
Abstract
One of the most important aspects of supercomputer development in the post-Moore era is the interconnect technologies that allow one to unite a multitude of processing elements into a well-synchronized computing system. Novel types of supercomputer interconnect require careful benchmarking and compliance with the requirements of modern hardware trends. GPU-based heterogeneous computing is one of the most important current avenues for building high performance computing systems, and the support of GPU-aware MPI technology is a requirement for any competitive interconnect. In this paper, we describe a UCX API based GPU-aware MPI implementation for the Angara interconnect. Performance analysis for peer-to-peer, MPI_Bcast and MPI_Reduce operations is presented, as well as for the rocHPL benchmark and for a typical biomolecular model within the LAMMPS molecular dynamics code. The deployment of the Desmos supercomputer equipped with both Angara and InfiniBand FDR allows us to make an accurate comparison of these two types of interconnect using the latter as a reference.
Introduction
The growth in the computing power of supercomputers is provided not so much by the processor frequency as by the increase in the number of computational nodes and the number of cores. For this reason, the contribution of high-speed interconnect to the maximum computing performance of a supercomputer permanently increases. This trend makes it promising to create high-performance computing systems with interconnects that provide the lowest latency and the highest throughput.
There exist several interconnects that provide low latency (about 1μs) and high throughput (several tens of GBytes per second). Among the former leaders of this industry, we can mention Quadrics Petrini et al. (2002) (1996-2009), Myrinet Boden et al. (1995) (since 1995) and Birrittella et al. (2015) (2015-2019). Currently, the market is dominated by InfiniBand (since 2000) with a small share of other types of interconnects.
InfiniBand is an open standard for high performance network communications. The most commonly used InfiniBand implementations rely on NVIDIA Mellanox hardware, with switches typically arranged in a fat tree topology. HDR 200 Gb/s is the sixth generation of the NVIDIA InfiniBand architecture. HDR has 0.6μs low-level latency, the obtained MPI latency is 1μs Ruhela et al. (2020).
Cray (HPE) released the Slingshot interconnection network De Sensi et al. (2020). Slingshot uses an optimized Ethernet protocol, which allows it to be interoperable with standard Ethernet devices while providing high performance to HPC applications. Slingshot switches have ports with 200 Gbit/s each and support arbitrary network topologies, the default topology is Dragonfly Kim et al. (2008). The low-level latency of Slingshot is 1.85μs between two nodes.
Among other types of low-latency interconnects, we can mention the Extoll interconnect Nüssle et al. (2009); Neuwirth (2022), the Tofu interconnect Ajima et al. (2018) and the BullSequana eXascale Interconnect (BXI) interconnect Emmanuel et al. (2021). Currently, other types of interconnect aimed at exascale computing are in development Lu et al. (2022); Bossard (2023); Ammendola et al. (2024).
At the moment, we can refer to two types of interconnect in development in Russia: the Angara interconnect was developed by JSC NICEVT Mukosey et al. (2015); Simonov and Brekhov (2020) and the SMPO-10G is under development in the Russian Federal Nuclear Center – All-Russian Research Institute of Experimental Physics Basalov and Vyalukhin (2012). During the last few years, the Angara interconnect has had a history of practical deployment Akimov et al. (2018); Stegailov et al. (2019a); Goncharuk et al. (2022); Mukosey et al. (2024).
The rise of GPU-computing increases the role of RDMA-based technologies that enables data exchanges among GPUs without explicit copying the data from the GPU memory into the host memory. Such an RDMA-based technologies is therefore the basis for GPU-aware MPI implementation. In this paper, we present the working prototype of such a technology for the Angara interconnect.
For the development of both low-level software and parallel algorithms, it is very beneficial to have tools for detailed benchmarking of their runtime behavior. Another instructive guide can be provided by a carefully designed comparison of new technologies with existing solutions. To use these design concepts in this work, we use the OSU benchmarks and the Score-P infrastructure to collect the low-level performance data. The performance of the MPI_Bcast collective operation is considered. We deploy the GPU-aware MPI based rocHPL implementation of the High Performance Linpack benchmark as our performance target and InfiniBand FDR interconnect as a reference in assessing the runtime behavior of the Angara interconnect.
Among different types of HPC application, molecular dynamics (MD) modeling is one of the most important use cases where GPU acceleration is very effective (e.g. Kondratyuk et al. (2021); Pavlov et al. (2024)). In this work, we use one of the most versatile MD codes LAMMPS Thompson et al. (2022) with its Kokkos-based GPU-backend to validate the capability of GPU-aware MPI over Angara interconnect.
Related work
In the seminal paper of Ang Li et al. Li et al. (2019) the authors characterized and evaluated six types of modern GPU interconnects, including PCIe, NVLink-V1, NVLink-V2, NV-SLI, NVSwitch, and InfiniBand with GPUDirect-RDMA, using the Tartan Benchmark Suite over six GPU servers and HPC platforms: NVIDIA’s P100-DGX-1, V100-DGX-1, DGX-2, RTX2080-SLI systems, and ORNL’s SummitDev and Summit supercomputers, covering both Peer-to-Peer and Collective communication patterns.
Performance analysis tools for GPU-oriented HPC applications is a growing topic in the literature Zhou et al. (2020, 2021, 2022); Darche and Dagenais (2023). Visualization of profiling and tracing in CPU-GPU programs is a subject of current development Fiorini and Dagenais (2022), as well as analysis of the advantages and disadvantages of various GPU-related data-transfer modes Potluri et al. (2013); Li et al. (2023) in the broad context of the performance of HPC applications Mills et al. (2021); Azad et al. (2023); Tronge et al. (2023).
The development of the Score-P infrastructure was described by Dieter Mey et al. Mey et al. (2012) and its latest features aimed at performance-portable accelerated computing are discussed by Robert Dietrich and co-authors Dietrich et al. (2021). The HPCToolkit software exemplifies an alternative set of tools for versatile performance analysis of software running of supercomputers Adhianto et al. (2024).
The optimization of the collective broadcast operation is an active field of research Hoefler et al. (2007); Awan et al. (2018); Chu et al. (2018); Awan et al. (2019). MPI_Bcast optimization is shown to be beneficial for applications such as LAMMPS running on large-scale HPC systems Qi et al. (2025).
Using moderate-scale prototype supercomputers to benchmark novel hardware and software technologies was an idea behind the DEEP projects Kreuzer et al. (2018).
In this paper, we extend our preliminary recent work Ismagilov et al. (2025) and further demonstrate the results for larger number of computing nodes over Angara interconnect for the rocHPL benchmark. Here we consider the LAMMPS MD code as a real-life application that uses GPU-aware MPI. Comparison with InfiniBand FDR is extended to MPI_Bcast and MPI_Reduce collective operations. Two types of parallel performance analysis tools are used: Score-P and HPCToolkit. The results of microbenchmarks are compared with the real-life applications behavior.
Hardware
The hybrid Desmos supercomputer in JIHT RAS was the first supercomputer based on the Angara network with a detailed analysis of its performance. In September 2018, Desmos (equipped with AMD FirePro S9150 GPUs) was ranked No.45 in the Top50 list of supercomputers in Russia and CIS (the open-source HPL-GPU benchmark based on OpenCL Rohr et al. (2015) was used to run the HPL benchmark). The upgraded Desmos with AMD MI50 GPUs obtained No. 39 of Top50 in March 2021 with the proprietary AMD HPL-GPU implementation and reached No. 37 in March 2023 with the open-source rocHPL implementation (in the last case the InfiniBand FDR interconnect was used, which was added to Desmos as an alternative interconnect to Angara).
The main characteristics of the Desmos supercomputer.

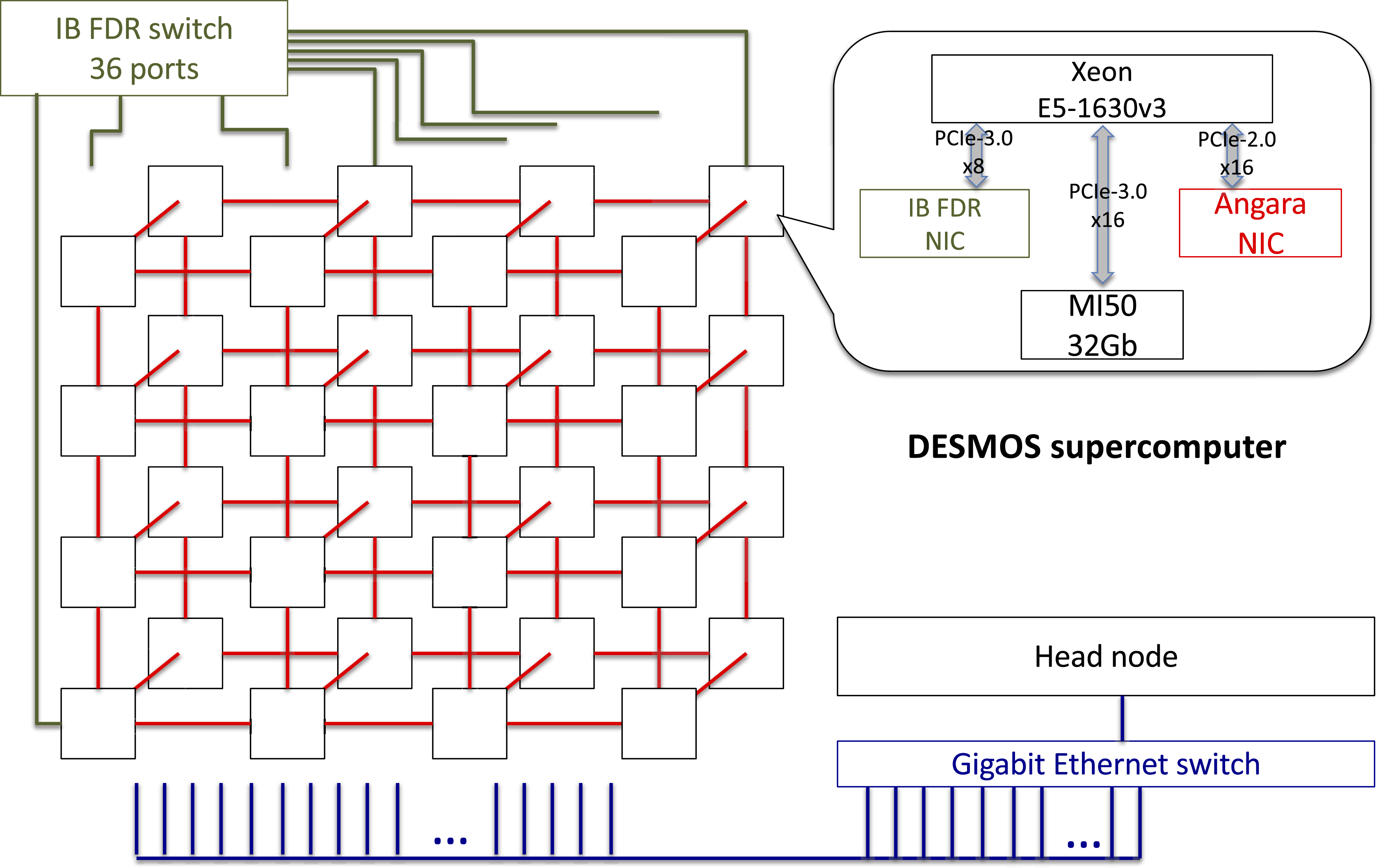
The scheme of the Desmos supercomputer with 32 nodes equipped with Angara, InfiniBand FDR and AMD MI50 GPUs. PCIe connectivity within a computational node is shown.
The benchmark results of this study have been obtained either with the default frequency policy of AMD MI50 GPUs computing units (that uses dynamic voltage and frequency scaling), or at a fixed computing units frequency of 1282 MHz (set via the rocm-smi options ‘setsclk 4’ and ‘setprofile COMPUTE’).
GPU-aware MPI over Angara
Low-level host-device data transmission mechanism
MPI is a standard API for distributed and parallel application development that can scale to multi-node clusters. To facilitate porting of applications to clusters with GPUs, the AMD ROCm software framework enables various technologies. Using these technologies, one can add GPU memory pointers to MPI calls and enable ROCm-aware MPI libraries to deliver optimal performance for both intra-node and inter-node GPU-to-GPU communication.
The AMD kernel driver exposes remote direct memory access (RDMA) through the PeerDirect interfaces. This allows network interface cards (NICs) to read and write directly to RDMA-capable GPUs device memory, resulting in high-speed direct memory access (DMA) transfers between GPUs and NICs. These interfaces are used for optimization of inter-node MPI message communications.
The Unified Communication Framework (UCX) is an open-source cross-platform framework that offers a unified set of communication interfaces for a variety of network programming models and interfaces. UCX utilizes ROCm technologies to execute different primitives of network operation. UCX is the standard communication library for InfiniBand and RDMA over Converged Ethernet (RoCE) network interconnects. To enhance data transfer performance, various MPI libraries (e.g. OpenMPI) can utilize UCX internally.
Khalilov et al. (2022) describes the first prototype implementation of an extended Angara API in UCX to support remote GPU memory reads and writes. For this purpose, the Linux kernel module angara_memreg was implemented to register both host and device memory. It allows users to pin an allocated memory and get its physical address. This module was initially based on ROCm v3.7 Khalilov et al. (2022), but since ROCm v4.2 the ROCmRDMAmodule has been integrated into the ROCK kernel driver and has undergone some changes. As part of this work, the angara_memreg module has been adapted for ROCm v5.3.3.
In addition, in Khalilov et al. (2022), the implementations of 3 transfer protocols were presented for different message sizes: Eager, Segmentation-and-Reassembly (SAR) and Large Message Transfer (LMT). The Eager and SAR protocols, which are used for small and medium-sized messages, have a similar implementation using the angara_put blocking operation, which uses the CPU on a critical path when transferring data between GPUs. This is done by using an optimized version of the memcpy function to copy data between the device and host memory. The implementation of the LMT protocol, on the other hand, is based on put_zcopy/get_zcopy schemes using non-blocking versions of Put/Get operations (angara_offload_put/angara_offload_get), which allow sending data in a zero-copy fashion between GPUs without using a CPU and intermediate buffering. This operation is based on the angara_get non-blocking operation that implements data transmission from a source offset in one physical address space to a destination offset in another physical address space. If the destination of angara_get belongs to the processing element (PE) of the process that sent the request, it will be an angara_offload_get operation. In contrast, if the source of angara_get belongs to the PE of the process that sent the request, then it will be an angara_offload_put operation.
The data transmission confirmation mechanism for the put_zcopy/get_zcopy schemes presented in Khalilov et al. (2022) was found to be incorrect. Its deficiency resulted in data corruption or incomplete data transmission events. Figure 2 presents an updated mechanism for Angara, which determines the completion of sending and receiving operations based on Completion Markers (CMs). At first, a special CM memory is allocated on each node. This CM memory stores a predefined value. For the LMT protocol, using the get_zcopy scheme, a Get CM request is sent (via angara_offload_get) after all Get Data requests have been sent (also via angara_offload_get). The CM will be received only in the case that all data on the node have been received, because angara_offload_get operations are performed in the order in which they were called. In the put_zcopy scheme, data is sent to another PE by the angara_offload_put operation. The CM marker is sent to itself by the angara_offload_put operation to confirm that all data have been sent. The CM will be received only if all data have been sent, because angara_offload_put operations are performed in the order in which they were called. The updated transmission confirmation mechanism for put_zcopy and get_zcopy data transfer schemes for Angara. Each Angara network endpoint is numbered and called a Processing Element (PE).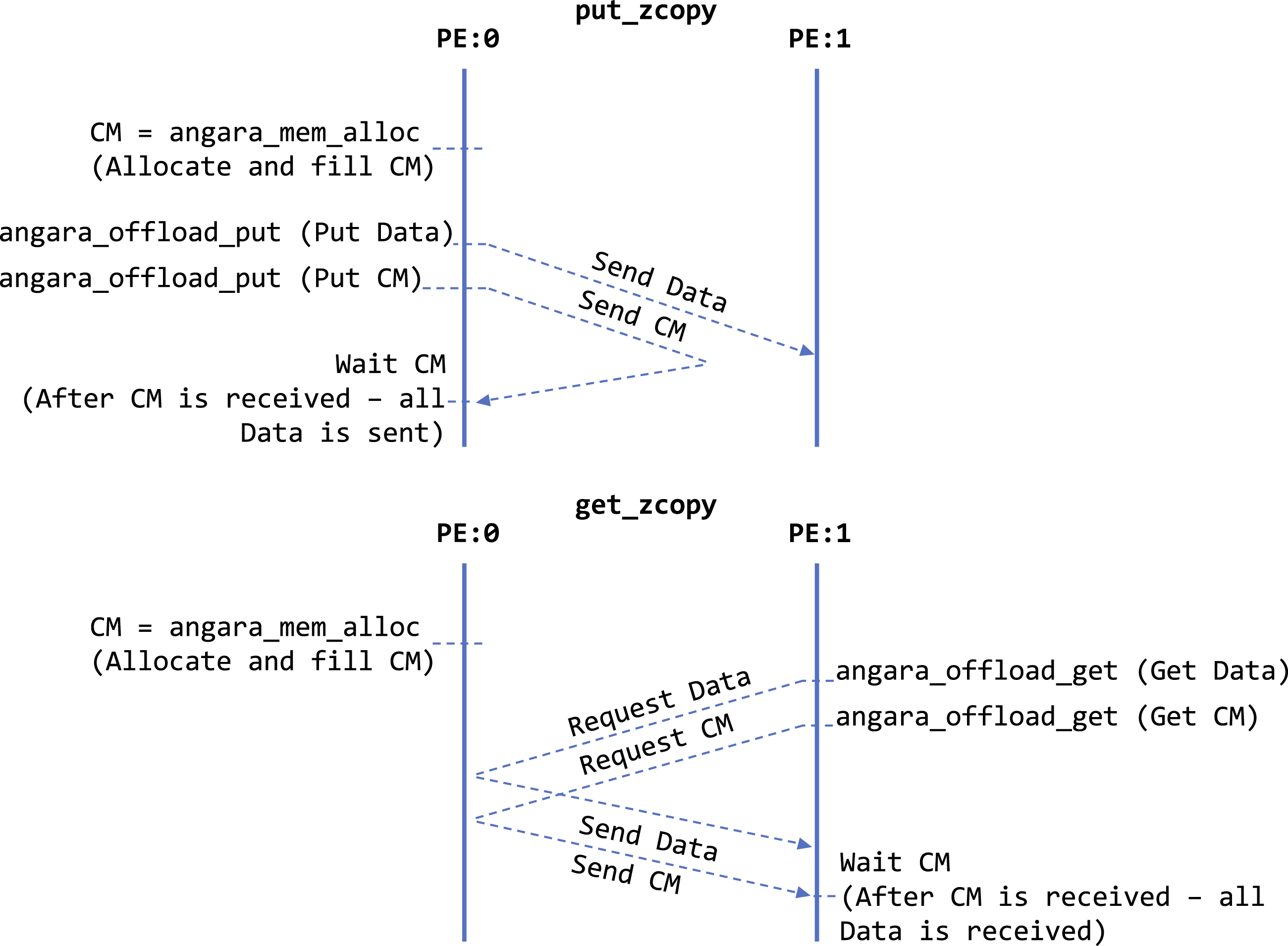
The get_zcopy scheme has a peculiarity: it is impossible to perform the angara_offload_get operation in its own memory. To resolve this issue, one of the ports on the Angara network adapter has been configured in debug mode, which returns all the data sent to that port (loopback). The Angara network software stack has been adapted to enable this functionality.
These corrections allowed the OSU Micro Benchmarks 7.5 communication tests, the rocHPL benchmark and LAMMPS to work using the GPU-aware MPI as implemented in OpenMPI with UCX.
MPI_Bcast and MPI_Reduce benchmarks
In the previous paper Ismagilov et al. (2025), a comparison of latency and bandwidth was presented for Host-to-Host and Device-to-Device peer-to-peer packet transfers over Angara and over InfiniBand FDR. Both interconnects showed similar results on Desmos. Here, we extend this comparison to the MPI_Bcast and MPI_Reduce collective operations.
OpenMPI includes different optimized algorithms for collective operations Bernholdt et al. (2024) (under the ‘coll tuned’ subset of the OpenMPI’s modular component architecture). Nine ‘coll tuned’ options for MPI_Bcast and seven options for MPI_Reduce have been compared both for Angara and for InfiniBand FDR (Figure 3). Moreover, Nvidia provides an optimized standalone hcoll library for collective communication over InfiniBand interconnect that can be integrated into any MPI. Figure 3 shows that using OpenMPI with hcoll with its default parameters gives the best performance for MPI_Bcast at small and large message sizes. However, for MPI_Reduce, the performance of hcoll is slightly worse than that of the algorithms in_order_binary (6) and rabenseifner (7). The benchmark results of osu_latency, osu_bw, osu_bcast and osu_reduce for Device-to-Device peer-to-peer packet transfers over Angara and over InfiniBand FDR (dashed lines show message sizes of about 100 Mb typical for broadcast operations in rocHPL runs considered and the 63 kB message size typical for our example model in LAMMPS).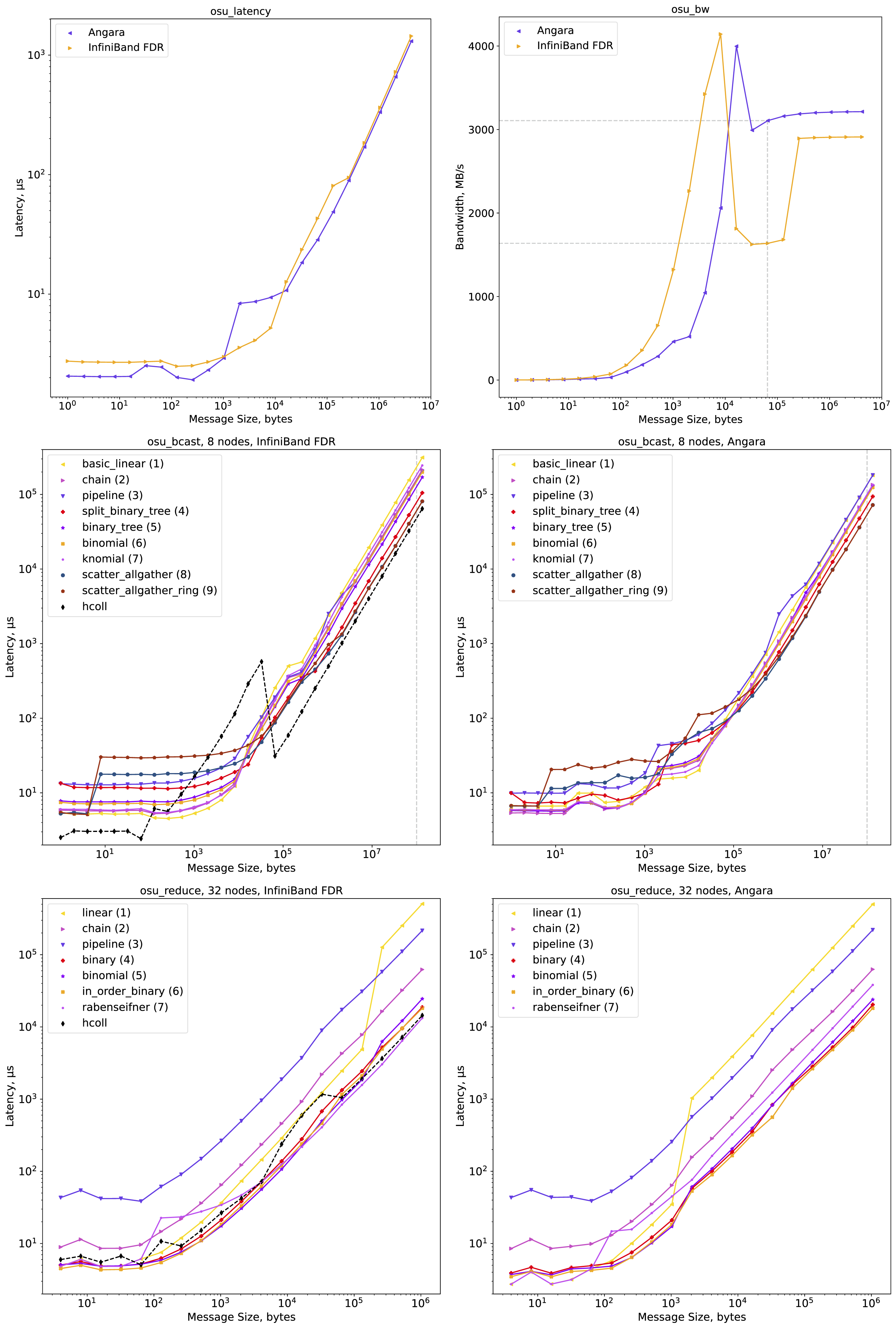
Designing a collective communication algorithm that comprehensively takes into account hardware realities, such as network topology and support for network features, is inherently complex and goes beyond the scope of this work. Previously, we have estimated that topology-aware algorithms for the Angara interconnect will be beneficial at the number of nodes significantly higher that 32 available in Desmos. In this study, we assess available implementations with their default settings.
MPI analysis: Score-P and HPCToolkit
In the rapidly growing field of high-performance computing (HPC), optimizing application performance is critical to achieving efficient use of computing resources. Performance analysis tools are essential for identifying bottlenecks, improving code efficiency, and ensuring scalability. Score-P (Scalable Performance Measurement Infrastructure for Parallel Codes) is one such tool that has gained significant traction in the HPC community. It is a universal and scalable performance measurement infrastructure designed to support a wide range of HPC applications. Score-P combines profiling, tracing and online parallel program analysis capabilities to provide a comprehensive environment for performance tuning.
Score-P supports various instrumentation techniques to suit different application needs and levels of user expertise. Automatic source code instrumentation uses tools like OPARI2 and PDT (Program Database Toolkit) to insert probes into the source code with minimal manual intervention. Compiler-based instrumentation directs the compiler to include performance measurement probes during the compilation process, ensuring precise and low-overhead instrumentation. Manual instrumentation allows advanced users to insert Score-P API calls into their code to measure specific regions of interest, providing fine-grained control over the performance data collected.
Another performance and measurement tool we have used in our work is HPCToolkit, version 2023.03. While Score-P primarily uses automated source and binary instrumentation to collect detailed event traces, HPCToolkit relies on so called asynchronous sampling of the program’s performance metrics, which is a fundamentally different approach.
When a hardware performance counter overflows or a timer event occurs, HPCToolkit interrupts the program execution, captures and unwinds the call stack, attributes the performance cost to the calling context, and then resumes the program. Later, these data can be analyzed to create a hierarchical profile.
The main advantage of this approach is its low overhead Froyd et al. (2005); Lehr et al. (2017). It does not require any binary modification or recompilation for measurement. One only needs to compile the program with debug symbols, which can be done without disabling compiler optimizations, allowing for the analysis of highly optimized code.
One of the disadvantages is that, if the sampling rate is too low, it can miss short-lived performance events or infrequent routines. In contrast, Score-P’s instrumentation can provide precise counts for such events.
We have built the latest development version of Score-P (9.0-dev) due to multiple bugs related to ROCm found in older versions. For rocHPL and LAMMPS instrumentation we have built this tool with OpenMPI 4.1.1/5.0, ROCm 5.3.3 and AMD clang v.15.0.0 compiler. To instrument rocHPL with Score-P support, we have edited the install. sh script (provided by the rocHPL developers for cmake). For compatibility reasons in the stage of cmake configuration of rocHPL we should add
rocHPL performance analysis
The HPL benchmark plays an significant role in the evaluation of HPC systems performance. However, its open-source GPU-oriented implementations are scarce. There was an open-source HPL-GPU implementation based on OpenCL Rohr et al. (2015). This implementation was based on the GPU-offloading paradigm, and very careful tuning of the CPU-GPU workload distribution was required in order to reach maximum performance. AMD has published a new implementation of rocHPL with the focus on HIP technology. This implementation uses GPUs-aware MPI capabilities for data transfers between different GPUs. In this work, we compare the performance of rocHPL execution on Desmos over InfiniBand FDR and over Angara interconnects, use Score-P and HPCToolkit in order to collect the execution traces and use python toolchains for analysis of traces in OTF2 format.
rocHPL has two variants for broadcast data transfers in its HPL_bcast function: through peer-to-peer operations or through the MPI_Bcast collective operation. In the former case, one can choose one of the six algorithms (in HPL.dat configuration file for rocHPL). In the latter case, an algorithm of MPI_Bcast should be chosen among the variants provided by an MPI implementation (e.g. OpenMPI in our tests). rocHPL performance dependence on the GPU frequency (sclk) is shown in Figure 4. The total performance of rocHPL on 32 nodes of Desmos in TFlops for different sclk settings (0–8) of the AMD MI50 GPU driver (sclk level 4 is marked by dashed lines).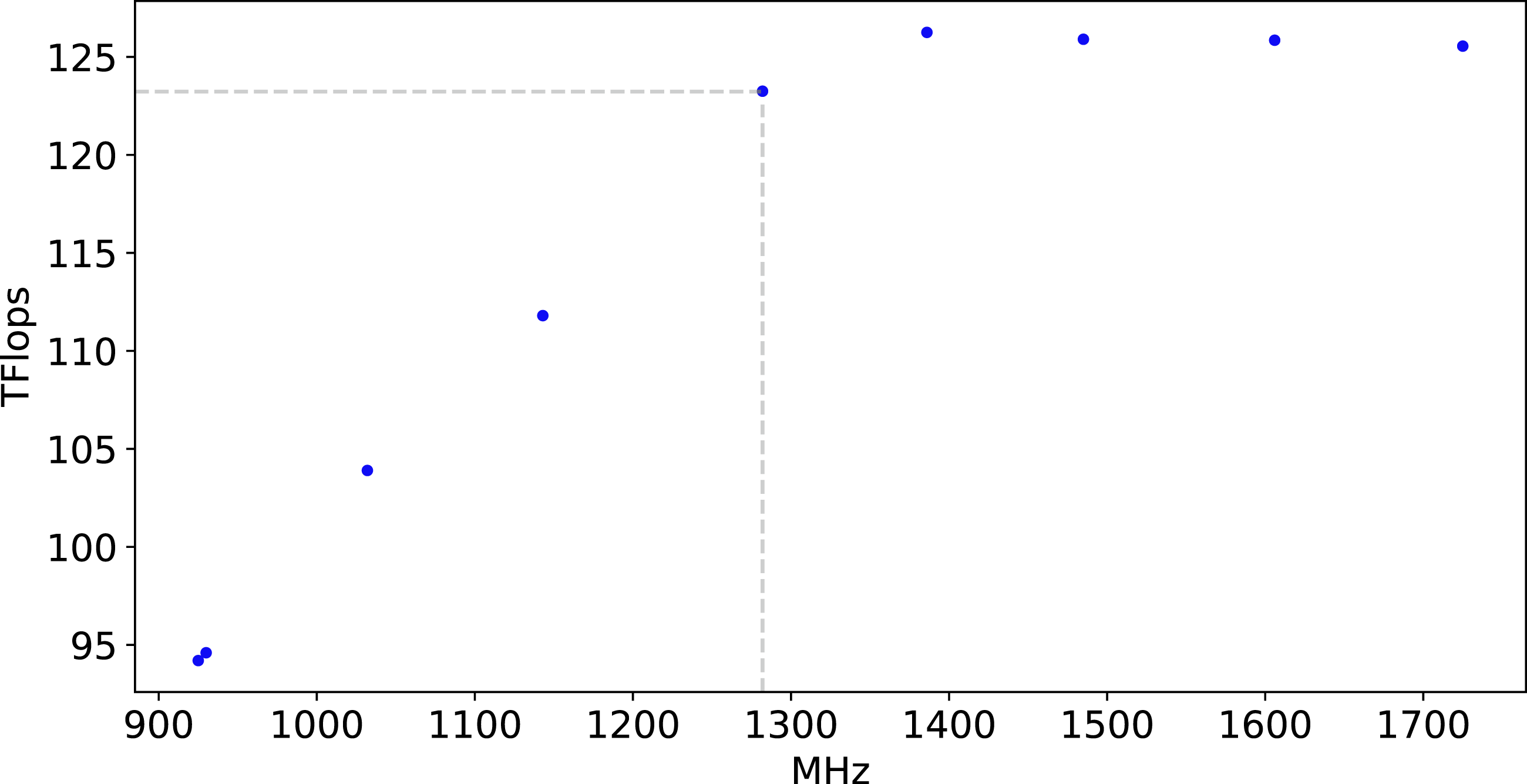
Benchmarking results
The rocHPL benchmark can be configured using the HPL.dat input file. The most significant parameters in HPL.dat are P, Q, N and NB. P and Q represent the number of rows and columns in the MPI grid. Product P × Q represents the number of MPI processes used by HPL. To achieve better efficiency, P should be configured to be smaller than or equal to Q. Setting P and Q as close to a perfect square as possible may also improve performance. N represents the total number of rows and columns in the global matrix, with the best performance coming from matrices that use about 80% or more of total memory. The value of NB, which represents the panel size in the blocking algorithm, can be configured on the basis of CPU architecture. We configure NB = 384 for our tests. In addition, the internal implementation of the broadcasting algorithm within the HPL_bcast function can be chosen. This algorithm can be configured as a collective MPI_Bcast if the HPL_USE_COLLECTIVES macro is defined, otherwise it will be based on MPI peer-to-peer transfers. The type of peer-to-peer algorithm depends on the value of the BCASTs parameter in HPL.dat:
UCX_RNDV_THRESH specifies the threshold at which the UCX communication framework transitions to the rendezvous protocol for data transfer. In the case of Angara, this parameter was determined empirically through comparative throughput measurements. Given that the efficiency of Eager and SAR protocols are strongly influenced by the CPU, the optimal threshold value is not universal and may vary significantly across different hardware.
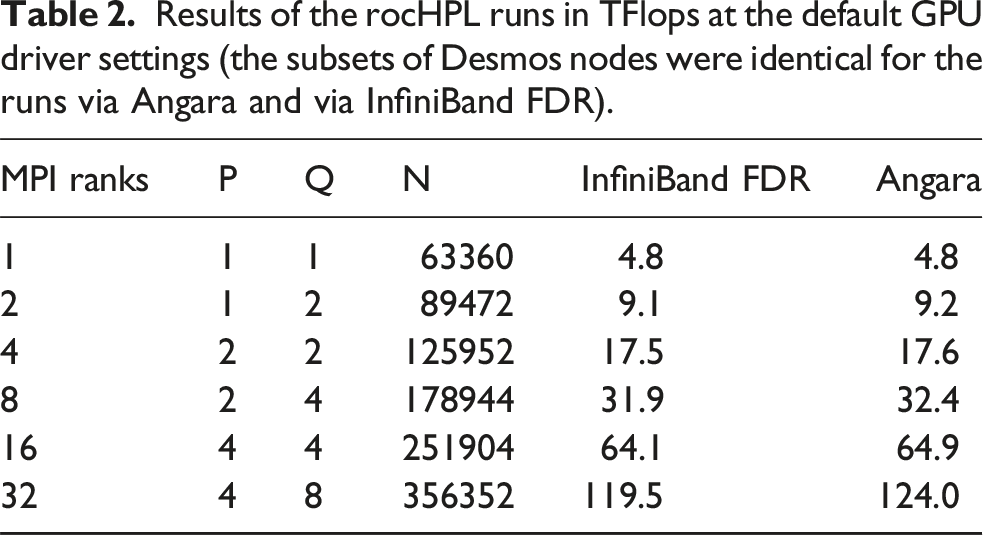
Results of the rocHPL runs in TFlops at the default GPU driver settings (the subsets of Desmos nodes were identical for the runs via Angara and via InfiniBand FDR).
Results of the rocHPL runs in TFlops for collective and peer-to-peer implementations of the broadcasting algorithm in the HPL_bcast function with OpenMPI using either different algorithms within ‘coll tuned‘ or the hcoll library (32 nodes with sclk = 4, P = 4, Q = 8, N = 356352, NB = 384).
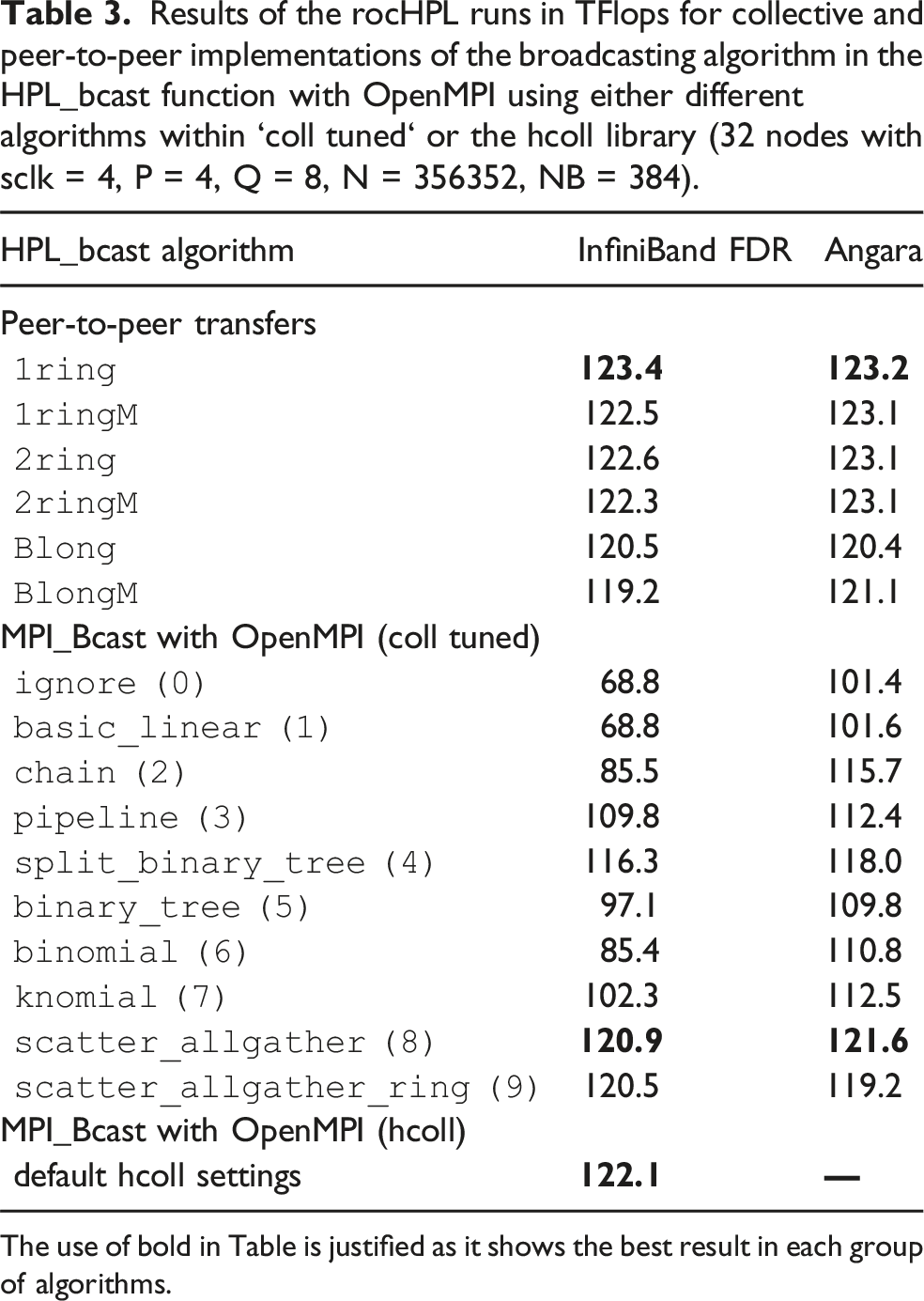
The use of bold in Table is justified as it shows the best result in each group of algorithms.
If we want to relate the osu_bcast results with the performance of rocHPL, it is necessary to notice that: (1) the communication transmitted in rocHPL is determined by the parameter Q, which is why we present MPI_Bcast results for 8 nodes in Figure 3, and (2) the typical message sizes broadcasted in the rocHPL runs are about 100 Mb. The rocHPL benchmarks described allow us to draw the following conclusions. (1) There is a strong correlation between the performance of osu_bcast and the performance of rocHPL with respect to the choice of the communication algorithm. The scatter_allgather (8) algorithm provides the best results for Angara and for InfiniBand FDR. (2) The scatter of rocHPL performance with respect to different communication algorithms is less pronounced for Angara interconnect than for InfiniBand FDR. In general, we can explain this fact by the better connectivity of nodes for the Angara case, where each node has 5 links that go to neighboring nodes.
Results of the rocHPL runs in TFlops for Angara with and without Score-P instrumentation (32 nodes with sclk = 4, P = 4, Q = 8, N = 356352, NB = 384).

rocHPL execution traces
The fragments of the rocHPL execution traces obtained through Angara are presented in Figure 5. In order to analyze the dependence of the interconnect behavior with rocHPL performance, we focus our attention on the HPL_bcast function of rocHPL. Figure 5 illustrates HPL_bcast calls among 32 MPI ranks in two steps of rocHPL execution (approximately 10 seconds after its start). We analyze the distribution of the HPL_bcast duration values (D). Figure 6 shows the distributions of the D values. The fragments of two rocHPL runs over Angara: the upper trace corresponds to the peer-to-peer The distributions of durations (D) collected for the whole rocHPL runs (32 nodes, P = 4, Q = 8, N = 356352, NB = 384) for the peer-to-peer case (left) and for the MPI_Bcast case (right). In each case, the comparison with the fixed GPU frequency (sclk = 4) is shown.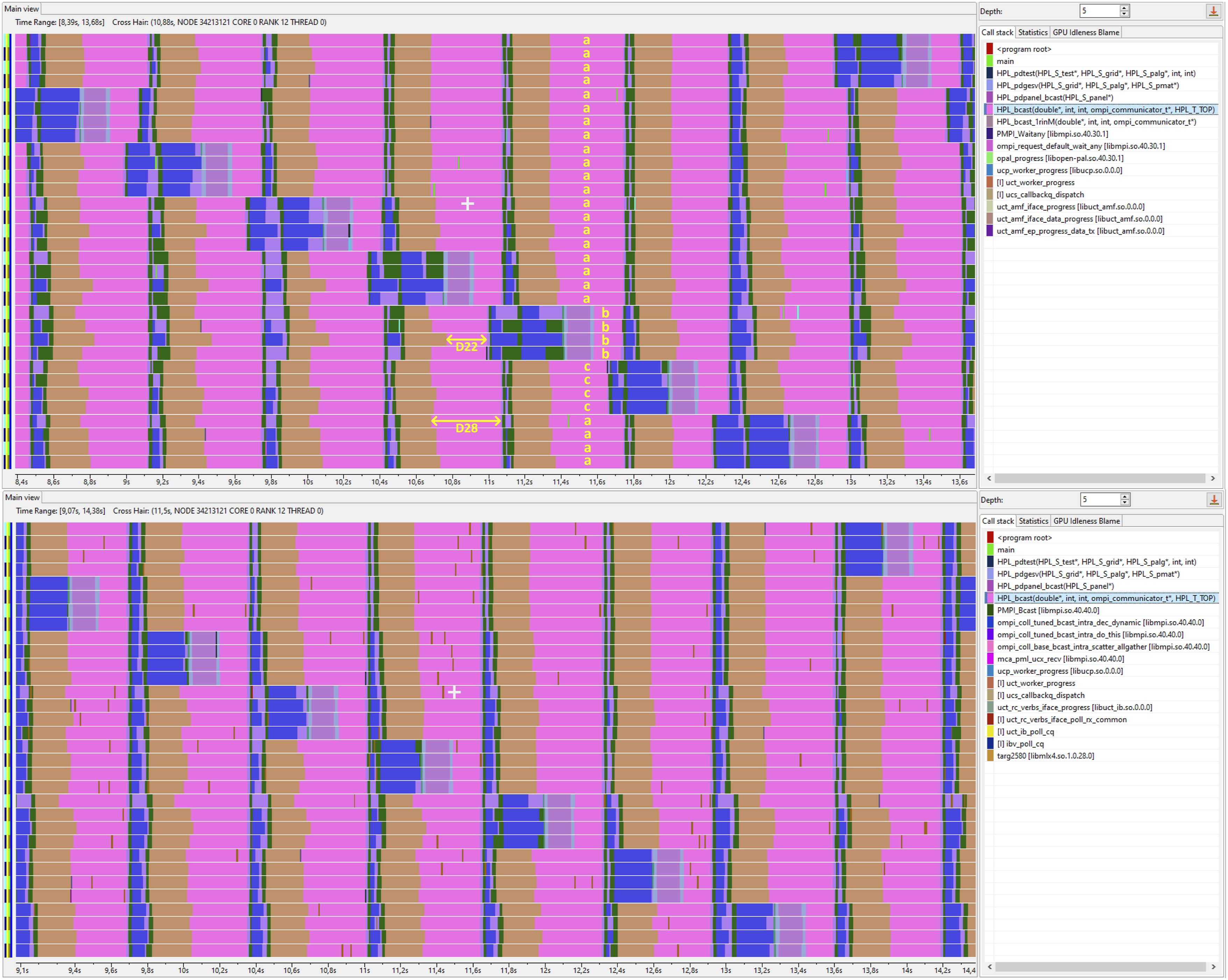
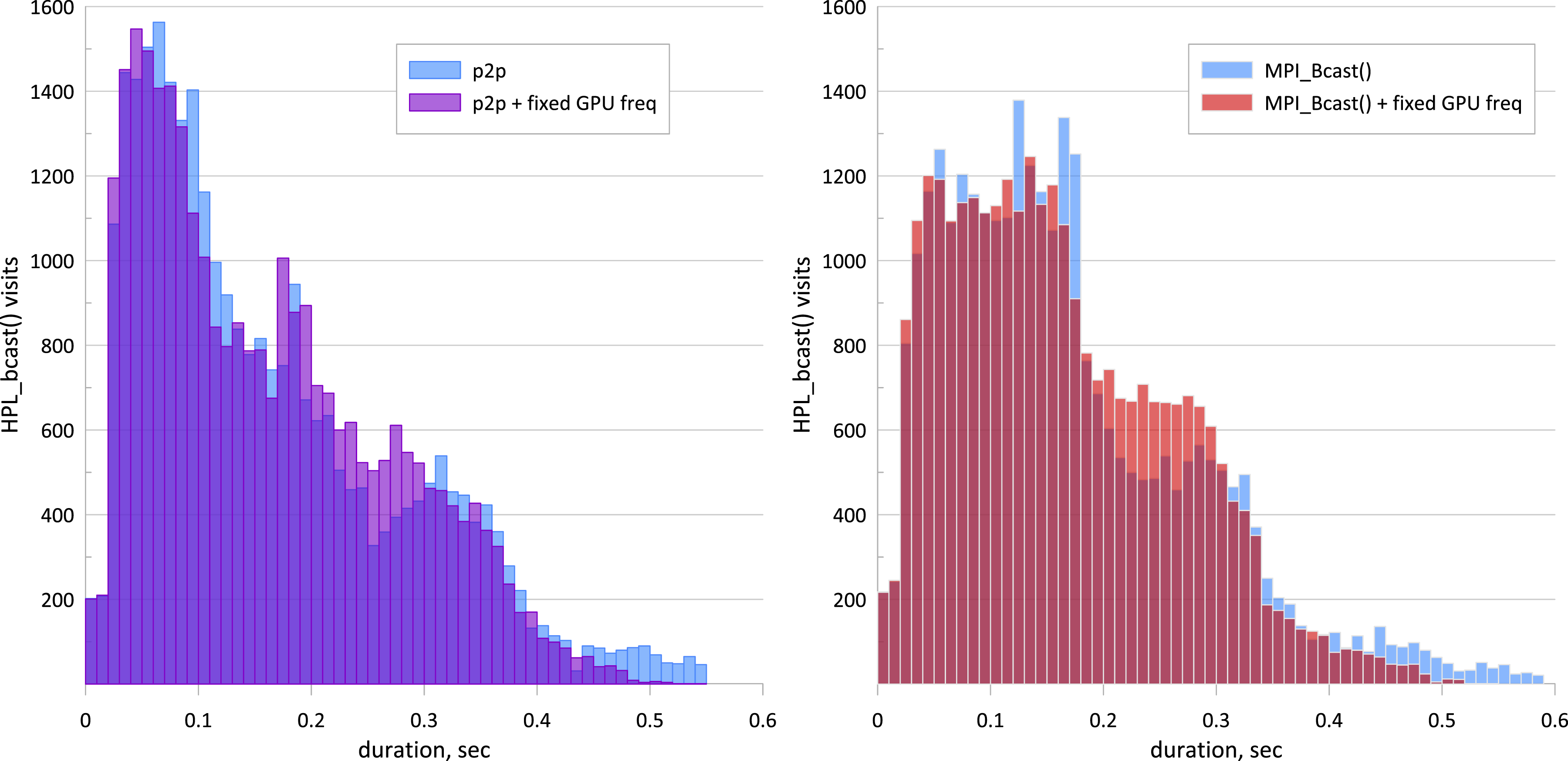
We could propose that the difference in HPL_bcast entry times is connected with the variation in the frequency of the GPU. This proposal is in agreement with the distributions obtained.
In both cases, the number of broadcasts that are not completed by 0.38 seconds is reduced approximately twice when the GPU clock is fixed. Therefore, frequency control could contribute not only to energy savings directly but indirectly as well via improvement of synchronization (e.g., see Bratek et al. (2023)).
LAMMPS performance analysis
As an example of a real-life problem, we consider molecular dynamics modeling in LAMMPS. The model is a biomolecular system: hEGFR Dimer of 1IVO and 1NQL, HECBioSim (2025). Different types of atoms are present in the model: 21,749 protein atoms, 134,268 lipid atoms, 309,087 water atoms and 295 ions. The total number of atoms is 465,399. The model combines both short-range interatomic potentials and long-range electrostatics. The Kokkos GPU backend is used in LAMMPS that is based on GPU-aware MPI technology Thompson et al. (2022); Hagerty et al. (2023).
Here we consider this model in LAMMPS executed on 16 nodes of Desmos with fixed GPU frequencies (sclk 4, profile COMPUTE). Figure 7 shows two trace fragments of 200 μs (that is much shorter than one MD step) in the LAMMPS calculations considered. Vampir is used for visualization Williams and Brunst (2023). MPI communications in LAMMPS are dominated by peer-to-peer transfers. With the chosen system size and the number of nodes, the prevailing message size is 63 kB, where osu_bw shows the largest difference of InfiniBand FDR and Angara (Figure 3). Interestingly, we see in these 200 μs fragments that the data transfer rates given by osu_bw for this message size for InfiniBand FDR and for Angara are not reached. The peer-to-peer communication pattern is rather stochastic, and there are extended periods of time between MPI_Send starts sending and MPI_Irecv starts. Therefore, we can conclude that in the particular case considered, the data transfer rates measured by Score-P are determined by the LAMMPS data transfers algorithm and not by the interconnect itself. Figure 8 shows the maximum and average data transfer rates for the same MD runs on a scale of 13 s. Here we see that the average data transfer rate is identical. However, Angara demonstrates somewhat high maximum data transfer rates in agreement with the osu_bw results for 63 kB. Two 200 μs fragments of LAMMPS traces with MPI communications visualized by Vampir for the biomolecular model considered (hEGFR Dimer of 1IVO and 1NQL) running on 16 nodes of Desmos via InfiniBand FDR and via Angara. In each case, the lower bar chart is synchronized with the trace timeline and shows the data transfer rate statistics (the pink chart shows the maximum rates and the orange chart shows the average rates in the corresponding time bin). Two 13 s fragments of LAMMPS traces for the same MD runs via InfiniBand FDR and via Angara as in Figure 7. Similarly, the pink and orange charts show the maximum and average data transfer rates.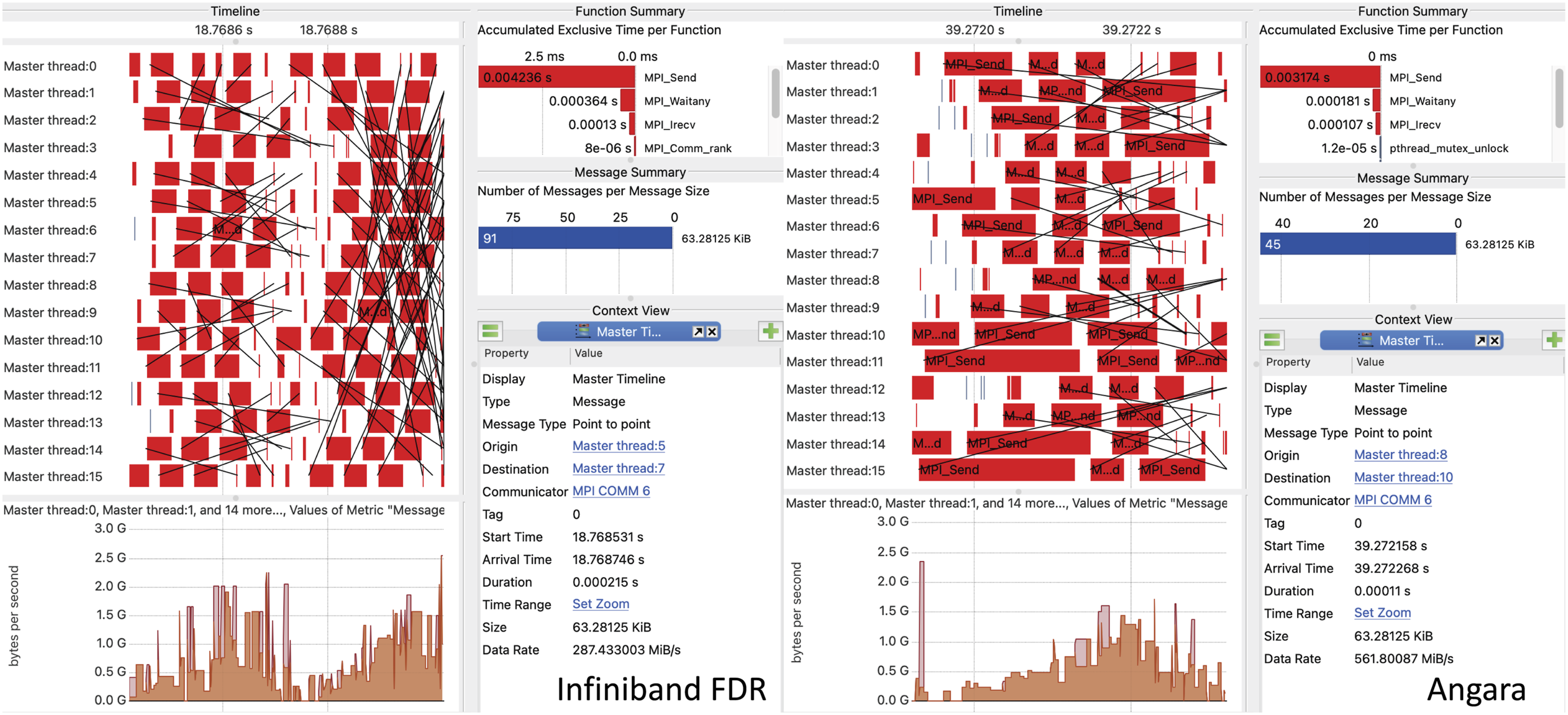
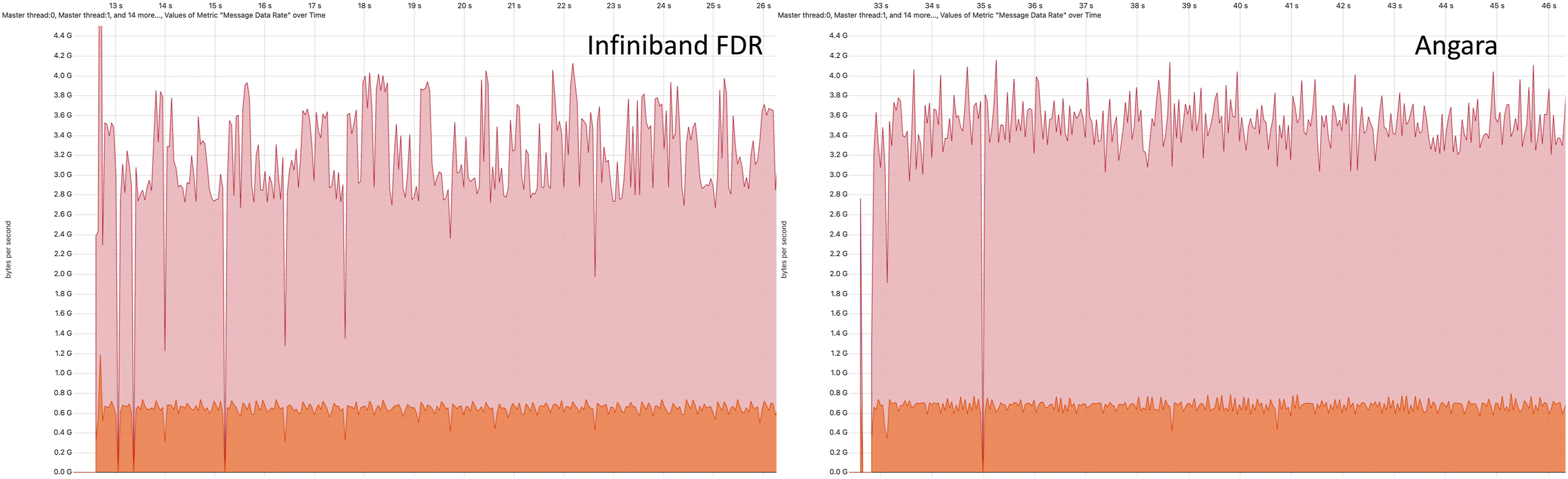
Statistical averaging over 5 MD runs gives the following calculation speed values: 4.77 ± 0.03 ns/day for FDR and 4.79 ± 0.02 ns/day for Angara. The percentage of communication time reported by LAMMPS is 8.44 ± 0.06% for FDR and 6.38 ± 0.02% for Angara. These small differences agree with the observed fact that for the case considered, the peer-to-peer exchanges in LAMMPS are limited neither by InfiniBand FDR nor by Angara data transfer speeds.
Conclusions
The implementation of GPU-aware MPI technology for the Angara interconnect based on the UCX API has been described in detail.
In this work, our previous peer-to-peer communications tests Ismagilov et al. (2025) have been extended to collective MPI_Bcast and MPI_Reduce operations. All broadcast and reduce algorithms implemented in OpenMPI have been considered for both Angara and InfiniBand FDR. The
The rocHPL runs with default parameters of the GPU driver and OpenMPI show quite similar performance for both types of interconnect, with Angara giving slightly more TFlops. After fixing the GPU frequency, different variants of the broadcast implementation in rocHPL have been compared: the
The rocHPL application has been instrumented with Score-P infrastructure and additionally traced by HPCToolkit, and its performance has been studied for Angara and for InfiniBand FDR in terms of runtime traces for all 32 nodes of Desmos. The analysis shows that the overhead of using Score-P infrastructure is rather small for rocHPL.
Statistical analysis of the rocHPL traces confirms that fixing of GPU operation frequency improves synchronization and decreases duration of the longest collective data transfers.
An example of a biomolecular model in LAMMPS with the Kokkos GPU backend running on 16 nodes of Desmos has been considered as well. The peer-to-peer communication pattern in this case is rather stochastic and the data transfer rates measured by Score-P are determined by the LAMMPS data transfer algorithm and not by the interconnect itself. The small difference of LAMMPS performance in this case agrees with the observed fact that for the case considered the peer-to-peer exchange rates in LAMMPS are not limited by InfiniBand FDR or Angara.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was supported by the Russian Science Foundation grant No. 20-71-10127. The instrumentation of rocHPL and the analysis of its traces were performed by Felix Smirnov within the framework of the HSE University Basic Research Program. The analysis of LAMMPS performance was performed with the support of the Ministry of Science and Higher Education of the Russian Federation (State Assignment No. 075-00269-25-00).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.