
Abstract
We present a highly scalable demonstration of a portable asynchronous many-task programming model and runtime system applied to a grid-based adaptive mesh refinement hydrodynamic simulation of a double white dwarf merger with 14 levels of refinement that spans 17 orders of magnitude in astrophysical densities. The code uses the portable C++ parallel programming model that is embodied in the HPX library and being incorporated into the ISO C++ standard. The model represents a significant shift from existing bulk synchronous parallel programming models under consideration for exascale systems. Through the use of the Futurization technique, seemingly sequential code is transformed into wait-free asynchronous tasks. We demonstrate the potential of our model by showing results from strong scaling runs on National Energy Research Scientific Computing Center’s Cori system (658,784 Intel Knight’s Landing cores) that achieve a parallel efficiency of 96.8% using billions of asynchronous tasks.
1. Introduction
As high-performance computing (HPC) moves toward increasingly diverse architectures and larger processor counts, the HPC community is considering a range of new models. Newly evolving manycore and heterogeneous architectures present many programming challenges suggesting that a move beyond traditional HPC programming models may provide substantial benefits. In this article, we describe an approach to portable application programming at scale with a novel runtime and programming model. We demonstrate our approach with a real application on modern hardware. Our programming model approach emphasizes the following attributes: Scalability: Enable applications to strongly scale to exascale systems. Programmability: Reduce the burden we are placing on HPC programmers. Performance portability: Eliminate or significantly minimize requirements for porting to future platforms. Energy efficiency: Maximally exploit dynamic energy saving opportunities, leveraging the trade-offs between energy efficiency, resilience, and performance.
In this article, we show how several of these objectives can be realized with a scalable simulation in modern time-domain astrophysics.
Advanced time-evolving astrophysical simulations are only now becoming possible with new hardware and programming models. In particular, we show how our programming model approach enables the simulation of transient events caused by stellar mergers, which are spectacular, interesting, and fundamental phenomena in our universe. Their study pays dividends in the broadest possible ways, leading to insights into both astrophysics and fundamental physics. Additionally, until recently, merger events have been rarely observed, because they are short lived and can happen anywhere in the sky. Early in the next decade, the behemoth Large Synoptic Survey Telescope (Željko et al., 2008) study will begin. With a combination of a large telescope and a large field of view, this study will be 40 to 1000 times more powerful than any survey done before. It will finally present us with a real chance to detect traditionally elusive events like double white dwarf (DWD) mergers in great numbers (1 million new transients per night). Numerical simulations can help identify the signatures of the most interesting mergers within this very high volume of transients.
In Section 2, we describe the stellar merger problem we wish to solve. In Section 3, we briefly describe OctoTiger. In Section 4, we lay out the HPX model and discuss Futurization, and in Section 5, we describe how OctoTiger uses futurization. We executed this model on National Energy Research Scientific Computing Center’s (NERSC) Cori machine, described in Section 6. The results of node-level and full-system scaling are detailed in Section 7. In terms of portability, we note that the same source code running at scale on Cori can also be compiled and run on an Apple Laptop. In Section 8, we describe how our experiment demonstrates the ability of HPX to realize scalability, programmability, and performance portability.
2. The physical problem
Interacting binary star systems are potential progenitors of a wide array of astrophysical phenomena. As a result, they have received attention from across the astrophysical community. Some groups have modeled mergers of DWDs as progenitors of Type 1a supernova (see Figure 1) (Dan et al., 2011, 2012; Guillochon et al., 2010; Katz et al., 2016; Pakmor et al., 2011; Zingale et al., 2009). White dwarf mergers that are not massive enough to cause a Type 1a supernova to leave an observable remnant can be studied by continuing the model past the point of merger (Dan et al., 2014; Montiel et al., 2015; Raskin et al., 2012; Schwab et al., 2012; Staff et al., 2012). The beauty of a merger is that a vast range of fundamental physical phenomena with countless connections to all areas of astrophysics are packed into a small volume and a short time. However, this information can only be decoded with a suitable set of observations and numerical simulations.
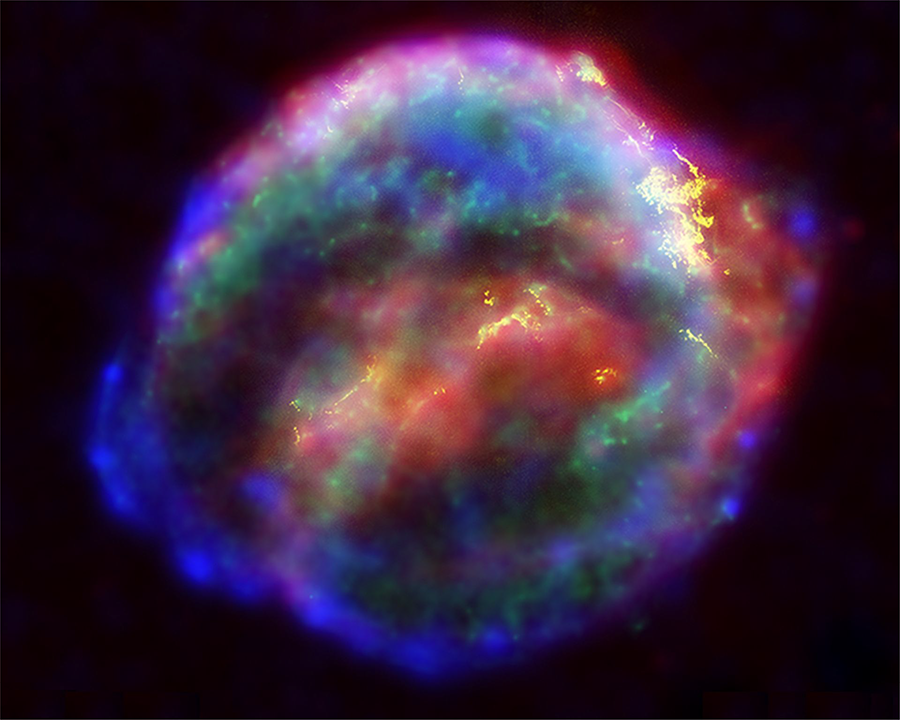
A false-color composite image of the supernova remnant nebula from SN 1604 (Sankrit and Blair, 2004). Visible to the naked eye, Kepler’s star was brighter at its peak than any other star in the night sky, with an apparent magnitude of −2.5. It was visible during the day for over 3 weeks. While discovered in Kepler’s time, new studies are trying to resolve the question of whether or not DWD mergers cause Type 1a supernova. DWD: double white dwarf.
Practically, DWD simulations feature tremendous variances in scale between the simulated physical entities. Figure 2 presents the early stages of the formation of the mass-transfer stream and accretion disk in a binary star where the primary star or accretor (on the left) is five times more massive than the donor star. Some binaries merge and others, such as this one, are expected to be stable to mass transfer. If the accretor is compact enough, the accretion stream will miss the donor on the first pass and form a disc. Figure 3 shows the same system after an accretion disc begins to form. These binary systems, known as AM Canum Venaticorum (AM CVn) systems, exist in a state of mass transfer for millions of years as the donor slowly transfers matter to the accretor and the orbital separation widens. When mass transfer first ensues, they have orbital periods of only a few minutes. The mass transfer causes the orbit to separate, and the AM CVns we observe typically have periods between 10 min and 40 min. Periodic instabilities in the disc can result in dwarf nova. The buildup of helium in the disc can periodically detonate as a subluminous supernova known as a Type “.1a” (point one a) supernova. Stable mass transfer cases require thousands of orbits to simulate and thus necessitate both extreme computation scales and the conservation of angular momentum. In a simulation, we find that a dynamically adapting grid to capture many orders of magnitude of scales and accurate angular momentum conservation is required to properly evolve and distinguish these different outcomes. For example, it is necessary to resolve the grid around the accretion stream with high resolution. Thus, many groups have turned to adaptive mesh refinement (AMR) methods (Kadam et al., 2017; Katz et al., 2016) to address these problems. The simulations described in this article use up to 14 levels of refinement (LoRs), to simulate more than four magnitude difference in resolution of space across the computational domain. Multiple coupled physics solvers with very different performance characteristics and algorithmic complexities are combined to adequately simulate the behavior of DWD systems. Rapidly changing physical quantities with steep gradients require the mesh to dynamically change in resolution. Consequently, the resulting application is highly irregular and frequent load balancing over the course of a simulation is required.
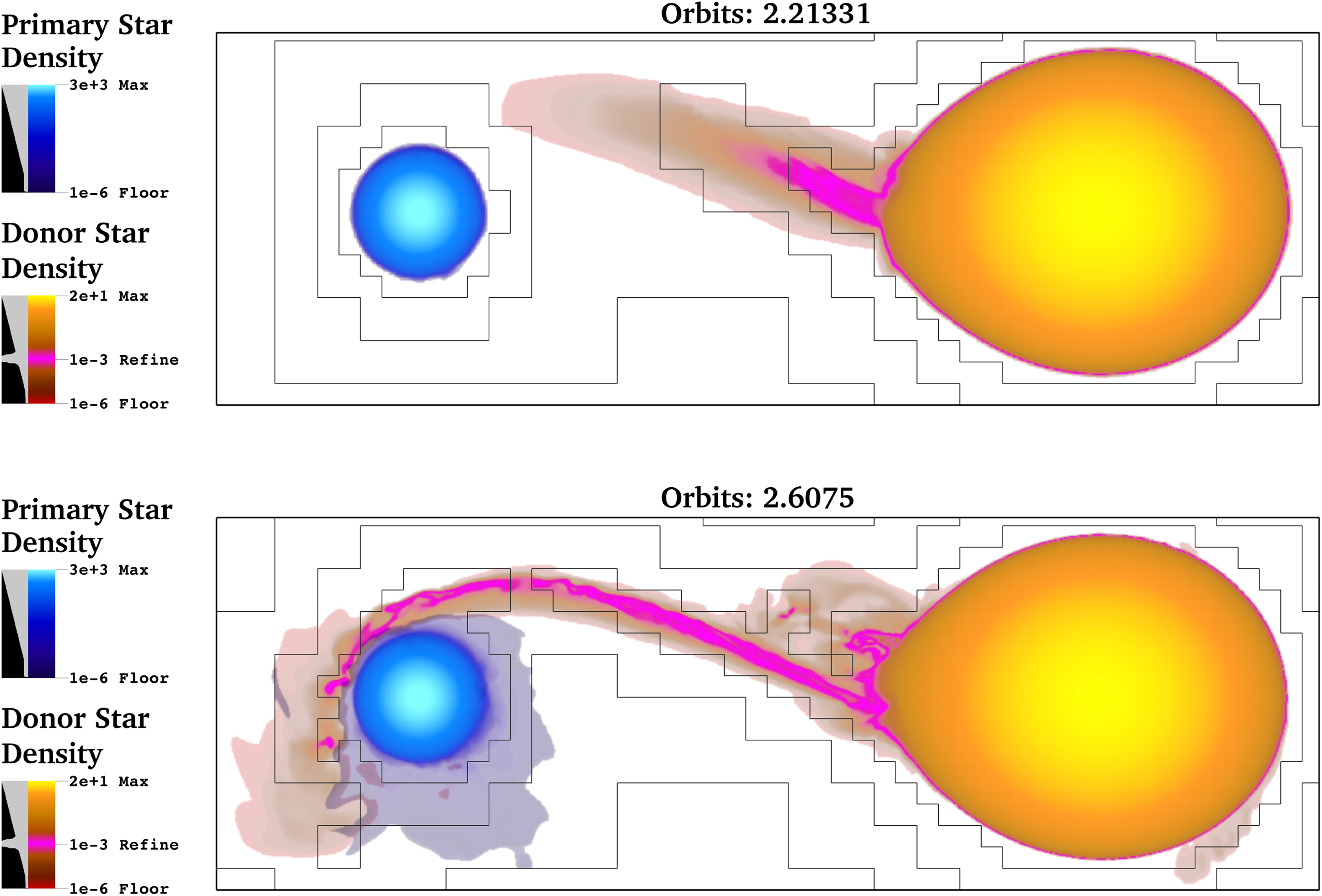
The early stages of mass transfer in a binary star system. The accreting star is five times more massive than the donor star.
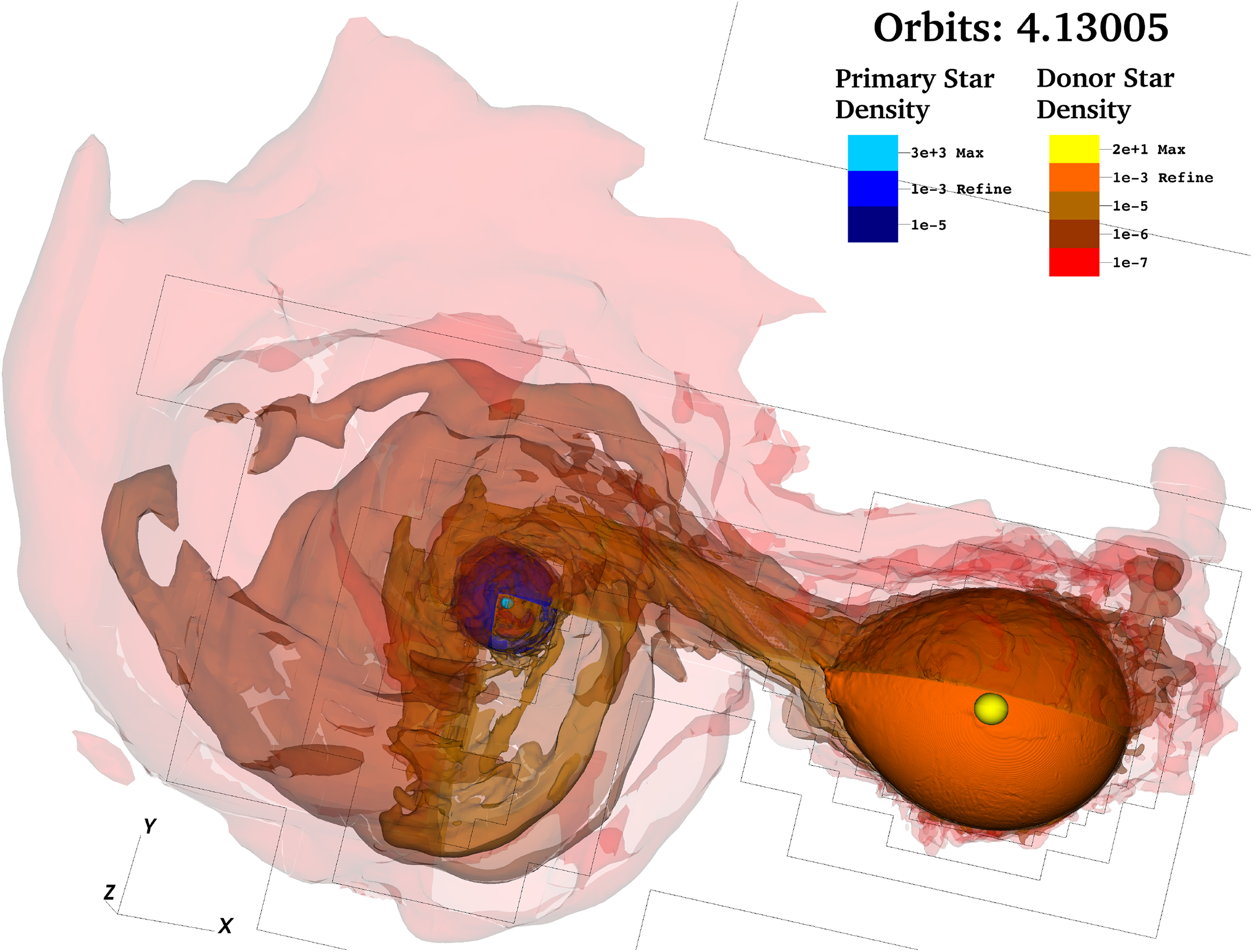
A 3-D contour plot of the system in Figure 2 after an accretion disc begins to form. 3-D: three-dimensional.
3. The OctoTiger simulation package
In this article, we detail programming model updates to create OctoTiger, a three-dimensional (3-D) finite-volume octree AMR hydrodynamics code with Newtonian gravity (Marcello et al., 2016; STE||AR Group, 2017d). It is a successor to previous codes described by Byerly et al. (2014), D’Souza et al. (2006), Kadam et al. (2016), Lelbach et al. (2013), Lindblom et al. (2001), Motl et al. (2007, 2017), Ott et al. (2005), and STE||AR Group (2017c). In OctoTiger, the astrophysical fluid is modeled using the inviscid Euler equations. These are solved using a finite-volume central scheme (Kurganov and Tadmor, 2000). Species within the fluid are evolved as passive scalars. We use an angular momentum conserving hydrodynamic solver, based on the methods described by Desprésa and Labourasse (2015). The gravitational potential and force are computed using a modified version of the fast multipole method (FMM) (Dehnen, 2000) that conserves linear momentum to machine precision. With our extension to the method (Marcello, 2017; Marcello et al., 2016), OctoTiger’s FMM solver also conserves angular momentum to machine precision. The code’s capability to conserve angular momentum at scale is novel and facilitates long-running ab initio simulations spanning thousands of orbits, such as stable mass transfer binaries (see Figure 3).
The computational domain in OctoTiger is based on a 3-D octree AMR structure. Each node in the structure is an N × N × N Cartesian subgrid (in this work, N = 8) and may be further refined into eight child nodes, each containing its own N × N × N subgrid with twice the resolution of the parent. The AMR structure is properly nested, meaning that there is no more than one jump in refinement level across adjacent leaf nodes. The AMR refinement criteria are based on density. These refinement criteria in the current simulation are checked every 15 time steps to see whether refinement or coarsening is required, based on the minimal number of time steps required for a feature of the flow to propagate between two cells. After each refinement/coarsening step, the subgrids need to be redistributed, introducing a need for dynamic load balancing. The images in Figure 2 show how the AMR grid is dynamically refined as the simulation progresses to properly reflect density changes in the mass-transfer stream. In the top image, the accretion stream has not formed yet, and the region between the stars is not fully refined as it does not fall below the refinement criteria density of 1e-3. In the bottom image, the accretion stream, now fully formed and refined, has just missed the primary star. Over time, the material from the stream will slowly form an accretion disk around the primary.
4. Programming model considerations
We developed the OctoTiger application framework (STE||AR Group, 2017d) in ISO C++11 using HPX (Heller et al., 2012, 2013, 2016; Kaiser et al., 2014, 2015; STE||AR Group, 2017a). HPX is a C++ standard library for distributed and parallel programming built on top of an asynchronous many-task (AMT) runtime system. Such AMT runtimes may provide a means for helping programming models to fully exploit available parallelism on complex emerging HPC architectures. The HPX methodology described here includes the following essential components: An ISO C++ standard conforming API that enables wait-free asynchronous parallel programming, including futures, channels, and other asynchronization primitives. An active global address space (AGAS) that supports load balancing via object migration. An active-message networking layer that ships functions to the objects they operate on. A work-stealing lightweight task scheduler that enables finer-grained parallelization and synchronization.
The design features of HPX allow application developers to naturally use key parallelization and optimization techniques, such as overlapping communication and computation, decentralizing control flow, oversubscribing execution resources, and sending work to data instead of data to work. Using Futurization, developers can express complex dataflow execution trees that generate billions of HPX tasks that are scheduled to execute only when their dependencies are satisfied (see Section 4.2.1). Additionally, HPX also provides a performance counter and adaptive tuning framework that allows users to access performance data, such as processor utilization, task overheads, and network throughput (see Section 5.2).
4.1. Background
Parallel programming models are emerging to meet the challenges of manycore, heterogeneous, and exascale architectures. Models call on the AMT methodology to efficiently avoid artificial barriers and overlap communication with computation to hide unavoidable latencies (Anderson et al., 2013; Dekate et al., 2012; Huck et al., 2015; USDOE, 2012; Wheeler et al., 2008). While the concepts of AMT systems are emerging in many modern programming models, some of the more advanced competing implementations of new programming models with similar concepts include Charm++ (Kumar et al., 2004), Intel Cilk Plus (Intel, 2017a), OpenMP with tasking (deSupinski et al., 2017), Chapel (Chamberlain et al., 2007), Intel SPMD Program Compiler (Intel, 2017b), X10 (Charles et al., 2005), and Legion (Bauer et al., 2012).
Parallelism is expressed and presented to the user in different ways in each of these solutions, but a trend toward asynchronous programming is evident. While the majority of the task-based programming models focus on dealing with node-level parallelism, HPX presents a single model to the programmer that supports both local and remote execution. This concept assures a uniform programming model that is architecture independent.
Many applications must overcome the scaling limitations imposed by current programming practices by embracing an entirely new way of coordinating parallel execution. Fortunately, this does not mean that we must abandon all of our legacy code. HPX can use MPI as a highly efficient portable communication platform and, at the same time, serve as a back end for OpenMP, OpenCL, or even Chapel while maintaining or even improving execution times. This opens a migration path for legacy codes to a new programming model that allows old and new code to coexist in the same application.
Within the astrophysics community, two recent and important contributions that use asynchronous tasking and AMR are SWIFT (Schaller et al., 2016) and ChaNGa (Menon et al., 2015). SWIFT scales up to 100 K cores with 60% parallel efficiency, and ChaNGa has demonstrated scalability up to 500 K cores with 93.4% parallel efficiency. SWIFT code uses asynchronous tasking to blend computation and communication, in a similar manner to HPX, but its parallel runtime is application-specific and not designed for reuse. ChaNGa uses Charm++ (Kumar et al., 2004) and is tied to the Charm++ compiler and runtime. In contrast to both, HPX is a library-only generic solution that implements standardized C++ APIs and can be applied to existing C++ code with minimal modifications.
4.2. Fundamental properties of the HPX model
One goal of this article is to demonstrate the viability of the HPX programming model through a portable standards conforming application and to demonstrate that application at scale. OctoTiger fully embraces the C++ parallel programming model, including additional constructs that are incrementally being adopted into the ISO C++ standard. The programming model views the entire supercomputer as a single C++ abstract machine. A set of tasks operates on a set of C++ objects distributed across the system. These objects interact via asynchronous function calls; a function call to an object on a remote node is sent as an active message to that node. A powerful and composable primitive, the future object, is used to represent and manage asynchronous execution and dataflow.
A crucial property of this model is the semantic equivalence between local and remote operations. This provides a unified approach to vector-, core-, and node-level parallelism based on proven generic algorithms and data structures in the ISO C++ standard today. The programming model is intuitive and enables performance portability across a broad spectrum of the landscape of increasingly diverse supercomputing hardware. Results of using the HPX model on additional architectures will be presented in a future publication.
4.2.1. Futurization
The fundamental asynchrony primitive in the C++ parallel programming model is the
The continuation-attaching operation is very powerful because it enables continuation passing style (CPS) (Appel and Jim, 1989) asynchrony. CPS ensures that tasks that have data dependencies do not start executing until all their dependencies are satisfied. This approach has been shown to reduce unnecessary waiting and avoid latency (Syme et al., 2011).
Rewriting synchronous blocking code as a chain of wait-free continuations can be achieved through the straightforward futurization technique, as depicted in Table 1. The futurization technique allows a delay of direct (sequential) execution to avoid synchronization. The futurized code no longer directly calculates results but instead generates a dynamic execution tree, representing the inherent data dependencies of the original algorithm. The execution of this tree can now be parallelized by the underlying AMT runtime, yielding the same result as the original code. Some programming languages, such as F# and C#, have introduced powerful language facilities that simplify this transformation (Bierman et al., 2012; Syme et al., 2011). Such a feature, based on await in C#, has recently been introduced to the C++ programming language via an ISO Technical Specification (C++ Standards Committee, 2017b) and will further simplify the process of futurizing existing code.
The Futurization Technique.a,b

a This table shows sequential C++ constructs (left column) and the corresponding constructs after applying a transformation called Futurization (center and right columns)
b This technique transforms sequential code into wait-free asynchronous tasks with explicit data dependencies. The right column uses the ISO C++ Coroutines Technical Specification (C++ Standards Committee, 2017b) that provides language-level support for this transformation. T, U, and V are types; t, u, and v are variables of those types; and f, g, and h are functions.
Futures are created by control structures, generic routines parameterized on execution semantics, such as C++11 std:: async (C++ Standards Committee, 2011; [futures.async]) or the C++17 parallel algorithms library (C++Standards Committee, 2017a; [algorithms.parallel]). Execution policies describe the constraints and parameters of execution (
5. Methodology
We use HPX Futurization in OctoTiger to eliminate global barriers and thus reduce barriers to optimal parallel performance as much as possible. The only phases of OctoTiger that require a global barrier are (1) rebalancing the AMR tree after refinement/coarsening and (2) computing and distributing the maximum allowed time-step size.
We implement AMR operations in a natural way that is generic and can be easily parallelized: traverse the tree recursively, apply a transformation (ex: refinement/coarsening, migrate children, performing a time step) to each tree node, and return a recursively reduced result.
The sequential version of this algorithm is shown in listing 1. If a specific node is refined, that is if it contains children, we recurse in a depth-first pattern. The computation for the current node is combined with the results returned by the traversal from the children, leading to a natural way to gather results and propagate values from the leaves to the root. The downside to this approach is that a stack overflow might occur when executing trees of great depth, due to excessive recursion.
Natural recursive tree traversal.

By applying the Futurization techniques, the formulation of tree traversal can be parallelized. The futurized traversal algorithm is presented in listing 2. Instead of direct recursion, we recurse asynchronously. The computation for a given tree node, representing a subgrid in OctoTiger, is overlapped with the children computations. When communication with possibly remote tree node objects takes place, it is transparently hidden by other ongoing computations. This futurized tree traversal is the basic parallel pattern implemented in OctoTiger, including the most expensive operations:
Futurized recursive tree traversal.

The extension of this approach to a distributed memory application using AGAS is straightforward. We simply register the tree node objects with AGAS and store globally unique identifiers (GUIDs) in the children array instead of storing the objects themselves. The GUIDs can be thought of as global pointers. A GUID can be passed as the second argument to async (after the function to be invoked, before the arguments to the function) to make asynchronous RPC. The children may reside on the same node as the parent, or they may be distributed over various different compute nodes; the algorithm works in both cases because of the semantic equivalence of local and remote interfaces in our model.
The Check whether each node in the octree needs to be refined or coarsened, and if so, mark it for refinement and ensure the correct refinement levels of its neighbors (e.g. proper nesting). Count the total number of tree nodes and the number of tree nodes in each child via recursive reduction. Move tree nodes that are being rebalanced. A space filling curve is used to determine the distribution. Migration is initiated by parent tree nodes. Update references to neighboring tree nodes. Old references may be outdated due to the preceding steps.
The step phase implements the hydrodynamics and gravity solvers. Each tree node has its own N3 subgrid containing the evolved variables for the solvers. The futurized fluid solver, gravity solver, and time-step size propagation differ from the other futurized tree traversals. The hydrodynamics and gravity solvers depend on ghost zone data (zones of data that are shared between processors, usually on the boarder of grids separated for parallel computation) from neighboring regions and the dynamically computed time-step size from a reduction on the previous time step’s entire tree.
To avoid introducing needless waiting during these solves and exchanges, OctoTiger uses a
The associated state and storage for each epoch’s
A simplified example of a
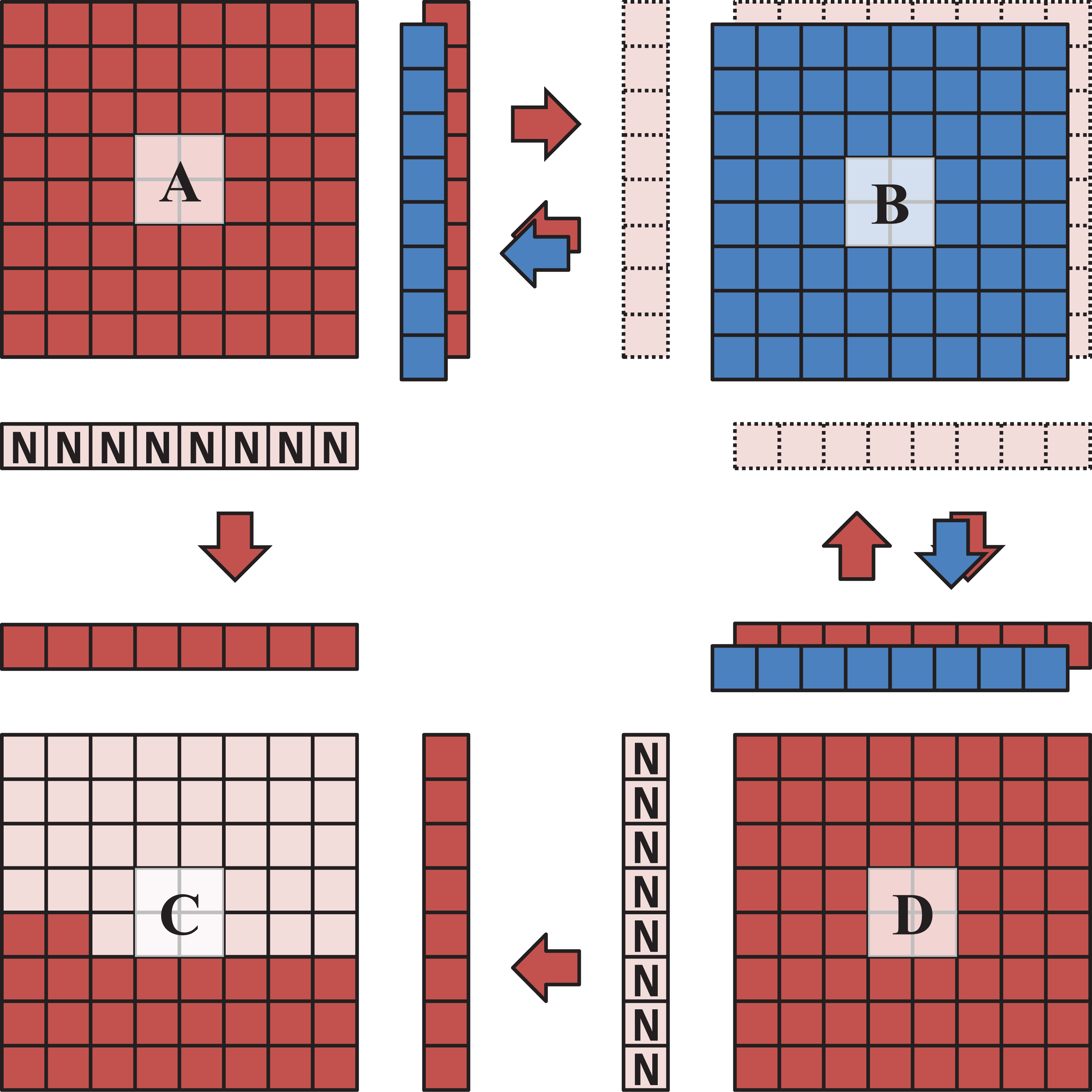
Depiction of ghost zone exchange patterns.
To advance the hydrodynamics variables for each cell, a single substep in time requires knowledge of the variables in the neighboring three cells on each side and in each dimension. These ghost zones are updated after every substep, with each tree node sending the required data from its interior (non-ghost zone) cells to its neighboring tree nodes. When a leaf node has no neighboring tree node at the same LoR, the ghost zones are interpolated from the neighboring tree nodes of its parent.
Like the hydrodynamics solver, the FMM solver also requires data from neighboring tree nodes on the same level. It also requires data from its child and parent tree nodes. Each tree node executes three steps for the FMM algorithm: Compute multipoles by combining multipoles from its children tree nodes and communicate multipoles to its parent tree node and the relevant subsets to its neighboring tree nodes. Compute the Taylor expansion of the gravitational interaction between multipoles, including those from neighboring tree nodes on the same refinement level. Add its own Taylor expansion to the Taylor expansion of the gravitational potential from its parent tree node and communicate the total Taylor expansions to its children tree nodes.
The FMM solver requires four cells of ghost zone data from its neighboring tree nodes. Because of the large amount of neighboring data required, rather than storing ghost zone cells for the FMM solver, the data from neighboring cells are discarded once the relevant interactions are computed.
5.1. Vectorization
The combination OctoTiger with HPX uses the Vc (Kretz, 2015a; Kretz and Lindenstruth, 2011) library for the portable expression vector parallelism. This library is advancing toward potential standardization in the C++ programming language (Kretz, 2015b, 2015c, 2016, 2017). The Vc library enables explicit and portable vectorization through vector data types (
5.2. Performance counters and APEX
Within our HPX implementation is a performance counter framework with a uniform interface for extracting arbitrary information including performance metrics, queue lengths, execution times of crucial functions, memory footprint, network utilization, or any other aspect of application or runtime system behavior. The counters are accessible through AGAS and are available at the thread, process, or system level. The counters can be queried periodically, on demand, or at the end of execution. They are output either to the terminal or to a file in a variety of formats.
The HPX implementation is also integrated with the Autonomous Performance Environment for eXascale (APEX) (Huck et al., 2015; XPRESS APEX, 2017). The APEX environment provides a lightweight performance measurement and control library specifically designed for use in HPX and has been extended to other runtime systems. It is integrated into the task scheduler within HPX, providing direct measurement of every task scheduled by the runtime. Unlike other parallel performance measurement libraries, APEX includes support for direct timing of tasks that yield and resume, even if resumption happens on a different OS thread than the one that yielded the task. The aforementioned HPX counters are also stored in APEX along with hardware and OS utilization/status counters.
Optionally, APEX can be integrated with TAU (Shende and Malony, 2006) for detailed profiling, sampling and tracing, and PAPI (Dongarra et al., 2001) for hardware counter and GPGPU support. Alternatively, APEX can utilize the OTF2 (Eschweiler et al., 2012) library for full event tracing for analysis and visualization in Vampir (Knüpfer et al., 2008). The APEX environment gathers system health and utilization information through available user-space OS methods such as the /proc virtual file system. Power and energy data are available through the Cray PM Counters (Martin and Kappel, 2014) or Linux Power Capping Framework (Linux Kernel Organization, 2017) interface.
On its own, APEX maintains an internal performance state that is asynchronously updated by the HPX runtime as a scheduled task. Measurement overheads are typically less than 2–3%. The APEX measurement artifacts include process-level profiles, concurrency and scatter plot charts, and formatted text output. During this research, APEX was used to help identify, resolve, and verify a serialization bottleneck during the tree formation and rebalancing steps of the regridding phase of OctoTiger, as shown in Figure 5.
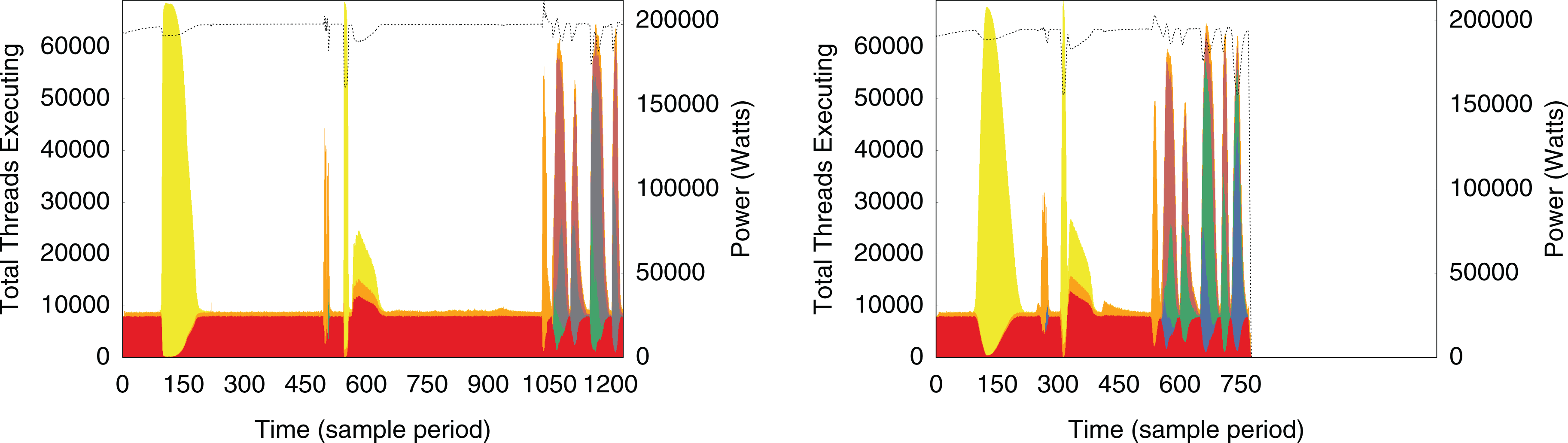
Concurrency views using APEX of OctoTiger running on 1024 nodes of Cori. Higher values indicate better system utilization. The figure on the left shows a profile of OctoTiger prior to Futurization. There are two long periods of serial execution: (1) after the checkpoint load and grid creation stage (first yellow bulge) and (2) after the first gravity solve (center), followed by two time steps. The figure on the right shows the same sequence of events after applying the Futurization methodology to make the regridding algorithm (i.e. used during checkpoint loading) more scalable. Each color represents an HPX task type, and the aggregate power consumption (Watts) across nodes is visible as a dashed black line. The axis scales are equivalent. APEX: autonomous performance environment for eXascale.
6. Experimental setup
The primary system used for the experiments in this article is a Cray XC40 installation at the NERSC located in Berkeley, California, USA (He et al., 2018) known as Cori. Significant dedicated time on the Cori machine enabled the accurate scaling measurements presented here. Cori consists of two phases, phase 1 consisting of an Intel Haswell partition and phase 2 consisting of an Intel Knight’s Landing (KNL) partition. For the following system description and results, we limit our discussion to phase 2. The phase 2 system consists of 9688 nodes; each node has a single Xeon Phi 7250 processor with 68 cores and 272 hyperthreads (HTs) (Intel, 2017c). Therefore, there are 658,784 cores and up to 2.6 million threads overall. The whole system has a peak double precision floating point performance of approximately 29.1 PFLOP/s is an aggregated main memory capacity of approximately 1.1 PB. Cori uses a Cray Aries interconnect and has a global bandwidth of approximately 45 TB/s.
The Intel KNL Xeon Phi 7250 processor supports the AVX512 instruction set and has two 512-bit fused-multiple-add vector units per core. Each Xeon Phi 7250 is capable of up to 3 TFLOP/s (double precision). The KNL cores are derived from the Intel Atom architecture that has lower scalar performance compared to contemporary Intel Xeon processors (Doerfer et al., 2016). In addition to 96 GB of DDR4 for main memory, the Xeon Phi 7250 has 16 GB high bandwidth memory (MCDRAM). The bandwidth of the MCDRAM is 460 GB/s. The MCDRAM can be configured as a direct mapped cache or as explicitly programmable memory (Doerfer et al., 2016). The KNL processor can be configured in three different NUMA clustering modes: (1) all-to-all, (2) quad, and (3) sub-NUMA-clustering. Each mode determines the configuration of the entries in distributed hash table among tiles for virtual address translation. The latencies for memory access are highest in the first case and lowest in the third (Sodani, 2015).
After a first initial evaluation of the achievable performance, the single-node performance did not vary significantly between the different clustering and high bandwidth memory modes. Thus, we used the Quad mode (NERSC’s default) and configured the MCDRAM as a cache.
In our experiments, we used the software listed in Table 2 . Experiments were also performed with other compilers; however, the computations were significantly slower, so we chose to use GCC. To measure execution times, we used
Software versions used in our experiments.

7. Results
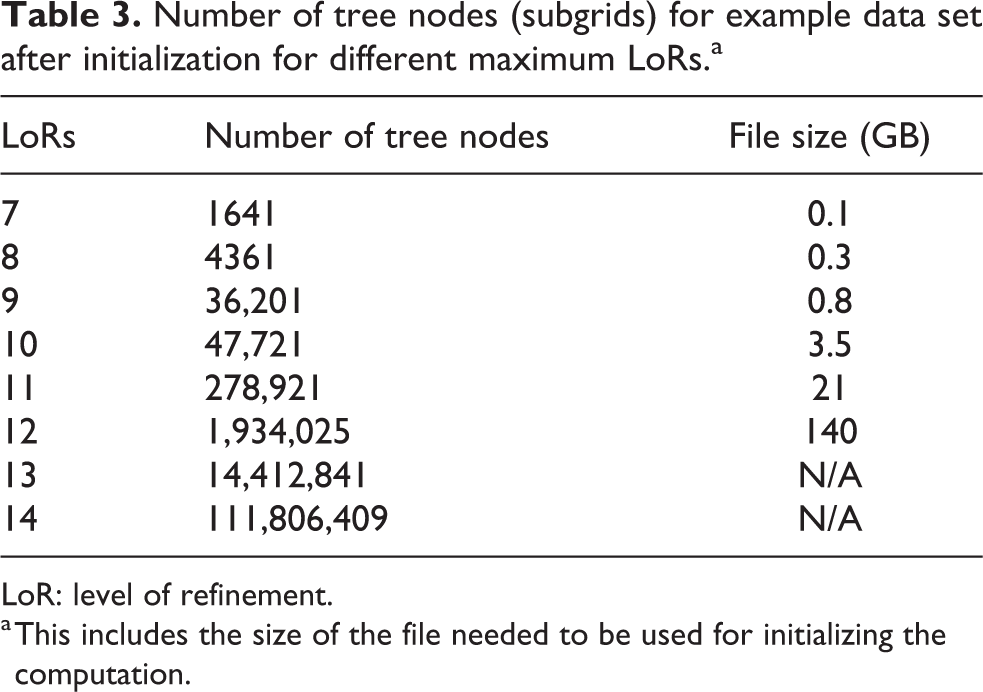
The following section presents results from strong scaling experiments with OctoTiger on Cori (NERSC, 2017b) and demonstrates the scalability of our approach. The problem size was controlled by setting the maximum LoRs (see Table 3). The effectiveness of the Futurization of OctoTiger was observed by profiling the application with the APEX toolkit (see Figure 5). The results presented include input/output (I/O) in the initialization phase and plain computation time for the remaining part.
Number of tree nodes (subgrids) for example data set after initialization for different maximum LoRs.a
LoR: level of refinement.
a This includes the size of the file needed to be used for initializing the computation.
7.1. Node-level scaling
First, we look at single node scalability to determine a suitable number of cores and processing elements per core for performing the distributed memory full-system scaling experiments.
Figure 6 shows the scalability of an OctoTiger 7 LoR 10 time-step simulation on a single KNL node with different numbers of HTs per core. This experiment shows that using two HTs per core gives the best overall performance, with a parallel efficiency of approximately 87%. This is approximately 1.3× speedup over the results for one HT per core.
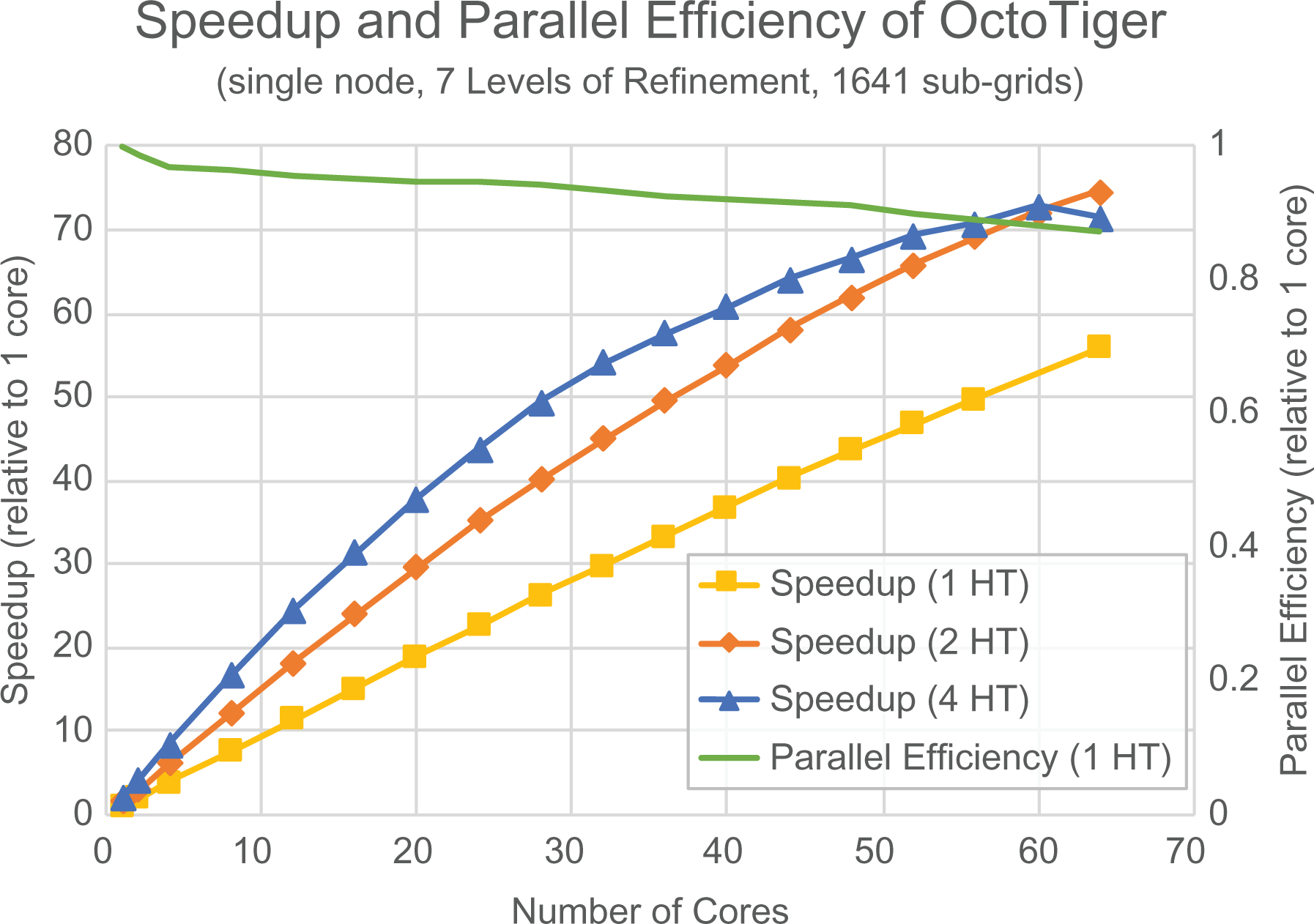
The speedup and parallel efficiency of OctoTiger strong scaling experiments on a single KNL node with different numbers of HTs per core is shown above. The two HTs per core case perform best. It achieves a speedup of approximately 55.9× when scaling from 1 to 64 cores, corresponding to a parallel efficiency of approximately 87%. This is approximately 1.3× speedup over the results for one HT per core. KNL: Knight’s Landing; HT: hyperthread.
This demonstrates the applicability of the futurization technique on manycore system like the KNL. By having the system oversubscribed with 24 tree nodes per core, we were able to exploit the on-node parallelism efficiently. Increasing the number of subgrids per core even further does not show significant improvements with respect to scalability. Reducing this number, however, leads to a drop in performance.
7.2. Full-system scaling
To assess scalability and distributed performance of our futurized application, we did strong scaling runs for different LoRs. Figure 7 provides an overview of the results.
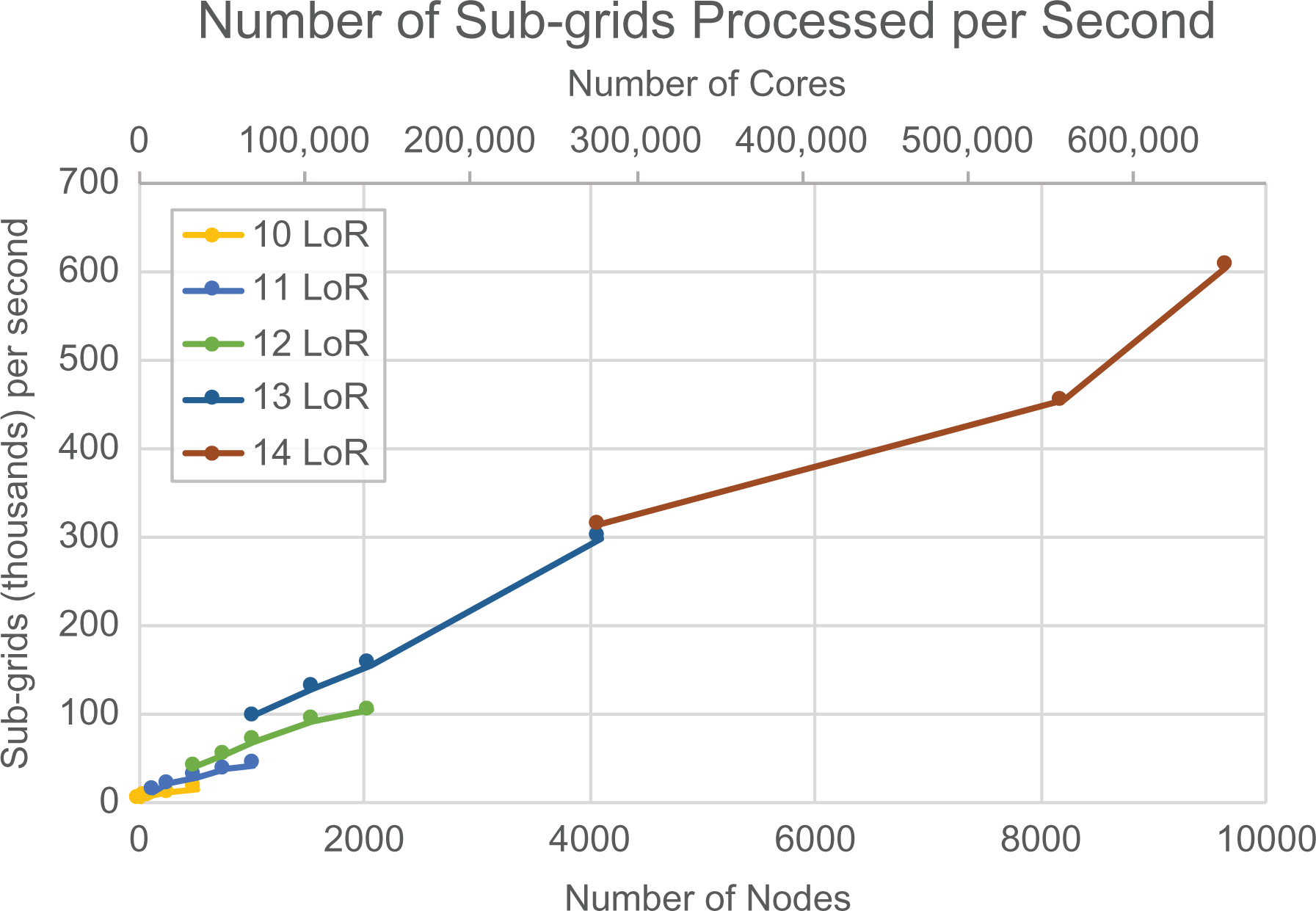
The results of OctoTiger strong scaling runs up to 655,520 cores on Cori for different problem sizes—for example, different maximum LoRs. This graph indicates close to perfect scalability for each problem size, with a clear improvement of performance from one LoR to the next because of increased latency hiding and parallel work due to higher oversubscription (higher number of subgrids per core). The larger problem sizes cannot be run on a smaller number of cores because they will exceed memory capacity. LoR: level of refinement.
Because we are strong scaling, the speedup naturally flattens off after the number of subgrids per core drops below a certain value. In our experiments, this was happening at 100 subgrids per core. The overall speedup from 10 LoR at 16 compute nodes (approximately 44 subgrids per core) to 14 LoR at 9640 compute nodes (approximately 171 subgrids per core) is approximately 342×, corresponding to a parallel efficiency of 56.8%. Since the number of subgrids per core is not the same, the comparison does not fully reflect the scalability of OctoTiger. However, it can be clearly observed that excellent scalability can be achieved by providing sufficient work to be executed by each core.
To further demonstrate the scalability of OctoTiger and show the effects of futurization at scale, Figures 8 and 9 provide a breakdown of performance of the different stages of the application.
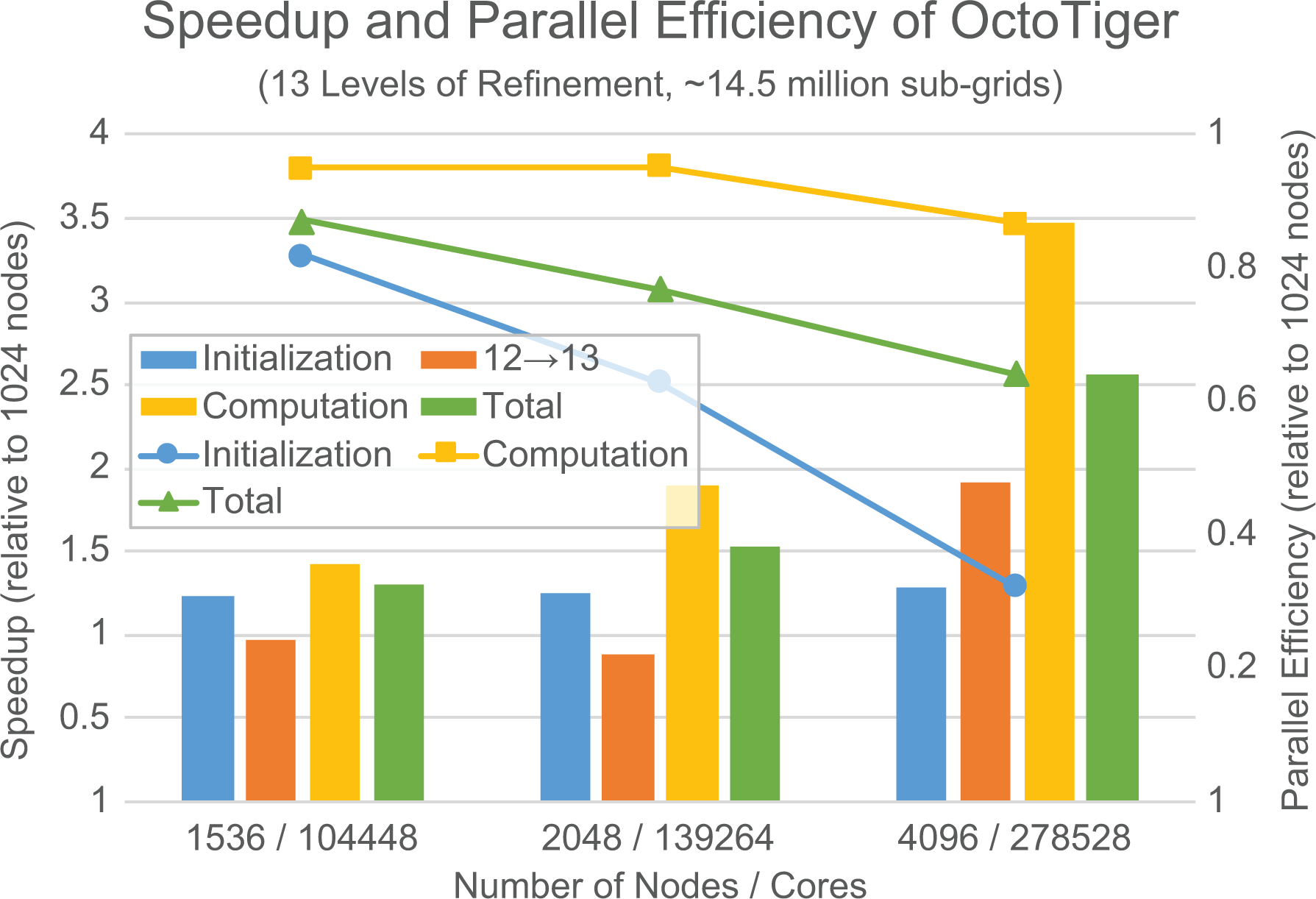
Speedup (bars, left axis) and parallel efficiency (lines, right axis) of OctoTiger strong scaling are a problem with 13 LoR up to 1024 KL nodes/69,632 cores on Cori. The graphs show separate speedup and parallel efficiency results for three application stages (initialization, initial regridding from the 12 LoR restart file to 13 LoR, and the actual computation). The computational phase achieves a speedup of approximately 3.46× when scaling from 1024 nodes to 4096 nodes, corresponding to a parallel efficiency of approximately 87%. LoR: level of refinement; KNL: Knight’s Landing.
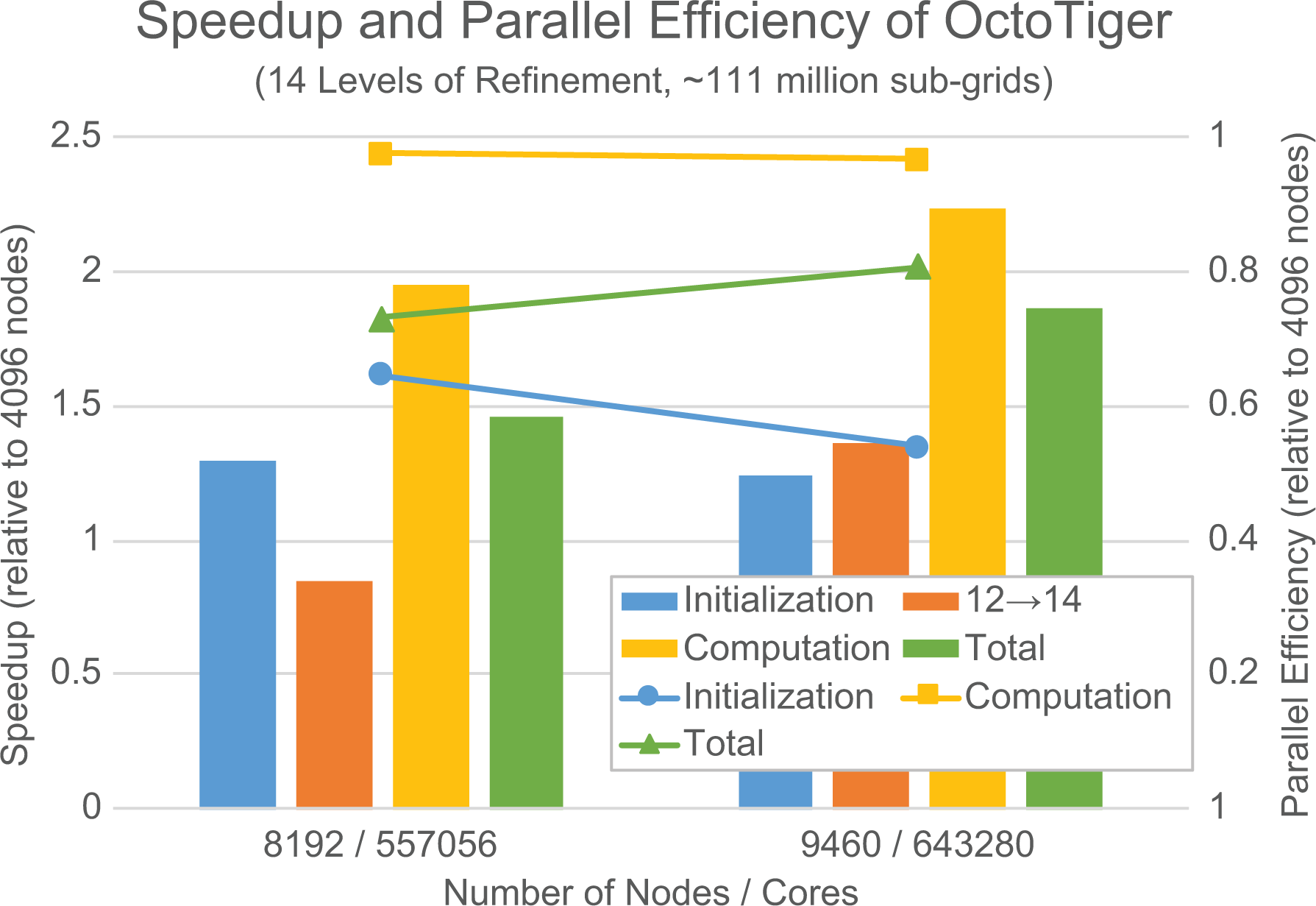
Speedup (bars, left axis) and parallel efficiency (lines, right axis) of OctoTiger strong scaling are a problem with 14 LoR up to 4096 KL nodes/278,528 cores on Cori. The graphs show separate speedup and parallel efficiency results for three application stages (initialization, initial regridding from the 12 LoR restart file to 14 LoR, and the actual computation). The computational phase reaches a speedup of approximately 2.24× when scaling from 4096 nodes to 9460 nodes corresponding to a parallel efficiency of approximately 96.8%. LoR: level of refinement; KNL: Knight’s Landing.
These figures show that when executing the 13 LoR and 14 LoR problems, the futurized tree traversal, described in Section 5, is able to scale up to the full Cori system—for example, 655,520 cores. While the initialization of the problem, which includes loading the initial octree from disk, is hampered by I/O limitations, the actual computation exhibits a parallel efficiency of 96.8% (obtained by the strong scaling of the 14 LoR problem from 4096 nodes to 9640 nodes). The sustained aggregated bandwidth for loading the initialization file was at 1.4 GB/s with reading concurrently from 2048 nodes while performing initialization. The data were read from the burst buffer, spread across 50 burst buffer nodes. This only uses a fraction of the available bandwidth. Future work will improve this with proper support for parallel I/O. We started the scaling experiment for the 14 LoR problem at 4096 nodes as it does not fit in memory on a smaller number of compute nodes. On the other hand, the scaling of the 13 LoR problem is limited by the lack of work, as the number of subgrids per core drops to approximately 51 at 4096 nodes, causing the parallel efficiency in this case to be reduced to approximately 87%.
8. Conclusions and implications
The OctoTiger simulations presented here show the onset of a stable mass transfer stream and the initial few orbits during which an accretion disk forms with excellent detail. Additional orbits are needed for the disk to fully develop and reach a quasi-steady state. Ultimately the disk will transport angular momentum outward and tidal forces will return this angular momentum to the orbit. The stability and final fate of the binary do depend on this further evolution, but the intent of this article is to demonstrate the capability of OctoTiger and HPX. Notably, futurized HPX applications can strong scale out to hundreds of thousands of cores. As for application portability, we note that the same source code we ran at scale on Cori we also ran on an Apple Laptop using HPX and compiled with GCC.
The OctoTiger advances show the potential to substantially reduce the time to solution for high fidelity DWD merger simulations. Experiments that previously took weeks or months of computational effort can now be performed in a matter of days on petascale systems like Cori. This scalability will make it possible to simulate evolutions over more orbits and allow us to make these simulations more realistic by including more compute-intensive physical effects such as radiative transfer, light curve generation, radiation hydrodynamics, and nuclear reactions. Code development along these lines is already underway.
This work also has several implications for parallel programming and
The standard C++ parallelism, concurrency, and memory models are easily programmable, portable, and performant. Further additions to the ISO C++ standard will allow the world’s approximately 4.4 million C++ programmers (Kazakova, 2015) to write applications that generate billions of tasks across hundreds of thousands of heterogeneous cores within a hierarchical and heterogeneous memory space. In leveraging concepts such as
To be sustainable and maintainable, scientific applications must not only perform well but must also perform portably, a feat that will become difficult as hardware becomes more diverse, heterogeneous, and hierarchical. High-level abstractions will become pivotal. We believe our work lays a foundation and a potential vision for developing
Footnotes
Acknowledgements
The authors would like to thank Brandon Cook, Dave Paul, Stephen Leak, Doug Jacobson, and Jack Deslippe for NERSC technical support. Additionally, the Talapas HPC cluster and the HPC Research Core Facility at the University of Oregon were used in the course of this research. Support for this work was also provided through the X-Stack program. Further, the authors would like to acknowledge the Center for Computation and Technology at Louisiana State University, the Department of Computer Science 3—Computer Architecture at the University of Erlangen Nuremberg, and the Institute for Parallel and Distributed Systems at the University of Stuttgart. Comments on the paper content by Hans Johansen and Tim Mattson are greatly appreciated. The authors further acknowledge the following individuals for various contributions: Agustín (K-Ballo) Bergé, Kundan Kadam, Joel E. Tohline, Nigel Tan, Dietmar Fey, Ram Ramanujam, Nick Chaimov, and Allen D. Malony.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the US Department of Energy (DoE) Office of Science’s (SC) Advanced Scientific Computing Research (ASCR) program (under contract DE-AC02-05CH11231) using resources of the NERSC. Support for this work was also provided through the X-Stack program by the US DoE SC ASCR program under contracts DE-SC0008638 and DE-SC0008714. This work was also supported by the European Union’s Horizon 2020 research and innovation program under grant agreement 671603 (AllScale). The development of the OctoTiger code is supported through the National Science Foundation award 1240655 (STAR). This research was partially supported under US DoE under contract DE-AC02-05CH11231 for Lawrence Berkeley National Laboratory that is operated by the University of California, contract DE-AC52-06NA25396 for Los Alamos National Laboratory that is operated by Los Alamos National Security, LLC (LA-UR-17-31311), and contract DE-AC52-07NA27344 for Lawrence Livermore National Laboratory operated by Lawrence Livermore National Security, LLC.