
Abstract
High-resolution simulations of polar ice sheets play a crucial role in the ongoing effort to develop more accurate and reliable Earth system models for probabilistic sea-level projections. These simulations often require a massive amount of memory and computation from large supercomputing clusters to provide sufficient accuracy and resolution; therefore, it has become essential to ensure performance on these platforms. Many of today’s supercomputers contain a diverse set of computing architectures and require specific programming interfaces in order to obtain optimal efficiency. In an effort to avoid architecture-specific programming and maintain productivity across platforms, the ice-sheet modeling code known as MPAS-Albany Land Ice (MALI) uses high-level abstractions to integrate Trilinos libraries and the Kokkos programming model for performance portable code across a variety of different architectures. In this article, we analyze the performance portable features of MALI via a performance analysis on current CPU-based and GPU-based supercomputers. The analysis highlights not only the performance portable improvements made in finite element assembly and multigrid preconditioning within MALI with speedups between 1.26 and 1.82x across CPU and GPU architectures but also identifies the need to further improve performance in software coupling and preconditioning on GPUs. We perform a weak scalability study and show that simulations on GPU-based machines perform 1.24–1.92x faster when utilizing the GPUs. The best performance is found in finite element assembly, which achieved a speedup of up to 8.65x and a weak scaling efficiency of 82.6% with GPUs. We additionally describe an automated performance testing framework developed for this code base using a changepoint detection method. The framework is used to make actionable decisions about performance within MALI. We provide several concrete examples of scenarios in which the framework has identified performance regressions, improvements, and algorithm differences over the course of 2 years of development.
Keywords
1. Introduction
1.1. Motivation
The Greenland and Antarctic ice sheets contain the largest reserves of fresh water on Earth and have the greatest potential to cause changes in future sea level. The Special Report on the Ocean and Cryosphere in a Changing Climate (SROCC) Oppenheimer et al. (2019) pointed to ice sheets as one of the dominant contributors to rising and accelerating global mean sea level and stated that sea level will continue to rise for centuries due to mass loss from ice sheets. Projections for future sea-level rise are dependent on the ability of ice-sheet models (ISMs) to simulate ice-sheet mass loss, via a wide range of processes and instabilities, but major uncertainties in ice-sheet dynamics currently exist Oppenheimer et al. (2019); Pattyn et al. (2017).
In their 2007 Fourth Assessment Report, the Intergovernmental Panel on Climate Change (IPCC) defined clear deficiencies in then state-of-the-art ISMs’ ability to accurately capture dynamic processes and generally did not include these models when estimating future sea-level rise Randall et al. (2007). Ice-sheet modeling improved dramatically with progress from many community supported ice-sheet models Cornford et al. (2013); Gagliardini et al. (2013); Larour et al. (2012); Rutt et al. (2009); Winkelmann et al. (2011), and the IPCC’s Fifth Assessment Report noted the increased use of ISMs in climate models; however, major uncertainties remained Flato et al. (2014). Since then, there have been many studies which use multiple computational models to narrow these uncertainties; however, increasing computational cost remains a limiting factor Edwards et al. (2021); Seroussi et al. (2020); Levermann et al. (2020); Goelzer et al. (2020); Payne et al. (2021). The SROCC noted that high-resolution simulations without model simplifications are ultimately needed to obtain accurate projections of future global mean sea level Oppenheimer et al. (2019).
The increasing fidelity and resolution of ISMs pose significant computational challenges and demand their adoption of modern software techniques. This article focuses on performance portable methods and optimizations that can be used to improve and maintain scalable performance in the presence of ever-changing models, software and hardware.
1.2. Performance portability
High-resolution simulations of ice-sheet dynamics require a massive amount of memory and computation from large high-performance computing (HPC) clusters, which coincidentally have undergone a dramatic change over the past decade. The current list of fastest supercomputers TOP500 (2021) shows a diverse set of computing architectures, which typically include processors and accelerators from a variety of vendors. Software portability across these architectures is important for productivity, as the life cycle of a code base is typically much longer than the life cycle of individual supercomputers.
Though it may be tempting to construct a highly optimized implementation for current HPC systems, this type of software development will become increasingly harder to maintain as future models, software and hardware, become increasingly more complex. This motivates the need for fundamental abstractions to be present at the application-level during code development. In response to these ongoing challenges in HPC, performance portability has grown to become crucial for simulating physical phenomena at high resolutions.
Even with the urgency of the challenge, there is still no consensus on a clear definition for the term “performance portability” Neely (2016); Pennycook et al. (2021). In general, performance portability for an application means that a reasonable level of performance is achieved across a wide variety of computing architectures with the same source code. Here, “performance” and “variety” are also admittedly subjective. In Pennycook et al. (2016, 2017), performance portability is quantified through efficiencies based on both application and architecture performance for a given set of platforms. In Yang et al. (2018), this is extended to include the “roofline” model which captures a more realistic set of empirically determined performance bounds. In this article, we do not perform any quantitative performance analysis which would measure how efficiently the application performs on a given architecture (e.g., percentage of peak bandwidth or FLOP rate). Instead, this article focuses more on metrics for application-level performance portability such as application execution time and scalability efficiencies. This was sufficient to highlight performance improvements and identify areas that need improvement within the application.
As ISM codes evolve to be more robust, accurate, performant, and portable on the latest HPC systems, a heavier burden is placed on software developers to support and improve functionality. Maintaining developer productivity is crucial for delivering on scientific discovery. Unfortunately, productivity is difficult to quantify, with a wide range of possible metrics Forsgren et al. (2021). For scientific software development, version control and automated testing have been challenging to integrate Kanewala and Bieman (2014); Peng et al. (2021) but have shown to be effective methods for improving productivity.
Automated testing becomes even more important as performance portable libraries and frameworks improve and expand their capabilities. As discussed in Pennycook et al. (2021), these libraries and frameworks strive to improve developer productivity by reducing programming complexity and the need for platform-specific tuning while maintaining and improving performance. Staying up-to-date with these libraries and frameworks becomes crucial for maintaining an active code base which utilizes the latest HPC machines; however, maintaining performance portability in the presence of active development can be a difficult task. Small changes within a compiler, library, architecture, or code can cause dramatic changes to performance and performance deficiencies can be difficult to identify retroactively. Automated performance testing offers a means to improve productivity by reducing the time it takes to identify performance regressions and improvements to performance portability.
1.3. Previous related work
Traditionally for HPC, ISM codes relied solely on Message Passing Interface (MPI) libraries to achieve performance on supercomputers. MPI focuses on distributed memory parallelism, where memory may need to be communicated across multiple compute nodes. In Gagliardini et al. (2013), a 60% weak scalability efficiency is computed on a set of Greenland ice-sheet meshes for the full Stokes solver in Elmer/Ice using 168 to 1092 cores. The computational component of the hybrid “SSA + SIA” model in PISM is found to scale well on up to 1024 cores in Dickens (2015) but the I/O component is found to scale poorly. In Fischler et al. (2021), low-overhead performance instrumentation is developed for the “Blatter-Pattyn” model in ISSM and good scaling is found on up to 3072 cores. The study finds that matrix assembly and I/O begins to scale poorly and highlights the importance of continuous performance monitoring.
A code with MPI-only parallelism is not able to take advantage of the computational throughput available on shared memory architectures including compute nodes with dedicated GPUs. GPUs can provide substantial performance improvements to existing ISMs if properly utilized. In Brædstrup et al. (2014), a CUDA implementation of the “iSOSIA” approximation is used to show that higher-order ice flow models can be significantly accelerated with NVIDIA GPUs. FastICE is introduced in Räss et al. (2020) as a parallel, GPU-accelerated full Stokes solver developed in CUDA, which utilizes a matrix-free method with pseudo-transient continuation. This is extended to a portable framework written in Julia in Räss et al. (2022) and a parallel efficiency over 96% on 2197 GPUs is achieved.
In this work, the velocity solver in MPAS-Albany Land Ice (MALI), which uses the “Blatter-Pattyn” model formulation, is extended to be performance portable using a multigrid preconditioned Newton-Krylov method where extensive improvements have been made to matrix assembly performance. The performance and scalability of MALI and its velocity solver is analyzed on multiple architectures, including Intel Knights Landing (KNL) and NVIDIA V100 GPUs. The testing framework in MALI is also extended to include performance monitoring with automated detection of performance regressions and improvements using a unique changepoint detection method.
MALI (Hoffman et al. (2018)) is an ice-sheet model built on top of two main libraries: The MPAS (Model for Prediction Across Scales) library Ringler et al. (2013), written in Fortran and used for developing variable resolution Earth system model components, and Albany, a C++ finite element code for solving partial differential equations Salinger et al. (2016). The performance of MALI is dominated by the solution of the first-order approximation to the Stokes equations (hereafter simply first-order velocity or first-order; see Section 2 below); hence, the performance portability efforts described in this work have been mainly targeting the C++ implementation of these equations in Albany. We note that MALI can model several additional physical processes including the ice temperature evolution, subglacial hydrology, and iceberg calving Hoffman et al. (2018).
Albany uses high-level abstractions to integrate Trilinos libraries Heroux et al. (2005) and the Kokkos programming model Edwards et al. (2014); Trott et al. (2022) for performance portable code across a variety of different architectures. Albany follows an “MPI + X” programming model, where MPI is used for distributed memory parallelism and the Kokkos library is used for shared memory parallelism. Kokkos provides abstractions for parallel execution and data management of shared memory computations in order to obtain optimal data layouts and hardware features, reducing the complexity of the application code. The performance portable implementation in Albany is described in detail in Demeshko et al. (2018), where the authors highlight finite element assembly performance for Aeras, the atmospheric dynamical core implemented in Albany.
Albany Land Ice (ALI) is first introduced in Tezaur et al. (2015a) under the name Albany/FELIX. In Tezaur et al. (2015b); Tuminaro et al. (2016), the scalability of the multigrid preconditioned velocity solver is analyzed on up to 1024 cores. An initial study on the performance portability of the finite element assembly showed deficiencies in distributed memory assembly on GPU architectures in Watkins et al. (2020), but performance and scalability were reasonable among different architectures.
In this article, we highlight recent improvements to finite element assembly that eliminate previous deficiencies. We also begin analyzing a new, performance portable velocity solver in ALI and expand our performance analysis to MALI.
1.4. Main contributions
The MALI code was developed in response to the growing challenges in developing a more accurate and efficient ISM Hoffman et al. (2018). In this article, the performance portable features of MALI are introduced and analyzed on the two supercomputing clusters: NERSC Cori and OLCF Summit. A changepoint detection method is also introduced and tested for automated performance testing on next generation architectures. The main contributions of this work are summarized as follows: • Insights into the development of a performance portable, finite element code base using high-level abstractions from Trilinos libraries and the Kokkos programming model. • A description of new, performance-enhancing features introduced in MALI and an analysis demonstrating the expected improvements on different HPC architectures, including Intel Knights Landing (KNL) and NVIDIA V100 GPUs. • A weak scalability study and a demonstration of speedup over CPU-only simulations. • Insights into the development of a changepoint detection method for automated performance testing and demonstrations of tracking performance regressions, improvements, and differences between algorithms.
The methods introduced focus on improving performance portable modeling in MALI but are extensible to other applications targeting HPC. To the best of our knowledge, this is the first example of performance portability in a large, active code base which runs large simulations of ice sheets.
The remainder of this article is organized as follows. Section 2 introduces the ice-sheet equations relevant to our analysis. Section 3 gives a detailed overview of how these equations are implemented, solved, and verified in MALI. In Section 4, the methods used to achieve, improve, and maintain performance portability in MALI are introduced. Section 5 provides three numerical examples that demonstrate the expected performance of MALI on HPC systems and the utility of automated performance testing. Conclusions are offered in Section 6.
2. The governing ice-sheet equations
In this section, the main equations governing ice-sheet dynamics are briefly discussed. The section begins with a description of the first-order velocity equations and is followed by a description of the mass continuity equations. More information can be found in Hoffman et al. (2018); Tezaur et al. (2015a). In this work, we will always assume a “topologically extruded” ice-sheet geometry, meaning that the ice-sheet geometry can be obtained by vertically extruding the two-dimensional (2D) basal area, according to the local ice thickness. A consequence of this assumption is that the margin of the ice sheet is always vertical, though the ice thickness is typically small at grounded glacier termini.
At the ice-sheet scale, ice behaves as a highly viscous, shear-thinning, incompressible fluid and can be modeled by nonlinear Stokes equations. In this article, a first-order approximation Dukowicz et al. (2010); Schoof and Hindmarsh (2010) of the Stokes equations is considered, often referred to as the “Blatter-Pattyn” model Blatter (1995); Pattyn (2003) or the “first-order” model. The model is quasi-static with static velocity (momentum balance) equations coupled to a dynamic thickness (mass) equation. In conservative form, the three-dimensional (3D), first-order velocity equations are written as
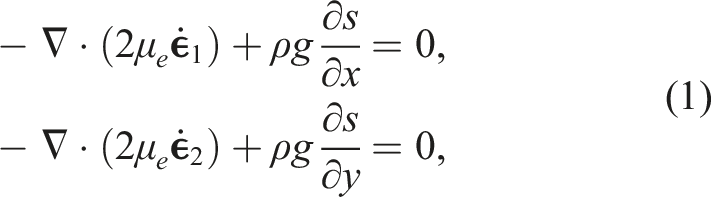
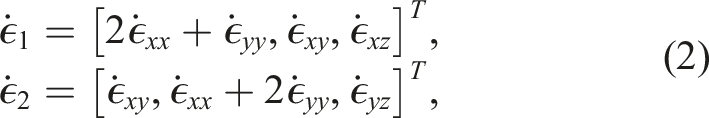
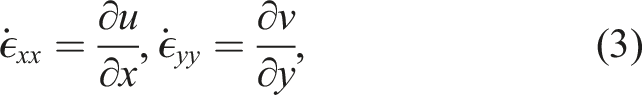
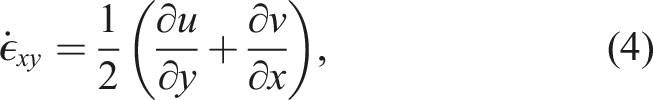
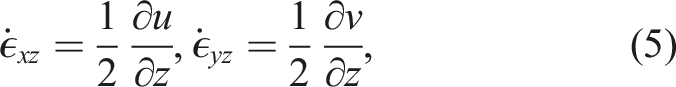
The effective viscosity, μ
e
, in equation (1) is derived from Glen’s flow law Cuffey and Paterson (2010); Nye (1957) and is written as

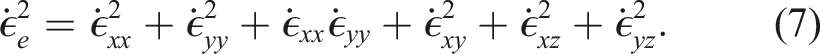
The flow law rate factor in equation (6) is strongly temperature dependent and is determined through an Arrhenius relation
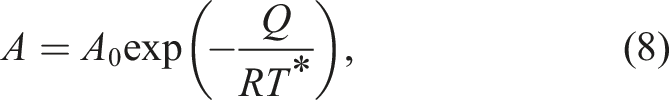
The boundary conditions are best described by partitioning the surface of the 3D ice-sheet domain into upper, lower, and lateral surfaces 1. A homogeneous boundary condition on the upper surface (atmosphere pressure is neglected), 2. A Robin boundary condition on the lower surface, representing a linear sliding law at the bed, 3. A dynamic Neumann boundary condition at the ice margin accounting for the back pressure from the ocean where the ice is submerged (note that by convention z = 0 represents the sea level),
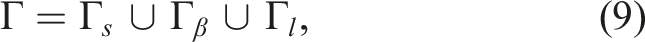
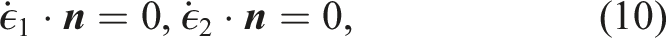
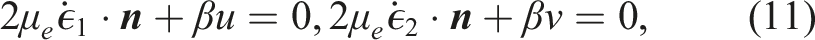
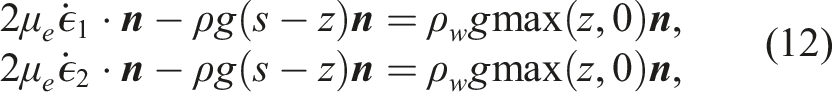
The steady velocity equations described above are coupled to a dynamic equation for the conservation of mass. Specifically, as the ice sheet evolves in time, mass continuity is enforced through the following equation
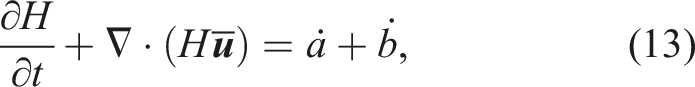
3. Implementation in MALI
In this section, we describe how the governing equations introduced in Section 2 are discretized and implemented in MALI, focusing in particular on the C++ velocity solver model in ALI. We first give a high-level overview of the implementation and then provide a detailed description for the two more computationally expensive components relevant to the article: the finite element assembly and the preconditioned linear solver. A brief description of the MALI testing framework follows.
3.1. Overview
The ice thickness H in equation (13) is discretized in MPAS with an upwind finite volume method on an unstructured, two-dimensional, Voronoi grid Hoffman et al. (2018). At every time step, the first-order velocity equations (Section 2) are solved in ALI Tezaur et al. (2015a). Briefly, the equations are discretized using low-order nodal prismatic finite elements on a 3D mesh extruded from a triangulation dual to the MPAS Voronoi mesh. The discrete version of the velocity equations can be written in the compact form
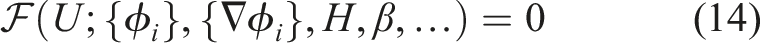
Here U is the solution vector, containing the values of ice velocity at the mesh nodes. {ϕ
i
} and {∇ϕ
i
} are the sets of the basis functions and their gradients.
A damped Newton’s method is used to solve the nonlinear discrete system (14)
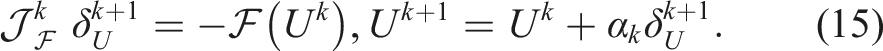
Here
Figure 1 shows a flow chart of ice-sheet dynamics in MALI, focusing on high-level components in the velocity solver in ALI. Each node of the flow chart is described below with references to relevant Trilinos packages. • • • • • • • • • • • • • A flow chart depicting the workflow in MALI, focusing on high-level components in the velocity solver in ALI. The shapes of the nodes are constructed to show performance relevant characteristics of the code while the colors are used to differentiate high-level abstractions. In this case, ellipses represent portions of code with MPI communication and rounded rectangles represent portions of code which do not require MPI communication. The conditionals, LC (linear solver converged), NC (nonlinear solver converged), and FT (final time step), are represented with diamonds. The red-orange nodes represent the computation required for explicit time stepping of ice thickness, H, in MPAS, the purple node represents preconditioner construction (PC), and the pink nodes represent the linear solver required to solve (15). Finite element assembly begins and ends with distributed memory assembly colored in yellow but also performs shared memory processes colored in blue.
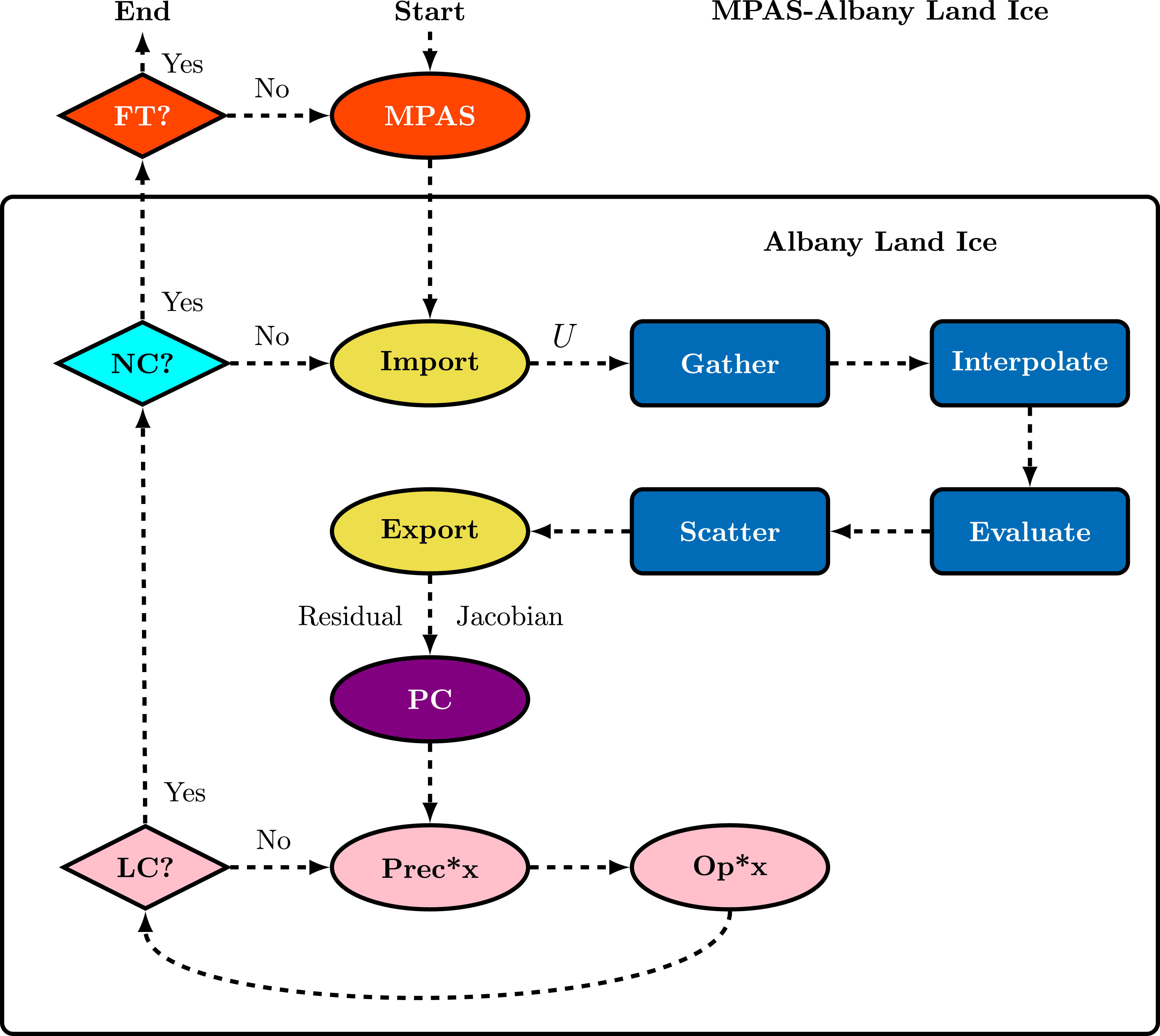
By constructing high-level abstractions for solving nonlinear partial differential equations and utilizing Trilinos packages as components, application developers are able to apply existing performance portable algorithms which are actively supported and improved by experts. Developers are also able to utilize the same algorithms on multiple applications, allowing for greater impact and increased sustainability.
3.2. Finite element assembly
The finite element approach implemented in Albany is designed to easily incorporate multiple physics models with graph-based evaluation using the Trilinos/Phalanx package Pawlowski et al. (2012a,b); Salinger et al. (2016). The assembly is decomposed into a set of nodes called “evaluators.” Evaluators have a specified set of inputs and outputs and are organized in a directed acyclic graph (DAG) based on dependencies. Figure 2 shows a simplified example of a DAG for the for finite element assembly in Albany. The inherent advantage of using a DAG is the increased flexibility, extensibility, and usability of using modular evaluators when performing finite element assembly. The DAG also provides potential for task parallelism. The disadvantage of using a DAG is that there is a potential for performance loss through code fragmentation and a static graph can also lead to repetition of unneeded data movement and computation. This is discussed in more detail in Section 4.1. Albany uses a directed acyclic graph (DAG) for finite element assembly. In this example, a global residual is constructed by interpolating the solution and a parameter onto quadrature points. Basis functions are also needed to complete the interpolation which depends on physical coordinates. In the case of the first-order equations, the solution is the ice velocity. One example of a parameter could be the surface height.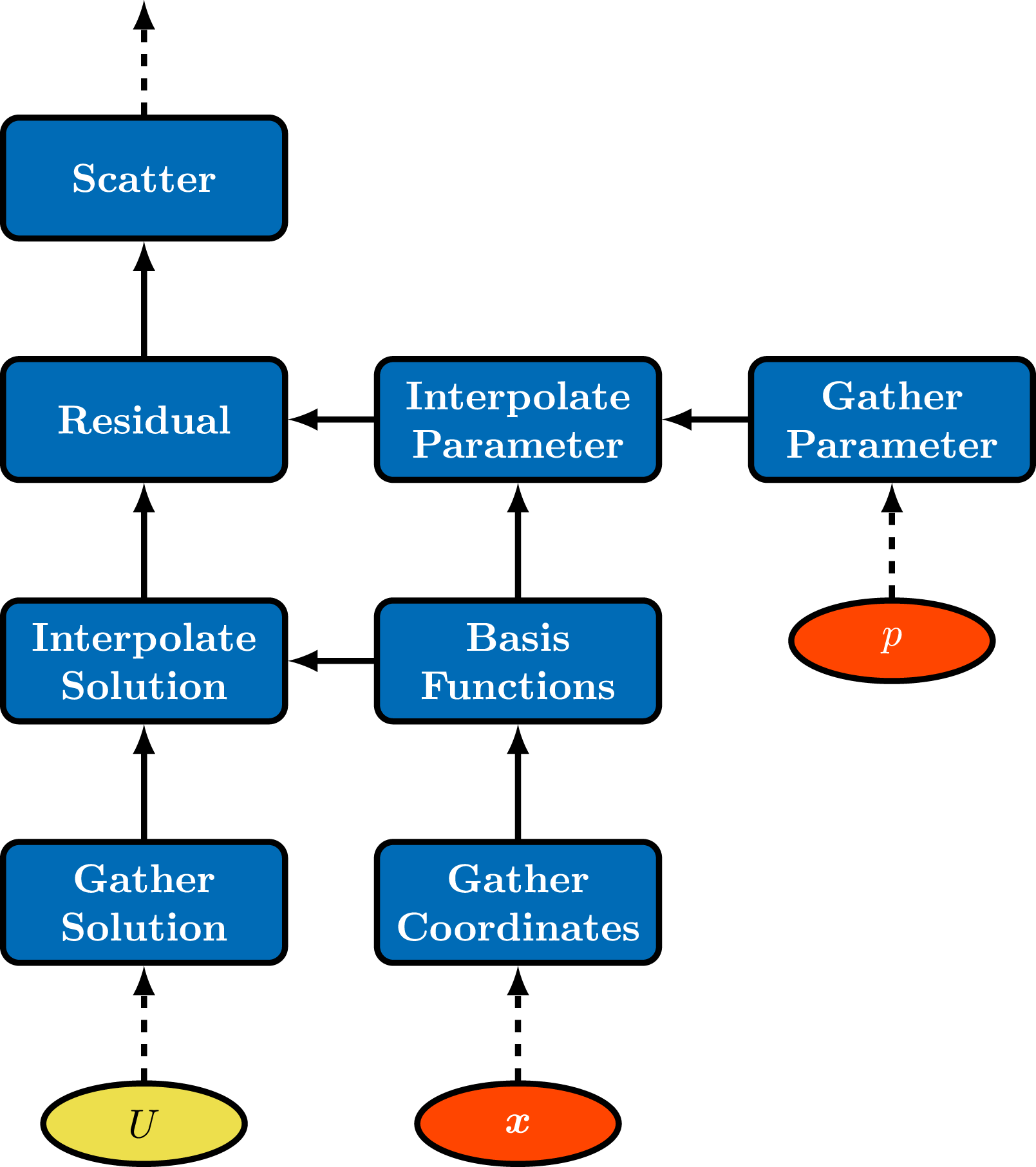
Albany utilizes automatic differentiation to compute the Jacobian matrix and enable Newton-like methods for the solution of nonlinear partial differential equations. More generally, the finite element assembly in Albany is designed for embedded analysis using template-based generic programming Pawlowski et al. (2012a,b); Salinger et al. (2016). Embedded analysis, such as derivative-based optimization and sensitivity analysis, for partial differential equations requires construction of mathematical objects such as Jacobians, Hessian-vector products, and derivatives with respect to parameters. Albany utilizes C++ templates and operator overloading to perform automatic differentiation using the Trilinos/Sacado package Phipps and Pawlowski (2012). Sacado provides multiple data types for storing the derivative components, each with their own relative advantages and disadvantages. The DFad options set the number of derivative components at runtime and are hence the most flexible but least efficient option. The SLFad options set the maximum number of derivative components at compile time, making this option both flexible and relatively efficient. The most efficient but least flexible option is SFad. For this option, the number of derivative components is set at compile time. In MALI, we generally select the SFad type whenever possible, so as to achieve the best possible performance. The difference in performance with the various options is most profound in a GPU run, due to the substantial cost of performing dynamic allocation on the GPU.
Finite element evaluators also contain Kokkos parallel execution kernels for performance portability on shared memory architectures Demeshko et al. (2018); Watkins et al. (2020). Kokkos utilizes memory and execution spaces to determine where memory is stored and where code is executed. Phalanx evaluators utilize MDField with Kokkos View for memory management and evaluators can be used as a Kokkos functor to perform parallel operations. Sacado operators have also been designed to work with Kokkos. Figure 3 shows a simplified example of an evaluator with Kokkos. The first-order local residual computation is performed in a Phalanx evaluator that uses Kokkos for shared memory parallelism and Sacado for automatic differentiation. This is a simplified example of the computation of a single term in the residual. When called with a double EvalT type, the routine returns the residual; when called with a Fad EvalT type, automatic differentiation is applied and a Jacobian is returned.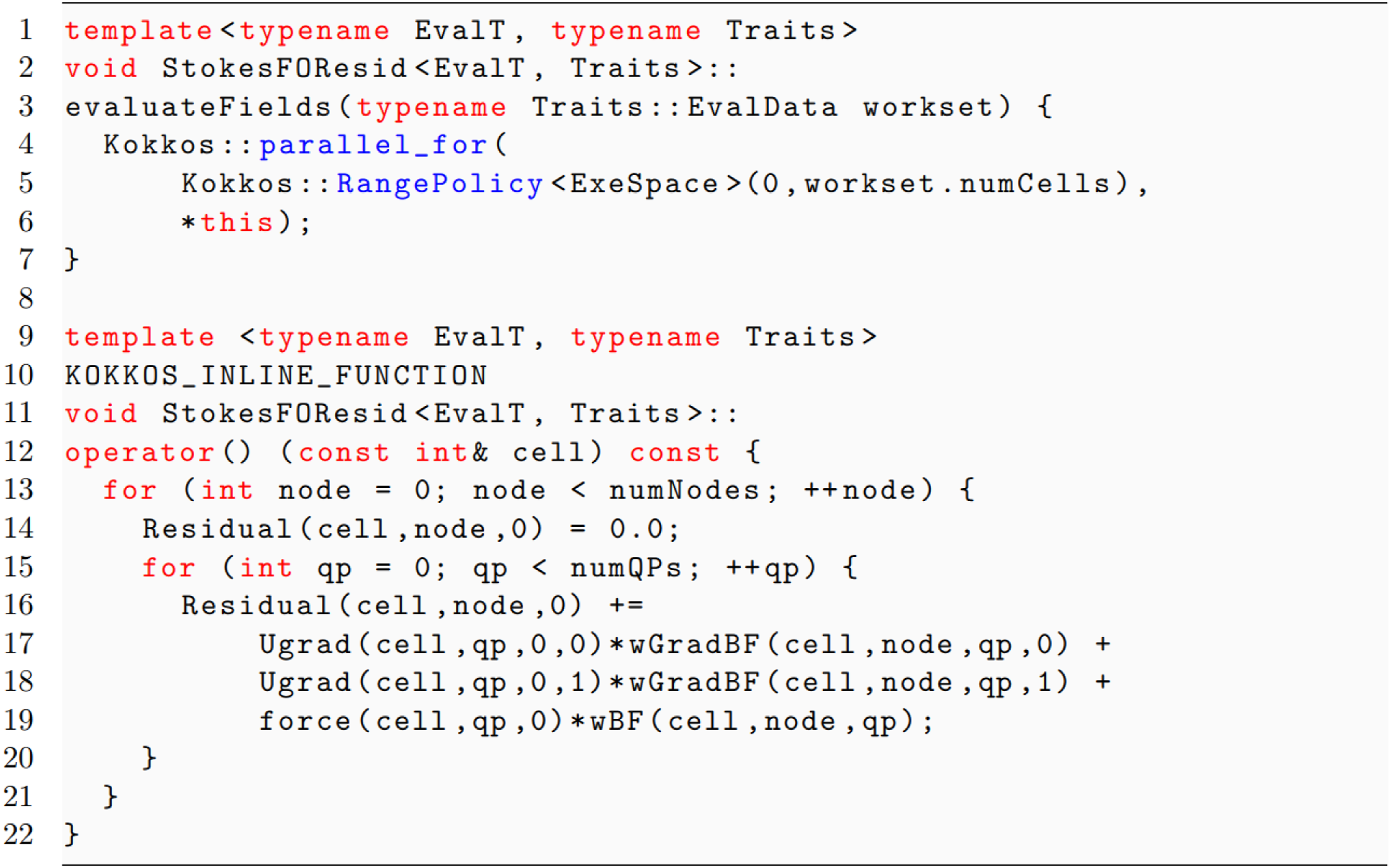
The Phalanx evaluation type is passed via the template parameter EvalT and dictates whether a residual with a double type or a Jacobian with a Fad type is computed. A Kokkos RangePolicy is used to parallelize over cells over an execution space, ExeSpace. In this article, only the Serial and CUDA executions spaces are used to differentiate between CPU and GPU execution but other execution spaces are also available. The properties of each case are described in more detail in Demeshko et al. (2018); Watkins et al. (2020).
3.3. Preconditioner for linear solve
A primary challenge in simulating ice-sheets at scale is solving the linear system associated with a thin, high-aspect ratio mesh. It has been shown Brown et al. (2013); Isaac et al. (2015); Tuminaro et al. (2016) that multigrid methods can be used to address the challenges arising due to the anisotropic nature of the problem, although alternative methods have been proposed Chen et al. (2019); Heinlein et al. (2022). The performance of the linear solver is thus primarily dictated by the efficacy of the multigrid preconditioner. The MDSC-AMG preconditioner introduced in Tuminaro et al. (2016) is specifically designed for ice-sheet meshes where a mesh is first constructed from 2D topological data and extruded in the vertical direction to construct a 3D mesh. The primary strategy for the multigrid hierarchy is to coarsen the fine mesh in the vertical direction until a single layer is reached and apply smoothed aggregation algebraic multigrid (SA-AMG) on the plane. Here, we are able to take advantage of the performance portable implementations of SA-AMG and point smoothers implemented in Trilinos/MueLu and Trilinos/Ifpack2.
3.4. Testing
Software quality tools are a central part of the Albany code base and are crucial for developer productivity Salinger et al. (2016). Rather than using a fixed release of Trilinos, ALI is designed to stay up-to-date with Trilinos’ version of the day, to ensure that the code inherits the most up-to-date additions and improvements to Trilinos. This requires a close collaboration between Albany and Trilinos developers and ensures rapid response to issues that might arise. The current nightly test harness includes unit, regression and performance tests on Intel and IBM multicore CPUs, as well as NVIDIA GPUs, and is monitored on a dedicated dashboard.
4. Methods for improving and maintaining performance portability
In this section, we discuss the major enhancements made to MALI to both improve and maintain performance portability. We provide three examples of finite element assembly optimizations, which improved performance on both CPU and GPU systems. Memoization is utilized to avoid unnecessary data movement and computation from the MALI workflow. Optimizations in matrix assembly and boundary condition computation led to significant speedups on both CPU and GPU and a large reduction in memory usage. We also provide a brief description of a new, performance portable MDSC-AMG preconditioner implemented in Trilinos/MueLu and tuned for ice-sheet modeling. Last, we provide a description of an automated performance testing framework for identifying regressions, improvements and performance differences between algorithms.
4.1. Memoization
A static DAG similar to the one shown in Figure 2 is executed when a new global residual or Jacobian is needed within the nonlinear solver. This leads to a repetition of unnecessary data movement and computation when input quantities do not change between calls of the DAG. A performance gain can be achieved by storing the results of expensive nodes in the DAG and returning the stored results when input quantities do not change. This process is known as memoization.
In Albany, memoization is implemented by constructing a new DAG which only follows changes caused by the solution. Figure 4 shows an example of the new DAG created by performing memoization in Figure 2. The first call executes the original DAG while storing all intermediate quantities. Then, the new DAG is called by default while the original DAG is only called when there is a change to a parameter or the coordinates. An initial speedup of roughly 1.4 on CPUs and 1.5 on GPUs was found when analyzing finite element assembly performance relative to the assembly without memoization. Albany uses memoization to create a new DAG which only depends on changes to the solution. This avoids unnecessary data movement and computations when parameters and coordinates do not change. For example, in the case of first-order equations, the surface height does not change at each nonlinear iteration.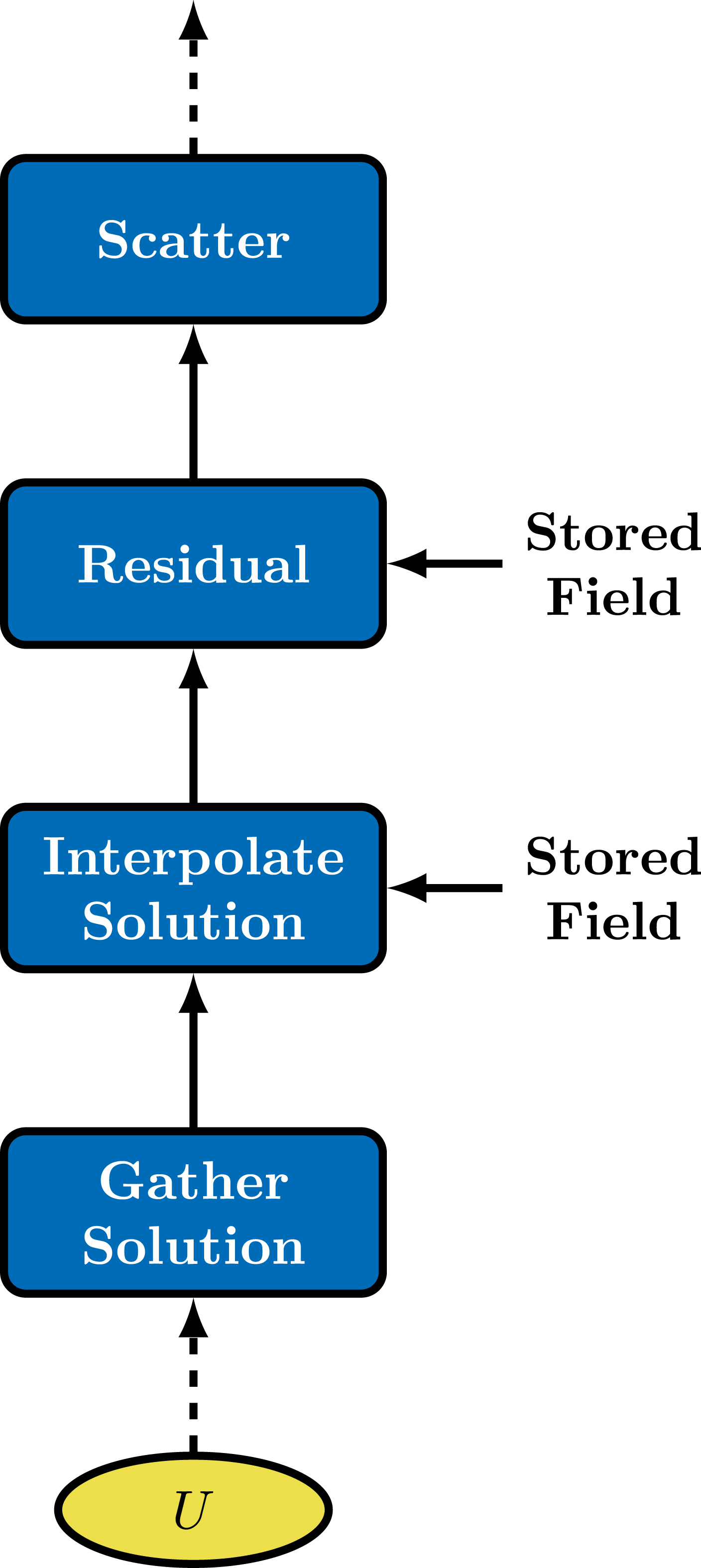
As discussed in Section 3, the finite element assembly of residual and Jacobian is performed on an “overlapped” distribution of the degrees of freedom (DOF), while linear systems require a “unique” distribution of DOF.
Until recently, Albany was using two separate Tpetra CrsMatrix objects for the Jacobian: an overlapped version for finite element assembly, and a non-overlapped version for linear solvers. An export operation (involving MPI communication) was used to copy data between the overlapped and the unique matrices, migrating off-processor rows to their owner.
We improved this portion of the library by switching to the new Tpetra FeCrsMatrix objects, which can store overlapped and non-overlapped matrix in a single object, by storing the “owned” rows first, followed by the off-processor ones. This arrangement allows to build the non-overlapped matrix as a “subview” of the overlapped one. The benefit is twofold: The memory footprint for the Jacobian is roughly halved, plus no copy is needed to transfer data for the local rows from the overlapped Jacobian to the non-overlapped Jacobian. This translated to a speedup of roughly 1.1 on CPUs and 2.1 on GPUs when analyzing finite element assembly performance relative to the old implementation.
4.2. Boundary conditions
In order to achieve high performance on GPUs, fields corresponding to boundary data needed to be aligned for coalesced access on the device. The process is described in detail in Carlson et al. (2020) for a different problem and is summarized in Figure 5. Originally, boundary data were stored using the same layout as a volume field with a data structure that contained a list of indices corresponding to cells that belong to the boundary. This effectively meant that each thread in a device block was loading data from non-consecutive locations in memory which is a highly inefficient access pattern for GPUs. By aligning boundary data to match the layout of the side set mapping data structure, all boundary fields are now read efficiently within a device kernel. Modifying the boundary data layouts had the additional benefit of significantly reducing memory usage for both CPU and GPU. A speedup of roughly 1.2 and 8.7 was achieved on CPUs and GPUs, respectively, when analyzing finite element assembly performance relative to the old implementation. Boundary data were originally stored as a volume field combined with a mapping data structure for accessing appropriate boundary cells. It is now aligned to match one-to-one with the side set map and can be read in a coalesced fashion on the device.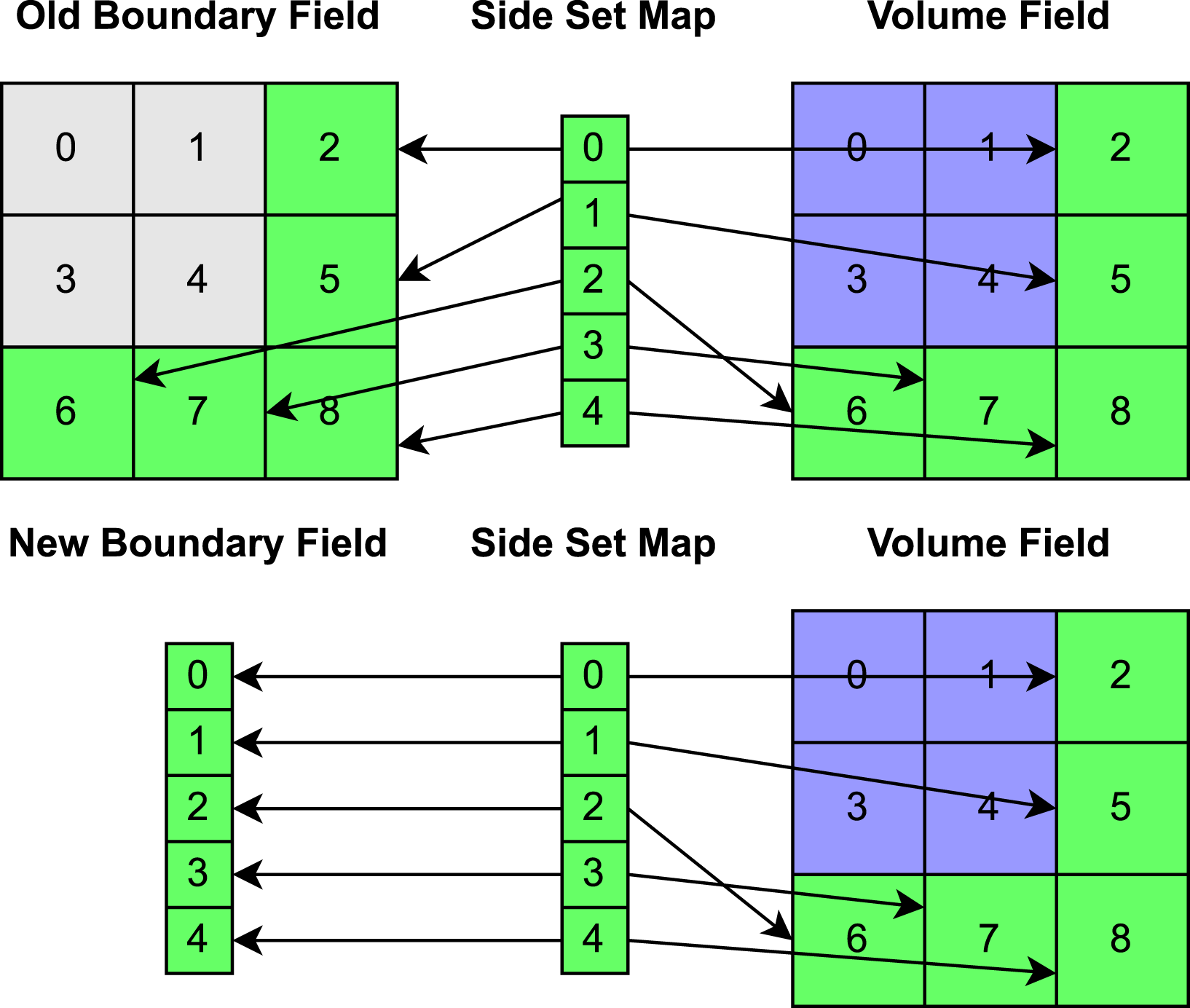
4.3. Matrix dependent semicoarsening-algebraic multigrid
Performance portable SA-AMG is provided by Trilinos/MueLu and is activated by using the Kokkos version of each component. This was extended to also include performance portable matrix dependent grid transfers for semicoarsening to complete the performance portable MDSC-AMG preconditioner introduced in Section 3.3.
The Kokkos version of MDSC (MDSC-Kokkos) uses Kokkos view as temporary data structures while assembling the prolongation matrix. Kokkos parallel_for is used to fill the contribution from each vertical line in parallel. A block tridiagonal system is assembled for each coarse layer in a vertical line on the fly. The system is then solved inline within the kernel using KokkosBatched SerialLU from Kokkos Kernels Trott et al. (2021) where each thread performs an LU factorization without pivoting. The performance portable implementation is designed specifically as a batched direct solver for many small matrices and, in this case, additional optimizations are not needed. Once the solution is obtained, it is placed directly in the prolongation matrix.
Three performance portable point smoothers are provided by Trilinos/Ifpack2: MT Gauss-Seidel, Two-stage Gauss-Seidel, and Chebyshev. An autotuning framework using random search via Scikit-learn Pedregosa et al. (2011) is developed and used to determine the best smoother parameters for a small ALI test problem. We found that the performance portable smoothers did not outperform the serial line and point Gauss-Seidel smoothers in CPU simulations but Chebyshev smoothers performed the best in GPU simulations. Thus, the best CPU simulations continue to use the original line and point Gauss-Seidel smoothers, while GPU simulations utilize the Chebyshev smoothers.
4.4. Automated performance testing
Performance tests are constructed as an extension of nightly regression tests. For example, a regression test might compute the steady-state solution of equation (1) on a coarse Greenland mesh and compare computed surface velocities with known surface velocities. A performance test would perform the same calculation but also compare the end-to-end wall-clock time of the simulation to a specified value. Unfortunately, HPC clusters regularly exhibit large variations in performance causing performance tests to fail without any changes to the software. Thus, this method of performance testing is rarely used and changes in performance can go unnoticed for weeks or months.
A fundamental problem in maintaining performance tests is the ability to assess variations in performance on HPC systems. This requires a statistical approach to determine performance regressions and improvements. This is exemplified in Hoefler and Belli (2015) where the authors provide methods of measuring and reporting performance on HPC systems. Performance regressions, or performance degradation in software execution, can occur through various mechanisms, including changes in compilers, third party libraries, hardware, and software. As the number of developers of scientific software stack grows, the likelihood of performance regressions increase. This is addressed by developing a framework that automatically collects performance metrics and applies a changepoint detection method to the data to detect changes in performance during nightly testing.
Changepoint detection is well-researched in many fields Aminikhanghahi and Cook (2017); Brodsky (2016); Tartakovsky et al. (2014); Daly et al. (2020) and is the process of finding abrupt variations in time series data. A changepoint detection method performs hypothesis testing between the null hypothesis, H0, where no change occurs and the alternative hypothesis, H
A
, where a change occurs. Given the performance metric time series
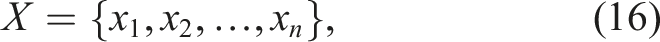
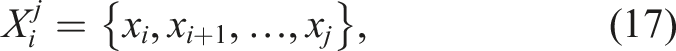
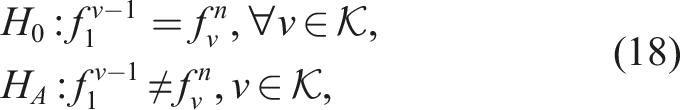
A two-sample t-test of

A performance metric time series is likely to contain multiple changepoints. A sequential method is used to differentiate the time series based on previously identified changepoints. Once a changepoint is detected, the method disregards any data prior to the changepoint. This ensures that changepoints are not retroactively changed as new data are introduced.
Due to the large variation in HPC systems, the time series data generating on these platforms may also contain outliers which can be identified as changepoints. Multiple methods are used to ensure that the changepoints are accurate in the presence of outliers: 1. In any single t-test, outliers are identified on both distributions using the median absolute deviation Leys et al. (2013) with a threshold comparable to 3 standard deviations. We remove at most 10% of the total data. 2. A minimum number of consecutive detections, m, of the same changepoint are needed before confirming a changepoint. This helps dilute the influence of an outlier. 3. As the time series is traversed sequentially, the sample size or “lookback window” for each test is limited by w observations. This helps avoid hypersensitivity where the smallest change in the time series becomes significant when the sample size is too large.
Algorithm 1 along with its modifications for multiple changepoint detection is implemented in Python and executed during nightly performance testing. The log-transformed values are used because a log-normal distribution seems to fit the data slightly better than a normal distribution. A significance level of α = 0.005 is chosen to ensure confidence and only the k = 10 largest changes are considered. m = 3 consecutive detections are needed to confirm a changepoint and a lookback window of w = 30 is chosen. This typically means that a minimum of 3 days are needed to detect a changepoint but this depends on data variability. Daily results are reported on an automated Jupyter notebook and posted online (see https://sandialabs.github.io/ali-perf-data/), and performance regressions are reported through an automated email report.
Performance regressions and improvements are quantified by utilizing changepoints to define subsets within the time series. Given a changepoint and two subsets, a 99% confidence interval (CI) for the difference in mean on log-transformed values is computed using a t-distribution. When transformed back, a relative performance ratio (speedup or slowdown) is given for the regression or improvement. Equation (19) shows an example of how the relative performance is computed
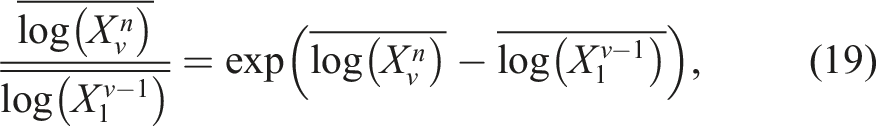
For performance comparisons, the difference in mean on log-transformed data between two performance tests needs to be established. A paired t-test is performed by taking the difference between the log-transformed data for the two tests where the dates intersect. The changepoint detection method is used on this data to identify subsets and a 99% confidence interval (CI) for the difference in mean on log-transformed data is computed on each subset. This is also computed as a relative performance ratio when transformed back.
5. Numerical results
In this section, the performance of MALI and standalone ALI is analyzed on two variable resolution Greenland ice-sheet meshes and a series of increasing higher resolution Antarctic ice-sheet meshes. In the first Greenland case, MALI is compared with and without the features described in Sections 4.1 and 4.3, and performance improvements are shown across all HPC architectures. In the second case, a weak scalability study of Antarctica shows that simulations perform best when utilizing the GPUs on modern HPC systems. In the last Greenland case, several examples are given on how the changepoint detection method described in Section 4.4 is used to identify performance regressions, improvements, and differences in algorithm performance. What follows is a brief description of the experimental setup.
MALI software repositories.

The code is compiled with the Kokkos Serial execution space for CPU-only simulations and CUDA for simulations utilizing GPUs. CPU-only simulations are executed with MPI ranks mapped to cores while GPU simulations are executed with MPI ranks mapped to GPUs. In all experiments, CUDA-Aware MPI is turned off and CUDA_LAUNCH_BLOCKING is turned on.
MALI simulations are executed on the three platforms or four architecture nodes given below. A limited number of cores are utilized on some systems in order to keep a core idle for system operations. On Summit, an MPI-only simulation using only the CPU is tested along with an MPI + GPU simulation.

The MALI timers described below are used to collect the average wall-clock time across MPI processes.

5.1. MALI Greenland ice-sheet 1-to-10 km variable resolution case
The MALI Greenland ice-sheet 1-to-10 km variable resolution simulation is executed with and without the specific features described below.

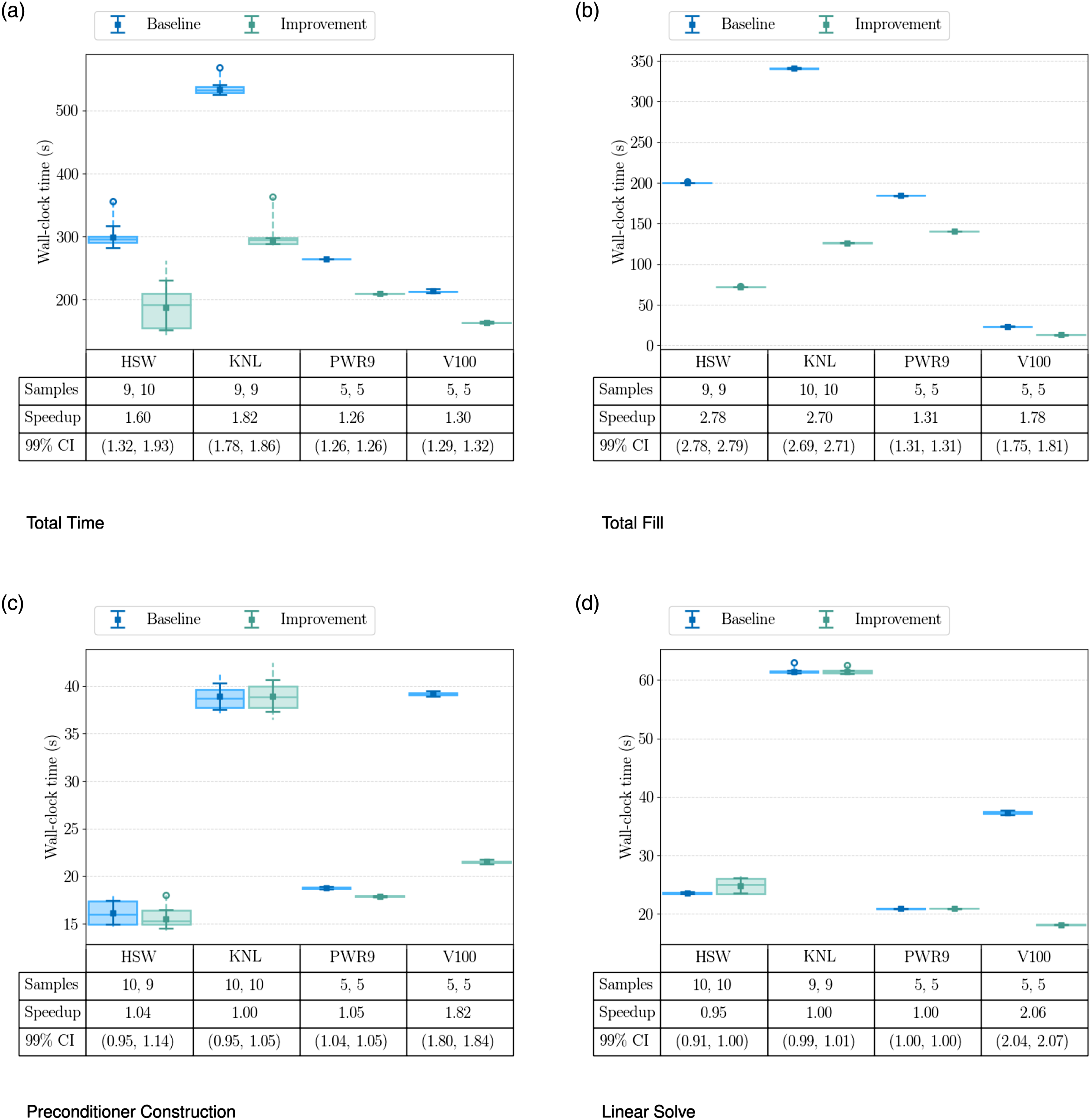
The MALI Greenland ice-sheet 1-to-10 km variable resolution simulation is executed multiple times on 8 nodes of four architectures (Cori: HSW, KNL; Summit: PWR9, V100) and two cases in order to capture improvements across four timers. Architectures, timers and cases are defined in Tables 2–4, respectively. The lower/upper quartiles are shown along with the median in a box plot while a dashed line is used to show the full data range. The sample size is trimmed using the methods discussed in Section 4.4 and outliers are shown as circles. The trimmed sample sizes for the baseline and improvement are given in the table as a pair and a mean error bar is plotted. The speedup from the improvement relative to the baseline is also given along with a confidence interval (CI). CIs are reported as (LL, UL) where LL is the lower limit and UL is the upper limit. (a) Total Time; (b) Total Fill; (c) Preconditioner Construction; (d) Linear Solve.
The MALI Greenland ice-sheet 1-to-10 km variable resolution simulation is executed multiple times on 8 nodes of 4 architectures (Cori: HSW and KNL; Summit: PWR9 and V100) and two cases in order to capture improvements in the linear solve. Architectures and cases are defined in Tables 2 and 4, respectively. The table below shows the average number of linear iterations (Avg. Lin. Its.) and the total linear solve time across 26 nonlinear iterations (2 nonlinear solvers) for all cases. A 99% confidence interval is reported (when statistically significant) as (LL, UL) where LL is the lower limit and UL is the upper limit.
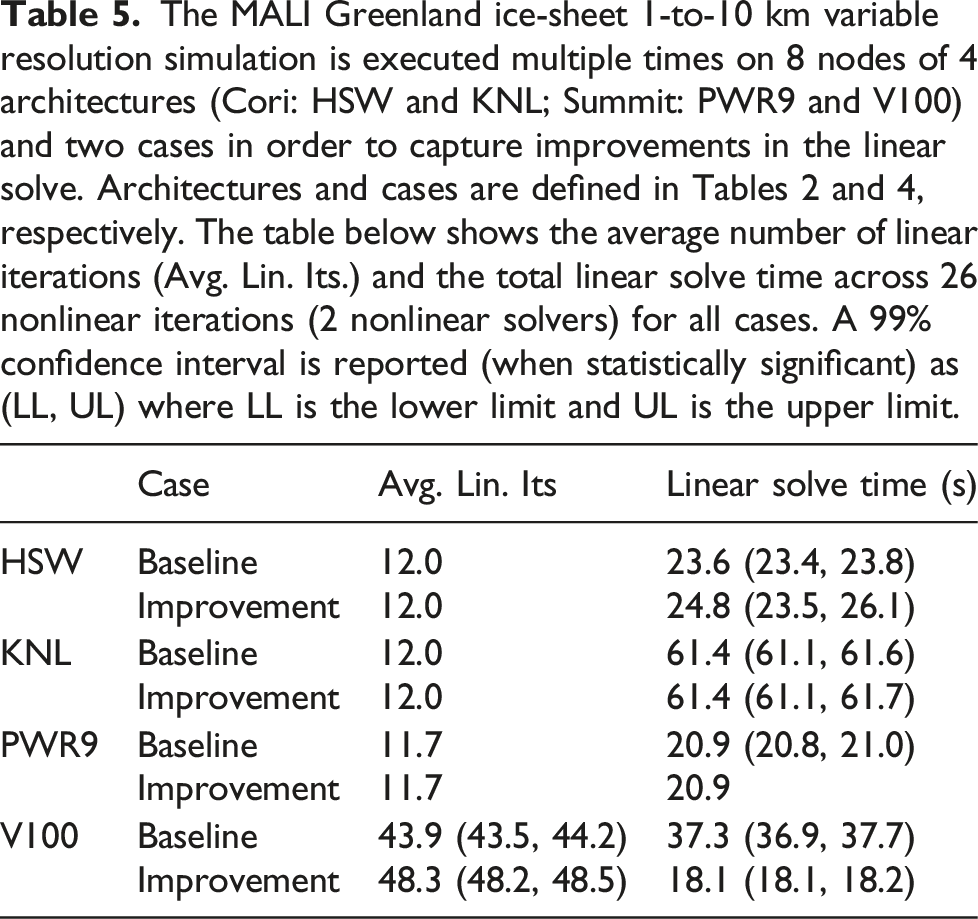
Figure 6(a) shows the overall performance improvement in MALI from the addition of memoization, MDSC-Kokkos, and GPU preconditioner tuning. There is a statistically significant performance improvement across all architectures despite the large variation on Cori. Last, Figure 7 shows the proportions of total wall-clock for each architecture, case and timer. The plot shows that on CPU platforms, The MALI Greenland ice-sheet 1-to-10 km variable resolution simulation is executed multiple times on 8 nodes of four architectures (Cori: HSW, KNL; Summit: PWR9, V100) and two cases. Architectures, timers and cases are defined in Tables 2–4, respectively. This plot shows the ratio of each timer compared to 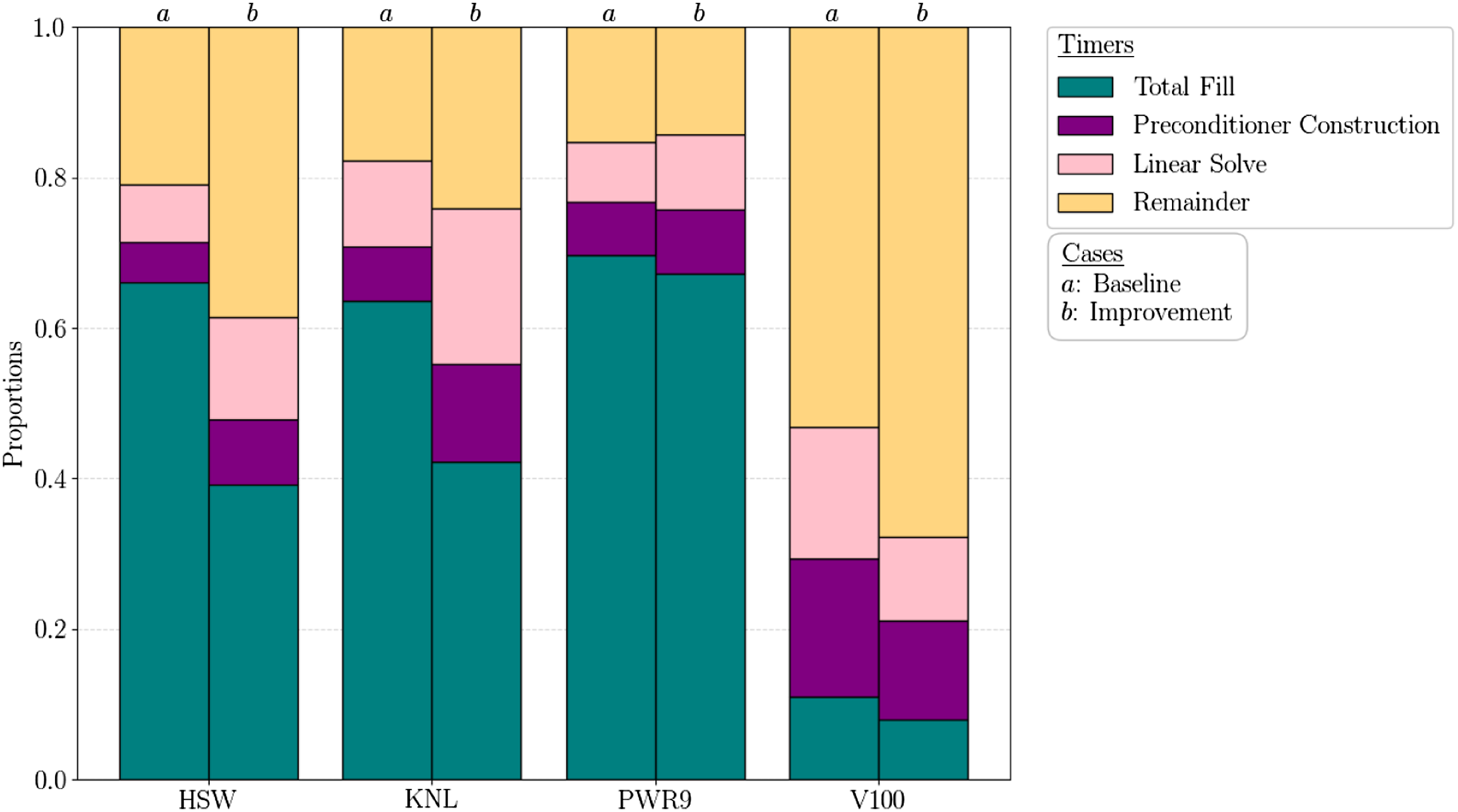
5.2. ALI Antarctica ice-sheet weak scalability study
A series of increasingly higher resolution Antarctic ice-sheet simulations are executed in a weak scalability study on four architectures. The table below shows the computing resources and degrees of freedom (DOF) associated with each case.

In this case, standalone ALI is used to perform a single nonlinear solve where the tolerances for the nonlinear and linear solvers are set to 10−5 and 10−6, respectively, to ensure the final result and number of nonlinear iterations would be the same across architectures. Simulations are executed with all improvements described in Section 4. Similar to the Greenland case in Section 5.1, multiple samples are collected for each case using the same allocation and a mean error bar is computed. Two-sample t-tests of the mean difference of the logarithm between the PWR9 and V100 cases are also performed and a 99% confidence interval for the speedup of the GPU relative to the CPU-only simulation is given in Figure 8. The first notable result is that the A series of increasingly higher resolution Antarctic ice-sheet simulations are executed in a weak scalability study on four architectures (Cori: HSW, KNL; Summit: PWR9, V100). Four timers are captured. These are defined in Table 3. The mean error bar, median and lower/upper quartiles of each case are given along with outliers shown as circles. The speedup from the V100 CPU-GPU simulation relative to the POWER9 CPU-only simulation is also shown along with a confidence interval (CI). CIs are reported as (LL, UL) where LL is the lower limit and UL is the upper limit. (a) Total Solve; (b) Total Fill; (c) Preconditioner Construction; (d) Linear Solve.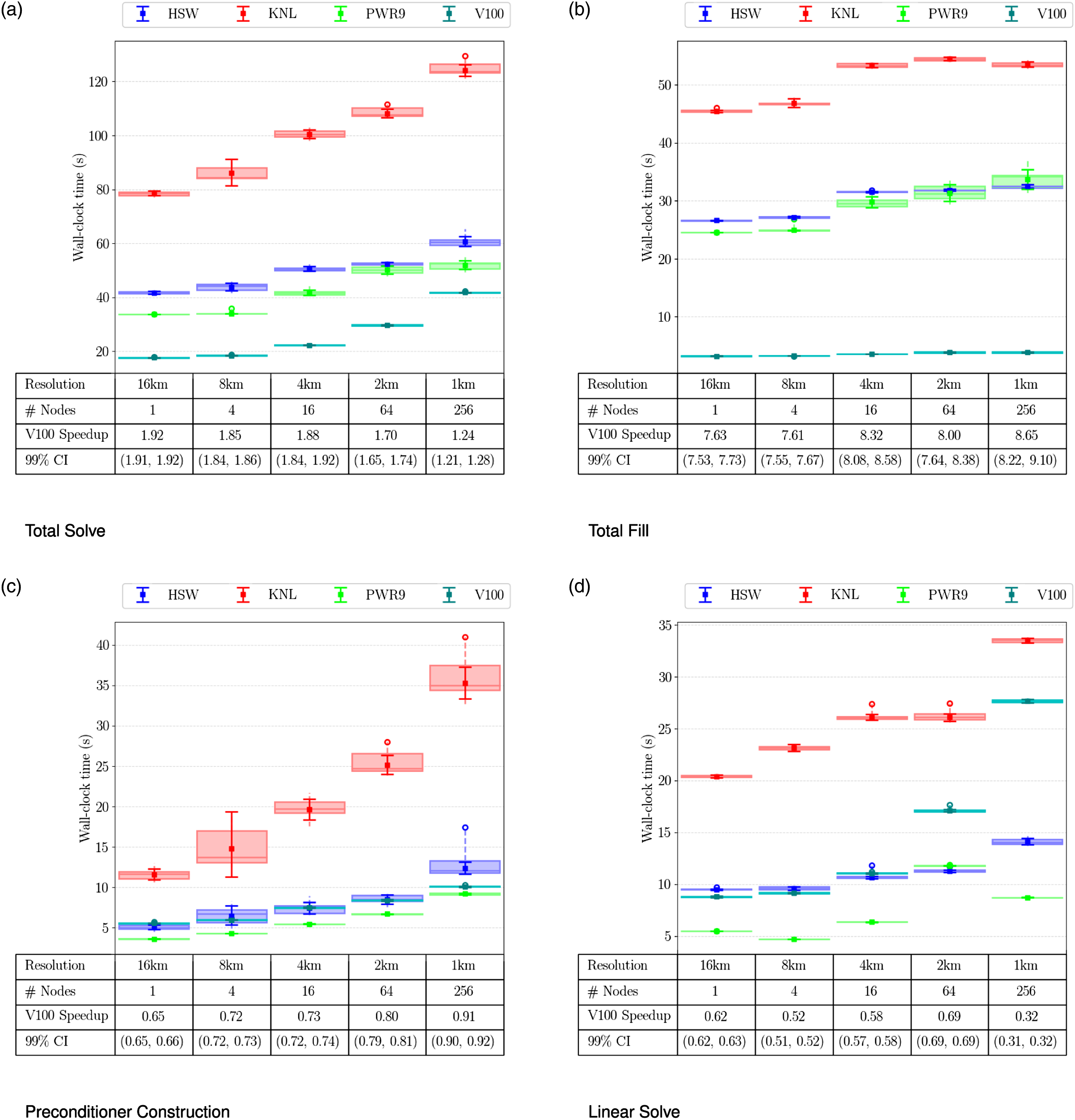
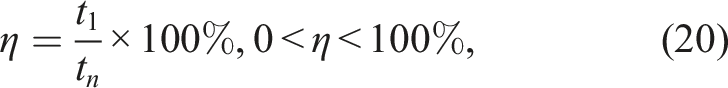
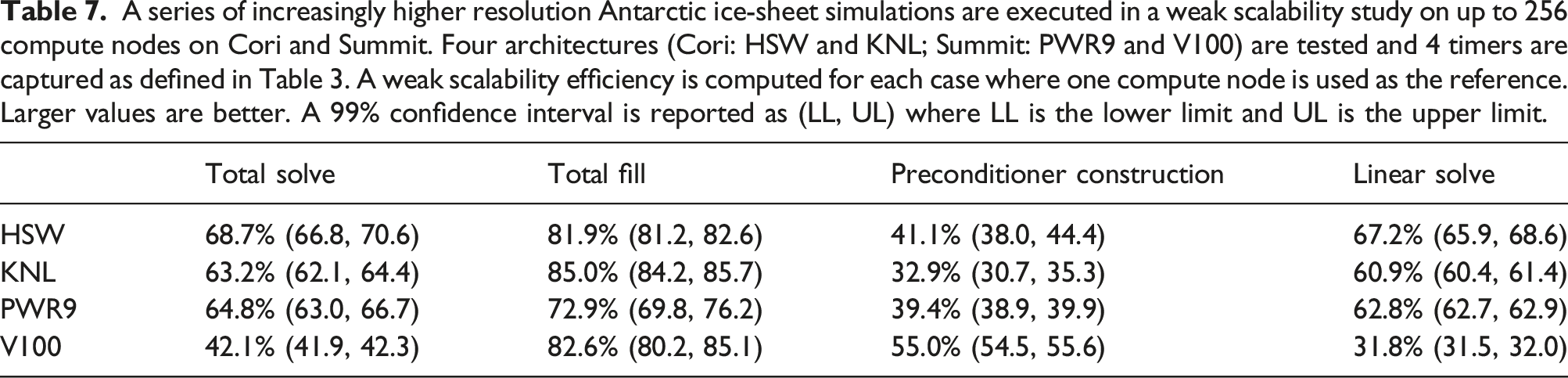
A series of increasingly higher resolution Antarctic ice-sheet simulations are executed in a weak scalability study on up to 256 compute nodes on Cori and Summit. Four architectures (Cori: HSW and KNL; Summit: PWR9 and V100) are tested and 4 timers are captured as defined in Table 3. A weak scalability efficiency is computed for each case where one compute node is used as the reference. Larger values are better. A 99% confidence interval is reported as (LL, UL) where LL is the lower limit and UL is the upper limit.
A series of increasingly higher resolution Antarctic ice-sheet simulations are executed in a weak scalability study on four architectures (Cori: HSW and KNL; Summit: PWR9 and V100). The table below shows the total number of nonlinear iterations (1 nonlinear solve), the average number of linear iterations (Avg. Lin. Its.) per nonlinear iteration for all cases and the total linear solve time. A 99% confidence interval is reported (when statistically significant) as (LL, UL) where LL is the lower limit and UL is the upper limit.
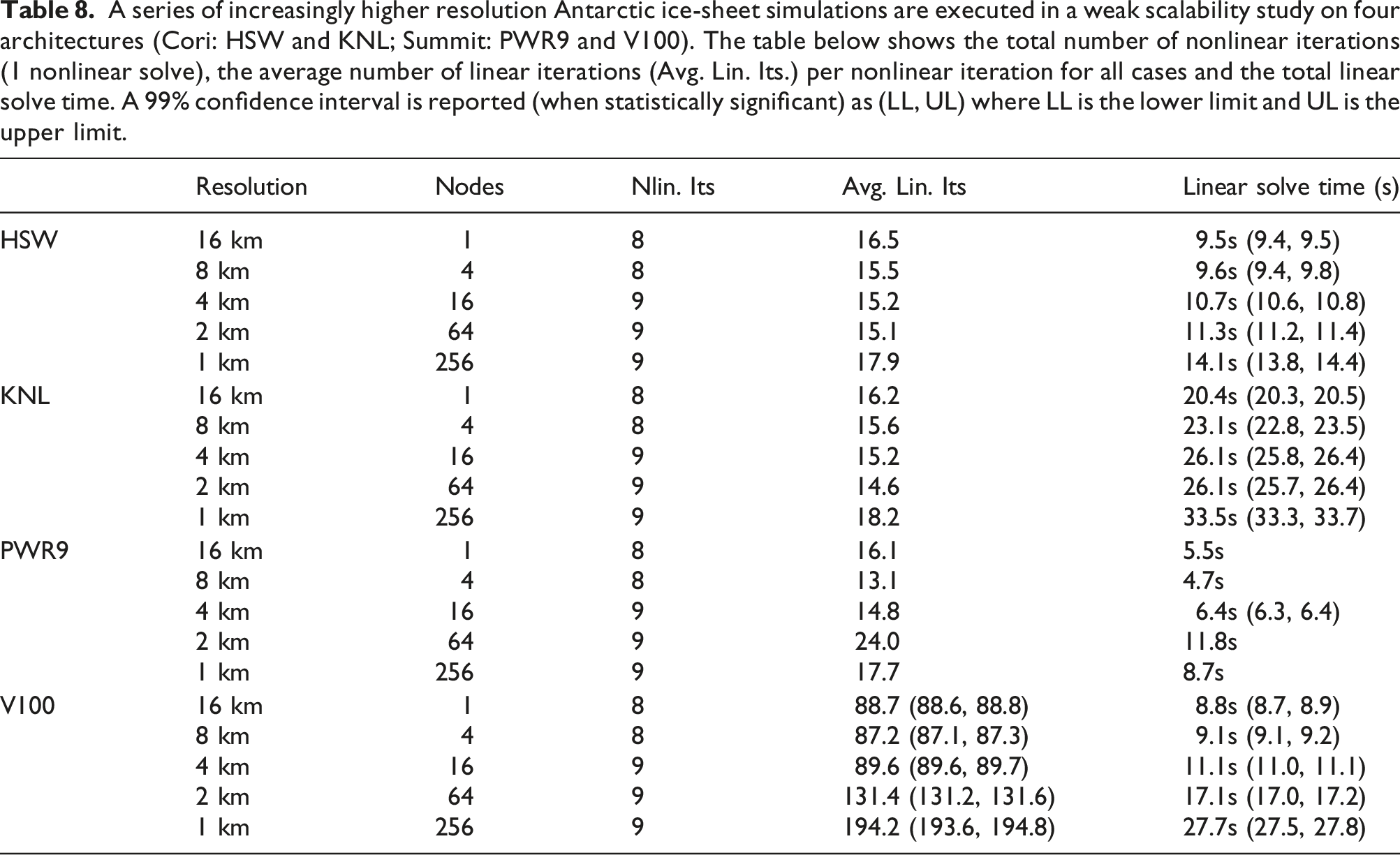
The average number of linear iterations from the GPU linear solve is much larger (reaching the maximum iteration constraint) at 256 compute nodes which contributed to worse scaling. The PWR9, CPU-only case also has much smaller linear solve times compared to the other architectures.
Figure 9 shows the proportions of total wall-clock for each architecture, resolution and timer. On CPU platforms, A series of increasingly higher resolution Antarctic ice-sheet simulations are executed in a weak scalability study on four architectures (Cori: HSW, KNL; Summit: PWR9, V100). Timers are defined in Table 3. This plot shows the ratio of each timer compared to 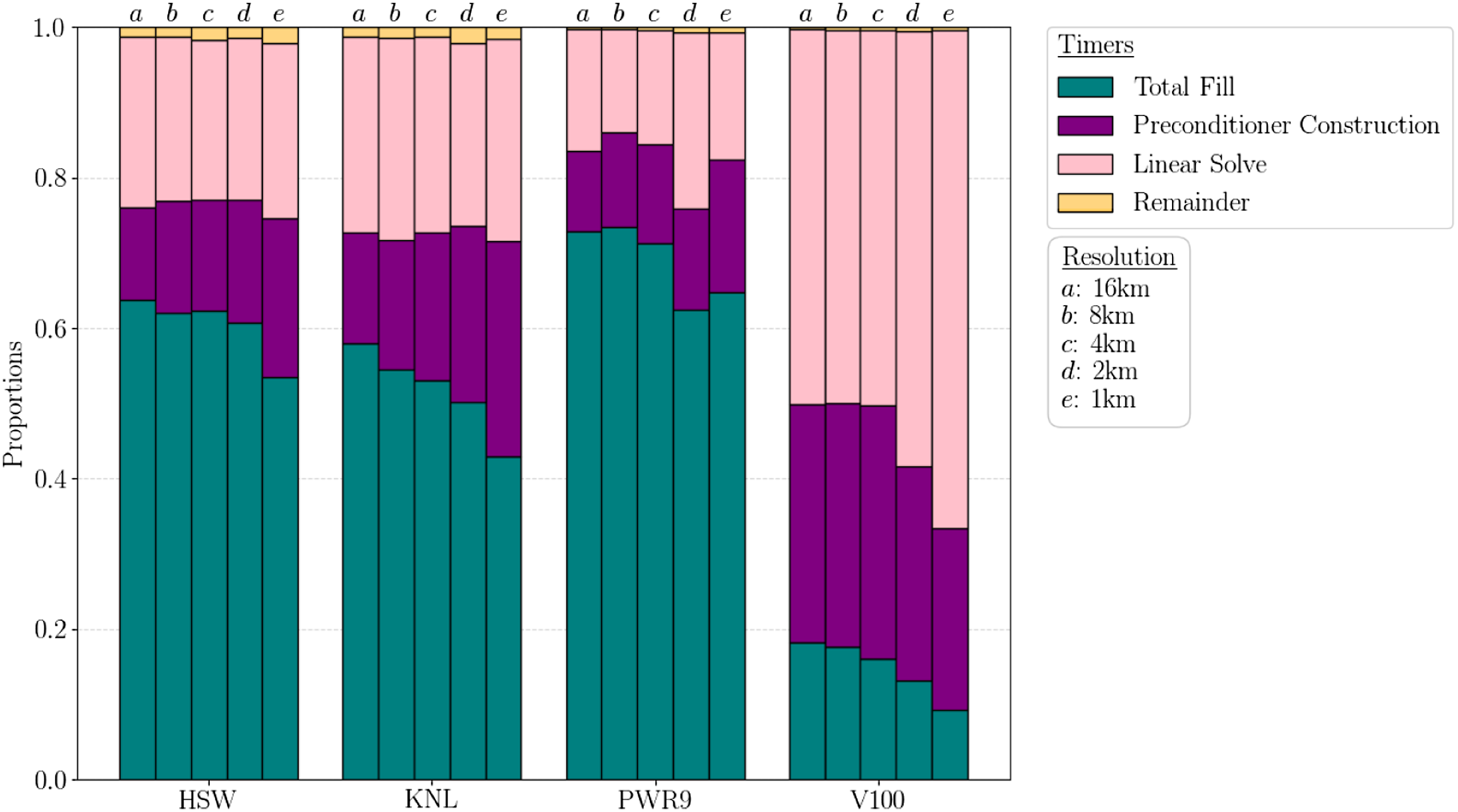
5.3. ALI Greenland ice-sheet 1-to-7 kilometer variable resolution performance test
ALI nightly performance tests are executed nightly on the two small clusters given below.
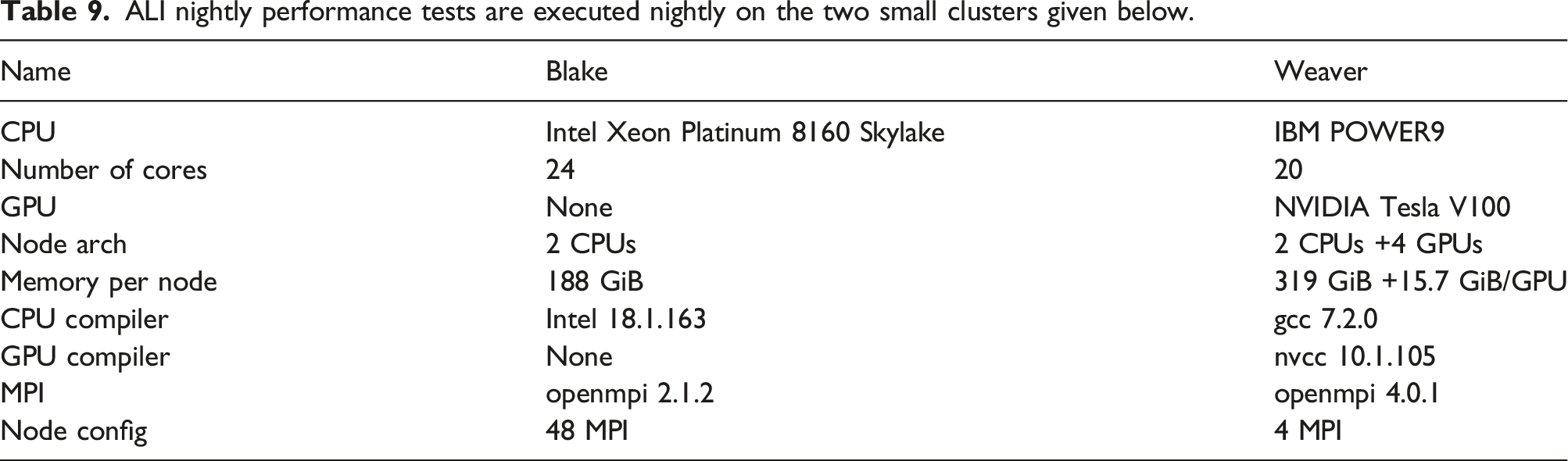
The simulations executed on Blake and Weaver utilize eight and two nodes, respectively. The historical The ALI Greenland ice-sheet 1-to-7 km variable resolution simulation is executed nightly on two platforms in order to detect regressions and improvements. Blue markers are recorded wall-clock time. Means are computed between changepoints and are indicated by solid red lines. The dotted red lines are ± two standard deviations. (a) Total Time on 8 Blake nodes (384 Skylake cores); (b) Total Time on 2 Weaver nodes (8 V100 GPUs).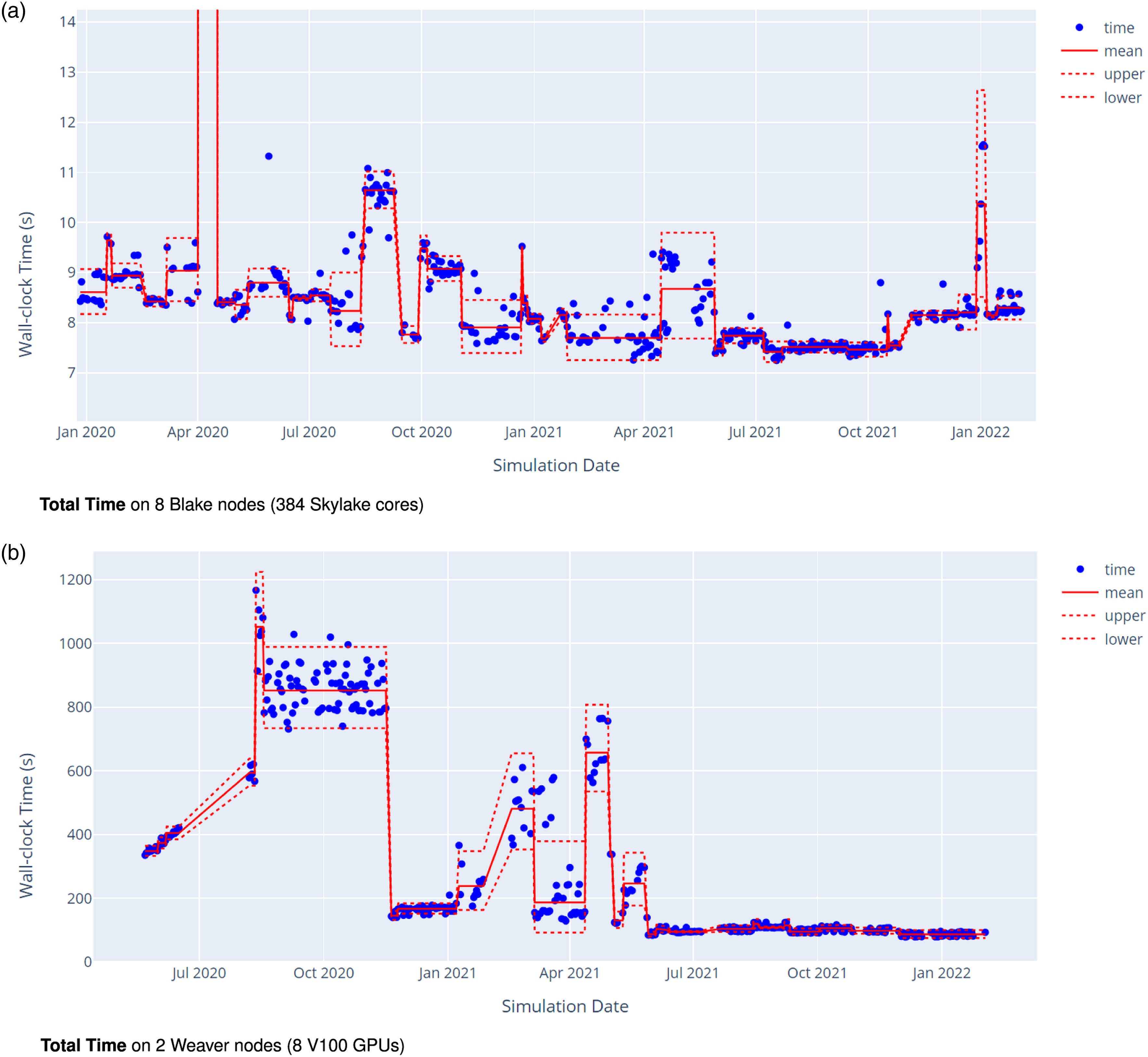
Figure 10 also shows many performance regressions and improvements over the course of the time series. One recent example is the transition to Kokkos 3.5.0 which caused a regression to CPU performance. The regression along with the improvement from the fix is shown in Figure 11. In this particular case, the usage of Kokkos atomic_add was changed for the Serial execution space. This caused a 15% (99% CI: 14%, 16%) slowdown to Total Fill. This was then fixed manually in Albany by avoiding the use of atomic_add when running with a Serial execution space. After the change, Figure 11(b) shows that the performance improved by 15% (99% CI: 13%, 16%), reverting the performance loss due to the original regression. Since then, the issue was reported and a fix has been introduced into Kokkos. The ALI Greenland ice-sheet 1-to-7 km variable resolution simulation is executed nightly on Blake in order to detect regressions and improvements. Blue markers are recorded wall-clock time. Means are computed between changepoints and are indicated by solid red lines. The mean values are also given in the blue box along with a 99% confidence interval (CI). CIs are reported as (LL, UL) where LL is the lower limit and UL is the upper limit. The dotted red lines are ± two standard deviations. Lastly, the blue boxes also show ratios (speedup, slowdown) between sets with a 99% CI. This particular case highlights a performance regression and its later improvement from the fix. (a) Total Fill regression; (b) Total Fill improvement.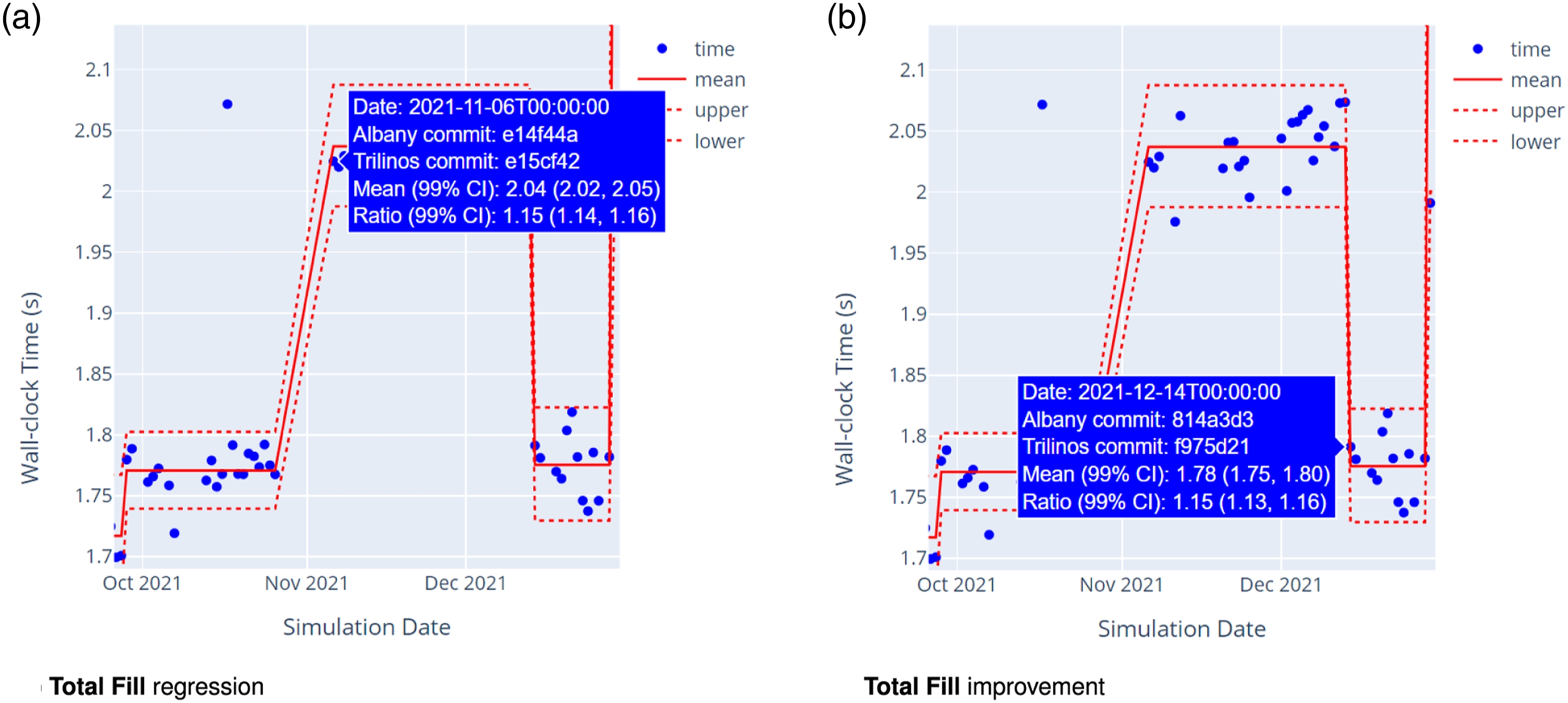
Algorithm performance comparisons can also be historically tracked within the performance testing framework. One example is the performance comparison of the finite element assembly with and without memoization. In this case, two performance tests which store the wall-clock time of 100 residual and Jacobian evaluations are tracked. Figure 12 shows the observations between the two cases paired by simulation date on Blake and Weaver. Both plots show that the test with memoization has performed faster than the test without memoization throughout the entire time series. On the CPU platform shown in Figure 12(a), the relative performance has not changed much but on the GPU platform in Figure 12(b) the relative performance has increased over time. The key difference in this case was the boundary condition improvements which significantly reduced the The ALI Greenland ice-sheet 1-to-7 km variable resolution finite element assembly tests with and without memoization are executed nightly on two platforms in order to detect regressions, improvements and analyze comparisons. Observations from the two cases are joined by date by taking the difference between the log of the timer data and plotting the relative performance (speedup, slowdown) with markers. Solid lines indicate means between changepoints and dotted lines represent a 99% confidence interval for the mean. (a) Total Fill on 8 Blake nodes (384 Skylake cores); (b) Total Fill on 2 Weaver nodes (8 V100 GPUs).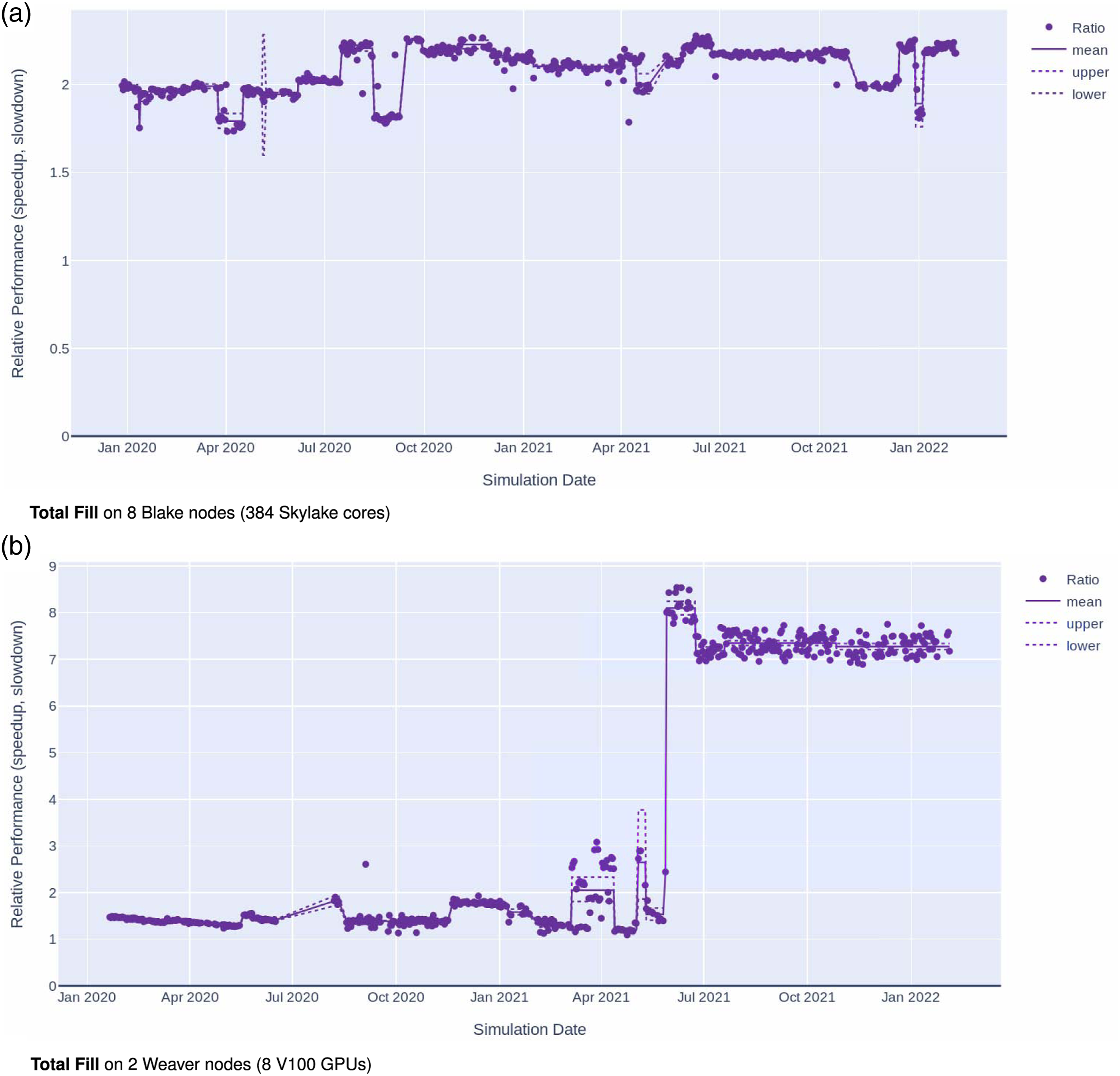
The time series since the most recently detected changepoint can be used to determine whether the latest relative performance for memoization is statistically significant. A paired t-test is used to test the mean difference and the data is summarized as shown in Figure 13. The results show that the current estimated speedup from memoization for this case is 2.22 (99% CI: 2.21, 2.23) on CPU platforms and 7.28 (99% CI: 7.21, 7.34) on GPU platforms. The ALI Greenland ice-sheet 1-to-7 km variable resolution finite element assembly tests with and without memoization are executed nightly on two platforms in order to detect regressions, improvements and analyze comparisons. Observations from the two cases are joined by date by taking the difference between the log of the timer data and performing a paired t-test. The figures show sample sizes since the last changepoint for each test as well as mean wall-clock times (s) and standard deviation. The paired relative performance (speedup) is also given along with the standard error, p-value and a 99% confidence interval (CI). CIs are reported as (LL, UL) where LL is the lower limit and UL is the upper limit. (a) Total Fill on 384 Skylake cores. (b) Total Fill on 8 V100 GPUs.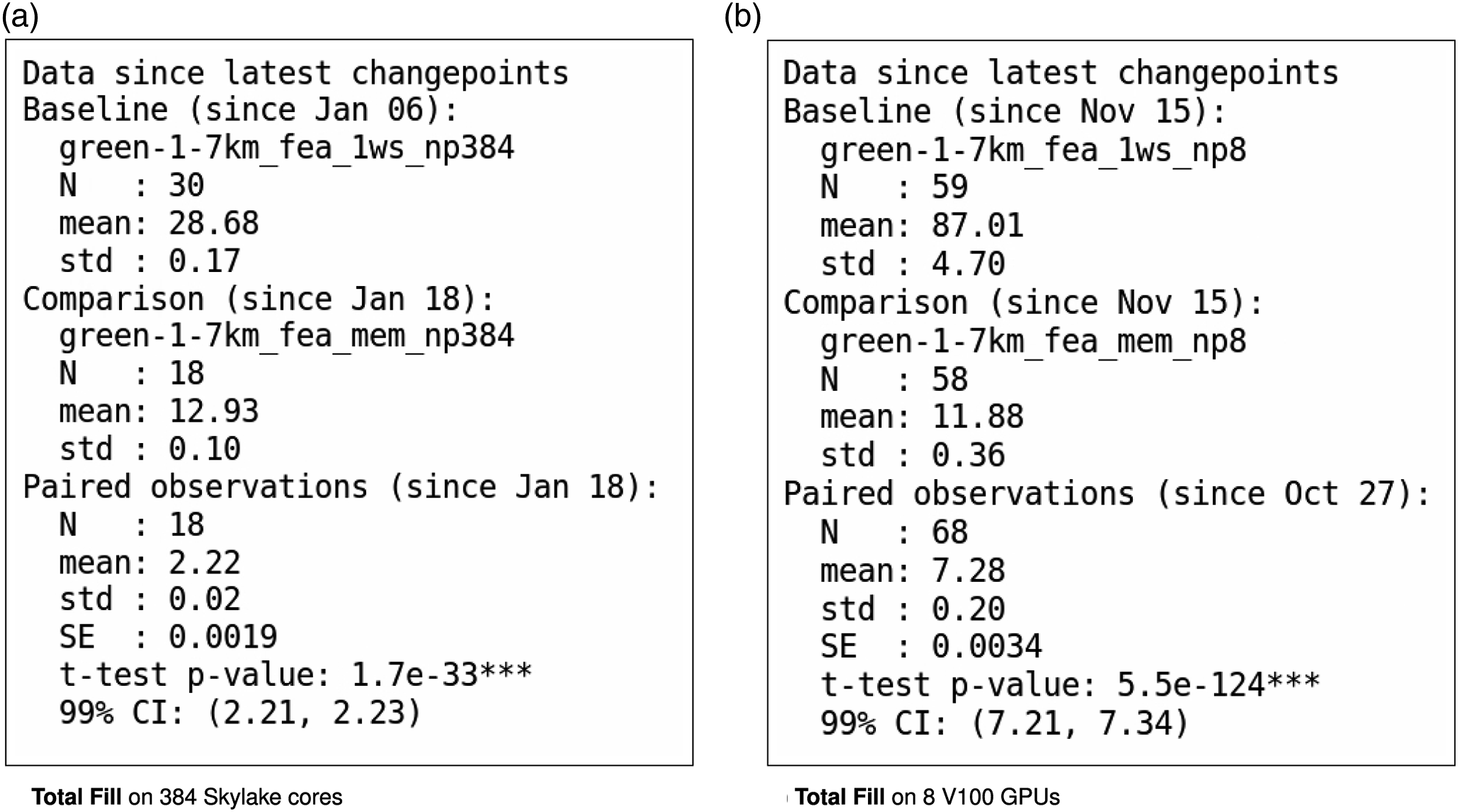
6. Conclusions
In this article, the performance portable features of MALI are introduced and analyzed on two supercomputing clusters: NERSC Cori and OLCF Summit. First, the first-order velocity model and the mass continuity equation are introduced along with their implementations within Albany Land Ice and MPAS, respectively. This is used to further describe improvements that have been made to the finite element assembly process and linear solve within MALI. The new features focus on improving performance portability in MALI but are extensible to other applications targeting HPC systems.
Two numerical experiments are provided to analyze the expected performance on different HPC architectures. The first case utilized MALI to simulate an initial state calculation and single time step for a Greenland ice sheet 1-to-10 km resolution mesh and compared baseline simulations without specific features with improved simulations with the features described in the paper. The results show that finite element assembly with memoization, MDSC-Kokkos and tuned smoothers are performant across all architectures with an expected speedup of 1.60 (99% CI: 1.32, 1.93) on Cori-Haswell, 1.82 (99% CI: 1.78, 1.86) on Cori-KNL, 1.26 on Summit-POWER9, and 1.30 (99% CI: 1.29, 1.32) on Summit-V100. The study also highlights specific regions in need of improvement in the model. In particular, the need to improve the performance of the coupling between MPAS and Albany, the finite element assembly process on CPUs, and the preconditioner on GPUs.
The second numerical experiment utilized ALI to perform a steady-state simulation of the Antarctic ice sheet on a series of structured meshes in a weak scalability study. The results show that simulations on Summit-V100 perform the best with a 1.92 (99% CI: 1.91, 1.92) speedup over Summit-POWER9 in the low resolution case and 1.24 (99% CI: 1.21, 1.28) speedup over Summit-POWER9 in the high-resolution case. The best results on Summit are shown during finite element assembly where the speedup over Summit-POWER9 is 8.65 (99% CI: 8.22, 9.10). The results also show good weak scaling in finite element assembly for CPU/GPU but poor weak scaling in the preconditioner on CPU/GPU and in the linear solve on GPU architectures. Further analysis shows that the average number of linear iterations per nonlinear iteration increases dramatically as the resolution increases, highlighting the need for a more scalable preconditioner for this particular problem. Since the preconditioner did not weak scale particularly well on GPUs, a strong scalability analysis was not performed. Future work will focus more on improving solver performance.
This article also introduces a changepoint detection method for automated performance testing. A detailed description of the method is given along with examples of how the method can be used to detect performance regressions, improvements, and differences in algorithm performance over time. In this case, an automated performance testing framework is used with ALI to simulate the Greenland ice sheet using a 1-to-7 kilometer variable resolution mesh. The results show the method being exercised on 2 years of data and an example of a successful detection of performance regression and improvement. The results also show an example of a nightly performance comparison where two tests are used to compare ALI with and without memoization. This case was used to show how the method can be used to detect regressions and improvements in algorithm performance over time as the utility of memoization has improved to up to 7.28 (99% CI: 7.21, 7.34) speedup over simulations without memoization on GPU platforms over the course of 2 years.
Data availability statement
The performance testing framework and data is available in,
The results are accessible via a browser here:
Performance data, pre-processing scripts and post-processing scripts are available in,
under the directory paper-data/watkins2022performance.
Footnotes
Acknowledgments
The authors thank Trevor Hillebrand from Los Alamos National Laboratory for help with setting up the ice-sheet grids, datasets, and for fruitful discussions. The authors also thank Luc Berger, Christian Glusa, Mark Hoemmen, Jonathan Hu, Brian Kelley, Jennifer Loe, Roger Pawlowski, Siva Rajamanickam, Chris Siefert, Raymond Tuminaro, and Ichitaro Yamazaki from Sandia National Laboratories for their help with Trilinos components and Si Hammond for troubleshooting on Sandia HPC systems.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Support for this work was provided through the SciDAC projects FASTMath and ProSPect, funded by the U.S. Department of Energy (DOE) Office of Science, Advanced Scientific Computing Research and Biological and Environmental Research programs. This research used resources of the National Energy Research Scientific Computing Center (NERSC), a U.S. Department of Energy Office of Science User Facility operated under Contract No. DE-AC02-05CH11231. This research used resources of the Oak Ridge Leadership Computing Facility at the Oak Ridge National Laboratory, which is supported by the Office of Science of the U.S. Department of Energy under Contract No. DE-AC05-00OR22725.
Disclaimer
This paper describes objective technical results and analysis. Any subjective views or opinions that might be expressed in the paper do not necessarily represent the views of the U.S. Department of Energy or the United States Government. Sandia National Laboratories is a multimission laboratory managed and operated by National Technology and Engineering Solutions of Sandia, LLC, a wholly owned subsidiary of Honeywell International, Inc., for the U.S. Department of Energy’s National Nuclear Security Administration under contract DE-NA-0003525.
Author biographies
Jerry Watkins is a computational scientist in the Quantitative Modeling & Analysis department at Sandia National Laboratories in Livermore, CA. His research focuses on high-order numerical methods, computational fluid dynamics and high performance computing. He has a Ph.D. from Stanford University in Aeronautics & Astronautics.
Max Carlson is a postdoctoral researcher in the Quantitative Modeling & Analysis department at Sandia National Laboratories in Livermore, CA. He received his computer science Ph.D. from the University of Utah in 2022. His current research focus is on portable high performance computing, anomaly detection in climate simulations, and blackbox optimization for software performance-tuning.
Kyle Shan is a data scientist working in Technology Development at Micron Technology, where his work includes process monitoring, defect modeling, and data visualization. He has a Master’s in Computational Mathematics and Engineering from Stanford University.
Irina Tezaur is a distinguished member of technical staff in the Quantitative Modeling Department of Sandia National Laboratories. Her research interests include numerical methods for partial differential equations, reduced order modeling, multiscale coupling methods, scientific computing/HPC, and climate modeling. Tezaur received her Ph.D. degree in computational and mathematical engineering from Stanford University. She is a member of the IEEE Computer Society, Society for Industrial and Applied Mathematics, Society of Women Engineers, American Geophysical Union, and U.S. Association for Computational Mechanics as well as a full member of the Sigma Xi Scientific Research Society.
Mauro Perego is a computational scientist at the Center for Computing Research, Sandia National Laboratories. His work spans several aspects of scientific computing, including the discretization and solution of nonlinear partial differential equations, numerical optimization, uncertainty quantification and scientific machine learning. His current research is in large part applied to ice sheet modeling, with the ultimate goal of providing reliable projections of sea-level rise.
Luca Bertagna is a software engineer at Sandia National Laboratories in Albuquerque, NM. His work focuses mostly on development of sustainable, performant, and portable software for large scale problems. He received his PhD in applied mathematics at Emory University in 2014, with a dissertation on numerical methods on blood flow problems.
Carolyn Kao is a Quantitative Analyst at London Stock Exchange Group in London, UK. She worked on this research as a Master student in Computational and Mathematical Engineering at Stanford. Her current areas of interest lie in pricing and modeling across various asset classes, alongside the application of Data Science in the realm of quantitative finance.
Matthew Hoffman is part of the Fluid Dynamics and Solid Mechanics group at the Los Alamos National Laboratory in Los Alamos, New Mexico, U.S.A. He leads the ice-sheet modeling team at Los Alamos National Laboratory, and has interests in glacier basal physics, ice-sheet/ocean interactions, and regional sea-level change. Hoffman received his Ph.D. in Environmental Sciences and Resources from Portland State University. He is a member of the American Geophysical Union and the International Glaciological Society.
Dr. Price is a staff scientist in the Fluid Dynamics and Solid Mechanics group of the Theoretical Division at Los Alamos National Laboratory (LANL). Steve received his BS in geology from the University of North Carolina in 1995, his MSc in geology from the Ohio State University in 1998, and his PhD in geophysics from the University of Washington in 2006. Since joining LANL as a postdoc in 2008 he has led projects focused on improving our understanding of the Earth’s cryosphere in a changing climate, including two five-year Department of Energy (DOE) projects focused on the development, application, and integration of advanced ice sheet models into DOE’s flagship climate model, the Energy Exascale Earth System Model (E3SM). Since 2013 he has helped lead cryospheric science efforts within E3SM and since 2017 he has served as the LANL point-of-contact for the E3SM project.