
Abstract
Large-scale astronomical image data processing and prediction are essential for astronomers, providing crucial insights into celestial objects, the universe’s history, and its evolution. While modern deep learning models offer high predictive accuracy, they often demand substantial computational resources, making them resource-intensive and limiting accessibility. We introduce the Cloud-based Astronomy Inference (CAI) framework to address these challenges. This scalable solution integrates pre-trained foundation models with serverless cloud infrastructure through a Function-as-a-Service (FaaS). CAI enables efficient and scalable inference on astronomical images without extensive hardware. Using a foundation model for redshift prediction as a case study, our extensive experiments cover user devices, HPC (High-Performance Computing) servers, and Cloud. Using redshift prediction with the AstroMAE model demonstrated CAI’s scalability and efficiency, achieving inference on a 12.6 GB dataset in only 28 seconds compared to 140.8 seconds on HPC GPUs and 1793 seconds on HPC CPUs. CAI also achieved significantly higher throughput, reaching 18.04 billion bits per second (bps), and maintained near-constant inference times as data sizes increased, all at minimal computational cost (under $5 per experiment). We also process large-scale data up to 1 TB to show CAI’s effectiveness at scale. CAI thus provides a highly scalable, accessible, and cost-effective inference solution for the astronomy community. The code is accessible at https://github.com/UVA-MLSys/AI-for-Astronomy.
Introduction
Astronomical images are vital to modern astrophysics, offering key insights into celestial objects, such as their shape (Willett et al., 2013), distance (Hubble, 1929), and other fundamental characteristics that define our understanding of the universe. Large surveys like the Dark Energy Spectroscopic Instrument (DESI) (Fan et al., 2019) and the Sloan Digital Sky Survey (SDSS) (Gunn et al., 1998) provide extensive image datasets with unique attributes. For example, SDSS images consist of five spectral bands—u, g, r, i, and z—each focused on specific wavelengths: Ultraviolet (u) at 3543 Å, Green (g) at 4770 Å, Red (r) at 6231 Å, Near Infrared (i) at 7625 Å, and Infrared (z) at 9134 Å.
Deep learning foundation models trained on large-scale astronomical image datasets have proven to be powerful tools for improving the accuracy and efficiency of tasks such as redshift prediction, morphology classification, and similarity search (Fathkouhi and Fox, 2024; Hayat et al., 2021; Parker et al., 2024). Figure 5 highlights several notable deep-learning architectures that leverage astronomical images for prediction. For example, AstroCLIP (Parker et al., 2024) uses an image transformer with a 307M-parameter encoder, pretrained on approximately 197K images. AstroMAE (Fathkouhi and Fox, 2024) combines frozen pretrained weights with fine-tunable parameters, totaling 10.4 M learnable parameters. Similarly, Henghes describes the use of photometric redshift estimation to (Henghes et al., 2022) train their model on one million SDSS images using 7.8 M parameters. In comparison, AstroMAE, trained on about 650 K images, showed significant performance improvements over the (Henghes et al., 2022) model in redshift prediction.
While these models yield impressive results, their large parameter counts require substantial computational resources, making both training and inference resource-intensive. The memory and computing resources on a standalone device become a limitation for users to run on large datasets and foundation models. There is a need for advanced infrastructure to overcome the limit of high-performance inference accessibility for many users (Neely, 2021). Serverless computing is a recently popular Function-as-a-Service (FaaS) (Li et al., 2022), that lets developers write cloud functions in high-level languages (e.g., Python) and takes care of the complex infrastructure management itself.
This study proposes a highly scalable serverless computing framework for using AWS (AWS, 2024) to enhance the accessibility of a pretrained foundation model for astronomical images. This effectively reduces the computational demands on individual users. In summary, we offer the following contributions. A novel Cloud-based Astronomy framework (named “Cloud-based Astronomy Inference” (CAI)) to significantly enhance the scalability of foundation model inference on large astronomical images. Detailed experiments on the redshift prediction task using real-world galaxy images from the SDSS survey, comparing CAI’s performance with other computing devices (e.g., personal, and HPC). Our comprehensive performance analysis with inference time and throughput demonstrates that CAI effectively improves the scalability of foundation model inference in astronomy.
Related work
The immense size of astronomy datasets has made cloud services essential for efficiently storing and processing this data. Faaique highlighted the significant challenges such massive volumes pose, emphasizing cloud computing as a key solution to managing these issues (Faaique, 2024). Kim and Hahm investigated requirements for cloud computing used by scientists dealing with the increasing size of big science datasets (Kim and Hahm, 2011). Gill and Buyya accepted the invaluable nature of cloud computing for large astronomy datasets and used an astronomy case study to test their proposed cloud computing model that improves failure management (Gill and Buyya, 2020). Khlamov et al. argued that cloud services are nearly indispensable for managing astronomy datasets, especially those dense in metadata and images (Khlamov et al., 2022). In their study on variable star photometry, they implemented a Software-as-a-Service (SaaS) model to effectively address the substantial storage demands.
De Prado et al. leveraged cloud computing for the Mosaic tool, enabling the rapid and efficient creation of sky mosaics from images captured across different sky regions (De Prado et al., 2014). Zhang et al. implemented the distributed astronomy image processing toolkit called Kira by running Apache Spark on an Amazon EC2 cloud (Zhang et al., 2020). Their speed-up results and throughput indicate that this parallelized computing method is compatible with astronomy applications. Sen et al. underscored the minimal scalability concerns of cloud services, noting the effectiveness of cloud-based distributed frameworks for tasks like redshift prediction (Sen et al., 2022). Furthermore, Parra-Roy´on et al. leveraged Function-as-a-Service (FaaS) models and decision-making systems to manage the computationally intensive processing of radio astronomy data (Parra-Royón et al., 2024).
These studies highlight the essential role of cloud services in overcoming the computational and storage challenges inherent in modern astronomical research. To our knowledge, no prior work has leveraged serverless computing (AWS, 2024) to enhance the scalability of foundation models for astronomical images.
Problem statement
In astronomical imaging, much of the research has focused on enhancing deep learning model performance, with comparatively less attention to scaling inference capabilities. Although recent foundation models, trained on extensive astronomical image datasets, demonstrate versatility across various tasks, their high parameter count limits usability and scalability due to infrastructure constraints. To address this, a scalable framework is essential for efficient inference on large image volumes without added financial burdens. We introduce Cloud-based Astronomy Inference (CAI), which employs the Function-as-a-Service (FaaS) (Böhringer, 2022) to enhance the scalability of foundation models trained on astronomical images. Based on our review, CAI is the first framework specifically designed to address the inference scalability of foundation models in astronomical imaging.
Although dark energy constitutes approximately 95% of the universe’s energy, our understanding of this mysterious force remains profoundly limited. Investigating and exploring its nature requires a large-scale collection of galaxy images, supported by advanced cosmological methods and theories (Jones et al., 2024). A cornerstone of these methods is the precise determination of a critical parameter: redshift. Redshift measures how much the light from a celestial object has been stretched, providing crucial insights into the distances of these objects and the expansion of the universe (Hubble, 1929).
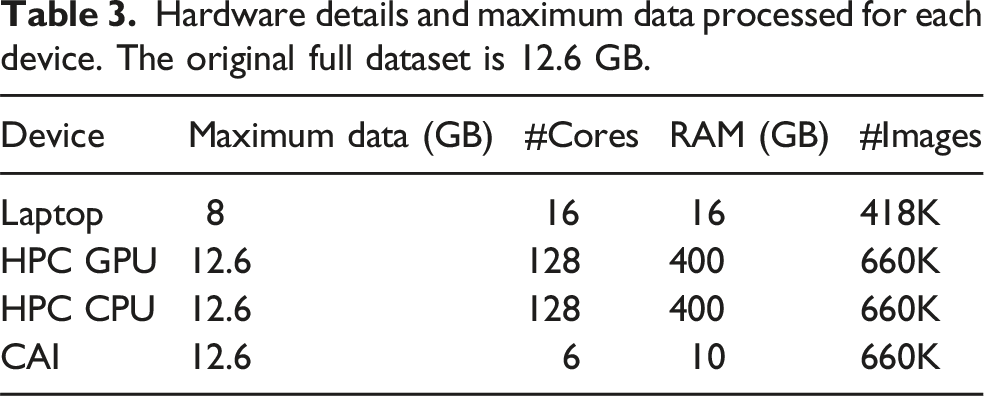
In astronomical data analysis, the choice of computing infrastructure has a significant impact on efficiency, scalability, cost, and accessibility. Personal computing devices, such as laptops and desktops, provide the most straightforward and accessible environment for initial exploration and analysis of a limited scale. These devices have low upfront costs and minimal setup requirements, making them suitable for preliminary testing, educational purposes, or small datasets. However, limited memory and computational capabilities severely restrict their use for larger datasets or complex models. In our experiments, personal devices were unable to handle datasets larger than 8 GB, underscoring their limited suitability for extensive astronomical data analysis. High-performance computing (HPC) CPUs offer robust computational power and ample memory, enabling researchers to process large datasets effectively. These systems are reliable, capable of extensive batch processing, and suited to complex computational tasks that may not easily parallelize on GPUs. GPUs within HPC environments significantly accelerate deep learning tasks due to their parallel processing architecture, which excels at inference workloads involving matrix operations typical of neural networks. HPC GPUs achieved much faster inference (140.8 s) compared to CPUs. GPUs are ideal for intensive model training and moderately large-scale inference tasks. However, GPU-based HPC systems come with high fixed and variable costs, as well as resource allocation complexities, making them less accessible to individual researchers or smaller institutions.
In this study, we evaluate the CAI scalability by applying it to the prediction of redshifts. For this purpose, we selected AstroMAE due to its superior performance and because it is pre-trained on a larger dataset. Our proposed CAI framework leverages serverless cloud computing infrastructure to provide an optimal balance of scalability, cost-efficiency, and accessibility. CAI’s linear scalability and minimal computational cost offer substantial advantages over traditional infrastructure. CAI eliminates upfront costs, complex maintenance, and resource management tasks associated with HPC clusters.
Future work will explore the scalability of additional models discussed in this context.
Methodology
We first collect the AstroMAE model pretrained on the large astronomy dataset. Then deploy it to our proposed cloud architecture for an inference scalability benchmark.
AstroMAE
AstroMAE (Fathkouhi and Fox, 2024) is a recent foundation model that captures general patterns in galaxy images for redshift prediction. It has two major phases.
Pretraining
Figure 1 illustrates the pretraining process of AstroMAE’s masked autoencoder (Devlin, 2018). The masked autoencoder aims to reconstruct masked patches using unmasked ones. We mask 75% of the embedded patches; the remaining 25% are fed into the encoder. Initially, images are segmented into uniform patches of size 5 × 8 × 8 and embedded into 192-dimensional vectors with positional embedding. The architecture of masked autoencoder of AstroMAE (Fathkouhi and Fox, 2024).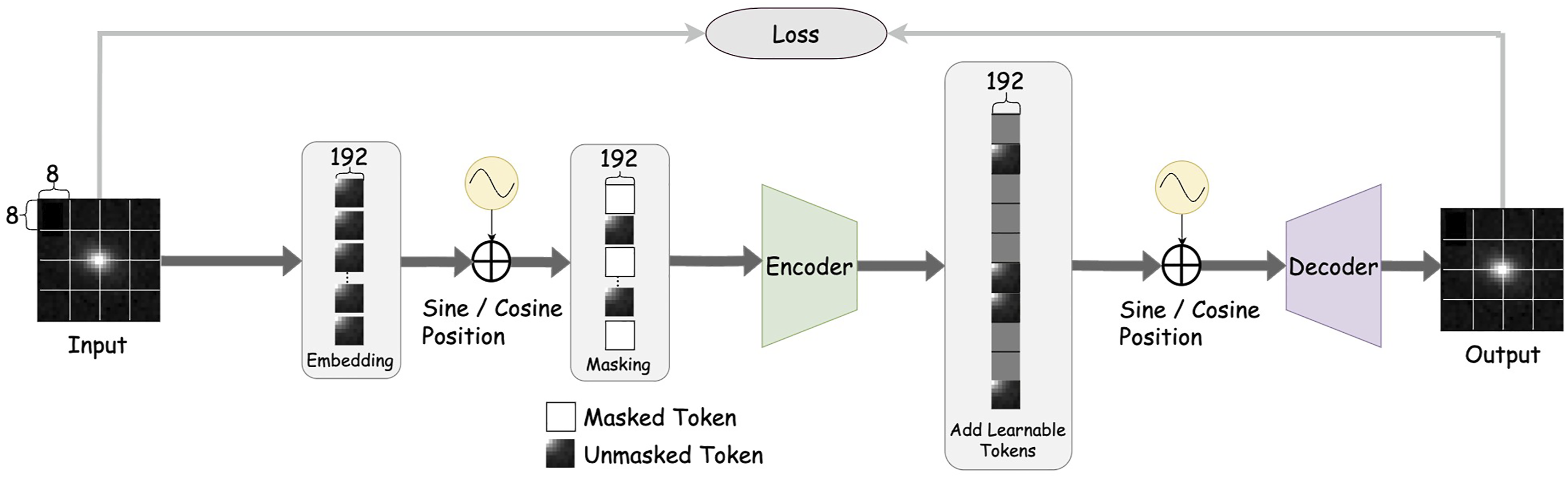
The reconstructed masked patches are compared to their original patches, enabling the model to learn meaningful representations. To promote learning of data patterns instead of memorizing patch positions, the embeddings are randomly shuffled before being input to the encoder. Compared to other pretraining methods like contrastive learning (Chen et al., 2020), the masked autoencoder does not rely on specific augmentations, which can potentially increase the dataset size and computational demands. In contrast, AstroMAE’s masked autoencoder processes 25% patches, making it significantly more efficient. A crucial step for working on large astronomy data. AstroMAE also uses a modified ViT (Wang et al., 2022), which contains a parallel convolutional module and performs even better.
Fine-tuning
During fine-tuning, the decoder is removed, leaving a frozen encoder that works with two additional models: a parallel Inception model and a magnitude block. The outputs from the frozen encoder, Inception model, and magnitude block are first processed through several layers individually, then concatenated and passed through additional layers for final processing.
Let V ∈ R I represent the image data and O ∈ R M represent the magnitude data, where I and M denote the dimensions of the image and magnitude data spaces, respectively.
A frozen pretrained encoder E: R
I
→ R
C
generates a latent space representation L
E
from the image V:

Similarly, an inception model W: R
I
→ R
Q
extracts features L
W
from the same image of Figure 2(a). AstroMAE fine-tuning architecture.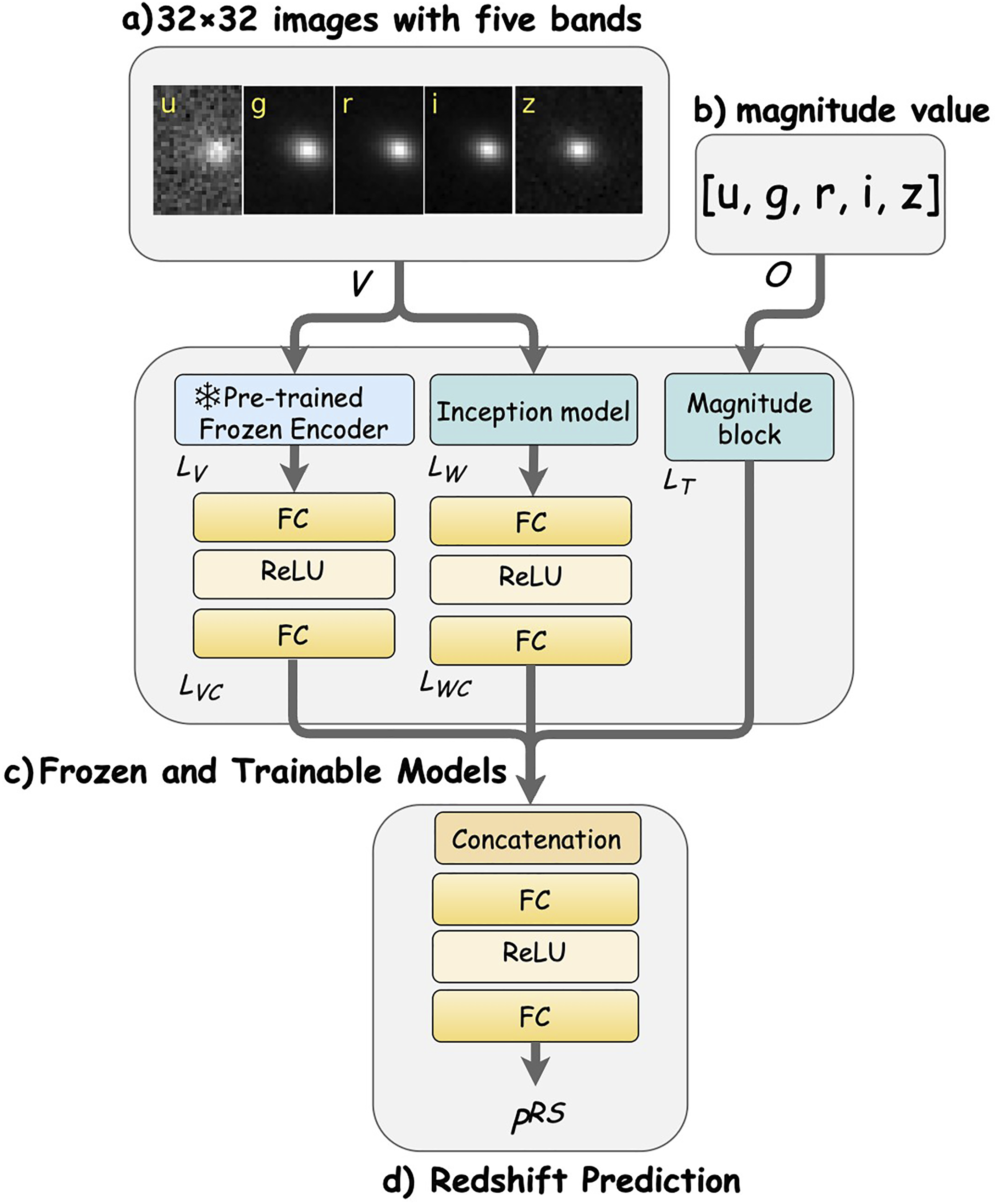

The magnitude data O from Figure 2(b)) is processed through a magnitude block S: R
M
→ R
T
, resulting in magnitude features L
T
:

To further process these image features, AstroMAE applies two fully connected layers with a ReLU activation in between to both L
E
and L
W
. The resulting features are denoted as L
EC
and L
WC
, representing the processed outputs of the frozen encoder and the inception model in Figure 2(c), respectively.
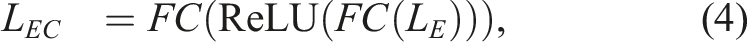
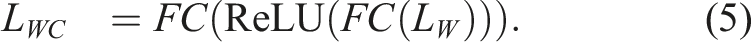
Finally, the redshift prediction P
RS
is obtained as shown in Figure 2(d)) by concatenating L
T
, L
EC
, and L
WC
, and then passing them through two fully connected layers with a ReLU activation function in between:
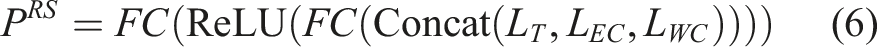
The predicted redshift P
RS
is compared with the actual redshift R
RS
, and the cost is calculated using the Mean Squared Error (MSE) over N samples:
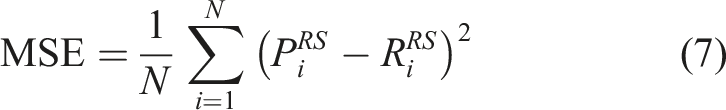
Redshift prediction using various architectures with AstroMAE (Fathkouhi and Fox, 2024). Pcm-AstroMAE performs the best (in Bold) and is the selected architecture in AstroMAE.
The AstroMAE encoder is pretrained on 80% of the data, 10% for validation, and the remaining 10% for fine-tuning. For fine-tuning, this 10% is further split into 70% for training, 10% for validation, and 20% for testing. The results in Table 1 are based on inference over the 20% testing samples from the fine-tuning model. The results underscore the rationale behind AstroMAE’s architectural choices.
Plain-ViT and pcm-ViT models exhibit better results compared to their from-scratch counterparts due to pretraining. Pcm-ViT outperforms plain-ViT in both cases, suggesting that self-attention alone lacks high-frequency information, which convolutional layers intuitively capture. The Inception-only model does not outperform pcm-ViT trained from scratch. This highlights that while high-frequency information captured by the inception module is beneficial, broader, low-frequency patterns are also essential for accurate redshift prediction. Similarly, pcm-ViT and plain-ViT achieve better results when combined with the inception model. So AstroMAE incorporates the Inception model, enhancing the model’s ability to capture detailed features.
Moreover, the image data alone may be insufficient for optimal redshift predictions. A comparison between pcm-ViT and plain-ViT inception models with the proposed AstroMAE incorporating an additional magnitude block, as shown in Figure 2, supports this insight. So magnitude values for each image band are integrated during fine-tuning.
Proposed framework: CAI
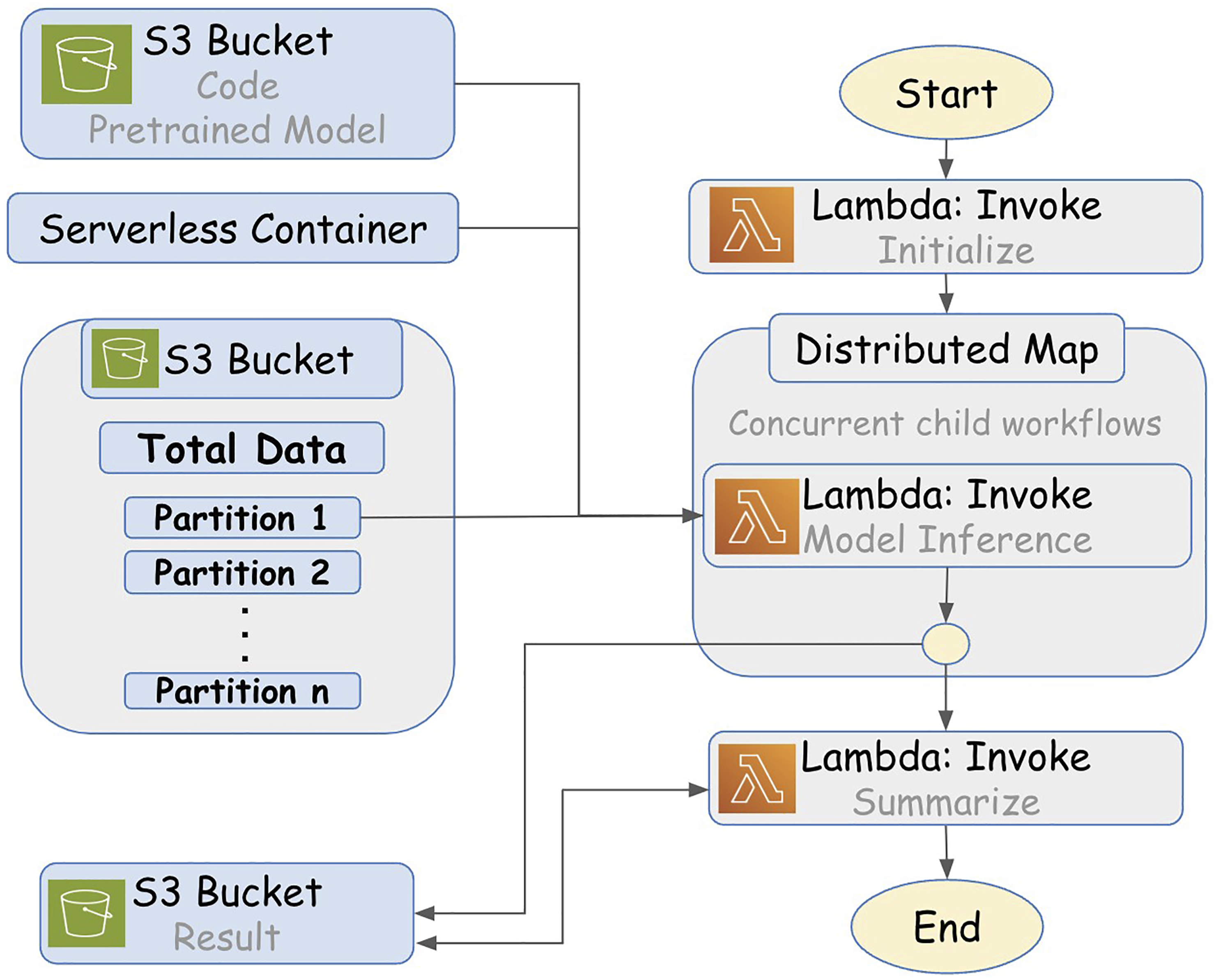
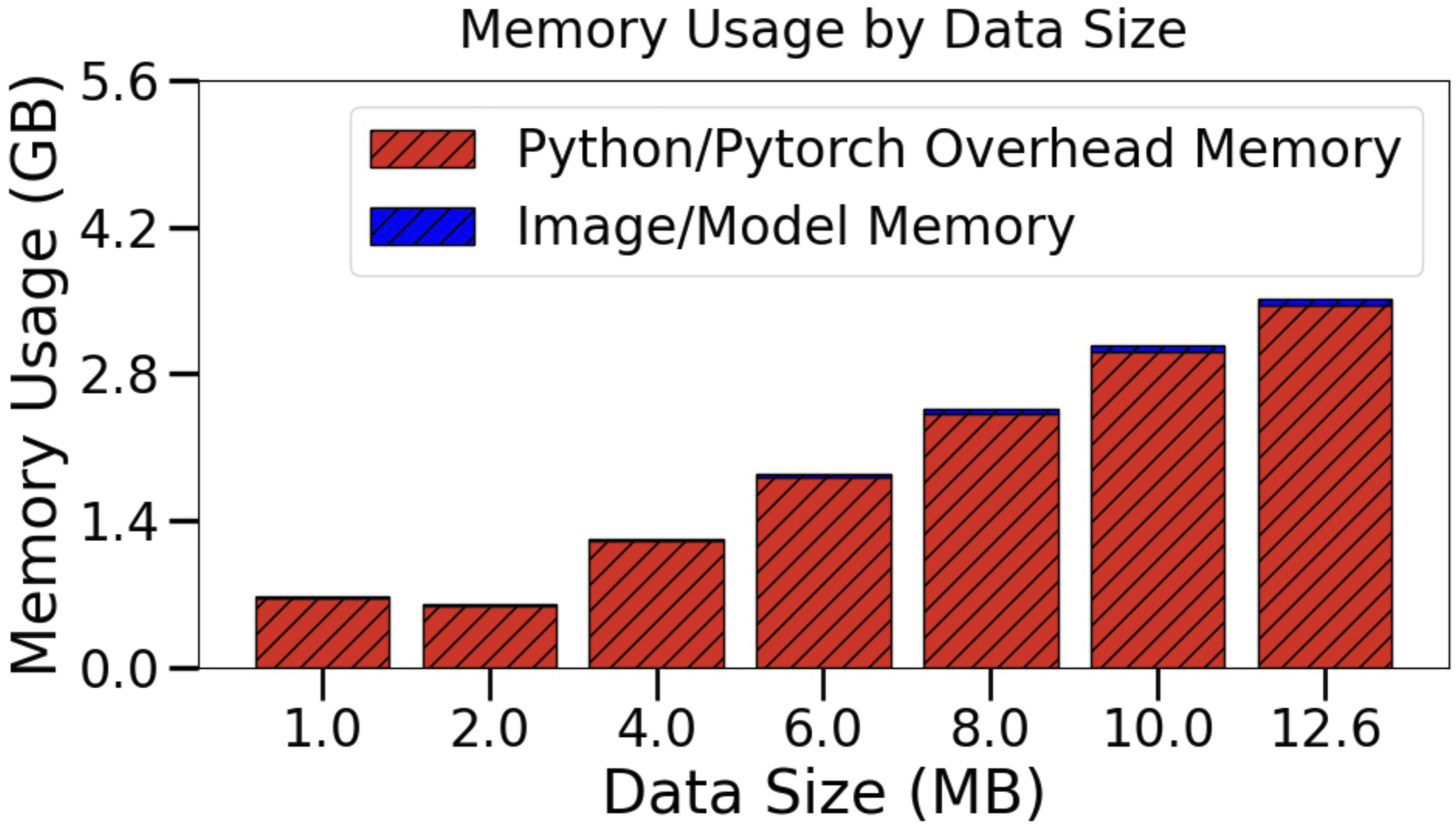
Analyzing large astronomical data requires advanced distributed systems to handle concurrent jobs at scale. We propose a novel cloud architecture called Cloud-based Astronomy Inference (CAI), using AWS Lambda functions (AWS, 2024) to solve this challenge with significant speed-up improvement. Figure 3 shows an overview of the proposed framework. It has the following steps. 1. 2. 3. S3 Bucket: Storage for code, the pre-trained model, and data. Each child process loads the code, model, and partitioned data (assigned by the initialization state). We use the Python Boto3 library to interact and interface with our AWS S3 Bucket. Serverless Container: The container is a custom AWS Lambda runtime created that includes all required software dependencies. The AWS Lambda function performing model inference is executed inside this runtime. Distributed Map: The distributed map state iteratively executes its child jobs based on the input array. We can control how many jobs run concurrently. Each Lambda job has a maximum of 10 GB of RAM available (AWS limitation). 4. CAI framework overview using AWS Lambda Functions. It uses an AWS S3 bucket for data, code, and result storage. The state machine defines the workflow execution steps using AWS Lambda functions and distributed maps. Parallel execution is achieved through data partitions for almost linear high-performance inference scaling. AWS Lambda Memory Usage by Partition Data Size. We empirically size the dataset based on the partition data size in MB.
Experiments
We intend to showcase how CAI is a novel approach for computing redshift prediction compared to other devices. This section thoroughly outlines the dataset used in our experiment, the metrics we use to assess each device, the experimental setup, and the analysis of our results .
Dataset
The dataset used in this study is prepared following Fathkouhi and Fox (2024) and originates from Pasquet et al. (2019). It has
Implementation
We used Python 3.11 with PyTorch 2 as the core framework. Also, NumPy 1.2 and Pandas 2.2 for data analytics. Additionally, Timm 0.4.12 was independently installed to provide access to specific model architectures compatible with PyTorch (Paszke et al., 2019). The FMI and Boto3 libraries were used on AWS for the CAI implementation.
AstroMAE model
AstroMAE provides two pretrained models: the first is pretrained using 80% of the data, as discussed earlier, and the second, which is employed in this study, is pretrained using the entire dataset. Both pretraining and fine-tuning are conducted on four A100 GPUs. Pretraining takes approximately 3 days, while fine-tuning on the full dataset requires around 10 hours.
Evaluation metrics
Evaluation metrics.

These metrics effectively measure scalability. Processors that can complete inference on the full dataset are strongly preferred to those that cannot due to their memory limitations. When working with large astronomy datasets, this is more crucial. Faster model inference allows researchers to conduct more analyses. Lastly, a higher throughput means more data can be processed in less time. These metrics are interdependent, and an ideal scalable framework can complete the inference on the full dataset and maximize inference throughput while minimizing time. We measure inference time using the PyTorch Profiler.
Experiment setup
We compare the following processors: a personal laptop, an HPC CPU, an HPC GPU, and our proposed CAI. Figure 5 shows their specifications, and Table 3 lists the maximum dataset size they can handle. A batch size of 512 is used throughout the experiment. Each experiment combination is repeated three times, and the average metrics are reported. The parameter counts for recent deep learning-based methods developed for astronomy images, capable of inference across diverse computing environments—including a personal laptop, HPC CPUs, HPC GPUs, and our proposed cloud-based framework, CAI. A pre-trained AstroMAE model is used for the inference scaling experiments. Hardware details and maximum data processed for each device. The original full dataset is 12.6 GB.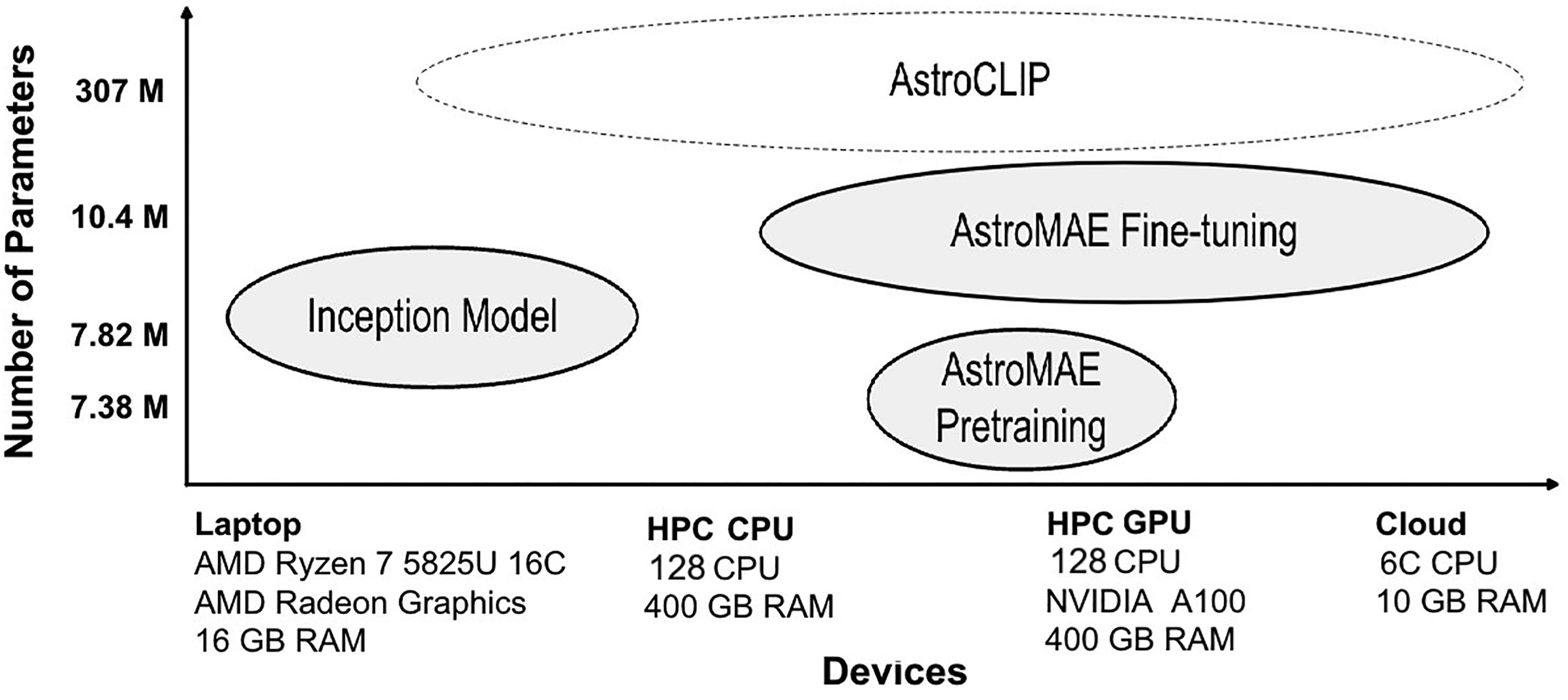
Performance results and analysis
Figure 6 shows that the inference time increases with data size. The personal laptop could not perform inference on the larger dataset sizes and is much slower due to memory limitations. The HPC with a GPU is way faster than a CPU and a personal laptop. However, CAI maintains a considerably stable inference time and performs best, due to its parallel executions, which is more evident with larger data sizes. Inference time versus dataset size by processor (batch size 512). Each combination is run three times, and the average is reported. CAI performs better than an HPC GPU with its consistent scaling with increasing data size.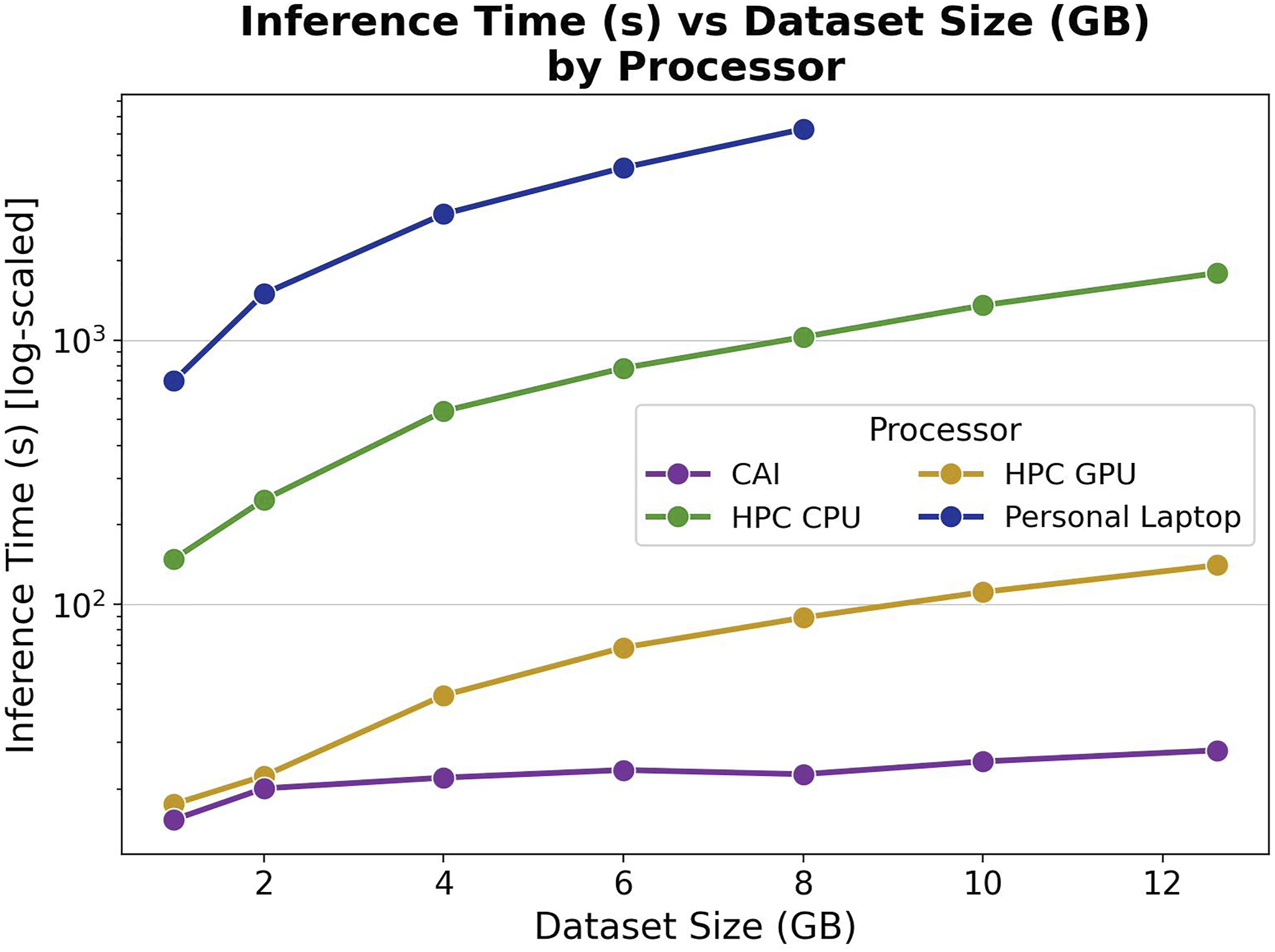
Model inference on the total data takes 1793 s, 140.8 s, and 28 s on the HPC CPU, HPC GPU, and CAI, respectively. The personal laptop could run with a maximum of 8 GB and took an average of 6283 seconds. This showcases that personal devices are limited by memory and not feasible for the long run-times with astronomy data. Our proposed CAI is an attractive approach due to the faster inference speed despite running on a CPU only.
Figure 7 shows the throughput of the devices for 1 GB data size. 1 GB was chosen due to the limitation of the personal laptop, taking significant time with a small batch size and larger data. Both the HPC GPU and CAI have significantly higher throughputs. CAI has the highest throughput (bps) for batch sizes 32, 64, and 128 (0.25 B bps, 0.34 B bps, and 0.42 B bps, respectively). The HPC GPU has the highest throughput (bps) for batch sizes 256 and 512 (0.42 B bps and 0.61 B bps). After the CAI and the HPC GPU, the HPC CPU tends to have the next highest throughput, followed by the personal laptop. Average throughput (bps) versus batch size by single node device to serverless computing using the 1 GB dataset on a log scale. Three executions were completed for each batch size and processor combination, and the average throughput is displayed.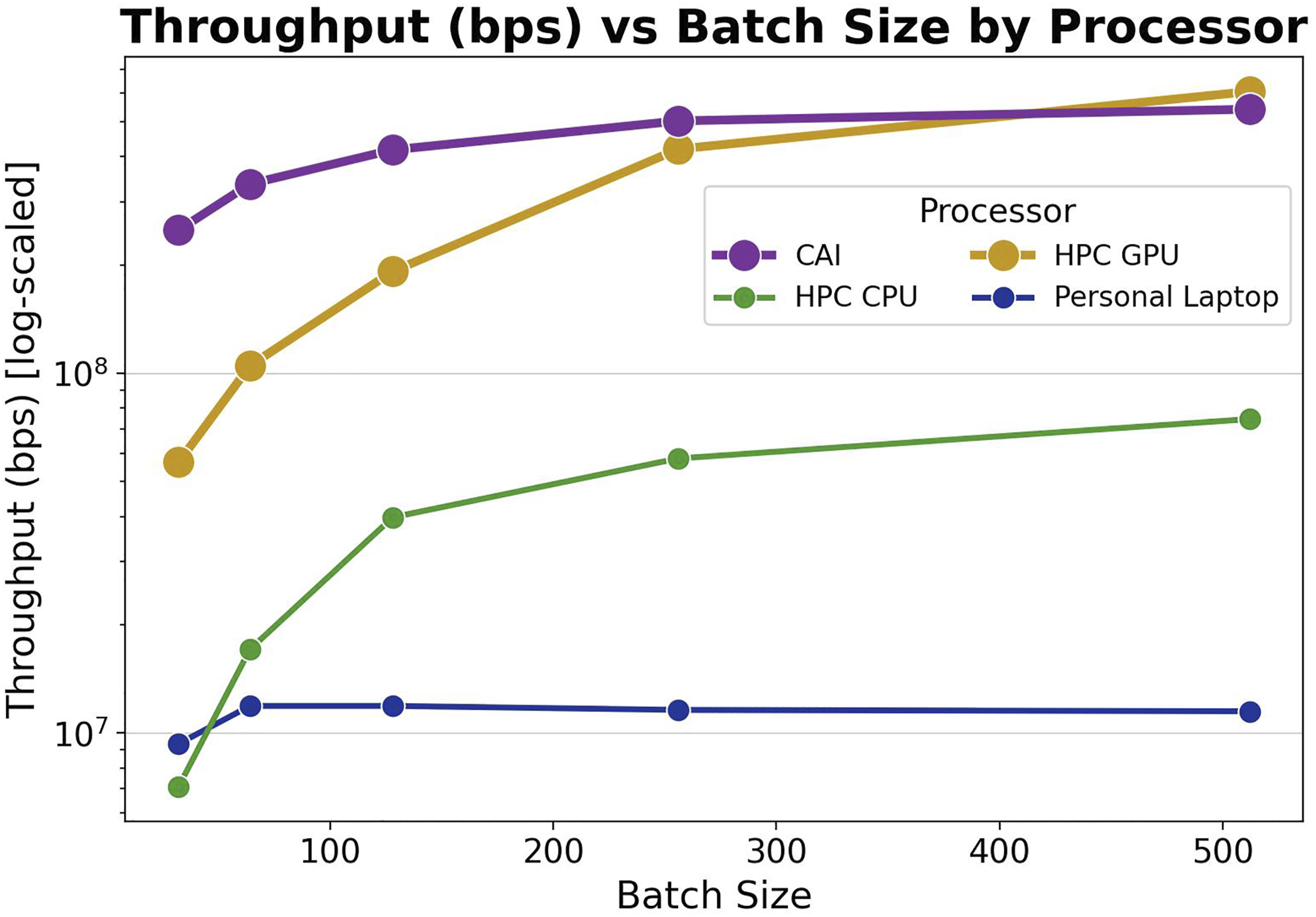
The trend of throughput (bps) by the processor is that throughput (bps) increases as batch size increases, and the throughput increase rate declines with increasing batch sizes. This is because there is an overhead computation cost at the beginning of iterating through each batch. The smaller batch sizes have more batches to iterate through, so although we might expect data to be processed quicker with smaller batch sizes, the increased frequency of the overhead computational cost can add up and lower the throughput. In fact, in Figure 7, CAI appears to plateau at the batch size of 256, and the personal laptop appears to plateau at the batch size of 64.
Serverless computing for scalable cosmic AI
Figure 8 shows the CAI average model inference time in seconds for different data sizes. This complements Figure 6 but shows the CAI performance in more detail. The inference time here is the runtime of the Model Inference State (Figure 3), which completes only when all concurrent Lambda functions are done. This ensures we get the correct performance in practice. The individual Lambda jobs finish much faster, but that doesn’t truly reflect the throughput. CAI average model inference time for different data sizes. The average time remains almost linear, even as the data size is scaled up due to concurrent jobs.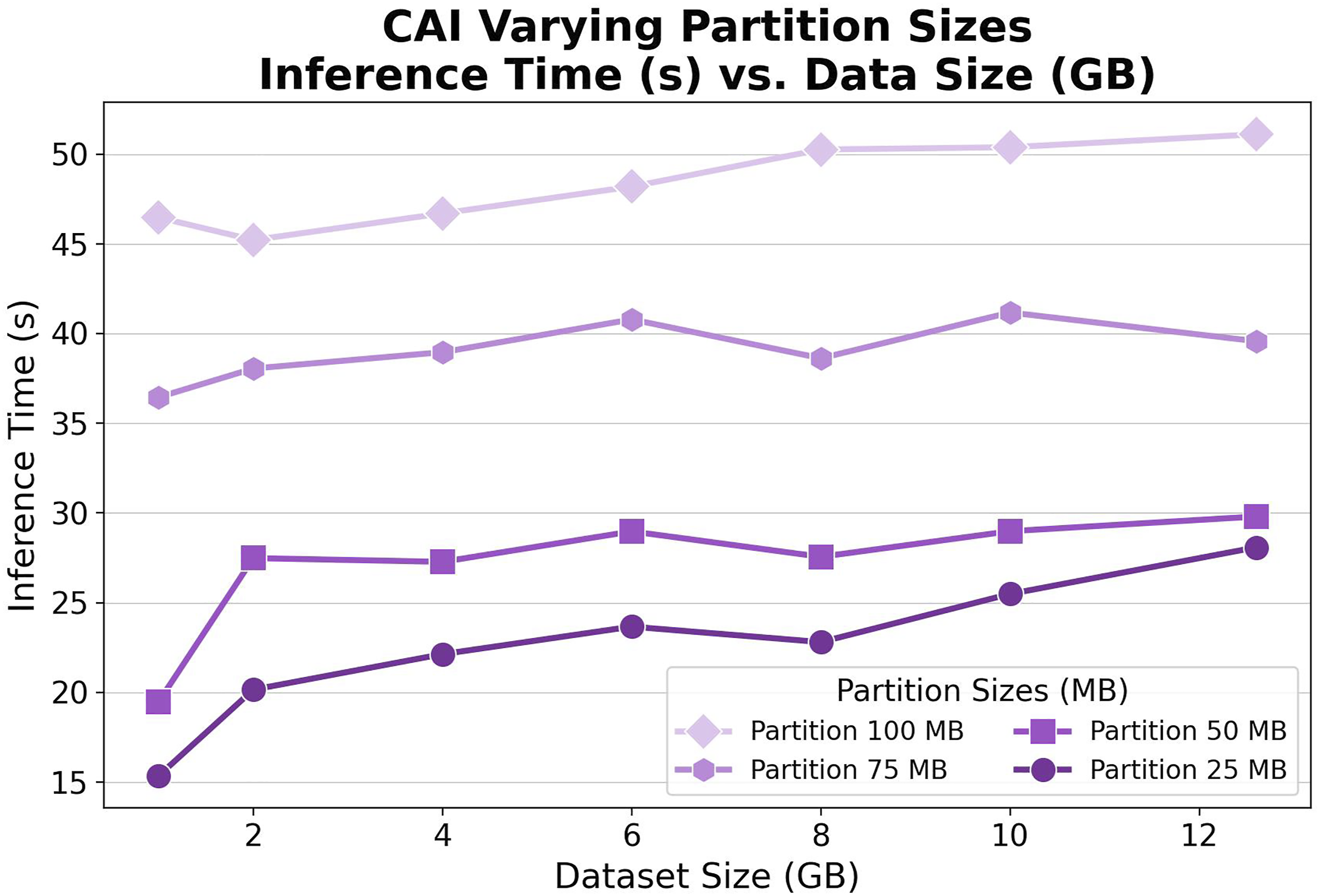
Despite increasing the dataset size, the inference time in CAI is almost constant. For example, for the 100 MB partition, the average inference time for the 1 GB dataset is 23.02 s and only increases by 1.56 s to 24.58 s for the full 12.6 GB dataset. Furthermore, for the 25 MB partition, the average inference time for the 1 GB dataset is 6.56 s and subtly decreases by 0.73 s to 5.83 s for the full 12.6 GB dataset. This is due to the parallel processing of the large data into smaller partitions. Since each child workflow is running model inference on a small partition of data independently, the overall run time depends mostly on the execution time for that partition.
Figure 9 shows the throughput for those different partition sizes across data sizes. For each dataset size, the 25 MB partition has the highest throughput, then the 50 MB partition, then the 75 MB partition, and lastly, the 100 MB partition. At the full dataset size of 12.6 GB, the 25 MB partition has an average throughput of 18.04 B bps, the 50 MB partition has an average throughput of 9.70 B bps, the 75 MB partition has an average throughput of 6.66 B bps, and the 100 MB partition has an average throughput of 5.12 B bps. With a smaller partition, we can use more concurrent jobs, increasing the throughput. CAI Average Throughput for Different Data Sizes. These results are obtained from concurrent jobs and utilize a batch size of 512 for various partition sizes.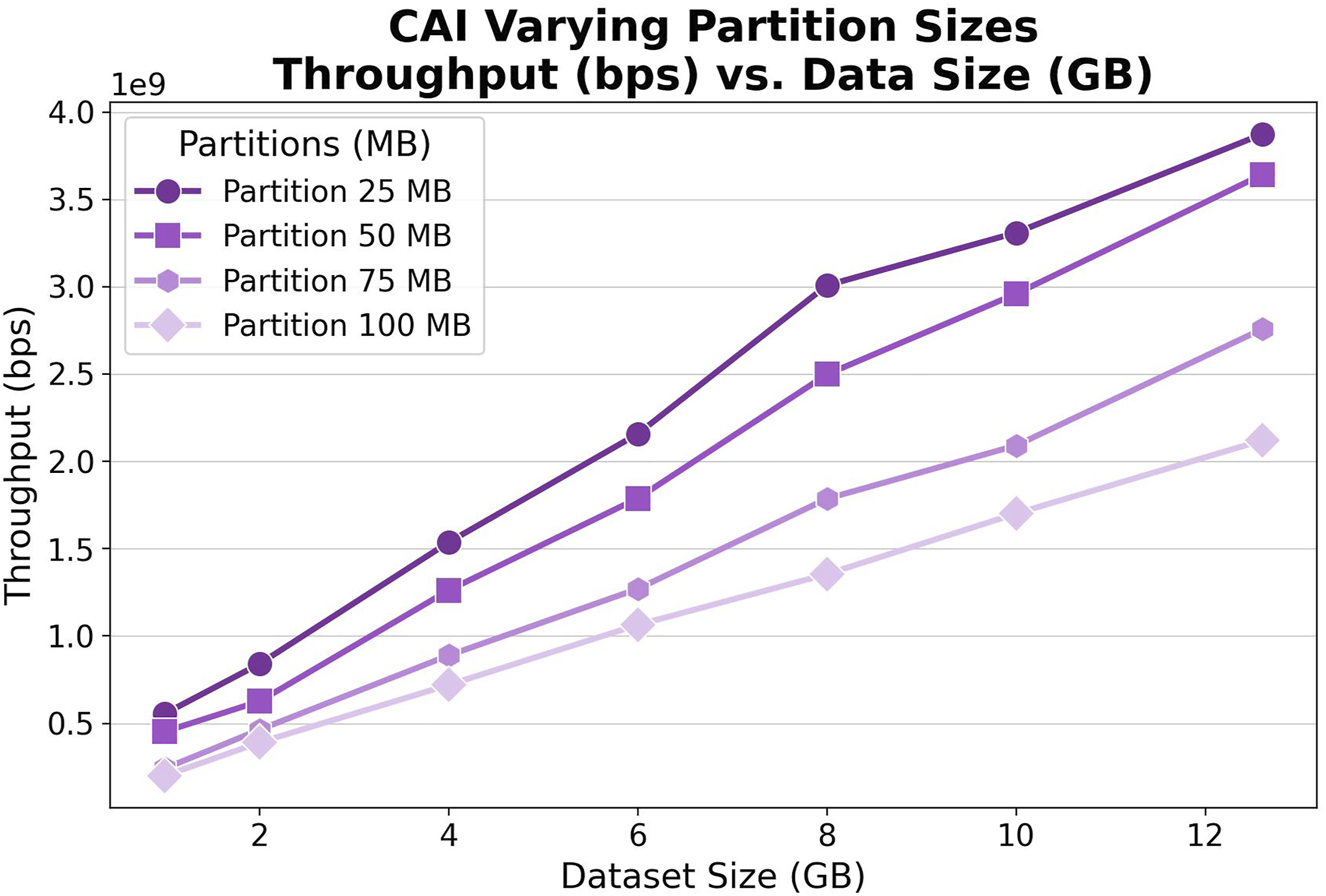
With AWS Lambda, it is quite trivial to scale out horizontally to handle large dataset sizes. Figure 10 details the number of invocations and inference duration to illustrate scalability. The number of invocations is determined by dividing the partition size by the dataset size. CAI: number of AWS Lambda Function invocations for different data sizes. Similar to figure 9, results use a batch size of 512 and are displayed across partition sizes.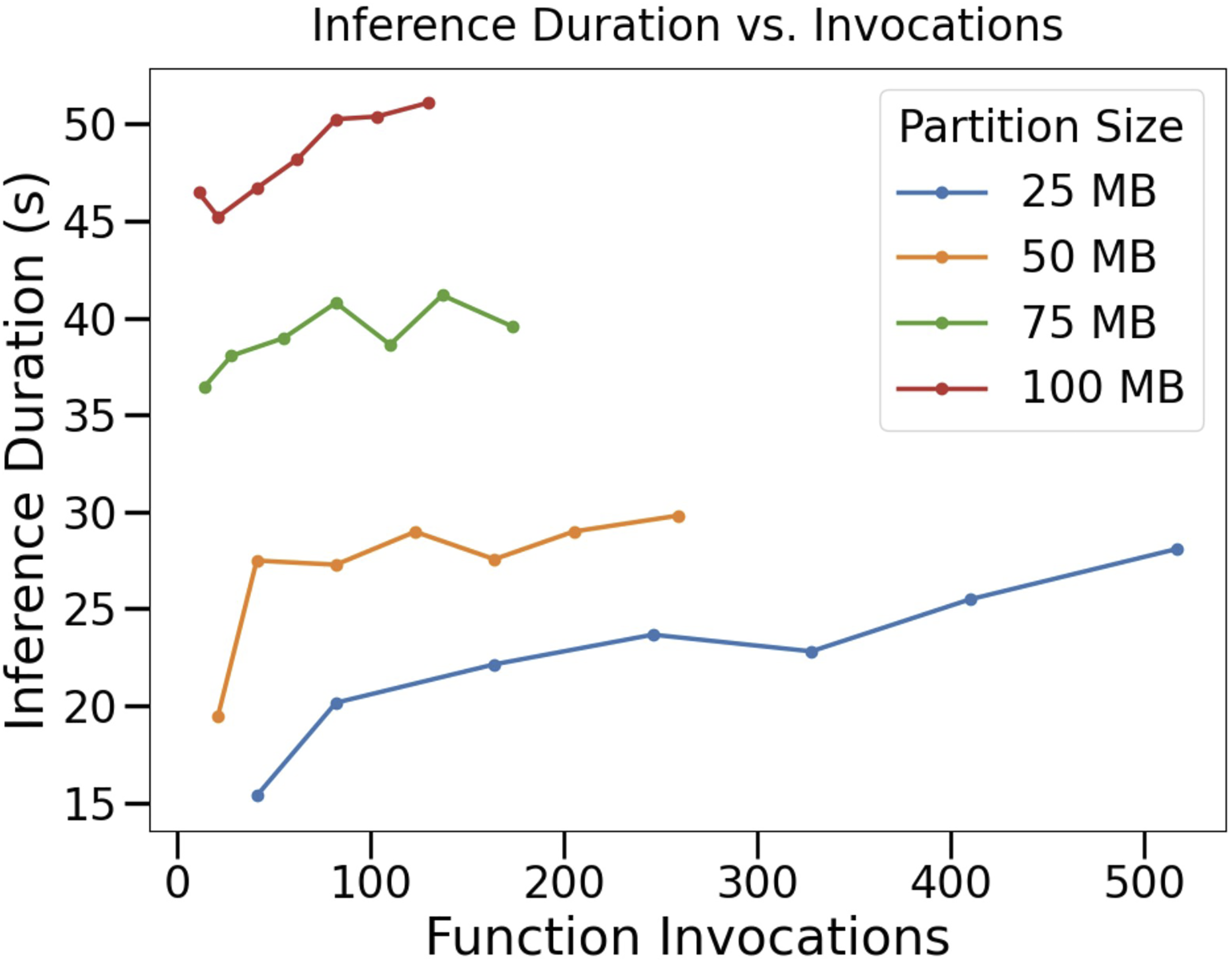
AWS lambda costs for CAI executions.

Data Parallel AWS Lambda configuration.

An estimation of AWS computation cost for inference on the total dataset up to one terabyte data size. Cost in US cents is requests × duration(s) × memory (GB) × 0.00001667.
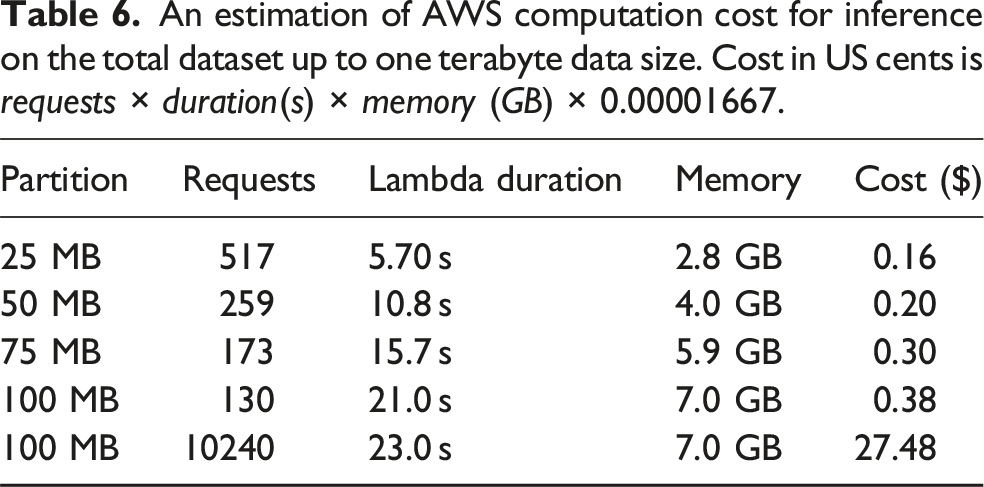
All this amounts to under five US dollars to execute the experiments for all but the largest experiment. One novelty aspect of CAI is related to the costs of executing astronomy inference compared to similar costs on HPC clusters or other ”rack and stack infrastructure.”
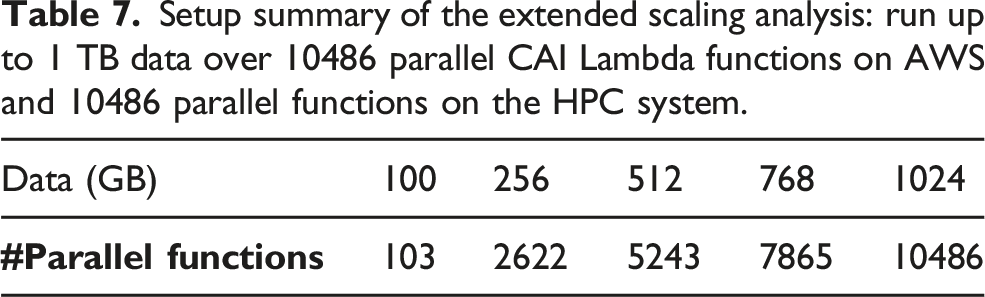
Large scale experiment and analysis
Setup summary of the extended scaling analysis: run up to 1 TB data over 10486 parallel CAI Lambda functions on AWS and 10486 parallel functions on the HPC system.
HPC CPU setup
The HPC environment uses the SLURM job scheduler (Jette and Wickberg, 2023) to submit a large number of concurrent jobs. Similar to CAI, each job processes a single file partition on a single CPU core. The ‘srun‘ Python command then executes the inference on all allocated CPU cores. The concurrency limit for CPU cores on the HPC was 6000; beyond that, it’ll wait for the running jobs to finish. The virtual environment uses the same Python library versions as the AWS CAI framework. Each HPC node had a maximum of 96 cores and 750 GB of memory.
Results and discussion
Figure 11 shows the average inference time for both the CAI framework and the HPC CPU environment across various large datasets, from 100 GB to 1024 GB. The results clearly demonstrate the superior scalability of the CAI framework. Extended large-scale scaling experiment: Comparing CAI Lambda and the HPC system on inference time with up to 1 TB of data and 10,486 parallel functions.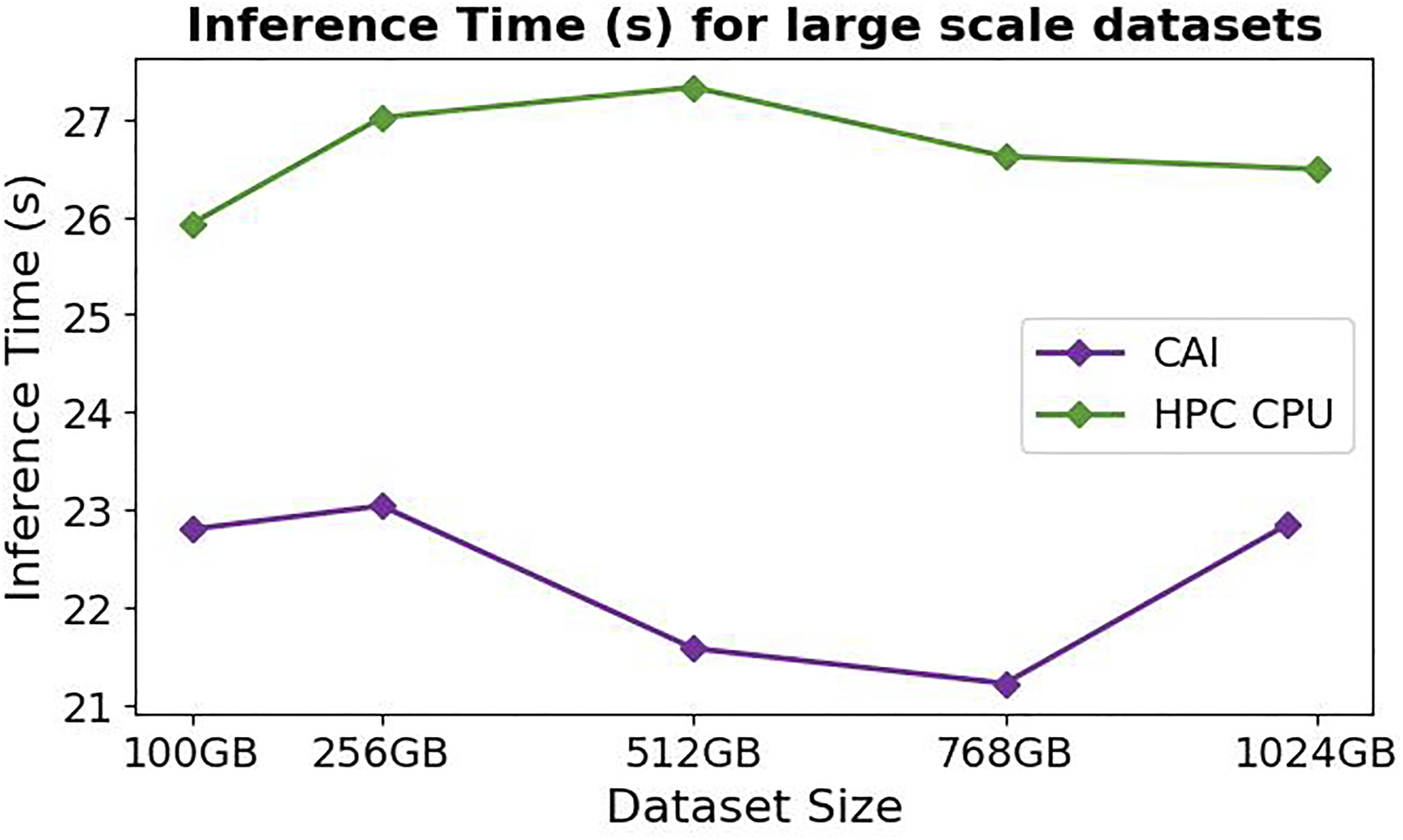
CAI maintains a consistently low inference duration across the entire range of dataset sizes. This linear scalability is a direct result of its serverless architecture, which allows a high degree of parallelization by processing multiple data partitions concurrently. The inference time is primarily dependent on the time it takes to process a single data partition, not the total dataset size.
Conclusion and future work
This paper presents a novel cloud-based framework, CAI, designed to enhance the inference scalability of foundation models trained on astronomical images. Our study highlights the essential role of cloud services in overcoming the computational and storage challenges inherent in modern astronomical research. We have leveraged serverless computing to enhance the scalability of foundation models via partitions and data parallel optimizations.
To showcase the attractive capabilities of CAI, we used a recent foundation model, fine-tuned for redshift prediction, in our experiments. Comprehensive evaluations across varying dataset sizes and computing devices demonstrate CAI’s robustness in scaling almost linearly on the inference and high throughput for large-scale astronomical image datasets. Note that this framework can be applied to additional critical astronomy inference tasks, such as morphology classification and star formation history. Future work will also involve testing other foundation models developed for astronomical images and spectra.
In the future, we plan to introduce integration with
Footnotes
ORCID iDs
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the NSF-Simons AI Institute for Cosmic Origins (CosmicAI: Grant 2421782) Seed Grant. NSF CF-1918626 Expeditions: Collaborative Research: Global Pervasive Computational Epidemiology, and NSF Grant 2200409 for CyberTraining:CIC: CyberTraining for Students and Technologies from Generation Z. NSF - 2504401 OAC Core: RINAS: Data I/O CyberInfrastructure for Extreme-scale Foundation Model and Generative AI Training on HPC.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Author biographies