
Abstract
In this article, we present a new hybrid algorithm to enable and scale the high-performance conjugate gradients (HPCG) benchmark on large-scale heterogeneous systems such as the Tianhe-2. Based on an inner–outer subdomain partitioning strategy, the data distribution between host and device can be balanced adaptively. The overhead of data movement from both the MPI communication and the PCI-E transfer can be significantly reduced by carefully rearranging and fusing operations. A variety of parallelization and optimization techniques for performance-critical kernels are exploited and analyzed to maximize the performance gain on both host and device. We carry out experiments on both a small heterogeneous computer and the world’s largest one, the Tianhe-2. On the small system, a thorough comparison and analysis has been presented to select from different optimization choices. On Tianhe-2, the optimized implementation scales to the full-system level of 3.12 million heterogeneous cores, with an aggregated performance of 623 Tflop/s and a parallel efficiency of 81.2%.
1. Introduction
The ever growing demand in extreme scale computing continues to push the performance limit of supercomputers to higher levels. Nowadays, heterogeneous architecture has become a competitive choice to build supercomputing systems that run at desired computational rates and fit within an affordable power envelope. Such systems are equipped with both multi-core CPUs and many-core accelerators; examples include Tianhe-2, which is comprised of both Intel Xeon CPUs and Intel Xeon Phi coprocessors, and Titan, which consists of both AMD Opteron CPUs and NVIDIA Tesla K20x GPUs. In order to fully exploit the computing capacity of a heterogeneous computer, people need to study on how to keep the load balance among different processing units, reduce data movement between heterogeneous resources, and conduct vectorization/parallelization in the many-core accelerator, among other considerations.
The high-performance conjugate gradients (HPCG) benchmark, recently introduced to the high-performance computing world, aims to better correlate computation and data access patterns found in many applications today. Compared to the high-performance LINPACK (HPL), which is the de facto standard to rank supercomputing systems on the TOP500 List, HPCG pays closer attention to real-world applications and contains more typical scientific computing operations, such as the Krylov subspace iteration, the sparse matrix–vector multiplication, the overlapping additive Schwarz preconditioner, the geometric multigrid V-cycle, and the symmetric Gauss–Seidel relaxation. It is a challenging task to optimize these operations on a leadership heterogeneous system with high computing power, yet relatively low data-moving capability.
Announced in June 2013, and taking the top place on the TOP500 List since then, Tianhe-2 remains the largest heterogeneous system to date. There are over 3 million hybrid cores available for Tianhe-2, with less than 10% coming from the Intel Xeon CPUs and the rest from the Intel Xeon Phi accelerators based on the many integrated core (MIC) architecture. Questions have arisen on how to leverage these millions of cores in extreme scale computing. We believe methodologies and technologies applied in optimizing HPCG on Tianhe-2 may shed some light on possible answers. After making a first attempt to optimize and scale HPCG on Tianhe-2 without using the MIC accelerators (Zhang et al., 2014), we proposed a hybrid CPU-MIC algorithm (Liu et al., 2014) for single-node HPCG optimization. Recently, we further polished the hybrid algorithm and pushed forward to enable a full-system run on Tianhe-2, achieving 623 Tflop/s, a new performance record on the HPCG List of 2014.
In this article, we will provide a detailed overview of the proposed hybrid algorithms and optimization methodologies applied in optimizing HPCG on Tianhe-2. First, based on an inner–outer subdomain partitioning strategy, we propose a new data partition algorithm in order to make a balanced utilization of host and device and reduce the data movement overhead at the same time. Second, different parallelization and optimization methods are exploited on the most time-consuming kernel in HPCG. Third, we list the various optimization techniques on both CPU and MIC for other performance-critical kernels. Finally, performance results on both a small heterogeneous system and the Tianhe-2 supercomputer are presented and analyzed.
2. Basic HPCG algorithm
Originally proposed by Dongarra and Heroux (2013), the HPCG benchmark focuses on measuring the capability of a supercomputer in solving a large sparse linear system. As detailed in Dongarra and Luszczek (2013), the linear system solved in HPCG is obtained from discretizing the Poisson equation
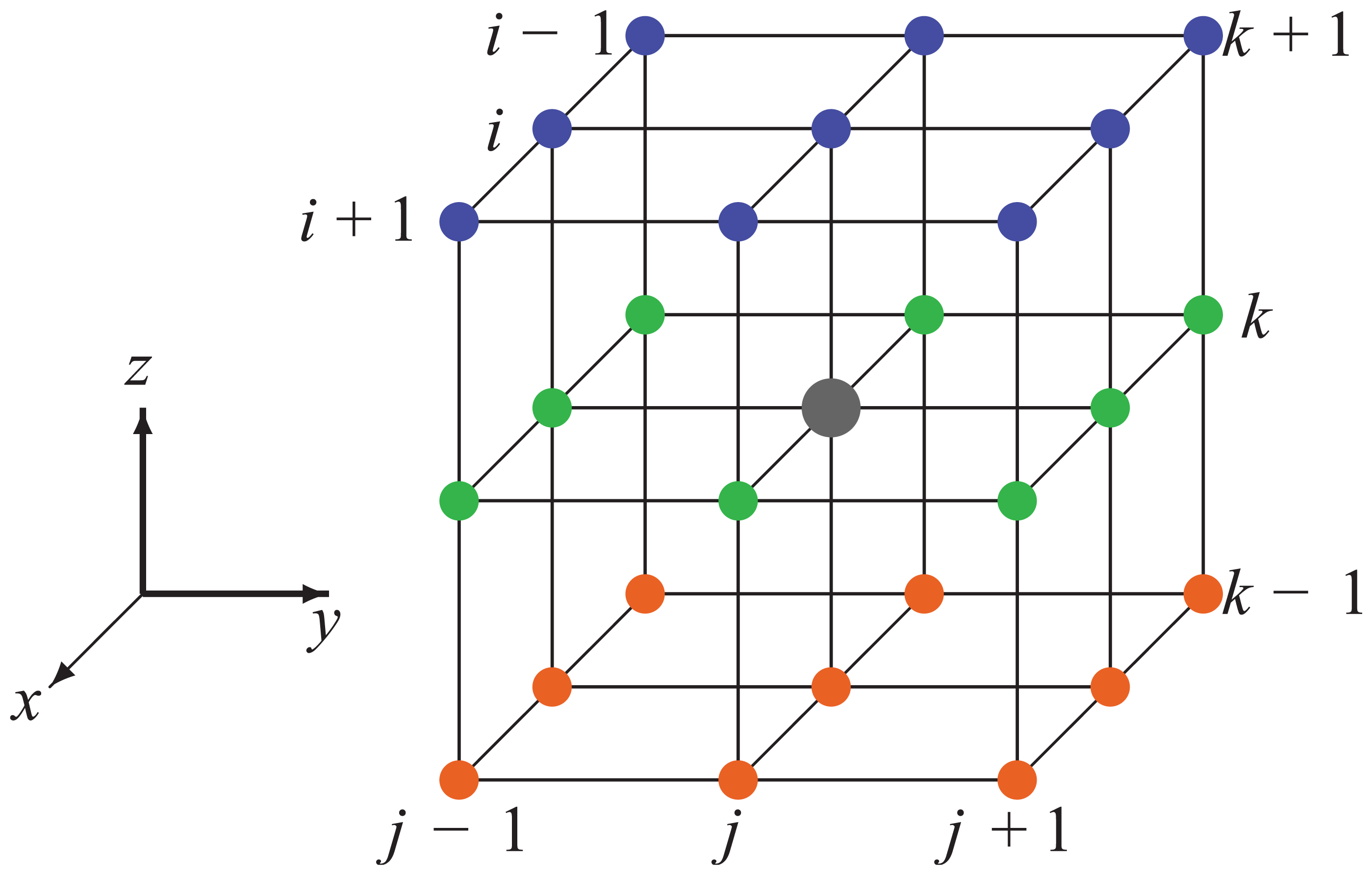
The 3-D 27-point stencil in HPCG.
In HPCG, the linear system

The preconditioner M−1 used in HPCG is based on a V-cycle geometric multigrid method, as shown in Algorithm 2. In the algorithm, a symmetric Gauss-Seidel (SymGS) method is used as the coarsest level solver and the pre- and post-smoothers as well. Here SymGS(x, r) denotes a SymGS iteration, where r is the right-hand side and x is the initial guess of the solution vector. More specifically, SymGS(x, r) is equivalent to:
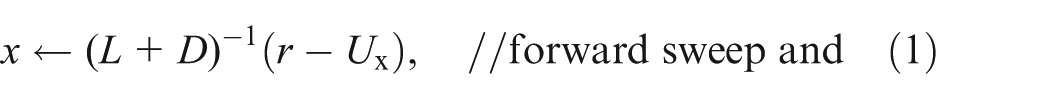
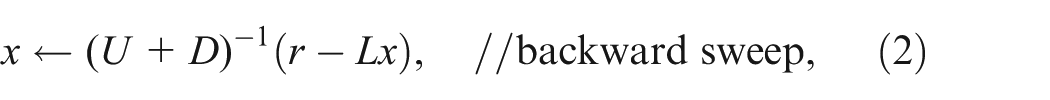
where D is the diagonal of A, and L and U are the strict lower and upper triangular parts of A, respectively. It is worth noting that the ordering of unknowns affects the behavior of the SymGS smoother. By default, a natural ordering of the grid points is used in HPCG. A user-defined ordering is allowed, including the red–black reordering techniques to improve the locality or increase the concurrency of the SymGS smoother. But caution has to be applied when using these methods because both the time cost on reordering the matrix and the possibly increased number of CG iterations will be counted as performance penalties.
V-cycle for

HPCG uses a 3-D domain decomposition strategy for distributed parallel computing. The whole domain is partitioned into smaller subdomains, each of which is assigned to a message passing interface (MPI) process. Two types of MPI communications exist in HPCG. One is the MPI allreduce communication required in each vector dot product. The other is the neighboring communication in the SpMV and SymGS sparse matrix kernels used to exchange the boundary data (i.e. halos) of each subdomain with its neighbors.
3. Hybrid CPU-MIC algorithm
To maximize the utilization of different computing resources in a heterogeneous system, a hybrid algorithm for data partitioning is required. The algorithm is not only responsible for assigning tasks among the host and device but also used to coordinate the asynchronous computation/communication between them. In this section, we propose and analyze a new data partitioning strategy, along with corresponding methods to reduce the data movement overhead.
3.1. Inner–outer subdomain partition
In each subdomain, there are two types of grid points. For points dependent on the halo data, the computation cannot be started until finishing the halo exchange procedure. The rest are, however, halo-independent points that can be processed locally without waiting on any MPI communication. Based on these facts, we propose an inner–outer partitioning method. In the new partitioning method, a subdomain is divided into one or several regular inner tasks and an irregular outer task. Each inner task is processed by an accelerator, while the whole outer part is processed by the CPU. Figure 2(a) shows a schematic diagram of the inner–outer partition for the case of three MIC devices.
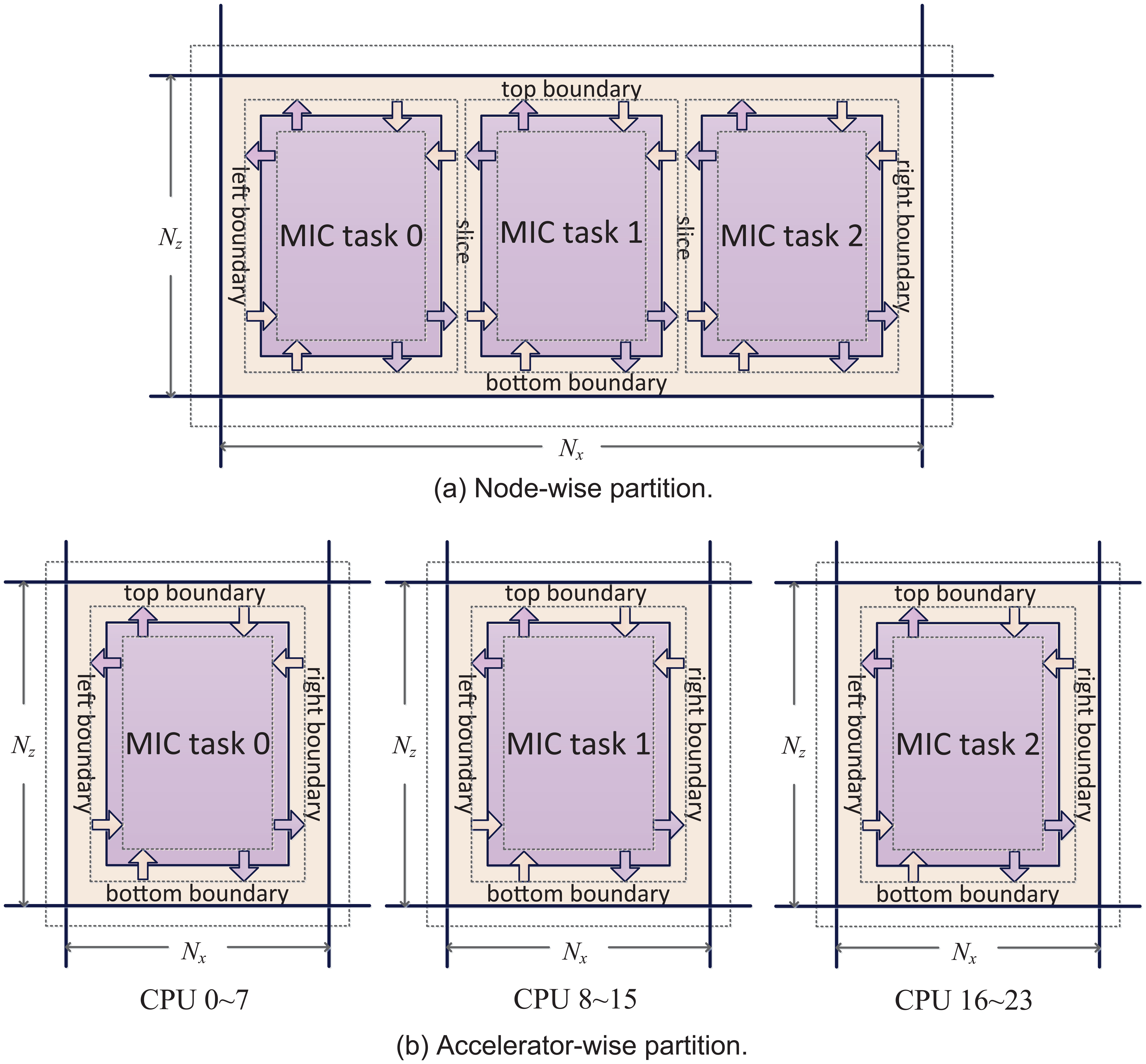
The inner–outer subdomain partitioning methods for the case of three MIC devices. Only the x–z cross section is shown for simplicity.
There are several advantages of the inner–outer partitioning strategy.
The inner task assigned to each accelerator is halo independent, therefore the computation done on the accelerator can be started immediately without waiting for the halo data from remote nodes to arrive.
The ratio of the inner–outer tasks can be adjusted according to the computing capacity of the host and device to improve the load balance between them.
Direct data transfer between accelerators, which may not be available on some platforms (e.g. for MIC devices when running on offload mode), is avoided by leaving slices for the CPU between inner tasks.
The required volume of transferred data between the host and device is roughly in proportion to size of the inner–outer interface, which is small as compared to the whole subdomain.
On Tianhe-2, since there are three MIC accelerators in each computing node, we have two possible ways to perform the inner–outer partition. One is the node-wise partition, as shown in Figure 2(a), in which each computing node is assigned one MPI process corresponding to a subdomain that is further partitioned to three MIC tasks and one outer task. The other method uses the accelerator-wise partition, where each computing node is assigned three MPI processes, with each one corresponding to a subdomain. The subdomain in the accelerator-wise parition is smaller as compared to the one in the node-wise partition, with each one partitioned to only one inner task for the MIC device and one outer task for the CPU. A schematic diagram of the accelerator-wise inner–outer partition is shown in Figure 2(b). There is a trade-off in selecting from the two alternatives of the inner–outer partitioning method. The node-wise version, successfully applied stencil computations (Xue et al., 2014) and later for the single-node optimization of HPCG (Liu et al., 2014), seems preferable to the accelerator-wise version because the total number of MPI processes is minimized. But further analysis of the cost of MPI communication suggests the opposite.
Suppose there are p computing nodes available, then the total number of MPI processes is p for the node-wise partition and 3p for the accelerator-wise partition. Further assume that in either case, the total number of points in the MIC task is the same, which is usually proportional to the local memory capacity of the MIC device. Then for the accelerator-wise partition, it is natural to set the size of the MIC task to be a regular cube with length n to minimize communication overhead. And for the node-wise partition, we denote the length of a MIC task to be nx, ny, and nz in each dimension. Since the volume of the MIC task is the same in the two versions, we have
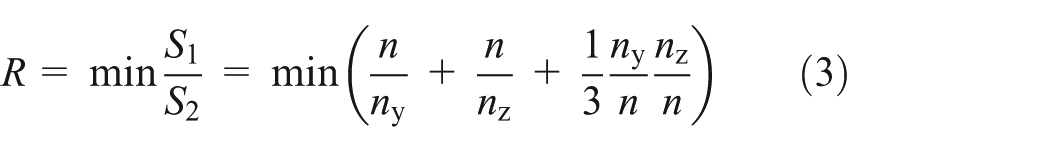
leads to
Another disadvantage of the node-wise partition comes from the allocation overhead, which introduces penalty to the final HPCG performance. In a previous work (Liu et al., 2014), we found that in the current offload programming environment, the allocation procedure on the three MIC devices cannot be completely done in a truly multi-threaded asynchronous way. The measured cost of doing so grows almost linearly as the number of MIC devices increases. When using the accelerator-wise alternative instead, allocating on the three MIC devices can be done independently with almost no extra cost. Based on the above facts, we choose to use the accelerator-wise version of the inner–outer partitioning method in what follows.
3.2. Load balance between host and device
In the inner–outer partitioning method, all the interior boundaries of a subdomain are of the same thickness on each grid level of the V-cycle multigrid preconditioner. Denote the length of the subdomain to be Nx, Ny, and Nz in the three dimensions, respectively. Let L be the thickness of the outer part at the finest grid level. The number of points in the MIC task is then
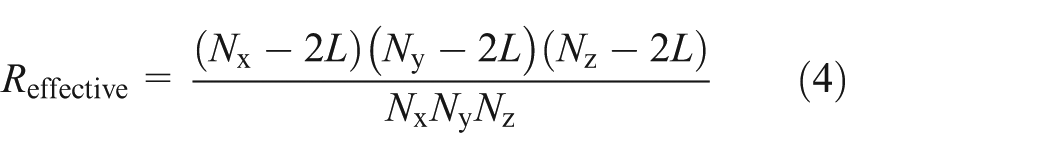
and
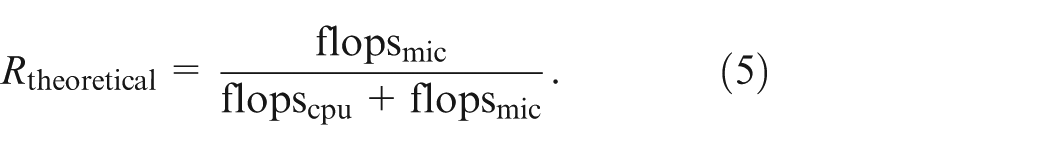
To achieve an ideal load balance between CPU and MIC, we expect that the effective ratio is larger than, but close to, the theoretical ratio; that is,
Figure 3 lists some typical values of Reffective calculated according to equation (4) in the case that the subdomain is a regular cube with length N and boundary thickness L. From Figure 3, we observe that larger values of N help increase Reffective to the ideal value, but larger values of L dramatically worsen it. When the subdomain is not regular, then it is easy to verify that the effective ratio is smaller than Reffective in equation (4), with
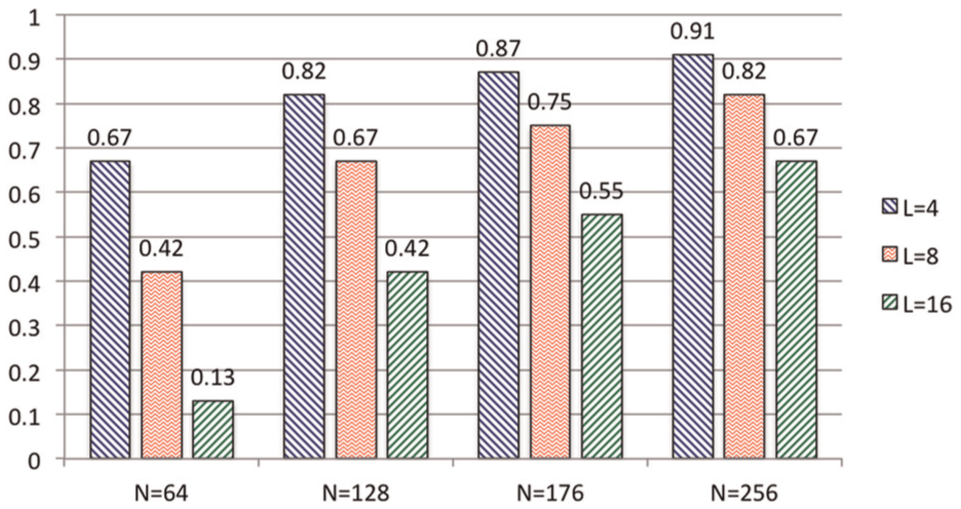
The effective ratio (Reffective) for different subdomain size (N3) and boundary thickness (L).
For the boundary thickness L, we need to set it carefully to obtain a consistent partition on each level while maintaining a good load balance between the host and device at the same time. Since HPCG uses a four-level MG with a fine to coarse ratio of 2, it is natural to consider setting L on the finest level to be a multiple of 8. Figure 4(a) shows the data partition done on each level of the V-cycle MG when
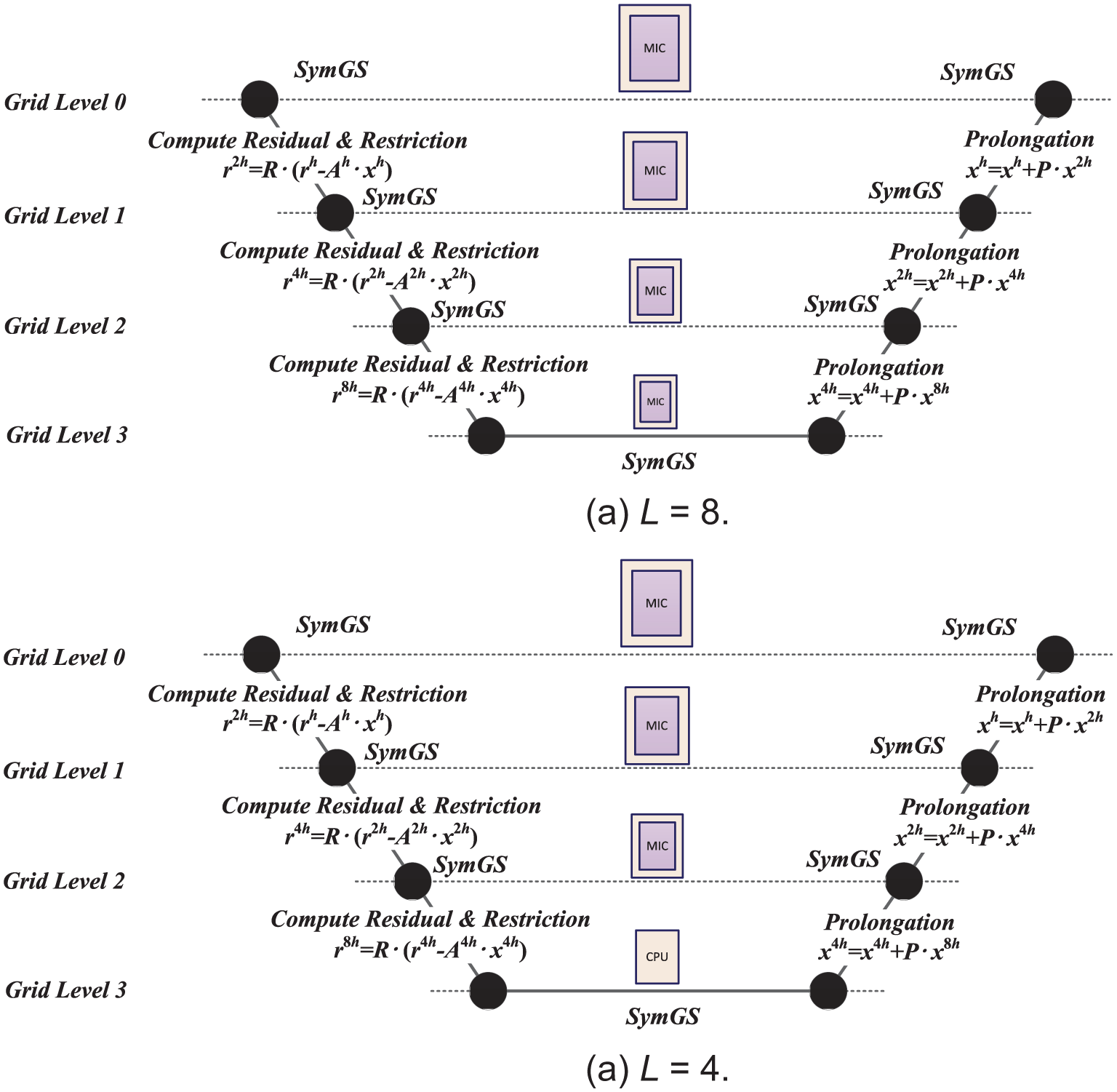
The V-cycle multigrid preconditioner and the corresponding hybrid inner–outer partitioning methods for different choices of the boundary thickness L on the finest level.
3.3. Reducing data movement overhead
There are two types of data movement that may significantly affect the overall performance of HPCG. One is the MPI neighboring communication for halo exchange among different computing nodes. The other is the local peripheral component interconnect express (PCI-E) transfer between CPU and MIC within each heterogeneous node. Both types of data movement can benefit from the proposed inner–outer subdomain partitioning method due to the reduced amount of data dependency between host and device. To further reduce the overhead of the data movement, we conduct some additional optimizations as follows. First, we notice that both types of data movement can be safely removed in the SymGS kernels for pre-smoothing and coarsest-level solving because the initial guess is 0. Then we go through all kernels that still require the two types of data movement and list them in Table 1. In order to seek an opportunity to overlap the data movement with computation, we also list in the table the preceding kernels that could be fused with the current ones. Without the loss of generality, in the following discussion, we take SpMV in the main CG loop as an example of the current kernel, which can be fused with the preceding kernel WAXPBY.
List of all kernel pairs that can be fused to reduce data movement overhead in HPCG.

For analysis, we divide each type of the data movement into four steps: (1) packing data, (2) starting data movement, (3) moving data, and (4) finishing data movement. Note that when using the blocking or synchronized data movement subroutines on the MPI or PCI-E level, the last three steps are not separated. In practice, we use the nonblocking and asynchronous functions to seek a better chance to reduce the overhead of data movement.
3.3.1. The unfused schedule
In the reference implementation of HPCG, the exchange of halo data is done at the beginning of the current kernel, and the computation is not started until the MPI communication is finished. Based on the reference implementation of HPCG, a simple hybrid schedule, as shown in Figure 5(a), can be designed by taking into account the four-step decomposition of the MPI communication. After packing the halo data in step (1), nonblocking point-to-point communications are posted in step (2). During the MPI communication of step (3), intra-node data transfers between host and device via duplex PCI-E transfer are inserted in an asynchronous way. Finally, in step (4), a synchronization point is introduced to finish the nonblocking MPI point-to-point communication. This simple schedule successfully allows all the heterogeneous units to work simultaneously and overlaps a portion of MPI neighboring communication with computation. However, at the beginning of the current kernel, before doing computation on the inner task, the MIC device has to wait for the end of a number of operations, including the packing and starting of the MPI communication, and all four steps to transfer data from host to device. The overhead introduced by these operations may highly degrade the sustained performance on the MIC accelerator.
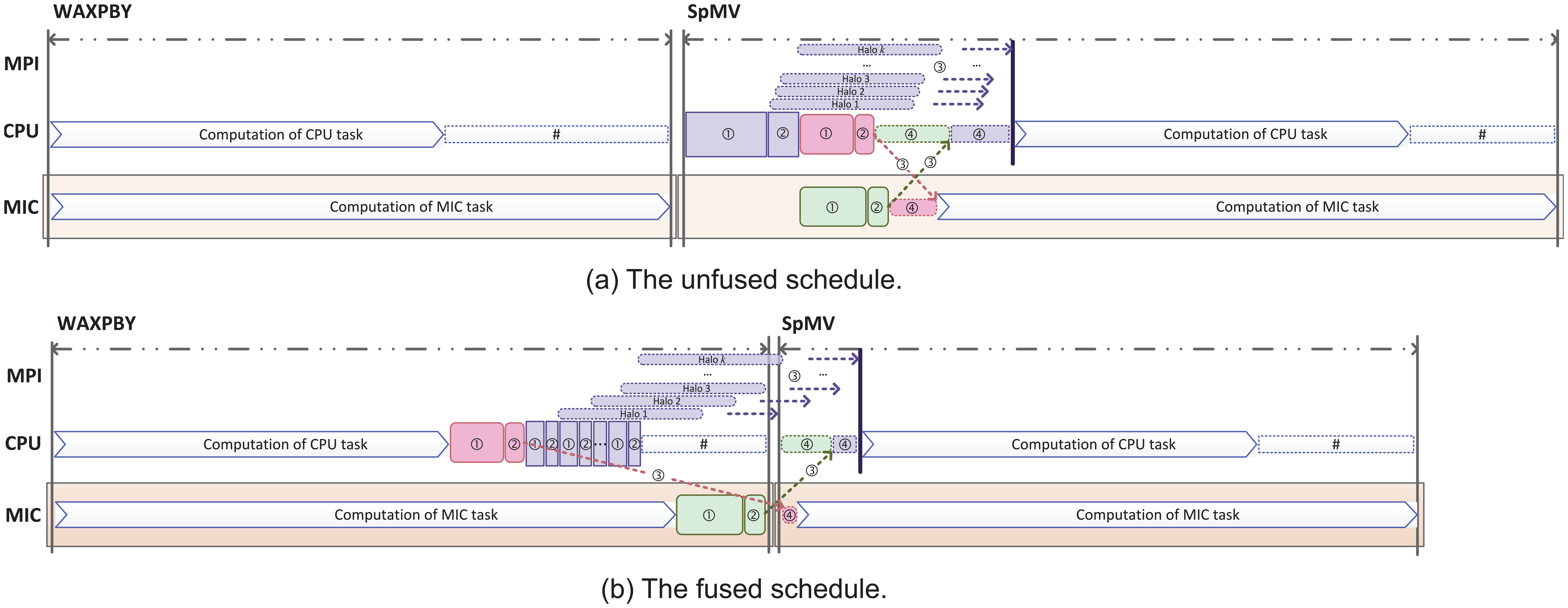
Heterogeneous schedules to reduce the data movement overhead from both MPI neighboring communication and PCI-E data transfer. The length of the dashed line with double-sided arrows represents the total consumed time. The “#” marked blocks on the CPU represent the time spent waiting for the MIC to finish the computation, and the blank space on the MIC indicates the idle time.
3.3.2. The fused schedule
Assuming that the computation done on CPU and MIC requires exactly the same time, when the unfused schedule in Figure 5(a) is used, MIC has to wait for the CPU to finish processing the SpMV kernel because the computation of the outer part is started later than the inner one. That is why we set
4. Parallelization and optimization of SymGS
The SymGS kernel in the MG preconditioner consumes a large portion of the running time of HPCG. Two major difficulties exist in optimizing and parallelizing SymGS. One is the strong data dependency required to update values of grid points in the SymGS iteration, and the other is the large memory footprint required to repeatedly access the large sparse matrix and the dense vectors. The strong data dependency makes SymGS hard to parallelize. Although a red–black relaxation can be used to enhance the concurrency, it often comes along with a performance penalty due to the increased number of iterations. The high cost of memory access in SymGS, on the other hand, calls for a carefully designed algorithm, possibly in combination with the red–black reordering method, to fuse certain operations such that the locality can be effectively improved.
4.1. Forward–backward fused SymGS
There are two sweeps in the SymGS smoother, namely, the forward and the backward sweeps as defined in equations (1) and (2), respectively. For a grid with N unknowns, the number of nonzeros in the sparse matrix A is almost 27N in total. On a system with 64-bit doubles and 32-bit integers, each sweep of SymGS involves about 12 ×27N bytes memory access from A and at least 16N bytes from the two vectors r and x, but only performs about 54N floating-point operations. The resulting computation to memory ratio of SymGS is less than 0.17 flop/byte, which makes HPCG seriously memory bound.
A key to improving the performance of SymGS is to increase the temporal locality of the data access. Because the forward sweep is immediately followed by the backward sweep in SymGS, it is possible to reuse the data of the sparse matrix by properly fusing the two sweeps. The fusion technique can be incorporated with any red–black relaxation in SymGS. For example, we do a red–black reordering only along dimension z. The update of the zi plane only depends on the zi plane itself and the two adjacent planes of the other color. We draw a dependency graph in Figure 6, where each node represents the update of a colored plane in the z dimension. The processing steps of the original red–black relaxation for SymGS are also shown in the figure. In each step of the red–black SymGS, concurrency is increased because all planes of the same color in the same “horizontal” level of the graph can be processed in parallel. To increase the temporal locality, we expect to reuse the result of the forward sweeps as early as possible. In the dependency graph, the data reuse can be improved by exploiting the graph in the “vertical” direction. For example, after finishing the forward sweeps of z0 and z2 red planes, we may perform the forward sweep of z1 black plane, immediately followed by the backward sweep of the same z1 black plane, then the backward sweep of the z0 red plane. In this way, the computed result in the z0 plane can be obtained as early as possible and the data reuse distance can be greatly shortened. Based on this observation, we propose a forward–backward fused SymGS (Zhang et al., 2014) as presented in Algorithm 3. It is worth noting that the fusing technique for the SymGS in HPCG, with certain generalizations, can be applied in other applications of stencil computing.
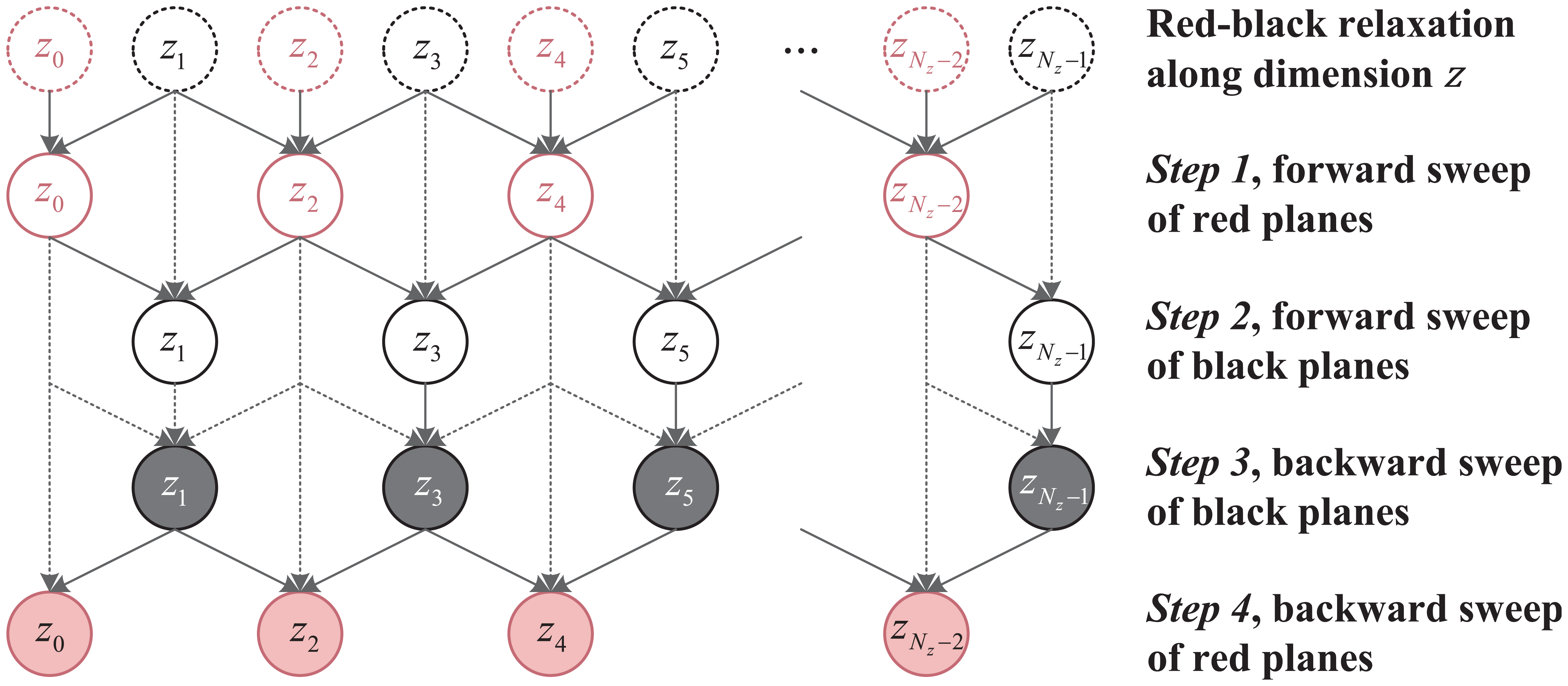
Dependency graph among xy planes in SymGS after a red–black relaxation along dimension z.
Forward–backward fused SymGS

4.2. Parallelization of fused SymGS
Based on the forward–backward fused SymGS in Algorithm 3, we propose some architecture-aware parallelization methods, with the first two for the inner task of size
4.2.1. fusez-rby
This method employs another red–black relaxation along dimension y to enable multi-threading parallelization. Each thread performs computation in a number of successive x pencils, as shown in Figure 7(a), where circled numbers indicate the updating order. In practice, we spare one physical core in the MIC accelerator for the Intel Many-core Platform Software Stack (MPSS) and offload-related services and enable the four hardware threads on all the rest of the cores to maximize the performance. Considering the Intel Xeon Phi 31S1P in Tianhe-2,
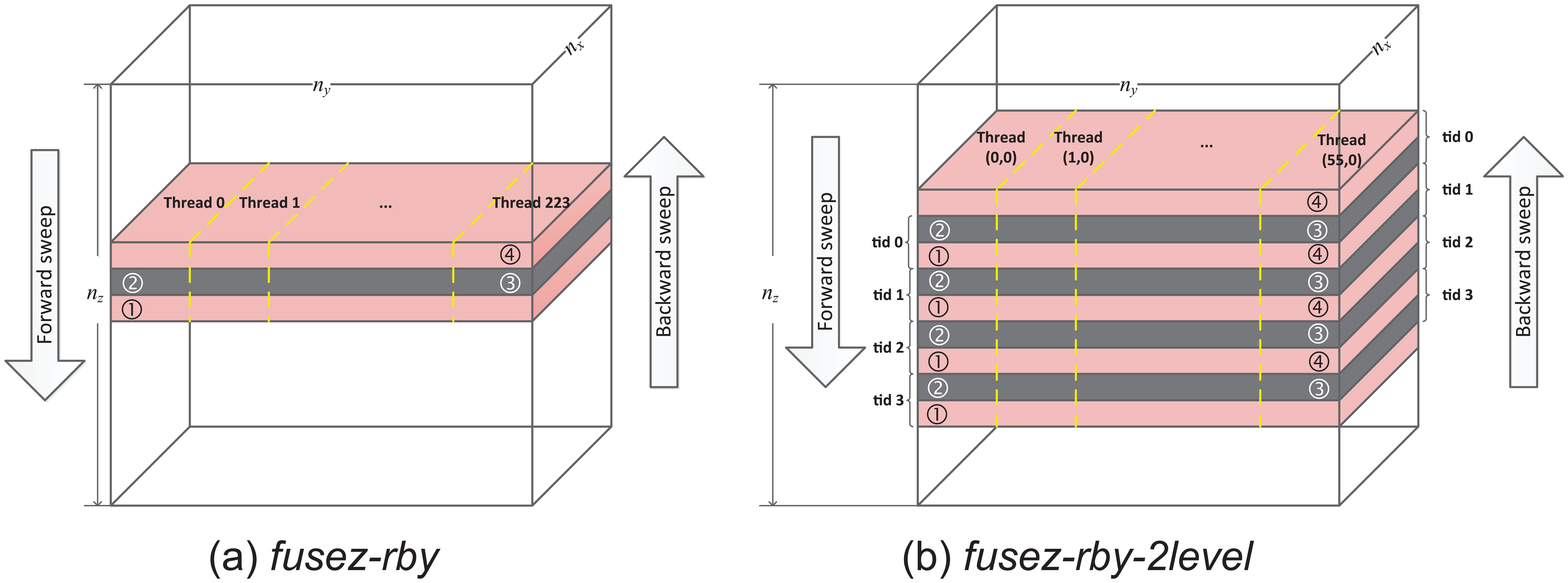
Different parallelization methods of SymGS with red–black relaxing and forward–backward sweep fusing in dimension z.
4.2.2. fusez-rby-2level
For a task size with a small ny, fusez-rby suffers from both limited parallelism and load imbalance. On an Intel Xeon Phi 31S1P, there are 224 threads available on the platform, with every four running concurrently on the same core. We thus propose a two-level parallelization method, referred to as fusez-rby-2level, to split threads into groups according to their affinity. Let the two-tuple (gid, tid) identify a certain thread, where gid is the group id and tid is the local thread id in the thread group. Since the four hardware threads of the same core share the on-chip resources such as L2 cache and L2 translation lookaside buffer (TLB), we may assign them to the same group by setting
4.2.3. fusez-rby for the outer task
Different from the MIC accelerator, the CPU has a very large L3 cache to handle the increased working set resulting from the fusion of forward–backward sweeps in SymGS. But Algorithm 3 cannot be directly applied due to the irregular shape of the outer task. To apply it, we divide the outer part into three regular parts. The top and bottom parts are regular cubic blocks. The medium part is the most complex, of which each xy plane is a hollowed rectangular. We store the outer part in a contiguous region in row-major order and propose a variant of Algorithm 3 to fuse the forward and backward sweep among the consecutive three parts. The simplified pseudo code is shown in Figure 8, along with the parallelization method used in each plane. Analogously, a red–black relaxation along dimension y is employed to enable parallelization for both types of planes. On the hollowed plane, we distribute the computational loads evenly by the number of data points among all CPU threads.
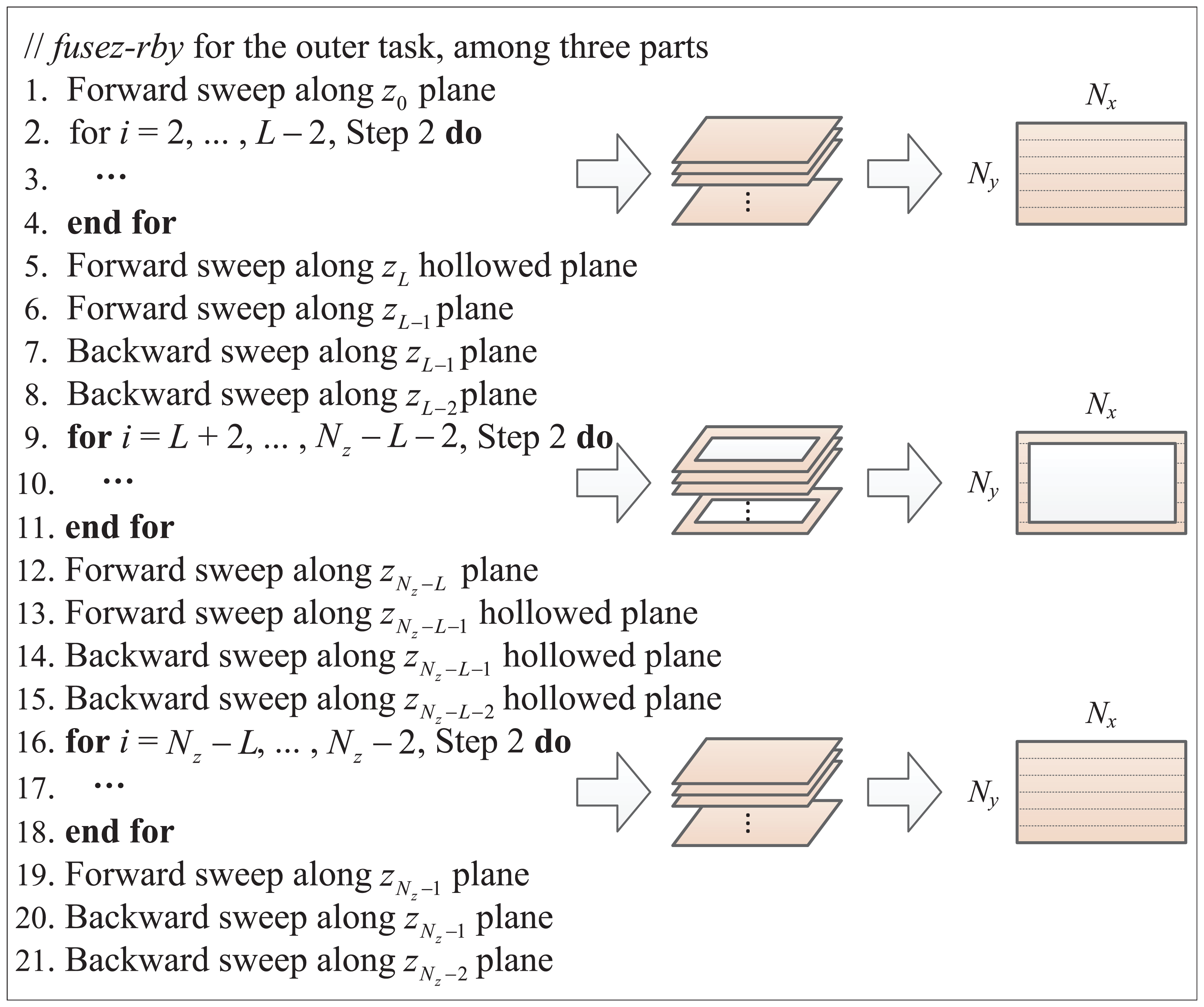
Fused forward–backward sweeps in SymGS when processing the outer part. Here L is the boundary thickness of inner–outer partition.
4.3. Block multicolor reordering for SymGS
The application of red–black reordering destroys the inherent dependency among data points according to a certain pattern, thus leading to a convergence penalty. For example, when applying the previously mentioned red–black coloring along dimension z in SymGS, the number of CG iterations increases from 50 to about 67. When using a red–black reordering in dimension y without fusion, denoted as rby, the exploited parallelism is usually too low for the MIC platform and often suffers from load imbalance. To assess the trade-off between the improved concurrency and the convergence penalty, we propose a variant of the block multicolor reordering (Iwashita and Shimasaki 2003). The proposed variant is also based on the two-level parallelization idea, and it is feasible to choose another group size. As shown in Figure 9, we first distribute the tasks along dimension y among thread groups and then along dimension z among threads within a group. Afterward, a block four-color reordering is used within a thread to evenly split the data points into four parts along two dimensions and designate four colors. Points with the same color are smoothed one after another as the original order in the sequential SymGS. In this way, the required number of iterations are around 57 in most cases. The corresponding part in sparse matrices and vectors related to a thread can be stored contiguously to further improve the locality. Similar fast synchronization functions are also developed for this case.
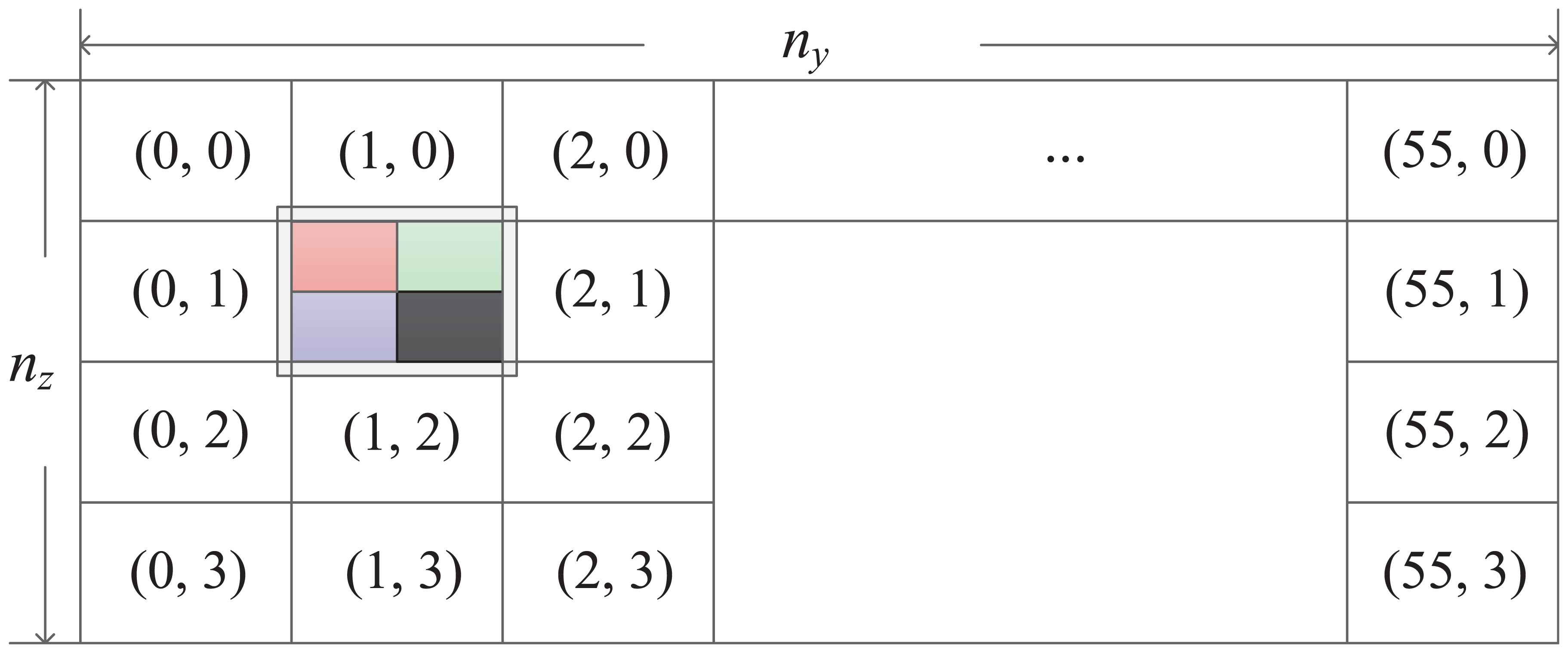
Block multicolor reordering relaxation applied in SymGS on the MIC platform.
All of the above parallelization methods are implemented in our optimized HPCG code. We choose, by experiment, the most appropriate version for each grid level to adapt with different task sizes.
5. Other optimization details
In addition to the parallelization and optimization of SymGS, we also exploit various optimization techniques for those performance-critical kernels on both CPU and MIC. These techniques are broadly employed in many references, therefore we only mention them briefly.
5.1. Optimizations on MIC
5.1.1. Sparse matrix storage format
The standard Compressed Sparse Row (CSR) format is employed in the HPCG reference implementation. The format is widely used but usually inefficient and unable to automatically exploit the regular patterns in the sparse matrices. Among various available storage formats, the ELLPACK format and its variants, such as the sliced ELLPACK (SELLPACK) format, are commonly applied on both graphics processing unit (GPU) and MIC (Monakov et al., 2010; Liu et al. (2013), because they not only save the array to store the row index of nonzeros but also are more efficient for single instruction, multiple data (SIMD) vectorization. To optimize sparse matrix kernels on MIC, we use a simplified SELLPACK format with a slice height of 16 to exploit the potential locality of the input vector in SpMV, where the slice height is determined by the 32-bit integer SIMD width of the MIC architecture. The matrix within a slice is stored in a column-major order. Note that we only make use of the SELLPACK format to split the dimension x into several blocks, and padding is done if the size of dimension x is not a multiple of 16. We can manually vectorize the code with the 512-bit wide SIMD intrinsics.
5.1.2. Vectorization of SpMV
In SpMV, elements of the input vector are collected by a gather instruction according to the column indices. All the arrays are well aligned on cache line boundaries so that aligned load and store instructions are used in most cases. The output vector is overwritten completely by the computed results in SpMV. Thus, the streaming store instructions are used instead to avoid wasting memory bandwidth by reading the original content from memory to cache.
5.1.3. Vectorization of SymGS
The optimized code of SymGS resembles greatly with that of SpMV. The points along dimension x are preserved for SIMDization, which is the reason we only parallelize SymGS along dimensions y and z in Section 4. In order to vectorize SymGS, we further apply a red–black relaxation along dimension x and rearrange the points with the same color contiguously in memory. As a result, every 16 points with the same color are grouped into a slice and smoothed simultaneously by a series of vectorized instructions, 236 exactly in our implementation.
5.2 Optimizations on CPU
5.2.1. Sparse matrix storage format
As for the outer part, the corresponding sparse matrix is stored in the ELLPACK format in row-major order because of the nonuniform length of dimension x. However, the stored number of nonzeros per row is padded to be a multiple of the double precision SIMD width (4 for AVX) to ensure the usage of efficient load and store instructions.
5.2.2. Vectorization
Due to the absence of the gather instruction on AVX-based architectures, we access the elements of the input vector using scalar instructions and then compose them to an SIMD vector. The reduction among the four doubles in a vector register is done by scalar instructions as well. The above facts suggest that vectorization on CPU will be less efficient than on MIC, which is consistent with our test results to be shown in Section 6.1. Apart from this, the vectorization in other cases is more or less the same as the one used on the MIC architecture.
5.3 Other common optimizations
In SpMV and all dense vector kernels, there is no data dependency in the computing order, and very little opportunity for data reuse. Parallelizations of these kernels are simply implemented by OpenMP pragma statements with a static schedule strategy. Each thread is bounded to a specified core according to the compact affinity. On the MIC side, we enable the 2MB pages, instead of the default 4 KB, to improve the TLB hit rate as well as reduce the overhead of data transfer and memory allocation.
In addition, we observe that the residual computed by SpMV in the MG is immediately used in a restriction. As a result, only 1/8 of the residual vector is transferred to and used by the coarser grid. Therefore, we fuse these two operations into one to eliminate the redundant 7/8 calculations as done in (Williams et al., 2012). The major advantage of this technique is the reduction of the computational cost. And the major disadvantage, on the other hand, is that it results in a more complicated memory access pattern (i.e. stride access instead of contiguous) on the fine levels. Optimizations such as loop unrolling and manual prefetching are employed to further enhance the overall performance.
6. Performance and analysis
Two heterogeneous systems are used in the tests, including a smaller one for single-node performance evaluation and, a much larger one, the Tianhe-2, for million-core scalability runs. Table 2 lists the detailed configuration of the two systems. On the small cluster, 8 CPU threads from the same socket and 240 MIC threads are working together on an inner–outer subdomain. On Tianhe-2, we enable 224 threads on each MIC accelerator and assign 6 CPU cores to cooperate with it. Consequently, the rest of the CPU cores in each computing node are left to handle the MPI communication.
The configuration of the two heterogeneous systems.
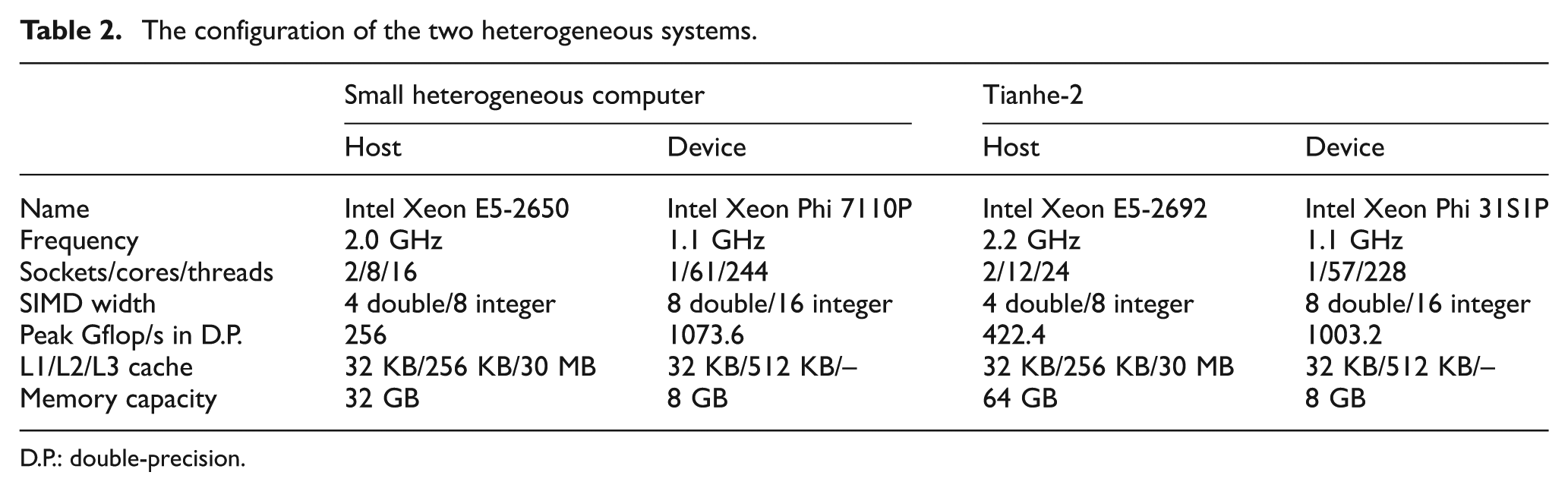
D.P.: double-precision.
6.1. Effects of parallelizing SymGS
To compare the various parallelization and optimization choices of SymGS in Section 4, we conduct some experiments to assess their effects here. A simple four-color reordering in dimension y and z, rbzy, is also implemented and tested for comparison. The testing results are shown in Figure 10.
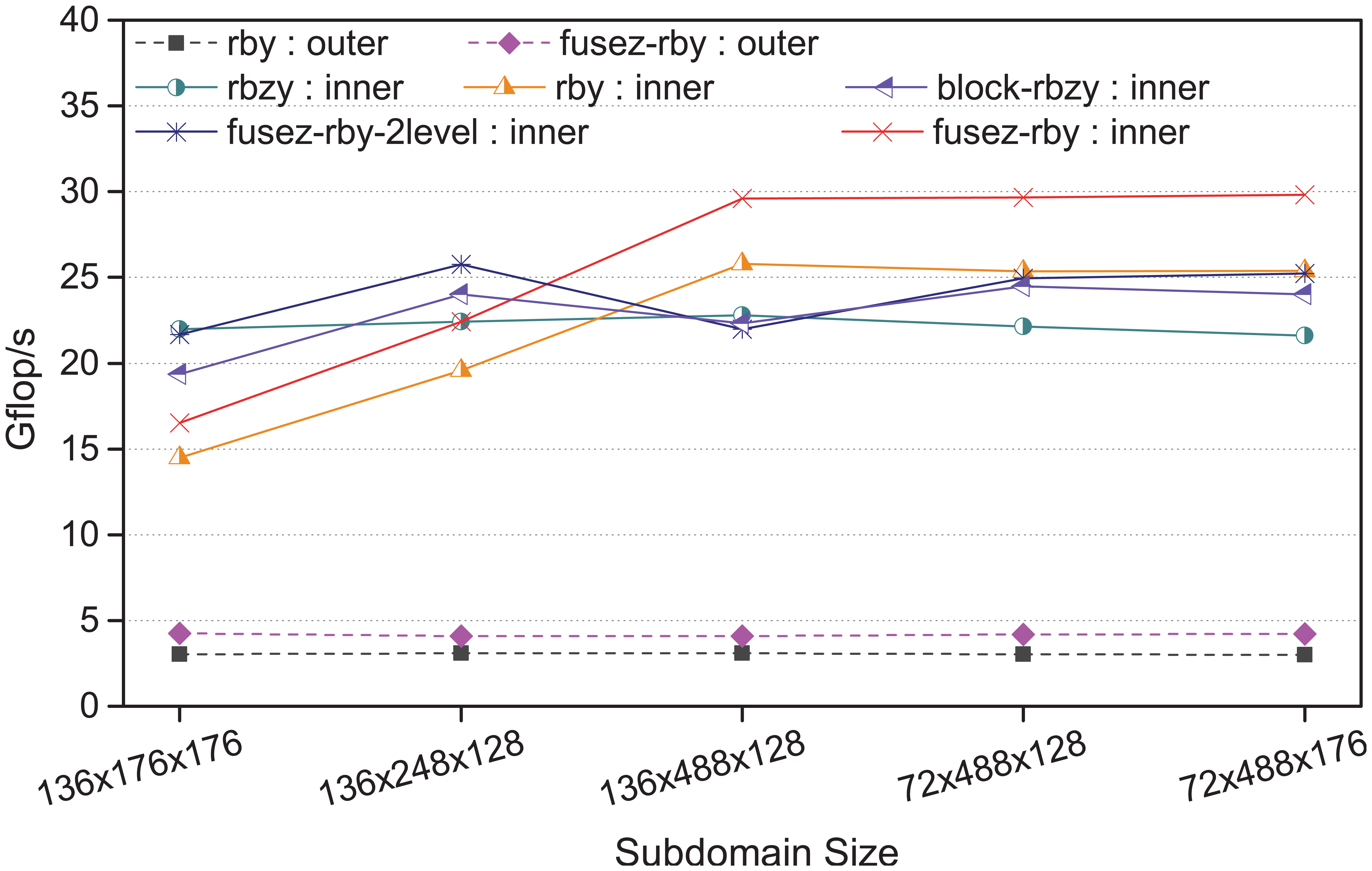
Raw performance of SymGS on the finest grid when using various parallelization methods. The labels with suffix “: inner” represent the corresponding parallelization method used for the inner part while “: outer” for the outer part.
We observe that fusez-rby always outperforms rby for either the regular inner part or the irregular outer part. The averaged speedup of fusez-rby over rby is around 1.16× on MIC and around 1.37× on CPU. The higher speedup on CPU is expected because the CPU has a large L3 cache and MIC does not. From the algorithmic perspective, the fused algorithm can reduce the memory traffic by half, but the performance gain on the MIC side is greatly limited by the small L2 cache size.
A further observation indicates that in the case where the subdomain has a small length in dimension y, fusez-rby may suffer from the low degree of parallelism and result in load imbalance, even when a balanced loop distribution among different cores is enforced. The two-level parallelization method fusez-rby-2level can be used to improve the load balance. However, when the length in dimension y is large enough, the extra unrolling along dimension z in the two-level method leads to a larger working set, which may overflow the L2 cache.
Comparing in terms of parallelism, the general four-color reordering method rbzy provides the highest degree of parallelism, which is
In view of the convergence rate, two of the five tested methods, rby and block-rbzy, are able to achieve the expected convergence in around 57 iterations, and the rest all lead to much larger numbers of iterations. Among the two, block-rbzy can be considered as the two-level parallelization version of rby. Because of the fast convergence rate, the two parallelization methods are chosen to parallelize SymGS on the finest grid level for MIC. The other three methods are used to adapt with the size of the problem on other levels. As for the outer task on the CPU side, the fused method, fusez-rby, is always used since it barely affects the overall convergence rate. Because of the small data amount, a basic red–black relaxation method of SymGS along dimension z, rbz, is particularly applied to parallelize the coarsest-level SymGS. A complete list of the parallelization methods of SymGS on different grid levels for both MIC and CPU are presented in Table 3.
A complete list of the parallelization methods of SymGS applied on different grid levels for both MIC and CPU.

6.2. Single-node performance
We fix the subdomain size to 136 × 176 × 176 and evaluate the effect of different optimization techniques by incrementally adding them in our hybrid kernels. The results are illustrated in Figure 11. In the baseline implementation, the sparse matrix format is replaced with the optimized ones, but the SIMD vectorization is not applied. We analyze the results in the figures as follows.
The raw performance breakdown in HPCG with different optimizations applied.
6.2.1. Vectorization (simd)
Compared to the baseline version, the SIMD vectorization leads to an averaged speedup of 4.92× on MIC and 1.23× on CPU. The speedup on MIC is high due to the vectorization-friendly SELLPACK sparse matrix format and the regular shape of the inner task. Note that some code transformations are done in sparse matrix kernels for efficient vectorizing.
6.2.2. OpenMP parallelization (omp)
Based on the red–black relaxation and other optimizations for the storage of matrices and vectors, the speedup due to OpenMP multi-threading is remarkable, which is averaged to 53.57× on MIC and 2.40× on CPU.
6.2.3. Customized thread communication (thread-comm-opt)
There is a notable 24% speedup on MIC when replacing the original OpenMP synchronization with our customized lightweight thread communicating tool in SymGS. It indicates that the synchronization overhead among hundreds of MIC threads is substantial and critical to the performance.
6.2.4. Fused schedule (schedule)
Using the fused schedule presented in Section 3.3, the data movement overhead is reduced, leading to another 4% improvement of the final performance.
6.3. Million-core performance
A full-system scale test is conducted on Tianhe-2 to 16,000 heterogeneous nodes. The results, including the aggregated HPCG performance and the parallel efficiency, are shown in Figure 12. In the test, the subdomain size is also fixed to 136 × 176 × 176. A single-node performance of 48 Gflop/s is achieved on Tianhe-2. Compared to the raw performance of 58 Gflop/s, the performance penalty is around 14% due to the convergence degradation and another around 5% due to the preparation of optimized data structures. In a previous work (Park et al., 2014b), a single-node performance of 46 Gflop/s on Tianhe-2 was reported, where an MIC-only approach was used. The performance improvement of our hybrid CPU-MIC algorithm over the MIC-only approach is below ideal due to the offload overhead for the cooperative heterogeneous computing and the fact that CPU is responsible for all MPI communication and therefore not working at the full capacity. But it is sufficient to help sustain a better performance at the extreme scale. The hybrid implementation successfully scales to 16,000 computing nodes, with an aggregate performance of 623 Tflop/s and a parallel efficiency of 81.2%.
Aggregate performance and weak scalability of HPCG on Tianhe-2. Three MPI processes are running on a single node, with each one controlling a subdomain.
7. Related work
Stencil computation, often found in many scientific computing applications, is widely studied on x86 CPUs and emerging many-core architectures (Datta et al., 2008; Wellein et al., 2009; Wonnacott, 2000), of which the work mainly concentrates on methods such as temporal blocking and time skewing. A large number of optimization techniques, such as software pipelining, register blocking, row or column sorting, and dynamic load scheduling, are studied in Vuduc et al. (2005), Williams et al. (2009), Monakov et al. (2010), and Liu et al. (2013) to optimize SpMV, the basic operation in a sparse iterative solver. The above work plays an important role in guiding our optimizations of all sparse matrix kernels in HPCG.
Preconditioners are now commonly used to accelerate the convergence of iterative solvers. Thus, much work has been done on parallelizations and optimizations of preconditioners such as MG and SymGS on various platforms. For example, Kowarschik et al. (2000) and Wallin et al. (2006) employ fused updating of red and black points, temporally blocking, and fine-grained locking to optimize and parallelize Gauss–Seidel on multi-core CPUs. Courtecuisse and Allard (2009) focus on optimizing Gauss–Seidel on both multi-core CPUs and GPUs, while Williams et al. (2012) have made an important contribution on improving the performance of the geometric multigrid method on the Intel Xeon Phi coprocessor in the native execution mode. Their work is of great help in designing our optimized algorithms for HPCG, but special efforts must be made because SymGS in HPCG is based on sparse matrix kernels that have much more complex memory access patterns.
HPCG has drawn increasingly more attention from both academia and industry since it was announced. As a result, some preliminary research has emerged in the recent year, including Kumahata et al. (2014) on the K computer, Phillips and Fatica (2014) on NVIDIA GPU clusters, and Park et al. (2014a, 2014b) and Sridevi (2014) on Intel CPU and MIC clusters. Among them, by treating each Xeon Phi device as an independent node, the works of Park et al. (2014a, 2014b) and Sridevi (2014) support running HPCG on CPU-MIC heterogeneous systems in the symmetric programming mode. Overall, our work is distinct from the others in optimizing HPCG based on a heterogeneous CPU-MIC algorithm to enable the cooperative computing among hybrid resources.
8. Concluding remarks
In this work, we have proposed a hybrid CPU-MIC algorithm to enable and scale the HPCG benchmark on the world’s largest heterogeneous supercomputer, Tianhe-2. The hybrid algorithm is based on an inner–outer subdomain partitioning strategy that not only adapts to achieve a good load balance between host and device but also helps reduce the data movement overhead. Various parallelization and optimization techniques have been exploited and analyzed in detail to maximize the performance gain from both CPU and MIC. Among them, we pay special attention to the assessment of the trade-off between the locality and concurrency, especially in the symmetric Gauss–Seidel operation. A thorough performance analysis has been provided on a small CPU-MIC computer to compare among different optimization choices. The test results on Tianhe-2 show that our hybrid implementation of HPCG has successfully scaled to the full-system scale of 3.12 million heterogeneous cores, with an aggregated performance of 623 Tflop/s and a parallel efficiency of 81.2%, which is a new record on the HPCG List of 2014.
Footnotes
Acknowledgements
The authors would like to express their appreciations to the anonymous reviewers for the invaluable comments that greatly improved the quality of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was supported in part by NSF China (grants# 91530103, 61170075) and the National High-Tech R&D Program of China (grant# 2015AA01A302).
Author biographies
Yiqun Liu received her PhD in computer science from the Institute of Software, Chinese Academy of Sciences (ISCAS) in 2015. Currently, she is a senior research and development engineer at IDL, Baidu Inc. Her research mainly focuses on code optimization and deep learning.
Chao Yang is a professor at ISCAS. He received his PhD in computer science from ISCAS in 2007. His research interests include numerical analysis and modeling, large-scale scientific computing, and parallel numerical software.
Fangfang Liu is an associate professor at ISCAS. Her research interests are iterative methods and preconditioning techniques for sparse linear systems and high-performance numerical library. She received her MS in mathematics from the Jilin University in 2006.
Xianyi Zhang is a research fellow at the University of Texas at Austin (UT-Austin). Before joining UT-Austin in 2015, he had been working at ISCAS since 2007. He received his PhD in computer sicence from ISCAS in 2014 and obtained his MSc and BS from the Beijing Institute of Technology in 2007 and 2005, respectively.
Yutong Lu is a professor at National University of Defense Technology (NUDT), China. She received her BS, MS, and PhD in computer science from NUDT. Her research interests include large-scale system management, high-speed communication, distributed file system, and advanced parallel programming environments.
Yunfei Du is an associate professor at NUDT. His research interests focus on parallel and distributed systems, fault tolerance, and scientific computing. He received his PhD from NUDT in 2008.
Canqun Yang received his MS and PhD in computer science from NUDT in 1995 and 2008, respectively. Currently, he is a professor at the university. His research interests include programming languages and compiler implementation.
Min Xie is a professor at NUDT. His research interests include high-speed interconnect, programming model, and parallel and distributed computing. He received his PhD in computer science from NUDT.
Xiangke Liao received the BS from Tsinghua University in 1985, and MS from NUDT in 1988, both in computer science. Currently, he is a professor and the dean of College of Computer Science, NUDT. His research interests include high-performance architecture, operating systems, software engineering, and parallel and distributed processing.