
Abstract
Krylov subspace iterative solvers are often the method of choice when solving large sparse linear systems. At the same time, hardware accelerators such as graphics processing units continue to offer significant floating point performance gains for matrix and vector computations through easy-to-use libraries of computational kernels. However, as these libraries are usually composed of a well optimized but limited set of linear algebra operations, applications that use them often fail to reduce certain data communications, and hence fail to leverage the full potential of the accelerator. In this paper, we target the acceleration of Krylov subspace iterative methods for graphics processing units, and in particular the Biconjugate Gradient Stabilized solver that significant improvement can be achieved by reformulating the method to reduce data-communications through application-specific kernels instead of using the generic BLAS kernels, e.g. as provided by NVIDIA’s cuBLAS library, and by designing a graphics processing unit specific sparse matrix-vector product kernel that is able to more efficiently use the graphics processing unit’s computing power. Furthermore, we derive a model estimating the performance improvement, and use experimental data to validate the expected runtime savings. Considering that the derived implementation achieves significantly higher performance, we assert that similar optimizations addressing algorithm structure, as well as sparse matrix-vector, are crucial for the subsequent development of high-performance graphics processing units accelerated Krylov subspace iterative methods.
Keywords
1. Introduction
Krylov subspace iterative methods (Saad, 2003) are among the most popular for solving large sparse linear systems. Against the background of an increasing number of computer systems featuring hardware accelerators like graphics processing units (GPUs) (Kogge et al, 2008; top), the efficient use of the available computing power requires their inclusion in the computation. Moreover, the very high memory bandwidth of a GPU (and an energy efficiency currently four to five times higher than multicore central processing units (CPUs) (Anzt et al., 2015)), motivate the development of new software technologies for their use in sparse computations. A straightforward way to employ accelerators in Krylov subspace solvers is to offload all matrix and vector computations to the device using library functions. However, recent research has shown that this approach may provide appealing performance improvement against a CPU-restricted code, but fails to leverage the full potential of the accelerator (Aliaga et al., 2013; Anzt et al., 2014a). Using generic kernels provided by libraries fails to give the benefits of data reuse, which is a key optimization strategy for memory-bound computations and algorithms. Custom-designed kernels can provide a work-around by merging multiple arithmetic operations, and keeping data in shared memory whenever possible. Aside from that, the sparse matrix-vector product needed to generate the Krylov subspace (Saad, 2003) is often the computationally most expensive part of the algorithms. Hence, accelerating this kernel, e.g. by accounting for the properties of the specific problem and integrating it into the implementation, is often seen as the major challenge when porting and optimizing Krylov solvers on GPUs.
1.1 Related work
Although the memory-bound characteristics of sparse iterative solvers pose a challenge when porting them to throughput-processors like GPUs, significant research efforts focus on deriving efficient implementations. As the sparse matrix-vector product (SpMV) serves as the backbone of many iterative solvers, the acceleration of this stand-alone building block is often considered as the key to enhancing the performance of the complete class of iterative methods. Matrix storage formats and sophisticated kernels accounting for the specific hardware and matrix characteristics have been extensively studied in literature (Bell and Garland, 2008; Monakov et al., 2010; Kreutzer et al., 2013; Anzt et al., 2014b). Performance comparisons reveal that leveraging the computational power of GPU accelerators can also be beneficial when considering the total iterative solver runtime (Dorostkar et al., 2014; Li and Saad, 2013; Lukash et al., 2012). Aside from research implementations, several open-source software packages provide GPU-support for solving sparse linear systems (MAGMA, b,c; NVIDIA, 2013a; MAGMA, a). The implementation of the biconjugate gradient stabilized method (BiCGSTAB) and the custom-designed kernels we use for our analysis in this paper are taken from the MAGMA (MAGMA, a) numerical linear algebra library. The performance of the BLAS-1 and BLAS-2 CUDA kernels that are typically needed for all iterative methods, can be improved by reducing the communication of the memory-bound operations to GPU main memory. In Filipovic et al. (2013) the authors have shown how this can be achieved by using a source-to-source compiler that merges vector and dense matrix-vector operations. Sparse iterative solvers have been addressed with similar algorithmic modifications in Aliaga et al. (2013), where the authors have shown how custom-designed kernels improve performance and energy-efficiency of a GPU implementation for the Conjugate Gradient iterative solver. In Anzt et al. (2014a), this idea was extended to a more generic approach using the BiCGSTAB (van der Vorst, 1992) algorithm as a target application; aside from applying the aggregation of multiple arithmetic operations into a single kernel to reduce GPU memory traffic and CPU-GPU communication, the authors proposed a kernel computing multiple dot products simultaneously, and derived a model providing an a-priori approximation of the expected performance improvement.
1.2 Outline
In this paper we extend these results by combining the communication reduction ideas, with the optimization of the sparse matrix-vector product. Also, we derive a theoretical communication bound for the GPU implementation of the BiCGSTAB solver, and include a model that predicts the performance savings. We structure the paper as follows; we begin in Section 2 with a brief characterization of the Krylov subspace solvers, and review the BiCGSTAB algorithm as a typical representative. For this, we also introduce a baseline reference implementation, based on the cuBLAS library which we use for further analysis. In Section 3 we propose modifications to the distinct building blocks typical of a Krylov subspace solver; in Section 3.1 we discuss the importance of the sparse matrix-vector product, and present a GPU kernel that computes the multiplication at significantly higher performance than the default CSR-based implementation. We derive application-specific kernels in Subsections 3.2 and 3.3 by merging multiple arithmetic operations, and provide a lower bound of the communication volume needed for a parallel implementation of BiCGSTAB. On the hardware platform we introduce in 4.1, we present the performance results for the optimized algorithm-specific kernels we developed in Sections 4.2, 4.3 and 4.4. Based on these modifications, in Subsection 4.5, we derive a model quantifying the expected performance improvements and use experimental results to validate the model, revealing the superior performance of the reformulated BiCGSTAB algorithm across the complete range of SpMV dominance.
2. Krylov subspace solvers
Krylov subspace solvers (Saad, 2003) are among the most widely used methods for solving sparse linear systems iteratively. The methods are based on the idea of approximating the solution in a Krylov subspace of increasing dimension. In the basic approach, the subspace of dimension d is generated by the system matrix A, and a vector s as the subspace spanned by the projections of s under the first d powers of A, that is
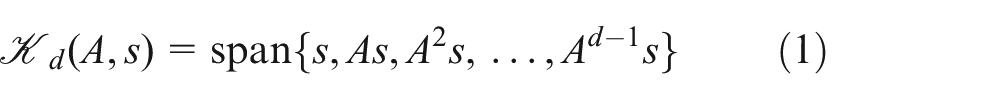
To solve a system Ax = b of dimension n, Krylov methods use a starting vector x0 and an initial residual r0 = b−Ax0 to generate a sequence of approximations xi in Ki(A, r0). In the absence of roundoff error and a breakdown caused by division by zero, the exact solution is reached after a finite number of steps (Saad, 2003). However, in particular when enhancing the method with a sophisticated preconditioner (Saad, 2003), a good approximation is typically available after few iterations, much smaller than the theoretical limit, which makes Krylov methods attractive as iterative solvers. Among the most popular methods are the Conjugate Gradient Method (Hestenes and Stiefel, 1952) for solving symmetric positive definite systems, and the GMRES and BiCGSTAB algorithms for solving nonsymmetric linear systems of equations (Saad, 2003). While there exists a large variety of Krylov subspace solvers, they are all comprised of the following building blocks:
To generate the Krylov subspace, every iteration contains at least one SpMV product 1 . Typically, this operation accounts for a significant part of the computational cost of the solver. Indeed, the SpMV is memory bound as well as latency bound, due to the irregular memory accesses to the vector’s elements. This makes it notoriously slow and hard to optimize, and in the end being able to achieve only a fraction of the peak performance of modern architectures.
In the generation of the Krylov subspace, the pairwise orthogonalization of the vectors has to be ensured. This requires the computation of scalar products, which include global reductions. Despite parallelization approaches like the fan-in algorithm (Ashcraft et al., 1990), reductions usually pose a bottleneck when running on parallel platforms, as they require synchronization and communication between the processors.
Even though local vector updates are inherently parallel and hence suitable for highly parallel architectures like GPUs, they are also memory bound. Therefore, optimizing the number of reads/writes during the updates is a major goal towards a significant performance improvement.
In order to accelerate Krylov subspace solvers, in Section 3 we derive algorithm-specific kernels that reflect the aforementioned building blocks, but improve the performance by increasing the computational intensity. For better cache reuse, we gather multiple vector updates into a single kernel, and derive a parallel reduction kernel capable of handling multiple scalar products simultaneously. Furthermore, we break up the barriers between the building blocks by merging vector updates with the first part of a scalar product into a single kernel. Although we have shown (Anzt et al., 2014a) that an equivalent kernel merging is possible for the sparse matrix-vector product, we refrain from this modification to maintain the genericness of the matrix-vector kernel, but present an alternative to the basic CSR-based kernel in Section 3.1, which achieves significantly higher performance.
Although the focus of this paper is on the BiCGSTAB solver, our algorithm redesign techniques, new kernels, and performance improvements can be projected easily through the developed main building blocks to other Krylov subspace methods.
2.1 Biconjugate gradient stabilized method
The BiCGSTAB method was developed by van der Vorst (1992) with the objective to improve stability and convergence of the BiCG method. It belongs to the above introduced class of Krylov subspace solvers and can be used to solve linear systems of equations that are not necessarily symmetric and positive definite (Saad, 2003). BiCGSTAB’s usually fast convergence makes it an attractive candidate when targeting the numerical solution of partial differential equations via finite element or finite difference methods (Braess, 2007).
The BiCGSTAB method for solving the linear system Ax = b, where

Algorithmic description of the BiCGSTAB method (Barrett et al., 1994) (left), and a reference GPU implementation for the iteration loop using the cuBLAS library (right).
An implementation of BiCGSTAB for GPU-accelerated platforms (Sawyer, 2011) was originally drafted as an example for a course on GPU-enabled libraries. In that implementation, all matrix and vector operations are handled by the accelerator using NVIDIA’s cuBLAS library. The essential operations of the iteration loop are given on the right side in Figure 1. As the intention of this implementation was to provide a high-performance BiCGSTAB through the highly optimized cuBLAS library, which is a common and highly efficient practice, we take it as a reference implementation to compare against the new developments.
3. Reformulation of the BiCGSTAB algorithm
The reference implementation of BiCGSTAB using cuBLAS functions, as presented previously, yields appealing performance improvement compared to the CPU code, but it also misses some performance improvement opportunities. For example, a better resource utilization can be achieved by improving the sparse matrix-vector product and designing application-specific routines, reducing the number of kernel calls, GPU memory transfers and GPU-host communications (Aliaga et al., 2013). To this end, a reformulation of the algorithm in Figure 1 is inevitable. Gathering similar operations (e.g. component-wise vector operations, dot products and scalar operations) allows the programmer to design algorithm-specific kernels with higher computational intensity than the replaced cuBLAS functions. Merging several arithmetic operations into one kernel enables a better GPU utilization by reducing the number of kernel calls and data communications. While Figure 2 provides a general overview of the original cuBLAS reference implementation and the new implementation featuring these improvements, we discuss the distinct optimizations and modifications we propose to the classical formulation of the algorithm in the following sections. Considering the building blocks identified in Section 2 to be characteristic for Krylov methods, we address the optimization of the matrix-vector product in Section 3.1, the reductions related to scalar products in Section 3.2 and the reduction of memory transfers related to parallel vector updates in Section 3.3. Note that in contrast to the approach in Anzt et al. (2014a), we refrain from combining the matrix-vector multiplications with other operations. Although this results in small performance penalties, we argue that the flexibility of choosing the SpMV kernel according to the target problem has a higher priority. Thus, we want to point out that our communication-avoiding (CA) optimizations are for the standard Krylov methods, and we do not investigate the potential of breaking up the data dependency between the sparse matrix-vector multiply and the dot products as was seen in recent work on the s -step and communication-avoiding Krylov methods (Hoemmen, 2010; Yamazaki et al., 2014).
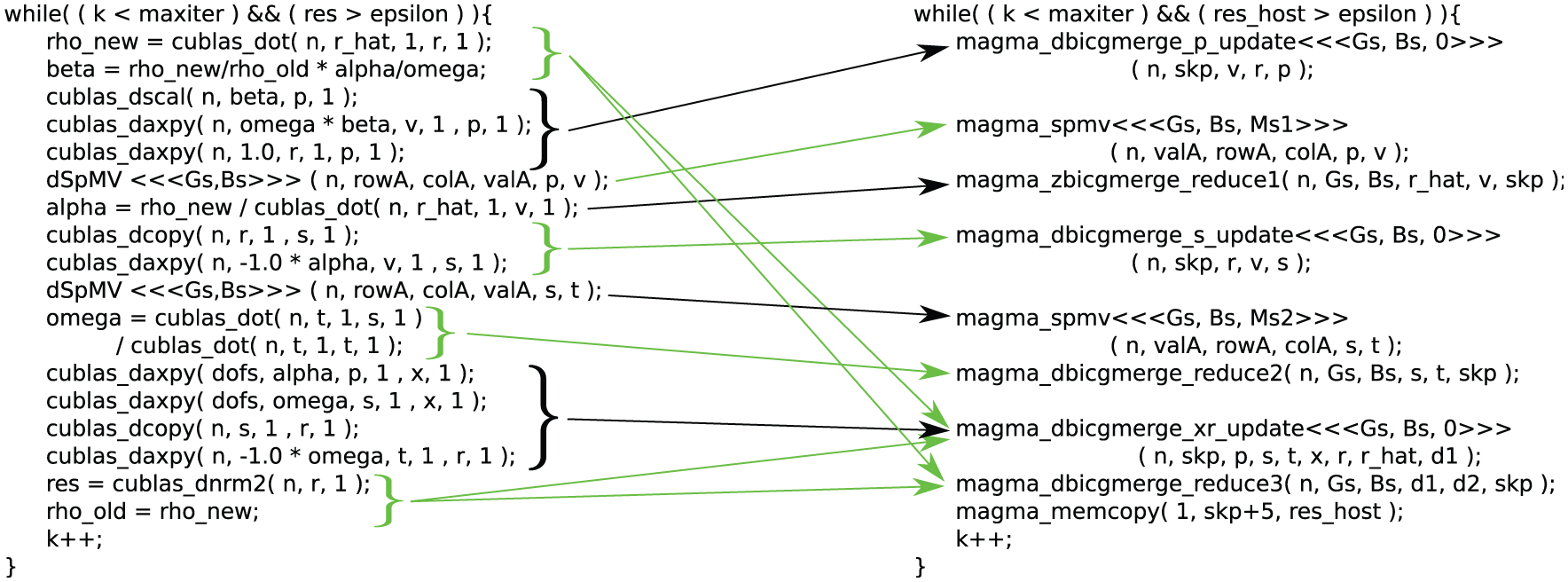
Visualizing the reformulation of the reference BiCGSTAB implementation (left) to the optimized version (right). While all parameters remain in GPU memory, note the explicit transfer of the residual back to the host in the last line.
3.1 Accelerating the sparse matrix-vector product
In the iterative solution of sparse linear systems with the Krylov subspace methods, the matrix-vector product (which generates the vector space) is usually the dominant contributor to the overall computational cost of each iteration. Hence, a significant effort is spent on developing storage formats and corresponding computational kernels that are suitable for efficient execution on the target architecture. In the spirit of reducing data transfers, one key objective when targeting GPUs is to allow for coalescent memory access in the matrix-vector kernel. Aligning the data in memory does not decrease the number of useful transfers, but it decreases the number of “wasted” transfers, as every access touches a set of bytes contiguous in memory (in the case of NVIDIA GPUs it is 32 bytes NVIDIA). If a request only uses a subset of these bytes, either by requesting only a single floating point number, or several non-contiguous entries scattered in memory, the remaining transfer capacity is lost. Hence, a coalescent memory access virtually decreases the data transfers by reducing the wasted transfer capacity. Unfortunately, no GPU kernel exists for the matrix-vector product that is superior in terms of performance for all sparse matrices. Instead, the performance varies depending on the structure of the matrix. Typically, sparse matrices exhibit varying sparsity patterns, and when used inside iterative solvers, any given kernel can be outperformed by another kernel for at least one matrix with just the right structure. Hence, we do not claim that the sparse matrix-vector kernel that we present next is the best one available, but a performance analysis in Anzt et al. (2014b) has shown that it achieves very good performance on the wide range of tested matrices and it also compares favorably to the highly-tuned implementations provided in NVIDIA’s cuSPARSE library (NVIDIA, 2013a).
For dense matrices it is usually reasonable to store all matrix entries in a consecutive position in the computer memory. For sparse matrices, which are typical targets for Krylov-subspace solvers and may be characterized by a large number of zero elements, storing these zeros is not only unnecessary for numerical properties, but would clearly result in significant storage overhead. Various storage layouts exist that aim to reduce the memory footprint of the sparse matrix by storing only a fraction of the elements explicitly (mostly the non-zero ones), and do not store all other (zero-) elements (Barrett et al., 1994; Williams et al., 2010; Buluç et al., 2011). We note that numerous ideas also exist on how to benefit from additional matrix characteristics like symmetry, tridiagonal form, or a special (and thus predictable) sparsity pattern. The CSR format (Barrett et al., 1994) is based on the straightforward idea that only non-zero entries of the matrix are stored. In addition to the array of
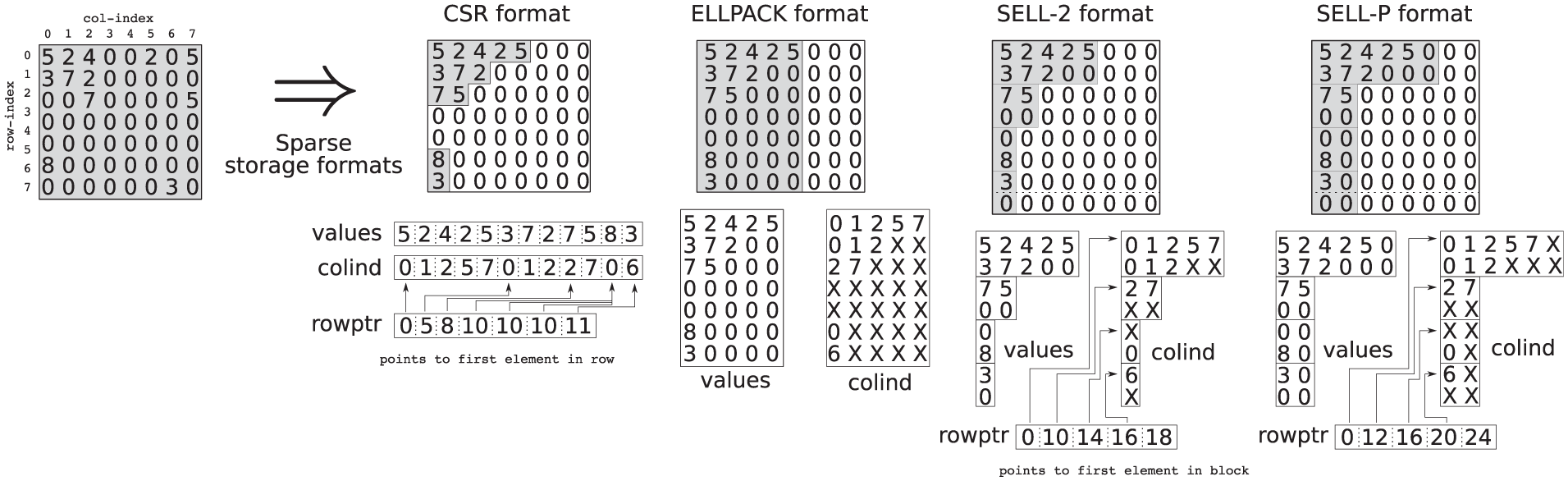
Dense and sparse matrix storage format representation (Anzt et al., 2014b). The memory requirement is visualized with the grey areas. Notice that using SELL-C with the blocksize b = 2 (SELL-2), requires adding one row to the original matrix. Furthermore, padding the SELL-P format to a rowlength divisible by 2 (t = 2), requires explicit storage of some additional zeros.
Another approach for reducing the computational overhead, without lowering the storage overhead, involves storing the number of non-zero elements in each row in an additional array and computing the partial products only for the non-zero elements. This approach was proposed in combination with assigning multiple threads to one row of the matrix in Anzt et al. (2014b), and the corresponding benchmark results showed the superiority of this idea over the plain ELLPACK format on GPUs. It is beneficial to assign multiple threads to one row and integrate it into an optimized hardware-aware implementation of the sparse matrix-vector product for the SELL-C/SELL-C-σ matrix format (Anzt et al., 2014b). For this purpose the SELL-P format (P for”padded”) was introduced as a natural extension to the SELL-C/SELL-C- σ with the hardware capabilities in mind. The padding of the rows with zeros is such that the rowlength of each block becomes a multiple of the number of threads assigned to each row, see Figure 3 for t = 2.
In the sparse matrix-vector product kernel for the SELL-P format, the threads of the GPU thread-block handle one slice of the partitioned ELLPACK. The threads are arranged in a b × t 2D thread grid, where b is the number of rows in one slice and t the number of threads assigned to each row, see Figure 4. For each slice, the kernel computes the number, max_, of necessary multiply-add’s that each thread has to handle, and the threads proceed with this information. Once all the data is processed, the partial products are written into shared memory, and a fan-in algorithm with an increment of the thread count computes the sum for each row in shared memory. Accounting for the parameters α and β in the SpMV operation y =α·Ax+β y, the result is written back into the global memory. The grid necessary to launch the thread blocks has to cover the complete matrix, i.e. the number of blocks is equal to s, the number of slices the matrix is partitioned into. As this number is typically large, a 2D grid of thread blocks, with both grid dimensions close to
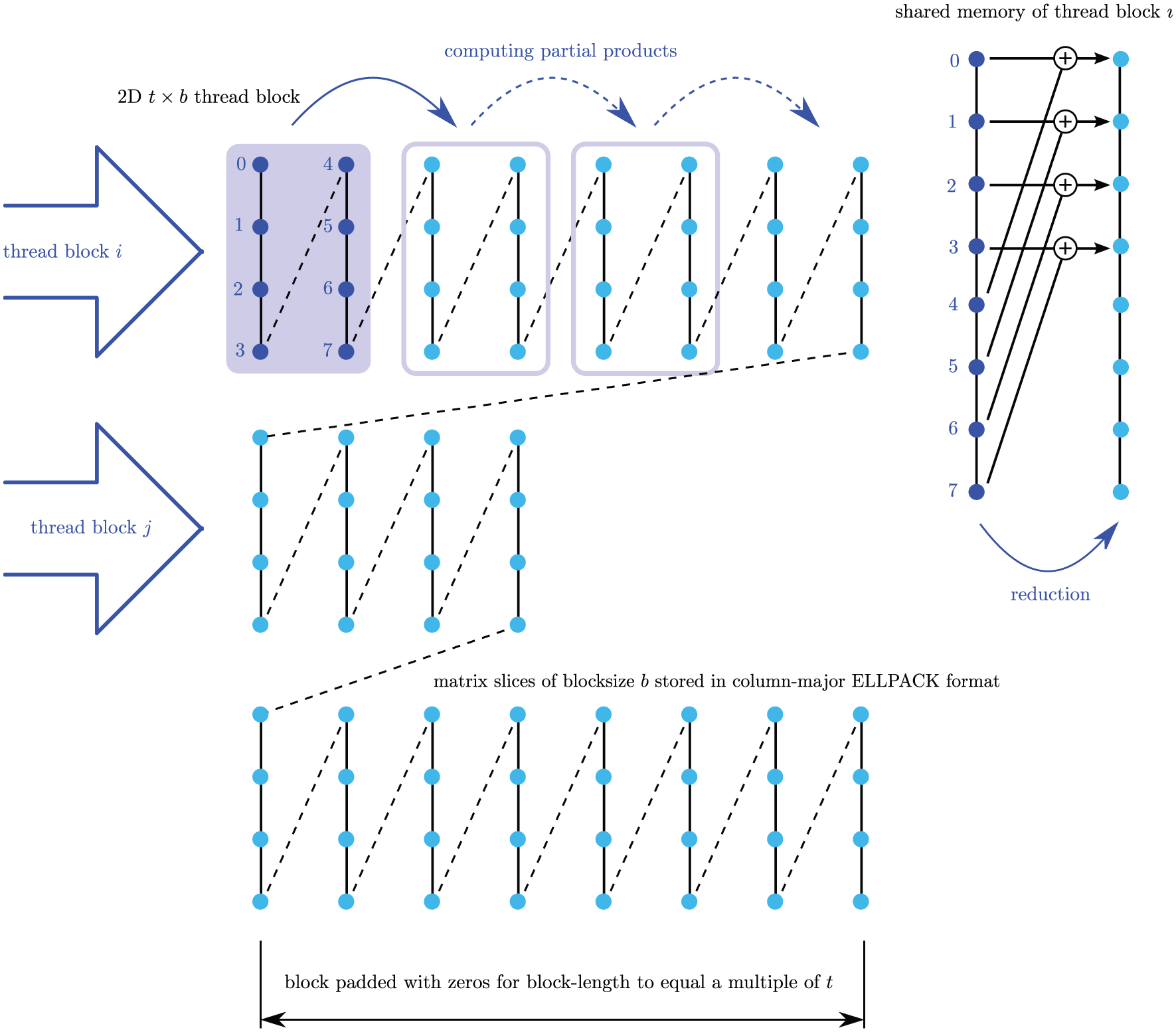
Visualization of the SELL-P memory layout and the SELL-P SpMV kernel, including the reduction step using the blocksize b = 4 (corresponding to SELL-4), and t = 2 (Anzt et al., 2014b).

Left: SpMV kernel implementation for the SELL-P sparse matrix format for t = 8 (Anzt et al., 2014b). Right: Algorithm-specific kernel implementation for
3.2 From dot product to matrix-vector multiply
NVIDIA’s cuBLAS library provides an efficient routine to compute dot products on the GPU. However, as soon as multiple dot products need to be computed consecutively, performance suffers from memory access and the fact that the reduction for each vector is handled consecutively and independently from one another. This motivated us to come up with a kernel capable of computing multiple dot products at once and reducing the vectors simultaneously. Although the most common form of BiCGSTAB only requires the parallel computation of two dot products, we aim for a general approach here. As an additional use case, we consider the fact that the computation of a set of dot products with one vector being part in all of them can also be seen as a matrix-vector multiplication ATx, where A is a tall and skinny matrix (number of rows of A far excceeds the number of columns).
The common practice in parallel matrix-vector multiplication is to assign a fixed set of rows/columns to each processing unit for the A non-transpose/transpose cases, respectively. But this approach becomes inefficient if A consists of less rows/columns than the number of the processing units available. Especially when targeting GPUs, handling columns by threads is not suitable for the AT x computation, as the typically used thread number will exceed the number of columns by orders of magnitude. The MAGMA library (MAGMA, a), developed at the Innovative Computing Lab (ICL) at the University of Tennessee, overcomes this by assigning one SMX processor to each column, and splitting each column into chunks that are then handled by different threads. To have all 13 SMXs of the K20c GPU working, the matrix needs at least 13 columns (Corporation, 2012). Each column is then split into parts according to the block size, and each thread strides over the complete column, handling one element in every part. In the end, the partial sums computed by the distinct threads are collected using the fan in summation.
Using the ideas based on the dot product where computing units process in a tree-reduction fashion, we extend the implementation proposed in Aliaga et al. (2013) to process multiple vector products simultaneously. The advantage of this algorithm is that instead of only one, all SXMs are utilized to compute the reduction of a single column, with the drawback of additional memory usage. Like in the MAGMA implementation, each thread of a thread block (handled by one SXM) strides over the complete column, but the usage of all SMXs reduces the number of column chunks and the computations of each thread considerably. The price for this is that every multiprocessor, once the reduction for the thread block is completed, has to write data to the global memory and synchronize with the other multiprocessors after each reduction step, as the partial sums computed by the different thread blocks are used in the next reduction step.
By reordering the operations in the BiCGSTAB method, we can gather two sets containing two consecutive dot products using the same vector in both computations. For efficient processing, the merged implementation uses the vector
3.3 Merging multiple arithmetic operations into one kernel
Optimizing communications in memory-bound algorithms is often impossible by using only BLAS functions. For example, the BLAS-based computation of
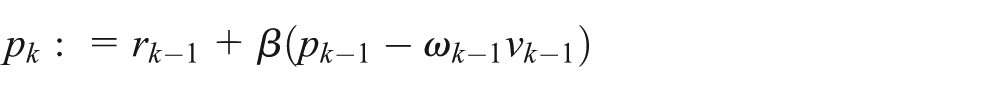
from line 11 of Figure 1 would result in three BLAS calls (lines 4-6 in Figure 1, right). Every routine reads the data from the main memory, computes, and writes the result back. As vector operations (Level 1 BLAS) are memory-bound, the 8n+4 memory transfers (5n+4 reads and 3n writes) limit the performance. Significant improvements can be achieved by “merging” the BLAS functions into a new kernel (see Section 4.4, Figure 9), where data movement is reduced down to the optimal (for this particular case 3n+4 reads and n writes).
Deriving a model reflecting the total data communication volume of one BiCGSTAB iteration is difficult as the memory footprint of the sparse matrix-vector products depends on the used storage format, the kernel implementation and the matrix characteristics. While the memory volume for the matrix in a certain format is usually available (nnz floating point numbers and nnz+n+1 integers for CSR, see Section 3.1), the computation of the product with a vector x requires (for matrices containing off-diagonal entries) typically more than n additional memory reads, as entries of x are needed multiple times and may not all be kept in cache. Against this background, and with the motivation to keep the modularity of the SpMV, we introduce the constant
For the optimization of data transfers, we introduce the following proposition, providing a lower bound of the necessary communication volume:
Proof. Let us assume the parallel computing platform is equipped with n (n ≥ 2) independent processors, where n is the size of the linear system to which the iteration method is applied. Furthermore, each processor may be equipped with cache sufficiently large to keep all scalars and one component of each vector used in the algorithm, in local memory. We refer to this setup as”data-optimal layout,” as all vector operations can be executed in parallel without partitioning the vectors. Communication between these n processors is possible via broadcast (one-to-all messages). This allows the system to compute dot products by the processors consecutively, broadcasting their local sums, and adding any incoming partial sums to form the dot product. In this scenario, all vector updates and local sums can be computed locally without accessing the global memory. The only data read/write phases are at the beginning and end of a processing phase. These phases are defined by the sparse matrix vector products: the modularity of the SpMV building block may require a rearrangement of the processors and flushing all local vector memory (the scalars may be kept). Hence, before each SpMV, all data that will be needed in the future has to be written to the global memory, and after completion of the SpMV, the vectors for the next phase have to be read from global memory. As a result, the iteration loop of the BiCGSTAB has two vector-parallel computation phases interspersed by the SPMV kernels:
Obviously, this data-optimal layout catches the lower bound of data transfers, as any setup with more processors results in idle processors. Any setup with less processors requires one processor to load multiple entries for each vector, perform multiple broadcasts of partial sums for a dot product, and write multiple entries of each vector to global memory. For this reason, we now use the data-optimal setup to prove the proposition by mathematical induction.
For a data-optimal setup of dimension n (n unknowns in the linear system, n processors
Let n = 2. In the vector-parallel computation phase
The data transfer cost for
Consider a system of n+1 unknowns and a subset of n processors
Subsequently, we show that the optimization introduced in Figure 2 reaches this lower bound for the given GPU hardware consisting of fewer than n processors. Using this aforementioned notation, we compare in Table 1 the total GPU memory access in one BiCGSTAB iteration. To account for the additional reduction step that may be necessary when computing dot products, we included the term
Comparison of GPU memory access for the BLAS-based BiCGSTAB (see right of Figure 1) and the merged variant. The term

see right of Figure 1; 3not accounting for the SpMV kernels;
4. Numerical results and experiments
4.1 Experimental setup
In this paper we pursue an incremental approach, where we support all algorithmic and conceptual modifications to the reference implementation with experimental results. We obtain those results from a Tesla K40 GPU that belongs to the Kepler line of NVIDIA’s hardware accelerators, with a theoretical peak performance of 1,682 GFlop/s (double precision). The host system has a theoretical peak of 333 GFlop/s, main memory size of 64 GB, and the theoretical bandwidth is up to 51 GB/s. On the K40 GPU, the 12 GB of main memory, accessed at a theoretical bandwidth of 288 GB/s, is sufficiently large to keep all the matrices and all the vectors needed in the iteration process. We limit our analysis to double precision, and to ensure the accuracy of the data we usually run every experiment 1,000 times and either average the values or report the total time. The host processor was an Intel Xeon E5 (codename: Sandy Bridge, model
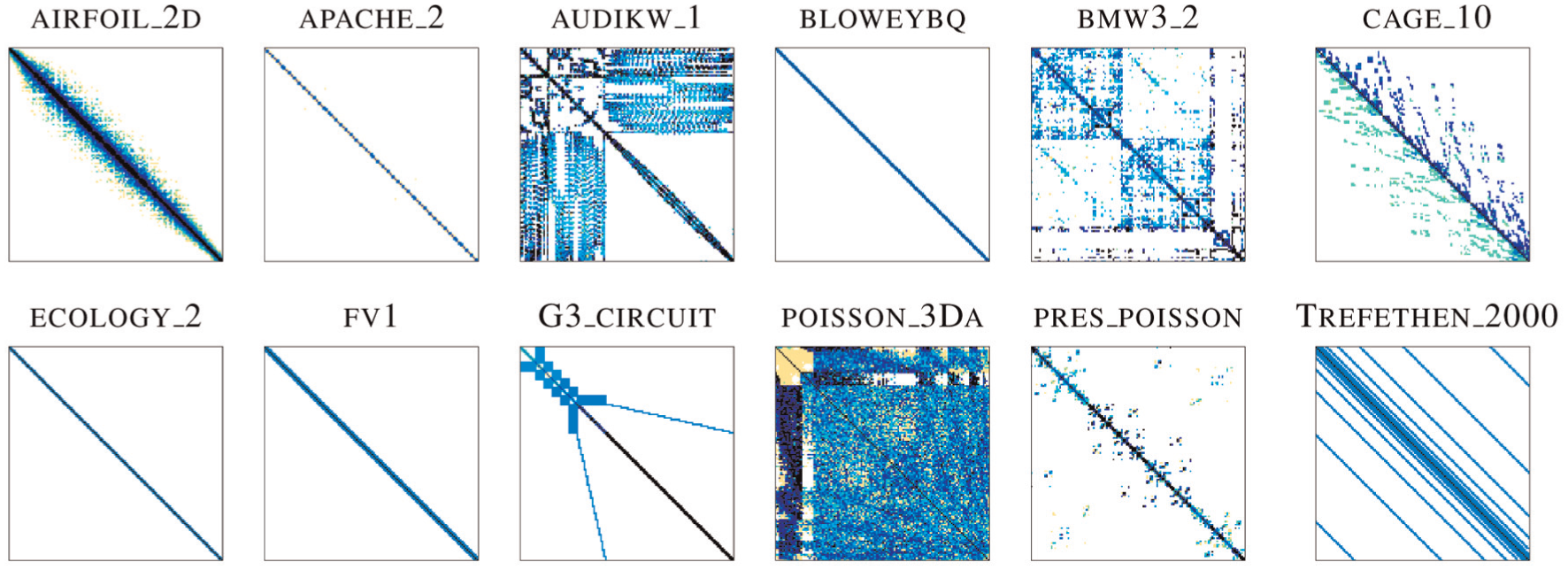
Sparsity structure of the selected test matrices.
Description and properties of the test matrices.
4.2 Performance of the SELL-P SpMV
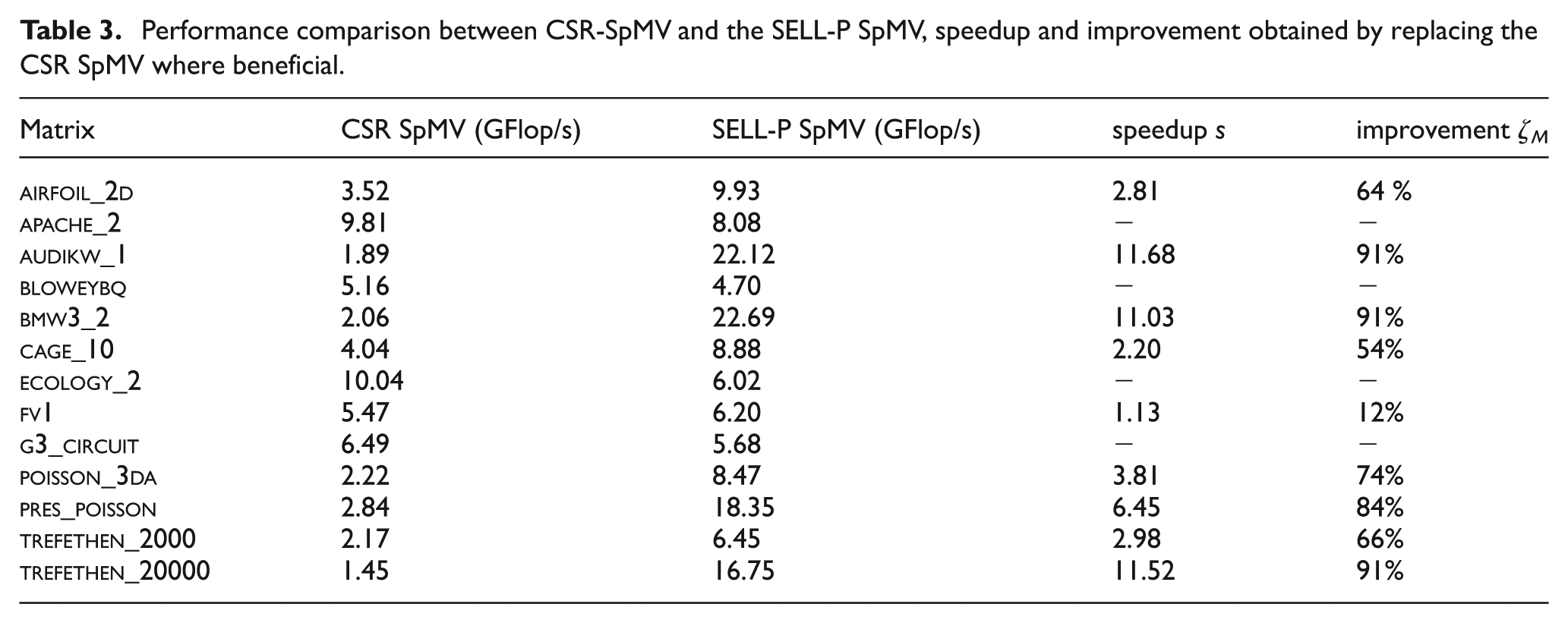
In Anzt et al. (2014b), a comprehensive performance comparison reveals the competitiveness of the SELL-P SpMV against other highly-tuned implementations, including NVIDIA’s in-house developments available via the cuSPARSE library (NVIDIA, 2013a). A comparison to multicore CPU approaches is available in Anzt et al. (2015). We refrain from including all options in this paper, but instead limit our focus on the potential improvement obtained by replacing the standard CSR-based kernel with the SELL-P format. In Table 3 we list the performance achieved by either of the implementations, and, in the case of superior SELL-P performance, the speedup s is obtained by replacing the standard CSR SpMV. The results reveal that no overall-superior SpMV format exists, and particularly for very sparse system, the basic CSR may provide a higher performance, see
Performance comparison between CSR-SpMV and the SELL-P SpMV, speedup and improvement obtained by replacing the CSR SpMV where beneficial.
4.3 Tuning of merged dot products
The limited cache size in GPUs poses restrictions when aiming for the simultaneous reduction of multiple vectors, as the shared memory is the key to the efficiency of the implementation. We overcome this bottleneck by processing the data in chunks of vectors allowing for efficient cache usage. Note that the number of vectors in every chunk is dependent on the hardware characteristics, the block size, and the precision format used, but independent of the vector length.
According to the performance shown on the left in Figure 7 (see line labeled MDOT for the multi-dot-product kernel) a chunk size of 4 seems reasonable for our implementation. The obtained kernel using the chunk-size of 4 and labeled as MDGM in Figure 7 shows minor performance loss when hitting the reload barrier, but then stabilizes around 8 Gflop/s, outperforming the sequence of cuBLAS dot products by a factor of two. The difference becomes smaller for larger vectors, as the kernels approach their asymptotic performance peaks of about 18 and 14 Gflop/s, respectively (see left of Figure 8). The comparison with the matrix-vector product kernels is interesting. While NVIDIA’s implementation (CUGeMV) is not at all able to keep up with the MDGM for tall and skinny matrices, the matrix-vector product provided by MAGMA (MAGMA _GeMV), where one SXM handles one vector, catches up with the cuBLAS dot product as soon as four dot products are needed, and thus, 4 SXMs are used. On the right of Figure 8 we show the superiority areas of MDGM and MAGMA _GeMV as a function of the vector length. As expected, the more column-dominated a matrix is, the more reasonable the usage of MDGM is where all SXMs are used for every row. A direct comparison of MDOT against NVIDIA’s dot product for different vector sizes is given on the left in Figure 8. The first observation is that, when computing only one dot product, the MDGM outperforms the cuBLAS implementation for small lengths, while cuBLAS yields slightly higher performance as soon as the vector length exceeds 106. Close inspection reveals that the performance of MDOT decreases slightly at around 200,000. This stems from the iterative reduction procedure; for larger vectors one reduction step is not sufficient, rather a second kernel is needed (see line 62–72 in
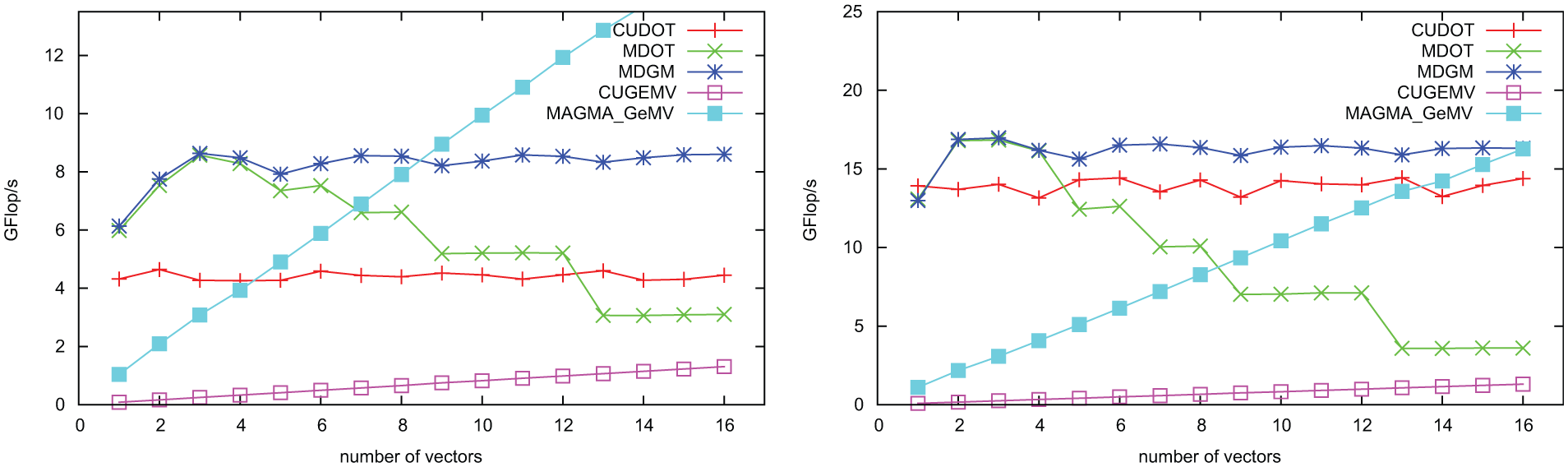
Performance comparison between cuBLAS dot product, the developed simultaneous dot product implementations MDOT and MDGM, and the matrix-vector products from NVIDIA and MAGMA, respectively for a vector length of 100,000 (left) and 1,000,000 (right).
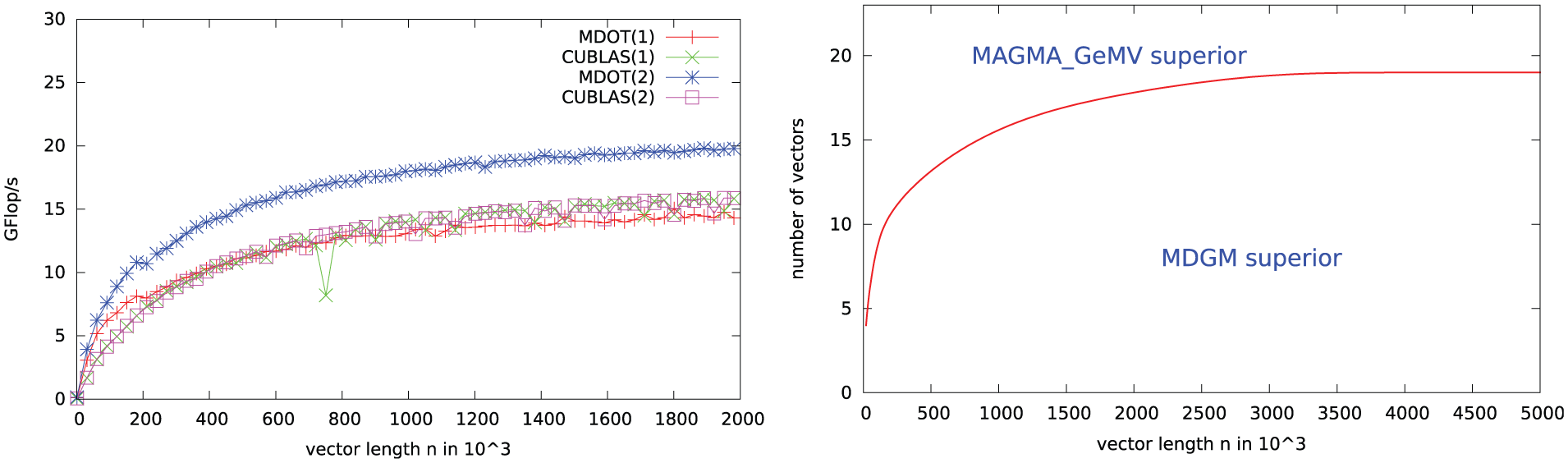
Left: Performance comparison (double precision) between cuBLAS and MDOT executing 1 and 2 vector products. Right: Superiority areas of MDGM and MAGMA’s matrix-vector kernel.
When adding a second dot product with one vector shared by both operations (see data labeled MDOT(2) and cuBLAS(2) in Figure 8, left) the performance of MDOT increases by about one third due to reuse of one vector and the simultaneous reduction of two vectors. For cuBLAS we do not observe any performance improvement when executing two consecutive dot products. Improvement would only become possible by using a compiler capable of detecting the reuse of one vector.
4.4 Reducing communication through merged kernels
Figure 9 shows the new “merged” kernel updating the vector p that we discussed in Section 3.3. As the data movement is reduced down to 3n+4 reads and n writes (50% reduction against the set of cuBLAS routines), we expect an asymptotic speedup of 2, which is reflected on the right side of Figure 9 where the update of p using cuBLAS functions reaches, for large vector sizes, only 11.5 Gflop/s compared to 22.4 Gflop/s of the
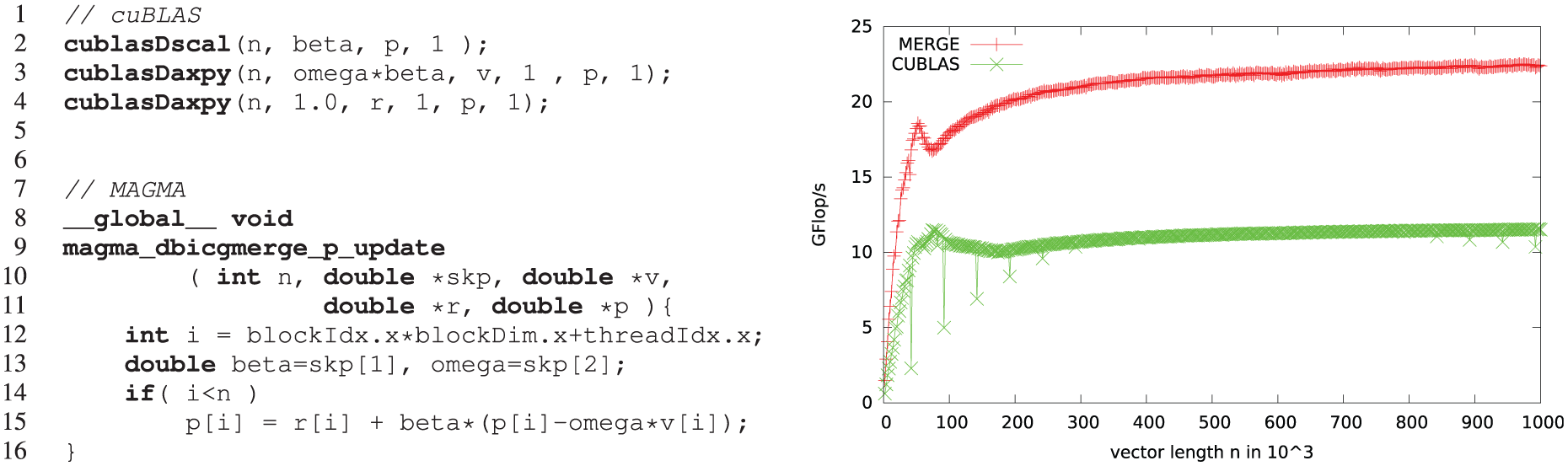
Left: cuBLAS library calls and an algorithm-specific kernel (labeled MAGMA) for the update of vector p (see line 11 in Figure 1). Right: Comparison of the respective performance.
4.5 Experimental comparison with performance model guiding the optimizations
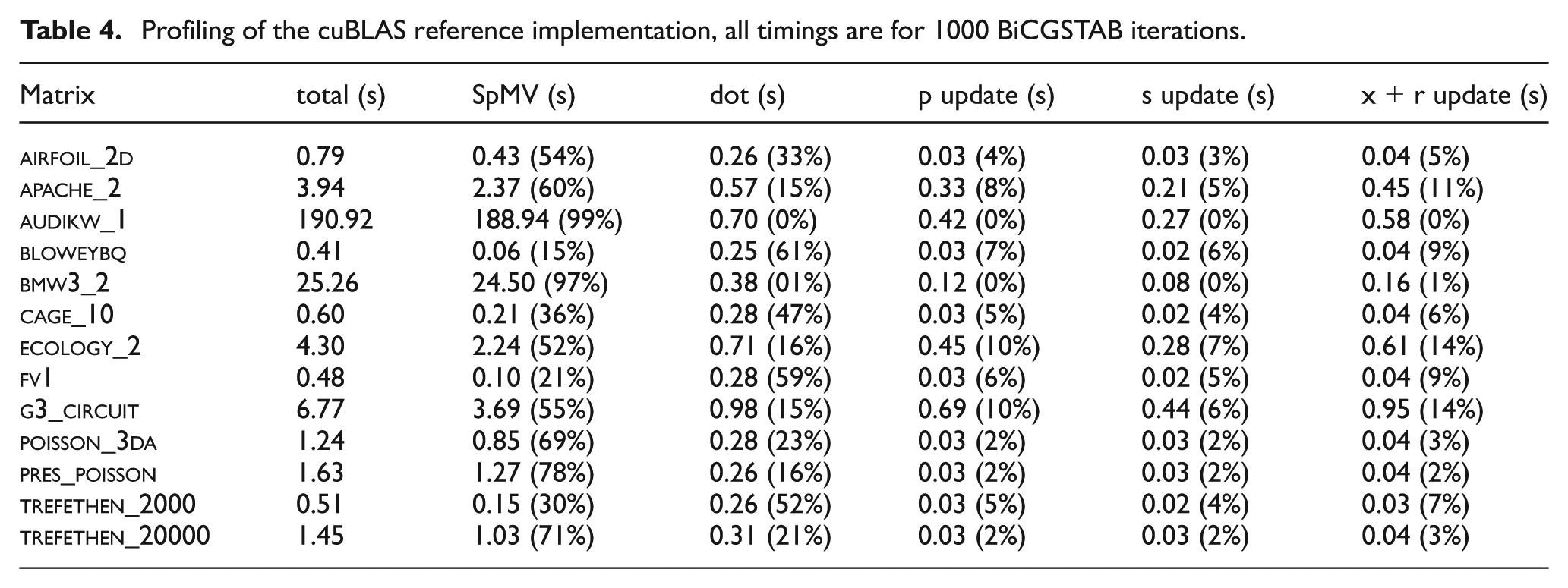
In the previous sections, we have proposed different optimizations and modifications to the BiCGSTAB algorithm structure and its implementation on a GPU-accelerated system. In this section, we aim for a theoretical model quantifying the improvements that the modifications are expected to achieve in experiments using the set of test matrices introduced in Section 4.1. In Table 4, we profile the cuBLAS reference implementation for the different test matrices. Step by step we now develop a model providing estimations for the savings rendered by the modifications we proposed in the previous sections.
Profiling of the cuBLAS reference implementation, all timings are for 1000 BiCGSTAB iterations.
An almost problem-independent improvement is the reduction of memory transfers we realized in Section 3.3, where we merged multiple arithmetic operations into one kernel. While we left the sparse matrix-vector product untouched, we aggregated vector updates, and, whenever possible, included the first part of a scalar product computation. Hence, an accurate model would require distinguishing between the”reading” and the”reduction” phase of dot products. However, we argue that the”reduction” part is usually dominating the computational cost, and exclude the dot products from the memory-improved parts.
Against the background of estimating the memory savings for the remaining parts as
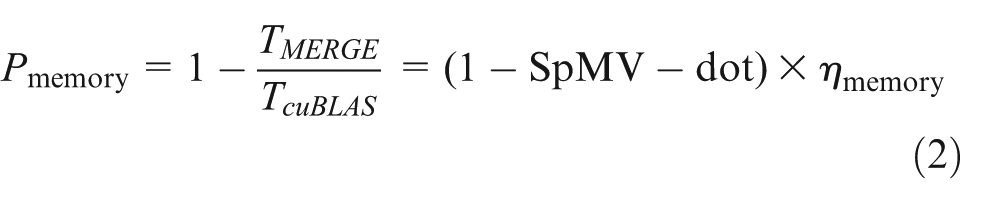
Ordering the matrices according to the combined SpMV and dot dominance (see Table 4), we visualize the savings obtained by the reduced memory transfers in Figure 11 (see’memory’). This model is independent of the characteristics of the target matrix and the applied sparse matrix-vector kernel, as we did not merge the SpMV with any other operation to maintain the genericness of the algorithm. The size of the problem, already impacting the dominance of (SpMV+dot) operations, becomes even more important as soon as we extend the model by also accounting for the improvements rendered by the aggregated dot product (MDOT) we proposed in Section 3.2, which is capable of computing multiple dot products simultaneously. The improvements when switching from cuBLAS to MDOT are dependent on the vector size, and in order to quantify them, we run experiments on the sequence of dot products that occur in the BiCGSTAB algorithm; two sets of consecutive dot products sharing one of the vectors and one separate dot product (see left of Figure 10). For the remainder of the paper, we use the following function (produced with a regression fit of the experimental results) to approximate the runtime savings (shown on the right of Figure 10)
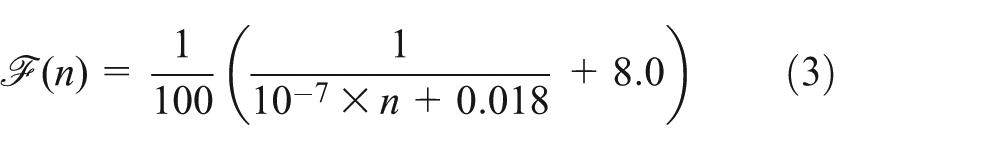
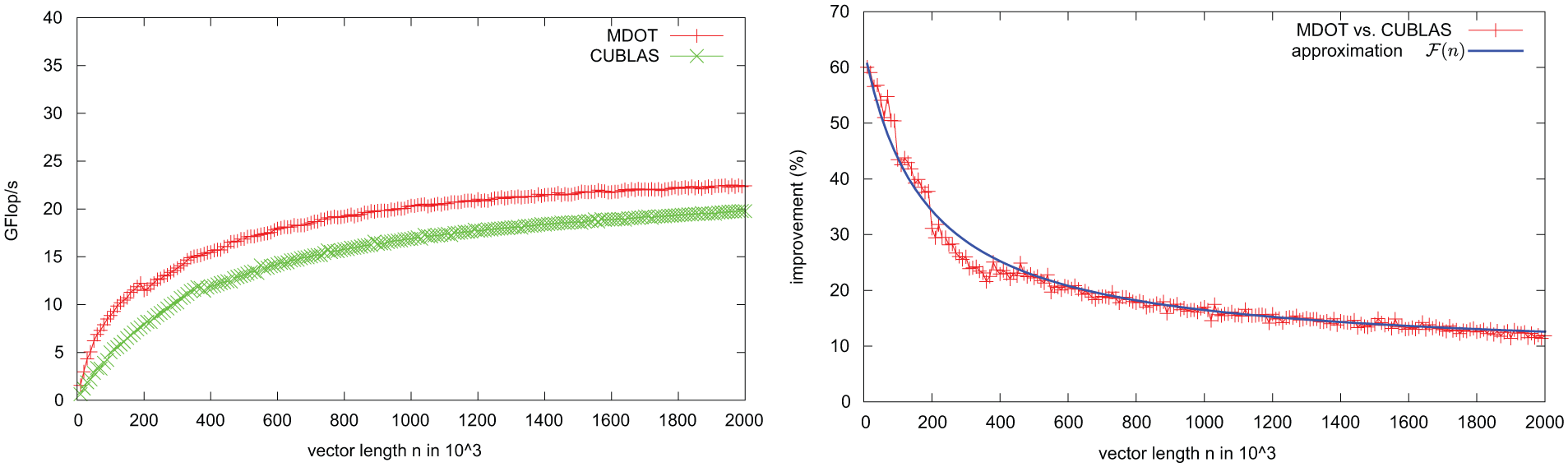
Performance comparison (left) and size-dependent runtime improvement (right) between cuBLAS and MDOT in the sequence of dot products in BiCGSTAB.
We now combine the improvements due to data locality of MDOT in equation (4), which models the expected improvement that depends on the matrix size n, and the relative portion of the sparse matrix-vector kernel (SpMV), and the dot product (dot) in one iteration, respectively. Using this equation, it is possible to predict the runtime savings when switching from the cuBLAS to the merged implementation without changing the sparse matrix-vector kernel, when having knowledge about the matrix size exclusively (visualized in Figure 11 as’memory+dot’).
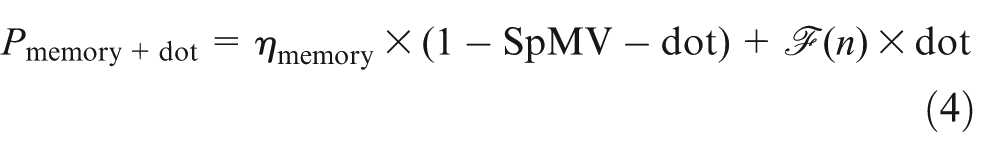
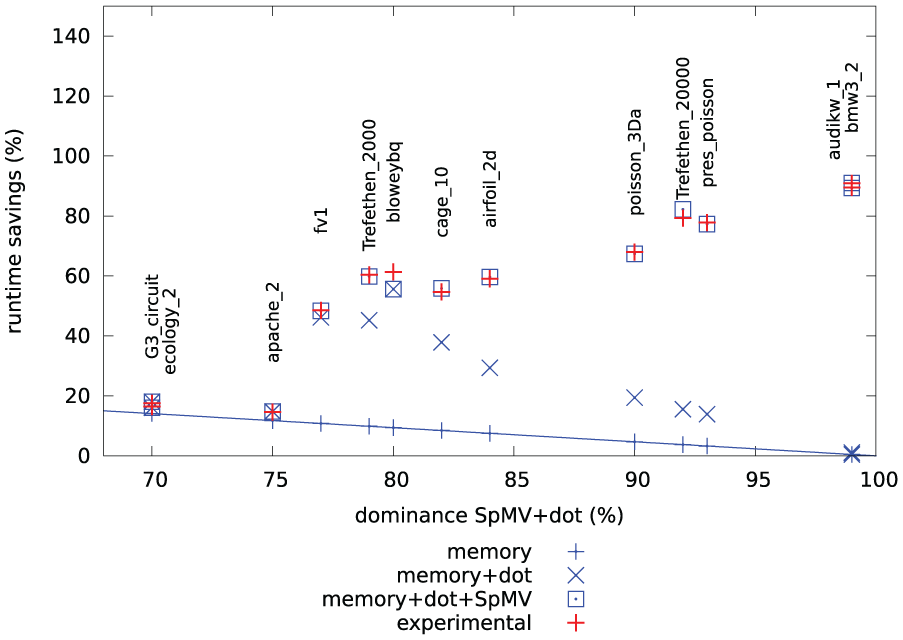
Estimated (blue) and experimental (red) performance improvement obtained by replacing the cuBLAS reference implementation with the reformulated version, depending on the matrix-vector kernel dominance in the original code.
Predicting the improvements obtained by also replacing the CSR-SpMV with a more sophisticated matrix-vector kernel requires detailed knowledge of the characteristics of the sparse matrix. Although approaches exist to classify sparse matrices for SpMV performance prediction (Malossi et al., 2014), we limit our model to the experimental SpMV performance analysis providing the data given in Table 3. Combining the listed improvements obtained by switching to the SELLP-SpMV with the time fraction spent on the sparse matrix-vector kernel (see Table 4), we can extend the model to account for the reduced memory transfers, the aggregated dot products and the improved SpMV
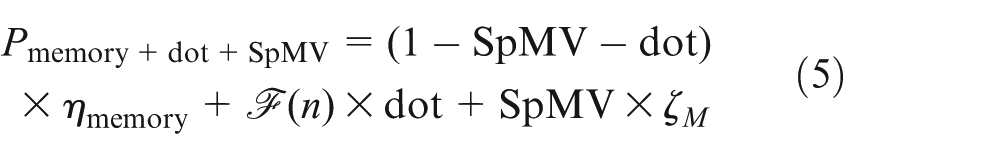
Comparing the predictions Pmemory+dot+SpMV visualized as’memory+dot+SpMV’ in Figure 11 with data obtained from runtime experiments based on 1000 BiCGSTAB iterations (labeled as’experimental’), we observe that the model is in most cases able to provide very good estimations, better than the linear model based exclusively on the memory improvement, and the model Pmemory+dot.
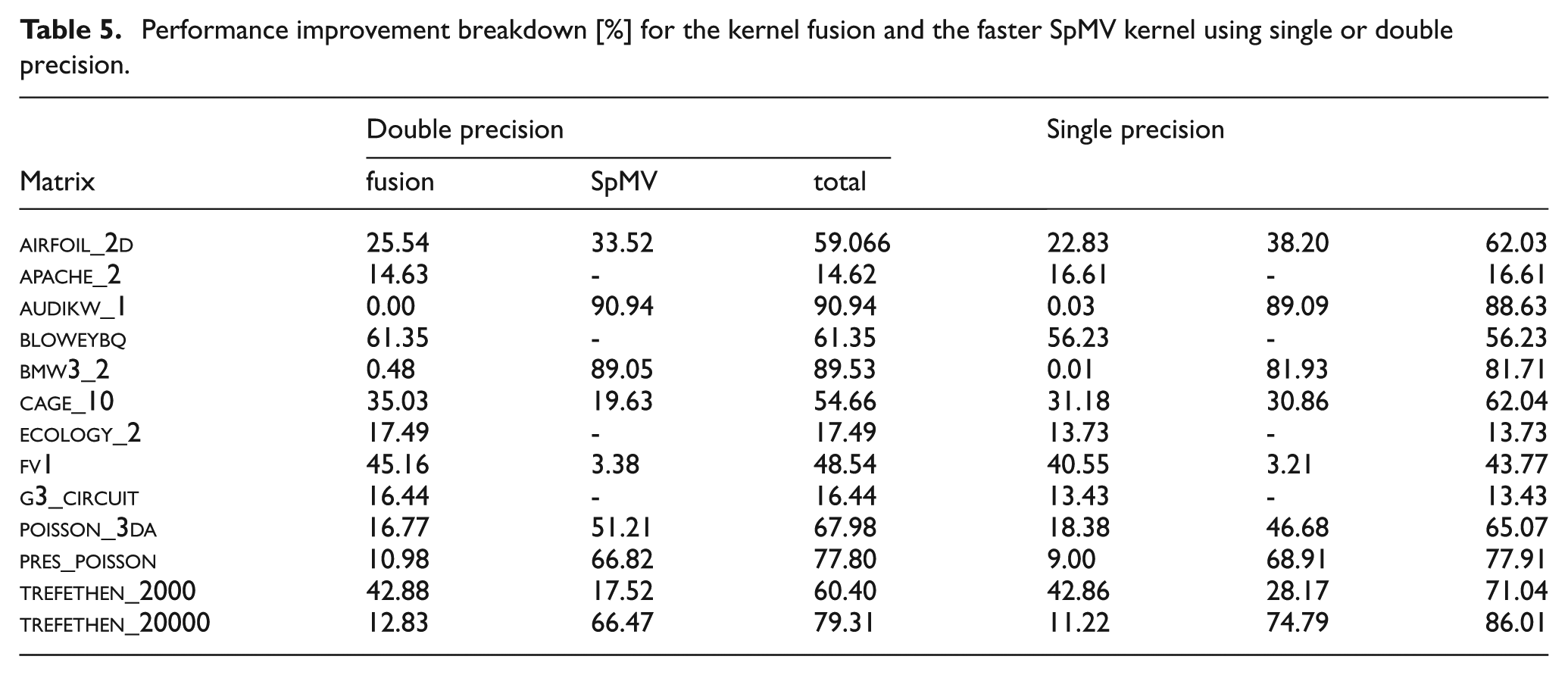
The acceleration shown in Figure 11 breaks down into improvements coming from applying the kernel fusion technique to reduce the communication, and, for some matrices, the improvements coming from the faster SpMV kernel. A detailed analysis on these contributions can be found in Table 5. Although double precision accuracy is usually considered mandatory for scientific computing, we also include single precision results, as techniques like iterative refinement (Buttari et al., 2007; Baboulin et al., 2009) allow us to leverage the single-precision performance of GPUs while maintaining double-precision accuracy of the solution (Anzt et al., 2010). As the CSR and SELL-P data structure for the matrices consist of integer and floating point arrays, the SpMV acceleration for single precision can be quite different than the double precision acceleration. At the same time, the consistent communication-related performance improvements can be used to verify the model’s accuracy.
Performance improvement breakdown [%] for the kernel fusion and the faster SpMV kernel using single or double precision.
Beyond the successful validation of the derived model, we observe that the main goal of our work was achieved as well; the new BiCGSTAB implementation outperforms the cuBLAS reference implementation for all test cases. Depending on the matrix characteristics, the merged version based on either the CSR or the SELL-P matrix-vector kernel achieves runtime reductions between 20% and 90%. The fact that these improvements are distributed over the spectrum of the SpMV dominance shows that the modifications have to go hand-in-hand to ensure problem-independent performance improvement.
5. Conclusion
Taking the BiCGSTAB method as representative for a Krylov subspace solver, we have investigated how to leverage the performance potential of graphics processing units. The optimized implementation reformulates the algorithm, merges multiple arithmetic into algorithm-specific kernels to reduce the memory traffic, keeps all data in GPU memory to remove pressure from the PCI connection, uses new highly-efficient dot product kernels able to reduce multiple dot products simultaneously, and replaces the standard CSR-based matrix-vector product by the SELL-P kernel where beneficial. Compared to a reference implementation where the arithmetic operations of the mathematical formulation are directly translated into cuBLAS function calls, the new implementation yields appealing performance improvements from 20% to 90% for matrices taken from the University of Florida Matrix Collection. Furthermore, we have derived a model that succeeds in predicting the performance improvements. This model is based on the reduced memory accesses, the faster execution due to our new and optimized dot product, and the accelerated SpMV. While we focused on BiCGSTAB, the necessity of method-specific kernels to achieve high performance on GPUs also applied to other Krylov subspace methods. Deriving models similar to ours may provide a-priori insight into whether a specific solver is suitable for a custom-designed GPU implementation when considering the achieved performance improvements. Future research should focus on including preconditioner techniques, as preconditioning is often the key to efficiency when solving sparse linear systems via Krylov subspace methods. Also, the integration of a matrix powers kernel may yield additional benefits due to reduced communication and synchronization.
Footnotes
Funding
This material is based upon work supported by the National Science Foundation under Grant No. ACI-1339822, Department of Energy grant No. DE-SC0010042, and the Russian Scientific Fund, Agreement N14-11-00190.
Notes
Author biography
Hartwig Anzt is a PostDoctoral researcher in Jack Dongarra’s Innovative Computing Lab (ICL) at the University of Tennessee. He received his Ph.D. in mathematics from the Karlsruhe Institute of Technology (KIT) in 2012. Dr. Anzt’s research interests include simulation algorithms, sparse linear algebra, hardware-optimized numerics for GPU-accelerated platforms, communication-avoiding and asynchronous methods, and power-aware computing.
Stanimire Tomov is a Research Director in the Innovative Computing Laboratory (ICL) at the University of Tennessee. Tomov’s research interests are in parallel algorithms, numerical analysis, and high-performance scientific computing (HPC). He has been involved in the development of numerical algorithms and software tools in a variety of fields ranging from scientific visualization and data mining to accurate and efficient numerical solution of PDEs. Currently, his work is concentrated on the development of numerical linear algebra libraries for emerging architectures for HPC, such as heterogeneous multicore processors, graphics processing units (GPUs), and Many Integrated Core (MIC) architectures.
Piotr Luszczek is a Research Director at the University of Tennessee. His research interests include large scale parallel algorithms, numerical analysis, and high-performance computing (HPC). He has been involved in the development and maintenance of widely used software libraries for numerical linear algebra. In addition, he specializes in computer benchmarking of supercomputers using codes based on linear algebra, signal processing, and PDE solvers.
William Sawyer is a computational scientist at the Swiss National Supercomputing Centre (CSCS), in Lugano, Switzerland, a branch of the Swiss Federal Institute of Technology, Zurich (ETH), and supports CSCS’s customers from the Geosciences. He completed his dissertation on”Efficient Numerical Methods for the Shallow Water Equations on the Sphere” in 2006 at the ETH Zurich. He has an extensive research record in the field of parallel applications and algorithms for HPC platforms, in particular for numerical weather prediction, climate models and data assimilation systems.
Jack Dongarra holds appointments at the University of Tennessee, Oak Ridge National Laboratory, and the University of Manchester. He specializes in numerical algorithms in linear algebra, parallel computing, use of advanced computer architectures, programming methodology, and tools for parallel computers. His contributions to the HPC field have received numerous recognitions including the IEEE Sid Fernbach Award (2004), the first IEEE Medal of Excellence in Scalable Computing (2008), the first SIAM Special Interest Group on Supercomputing’s award for Career Achievement (2010), and the IEEE IPDPS 2011 Charles Babbage Award. He is a fellow of the AAAS, ACM, IEEE, and SIAM and a member of the National Academy of Engineering.