
Abstract
We describe the parallelization of the solve phase in the sparse Cholesky solver SpLLT when using a sequential task flow model. In the context of direct methods, the solution of a sparse linear system is achieved through three main phases: the analyse, the factorization and the solve phases. In the last two phases, which involve numerical computation, the factorization corresponds to the most computationally costly phase, and it is therefore crucial to parallelize this phase in order to reduce the time-to-solution on modern architectures. As a consequence, the solve phase is often not as optimized as the factorization in state-of-the-art solvers, and opportunities for parallelism are often not exploited in this phase. However, in some applications, the time spent in the solve phase is comparable to or even greater than the time for the factorization, and the user could dramatically benefit from a faster solve routine. This is the case, for example, for a conjugate gradient (CG) solver using a block Jacobi preconditioner. The diagonal blocks are factorized once only, but their factors are used to solve subsystems at each CG iteration. In this study, we design and implement a parallel version of a task-based solve routine for an OpenMP version of the SpLLT solver. We show that we can obtain good scalability on a multicore architecture enabling a dramatic reduction of the overall time-to-solution in some applications.
1. Introduction
In this study, we are solving the linear system

where A is a large sparse symmetric positive-definite matrix. In order to do this, we use a direct method where the solution process consists of three main steps: the analyse, the factorization and the solve phases. We use a Cholesky factorization given by

where L is a sparse lower triangular matrix, and P is a permutation matrix needed to preserve the sparsity. Since L is triangular, the solution can be obtained using a forward substitution step

followed by a backward substitution step

so that
In this article, we concentrate on the steps in equations (3) and (4). Most work on sparse solvers concentrates on the factorization in equation (2) because that is the most costly step of the solution process. As a consequence, the solve phase is often not as optimized as the factorization in the state-of-the-art solvers, and opportunities for parallelism are often not exploited in this phase. However, in some applications, the time spent in the solve phase is comparable to or even greater than the time for the factorization, and the user could dramatically benefit from a faster solve routine. This is the case, for example, for a conjugate gradient (CG) solver using a block Jacobi preconditioner. The diagonal blocks are factorized once only, but their factors are used to solve subsystems at each CG iteration.
Runtime systems such as StarPU (Augonnet et al., 2011), OpenMP and PaRSEC (Bosilca et al., 2013) provide a high-level API for implementing task-based algorithms where the directed acyclic graph (DAG) of tasks can be represented using different models. The most user-friendly model is the sequential task flow (STF) supported by the vast majority of runtime systems. Alternative models include the parametrized task graph (PTG) model supported by only a few runtime systems such as PaRSEC. Although the PTG model can offer some benefits in terms of performance over the STF model, it is generally much more difficult to use in practice especially in the context of sparse algorithms where the task dependency pattern is very irregular.
When using runtime systems, the runtime system is responsible for handling the DAG on the target architecture by managing the data dependencies, data coherency and task scheduling. One main advantage of this compared to using low-level synchronization mechanisms lies in the fact that it offers better portability and maintainability of the code. Furthermore, we conducted extensive experiments on using runtime systems in previous work for a sparse Cholesky factorization. We used both the STF model (Duff et al., 2018) and the PTG model (Duff and Lopez, 2018), in the context of the SpLLT solver, and we showed it was efficient in terms of performance when running on multicore architectures compared to the state-of-the-art solver HSL_MA87 from the Harwell Subroutine Library (HSL) (http://www.hsl.rl.ac.uk/).
In this article, we extend our approach to the solve phase in SpLLT and design DAG-based algorithms for implementing the parallel version of the forward and backward substitutions. Our implementation relies on an STF model, and the parallelization is achieved using the tasking features available in the OpenMP standard. We experimentally show that, using our DAG-based approach, we are able to obtain much better performance for computing the forward and backward substitutions on multicore architectures compared to the state-of-the-art solvers PARDISO, PaStiX and HSL_MA87.
In Section 2, we discuss the solve phase for dense systems, since we will use similar kernels in our sparse solve phase. We then describe the sparse solve algorithm in Section 3 before considering how to implement this in parallel in Section 4. We present our experimental results in Section 5 where we illustrate the scalability both with respect to the number of cores and to the number of right-hand sides (nrhs). We also compare our code with other state-of-the-art codes. Finally, we present some conclusions in Section 6.
2. DAG-based dense forward and backward substitutions
In this section, we discuss in detail the forward and backward substitutions for the case of dense matrices. For the sake of clarity and without loss of generality, we do not include the permutation matrix in this section. When performing these operations, we first partition the lower triangular dense factor
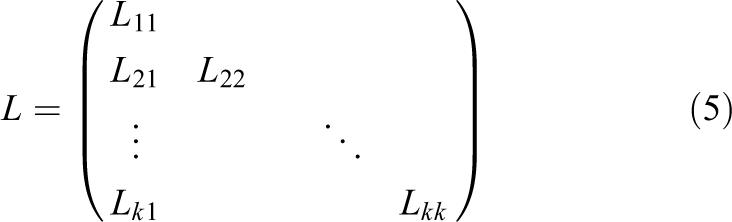
where
We first discuss the forward substitution in Section 2.1 before considering the backward substitution in Section 2.2.
2.1. Forward substitution
Consider first the forward substitution in equation (3) that we present in Algorithm 1.
forwardSolve (L, b, nb)


Algorithm 1 shows that the forward substitution requires two computational kernels. The first kernel at line 3 corresponds to the classical triangular solve, that is referred to hereafter as the solve kernel, denoted by dtrsv in the BLAS (Blackford et al., 2002). We note that the solve kernel is different from the above-mentioned solve phase and is indeed just part of this phase. The second kernel at line 5 is the update of the right-hand side by performing a matrix–vector product, which is referred to hereafter as the update kernel, dgemv in BLAS parlance.
From Algorithm 1, we note that the update follows the solution of part of the right-hand side and triggers the solution of another part of b. That is, there is a dependency between the update and the solve. We can generate a DAG to show the dependencies in Algorithm 1. To illustrate this, we consider the case
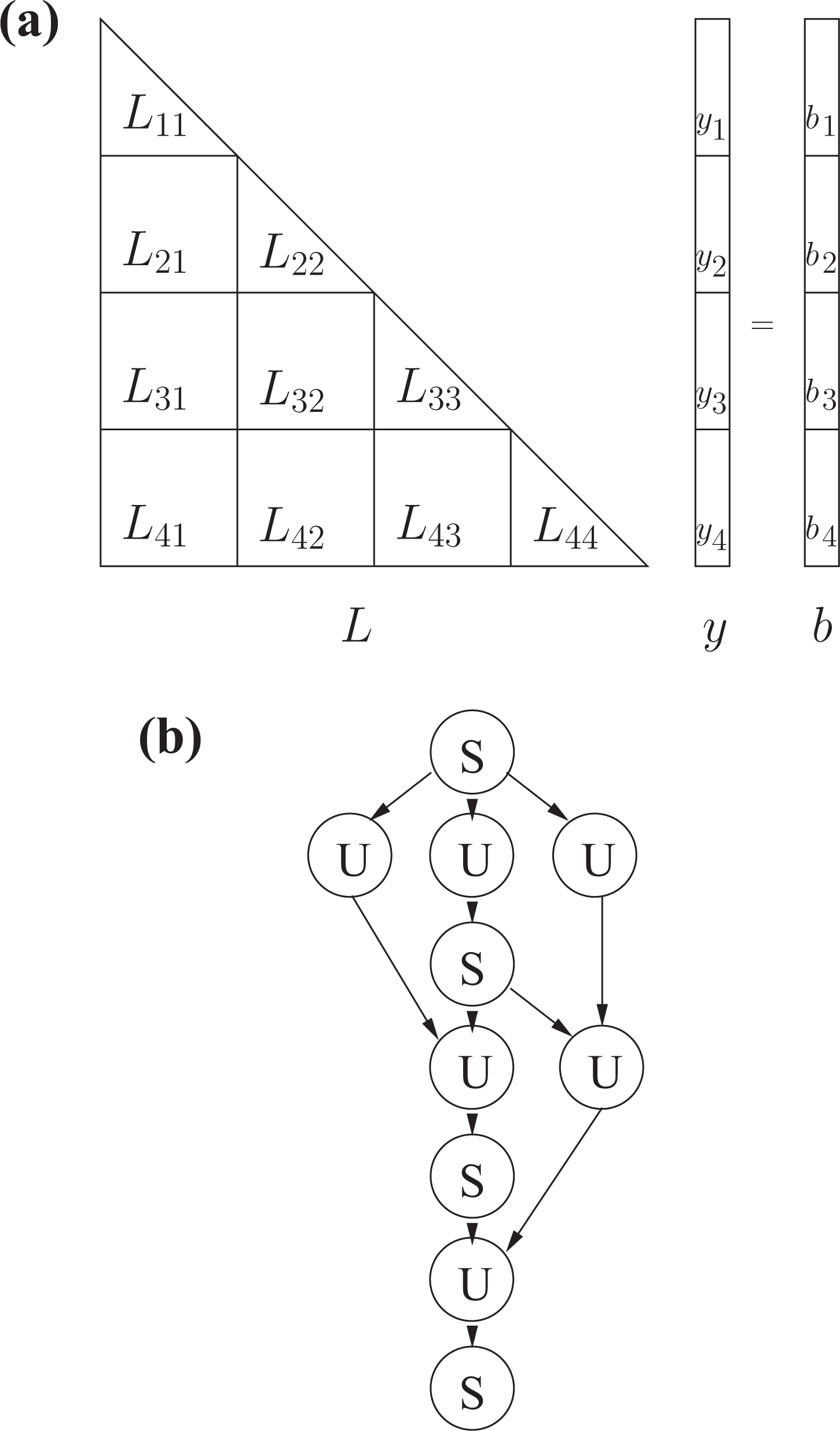
DAG associated with the forward solve on a partitioned L, as presented in Algorithm 1, with
The DAG starts by solving the equation
2.2. Backward substitution
Once the forward substitution has returned the vector y, the solve phase performs a backward substitution to solve equation (4). In this equation, we use the transpose of L to compute the solution vector x. However, this substitution does not really differ from the previous one, only the loop order is changed, as shown in Algorithm 2. Similar to the forward substitution, this algorithm requires two computational kernels, the solve kernel and the update kernel, which give the same DAG as shown in Figure 1(b).
backwardSolve (L, y, nb)


3. DAG-based solve in sparse case
In this section, we extend the algorithms presented in Section 2 to the sparse case. We now consider A as a sparse matrix of dimension n × n. The first step for solving equation (1) in SpLLT is the analysis of the pattern of the matrix A in order to reduce the fill-in in L during the factorization. This approach to solving sparse systems is well–documented, and we refer the reader to Duff et al. (2017) for the details. This step can use an ordering algorithm such as AMD (Amestoy et al., 1996) or Metis (Karypis and Kumar, 1998). The analysis then generates a tree representation for the factorization process. We first present the internal representation of the L factor in SpLLT and then discuss the design and implementation of the forward and backward substitutions.
3.1. Internal representation of the L factor
At the root node of the tree, that part of the L factor is held as a dense lower triangular matrix, and we will partition it as in equation (5). For the other tree nodes, the L factor is stored as a dense trapezoidal matrix,

In the parlance of tree-based factorizations, the block
We illustrate this in Figure 2, where the factor L consists of three nodes. The parts of the DAG associated with the leaves of the tree are very similar to the DAG shown in Figure 1. We label the blocks from the leaves to the root. If there are rows in common between blocks
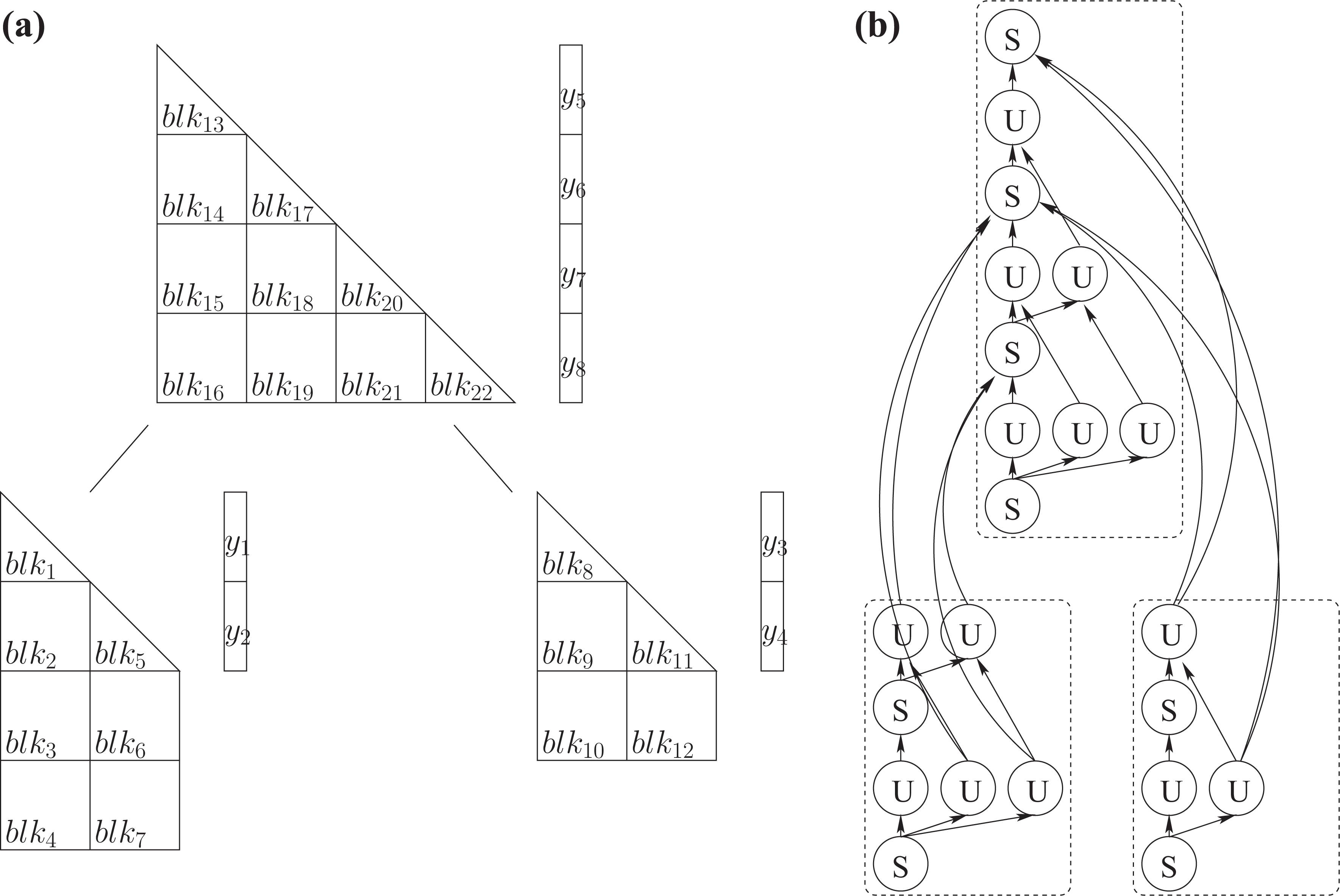
Tree representation of the sparse triangular factor L and its associated DAG for the forward solve. The matrix corresponding to each node is partitioned into blocks of size nb, as in equation (5). The nodes labelled S correspond to a call to the solve kernel (line 3), and the nodes labelled U correspond to a call to the update kernel (line 5). (a) Partitioned L matrix and (b) associated DAG. DAG: directed acyclic graph.
For efficient implementation of the forward substitution, we must modify Algorithm 1 to take account of three elements. Firstly, the L factor is spread over the nodes of the tree. Secondly, the shape of the
3.2. Dense kernels and data movement
Our construction of the tree representation of the factor L is such that the rows of a node may not correspond to contiguous entries in b. However, the computational kernels do not handle indirect addressing. This leads to data movement between the global vector and a local vector so that the data are contiguous in the local vector. Thus, a local vector is associated with each node of the tree and is split into two parts: the part associated with
3.2.1. Forward solve and forward update kernels
We illustrate the two parts of
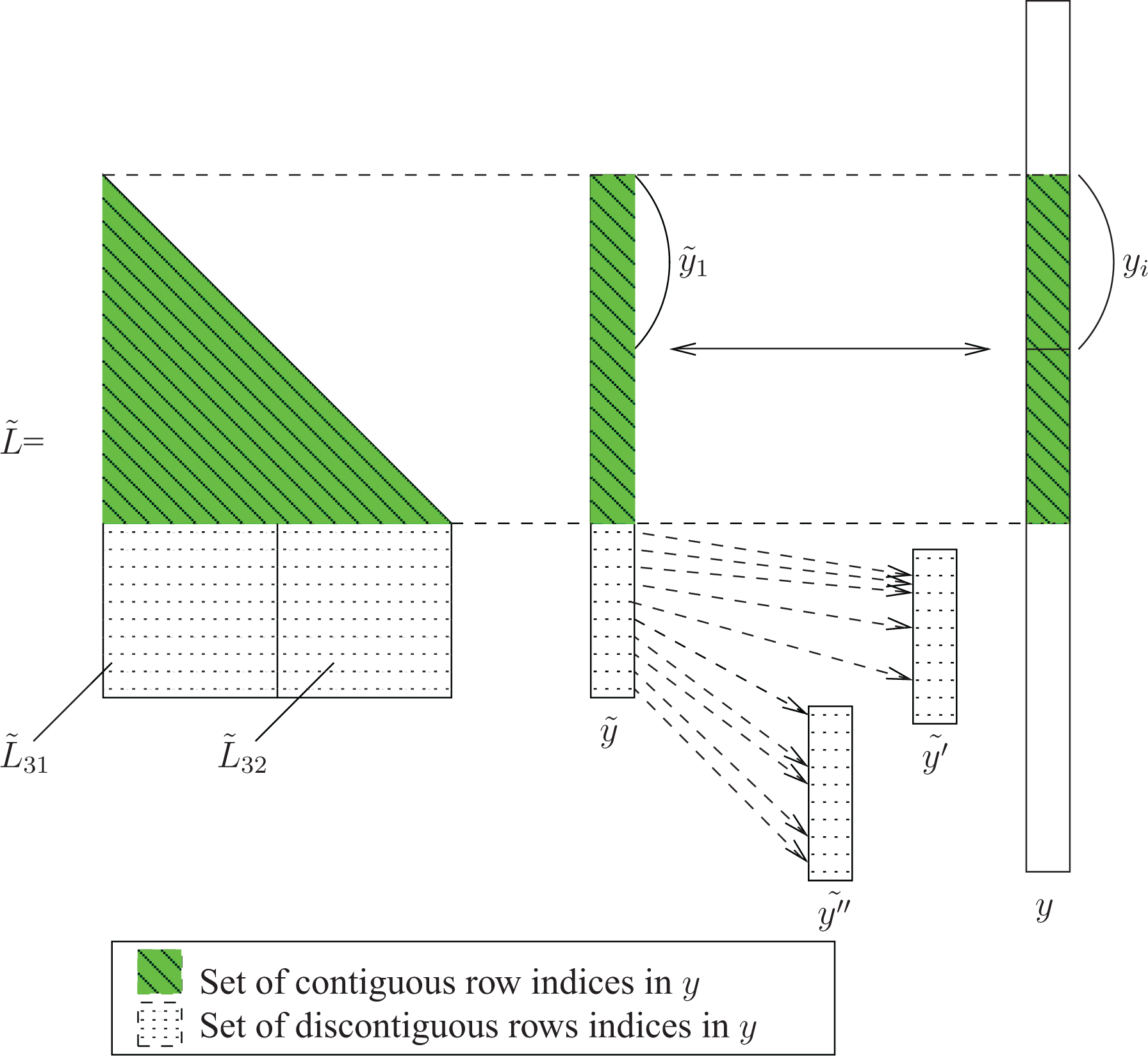
Data movement required by the computation of
3.2.2. Backward solve and backward update kernels
The backward substitution shares the same data locality issues as for the forward substitution. Consider the same node as in Figure 3 with its associated dense lower trapezoidal matrix
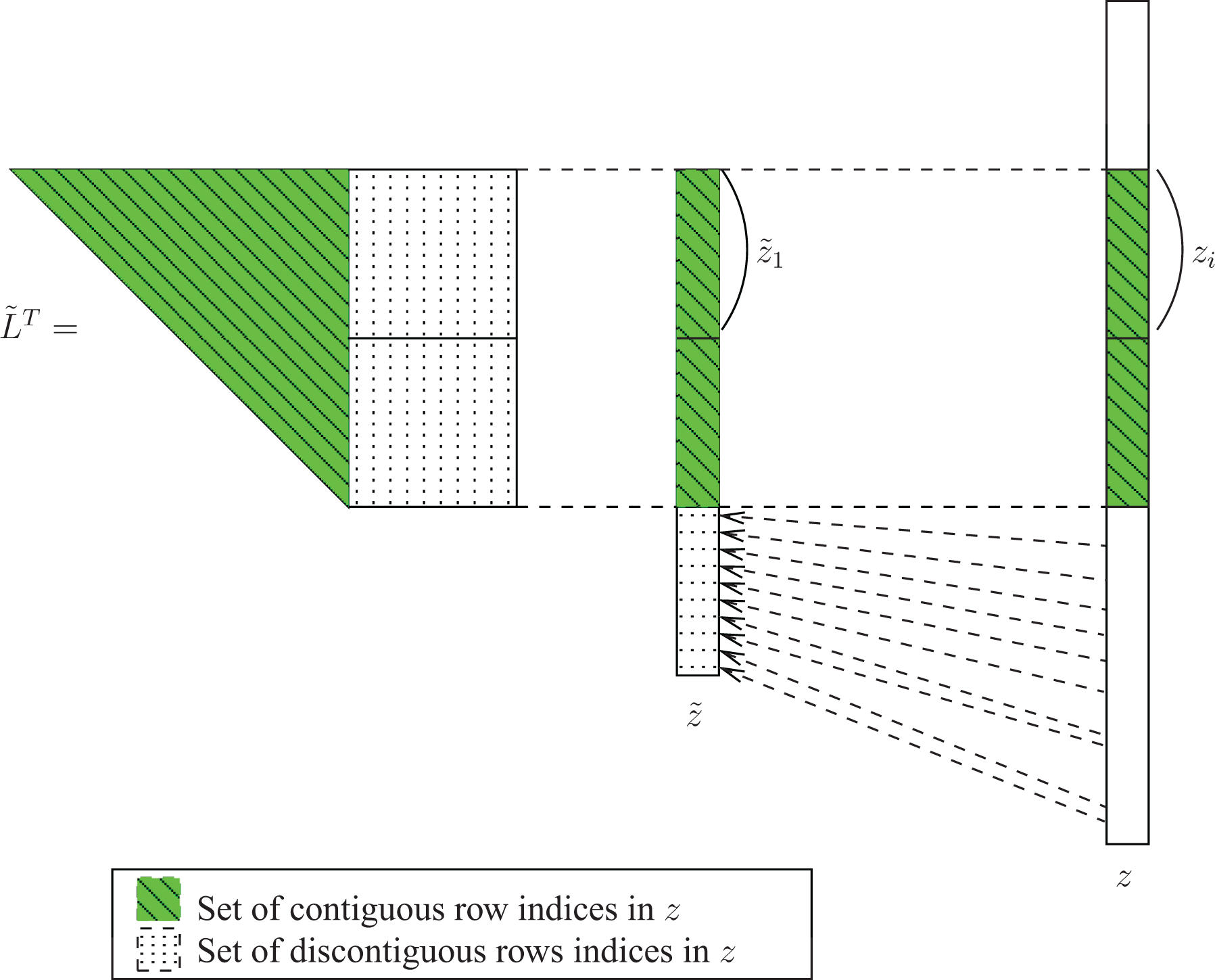
Data movement required by the computation of
3.3. Sequential sparse forward solve algorithm
Moving from the dense forward solve in Algorithm 1 to the sparse case requires several changes. Firstly, as shown in Figure 2, the L factor is now a tree, where the nodes are associated with trapezoidal matrices, and has internode dependencies. Secondly, as shown in Figures 3 and 4, processing
forwardSolve (L, b, nb)


The backward substitution algorithm is very similar but, in this case, we use the L factor starting with the root node and working down the tree to the leaf nodes.
4. Parallel implementation of the solve phase
As mentioned in Section 1, the parallel implementation of our task-based algorithms, introduced Section 3, is achieved using a runtime system which is responsible for executing the DAG in parallel on the target architecture. This involves enforcing data dependencies to ensure the correctness of the execution and managing the task scheduling for efficiently exploiting the resources. This design strategy has the advantage of producing a code that is portable and easy to maintain.
For our implementation, we decide to rely on an STF model for its greater usability than the PTG model in the context of complicated algorithms such as sparse forward and backward substitutions. The difficulties for exploiting a PTG model compared to the STF model were exposed in previous work for the parallelization of the factorization phase in SpLLT (Duff and Lopez, 2018). The simplicity of the STF model lies in the fact that the parallel code is very similar to the sequential one. In this model, the tasks are submitted to the runtime system following the sequential algorithm and for each task, the manipulated data must be associated with a data access such as Read (R), Write (W) and Read–Write (RW) depending on the operations performed on the data. Using the task submission order and data access information, the runtime system is capable of building the DAG such that the sequential consistency is guaranteed during the parallel execution. Finally, we choose to use the OpenMP standard for our implementation, because we observed in previous work that it comes with a slightly lower overhead for the task management than a runtime system with many extra features such as StarPU (Duff et al., 2018).
In the following, we first show how the data dependency is determined using the representation of the factor L, and then, we describe the task management with OpenMP.
4.1. Data dependencies of a task
From the DAG as presented in Figure 2(b), we associate a task with a computational kernel that takes as input a block within a node of the tree and the related part of the input and output vector. The sparse aspect requires an additional task that handles the indirect addressing. This task forms the local vector by adding the contributions of the children. The submission of the tasks related to the forward substitution is presented in Listing 1. The computational operations within a node in Algorithm 3 are now considered as tasks that are submitted to the runtime system. We provide in addition the access mode to the data in each task to enable the runtime system to detect the dependencies between tasks.
Task-based implementation of Algorithm 3.


The data accessed local to a node, in lines 9, 11, 16 and 20, is similar to the dense case in Algorithm 1 and is independent of the pattern of the matrix. However, the sparse aspect requires gathering entries from a set of local vectors that share rows with the local vector,
We show how
getForwardDependencies (L, node,


The submission of the tasks for the backward substitution is similar to the forward substitution, except for the computations of the data dependencies, where the role of child nodes is replaced by the ancestor nodes.
4.2. Management of the tasks
Our implementation uses the runtime system OpenMP, Release 4.5. This release offers a runtime system that schedules the execution of tasks with dependencies. There are several ways to describe the dependencies. One simple way is to provide the address of the data that are being accessed through a read, write or read/write mode as in Listing 1. Thus, the dependencies have to be known at compilation time by OpenMP. However, the set dep returned by Algorithm 4 has a variable length and its length cannot be predicted prior to the execution of the code.
To handle a variable length of dependencies in OpenMP, we use a k-ary tree combined with synchronization tasks to control the scheduling of the task. A synchronization task is a task submitted to the runtime system that does nothing, like a no-op instruction, except to release a dependency for further use. The purpose of using a k-ary tree is to reduce the number of tasks from
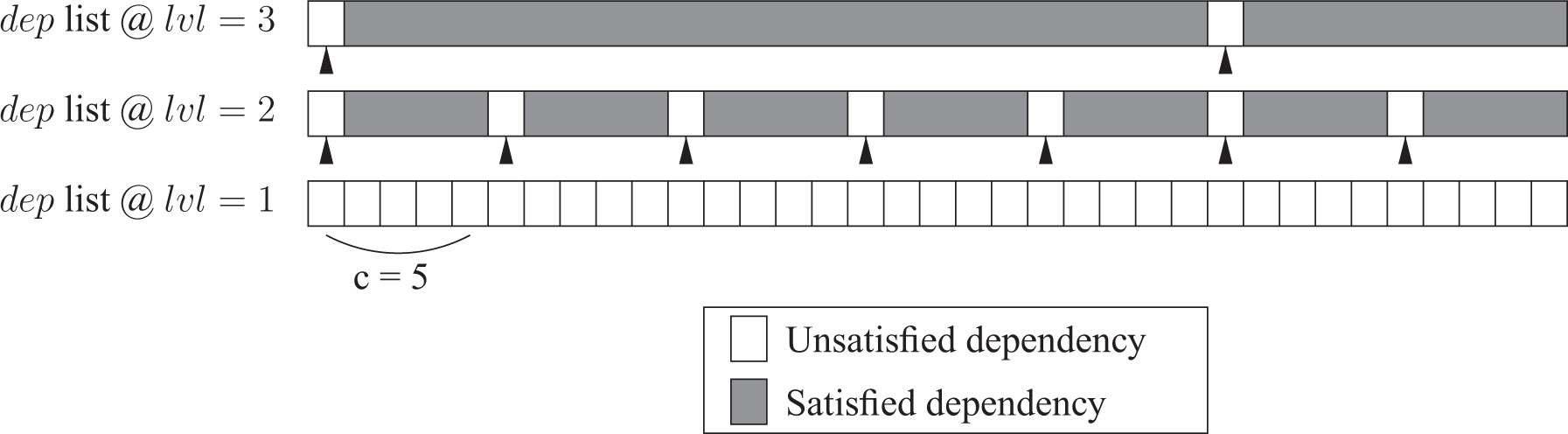
Content of the set dep at each level of the k-ary tree, with a chunk size
Along with this k-ary tree, we use a case statement over the number of unsatisfied dependencies in dep, where each case corresponds to the submission of a (synchronization) task having i dependencies (
4.3. The pruning strategy
It is worth noting that the matrix sizes in the tree can vary significantly between the nodes of the tree. More specifically, the matrices are generally small near the leaf nodes and get bigger as we traverse the tree toward the root node. As a consequence, there is plenty of inter-level parallelism at the bottom of the tree with limited opportunity for intra-node parallelism. On the other hand, there is much less inter-level parallelism near the top of the tree, where there is much more intra-node parallelism. In our task-based algorithm, this would result in the creation of many small granularity tasks at the bottom of the tree which can be costly for the runtime system to manage compared to the actual workload being performed in these tasks. In addition, inter-level parallelism at the bottom of the tree can greatly exceed the amount of available resources. Therefore, a large number of tasks is generated at this level, increasing the cost for the task scheduling without bringing much benefit in terms of performance. In order to alleviate these problems, we employ a tree pruning strategy, largely inspired by the one used in the qr_mumps solver and described in the work of Buttari (2012). This allows us to dramatically reduce the number of small granularity tasks in the DAG. This pruning strategy aims at identifying a set of subtrees which are processed as a single task meaning that each subtree is processed in serial mode.
In more detail, the pruning algorithm performs a top-down traversal of the tree and selects a sufficiently large set of independent nodes in the tree so that the computational weight of the subtrees rooted at each node in this set is balanced. In practice, we force the number of subtrees to be equal to at least twice the number of resources, because we want to generate enough parallelism to compensate for potential load imbalance during the execution of the subtree within the whole DAG. One potential source of imbalance is that the metric used for estimating the computational weight for each subtree, the number of floating-point operations, might not accurately reflect the execution time.
This pruning strategy allows us to dramatically reduce the number of tasks submitted to the runtime system as well as the number of dependencies in the DAG. Moreover, processing the subtrees as a single task improves the exploitation of data-locality which increases the kernel efficiency.
5. Experimental results
In order to assess the performance of the solve phase of our SpLLT code, we ran tests on a set of 37 symmetric definite positive matrices, presented in Table 1. These matrices come from the Suitesparse matrix collection Davis and Hu (2011) and are those used in the work of Duff et al. (2018) and Hogg et al. (2010). They correspond to a wide range of different applications including computational fluid dynamics (CFD), circuit simulation, finite element modelling (FEM) and gas reservoir modelling. The dimensions of the matrices range from
Test matrices and their characteristics without node amalgamation.a
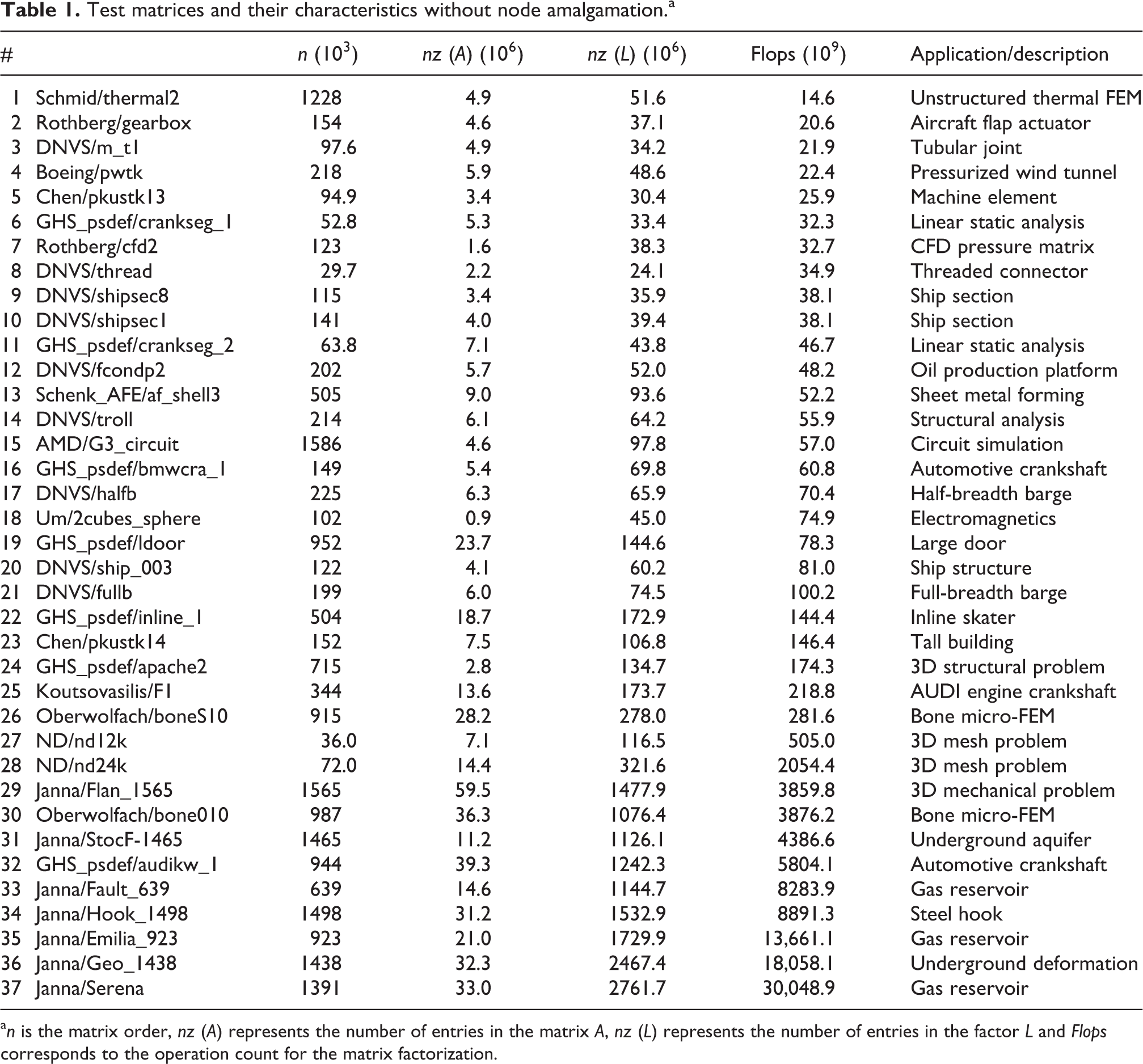
a n is the matrix order, nz (A) represents the number of entries in the matrix A, nz (L) represents the number of entries in the factor L and Flops corresponds to the operation count for the matrix factorization.
We perform the tests on a multicore machine which has two Intel Xeon E5-2695, v3 CPUs, that is 2 NUMA nodes composed of 14 cores each, with a total 128 GB of memory. Each core has a theoretical peak of 36.8 GFlop/s for a frequency of 2.3 GHz, so the peak of the multicore node is 1.03 TFlop/s in double precision. The code is compiled with GNU 6.2 and MKL 17.0.2 and linked to Metis 5.1.0 and SPRAL (https://github.com/ralna/spral/). In most cases, we display results on a representative subset of matrices. We have done preliminary tests to study the reproducibility of the execution times of the machine by solving equation (1) 10 times and increasing nworker. Figure 6 shows the range in the times for the solve phase on four of our test problems by horizontal bars. We note that this range can be noticeable when there are few workers, but this variability decreases markedly when nworker increases.
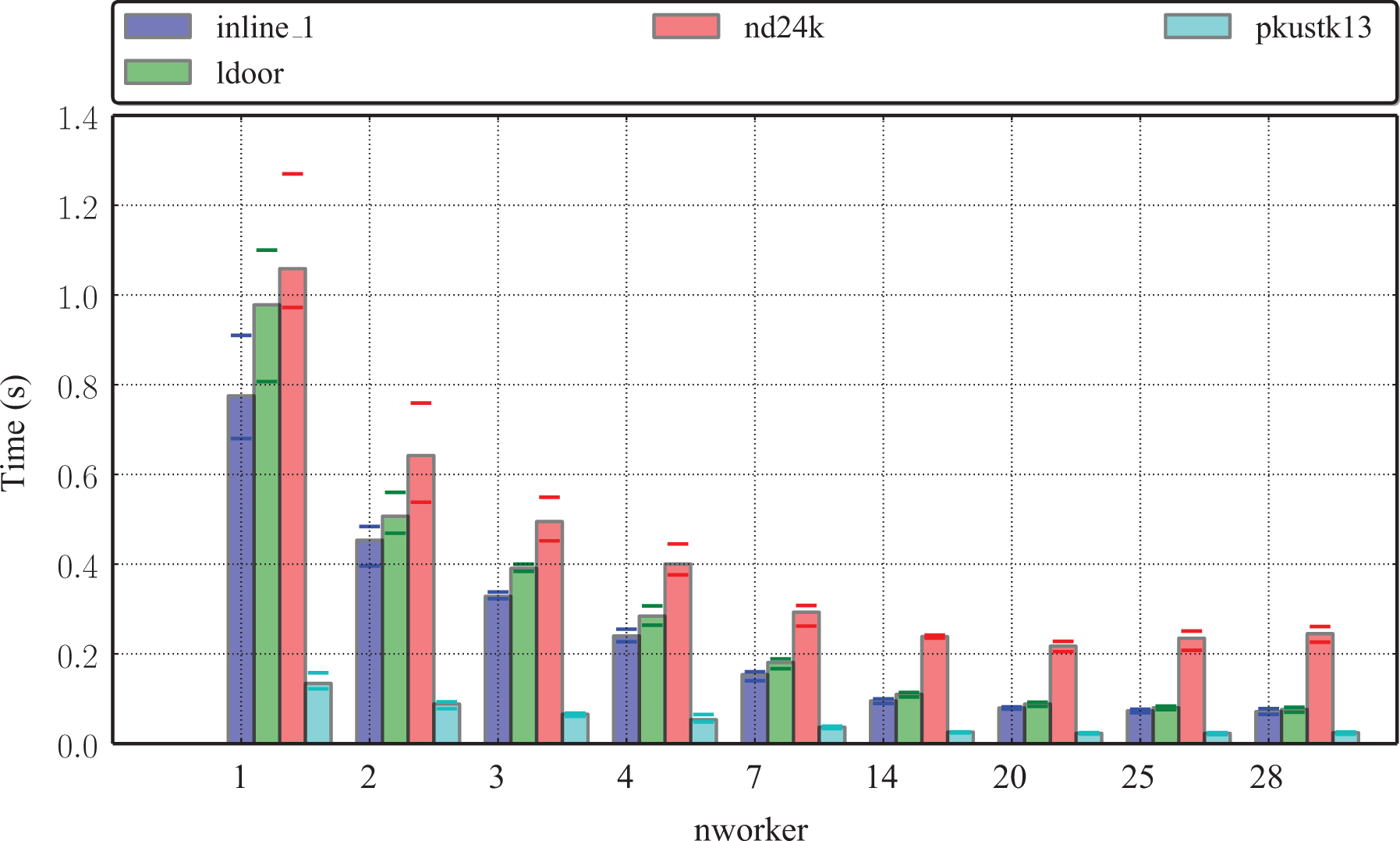
Reproducibility of execution times.
We study the impact of pruning in Section 5.1, of synchronization tasks in Section 5.2 and of block size in Section 5.3. In Sections 5.4 and 5.5, we then compare the solve phase of SpLLT with Intel MKL PARDISO 17.0.2 (Schenk and Gärtner, 2002) and PaStiX (Hénon et al., 2002) by increasing nrhs in Section 5.4 and nworker in Section 5.5.
5.1. Impact of pruning on the performance
In this section, we illustrate the impact of using the tree pruning algorithm discussed in Section 4.3 on the solve times. For this, we performed the solve on a subset of the matrices given in Table 1 using one right-hand side and for a number of workers ranging between 1 and 28. Note that for this experiment, we selected the matrices which perform a high number of floating-point operations during the factorization. Our results, given in Table 2, include the solve times, with and without pruning, as well as the number of subtrees selected by the pruning algorithm when using 1, 2, 4, 14 and 28 workers.
The solve time (s) and number of subtrees when pruning is either enabled or disabled.
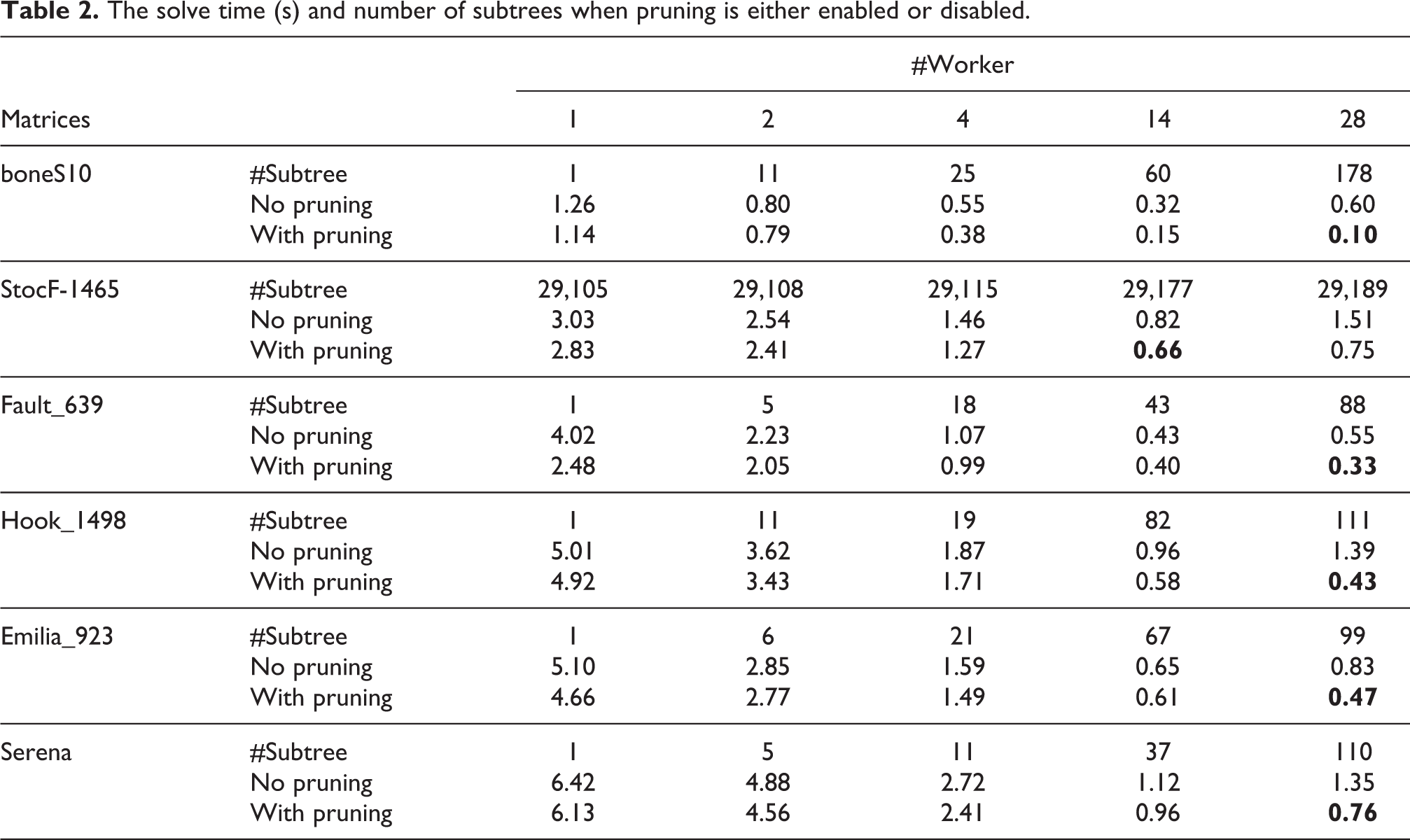
It should be noted that for all tested matrices, the best solve times are obtained when the tree pruning algorithm is enabled. Moreover, the impact of pruning is particularly high when nworker is large. For instance, enabling the tree pruning for boneS10 when using 2 workers is insignificant whereas the solve time is divided by a factor of 6 for this matrix when enabling tree pruning on 28 workers. Another notable effect of using tree pruning is that, although the solve times between 14 workers and 28 workers tend to increase without tree pruning, they keep decreasing if tree pruning is activated. This shows the benefits of using the pruning strategy to improve the scalability of our algorithm on a large number of resources.
As mentioned in Section 4.3, the tree pruning strategy improves the performance mainly for the following two reasons: firstly, it reduces the number of tasks in the DAG and more particularly small granularity tasks, and secondly, it increases kernel efficiency by improving the exploitation of data locality. This can be seen when looking at the data in the first column of Table 2. When using only one worker and disabling the pruning, all the tasks in the DAG are generated, submitted to the runtime system and processed by a single thread. On the other hand, when the pruning is enabled, the number of subtrees is equal to one which means that only one task, responsible for processing the whole tree, is generated. In this case, the cost for the task management is negligible and, as we can see in Table 2, the solve times are always reduced.
5.2. Impact of the number of synchronization tasks on the performance
As discussed in Section 4.2, tasks have a variable number of dependencies that we handle through a k-ary tree. In this section, we give details of the effect of the synchronization tasks on the solve time. We consider the case of 1 right-hand side and 64 right-hand sides. Table 3 presents the results on the same subset of matrices as in Table 2. We first focus on the case of one right-hand side where the pruning is disabled. We observe that the time to solve is the highest when c is equal to two. Moreover, the number of synchronization tasks is divided by at least a factor of 3 when increasing the chunk size from 2 to 3. After some point, the number of synchronization tasks is low enough that reducing it further does not noticeably improve the execution time. When pruning is used, we observe that the number of synchronization tasks is divided by at least a factor of 2 for a chunk size of 2. This means that the sensitivity of the times on the chunk size is much reduced when pruning is used. Likewise, when we solve for 64 right-hand sides, the extra work required means that the number of synchronization tasks has little impact on the time, with or without pruning. The arithmetic intensity in the kernels is much larger than the overhead of scheduling and executing synchronization tasks.
Time and number of synchronization tasks for our SpLLT solve with respect to the chunk size.a
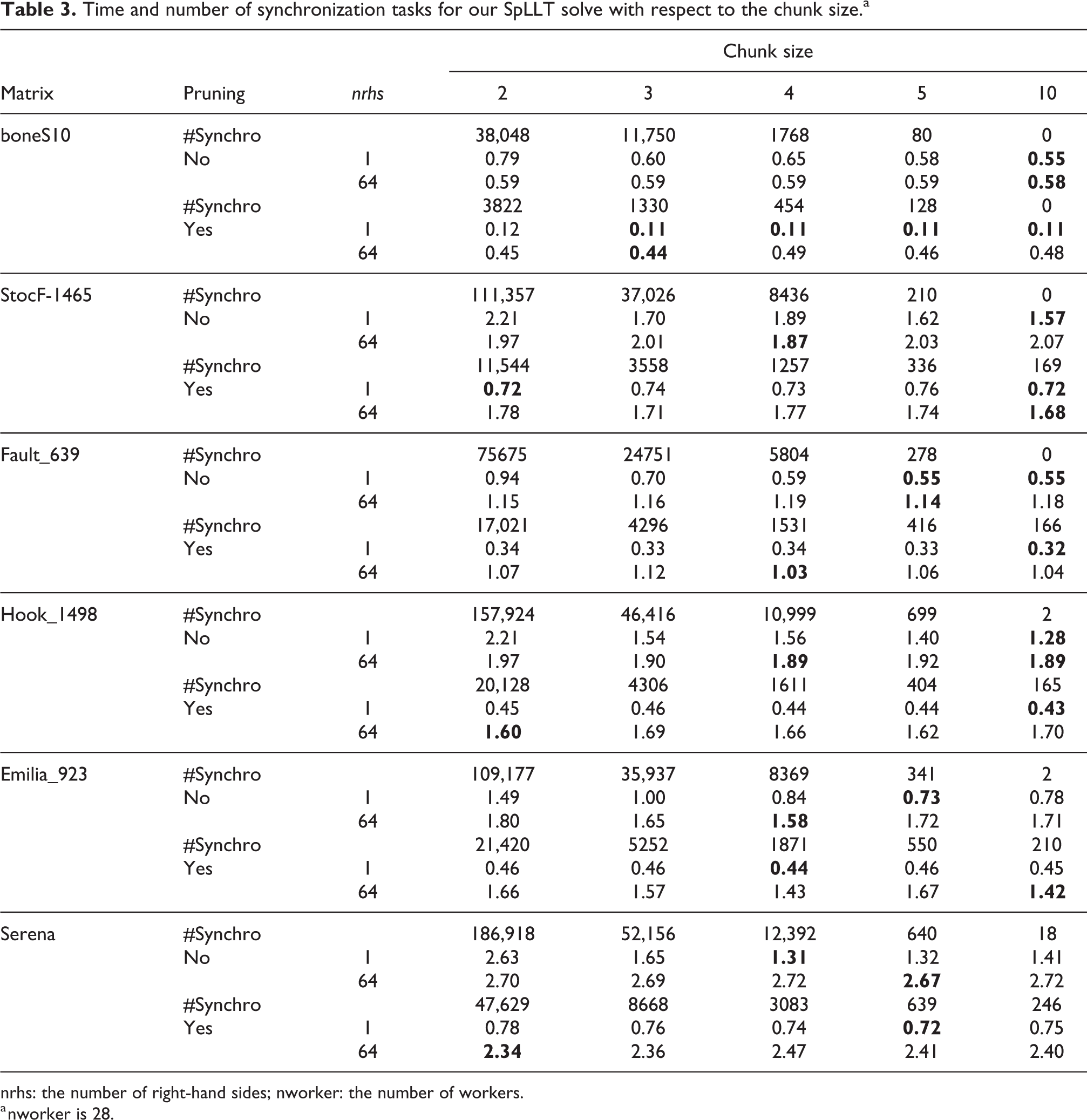
nrhs: the number of right-hand sides; nworker: the number of workers.
a nworker is 28.
However, it is possible that for larger workloads than our test matrices, a small chunk size would penalize the performance because of a high number of synchronization tasks. For this reason, we use a chunk size of 10 in our solver that we consider to be large enough to avoid noticeable impact on the results on the tested matrices and potentially on bigger problems as well.
5.3. Impact of the block size on the performance
In this section, we study the impact of the block size on the time to solve the system and show our results in Table 4. We consider matrices that require a large number of flops during the factorization so that the block size should be greater than 256. We set nworker to 28 and nrhs to 128. For all these matrices, the optimal block size for the solve phase is lower than the optimal block size for the factorization. This leads us to conclude that we should use a different block size, depending on nrhs and the application. For example, in a code like preconditioned CG, the overall performance may depend on the time spent in applying the preconditioner. In that case, an efficient factorization is not as important as an optimal solve. We use a default block size of 256 in the following experiments to obtain a fair comparison with other solvers.
The effect of different block sizes on both the factorize and solve phases.a
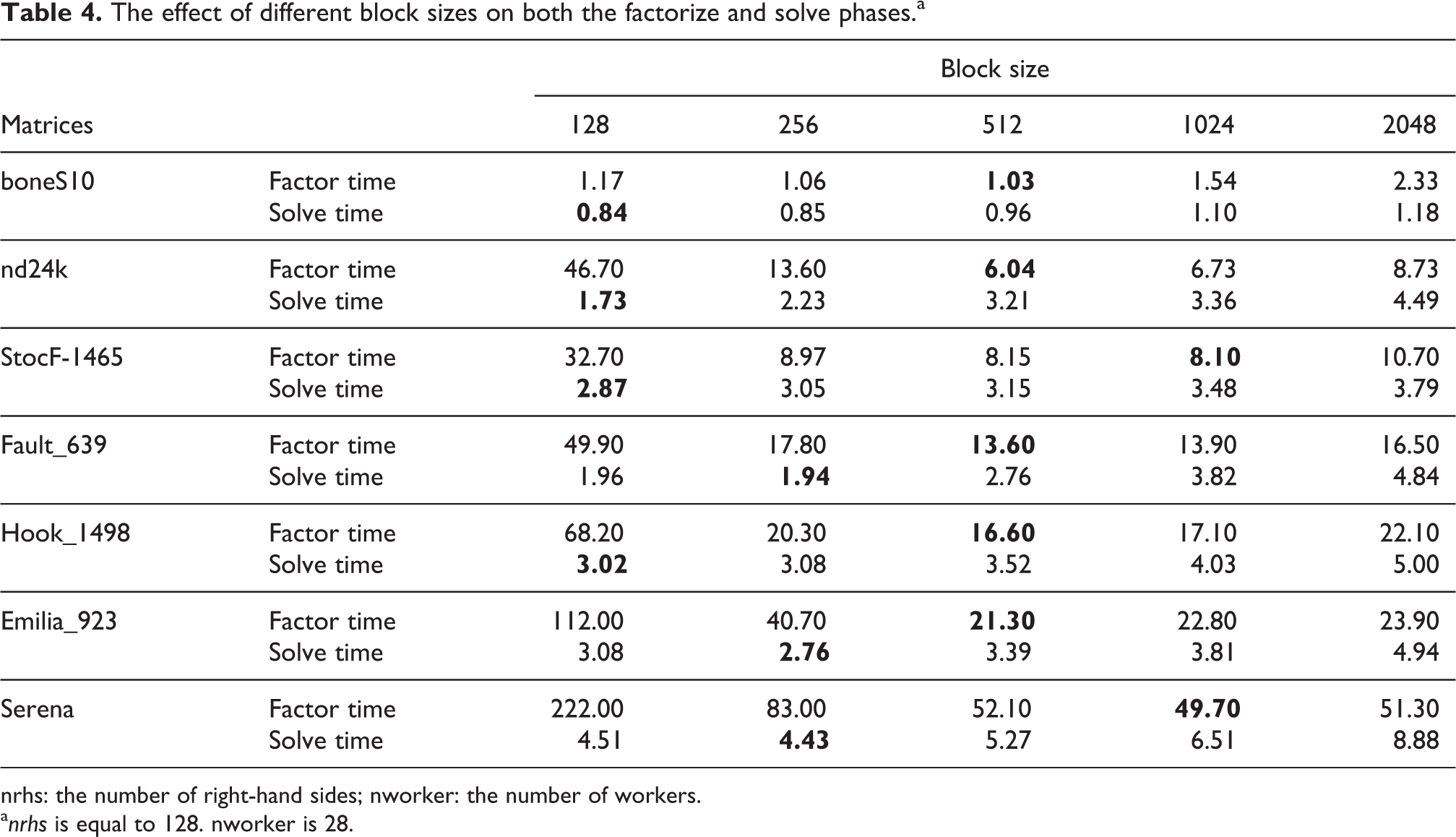
nrhs: the number of right-hand sides; nworker: the number of workers.
a nrhs is equal to 128. nworker is 28.
5.4. Strong scaling on nrhs
In this section, we focus on the effect of nrhs on the time to solve the system. We fix nworker to 28 and the block size to 256, and we vary nrhs from 1 to 128 in powers of 2.
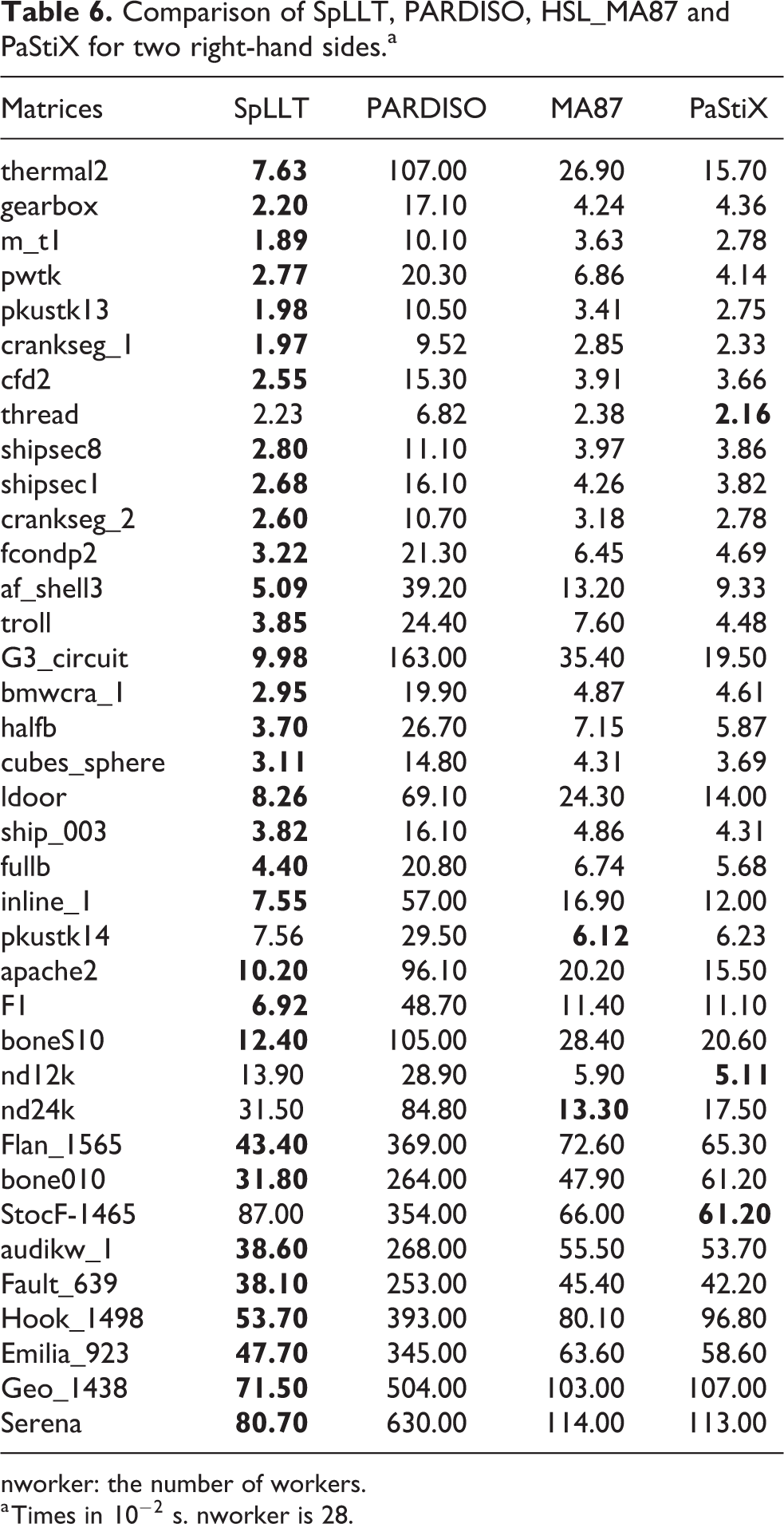
We first compare, in Tables 5 and 6, SpLLT with PARDISO, PaStiX and HSL_MA87 when solving for one or two right-hand sides. These results show that PARDISO is the slowest for all the matrices in Table 1. SpLLT is the fastest to solve the system, up to 8 times faster than PARDISO for one right-hand side and up to over a factor of 10 on two right-hand sides. There are only five problems in Table 1 for which SpLLT is not the fastest of all four codes for both one right-hand side and two right-hand sides. In two cases, the difference from the fastest code is marginal. The only matrices for which SpLLT is significantly slower are the two matrices nd12k and nd24k and the matrix StocF-1465. In the case of the first two, the assembly tree has long chains that are not combined by pruning so the runtime overhead for many small tasks causes the poor performance. If we force more node amalgamation in the analyse phase, the number of long chains decreases significantly, pruning is more effective, and we are much more competitive. The StocF-1465 matrix is very reducible with many 1 × 1 blocks. Again our pruning has little effect and we are penalized by the number of small tasks. We recommend that reducibility is respected in the solution process, and elimination techniques are only used on irreducible blocks. We see that on one of the matrices, Emilia_923, PaStiX is faster than SpLLT for one right-hand side (43.70 × 10−2 s vs. 44.70 × 10−2 s) and SpLLT is faster than PaStiX for two right-hand sides (47.70 × 10−2 s vs. 58.6 × 10−2 s). The solve time for SpLLT on two systems is always lower than solving one system twice.
Comparison of SpLLT, PARDISO, HSL_MA87 and PaStiX for one right-hand side.a
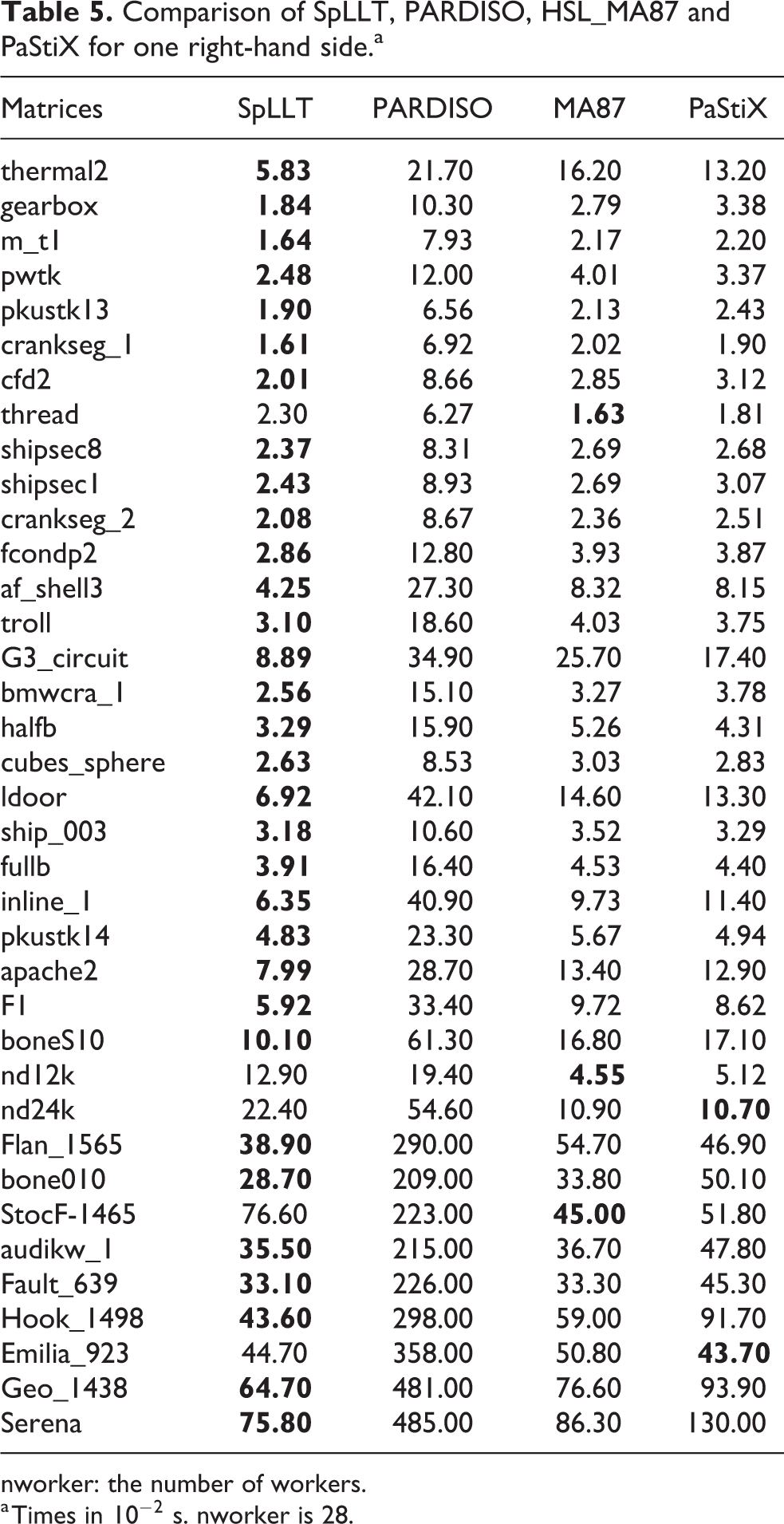
nworker: the number of workers.
a Times in
Comparison of SpLLT, PARDISO, HSL_MA87 and PaStiX for two right-hand sides.a
nworker: the number of workers.
a Times in
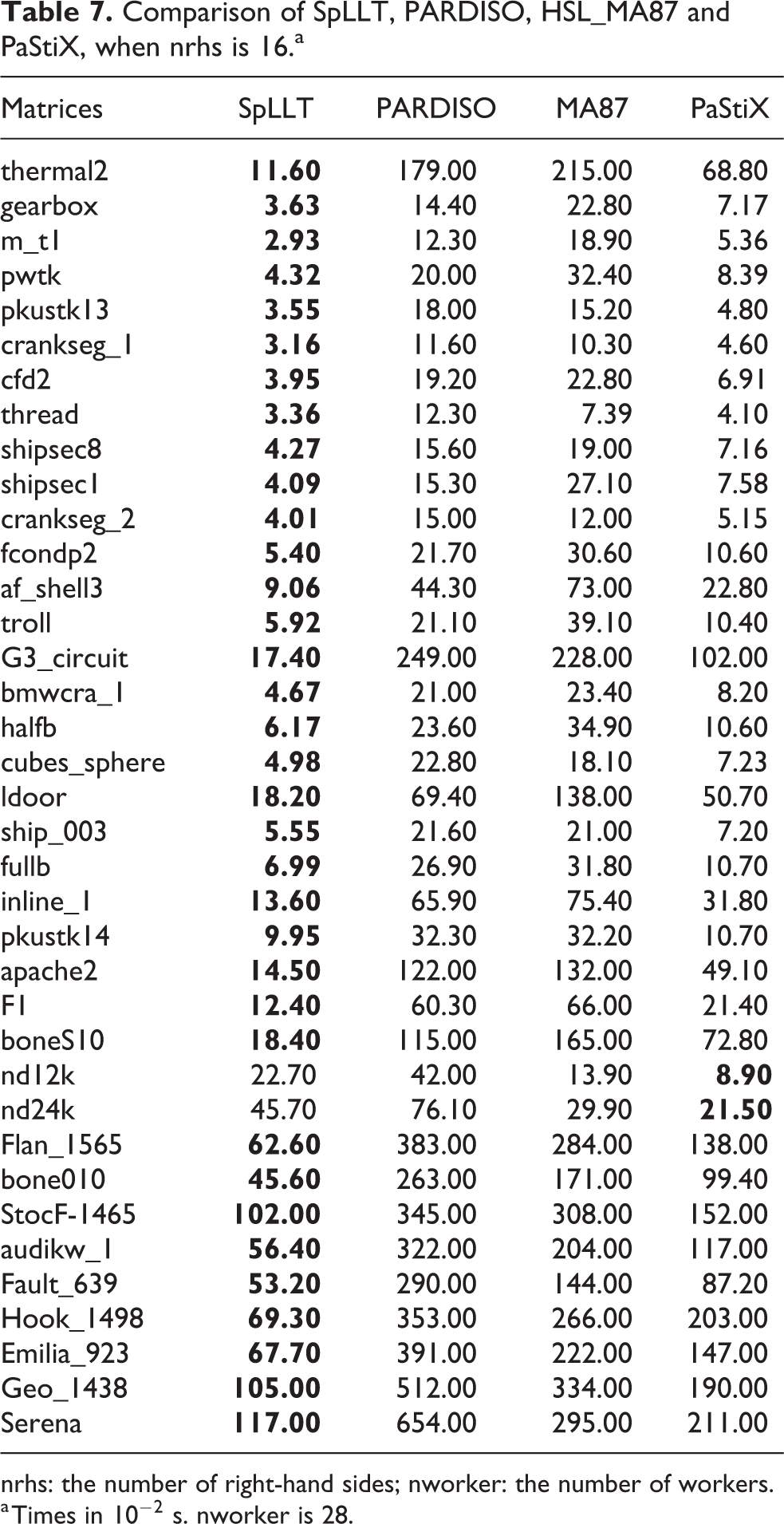
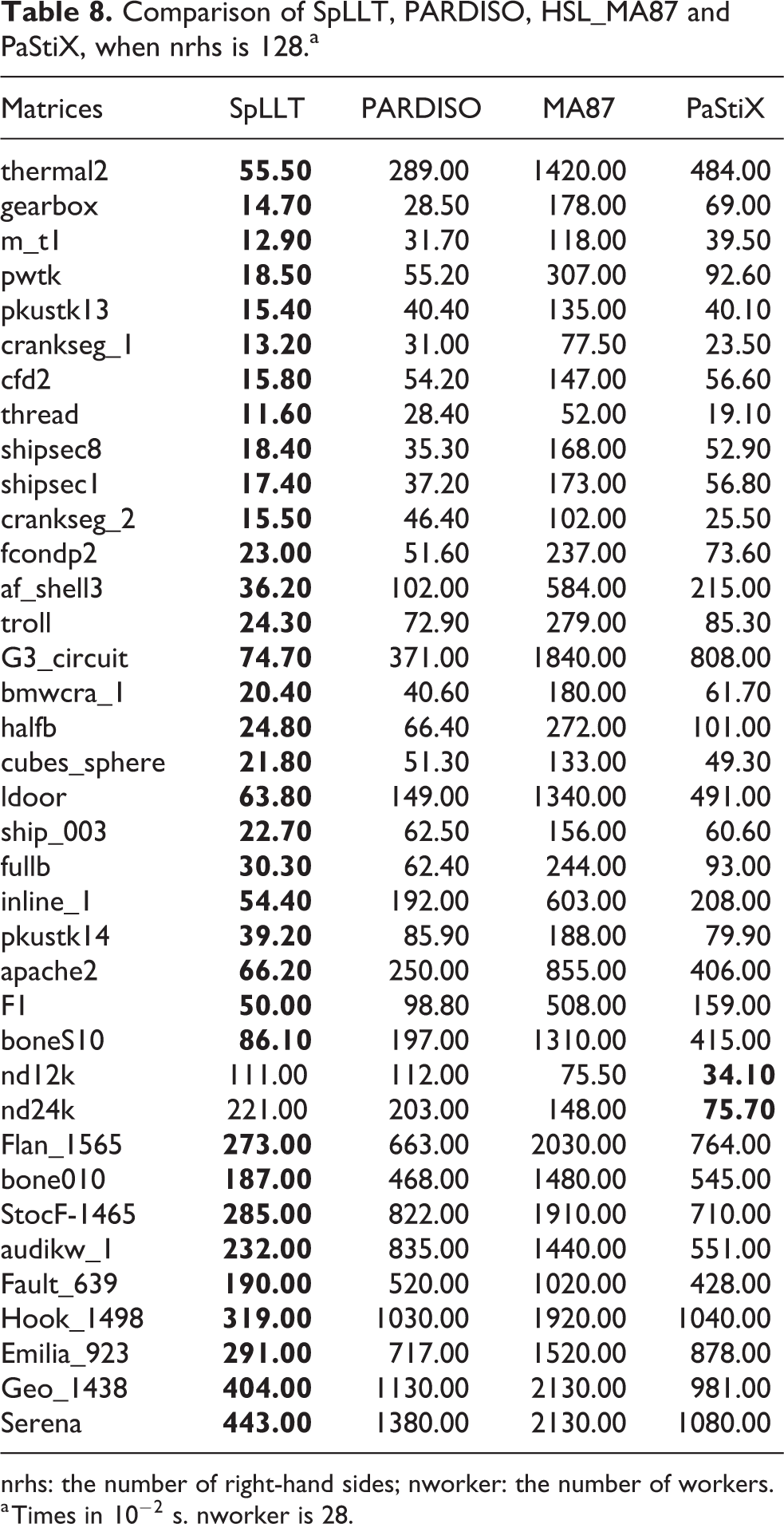
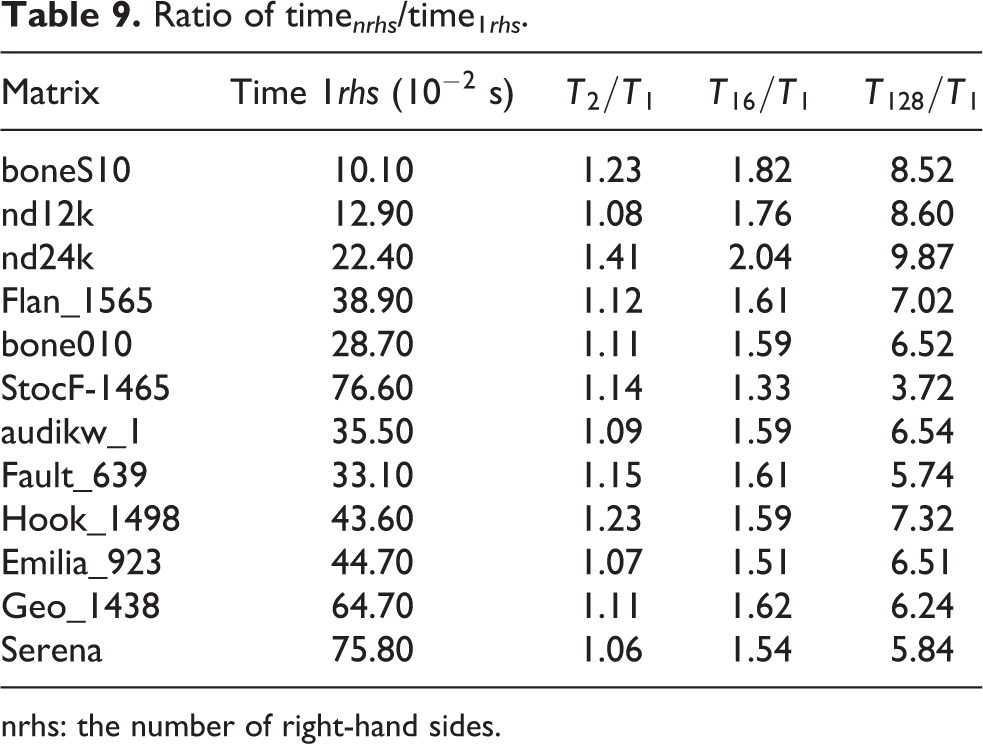
We investigate this for more right-hand sides. In Tables 7 and 8, we give the time for SpLLT, PARDISO, PaStiX and HSL_MA87, for all matrices of Table 1 when solving for 16 and 128 right-hand sides. When nrhs increases, PaStiX and HSL_MA87 become less competitive than SpLLT. We show the ratio of the time for solving several right-hand sides to the time to solve one right-hand side in Table 9. These results show that the power of level 3 BLAS means that there is often very little overhead for solving two right-hand sides over one and the extra cost when solving for 16 or 128 right-hand sides is remarkably low.
Comparison of SpLLT, PARDISO, HSL_MA87 and PaStiX, when nrhs is 16.a
nrhs: the number of right-hand sides; nworker: the number of workers.
a Times in
Comparison of SpLLT, PARDISO, HSL_MA87 and PaStiX, when nrhs is 128.a
nrhs: the number of right-hand sides; nworker: the number of workers.
a Times in
Ratio of time nrhs /time1rhs .
nrhs: the number of right-hand sides.
Since HSL_MA87 does not scale with nrhs, in the following, we compare the time to solve for SpLLT with PARDISO and PaStiX, and we display the ratio of times in Figure 7.
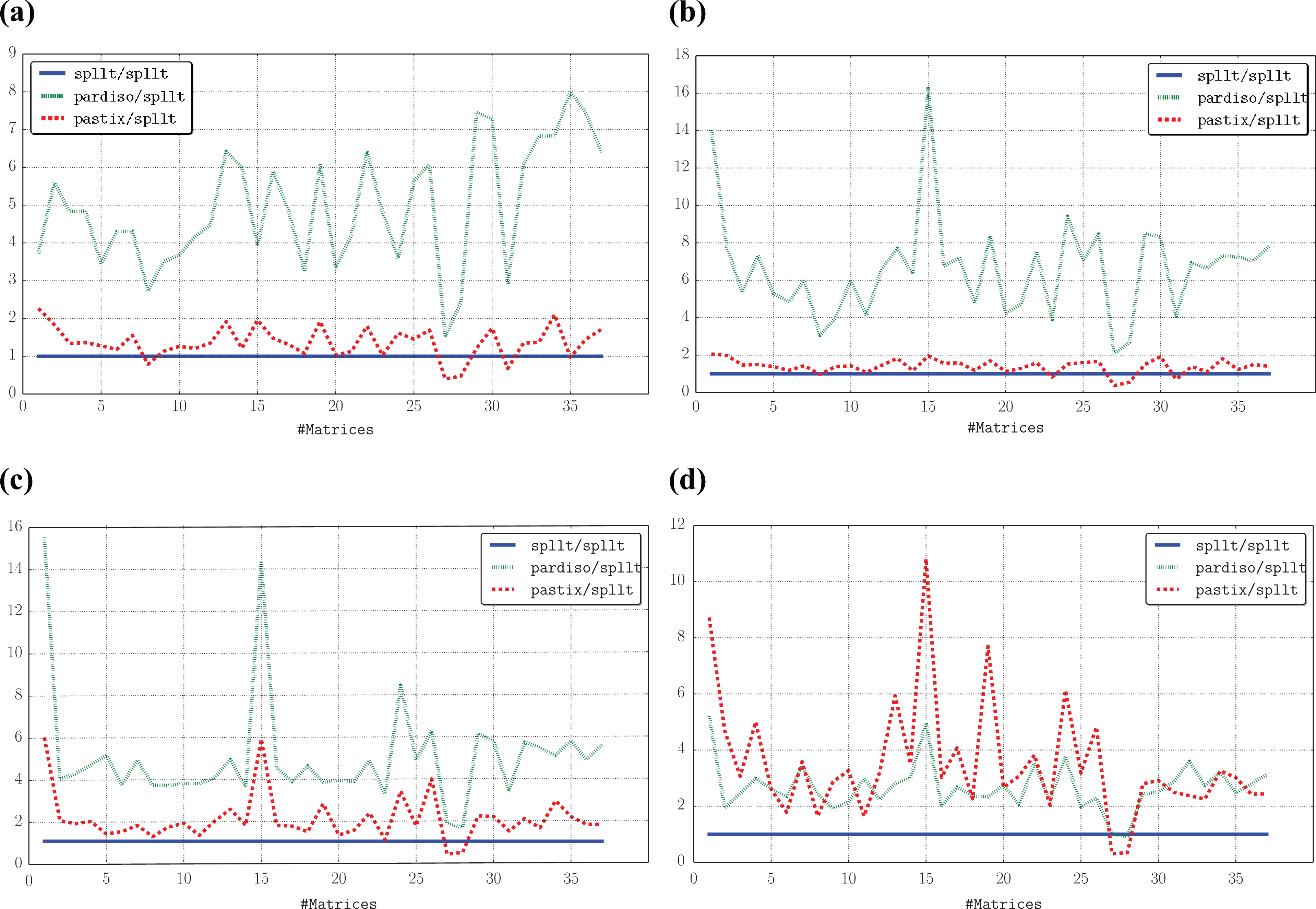
Comparison of the times to solve the system with multiple right-hand sides using PARDISO and PaStiX, relative to SpLLT. nworker is set to 28, and nrhs is equal to (a) 1, (b) 2, (c) 16 and (d) 128. nrhs: the number of right-hand sides; nworker: the number of workers.
Figure 8 presents two representative problems that illustrate the behaviour of each solver. For all nrhs, SpLLT is the fastest solver sometimes by a considerable amount. PaStiX scales much worse than SpLLT as nrhs increases. The scalability of PARDISO can vary considerably (see Serena). Since the source code for PARDISO is not distributed, we do not know why this is the case. We have similarly erratic scalability for several other matrices in our test set. In Figure 8(a), SpLLT is eight times faster than PARDISO for two right-hand sides, and these two curves increase almost similarly when nrhs increases. On the other hand, the time to solve using PaStiX is close to SpLLT for 2 right-hand sides but is 5 times slower on 128 right-hand sides. In general, SpLLT scales better than the other codes.
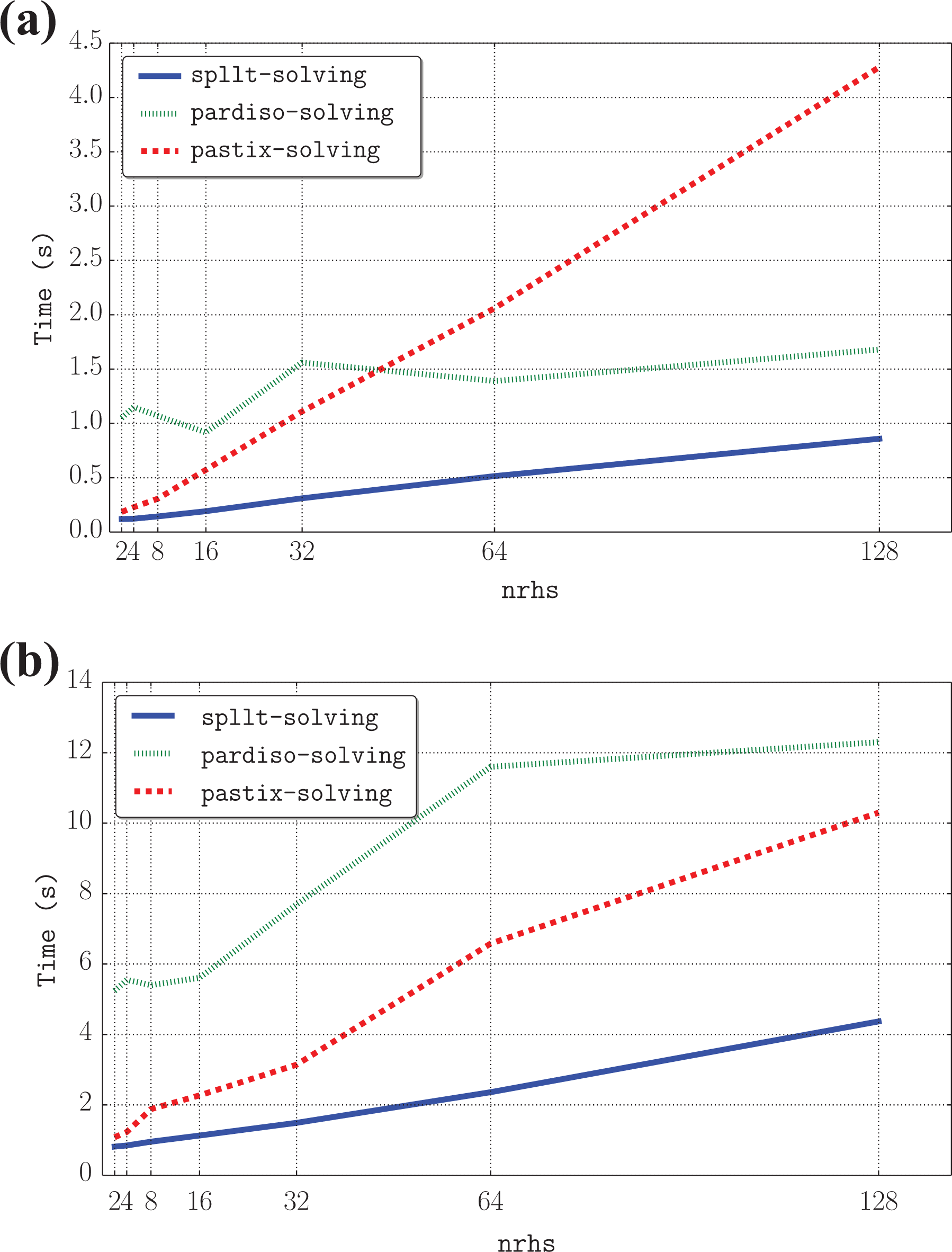
Comparison of the time to solve the system with multiple right-hand sides using SpLLT, PARDISO and PaStiX. nworker is set to 28, and nrhs increases from 2 to 128 in powers of 2. (a) boneS10 and (b) Serena. nrhs: the number of right-hand sides; nworker: the number of workers.
5.5. Strong scaling on nworker
In this section, we study the impact of nworker on the time to solve a system with 1 right-hand side and 64 right-hand sides. nworker increases from 1 to 28, and the block size is 256. We first consider one right-hand side and present some results in Figure 9. We use the same two matrices as in Figure 8. The experiments show that for a small number of workers, the time to solve using SpLLT is greater than both other solvers. When nworker increases, the solid curve that represents SpLLT becomes closer to the other curves. For 28 workers, SpLLT is the fastest solver.
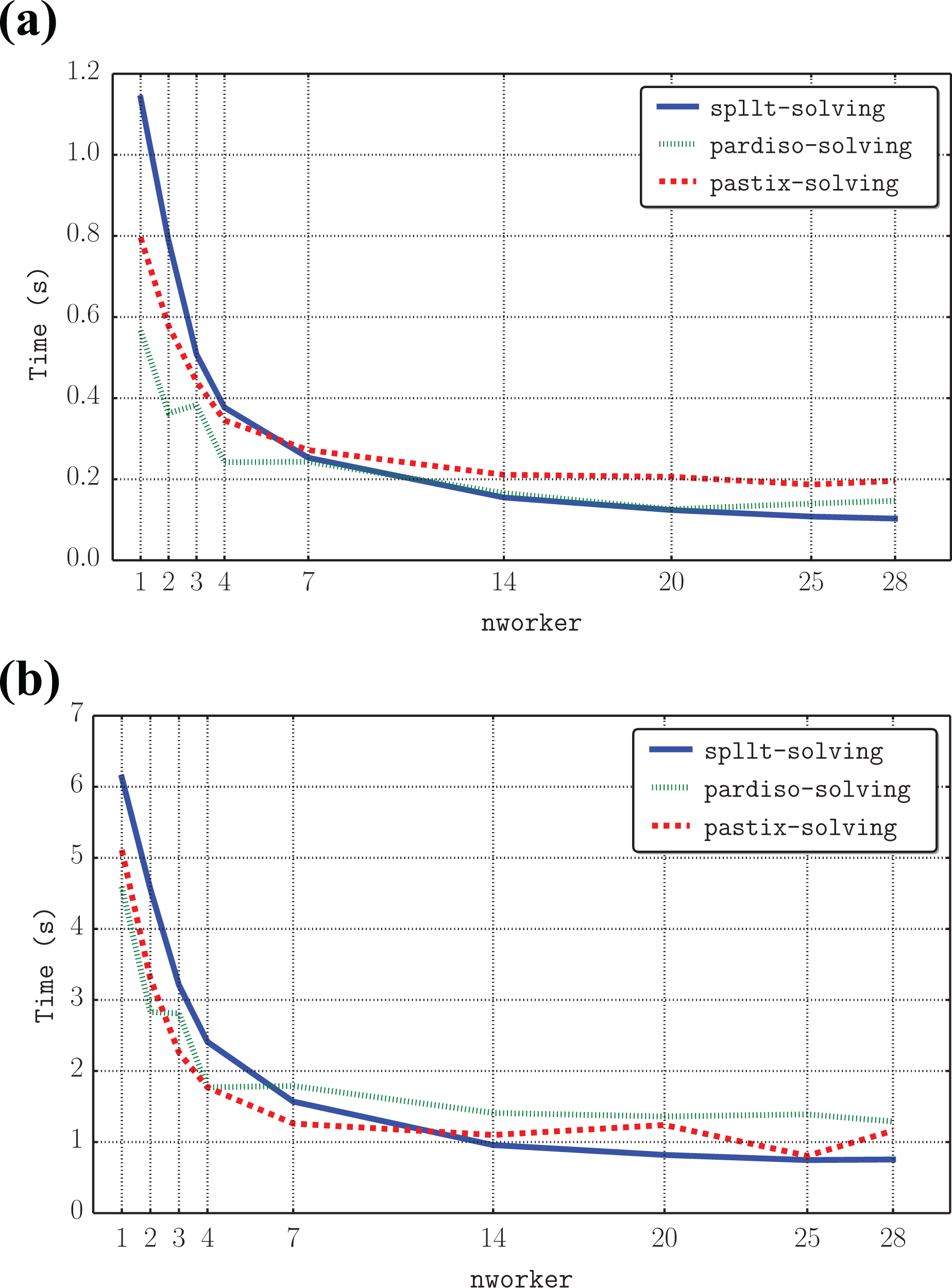
Comparison of the time to solve the system with one right-hand side for SpLLT, PARDISO and PaStiX. (a) boneS10 and (b) Serena.
Figure 10 shows the impact of increasing nworker when there are 64 right-hand sides. SpLLT is more competitive than for a small nrhs. In fact, SpLLT outperforms PARDISO for all numbers of workers and is faster than PaStiX when nworker increases. For more than nine workers, these two representative problems show that SpLLT is clearly the fastest solver.
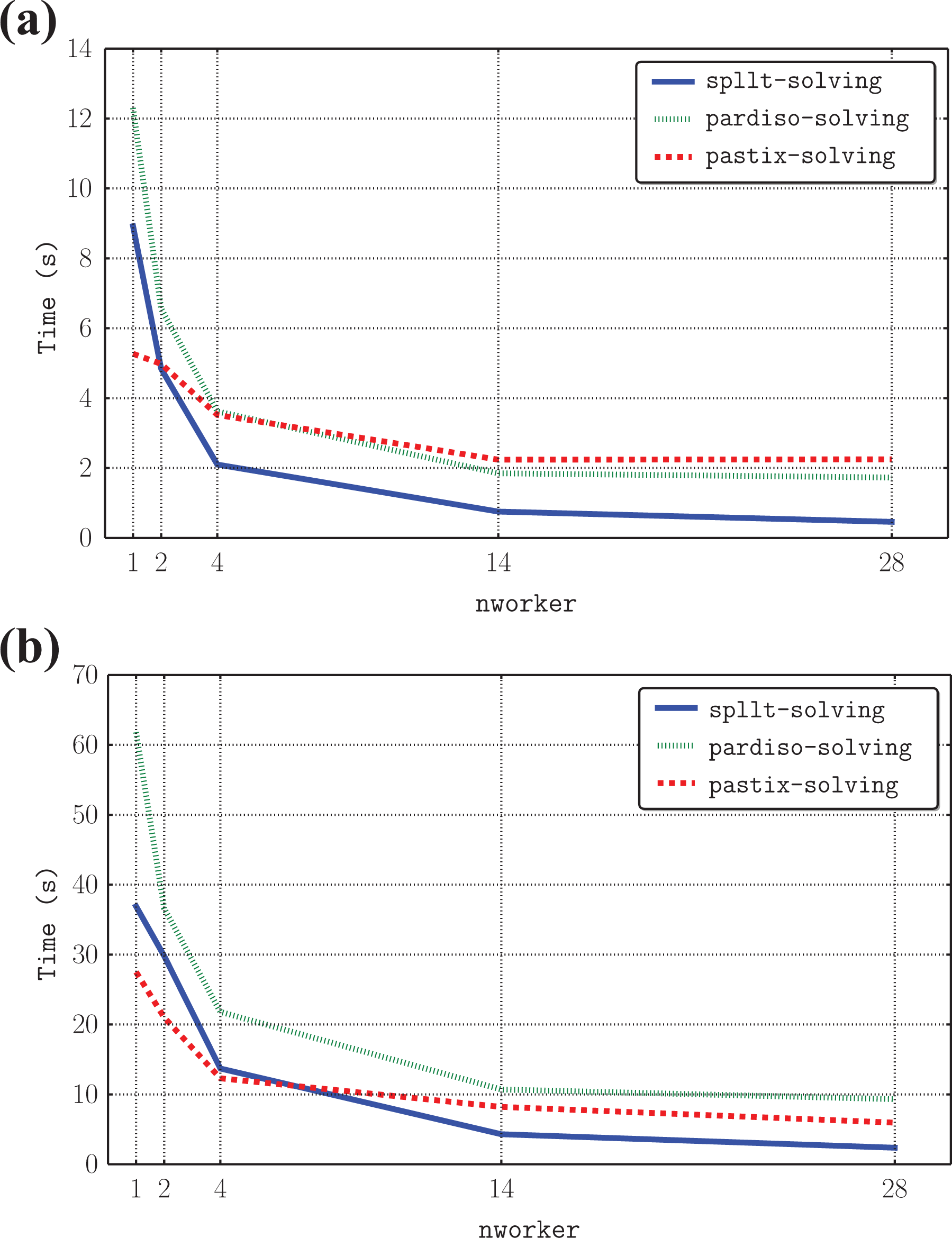
Comparison of the time to solve the system with 64 right-hand sides for SpLLT, PARDISO and PaStiX. (a) boneS10 and (b) Serena.
5.6. Application case: Enlarged CG solver
In this section, we present some results obtained with the enlarged CG solver (ECG) (Grigori and Tissot, 2017). Our runs in this section are on a different machine to our earlier results. We use the Kebnekaise system at Umeå in Sweden (https://www.hpc2n.umu.se/resources/hardware/kebnekaise). Each compute node contains 28 Intel Xeon E5-2690v4 cores organized into 2 NUMA islands with 14 cores in each. The nodes are connected with an FDR Infiniband Network. The total amount of RAM per compute node is 128 GB. ECG and SpLLT are compiled with Intel 18.0.1 and linked to Metis 5.1.0.
The ECG solver is a preconditioned CG solver that augments the number of working vectors to reduce the number of iterations as well as to obtain better parallelism and to reduce the amount of communication. ECG uses a block Jacobi preconditioner. Although each diagonal block is factorized only once, the solve of each associated local system is performed at each iteration of ECG. Table 10 presents the time to solve the global system with ECG using PARDISO or SpLLT on a subset of matrices from Table 1. We show results from 16 MPI processes to 256 MPI processes. We see little difference in solution times for the shipsec1 problem but, on the two other problems that are 10 times larger, we observe that replacing the PARDISO Solver with the SpLLT solver leads to a speed-up over a factor of 2. In all cases, solving the system with 16 MPI processes using SpLLT is faster than using PARDISO with 32 MPI processes.
Time to solution using PARDISO and SpLLT.a
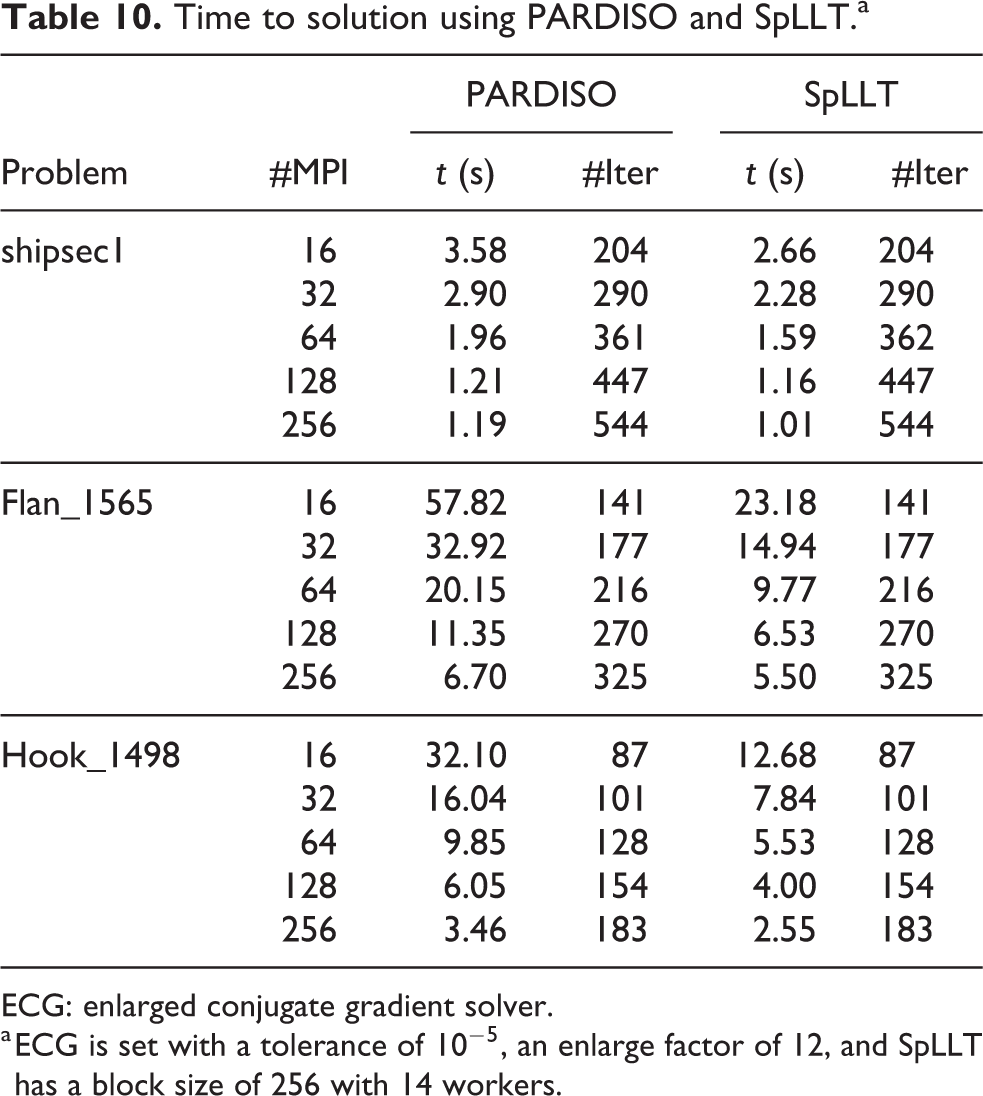
ECG: enlarged conjugate gradient solver.
a ECG is set with a tolerance of
6. Conclusions
We have designed, implemented and tested new routines for the forward and backward substitution steps in the parallel solution of sparse positive definite systems using a Cholesky factorization. We have given details of how our design exploits parallelism while keeping data movement low. We have developed a code that we have tested on a multicore node and have targeted and achieved good scalability both with respect to the number of cores and to nrhs. We have compared our code to other state-of-the-art codes and shown that it is usually far superior sometimes outperforming the other codes by a factor of over 10. We have shown that our code is strongly scalable both for cores and right-hand sides.
Finally, we have tested our code within a real application and shown big gains over the previous version that used another solver. We are continuing our work with the authors of ECG at Inria and have seen even bigger gains on markedly larger problems than those used in this article. For example, on a matrix from a diffusion problem of order nearly 5 million with over 34 million entries, we reduce the solution time by a factor of nearly 3 on 16 MPI processes and by a factor of nearly 2 on 256 processes.
Footnotes
Acknowledgements
The authors would like to thank Tyrone Rees of RAL for his comments on an early draft of this article and the High Performance Computing Center North (HPC2N) at Umeå University for providing computational resources and valuable support for the work in Section 5.6.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the NLAFET Project funded by the European Union’s Horizon 2020 Research and Innovation Programme under Grant Agreement 671633.