
Abstract
Future extreme-scale high-performance computing systems will be required to work under frequent component failures. The MPI Forum’s User Level Failure Mitigation proposal has introduced an operation, MPI_Comm_shrink, to synchronize the alive processes on the list of failed processes, so that applications can continue to execute even in the presence of failures by adopting algorithm-based fault tolerance techniques. This MPI_Comm_shrink operation requires a failure detection and consensus algorithm. This paper presents three novel failure detection and consensus algorithms using Gossiping. Stochastic pinging is used to quickly detect failures during the execution of the algorithm, failures are then disseminated to all the fault-free processes in the system and consensus on the failures is detected using the three consensus techniques. The proposed algorithms were implemented and tested using the Extreme-scale Simulator. The results show that the stochastic pinging detects all the failures in the system. In all the algorithms, the number of Gossip cycles to achieve global consensus scales logarithmically with system size. The second algorithm also shows better scalability in terms of memory and network bandwidth usage and a perfect synchronization in achieving global consensus. The third approach is a three-phase distributed failure detection and consensus algorithm and provides consistency guarantees even in very large and extreme-scale systems while at the same time being memory and bandwidth efficient.
1 Introduction
Resilience (Geist, 2016) is a critical challenge as high-performance computing (HPC) systems continue to increase component counts, individual component reliability decreases (due to shrinking process technology (Baumann, 2005) and near-threshold voltage operation (Kaul et al., 2012)), and software complexity increases (Snir et al., 2014). In spite of frequent faults, errors and failures, parallel application correctness and execution efficiency are essential to ensure the success of extreme-scale HPC systems.
As cost constraints limit resilience mitigation in hardware, a cooperative approach between hardware and software is needed to efficiently mitigate faults, errors, and failures at the appropriate layer. However, application-level checkpoint/restart has been the dominant HPC fault-tolerance method for decades. Every detectable uncorrectable error results in a complete application abort and restart from previously saved checkpoint state, even if the error could have been more efficiently handled by the application, e.g., using forward error correction with erasure codes (Kaplan et al., 2012).
Algorithm-based fault tolerance (ABFT) (Huang and Abraham, 1984; Kaplan et al., 2012; Ltaief et al., 2008) may be able to deal with loss of application state, such as that caused by a failing compute process or node, more efficiently through reconfiguration and adaptation without the need for a more drastic recovery measure, such as a global rollback. The employed fault-tolerance techniques by the application may include error correction using data redundancy or encoding, and re-execution using local checkpoints.
The Message Passing Interface (MPI) is the dominant parallel programming interface for facilitating communication between compute processes in HPC. Despite its popularity, MPI is not fault tolerant. Recent efforts in MPI fault tolerance focused on user-level failure mitigation (ULFM) (Bland et al., 2012). The proposed ULFM extensions to the MPI standard enable applications to be notified of MPI process failures, to create a new MPI communicator object that excludes known failed MPI processes from further communication using the MPI_Comm_shrink() operation, and to achieve a uniform agreement on a value among the non-failed MPI processes using the MPI_Comm_agree() operation.
This paper particularly focuses on the implementation of the proposed MPI_Comm_shrink() operation and its need to perform an agreement on the group of failed MPI processes among the non-failed MPI processes, even while MPI process failures occur. More precisely, the new MPI communicator object created by the collective MPI_Comm_shrink() operation contains a consistent group of MPI processes at every participating MPI process that excludes at least every failed MPI process that has previously raised a failure notification to the application. MPI processes that fail during the MPI_Comm_shrink() operation may be excluded as well, but consistently at every participating MPI process.
According to the ULFM proposal, only fail-stop process failures are considered; when a process fails, it stops communicating with the rest of the processes. The method of failure detection is not defined. However, the ULFM proposal specifies that an operation involving a failed MPI process must always complete in a finite amount of time. If an operation does not involve a failed MPI process, it must not raise a MPI process failure exception. This provides implementers with different options for failure detection. For example, a correct MPI implementation may provide failure detection only for MPI processes involved in an ongoing operation and may postpone detection of other failures until necessary. The knowledge about detected failed MPI processes is local and only constructed as a globally consistent state in the form of a new MPI communicator object using the MPI_Comm_shrink() operation, thus requiring a fault-tolerant consensus algorithm to uniformly agree on the group of failed MPI processes.
This work investigates the use of Gossip-based protocols to detect failures and disseminate this information in a consistent manner to support the MPI_Comm_shrink() operation. The proposed consensus algorithms can also be used to support the MPI_Comm_agree() operation.
Epidemic (or Gossip-based) protocols are a robust and scalable communication paradigm to disseminate information in a large-scale distributed environment using randomized communication. They have the advantage of inherent robustness and scalability with respect to global communication schemes based on deterministic communication patterns. Applications and services based on Gossip-based protocols for large- and extreme-scale systems have been proposed in many fields of distributed computing. Recently, Gossip-based protocols have also been applied in the context of HPC (Barak et al., 2015; Soltero et al., 2013; Straková et al., 2013).
In the paper Katti et al. (2015), two Gossip-based failure detection and consensus algorithms using randomized pinging were developed and tested by means of simulations. Stochastic pinging is used to quickly detect failures and disseminate them to fault-free processes during Gossip. The first algorithm stores the system view in a matrix at each process to facilitate consensus detection. It detects failures before and during the execution of the algorithm and is hence completely fault tolerant. The second algorithm detects consensus on the failed processes using a heuristic method based on a list of failed processes, thus improving the memory scalability with respect to the first algorithm. It also transfers less Gossip data as only the list of failed processes is sent and hence consumes negligible network bandwidth. This paper complements and extends the work in Katti et al. (2015) by adding a third algorithm. The third algorithm presented in this paper is analogous to the three-phase commit (Skeen, 1981) protocol but it is completely distributed. It accurately detects consensus on the failures using a Gossip-based aggregation protocol while still maintaining only the list of failed processes. Thus, it also has the high memory scalability and consumes less network bandwidth than the first algorithm. For all algorithms, the number of Gossip cycles to detect consensus scales logarithmically with the system size.
The paper is structured as follows. Section 2 details the proposed Gossip-based failure detection and consensus algorithms, where Section 2.1 focuses on failure detection using stochastic pinging, Section 2.2 on achieving consensus using global knowledge and a deterministic consensus detection method, and Section 2.3 on achieving consensus using a heuristic consensus detection method. Section 3 introduces the three-phase consensus detection method on the occurred failures. Section 4 discusses the algorithms’ performance and presents experimental results. Section 5 discusses related work. Section 6 concludes the paper with a summary and a discussion of future work.
2 Gossip-based failure detection and consensus
The MPI_Comm_shrink() operation must implement a consensus algorithm that achieves agreement on the set of failed MPI processes that have previously raised a failure notification, i.e. on the group of known failed MPI processes at each participating MPI process at the start of the operation. MPI process failures that occur during the operation will eventually be detected and corresponding failure notifications will be raised during successive MPI communication operations. To avoid coarse-grain iterative agreement on the group of failed MPI processes with successive calls to MPI_Comm_shrink() by an application, the consensus algorithm may additionally include an agreement on the group of MPI processes that fail during the MPI_Comm_shrink() operation, i.e. during the consensus algorithm.
In both cases, the consensus algorithm needs to be fault tolerant, i.e. deal with already known or newly detected MPI process failures. Also, in both cases, a complete failure detector is implemented that detects fail-stop MPI process failures by combining failure detection and consensus. Every MPI process independently detects MPI process failures. Consensus on the failed MPI processes is then achieved by aggregating these MPI process failure detections with the help of a consensus algorithm.
A straightforward way to detect MPI process failures during the MPI_Comm_shrink() operation is pinging, wherein a process asks another whether it is alive. A reply indicates a positive response, while a failure notification from the underlying MPI runtime marks a negative response. The failure detector in the MPI runtime can be based on a simple communication timeout. In an alternative method, a process periodically sends a heartbeat message to let another process know that it is alive. The receiving process monitors the incoming heartbeat messages and marks a process as failed upon a failure notification from the underlying MPI runtime. The failure detector can be based on a simple communication timeout for the periodic heartbeat. The work presented in this paper is based on pinging for failure detection during the MPI_Comm_shrink() operation.
The consensus during the MPI_Comm_shrink() operation involves all fault-free processes agreeing on the group of failed processes. In general, a solution to the consensus problem exists only in certain environments (Turek and Shasha, 1992). For instance, consensus is not possible in completely asynchronous environments (Fischer et al., 1985). However, in an asynchronous environment, failures can still be detected with completeness and accuracy, leading to a uniform view of the system at each process (Chandra and Toueg, 1996), although, group membership may not be agreed upon (Chandra et al., 1996). In the context of MPI, the proposed ULFM extensions are based on realistic assumptions, such as fail-stop, no recovery, a synchronous model, and only short periods with exceptionally high MPI process failure rates.
This paper presents three scalable failure detection and consensus algorithms for MPI_Comm_shrink() based on Uniform Gossiping. The Gossip messages are implicitly used to implement stochastic failure detection. Consensus is achieved and detected by maintaining the system state in a matrix or by maintaining a failed process list at each process. Gossip messages carry failure information with them and disseminate known failures at exponential speed. When a process p sends a Gossip message to process q, this process q comes to know about the failures that were directly detected by p, thus detecting failures indirectly. This Gossip message from p not only contains the failures directly detected by p, but also indirectly detected failures through received Gossip messages. These indirect detections of process p are propagated as well to process q, resulting in exponential information dissemination. When the failure information of a process is disseminated to all fault-free processes, consensus on its failure is reached in a logarithmic number of Gossip cycles (as shown in the experiments in Section 4).
The proposed failure detection and consensus algorithms work under the following assumptions.
Processes are assumed to be connected by a reliable communication medium.
A synchronous system model is assumed, i.e. a non-failed MPI process responds to a message within a known, finite amount of time.
The fail-stop model is assumed, i.e. a failed MPI process stops communicating.
Faults are assumed to be permanent, i.e. a failed MPI process does not recover.
A process once detected as failed is detected to have failed by all the processes eventually.
Periods of system stability are assumed, i.e. MPI process failures during the consensus algorithm will, at some point, stop for a long enough period to reach consensus.
2.1 Failure detection using stochastic pinging
In this section, we discuss the MPI process failure detection feature of a MPI_Comm_shrink() operation using stochastic pinging as part of a Gossip-based protocol. Every process independently detects failures by pinging a random process periodically. During a Gossip cycle of length

Failure detection using pinging.
During a cycle of Uniform Gossiping, the probability of a process being selected as destination of zero, one or more ping messages follows a binomial distribution and, hence, places minimum burden on each process in turn increasing the scalability of failure detection. Ultimately any failed process is quickly detected by one or more of the non-failed processes, thus initiating the epidemic exponential propagation of information to achieve consensus. The adopted Gossip-based approach can tolerate moderate-to-low message loss rates and delays as it is intrinsically fault tolerant.
2.2 Consensus using global knowledge
In this section, we discuss achieving consensus on the set of failed MPI processes during the MPI_Comm_shrink() operation by maintaining global knowledge at each MPI process. As shown in the algorithm of Figure 2 each process p detects failures by pinging random processes and maintains a fault matrix

Failure consensus by global knowledge (Algorithm 1)
Every process initializes with the assumption that every other process in the system is alive and no other process has yet detected any failures (lines 1–5 of Figure 2).
To detect failures, every
Upon reception of a Gossip (ping or reply) message at p from r, the local fault matrix
Finally, to check if consensus has been reached on the failure of a process k at p, a logical OR operation is performed between the corresponding elements of the kth column of the fault matrix and its pth row. Consensus is reached when all fault-free processes have detected the faulty one (lines 9–19).
In this algorithm processes have to maintain local knowledge of the entire system state, with
2.3 Efficient heuristic consensus
Maintaining a matrix of size

Efficient failure consensus (Algorithm 2).
Each process maintains a fault list
Every process starts with the assumption that every other process in the system is alive and, hence, has its fault list empty (line 1 of Figure 3).
To detect failures, every
Upon reception of a Gossip (ping or reply) message at p from r, the remote fault list
The failure detection and this failure information propagation continues for the initial
In Algorithm 1, when a process p has detected consensus on k it is certain that all processes have detected the failure of k, although they may not have detected consensus yet, whereas in Algorithm 2, when a process p has detected consensus on k, some processes may have not detected the failure of k yet. The initial propagation phase of
3 Three-phase consensus
Gossip-based aggregation protocols are used to compute global aggregation functions such as sum, count, average, etc. in a distributed system. The number of Gossip cycles required to compute an aggregation function is shown to be logarithmic in the system size (Kempe et al., 2003). Checking for consensus on a failed process involves counting the number of fault-free processes that have detected the failed process. To this aim, an epidemic aggregation protocol for the count function can be employed. In the approach proposed in this section, processes detect failures that have occurred in the system in the same way as in the previous approaches; they store failed processes in a local list such as Algorithm 2 and adopt an ad-hoc epidemic aggregation protocol to detect the consensus. The Gossip-based aggregation protocol proposed in Blasa et al. (2011) is used here.
The epidemic consensus protocol operates in three phases: (1) failure detection and propagation, (2) consensus and (3) commit. In phase 1, failures are detected and propagated to all the processes using stochastic pings and Gossiping. During this phase, an epidemic aggregation is also used to build local estimates of the number of fault-free processes which have detected a failure. The local estimate of this detection count at a process is indicated as
The algorithm shown in Figure 4 is executed at every process p. The processes use the same length of the Gossip cycle,

Three-phase consensus (Algorithm 3).
After initialization a process p performs three tasks during each Gossip cycle: failure detection, failure list update and check for consensus. Every process starts with the assumption that every other process in the system is alive: at initialization the local fault list is empty (line 1).
To detect failures, every
Upon receipt of a Gossip (ping/reply) message at p from j, the remote fault list,
Finally, to check if consensus has been reached on the failure of a process r in the list,
4 Performance evaluation
4.1 Algorithm analysis
In all three algorithms, the failures are detected using stochastic failure detection which adopts a ping-reply communication during each Gossip cycle. The number of ping messages a process receives during a Gossip cycle follows binomial distribution. Hence, the probability of a process receiving multiple ping messages is very low and so is the probability of a failed process not receiving a ping message. Therefore, any failed process in the system is detected within the first few Gossip cycles.
Once a failure is detected, it is disseminated to the fault-free processes in the system using the ping-reply Gossip messages. Pittel (1987) and Shah (2009) show that the number of Gossip cycles required for a piece of information to be disseminated from the originator to all of the processes in the system is logarithmic in system size. Algorithms 1 and 2 hence achieve consensus on the detected failure in a logarithmic number of Gossip cycles. The two messages, ping and reply, in a Gossip cycle double the information dissemination speed. Moreover, processes independently detecting failures directly and merging these multiple failure detection information while dissemination further increases the propagation speed and reduces the consensus time.
Algorithm 3 disseminates the failures detected and counts the number of fault-free processes that this information has reached using the aggregation protocol. (Kempe et al., 2003) shows that the number of Gossip cycles required for computing the aggregation function is
The number of Gossip messages in each cycle is two and, hence, the number of Gossip messages needed by the algorithms to detect consensus at each process is twice the number of Gossip cycles taken.
The first algorithm requires
4.2 Experimental results
All three algorithms were implemented in the form of MPI applications, using basic MPI point-to-point communication primitives. The fault matrix of Algorithm 1 is implemented as an integer matrix, whereas failed process details in Algorithms 2 and 3 are either integers or floating point numbers as appropriate. Fault injection was simulated by excluding a process from further communication.
The experiments were performed on two Linux cluster computers, one at the University of Reading (UREAD) and one at the Oak Ridge National Laboratory (HAL9000). Algorithms 1 and 2 were tested on the UREAD cluster and Algorithm 3 was tested on the HAL9000 cluster.
The UREAD cluster has one head node and 16 compute nodes. The head node has two AMD Opteron 4386 3.1 GHz processors with eight cores per processor and 64 GB RAM. The compute nodes have one Intel Xeon E3-1220 3.1 GHz processor with four cores per processor and 16 GB RAM. The entire system has a total of 80 compute cores. The nodes are connected by Gigabit Ethernet. The system is running the Ubuntu 12.04 LTS operating system and Open MPI 1.6.5.
The HAL9000 cluster has one head node and 16 compute nodes. The head node has two AMD Opteron 2378 2.4 GHz processors with four cores per processor and 8 GB RAM. The compute nodes have two AMD Opteron 2378 2.4 GHz processors with four cores per processor and 8 GB RAM per node. There are 128 cores for compute and 8 cores on the login/head node. The nodes are connected by Gigabit Ethernet (1 Gbps). The system is running Ubuntu 14.04 LTS, Open MPI 1.10.1 and GCC 4.8.
Experiments were executed using the Extreme-scale Simulator (xSim 0.5 on UREAD and xSim 0.8 on HAL9000) (Böhm and Engelmann, 2011; Engelmann, 2014; Naughton et al., 2014) atop the Linux cluster(s) to evaluate the algorithms at significantly larger scale than the available physical system. xSim is a performance investigation toolkit that permits running MPI applications in a controlled environment with a large number of concurrent execution threads, while observing application performance and resilience in a simulated extreme-scale system. Using a lightweight parallel discrete event simulation, xSim executes an MPI application on a much smaller system in a highly oversubscribed fashion with a virtual wall clock time, such that performance data can be extracted based on a processor and a network model. xSim is designed like a traditional MPI performance tool, as an interposition library that sits between the MPI application and the MPI library, using the MPI profiling interface. In previous experiments, it has been run up to 134,217,728 communicating MPI ranks using a 960-core Linux cluster.
The simulator was deployed on the Linux cluster computer by associating one simulator MPI process per physical processor core. Within each simulator MPI process, a number of concurrent execution threads are executed, each representing an individual MPI process that is located on a processor core within a simulated HPC system. The execution timing of these simulated MPI processes is based on a processor model with a one-to-one performance match to the physical AMD processor core the simulator is running on and a network interconnect model with a basic star topology, 1
The maximum number of Gossip cycles in the experiments was set to
4.2.1 Consensus using global knowledge
The Gossip cycle length for a given system size was set to allow the matrix merge operations to complete within the cycle. The cycle length was 10, 100 and 1000 ms respectively for system sizes
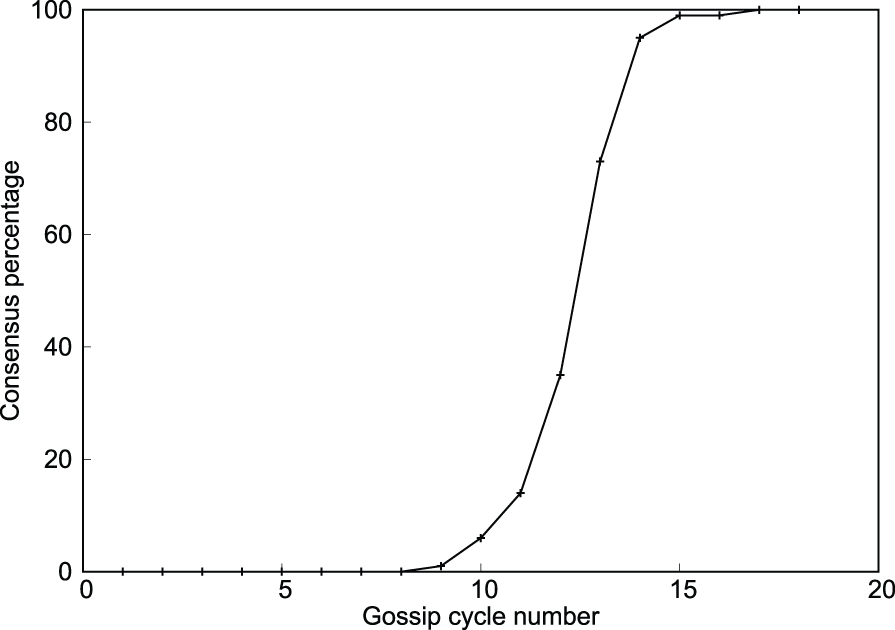
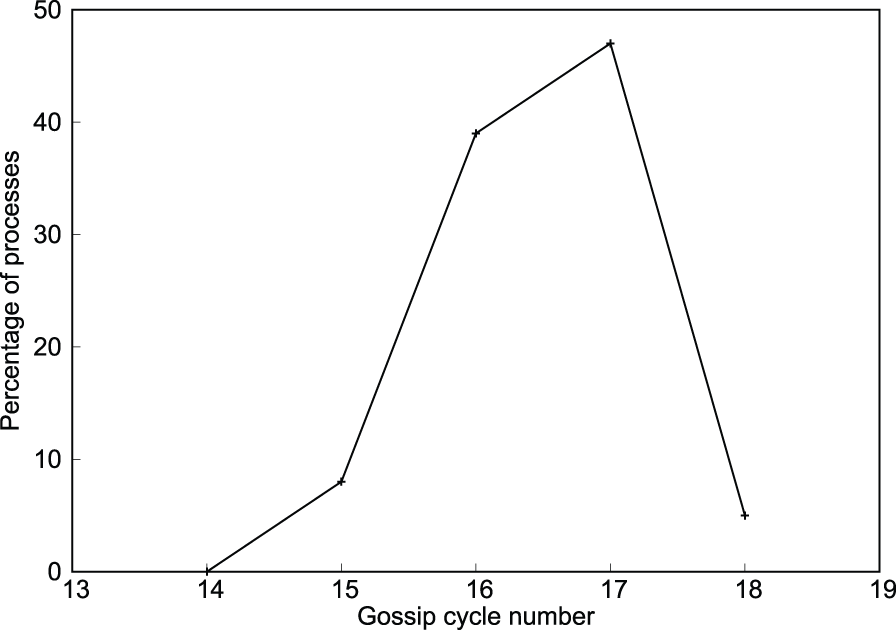
Failures were injected right before the failure detection and consensus algorithm is run. Figure 5 shows the relation between the number of cycles taken to reach consensus and the system size for a single failure injected before the algorithm. It is evident that the number of cycles to reach consensus varies logarithmically with the system size. Figure 6 shows the exponential spreading of failure detection information at a particular process for the injected failure. Both figures demonstrate the logarithmic complexity of the algorithm. Figure 7 shows the distribution of the cycle number at which different processes reach consensus. In Figure 8, multiple (four) failures were injected before the algorithm and their effect on consensus time was observed. It took only one or two cycles more than in the single-failure case (Figure 5).
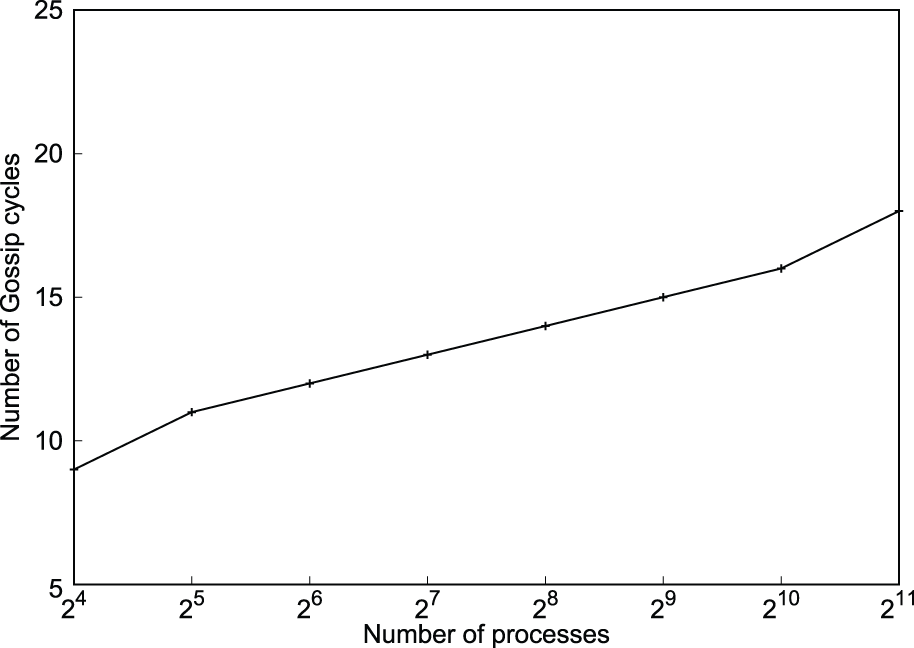
Number of cycles to achieve global consensus after a single failure injection (Algorithm 1).
Local consensus progress at a process after a single failure injection for system size of 2048 (Algorithm 1).
Consensus detection spread for a system size of 2048 (Algorithm 1).
Number of cycles to achieve global consensus after multiple (4) failures, which were injected before algorithm execution (Algorithm 1).
Failures were injected during its execution to test the fault-tolerance property of the algorithm. In Figure 9, multiple (four) failures were injected into randomly chosen processes at random cycles. The number of cycles needed to reach consensus increased slightly. The algorithm is completely fault tolerant.
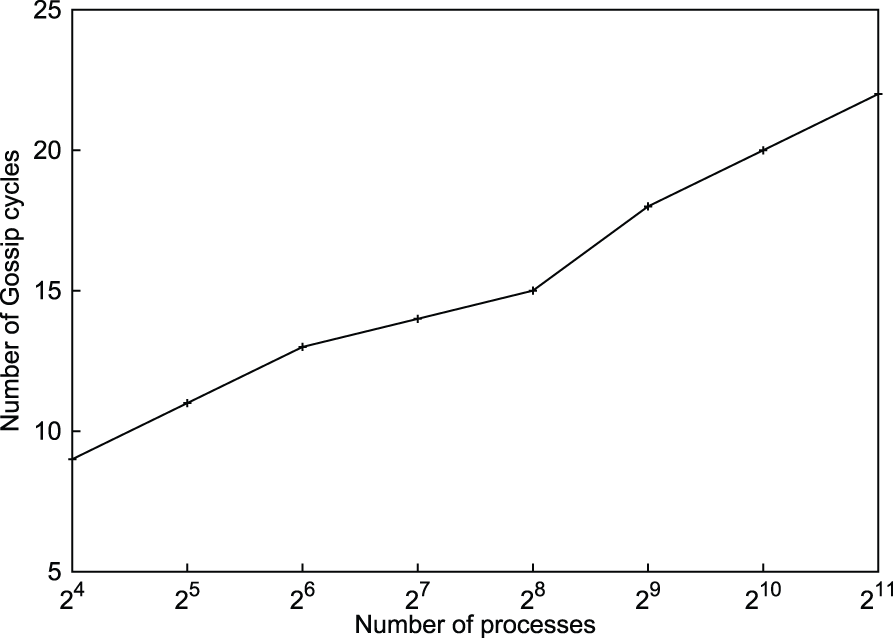
Number of cycles to achieve global consensus with multiple (4) failures, which were injected during algorithm execution (Algorithm 1).
4.2.2 Efficient heuristic consensus
The
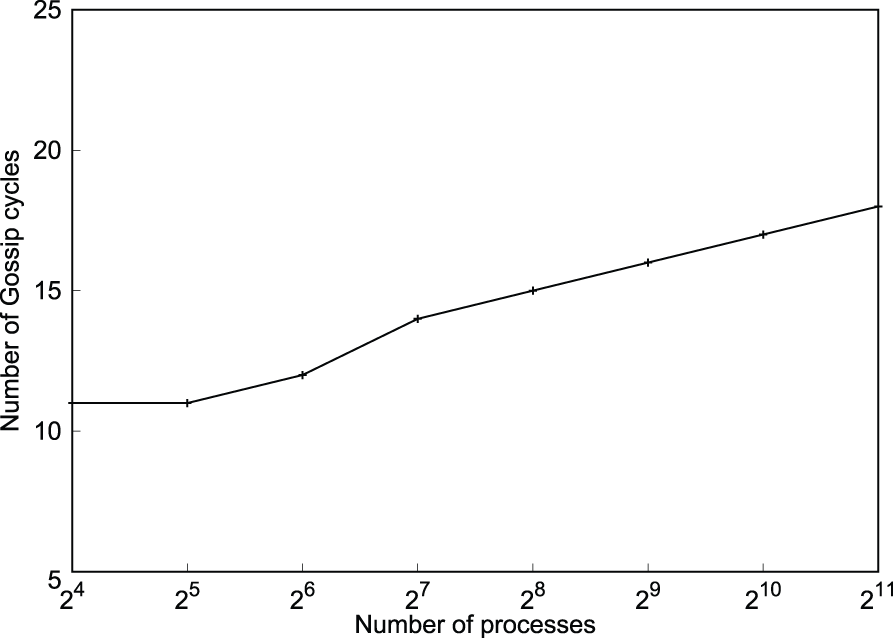
Figure 10 shows the relation between the number of cycles taken to reach consensus on a single injected failure and the system size. It is evident that the number of cycles to reach consensus varies logarithmically with the system size as expected. Moreover, in this case no variance in the cycle number at which different processes reach consensus was observed, thus achieving perfect synchronization. The algorithm will detect consensus on any number of failures injected before it is run.
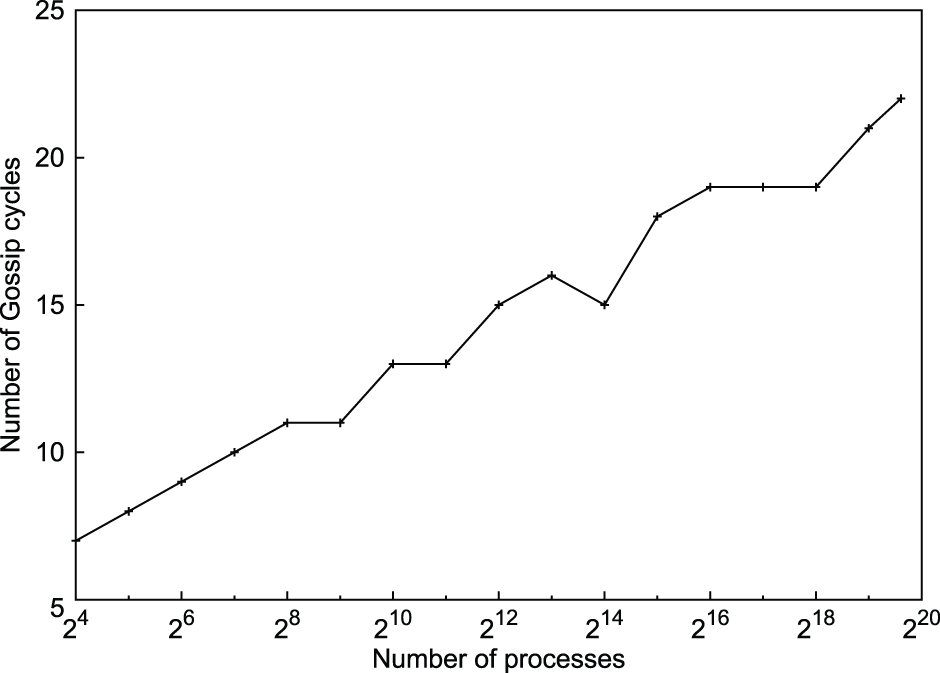
Number of cycles to achieve global consensus after a single failure injection (Algorithm 2).
The algorithm is scalable in terms of memory as it needs to store only the list of failed processes at each process. The two algorithms were compared for their bandwidth utilization. The amount of data exchanged between simulated MPI processes is reported by xSim. Figure 11 shows the bandwidth consumed per process at increasing system sizes. It can be observed that the heuristic-based algorithm transfers a negligible amount of data and is significantly more efficient than the algorithm using global knowledge.
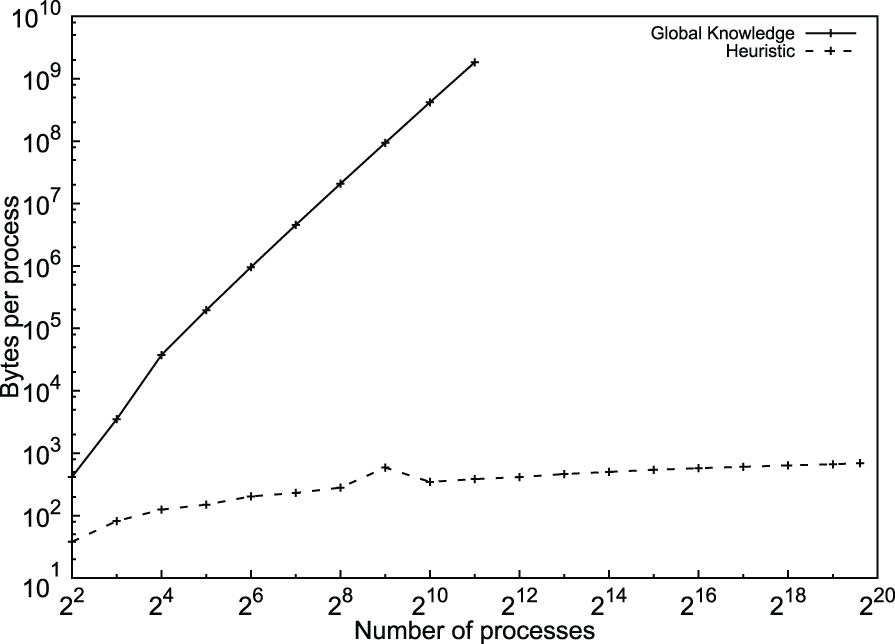
Total bandwidth utilization of the consensus algorithms with a single failure injection (Algorithms 1 and 2).
4.2.3 Three-phase consensus
The epidemic three-phase failure consensus algorithm was tested by injecting a single failure. It can detect any number of failures injected before it is run. The single injected failure was detected, propagated to all the processes (phase 1), the processes detected consensus (phase 2), and committed on the injected failure (phase 3). Measurements of these three phases have been collected for different system sizes.
Figure 12 shows the relation between the system size and the number of cycles taken to propagate, reach consensus and also to commit on the injected failure. The tolerance between the estimated counts (for both propagation and consensus) and the actual number of fault-free processes in the system was set to 0.1%. The propagation, consensus and commit times all vary logarithmically with the system size.
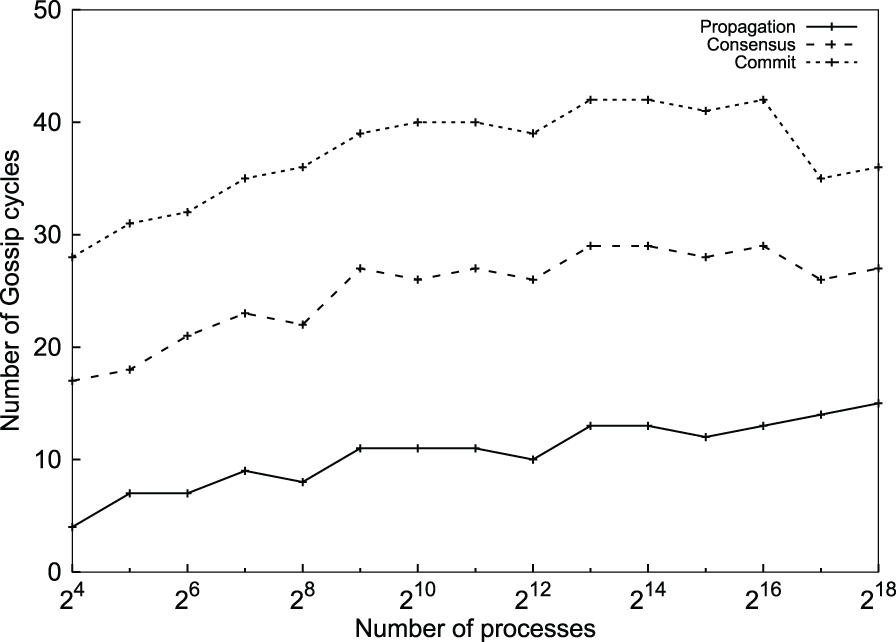
Number of cycles taken for propagation, consensus, and commit (Algorithm 3).
Figure 13 shows the exponential progress of the propagation, consensus, and commit phases for the system size of 262,144 at 0.1% tolerance. The injected failure is detected and propagated at exponential speed; consensus and commit are, then, detected on it and they progress at exponential speed in the system.
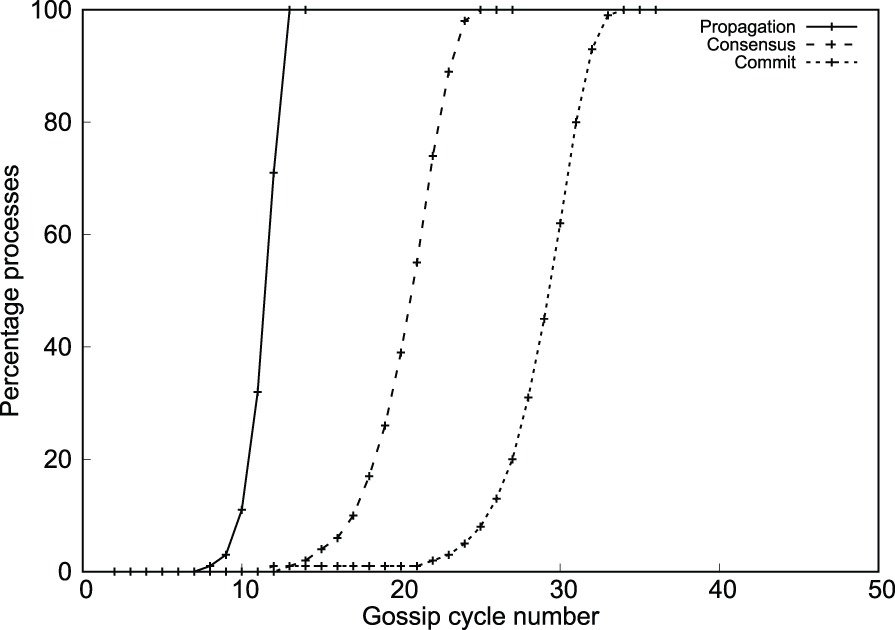
Propagation, consensus, and commit progress (Algorithm 3).
The estimated count values for propagation and consensus at rank 0 for the system size 262,144 at 0.1% tolerance is shown in the Figure 14. They quickly converge to the number of fault-free processes in the system as the Gossip progresses. It is an indication that the failure information has propagated to all of the fault-free processes in the system and consensus is detected by each fault-free process.
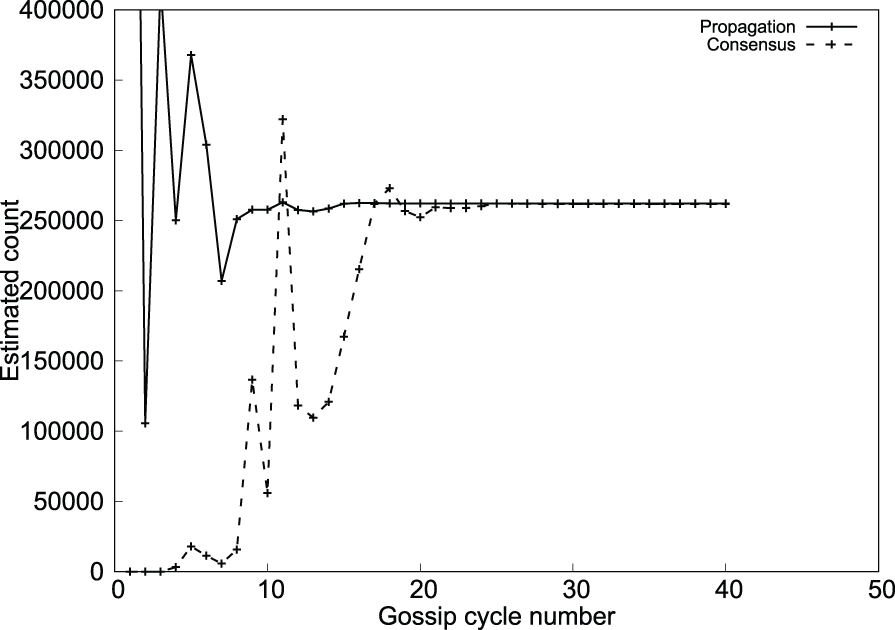
Convergence of estimated count values over the Gossip cycles (Algorithm 3).
The algorithm’s performance for different tolerance values is shown in Figure 15 for the system size of 65,536. Consensus and commit detection are delayed as the tolerance is reduced for increased accuracy.
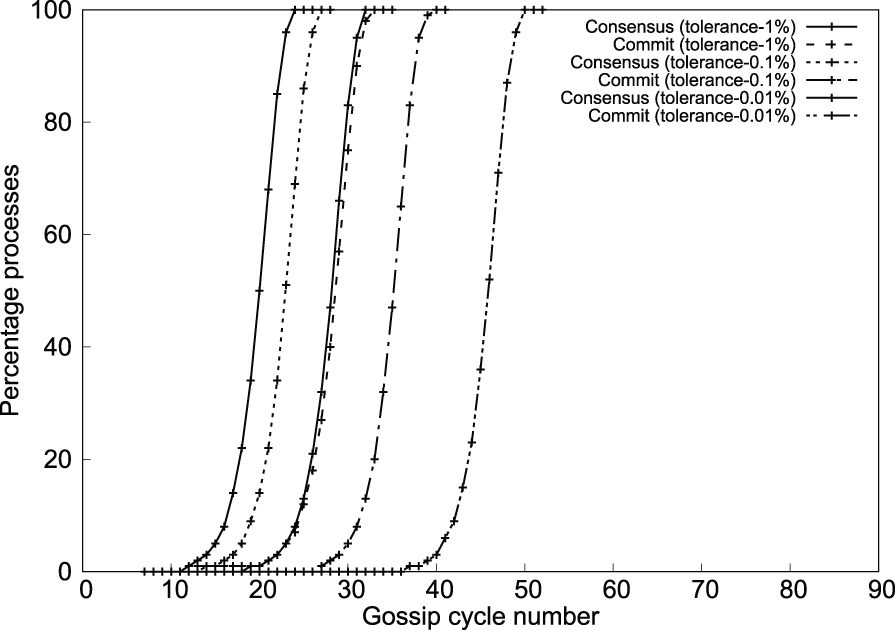
Consensus and commit comparison for different tolerances (Algorithm 3).
5 Related work
This section discusses failure detection and consensus algorithms that have been considered for HPC and compares them with the proposed algorithms.
5.1 Failure detection algorithms
5.1.1 Heartbeat-based approaches
A failure-detection algorithm, for fail-stop type failures, using heartbeat messages was proposed in Ranganathan et al. (2001). Every process maintains a log, called a Gossip list, that contains a number (called heartbeat value) for each member process to represent its aliveness. Every
In the proposed algorithms, there is direct failure detection without passing through the suspicion phase of the above Gossip-based failure detection. Also, since suspicions become detections after a majority vote, the assumption that no more than one third of processes do not fail during a single Gossip iteration is relaxed in the proposed approach.
Another heartbeat-based low-overhead failure-detection algorithm was proposed in Bosilca et al. (2016). Processes are organized in the form of a ring and each process monitors only its predecessor using heartbeats and timeouts. A process periodically sends heartbeat messages to its monitor and the monitor detects the process’s failure if it does not receive heartbeat message for a predefined period. Once a process detects a failure, it broadcasts this information to all the fault-free processes using an all-to-all reduction topology. It assumes that no more than k failures occur, where
In contrast, the proposed algorithms detect failures and consistently disseminates them to all the fault-free processes, simultaneously, thus requiring no failure free operation overhead. Also, the epidemic algorithms are intrinsically fault tolerant and can tolerate any number of failures without any constraint on the failure strike frequency.
5.1.2 Ping-based approaches
The algorithm for failure detection given in Gupta et al. (2001) is based on randomized pinging. A process p randomly pings another process q. If a reply is received in time then q is found to be alive. Otherwise p asks k randomly chosen peers to ping q as well. If no peer receives a reply, p detects q to have failed. This approach to failure detection takes network link failures into account along with process failures.
5.2 Consensus algorithms
Both centralized, i.e. using a coordinator, and completely distributed consensus algorithms are available. Fault-tolerant versions of the two-phase and three-phase consensus algorithms are discussed in the following. Distributed consensus algorithms based on Gossiping, which is inherently fault tolerant, are also discussed.
5.2.1 Coordinator-based approaches
Failures that happen during the execution of the two-phase consensus are not included in the final list and a coordinator failure aborts the algorithm. Hence, it is not a completely fault-tolerant consensus algorithm. In contrast, the first two algorithms presented in this paper are completely fault tolerant, as they tolerate failures during the execution.
In the BALLOTING phase, the root generates a ballot (which is a sequence number to differentiate between iterations) and broadcasts it, including the known list of failed processes. The child, upon receipt of the broadcast message, checks whether it has any new failed processes known to it but not in the ballot it received. It sends a REJECT message piggybacked with the ACK message including the new failed processes if any; it accepts the ballot otherwise and sends an ACCEPT message piggybacked with the ACK message. The root starts the next phase if it receives an ACCEPT message piggybacked with the ACK message from all of its children and if any child rejects the ballot it updates its set of failed processes and tries again. In the second phase, the root broadcasts the AGREE message with the ballot. Now the participants know that the ballot has been agreed upon by everyone and they agree to the ballot for the second phase. Then the root starts the third phase by broadcasting the COMMIT message. The participants upon receipt of the COMMIT message commit to the ballot.
A failure of the root is checked by every process and when a process detects that all processes with ranks lower than itself have failed it appoints itself as the new root. The new root restarts the algorithm from whatever state it is in. Note that if the root fails when it is in the BALLOTING state, the new root has to start all over again, wasting all of the iterations performed so far. Failures of participants are handled by repeating phase one of the algorithm with a new sequence number included in the ballot. When a broadcast message belonging to an old iteration arrives at a process, which is not in the BALLOTING state, a NAK with AGREE_FORCED is forwarded to the root to clean up the old circulating broadcast messages. This message is also used by the root to start phase 2 of the algorithm (with the assumption that process failures will subside and cease).
It was tested by injecting failures into randomly chosen processes before and during the execution. The processes that fail during the operation of the algorithm may or may not be included into the final list of failed processes. Moreover, every failure that happens while the algorithm is running requires the algorithm to start all over again by rebuilding the communication structure. The algorithms proposed in this paper do not require any communication structure.
5.2.2 Gossip-based approaches
In Gossip-based approaches, failure detection is performed as explained in Section 2.1 and consensus is (in combination with failure detection) also implemented using Gossiping (Ranganathan et al., 2001), and hence completely fault tolerant. Each process maintains a suspicion matrix S to store the status of processes as detected by all of the processes. An entry
Because every process needs to maintain a suspicion matrix of
The proposed approach in this paper bypasses the failure suspicion phase based on distributed diagnosis. Since suspicions become detections after a majority vote, the assumption that no more than one third of processes do not fail during a single Gossip iteration is relaxed in this approach.
Experiments in the state-of-the-art HPC failure detection and consensus literature, have featured not more than a few thousand processes, whereas the proposed algorithms (Algorithms 2 and 3) scaled to hundreds of thousand processes on a small cluster computer.
6 Conclusion and future work
Failure detection and consensus for a fault-tolerant MPI enable HPC applications to adopt algorithm-based fault-tolerance techniques to cope with MPI process failures more efficiently. Centralized methods for failure detection and consensus are based on a coordinator and do not scale well to very large and extreme-scale systems. Completely distributed algorithms based on Gossiping that were previously proposed in the literature consume an inordinate amount of time, memory and network bandwidth.
In this work three novel failure detection and consensus algorithms that use randomized pinging were presented. The first approach is based on global knowledge: each process maintains a local view of the entire system state to achieve consensus on failed processes. A Gossip protocol is used to detect failures and to exponentially propagate them in the system until the local views converge. The second algorithm does not rely on global knowledge and adopts a heuristic method to achieve consensus on failures. The third algorithm maintains only a list of failures as in the second algorithm and detects consensus using three phases incorporating a Gossip-based aggregation protocol. The same Gossip messages used for failure information dissemination are also used for detecting the failures stochastically thus integrating both failure detection and consensus.
All of the algorithms were implemented as MPI applications and tested using the Extreme-scale Simulator. The results confirm their expected scalability and fault-tolerance properties. In the algorithms, the number of Gossip cycles to achieve consensus on failures scales logarithmically with the system size. The second algorithm has significantly lower memory and bandwidth utilization and has shown to be able to achieve a perfect consensus synchronization as well. The third algorithm retains the scalability of the second algorithm and detects consensus accurately using an aggregation protocol for the count aggregation function.
The first algorithm can be implemented with Boolean matrices at each process to increase scalability. The second and third algorithms’ memory scalability can be further improved by maintaining the status of processes in a bit vector, if the number of failures in the system is high. It would also be interesting to investigate an efficient algorithm with a different heuristic approach for detecting consensus asynchronously and without the guaranteed initial propagation phase: this would allow detecting consensus on failures that happen both before and during the execution of the algorithm. Investigating processes entering alive state from faulty state is also interesting. This would avoid false positives and also allow process recovery.
Further future work in this area focuses on implementing MPI_Comm_shrink() and MPI_Comm_agree() with different approaches (static and dynamic tree, as well as, the different Gossip-based variants) and compare them using the Extreme-scale Simulator with architectural models of future-generation HPC systems.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Amogh Katti was supported by the Felix Scholarship for his PhD project. This work was sponsored by the US Department of Energy’s Office of Advanced Scientific Computing Research. This manuscript has been authored by UT-Battelle, LLC under Contract No. DE-AC05-00OR22725 with the US Department of Energy.