
Abstract
This paper presents a limited-area atmospheric simulation of a tropical cyclone accelerated using GPUs. The OpenACC directive-based programming model is used to port the atmospheric model to the GPU. The GPU implementation of the main functions and kernels is discussed. The GPU-accelerated code produces high-fidelity simulations of a realistic tropical cyclone forced by observational latent heating. Performance tests show that the GPU-accelerated code yields energy-efficient simulations and scales well in both the strong and weak limit.
1. Introduction
Tropical cyclones (TCs) are a natural hazard that significantly impact human life and economies. Despite their huge impact, TC evolution is a physical process that is poorly understood. In particular, the prediction of TC intensity has been a challenging problem because of complexities in the multiscale interactions of convective-scale processes and synoptic-scale environment (Fischer et al., 2019). This is true especially when TCs undergo rapid intensification (RI), where TCs drastically intensify in a short period of time – typically change in wind speed of around 30 knots within 24 hours. To explore and study the RI mechanisms, we perform high-fidelity TC simulations. Modeling and numerical simulations of TCs can enhance our understanding of the underlying geophysical processes and may improve the accuracy of forecasts and risk assessment. However, one of the main challenges in the modeling of TC evolution is the high computational cost to resolve the fine-scale features needed for accurate prediction of TC intensity. To achieve computationally efficient simulations, we port a limited-area atmospheric model to the graphics processing unit (GPU) using a multi-CPU multi-GPU approach.
A nonhydrostatic atmospheric model is used to simulate TC evolutions. The code we use to perform these simulations is called xNUMA, a new version of the NUMA (Nonhydrostatic Unified Model of the Atmosphere) code (Giraldo et al., 2013; Kelly and Giraldo, 2012). The xNUMA code is designed specifically for a multiscale modeling framework (MMF) for atmospheric flows, and is written in modern Fortran using an object-oriented approach. Because all the spatial discretization and time-integration methods are encapsulated in the form of objects, it is capable of instantiating multiple simulations simultaneously during execution.
Previously, the NUMA nonhydrostatic atmospheric model, which employs element-based Galerkin methods, was ported to GPUs (Abdi et al., 2019a, 2019b) using OCCA (Medina et al., 2014). Various time integration methods, including explicit and semi-implicit schemes, were ported and demonstrated good scalability for numerical weather problems. However, using a hardware-agnostic application programming interface (API) like OCCA increases development complexity. It requires writing an entirely separate parallel branch of code in different languages, as well as modifying data structures and kernel execution patterns. In this work, we explore a hardware-specific directive-based approach to simplify offloading while maintaining performance.
In porting xNUMA to GPUs, we chose to approach the problem using a directive based implementation. The main advantage of directive-based approaches is the ability to easily make large GPU coding contributions to the code base while still maintaining a correct and performant CPU code base. In this work, we ported xNUMA to GPUs using the OpenACC programming standard (OpenACC Organization, 2020) as implemented in the NVIDIA compiler (NVIDIA Corporation, 2025).
High-order Galerkin methods are attractive for hurricane research due to their low numerical dissipation. An earlier study (Guimond et al., 2016) revealed that high-order methods better capture the vortex response to asymmetric thermal perturbations in hurricane RI due to reduced damping of heat and kinetic energies. Recently, an adaptive mesh refinement technique has been incorporated into the high-order Galerkin method to efficiently capture the fine features of hurricanes (Tissaoui et al., 2024).
High-order Galerkin methods have been shown to be performant on GPUs and well-suited for modern high-performance computing architectures. The Center for Efficient Exascale Discretizations (CEED) project documented applications of these methods in (Kolev et al., 2021). The finite element solver MFEM has been ported to GPUs (Andrej et al., 2024; Vargas et al., 2022) by integrating the RAJA abstraction layer, which facilitates access to various backend programming models for parallelization of loop kernels. The spectral element Navier-Stokes solver Nek5000 has been ported to GPUs using OpenACC (Otero et al., 2019) and OCCA (Fischer et al., 2022). These works commonly adopted a matrix-free approach for GPU acceleration and reported performance improvements as the polynomial order of the basis functions increased.
The remainder of the paper is organized as follows. Section 2 describes the nonhydrostatic atmospheric model. In this section, the governing equations, spatial, and temporal discretizations are summarized. Section 3 presents the porting and optimization of the code for single and multiple GPU systems. Section 4 presents the numerical setup for tropical cyclone simulations. Section 5 shows the performance test results. The conclusions are drawn in Section 6.
2. Nonhydrostatic atmospheric model
2.1. Governing equations
We chose the nonconservative equation set (Set2NC) from (Giraldo et al., 2010), which has been employed in our previous works (Abdi et al., 2019a; Giraldo et al., 2013; Kang et al., 2025). For a fixed spatial domain Ω and time interval
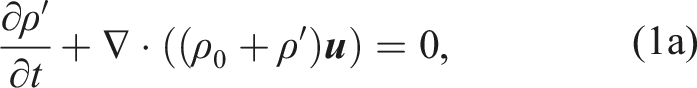
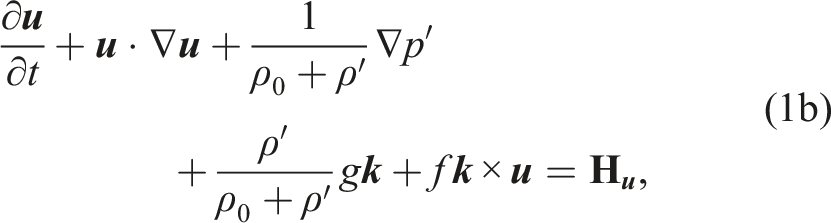
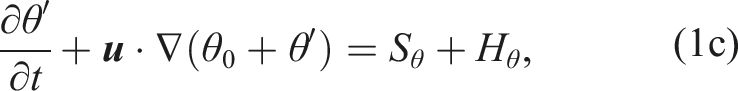
Where ρ0 is the reference density, ρ′ is the density perturbation,
Equation (1) can be rewritten in compact form as

The pressure is related to density and potential temperature through the equation of state for dry air,

2.2. Element-based Galerkin method
We use an element-based Galerkin method for the spatial discretization for the governing equations, following the methodology described in (Giraldo, 1998, 2020). This has been implemented in xNUMA (Kang et al., 2025). In this section, we provide a brief summary of the method and refer readers to (Giraldo, 2020; Kang et al., 2025) for details.
The computational domain
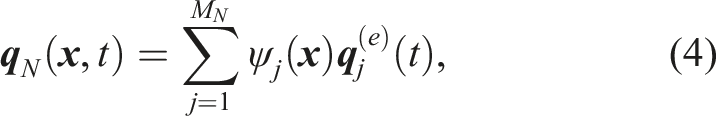
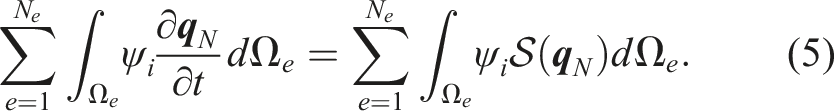
We employ LGL quadrature with collocation (integration points coincide with interpolation nodes), which renders the mass matrix to be diagonal. Global assembly via direct stiffness summation (DSS) (Giraldo, 2020) produces:
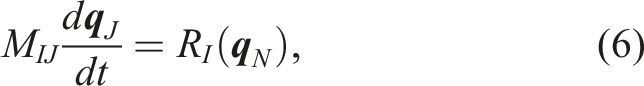

2.3. Implicit-explicit (IMEX) time integration
We integrate the semi-discrete equation (7) in time using an implicit-explicit (IMEX) time integrator (Giraldo et al., 2013), which splits the operator
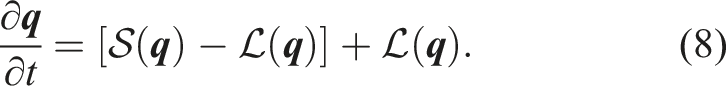
The terms enclosed in the square bracket represent the slower advective waves and are discretized explicitly. The remaining terms, in the linear operator
The linear system arising from the implicit part of the IMEX formulation is solved using the GMRES Krylov subspace method (Saad and Schultz, 1986) in a fully matrix-free fashion. In this approach, the linearized operator is computed on the fly with no information precomputed or stored. The only memory required is to store the Krylov vectors, which are typically fewer than 20 in the simulations presented.
The complexity of the algorithm is analyzed in our earlier work. Detailed information can be found in our previous paper (Kang et al., 2025).
2.4. Tensor-based hyper-diffusion
We add numerical hyper-diffusion to improve the stability of the numerical scheme. In particular, we implemented a modified form of the original formulation proposed by (Guba et al., 2014), which has also been used in the NUMA model (Giraldo et al., 2024). This modification reduces memory requirements. The hyper-diffusion term is given by

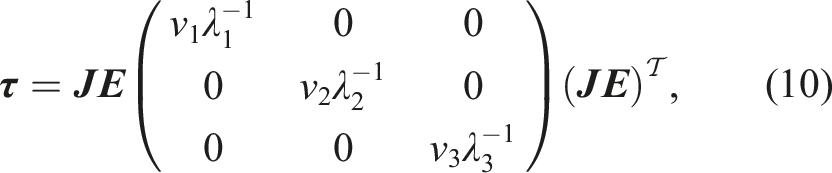
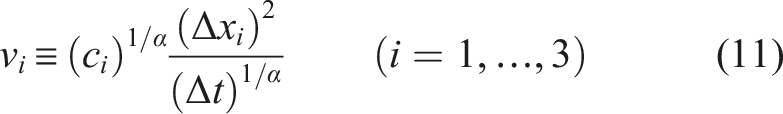
3. GPU implementation
3.1. Base code
The xNUMA code is written in modern Fortran and the base CPU code is parallelized using a Message Passing Interface (MPI) implementation. The simulator utilizes the dynamical core of the nonhydrostatic unified model of the atmosphere, referred to as NUMA (Giraldo et al., 2013; Kelly and Giraldo, 2012). Each simulator object encapsulates the data and functions that define a simulation, including input data, spatial discretization, time integration, and solvers.
The CPU baseline employs MPI for distributed memory parallelism, using element-based domain partitioning where each MPI rank handles a balanced subset of elements (Kang et al., 2025). We chose to keep the grid columns within a partition for potential use of a column-based microphysics model. Inter-rank communication is required for global DSS operations that assemble element contributions across partition boundaries. The multi-GPU implementation extends this parallelization strategy by assigning each GPU to an MPI rank. For detailed descriptions of the CPU implementation, including domain decomposition layouts, computational stencils, and parallel communication patterns, see (Kang et al., 2025; Kelly and Giraldo, 2012).
3.2. OpenACC implementation
In this work, we ported the time integration task, a main component of the simulation, to GPUs using OpenACC directives. Figure 1 illustrates the simulation workflow on the CPU and GPU. Initially, the simulation is set up on the CPUs by reading input parameters, creating the grid, and computing the initial conditions. Subsequently, all data is transferred to GPUs using OpenACC directives to copy data from the CPU to the GPU. On the GPUs, the simulation advances in time by calculating the RHS vector, performing GMRES iterations, and updating the state vector. To output XML outputs and diagnostics, we transfer the GPU value for the state vector to the CPU, again using OpenACC directives. For this work, we have included all data management directives explicitly rather than using NVIDIA compiler implemented unified or managed memory approaches. These latter memory approaches can simplify porting, but can require either code refactoring (managed memory) or bleeding edge software/hardware (unified memory) to function properly. Explicit data management gives us minimal code change requirements while providing the ability to maximize performance. Simulation workflow on the CPU and GPU.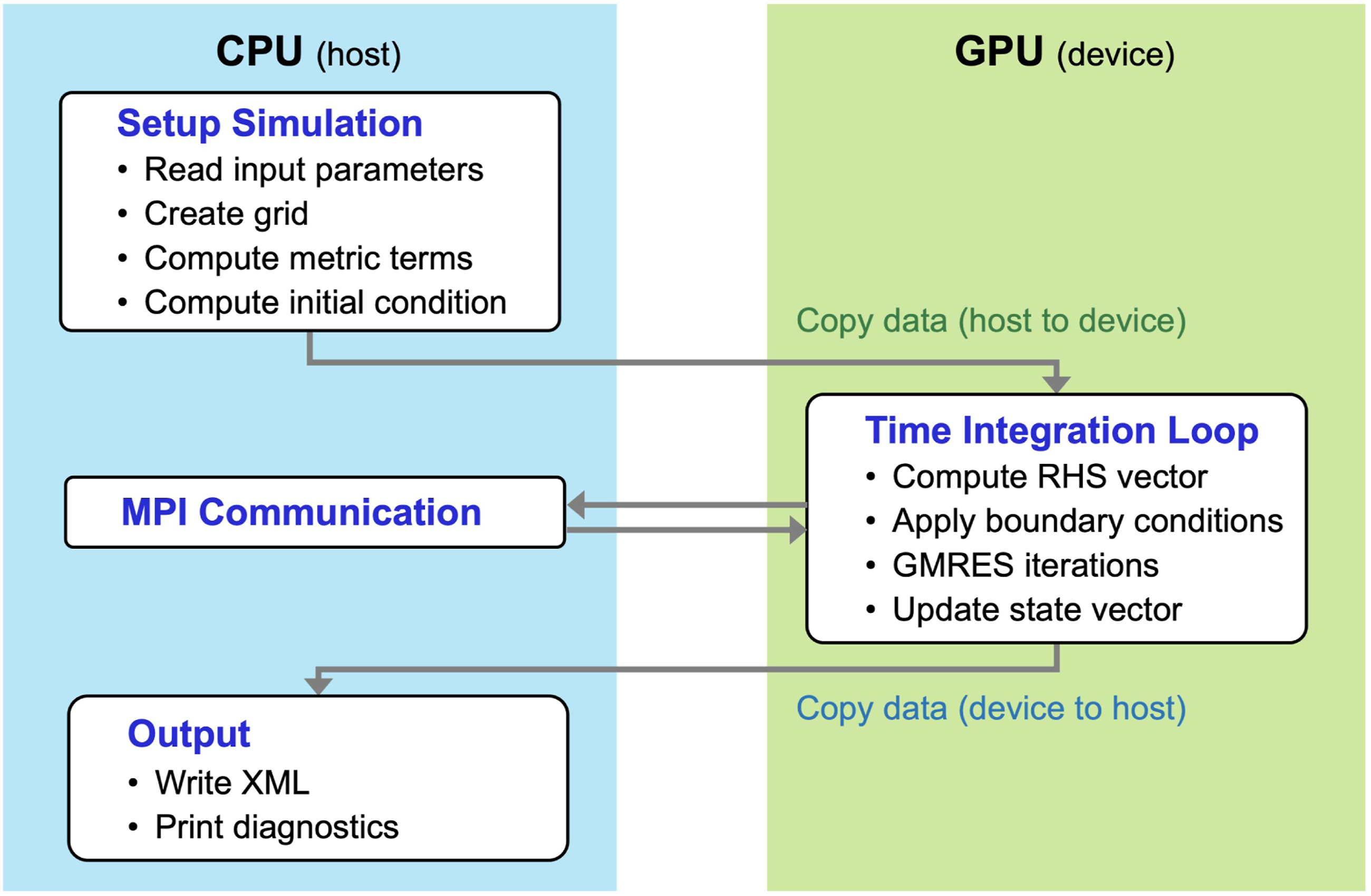
For communication across GPUs, we utilize OpenACC interoperability features that enable MPI communication directly between GPUs. The
To verify the correctness of the GPU implementation, we compared the prognostic variables computed by the CPU-only and GPU-accelerated simulations using PCAST. The results showed agreement within machine precision for all state variables, which confirms the correctness of the OpenACC-based porting.
3.3. RHS function


3.4. Gradient kernel


3.5. Assembly function


4. Simulation setup
4.1. Numerical setup
We simulate a tropical cyclone case using the GPU-accelerated code. The computational domain is a 3D box with horizontal dimensions of 800 km and a vertical height of 20 km, defined as Ω = [−400, 400] × [−400, 400] × [0, 20] km. Doubly periodic boundary conditions are applied at the lateral boundaries, and a no-flux boundary condition is enforced at the bottom surface. To absorb upward gravity waves and prevent reflections, an implicit sponge layer (Kang et al., 2025; Klemp et al., 2008) with a thickness of 4 km is imposed at the top of the domain.
Several values for horizontal grid spacing are tested, with
The values for the reference variables are taken from the background sounding provided in (Jordan, 1958). Figure 2 presents the profiles of reference potential temperature and reference pressure with respect to height. In the simulation, background wind is not considered. Soundings for tropical cyclone simulations: reference potential temperature θ0 and reference pressure p0.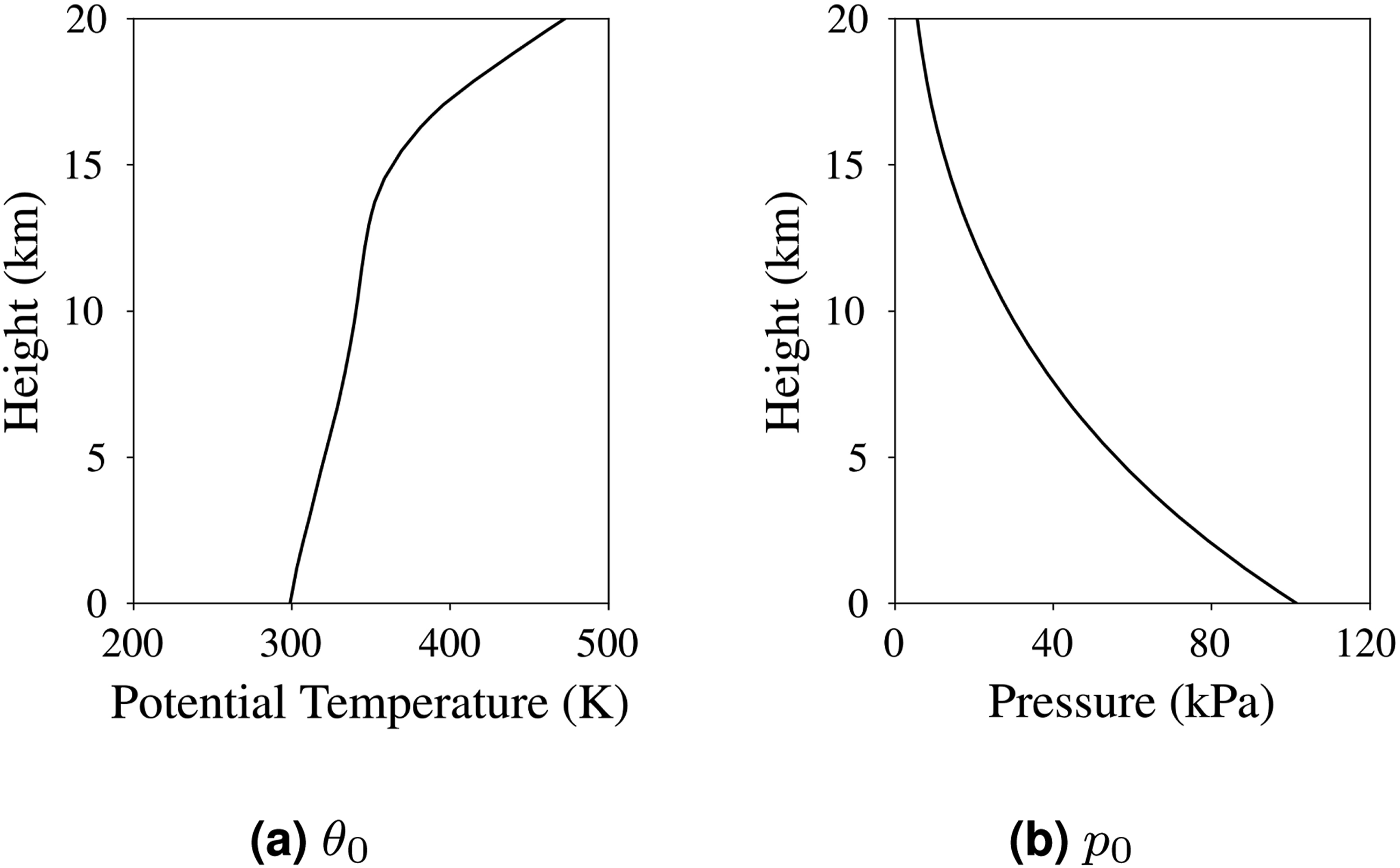
The tropical cyclone is initiated by an idealized vortex used in (Guimond et al., 2016). This vortex is modified from the original form (Nolan et al., 2007; Nolan and Grasso, 2003) to enforce zero velocities at the lateral boundaries. In this vortex, the azimuthal-mean tangential velocity is defined as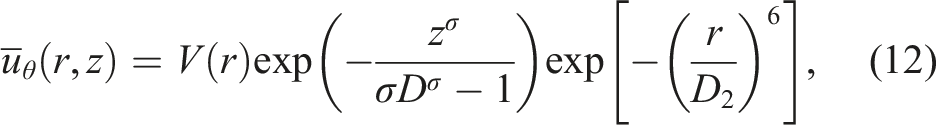
The RI of tropical cyclones is driven by the vortex response to latent heating injected into the boundary layer. In this research, we incorporate the observational latent heating into the source term S
θ
in Eq. 1c. A time-varying 3D observational heating profile was obtained from airborne Doppler radar measurements during the RI of Hurricane Guillermo (1997) (Hasan et al., 2022). Figure 3 presents snapshots of the asymmetric spatial distribution of latent heating at different time points. Over the duration of 6 hours, 11 sampling points of latent heating are used to interpolate the heating source term. Latent heating in the region [−60, 60] × [−60, 60] × [0, 20] km.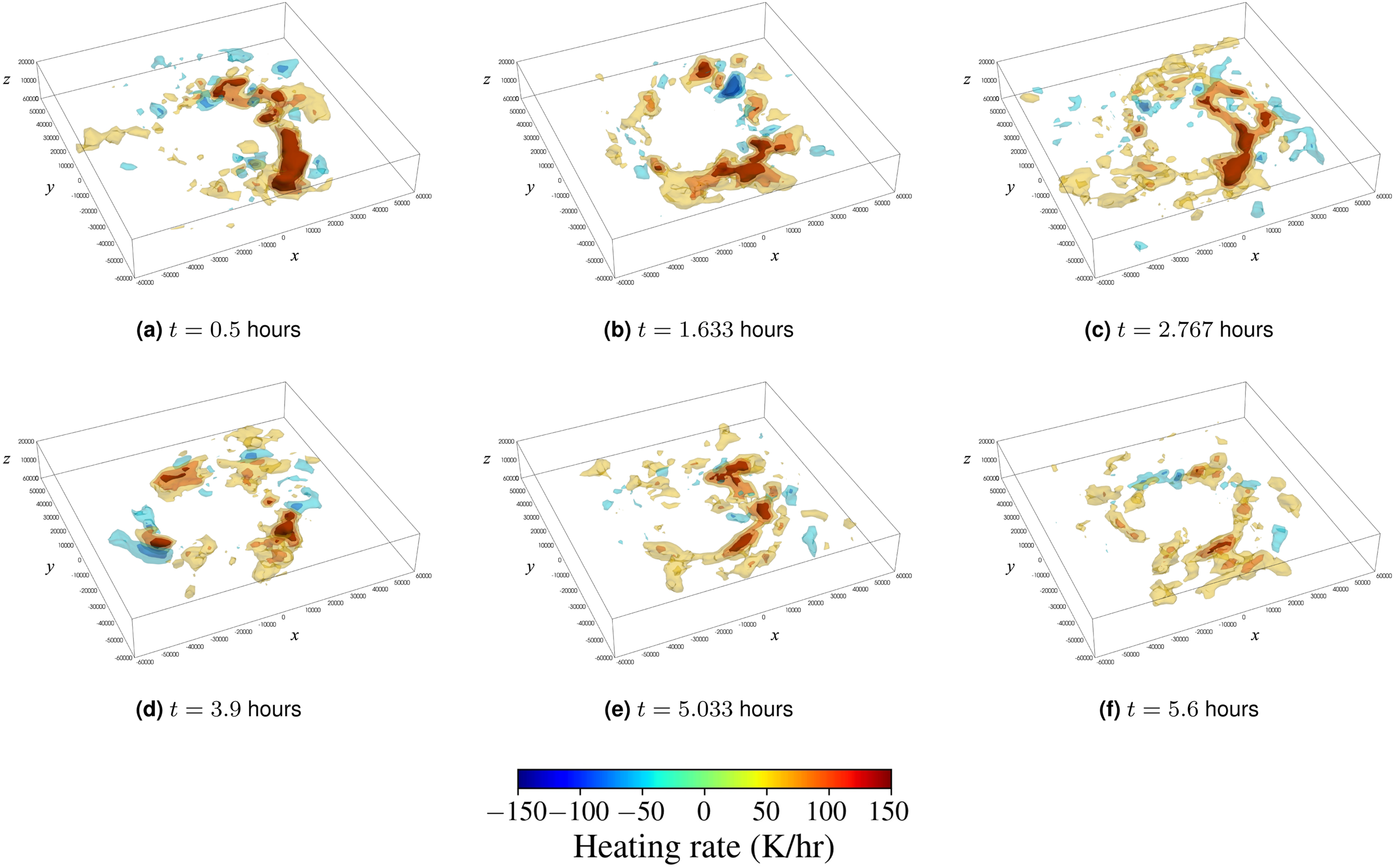
4.2. Computing system
The performance of the GPU code for tropical cyclone simulations is evaluated on the Delta system, which was ranked No. 100 in the November 2025 TOP 500 list (top500.org, 2025). Delta is an advanced computing resource maintained by the National Center for Supercomputing Applications (NCSA) at the University of Illinois, and supported by the National Science Foundation (NSF). While Delta provides access to NVIDIA A100 and H200 GPUs, we only use A100 GPUs for performance tests in this study. Delta features 100 A100 GPU nodes, and each node is equipped with 64 AMD EPYC 7763 (Milan) CPUs and 4 A100 GPUs. The compute nodes are connected via a low-latency high-bandwidth HPE/Cray Slingshot interconnect.
The parallel code is compiled using NVIDIA HPC compilers (version 22.5), which include OpenMPI compiler wrappers. All performance tests in this study are conducted using double-precision calculations.
5. Numerical results and performance analysis
5.1. Numerical results
Figures 4 and 5 show the velocity magnitude and potential temperature perturbation, respectively, on the y-z plane at the center of the domain. In the initial state at t = 0 hours, a single idealized vortex defined by equation (12) is located at the center near the surface, with no thermal perturbation. By injecting thermal energy into the dynamical system, a strong updraft develops in the eyewall and leads to asymmetric and complex vortex structures. Figure 6 shows the vortical structures in the eye and spiral bands of the tropical cyclone at t = 6 hours. Velocity magnitude at the middle y-z plane. (The domain is vertically stretched by a factor of 10 for visual purposes). Potential temperature perturbation at the middle y-z plane. (The domain is vertically stretched by a factor of 10 for visual purposes). Vortical structures in the eye and spiral bands of the tropical cyclone at t = 6 hours. (Vortices are visualized using the Q-criterion).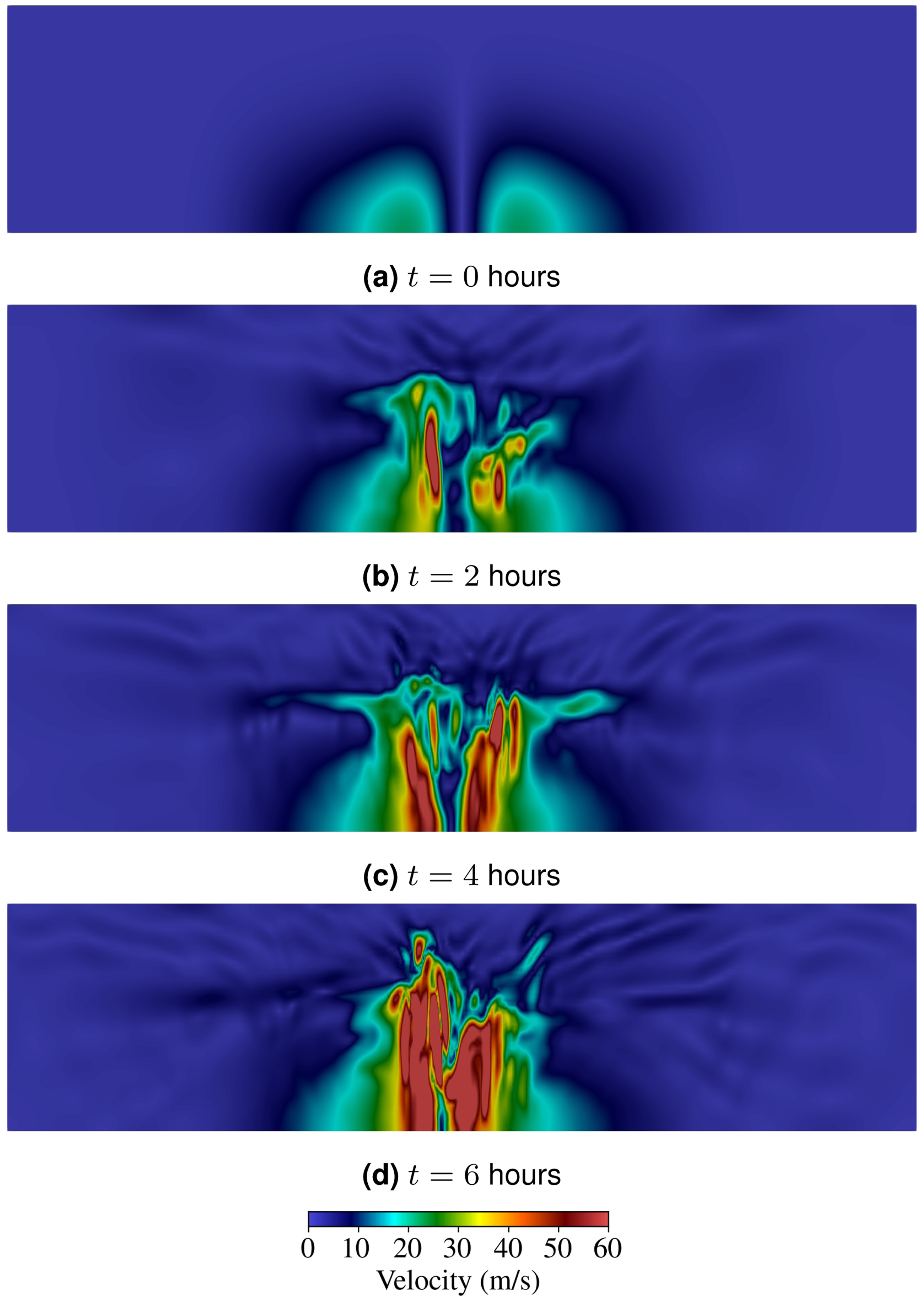
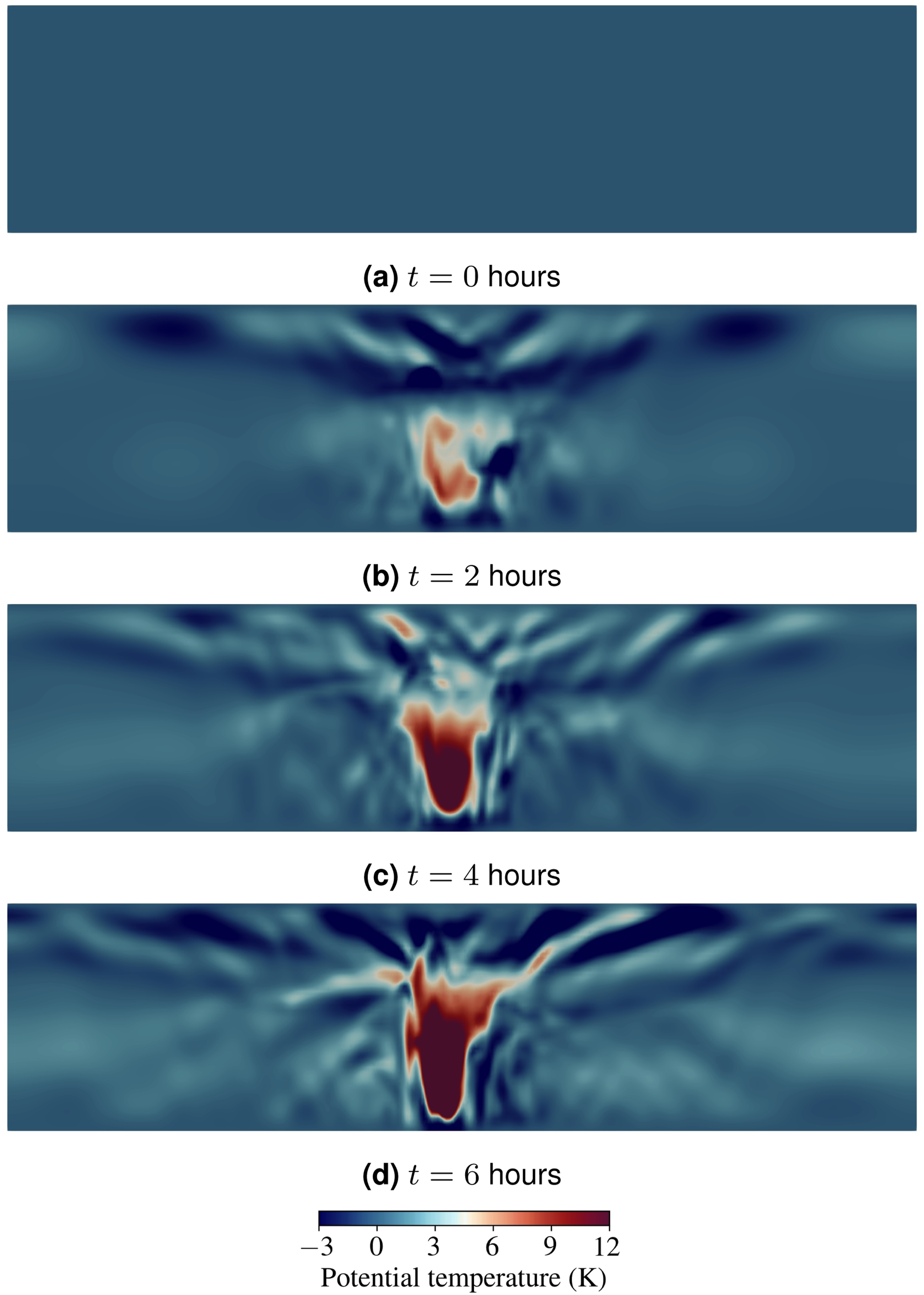
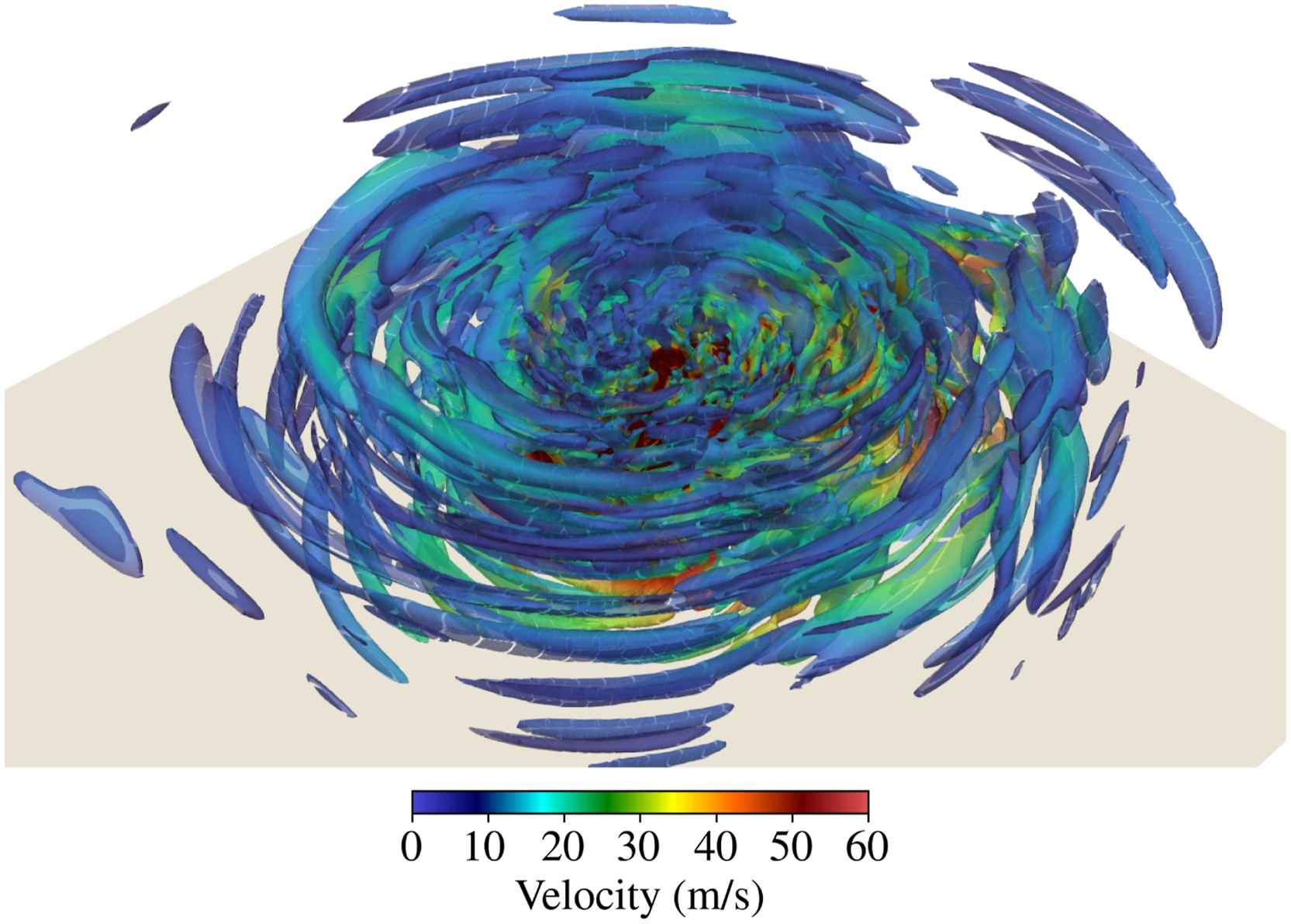
Figure 7 shows the velocity magnitude on the horizontal plane at various heights. Uneven temperature distribution near the surface significantly contributes to the asymmetric structure of the tropical cyclone, where the extent of asymmetry varies with height. Velocity magnitude at t = 6 hours in the horizontal region [−20, 20] × [−20, 20] km at various heights.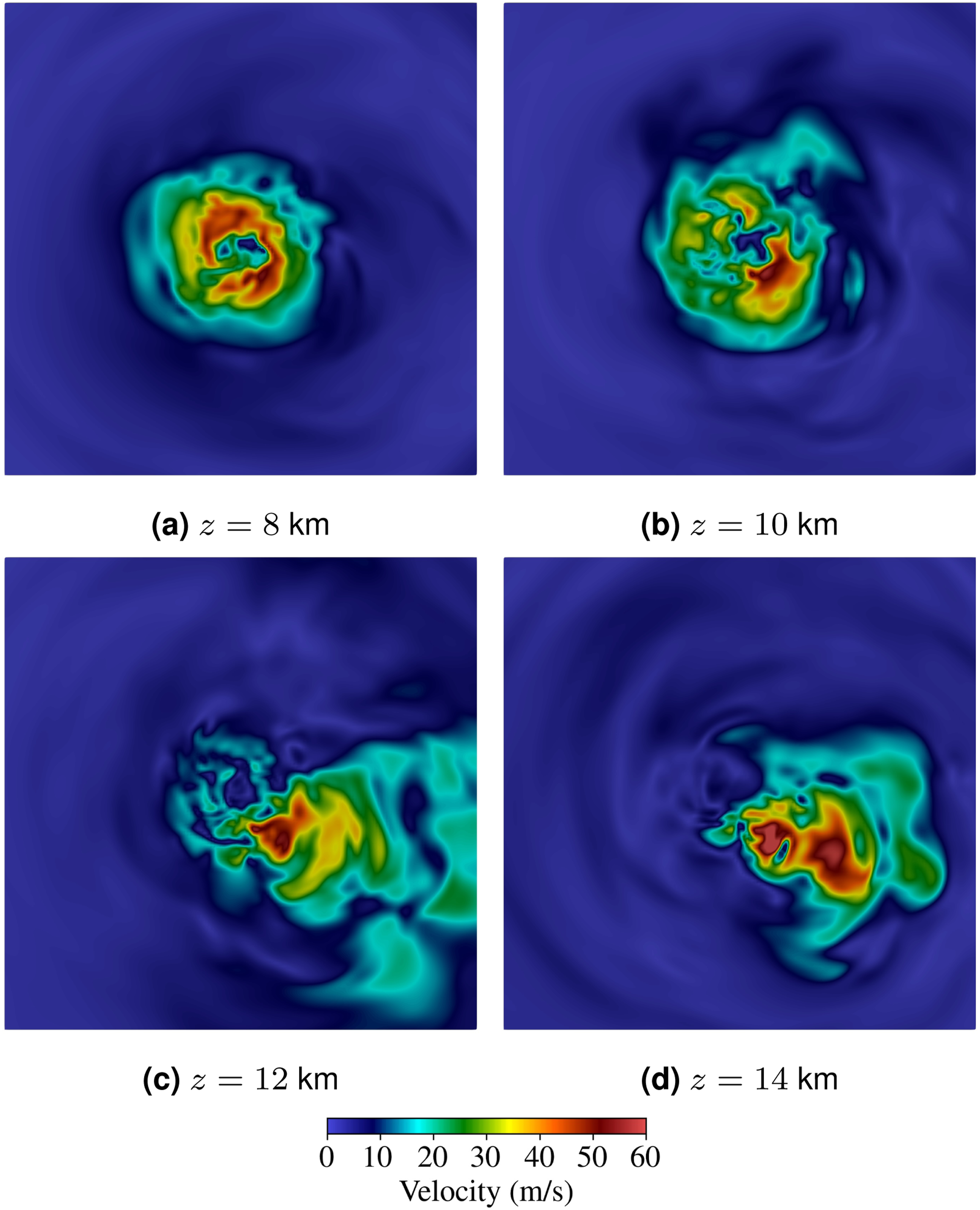
In order to quantify the magnitude of the vortex, we use the index of maximum tangential velocity and denote it as the RI velocity. In this work, the RI velocity is defined as the maximum of azimuthal-averaged tangential velocity as follows: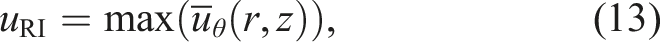
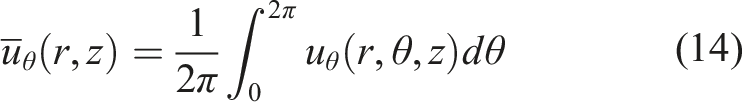

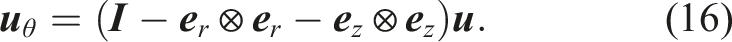
Here, 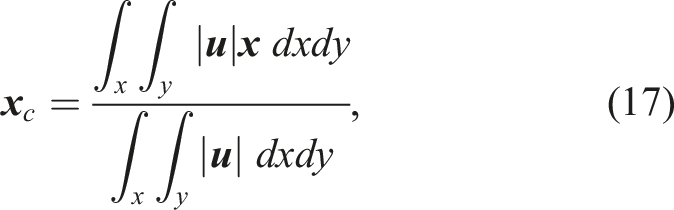
We propose a simplified calculation of azimuthally-averaged velocity, as given in equation (14). The azimuthally-averaged velocity is approximated as the arithmetic mean of points that fall within a narrow circular strip at each radial distance r
i
and height z
i
. This circular strip is defined as 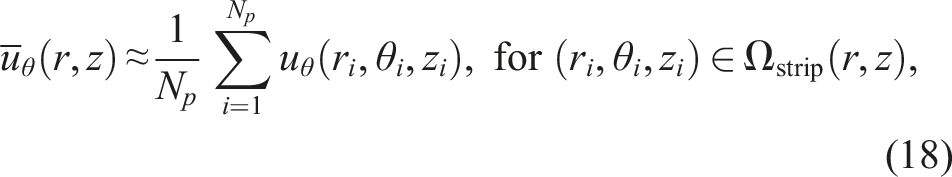
Figure 8 presents the time evolution of the RI velocity at various grid resolutions, together with the maximum horizontal velocity. The RI velocity is calculated using 50 equi-width strips to average the tangential velocity. At all grid resolutions, the RI velocity exhibits a significant increase exceeding 20 m/s from its initial state. This is higher than the typical RI threshold of 13 m/s, which indicates that the occurrence of the RI event is effectively captured. The RI velocity produces a similar curve across all the resolutions and converges when the grid resolution is finer than Δx = 2 km, whereas, the maximum horizontal velocity shows larger variance between the profiles of different resolutions. Maximum horizontal velocity (umax) and RI velocity (uRI) at resolutions 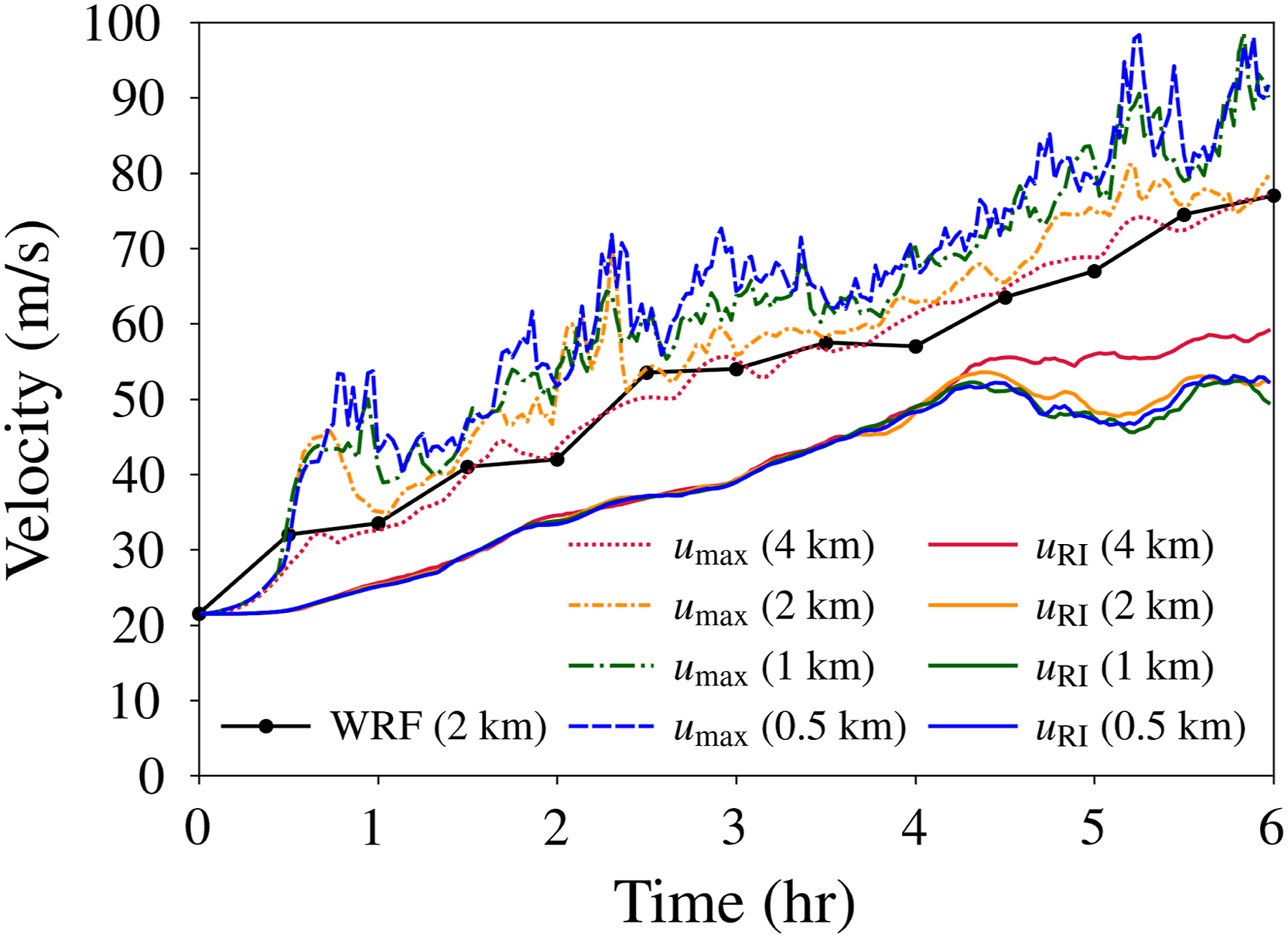
The maximum horizontal velocity results are compared with those obtained using the Weather Research and Forecasting (WRF) model with reduced eddy viscosity and a horizontal grid spacing of 2 km (Hasan et al., 2022). The resulting time series show good agreement between the two models, which validates the present simulation results.
5.2 Speedup and energy consumption
Comparison of total energy consumption during 100 time steps between CPUs (AMD EPYC 7763) and GPUs (NVIDIA A100).
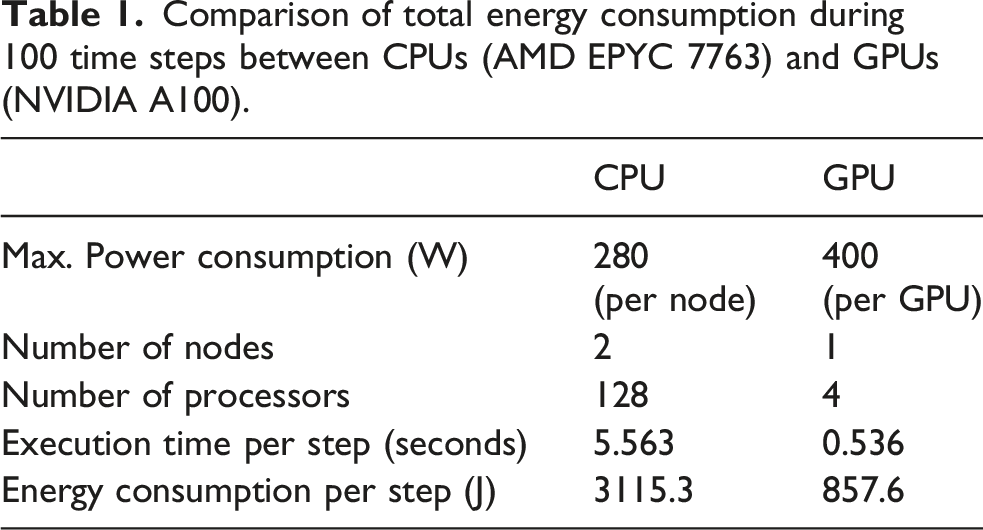
Execution times are measured for the time integration loop, i.e., after the simulation setup stage in Figure 1, over 100 time steps from the initial state. The CPU run employs the base code, originally optimized for CPUs. The GPU-accelerated code achieves approximately 10.4× speedup over the CPU code for the current configuration. This speedup is likely due to the higher FLOP capacity of the GPU and reduced communication overhead from the smaller number of processors.
The energy consumption per time step in the GPU simulation is approximately 3.63× lower than that of the CPU simulation. Although a single GPU consumes more power than a single CPU node, the total energy consumption is significantly reduced in the GPU run due to 10.4× speedup. This indicates that the GPU implementation offers greater energy efficiency compared to the purely CPU-based approach. To emphasize this point, Table 1 shows that 4 GPUs are 3.63× more efficient than 128 CPUs; therefore, we require 128/4 × 3.63 ≈ 116 CPUs to match a single GPU. To perform equivalent simulations that we performed on 256 GPUs would require nearly 30,000 CPUs (approximately 4.5× the CPU capacity of Delta).
5.3. Scalability
To evaluate the scalability of the GPU implementation, we measure the strong and weak scaling performance.
Figure 9 shows the strong scaling of the GPU implementation. The grid is composed of 160 × 160 × 24 fifth-order elements, which results in a total of 663,552,000 DOFs. Strong scalability tends to degrade as the number of GPUs increases. This can be attributed to increased GPU memory access latency, and its effects become relatively more significant as each rank holds a smaller portion of the problem. It is noteworthy that GPUs are the most performant when they are fully saturated. Strong scaling of the GPU implementation.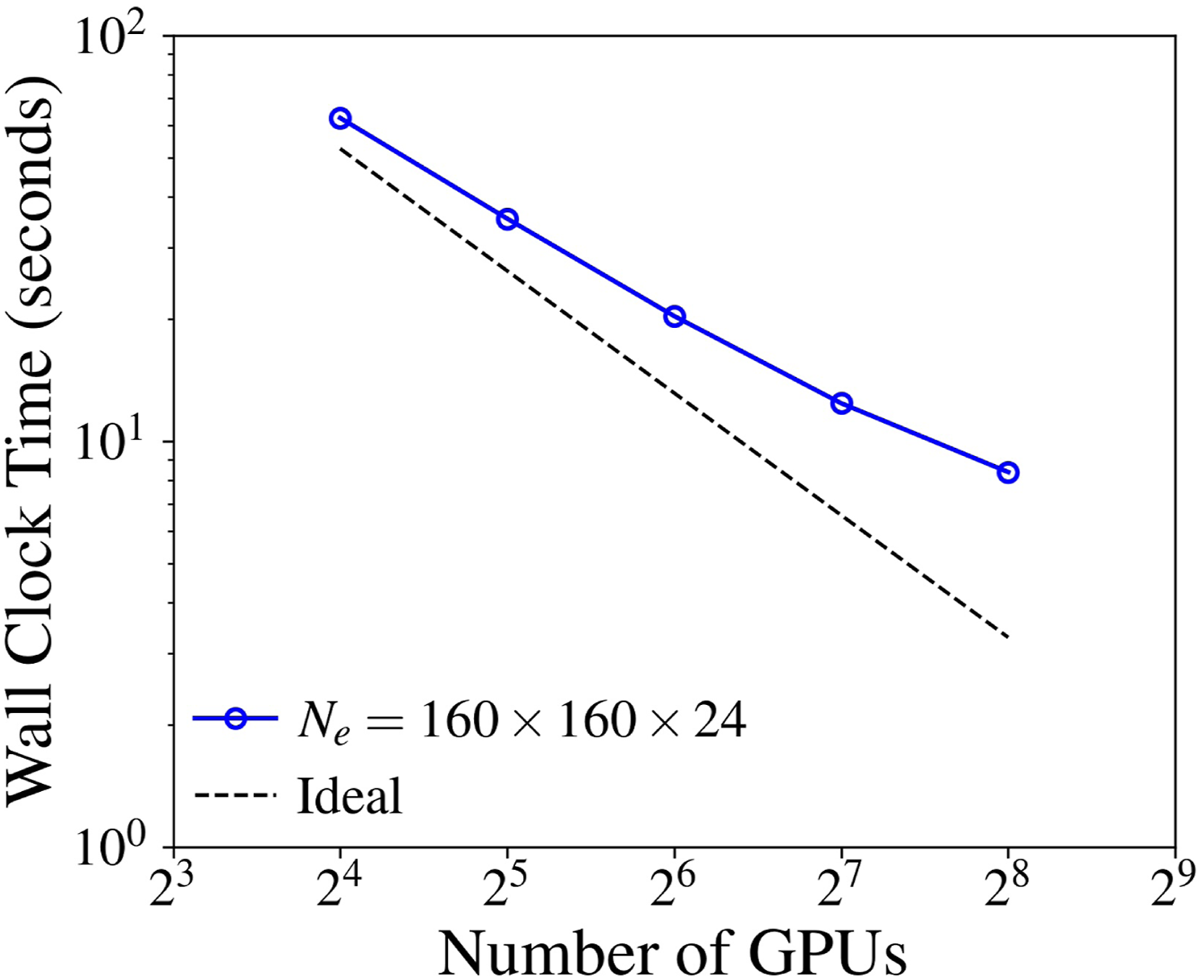
For weak scaling, the grid size is increased proportionally to the number of GPUs. To achieve this, the grid resolution is doubled while keeping the number of elements per GPU at 40 × 40 × 24 (41,472,000 DOFs), and the temporal resolution constant at Δt = 0.5 seconds (the largest problem shown has 5.31 billion DOFs). The order of basis function is N = 5 in all direction. Figure 10 shows the wall clock time per time step for the weak scaling test. The execution time converges as the number of GPUs increases. This trend arises because larger problem sizes require more GMRES iterations for the implicit solve. In this work, the maximum number of GMRES iterations is limited to 20. This result highlights the high performance and scalability of the code. Weak scaling of the GPU implementation.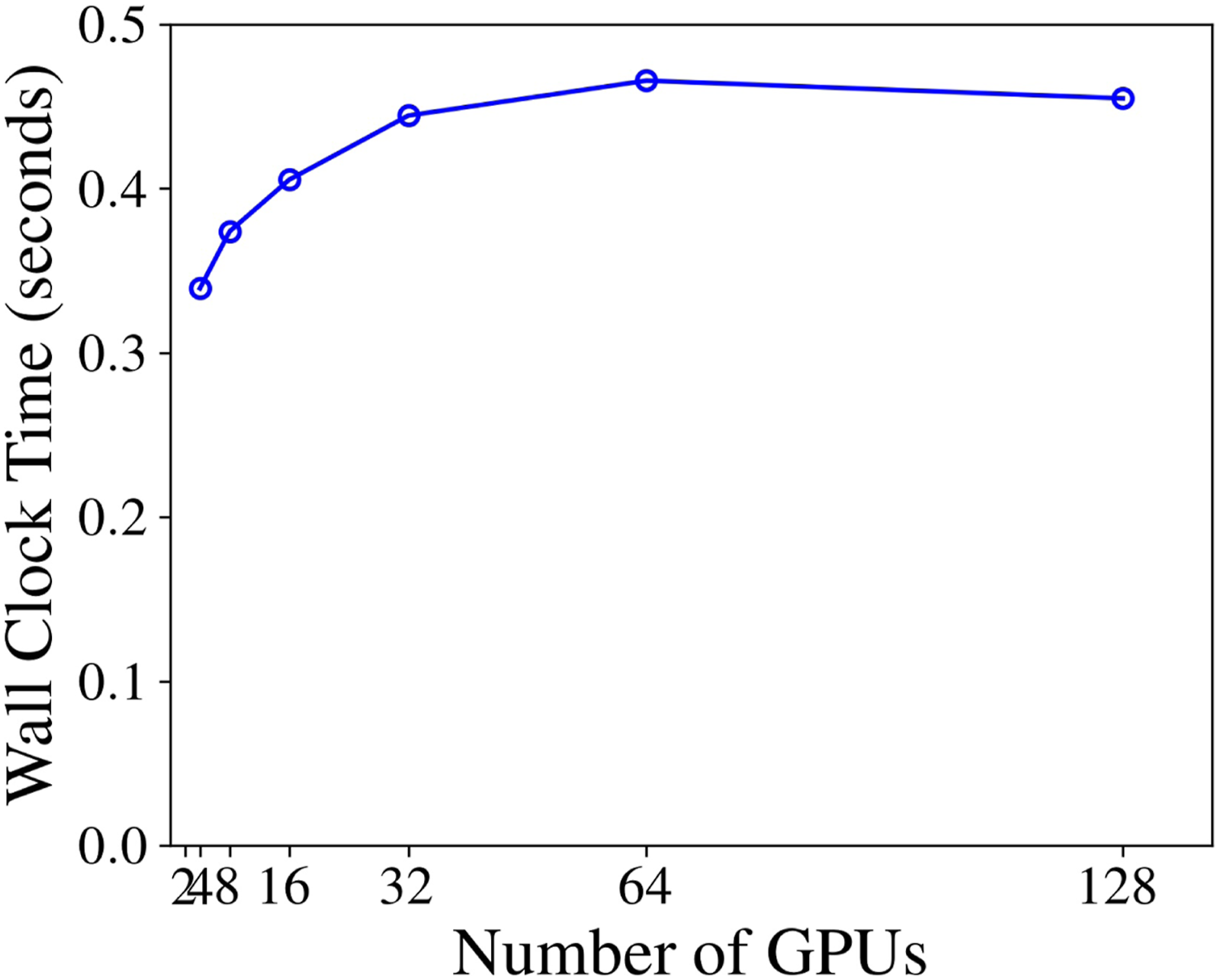
5.4. Kernel performance
We evaluate the performance of the main kernels to compute the RHS vector in Algorithm 1 using the roofline model (Williams et al., 2009). While both gradient and divergence operators are also invoked within the Laplacian subroutine in the code, our analysis focuses on these kernels within the RHS routine. The roofline model uses the metrics of double-precision floating point operations rates in GFLOPS/s, bandwidth in GB/s, and the arithmetic intensity (GFLOPS/GB). The measured peak performance and bandwidth of NVIDIA A100 GPUs in the test are 7329 GFLOPS/s and 1506 GB/s, respectively.
Figure 11 shows the GFLOP/s performance, arithmetic intensity, and roofline plots for various orders of the basis function, where the number of DOFs is held constant. The gradient and divergence kernels are computationally intensive and achieve higher performance as the order of the basis function increases. The measured performance for the gradient kernel ranges from 9.5% to 12.3% of the peak performance, while the divergence kernel achieves between 4.1% and 6.2%. In the gradient kernel presented in Algorithm 2, we fused the three innermost loops corresponding to the differentiation matrix multiplications in the ξ-, η-, and ζ-directions into a single loop. This optimization reduces global memory accesses and improves register reuse by reusing the q array for the state vector within the same thread. In contrast, the divergence kernel launches separate loops for each differentiation operation, which results in lower performance; however, it accounts for only a small fraction of the total runtime. GFLOP/s performance, arithmetic intensity, and roofline model for four main kernels in the RHS function.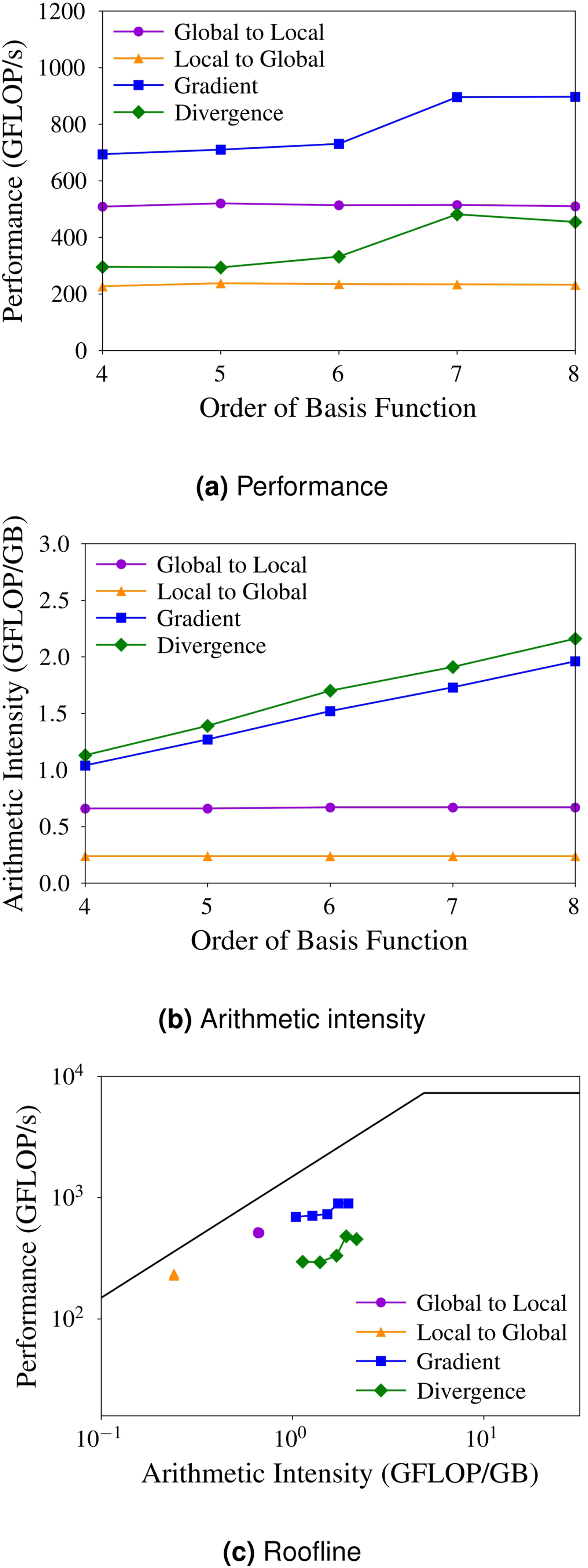
The higher-order basis functions result in greater arithmetic intensity and consequently higher performance, as shown in Figure 11. This implies the potential of high-order methods to better exploit GPUs capabilities. In contrast, the performance of the global-to-local and local-to-global kernels remain independent of the basis function order, 7.1% and 3.2% of the peak performance, respectively, as they simply loop over the grid points and their associated DOFs.
6. Conclusions
In this work, we ported the nonhydrostatic atmospheric model xNUMA to GPUs using the OpenACC programming model. This approach facilitates simple maintenance of the code. The entire time-integration process, including implicit and explicit steps, is performed on the GPU. A matrix-free implementation of the implicit solution is well-suited for GPU computations.
The model successfully simulates realistic tropical cyclones on GPUs and captures the RI process. The simplified calculation of azimuthally-averaged velocity yields converged results of RI across various horizontal grid spacings.
The GPU-accelerated code yields an energy-efficient simulation, achieving a 3.63× improvement over the CPU version. The GPU implementation demonstrates both strong and weak scaling, as well as efficient kernel performance on NVIDIA A100 GPUs. We expect that this research will help accelerate high-fidelity simulations for numerical weather prediction.
Our future work includes the following: • Using the initial state obtained from observational data to produce more realistic tropical cyclones. • Adding a precipitation microphysics model to simulate moist dynamics of tropical cyclones. • Accelerating the multiscale modeling framework (Kang et al., 2025) using GPUs. • Developing an efficient and GPU-portable preconditioner for the implicit solver.
Footnotes
Acknowledgements
The authors gratefully acknowledge the help and support from Dave Norton (NVIDIA) for helping us get started on this path. This work was supported by the Office of Naval Research under Grant No. N0001419WX00721. F. X. Giraldo was also supported by the National Science Foundation under grant AGS-1835881. This work was performed when Soonpil Kang held a National Academy of Sciences’ National Research Council Fellowship at the Naval Postgraduate School. Part of Soonpil Kang’s work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344. LLNL-JRNL-2004409. This work used Delta at the National Center for Supercomputing Applications (NCSA) through allocation MTH240030 from the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, which is supported by National Science Foundation (NSF).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: National Centre for Supercomputing Applications; MTH240030; Lawrence Livermore National Laboratory; DE-AC52-07NA27344; National Science Foundation; AGS-1835881; Office of Naval Research; N0001419WX00721.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.