
Abstract
The state-of-the-art supercomputing infrastructures are equipped with accelerators, such as graphics processing units (GPUs), that operate as coprocessors for each workstation of the distributed memory system. The multi-projection type methods are a class of algebraic domain decomposition methods based on semi-aggregation techniques. The multi-projection type methods have improved convergence behavior, as the number of subdomains increases, due to the corresponding augmentation of the semi-aggregated local linear systems with more coarse components, while the number of fine components is reduced. Moreover, limited amount of communications among the workstations is required by the proposed method. The utilization of the available GPUs allows an increase in the number of subdomains along with finer-grained parallelism, leading to improved performance. A load-balancing algorithm that ensures the concurrency of the computations on multicore processors and GPUs is proposed. Flexible parallel preconditioned Krylov subspace iterative methods enhanced with multi-projection type methods have been designed appropriately in order to have improved performance, compared to CPU-only or GPU-only executions, by exploiting the available CPUs and GPUs of the distributed memory system concurrently. The unsymmetric local linear systems are solved by the preconditioned Bi-Conjugate Gradient STABilized (BiCGSTAB) method enhanced with the modified generic factored approximate sparse inverse preconditioner, whereas the preconditioned conjugate gradient (CG) method along with the symmetric factored approximate sparse inverse preconditioner is used for the symmetric positive definite local coefficient matrices. Numerical results regarding the convergence behavior, the performance, and the scalability of the proposed method for several problems are given.
Keywords
1. Introduction
Let us consider the sparse linear system

where A is the coefficient matrix, b is the right-hand-side vector, and x is the solution vector. Linear systems of the form (1) often arise from the discretization of partial differential equations (PDEs) using methods such as finite differences or finite elements. The preconditioned Krylov subspace iterative methods have been widely used for solving such linear systems due to their parallel performance and reduced memory requirements compared to the class of direct methods (Saad, 2003). The preconditioned form of equation (1) is given as follows

where M is a suitable preconditioning matrix. Domain decomposition methods are efficient parallel preconditioning schemes that have been used extensively for solving linear systems on distributed memory systems (Chan and Mathew, 1994; Toselli and Widlund, 2005). The domain can be partitioned either geometrically (Saad, 2003; Smith et al., 2004; Toselli and Widlund, 2005) or algebraically (Ferronato et al., 2014; Manguoglu, 2012; Zhu and Sameh, 2017) using graph partitioning algorithms such as METIS (Karypis and Kumar, 1998). The METIS partitioning algorithm utilizes the algebraic properties of the graph corresponding to the coefficient matrix A partitioning it into disjoint subgraphs (subdomains) with minimum edge-cut. Algebraic domain decomposition methods can be combined with multilevel techniques, derived from the algebraic multigrid method, and have been shown to provide satisfactory convergence behavior and performance (Bank and Smith, 2002; Bank et al., 2015; Mitchell, 1997). The aforementioned methods compute fine–coarse subdomains and solve the local linear systems using multigrid cycle techniques. Aggregation-based multigrid (Notay, 2006, 2010) utilizes aggregated-coarse grids based on pairwise aggregation, retaining almost constant number of iterations for convergence to a prescribed tolerance and has satisfactory weak scaling.
The graphics processing units (GPUs) of distributed memory systems have been used to improve the performance of domain decomposition methods. The finite element tearing and interconnecting method (Farhat et al., 2000) has been implemented for hybrid (CPU-GPU) systems, along with a dynamic load-balancing technique (Papadrakakis et al., 2011), having satisfactory parallel performance. Moreover, the domain decomposition methods combined with a communication-avoiding Generalized Minimum RESidual restarted (GMRES(m)) method have been shown to be scalable on GPU clusters (Yamazaki et al., 2014a, 2014b). Different approaches for implementing domain decomposition methods on GPUs have been examined on problems from several scientific fields (Babich et al., 2011; Luo et al., 2011; Osaki and Ishikawa, 2010).
Recently, a class of algebraic domain decomposition-type methods, based on semi-aggregation techniques, namely multi-projection methods (MPMs), has been proposed. The proposed class has improved convergence behavior compared to the classical domain decomposition methods, especially as the number of subdomains increases, as well as satisfactory scalability (Moutafis et al., 2017a, 2017b). The improved convergence behavior of the MPM preconditioning scheme, resulting from the increase of the number of subdomains, has been presented in the context of symmetric positive definite (SPD) problems and specifically for the Poisson 3-D model problem in Moutafis et al. (2017a). The MPM preconditioning scheme requires solving local linear systems, which consist of fine and coarse (aggregated) components. The additional aggregated components require slightly more computational work for solving the local linear systems, however, they lead to less number of required iterations for convergence to the prescribed tolerance. In contrast to classical domain decomposition solvers (Smith et al., 2004), the aggregated components, related to the global information of the whole domain, provide better approximation to the exact solution of the fine components, therefore improved convergence behavior is expected, especially when the number of aggregates increases. The MPM can be described as an augmented restricted additive Schwarz (RAS) method (Cai and Sarkis, 1999), in which aggregated (coarse) components, instead of overlapping components, are involved in the local linear systems. The RAS method is based on overlapping domain decomposition techniques, whereas the MPM restricts the whole domain into coarse components by aggregating the fine components of each subdomain. A detailed comparison of the MPM preconditioning scheme with the RAS method, with various overlapping levels, and the Block Jacobi method has been given in Moutafis et al. (2017a). The proposed scheme has improved convergence behavior, performance, and scalability for solving various general large sparse linear systems compared to the aforementioned methods (Moutafis et al., 2017a). Aggregation-based multigrid (Notay, 2006, 2010) utilizes a hierarchy of aggregated (coarse) grids, whereas the MPM scheme requires the solution of multiple semi-aggregated (fine and coarse components) subdomains concurrently. The domain decomposition methods are suitable for GPU clusters; thus, the solution process of the local linear system of each subdomain can be further accelerated by the GPUs (Papadrakakis et al., 2011; Yamazaki et al., 2014b).
In the case of the MPM preconditioning scheme (Moutafis et al., 2017a), the local linear systems are solved by a direct method; however, the forward/backward substitution process required by direct methods cannot be efficiently parallelized on GPUs. In Anzt et al. (2015a), a block asynchronous Jacobi method has been used for approximating the forward/backward substitution process. Moreover, a recursive approach of the factorized sparse approximate inverse (FSAI) preconditioner (Kolotilina and Yeremin, 1993), providing improved parallel performance than the classical FSAI for banded matrices, has been proposed (Bergamaschi and Martínez, 2012). Alternatively, it can be used a preconditioned iterative method, in conjunction with a sparse approximate inverse matrix, which is suitable for parallelization on many-core architectures, since it is composed of sparse matrix–vector products, inner products, and vector norms.
A hybrid parallel MPM-type preconditioning scheme is proposed along with a load-balancing algorithm, aiming to exploit the computational resources of a GPU cluster. The Bi-Conjugate Gradient STABilized (BiCGSTAB) (Van der Vorst, 1992) enhanced with the Modified Generic Factored Approximate Sparse Inverse (MGenFAspI) preconditioner (Filelis-Papadopoulos and Gravvanis, 2016) has been used for solving the unsymmetric local linear systems, whereas the preconditioned conjugate gradient (CG) method (Hestenes and Stiefel, 1952), enhanced with the symmetric factored approximate sparse inverse (SFASI) preconditioner (Kyziropoulos et al., 2016), has been used for the SPD cases. Moreover, the hybrid parallel computing paradigm, using both multi-/many-core processing and GPUs, is expected to improve the performance compared to the CPU-only or the GPU-only cases. The load balancing of the workload affects significantly the parallel performance of the proposed method; therefore, an algorithm based on benchmark results has been designed and implemented to ensure evenly distributed workload. The flexible variants of the preconditioned CG (Golub and Ye, 1999) (inexact preconditioned CG (IPCG)) and the GMRES(m) (Saad, 1993) (flexible GMRES(m) (FGMRES(m))) methods have been used along with the MPM preconditioning scheme, allowing the solution of the local linear systems with decreased tolerance. In Section 2, the MPM preconditioning scheme and the MGenFAspI preconditioner are described. In Section 3, the load-balancing technique is presented. In Section 4, implementation details concerning the FGMRES(m) method and the IPCG method, enhanced with the MPM preconditioning scheme, are given along with the description of the parallelization on the CPU/GPU cluster. The convergence behavior, the performance, and the scalability of the proposed method have been examined by several numerical experiments, which are presented in Section 5. The proposed method is compared to the RAS method (Cai and Sarkis, 1999).
2. MPM enhanced with the MGenFAspI
2.1. Multi-projection method
The class of multi-projection-type methods (Moutafis et al., 2017a, 2017b) utilizes semi-aggregated techniques to project a linear system of the form (1) into “

Moreover, let us also consider the fine–coarse subdomains Zj
, whose components are the fine components of
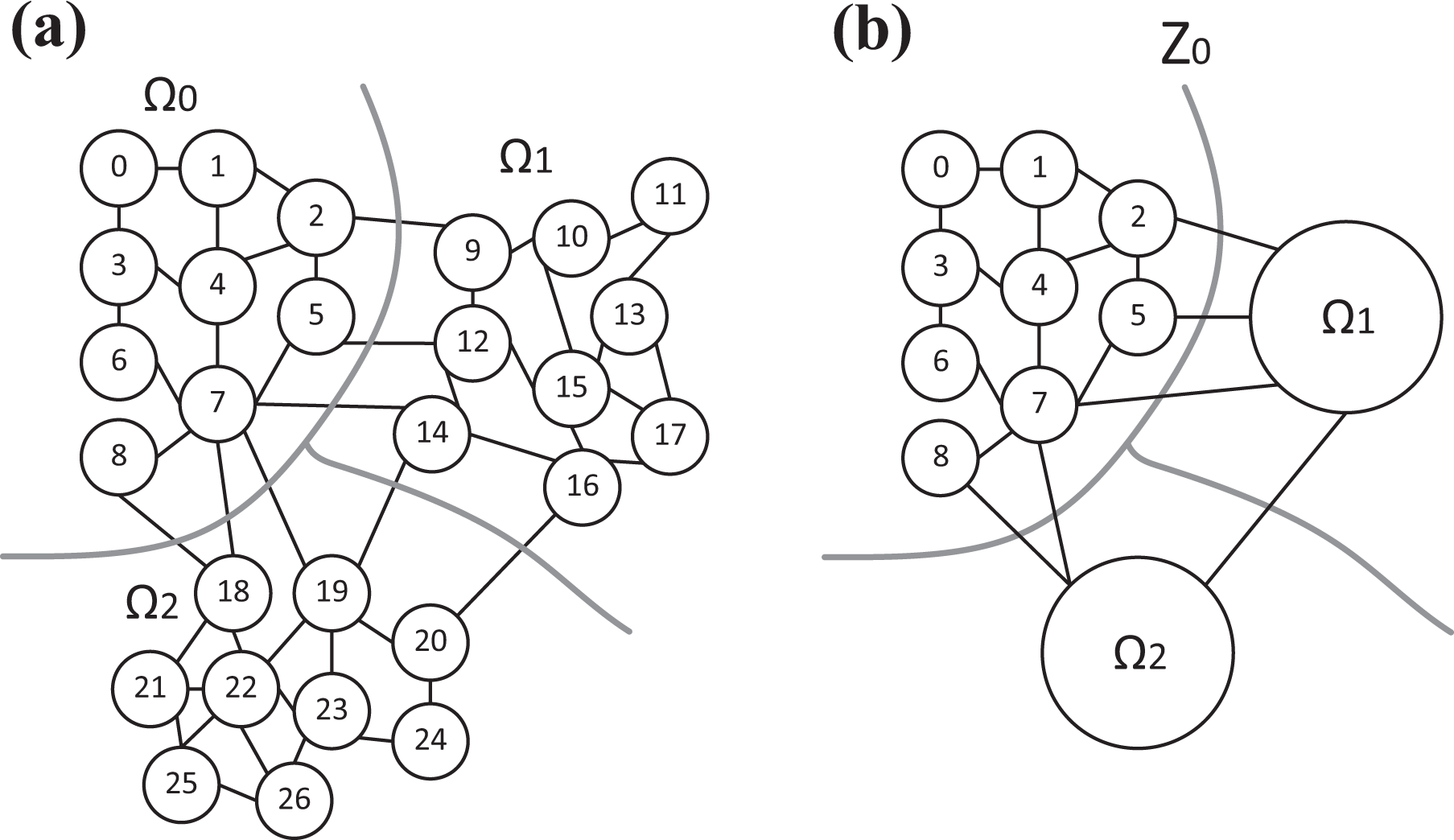
(a) An arbitrary graph, partitioned into three subdomains, and (b) the corresponding fine–coarse subdomain Z 0 are shown.
The local linear systems can be written as follows

or equivalently

The prolongation matrices Vj are given by the following expression
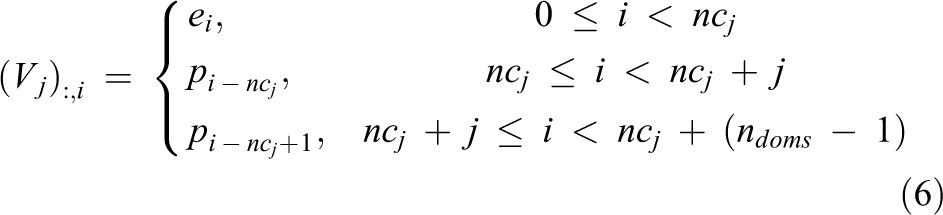
where ei
is the suitable column vector of the
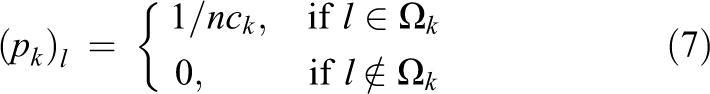
The local linear systems (4) can be solved by the BiCGSTAB-CG method enhanced with an MGenFAspI-SFASI preconditioner. Factored approximate inverse matrices such as MGenFAspI or SFASI require only sparse matrix–vector products, in contrast to the forward/backward substitution, required by the traditional Incomplete LU (ILU)-preconditioning. Therefore, the preconditioned BiCGSTAB-CG enhanced with the MGenFAspI-SFASI matrix is expected to have improved parallel performance on GPUs compared to ILU-preconditioning. The local solution vector xj can be reordered in a block form as

where
MPM preconditioning scheme algorithm using the MGenFAspI-SFASI


It should be stated that the MPM preconditioning scheme requires an all-gather process to form the coarse part of each local right-hand-side vector bj
. The required time for the aforementioned procedure is insignificant compared to the other parts of the algorithm, since the size of the coarse vector, which is sent, is only
2.2. Modified generic factored approximate sparse inverse
The MGenFAspI matrix (Filelis-Papadopoulos and Gravvanis, 2016) of a coefficient matrix A is of the form

where G is the upper triangular factor and H is the lower triangular factor of the approximate inverse M. The MGenFAspI matrix is computed based on the L and U factors, obtained by incomplete LU factorization procedure of a coefficient matrix A (Saad, 2003)

where E is the error matrix. The setup phase of the MGenFAspI matrix requires the a priori knowledge of the sparsity pattern of the factor matrices G and H (Chow, 2000, 2001). Hence, the factors L and U are sparsified using a predefined drop tolerance (droptol) and then raised to a predefined power (level of fill), that is, lfill (Chow, 2000, 2001), to obtain the sparsity patterns. The factors
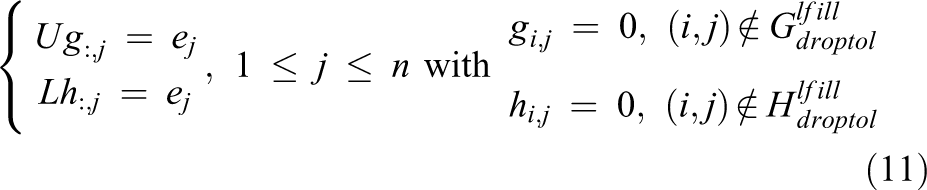
where n is the size of the coefficient matrix A, and
It should be mentioned that the computation of the local MGenFAspI matrices is an inherently parallel process, since each core of the parallel system computes the corresponding MGenFAspI matrices (Gj and Hj ) for each subdomain concurrently.
The main differences between MGenFAspI (Filelis-Papadopoulos and Gravvanis, 2016) and FSAI matrices are as follows. (a) The sparsity pattern of MGenFAspI is computed based on powers of sparsified matrices (Chow, 2000) of the factors L and U computed from incomplete factorization procedures, while in the case of FSAI, the sparsity pattern is computed by powers of the lower triangular part of the coefficient matrix. (b) In the case of MGenFAspI, computation is performed by a column-wise decoupled restricted solution procedure using the explicitly known factors L and U computed from incomplete factorization procedures, while FSAI is based on minimization of the Frobenious norm
Further details concerning the MGenFAspI matrix are given in Filelis-Papadopoulos and Gravvanis (2016). Moreover, the corresponding symmetric version of MGenFAspI, namely, SFASI that is used for SPD coefficient matrices is described extensively in Kyziropoulos et al. (2016).
3. Load balancing
The workload of the MPM preconditioning scheme should be evenly balanced among the available computational resources to allow concurrent computations. In the MPM preconditioning step, each workstation of the distributed memory system has to solve

where n is the size of the coefficient matrix A, and consequently, the total number of components in Zj is given by
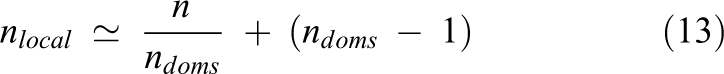
Furthermore, let us assume that the architecture of the GPU cluster has one GPU for each available multicore processor and the number of processors of the cluster is equal to the number of GPUs (
The number of subdomains assigned to the GPU
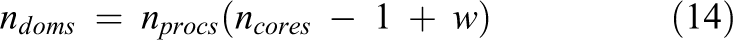
In Figure 2, the workload distribution in a compute node, having two multicore processors and two GPUs, is schematically presented. For designing a load-balancing algorithm, a benchmark test should be chosen to estimate
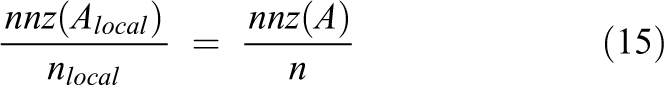
and
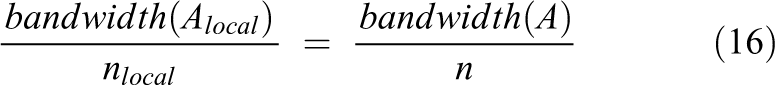
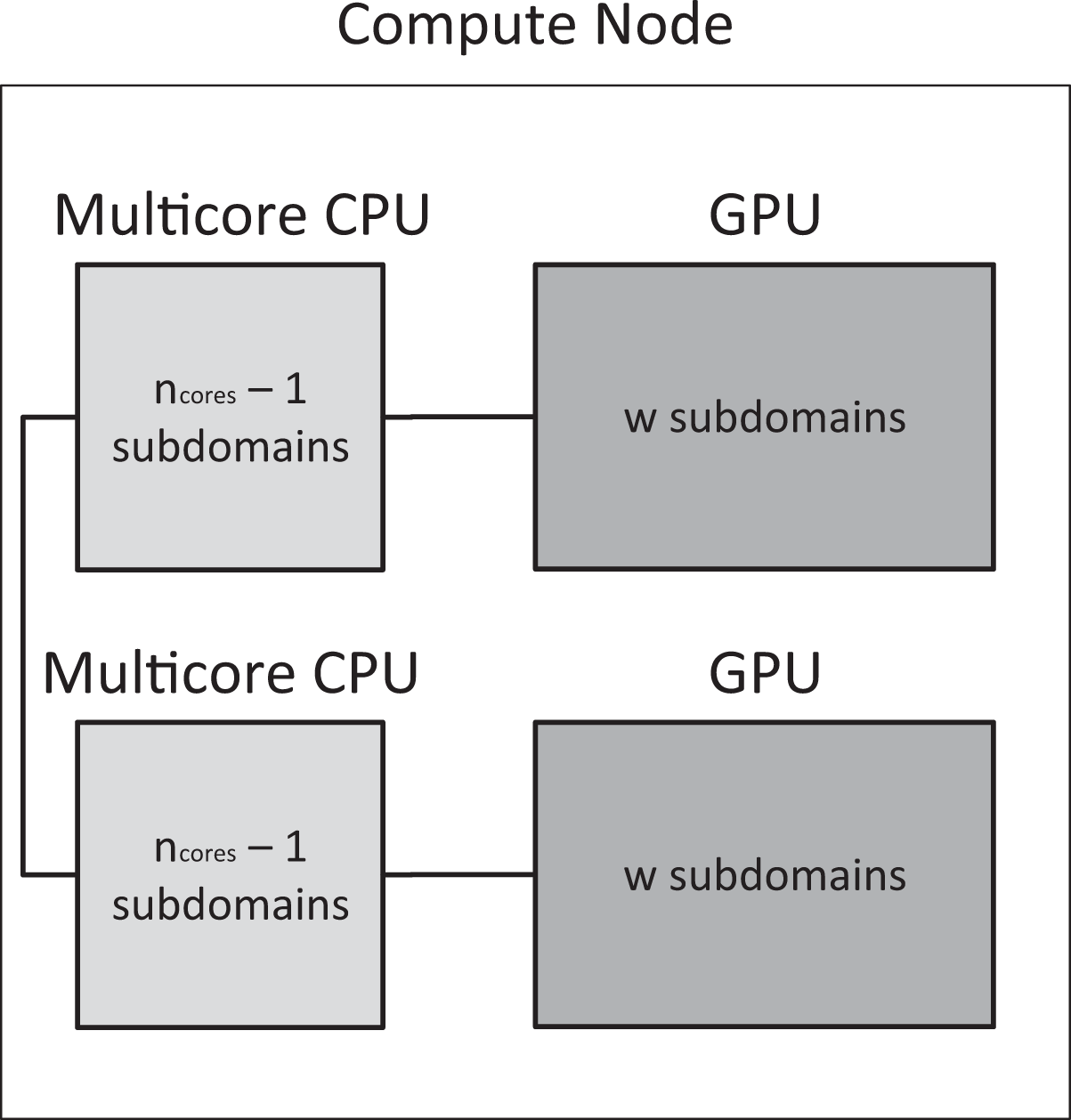
The distributed workload in a single node of the distributed memory system, having two multicore processors and two GPUs, is depicted. GPU: graphics processing unit.
It should be mentioned that the diagonal elements of the random matrix were chosen to be nonzero according to common sparsity patterns of coefficient matrices, derived from finite differences and finite elements methods. In Figure 3, the sparsity pattern of a random matrix with
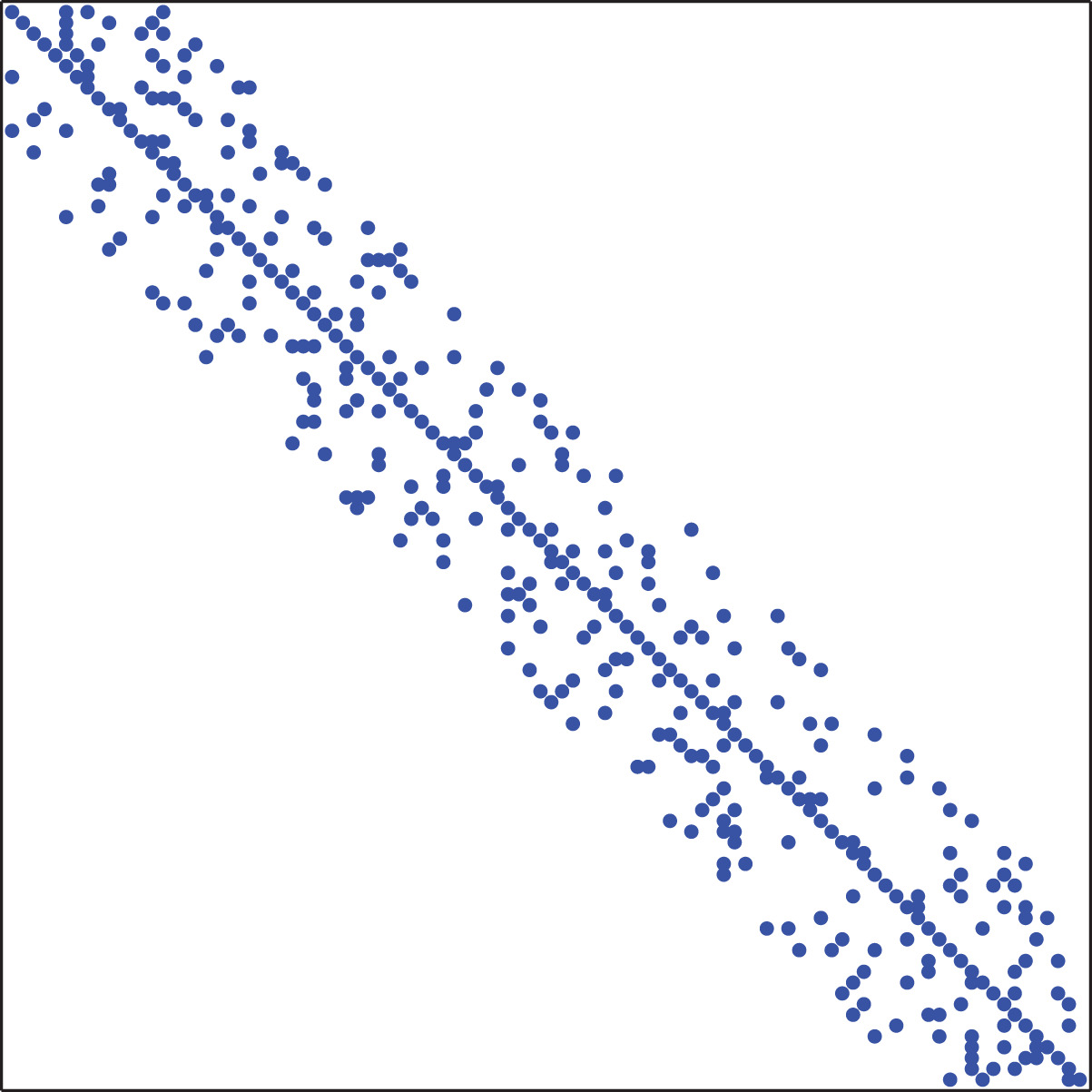
The sparsity pattern of a random matrix with
Let us denote with
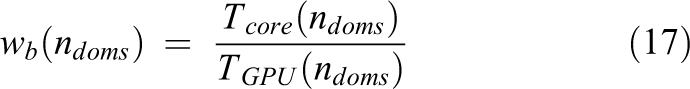
The value of wb
should not be larger than w, otherwise
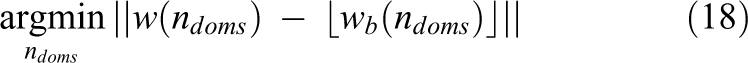
Let us consider a distributed memory system, equipped with 32 processors (10× cores) and 32 GPUs, and a coefficient matrix A of dimension
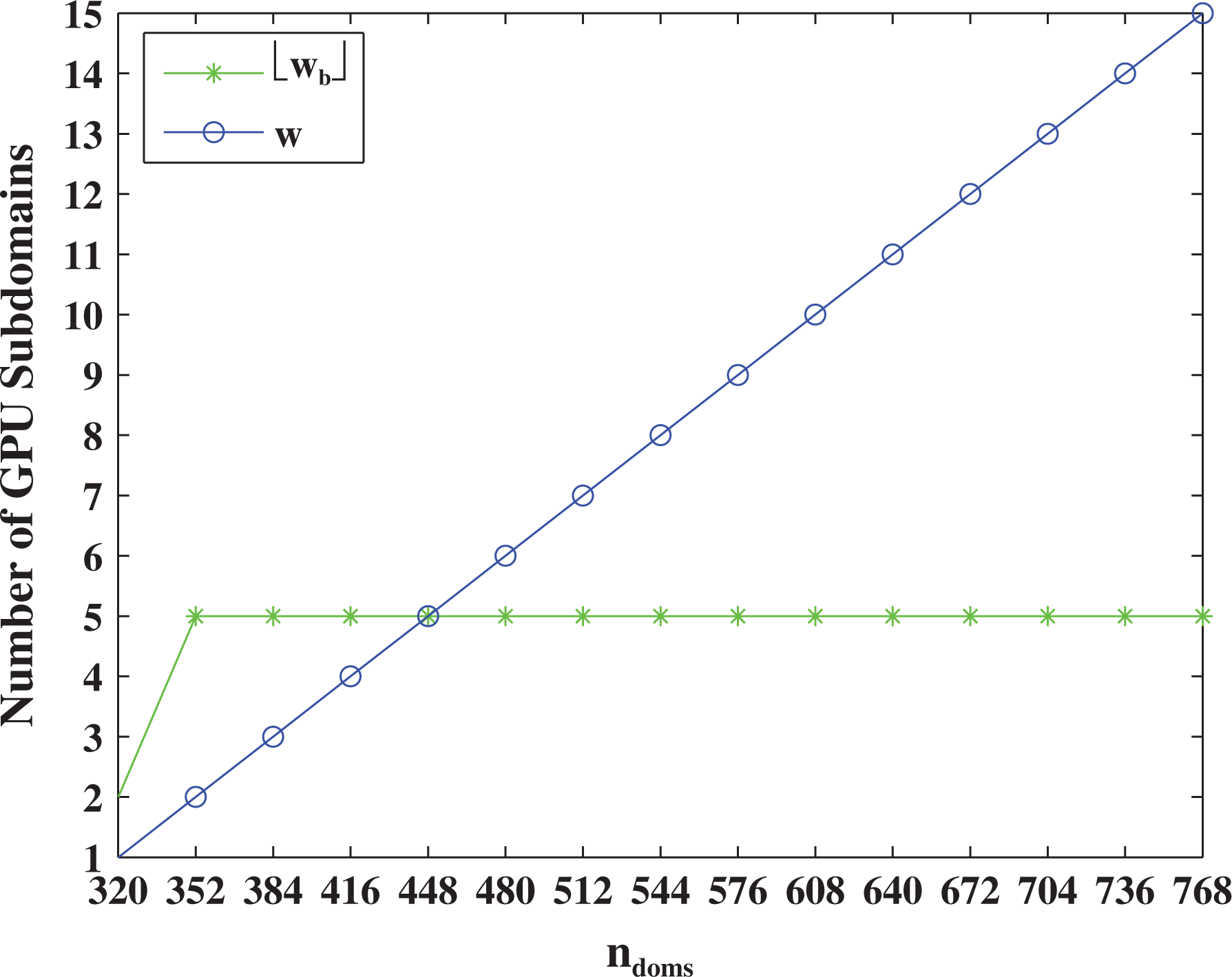
The
Load Balancing algorithm


The

where
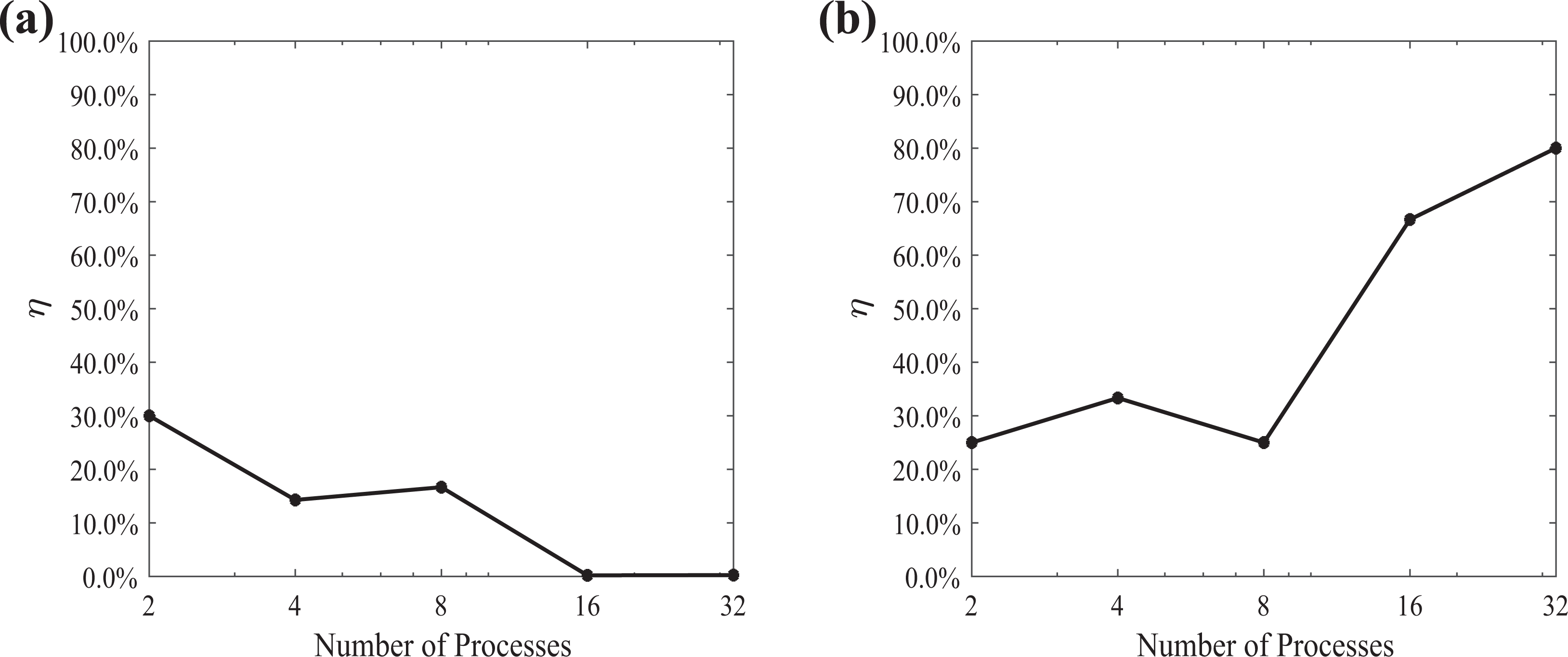
The relative error of w using the random benchmark coefficient matrix for (a) the coefficient matrix A of dimension
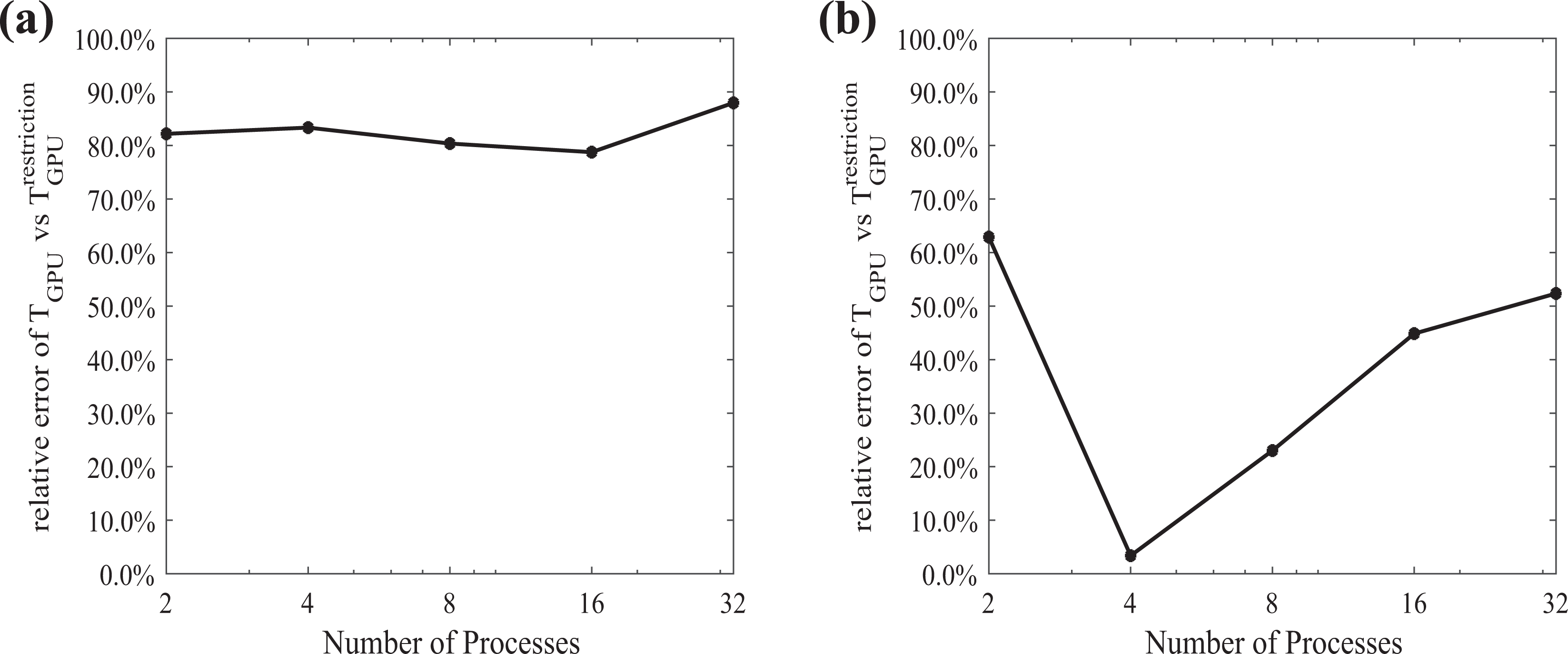
The relative error between the elapsed time on the GPU for the sparse matrix–vector multiplication, using the random benchmark coefficient matrix, with the average elapsed time from the resulting local coefficient matrices (a) for a coefficient matrix A of dimension
It should be mentioned that the relative error between the elapsed time of the sparse matrix–vector multiplication on the GPU and the random benchmark coefficient matrix model is substantial. This stems from the fact that in the local coefficient matrix, the rows and the columns corresponding to the aggregated (coarse) components have increased number of nonzero elements compared to rows corresponding to the fine components. In the case of large number of nonzero elements in some rows of the coefficient matrix, the parallelization and, thus, the performance of the sparse matrix–vector multiplication on the GPU are affected negatively, due to asymmetric workload of the GPU threads. An example of the sparsity pattern of a local coefficient matrix derived from the discretization of the 2-D Poisson problem with the finite difference method, partitioned into 16 subdomains, is shown in Figure 7.
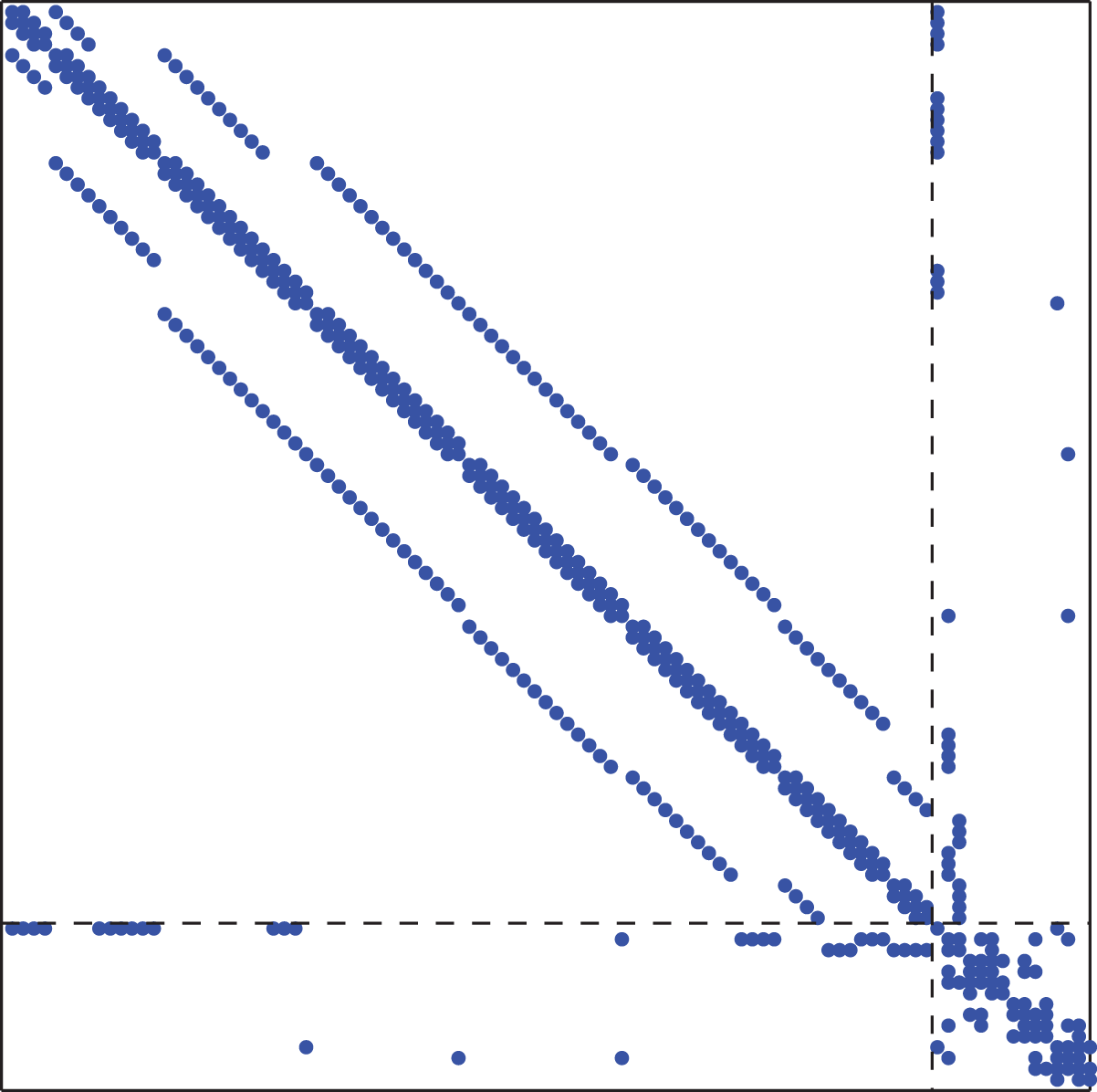
An example of the sparsity pattern of a local coefficient matrix derived from the discretization of the 2-D Poisson problem with the finite difference method, partitioned into 16 subdomains, is shown.
In order to improve the model with respect to sparsity pattern of the local coefficient matrix of Figure 7 as well as the elapsed time required to compute the sparse matrix–vector multiplication, an alternative technique for forming the benchmark coefficient matrix has been used. For each different value of
However, load balancing also depends on the number of iterations that the preconditioned Krylov subspace iterative method requires to obtain the solution of each local linear system. In Figure 8, the histogram of the number of required iterations of the preconditioned CG method for solving the Poisson 3-D problem (
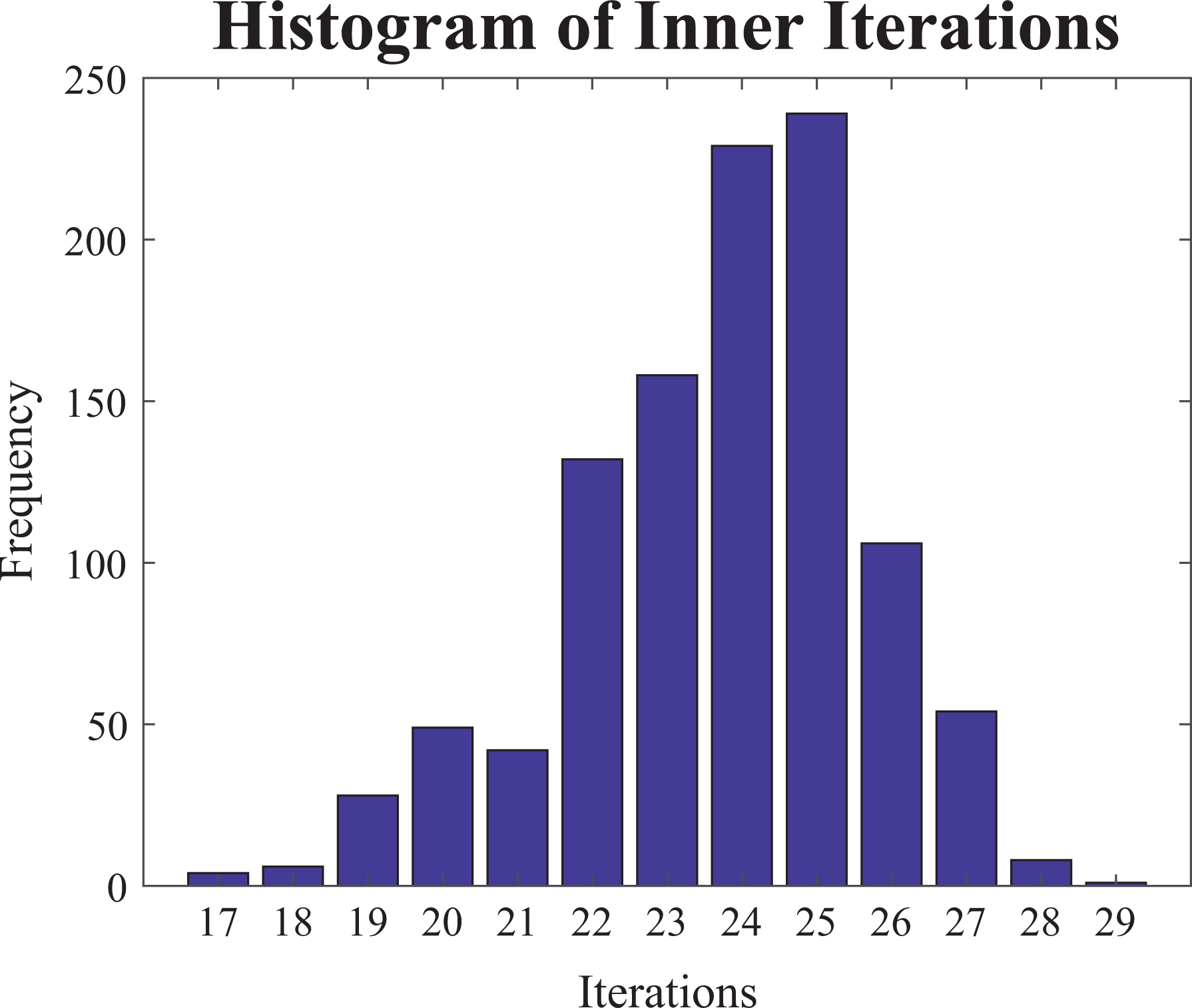
The histogram of the number of the required iterations for convergence of the preconditioned CG for solving the Poisson 3-D problem (
Moreover, it should be noted that the METIS graph partitioning algorithm partitions the graph corresponding to the coefficient matrix A with respect to the minimization of the edge-cut set. Consequently, the number of nonzero elements in the rows and the columns corresponding to the aggregated (coarse) components of each local coefficient matrix depends on the partitioning. The relative error of w, using the restriction technique to form the benchmark coefficient matrix, for the coefficient matrix A of dimension
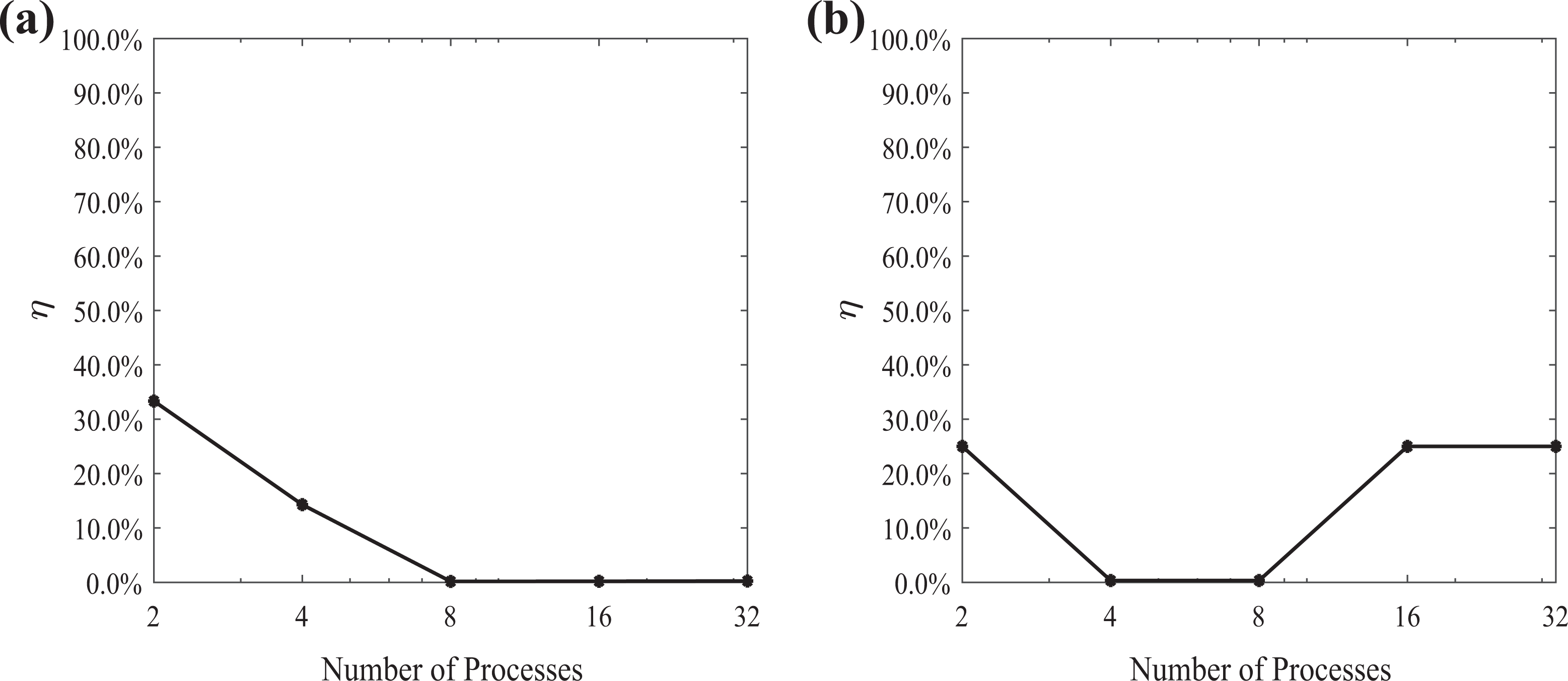
The relative error of w, using the restriction technique to form the benchmark coefficient matrix, for (a) the coefficient matrix A of dimension
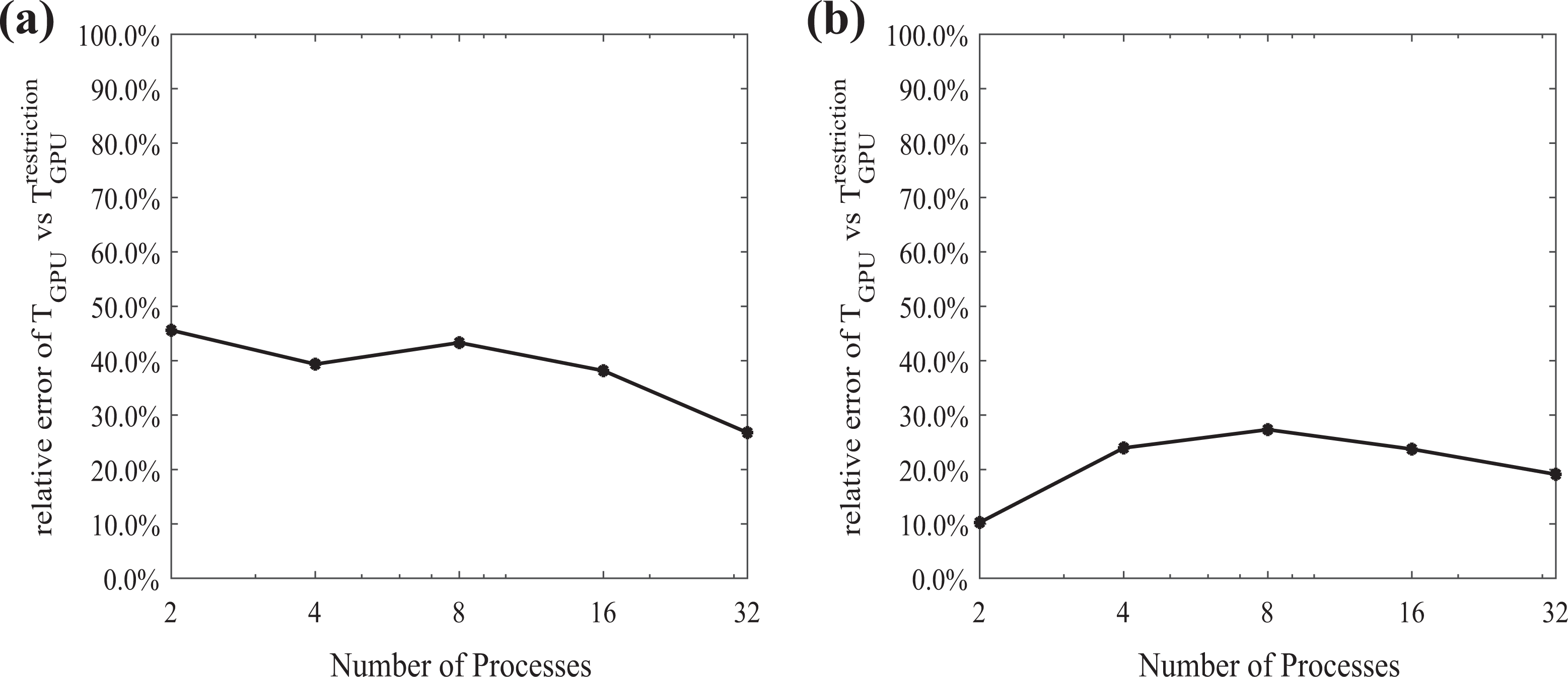
The relative error of the elapsed time for the sparse matrix–vector multiplication on GPU using the benchmark coefficient matrix, derived with the restriction technique, and using the average elapsed time of the resulting local coefficient matrices for (a) the coefficient matrix A of dimension
It should be stated that the
In Figure 11, the performance of the IPCG, enhanced with the hybrid MPM preconditioning scheme for the Poisson 3-D problem (
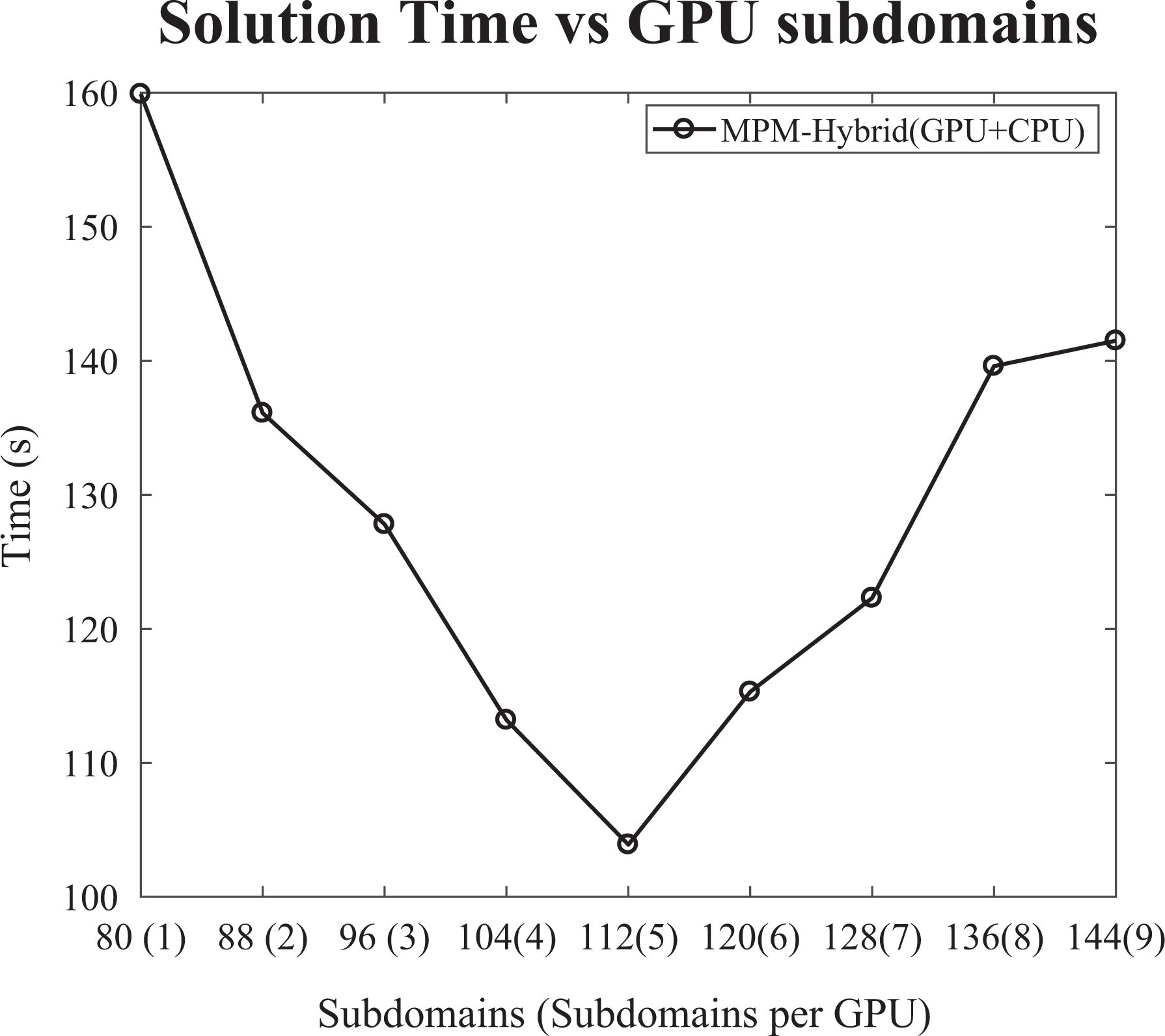
The performance of the proposed scheme for the Poisson 3-D problem (
The proposed load-balancing scheme is expected to evenly distribute the workload of the MPM among the CPUs and the GPUs. However, it should be noted that the following assumptions have been made: (a) the coefficient matrix of each local linear system should have similar size and sparsity pattern; (b) the local linear solver should require similar number of required iterations for convergence to the prescribed tolerance for every local linear system; and (c) the ratio
4. Implementation details
The flexible Krylov subspace methods have been implemented using neighboring communication. The linear system (1) is reordered according to the partitioning vector, computed by the METIS partitioning algorithm (Karypis and Kumar, 1998). The reordered linear system has limited amount of edges (nonzero elements) in the off-diagonal blocks due to the minimized edge-cut technique used by the METIS partitioning. Therefore, the neighbor-wise communications, among the compute nodes of the distributed memory system, required for the computation of the sparse matrix–vector, are reduced. Moreover, the Gram–Schmidt process of the FGMRES(m), applied to the linear system (1), is implemented block-wise, in order to require local inner products, local daxpys, and only one all-reduce communication operation per inner iteration. The Givens rotation process concerns the reduction of the Hessenberg matrix from the Arnoldi process to a triangular matrix, and it is computed redundantly in each workstation.
It should be noted that the MAGMA 2.2.0 GPU library (Anzt et al., 2015b) has been used for implementing the proposed method on GPU. The MAGMA built-in function of the preconditioned BiCGSTAB method (Anzt et al., 2017; Gravvanis et al., 2012) has been combined with the MGenFAspI matrix to solve the unsymmetric local linear systems, whereas for the SPD cases, the preconditioned CG method, enhanced with the SFASI matrix, has been used. In the MPM preprocessing phase, the MGenFAspI-SFASI matrices of the local linear coefficient matrices Aj
(5) are computed, concurrently by each core. The Aj
and the MGenFAspI-SFASI matrices, required for solving the local linear systems of the corresponding GPU,
It should be mentioned that the required wall-clock time of the preprocessing phase is not significant compared to the wall-clock time required for the solution phase, therefore the numerical results are focused on the performance of the latter. Thus, a more advanced load-balancing scheme concerning the preprocessing phase would impact the performance of the method negatively.
Furthermore, a pipeline technique, based on overlapping communication operations between the CPU and the GPU memory, is utilized for increasing the concurrency of the preconditioning step. In the MPM step, the communication concerning the local solution vectors is overlapped by the computations corresponding to the right-hand-side vector of the next GPU subdomain. Algorithm 3 describes the GPU overlapping communication of the MPM preconditioning step.
GPU Overlapping Communication MPM Preconditioning step


It should be mentioned that the
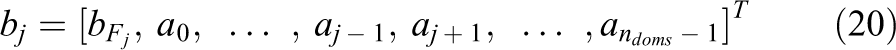
In the case of badly scaled problems, the termination criterion based on the actual residual vector may not be satisfied, even though the norm corresponding to the preconditioned residual satisfies the termination criterion (Saad, 2003). An a priori equilibration of the linear system should be used to acquire a solution that satisfies both termination criteria (Hoemmen, 2010; Sluis, 1969). The most cost-effective equilibration is row scaling (Hoemmen, 2010)

where Dr
is a diagonal row scaling matrix, which normalizes each row of the coefficient matrix A using the
5. Numerical results
Numerical experiments were carried out on ARIS High Performance Computing infrastructure in order to examine the convergence behavior, the performance, and the scalability of the proposed method. Each compute node is equipped with 2× Haswell-Intel Xeon E5-2660v3 (10 cores each), 64-GB RAM, and 2× NVIDIA Tesla K40-12 GB. The number of nonzero elements of the coefficient matrix A are denoted by
5.1. 2-D Poisson problem
The Poisson equation in two space variables has been discretized by the five-point stencil of the finite differences method. In Figure 12, the performance of the IPCG method, enhanced with the MPM preconditioning scheme (CPU-only case and hybrid case) for three different pairs of the number of CPUs and the number of subdomains. In the first case, as presented in Figure 12(a), the number of CPUs (i.e. number of processes) is proportionate to the number of subdomains, where each subdomain is mapped to one thread of the CPU. In the second case, as depicted in Figure 12(b), the number of subdomains is chosen according to the load-balancing algorithm of the hybrid (GPU + CPU) MPM preconditioning scheme, whereas the number of CPUs increases according to the powers of two. In the third case, as shown in Figure 12(c), it has been used more compute nodes and consequently CPUs, so that the number of the subdomains, selected by the load-balancing algorithm, can be mapped one-to-one to a CPU-thread. Moreover, the convergence behavior of the IPCG method, enhanced with the MPM preconditioning scheme, for the different number of subdomains is given in Table 1. It should be mentioned that the performance of the hybrid (GPU+CPU) MPM preconditioning scheme, Figure 12(b), is similar to the performance of the CPU MPM preconditioning scheme, in the case of having a larger distributed system without GPUs, Figure 12(c). Comparing the performance of the CPU MPM preconditioning scheme in Figure 12(a) and (b), in the cases that the increase in the number of subdomains, causes an improvement in the convergence behavior of the method, a corresponding improvement in the performance is noticed. In the rest of the cases that the number of iterations for convergence to the prescribed tolerance remains the same, the performance of the one-to-one mapping is slightly better. In the following numerical results, the number of subdomains has been chosen the same for all the MPM preconditioning scheme implementations, in order to maintain the same number of required floating point operations in each solution process and therefore to focus on examining the efficiency of the proposed method using a GPU cluster. The optimal parameters with respect to the hybrid (GPU + CPU) MPM scheme are used.
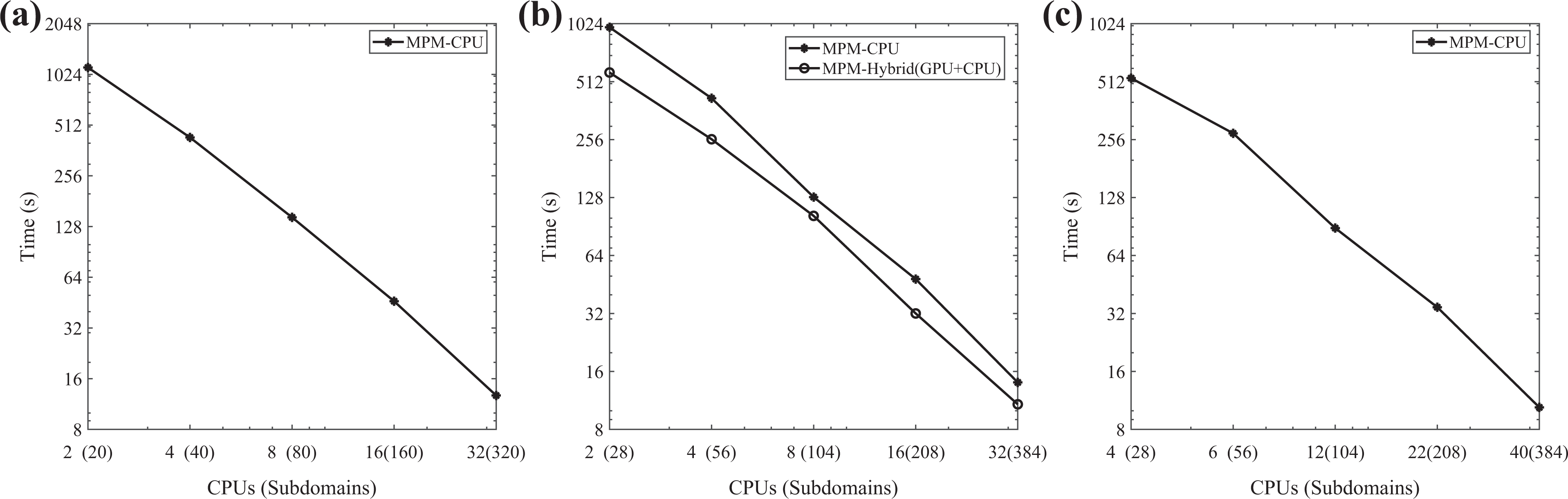
The performance of the IPCG method, enhanced with the MPM preconditioning scheme (CPU-only case and hybrid case), for three different pairs of the number of CPUs and the number of subdomains is shown. (a) The number of CPUs (i.e. number of processes) is proportionate to the number of subdomains, where each subdomain is mapped to one thread of the CPU. (b) The number of subdomains is chosen according to the load-balancing algorithm of the hybrid (GPU + CPU) MPM preconditioning scheme, whereas the number of CPUs increases according to the powers of two. (c) It has been used more compute nodes and consequently CPUs, so that the number of the subdomains, selected by the load-balancing algorithm, can be mapped one-to-one to a CPU-thread. GPU: graphics processing unit. IPCG: inexact preconditioned CG; MPM: multi-projection method.
The convergence behavior of the IPCG enhanced with the MPM preconditioning scheme of the 2-D Poisson problem (

IPCG: inexact preconditioned CG; MPM: multi-projection method.
The strong scalability diagram (logarithmic scale) of the proposed scheme for the 2-D Poisson problem (
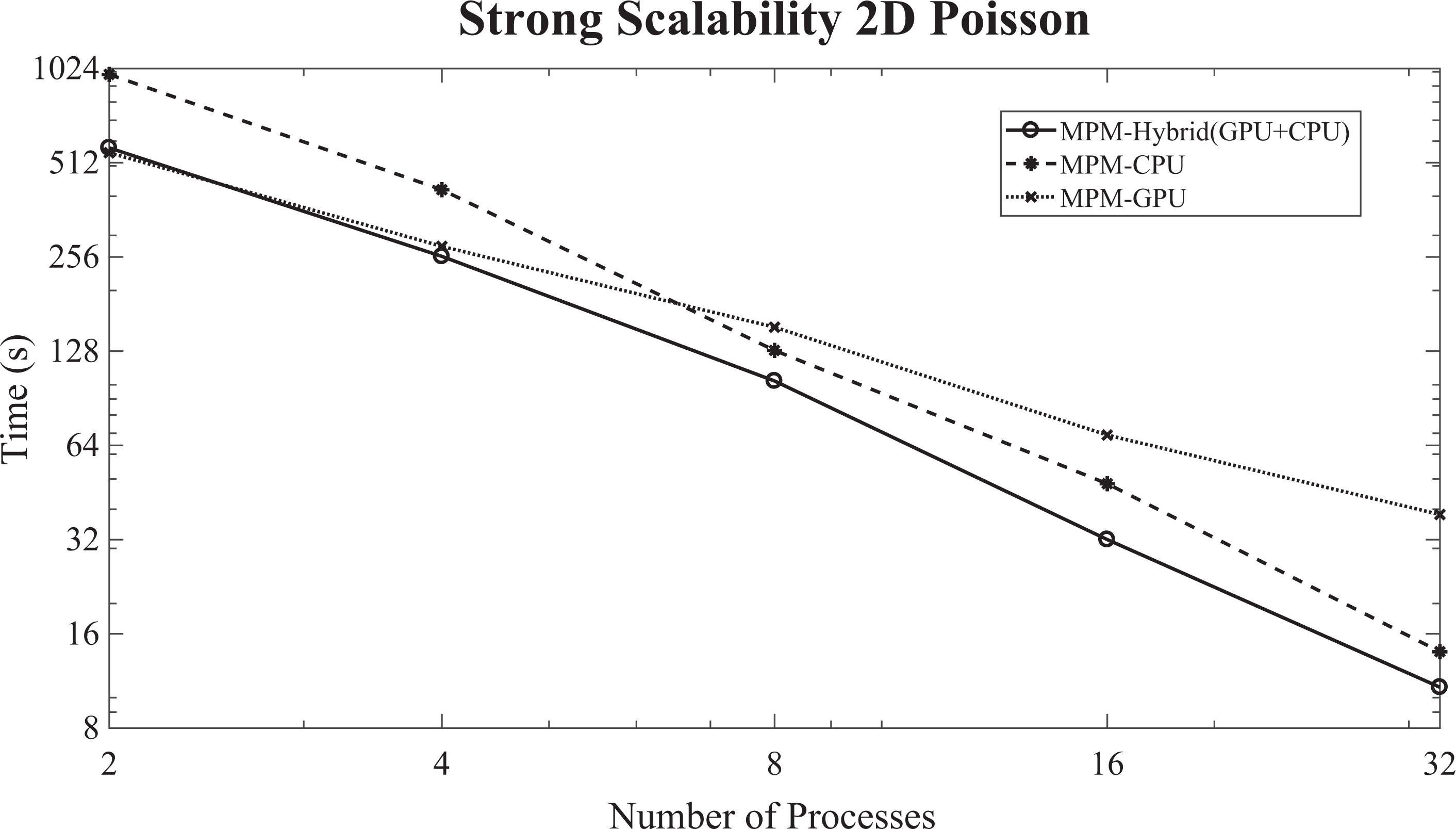
The strong scalability diagram (logarithmic scale) of the IPCG enhanced with the MPM preconditioning scheme for the 2-D Poisson problem (
The convergence behavior of the IPCG enhanced with the MPM preconditioning scheme for the strong scalability diagram of the 2-D Poisson problem (

IPCG: inexact preconditioned CG; MPM: multi-projection method.
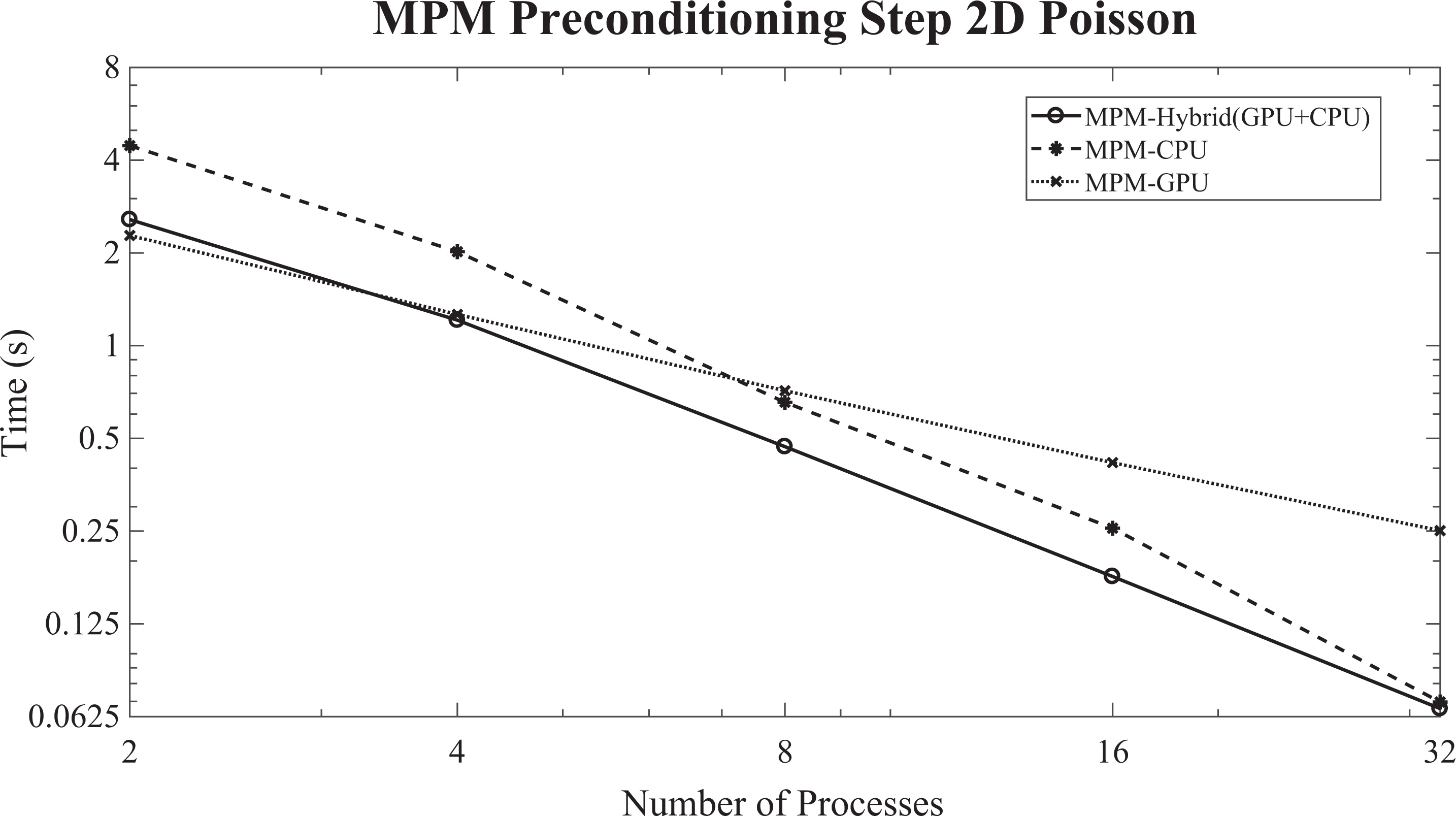
The performance (logarithmic scale) of the MPM preconditioning step for the 2-D Poisson problem (
The strong scalability of the IPCG method, enhanced with the hybrid (GPU + CPU) MPM preconditioning scheme, has improved performance compared to the CPU-only case. The improved performance of the proposed method relies on accelerating the MPM preconditioning step by utilizing the GPUs according to the proposed load balancing, Algorithm 2. The performance of the MPM preconditioning step, for the hybrid CPU/GPU case, is improved by a factor of up to 1.7×. In the case of a small number of processes, the GPU-only case performs better than the hybrid scheme. This is occurring due to the fact that the load-balancing algorithm was designed to ensure that the GPU would not be slower than one core of the CPU, whereas in these cases,
The time required for transferring the right-hand-side vectors from the CPU to the GPU in each MPM preconditioning step for the 2-D Poisson problem (
The time required for transferring the right-hand-side vectors from the CPU to the GPU in each MPM preconditioning step for the 2-D Poisson problem (
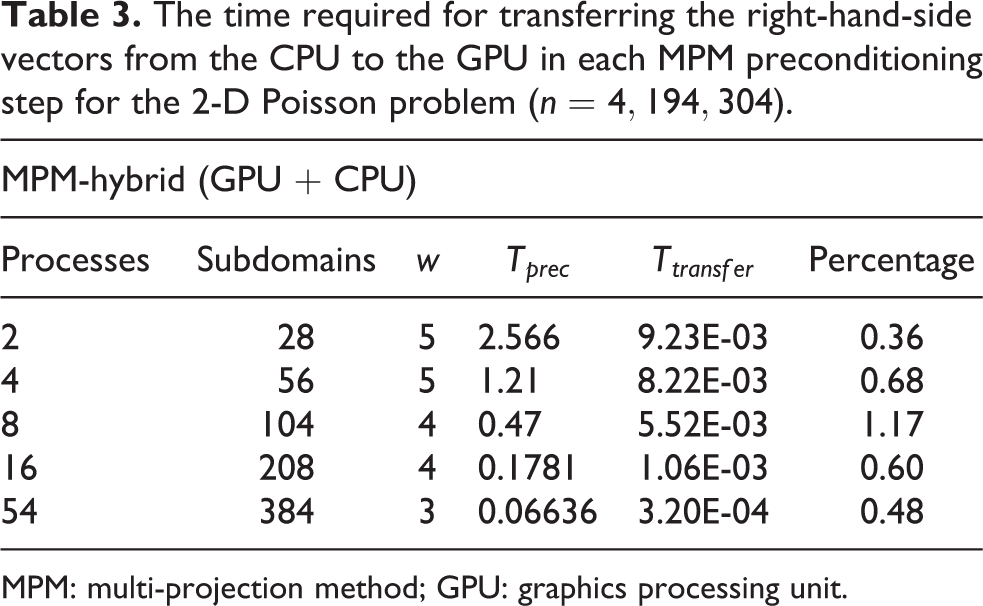
MPM: multi-projection method; GPU: graphics processing unit.
The weak scaling of the proposed scheme has been examined by solving the 2-D Poisson problem with
The sizes of the coefficient matrices A and the convergence behavior of the IPCG method, enhanced with the MPM preconditioning scheme, for the weak scalability diagram of the 2-D Poisson problem.

IPCG: inexact preconditioned CG; MPM: multi-projection method.
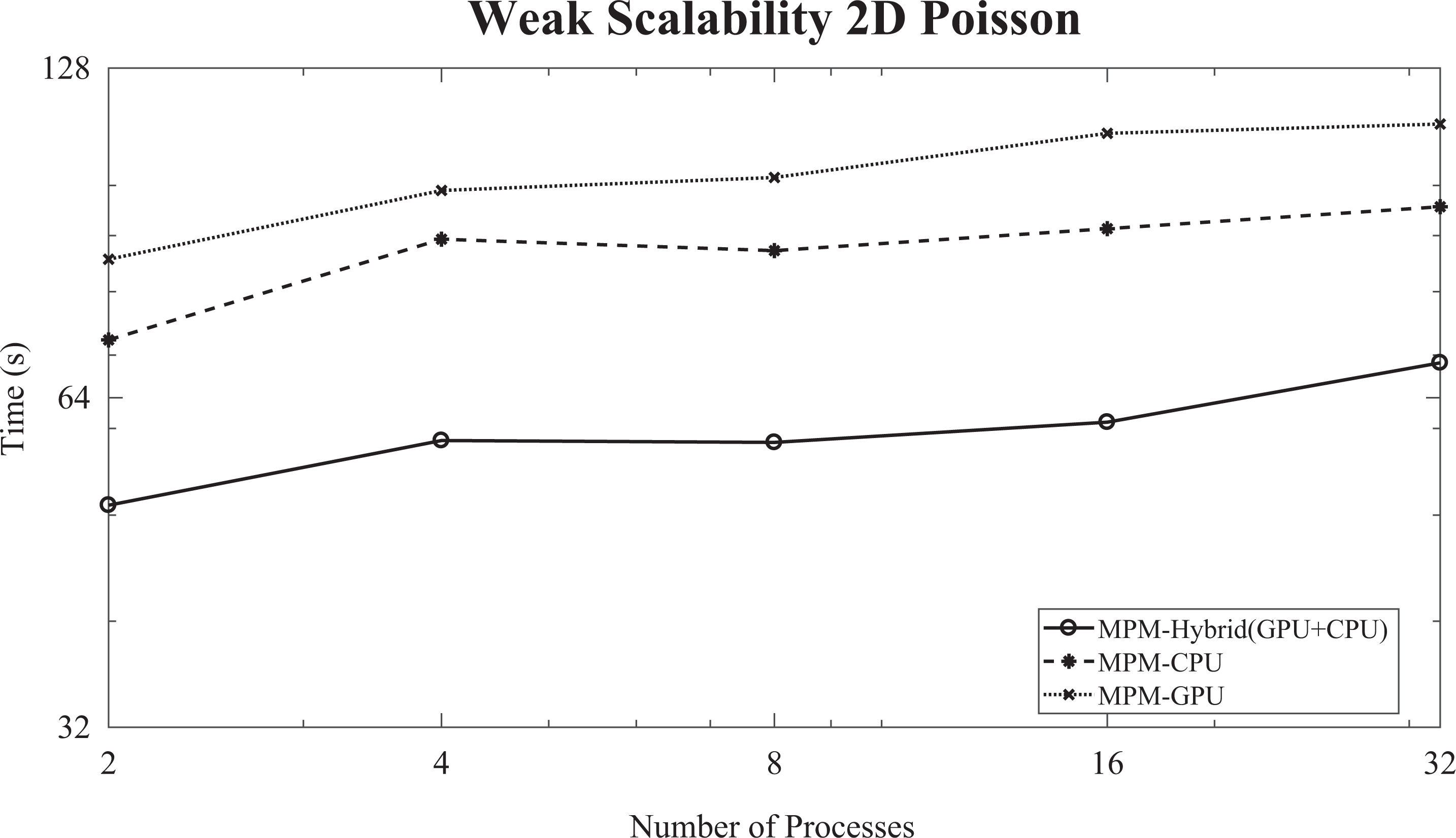
The weak scalability diagram (logarithmic scale) of the IPCG enhanced with the MPM preconditioning scheme for the 2-D Poisson problem (
5.2. 3-D Poisson problem
In order to further examine the convergence behavior and the parallel performance of the proposed method, the Poisson equation in three space variables discretized with the finite differences method has been considered. In Figure 16, the strong scalability diagram (logarithmic scale) of the IPCG method, enhanced with the MPM preconditioning scheme, for the 3-D Poisson problem (
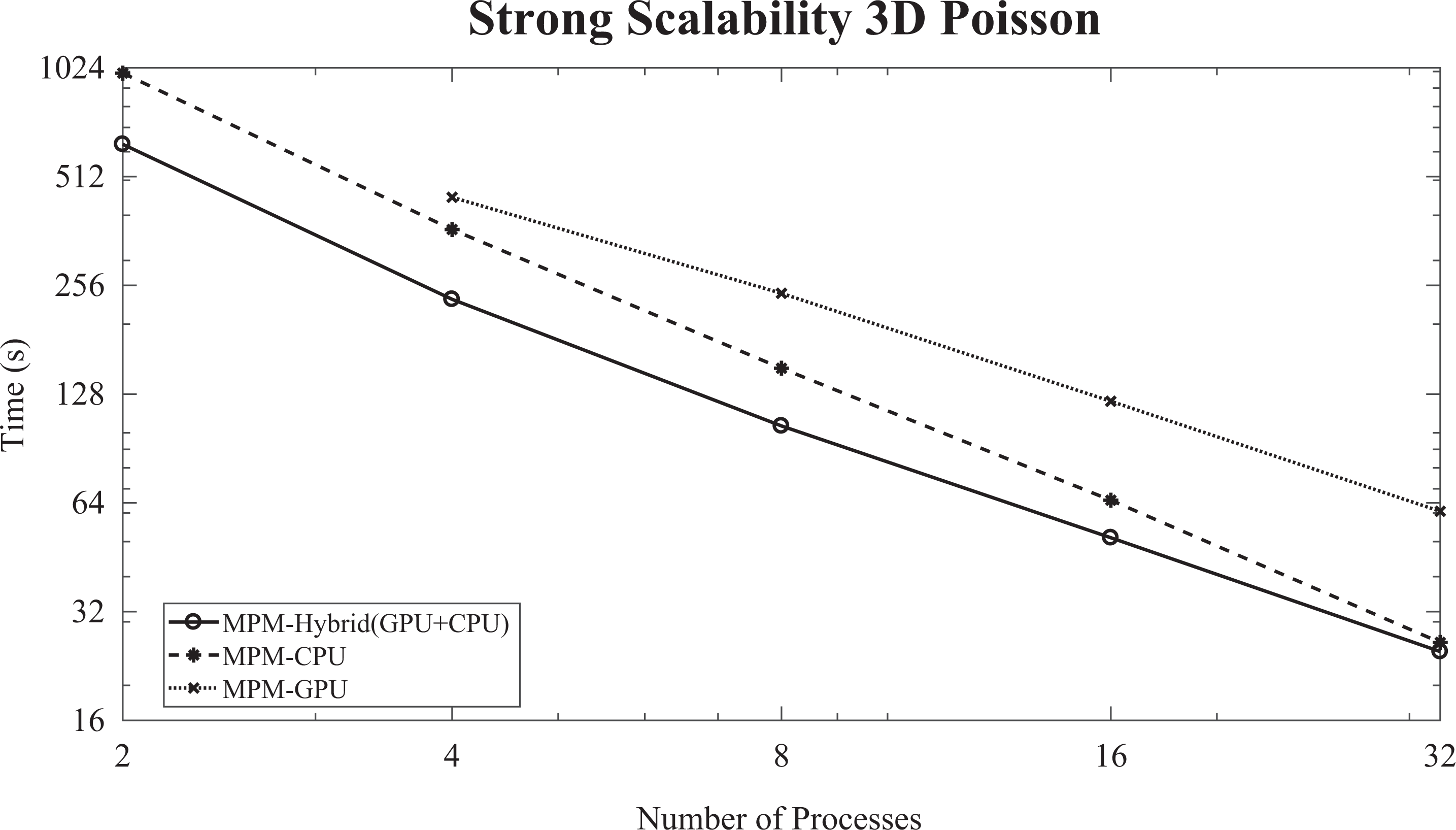
The strong scalability diagram (logarithmic scale) of the IPCG enhanced with the MPM preconditioning scheme for the 3-D Poisson problem (
The convergence behavior of the IPCG method, enhanced with the MPM preconditioning scheme, for the strong scalability diagram of the 3-D Poisson problem (

IPCG: inexact preconditioned CG; MPM: multi-projection method.
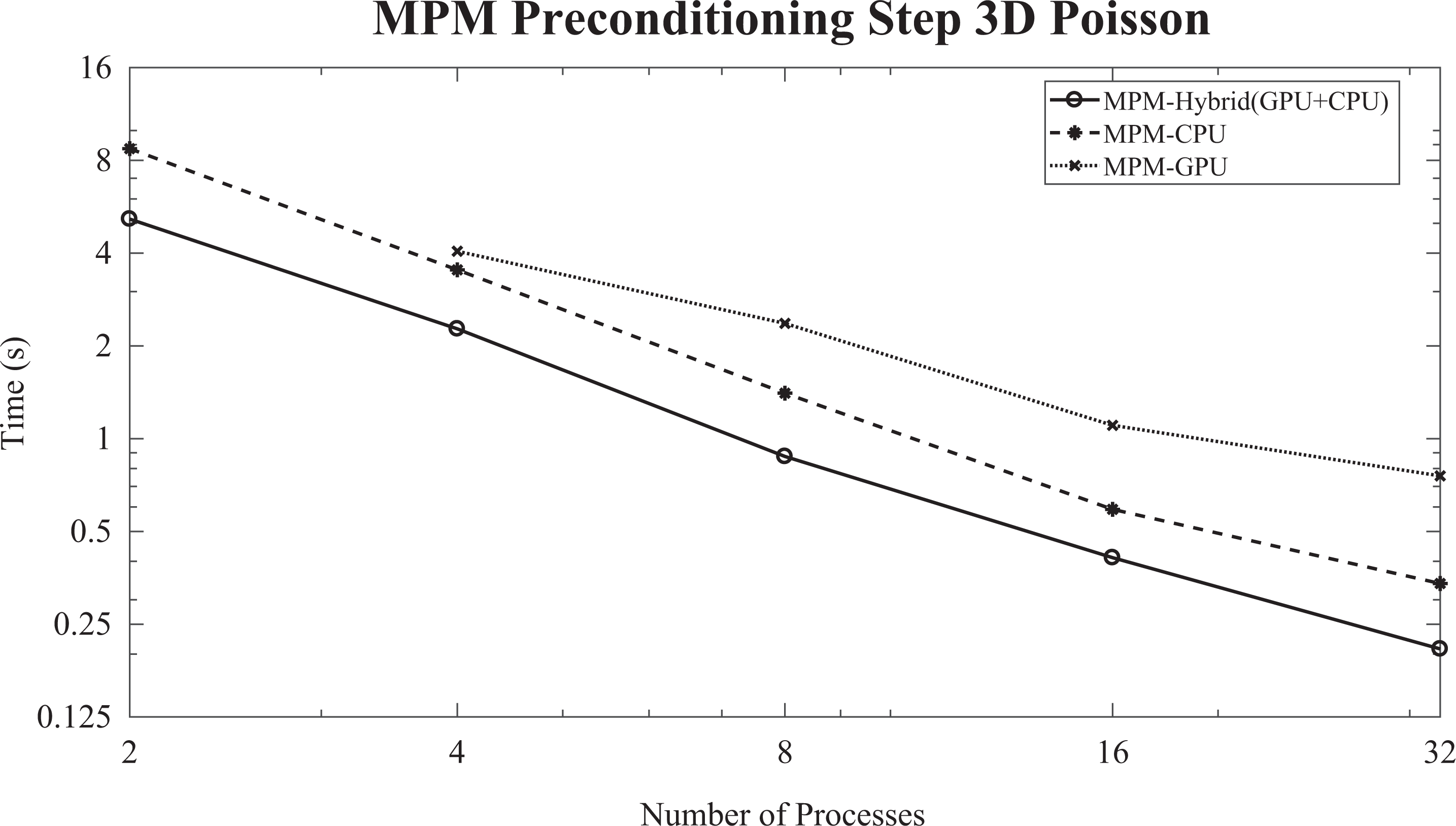
The performance (logarithmic scale) of the MPM preconditioning step for the 3-D Poisson problem (
Moreover, the weak scalability diagram (logarithmic scale) of the IPCG method, enhanced with the MPM preconditioning scheme, is presented in Figure 18. For each process added, the linear system is augmented by one million unknowns. The sizes of the coefficient matrices A and the convergence behavior of the proposed method for the weak scalability diagram of the 3-D Poisson problem are given in Table 6. It should be noted that the size of the linear system slightly affects the convergence behavior of the IPCG method, enhanced with the MPM preconditioning scheme. The required time for solving a linear system with 32 million unknowns is (0.65×) more than the time required for solving a linear system with 2 million unknowns, indicating the satisfactory weak scaling of the proposed method. The hybrid (GPU + CPU) MPM preconditioning scheme sometimes, for instance Figure 18, performs slightly more than twice faster than the GPU case, due to the increased number of offload operations, which cause a further delay. Additionally, the fact that the local linear systems, assigned to the GPUs, are solved one after the other, using fine-grained parallelism, causing the asymmetric workload on the GPU threads.
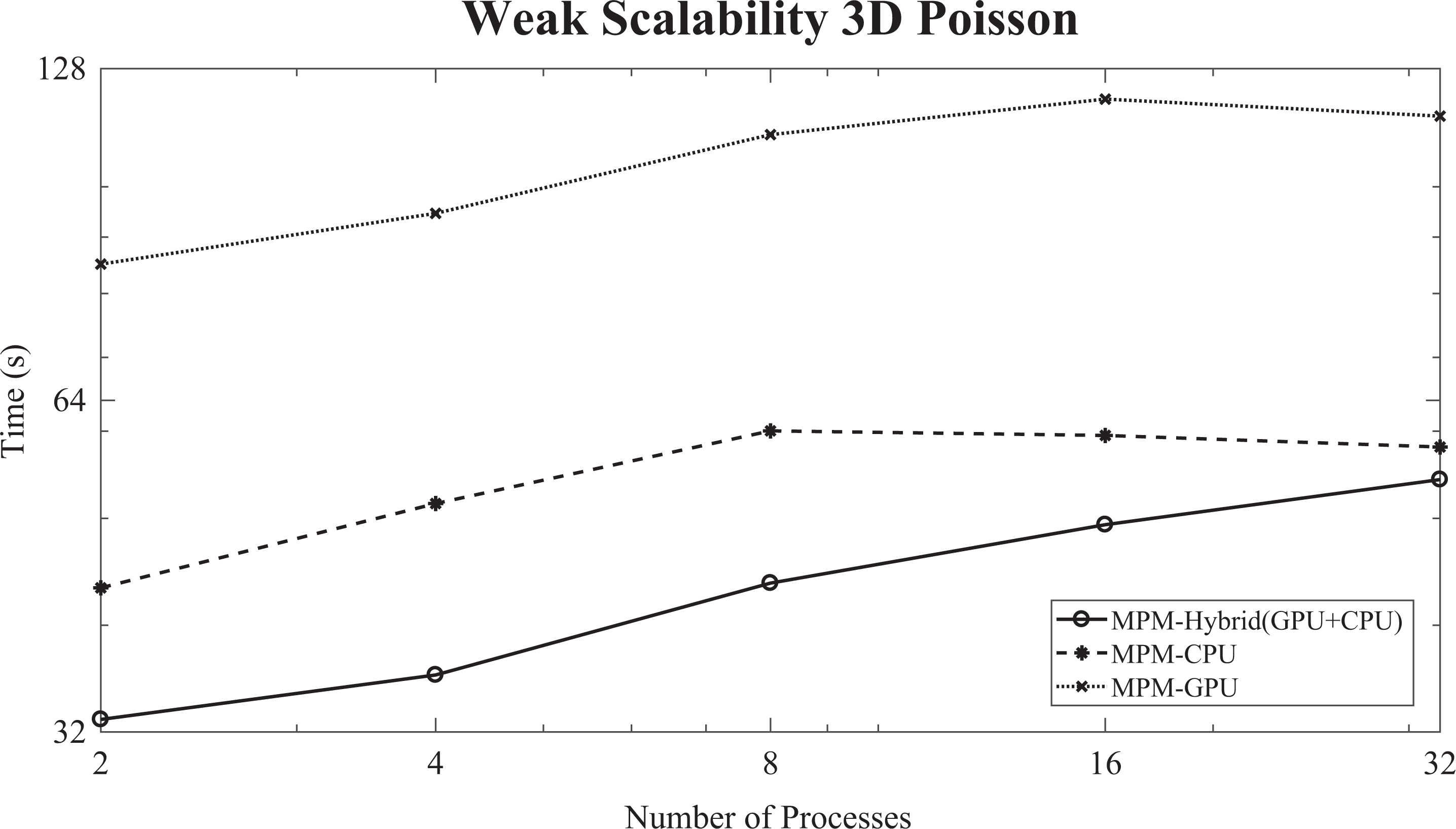
The weak scalability diagram (logarithmic scale) of the IPCG enhanced with the MPM preconditioning scheme for the 3-D Poisson problem (1 million unknowns per process) is shown. IPCG: inexact preconditioned CG; MPM: multi-projection method.
The sizes of the coefficient matrices A and the convergence behavior of the IPCG method, enhanced with the MPM preconditioning scheme for the weak scalability diagram of the 3-D Poisson problem.

IPCG: inexact preconditioned CG; MPM: multi-projection method.
5.3. SuiteSparse collection matrices
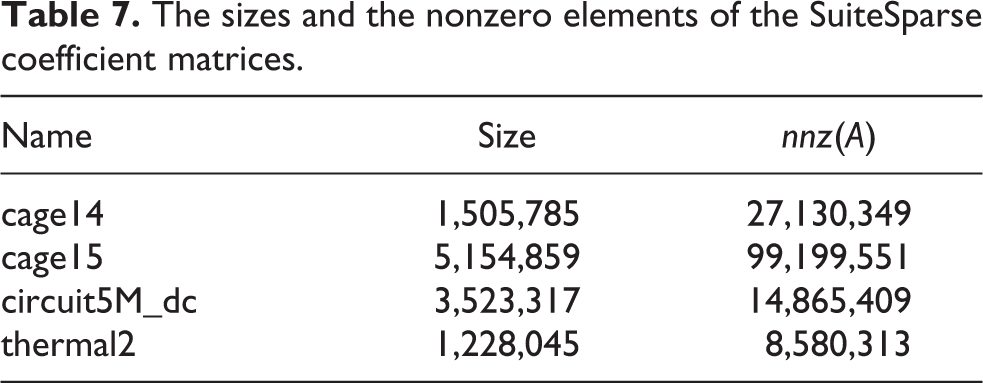
Numerical experiments were performed with various sparse coefficient matrices, obtained by the SuiteSparse matrix collection (Davis and Hu, 2011), examining the applicability, the convergence behavior, and the performance of the proposed method. The sizes and the nonzero elements of the SuiteSparse coefficient matrices are given in Table 7. The cage14, the cage15, and the circuit5M_dc are unsymmetric coefficient matrices, therefore are solved by the FGMRES(m) method enhanced with the MPM preconditioning scheme, whereas the thermal2 coefficient matrix is symmetric and is solved by the IPCG method along with the MPM preconditioning scheme.
The sizes and the nonzero elements of the SuiteSparse coefficient matrices.
The convergence behavior of the FGMRES(m)-IPCG method, enhanced with the MPM preconditioning scheme, for the SuiteSparse matrices is presented in Table 8. The strong scalability diagrams (logarithmic scale) of the proposed method for the SuiteSparse matrices, given in Table 7, are depicted in Figure 19. The performance (logarithmic scale) of the MPM preconditioning step for the SuiteSparse matrices, given in Table 7, is presented in Figure 20. The thermal2 problem case has been solved using up to 16 processes instead of 32, since the size and the number of nonzero elements are substantially reduced. In the cases of the cage14, cage15, and circuit5M_dc problems, the number of required iterations for convergence to the prescribed tolerance is retained constant as the number of subdomains increases, whereas it decreases for the thermal2 problem case. The performance and the strong scalability of the proposed method are improved using the hybrid CPU/GPU MPM preconditioning scheme, compared to the CPU-only and the GPU-only schemes, for every problem case and number of processes. Therefore, the load-balancing algorithm is suitable for general matrices and provides satisfactory speedup especially for large number of processes.
The convergence behavior of the FGMRES(m)-IPCG method in conjunction with the MPM preconditioning scheme for the SuiteSparse matrices, as given in Table 7.
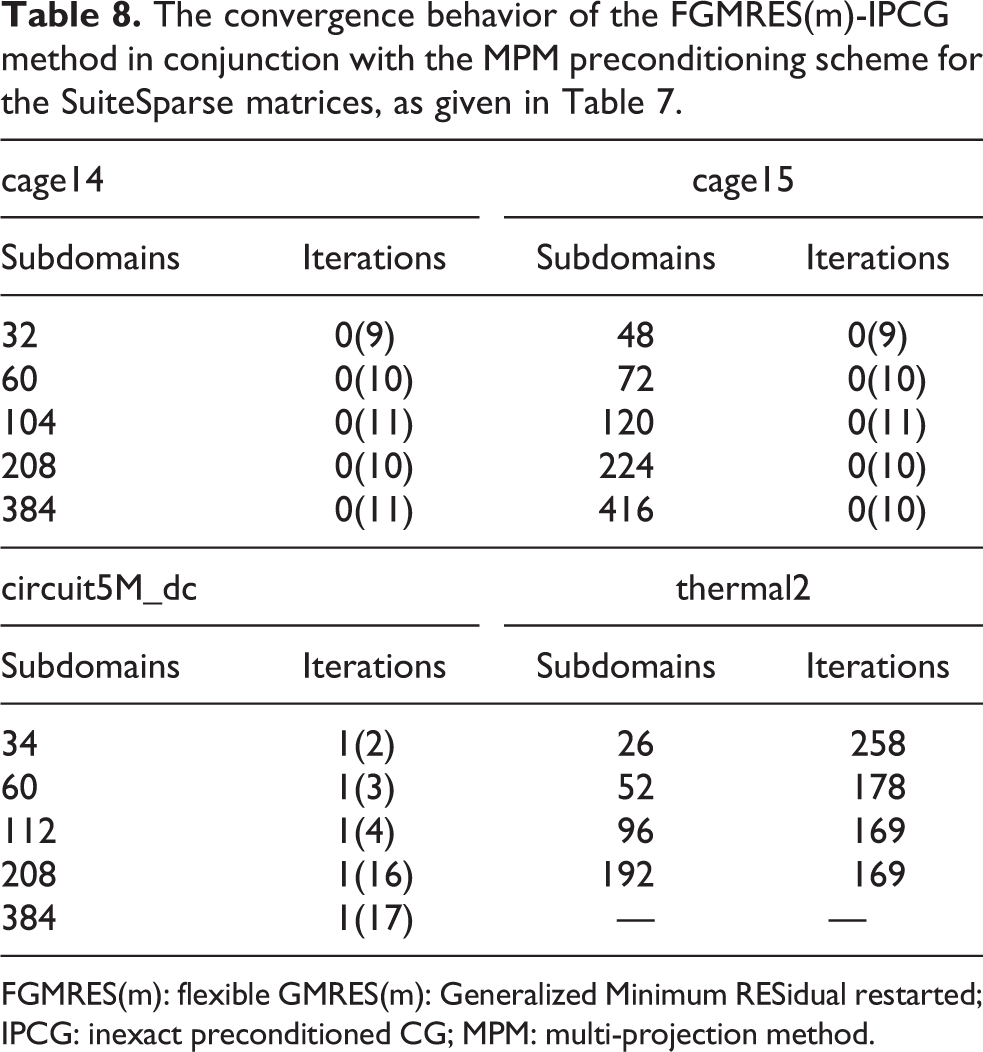
FGMRES(m): flexible GMRES(m): Generalized Minimum RESidual restarted; IPCG: inexact preconditioned CG; MPM: multi-projection method.
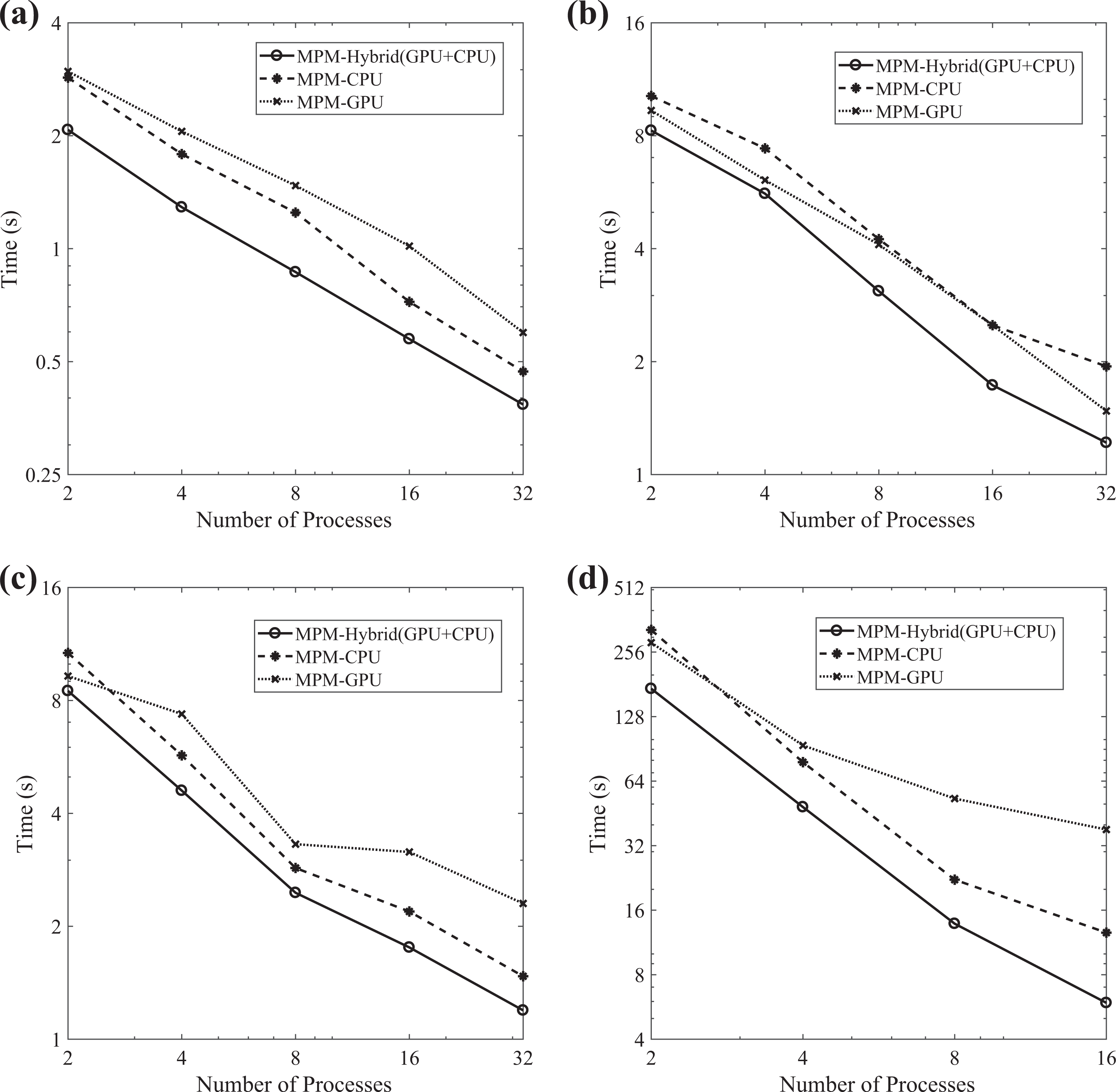
The strong scalability diagram (logarithmic scale) of the FGMRES(m)-IPCG enhanced with the MPM preconditioning scheme for the SuiteSparse matrices, as given in Table 7, is depicted: (a) cage14, (b) cage15, (c) circuit5M_dc, and (d) thermal2. IPCG: inexact preconditioned CG; FGMRES(m): flexible GMRES(m): Generalized Minimum RESidual restarted; MPM: multi-projection method.
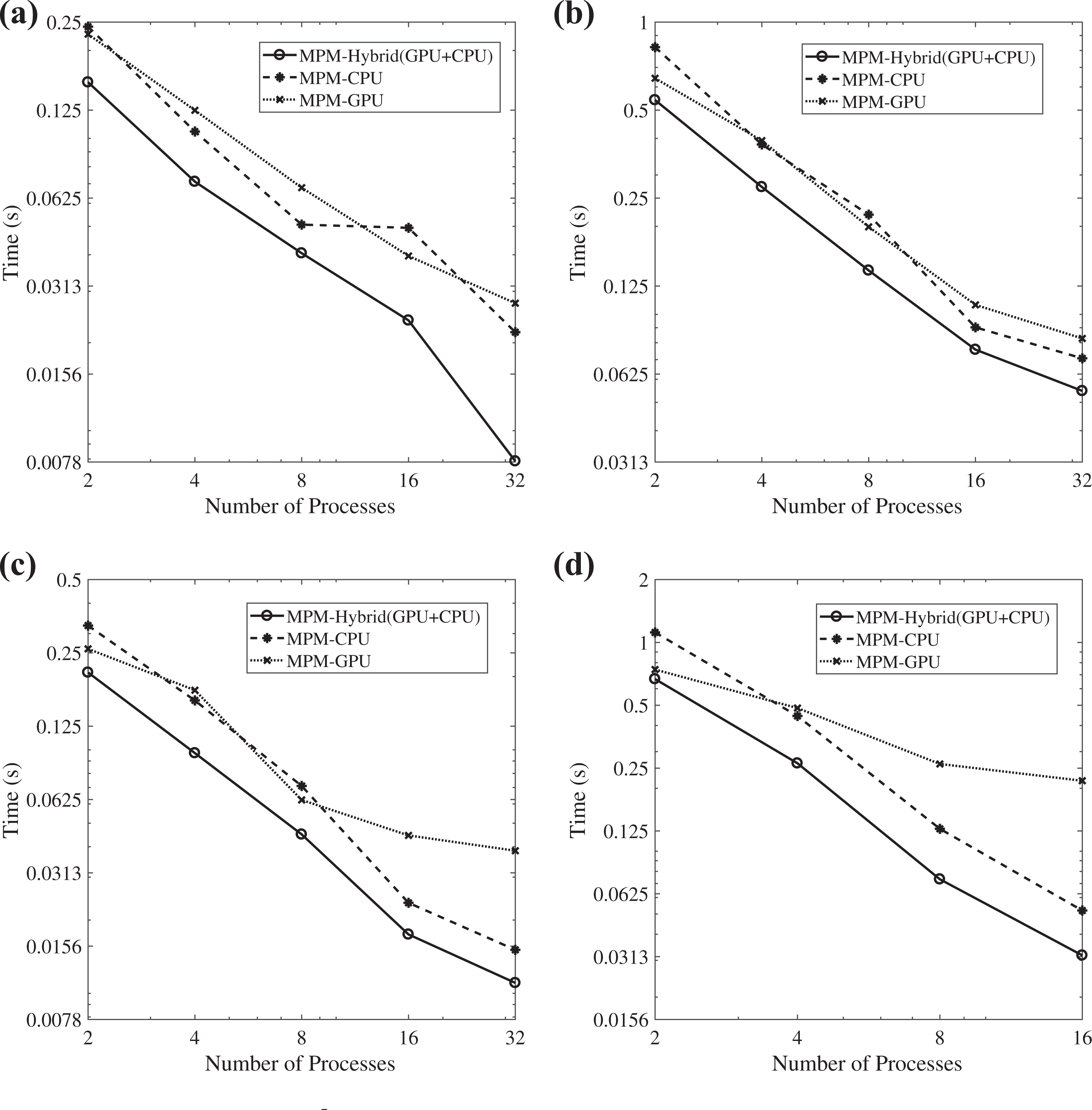
The performance (logarithmic scale) of the MPM preconditioning step for the SuiteSparse matrices, as given in Table 7, is presented: (a) cage14, (b) cage15, (c) circuit5M_dc, and (d) thermal 2. MPM: multi-projection method.
5.4. Comparison with local direct solver
The MPM can be implemented either by solving the local linear systems with a preconditioned Krylov subspace method or by using a direct method, such as PARDISO solver (Schenk and Gärtner, 2004). Numerical results concerning the latter case are presented in Moutafis et al. (2017a); however, a comparison with the proposed hybrid (GPU + CPU) MPM method is given in this subsection. It is well-known that the direct methods require excessive memory and substantial computational work, especially for large coefficient matrices, derived from 3-D problems. The proposed hybrid (GPU + CPU) MPM method has less memory requirements, allowing the solution of larger linear systems. The number of subdomains for the direct variant of the MPM preconditioning scheme has been selected such that each subdomain is mapped to one core of the distributed memory system. Whereas, for the hybrid scheme, it is selected according to the load-balancing algorithm. These choices have been made in order to present a more fair comparison between the two methods. For optimal performance, the hybrid (GPU + CPU) MPM scheme should be used with the number of subdomains that resulted from the load-balancing scheme, whereas the classical MPM scheme, with direct solver for the local linear systems, performs better by mapping one subdomain to one core of each processor. Assigning the same number of subdomains for both cases would cause a degraded performance for the classical MPM scheme, since only some cores would factorize (preprocessing phase) and solve (preconditioning step) two linear systems, instead of one. Therefore, significant increased floating-point operations would be performed by some cores, leading to unbalanced workload among the CPU cores. In Figure 21, the strong scalability diagram (logarithmic scale) of the total time for solving the 3-D Poisson problem (
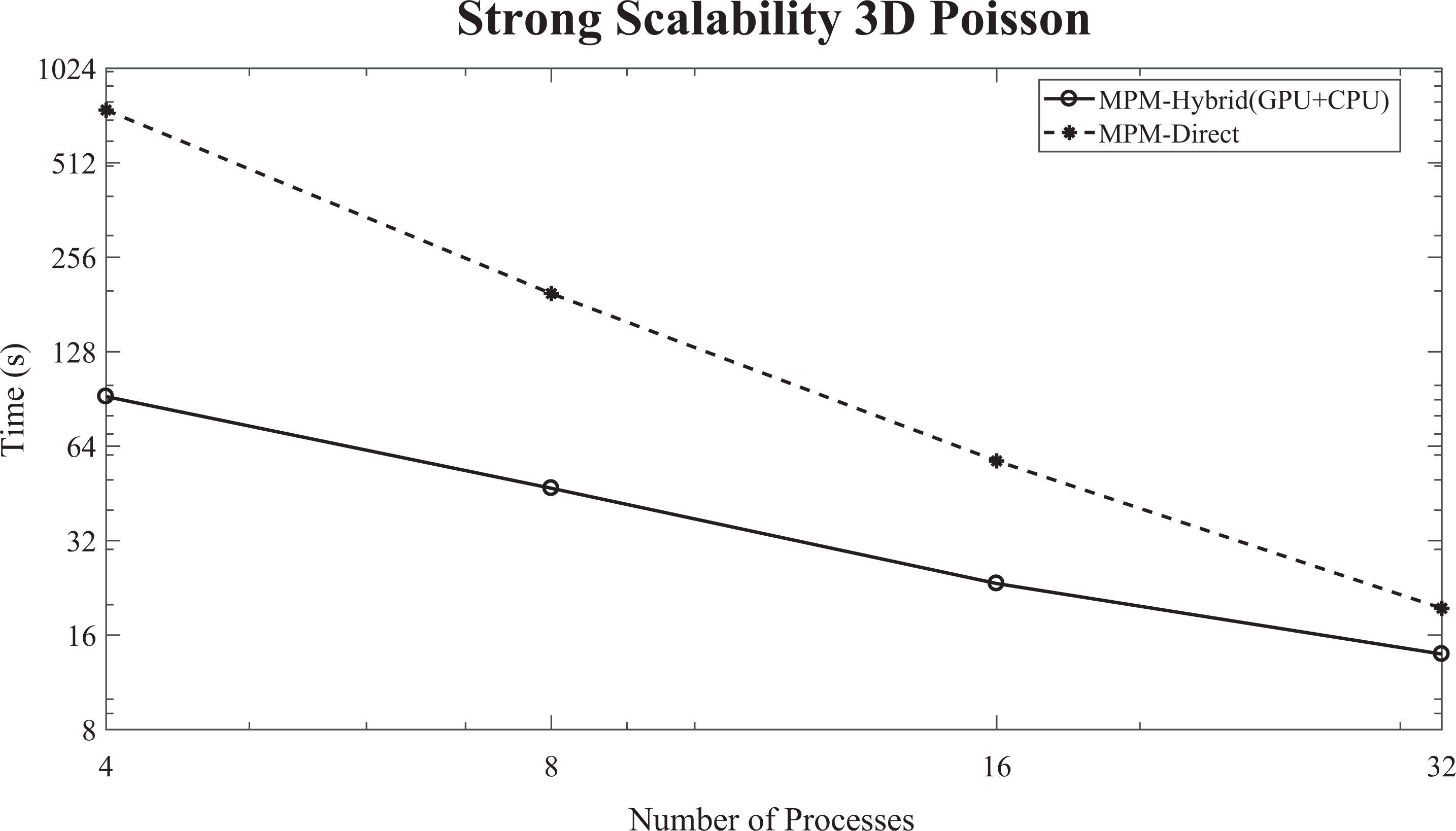
The strong scalability diagram (logarithmic scale) of the total time for solving the 3-D Poisson problem (
The convergence behavior of the IPCG method, enhanced with the hybrid and the direct MPM preconditioning schemes, for the 3-D Poisson problem (
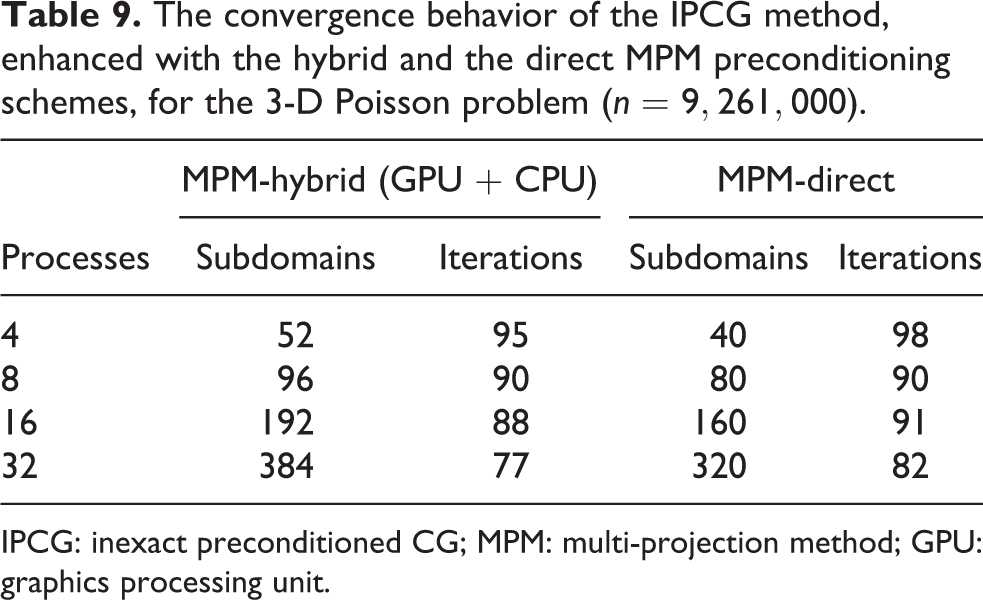
IPCG: inexact preconditioned CG; MPM: multi-projection method; GPU: graphics processing unit.
5.5. Comparison with RAS method
The proposed hybrid (GPU + CPU) MPM preconditioning scheme is compared to the RAS method preconditioning scheme (Cai and Sarkis, 1999) in order to further examine the convergence behavior, the performance, and the scalability. The RAS scheme is implemented for hybrid (GPU + CPU) workstations and is combined with the FGMRES(m) method for solving two-dimensional heterogeneous convection–diffusion problem (2-D hconvdiff) and three-dimensional heterogeneous convection–diffusion problem (3-D hconvdiff). The level of overlap is chosen to be either one (RAS-1) or two (RAS-2). The tolerance of the local preconditioned BiCGSTAB method is set to 1e-6.
The 2-D hconvdiff problem is derived from the following PDE
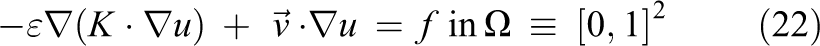

where
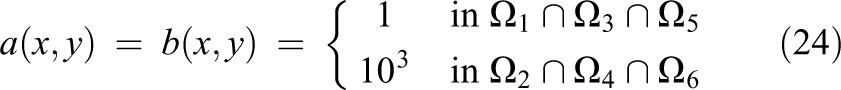
It should be noted that the domains
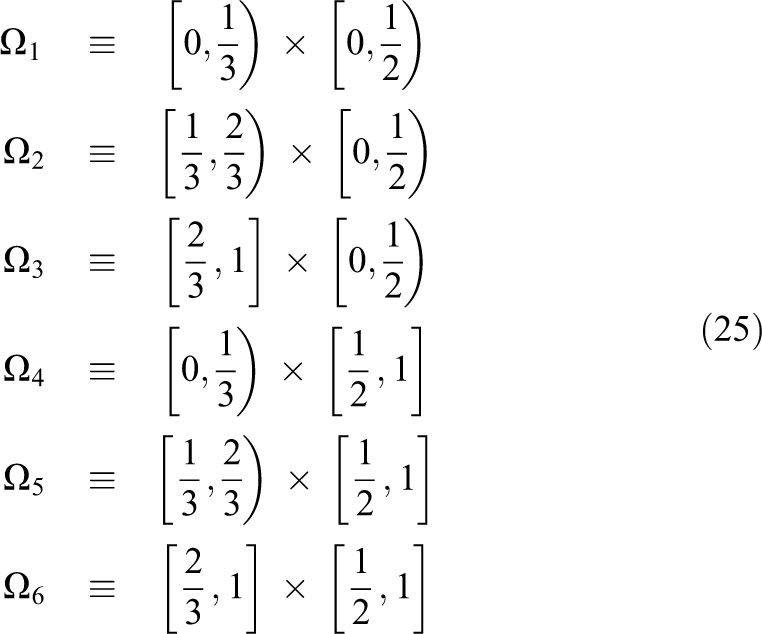
The vx
and vy
components of the vector
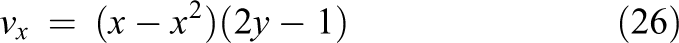
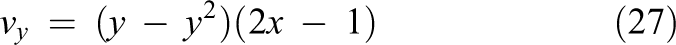
defining a convection term that is governed by a circular flow in the xy-direction. The five-point stencil of the finite difference method is used as discretization method. The 2-D hconvdiff problem
The convergence behavior of the FGMRES(m) method, enhanced with the MPM, the RAS-1, and the RAS-2 scheme, for both the cases of 2-D hconvdiff
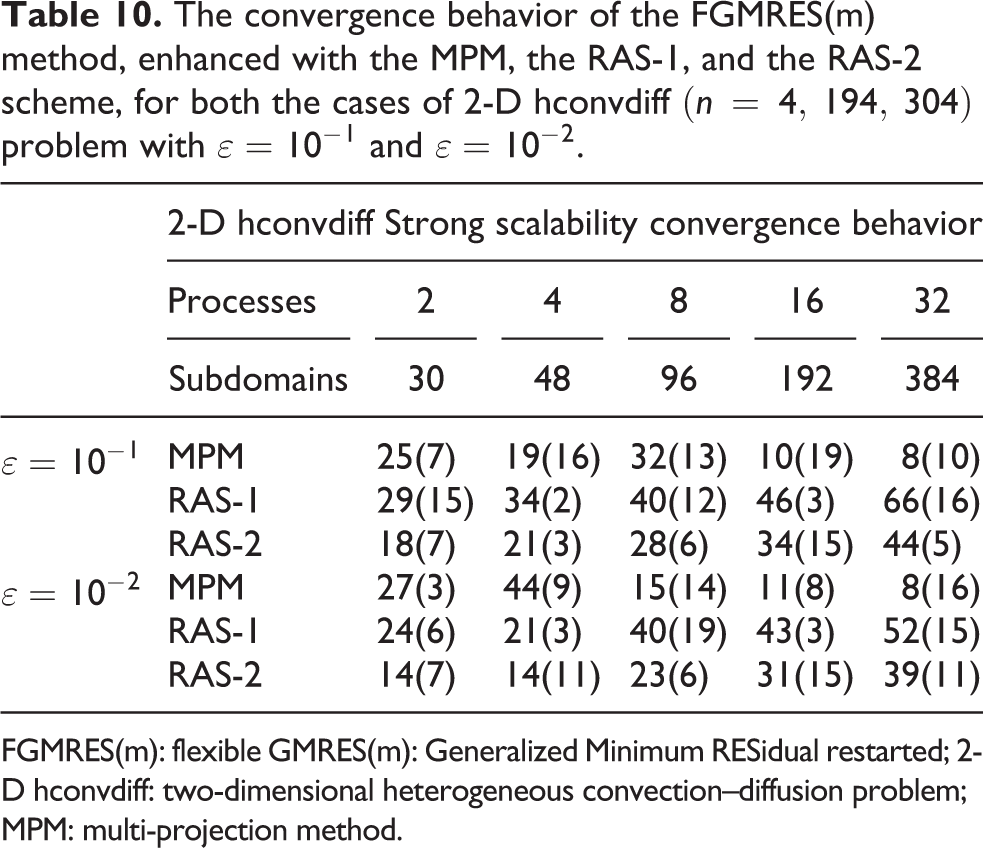
FGMRES(m): flexible GMRES(m): Generalized Minimum RESidual restarted; 2-D hconvdiff: two-dimensional heterogeneous convection–diffusion problem; MPM: multi-projection method.
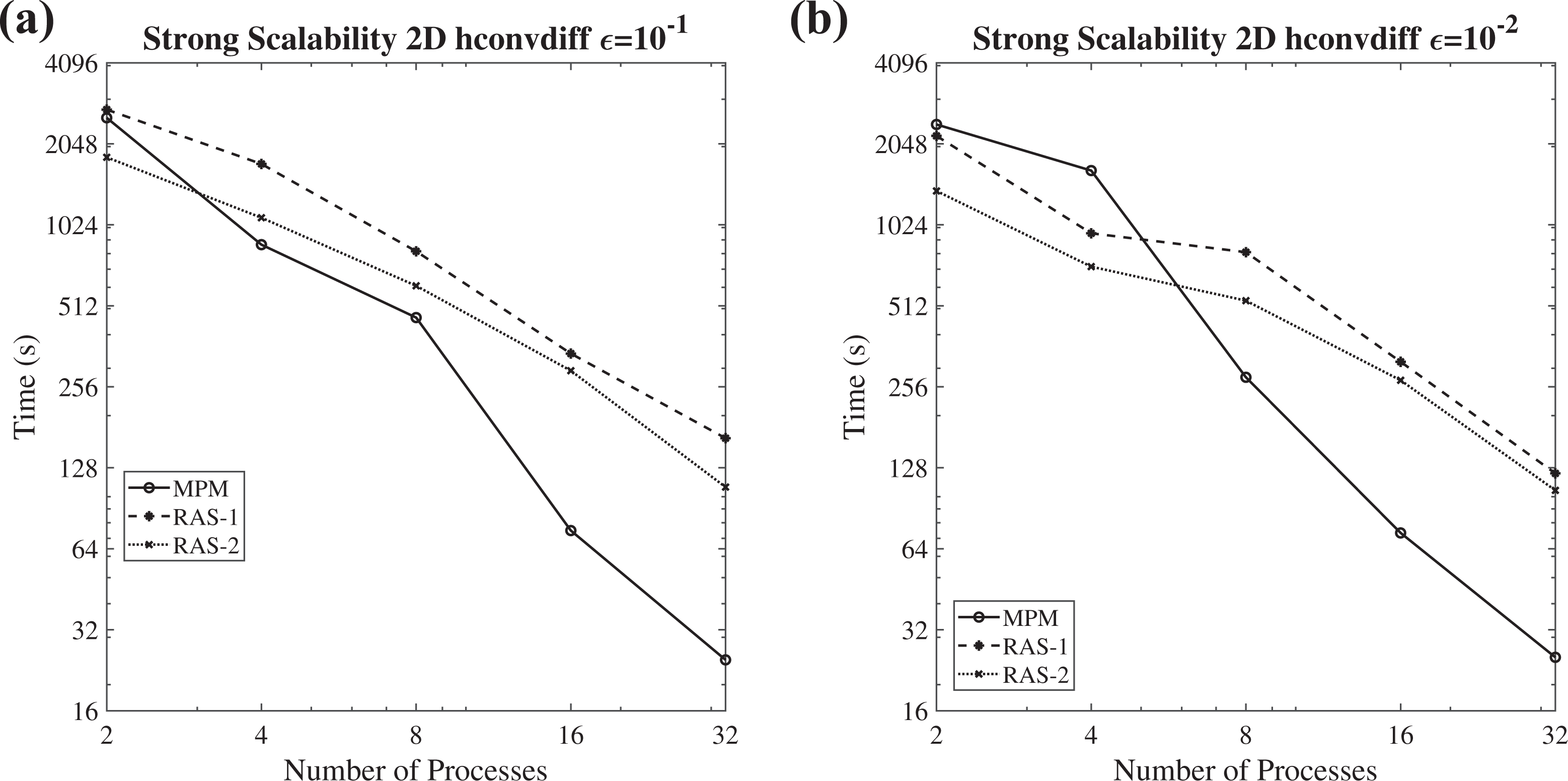
The strong scalability diagrams (logarithmic scale) of the FGMRES(m) along with the MPM, the RAS-1, and the RAS-2 scheme, for solving the heterogeneous convection–diffusion 2-D problem
In the case of larger number of subdomains, the MPM preconditioning scheme presents improved convergence behavior for solving the 2-D hconvdiff with both
The convergence behavior of FGMRES(m) method, in conjunction with the MPM, the RAS-1, and the RAS-2 scheme, for the weak scaling experiment of the 2-D hconvdiff problem with
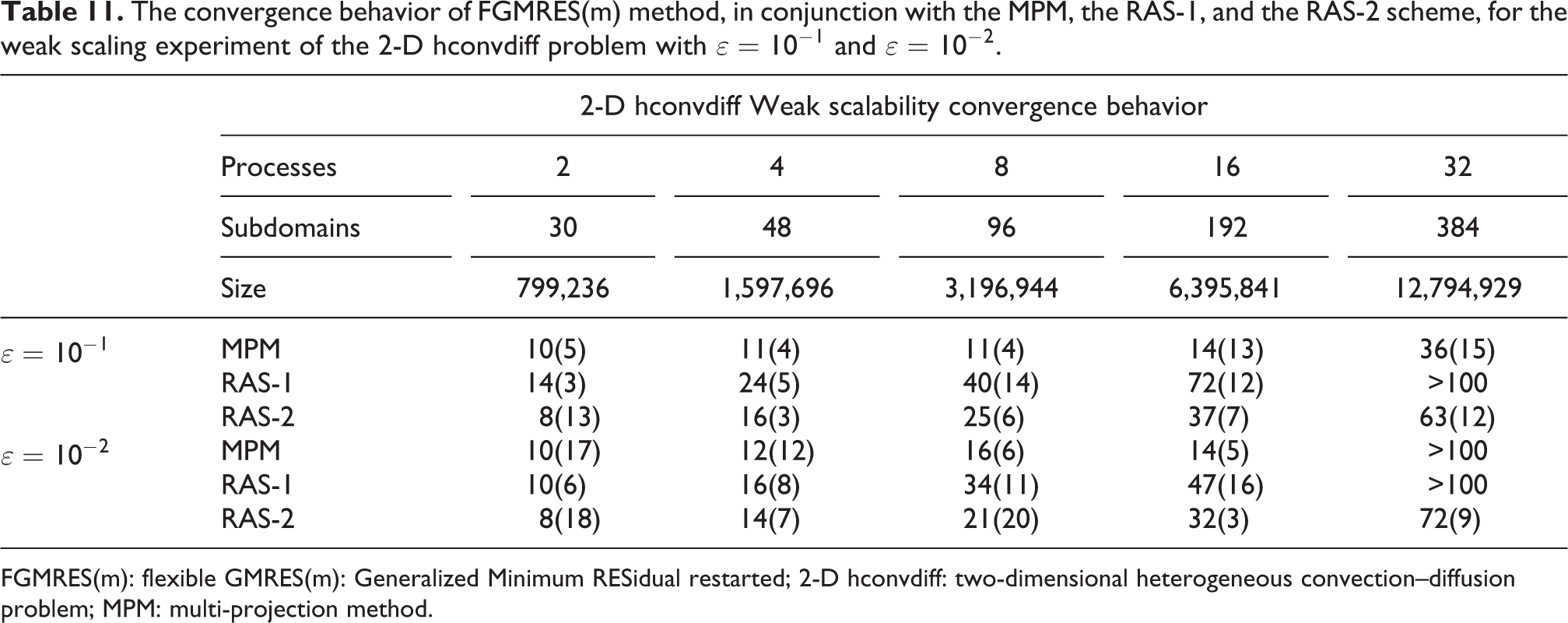
FGMRES(m): flexible GMRES(m): Generalized Minimum RESidual restarted; 2-D hconvdiff: two-dimensional heterogeneous convection–diffusion problem; MPM: multi-projection method.
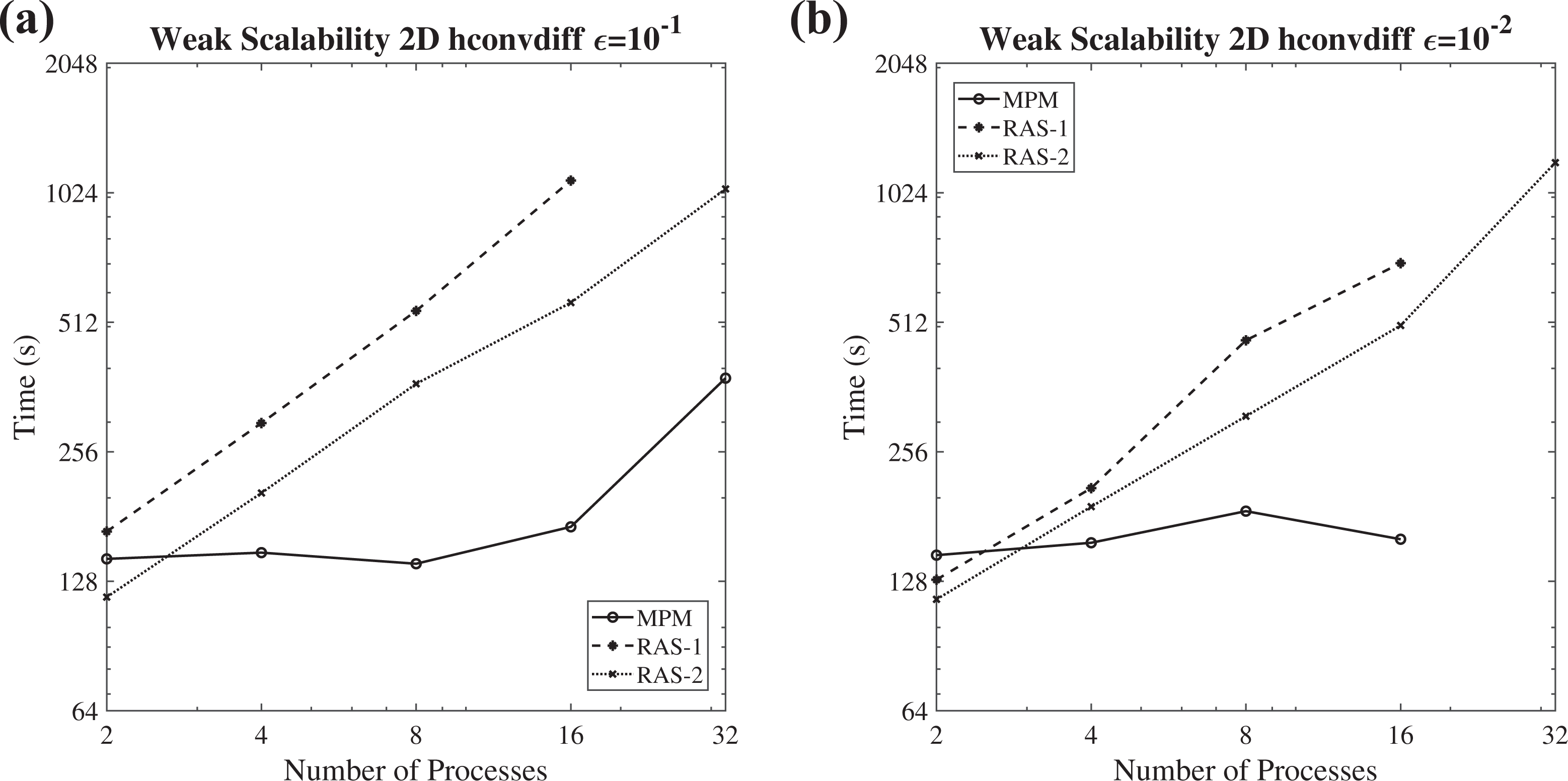
The weak scalability diagram (logarithmic scale) of the FGMRES(m) method, enhanced with the MPM, the RAS-1, and the RAS-2 scheme, for solving the heterogeneous convection–diffusion 2-D problem with (a)
The convergence behavior of the proposed method is improved compared to the RAS schemes in most of the cases, concerning the 2-D hconvdiff weak scaling experiment. In the case of 32 subdomains and
Furthermore, the 3-D hconvdiff is derived by the following PDE
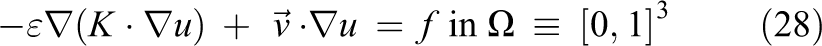

where
The matrix K is diagonal with piecewise constant function entries, described by the following set of diffusion coefficients in the x-, y-, and z-direction
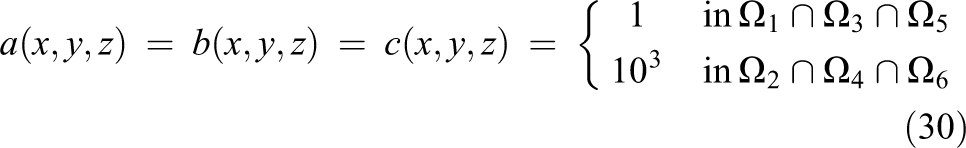
The domains
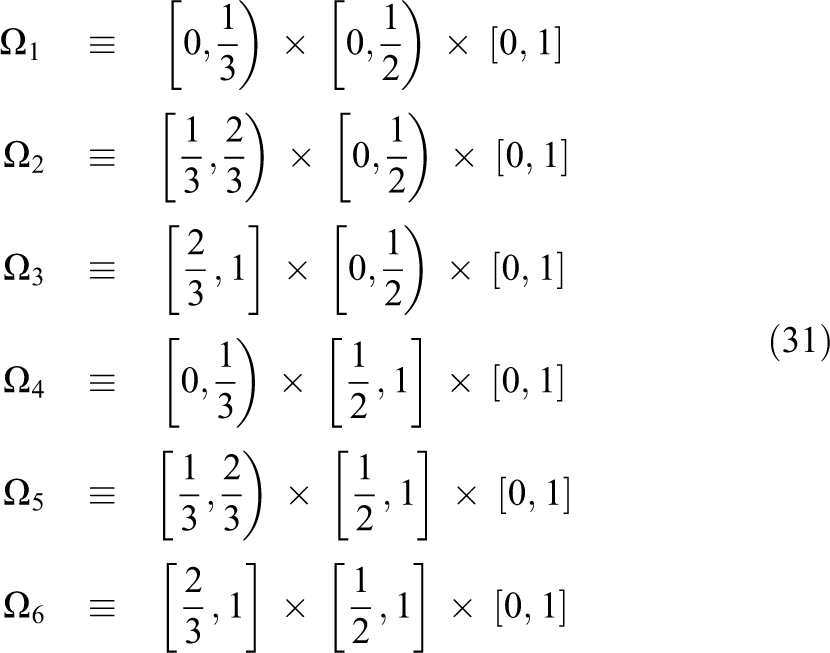
The
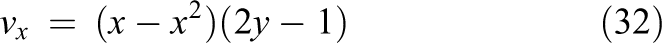
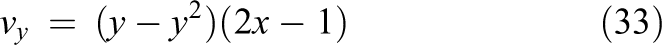

defining a convection term that is governed by a circular flow in the xy-direction and a sinusoidal flow in the z-direction. The seven-point stencil of the finite difference method is used as discretization method. The 3-D hconvdiff problem
The convergence behavior of the FGMRES(m) method, along with the MPM, the RAS-1, and the RAS-2 scheme, for the 3-D hconvdiff problem
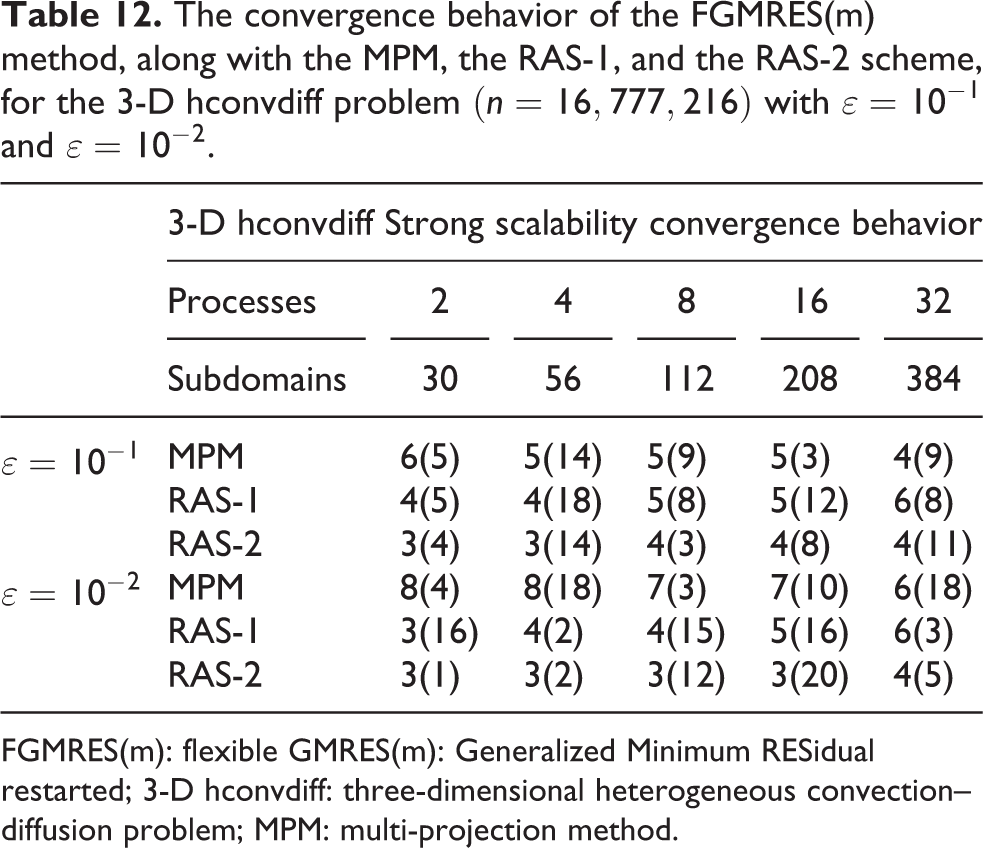
FGMRES(m): flexible GMRES(m): Generalized Minimum RESidual restarted; 3-D hconvdiff: three-dimensional heterogeneous convection–diffusion problem; MPM: multi-projection method.
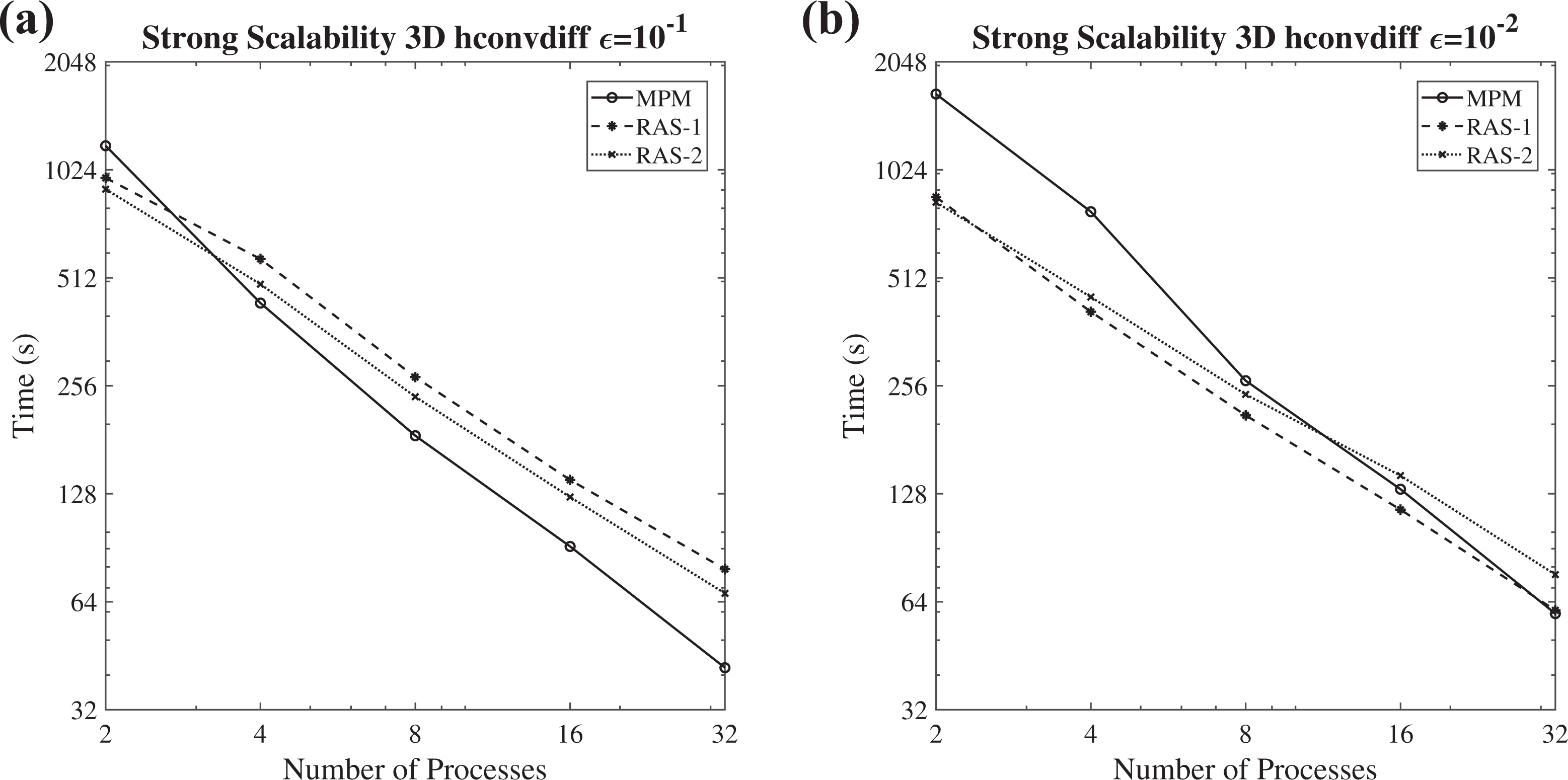
The strong scalability diagrams (logarithmic scale) of the FGMRES(m) along with the MPM, the RAS-1, and the RAS-2 scheme, for solving the heterogeneous convection–diffusion 3-D problem
In the case of
The corresponding weak scalability numerical experiment has been conducted for the 3-D hconvdiff problem, where the linear system is augmented by 1,000,000 unknowns per process. In Table 13, the convergence behavior of FGMRES(m) method, along with the MPM, the RAS-1, and the RAS-2 scheme, concerning the 3-D hconvdiff problem with
The convergence behavior of FGMRES(m) method, along with the MPM, the RAS-1, and the RAS-2 scheme, concerning the 3-D hconvdiff problem with
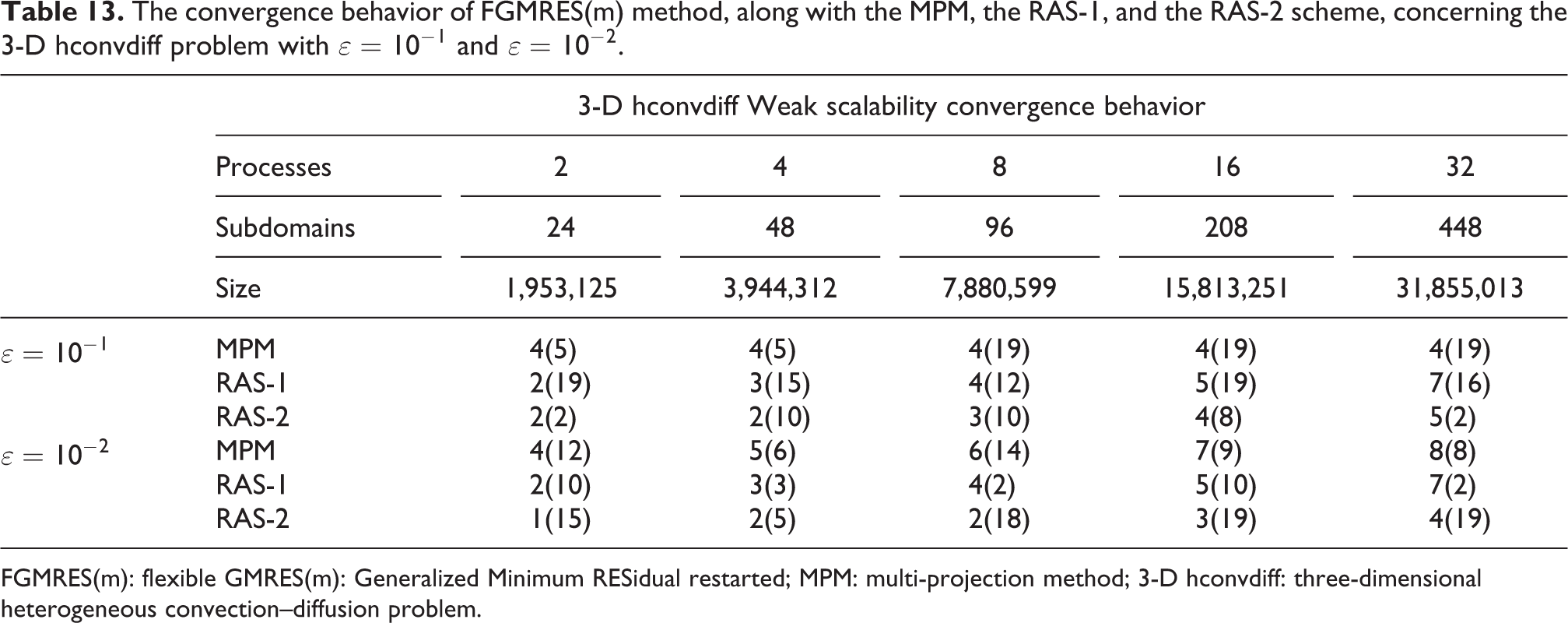
FGMRES(m): flexible GMRES(m): Generalized Minimum RESidual restarted; MPM: multi-projection method; 3-D hconvdiff: three-dimensional heterogeneous convection–diffusion problem.
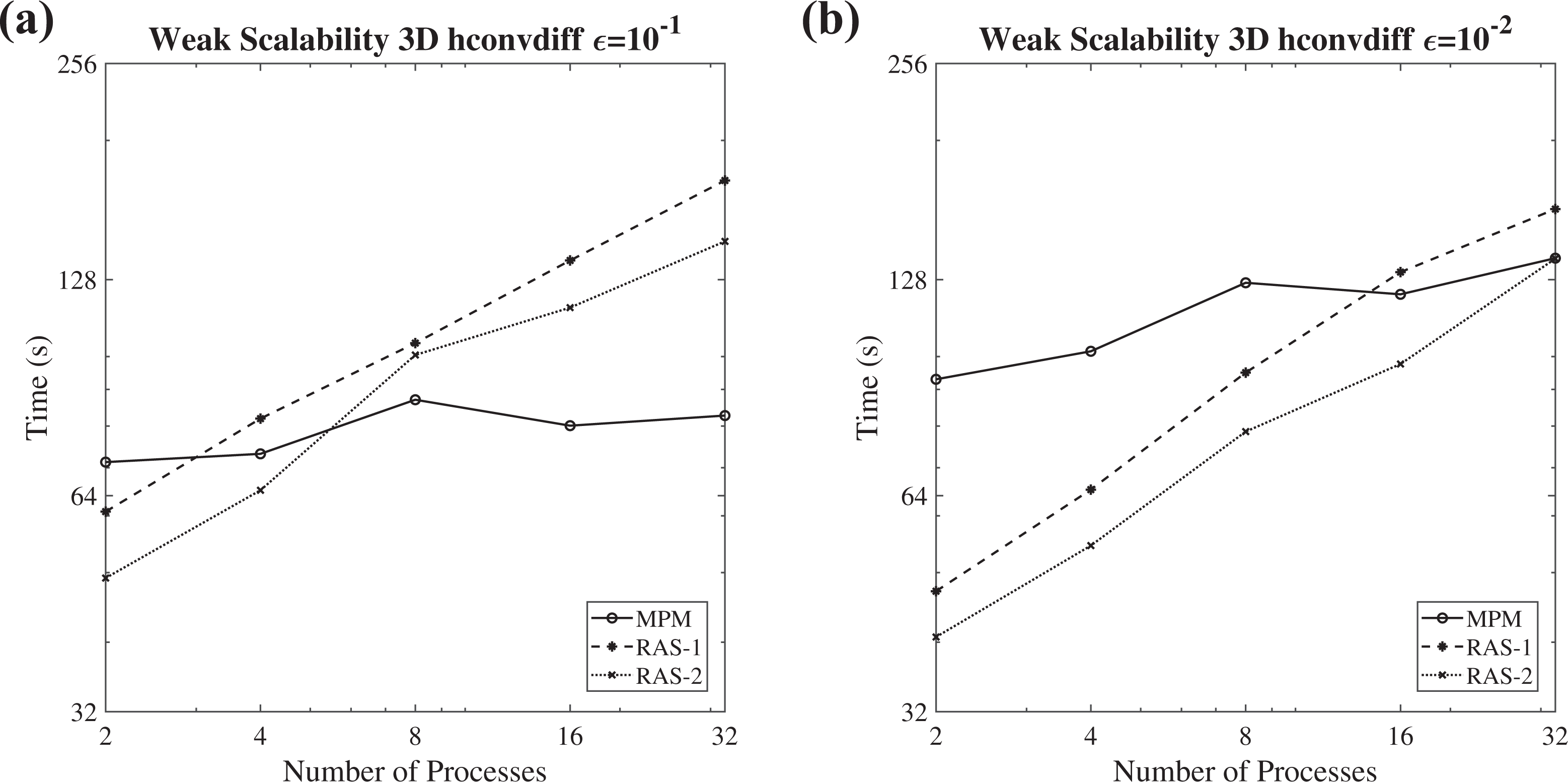
The weak scalability diagram (logarithmic scale) of the FGMRES(m) method, in conjunction with the MPM, the RAS-1, and the RAS-2 scheme, for solving the heterogeneous convection–diffusion 3-D problem for (a)
The MPM scheme requires almost constant number of iterations for convergence to the prescribed tolerance, especially for the
The comparison with the RAS preconditioning scheme indicates that the proposed method is suitable for large-scale GPU clusters, since it has improved convergence behavior as the number of subdomains increases, and presents satisfactory weak scaling.
6. Conclusion
The proposed hybrid MPM enhanced with generic factored approximate sparse inverse matrices has been shown to have satisfactory performance and convergence behavior for various model problems retaining almost constant number of iterations for convergence to the prescribed tolerance, for increasing numbers of subdomains. The hybrid MPM scheme, along with the proposed load-balancing algorithm, exploits the CPUs and GPUs of the distributed memory system appropriately, leading up to 1.7× speedup compared to the CPU-only case and up to 2× for the GPU-only case, especially for large number of subdomains. The BiCGSTAB-CG method, enhanced with the MGenFAspI-SFASI preconditioner, has been used for solving the local linear systems, since it can be parallelized efficiently in both the CPU and GPU environments. Furthermore, the use of coprocessors, such as GPUs, enables the concurrent processing of larger number of subdomains leading to improved convergence behavior of the hybrid MPM scheme. Future work will be concentrated on further improving the convergence behavior of the proposed method using different basis vectors in the semi-aggregation procedure. Moreover, advanced techniques based on communication avoidance and asynchronous communication would be combined with mixed precision computations on GPUs, resulting in improved performance for the FGMRES(m)-IPCG method along with the MPM preconditioning scheme. Another scientific area in which future work will be focused is the study of an analytical performance model for balancing the workload among the workstations.
Footnotes
Acknowledgment
The authors acknowledge the Greek Research and Technology Network (GRNET) for the provision of the National HPC facility ARIS under project PR004033-ScaleSciCompII and the project PR006053-ScaleSciCompIII.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research work of Byron E Moutafis, as a PhD candidate, was funded by the General Secretariat for Research and Technology (GSRT) and the Hellenic Foundation for Research and Innovation (HFRI) (Grant-Code: 1609).