
Abstract
We present a computational modeling framework for data-driven simulations and analysis of infectious disease spread in large populations. For the purpose of efficient simulations, we devise a parallel solution algorithm targeting multi-socket shared-memory architectures. The model integrates infectious dynamics as continuous-time Markov chains and available data such as animal movements or aging are incorporated as externally defined events. To bring out parallelism and accelerate the computations, we decompose the spatial domain and optimize cross-boundary communication using dependency-aware task scheduling. Using registered livestock data at a high spatiotemporal resolution, we demonstrate that our approach not only is resilient to varying model configurations but also scales on all physical cores at realistic workloads. Finally, we show that these very features enable the solution of inverse problems on national scales.
Keywords
1 Introduction
Livestock diseases have a major economic impact on farmers, the livestock industry, and countries (Hasonova and Pavlik, 2006; Knight-Jones and Rushton, 2013). Modeling and simulation of infectious disease spread are important in designing cost-efficient surveillance and control (Willeberg et al., 2011). One challenge is that disease dynamics and transmission routes for various pathogens are fundamentally different. Indirect transmission of pathogens via the environment for fecal–oral diseases requires a different model compared to diseases that spread with direct contact between individuals (Brooks-Pollock et al., 2015). Another challenge is to incorporate the increasing amount of epidemiologically relevant data into the models (Pellis et al., 2015). It is therefore desirable to have simulation tools that are flexible to various disease spread models yet efficient to handle the large amounts of available livestock data.
Due to uncertainties in the exact details in pathogen transmission (Greenwood and Gordillo, 2009) and the inherent random nature of animal interactions, stochastic modeling is natural and often required. Spatial models that include proximity to infected farms with local clustering of disease spread gained popularity during the foot-mouth-disease epidemic in 2001 (Keeling, 2005; Harvey et al., 2007; Stevenson et al., 2013). Another important route for disease spread is animal trade, creating a temporal network of contacts between farms (Masuda and Holme, 2013). It has been shown that the topology and connectivity of the network have great impact on the disease spread and on the effect of control measures (Büttner et al., 2016; Shirley and Rushton, 2005).
Stochastic models on discrete state-spaces are typically simulated using discrete event simulation (DES), a general approach to evolve dynamical systems consisting of discrete events including, in particular, continuous-time Markov chains (CTMCs) (Cassandras and Lafortune, 2008). As most realistic epidemiological models are formulated on a large state-space and/or need to be studied over comparably long periods of time, parallelization is desirable. The highest degree of parallelism is typically achieved by a decomposition of the spatial information, often represented as a graph or network, into a set of subdomains (Fujimoto, 1990). It is then up to the strategy for event handling at domain boundaries how well the concurrent execution scales and which overall degree of parallelism is extractable. As it may hinder scalability, a constraint that plays a crucial role in the design of parallel DES is to maintain the sequential ordering of events, that is, to preserve the underlying causality of the model.
In general, there are two types of boundary events that can occur during a simulation, which ultimately decide what will be the optimal parallelization strategy: those which are deterministic and essentially of fully predictable character and those which are stochastic and not predictable at an earlier simulation time (Fujimoto, 1999). To parallelize events that belong to the latter group, sophisticated approaches such as optimistic parallel DES algorithms have been proposed (Jefferson, 1985). These approaches may use speculative execution to enable scalability but must implement rollback mechanisms in case the event causality is violated (Carothers et al., 1999). Alternatively, in simulations where the domain crossing events are deterministic and thus predictable, conservative simulation may be used as it is possible to avoid causal violations altogether (Fujimoto, 1990; Heidelberger and Nicol, 1993). In particular, a parallel scheduler (Drozdowski, 2009) can be used to create an execution order which guarantees causality, as has been previously shown by Nicol and Liu (2002) and Xiao et al. (1999), notably with the focus on simulation of telecommunication networks.
In this article, we present an efficient and flexible framework for data-driven modeling of disease spread simulations. The model integrates disease dynamics as CTMCs and real livestock data as deterministic events. This allows us to create a temporal network of disease transmission, which has been shown to be a key aspect in modeling and simulation of spatial disease spread (Büttner et al., 2016; Shirley and Rushton, 2005). Previously, agent-based simulations based on synthetic data have been studied by others (Barrett et al., 2008; Yeom et al., 2014).
The way the model is defined allows us to predict future boundary events at any simulation time, and hence we are able to create parallel execution traces which respect causality. In particular, we find that dependency-aware task computing (Leijen et al., 2009; Subhlok et al., 1993) can be used to implement this approach with high efficiency, as all the necessary information to maintain spatial and temporal causality of events can be specified via dynamic creation of tasks and dependencies.
This is in contrast to previous approaches (Nicol and Liu, 2002; Xiao et al., 1999), as the scheduler is not an implicit part of the parallel simulation algorithm but can be chosen by the user from a wide selection of openly available libraries (e.g. OpenMP 4.0 and OmpSs, Duran et al., 2011; or StarPU, Augonnet et al., 2011). We show how the selected library is integrated into our simulation framework, by assigning parts of the sequential algorithm to independent tasks that are scheduled using a certain set of rules. We evaluate this approach using the task-parallel run-time library SuperGlue (Tillenius, 2015), which has been demonstrated to be an efficient scheduler of fine-grained tasks. Using our simulator on models with realistic workloads, we demonstrate scalability on a multi-socket shared-memory system and investigate when this approach is preferable in comparison to traditional parallelization techniques. As the achievable scalability clearly depends on the properties of the individual model, we in particular choose to investigate the influence of the model’s connectivity pattern.
The article is organized as follows. In Section 2, we introduce the mathematical foundation for our framework. In Section 3, we discuss the sequential simulation algorithm and the strategy for parallelization. In Section 4, we present numerical experiments carried out on benchmarks consisting of a recently proposed epidemiological model incorporating large amounts of registered data. We also include an example of an inverse problem for an epidemic model on national scales. Finally, in Section 5, we offer a concluding discussion around the central themes of the article.
2 Epidemiological modeling
We consider in this section a highly general approach to epidemiological modeling. Proceeding stepwise we start with a description of single-node stochastic SIR-type models in the form of CTMCs, using a compact notation that also encompasses externally defined events. We next couple an ensemble of such single-node models into a network with prescribed transitions in between the nodes to arrive at a global description. Finally, since most realistic models on multiple scales will typically incorporate also quantities for which a continuous description is more natural, we consider a mixed approach in which CTMCs are coupled to ordinary differential equations.
2.1 Discrete states
We shall use a compact notation for jump stochastic differential equations (jump SDEs) as follows. We assume a probability space
Given a rate function
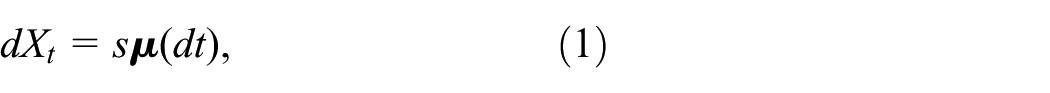
with scalar counting measure
The generalization of equation (1) to non-scalar counting measures is straightforward. Assuming
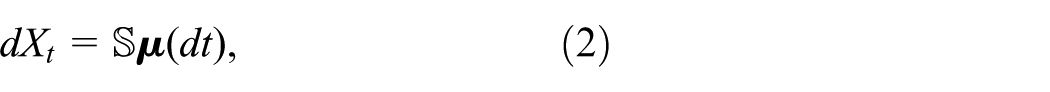
with
As a concrete example, consider the classical SIR model (Kermack and McKendrick, 1927):
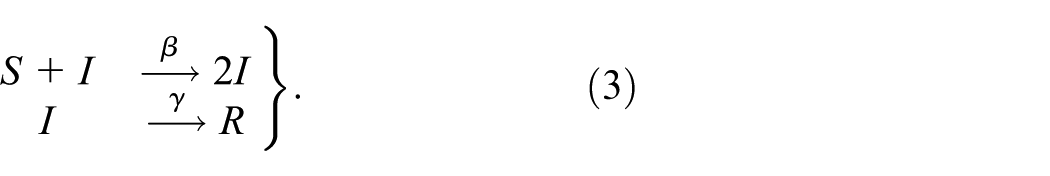
With state vector


With one small additional convention, the above notation also encompasses events that have been defined externally. Suppose, for example, in the SIR model, that susceptible individuals are to be added one by one at known deterministic times

and additionally define in terms of the Dirac measure:

Equation (2) now evolves the full dynamics of the coupled stochastic–deterministic model. Note that when removing individuals using this scheme, some care is required to be able to guarantee a non-negative chain.
2.2 Network model
Although the previous discussion is of completely general character, it makes sense to handle the collective dynamics of a possibly very large collection of nodes in a slightly more streamlined fashion. Assuming

Given an undirected graph
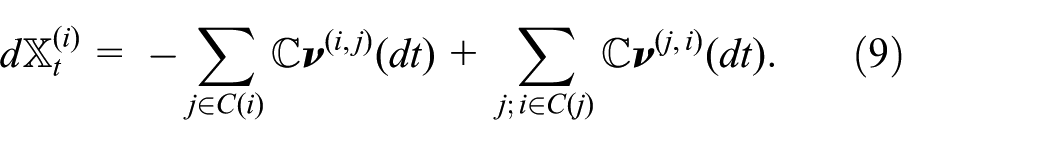
Note that in equation (9), global consistency is enforced as follows. The kth “outgoing” event is a change of state according to
Using superposition of equations (8) and (9) the overall dynamics becomes:
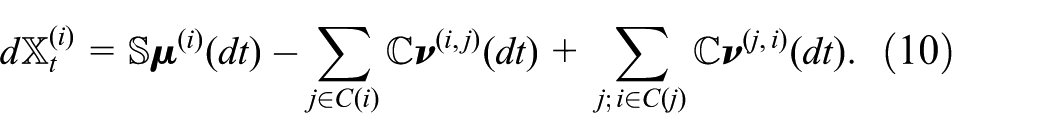
As before, we conveniently allow externally defined deterministic events to be included in this description using the equivalent construction in terms of Dirac measures.
2.3 Continuous states
In the previous description, we assumed essentially that individuals were counted, such that a discrete stochastic model was needed to accurately capture the dynamics of a possibly small and noisy population. In a multiscale model, however, it makes sense to allow also continuous state variables, representing, for example, environmental properties more naturally described in a macroscopic language.
Assuming an additional continuous state matrix
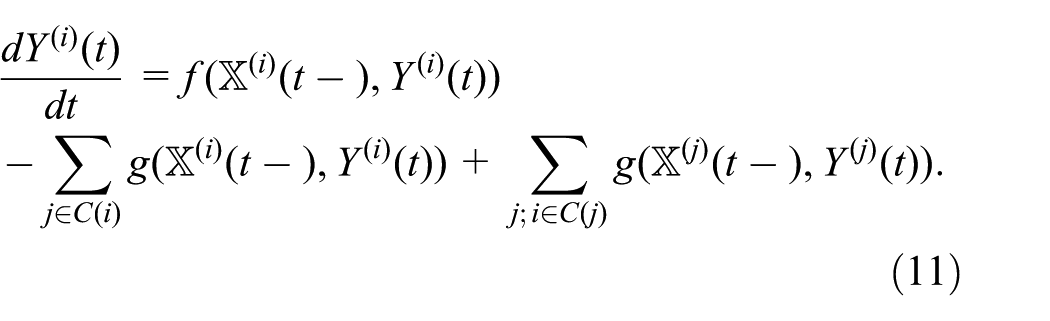
Importantly, with this addition, equation (10) can now depend on the continuous state variable:
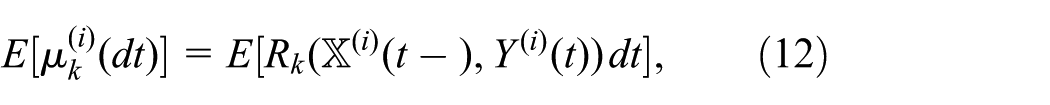
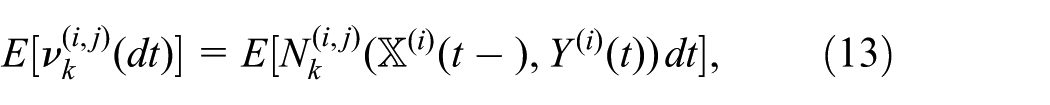
where of course k is in the range where the dynamics is stochastic rather than defined externally from a database.
Equations (10), (11), (12), and (13) form the basis for our epidemiological computational framework, next to be described.
3 Implementation
In the following section, we discuss the implementation details of our computational framework. We begin with indicating how numerical methods can be consistently designed to approximate the mathematical model arrived at previously. A description of the sequential solution algorithm and a presentation of the chosen parallelization strategy based on domain decomposition then follow. We propose to process events that cross domain boundaries as tasks and thus conclude with the introduction of dependency-aware task computing and an associated scheduling scheme.
3.1 Numerical methods
In order to be able to effectively incorporate finitely resolved temporal data as well as to obtain a parallelizable framework, we discretize time as
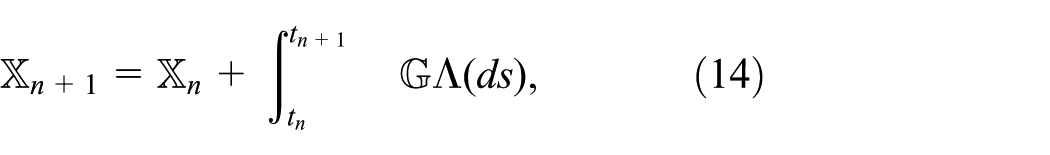
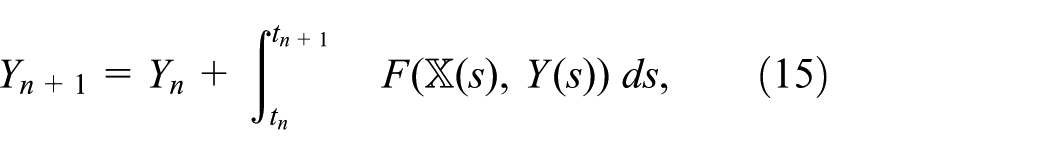
with the understanding that
Typical numerical approaches to equations (14) and (15) are constructed via operator splitting and finite differences (Engblom, 2015). As a representable example we take:
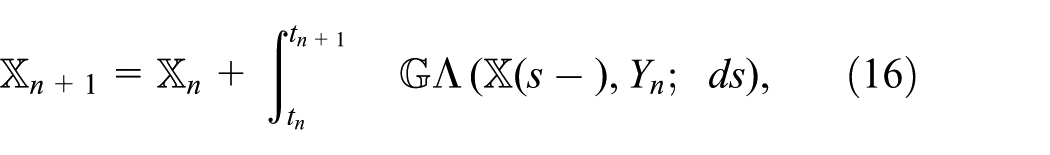
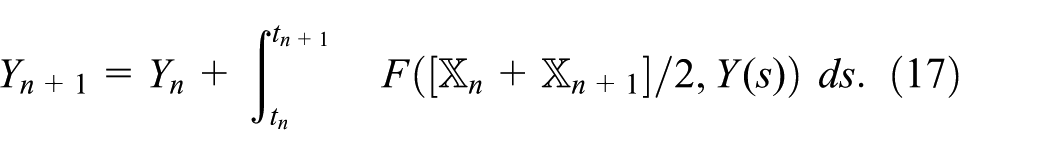
In equation (16), we freeze the variable Y at a previous time step and integrate the stochastic dynamics only. Next, in equation (17), we insert an average effective value of
To describe a more concrete numerical method, some assumptions are in order. Firstly, in equation (10), we assume that events connecting two nodes have been externally defined. In particular, this assumption is satisfied for the important case of domesticated herds of animals who move between nodes due to human interventions only. Secondly, in equation (11), we put
For this scenario, we can write down a concrete numerical method per node i as follows:
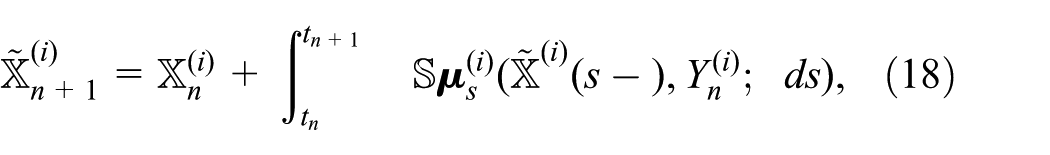
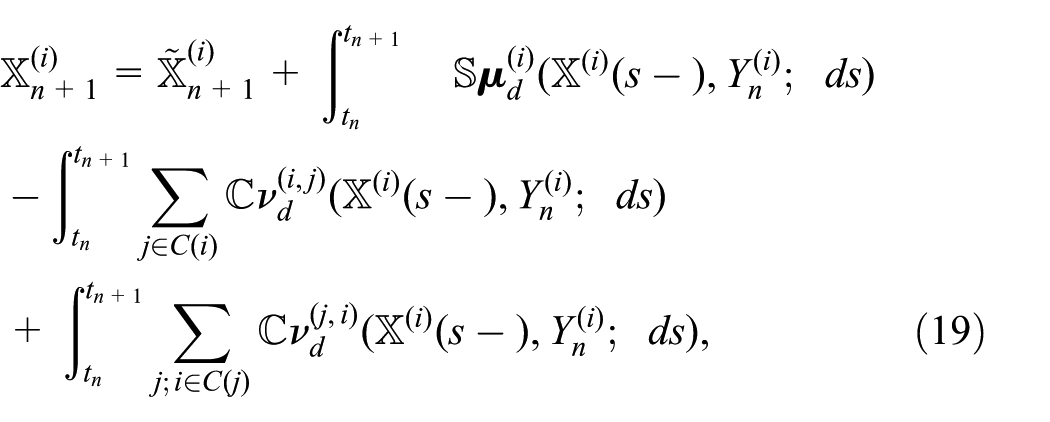
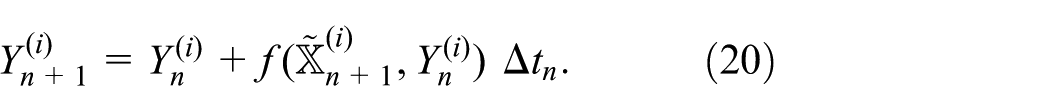
In equation (18), the stochastic part (subscript s) of the measure is evolved in time to produce the temporary variable
3.2 External events
Similar to the epidemiological events (equation (4)), the external events modify the discrete state according to a transition vector (equation (6)), but at a predefined time t.
We divide external events into two types: events of type


where t is the time of the event,
In the actual implementation, the transition vector is a column of the stoichiometric matrix (equation (6)) that is indexed by the event. When the event is processed at time t, it changes the state of node i according to:

The overall spatial domain of the model can be understood as a graph
3.3 Sequential simulation algorithm
The sequential simulation algorithm is divided into three parts: the processing of stochastic events (equation (18)), hereafter referred to as the stochastic step, the processing of external events (equation (19)), or deterministic step, and the update of the continuous state variable (equation (20)). These steps are processed repeatedly in the abovementioned order until the simulation reaches the end.
The stochastic step (Algorithm 1) is an adaptation of Gillespie’s Direct Method (Gillespie, 1977). The algorithm generates a trajectory from a CTMC. At first, the rates

Here,
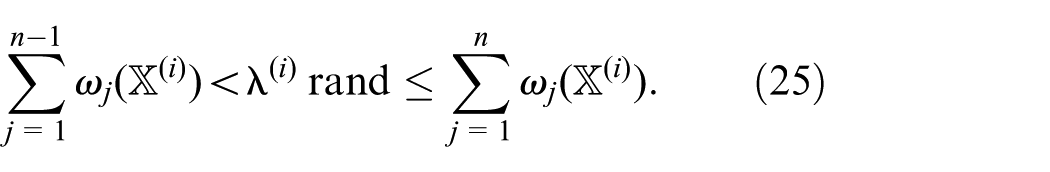

When n is found, we compute the state update according to the transition matrix (equation (4)), setting
The deterministic step works as a read and incorporate algorithm. It moves through the list of external events and processes them at the defined event time. In particular, if the event specifies a single compartment where the transition occurs, it can be directly applied to
Finally, the continuous state variable is updated. As discussed in Section 3.1, in this step, different numerical methods can be applied. Note that the thus updated continuous state generally affects the rate of stochastic events

The implementation of the algorithm is written in C. The overall design is inspired and partly adapted from the unstructured mesh reaction-diffusion master equation framework (Drawert et al., 2012; Engblom et al., 2009).
3.4 Parallel simulation algorithm
The parallelization starts with a decomposition of the spatial domain of the model understood as a graph
After partitions
Second, external events of type
The complexity of the data rearrangement is
Finally, the decomposed problem can be simulated in parallel. For simplicity, let us assume that each subdomain k is bound to one computing thread. Then every thread processes the stochastic step (equation (18)) and the update of the continuous variable (equation (20)) on private nodes of

In our study, we handle events in
3.5 Task-based computing
An increasing amount of scientific computations are parallelized using task-based computing (Berry et al., 2012; Haidar et al., 2014; Meng and Berzins, 2014). In order to apply this pattern, the programmer typically has to divide a larger chunk of work into a group of smaller tasks which can be processed asynchronously. A run-time library (Leijen et al., 2009; Subhlok et al., 1993) is then used to create an execution schedule of the tasks on the available parallel hardware.
If the granularity of tasks is sufficiently fine, the schedule will be denser and the idle time shorter. On the other hand, the scheduler synchronizes a larger number of small tasks which usually implies more overhead. See Gerasoulis and Yang (1993) for a thorough discussion on the impact of granularity.
If the scheduler supports dependency awareness (Perez et al., 2008), the programmer can further define a number of task dependencies. This is a critical feature if data are shared between tasks and therefore a processing order has to be enforced. The scheduler then manages the dependencies in the form of a directed acyclic graph and spawns tasks whenever all dependencies are met.
We believe that the usage of task-based computing is beneficial in our computational framework, as a small granularity of processes is given by the underlying modeling. In our approach, we aim to divide our computations into tasks and define a scheduling policy which guarantees causality of events although they are processed in parallel.
These scheduling rules can be implemented on any dependency-aware task scheduler, the only requirement for some of the scheduling policies is the support for dynamic addressing of a subset of dependencies, for example, via an array of pointers. For example, OpenMP 4.0 does not support this (OpenMP Architecture Review Board, 2013). In our computational experiments, we make use of the run-time library SuperGlue (Tillenius, 2015). In SuperGlue, dependencies are assigned to data and expressed via data versioning (Zafari et al., 2012). If a chunk of data is being processed by a task, a version counter representing the data access will be increased. Other tasks that are dependent on the chunk will be spawned whenever the new version becomes available. SuperGlue has been demonstrated to be an efficient shared-memory task scheduler that it is capable of operating at a comparably low synchronization overhead. The processing of dependencies and spawning of tasks is dynamic, and SuperGlue additionally supports load balancing by work stealing from over-utilized threads.
3.6 Scheduling and dependencies
We now define the tasks and their dependencies that are used in the task-based implementation of the parallel algorithm. Task
Task
If tasks are constructed for fine-grained processing, we schedule each event in
Both tasks
To maintain the causality of domain crossing events:
To maintain the causality between private subdomain updates and domain-crossing events: (b)
The presented processing policies lead to a different utilization of the task scheduler. Firstly, the task
4 Computational experiments
In the following section, we present results of computational experiments of our simulator. The following measurements were obtained on Sandy; a Dell Power Edge R820 computer system equipped with four Intel Xeon E5-4650 processors and eight cores on each socket. We restricted the execution to available physical cores, as timing results on hyper-threads were strongly fluctuating. We begin with a real-world simulation using animal movement data on national scales, followed by a synthetic benchmark for scalability at varying connectivity load, and we conclude with a compute-intensive parameter estimation example.
4.1 National scale simulation of VTEC bacteria spread
Verotoxigenic Escherichia coli O157: H7 (VTEC O157) is a zoonotic bacterial pathogen with the potential to cause severe disease in humans, notably children (Karmali et al., 1983a, 1983b; Riley et al., 1983). Cattle infected with VTEC O157 are an important reservoir for the bacteria and they shed the bacteria in the feces without any signs of clinical disease (Hancock et al., 2001). Reducing the prevalence of infected cattle in the population could potentially reduce the number of human cases. However, the epidemiology of VTEC O157 in cattle is complex and targeted interventions to control the bacteria require a thorough understanding of the source and transmission routes (Hancock et al., 2001).
To explore the feasibility of national scale simulations to improve the understanding of the underlying disease spread mechanisms, we have created a model of the VTEC O157 dynamics, using the presented framework. European Union legislation requires member states to keep register of bovine animals including the location and the date of birth, movements between holdings, and date of death or slaughter (Anonymous, 2000, 2004). These records enable data-driven disease spread simulations that include spatiotemporal dynamics of the cattle population with regard to age structures, births, herd size, slaughter, and trade patterns.
The present computational experiment is based on all cattle reports to the Swedish Board of Agriculture over the period July 1, 2005 to 31 December, 2013. From these reports, three types of
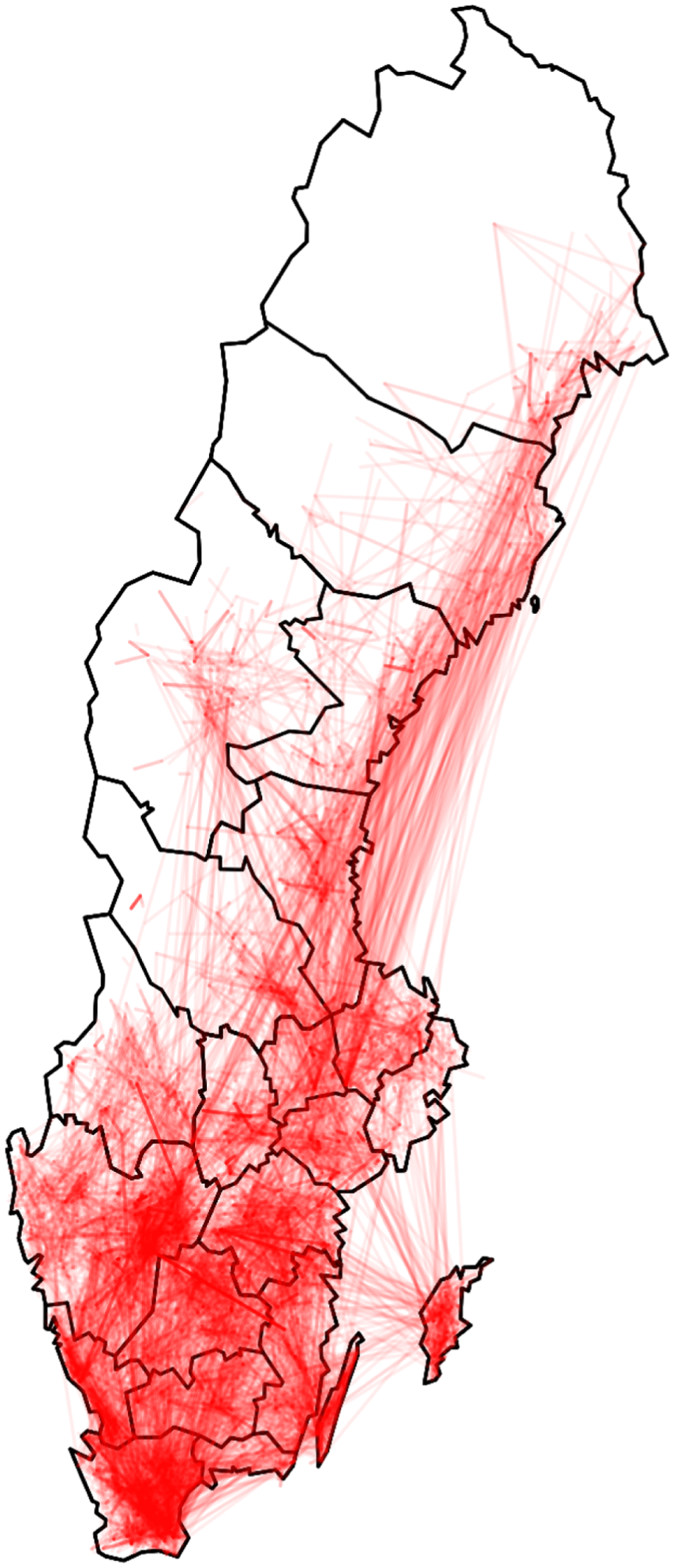
Visualization of cattle movements in the VTEC O157 disease spread simulation (Section 4.1). The arcs shown are a random subset of the complete dataset of ~108 recorded events. The source of the data is the national cattle register at the Swedish Board of Agriculture. VTEC O157: verotoxigenic Escherichia coli O157: H7.
Most infected cattle shed the bacteria less than 30 days before returning to the susceptible state, but calves shed for a longer period than adult cattle (Cray and Moon, 1995; Davis et al., 2006). To capture this, we let the intensity of the transitions between the states depend on the jth age category:

The rate for a susceptible individual on the ith node to become infected per unit of time is given by:
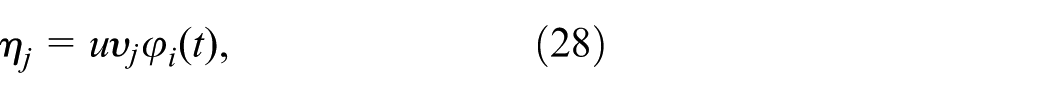
for

where
Finally, the continuous variable
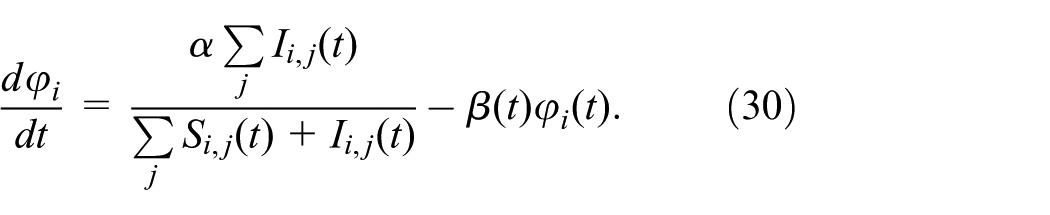
Again,
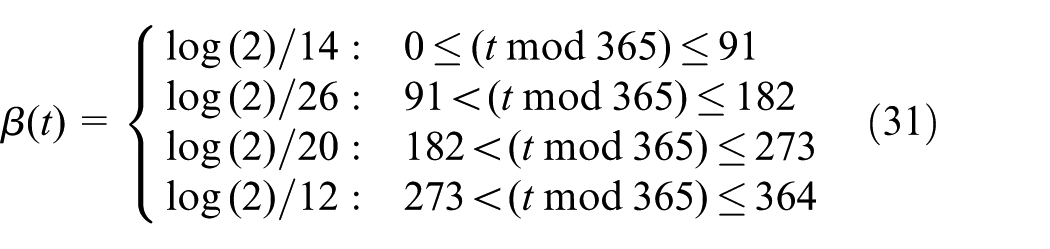
We first parallelized the simulation by spreading tasks
The scaling of the different approaches is shown in Figure 2. For the case of
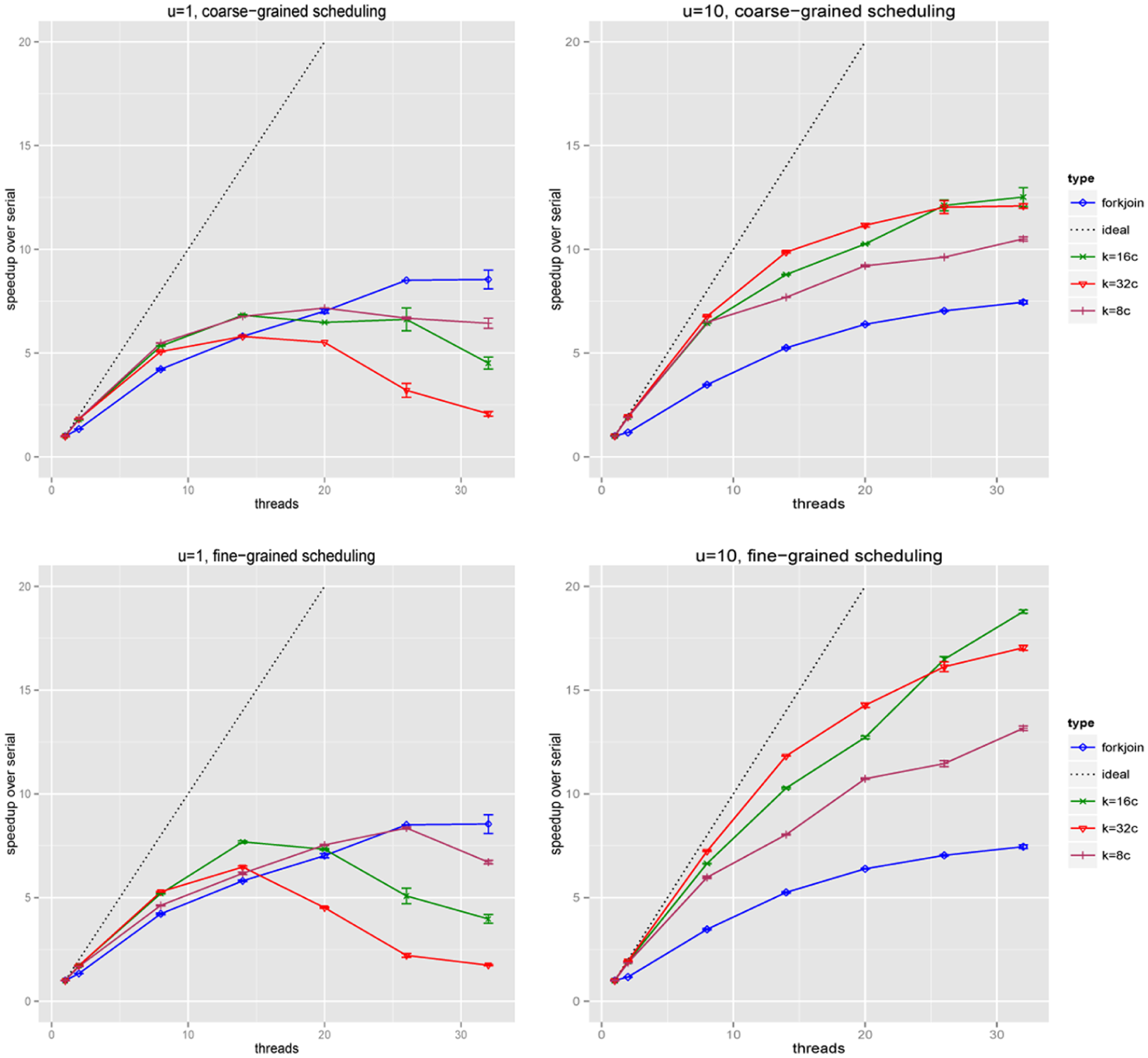
Performance measurements of the VTEC O157 model simulation on Sandy at varying scheduling approaches, task sizes, and scale factor u. The number of tasks k is chosen to be proportional to the number of threads c. In the OpenMP parallelization (“fork–join”), cross-boundary events are processed entirely in serial. Error bars represent the standard error in mean (n = 10). VTEC O157: verotoxigenic Escherichia coli O157: H7.
At
The dependency of the parallel efficiency on the factor u is further detailed in Figure 3. We observe that scheduling overhead and small task sizes prohibit a high efficiency of both task-based approaches if
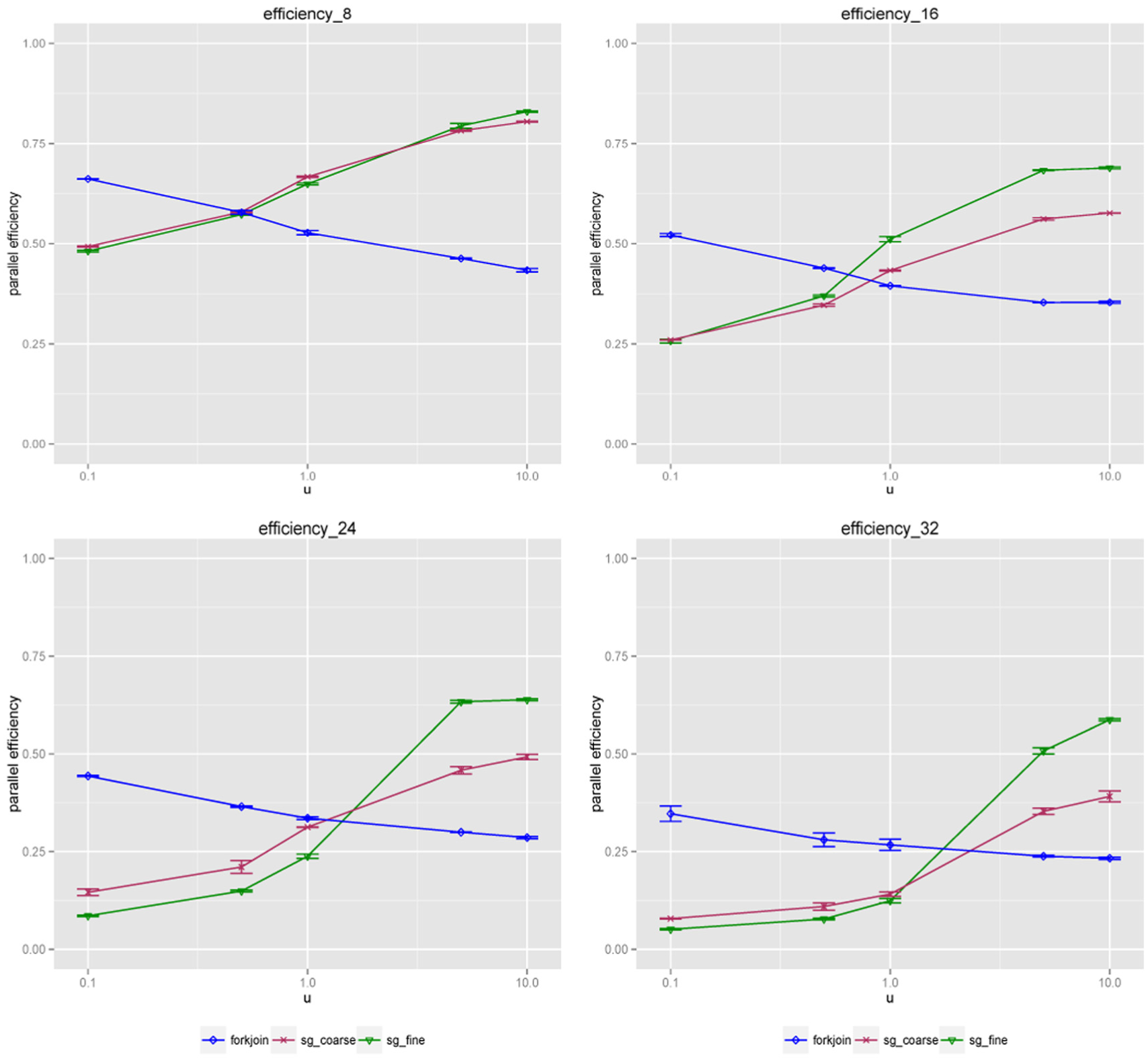
Parallel efficiency of the VTEC O157 model simulation on Sandy at varying factor u. For all task-based approaches the task size
We further present a set of characteristics of the coarse-grained and fine-grained simulations in Tables 1 and 2. As shown in Table 1, the granularity of the fine-grained task
Average task granularity ± the standard deviation and the total number of tasks created during the simulation at a given partitioning k.

Maximum ± full width at half maximum of the (right-skewed) histogram of waiting times for fulfilled task dependencies, and the average amount ± standard deviation of dependencies assigned to tasks at each discrete time interval

On the other hand, the advantage of the fine-grained scheduling is emphasized by the measurements shown in Table 2; the average waiting time to fulfill the dependencies for the fine-grained
The resulting execution trace is also visualized in Figure 4, where we show that fine-grained

Scheduling trace of the task-based approach; tasks
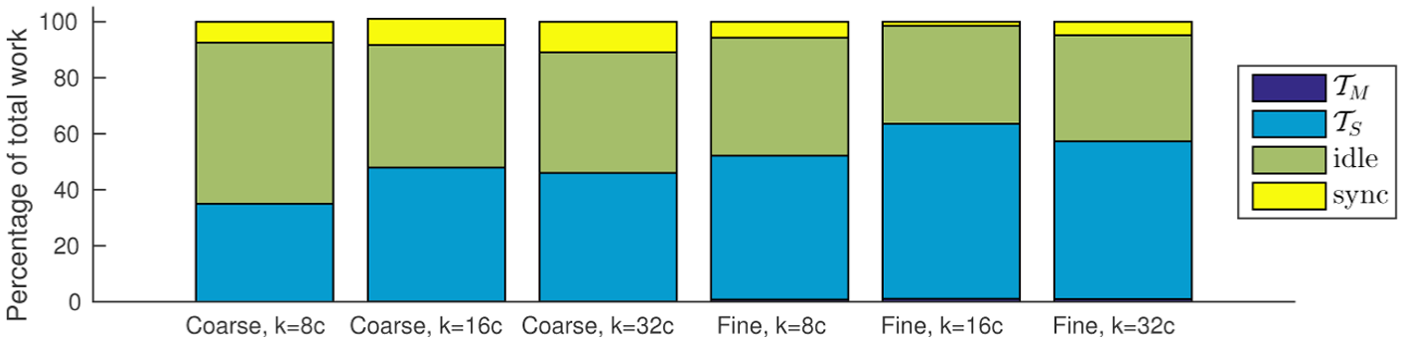
Percentage of total work spent on processing of tasks, synchronization (“sync”), and time spent waiting for dependencies (“idle”) for various scheduling policies when measured on 32 cores. Note that the relation of work to overhead agrees well with Figure 2.
For further details of the scheduling performance of the SuperGlue library in regard to the task sizes and the number of dependencies, we like to refer the reader to the benchmarks available in the study by Tillenius (2015).
4.2 Synthetic benchmark
The results in Section 4.1 indicate a delicate performance dependency on the balance between the local events and the effective connectivity of the network. To further investigate this, a synthetic benchmark with a fixed load of local events was created. This model consists of two compartments S and I only, both residing on

where the initial population size of each compartment
The nodes were arranged into k subdomains and a total of
The measurements obtained on the Sandy computer system at full thread consumption are presented in Figure 6. The parallel efficiency of all methods lies at
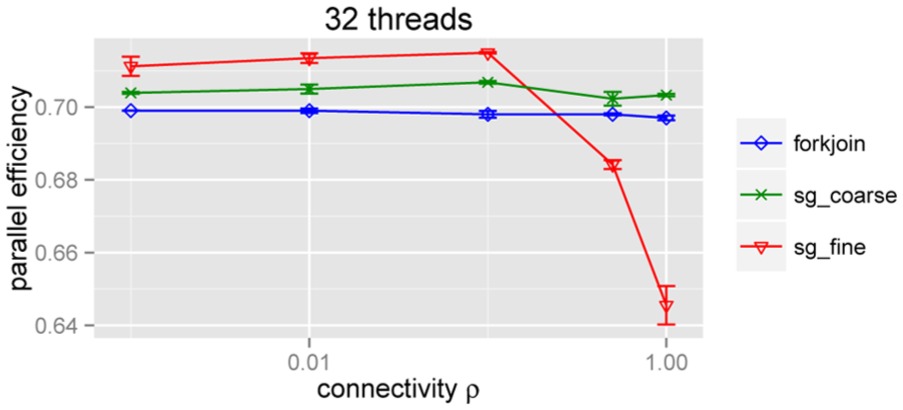
Parallel efficiency for the different methods on the synthetic benchmark. Error bars represent the standard error in mean (n = 10).
4.3 Feasibility of parameter estimation
A usually very compute intensive load case is the fitting of model parameters, typically using numerical optimization of some kind. The problem can briefly and ideally be described as follows; unknown is the set of parameters
To demonstrate the feasibility of parameter estimation in the current context, we use the epidemiological model introduced in Section 4.1 and first identify the set of parameters
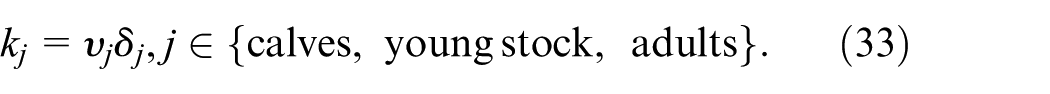
We let a reference solution be given by a single trajectory
To obtain a robust procedure, some kind of smoothing statistics should be considered. We chose to aggregate counts of animals in neighboring nodes into larger regions. To be precise, the overall domain was divided into 21 areas (coinciding with the Swedish county codes), after which the goodness of fit
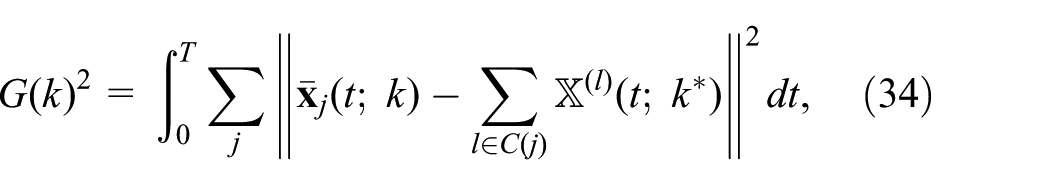
with:

and where the individual sample trajectories are given by:
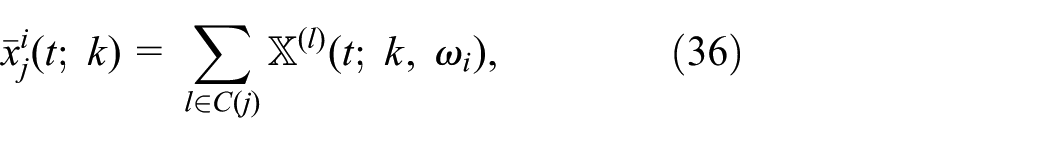
where N is the number of trajectories and
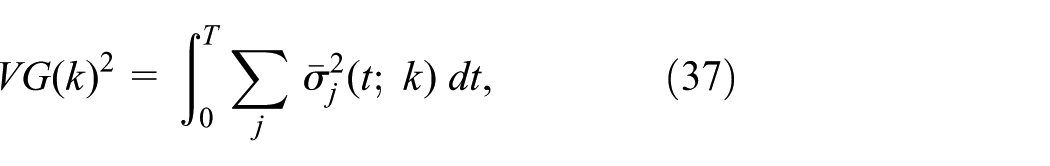
where:
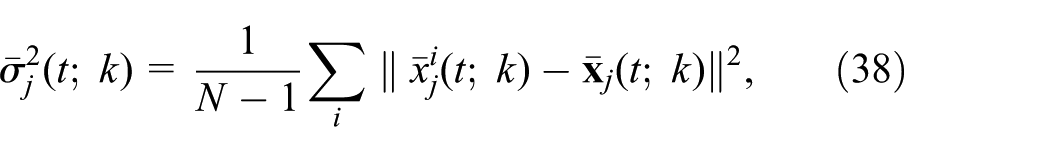
and use
Next, the parameter estimation problem is approached by solving the minimization problem:

In practice, we make use of the pattern search routine in (Hooke and Jeeves, 1961), which conceptually resembles the golden section search (Kiefer, 1953) in its narrowing of the search space. The numerical optimization routine evaluates (equation (34)) until the residual error reaches a defined threshold. In our tests, we varied the initial guess of the parameters
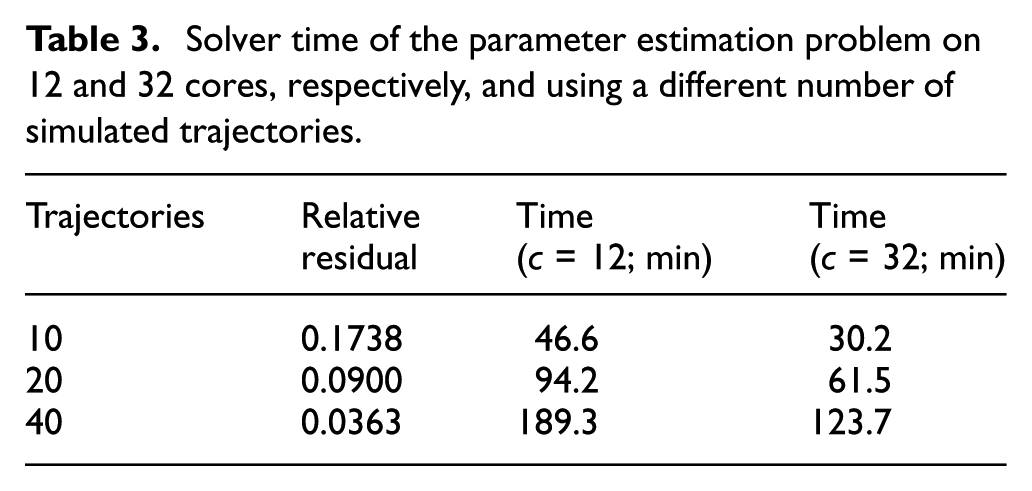
Since an increasing number of trajectories yields better estimates of the mean and variance, we simulate using different number of trajectories. We measure the total solver time on 12 and 32 computing cores, respectively, and we let the total number of iterations to be

Solver time of the parameter estimation problem on 12 and 32 cores, respectively, and using a different number of simulated trajectories.
The optimization landscape of the goal function (equation (4.8)), and hence the definiteness of the setup itself, is visualized in Figure 7. Due to the simple bisection search behavior of the numerical routine, the obtained parameters k are in fact the same for all displayed cases, although the relative residuals differ considerably.
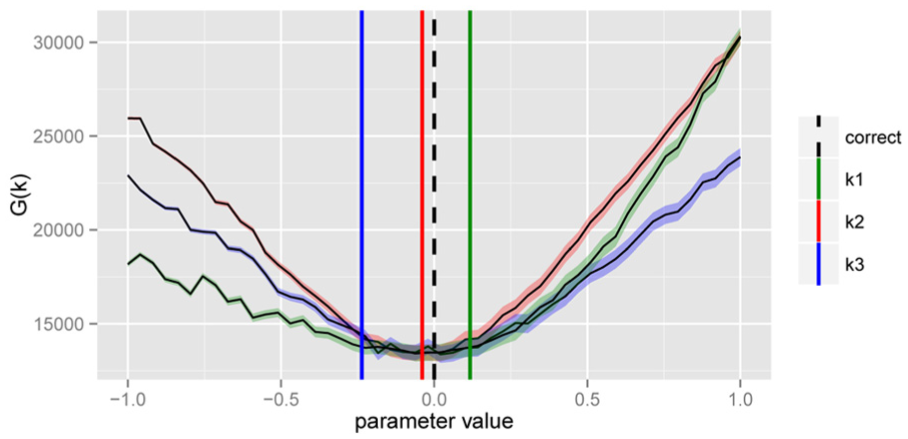
Goal function
Note that the obvious approach of parallelization by computing the N independent trajectories using separate threads by a sequential algorithm is unfavorable here, for two related reasons. Firstly, each executable needs to store a rather large state space in working memory. Secondly, each simulation must also access the complete database of externally scheduled events.
5 Conclusions
Modeling and simulation are important in designing surveillance and control of livestock diseases and of major economic importance. However, various pathogens require different models to capture the disease dynamics and transmission routes. Moreover, an increasing amount of epidemiologically relevant data is becoming available. We have addressed these challenges and present a flexible and efficient computational framework for modeling and simulation of disease spread on a national scale. The simulation involves two parts. Firstly, the algorithm evolves stochastic dynamics of the disease process. Secondly, a list processor incorporates database events such as entering, exit, or movement of individuals into the model state. The framework is highly flexible in that most conceivable epidemiological models are either directly expressible, or the framework may be straightforwardly extended to encompass also non-standard models. As a concrete example, it would be relatively easy to include intervention strategies such as vaccination programs in order to simulate the impact on the global dynamics.
We have explored different strategies to parallelize the simulator on multi-socket architectures. Firstly, we decomposed the spatial information and the list of deterministic events. We then observed that the decomposed problem can be simulated at a high parallel efficiency, which is limited only by the processing of cross-boundary events. We then created three parallel implementations of the simulator core; we used OpenMP to only parallelize private computations in a fork–join fashion, while cross-boundary events were processed in serial. Two further implementations use a dependency-aware task scheduler to create execution traces that interleave cross-boundary events and private computations with respect to their dependencies. We find that this strategy allows us to exploit shared-memory parallelism at a higher degree than the fork–join approach if task sizes are sufficiently large. We benchmark this approach using the SuperGlue task library but present a set of scheduling rules defining the parallel simulator on general terms, thus allowing it to be implemented also with other dependency-aware task libraries.
We benchmarked our simulator using a model of the spatiotemporal spread of VTEC O157 bacteria in the Swedish cattle population. The model contains 37,221 nodes and evolves
To further inspect the performance dependency on network properties, we constructed a synthetic benchmark where cross-boundary events were generated randomly. Here we found that the performance of the fork–join approach and the coarse-grained task approach scales well with a growing amount of cross-boundary events. Notably, the performance of the fine-grained task processing depends more strongly on the connectivity of boundary crossing events, thus favoring a more fragmented network.
In a final example, we used the simulator to carry out an experimental parameter fitting within the VTEC O157 bacteria spread model. We emphasize the high computational complexity of this task with multiple unknown parameters to fit and the need to use several full simulation runs to evaluate each parameter candidate. A similar load case results when different intervention strategies are to be evaluated. For example, even when several interventions reduce the infectious spread globally, a policy maker could be interested in finding the most cost-efficient strategy. With this work, we provide a powerful, highly general and freely available software, which can contribute to a rapid and more efficient development of realistic large-scale epidemiological models.
Future research will encompass studies of larger inverse problems, including more realistic data input, and more complex dynamics. Yet another point for future study is the scalability of the task-based approach in a distributed environment.
Footnotes
Acknowledgements
We thank Martin Tillenius for providing assistance with the use of SuperGlue.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was financially supported by the Swedish Research Council within the UPMARC Linnaeus center of Excellence (P. Bauer, S. Engblom).
Author biographies
Pavol Bauer is a PhD candidate at the Department of Information Technology, Uppsala University. He is associated with the Linnaeus center of excellence UPMARC, Uppsala Programming for Multicore Architectures Research Center. His research interests include scientific computing, high-performance computing, and modeling and simulation with applications in Biomedicine in general. He received his master degree in Computer Science from Vienna University of Technology in 2011.
Stefan Engblom is an associate professor at the Department of Information Technology, Uppsala University and is associated with the Linnaeus center of excellence UPMARC. His research is centered around scientific computing and numerical analysis with a focus in the biosciences. He received his PhD from the Uppsala University in 2008 and became a Docent there in 2013.
Stefan Widgren is a veterinary epidemiologist at the Swedish National Veterinary Institute and a PhD candidate at the Swedish University of Agricultural Sciences. His work is focused on animal disease surveillance as well as research on risk factors for introduction and spread of VTEC O157:H7 in Swedish cattle herds.