
Abstract
Coprocessors based on the Intel Many Integrated Core (MIC) Architecture have been adopted in many high-performance computer clusters. Typical parallel programming models, such as MPI and OpenMP, are supported on MIC processors to achieve the parallelism. In this work, we conduct a detailed study on the performance and scalability of the MIC processors under different programming models using the Beacon computer cluster. Our findings are as follows. (1) The native MPI programming model on the MIC processors is typically better than the offload programming model, which offloads the workload to MIC cores using OpenMP. (2) On top of the native MPI programming model, multithreading inside each MPI process can further improve the performance for parallel applications on computer clusters with MIC coprocessors. (3) Given a fixed number of MPI processes, it is a good strategy to schedule these MPI processes to as few MIC processors as possible to reduce the cross-processor communication overhead. (4) The hybrid MPI programming model, in which data processing is distributed to both MIC cores and CPU cores, can outperform the native MPI programming model.
1. Introduction
Emerging computer architectures and advanced computing technologies, such as Intel’s Many Integrated Core (MIC) Architecture 1 and graphics processing units (GPUs) (Kirk and Hwu, 2012), provide a promising solution to employ parallelism for achieving high performance, scalability and low power consumption. For example, the NSF sponsored Beacon supercomputer 2 contains 192 MIC-based Intel Xeon Phi 5110P coprocessors. It is ranked number 397 on the Top 500 list, 3 and number 1 on the Green 500 list as of June 2013. 4 The Stampede supercomputer 5 at the Texas Advanced Computing Center contains 6880 Intel Xeon Phi coprocessors. It can provide a computing performance of nearly 10 petaflops. The majority of the 10 petaflops comes from the MIC coprocessors.
The current Intel MIC architecture (i.e. Knights Corner) contains up to 61 low-weight processing cores, as shown in Figure 1. These cores are connected through a high-speed ring bus. Each core can run four threads in parallel. Because each core alone is a classic processor, traditional parallel programming models, such as MPI and OpenMP, are supported on each core. The MIC processors typically co-exist with multicore CPUs, such as Intel Xeon E5, in a hybrid computer node as coprocessors/accelerators. In the remainder of this paper, a single MIC card or device will be called a MIC processor or MIC coprocessor. The constituent processing core on a MIC card will be called a MIC core.
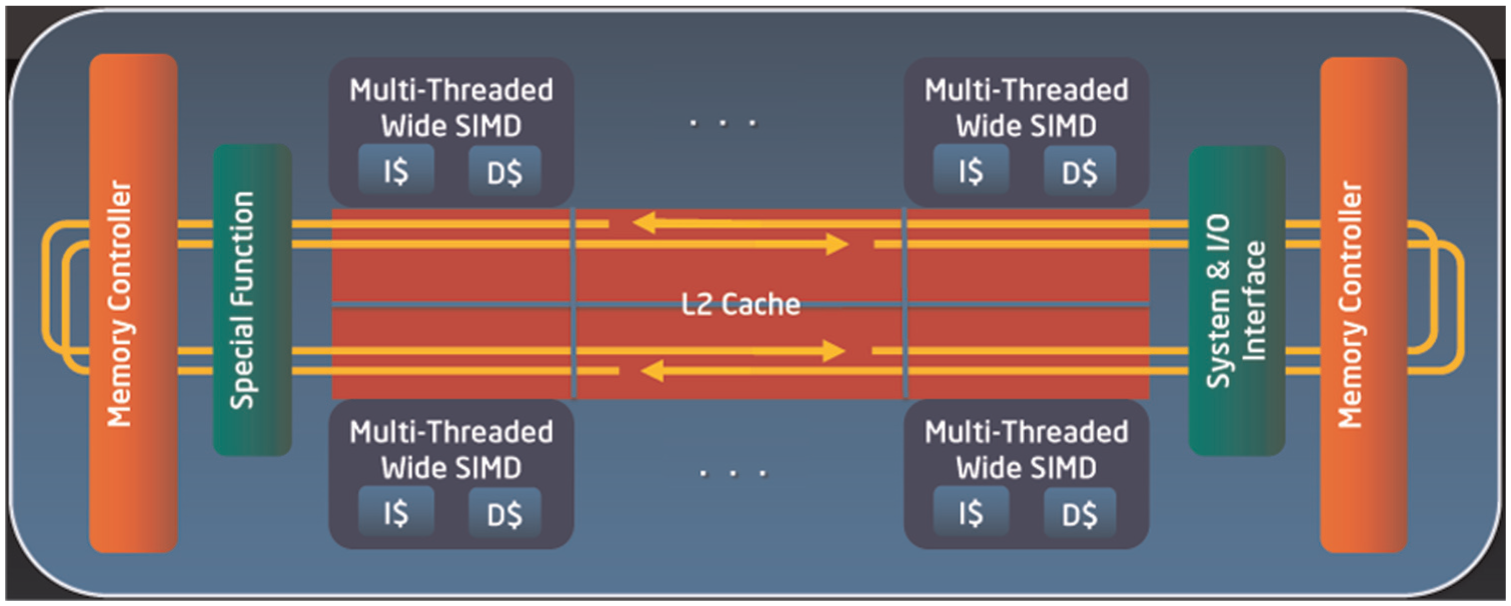
The architecture of Intel Xeon Phi coprocessor (MIC).
In this work, we conduct a detailed study regarding the performance and scalability of five execution modes on Intel MIC processors. In the first mode, the MPI process is directly run on each MIC core. In the second mode, we try to take advantage of the internal processing parallelism on each MIC core. Therefore, we launch four threads in each MPI process using OpenMP. Each MPI process is still run on a MIC core. In the third mode, only one MPI process is issued onto each MIC processor. Then OpenMP is used to launch threads to MIC cores. In the fourth mode, the MPI processes are run on the CPUs. The data processing is offloaded to the MIC processors using OpenMP. Only one thread is scheduled to one MIC core. The fifth mode is a variant of the fourth one. Four threads are scheduled to one MIC core in the fifth mode. We use two geospatial applications, i.e. Kriging interpolation and cellular automata (CA), to test the performance and scalability of a single MIC processor and a computer cluster with hybrid nodes.
Through this study, we have the following findings. (1) The native MPI programming model on the MIC processors is typically better than the offload programming model, which offloads the workload to MIC cores using OpenMP. (2) On top of the native MPI programming model, multithreading inside each MPI process can further improve the performance for parallel applications on computer clusters with MIC coprocessors. (3) Given a fixed number of MPI processes, it is a good strategy to schedule these MPI processes to as few MIC processors as possible to reduce the cross-processor communication overhead when the capacity of the on-board memory is not a limiting factor. (4) We also evaluate a hybrid MPI programming model, which is not officially supported by the Intel MPI compiler. In this hybrid model, the data processing is distributed to both the MIC cores and the CPU cores. The benchmarking results show that the hybrid model outperforms the native model.
The remainder of this paper is organized as follows. The Intel MIC architecture and the two major programming models are discussed in Section 2. We discuss the details of the benchmarks and the experiment platform in Section 3. In Section 4, we show the experiment results on a single MIC device. We also compare the performance of a single MIC device with a single Xeon CPU and the latest GPUs. Then we expand the experiment on two geospatial benchmarks to the Beacon cluster using many computer nodes in Section 5. We discuss some related work in Section 6. Finally, we give the concluding remarks in Section 7.
2. Intel MIC architecture and programming models
The first commercially available Intel coprocessor based on the MIC architecture is Xeon Phi, as shown in Figure 1. Xeon Phi contains up to 61 scalar processing cores with vector processing units. These cores are connected through a high-speed bi-directional, 1024-bit-wide ring bus (512 bits in each direction). In addition to the scalar unit inside each core, there is a vector processing unit to support wide vector processing operations. Further, each core can execute four threads in parallel. The communications between the cores can be realized through the shared memory programming models, e.g. OpenMP. In addition, each core can run MPI to realize communication. Direct communication between MIC processors across different nodes is also supported through MPI.
Figure 2 shows two approaches to parallelizing applications on computer clusters equipped with MIC processors. The first approach is the native model, as shown in Figure 2(a). In this model, the MPI processes directly run on the MIC processors. There are two variants under this model. (1) Let each MIC core directly host one MPI process. In this way, the 60 cores on the Xeon Phi 5110P, which is used in this work, are treated as 60 independent processors while sharing the 8 GB on-board memory. (2) Only issue one MPI process on one MIC card. This single MPI process then spawns threads running on many cores using OpenMP. The second approach is to treat the MIC processors as clients to the host CPUs. As shown in Figure 2(b), the MPI processes will be hosted by CPUs, which will offload the computation to the MIC processors. Multithreading programming models such as OpenMP can be used to allocate many MIC cores for data processing in the offload model.
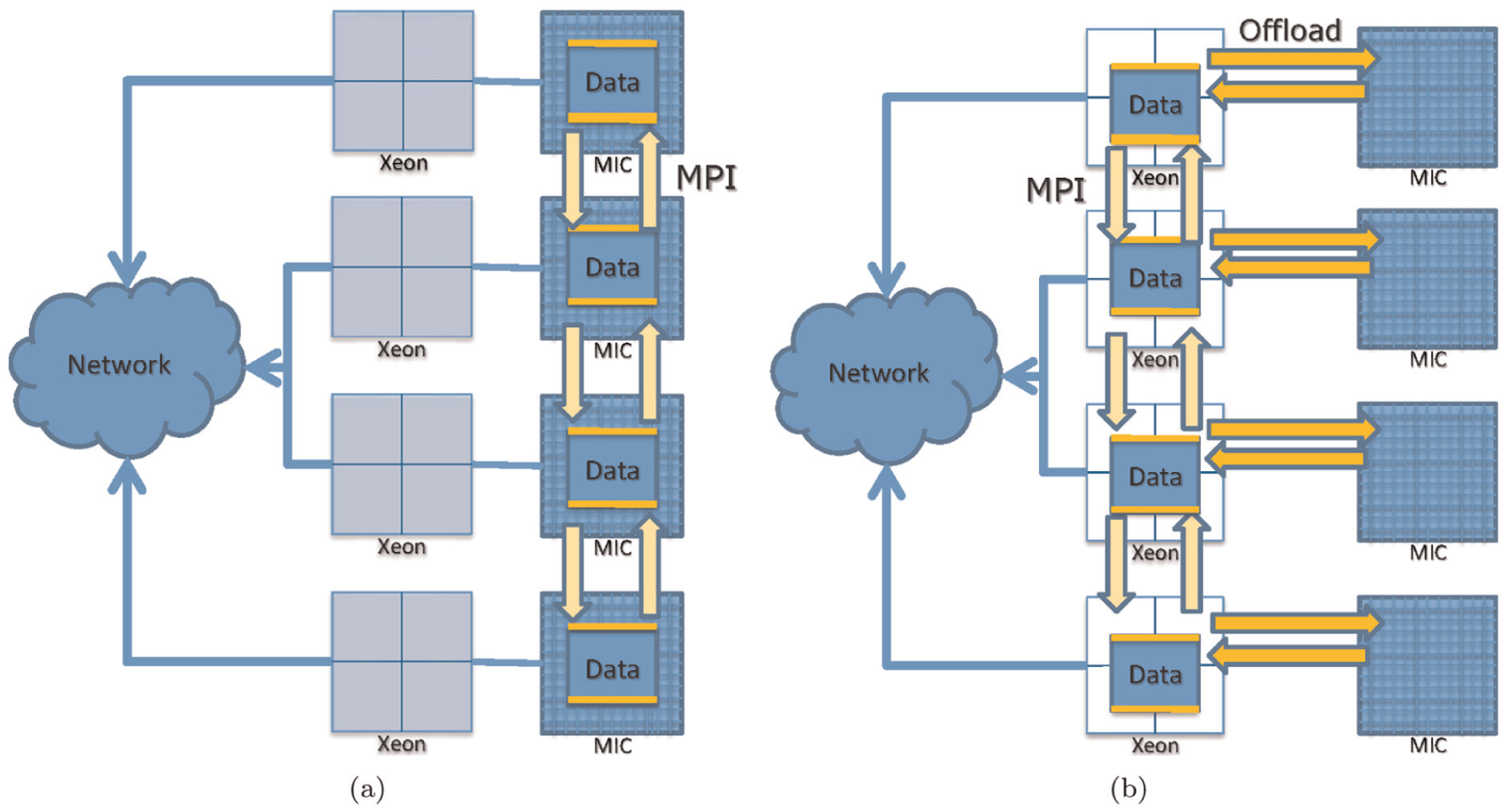
Two different parallel programming models on MIC based computer clusters. (a) In the native model, MPI processes directly run on MIC cores. (b) In the offload model, MPI processes run on CPU cores, which offload computation to MIC cores.
In this work there are five different parallel implementations in these two models as follows.
Native model: In this model, MPI processes directly execute on MIC processors. There are further three implementations.
– Native-1 (N-1): Issue one MPI process onto each MIC core. If n MIC cores are allocated, then n MPI processes are issued. Each MPI process contains only one thread. – Native-2 (N-2): Issue one MPI process onto each MIC core. Each MPI process contains four threads. – Native-3 (N-3): Issue only one MPI process onto each MIC card. Then allocate many MIC cores using OpenMP. On each MIC core, issue four threads.
Offload model: In this model, the CPU offloads the work to the MIC processor using OpenMP. There are further two implementations.
– Offload-1 (O-1): Issue one thread onto each MIC core. If n MIC cores are allocated, then n threads are issued. – Offload-2 (O-2): Issue four threads onto each MIC core. If n MIC cores are allocated, then 4×n threads are issued.
3. Experiment setup
3.1. Benchmarks
Two geospatial applications are chosen to represent two types of benchmarks in high-performance computing: the embarrassingly parallel case and the intense communication case.
3.1.1. Embarrassingly parallel case: Kriging interpolation
Kriging is a geostatistical estimator that infers the value of a random field at an unobserved location (Jensen, 2004). Kriging is based on the idea that the value at an unknown point should be the average of the known values of its neighbors.
Kriging can be viewed as a point interpolation that reads input point data and returns a raster grid with calculated estimations for each cell. Each input point is in the form (xi , yi , Zi ) where xi and yi are the coordinates and Zi is the value. The estimated values in the output raster grid are calculated as a weighted sum of input point values as in (1).

where wi is the weight of the ith input point. Theoretically the estimation can be calculated by the summation through all input points. In general, users can specify a number k so that the summation is over k nearest neighbors of the estimated point in terms of distance. This decrease of computation is due to the fact that the farther the sampled point is from the estimated point, the less impact it has on the summation. For example, the commercial software ArcGIS 6 uses the 12 nearest points (i.e. k = 12) in the Kriging calculation by default. In this benchmark, embarrassing parallelism can be realized since the interpolation calculation over each cell has no dependency on the others.
In the Kriging interpolation benchmark, the problem space as shown in Figure 3(a) is evenly partitioned among all MPI processes as shown in Figure 3(b), in which we use four processes as an example. The computation in each MPI process is purely local, i.e. there is no cross-process communication.
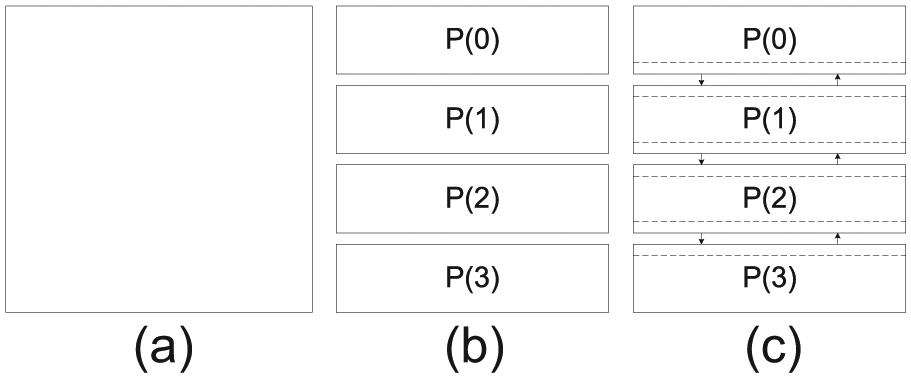
(a) Data partition and (b), (c) communication in two benchmarks: (b) in Kriging interpolation there is no communication among MPI processes (i.e. P(I) in the figure) during computation; (c) in Game of Life, MPI processes need to communicate with each other in the computation.
The input size of this benchmark is 171 MB, consisting of 4 data sets with the respective sizes of 29, 37, 48, and 57 MB. Each data set has 2191, 4596, 6941, and 9817 sample points, respectively. The output raster grid for each data set has a consistent dimension of 1440×720. In other words, each data set will generate a 1440×720 grid. The value of each point in the output grid needs to be estimated using those sample points in the corresponding input data set. In our experiments, the value of an unsampled point will be estimated using the values of the 10 closest sample points, i.e. k = 10. These four data sets are processed in a sequence. For each data set, the generation of its corresponding output grid is evenly distributed among all MPI processes. In order to generate the value of a point in the output grid, all of the sampled points in the data set need to be scanned to find the 10 closest sample points. The pseudocode of Kriging interpolation is illustrated in Figure 4.

Pseudocode of Kriging interpolation. The inner
3.1.2 Intense communication case: cellular automata
CA are the foundation for geospatial modeling and simulation. Game of Life (GOL) (Gardner, 1970), invented by British mathematician John Conway, is a well-known generic CA. It consists of a collection of cells that can live, die or multiply based on a few mathematical rules.
The universe of the GOL is a two-dimensional square grid of cells, each of which is in one of two possible states, alive (‘1’) or dead (‘0’). Every cell interacts with its eight neighbors, which are the cells that are horizontally, vertically, or diagonally adjacent. At each step in time, the following transitions occur.
Any live cell with fewer than two live neighbors dies, as if caused by under-population.
Any live cell with two or three live neighbors lives on to the next generation.
Any live cell with more than three live neighbors dies, as if by overcrowding.
Any dead cell with exactly three live neighbors becomes a live cell, as if by reproduction.
In this benchmark, the status of each cell in the grid will be updated for 100 iterations. In each iteration, the statuses of all cells are updated simultaneously. The pseudocode is illustrated in Figure 5. In order to parallelize the updating process, the cells in the square grid are partitioned into stripes along the row-wise order. Each stripe is handled by one MPI process. At the beginning of each iteration, each MPI process needs to send the statuses of the cells along the boundaries of each stripe to its neighbor MPI processes and receive the statuses of the cells of two adjacent rows as shown in Figure 3(c).

Pseudocode of Game of Life.
3.2. Experiment platform
We conduct our experiments on the NSF sponsored Beacon supercomputer 2 hosted at the National Institute for Computational Sciences (NICS), University of Tennessee.
The Beacon system (a Cray CS300-AC Cluster Supercomputer) offers access to 48 compute nodes and 6 I/O nodes joined by FDR InfiniBand interconnect, which provides a bi-directional bandwidth of 56 Gb/s. Each compute node is equipped with 2 Intel Xeon E5-2670 8-core 2.6 GHz processors, 4 Intel Xeon Phi (MIC) 5110P coprocessors, 256 GB of RAM, and 960 GB of SSD storage. Each I/O node provides access to an additional 4.8 TB of SSD storage. Each Xeon Phi 5110P coprocessor contains 60 1.053 GHz MIC cores and 8 GB GDDR5 on-board memory. Altogether Beacon contains 768 conventional cores and 11,520 accelerator cores that provide over 210 TFLOP/s of combined computational performance, 12 TB of system memory, 1.5 TB of coprocessor memory, and over 73 TB of SSD storage.
The compiler used in this work is Intel 64 Compiler XE, Version 14.0.0.080 Build 20130728, which supports OpenMP. The MPI library is intel-mpi 4.1.0.024.
4. Experiments and results on a single device
Since a single Intel Xeon Phi 5110P processor is a 60-core processor, it is worthwhile to investigate the performance and scalability of a single MIC processor alone.
4.1. Scalability on a single MIC processor
When the MPI programming model is used to implement the Kriging interpolation application, the workload is evenly distributed among MPI processes. In this benchmark, there are four data sets. For each data set, the output is a 1440×720 raster grid. In the MPI implementation, we increase the number of MPI processes from 10 to 60 with a stride of 10 processes. The computation of 720 columns of the output grid is evenly distributed. The 50-process configuration is skipped because 720 columns cannot be distributed among 50 processes equally. For the offload programming model, we use OpenMP to parallelize the for loops in the program. The OpenMP APIs will automatically distribute workload to the MIC cores evenly.
The detailed execution times of the Kriging interpolation benchmark under both programming models while each MIC core hosts only one thread are listed in Table 1. By looking at the time curves in Figure 6, we can find that both models show a good strong scalability for this application. Their performance in terms of interpolation time is very close too. The reason we do not include the write time in Figure 6 is that the write time may become dramatically lengthy when the number of MPI processes increases. In the Kriging interpolation application, each output raster grid is written into a file. When many MPI processes try to write to the same file, their writes need to be serialized. Further, the arbitration takes a lot of time. This effect is not very significant when one MIC processor is used. Later, we will find that the write time can become extremely significant when many MIC processors are allocated.
Performance of Kriging interpolation on a single MIC processor (unit: second).
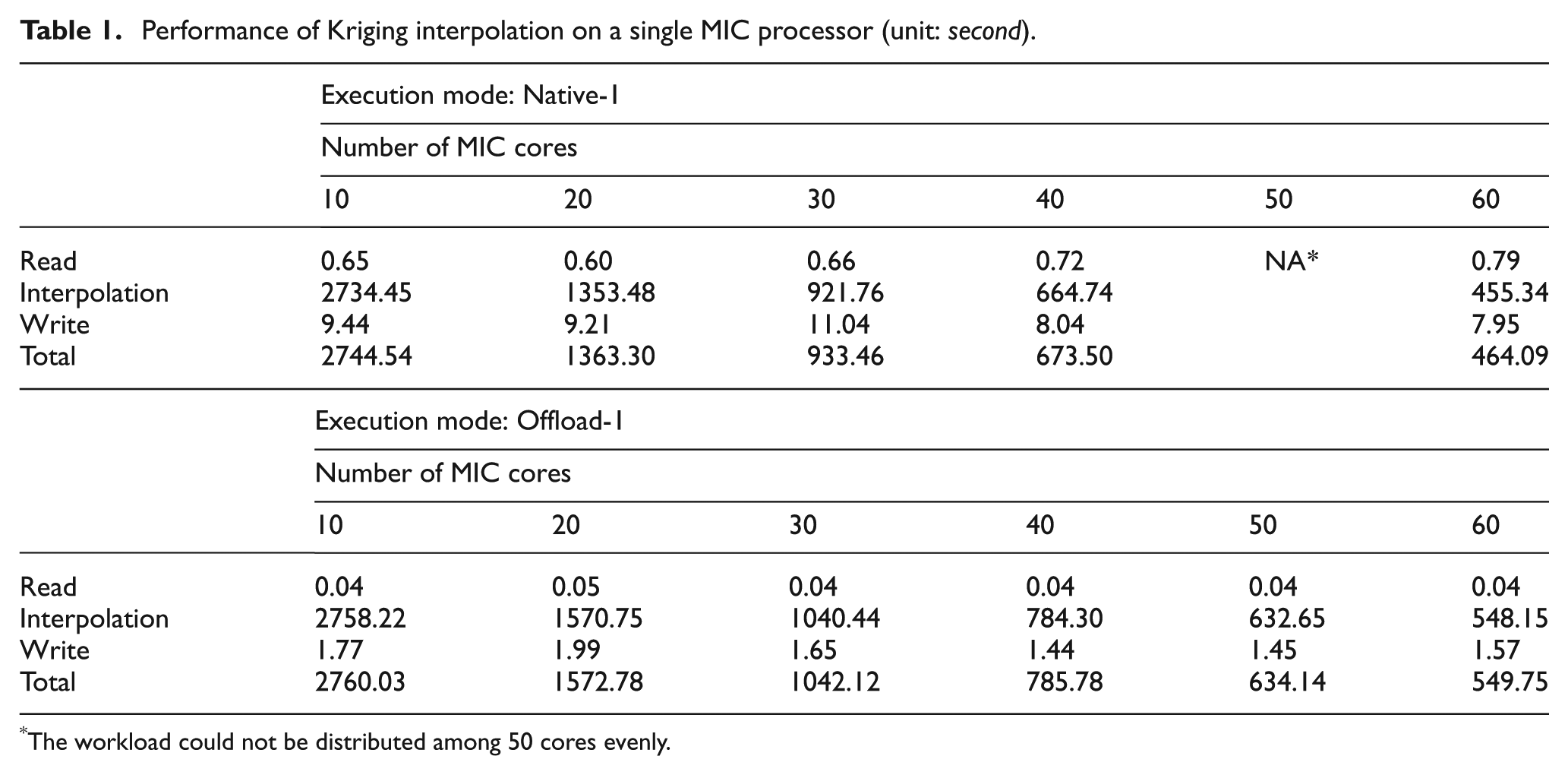
The workload could not be distributed among 50 cores evenly.
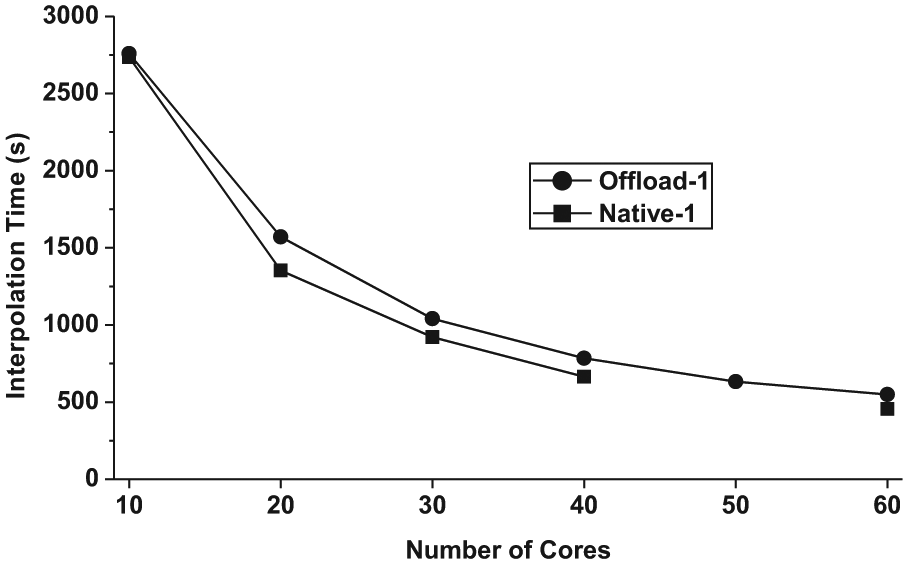
Performance of Kriging interpolation on a single MIC processor. For both implementations, only one thread runs on a MIC core. The native implementation outperforms the offload one with a small margin.
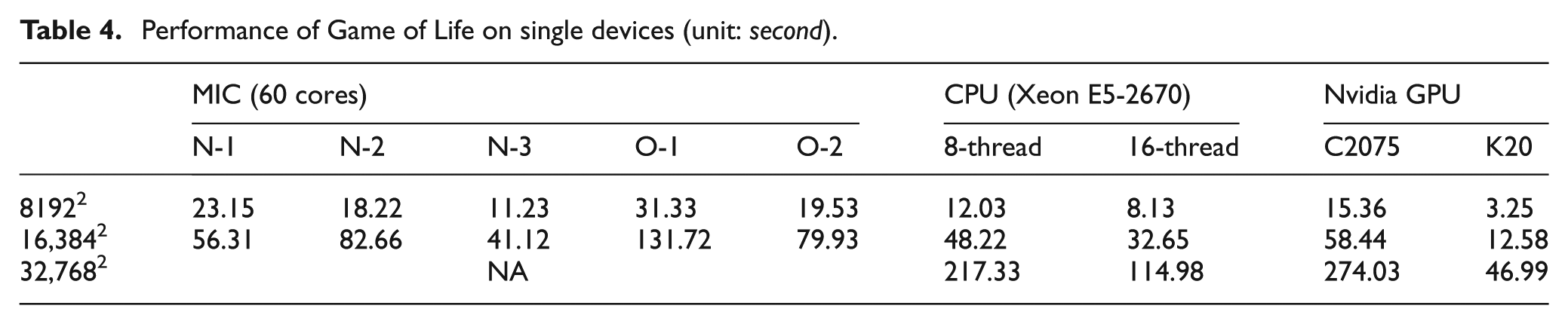
For GOL three different grid sizes are tested, i.e. 8192×8192, 16,384×16,384, and 32,768×32,768. However, we encounter either out-of-memory error or runtime error for the 32,768×32,768 case when only one MIC processor is used. From the results in Table 2, it can be found that the native model consistently outperforms the offload model for this intense communication case. By looking at the performance curves in Figure 7, we can find that both programming models show strong scalability when the number of cores increases from 10 to 20. Beyond that, both models lose the strong scalability although the total computation time still decreases. For both problem sizes, the reduction of workload is gradually offset by the increase of communication overhead when the number of cores increases. Further, when more cores are allocated, the memory access demand increases as well. Eventually, the communication and memory bandwidth become the limiting factors for the performance.
Performance of Game of Life on a single MIC processor (unit: second).
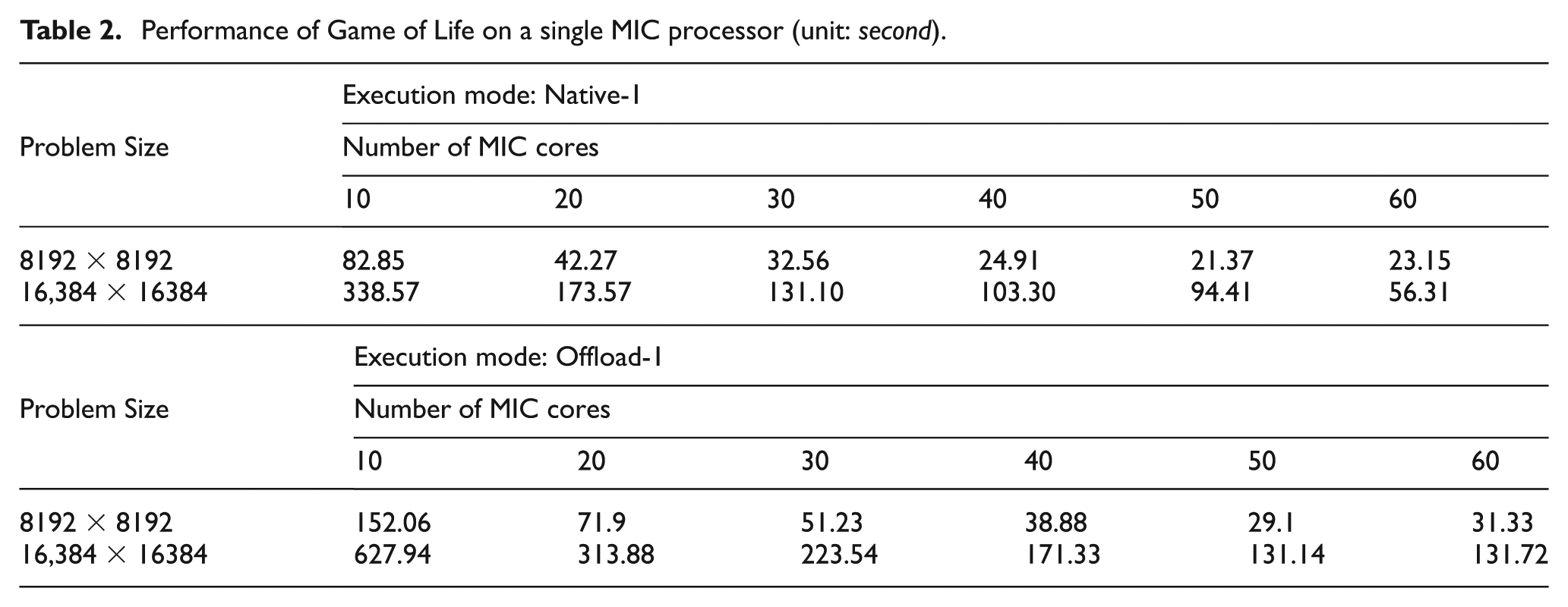
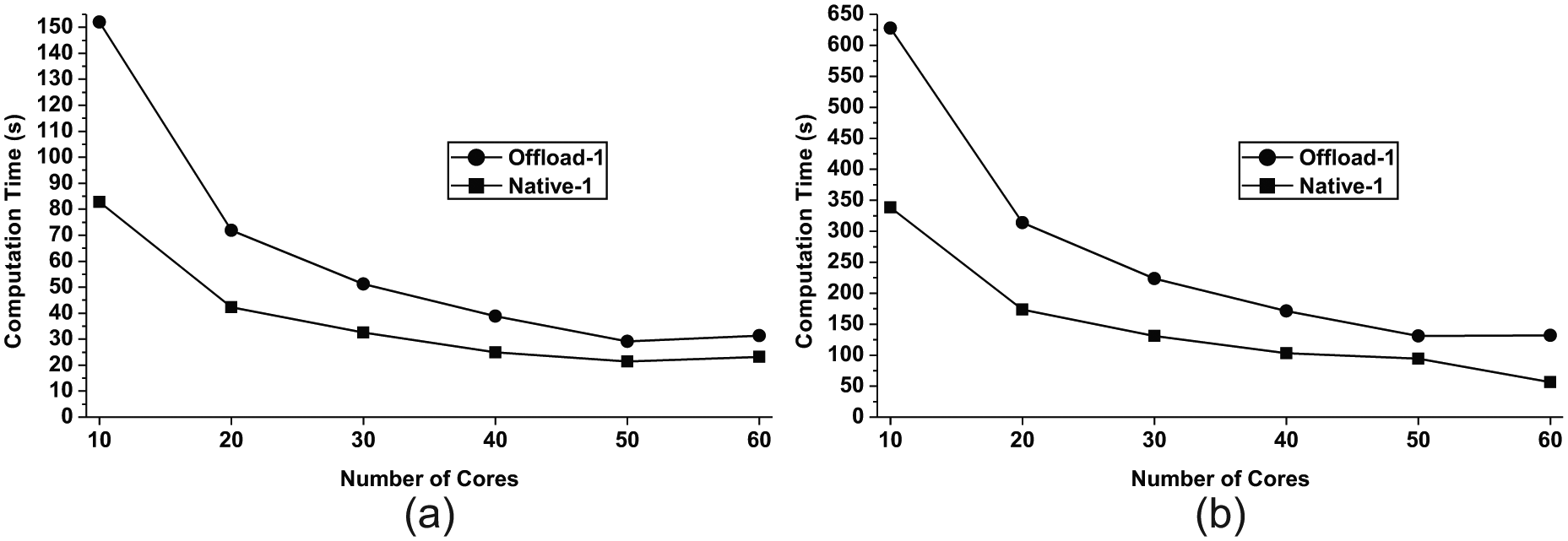
Performance of Game of Life on a single MIC processor: (a) 8192×8192; (b) 16,384×16,384. The native model outperforms the offload model with a big margin when only a few cores are used. The performance gap decreases as more cores are allocated.
4.2. Performance comparison of single devices
As an emerging new technology, it is worthwhile to compare the performance of the Intel MIC processor with the other popular accelerator, i.e. GPU. Furthermore, it is a routine to include very powerful multicore CPUs in supercomputers. Therefore, we conduct a comparison among these three technologies at the full capacity of a single device. For Intel Xeon Phi 5110P, we use all 60 cores under two programming models for 5 different implementations. For the 8-core Xeon E5-2670 CPU on Beacon cluster, we use OpenMP to issue either 8 or 16 threads. For GPU, we test two devices, the Nvidia Tesla C2075 based on Fermi architecture (NVIDIA Corporation, 2009) and the Tesla K20 based on Kepler architecture (NVIDIA Corporation, 2012). The CUDA version is 5.5.
The execution times of Kriging interpolation on various devices are listed in Table 3. It can be found that the performance of the MIC processor and the CPU is at the same order of magnitude. When running at the full capacity, the performance of the Intel Xeon Phi 5110P is equivalent to the Xeon E5-2670. By increasing the number of threads in an MPI process to four, the Native-2 implementation is able to improve the performance by three times compared with Native-1 implementation. However, the Native-3 implementation, i.e. one MPI process with 240 threads, has the much worse performance. We varied the number of threads in the MPI process and found that the performance did not change significantly. We speculate that the OpenMP library does not work well with the Kriging interpolation under Native-3 programming model. For Xeon CPU the 16-thread CPU implementation is almost two times faster than the 8-thread implementation because each CPU core can execute two threads simultaneously. Both GPUs are able to improve the performance by one order of magnitude. Further, K20 is more than two times faster than C2075, as shown in Figure 8.
Performance of Kriging interpolation on single devices (unit: second).
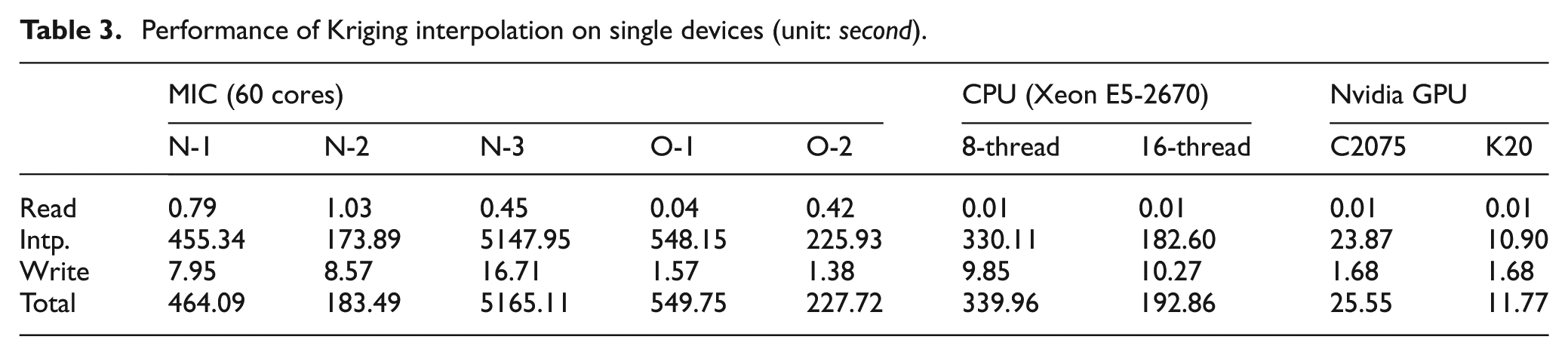
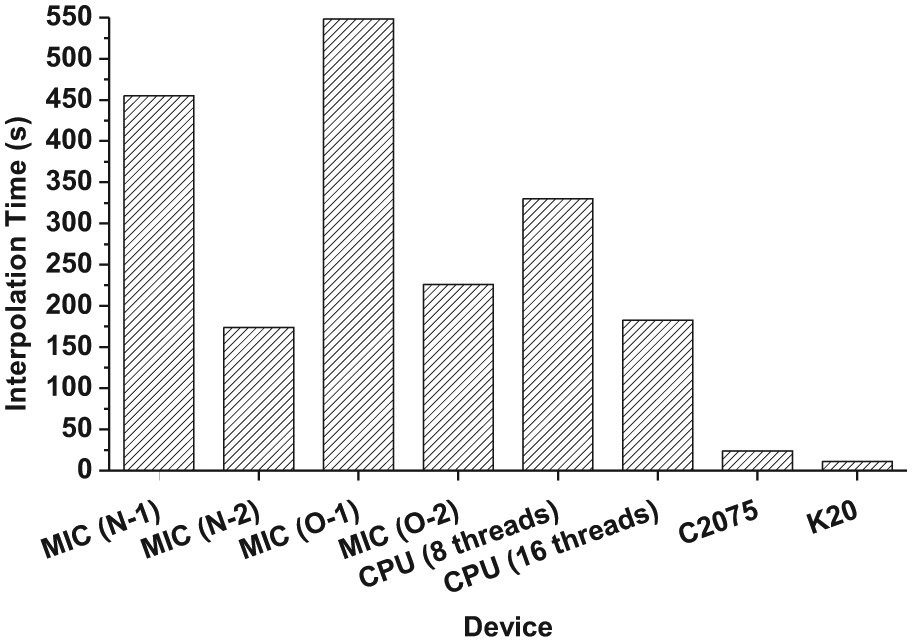
Performance of Kriging interpolation on single devices (excluding Native-3 implementation on Intel MIC device).
The performance results of GOL on three different types of processors are listed in Table 4. The performance of both models on the MIC processor is at the same order of magnitude as the implementations on the CPU and the C2075. All five implementations work quite well on MIC and the native model is typically better than offload model. The Native-3 implementation has the best performance compared with the other four implementations on MIC. Overall the K20 implementation is generally one order of magnitude better in terms of performance compared with other implementations.
Performance of Game of Life on single devices (unit: second).
5. Experiments and results using multiple MIC processors
We also conduct the experiments using multiple MIC processors to demonstrate the scalability of the parallel implementations for those two geospatial applications. For both benchmarks we have five parallel implementations on the Beacon computer cluster using multiple nodes.
We want to show the strong scalability of the parallel implementations as the case on the single device. Therefore, the problem size is fixed for each benchmark while the number of participating MPI processes is increased.
5.1. Comparison among five execution modes
5.1.1. Kriging Interpolation
We allocate 2, 4, 8, and 16 MIC processors for 4 different implementation cases. For the Native-1 and the Native-2 implementations, m×60 MPI processes are created if m MIC processors are used. For the Native-3, Offload-1, and Offload-2 execution modes, m MPI processes are created if m MIC processors are used. As mentioned before, for each output raster grid, the generation of the 720 columns is evenly distributed among the MPI processes. Therefore, only 360 or 720 MPI processes, which execute on 360 or 720 MIC cores, are created when 8 or 16 MIC processors are allocated, respectively, for both Native-1 and Native-2 cases.
The detailed results of the five execution modes for Kriging interpolation are listed in Table 5. It is noticed that the system does not return results when more than 2 MIC processors are used for Offload-2 execution mode. We can find that the write time grows dramatically when more MIC processors are used for both Native-1 and Native-2 execution modes. As mentioned before, the serialization of the write and the arbitration among the numerous MPI processes contribute to the lengthy write process. Therefore, we only include the interpolation time, which includes both the time spent on data processing and the time spent on cross-processor communication, when comparing the performance of the four execution modes in Figure 9. We do not include Native-3 in Figure 9 because its interpolation time is significantly larger than other execution modes although it obeys the strong scalability. It can be found that the Native-1 and the Offload-1 execution modes have the very close performance for this benchmark. When the multithreading is applied in each MPI process on the native MPI programming model, the performance can be improved by roughly three times. This case shows that it is not enough to only parallelize application to all the cores on MIC processors. It is equally important to increase the parallelism on each MIC core to further improve the performance.
Performance of Kriging interpolation under various execution modes on multiple MIC processors (unit: second).
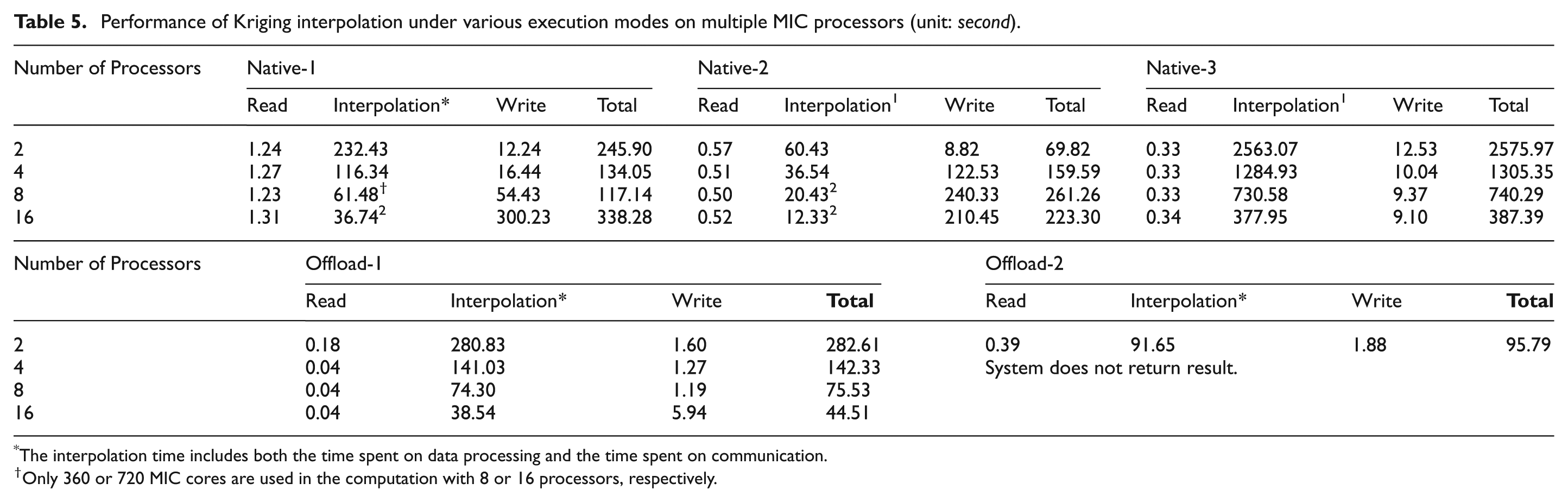
The interpolation time includes both the time spent on data processing and the time spent on communication.
Only 360 or 720 MIC cores are used in the computation with 8 or 16 processors, respectively.
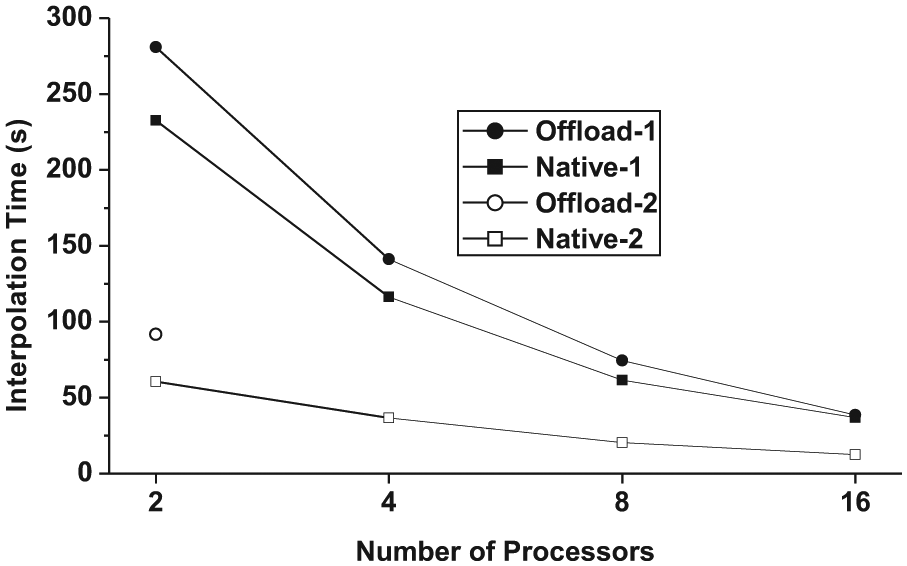
Performance of Kriging interpolation under various execution modes on multiple MIC processors (excluding Native-3 execution mode).
5.1.2. Conway’s Game of Life
For GOL on multiple MIC processors, three different grid sizes are tested, i.e. 8192×8192, 16,384×16,384, and 32,768×32,768. By observing the performance results in Table 6 and Figure 10, it can be found that the behavior is quite different from the performance behavior of Kriging interpolation. First, the strong scalability does not hold for all five execution modes. Although the offload execution modes are still able to reduce the computation time to half when moving from 2-processor implementation to 4-processor implementation, the performance plateaus afterwards. For Native-1 and Native-2 execution modes, it almost stops scaling when more processors are allocated. Apparently, for this communication dense application, there is not much performance gain when increasing the number of MIC processors from 4 to 8 and 16. When the grid is partitioned into m×60 MPI processes on m MIC processors, the performance gain from the reduced workload on each MIC core is easily offset by the increase of the communication cost among the cores. Therefore, it is critical to keep a balance between computation and communication for achieving the best performance. For Native-3 execution mode, there is a big increase of computation time from one-processor implementation to multiple-processor implementation. Native-3 execution mode is not officially mentioned in the programming guide on Beacon computer cluster. Therefore, we speculate that the library support for Native-3 execution mode on multiple devices is premature at this moment.
Performance of Game of Life under various execution modes on multiple MIC processors (unit: second).

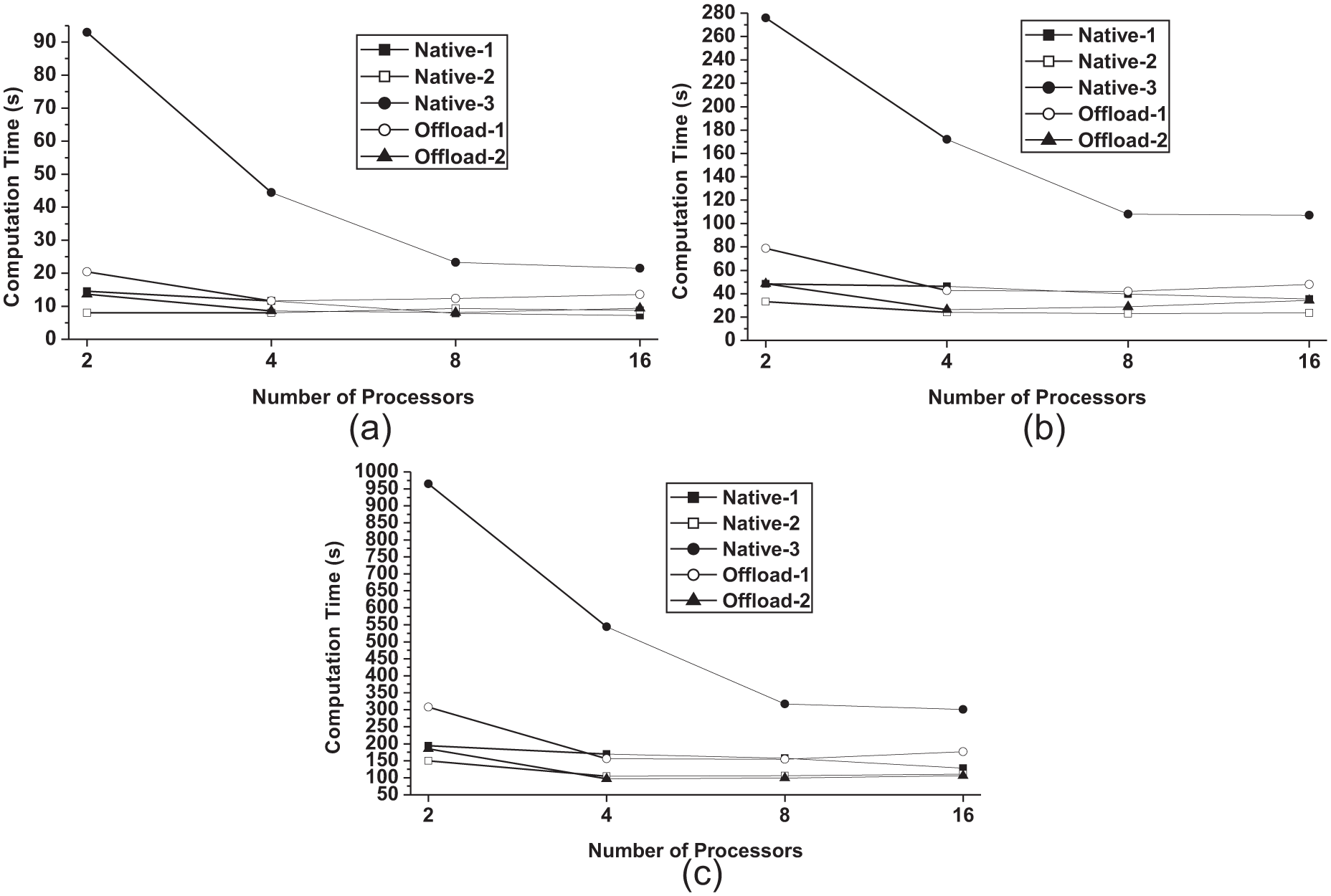
Performance of Game of Life under various execution modes on multiple MIC processors: (a) 8192×8192; (b) 16,384×16,384; (c) 32,768×32,768.
5.2. Experiments on the MPI@MIC_Core+OpenMP execution mode
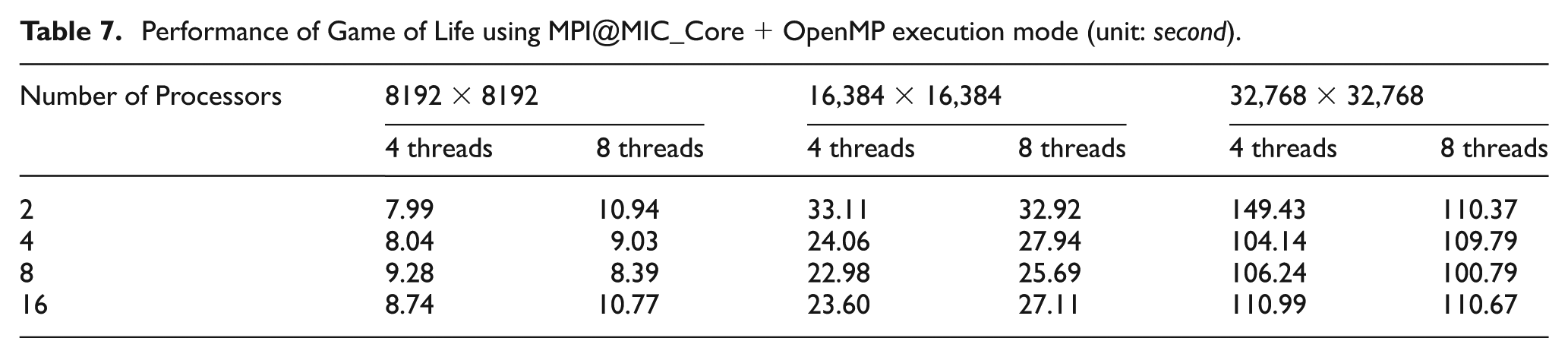
For the implementations using the Native-2 execution mode in Section 2, the number of threads running on each MIC core is four, which is the number of threads a MIC core can physically execute in parallel. We also want to check the potential of performance improvement by running more threads on a single core. Therefore, in addition to the case of four, we double the number of threads to eight for the GOL benchmark. The results are listed in Table 7. It can be found that the benefit of adding more threads to MIC cores is very marginal. For small problem sizes, e.g. 8192×8192, the 8-thread OpenMP implementation actually has a worse performance than the 4-thread OpenMP implementation for most cases. For this communication-intensive benchmark, partitioning the computation into more threads introduces more cross-thread communication overhead. For large problem sizes, it is still possible to achieve some performance benefit if each MPI process is given a relatively large amount of data, e.g. 32,768×32,768 partitioned into 120 MIC cores.
Performance of Game of Life using MPI@MIC_Core+OpenMP execution mode (unit: second).
5.3. Experiments on the Offload-1 execution mode
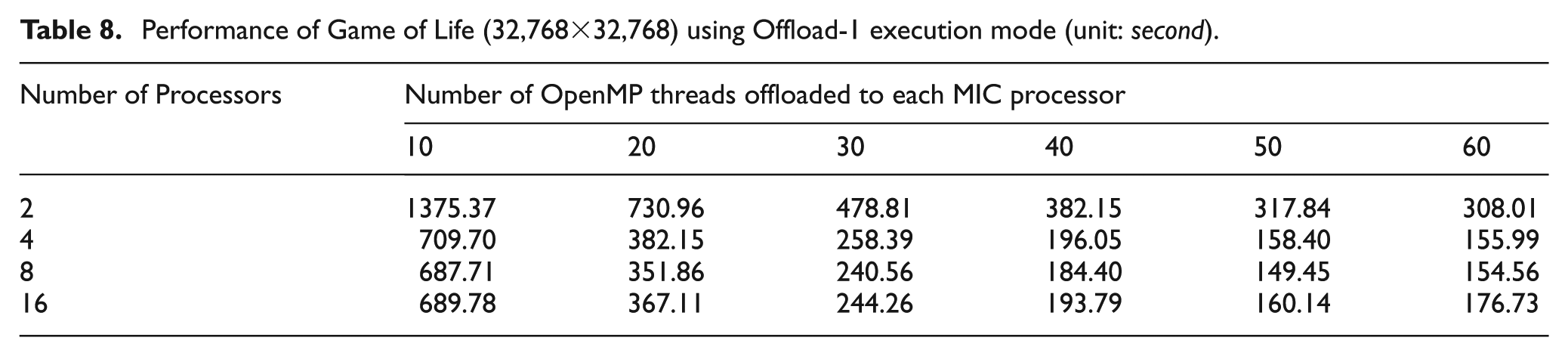
For the implementations using the Offload-1 execution mode in Section 2, the number of OpenMP threads offloaded to the a MIC processor by an MPI process, which runs on the CPU, is 60, i.e. one OpenMP thread per MIC core. In this experiment, we change the number of threads offloaded to the MIC processor by the MPI process from 10 to 60, as shown in Table 8 and Figure 11. In each case, when the number of threads increases from 10 to 30, the scalability holds. When more threads are scheduled, the computation time decreases, however, at a much smaller rate. For most cases, the computation time actually grows when the number of offloaded threads is increased from 50 to 60. This performance degradation may be due to the increased inter-thread communication overhead.
Performance of Game of Life (32,768×32,768) using Offload-1 execution mode (unit: second).
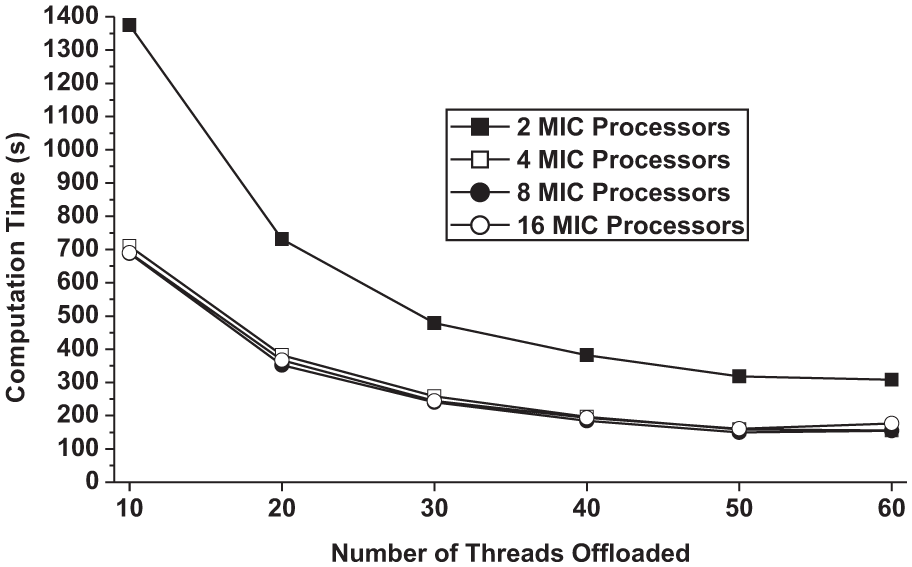
Performance of Game of Life (32,768×32,768) using Offload-1 execution mode. The number of threads on a MIC processor is increased from 10 to 60.
We also can find that the performances are almost the same for implementations using more than two MIC processors. Apparently when four or more MIC processors are allocated, the cross-processor communication overhead becomes dominant in the computation process so that adding more processors will not increase the overall performance.
5.4. Experiments on the distribution of MPI processes
When an MPI parallel application runs on a computer cluster with nodes consisting of manycore processors such as Xeon Phi, the distribution of MPI processes is not uniform. Some MPI processes are scheduled to the cores on the same processor. The others are scheduled to different processors. Two MPI processes on the same processor are physically close to each other. On the other hand, two MPI processes on two separate processors are distant. The difference of the distance between two MPI processes will cause the disparity of the inter-MPI communication time.
We design a simple benchmark consisting of only 2 MPI processes using native programming model. In this benchmark, MPI process_A sends 500 MB data to MPI process_B. Then MPI process_B returns the 500 MB data back to MPI process_A. We have two options to run the benchmark. In Implementation_1, both MPI processes are scheduled to the same MIC processor. In Implementation_2, these two MPI processes are scheduled to two separate MIC processors. It turns out that Implementation_1 and Implementation_2 take 1.59 seconds and 2.81 seconds, respectively. Apparently, the longer distance between the two MPI processes in Implementation_2 contributes to the more time spent on communication.
The location difference of MPI processes can result in the performance disparity of an application when it is executed under different MPI configurations while the total number of MPI processes is the same. Figure 12 illustrates the different performances of the GOL benchmark using the various configurations when 120 MPI processes run on 120 MIC cores. Each MPI process contains only one thread. In the 2×60 configuration, 2 MIC processors are allocated, each of which hosts 60 MPI processes. When the number of MIC processors doubles, the number of MPI processes on a processor is halved. The more processors are allocated, the more cross-processor communication, which brings down the performance. Therefore, when the capacity of the on-board memory is not a limiting factor, it is typically a good strategy to schedule as many MPI processes to a single MPI processor as possible to minimize the cross-board communication overhead.
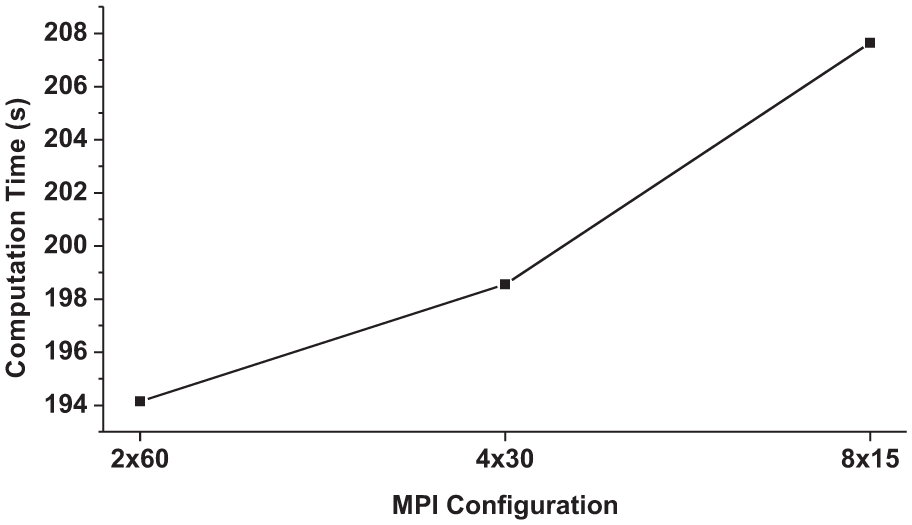
Performance of Game of Life (32,768×32,768) under different MPI configurations using Native-1 execution mode. Given 120 MPI processes, 2×60 means that 120 processes are distributed in 2 MIC cards, each of which hosts 60 processes. The fewer MIC cards are used, the better the performance.
5.5. Hybrid MPI versus native MPI
Another programming/execution model that is not officially supported on the Beacon computer cluster is the Native MPI@Hybrid CPU/MIC, i.e. the MPI processes run on both CPUs and MIC processors. The results in Section 4.2 already demonstrate the impressive performance of the latest multicore CPUs. Therefore, it is necessary to use both processors in the applications. We first implement the Kriging interpolation on the 57 MB data set using 16 MPI processes on a single Xeon E5-2670 CPU, which support 16 parallel threads. The total execution time is 46.02 seconds. Then we implement the same application using a 16 + 14 hybrid MPI model, i.e. 16 MPI processes on a single Xeon CPU and 14 MPI processes on 14 MIC cores of a single card, 7 the total execution time is 24.75 seconds, an almost 2×speedup. Again, each MPI process contains only one thread in this sub-study.
We also carry out the hybrid MPI programming model on a separate workstation, which contains one Xeon E5-2620 CPU and two Xeon Phi 5110P cards. On this platform, we use the GOL (16,384×16,384) as the benchmark. The native MPI implementation of 120 MPI processes on two MIC cards takes 30 seconds. The 12 + 120 hybrid MPI implementation in which the additional 12 MPI processes run on the single CPU takes 27.42 seconds. The 1.1×speedup aligns with the ratio of number of MPI processes between the hybrid model and the native model.
6. Related work
MPI and OpenMP are two popular parallel programming APIs and libraries. MPI is primarily for inter-node programming on computer clusters. On the other hand, OpenMP is mainly used for parallelizing a program on a single device. Krawezik compared MPI and three openMP programming styles on shared memory multiprocessors using a subset of the NAS benchmark (CG, MG, FT, LU) (Krawezik, 2003). Experimental results demonstrate that OpenMP provides competitive performance compared with MPI for a large set of experimental conditions. However, the price of this performance is a strong programming effort on data set adaptation and inter-thread communications. Numerous benchmarks have been used to evaluate the performance of supercomputers. For example, the HPC Challenge (HPCC) benchmark suite and the Intel MPI Benchmark (IMB) are used to compare and evaluate the combined performance of processor, memory subsystem and interconnect fabric of five leading supercomputers: SGI Altix BX2, Cray XI, Cray Opteron Cluster, Dell Xeon cluster, and NEC SX-8 (Saini et al., 2006, 2008). The portability and performance efficiency of radio astronomy algorithms are discussed in Malladi et al. (2012). Derivative calculations for radial basis function were accelerated on one Intel MIC card (Erlebacher et al., 2014). We use two representative geospatial applications with different communication patterns for benchmarking purpose. Although they are both domain-specific applications, many applications in other domains share the same internal communication patterns as these two cases.
Schmidl et al. (2013) compared a Xeon-based two-socket compute node with the Xeon Phi stand-alone in scalability and performance using OpenMP codes. Their results show significant differences in absolute application performance and scalability. The work in Saini et al. (2013) evaluated the single-node performance of an SGI Rackable computer that has Intel Xeon Phi coprocessors. NAS parallel benchmarks and CFD applications are used for testing four programming models, i.e. offload, processor native, coprocessor native and symmetric (processor plus coprocessor). They also measured the latency and memory bandwidth of L1, L2 caches, and the main memory of Phi; measured the performance of intra-node MPI functions (point-to-point, one-to-many, many-to-one, and all-to-all); and measured and compared the overhead of OpenMP constructs. Compared with Saini et al. (2013), our work in this paper presents the results on single MIC device as well as on multiple MIC cards. Further, we discuss multiple variances of the native models and the offload models.
7. Conclusions
In this work, we conduct a detailed study regarding the performance and scalability of the Intel MIC processors under different parallel programming models. Between the two programming models, i.e. native MPIs on MIC processors and the offload to MIC processors, the native MPI programming model typically outperforms the offload model. It is very important to further improve the parallelism inside each MPI process running on a MIC core for a better performance. For embarrassingly parallel benchmarks such as Kriging interpolation, the multithreading inside each MPI process can achieve three times speedup compared with the single-thread MPI implementation. Due to the fact that the physical distance between two MPI processes may be different under various MPI distributions, it is typically a good strategy to schedule MPI processes to as few MIC processors as possible to reduce the cross-processor communication overhead given the same number of MPI processes. Finally, we evaluate the hybrid MPI programming model, which is not officially supported by the Intel MPI compiler. Through benchmarking, it is found that the hybrid MPI programming model in which both CPU and MIC are used for processing is able to outperform the native MPI programming model.
Footnotes
Acknowledgements
This research used resources of the Beacon supercomputer, which is a Cray CS300-ACTM Cluster Supercomputer. The Beacon Project is supported by the National Science Foundation and the State of Tennessee. The authors would also thank Nvidia Corporation for GPU donations.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
Author biographies
Miaoqing Huang is an assistant professor at the Department of Computer Science and Computer Engineering, University of Arkansas since 2010. His research interests include manycore computer architecture, high-performance computing, and hardware-oriented security. He earned his bachelor degree in electrical engineering from the Fudan University in 1998 and his doctoral degree in computer engineering from The George Washington University in 2009.
Chenggang Lai received the BS degree in electric engineering from the Shandong University, China, in 2012. He is currently pursuing a PhD degree in computer engineering at the University of Arkansas. His research interests include high-performance computing and algorithm design for big data.
Xuan Shi is an assistant professor in the Department of Geosciences at the University of Arkansas with expertise in distributed GIS, GIS interoperability and semantic Web services, and high-performance geocomputation covering topics about vector geometric calculation, spatial modeling over raster grid, and process and analytics on satellite imagery and aerial photos. His research has been supported by NSF, DOE and NIH and awarded with XSEDE allocation on supercomputers Kraken, Keeneland and Beacon.
Zhijun Hao received his BS degree in electrical engineering from the Hangzhou Dianzi University in 2006 and PhD degree in computer science from the Fudan University in 2014. His research interests include operating system and system virtualization focusing on reusing device drivers across different Operating Systems and ISA
Haihang You is a professor at the Institute of Computing Technology, Chinese Academy of Sciences. Prior joining ICT, Dr. You was research scientist at National Institute of Computational Sciences at Oak Ridge National Laboratory and Innovative Computing Laboratory at University of Tennessee. Dr. You’s research interest is in the field of high performance computing, specifically parallel algorithm, numerical algorithm, workload analysis, and performance optimization and autotuning.