
Abstract
Heterogeneous parallel platforms, comprising multiple processing units and architectures, have become a cornerstone in improving the overall performance and energy efficiency of scientific and engineering applications. Nevertheless, taking full advantage of their resources comes along with a variety of difficulties: developers require technical expertise in using different parallel programming frameworks and previous knowledge about the algorithms used underneath by the application. To alleviate this burden, we present an adaptive offline implementation selector that allows users to better exploit resources provided by heterogeneous platforms. Specifically, this framework selects, at compile time, the tuple device-implementation that delivers the best performance on a given platform. The user interface of the framework leverages two C++ language features: attributes and concepts. To evaluate the benefits of this framework, we analyse the global performance and convergence of the selector using two different use cases. The experimental results demonstrate that the proposed framework allows users enhancing performance while minimizing efforts to tune applications targeted to heterogeneous platforms. Furthermore, we also demonstrate that our framework delivers comparable performance figures with respect to other approaches.
1. Introduction
In recent years, heterogeneous parallel architectures have provided a way to improve performance and energy efficiency better than other alternatives. However, platforms comprising diverse devices (such as multi-cores, Graphics Processing Unit (GPUs), Digital Signal Processor (DSPs) and Field Programmable Gate Array (FPGAs)) are notoriously more difficult to program effectively, since they demand for distinct frameworks and application programming interfaces. 1 This fact has led to multiple implementations of the same algorithm but targeted to different devices. Therefore, an additional issue arises when programming for heterogeneous platforms: to select the most suitable device and routine implementation to solve a given problem. Usually, in order to improve performance, developers need to analyse a priori the target platform and the application, along with its implementation alternatives and available libraries. To achieve this goal, some aspects need to be considered. For instance, some libraries exhibit better behaviour than others for a given problem size. 2 Also, devices can have different features (such as the number of cores, processor frequency or memory size), and thus, they may influence, or even restrict, the use of a specific library routine.
An approach to cope with this problem is to manually select the algorithm implementation and map the execution onto the underlying parallel device based on past knowledge. Nevertheless, this procedure becomes complex when dealing with multiple devices and libraries. A common technique is to define a set of constraints in order to guide a runtime scheduler to select the most suitable implementation. This technique, however, has non-negligible performance overheads, since it is necessary to re-evaluate the selection each time a routine is called. An alternative to the aforementioned technique is to shift the decision-making task directly at compile time. Several proposals leveraging this static approach and based on analytic models, machine learning and adaptive optimization methods can be found in the literature. 3 However, these approaches also incur in non-negligible profiling costs at runtime and/or modelling overheads at compile time. Therefore, there exists a trade-off between runtime overheads and profiling techniques in both approaches that needs to be considered depending on the target application. Given the foregoing, in this article, we enrich the current state-of-the-art about static approaches with the following contributions:
We present an offline implementation selector framework that leverages a profile-guided approach and is able to decide, among compilations, the tuple device-implementation that delivers the best performance based on historical information.
We enable portability of the approach using two novel features part of the standard C++ language, concepts and attributes, as for the end-user interfaces.
We evaluate the performance of the selector by analysing its convergence time and benefits to minimize execution time using the general matrix–matrix multiplication (GEMM) kernel and an image processing application.
We demonstrate that the framework self-tunes to platform changes and delivers comparable performance figures with respect to a runtime approach from the state-of-the-art.
The remainder of the article is structured as follows. Section 2 reviews the existing works about implementation selectors and decision-making models. Section 3 describes the concepts and attributes of C++ language features along with the hardware parallel platform description language (HPP-DL). Section 4 introduces our adaptive offline implementation selector framework and its decision algorithm. Section 5 evaluates the convergence time and performance benefits of the adaptive selector and compares it with a runtime approach. Finally, Section 6 closes the article with some concluding remarks and future works.
2. Related work
Since heterogeneous platforms have spread across the scientific community, different implementations of the same algorithm have been developed for specific devices. For example, several numerical libraries comprising highly tuned kernels, from BLAS and LAPACK, are available for several computing architectures, for example, cuBLAS 4 for nVidia GPUs, GSL 5 for multi-/many-core processors and so on. This situation reveals a new challenge: to select the most suitable device and routine implementation to solve a given problem. To tackle this issue, two different approaches have been traditionally taken: (i) runtime schedulers, able to map and execute kernels from multiple libraries on accelerators available in a heterogeneous platform and (ii) static tools that select, at compile time, the most appropriate implementation according to past knowledge. Obviously, dynamic approaches are more flexible in terms of mapping tasks to devices accordingly, for example, on load parameters, while static approaches have to use concrete implementations during the entire application run.
Some research works using static approaches can be found in the literature. For instance, the work by Wang et al. 6 presents a mapping model based on machine learning techniques, which is tied to the training platform. Other works, as presented by Tan et al., 7 propose an automatic system based on source code analysis that maps user calls to optimized kernels. Similarly, Shen et al. 8 propose an analytic system for determining which hybrid programming configuration is optimal for a given problem.
On the other hand, dynamic approaches are also greatly extended in the community. Particularly, the OmpSs
9
programming framework leverages an extended set of OpenMP-like pragmas to support asynchronous parallelism and exploit task-parallelism of applications via data dependencies. Concretely, among the pragma options, the
3. Background
This section gives a brief overview about the two C++ language features used for developing the implementation selector interface: C++ attributes and concepts. Furthermore, we describe the HPP-DL leveraged by the selector to keep track of available resources.
3.1. The C++11 attributes
Attributes are a new feature of the C++11 language for defining properties to programming entity units. The power of the attributes is that they provide extra information to the compiler in order to perform a given action to the entity that has been annotated. One of the main advantages of the attributes with respect to pragmas is their flexibility, as they can provide properties to any entity, for example, variables, functions or types and do not need to appear on a separate line.
11
The basic syntax for attributes in C++11 is defined with:
However, unlike attributes from other languages, C++11 attributes are compiler-defined, that is, the user cannot define their own attributes at runtime. Indeed, the C++ runtime type identification mechanism does not keep any attribute information, so the knowledge given in the attributes is not accessible from the user application. On the contrary, attribute extensions require modifications in the C++ compiler. Therefore, the purpose of this feature is to allow future C++ extensions without extending the set of keywords nor grammar.
3.2. The C++ concepts
Concepts are a novel extension of the C++ programming language that allows defining and evaluating, at compile time, constraints set on template arguments.
12
Particularly, concepts deliver a better support for error checking in generic programming contexts, thus, they can be seen as a mechanism to prevent and diagnose improper uses of templates. In general, concepts allow to overloading templates and disabling those whose types do not satisfy the predefined constraints. Lexically, concepts can be expressed with the keywords
To enable portability of our framework, we use both attributes and concepts as for the user interfaces. However, given that the concepts are a novel feature of the language, they are not yet supported by all the current C++ compilers. In contrast, attributes are a feature of the C++ language that is already supported by any compiler. In a nutshell, attributes are easier to use than concepts but at the expense of modifying the compiler internals or using an external parsing tool to process them.
3.3. The HPP-DL
The HPP-DL is an open specification that leverages hierarchical models for describing features of heterogeneous parallel platforms. 14 This language is intended to be used for making platform-specific information available to developers and tools, such as auto-tuners, compilers, schedulers or runtime systems.
This specification comprises information about the following classes: (i) components describe the hardware resources of the platform, involving processors (CPU sockets), cores, main memory, GPUs or OpenCL-based devices; (ii) links represent relationships between two components in one way and incorporate information about data transmission: throughput and latency and (iii) resources portray interfaces for accessing to computing devices attached, for example, FPGAs or DSPs. These resources comprise I/O ports, IRQs or address ranges.
4. The adaptive offline implementation selector
In this section, we describe the adaptive and offline implementation selector framework as the main contribution of this article. Figure 1 shows the general workflow of this framework. As can be seen, in a first step, the system administrator provides users with all the possible implementations of a function by producing, using the header generation tool, all necessary function wrappers for the two proposed interfaces, that is, attributes and concepts. This command-line tool takes, for each function to be replaced, the following arguments: (i) the function name, (ii) all the available implementation names (e.g. GSL or clBLAS) and (iii) the supported devices (e.g. CPU or GPU). With this information, the command-line tool generates the wrappers whose name is a concatenation of the three aforementioned arguments. Afterwards, the function wrappers in the generated header files should be completed by the administrator with the corresponding code for calling to specific implementations. Note that all generated headers are automatically instrumented for measuring execution time. This is done in order to support the profile-guided approach implemented by the selector. Additionally, the headers generated incorporate the required code to support the framework interfaces. In parallel, the administrator should also obtain required hardware information, using the automatic tool provided for storing it into an
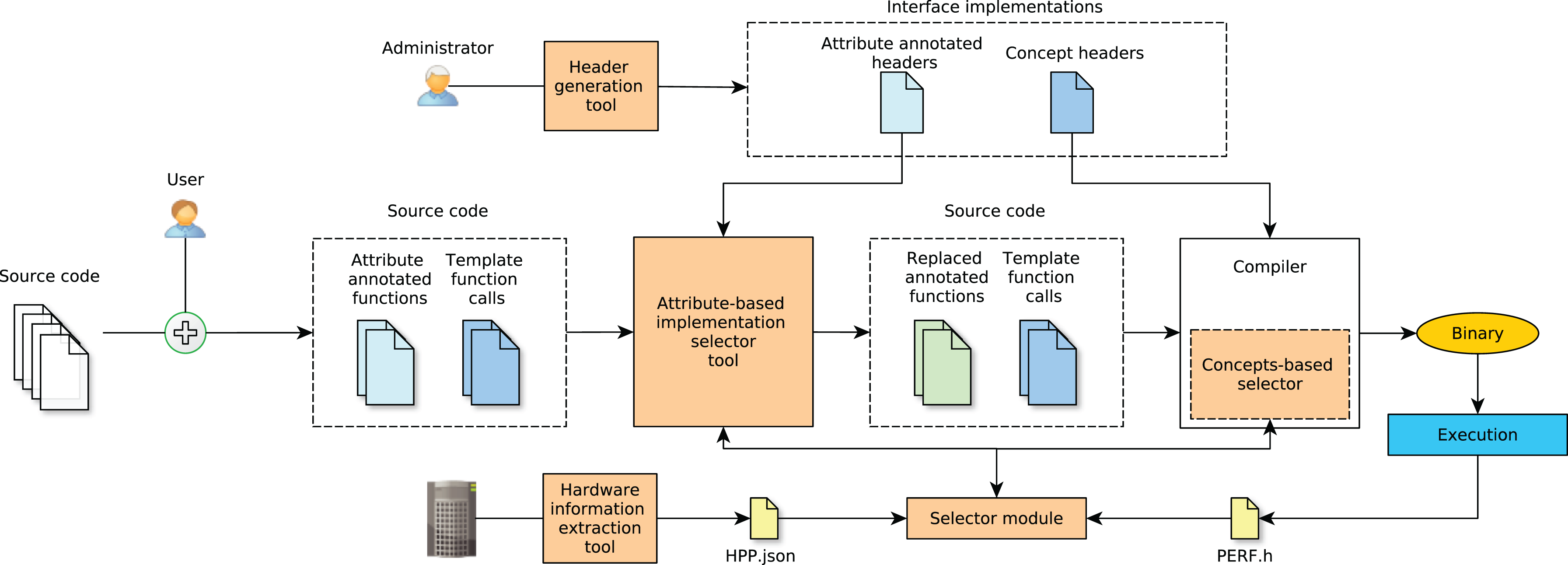
Diagram of the adaptive offline implementation selector.
On the other hand, users should call the interfaces, generated by the administrator and present in the header files, and provide static information (e.g. problem size) to the selector in the form of attributes or template arguments. Next, the attribute and concepts-based implementation selectors call, respectively, to the selector module so as to determine the most suitable implementation based on historical data and the static information provided by the user. Finally, once the application has been compiled and executed, the performance file (
In the following sections, we describe how the concepts and the attribute mechanisms should be used within the framework. Next, we enumerate the steps taken by the selector module.
The attributes-based interface
The interface of the framework based on C++ attributes is intended to define constraints in order to guide the compiler to select a concrete implementation among the available ones. These attributes are part of our previous work presented in the study by Sanchez et al. 15
4.1.1. Administrator actions
First, the administrator needs to run the header generation tool, with the attributes flag option set, so as to generate the headers containing the annotated function wrappers for a given algorithm. Listing 1 shows an example of generated code for the

Generated header file for attribute-annotated function implementations.
4.1.2. Users actions
On the other hand, the users are responsible for annotating candidate function calls in the application code in order to be analysed by the attribute-based implementation selector tool of the framework. These C++ attributes are as follows:
For instance, Listing 2 contains an example of user code with different C++ attribute-annotated function calls that match the interface

User-annotated function interfaces.

Replaced attributes by implementations.
4.2. The concepts-based interface
The interface of the framework based on concepts is an alternative to the aforementioned mechanism based on attributes that pursue the same goal.
4.2.1. Administrator actions
In this case, the system administrator uses the header generation tool with the concepts flag option set to introduce an algorithm implementation and the devices supported. Listing 4 shows an example of generated code for the

Generated header file for concepts function implementations.
4.2.2. User actions
Moreover, the users call the supported function interfaces providing the necessary information, in the form of template arguments, so as to guide the compiler through the framework to link against concrete implementations. As an example, the first call to function

Concepts mechanism used in the
4.3. The selector module
This section describes the internal algorithm of the adaptive implementation selector module. This algorithm has been implemented for accepting the two aforementioned interfaces: attributes and concepts. Note that the attributes-based implementation selector has been developed as a preprocessing tool using the Clang 3.8.0 compiler Application Program Interface (API), while the concepts-based selector is implicitly embedded into the semantic concepts code and interpreted by the compiler itself.
The selection algorithm implemented by our framework is entirely based on the problem size and boundaries specified by the user. Depending on this information, the algorithm proceeds as follows:
If the template argument or attribute for a fixed size is set, the selector takes the implementation offering the minimum execution time. This is done using the information stored in the
On the contrary, if the developer has indicated a range of possible problem sizes, the selector module computes the area under the performance curve (or integral) between the ranges for each implementation available. This information allows the selector to take the implementation that has the smallest area between the ranges. As shown in Figure 2(b), if the user selects the range 256–512, the selector module will compute the integrals for the five implementations available. Afterwards, it will compare the areas below the curves and take that having the smallest area, that is, GSL. Note that if there are no performance values in the range boundaries, the values that intersect the boundaries are computed via linear interpolation. As in the previous option using a fixed size, if there are two or more implementations whose integral value is equal, the selector will pick one randomly.
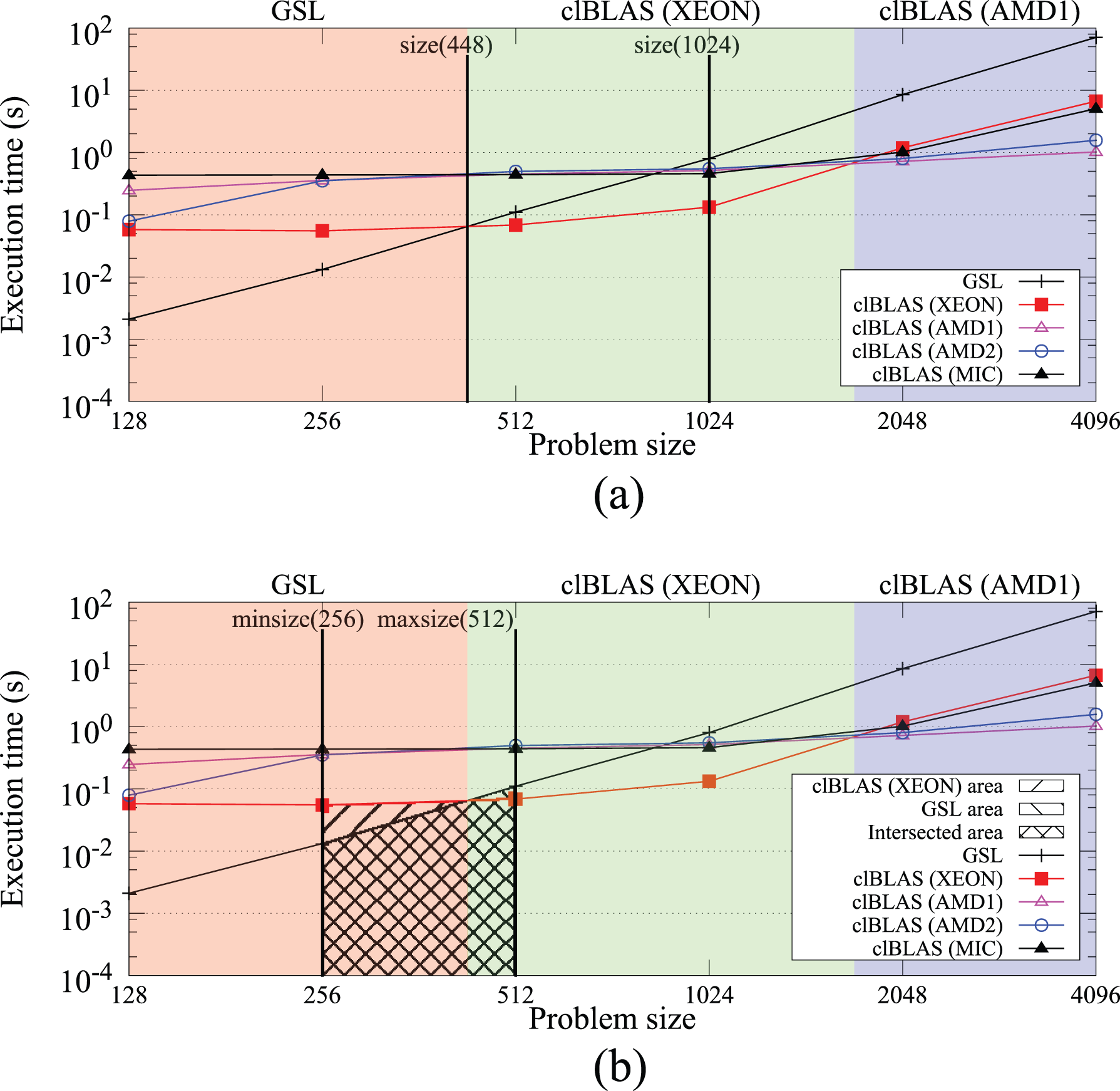
Execution time of the
Note that, at present, the selection algorithm only considers the problem size to select the fastest implementation. In the future, we plan to extend the set of user template arguments and attributes to allow users to specify other kinds of restrictions, such as memory usage or energy consumption. This will allow the selector to make multi-objective optimizations.
Experimental evaluation
In this section, we evaluate the behaviour of our adaptive offline implementation selector using the dense matrix–matrix multiplication (
The platform used to assess the framework is equipped with an Intel Xeon processor, two AMD Radeon GPUs (connected via PCI Express 3.0) and an Intel Xeon Phi co-processor. Table 1 describes the details of these components. The OS running on this platform is a Linux Ubuntu 14.04 and the compiler is GCC v5.0 with the concepts-lite extension enabled.
Heterogeneous test bed platform.

Regarding the use cases, for the
5.1. Evaluation of the accuracy and performance
In this section, we evaluate the accuracy and performance of the implementation selector for both use cases. Figure 3 depicts the accuracy of the decisions made by the selector and the performance attained using fixed sizes and ranges of sizes through different number of training iterations. In order to train the system, in each iteration, we execute an instance of the
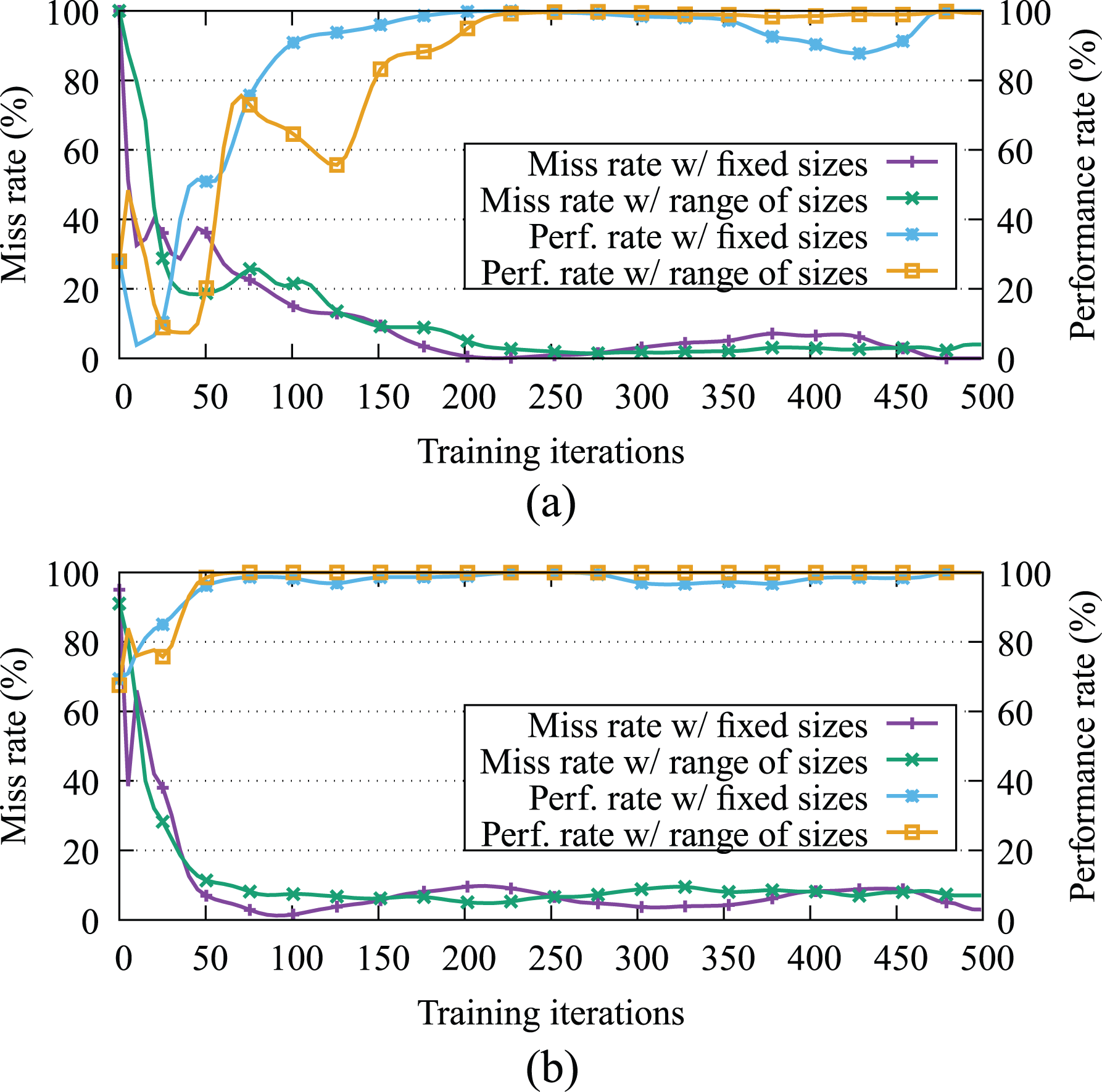
Progress of the miss and performance rates of the selector for the GEMM and STEREOBM. (a) Miss and performance rates for GEMM, (b) Miss and performance rates for STEREOBM.
As can be seen in Figure 3(a), the miss rate progress for the
Evaluation of the adaptability
Next, we evaluate the adaptability of the selector to make appropriate decisions when a new device (and implementation) is attached to the heterogeneous platform each 100 training iterations. Figure 4 analyses the quality of the selections in this scenario for both
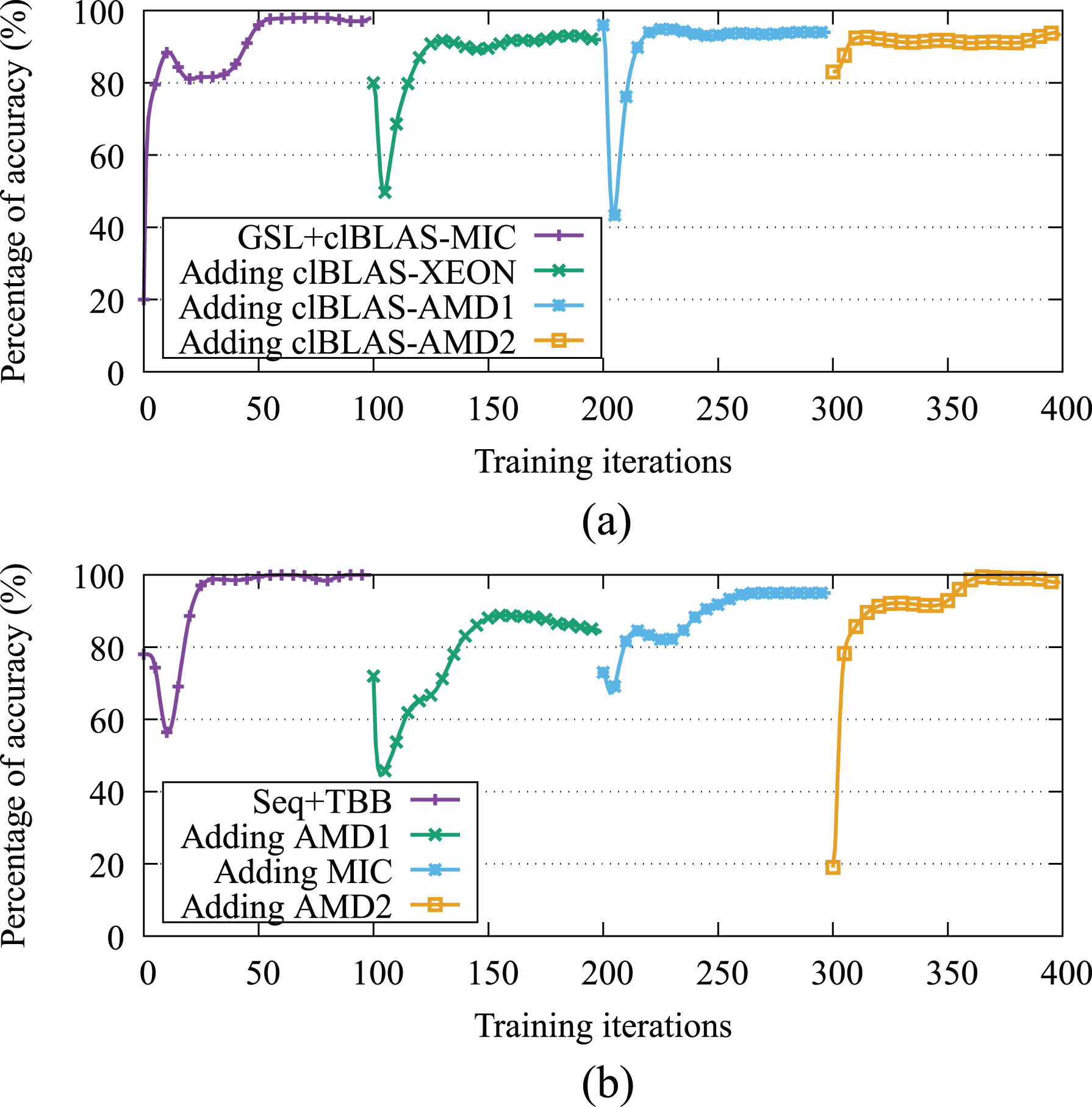
Progress of the accuracy of the selector for the GEMM and STEREOBM when adding new devices. (a) Accuracy using ranges of sizes for GEMM, (b) Accuracy using ranges of sizes for STEREOBM.
Comparison with alternative approaches
As stated in Section 2, several static and dynamic approaches that allow selecting different implementations of a same algorithm can be found in the literature. In this section, we validate the performance benefits of our adaptive offline implementation selector with a real runtime scheduler. Concretely, we compare our approach with the versioning runtime scheduler counterpart from the OmpSs programming model, 9 as it offers a similar implementation selector to our static solution.
To compare our solution (AIS) with OmpSs, we developed an application composed of two 50 iteration loops that computes the matrix–matrix product (
Figure 5 depicts the execution progress of this application. As observed, AIS starts from the first loop iteration selecting the implementations that perform best for the different matrix sizes. Note that AIS has been previously trained performing 100 executions of the
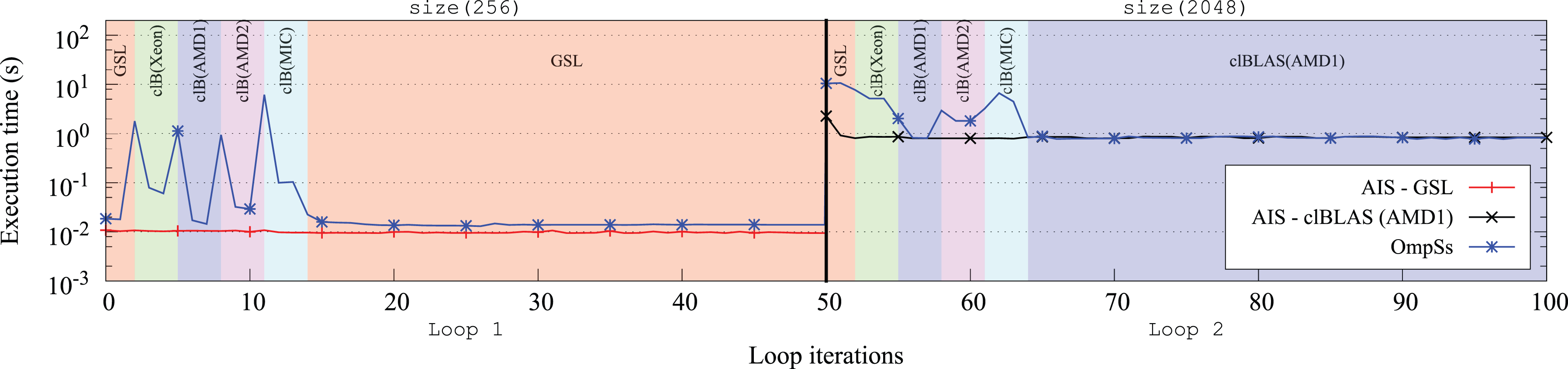
Execution progress of two 50 iteration loops computing the
Conclusions
In this article, we have presented an adaptive offline implementation selector for heterogeneous platform that selects automatically the tuple device implementation delivering the best performance according to the problem size and historical information. Thanks to this approach, our framework shifts the decision-making process at compile time, so that overheads related to dynamic scheduling approaches are also shifted in a negligible profiling process. Furthermore, our framework is hardware independent; therefore, it is possible to freely add or remove devices of the platform without incurring significant overheads. To enable portability, our implementation selector leverages two novel C++ features (attributes and concepts), inherent to the standard C++ programming language.
To evaluate the benefits of this framework, we analysed the performance and accuracy of the tool using two different use cases: the GEMM and an image processing application. The experimental results prove that the selector enhances performance while minimizes efforts to tune applications targeted to heterogeneous platforms. Furthermore, the results also show that our framework delivers comparable performance figures with respect to the OmpSs versioning runtime scheduler.
As future work, we plan to extend the set of C++ attributes in order to allow users to specify other kinds of restrictions, such as memory usage or energy consumption. Furthermore, we also aim to incorporate a static partitioning module for supporting multiple devices in shared and distributed memory systems. Another goal is to integrate the attribute-based selector tool as part of the Clang C++ compiler.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been partially supported by the Spanish ‘Ministerio de Economía y Competitividad’ under the project grant TIN2016-79637-P ‘Towards Unification of High Performance Computing (HPC) and Big Data Paradigms’ and the EU Projects ICT 644235 ‘