
Abstract
Achieving peak performance for ocean models on modern high-performance computing (HPC) architectures requires extensive, costly code rewrites that are not only time-consuming and error-prone but also highly architecture-specific and require numerics experts to be proficient in parallel programming models or domain-specific languages (DSLs). In this paper we introduce Poseidon, a source-to-source code optimization tool that employs numerics & HPC co-design. We developed an uplifting approach to a hypergraph for the data flow and to our own Poseidon Intermediate Representation (PosIR) for the computations, which recovers for the first time high-level information and semantics about the computations and memory management that are typically lost during the conversion of numerical algorithms to source code. This representation is then employed for model-driven optimizations. In the backend, we inject source code back into the original code supporting different target HPC architectures, reusing the existing model as the runtime. Our evaluation investigates OpenMP and OpenACC parallel programming models on CPUs and GPUs. We demonstrate Poseidon’s capability of automatic parallelization and optimization of existing Fortran code, with comparisons to state-of-the-art parallelized code with performance improvements of up to × 2.60 and automatically reducing the required memory footprint by up to × 2.29.
Keywords
1. Introduction
Ocean simulations rank among the most computationally demanding codes for extreme-scale computers. Achieving high efficiency in these simulations is crucial for reducing the carbon footprint associated with their execution, lowering procurement costs, and enabling higher-resolution simulations. Higher resolution, in turn, leads to more accurate weather forecasts (ECMWF, 2021) and climate reports (Calvin et al., 2023).
These numerical models have been developed over decades and are predominantly developed in Fortran. The source code represents a vast repository of accumulated knowledge, which is the true asset of these developments. Porting such extensive and intricate codebases to other DSLs would require substantial financial investments, necessitate convincing a large community (often exceeding 1000 users) to adopt a different language, and carry the significant risk of introducing errors due to a lack of understanding of the existing code. These challenges make such a transition highly complex and potentially disadvantageous.
A compromise is often taken using code annotations with OpenMP or OpenACC. However, such code annotations often disturb unfamiliar developers, bugs can be introduced by model developers due to code that is not valid under existing annotations, and no standard best-performing parallel programming model exists for all architectures. Instead, source-to-source compilers such as Rose (Quinlan and Liao, 2011) and PSyclone (Adams et al., 2019; Siso et al., 2023) could be used, but they have similar limitations to existing compilers.
One of the biggest challenges for automatic tools is that transferring the discrete mathematical equations into source code leads to a loss of knowledge on the meaning of variables, loops, computations, etc., hindering the compiler from performing optimizations that would be possible once this deeper understanding could be regained. A brief discussion on this for ocean simulations on structured grids – the main focus of the present work – will be provided in Sec. 2. This is followed by introducing for the first time Poseidon, enabling us to finally reduce the gap between the high-level mathematical equations and the lower-level source code in Sec. 3–7 with results given in Sec. 8. Although our source-to-source approach with deeper optimizations is novel thanks to the uplifting process, some concepts are partly similar to related developments discussed in Sec. 9. Finally, our work should not be seen as some free-lunch source-to-source performance optimizations, but as a novel methodology to approach portability of legacy code of which we will provide an of pros and cons in Sec. 10.1 followed by a summary in Sec. 11.
2. Ocean models
This section provides the necessary background on ocean models on structured grids for an improved understanding of the presented approach. Ocean models are composed of multiple modules where the dynamical core is responsible for solving the governing equations of fluid dynamics, and modern dynamical cores use splitting methods into two main solver components: The baroclinic parts of three-dimensional fluid dynamics equations and the barotropic solver which is purely horizontal. These barotropic solvers pose particular challenges due to the numerical stiffness, requiring time steps 50 times smaller than the baroclinic one, and will be the focus of this work.
2.1. Barotropic solver in ocean models
This section briefly describes a barotropic solver, used, e.g., in NEMO (Madec et al., 2024) (for global ocean circulation and climate) and Croco (Auclair et al., 2024) (regional ocean model for simulating coastal processes), to discuss the challenges it poses to compilers. In its easiest form, it is given by the following Partial Differential Equations (PDEs):
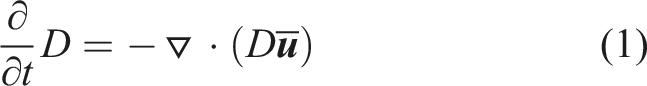
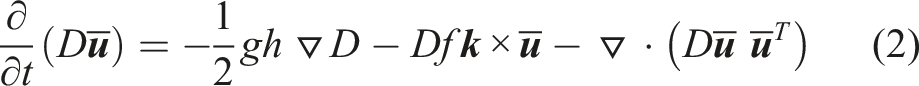
To give a better impression, we provide in Figure 1 a simplified 1D example of the placement of degrees of freedom providing the grid iteration space with StrD/EndD and StrU/EndU referring respectively to the start and end indices of D and u related variables where the start/end indices might even change depending on the choice of boundary conditions, see image. Supplemental arrays are then required to store not only the state required for the next time step (D and Simplified 1D example of a staggered grid.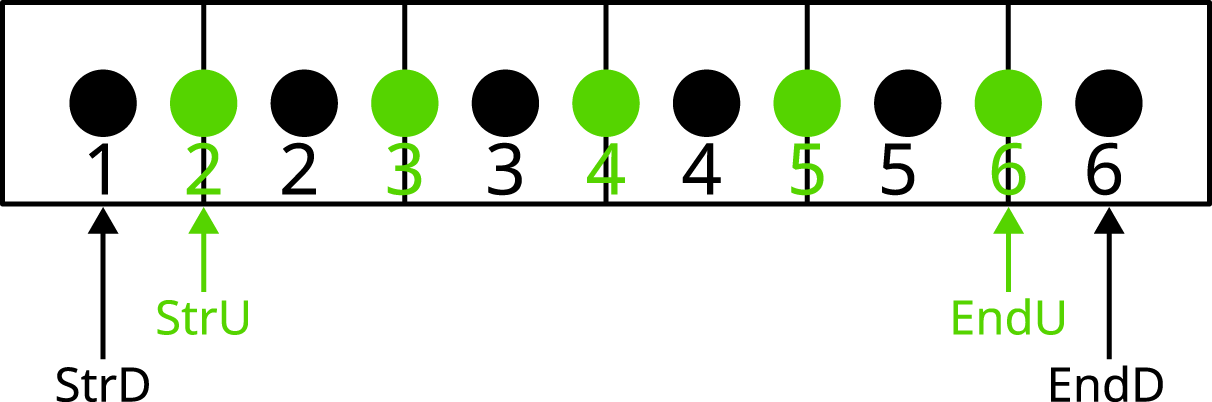
For both NEMO and Croco models, the barotropic solver is based on an explicit multi-stepping scheme (Shchepetkin and McWilliams, 2009) with further mathematical details skipped here for the sake of brevity. Its implementation is realized by extending an array with an additional dimension used in a round-robin fashion (modulo) to store the previously computed states of earlier time steps, and by overwriting results that are not further required.
The barotropic solver only uses 1D and 2D low radius stencils (up to ± 1) and is thus highly memory bound.
2.2. Compiler restrictions
The motivation of our work is given by the significant loss of numerical knowledge during the discretization process of the governing equations, hindering compilers from performing optimizations.
Without a doubt, some of the aforementioned problems could be solved partly with changes in the code, but this would still not provide a solution to all observed compiler limitations, and further require hand-written parallelization and offloading to GPUs.
2.3. HPC characteristics
From an HPC perspective, PDE solvers for the NEMO and Croco ocean models are realized with a set of nested loops and stencil access patterns with a size of ± 1 originating from lower-order spatial approximations (e.g., finite differences). Such patterns are known to be highly memory bound which is one of the main tackling points of our approach.
Next, we will discuss Poseidon as a potential way to overcome all of these challenges.
3. Poseidon
Poseidon is a source-to-source compiler designed to optimize simulation models on structured grids written in Fortran. It assumes array updates to be programmed with multiple nested loops iterating over the array elements and updating them with stencil-like access patterns from other arrays (Datta et al., 2008, 2009; Hagedorn et al., 2018; LeVeque, 2007; Liu et al., 2024; Nguyen et al., 2010; Rawat et al., 2019; Wahib and Maruyama, 2014). For ocean simulations used in production by hundreds of users, non-standard large software packages (e.g., ROSE (Quinlan and Liao, 2011), LLVM extensions, etc.) or software without long-life support is avoided. Poseidon is solely based on Python with a single dependency to the open-source Python package PSyclone, which has long-life support and is open source. Our development can be used without requiring extensive installation and configuration of complex software stacks, thereby addressing the main concerns of the user community. Next, we will discuss the different stages of Poseidon with an overview in Figure 2. Overview of Poseidon’s stages. We make use of PSyclone in the uplifting and backend, which are part of the connector (box with dashed lines) specific to each PDE model. Internally (within the purple box), Poseidon works with a representation independent of particular programming models or PDE solvers.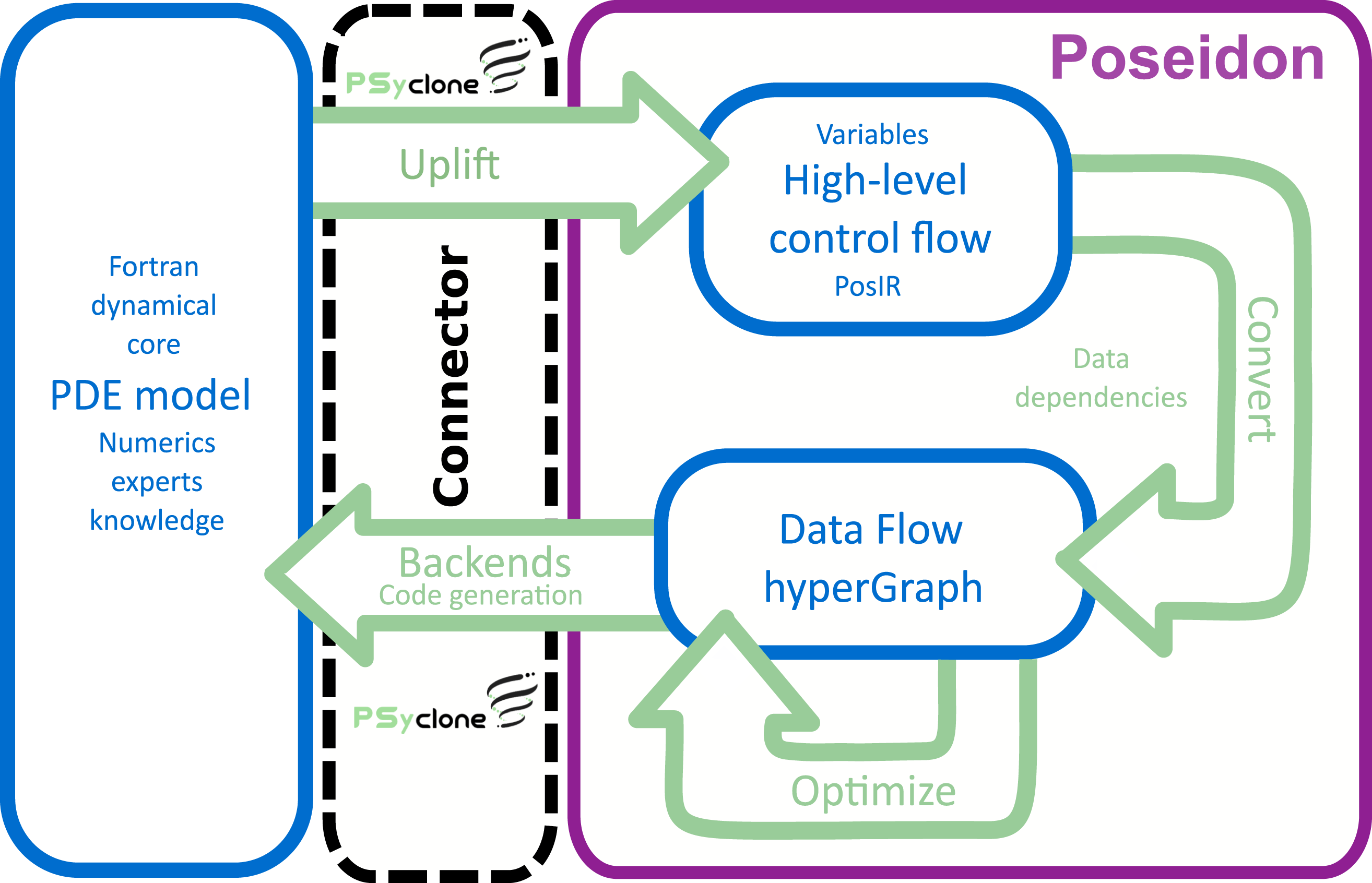
4. Connector: Uplifting to control flow
We start by discussing the uplifting to the control flow, which is the process of enriching the source code with high-level information about the numerical model and its variables. The Poseidon uplifter parses and extracts the variable information from a PDE model and characterizes the code for followup optimization steps. We introduce here the notion of a connector, responsible for parsing the relevant code, creating an intermediate representation suitable for the next step. A connector also writes back generated code and can modify existing code as discussed later as part of the backend. Since each PDE model is programmed differently, each one has its own connector tailored to how the PDE model is written. Connectors are however not DSLs, since they do not introduce new language features to be used in the model source code, but rather treat the existing source code of the model as an embedded DSL used by numerics experts, and enrich it with high-level information, provided by the numerics experts, to be used by Poseidon. We will focus on the main uplifting aspects shared among all connectors.
4.1. Variable uplifting & management
Poseidon uses a VAriable Management (VAM) where all used variables must be registered. During the uplifting, the connector registers all used scalars and arrays for variable management, including their rank, dimension, and type. Also, the VAM retains (partly implicitly) information on where they are defined, allocated, and initialized, which becomes crucial in the backend, e.g., to remove or allocate additional arrays in memory. The VAM distinguishes between the following variable types where N refers to the number of dimensions the solver was written for: • • • • •
Two crucial operations are supported for each variable in the VAM for further processing:
Note that these operations do not yet create any code or a code representation but are solely done in the VAM representation itself, leaving it up to the code generation in the backend to consider this, leading to a clear separation of concerns. Relevant for gaining back lost numerical information, the grid-related arrays are enriched with information about which grid they correspond to. Also, information on the variable lifetime is added, e.g., whether its data is still relevant after the time step is finished, allowing for further optimization of the memory footprint (see Obs. #4).
After the uplifting of variables, Poseidon uses these variables solely in its internal representation as a matter of separation of concerns, hiding where they are actually used in the code itself.
4.2. Control flow
After the registration of variables, the computations are extracted to a control flow with a macroscopic level (see, e.g., task-based control flows (Sinnen, 2007) for similar concepts) where a single node of the control flow can represent multiple operations.
4.2.1. Segmentation and characterization
For this, we first preprocess the code using PSyclone to make it suitable for further processing, which – depending on the model – can include, e.g., rewriting array slicing syntax to loops, inlining functions to simplify interprocedural dependency analysis, eliminating dead if-branches and further features provided by PSyclone. The next task is then to further process the PSyclone IR (PSyIR) with Poseidon performing a segmentation into a coarse-grained control flow where we characterize each code block into four node types in the following order or matching: • • • •
To segment and characterize a PSyIR source code representation given in Annotated Syntax Tree (AST), we use a context-free grammar given in Backus-Naur form in Figure 3 with the starting symbol α, the empty word ϵ, and canonically given terminal symbols. The derivation of the terminal blackbox node B* shall be defined as everything not matched by the grammar symbols K
L
, K
B
, and C. Grammar in Backus-Naur form for uplifting the source code to the control flow with starting symbol α. See text for more details.
4.2.2. Variable closure
For each node, including blackbox ones, we keep track of the variable closure, namely lists of which variables are read, written, and used within the nodes, see “input/output data” boxes in Figure 4. All of these variables have been previously registered to the VAM (see Sec. 4.1). Two examples of the constructed control flow nodes. (top) Computation node with a source code segment uplifted to the PosIR. (bottom) Kernel loop node representing finite difference computations.
Failing to determine the correct variable closure, e.g., for calls to external routines with side effects, will render Poseidon either unable to perform optimizations (due to too many variables in the closure, hence obsolete dependencies) or lead to incorrect code generation (due to missing variables in the closure, hence missing dependencies). For example, assuming side effects to all variables in a called routine would prevent any variable from being removed, whereas omitting side effects to a variable would lead to missing dependencies and incorrect code generation as the routine might be called before or after the variable is updated.
4.2.3. Poseidon IR
Computation blocks of the form C by themselves or within kernel loops are further uplifted to Poseidon IR (PosIR). This representation is a list of assignments with a tree-like structure on the right-hand side, whose representation is bijective to the PSyIR concerning the subset of Fortran language supported by PosIR. We refer to compiler literature for such representations (Alfred et al., 2007) and point out two main features of PosIR: (1) (2)
Both features avoid special handling of arrays and scalars and if-branches in the kernels, simplifying further analysis and rewriting of such code discussed later. After these steps, the macro-control flow of one solver step is entirely given by a list of nodes with examples in Figure 4.
5. Data flow graph
With Poseidon’s separation of concerns, the control flow is now independent of the PDE model code itself. Given the list of nodes in the control flow, each node contains the variable closure on the read and written variables it accesses. Based on this variable closure, a Data Flow Graph (DFG) can be constructed (see, e.g., Sinnen (2007)) where Poseidon uses a hypergraph with an example given in top image in Figure 5 (including further transformations explained later). In this graph, each node Exemplary DFG of the barotropic solver produced by Poseidon with data flow from top (source node) to bottom (sink node). Ellipse-shaped nodes: hyperedges accounting for data flow via arrays - flows of scalar variables are not rendered. Box-shaped nodes: data flow nodes of different types - kernel loops (yellow), computations (blue), boundary cond. (red), blackboxes (black), communication (pink - not part of this work). corresponds to one node of the control flow and each hyperedge
corresponds to one node of the control flow and each hyperedge  to a data flow dependency of a variable. This includes also false dependencies on the data flow level with respective false dependency hyperedges to account for write-after-read and write-after-write dependencies (not displayed in the Figure). Rather than using a regular graph, such a hypergraph representation strongly simplifies the following DFG operations and the realization of different backends for task-based scheduling which is part of the following sections.
to a data flow dependency of a variable. This includes also false dependencies on the data flow level with respective false dependency hyperedges to account for write-after-read and write-after-write dependencies (not displayed in the Figure). Rather than using a regular graph, such a hypergraph representation strongly simplifies the following DFG operations and the realization of different backends for task-based scheduling which is part of the following sections.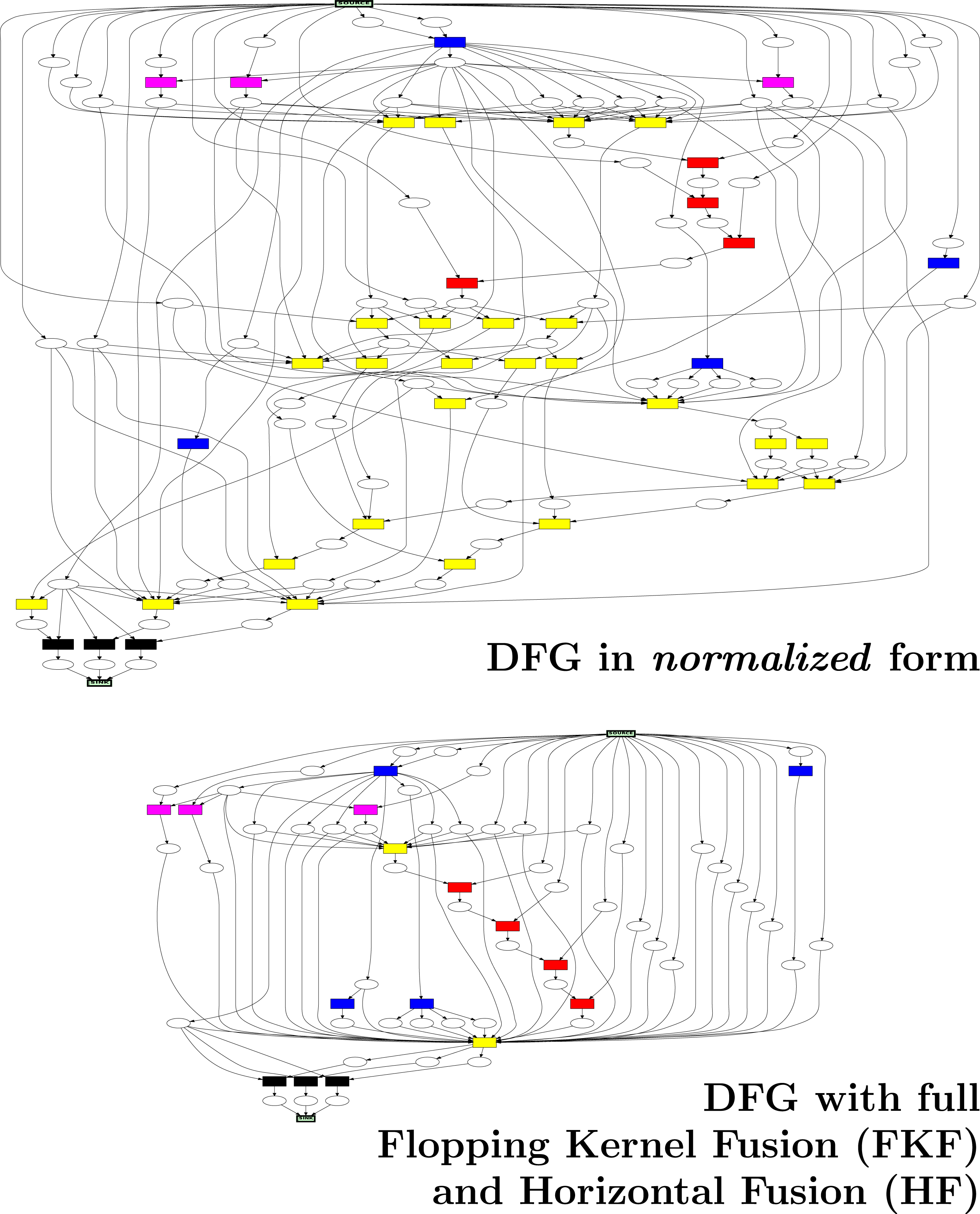
5.1. DFG operations
Next, we briefly describe the fundamental DFG operations supported by Poseidon. Rather than giving a detailed overview of all supported operations (including validation of the DFG, debug features, etc.), we focus on those relevant to rewriting the DFG during the optimization process discussed in the following section.
5.1.1. Normalization
Before performing any HPC optimizations, we first undo existing ones, such as hand-written loop fusion and array reuse, by splitting kernel loops writing to multiple arrays, shifting iteration ranges where required and ensuring each variable is assigned exactly once, by automatically rewriting the source code into what we call a normalized form, which forms the basis of further kernel-oriented optimizations detailed later on.
Due to the PosIR representation, with if-branches uplifted to conditional expressions, the body of kernel loops and boundary conditions consists only of a list of assignments. Based on this, we further define a kernel/boundary loop with PosIR to be in (a) Exactly one output variable array of dimension N is written to in each kernel loop, and this write happens in the last assignment of the kernel loop. (b) No relative indices, e.g., ubar [i+1,j], are allowed in the written array in the last assignment of the kernel loop. (c) For all N-D kernel loops, the variable array written in the last assignment of the kernel loop must not be read from in this kernel loop. (d) (N − 1)D kernel loops, i.e., boundary conditions, can read & write variable arrays.
Property (a) relates the kernel to the evaluation of one particular finite difference/volume operator (N-D) or to one particular boundary condition ((N − 1)-D), Property (c) avoids any false dependencies leading again to further advantages used, e.g., for parallel scheduling. Property (d) allows boundary conditions kernel loops to update variable arrays, without requiring full copies of them. All properties (a) - (d) result in a clearer algorithmic implementation of DFG operations in our development.
To obtain a code in normalized form, Poseidon provides the following DFG operations undoing common optimizations done by hand: • • •
If a kernel loop cannot be written in this form, Poseidon can still be used, but DFG operations operating solely on kernels in normalized form do not apply to this kernel loop. Despite using this normalized form often throughout the following optimization process, the kernel loop code that is finally produced is not necessarily in normalized form. What looks first as a de-optimization lifts us from being potentially stuck in a local extrema of an optimization process.
5.1.2. Fusion operations
Over the last decades, various fusion methods have been developed (Bacon et al., 1994; Ding and Kennedy, 2000; Liu et al., 2024; McKinley, 1998; McKinley et al., 1996; Qiao et al., 2019; Singhai and McKinley, 1996; Wahib and Maruyama, 2014). An overview of a selection of state-of-the-art fusion-based optimizations is presented in Figure 6. For the sake of better understandability, we provide only simplified examples: They are based on single-dimension loops, whereas loop fusion for ocean models is applied consecutively on all perfectly nested loops. Also, scalar variables found inside each loop must be dealt with and have been skipped for the sake of brevity. Furthermore, loop iteration ranges can also mismatch for ocean models due to grid staggering, see Sec. 2.1. Overview of pseudo code for different fusion approaches. (Left) Vertical and horizontal fusion, often performed by hand-tuning code. (Right) Kernel-oriented fusion, requiring either synchronization (top) or duplication of operations (bottom). Fusion marked with * is used in the present work.
We first discuss the two examples of vertical and horizontal fusion; see Liu et al. (2024):
Incentivized by HPC trends of increasing gap between computational and data access performance (Dongarra et al., 2024; McCalpin, 2016), we make use of a kernel fusion technique producing significantly more flops and not requiring conditional statements, and we will refer to it as Flopping Kernel Fusion (FKF), see right-lower code in Figure 6. As a result, it leads to an increase of computational intensity and decrease of the number of required memory access aligning even better with future trends in HPC. We would like to remind of the normalized form introduced in Sec. 5.1.1, converting the kernel loops to the most suitable form for reducing the complexity of developing the FKF. We will apply this FKF independently to the iteration range of the first loop following its mathematical understanding (see Obs. #2). We emphasize the following points: 1. We generate code that is not necessarily valid from a compiler perspective due to the lack of updating array data. 2. Multiple vertical FKF can lead to exponential growth of code. Consequently, it is rarely done by hand since it rapidly leads to hard-to-maintain code. Additionally, if done by hand, it can introduce subtle bugs that are difficult to trace. Compared to CKF, we have advantages: (a) avoiding the synchronization barrier with multiple duplications of computations and (b) being less restrictive on resources required for the scratch array, which is not required anymore.
Concerning Poseidon, support for HF, VF, and FKF operations on the hypergraph is provided. Also, not further discussed here, all operations support fusion with assignments to temporary scalars within kernel loops.
5.1.3. DFG operation validation
We strictly avoid trial-and-error approaches to detect invalid DFG operations in Poseidon. Instead, all fusion operations are validated before being applied to the DFG with algorithms based on hyperedges analysis (based on standard graph-analysis algorithms).
An example of an invalid kernel fusion DFG transformation is displayed in Figure 7. In the left DFG, “A” reads variable “Z” and “B” updates “Z”. This situation is caused by reusing variables multiple times (e.g., to reduce the memory footprint by hand). Invalid transformation.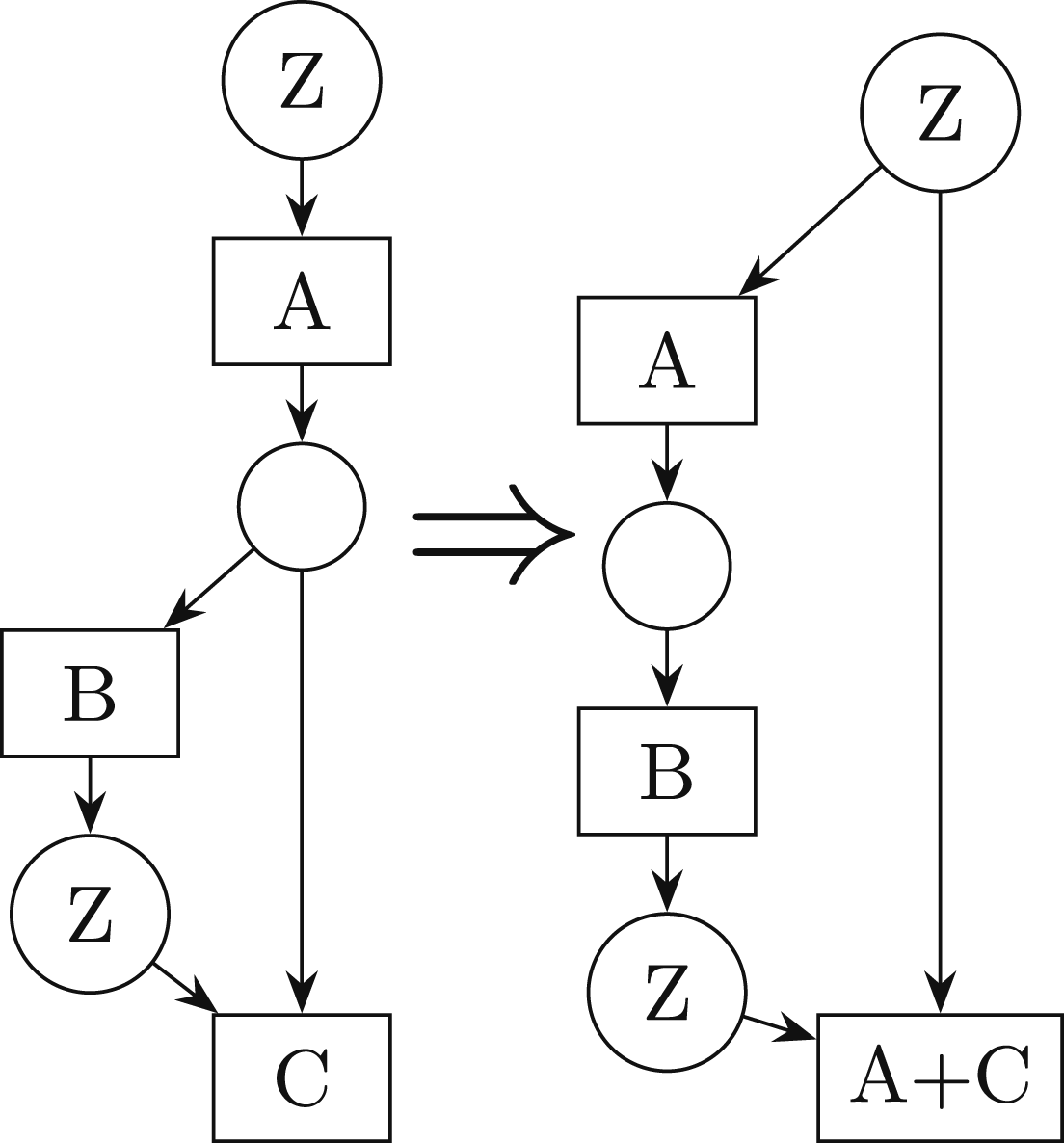
Here, FKF of “A” and “C” would lead to an invalid DFG: After fusion (depicted on the right DFG), the variable “Z” is still consumed by the merged node “A + C”, but before this node is executed, “Z” is updated/overwritten by node “B”. Poseidon checks for such invalid transformations by first determining the set of all nodes on all possible paths between the two nodes to be fused. The transformation is not allowed if one of these nodes on the path updates the variable used as an input of the node “A” to be fused.
Since the SSA form avoids such cases by, e.g., using a different variable for B’s output, we emphasize that such situations do not occur after normalization (see Sec. 5.1.1). Nevertheless, validation checks are still required for such dependencies that potentially occur due to blackbox nodes or code without normalized kernel loops.
6. Optimization of data flow graph
Finding the optimal sequence of operations to be applied on a DFG can be a complex process (Liu et al., 2024; Zhang and Mueller, 2013) that depends not only on the performance characteristics of the graph nodes but also on the target architecture. For this work, we use a trivial, purely model-driven optimization strategy, which, as shown later, is sufficient to closely approach the theoretical maximum speedup.
All kernel loops have a low computational density and are consequently memory bound (Williams et al., 2009), making reducing memory access a top priority. For each kernel loop, the number of memory accesses is given by the number of hyperedges related to array variables, and from hereon, we will refer to them as array hyperedges.
Incentivised by the high computational performance of HPC architectures, we will start by applying solely FKF. To apply FKF to kernel loops, we make the following observations: for kernel loops with multiple incoming array hyperedges and the output hyperedge connected to multiple children, fusing a kernel loop to only one other kernel loop can even lead to an actual increase in the number of array hyperedges. Therefore, if we fuse this kernel loop, we fuse it to all or no children kernel loops, consequently eliminating the fused kernel loop. Furthermore, such a strategy also reduces the complexity of the optimization space.
In each optimization iteration, one DFG operation can involve multiple DFG nodes. For FKF, the optimizer chooses the kernel loop with the maximum number of hyperedge arrays, which would be removed by fusing it with all its children. This information can be inferred efficiently from the information already encoded with the hypergraph edges of all involved kernel loops. Using this optimization criterion can lead to multiple candidates, and we use a second criterion by choosing the kernel loop with the smallest number of arithmetic instructions. Although this is a relatively trivial optimization criterion, we will observe it is sufficient to achieve results close to the maximum achievable speedup.
7. Backend
The backend of Poseidon generates code that can be compiled within the existing PDE model. Similarly to the uplifting process, the backend is part of the connector and requires to be tailored to each PDE model. The following algorithms are strongly aligned with task-based execution/programming models (cf. Fernández et al. (2014); Augonnet et al. (2009); Bauer et al. (2012); Sinnen (2007); OpenMP Architecture Review Board (2018)), and we will use when adequate the terminology “task” for “node”.
To determine the (1) Purely sequential over the task: each task will be enqueued and executed only after the previous one in source order has finished. (2) Asynchronous execution of task (only for GPUs): each task will be directly enqueued but must wait for the previous one in source order to be finished. (3) Parallel DAG scheduling: tasks are still enqueued in source order but wait for task dependencies to be fulfilled. Boundary condition loops shown sequentially in the DFG (see red boxes in Figure 5) are specially treated and executed in parallel alongside each other (See Obs. #3).
We support two different
The
Concerning the variables, some variables might now be referenced, that do not yet exist due to cloning (e.g., to convert the DFG into the SSA, see Sec. 4.1) or variables might not be required anymore (e.g., because they are not referenced anymore due to a kernel fusion). In the case of cloning, this requires the declaration of variables and also their initialization. In the case of deleted variables, their declaration, their initialization, and other references to them must be removed. How these variables are handled can strongly differ between PDE models, which is why the connector must be tailored to it, and PSyclone is used for interacting with Fortran code.
8. Results
Benchmarks were conducted using Grid’5000: We used the “Intel Xeon Gold 5318Y” for the CPU experiments on the “spirou” partition in Louvain. GPU experiments are based on “Nvidia H100 NVL (94 GiB)” from the “musa” partition in Sophia. We also conducted benchmarks on the Nvidia A100 GPU, which all looked similar to some scaling factors of the H100 results. Therefore, we only show plots for the H100, but discuss differences to the A100 if relevant.
Since the PDE solvers we are dealing with are memory-bound, we chose compilers providing the best performance on the target hardware based on a Fortran array stream benchmark, leading to the Intel LLVM-based compiler (2025.0.1.47, options -O3 -xHost) for CPUs and nvfortran (25.1-0, options -O3 -fast) with CUDA (12.2, driver 535.183.06) for GPUs, which provided close-to-peak performance on each vendor’s respective architecture. Numerical results were confirmed to match up to numerical precision.
To show the performance of Poseidon we use 1. The barotropic solver of Croco from the “soliton” test case in a research code, allowing us to focus on conducting detailed performance experiments with the same challenges during uplifting, but without the need to deal with the complexity of the full Croco development, and 2. a research code, “TP des Houches”, designed for data assimilation teaching purposes, implementing a bidimensional reduced gravity non linear shallow water equations model in a flat bottom rectangular domain.
8.1. Croco barotropic solver from the “soliton” test case
In the following plots, we will refer to
We will refer to different problem sizes as small (128 × 128), medium (1024 × 1024), and large (8192 × 8192). All benchmarks run 100 time steps where the first 10 time steps have been excluded from the measurements to avoid the influence of JIT compilation (on GPUs) and other hardware-related warmup. The average of the last 90 time steps is then taken as the final result.
8.1.1. CPU benchmarks
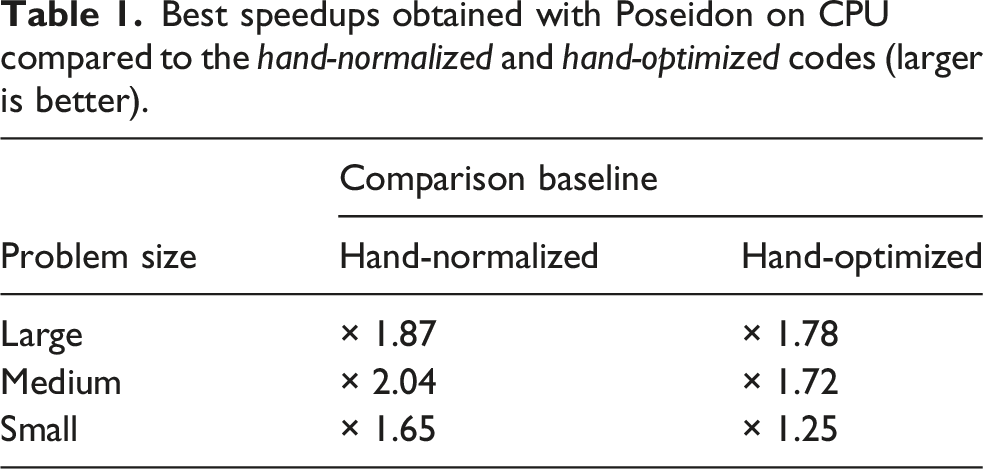
Results for CPUs are presented in Figure 8. We can observe Poseidon’s ability to robustly parallelize and optimize the PDE model with FKF. The low performance of DAG-based tasking is due to a bug in the LLVMIntel Fortran OpenMP frontend, where SIMD clauses are not taken into account for tasking, which was confirmed by Intel. Applying one horizontal fusion after a number of FKF leads to significant performance drops. This is due to various if-branches required to cope with different iteration spaces, leaving the compiler unable to vectorize. Using task-based DAG scheduled execution, we can observe that the performance drops for the last fusion operations. This suggest this is due to concurrent scheduling of task loops within DAG tasks, leading to the competition for resources causing such overheads. For small problem sizes (not shown here), the task-based execution suffers from severe tasking overheads, leading to a performance drop of over × 10. An overview of speedups after applying all DFG operations is given in Table 1. Benchmarks conducted on CPU with medium problem size with min/max plotted as transparent filled area. We compare the hand-normalized, hand-optimized, and Poseidon with FKF, HF optimizations, and different parallel DAG tasking strategies. Best speedups obtained with Poseidon on CPU compared to the hand-normalized and hand-optimized codes (larger is better).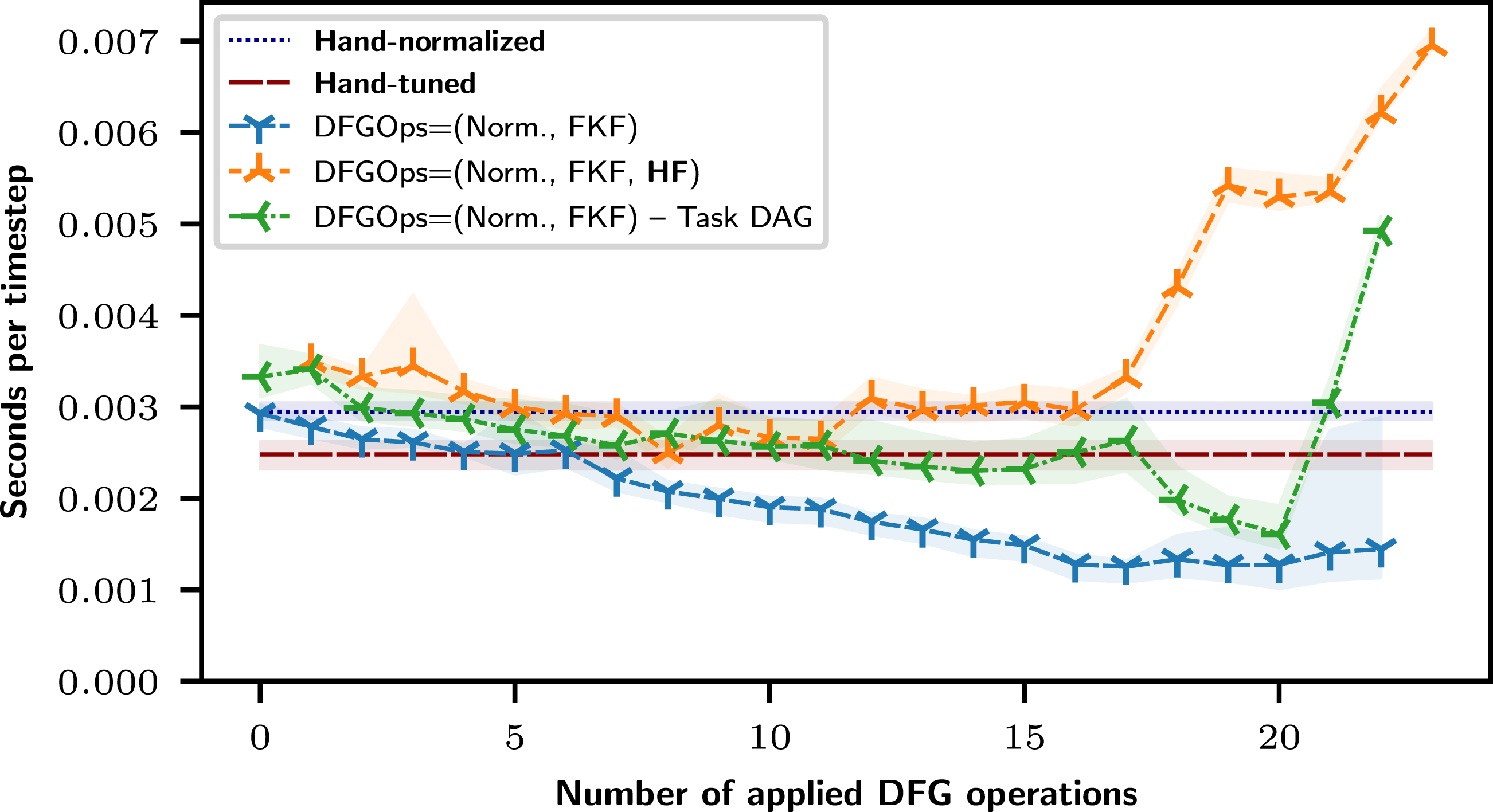
8.1.2. GPU benchmarks
We continue with in-depth performance experiments on the GPU as the most relevant target platform for NEMO & Croco models. For this, we investigate three different offloading strategies of kernels to GPUs; all realized in Poseidon’s backend (see Sec. 7): (a) ACC parallel loop only, (b) ACC parallel loop with async submission to a single queue and (c) ACC parallel loop with async dispatching of kernel loops to different queues for DAG tasking. We continue to point out the automatic parallel scheduling of boundary conditions to different queues to execute them in parallel.
We first investigate the results of a large problem size depicted in Figure 9 with each array exceeding the L2 cache size. This provides the optimal case for fusion strategies - avoiding memory access - for which we optimize. For such problem size, the kernel starting overheads are negligible, and the performance is dominated by the memory bandwidth, hence the different asynchronous execution strategies do not show significant differences. We can observe the normalized version of the code to be significantly slower than the hand-optimized one due to the additional memory access being introduced due to the normalization. Starting from this normalized form, we apply FKF DFG operations by choosing kernel loops to be fused next as described in Sec. 6. We observe a robust performance optimization for each of the first 16 fusion operations with some plateauing effects afterward. Nevertheless, by applying FKF, we continue to obtain more performance improvements. Finally, applying a single horizontal fusion (HF) after the FKF operations leads to the best performance, with a further speedup of about 1.11 compared to the best FKF-optimized version. Compared to the hand-optimized version, we can achieve significant speedups of about 2 (see Table 2 for details). Note that there are four kernel loops left that cannot be fused by FKF any further. Benchmarks conducted on GPU with large problem size and with min/max plotted as transparent filled area. For better comparison, baselines for hand-normalized/-optimized timings are drawn as a horizontal line, although no DFG operations are applied. (Left image) Benchmark comparisons of hand-normalized, hand-optimized, and Poseidon with DFG operations given in parentheses. If specified, HF is applied only once after a certain number of FKF, counting as one more DFG operation. The fully FKF-optimized version, followed by one more HF, provides the best results. (Right image) Bandwidth information and array utilization for the large problem size. The modeled bandwidth is based on the number of memory accesses and the size of the arrays. Best speedups obtained with Poseidon on GPU compared to the hand-normalized and hand-optimized codes (larger is better).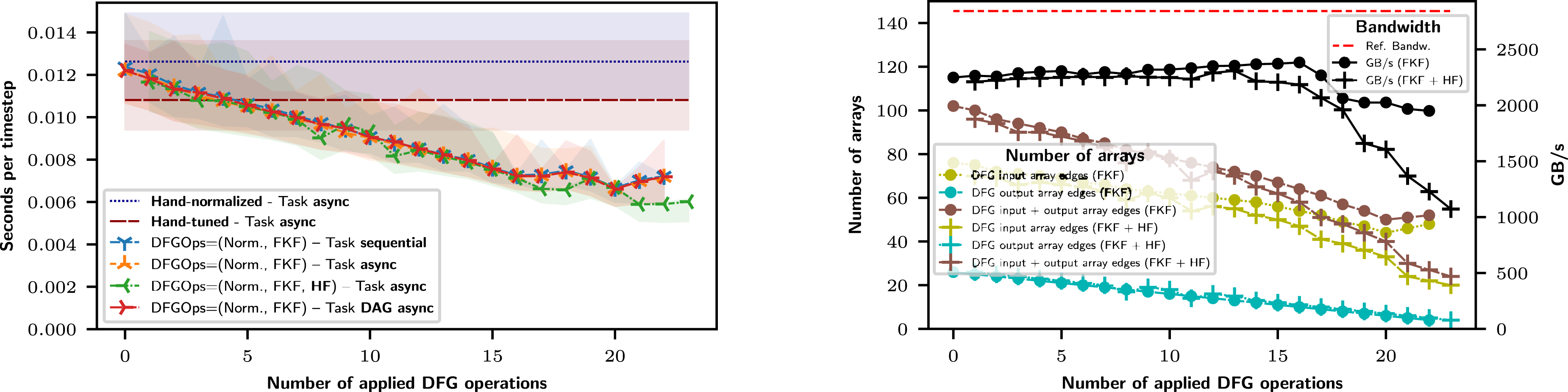

Next, we investigate the performance of the FKF optimization on the medium and small problem sizes with results shown in Figure 10. For the medium sized problem, we observe that parallel graph-based execution of the DFG nodes provides the best performance for many DFG nodes. The more FKF we apply, the more its runtime approaches the async dispatching of nodes to a single queue since fewer and fewer nodes are available for parallel execution. Benchmarks conducted on GPU with medium (left) and small (right) problem size with min/max plotted as transparent filled area. For better comparison, baselines for hand-normalized/-optimized timings are drawn as a horizontal line, although no DFG operations are applied. For the medium problem size, we observe that DAG async execution provides the best performance for a low number of applied DFG operations. This is different for the small problem size, where we observe overheads of parallel execution (and synchronization). In both cases, the fully FKF-optimized version followed by one more HF provides the best results.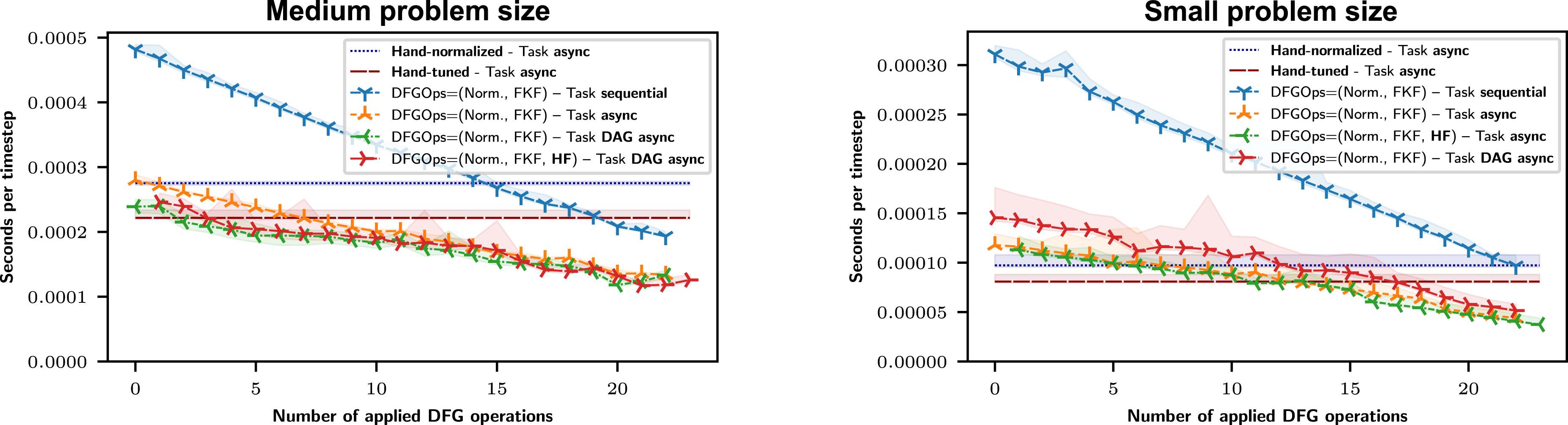
For the small problem size, we observe that the parallel dispatching no longer provides the best performance if no FKF is applied, but the async dispatching to a single queue performs best. We account for this relative slowdown by parallel dispatching and synchronization overheads.
Although this paper is more focused on the methodological side of source-to-source code transformation, we want to point out that the FKF followed by a single HF DFG optimization is not only a theoretical concept but also provides significant performance improvements in practice with speedups given in Table 2.
8.1.3. Bandwidth, memory footprint, theoretical speedup and impact on math
Since the fusion optimizations are motivated mainly by the bandwidth limitation, we also investigate how much bandwidth each time step consumes for the large problem size. We model the utilized bandwidth as follows: For each kernel loop, the number of accessed arrays is given by the number of respective DFG hyperedges, that is the number of input and output arrays of the kernel loop. Note that this takes cache effects into account, since each array is only counted once, no matter how many of its elements are read or written in the kernel loop. We multiply this with the byte size of each array (inferred from the resolution) and the number of time steps for benchmarking, providing the total number of bytes accessed in each kernel loop. The total bandwidth per second is divided by the time spent on the benchmarking time steps. We plotted this upper bound in the right top image of Figure 9 (top black line). We observe that, despite introducing more computations due to FKF, we stay close to the optimal bandwidth of the GPU for the first 16 FKF operations. Afterward, the memory bandwidth drops, which we account for by the increase in register usage, resulting in a loss of occupancy and therefore parallel requests to the memory. Nevertheless, despite this drop from the maximum bandwidth, FKF still leads to further speedups.
With GPUs becoming increasingly available in regular workstations and laptops, another desire is to run simulations of higher resolutions directly on a single GPU. Due to the VAM, Poseidon can free variables (scalars and arrays) when they are no longer needed due to the FKF operation. We can observe in Figure 9 a significant reduction of the required temporary arrays: Each FKF operation reduces the number of temporary arrays by one, and applying FKF to all nodes avoids allocating 22 temporary arrays. With 4 × 4 = 16 arrays for the multi-stepping arrays, and one temporary array left (output of upper kernel loop in Figure 5), Poseidon can reduce the memory footprint by (16 + 1 + 22)/(16 + 1) = 2.29. Hence, Poseidon can also be used to optimize for reducing the memory footprint.
Assuming the bandwidth is the only limiting factor for an arbitrary number of FKF, we can also compute the theoretical maximum speedup that can be obtained after FKF: The DFG with normalized nodes used here as an example has 102 input/output arrays in total. After all FKFs are applied, this is reduced to 52 arrays, leading to a potential speedup of 102/52 ≈ 1.96. Comparing this to the FKF benchmark plots, we conclude to be close to the optimal reachable speedup compared to the Hand-normalized baseline.
After obtaining this deeper understanding of the bandwidth limitation, we can also conclude that the multi-stepping method itself can be identified as the main performance limitation after FKF, since it requires reading in 3 times more arrays than a single-stepping method would require, making single-stepping methods a prime candidate for future bandwidth-limited HPC architectures.
8.2. “TP des houches” shallow water model
To also demonstrate the applicability of Poseidon to another application, we applied it to a code “TP des Houches” used for educational purpose. It is a shallow water model implemented in Fortran, which implements a bidimensional reduced gravity non linear equations model in a flat bottom rectangular domain, given by the following system of PDEs: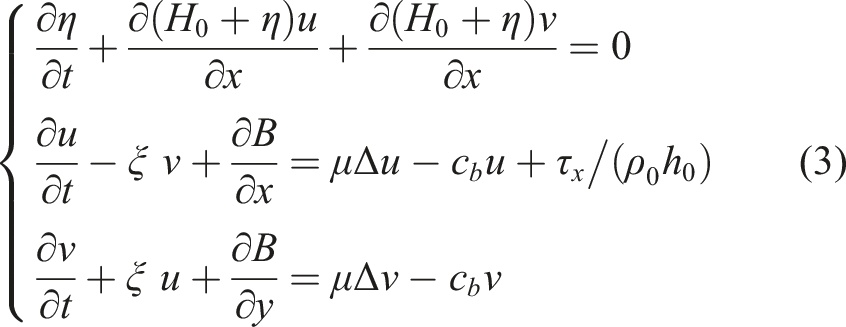
This PDE solver lacks a working OpenMP parallelization and we will use Poseidon to effectively parallelize and optimize it. We uplift the content of the time-stepping loop using Poseidon and obtain a DFG with 16 kernel loops and 24 boundary condition kernel loops. Without resorting to normalization, we applied FKF optimizations followed by up to two HF optimizations and ran CPU benchmarks on a large problem size (8192 × 8192) using OpenMP. We obtain a speedup of 9.73× compared to the sequential version. A straight-forward OpenMP parallelization would result in similar performance improvements. In addition, we obtain a speedup of 1.46× by applying FKF operations. Results are given in Figure 11. CPU benchmarks on the “TP des Houches” shallow water model with a large problem size using OpenMP, and with min/max plotted as transparent filled area. For better comparison, the baseline for unoptimized timings are drawn as a horizontal line, although no DFG operations are applied. Benchmark show unoptimized version and the Poseidon versions with DFG operations given in parentheses. If specified, HF is applied up to two times after a certain number of FKF, counting as more DFG operations. The fully FKF-optimized version, followed by two more HF, provides the best results.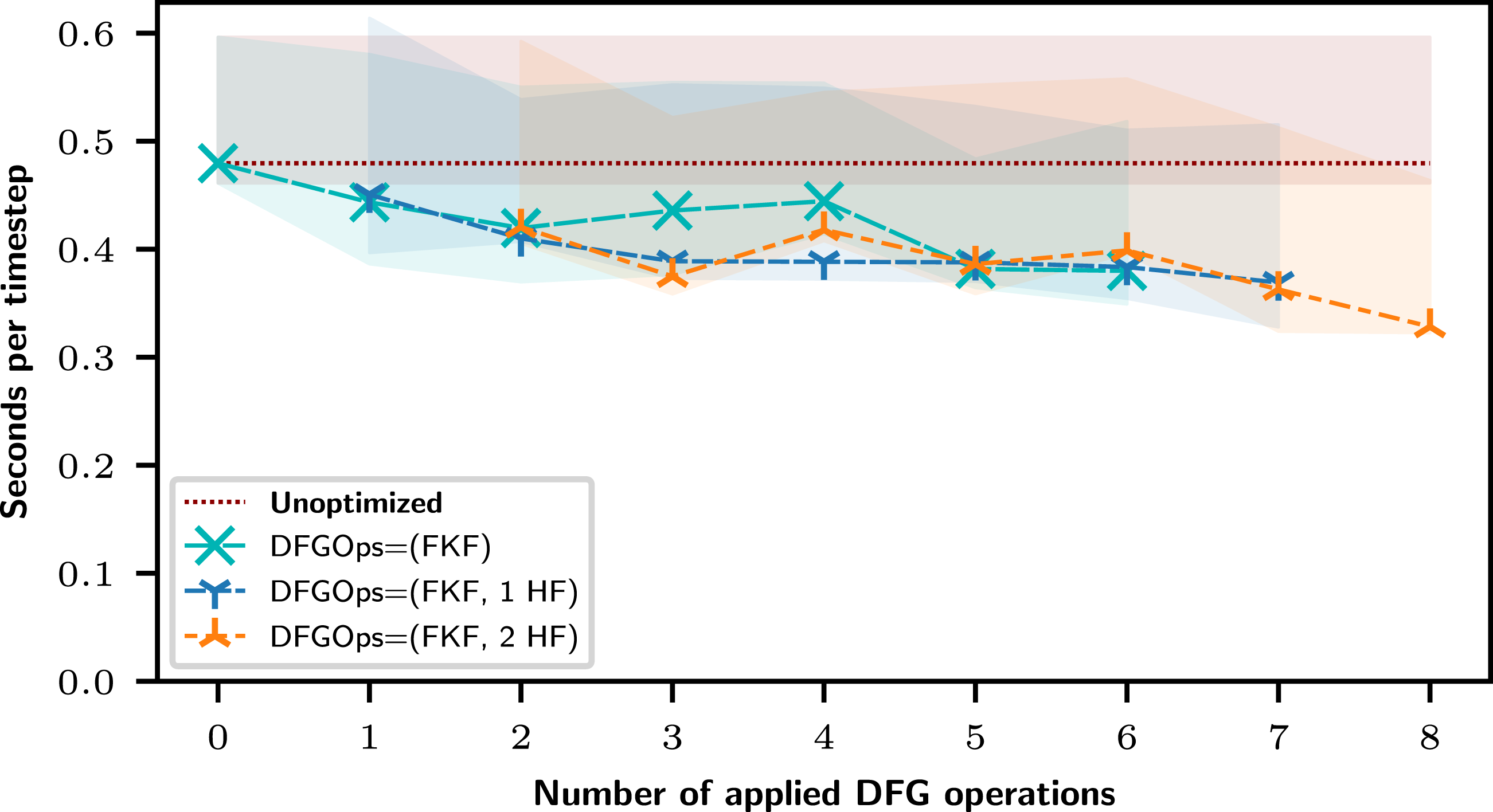
9. Related work
To our knowledge, it is the first time that a numerics-HPC co-design has been applied to automatically transform existing non-parallelized Fortran code into highly performing variants for GPUs and CPUs and reusing the same Fortran code for the backend. In addition, we address one of the operational requirements, which is to depend only on a small software stack that can be installed on any computer. Next, we will show relations of some subparts of Poseidon to other developments where we will skip well-known annotation-based approaches such as OpenMP and OpenACC for brevity.
Optimization for stencil computations has been a longer-standing research topic, and many approaches (see, e.g., Qiao et al. (2019); Wahib and Maruyama (2014, 2015); Hager and Wellein (2011); Nguyen et al. (2010); Hagedorn et al. (2018); Singh et al. (2018); Rawat et al. (2019); Datta et al. (2008); Zhang and Mueller (2013)) have been proposed to improve the performance of stencil codes on modern architectures. Our work exploits the increasing compute performance versus bandwidth ratio of modern computer architectures with FKF for the first time for solvers of such a complexity, with results close to the max. available bandwidth.
The standard way to obtain performance portability is the utilization of
There have also been
Other recent work (Liu et al., 2024) for GPUs required a substantial search time of at least half an hour, whereas Poseidon achieves significant performance improvements close to the maximum possible speedup on GPUs within less than 8 seconds for the best-performing variant (full FKF + 1 HF). Nevertheless, such an hybrid model-driven & autotuning approach will become necessary once more DFG nodes are dealt with and, even if only minor further speedups could be gained, using in addition their approach would be highly relevant for operational executions.
10. Limitations & impact
10.1. Poseidon’s limitations
We demonstrated a new approach to cope with automatic parallelization and optimization of existing Fortran code with a highly efficient model-driven optimizer that applies deep kernel fusion within a few seconds.
However, we do not want to raise the expectation that this will be applicable out-of-the-box to all Fortran code. Since each PDE model is written differently, Poseidon requires the adaptation of the connector for each PDE model. Further, Poseidon can only optimize what can be expressed in the VAM and the DFG. Also, optimizations can only be performed if kernel loops are transformed e.g. into a normalized form.
Some ocean models (e.g., NEMO) pose some particular challenges: E.g., modules using private array variables pose some limitations in the uplifting and backend parts in the connector to make them accessible with a rewritten DFG in the backend. We do not see this as a limitation of the core of Poseidon itself, but in the uplifting and backend that requires more extensive work in the future. An easy remedy would be to adapt existing PDE models to better fit the connectors requirements as part of a software co-engineering process.
10.2. Potential impact on existing compilers and programming models
We briefly summarize the two main limitations in the considered compilers and potential changes to overcome these limitations: (1) Compilers such as nvfortran avoid fusing loops under various circumstances, requiring developers to manually fuse loops to take advantage of fusion, but at the expense of code readability and maintenance. OpenMP already supports loop fusion for matching iteration ranges through OpenMP directives. Therefore, a first step for this would be to support more advanced loop & kernel fusions in such parallel programming models. (2) In addition, highly optimized PDE solvers (e.g., Croco) allocate a single data buffer, sliced into smaller buffers, only once at the beginning of the program (including its offloading or allocation on GPUs) rather than repeatedly allocating larger array buffers on the heap impacting performance for larger buffers. This leads to the drawback that, once data has been written to such buffers, compilers are unable to identify whether it is read afterwards, hence, are required to perform this update operation. An in-depth data-flow analysis across the entire program would be required to address this issue. To circumvent this issue, parallel programming models could be extended with ways providing information on the lifetime of data, e.g., whether data is not relevant after returning from the subroutine.
Addressing these two key points would already allow compilers being able to efficiently (with respect to compile time) perform some of the code optimizations of Poseidon, where we already expect substantial performance improvements for existing code. Such features do not need to be necessarily implemented into larger compiler suites, but source-to-source compiler tools such as Rose or, as Poseidon did, with PSyclone.
11. Summary
This paper introduces Poseidon, a novel framework designed to transform Fortran code into a high-level representation based on DFGs. By leveraging Poseidon IR, the framework supports advanced DFG operations, including kernel fusion and performance-oriented transformations, to optimize computations for modern HPC architectures. The backend in free-form Fortran retains Fortran compatibility, ensuring support for vendor-specific compilers and maximizing hardware performance. Experimental results demonstrate significant performance gains, with deep kernel fusion and loop fusion achieving up to 2.16× speedup compared to hand-optimized code and a compile-time of less than 8 seconds. Future work aims to extend Poseidon with features like automatic communication injection and efficient automatic differentiation.
Footnotes
Acknowledgements
We thank Peter Messmer and Lukas Mosimann for their exceptional support with the H100. We used Grammarly and Co-Pilot for improvements in language and style. Experiments presented in this paper were carried out using the Grid’5000 testbed, supported by a scientific interest group hosted by Inria and including CNRS, RENATER and several Univ. as well as other organizations (see ![]() ).
).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is based on funding provided by the IRGA Poseidon project, from ADUM and the Inria associate team “Crocodiles”.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.