High performance computing applications must be resilient to faults. The traditional fault-tolerance solution is checkpoint-recovery, by which application state is saved to and recovered from secondary storage throughout execution. It has been shown that, even when using an optimal checkpointing strategy, the checkpointing overhead precludes high parallel efficiency at large scale. Additional fault-tolerance mechanisms must thus be used. Such a mechanism is replication, that is, multiple processors performing the same computation so that a processor failure does not necessarily imply an application failure. In spite of resource waste, replication can lead to higher parallel efficiency when compared to using only checkpoint-recovery at large scale.
We propose to execute and checkpoint multiple application instances concurrently, an approach we term group replication. For exponential failures we give an upper bound on the expected application execution time. This bound corresponds to a particular checkpointing period that we derive. For general failures, we propose a dynamic programming algorithm to determine non-periodic checkpoint dates as well as an empirical periodic checkpointing solution whose period is found via a numerical search. Using simulation we evaluate our proposed approaches, including comparison to the non-replication case, for both exponential and Weibull failure distributions. Our broad finding is that group replication is useful in a range of realistic application and checkpointing overhead scenarios for future exascale platforms.
As plans are made for deploying post-petascale high performance computing (HPC) systems (Dongarra et al., 2009; Sarkar et al., 2009), solutions need to be developed to ensure resilience to failures. Failures occur because not all faults are automatically detected and corrected in the hardware components used to build production systems. For instance, the 224,162-core Jaguar platform experienced on the order of one failure per day (Zheng et al., 2012). On this platform, failures were thus common rather than exceptional for applications that enroll large numbers of processors. One recovers from a failure by resuming execution from a previously saved fault-free execution state, or checkpoint. Checkpoints are saved to resilient storage throughout execution, usually periodically. More frequent checkpoints lead to less loss when a failure occurs but to higher overheads during fault-free execution. A lot of the literature is devoted to developing checkpointing strategies that minimize expected job execution time, or makespan, including both theoretical and practical contributions (Young, 1974; Daly, 2004; Bouguerra et al., 2010; Jones et al., 2010; Venkatesh, 2010; Bougeret et al., 2011).
In spite of these efforts, the necessary checkpoint frequency for tolerating failures in large-scale platforms can become so large that processors spend more time checkpointing than computing. Consider an ideal moldable parallel application that can be executed on an arbitrary number of processors and that is perfectly parallel. The makespan with processors is the sequential makespan divided by . In a failure-free execution, the larger is, the faster the execution. But in the presence of failures, as increases so does the frequency of processor failures, leading to (i) more time spent in recovering from these failures and (ii) more time spent on more frequent checkpoints to allow for efficient recovery after each failure. Beyond some threshold values, increasing actually increases the expected makespan (Elnozahy and Plank, 2004; Oldfield et al., 2007; Schroeder and Gibson, 2007; Ferreira et al., 2011). This is because the mean time between failures (MTBF) of the platform becomes so small that the application experiences too many failures, and hence too many recovery and re-execution delays, to progress efficiently.
One possible solution to this problem is to increase the reliability of individual components, for example with more hardware redundancy. But this increase comes at a higher cost. Since system acquisition costs are typically constrained when designing a parallel platform, vendors must instead use commercial off-the-shelf (COTS) components. The reliability of these COTS components is defined by the product lifetime, as driven by the market. HPC systems with COTS components will thus experience higher failure rates at higher scales (Yang et al., 2012), thereby limiting parallel efficiency if only checkpoint-recovery is used at these scales. Furthermore, even if the MTBF of an individual component is a high, then the MTBF of a platform with components is . No matter how reliable the individual components, there is thus a value of above which errors are so frequent that they can prevent any application progress.
An age-old fault-tolerance mechanism is replication, by which several processors perform the same computation synchronously so that a fault on one these processors does not lead to an application failure. Because it leads to resource waste, replication has gained traction in the HPC context only relatively recently (Schroeder and Gibson, 2007; Engelmann et al., 2009; Zheng and Lan, 2009; Ferreira et al., 2011). The authors in Ferreira et al. (2011) ‘process replication’ by which each process in a parallel Message Passing Interface (MPI) application is replicated on multiple physical processors while maintaining synchronous execution of the replicas. This approach is effective because the MTBF of a set of replicas (which is the average delay for failures to strike both processors in the replica set) becomes much larger than the MTBF of a single processor, even when only two replicas are used.
Process replication may not always be a feasible option. Process replication features must be provided transparently as part of the MPI implementation, which is not the case for the most widely used MPI implementations today. However, the work in Ferreira et al. (2011) is a convincing proof of concept and shows that process replication can provide at least a partial answer to the fault-tolerance challenge for upcoming large-scale platforms. Therefore, it is reasonable to expect that production MPI implementations will provide process replication in the future (see also Fiala et al., 2012, which demonstrates the capability of a process-level redundant MPI, called redMPI). Another reason why process replication may not be usable is that not all parallel applications are implemented using MPI or MPI-like frameworks, but can instead be based on other parallel programming models and accompanying runtime systems (e.g. concurrent objects, distributed components, workflows, or algorithmic skeletons). Most existing such systems do not provide an equivalent to transparent process replication for the purpose of fault tolerance, and enhancing them with this capability may be non-trivial. When transparent replication is not (yet) provided by the runtime system, one solution could be to implement it explicitly within the application, but this is a labor-intensive process, especially for legacy applications.
In this work we propose and study a technique that we call group replication and that can be used whenever process replication is not available. This approach is agnostic to the parallel programming model, and thus views the application as an unmodified black box. The only requirement is that the application be moldable and startable from a saved checkpoint file. Group replication consists in executing multiple application instances concurrently. For exampe, two distinct -process application instances could be executed on a -processor platform. We note that (process or group) replication prevents the execution of an application that requires the aggregate memory of the full platform, and in this sense limits the scale of the application execution. However, such full-scale execution is likely impractical in the first place due to the need for a high checkpointing frequency. The processors would spend more time saving state than computing state, thus leading to low parallel efficiency.
At first glance, it may seem paradoxical that better performance can be achieved by using (process or group) replication. After all in the above example, 50% of the platform is ‘wasted’ to perform redundant computation. The key point here is that each application instance runs at a smaller scale. As a result each instance can use a lower checkpointing frequency, and can thus have better parallel efficiency when compared to a single application instance running at full scale. The application makespan can then be comparable to or even shorter than that obtained when running a single application instance. In the end, the cost of wasting processor power for redundant computation can be offset by the benefit of the reduced checkpointing frequency. Furthermore, in group replication, once an instance saves a checkpoint, the other instance can use this checkpoint immediately to ‘jump ahead’ in its execution. Hence, group replication is more efficient than the mere independent execution of several instances: each time one instance successfully completes a given ‘chunk of work’, all the other instances immediately benefit from this success.
To implement group replication the runtime system needs to perform the typical operations needed for system-level checkpointing: determining checkpointing frequencies for each application instance, causing checkpoints to be saved, detecting application failures, and restarting an application instance from a saved checkpoint after a failure. The only additional feature is that the system must be able to stop an instance and cause it to resume execution from a checkpoint file produced by another instance as soon as it is produced.
Our contributions in this work are as follows:
We propose group replication, an approach that can be implemented in practice with simple enhancements to a checkpointing infrastructure and that is applicable to blackbox applications regardless of the parallel programming model used. It can thus serve as a useful alternative when process replication is not feasible.
For exponentially distributed failures we derive a checkpointing period that minimizes an upper bound on application makespan.
For non-exponentially distributed failures we propose a dynamic programming (DP) approach that computes non-periodic checkpoint dates with a view to minimizing makespan.
For non-exponentially distributed failures we also propose a periodic checkpointing approach in which the period is computed based on a numerical search.
We compare all our approaches in simulation, both for exponential and Weibull failure distributions, and compare them to the no-replication case.
The rest of this paper is organized as follows. Section 2 discusses related work. Section 3 defines our theoretical framework. Section 4 describes our group replication approach. Section 5 gives our theoretical analysis assuming exponential failures. Section 6 presents our DP and our periodic checkpointing approaches in the case of general failures. Our simulation methodology is detailed in Section 7. All results are presented and discussed in Section 8. Section 9 concludes with a summary of our findings and future perspectives.
2. Related work
Checkpointing policies have been widely studied in the literature. In Daly (2004), Daly studies periodic checkpointing policies for exponentially distributed failures, generalizing the well-known bound obtained by Young (1974). Daly extended his work in Jones et al. (2010) to studying the impact of sub-optimal checkpointing periods. In Venkatesh (2010), the authors develop an ‘optimal’ checkpointing policy, based on the popular assumption that optimal checkpointing must be periodic. Bouguerra et al. (2010) prove that the optimal checkpointing policy is periodic for both exponential or Weibull failures, but with the assumption that all processors begin a new lifetime after each recovery and each checkpoint. We extended their results in Bougeret et al. (2011), where we dropped this assumption and developed optimal solutions for exponential failures and DP solutions for general failures, which have been shown to be effective for Weibull failures. The Weibull distribution is of interest because it is recognized as a reasonable approximation of failures in real-world systems (Heath et al., 2002; Schroeder and Gibson, 2006; Liu et al., 2008; Heien et al., 2011). Some of the results in this work build on our work in Bougeret et al. (2011).
In spite of all the above advances, the scalability of pure checkpoint-recovery approaches is limited (Elnozahy and Plank, 2004; Oldfield et al., 2007; Schroeder and Gibson, 2007). Replication has long been used as a fault-tolerance mechanism in distributed systems (Gärtner, 1999), and more recently in the context of volunteer computing (Kondo et al., 2007) and, together with checkpoint-recovery, in the context of grid computing (Yi et al., 2010). Even though it induces resource waste, because of the scalability limitations of pure checkpoint-recovery, replication has recently received more attention in the HPC literature (Schroeder and Gibson, 2007; Engelmann et al., 2009; Zheng and Lan, 2009; Ferreira et al., 2011).
In this work we study group replication, by which multiple application instances are executed on different groups of processors. Ferreira et al. (2011) recently studied an orthogonal approach, namely process replication, where each process of an MPI application is transparently replicated. Group replication cannot hope to outperform process replication, simply because process replication leads to a dramatically increased MTBF for each replica set. However, the advantage of group replication is that it is agnostic to the parallel programming model and runtime system, at the cost of only minor modifications to the checkpointing infrastructure. Consequently, it is a useful alternative when process replication is not (yet) available to an application, as discussed in Section 1.
3. Framework
We consider the execution of a parallel application, or job, on a platform with processors. We use the term ‘processor’ to indicate any individually scheduled compute resource (a core; a multi-core processor; a cluster node). We assume that system-level coordinated checkpoint-recovery is enabled (Wang et al., 2005).
The job consists of units of (divisible) work, which can be split arbitrarily into chunks. The job can execute on any number processors. Letting be the time required for a failure-free execution on processors, we consider three models:
Perfectly parallel jobs: .
Generic parallel jobs: . As in Amdahl’s law (Amdahl, 1967), is the fraction of the work that is inherently sequential.
Numerical kernels: . This is representative of a matrix product or an LU/QR factorization of size on a 2D-processor grid, where . In the algorithm in Blackford et al. (1997), and each processor receives blocks of size during the execution. Here, is the communication-to-computation ratio of the platform.
Each participating processor is subject to failures. A failure causes a downtime period of the failing processor, of duration . When a processor fails, the whole execution is stopped, and all processors must recover from the previous checkpoint. We let denote the time needed to perform a checkpoint, and denote the time to perform a recovery. The downtime accounts for software rejuvenation (i.e. rebooting; see Kolettis and Fulton, 1995; Castelli et al., 2001) or for the logical replacement of the failed processor by a spare. Regardless, we assume that after a downtime the processor is fault-free and begins a new lifetime at the beginning of the recovery period. This recovery period corresponds to the time needed to restore the last checkpoint. Assuming that the application’s memory footprint is bytes, with each processor holding bytes, we consider two scenarios:
Proportional overhead: with some constant, for cases where the bandwidth of the network card/link at each processor is the I/O bottleneck.
Constant overhead: with some constant, for cases where the bandwidth to/from the resilient storage system is the I/O bottleneck.
We assume that failures can happen during recovery or checkpointing. We assume that the parallel job is tightly coupled, meaning that all processors operate synchronously throughout the job execution. These processors execute the same amount of work in parallel, chunk by chunk. The total time (on one processor) to execute a chunk of size , and then checkpoint it, is . Finally, we assume that failure arrivals at all processors are independent and identically distributed.
4. Group replication execution protocol
Group replication consists in executing multiple application instances on different processor groups. All groups compute the same chunk simultaneously, and do so until one of them succeeds, potentially after several failed trials. Then all other groups stop executing that chunk and recover from the checkpoint stored by the successful group. All groups then attempt to compute the next chunk. Group replication can be implemented easily with no modification to the application, provided that the recovery implementation allows a group to recover immediately from a checkpoint produced by another group. Hereafter we formalize group replication as an execution protocol we call ASAP (‘as soon as possible’).
We consider groups, where each group has processors, with . A group is available for execution if and only if all its processors are available. In the case of a failure of a processor in a group, the downtime of this group is a random variable . This random variable can take values strictly larger than because while a processor in a group is experiencing a downtime, another processor in that group can experience a failure, thus prolonging the groups’ downtime beyond seconds. If a group encounters the first processor failure at time , we say that the group is down between times and .
ASAP proceeds in macro-steps, with a chunk of work processed during each macro-step. More formally, during macro-step , , each group independently attempts to execute the th chunk of size and to checkpoint, restarting as soon as possible in the case of a failure. As soon as one of the groups succeeds, say at time , all the other groups are immediately stopped, macro-step is over, and macro-step starts (if ). The only two necessary inputs to the algorithm are (i) the number of chunks, , and (ii) all chunk sizes, , chosen so that .
Before being able to start macro-step
, a group that has been stopped must execute a recovery so that it can resume execution from the checkpoint saved by a successful
group. Furthermore, this recovery may start later than at time
in the case where the group is down at time
. This is shown in an example execution in Figure 1. At time
, Group 2 completes the computation and checkpointing of the chunk for macro-step 1. During that macro-step, Group 1 experiences two downtimes, each of duration
, while Group 3 experiences a single downtime of duration
due to a failure at a first processor followed by a failure at a second processor before the end of the first processor’s downtime. At time
, Group 1 is down (experiencing a downtime caused by a sequence of three processor failures), so it cannot begin the recovery from the checkpoint saved by Group 2 immediately. Group 3, instead, can begin the recovery immediately at time
, but due to a failure it must reattempt the recovery. At time
it is Group 3 that completes the chunk for macro-step 2. As seen in the figure, the only groups that do not need to recover at the beginning of the next macro-step are the groups that were successful for the previous macro-step (except for the first macro-step for which all groups can start computing right away).
Execution of chunks and (macro-steps and ) using the ASAP protocol. At time , Group 1 is not ready, and Group 2 is the only one that does not need to recover.
5. Exponential failures
In this section we provide an analytical evaluation of ASAP assuming exponential failures. More specifically, we are able to compute the optimal number of macro-steps and the optimal values of the chunk sizes . Assume that individual processor failures are distributed following an exponential distribution of parameter . For the sake of the theoretical analysis, we introduce a slightly modified version of the ASAP protocol in which all groups, including the successful ones, execute a recovery at the beginning of all macro-steps, including the first one. This version of ASAP is described in Algorithm 1. It is completely symmetric, which renders its analysis easier: for macro-step to be successful, one of the groups must be up and running for a duration of . Note however that all experiments reported in Section 8 use the original version of ASAP , without any superfluous recovery during execution (as depicted in Figure 1).
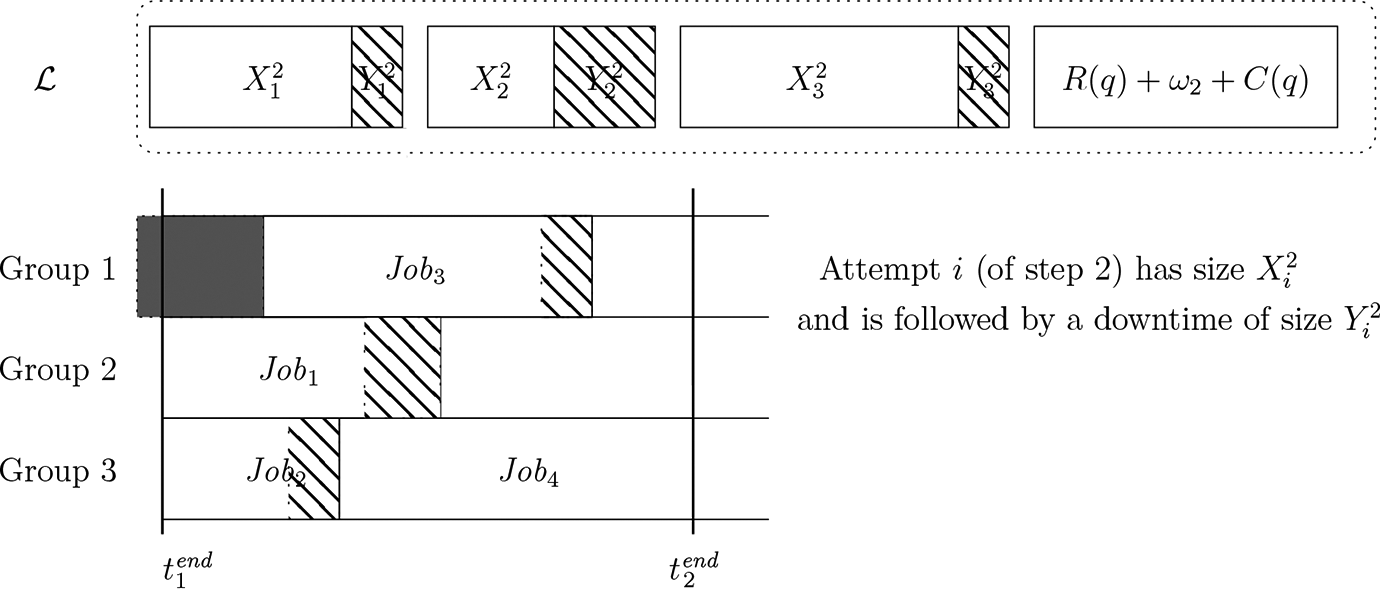
Consider the th macro-step, number the attempts of all groups by their start time, and let be the index of the earliest started attempt that successfully computes chunk . Figure 2 zooms in on the execution of the second macro-step (). Each attempt is called in the order of its start time, and is followed by a downtime, except for the last attempt, which is successful. In that example the successful computation of the chunk of size is the fourth attempt, , executed by Group 3. Consequently, , meaning that macro-step requires four attempts. The duration of each attempt is the sum of a sample of two random variables and , . corresponds to the duration of the th attempt at executing the chunk, and corresponds to the duration of the th downtime that follows the th attempt (if ). Note that for , and . All follow the same distribution , an exponential distribution of parameter , and all follow the same distribution , that of the random variable corresponding to the downtime of a group of processors. The main idea is to view the execution attempts as jobs, where the size of job is , and to distribute them across the groups using the classical online list scheduling algorithm for independent jobs (Pinedo, 2008, Section 5.6), as stated in the following proposition.
Zoom on macro-step of the execution depicted in Figure 1, using the notation of Algorithm 2. Recall that has size for , and has size .
Proposition 1. The th ASAP macro-step can be simulated using Algorithm 2: the last job scheduled by Algorithm 2 ends at exactly time .
This formulation makes it possible to derive the following theorem which gives an upper bound for the expected makespan of ASAP.
Theorem 1. The expected makespan of ASAP has the following upper bound:
where
is a random variable with distribution
. This bound is obtained when using
or
same-size chunks, whichever leads to the smaller value, where
The Lambert function is defined as .
This theorem can in turn be used to numerically compute the number of chunks and an upper bound on the expected makespan, provided that can be itself bounded. The following proposition provides such a bound.
Proposition 2. Let denote the downtime of a group of q processors. Then
The analytical derivations in Section 5 only hold for exponential failures. In the case of non-exponential failures we propose two algorithms for determining an execution of ASAP that achieves good makespan in practice: a ‘brute-force’ approach called BestPeriod and a DP approach called DPNextFailure.
6.1. Brute-force algorithm
The BestPeriod algorithm enforces a periodic execution of ASAP, meaning that all chunk sizes are identical. For a given number of groups, the period is computed via a numerical search among a set of candidate periods generated as follows: the work in Bougeret et al. (2011) makes it possible to compute an optimal period,
, for an application executed without replication on
processors subjected to exponential failures. In our case, with
groups and
processors, we compute this period for
processors. Besides
, we then generate 360 candidates as
and
for
, and 120 candidates as
and
for
, for a total of 481 candidate periods. We then evaluate each candidate period in simulation (see Section 7 for details on our simulation methodology) over 50 randomly generated experimental scenarios. We pick the candidate period that achieves the best average makespan over these 50 scenarios.
BestPeriod has two potential drawbacks. First, it enforces a periodic execution even though there is no theoretical reason why the optimal should correspond to a periodic execution if failures are non-exponential. Second, it requires running a large number of simulations (). With our current implementation each individual set of 481 simulations requires between 3 and 24 minutes on one core of a Quad-core AMD Opteron running at 2400 MHz. While this may indicate that BestPeriod is impractical, when compared to application makespans that can be several days long, the overhead of searching for the period may not be significant. Furthermore, the search for the period can be done in parallel since all simulations are independent. The search for the best period to execute an application on a large-scale platform can thus be done in a few seconds on that same large-scale platform.
6.2. DP algorithm
As an alternative to the brute-force algorithm in the previous section, one can resort to DP. We initially developed a DP algorithm to compute chunk sizes for each group at each step of the application execution. Even though this seems like a natural approach, it is only tractable (in terms of number of DP states) if the chunk sizes for each group are computed independently of those for the other groups. As a result, we found that the resulting algorithm does not achieve good results in practice.
In our previous work (Bougeret et al., 2011), when faced with an exponential number of DP states when using DP to minimize expected makespan, we opted for maximizing the expected amount of completed work before the next failure. We generalize this idea to the context of replication, doing away with the concept of chunk sizes altogether. More specifically, since the first failure only interrupts a single group, the objective is to maximize the expected amount of work completed before all groups have failed. This can be achieved with the DP algorithm presented hereafter. We make one simplifying assumption: we ignore the fact that once a group has failed, it will eventually restart and resume computing. This is because keeping track of such restarts would again lead to an exponential number of DP states. The hope is that our approach will work well in spite of this simplifying assumption.
Our DP algorithm, DPNextCheckpoint, is shown in Algorithm 3. It does not define chunk sizes, that is, amounts of work to be processed before a checkpoint is taken, but instead defines checkpoint dates. The rationale is that one checkpoint date can correspond to different amounts of work for each group, depending on when the group started to process its chunk: after either its last failure and recovery, its last checkpoint, or its last recovery from another group’s checkpoint. Input to the algorithm is the amount of work that remains to be done (
), the current time (
), the time at which the application started (
), and the times since the latest failure at each processor before time
(
). The output is the next checkpoint date and the expected amount of work completed before the next failure occurs.
DPNextCheckpoint proceeds as follows. At Line 5 function WorkAlreadyDone is called which returns, for each group, the time since it started processing its current chunk (i.e. the amount of work it has done to date). The groups are sorted in decreasing order of work performed to date (Line 6). The algorithm then picks the next checkpoint date for all possible dates between the current time and time , in other words, the time at which the last group would finish computing if no failure were to occur (Line 7). At the checkpointing date, the amount of work completed is the maximum of the amount of work done by the different groups that successfully complete the checkpoint. Therefore, we consider all the different cases (Line 10); that is, we consider which group , among the successful groups, has done the most work. We compute the probability of each case (Line 13). All groups that started to work earlier than group have failed (i.e. at least one processor in each of them has failed) but not group (i.e. none of its processors have failed). We compute the expectation of the amount of work completed in each case (Lines 14 and 15). We then sum the contributions of all the cases (Line 16) and record the checkpointing date leading to the largest expectation (Line 17). Note that the probability computed at Line 13 explicitly states which groups have successfully completed the checkpoint, and which groups have not. We choose not to take this information into account when computing the expectation (recursive call at Line 15) so as to avoid keeping track of which groups have failed, thereby lowering the complexity of the dynamic program. This is why the conditions do not evolve in the conditional probability at Line 13.
Algorithm 4 shows the overall algorithm, DPNextFailure, which uses DPNextCheckpoint (the Alive function returns, for a list of processors, the amount of time each has been up and running since its last downtime). Each time a group is affected by an event (a failure, or a successful checkpoint by it or by another group), it computes the next checkpoint date and broadcasts it to the group leaders. Hence, a group may have computed the next checkpoint date to be , and that date can be either un-modified, postponed, or advanced by events occurring at other groups and by their re-computation of the best next checkpoint date. In practice, as time is discretized, at each time quantum a group can check whether the current date is a checkpoint date or not.
Both Algorithms 3 and 4 have a complexity in . The term in comes from the computation of the probabilities at Line 13. This complexity can be lowered using the methodology outlined in Bougeret et al. (2011).
Our simulator implements two versions of the ASAP protocol in the case of exponentially distributed failures. The first version, OptExp , simply uses, for each group, the optimal and periodic policy established in Bougeret et al. (2011) for exponential failure distributions and no replication. To use OptExp with groups we use the period from Bougeret et al. (2011) computed with processors. The second, OptExpGroup, uses the periodic policy defined by Theorem 1. Both OptExp and OptExpGroup compute the checkpointing period based solely on the MTBF, assuming that failures are exponentially distributed. We nevertheless include them in all our experiments, simply using the MTBF value even when failures are not exponentially distributed. The simulator also implements BestPeriod (Section 6.1) and DPNextFailure (Section 6.2). Note that the execution times reported when using DPNextFailure include the time needed to run Algorithms 3 and 4. Based on the results in Bougeret et al. (2011), we do not consider any additional checkpointing policy, such as those defined by Young (1974) or Daly (2004) for instance.
7.2. Platform and job parameters
We consider platforms containing from 32,768 to 4,194,304 processors. We determine the job size so that a job using the whole platform would use it for a significant amount of time in the absence of failures, namely hours on the largest platforms ( years). In all experiments we use s, and s, s, and s, thus spanning the spectrum from relatively fast to relatively slow checkpointing/recovery. We also ran experiments with a very short s, but the results are virtually identical to those obtained with s and we do not present them. Finally, we use for generic parallel jobs, and for numerical kernels (see Section 3). Here, we only present and discuss the constant overhead scenario (). Results from the proportional overhead scenario are consistent with those for the constant overhead scenario and can be found in the companion research report (Bougeret et al., 2012).
7.3. Failure distributions
To choose failure distribution parameters that are representative of realistic systems, we use failure statistics from the Jaguar platform. Jaguar contained processors and is said to have experienced on the order of one failure per day (Zheng et al., 2012). Assuming a one-day platform MTBF leads to a processor MTBF equal to years. We generate both exponential and Weibull failures, the former serving as a best-case yet unrealistic scenario and the latter being representative of failure behavior in production systems (Heath et al., 2002; Schroeder and Gibson, 2006; Liu et al., 2008; Heien et al., 2011). For the exponential distribution of failure inter-arrival times, we simply set . For the Weibull distribution, which requires two parameters (a shape parameter and a scale parameter ) and which has density
for , we have . Based on the results in Heath et al. (2002), Schroeder and Gibson (2006), Liu et al. (2008), and Heien et al. (2011) we use either 0.5 or 0.7 for the value of . For small values of the shape parameter , the Weibull distribution is far from an exponential distribution, meaning that it is far from being memoryless. We resort to generating synthetic failure traces because it is unclear how to extrapolate production failure logs for current platforms, for example as available in Kondo et al. (2010), to post-petascale platforms in a reasonable manner. One option is to use smaller available failure logs and use oversampling to simulate failures on larger platforms. Unfortunately, such oversampling introduces bias, and the validity of the obtained results would be questionable.
7.4. Failure scenario generation
Given a -processor job, a failure trace is a set of failure dates for each processor over a fixed time horizon, which we set to two years in our simulations. The job start time is assumed to be at one year. We use a non-zero start time to avoid side-effects related to the synchronous initialization of all processors. Given the distribution of inter-arrival times at a processor, for each processor we generate a trace via independent sampling until the target time horizon is reached.
8. Simulation results
In this section, we only present simulation results for perfectly parallel applications under the constant overhead model. All trends and conclusions are similar regardless of the application and overhead models. For completeness, we provide the full results in a technical report (Bougeret et al., 2012). All results are averages over at least 50 instances, and all graphs show one-standard-deviation error bars.
8.1. Exponential failures
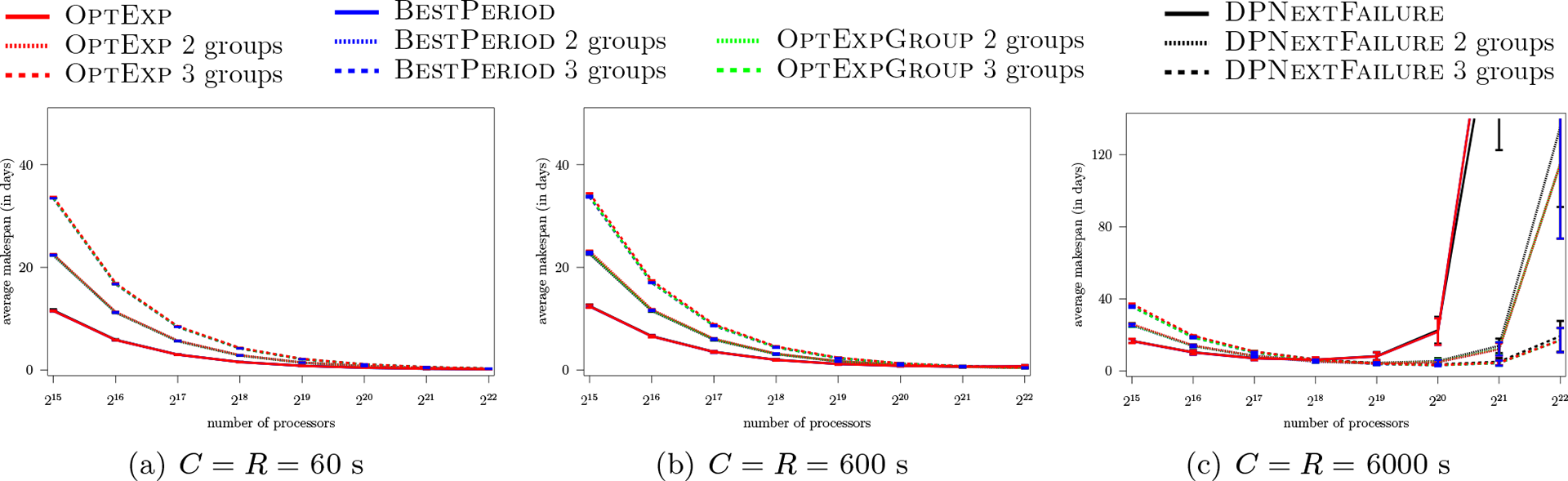
Figure 3 shows average makespan vs. the number of processors for our algorithms, each used assuming , or , and assuming exponential failures. A first observation is that many curves overlap each other: for a given all algorithms lead to similar average makespan. For instance, for 600 s and , and taking OptExp as a reference, the relative difference between the average makespan of OptExp and that of the other three algorithms is at most 6.81% (and only 2.31% when averaged over all considered numbers of processors). In spite of such small differences, several trends emerge. OptExp almost always leads to a higher average makespan than OptExpGroup (note that for the two algorithms are equivalent). Over the eight numbers of processors considered, the three values for , and the three values for (i.e. 72 scenarios), OptExp leads to average makespans shorter than that of OptExpGroup only four times (for 6000 s, for to processors, and by at most 3.27%). BestPeriod never leads to an average makespan higher than that of OptExp or OptExpGroup, and outperforms them by up to several percent across all the and values. DPNextFailure leads to mixed results, with equal or shorter average makespans than OptExpGroup (or BestPeriod), for 31 (respectively 24) of the 72 different scenarios.
Average makespan vs. number of processors, exponential failures, MTBF = 125 years.
A second observation is that the use of (i.e. multiple groups) often does not help and can even lead to larger average makespans. For 60 s, increasing from one to two, or from two to three, never leads to a lower average makespan for any of our algorithms. For 600 s, the only improvements are seen when going from one to two groups, for the OptExp, OptExpGroup, and BestPeriod algorithms, and only with more than processors. The relative improvements are at most 7.75% for processors, and between 25.40% and 41.09% for processors. No improvements are achieved when going from two to three groups. More improvements are seen for 6000 s. When going from one to two groups, improvements are achieved starting at processors, with improvements of up to between 93.64% and 95.17% at large scale, for all four algorithms. When going from two to three groups, relative improvements are seen starting at processors, reaching up to between 85.09% and 85.78% for all four algorithms.
For low and moderate checkpointing overheads, 60 s or 600 s, the average makespan decreases as the number of processors increases. Instead, for high checkpointing overheads, 6000 s, the average makespan initially decreases but starts increasing at large scale. This is particularly noticeable when using . For instance, the average makespan using OptExp goes from 21.83 s with processors to 249.39 s with processors: an increase by a factor of 11.42. The increase is similar with BestPeriod and marginally lower with DPNextFailure (a factor of 9.72). The reason for this makespan increase is simply that with a high checkpointing overhead, the parallel efficiency is low as processors spend more time on checkpointing activities than on actual computation. This observation is precisely the motivation for using (see Section 1). With , we still see increases in average makespans, but only by a factor of between 2.46 and 2.53 when going from processors to processors for all algorithms. With , this factor is between 1.34 and 1.39 for all algorithms. Therefore, the use of group replication improves parallel efficiency and can lead to scalability improvements. For instance, with or , regardless of the algorithm in use, it is not advisable to use processors as the makespan is lower when using processors. With instead, there is a reduction in average makespan when going from processors to processors for all our algorithms (the relative percentage reductions are between 14.58% and 18.81%).
Based on the above, we conclude that for exponential failures group replication can be useful when the checkpointing overhead is relatively large and/or when the scale of the execution is large. While large checkpointing overheads decrease parallel efficiency, the use of group replication makes it possible to limit this decrease or even to increase parallel efficiency at some scales. All our algorithms lead to comparable performances, with BestPeriod leading to good results despite being marginally outperformed by DPNextFailure in some instances. While these results are interesting, and although exponential failures have been studied in all previously published works, their relevance to practice is not clear given that real-world failures follow non-memoryless distributions. In the next section we present results for Weibull failures, which are more representative of real-world failure scenarios.
8.2. Weibull failures
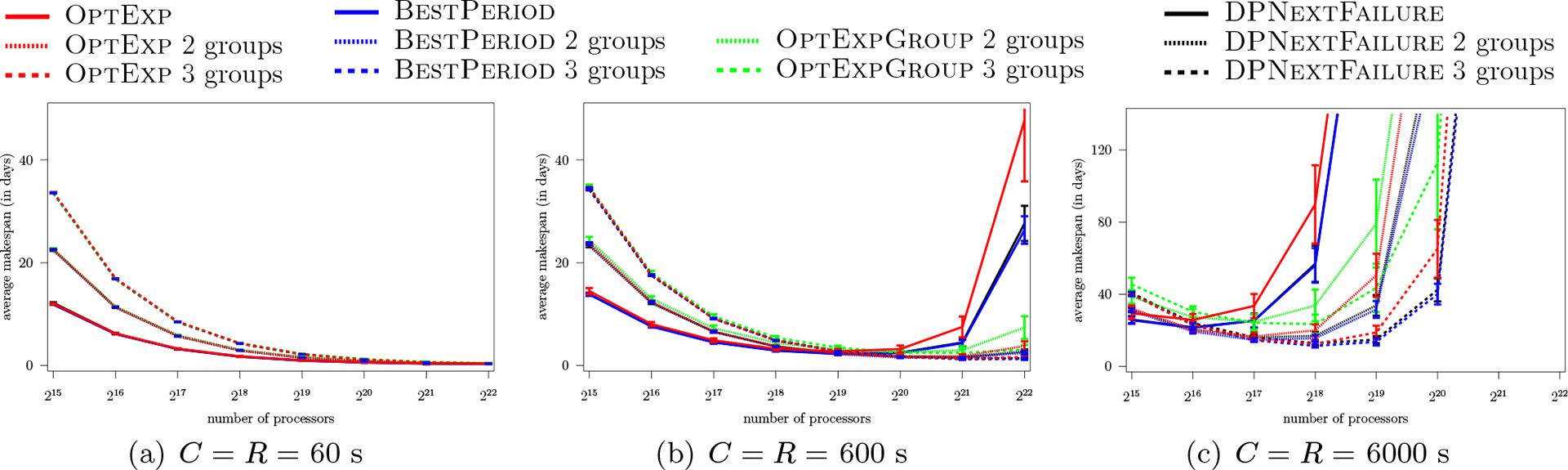
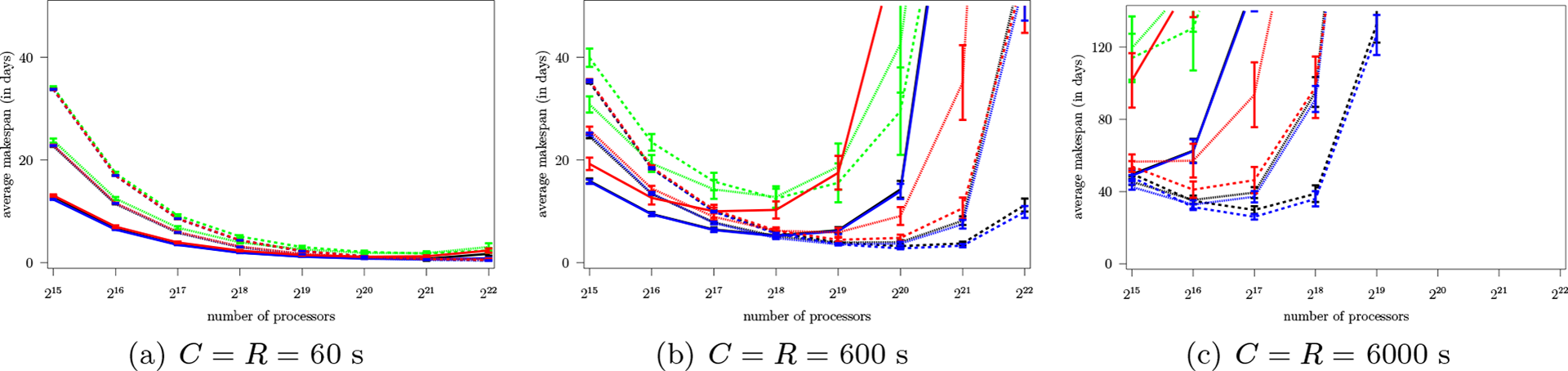
Figures 4 and 5 show results for Weibull failures with and , respectively. For low 60 s and for (Figure 4(a)), results are similar to those seen in the previous section for exponential failures: the use of multiple groups does not help, and all algorithms lead to sensibly the same performance. The gaps between the algorithms become larger for , that is, when the failure distribution is farther from the exponential distribution, with the advantage to BestPeriod (Figure 5(a)). For instance, for , processors, and using , BestPeriod leads to an average makespan lower than that of OptExp, OptExpGroup, and DPNextFailure by 10.46%, 51.04%, and 2.08%, respectively. A general observation in all the results for replication () with Weibull failures, regardless of the value of , is that OptExpGroup leads to much poorer results than all the other algorithms. This is because the analytical development of Theorem 1 relies heavily on the exponential failure assumption. As a result, OptExpGroup is outperformed even by OptExp, even though this algorithm also assumes exponential failures. In all that follows we no longer discuss the results for OptExpGroup.
Average makespan vs. number of processors, Weibull failures, , MTBF = 125 years.
Average makespan vs. number of processors, Weibull failures, , MTBF = 125 years.
For 600 s and , and unlike the results for exponential failures, at large scale the average makespan of the executions increases sharply while the average makespans for executions remain more stable (Figure 4(b)). In other words, even when checkpointing overheads are moderate, group replication is useful for increasing parallel efficiency once the scale is large enough. This result is amplified when failures are further from being exponential, in other words, for (Figure 5(b)). For , going from to is beneficial for OptExp starting at processors and for BestPeriod and DPNextFailure starting at processors. Going from to is beneficial for OptExp and BestPeriod starting at processors, and for DPNextFailure starting at processors. In terms of comparing the algorithms to each other, in Figure 5(b) all algorithms experience a makespan increase after the initial decrease. Only BestPeriod and DPNextFailure, when using , have a decreasing makespan up to processors. When going to processors, these algorithms lead to relative increases in makespan of 18.50% and 14.99%, respectively, and larger increases when going from to processors. Across the board, BestPeriod with leads to the lowest average makespan, with DPNextFailure with a close second. The average makespan of DPNextFailure is at most 15.66% larger than that of BestPeriod, and is in fact shorter at low scales (for and processors).
Results for 6000 s show similar but accentuated trends. For (Figure 4(c)) the main results are similar to those obtained for with 600 s. The best two algorithms are BestPeriod and DPNextFailure using , but both algorithms show an increase in makespan starting at processors. For (Figure 5(c)) this increase occurs at processors and is sharper for DPNextFailure than BestPeriod. Even though group replication helps, with such large checkpointing overheads parallel efficiency cannot be maintained beyond processors.
We conclude that although with exponential failures all our algorithms are more or less equivalent (see Section 8.1), with more realistic Weibull failures BestPeriod emerges as the best algorithm. The only algorithm that leads to makespans comparable to those of BestPeriod is DPNextFailure, but it never leads to a lower average makespan than BestPeriod at large scale. Even though DPNextFailure relies on a sophisticated DP approach, the brute-force but pragmatic approach used by BestPeriod turns out to be more effective. Even when using BestPeriod, our results show that application scalability is hindered by higher checkpoint overheads, which is expected, but also by lower values, that is, by less exponentially distributed failures.
8.3. Checkpointing contention
The results presented so far are obtained assuming that the checkpointing overhead () does not depend on the number of groups. There are cases in which this assumption could give an unfair advantage to group replication. Consider an application with a given memory footprint , in bytes, running on a platform with a total of processors. With no replication () the total volume of data involved in a checkpoint is . Assuming that is no larger than the aggregate RAM capacity of processors, then group replication can be used with . In this case, since each group executes the application, the total volume of data involved in a checkpoint at each group is also . Since groups may checkpoint/recover at the same time, the amount of data involved can be up to , or a factor larger than in the no-replication case.
To evaluate the impact of group replication on checkpointing overhead, we introduce a checkpointing contention model in our simulation. Whenever multiple checkpointing/recovery operations are concurrent, they receive a fair share of the checkpointing/recovery bandwidth. For instance, if checkpointing operations begin at the same time, and no other checkpointing or recovery occurs over the next time units, then all checkpointing operations finish after time units. More generally, considering that a checkpointing/recovery operation requires units of activity, over a time interval during which there are ongoing such operations each operation performs units of activity (if one of these operations requires fewer units of work to complete, consider a shorter interval).
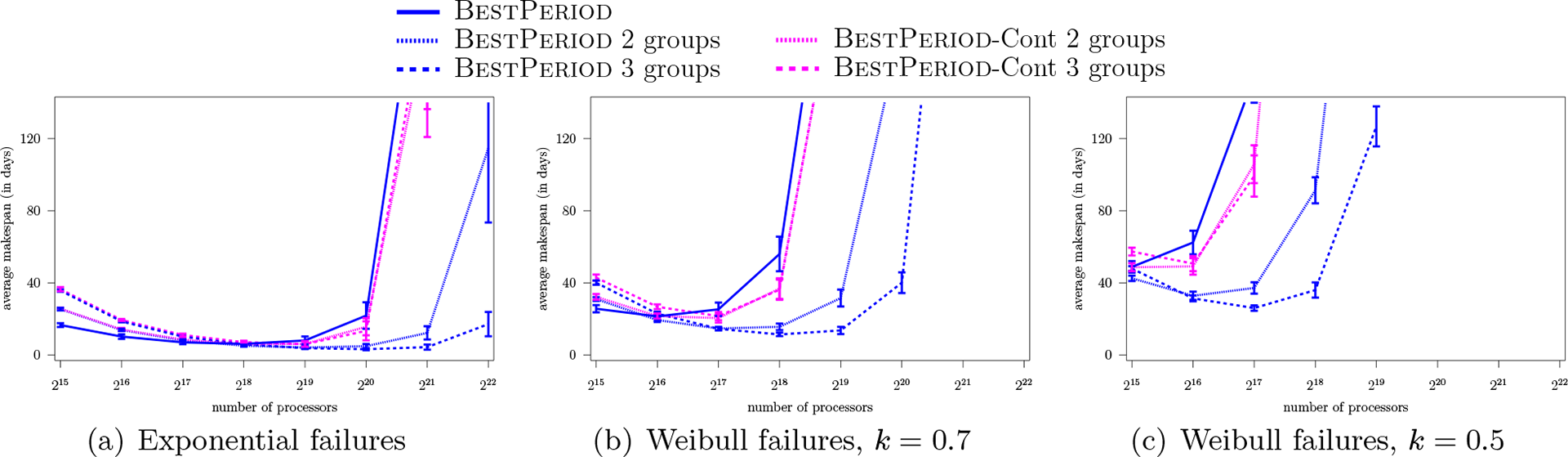
Our objective in this section is to determine whether group replication can still be beneficial when considering checkpointing contention. We repeated all the experiments presented in Sections 8.1 and 8.2. For 60 s, checkpointing contention has negligible impact on the results, and the impact for 600 s is lower than that for 6000 s. This is expected, since the larger the checkpointing/recovery overhead, the more likely it is that more than one group is engaged in checkpointing or recovery at the same time. Thus, among all our results, those for 6000 s should be the most disadvantageous for group replication. These are the results presented in Figure 6, which shows average makespan vs. number of processors for BestPeriod with and without contention (denoted by BestPeriod -Cont), for , for 6000 s, for exponential failures, and for Weibull failures with and .
Average makespan vs. number of processors, 6000 s, MTBF = 125 years.
As expected the average makespan of BestPeriod is increased due to checkpointing contention when multiple groups are used. However, even with contention, group replication outperforms the no-replication case at large scale. For exponential failures, using outperforms using as soon as the number of processors reaches , both with and without contention. Using outperforms using when there are either or processors with contention. The lowest average makespans with contention are achieved using either processors split into , or processors split into . For Weibull failures with , using outperforms using starting at processors, with or without checkpointing contention. With contention, using never outperforms using , and ties its performance starting at processors. For Weibull failures with , using outperforms using starting at processors with or without contention. With contention, using is beneficial over using when there are processors, but the lowest makespan overall is achieved with and processors.
We conclude that although checkpointing contention increases the makespan of group replication executions, the makespans of these executions are still shorter than that of no-replication execution at the same or slightly higher scales than when no contention takes place. One difference due to contention is that in our experiments using is never worthwhile.
9. Conclusion
In this work we have studied group replication as a fault-tolerance mechanism for parallel applications on large-scale platforms. We have defined an execution protocol for group replication, ASAP. We have derived a bound on the expected application makespan using this protocol when failures are exponentially distributed, which suggests a checkpointing period that can be used in practice. We have also proposed two approaches to minimize application makespan that are applicable regardless of the failure distribution: (i) a brute-force search for a checkpointing period, called BestPeriod, and (ii) a DP algorithm, called DPNextFailure Using simulation, and for a range of failure and checkpointing overheads, we have evaluated our proposed approaches and compared them to no-replication approaches from previous work. Our main findings are that (i) when considering realistic failures (e.g. Weibull distributed), group replication can significantly lower application makespan on large-scale platforms; (ii) our pragmatic BestPeriod approach outperforms the more sophisticated DPNextFailure DP approach; (iii) even when accounting for the contention due to concurrent checkpointing/recovery by multiple groups, group replication remains beneficial at large scale. Note that our group replication approaches lead to particularly good results when failures are far from being exponentially distributed, which several studies have shown to be the case in production platforms (Heath et al., 2002; Schroeder and Gibson, 2006; Liu et al., 2008; Heien et al., 2011).
An interesting direction for future work is to generalize this work beyond the case of coordinated checkpointing, for instance to deal with hierarchical checkpointing schemes based on message logging, or with containment domains (Chung et al., 2012). Both these techniques alleviate the cost of checkpointing and recovery, and would dramatically decrease checkpointing contention costs. Another interesting direction would be to compare the checkpoints saved by multiple groups as a way to detect silent errors or corrupted data. This would require modifying our approach so that at least two groups among compute a chunk of work successfully, thereby trading performance for reliability.
Footnotes
Funding
This work was partly supported by the French ANR White Project RESCUE, and by the INRIA international team ALOHA. Yves Robert is with Institut Universitaire de France.
Acknowledgments
We would like to thank the reviewers for their comments and suggestions, which greatly helped improve the final version of the paper.
References
1.
AmdahlG (1967) The validity of the single processor approach to achieving large scale computing capabilities. In: Proceedings of the American federation of information processing societies, pp. 483–485.
BougeretMCasanovaHRabieM. (2011) Checkpointing strategies for parallel jobs. In: Proceedings of the international conference on high performance computing, networking, storage and analysis (SC‘11).
4.
BougeretMCasanovaHRobertY. (2012) Using group replication for resilience on exascale systems. Research report no. RR-7876, INRIA, ENS Lyon, France. Available at: http://hal.inria.fr/hal-00668016. (accessed 16 September 2013).
5.
BouguerraMSGautierTTrystramD. (2010) A flexible checkpoint/restart model in distributed systems. In: Proceedings of parallel processing and applied mathematics, pp. 206–215.
6.
CastelliVHarperREHeidelbergerP. (2001) Proactive management of software aging. IBM Journal of Research and Development45(2): 311–332.
7.
ChungJLeeISullivanM. (2012) Containment domains: A scalable, efficient, and flexible resilience scheme for exascale systems. In: Proceedings of the international conference on high performance computing, networking, storage and analysis (SC‘12).
8.
DalyJT (2004) A higher order estimate of the optimum checkpoint interval for restart dumps. Future Generation Computer Systems22(3): 303–312.
9.
DongarraJBeckmanPAertsP. (2009) The international exascale software project: A call to cooperative action by the global high-performance community. International Journal of High Performance Computing Applications23(4): 309–322.
10.
ElnozahyEPlankJ (2004) Checkpointing for peta-scale systems: A look into the future of practical rollback-recovery. IEEE Transactions on Dependable and Secure Computing1(2): 97–108.
11.
EngelmannCOngHHScottSL (2009) The case for modular redundancy in large-scale high performance computing systems. In: Proceedings of the 8th IASTED international conference on parallel and distributed computing and networks, pp. 189–194.
12.
FerreiraKStearleyJLarosJHI. (2011) Evaluating the viability of process replication reliability for exascale systems. In: Proceedings of the ACM/IEEE conference on supercomputing.
13.
FialaDMuellerFEngelmannC. (2012) Detection and correction of silent data corruption for large-scale high-performance computing. In: Proceedings of the international conference on high performance computing, networking, storage and analysis (SC‘12).
14.
GärtnerF (1999) Fundamentals of fault-tolerant distributed computing in asynchronous environments. ACM Computing Surveys31(1): 1–26.
HeienRKondoDGainaruA. (2011) Modeling and tolerating heterogeneous failures in large parallel systems. In: Proceedings of the IEEE/ACM supercomputing conference (SC).
17.
JonesWDalyJDeBardelebenN (2010) Impact of sub-optimal checkpoint intervals on application efficiency in computational clusters. In: Proceedings of the international ACM symposium on high-performance parallel and distributed computing, pp. 276–279.
18.
KolettisNFultonND (1995) Software rejuvenation: Analysis, module and applications. In: Proceedings of the international symposium on fault-tolerant computing, p. 381.
19.
KondoDChienACasanovaH (2007) Scheduling task parallel applications for rapid application turnaround on enterprise desktop grids. Journal of Grid Computing5(4): 379–405.
20.
KondoDJavadiBIosupA (2010) The failure trace archive: Enabling comparative analysis of failures in diverse distributed systems. In: Proceedings of the IEEE international symposium on cluster computing and the grid, Los Alamitos, CA, pp. 398–407.
21.
LiuYNassarRLeangsuksunC. (2008) An optimal checkpoint/restart model for a large scale high performance computing system. In: Proceedings of the international parallel and distributed processing symposium, pp. 1–9.
22.
OldfieldRAArunagiriSTellerPJ. (2007) Modeling the impact of checkpoints on next-generation systems. In: Proceedings of the 24th IEEE conference on mass storage systems and technologies, pp. 30–46.
23.
PinedoM (2008) Scheduling: Theory, Algorithms, and Systems. 3rd edn. New York, NY: Springer.
SchroederBGibsonG (2007) Understanding failures in petascale computers. Journal of Physics: Conference Series78(1): 012022.
26.
SchroederBGibsonGA (2006) A large-scale study of failures in high-performance computing systems. In: Proceedings of the international conference on dependable systems and networks, pp. 249–258.
27.
VenkateshK (2010) Analysis of dependencies of checkpoint cost and checkpoint interval of fault tolerant MPI applications. Analysis2(8): 2690–2697.
28.
WangLKarthikPKalbarczykZ. (2005) Modeling coordinated checkpointing for large-scale supercomputers. In: Proceedings of the international conference on dependable systems and networks, pp. 812–821.
29.
YangXJWangZXueJ (2012) The reliability wall for exascale supercomputing. IEEE Transactions on Computers61(6): 767–779.
30.
YiSKondoDKimB. (2010) Using replication and checkpointing for reliable task management in computational grids. In: Proceedings of the international conference on high performance computing & simulation.
31.
YoungJW (1974) A first order approximation to the optimum checkpoint interval. Communications of the ACM17(9): 530–531.
32.
ZhengGNiXKaleL (2012) A scalable double in-memory checkpoint and restart scheme towards exascale. In: IEEE/IFIP 42nd international conference on dependable systems and networks workshops (DSN-W).
33.
ZhengZLanZ (2009) Reliability-aware scalability models for high performance computing. In: Proceedings of the IEEE conference on cluster computing.

 group. Furthermore, this recovery may start later than at time
group. Furthermore, this recovery may start later than at time 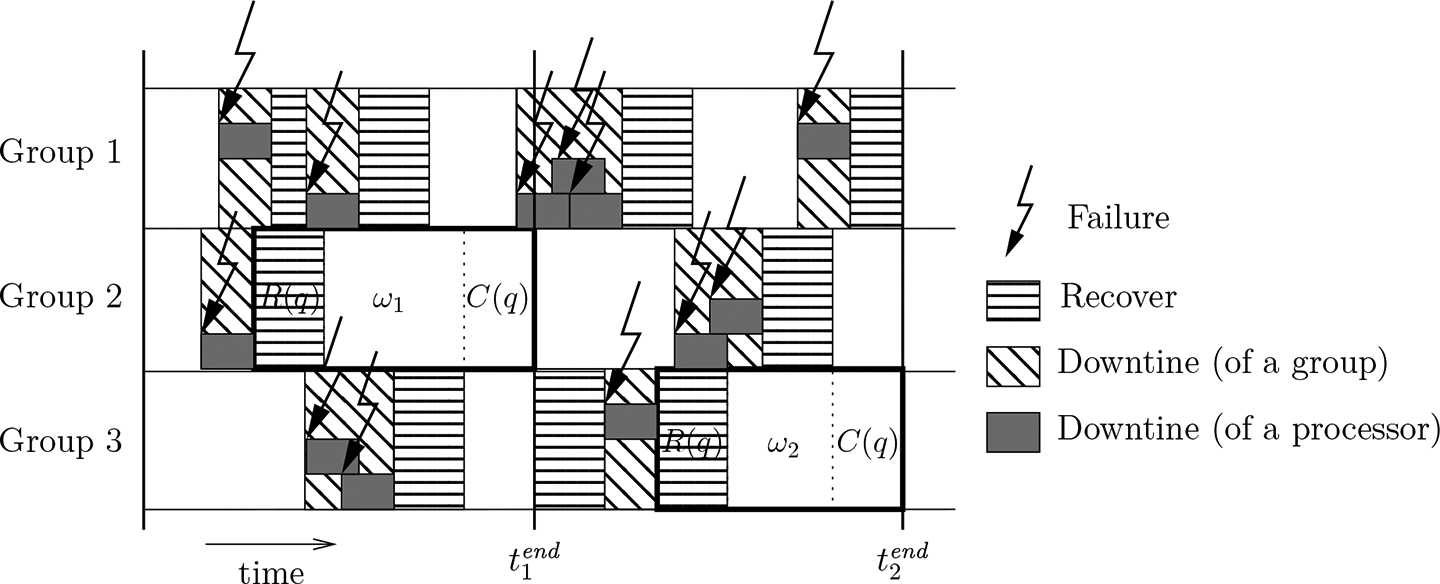
 where
where 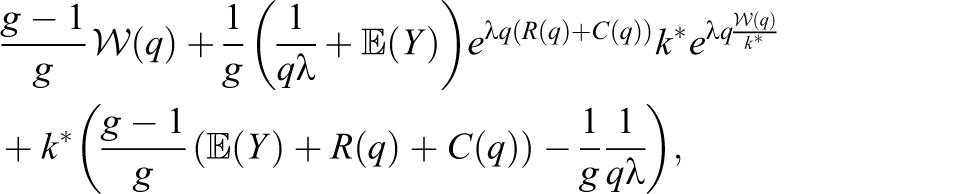
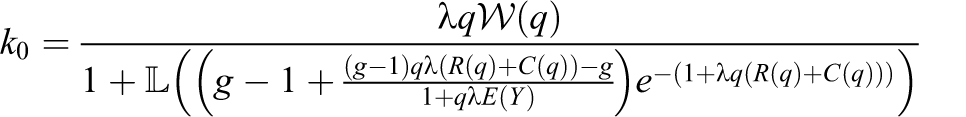
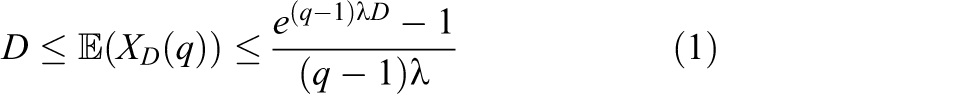

 latest failure at each processor before time
latest failure at each processor before time