
Abstract
Partial least squares path modeling (PLS) was developed in the 1960s and 1970s as a method for predictive modeling. In the succeeding years, applied disciplines, including organizational and management research, have developed beliefs about the capabilities of PLS and its suitability for different applications. On close examination, some of these beliefs prove to be unfounded and to bear little correspondence to the actual capabilities of PLS. In this article, we critically examine several of these commonly held beliefs. We describe their origins, and, using simple examples, we demonstrate that many of these beliefs are not true. We conclude that the method is widely misunderstood, and our results cast strong doubts on its effectiveness for building and testing theory in organizational research.
Keywords
Partial least squares path modeling (PLS) was developed in the 1960s and 1970s by Herman Wold (cf. Jöreskog & Wold, 1982) as an alternative to LISREL. However, Dijkstra (1983) soon proved that if PLS is used as an estimator for structural equation models (SEMs), the parameter estimates are both inconsistent and biased, leading to abandonment of further development. Nevertheless, PLS experienced a renaissance in more applied disciplines with proponents such as Fornell and Bookstein (1982) and later Chin (1998) and Hulland (1999), and recent publications in management journals indicate that its use is increasing (Antonakis, Bendahan, Jacquart, & Lalive, 2010; Echambadi, Campbell, & Agarwal, 2006; Gruber, Heinemann, Brettel, & Hungeling, 2010; Hair, Sarstedt, Pieper, & Ringle, 2012; Peng & Lai, 2012; Reinartz, Haenlein, & Henseler, 2009; Sosik, Kahai, & Piovoso, 2009). Following Atinc, Simmering, and Kroll (2011) we reviewed four leading management journals, Academy of Management Journal, Journal of Applied Psychology, Journal of Management, and Strategic Management Journal, and found 27 studies that used PLS, which are listed in Table 1; a third of these studies were published in the past 5 years, supporting the argument that the use of PLS is becoming more common.
Use of PLS in Selected Management Journals Ordered by Year (Academy of Management Journal, Journal of Applied Psychology, Journal of Management, Strategic Management Journal).
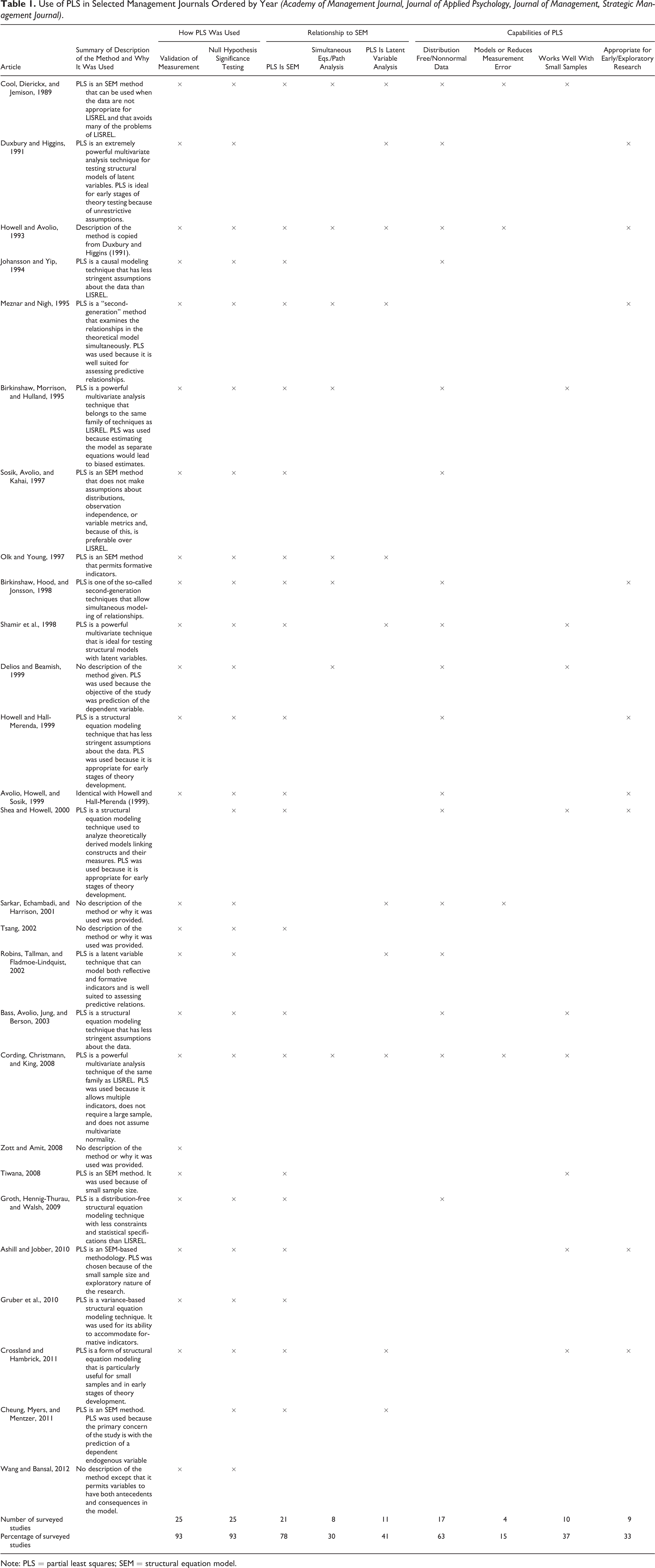
Note: PLS = partial least squares; SEM = structural equation model.
In contrast to its popularity in management research, PLS has been largely ignored in research methods journals. For example, there are no articles in Organizational Research Methods addressing the PLS method. In our review of other top research methods journals, we found one article about PLS (Henseler & Chin, 2010) published in Structural Equation Modeling and one article (Dijkstra, 1983) in Journal of Econometrics. No articles about PLS were found in Psychological Methods, Psychological Bulletin, or Econometrica.
The absence of articles on PLS in the research methods literature has led researchers in disciplines such as strategic management (Hulland, 1999), operations management (Peng & Lai, 2012), marketing (Hair, Ringle, & Sarstedt, 2011), group research (Sosik et al., 2009), and information systems (Gefen, Rigdon, & Straub, 2011) to develop their own guidelines on how to perform and evaluate PLS-based studies. We argue that most of these articles present an overly positive picture of the method, with some aggressively promoting the method as a “silver bullet” (Hair et al., 2011), a “success story” (Vinzi, Chin, Henseler, & Wang, 2010), or as a method with “genuine advantages” (Henseler & Sarstedt, 2013). However, many of these articles are not based on statistical theory or simulation studies but are based on beliefs about the method that earlier, similar articles have presented, leading to the perpetuation of commonly held beliefs that have not been demonstrated, that is, methodological myths and urban legends (Vandenberg, 2006).
This article addresses some of these beliefs and shows that they are incorrect or correct only with strong qualifications. Given the growing popularity of PLS-based studies in management research, this is a timely and important topic.
Overview of the PLS Method
As originally presented, the statistical model of PLS is identical to the original LISREL model (Jöreskog & Wold, 1982). This model is given in Equations 1 and 2, where 

The model is estimated by replacing the latent variables 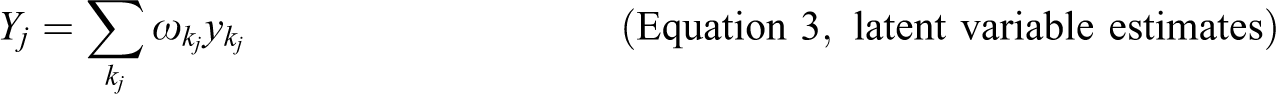
At this level of abstraction, PLS estimation is identical to estimation with OLS regression on summed scales or factor scores. PLS differs from these methods in that the indicator weights
During the inner estimation step, new latent variable score approximations are calculated as weighted sums of “adjacent” latent variable score approximations, that is, of latent variables related to the focal variable by regression relationships. During the outer estimation step, new indicator weights

In Mode B estimation,
2
the approximations 
The new indicator weights are then used to estimate new latent variable score approximations for the following iteration of inner estimation. The basic PLS algorithm is shown in Table 2. The only difference between PLS and OLS is the different method of indicator weighting.
The Basic PLS Algorithm (Lohmöller, 1989, p. 29).

Note: LV = latent variable; PLS = partial least squares.
aOther weighting schemes are path and factor weighting. However, the centroid weighting scheme is most frequently used and is the default method in much PLS software.
Statistical Myths and Urban Legends About the PLS method
We now discuss six beliefs about PLS that emerged from our review of the articles in Table 1 and the numerous articles providing guidelines on how to use the method and assess the results. Each subsection starts by describing the myth and reviewing its origins and supporting evidence. We use the simple two-construct model shown in Figure 1, along with simulated data sets, to demonstrate that many features ascribed to the PLS algorithm do not hold even in a simple example. The simple example was chosen for the sake of illustration and the ability to derive results analytically. However, we emphasize that our following arguments make no assumptions about the form or complexity of the model.
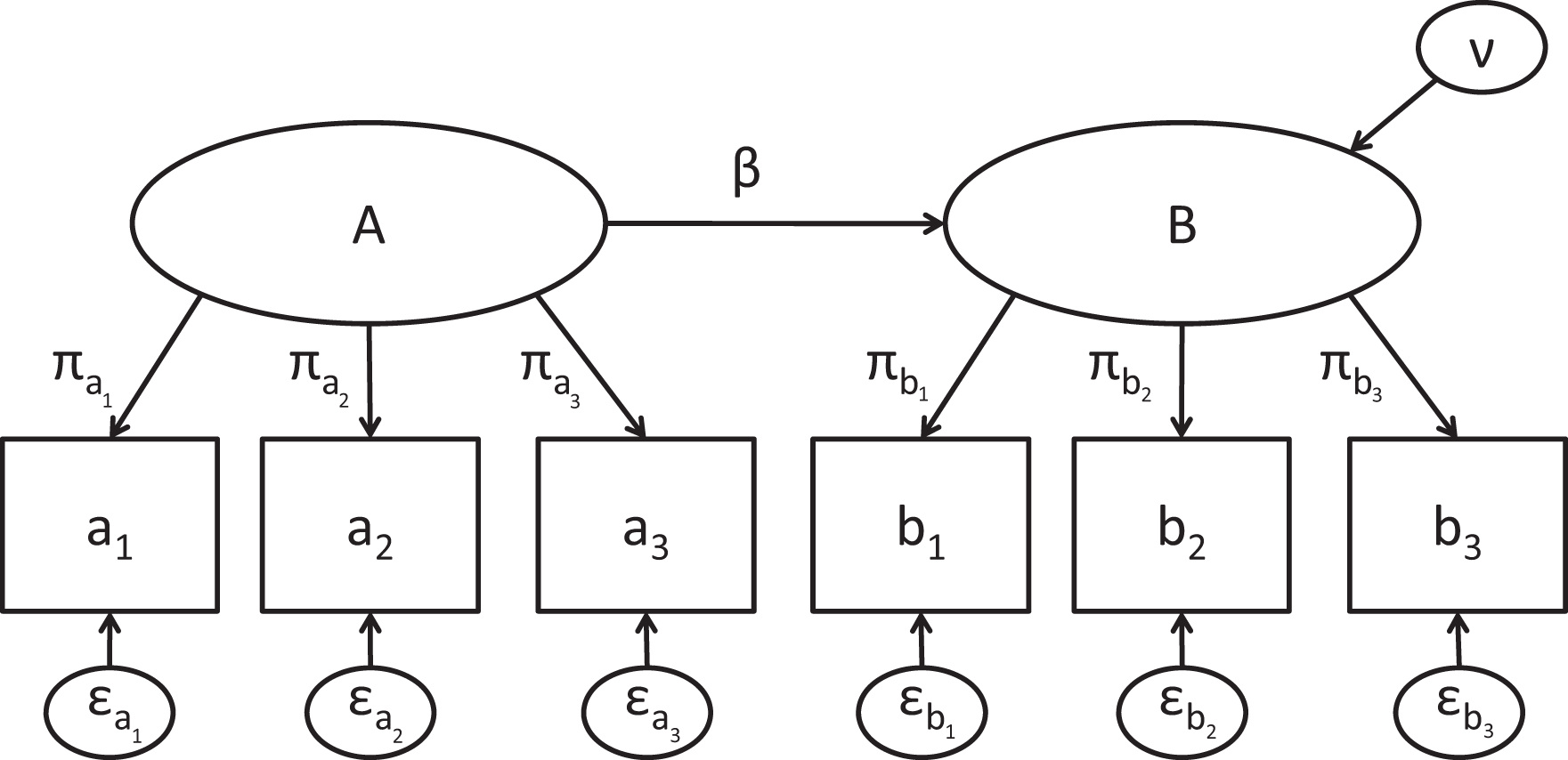
Example model with two constructs.
Myth 1: PLS Has Advantages Over Traditional Methods Because It Is an SEM Estimator
Almost every article in Table 1 and all of the guidelines on PLS present it as an SEM method, with some even emphasizing its differences from OLS on summed scales or factor scores (e.g., Gefen et al., 2011). This characterization cannot be found in the original articles on PLS (e.g., Wold, 1985b). Rather, it is attributable to a widely cited article by Fornell and Bookstein (1982). Nevertheless, even the original characterization as a latent variable modeling technique is misleading. In contrast to claims by many studies in Table 1, PLS does not estimate path models with latent variables, but with composites, and instead of using path analysis with simultaneous equations, PLS uses separate OLS regressions. Thus, it is conceptually closer to OLS regressions on summed scales or factor scores than to covariance structure analysis.
Although PLS can technically be argued to be an SEM estimator, so can OLS regression with summed scales or factor scores: Both fit the definition of the term estimator (Lehmann & Casella, 1998, p. 4) because they provide some estimates of model parameters. This, however, does not mean that PLS or OLS are good estimators in the sense of being consistent and unbiased. An estimator is consistent if its estimates converge to the population value as the sample size increases. It is unbiased if the mean of repeated estimates using samples drawn from the same population approaches the population value as the number of samples increases. PLS has been shown to have neither of these properties. In fact, Wold (e.g., 1985b) is quite clear that PLS estimates are inconsistent, Dijkstra (1983) presented a proof of this, and more recent PLS literature (e.g., Chin, 1998) also readily acknowledges that PLS estimates are biased.
In addition to providing inconsistent and biased estimates, the lack of an overidentification test is another disadvantage of PLS over SEM. Paths between variables in a simultaneous equations model can be constrained to zero. Such constraints make the model overidentified and allow testing whether the constrained model fits the data. Thus, this overidentification test can be used to rule out endogeneity (unmodeled dependencies) that would otherwise cause inconsistency of estimates (Antonakis et al., 2010). Overidentification tests also allow the researcher to rule out alternative causes, which is a key step in testing a model causally (Antonakis et al., 2010; Bollen, 1989, chap. 3). Because no overidentification test is available for PLS, PLS cannot test a model causally, but is limited to estimating statistical associations.
Despite the evidence, many of the reviewed articles argue that PLS supports causal modeling (Birkinshaw, Hood, & Jonsson, 1998; Cool, Dierickx, & Jemison, 1989; Delios & Beamish, 1999; Johansson & Yip, 1994; Shea & Howell, 2000), and some researchers have the misconception that using PLS avoids inconsistent and biased parameter estimates. For example, Birkinshaw, Morrison, and Hulland (1995) write that “to avoid obtaining biased and inconsistent parameter estimates for these equations, the [hypothesized model] must be analyzed using a multivariate estimation technique such as two-stage least squares or PLS” (p. 647). However, of these two estimators, only two-stage least squares is consistent.
In summary, although the argument that PLS is an SEM estimator is technically true, it is as correct to state that OLS regression is an SEM estimator. The lack of unbiasedness and consistency means that both methods will provide erroneous estimates. This, and the lack of an overidentification test, means that any potential advantage that might be obtained by specifying a research problem as an SEM model is lost (Antonakis et al., 2010; McDonald, 1996). The claim that PLS provides advantages because it is an SEM method is a methodological myth, and the current practice of labeling PLS as an SEM method, although correct in a strict technical sense, is very misleading.
Myth 2: PLS Reduces the Effect of Measurement Error
Some of the articles in Table 1 and some of the reviewed guidelines argue that PLS reduces the effects of measurement errors. Although most of these articles fail to explain how this is accomplished, any such advantage over OLS must be a result of the indicator weighting in PLS, because this is the only difference between PLS and OLS. As with most other myths that we discuss, this myth also seems to originate from the work by Fornell and Bookstein (1982), who state, without providing justification, that PLS separates irrelevant variance from the model. This unproven notion has been replaced more recently by the idea that PLS increases the reliability of the composites by using indicator weighting to minimize error (e.g., Gefen et al., 2011).
We first illustrate the effect of measurement error for Mode A weighting. Consider indicator 
In the two-construct example, under the default PLS assumption of standardized latent variables and indicators, the correlation between two indicators is the sum of the correlation caused by common antecedents and error correlation. Using covariance algebra one can write the correlation between indicators as follows:
Substituting Equation 7 into Equation 6 and rearranging the terms yields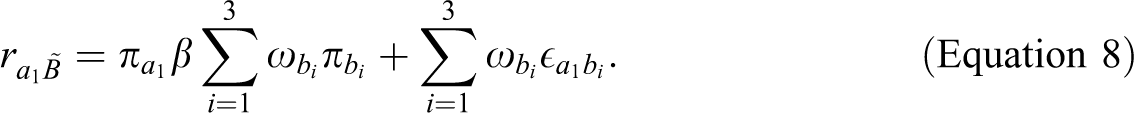
This equation shows that although the indicator weighting system takes the indicator reliability into account, it is highly sensitive to the correlated errors
With PLS Mode B, the indicator weights are defined based on regressions of the latent variable estimate on their indicators. Hence, they are also affected by the correlations between indicators of the same construct. In this regression, a set of highly reliable indicators is highly collinear, resulting in suppression effects and instability of the regression coefficients and the resulting indicator weights.
To illustrate these effects numerically for our two-construct example model, we simulated data for two conditions, one with no effect between constructs (
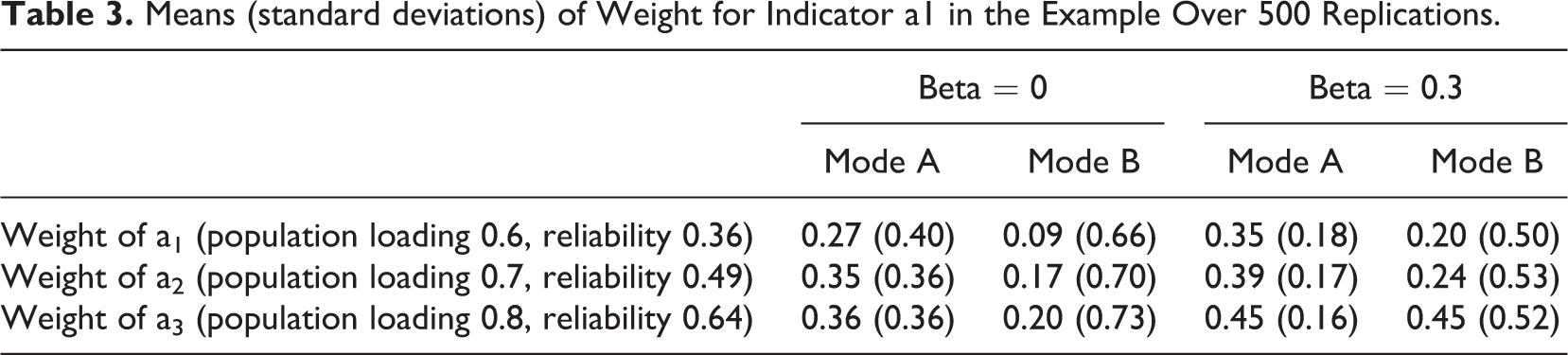
Figure 2 shows that for both PLS modes, summed scales provide better (more reliable) construct scores, and PLS Mode B performs substantially worse than PLS Mode A. The reason for this lower reliability can be seen in Table 3, which shows that, although on average more reliable indicators are weighted more highly, the effect of random correlations causes large variance in the weights, so that any individual replication is very unlikely to have weights even close to an optimal combination. In addition, the collinearity and suppression effects for Mode B estimation are seen clearly in the higher standard deviation of the weights. The lower means of Mode B weights are a result of occasional negative weights caused by collinearity.
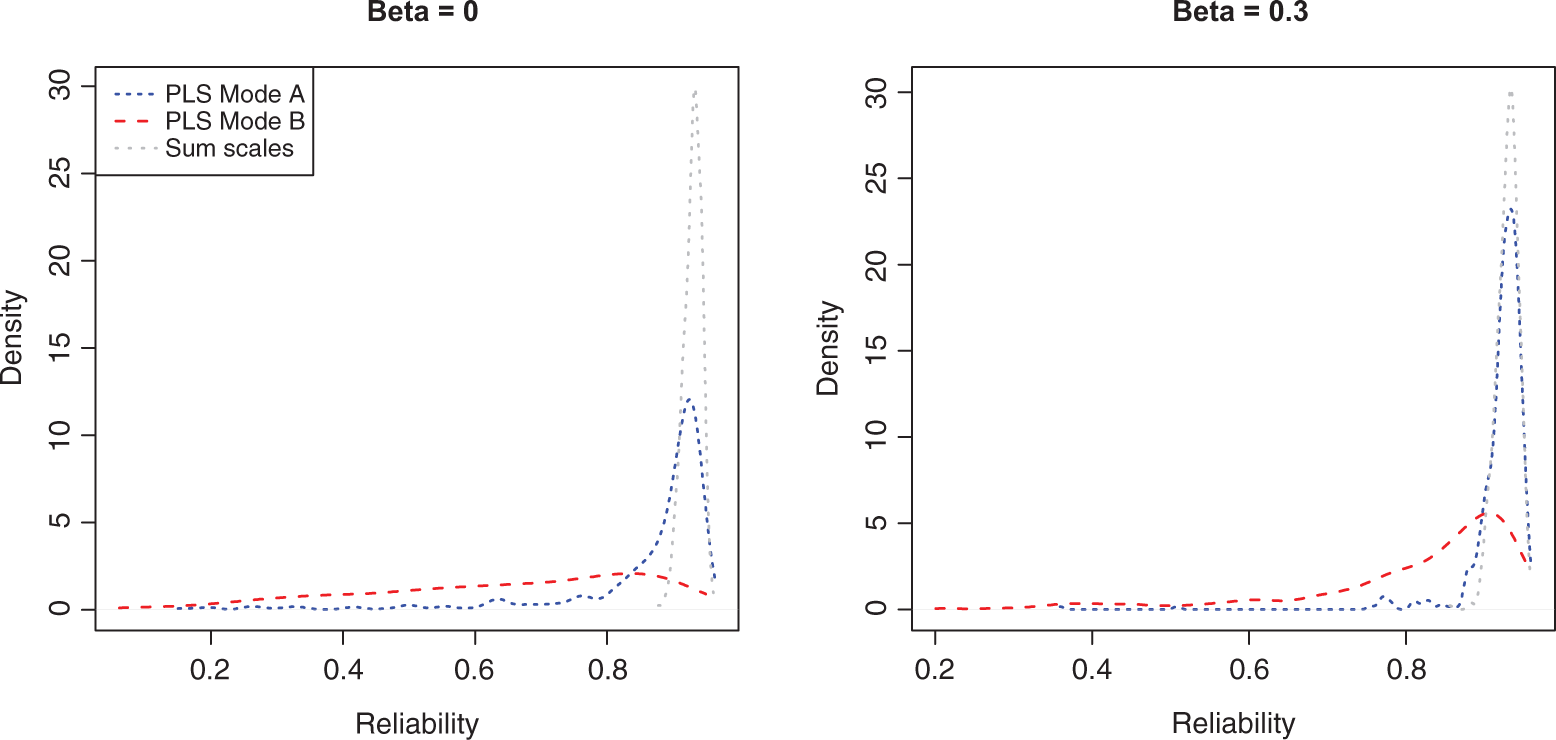
Distribution of reliability for partial least squares (PLS) Mode A, PLS Mode B, and summed scales in the two-construct model over 500 replications.
Means (standard deviations) of Weight for Indicator a1 in the Example Over 500 Replications.
We now show how the weighting affects the regression estimates between the latent variables. The standardized path estimate (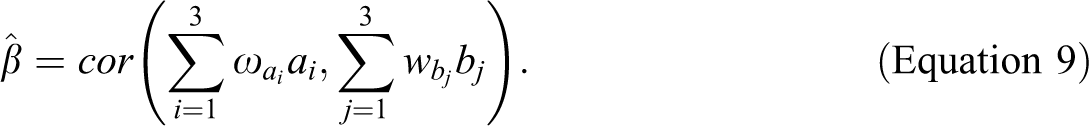
In PLS, the weights are chosen so that the construct estimates are standardized. Thus, the correlation is equal to the covariance, and one can write the covariance of sums as
Substituting Equation 7 into this and rearranging the terms yields the following: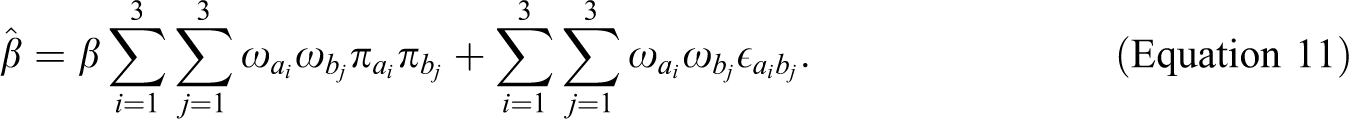
Equation 11 shows that not only the indicator weights but also the path coefficient estimates are affected by the correlated errors. The bias caused by unmodeled correlations is well known (Zimmerman & Williams, 1977), but the joint effect that causes this bias to be amplified by PLS has not been documented in prior literature. This is illustrated in Figure 3, which shows that the parameter estimates obtained from PLS are strongly biased away from zero, whereas no such bias exists when the model is estimated with regression on summed scales or SEM.
3
This effect is especially pronounced when
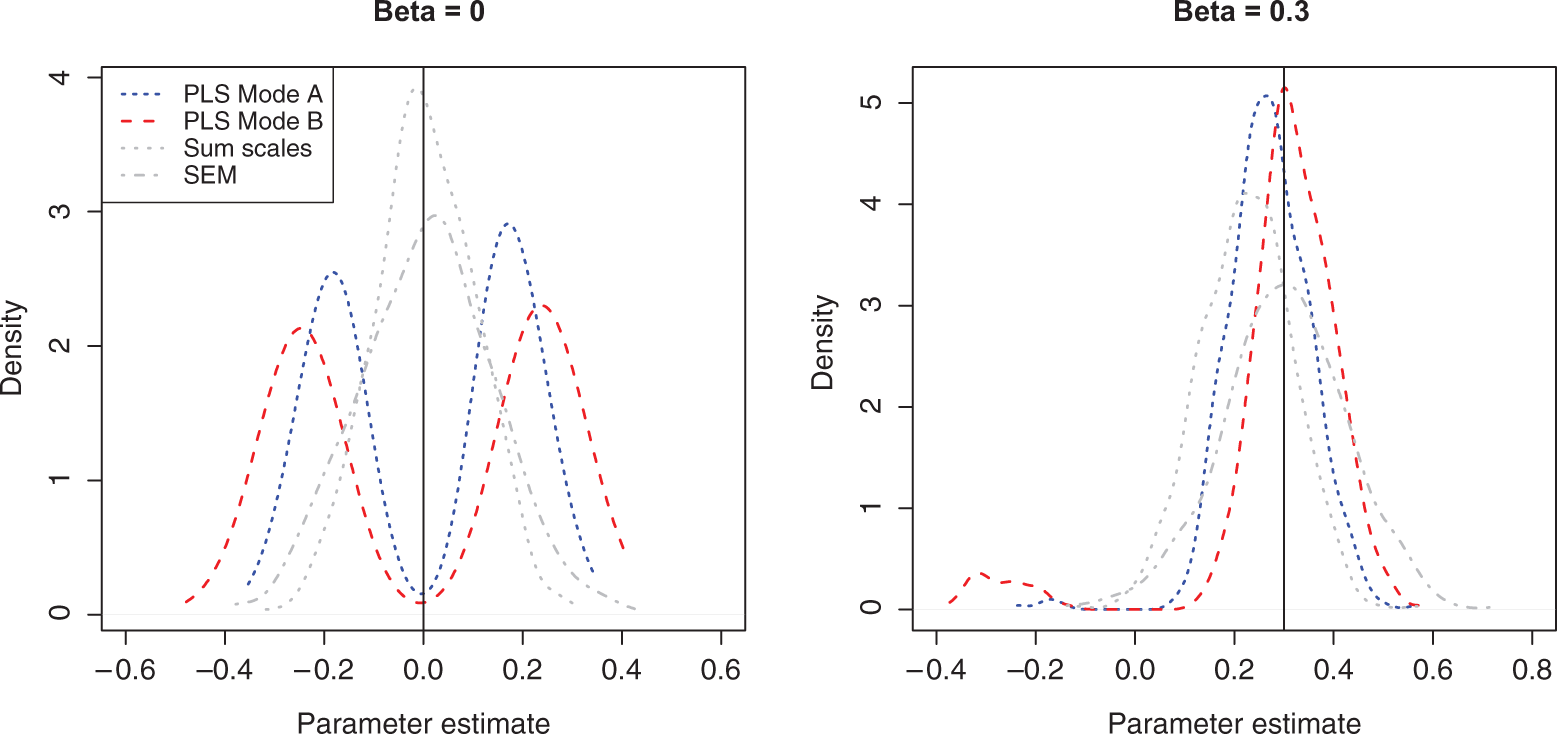
Distribution of parameter estimates for partial least squares (PLS) Mode A, PLS Mode B, summed scales, and structural equation modeling (SEM) in the two-construct model, 500 replications.
In contrast to the unsubstantiated claims that PLS reduces the effect of measurement error, we have shown that the indicator weights are strongly affected by error correlations and even the small chance correlations caused by sampling variation are sufficient to affect the weights, resulting in lower reliability composites than even simple summed scales.
The options available for reducing the effect of measurement error with composite variables are limited because any linear composite of indicators that contain error will also be contaminated with error. Random error in the composites causes attenuation of bivariate correlations resulting in bias in the regression estimates. Although it is possible to apply a correction and then use the disattenuated correlations in regression analysis, ML estimation of SEM models has superseded this approach (Cohen, Cohen, West, & Aiken, 2003, pp. 38-39, 473-474).
Myth 3: PLS Can Be Used to Validate Measurement Models
Most of the studies listed in Table 1 use PLS to validate measurement models, and many (e.g., Shamir, Zakay, Breinin, & Popper, 1998; Tiwana, 2008) even assume that PLS can be used to conduct a confirmatory factor analysis. Many researchers seem to also assume that statistics that are typically presented with the PLS results constitute a de facto model test: 7 of the articles listed in Table 1 use the terms model test, testing the model, or similar terminology. Again, these are beliefs that do not originate from Wold, who did not discuss model testing, validation, or fit, but rather used the term test for predictive relevance (without however clearly defining this concept).
The model assessment criteria currently used can be attributed to Fornell and Bookstein (1982), who presented a set of heuristics for assessing PLS models. The most commonly used are the composite reliability (CR) metric and the average variance extracted (AVE) statistic, which are both more or less directly based on factor loading estimates. In addition to these, a family of goodness-of-fit (GoF) indices exists that are calculated on the basis of the endogenous variable R2 values and indicator communalities (cf. Henseler & Sarstedt, 2013). There are also various standardized root mean squares of different model residuals (SRMR) that Lohmöller (1989) proposed to be used for model assessment, but we are not aware of any applications of these criteria.
Because the use of GoF indices was recently comprehensively and convincingly debunked by Henseler and Sarstedt (2013) and because of the obscurity of the SRMR indices, we focus on the AVE and CR statistics, which are commonly used in the studies that we reviewed. Aguirre-Urreta, Marakas, and Ellis (in press) showed that the CR indices are severely biased estimate of reliability of the composites. Moreover, the same issues apply also to the AVE statistic. First, their definitions do not include information about the indicator weights (Fornell & Larcker, 1981, pp. 45-46) but assume unweighted composites, which is intentionally violated in a PLS analysis. Second, they are based on factor loadings, but PLS does not calculate factor loadings, but composite loadings (McDonald, 1996, p. 248). These are always higher than factor loadings as they also explain part of the error variance, whereas a factor analysis explains only the common variance between the indicators. 4 Consequently, the CR and AVE statistics are also overestimated.
To show the effect of model misspecifications on the AVE, CR, (relative) GoF, and (indicator) SRMR statistics and to demonstrate that these heuristics are unable to reliably identify when the model does not fit data, we calculated these model quality metrics for our two-construct model with 500 replications (Table 4). The estimated model is always our two-construct example, and we vary the population model to make the estimated model misspecified (“Misspecified A, B, C” in Table 4). The last column in Table 4 shows the percentage of models in each condition that a researcher would accept as valid, based on commonly used cutoff values for the different heuristics. 5 This percentage should be high for the true model and low for the misspecified models. However, results show that this number is high for the composite reliability heuristic across all conditions; researchers are likely to accept all misspecified models as valid. This number is low for the SRMR heuristic across all conditions; researchers are likely to also reject the true model as invalid. The situation is even worse for the rGoF heuristic. By this heuristic, researchers are likely to reject only the true model and are likely to accept only the misspecified models. Finally, the two AVE-based heuristics appear to detect only the third misspecified model, making them unreliable indicators of misspecified models.
Model Fit Indices for the Example Model Estimated With Data From Four Different Population Models.
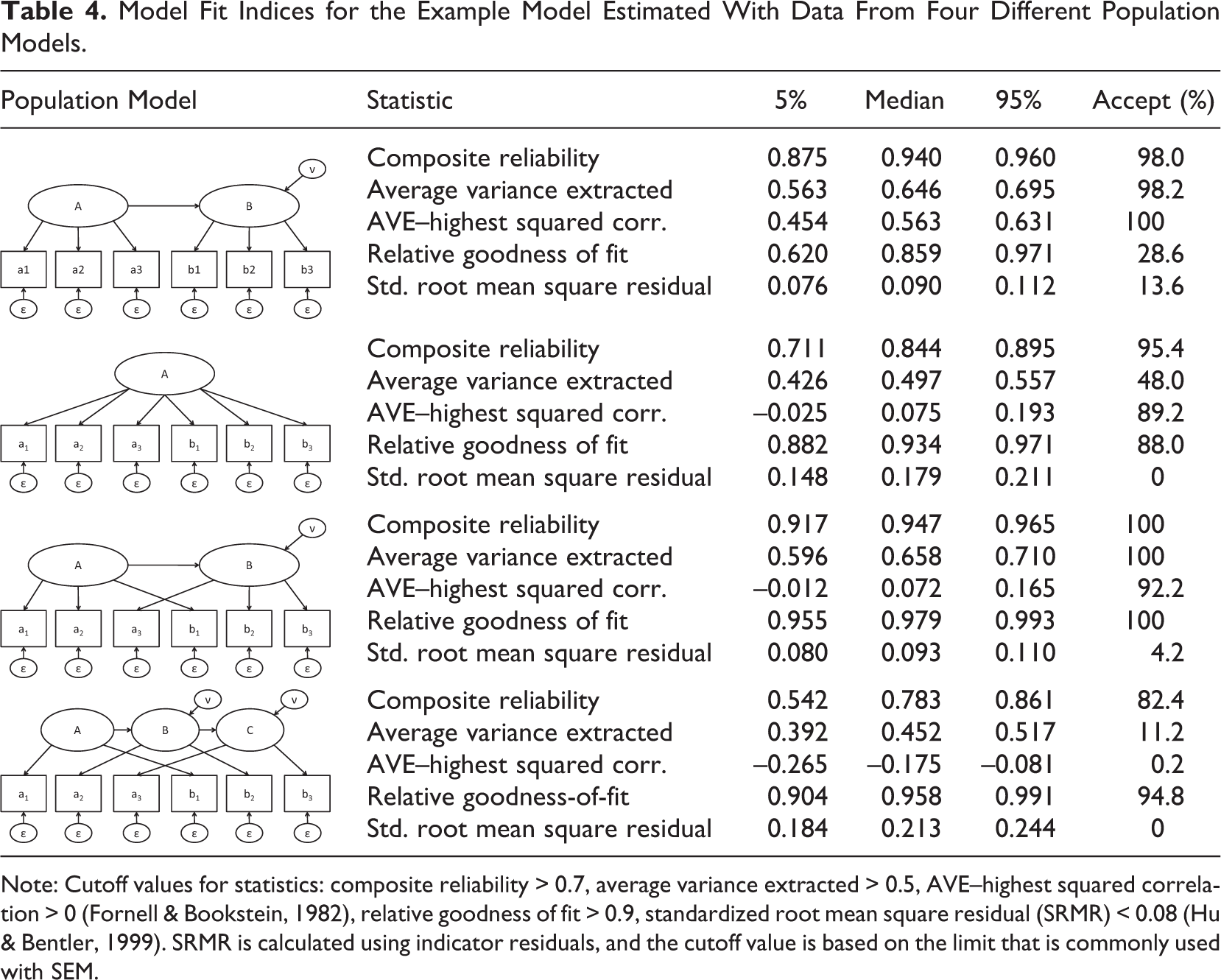
Note: Cutoff values for statistics: composite reliability > 0.7, average variance extracted > 0.5, AVE–highest squared correlation > 0 (Fornell & Bookstein, 1982), relative goodness of fit > 0.9, standardized root mean square residual (SRMR) < 0.08 (Hu & Bentler, 1999). SRMR is calculated using indicator residuals, and the cutoff value is based on the limit that is commonly used with SEM.
In contrast to these heuristics, the χ2 test of model fit provides a statistically sound way of identifying misspecified models for medium and large sample sizes, 6 and the field of psychometrics provides decades of guidance on how to validate measurement with factor analysis (cf. Nunnally, 1978). If desired, factor loadings can be obtained with common factor analysis, and the reliability of a composite with arbitrary weights can be estimated as described by Raykov (1997; see Aguirre-Urreta et al., in press, for how to apply the procedure with PLS analysis). Because of these better alternatives, the measurement model should never be evaluated based on the composite loadings produced by PLS or any statistic derived from these. In summary, we conclude that the idea that PLS results can be used to validate a measurement model is a myth.
Myth 4: PLS Can Be Used for Testing Null Hypotheses About Path Coefficients
Almost all of the articles listed in Table 1 use PLS for null hypothesis significance testing (NHST) of path coefficients, a practice that can be traced back to Fornell and Bookstein (1982). Under NHST, statistical inferences are made based on the p value, which is defined as “the probability of obtaining a value of a test statistic…as large as the one obtained—conditional on the null hypothesis being true” (Nickerson, 2000, p. 247). Thus, NHST relies on a known sampling distribution of the test statistic when the null hypothesis of no effect holds.
The current practice in PLS studies is to use bootstrapping to estimate the standard errors for the parameter estimates, calculate the ratio of a parameter estimate to its standard error, and compare this statistic to the t distribution to obtain the p value. The use of a t distribution assumes a normal distribution of the underlying parameter estimates. However, as shown in Figure 3, the distribution is not normal but of bimodal shape when the null hypothesis of no effect holds (
The use of bootstrapped confidence intervals (Wood, 2005) is an alternative to NHST for statistical inference. Even this approach can be problematic with PLS: Bootstrapping relies on the assumption that the bootstrap estimates follow the same distribution as the original statistic, but this is not always the case, leading to incorrect inference (cf. Bollen & Stine, 1992). Figure 4 shows the parameter estimate distribution for 500 replications of the simulation estimates and, for the first 5 of these replications, shows the bootstrap distribution of the parameters. It is clear that the bootstrapped replications do not follow the original sampling distribution in our simple example model. 7 Thus, we conclude that bootstrapped confidence intervals of PLS estimates should not be used for making statistical inferences until further research is available to show under which conditions, if any, the bootstrapped distribution follows the sampling distribution of the PLS parameter estimate.
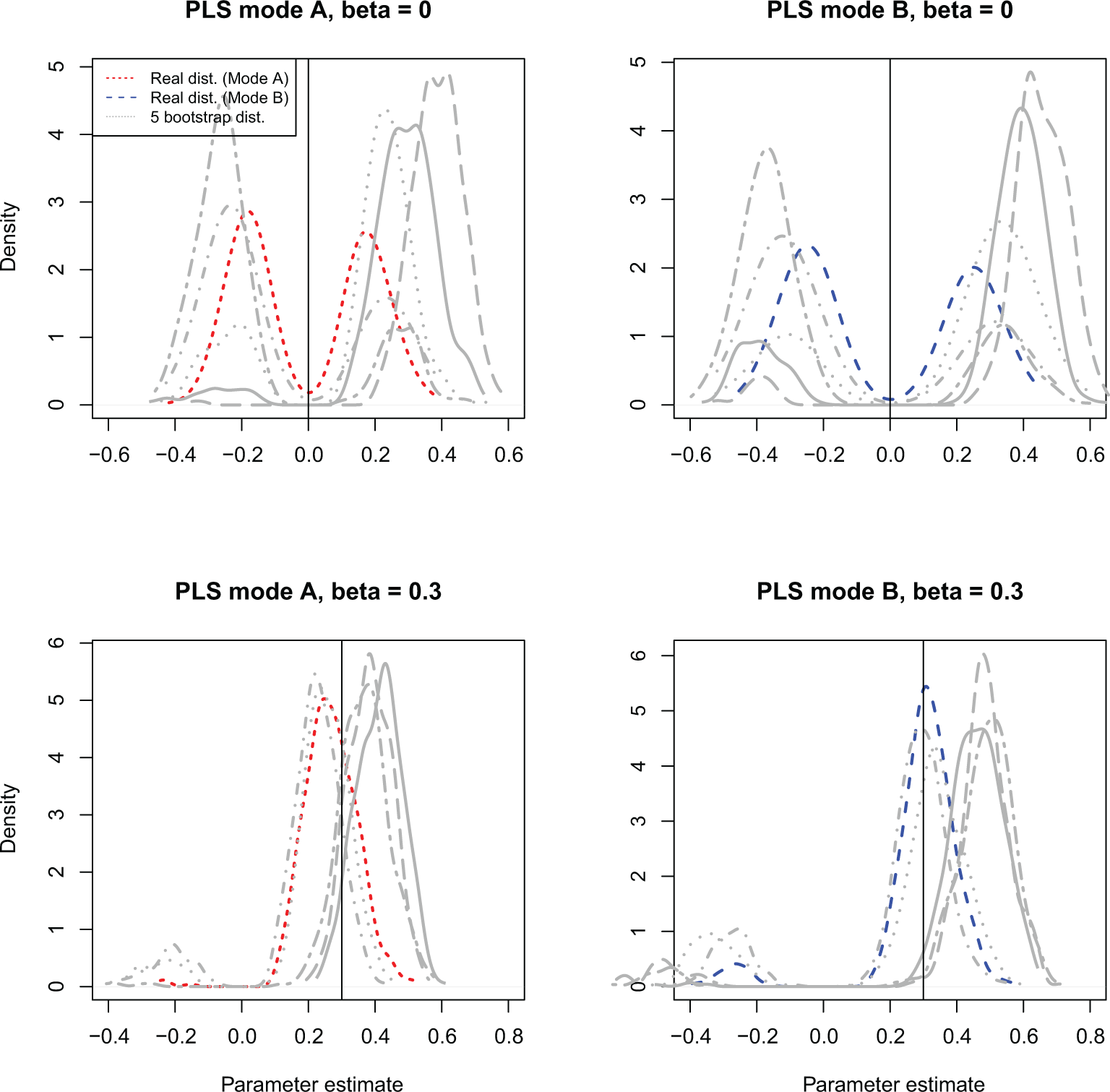
Distribution of parameter estimates over 500 replications and distribution of 500 bootstrap estimates for the first five replications for partial least squares (PLS) Mode A and PLS Mode B in the two-construct model.
Myth 5: PLS Has Minimal Requirements on Sample Size
The belief that PLS does not require a large sample size is widely held. This belief is repeated in 14 of the studies listed in Table 1, and several studies use sample sizes as small as 21 (Cool et al., 1989). The most common citations for the small sample size are two book chapters by Chin (1998; Chin & Newsted, 1999) and the article by Fornell and Bookstein (1982). The arguments presented in these articles can be traced to a single, unpublished conference paper by Wold (partly republished as Wold, 1985a). 8 However, that paper does not provide any evidence about the statistical power or parameter accuracy of PLS when applied to small samples, but clearly states that PLS parameter estimates converge to their population values only in the theoretical case of “consistency at large” where both the sample size and the number of indicators approach infinity.
In contrast to the lack of support for the myths discussed earlier, a study exists that seeks to provide empirical support for this belief. Chin and Newsted (1999) concluded that PLS generated more accurate parameter estimates than summed scales when the sample size was small. That study has been strongly criticized by Goodhue et al. (2012), who point out that although PLS estimates are slightly larger than regression estimates, so too are standard errors, and there is consequently no advantage in terms of statistical power. However, this result is challenged by a more advanced simulation study by Reinartz et al. (2009). They conclude that although PLS results are always more biased than ML-SEM results, PLS has more statistical power and lower mean estimation error when used with small sample sizes. However, the power estimates in their study are questionable because they are based on p values with an assumption of a t distribution, which we showed earlier to be flawed. Furthermore, their study does not test for false positives, so low p values may be a reflection of positive bias resulting from the use of an inappropriate significance test.
Although the results of these studies show that PLS estimates are on average larger than regression estimates and tend to get larger as the sample size decreases, none of the studies explained why this is the case. We suggest that the apparent advantage of PLS with small sample sizes is a fallacy that results from ignoring the effects of chance correlations. Earlier, we showed that correlated errors bias the PLS path estimates away from zero, leading to artificially inflated path estimates and possibly artificially inflated power. In addition, because the estimates were distinctly different from zero when there was neither an effect between the constructs nor a correlated error in the population (Figure 3), it appears that sampling error is sufficient to substantially distort the parameter estimates from their true value. As sampling error increases with decreasing sample size, there are more chance correlations that PLS can capitalize on; consequently the estimates are biased further from zero.
We illustrate the effect of sample size on PLS parameter estimates by simulating data for our two-construct example using three different sample sizes and either no effect (
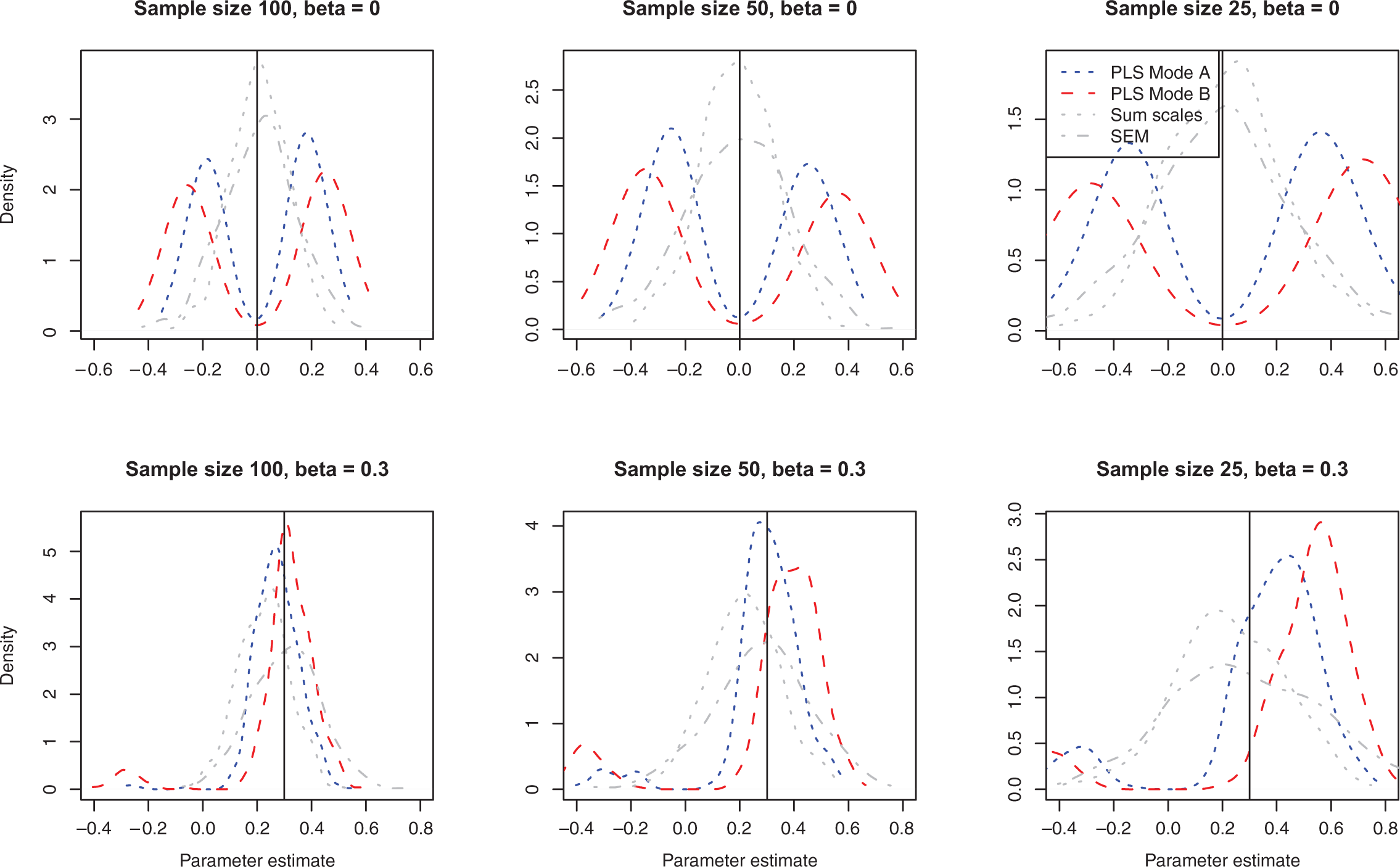
Distribution of parameter estimates for partial least squares (PLS) Mode A, PLS Mode B, summed scales, and structural equation modeling (SEM) with different sample sizes in the two-construct model, 500 replications.
The best remedy for small samples is to collect sufficient data to avoid the problem. SEM techniques for small samples (e.g., Herzog & Boomsma, 2009) and for estimating sample size requirements (e.g., Lai & Kelley, 2011) are actively studied, but fundamental laws of probability limit what can be accomplished. Because the sample size requirement is tied to the size of the model, one way to reduce the required sample size is to reduce the number of indicators by parceling (Landis, Beal, & Tesluk, 2000; Little, Cunningham, Shahar, & Widaman, 2002). Another potentially useful option is to use the limited information 2SLS estimator instead of the full information ML.
Myth 6: PLS Is Most Appropriate for Exploratory or Early Stage Research
When PLS was developed, it was “primarily intended for causal-predictive analysis in situations of high complexity but low theoretical information” (Jöreskog & Wold, 1982, p. 270). In the more recent literature, the notion of low theoretical information has led to the understanding that PLS path modeling is more an exploratory approach than a confirmatory one (Hair et al., 2011).
Using PLS as an exploratory or early-stage theory testing tool does not feature strongly in the early PLS articles. The exception is Lohmöller (1989), who, after comparing PLS and LISREL estimates, concluded correctly that “if [the researcher] is sure that the model is correct,…then he may accept the ML [maximum likelihood SEM] estimates” (p. 213). The corollary assumed by Lohmöller, neither logically implied nor correct, is that PLS is appropriate when the researcher is not sure that the model is correct. Lohmöller nevertheless concludes that “LS methods are…more explorative” (p. 213), implying that the term explorative refers to situations where the model may be incorrect. Similarly, Fornell and Bookstein (1982, p. 450) correctly state that “if one had reason to doubt the accuracy of the theoretical model and/or the validity of the indicators, the LISREL estimate would be exaggerated,” but, like Lohmöller (1989), they erroneously and without evidence conclude that “more credence should be given to the PLS estimate.”
Given that 7 of the studies listed in Table 1 argue for PLS’s suitability for exploratory research, it is problematic that none of the PLS authors explicitly and clearly explain the meaning of the term exploratory or explorative, nor do they explain how PLS supports exploration. In fact, all of the studies listed in Table 1 are presented in a way that is identical to studies applying SEM to test a prespecified model: A literature review is followed by the derivation of causal theory and formal hypotheses and, finally, the estimation of a single model.
One way to understand exploratory analysis is that exploratory methods should reveal patterns in the data (Mulaik, 1985) instead of testing a prespecified hypothesis or model. It is clear that PLS does not have this capability because the model must be completely specified prior to the analysis. Moreover, in contrast to widely used SEM estimators, PLS lacks diagnostic tools such as modification indices that can be used for model building in SEM.
Another way to understand exploratory work is by characterizing it in terms of three features: uncertainty about the correctness of the model, possibly poor measurement, and small sample sizes. However, earlier in this article we concluded that the idea that PLS has special capabilities to handle measurement error and small sample sizes is a myth. We have also demonstrated that PLS cannot be used to test models, that is, to reliably identify model misspecifications. If there is a possibility that the model is incorrect, one should certainly not use a method that cannot detect model misspecification. Finally, construct scores and path estimates calculated using information from an incorrect model are likely to be severely biased (Dijkstra, 1983; Evermann & Tate, 2010). We conclude that because of these weaknesses, PLS is not an appropriate choice for early-stage theory development and testing.
Many introductory texts on SEM describe different model building strategies and show how modification indices can be used for exploration. In addition, new SEM-based methods for exploratory analyses are actively developed (e.g., Asparouhov & Muthén, 2009). If, on the other hand, exploratory research refers to uncertainty about the model rather than the search for a model, we recommend using the 2SLS estimator that is less sensitive to model misspecification than the ML estimator (Bollen, Kirby, Curran, Paxton, & Chen, 2007).
Discussion and Conclusion
In the spirit of Vandenberg (2006), this article has examined statistical myths and urban legends surrounding the often-stated capabilities of the PLS method and its current use in management and organizational research. Tracing back the literature on PLS, we described the origins of each myth to show that they are not based on statistical principles, but misinterpret the original articles on PLS or attribute capabilities to the method based on incorrectly or misleadingly classifying it as an SEM method. We have illustrated why these beliefs are incorrect by using a simple model under conservative conditions (e.g., normal, complete data). Although we acknowledge this limitation, we are not aware of any statistical method that does not work well with a simple model under conservative conditions, but whose performance improves with model complexity. This is counterintuitive, and the PLS literature also makes no such claims. In fact, it often uses the exact same model that we have used (e.g., Chin, 1998). Second, as stated in the introduction, the statistical theory and formal analyses presented in our article do not depend on model complexity.
Despite its demonstrated shortcomings and lack of evidence of the advantages, management researchers increasingly use PLS for purposes that it is not suitable for. One reason that is frequently implicit in the applied literature appears to be a misunderstanding about the relative capabilities of PLS and the commonly used SEM estimators. Our review of several PLS studies shows that authors frequently argue that typical SEM estimators require a large sample size, assume multivariate normality, and have difficulties with some instances of formative indicators. Although some of these assertions were correct in the 1970s when PLS was developed, much has changed since then (Gefen et al., 2011). Nevertheless, the weaknesses of the most commonly used SEM estimators do not imply that PLS is necessarily superior. First, a great many analytical and simulation studies, going back to the early 1970s, have analyzed the behavior of SEM estimators in a wide range of different situations. In contrast, far fewer systematic empirical simulation studies of PLS have been conducted. Hence, comparatively little is understood about PLS, including its weaknesses. However, the absence of a demonstration of unsuitability of a method does not imply suitability of the method. Second, the choice between the typical SEM estimators and PLS is a false dichotomy. If one decides to estimate an SEM model using separate OLS regressions with construct scores, one can rely for guidance on decades of research on how to do this with summed scales or factor scores. In fact, our evidence suggests that even simple summed scales provide better reliability than PLS. When used with regression, these traditional methods to generate composites have test statistics with known distributions allowing NHST. In addition, using a model-based weighting system as used in PLS will guarantee problems with interpretational confounding (Burt, 1976).
If one were a cynic, one could add another reason for the popularity of PLS. Because PLS does not have a test of overall model fit (in contrast to SEM’s test of overall model fit) and its model quality heuristics cannot identify a misspecified model (Evermann & Tate, 2010), researchers who employ PLS never find themselves in a position where a model is decisively rejected by the evidence. Given the publication bias in many fields for “positive” results, it comes as no surprise that some researchers prefer PLS over SEM.
Despite the popularity of PLS, many claims about it must be included among the statistical myths and urban legends. In contrast to Hair et al. (2011), we conclude that PLS is decidedly not a “silver bullet,” and it is very difficult to justify its use for theory testing over SEM or even the more traditional combination of measurement validation with factor analysis and testing hypotheses with regression with summed scales or factor scores. PLS may be useful for purely predictive analyses, but we are not aware of any studies showing this to be the case either.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.