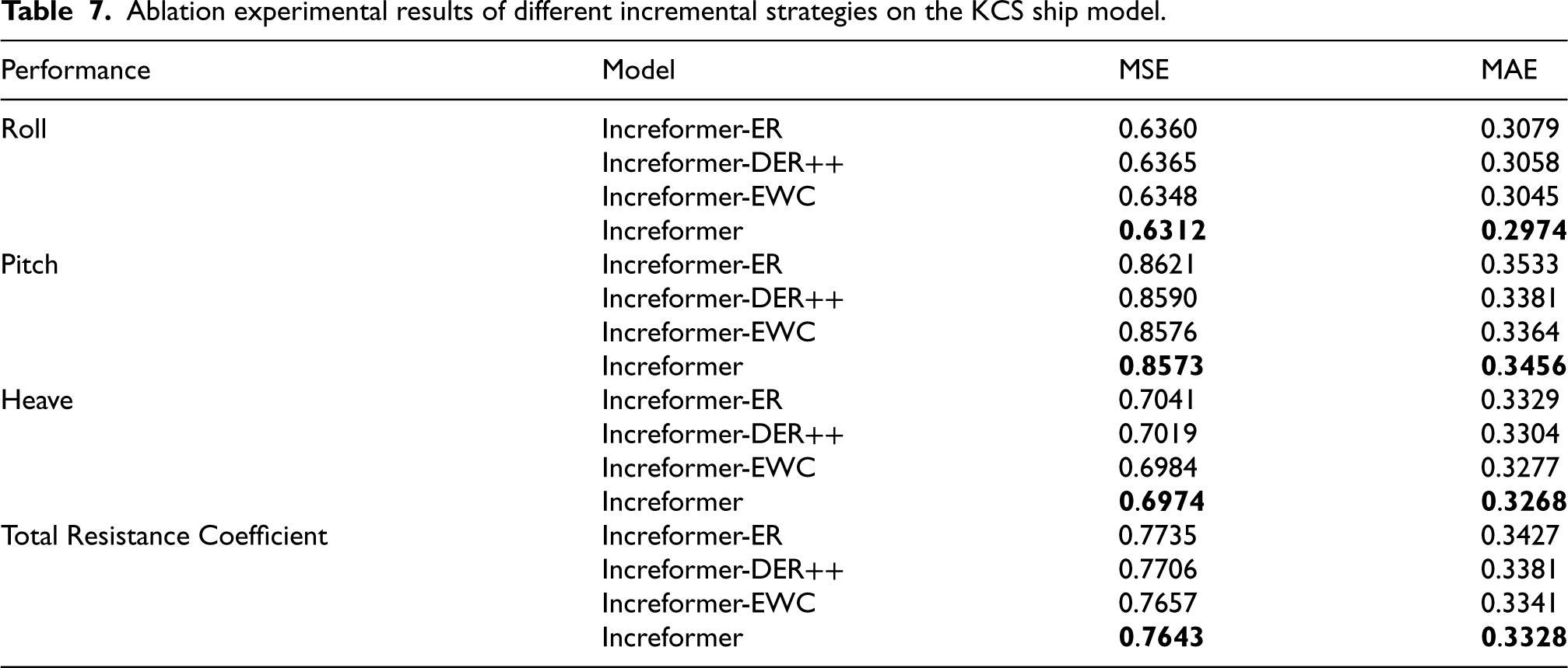
To verify the role and effectiveness of each functional module of the proposed Increformer model in ship performance forecasting, ablation experiments were conducted on the KCS ship model dataset. Variant models were obtained by removing different modules from the model, and comparative analysis was performed based on the calculation of evaluation metrics MAE (Mean Absolute Error) and MSE (Mean Squared Error). Initially, the continuous attention module was replaced with other advanced attention modules, including LogSparse attention and ProbSparse attention, and the corresponding comparison results are presented in Table 5. Subsequently, the continuous normalization (CN) module was replaced with layer normalization (LN), and the comparison results are depicted in Table 6. Finally, the incremental training method was switched to EWC, ER, and DER++, with the experimental comparison results shown in Table 7. During the process of replacing the various modules, all other parts were kept constant.
Ablation experimental results of different attention mechanisms on the KCS ship model.
Ablation experimental results of different attention mechanisms on the KCS ship model.
Ablation experimental results of different normalization methods on the KCS ship model.

Ablation experimental results of different incremental strategies on the KCS ship model.
The results for the attention mechanisms presented in Table 5 indicate that the continuous attention mechanism used in the Increformer model outperformed the sparse attention mechanisms in predicting the roll angle, pitch angle, heave value, and total resistance coefficient, with the MSE decreasing by 10.1%, 8.0%, 6.0%, and 8.4% respectively, and the MAE decreasing by 2.2%, 0.3%, 1.8%, and 2.7% respectively. According to the experimental results displayed in Table 7, it is clear that the continuous attention mechanism adopted in the Increformer model surpassed other attention mechanisms in terms of performance. This significant improvement confirms that the proposed continuous attention module is particularly suitable for online prediction environments and the processing of streaming data. The mechanism can effectively capture new trends and features in the data, thereby enhancing the response speed of the model to new information and the accuracy of its predictions.
Additionally, the experimental results presented in Table 6 show an increase in the error metrics of the model when the continuous normalization mechanism is removed. This result further confirms the significant role of the continuous normalization module in data stabilization and in facilitating the continuous learning of new knowledge by the model. By mitigating the impact of noise and outliers in the data, this module contributes to the model's more stable learning from continuously incoming data.
According to Table 6, regarding the substitution of incremental learning methods, it is evident that both EWC (Elastic Weight Consolidation) and TS-EWC (Time-Series Elastic Weight Consolidation) exhibit favorable predictive performance. However, TS-EWC demonstrates lower computational overhead and higher model updating efficiency. Compared to EWC, TS-EWC performs better as the occurrence of new data patterns increases, that is, when the number of tasks for network parameters to learn is continuously growing. In summary, the various modules of the Increformer model reduce computational costs and enhance the model's ability to capture associations in both the temporal and feature dimensions of the data. This effectively improves the timeliness and accuracy of ship performance forecasting.
Furthermore, the ablation results reveal that the performance gains arise not only from individual modules but also from their strong interdependence. Continuous normalization stabilizes feature distributions, enabling continuous attention to better capture evolving temporal patterns, while TS-EWC regulates parameter updates to balance adaptation and knowledge retention. When any component is replaced, this coordination is weakened, leading to degraded performance.
To enhance the accuracy of ship performance forecasting under wave conditions, an online prediction model called Increformer, which is based on incremental learning algorithms and the Transformer framework, has been proposed to address the issue of deteriorating online forecasting performance for ship hydrodynamics as prediction time increases and new data emerges. The model incorporates a continuous self-attention mechanism to explore the temporal dependencies between feature variables and employs a continuous normalization mechanism to provide a data stabilization scheme for the model under incremental scenarios. Meanwhile, the model ensures dynamic updates based on the TS-EWC (Time-Series Elastic Weight Consolidation) algorithm for more effective forecasting of new data. Experimental results demonstrate that Increformer significantly outperforms existing classic deep learning and incremental learning methods such as LSTM, Transformer, Informer, IncLSTM, DWE-IL, OnlineTCN, ER, and DER++ in terms of predictive performance and fit. Additionally, the model's universality is validated through experimental results on various ship type datasets.
Future work will focus on several directions to further improve Increformer. First, additional influential factors, such as wind speed, wave height, and wave period, will be incorporated to enhance predictive accuracy. Second, the parameter configuration and computational efficiency of the model will be optimized to improve scalability and support real-world deployment. Finally, interpretable optimization techniques will be integrated to provide more practical insights for ship performance forecasting.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China, (grant number 61672263, 62272202) and National Science and Technology Major Project of China (No. 2025ZD1600600).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.