
Abstract
Provisional stenting is the standard treatment for coronary bifurcation lesions, relying on real-time assessment of side-branch (SB) hemodynamics to guide intervention. Functional metrics such as fractional flow reserve (FFR) and instantaneous wave-free ratio (iFR) are used for this purpose. Still, their application in bifurcation lesions is limited by procedural complexity and the lack of preoperative planning tools. We developed a simulation-based machine learning (ML) framework to predict iFR under resting, and FFR under hyperemic conditions. The framework leveraged a synthetic hemodynamic dataset of 252 bifurcation lesions generated from 7 patient-specific geometries using HARVEY, a massively parallel computational fluid dynamics (CFD) solver. Anatomical variability was incorporated using four linear mixed-effects (LME) models to establish robust predictions. Two clinically relevant data-splitting strategies were evaluated: (1) a scenario excluding untreated cases, simulating models blind to new geometries, and (2) a scenario incorporating matched untreated cases, reflecting real-world conditions where preoperative anatomical data is available. Morphological features, including lesion severity, length, and curvature, were systematically varied alongside inherited anatomical parameters like bifurcation angle and side-branch count. Splitting approach 2 demonstrated superior predictive performance, achieving a maximum diagnostic accuracy of 0.847 (AUC: 0.899) for FFR and 0.797 (AUC: 0.874) for iFR. Mixed-effects models effectively account for patient-specific anatomical variability, with Bland-Altman analyzes confirming minimal bias between CFD and ML predictions. Incorporating preoperative anatomical information reduced variability and improved diagnostic accuracy across the studied thresholds. The proposed ML framework offers precise, real-time functional assessments of SB hemodynamics, reducing procedural uncertainty in provisional stenting strategies using only pre-operative lesion-specific features and a precomputed synthetic hemodynamic dataset of 252 bifurcation lesion instances. Using synthetic data sets and patient-specific anatomical insights, this approach paves the way for personalized coronary intervention planning, bridging the gap between computational modeling and clinical applicability.
Keywords
1. Introduction
Coronary bifurcation lesions, occurring in the division of a major coronary artery (main vessel; MV) and its side branch (SB), pose significant challenges in coronary interventions due to their complex morphology (Dash 2014; Kirat 2022; Liu et al., 2021). Virtual planning tools have the potential to provide preoperative assessments for each step of the stenting process, facilitating functionally informed treatment planning. However, high-throughput computational simulations used in virtual planners remain resource intensive (Vardhan et al., 2021; A. E. Randles 2013) with relatively long turnaround times, while faster machine learning (ML) surrogates typically require large training datasets from both pre- and post-stenting scenarios, which are often unavailable. To address these limitations, the fidelity of a simulation-based ML tool is assessed, using large datasets of precomputed CFD simulations for real-time hemodynamic evaluation of bifurcation lesions.
The standard treatment strategy for coronary bifurcation lesions is provisional stenting, which is preferred due to its procedural simplicity and success rates. In this approach, a single stent is initially deployed in the MV to restore adequate blood flow, with SB addressed only if necessary. If significant flow compromise occurs in the SB post-stenting, further intervention may involve rewiring and dilating the SB or, in some cases, the deployment of an additional stent as indicated in Figure 1(a). However, challenges such as SB rewiring difficulties and stent or balloon delivery problems persist, complicating successful outcomes in many patients (Simsek et al., 2022). Identifying patients who may benefit from SB stenting in advance (e.g., using virtual planners; Figure 1(b)) facilitates more precise procedural planning and reduces in-lab decision-making pressure. This approach optimizes the timing of the intervention by potentially eliminating the need for SB rewiring and functional evaluation inherent to conventional provisional stenting strategies, thus improving procedural performance and resulting in better patient outcomes. Comparison of the provisional pipeline for bifurcation intervention with the proposed virtual provisional approach (a). Implementation of synthetic bifurcation dataset pre and post MV intervention as training set to predict SB FFR/iFR post-MV intervention based on pre-operation lesion-specific features (b) obtained at initial angiogram evaluation (c). AI: artificial intelligence, CFD: computational fluid dynamics, FFR: fractional flow reserve, iFR: instantaneous wave-free ratio, MV: main vessel, SB: side branch.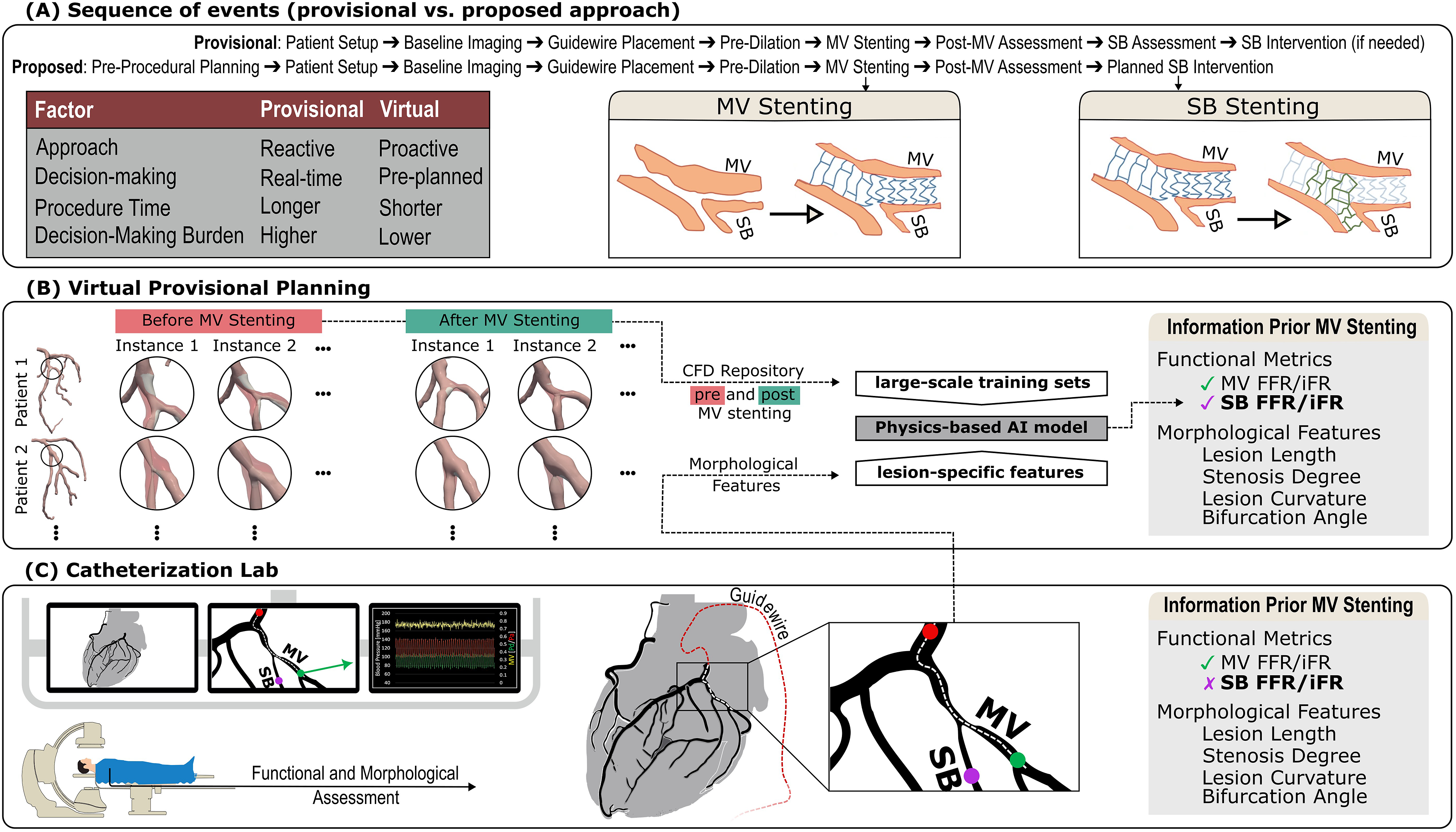
Functional assessment of coronary lesions, including bifurcation lesions, often relies on hemodynamic metrics to guide treatment decisions. The fractional flow reserve (FFR) is considered the gold standard for assessing the severity of coronary artery disease. FFR is determined by measuring the ratio of blood pressure distal to a stenosis to the pressure proximal to the stenosis (Figure 1(c)) during maximal hyperemia, typically pharmacologically induced (Scully et al., 2021; Vecsey-Nagy et al., 2021). To avoid the risks associated with pharmacologically induced hyperemia, functional assessment can alternatively be performed using the less invasive counterpart of FFR, the instantaneous wave-free ratio (iFR), which is measured under resting conditions (Verardi et al., 2018). Unlike FFR, iFR does not require induction of hyperemia, as it measures the pressure gradient across a lesion during diastole when microvascular resistance is naturally stable and minimum. FFR and iFR are both widely used for the functional assessment of coronary lesions, but the choice of which metric to use is often determined by institutional practices and patient-specific considerations. To account for this variability, this study develops separate tools to predict each metric, ensuring broad applicability across diverse clinical workflows. Although multiple clinical trials have shown comparable results for both iFR and FFR metrics (J. E. Davies et al., 2017; Götberg et al., 2017; Eftekhari et al., 2023), their application to bifurcation lesions presents unique challenges due to complex hemodynamic interactions and anatomical variability between MV and SB (H. S. Lee et al., 2022; Ghorbanniahassankiadeh et al., 2021). Technical limitations, such as manipulation and positioning of pressure wires, are well-known sources of variability and further add to procedural complexity, often necessitating sequential assessment of bifurcation branches, increasing the risk of misclassification (Mitomo et al., 2018). These complexities underscore the need for computational approaches capable of providing a clinically accurate functional assessment without the procedural challenges and risks. By simulating hyperemic and resting states in silico, computational fluid dynamics (CFD) offers a promising pathway for accurate and noninvasive assessment of bifurcation lesions.
Existing computational models and virtual planning tools have made notable strides in supporting coronary interventions by providing detailed hemodynamic insights and treatment strategies (Chiastra et al., 2016; Ghorbannia and LaDisa Jr. 2023; Tanade and A. Randles 2024; Tanade et al., 2024; Taylor et al., 2023). However, their clinical utility is often limited by resource-intensive computations that may not align with the real-time demands of interventional cardiology (Vardhan et al., 2019; Vardhan et al. 2021; Vardhan et al. 2022; Vardhan et al. 2024; Chidyagwai et al., 2022; A. E. Randles 2013; Tanade et al., 2022). For instance, stent deployment in the MV often leads to significant morphological and flow alterations, necessitating reevaluation of the SB in many cases. In the context of provisional stenting, the time between placing the MV stent and assessing the SB is critical for determining the need for further intervention in a provisional strategy. The intricate anatomy and hemodynamics of bifurcation lesions frequently extend the time required for comprehensive CFD simulations, limiting their ability to provide timely functional assessments during this pivotal window. However, these simulations can inform simulation-based AI models, which leverage key morphological features of the lesion ensuring that provisional functional assessments are available preoperatively.
Current AI-assisted surrogate models rely on computationally efficient reduced-order models for discrete lesions, which are fast enough to generate a large number of instances, creating controllable, representative, and reliable training datasets within a reasonable time frame (Tanade et al., 2022). However, for more complex lesions such as bifurcations, accurate reduced-order models remain undeveloped. This gap necessitates reliance on high-fidelity CFD simulations for training sets; while offering unparalleled accuracy, CFD significantly increases computational demands, particularly for generating large sample sizes. Additionally, the anatomical variability of bifurcation lesions generally dictates the need for a much larger sample size compared to discrete lesions, which are inherently less variable and easier to source (Ghorbannia and A. Randles 2024). Moreover, virtual provisional planners require representative training datasets both pre- and post-MV stent deployment, a need that is often unmet due to the scarcity of real-world data. These challenges strongly motivate the development of synthetic coronary datasets capable of replicating clinically relevant configurations of bifurcation lesions across a spectrum of anatomical variations. By generating such datasets, it becomes possible to create training sets that are not only controllable and representative but also reliable, addressing the critical gaps in current computational models and enhancing the applicability of AI-assisted tools for clinical decision-making.
The current work assesses the fidelity of simulation-based ML tools for the virtual evaluation of SB in coronary bifurcation lesions based on both hypermic and resting functional metrics, that is FFR and iFR. The assessment leverages a synthetic computational fluid dynamics (CFD) dataset of 252 bifurcation lesions generated using HARVEY, an accelerated blood flow solver (A. E. Randles 2013; Randles et al., 2013), enabling evaluation across a range of clinically relevant configurations and hemodynamic states.
2. Methods
2.1. Creating a synthetic coronary dataset for bifurcation lesions
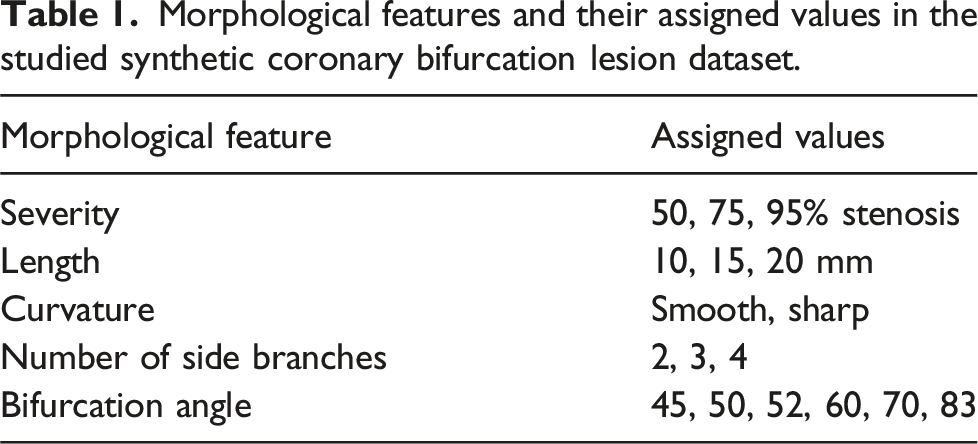
A synthetic database of 3D coronary geometries with set anatomical features spanning the common clinical range was created. To identify hemodynamic changes specific to certain anatomical features, a mechanistic pipeline was designed to ensure a controlled modification of the morphological characteristics, as indicated in Figure 2(a). Specifically, the bifurcation anatomy was artificially modified with the curvature, length, and occlusion level, by changing the lesion falloff, length, and percent stenosis across the bifurcation lesion. Based on previous studies (Louvard and Medina 2015; Vardhan et al., 2018), feature variations included curvature (smooth and sharp); length, 10, 15, and 20 mm; and percent stenosis, 50%, 75%, and 95% reduction in vessel diameter. Therefore, 3 × 3 × 2 modified geometries were created for each geometry and for the configurations representing untreated and treated MV configurations (x2), creating a total of 36 variations per patient-specific base model. Baseline geometries were acquired after IRB approval and from 7 patients who underwent clinically indicated coronary angiography at Brigham and Women’s Hospital, Boston MA (protocol #2015P001084) (Vardhan et al., 2022). Additionally, some of the inherited coronary features such as the number of left anterior descending (LAD) coronary artery side branches and the bifurcation angle were also included among the predictors. Table 1 summarizes the morphological features and their assigned values in the synthetic database studied. Pipeline for generation of the synthetic coronary dataset for bifurcation lesions (a), large scale CFD simulations (b), and CFD-derived ML prediction of side-branch hemodynamic significance (c). Bifurcation lesions were synthetically modified to create different stenosis degrees (×3), lesion length (×3), and curvatures (×2) at two configurations (×2) representing anatomy before (Untreated group) and after (Treated) main branch treatment. Overall 36 subcases (3 × 3 × 2 × (2) were created for each of the baseline geometries (×7) resulting in a synthetic coronary dataset of size 252 samples. High-fidelity 3D hemodynamic simulations of resting and hyperemic flow were performed on all geometries using HARVEY, a massively paralleled CFD solver. Untreated FFR/iFRs were used to train a ML model to predict side-branch FFR/iFR after main-branch treatment. Morphological features and their assigned values in the studied synthetic coronary bifurcation lesion dataset.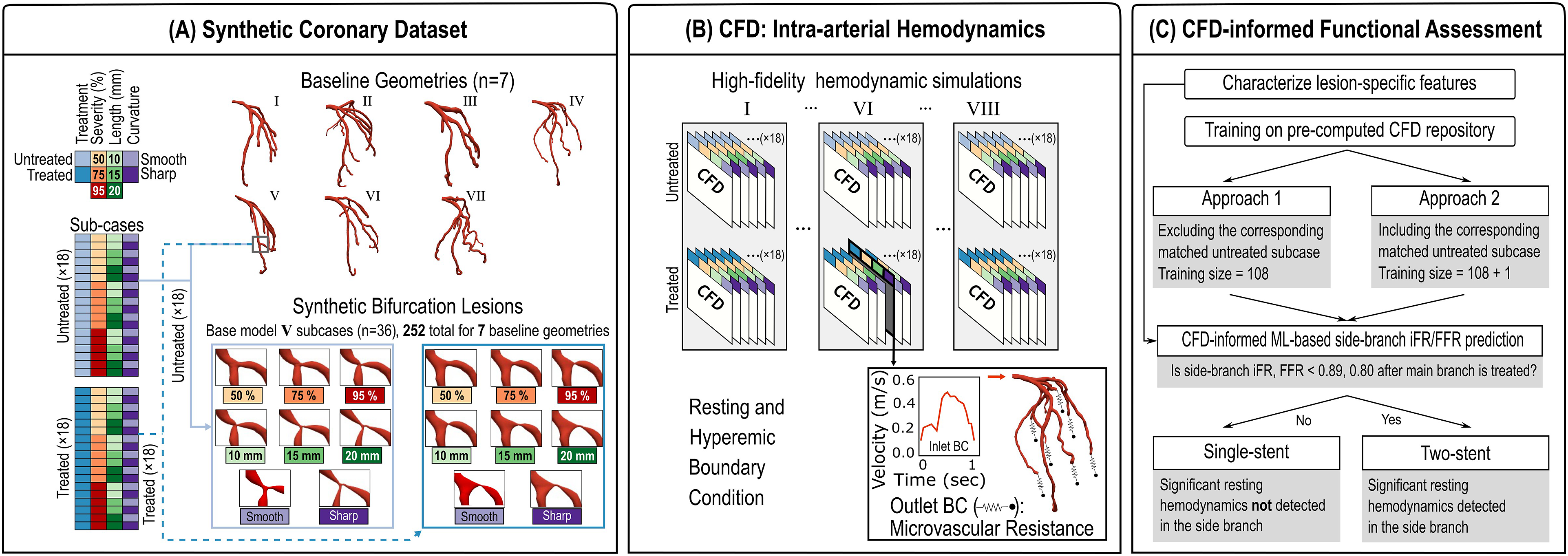
2.2. Deriving intra-arterial hemodynamics using computational fluid dynamics
CFD simulations were performed using HARVEY, a massively parallel hemodynamic solver that implements the lattice Boltzmann method (Randles et al., 2013). LBM is an alternate for the traditional Navier-Stokes equations which govern fluid flow (Krüger et al., 2017). In the Lattice Boltzmann Method (LBM), the probability distribution function f
i
(x, t) represents the population of particles located at lattice point x, at time t, with discrete velocity c
i
, moving around a fixed Cartesian grid
2.3. Functional assessment of coronary lesions via simulation-based ML models
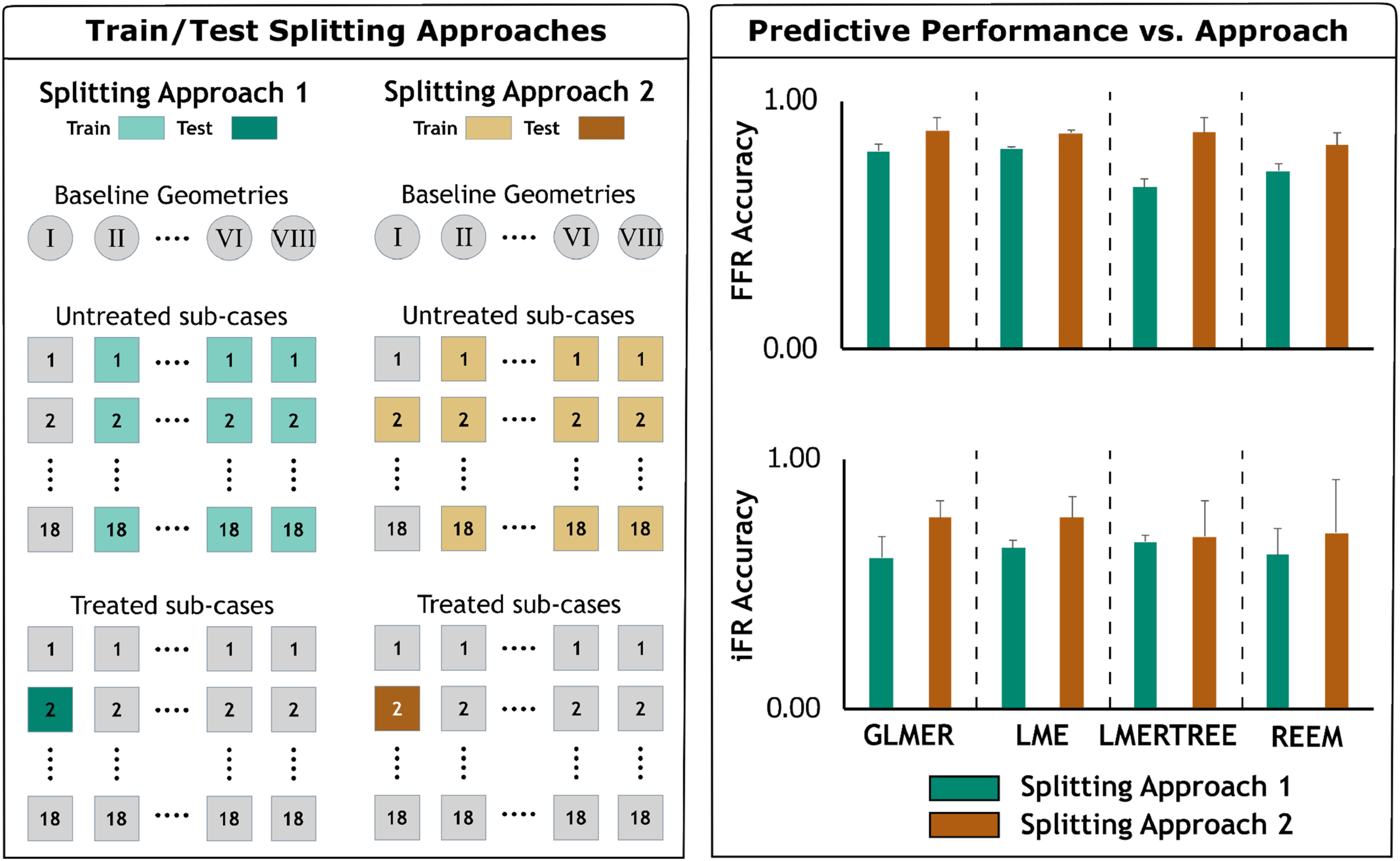
A hemodynamically informed ML model was trained on the untreated data set to predict whether side branch stenosis is significant after MV treatment. The created synthetic coronary database shared numerous bifurcation lesion features mimicking clinical conditions. Other sources of variation included patient-specific anatomical differences between 7 base models that could potentially introduce baseline differences in FFR/iFR computed for subcases generated from different base geometries. Therefore, a linear mixed effect (LME) model (Faraway 2006) was employed to account for correlations from repeated measurements, that is, different morphological feature values, on shared geometry. The • xi1 is the stenting status of the ith patient, • xi2 is the curvature of lesion in the ith patient, • xi3 is the length of lesion in the ith patient, • xi4 is the severity of lesion in the ith patient, • xi5 is the number of side branches in ith patient, and • xi6 is the bifurcation angle in ith patient. • Splitting Approach 1: A comprehensive analysis of all permutations, encompassing 1 out of every 7 base model for the test data set while excluding all untreated subcases within the training data. • Splitting Approach 2: A comprehensive analysis of all permutations, encompassing 1 out of every 7 base model for the test data set while retaining a single matched untreated subcase pair within the training data. We then assessed the accuracy of the prediction in the treated subcase with matching morphological features. Left panel: Splitting approaches used to identify training and testing datasets. Right panel: Comparison of predictive performance for studied ML models, that is, GLMER, LME, LMERTREE, REEM, at resting and hyperemic states, that is, iFR and FFR, respectively. For each treated case, two approaches were used to train the ML models. Approach 1 consisted of a comprehensive analysis of all permutations, encompassing 1 out of every 7 baseline geometries for the testing dataset while excluding all untreated sub-cases within the training data. Approach 2 consisted of a comprehensive analysis of all permutations, encompassing 1 out of every 7 baseline geometries for the testing dataset while retaining a single matched untreated sub-case pair within the training data. Splitting approaches were specifically designed for training/testing that is according to the clinically feasible scenario assuming the availability of the untreated sub-case for each new coming patient actually be available (Splitting approach (2) as compared to a completely blinded scenario where no information from new patient is involved (Splitting approach 1). We then assessed prediction accuracy on the treated sub-case with matching morphological features. Right panel shows an example for predicting on the second treated sub-case of baseline geometry I. Splitting approaches 1 and 2 were implemented on all treated sub-cases with averaged performances shown on the right panel.
The variable ϵ
i
captures a random variation in the FFR (or iFR) of the ith patient that is independent of the patient’s morphological features and measurements of other patients. There are two types of regression coefficients in the above model: fixed and random. The regression coefficients of fixed effects to estimate from the data are the intercept parameters β0 and slope parameters β
j
for j = 1, …, 6. The variable
3. Results
3.1. Incorporating clinically feasible scenarios for splitting train/test sets on large pre-computed datasets
A crucial aspect of our analysis was the implementation of two distinct splitting approaches to train the ML models (Figure 2(c)), mimicking different clinical scenarios. In the split approach 1, all permutations were examined, with one out of every 7 base models assigned to the test dataset while excluding all untreated subcases within the training data Figure 3(left). This approach assumed no anatomical information from the incoming patient. In contrast, splitting approach 2 incorporated a single matched untreated subcase pair within the training data, enabling the inclusion of specific pre-operative patient information assuming the anatomical features of the lesion (untreated configuration) are available through diagnostic imaging Figure 3(left). Here, we evaluate the accuracy of prediction in the treated subcase with similar morphological characteristics, reflecting a more clinically relevant scenario.
The results highlighted the superior performance of the splitting approach 2 compared to the splitting approach 1, as reflected in the accuracy values across all models tested as indicated in Figure 3 (right). Under the resting condition (i.e., iFR), splitting approach 2 achieved higher average accuracies for most models, with notable improvements in models such as REEM (average accuracy: 0.70 ± 0.22) and LMERTREE (average accuracy: 0.69 ± 0.14), compared to their respective performances under the splitting approach 1.
Similarly, under the hyperemic condition (i.e., FFR), the models consistently demonstrated higher accuracy with splitting approach 2. The GLMER model, for instance, achieved an average accuracy of 0.88 ± 0.05, while LMERTREE and LME both reached 0.87, with reduced variability (standard deviations of 0.06 and 0.02, respectively). These improvements reflect the clinical advantage of splitting approach 2, which incorporates anatomical information from untreated subcases. This approach not only improves prediction accuracy for treated subcases with similar morphologies, but also reduces variability across models, underscoring its robustness and alignment with realistic clinical scenarios.
3.2. Predictive performance of simulation-informed ML models for SB assessment
The functional assessment of SB has significant clinical relevance, providing crucial insights into the hemodynamic impact of coronary lesions. Leveraging our synthetic coronary dataset, our objective was to construct a comprehensive precomputed CFD repository, facilitating the training of predictive models of ML for SB in resting hemodynamic condition (through
Model predictive performance by method, state, and threshold.
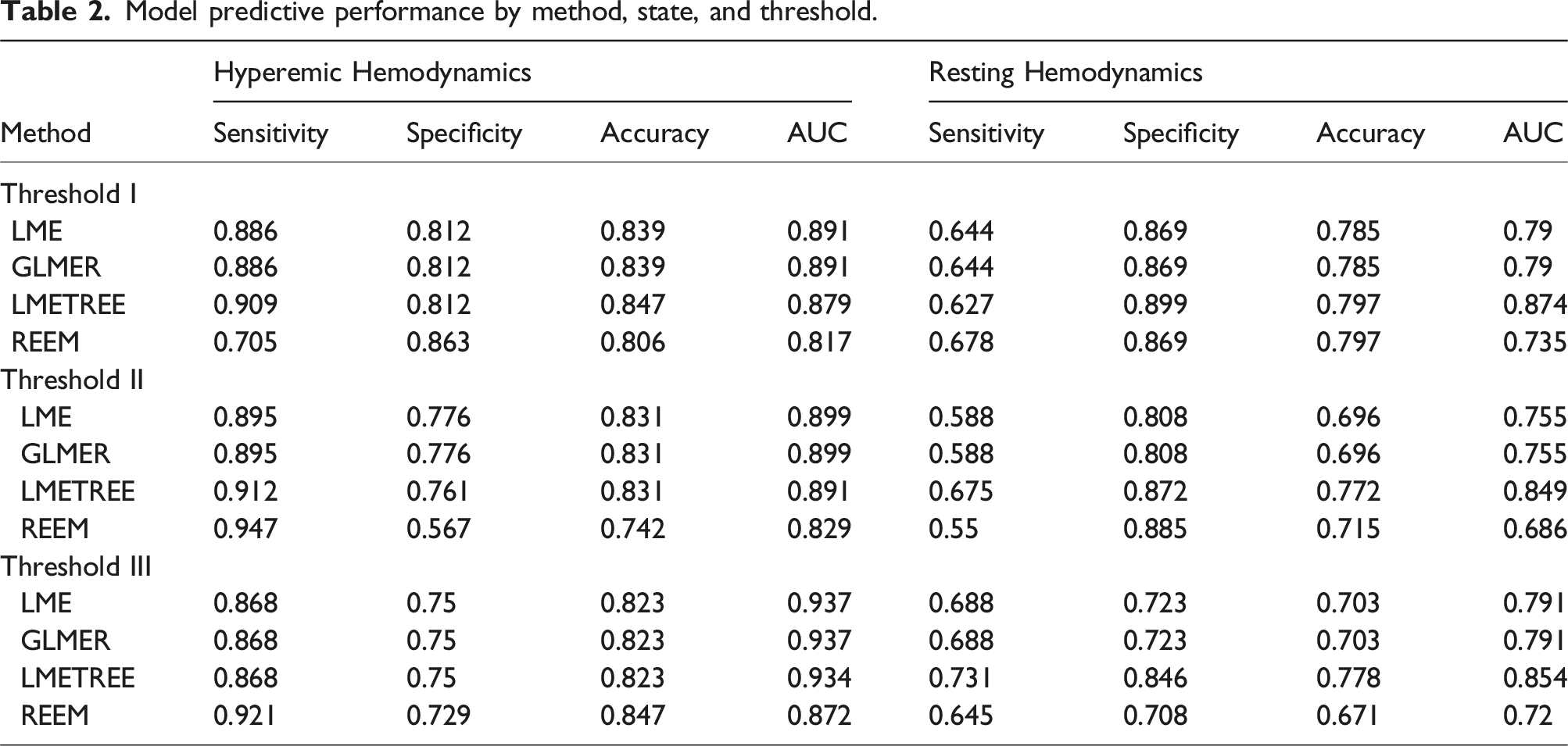
In contrast, splitting approach 2, which incorporated specific pre-operative bifurcation features, resulted in substantial improvements in predictive performance across all models and hemodynamic states studied. Therefore, Table 2 reports predictive performances only for splitting approach 2 with details of approach 1 provided in the supplementary materials. On average, for
The agreement between Bland-Altman plot for the best predictive model identified for side-branch FFR using training dataset consisting of a comprehensive analysis of all permutations, encompassing 1 out of every 7 baseline geometries for the testing dataset after inclusion of the single matched untreated sub-case pair within the training data (Splitting Approach 2).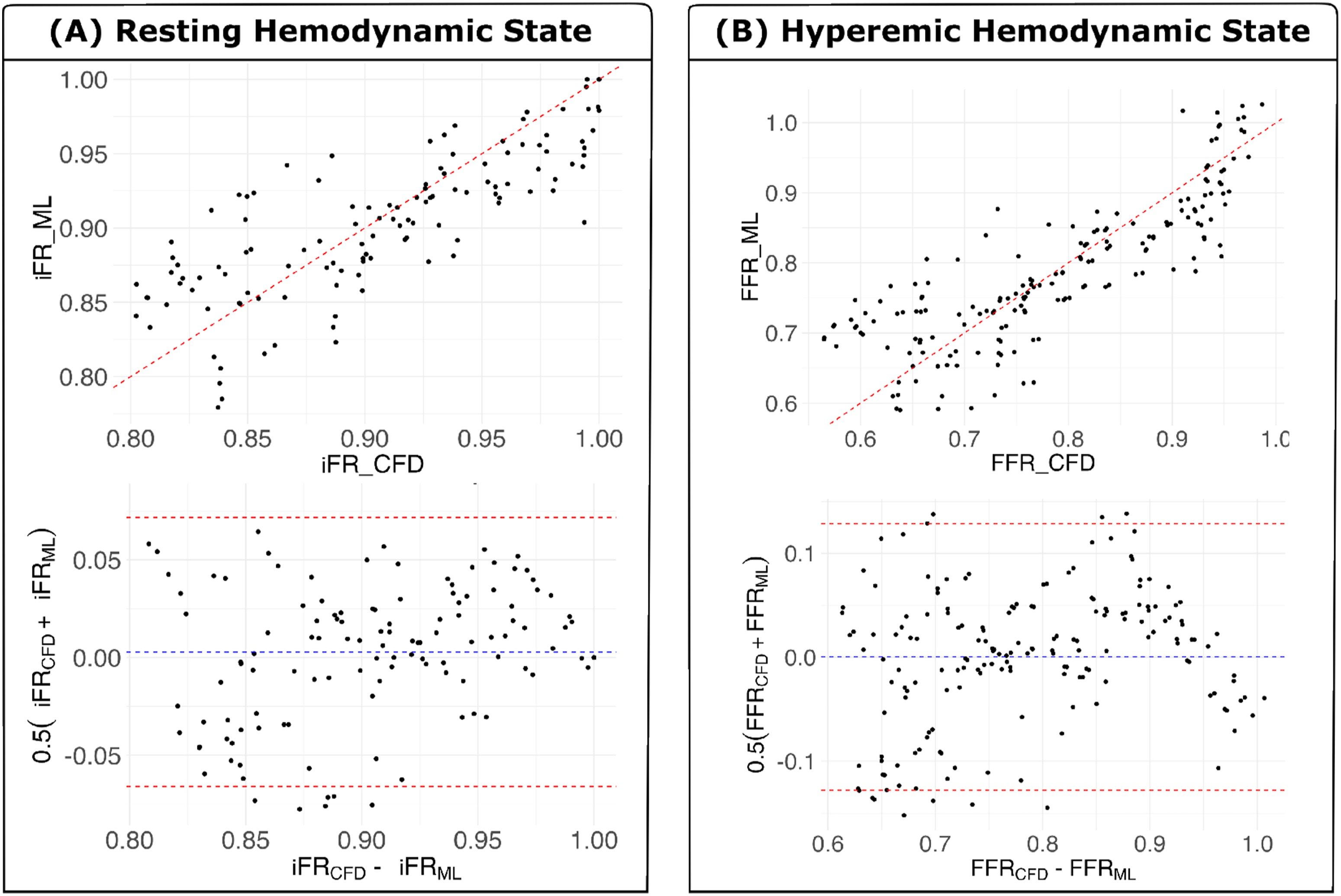
Finally, ROC analysis revealed significant improvements in AUC values under splitting approach 2 for both ROC performance of the predictive models, that is, LME, LMERTREE, GLMER, REEM. Top and bottom panels showing results for hyperemic and resting hemodynamic state at different thresholds; 0.750, 0.775, and 0.800 for FFR and 0.850, 0.870, 0.890 for iFR respectively.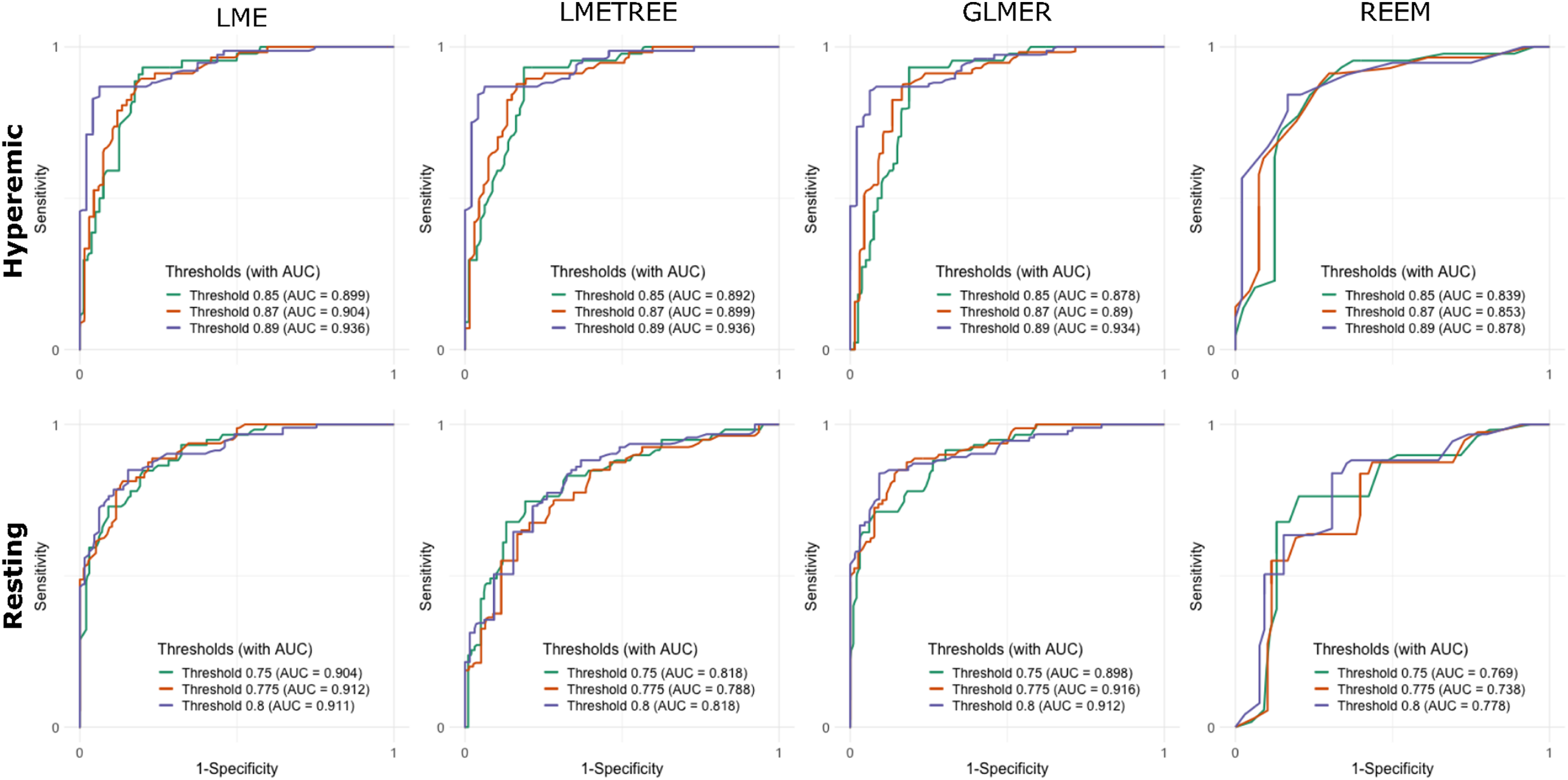
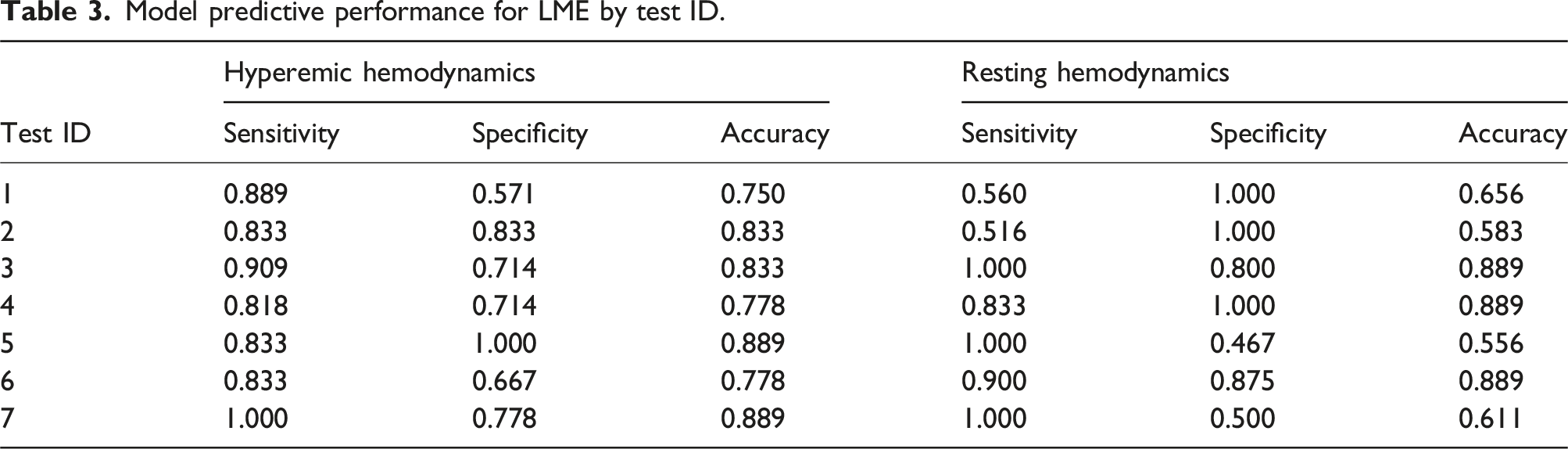
3.3. Effect of baseline patient-specific geometry on the predictive performance of the ML modes
Model predictive performance for LME by test ID.
4. Discussion
This work presents a comprehensive study that systematically investigated the influence of the morphology of the lesions on coronary bifurcation lesions and the hemodynamic significance of SB after MV treatment. The main findings of this study are as follows.
Firstly, our analysis revealed pronounced variability in both SB
Secondly, our investigation into the predictive performance of CFD-informed ML models highlighted the crucial role of incorporating patient-specific anatomical information for accurate prediction. The inclusion of matched untreated subcase pairs in the training data (i.e., splitting approach (2) improved the diagnostic accuracy of ML models, across various thresholds for both
Furthermore, the results of our study support findings from previous works that investigated different geometric features as determinants of diagnostic metrics, such as FFR and iFR (Chiastra et al., 2013; D-Y. Kang et al., 2018; Antoniadis et al., 2015; Rigatelli et al., 2017; LaDisa et al., 2022). Surface roughness and eccentricity, features of the lesion anatomy, have been shown to be independent predictors of coronary disease (D.-Y. Kang et al., 2018). Our work extends such investigations by systematically studying the effect of spatial characteristics of lesion anatomy specifically in bifurcation lesions using intra-arterial hemodynamics against clinical diagnostic measurements. Notably, our results further supported the importance of key bifurcation anatomical features, including lesion length and severity, when predicting hemodynamic variables across the lesion under both resting and hyperemic conditions.
It is essential to interpret the results of our study relative to several limitations. Despite the large sample size relative to previous work (Chu et al., 2018; Y. Yang et al., 2017; Peng et al., 2016), the study relied on a synthetic arterial database created from 7 patient cases, as assessing the impact of anatomical features on intracoronary hemodynamics with real patient data is challenging due to anatomical variations. Furthermore, while our dataset, derived from 252 configurations, is extensive, it is inherently constrained by its synthetic nature, limiting our ability to model every patient-specific anatomical feature. There remain anatomical variations unaccounted for, which are shared among sub-models derived from the same base model. Our use of mixed effect models was critical in explicitly accounting for these variations as random effects, thereby enhancing the robustness and applicability of our findings compared to alternative methods that do not inherently manage such datasets with hierarchical structure within their modeling frameworks. Identifying crucial anatomical features from this synthetic database generates hypotheses that merit further investigation in a larger cohort of patients with bifurcation lesion disease.
Regarding the predictive performance of the LME model used to predict SB hemodynamics (both
5. Conclusion
In conclusion, this study introduces a simulation-based machine learning framework that enables a precise and efficient evaluation of side-branch hemodynamics in coronary bifurcation lesions. Using a synthetic coronary dataset derived from high-fidelity CFD simulations and incorporating patient-specific anatomical variability through mixed-effects models, the framework achieved robust predictive accuracy for key functional metrics such as FFR and iFR. In particular, the inclusion of untreated matched subcase data significantly improved model performance, demonstrating the value of integrating the morphology of the lesion and patient-specific anatomical data for real-world applicability.
This work not only highlights the critical role of lesion-specific features and baseline variability in hemodynamic predictions, but also establishes a scalable, data-driven foundation for advancing coronary intervention planning. By bridging computational modeling with clinical workflows, the proposed framework paves the way for real-time, personalized treatment strategies and represents a significant step toward the realization of vascular digital twins. These advances have transformative potential to improve procedural outcomes and patient care in complex coronary interventions.
Footnotes
Acknowledgements
Computing support for this work came from Duke OIT, Duke Compute Cluster, and the Lawrence Livermore National Laboratory (LLNL) Institutional Computing Grand Challenge program.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research reported in this publication was supported by the National Heart, Lung, and Blood Institute of the National Institutes of Health under Award Number R21HL15856. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Ethical statement
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Author biographies
Arash Ghorbannia is a postdoctoral associate at the department of Biomedical Engineering at Duke University. His research interests are primarily related to cardiovascular biomechanics and the application of computational and experimental tools to improve diagnosis, monitoring, and management of cardiovascular diseases. He received his PhD from the Medical College of Wisconsin and Marquette University Joint Department of Biomedical Engineering in 2022.
Cyrus Tanade is a PhD candidate in Biomedical Engineering at Duke University. He received his M. Eng in Biomedical Engineering from University College London and Georgia Institute of Technology through an integrated bachelor’s-master’s program. He has been the recipient of the NSF GRFP fellowship and the 2020 IET prize. His research focuses on high performance computing, biomedical simulation, and cardiovascular disease.
Ayman Yousef is a PhD candidate in Biomedical Engineering at Duke University. His research interests lie in the application of machine learning and advanced in situ visualization and processing techniques to improve data analysis and projection of large-scale computational fluid dynamics.
Nusrat Sadia Khan is a PhD candidate in Biomedical Engineering at Duke University. Her research focuses on the development of vascular digital twins using high-performance computing and the application of machine learning algorithms for hemodynamic prediction. She received her bachelor’s degree in Biomedical Engineering from the Military Institute of Science and Technology in Bangladesh and completed her Master of Research in Human Movement Science from Victoria University, Melbourne.
Arpita Das is currently working as a Software Developer Engineer at Amazon Web Services. She completed her BS in Computer Science and Neuroscience from University of North Carolina at Chapel Hill. She has majorly focused her research on computational fluid modeling related to coronary artery disease.
Madhurima Vardhan Madhurima Vardhan is an Assistant Computational Scientist at the Argonne National Laboratory. Previously she was the Margaret Butler Fellow in the Argonne Leadership Computing Facility and worked in Google. She completed her PhD and MS degrees in Biomedical Engineering from Duke University. Her research is focused on combining Artificial Intelligence and High Performance Computing for advancing biomedical applications.
Jocelyn T. Chi is an Assistant professor in the Department of Applied Mathematics at the University of Colorado Boulder. Prior to joining CU Boulder she was an NSF Mathematical Sciences Postdoc in the Department of Mathematics at UCLA. Her research interests are in scalable statistical data analysis and computing using tools from randomized algorithms, machine learning, low rank matrix and tensor factorizations, stochastic optimization, and numerical analysis.
Sayan Roychowdhury received his PhD in Biomedical Engineering from Duke University in 2023. His thesis work leveraged the power of supercomputers to perform microscale blood flow and microfluidic device simulations, with a focus on fluid-structure interaction models to capture cellular dynamics. His research interests include numerically studying cancer cell transport and optimizing use of HPC resources. Currently he works as a life sciences consultant providing technology services for pharmaceutical and biotech companies.
Jane A. Leopold is the director of the Women’s Interventional Cardiology Health Initiative at Brigham and Women’s Hospital (BWH). An interventional cardiovascular medicine specialist, she is also an associate professor of medicine at Harvard Medical School (HMS). She received her medical degree at Boston University School of Medicine. She completed a residency in internal medicine at Beth Israel Deaconess Medical Center and two fellowships at Boston Medical Center—cardiovascular disease and interventional cardiology. Dr Leopold is board certified in cardiovascular disease and interventional cardiology. Dr Leopold developed the Women’s Interventional Cardiology Health Initiative at BWH, which uses advanced invasive diagnostic imaging and functional assessment devices to diagnose chest pain syndromes in women. The author of over 100 peer-reviewed publications, Dr Leopold’s research interests include preclinical and clinical studies in pulmonary arterial hypertension and she is the principal investigator of a National Institutes of Health funded center at BWH to perform deep phenotyping in patients with Groups 1-5 pulmonary hypertension. She also studies mechanisms by which aldosterone influences vascular structure and function and cardiovascular disease in women. Her research has received support from the National Institutes of Health and the American Heart Association.
Eric C. Chi is an Associate Professor in the Department of Statistics at Rice University. His current research interests are in statistical learning and numerical optimization and their application to analyzing large and complicated modern data in biological science and engineering applications.
Amanda Randles is the Alfred Winborne Mordecai and Victoria Stover Mordecai Associate Professor of Biomedical Sciences and Biomedical Engineering at Duke University. She has courtesy appointments in the Mechanical Engineering and Material Science, Computer Science, and Mathematics departments and is a member of the Duke Cancer Institute. Focusing on the intersection of high performance computing, machine learning, and personalized modeling, her group is developing new methods to aid in diagnosing and treating diseases ranging from cardiovascular disease to cancer. She has received the ACM Prize in Computing, the NIH Pioneer Award, the NSF CAREER Award, and the ACM Grace Hopper Award. She was named to the World Economic Forum Young Scientist List and the MIT Technology Review World’s Top 35 Innovators under the Age of 35 list and is a Fellow of the National Academy of Inventors. Amanda received her PhD in Applied Physics from Harvard University as a DOE Computational Graduate Fellow and NSF Fellow. Before that, she received her Master’s degree in Computer Science from Harvard University and her Bachelor’s degree in Computer Science and Physics from Duke University. Prior to graduate school, she worked as a software engineer at IBM on the Blue Gene supercomputing team. She has contributed to over 100 peer-reviewed papers, 121 granted US patents, and has about 75 pending patent applications.