
Abstract
Argument mining—the automatic identification, classification, and linking of argumentative text—has been studied in natural language processing (NLP) for more than a decade. Despite its claimed potential for applications in legal, political, and social contexts, it remained largely unexplored in organizational research. This article introduces aspect-based argument mining (ABAM) as a methodical innovation for studying how organizations justify decisions, construct legitimacy, and relate to their environments through communicative acts. By scaling up the analysis of argumentative structures beyond the limits of small-scale, qualitative studies, ABAM enables the recognition and systematic analysis of argumentation patterns in large text corpora that were hardly detectable with previous (computational) approaches. The potential is demonstrated by a longitudinal case study of Twitter debates on nuclear energy in Germany, revealing how shifting societal values—particularly the reframing of nuclear energy from a safety to a climate issue—produced growing misalignments between organizational talk of a political party organization and its social media environment.
Keywords
Organizational research has long recognized that communication and discourse are central to understanding how organizations justify decisions, build legitimacy, and relate to their environments (Cooren et al., 2011; Keyton, 2017; Phillips et al., 2008; Schoeneborn, 2011). In these processes, argumentation plays a decisive role as it serves to develop and articulate one's own positions, it makes decisions comprehensible, and it is a means of persuading others. For organizations, argumentation is not simply a rhetorical device, but also a fundamental mechanism that establishes a constitutive practice through which organizational realities are perceived and implemented (Cooren et al., 2011; Putnam, 2004). In this light, arguments are a key concept to be examined in many qualitative and quantitative methods of text analysis to gain deep insights into how organizations justify and frame their decisions (Grant et al., 2004).
To enable the analysis of increasingly large digital text data sets, computer-assisted methods such as corpus linguistics (Pollach, 2012) or topic modeling (Schmiedel et al., 2019) have been introduced to organizational research. In contrast to manually conducted analysis steps, already established computer-assisted methods tend to remain at rather basic levels of meaning when detecting and analyzing patterns of communication. In this article, we introduce aspect-based argument mining (Ruckdeschel & Wiedemann, 2022) as a new instrument for the computational toolbox of organization researchers, which provides insights from deeper semantic levels, thus further bridging the gap to interpretive approaches. It enables the identification, classification, and linking of arguments in large text datasets, thereby allowing computational analysis to be combined with theories such as system theory and legitimation (Ashforth & Gibbs, 1990; Luhmann, 1989), decision-making and organizational talk (Brunsson, 2007), different forms of organizational rhetoric (Bohn et al. 2026; Boyd & Waymer, 2011; Ihlen & Heath, 2018), impression management and communication (Allen et al., 2026; Bolino et al., 2016), or sensemaking (Weick et al., 2005). By focusing on how organizations and their environments develop and justify their positions, argument mining offers a new way to study the very processes through which meaning, decisions, and expectations are negotiated and justified in organizational life.
Regarding the study of decision-making processes, system theory states, for instance, that organizational decisions are inherently contingent—they could always have been made differently (Luhmann, 2000). To maintain legitimacy, organizations must therefore provide reasons why a particular decision is appropriate. For this, argumentation is primarily a means to make decisions appear rational in retrospect (Nassehi, 2005). It renders organizational decisions intelligible to their internal and external environment (stakeholders) and positions them within societal expectations (Brunsson, 2007; Suchman, 1995). Yet, organizational studies that explicitly focus on the role of argumentation are rare. Argumentation as a subject of analysis is usually embedded in broader qualitative methodologies, for instance, in empirical studies using participant observation (Mueller et al., 2004; Watson, 1995), interviews (Mueller et al., 2004; Schröder, 2013), as well as content, document, or discourse analysis (Luyckx & Janssens, 2016; Mueller et al., 2004; Nyberg et al., 2020; Putnam, 2004; Schröder, 2013). Some studies are based on larger amounts of documentary material collected from several companies over several months (Nyberg et al., 2020; Schröder, 2013), while others only examine (very) few documents. At its core, arguments can be viewed as communicative acts that express issue-specific standpoints and the justifications used to support or reject them, which must be reconstructed through an interpretive, context-dependent analysis process. Conventionally, argument analysis seeks to systematically identify, categorize, and relate these structures within and across texts.
Argument mining is a set of computational methods that automate parts of argument analysis by using natural language processing (NLP) to identify linguistic structures such as claims, premises, or issue-specific argument aspects in large amounts of text (Lawrence & Reed, 2019). The seminal argument mining task in NLP, introduced by Palau and Moens (2009), operationalizes one basic argument scheme by Walton (1998) that defines arguments as a combination of premises and a conclusion that are verbally linked in such a way that one or more of the former justify the latter. Focusing on a use case of analyzing legal texts, they suggest three consecutive computational steps: the detection of argumentative units, their classification into the functional types of either premise or conclusion, and the logical relation of co-occurring arguments as either supporting or attacking each other. Outside of legal texts, such as in news, social media, or organizational talk, arguments are rarely elaborated in detail and rather take the form of claims accompanied by certain hints for a justification. Aspect-based argument mining (ABAM) was introduced to better capture such “incomplete” arguments in empirical data (Ruckdeschel & Wiedemann, 2022). It is moving away from the formalization of arguments as generic, logically linked linguistic units toward issue-specific semantic units, namely stances toward the issue and legitimizing aspects such as references to societal values. By this, it allows the analysis of a wide range of document types and text genres relevant for organizational research that communicate argumentatively but in less formal ways, which drastically increases its applicability in the social science domain.
For organization research, ABAM allows tracing how arguments are used to justify, challenge, and reshape the positions of organizations and their environments in large datasets in cross-sectional and longitudinal perspectives. Hereby, our contribution is threefold. First, we introduce a step-by-step workflow for applying ABAM in organizational research. Second, we demonstrate its empirical utility in a longitudinal case study of the German nuclear-energy debate in social media. Third, we discuss how argument mining can inform research designs based on various methodologies and theories commonly used in organizational research. Through this integration, the article advances both the methodological and epistemological foundations for analyzing argumentative communication at scale in organizational research.
Argument Mining as a Method for Organizational Research
In the following, we will take a closer look at the task of argument mining and trace its development into a subfield of NLP with a large number of task definitions and areas of application. Further, we relate it to other computational text analysis methods that are already established in organizational research.
What Is Argument Mining?
Ontologically, we understand arguments as communicative social acts that cognitively justify a certain state, or demand a certain goal based on reasons. In the linguistic view, arguments consist of two unit types, premises as assertions from which a conclusion can be derived. One or more premises can be linguistically linked to a conclusion via discourse markers such as “because of” or “therefore” to indicate a logical relation (Palau & Moens, 2009). In real-world empirical data, however, such formal argument schemes are rarely present, as premises are often left implicit and discourse markers are seldom used. Instead, enthymemes, that is, arguments with hidden premises that rely on the recipients’ prior knowledge, or expressions of normative demands for changes to future orders of being, are much more common, for example, in the form of political claims that give little to no justification. ABAM takes this into account by suggesting a combination of automatic stance and aspect detection. Stances are defined with respect to a certain thematic issue, such as marihuana legalization, Brexit, or the civil use of nuclear energy. Aspects are defined as linguistic cues that serve as key rationales to support the stance (Ruckdeschel & Wiedemann, 2022). For example, the issue “Should we use nuclear power for energy production in Germany?” can bring forward claims such as “Bavaria needs nuclear energy as cheap energy for our industry.” The claim expresses a stance in favor of nuclear energy use and supports it with reference to a cost aspect, implying that it can be generated more economically than other energy sources, without relying on any discourse marker explicitly highlighting the argumentative relation between stance and aspect. In general, claims can be supported by multiple aspects in one single utterance, and they can take the form of different semantic concepts. For instance, aspects can be operationalized as generic frames, such as costs or safety, or as issue-specific frames, such as energy supply reliability (Vreese, 2005). Another operationalization could look for references to expert evidence or scientific study evidence to justify a claim (Rinott et al., 2015).
Argument Mining in Natural Language Processing
Palau and Moens (2009) introduced argument mining as a process of three steps. The first step aims at the automatic detection of argumentative propositions in textual units. For simplicity, their framework relies on the sentence level, that is, classifying entire sentences as being part of an argument or not. However, in many empirical datasets, arguments operate below the sentence level or go beyond it. To address this shortcoming, Trautmann et al. (2020) introduced the task of argument unit recognition. They propose annotating argument units as token spans for automatically classifying stance-taking sentence parts via sequence tagging.
In the second step, detected argument units are classified into functional types as either premise or conclusion. This step works well for carefully crafted argumentations as they typically occur in the legal domain. As mentioned earlier, this approach cannot detect “incomplete” arguments commonly used in news or online user comments. For this, stance classification has been introduced as a simpler task that only distinguishes supporting vs. opposing standpoints concerning a particular issue (e.g., Sobhani et al., 2015; Stab et al., 2018; Vamvas & Sennrich, 2020). Comparable to sentiment analysis that classifies texts as positive, neutral, or negative, stance classification distinguishes between claims taking either a pro-, a contra-, or no stance for a given text unit. To better capture the actual substance of an argument beyond the stance, newer works attempt to extract semantic features such as argument key points (Friedman et al., 2021), argument frames (Ajjour et al., 2019), argument aspects (Ruckdeschel & Wiedemann, 2022; Trautmann, 2020), or quality of arguments (Vecchi et al., 2021; Wachsmuth et al., 2024).
The third step strives to link the identified arguments within a document or a dialogical conversation as either supporting or attacking each other. As a result, complex argumentations consisting of chains of arguments that back up or counterargue a specific stance can be formally described and evaluated, for example, as a machine- and human-readable debate graph (Konat et al., 2016). Graphs extracted from larger text collections, such as conversational threads in internet forums or social media platforms, can be further mined for typical patterns, for example, to track most supported or increasingly attacked positions (Ruckdeschel et al., 2024). This capability represents a clear advantage for the analysis of social media data, as other computer-based approaches typically analyze user comments as isolated events in the data, hence neglecting their dialogical nature.
Positioning Argument Mining in the Field of Computational Text Analysis
Aiming at logical structures that express and justify particular viewpoints, argument mining differs fundamentally from other computational approaches to study large text collections that are already established in organizational research. Among the most widely adopted NLP approaches in organization research is topic modeling, which automatically separates a document collection into thematically coherent groups described by semantically coherent words. Jung et al. (2024), for instance, introduce an application for organization research with their word-text-topic approach that combines topic modeling with keyword and collocation extraction to inform data-driven processes for theory development. Pandey and Pandey (2019) use NLP-derived linguistic phrase patterns to inductively generate dictionaries that describe different dimensions of organizational culture. Both studies are good examples demonstrating the strength of unsupervised approaches in finding meaningful separations of large text datasets, which can be related to organization theory concepts. An application of topic modeling related to our exemplary case is conducted by Bohn and Gümüsay (2023), who investigate the complexity of the German energy production with a field theory approach operationalized by topic modeling and qualitative analysis of newspaper articles. They identify conflicting logic constellations in the public discourse that form a new type of field complexity. As helpful as topic modeling is for breaking down a large number of documents into thematic clusters, it is not designed to identify issue-specific stances or justifications.
In contrast to unsupervised topic modeling, supervised machine learning is used to classify texts into predefined categories based on manually coded training data (Kobayashi et al., 2018). Kovács (2025), for example, performs sentiment analysis to automatically classify online reviews in organizational contexts into emotional affect classes, such as positive, negative, and neutral, or more fine-grained star ratings commonly found in product reviews. ABAM, as well, relies on text classification for its first two tasks, stance detection and aspect sequence tagging (cf. Section 3). While stance detection at first glance appears similar to sentiment analysis, it is more challenging in the way that a certain stance toward an issue can be expressed with both a positive and a negative tone, depending on the justifying aspect.
The promise of diverse and value-adding applications of argument mining in various domains, such as the social sciences (cf. Vecchi et al., 2021), is being realized only recently (e.g., in studies by Haunss & Hollway, 2023, or Rieger et al., 2024). In our view, this is primarily because theoretical foundations, published datasets, and classification models only partially matched the discipline-specific requirements. Hence, the necessary adaptations for argument mining to new domains remained a rather labor-intensive endeavor in the past. Sentiment classifiers, for instance, can generalize well across various datasets due to less ambiguous word language features that carry positive and negative meanings independent of the issue discussed. The automatic analysis of arguments as a much more complex linguistic phenomenon requires a combination of consecutive steps as well as classification models that capture contextual meaning instead of only looking at word surface forms (Wiedemann & Fedtke, 2021). Transformer-based large language models (LLMs) such as BERT (Devlin et al., 2019) and its successors comprise the capability of modeling contextualized meaning of long text sequences (Jia & Lee, 2025; Wiedemann & Fedtke, 2021). Hence, they significantly increase the automatic classification performance even for complex, abstract categories. Fyffe et al. (2024), for instance, demonstrate an above-human performance of text classification of the Big Five personality items using transformer-based LLMs.
The Aspect-Based Argument Mining Workflow
With the introduction of pretrained language models (PLM) to NLP, the opportunity for validly capturing argumentative structures automatically came within reach for the social sciences. For application in organizational research contexts, we propose a workflow consisting of five steps to perform aspect-based argument mining adapted to domain-specific analysis requirements and datasets. Before applying ABAM, researchers need to make some basic design decisions. They must determine whether their data source and corpus size are suitable for large-scale argument analysis, define the thematic issue together with the stance and aspect categories to be detected, assess the annotation and validation resources available for domain adaptation, for example, in terms of human coders and machine learning capacities, and specify the theoretical lens through which the resulting patterns will be interpreted. These decisions shape how the workflow is implemented and what kinds of empirical claims it can ultimately support.
Domain-Adaptation to Organizational Research
For many years, NLP approaches to argumentation remained highly domain-dependent and generalized poorly across datasets and tasks. In organization research, text genres of very different kinds, such as reports and memos, corporate documents, customer reviews, or social and online media, are studied. To apply argument mining to these types of data, domain-specific training and test sets must be created. In the past, this required manual annotation of large datasets to obtain sufficient quality. Nowadays, with the transfer learning technologies based on PLMs, such adaptations can be achieved with a much more manageable effort (Cabessa et al., 2025). A combination of stance detection and a fine-grained, domain-specific classification of semantic aspects of arguments presents a useful operationalization in many contexts (cf. Egres & Sarlós, 2024, p. 4). Public datasets for stance detection allow training, respectively, fine-tuning of text classifiers that recognize pro and contra standpoints on a diverse set of issues. When using multilingual PLMs as base models, argument mining does to some extent even generalize across topics and languages (Toledo-Ronen et al., 2020).
As NLP research is primarily interested in automating ways of identifying, classifying, and relating argumentative structures from text, it rarely goes beyond this point to conduct an actual analysis that answers empirical research questions. Yet, the potential of argument mining for social science applications has been demonstrated by a few studies on the topic of nuclear energy. Jurkschat et al. (2022) investigate the longitudinal development of stances in British newspaper articles, finding that some formerly controversial aspects have developed into clear pro- and con-arguments over time, while other aspects become increasingly controversial. Haunss and Hollway (2023) find that changes in discourse networks consisting of argumentative claims and political actors (e.g., parties and civil society organizations) contribute to explaining Germany's pivot to a nuclear phase-out in 2011. Ruckdeschel et al. (2024) mine for salient support and attack patterns related to social values and their changes in long-term social media debates. We further develop our method based on these examples to open up argument mining as a tool for organizational research.
As presented in Figure 1, we adapt argument mining for organization research as a series of three consecutive tasks: (A) text classification for stance detection concerning a given issue, (B) aspect sequence tagging for extracting issue-specific argument aspects, and (C) detecting prevalent and salient argument patterns. Both classification tasks, A and B, can make use of transfer learning from argument mining datasets and pretrained LLMs to reduce the manual coding effort. Our suggested process delivers a machine-evaluable representation of the argumentative structures for each textual input, for example, posts from social media (see Figure 2 for an example input). From Task A, we receive a value for its stance (pro/con) or “no stance” for nonargumentative units for each text unit in our target dataset (cf. Table 2 for an example). For Task B, we put the notion of aspects into concrete terms with the concept of societal and issue-specific values (cf. Section 4 for a brief theoretical foundation). Mining for values in debates around selected issues requires issue-specific value sets that need to be defined by the researcher at the beginning of the argument mining process. We suggest performing Task B as a sequence tagging task that results in text spans containing the specific phrases referring to a particular value. For Task C, automatically classified argument structures can be combined with and aggregated by any metadata from the original dataset, for example, document type, authorship, or timestamp information, to detect (changes of) patterns in cross-sectional and longitudinal designs. Moreover, chains of arguments within a document or references to previous arguments, as common in social media conversation threads, can be described as either a support or an attack relation. A support argument takes the same stance as its preceding argument, whereas an attack argument expresses the opposing stance (Ruckdeschel et al., 2024).
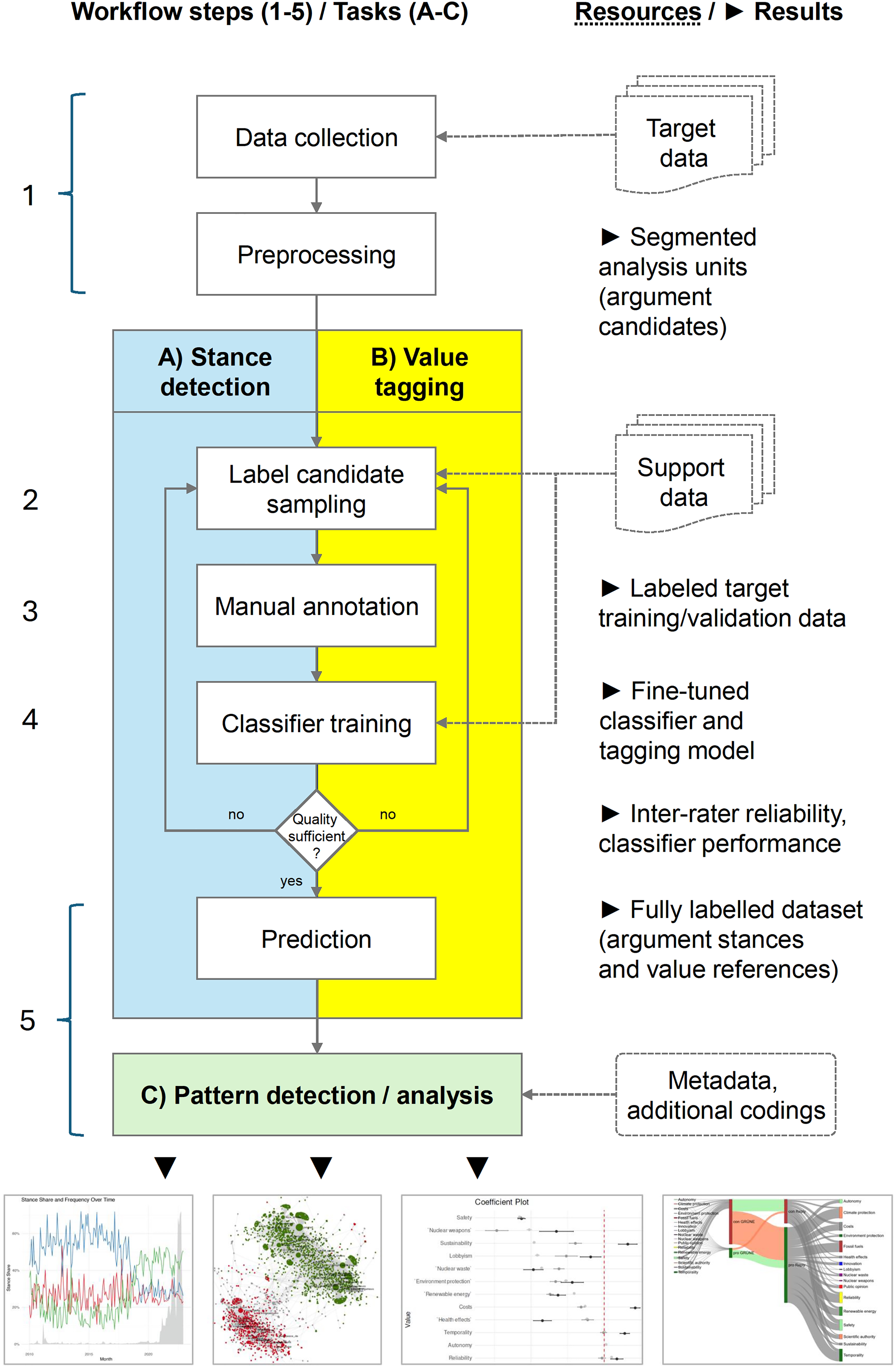
The adapted argument mining workflow.
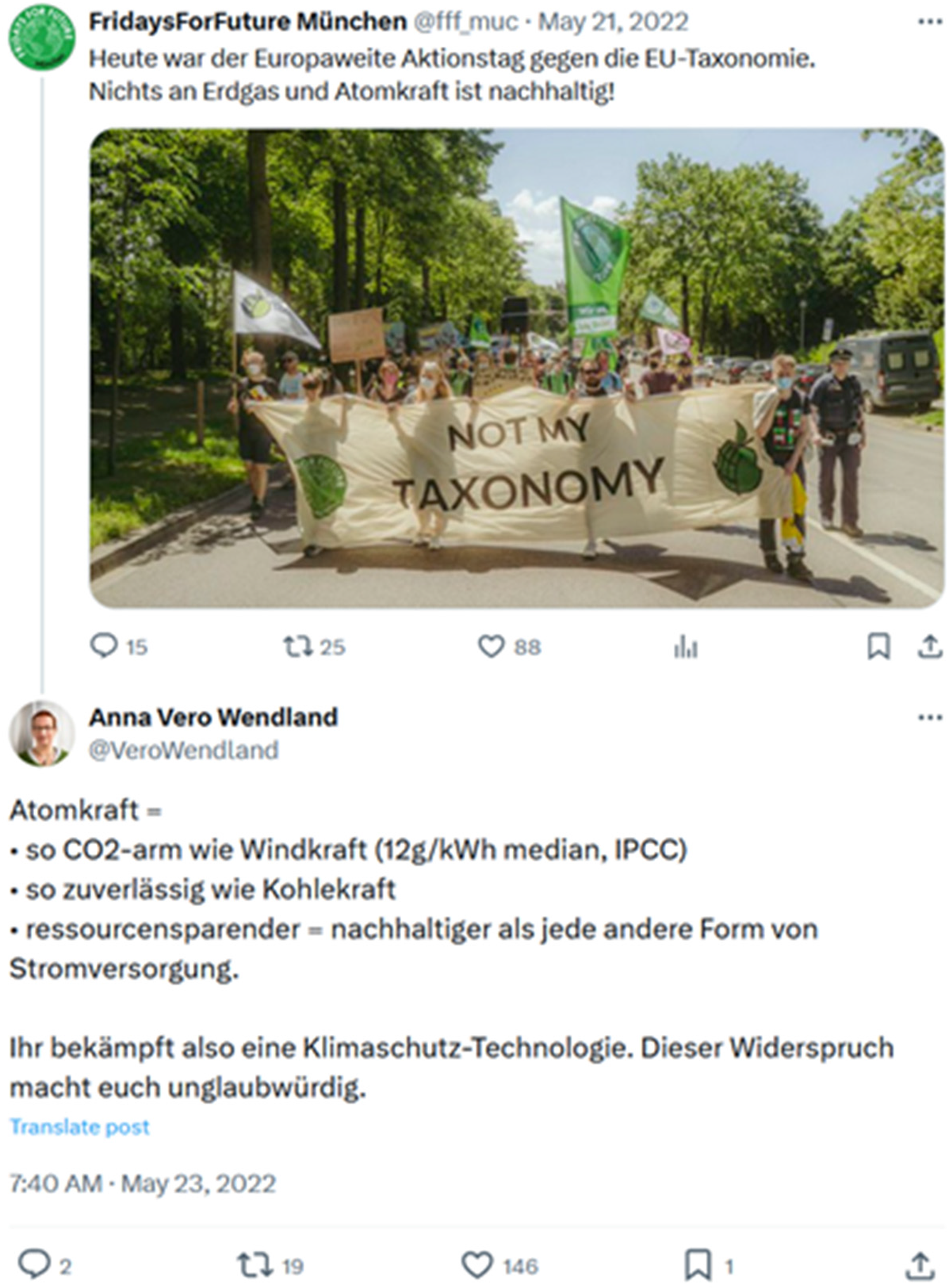
Sample tweet conversation.
Five-Step Workflow for Aspect-Based Argument Mining (ABAM).
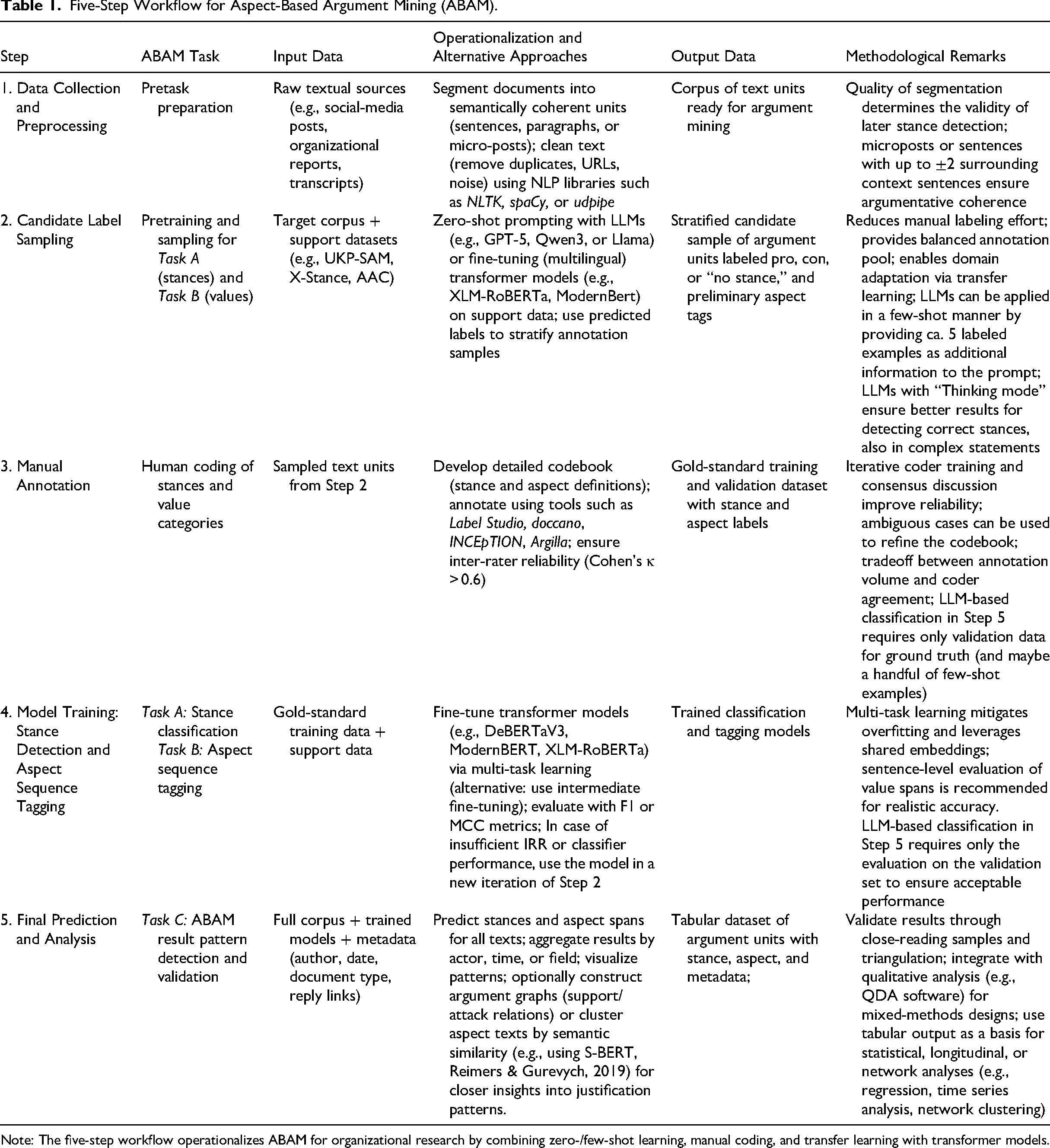
Note: The five-step workflow operationalizes ABAM for organizational research by combining zero-/few-shot learning, manual coding, and transfer learning with transformer models.
Example Results from the Argument Mining Process.
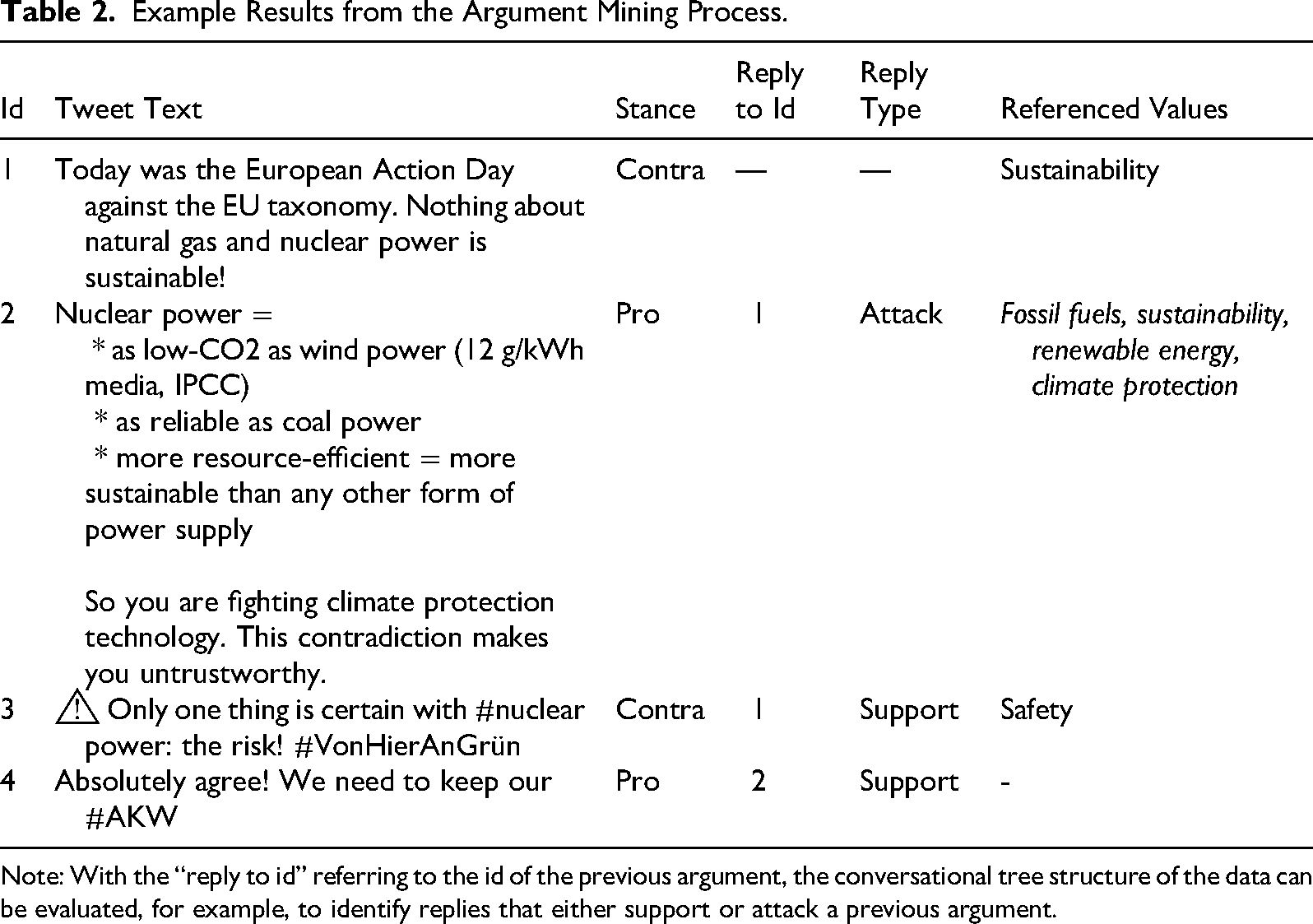
Note: With the “reply to id” referring to the id of the previous argument, the conversational tree structure of the data can be evaluated, for example, to identify replies that either support or attack a previous argument.
Five Steps of Aspect-Based Argument Mining
In the following, we describe five steps of the argument mining workflow in closer detail (see Table 1 for a summary of the workflow). The Python code to conduct the steps on a sample of the dataset from our case study can be found in a collection of Jupyter notebooks in this GitHub repository: https://github.com/Leibniz-HBI/orm-argument-mining.
Step 1: Data Collection and Preprocessing
In order to use argument mining effectively, researchers must collect digital sources that are likely to contain a considerable amount of argumentative text units. This data can, for instance, reflect the internal perspectives of the organization or provide insights into the organization–environment relationship based on public communication. Data and documents from websites can be acquired, for example, via web scraping (Haans & Mertens, 2024). Precompiled, carefully curated research corpora such as the ParLawSpeech dataset contain machine-readable full texts of bills, laws, and plenary speeches from eight European parliaments (Schwalbach et al., 2025) that can provide valuable contexts from governmental and administrative processes. Social media conversations from specialized platforms like Reddit for the digital avant-garde, X (formerly known as Twitter) for public opinion leaders, or LinkedIn for trends among business professionals can provide further rich and diverse sources for argument mining. Product reviews from online shops or company reviews from job portals would be examples of sources already studied intensively in organization research.
For NLP applications on longer documents, some preprocessing is usually required to segment them into smaller, semantically coherent sub-units. For argument mining, either paragraphs or sentences with sliding windows of up to two context sentences would be preferred (Rieger et al., 2024, p. 81). The recommended input of segmented data to a BERT-like classifier for Task A would then look like “<target sentence>[SEP]<context before>[SEP]<context after>” where [SEP] represents the special separator token which transformer models use to distinguish between different parts of the input (Rieger et al., 2024). Presenting the sentences in this order ensures that the model pays attention to the first sentence as the primary classification target and that context sentences are recognized as additional information only. In case the input sequence exceeds the maximum length (typically 512 tokens for BERT-like models), the order ensures that the least important part gets truncated first. Sentence splitting can be performed with libraries such as NLTK (Bird et al., 2009) and spaCy (Montani et al., 2023) for Python, or udpipe for R (Wijffels, 2017). Paragraph splitting can be achieved with document-specific regular expressions. Depending on the input documents, further preprocessing steps to reduce noise in the data might be necessary, for example, to de-hyphenate words or remove header/footer text extracted from PDF documents. Step 1 results in a representation of the entire collection as short texts, for example, micro-posts from social media, paragraphs from documents, or sentences with surrounding context that serve as the analysis unit for argument mining.
Step 2: Label Candidate Sampling for Target Data Adaptation
To ensure the validity of the entire process, the argument mining workflow needs manually labeled data from the target dataset that serves as the ground truth for training and validation of the machine classifiers. The problem is that argumentative text units can be relatively rare in many real-world data sets. Random samples usually contain a significant share of nonargumentative units, making it difficult to annotate large enough sets of pro- and contra-arguments for supervised machine learning. To circumvent this problem, we suggest employing zero-/few-shot learning as an effective transfer learning method (cf. Laurer et al., 2024) for a stratified sampling of label candidates. The basic idea is to train a candidate model on suitable support data for the respective task, stance detection, or aspect sequence tagging. Alternatively, researchers can rely on prompting a generative LLM such as Llama or GPT-5 in a zero-shot manner, that is, without any labeled examples, or a few-shot manner by attaching a small number of labeled examples to the prompt (Farjam et al., 2025). Predictions from such an initially trained/prompted model on texts from the target dataset are then used as intermediate labels that inform a stratified, balanced sampling of arguments referring to certain stances and/or aspects.
BERT-like models can be pretrained as candidate models on suitable argument mining datasets previously published by NLP researchers. As these publicly available datasets usually vary significantly in their language features from the target data, models trained on such support datasets do not generalize easily to applications in new domain contexts. Therefore, they should be used only as an entry point for adaptation to the target data. If some manually coded data is available from previous iterations of training data annotation (cf. Step 3), the procedure to train a candidate model for sampling further argument candidates can be altered to a setup where, in addition to the external dataset, the annotated target data is fed into the training process, too.
Fine-tuning of a PLM can be performed as multitask learning by training on two or more datasets in parallel or as intermediate fine-tuning, first on the support dataset and then on the actual target data. According to Weller et al. (2022), multitask learning is preferred when the target data is smaller than the support data. For the stance detection task, we recommend using the UKP Sentential Argument Mining corpus (UKP SAM) (Stab et al., 2018) with ca. 25,000 argumentative English sentences from web pages about eight controversial topics, the X-stance dataset (Vamvas & Sennrich, 2020) with 67,000 multilingual comments on more than 150 political issues from a Swiss election candidate website, or the multilingual XArgMining dataset with around 72,000 English-language sentences and their corresponding machine translations (Toledo-Ronen, et al. 2020) as support datasets. If multiple issues are contained in the support data, the input to the classifier (cf. Step 1) should be prepended as follows: “<issue>[SEP]<input>.” This way, the model can learn issue-specific associations between semantic features and stance labels while profiting from a large and diverse set of ways to express argumentative stances.
For the aspect sequence tagging task, we recommend the argument aspect corpus (AAC) by Ruckdeschel and Wiedemann (2022) as a support dataset providing ca. 5,000 argumentative sentences from four topics labeled with issue-specific aspect categories. As only four topics are covered, new studies will likely require the alteration of the value categories of the support dataset. To be able to find candidates for new value categories, the model target output can be altered from sequence tagging to a natural language inference (NLI) task (Laurer et al., 2024). For NLI, a BERT-like model is given two texts: a premise and a hypothesis. The model's job is to determine the relationship between them, classifying the hypothesis as either true (entailment), false (contradiction), or undetermined (neutral), given the premise. Pretrained NLI models such as the one published by Laurer et al. can be used for zero-shot labeling when presented with the input text as premise and the potential class label formulated as a hypothesis, for example, “<input>[SEP]This argument refers to the value of safety to support its stance on nuclear energy.” This way, PLMs can provide higher-than-chance accurate predictions for semantically expressive labels without any training data solely based on their internal knowledge representations. Again, predicted intermediate labels can be used to sample candidates for each aspect evenly from the target data. For a description of fine-tuning a transformer model with selected support data and/or manually labeled examples, see Step 4.
Step 3: Manual Annotation
To adapt candidate models to the target data, we must further train them on manually annotated samples. Training data must be labeled for both the stance detection and aspect sequence tagging tasks. First, an initial codebook needs to be developed that comprehensively describes how to detect stances and the intended value categories (cf. Barberá et al., 2021). Based on this codebook, human coders closely review and label the candidates for stance and aspect categories sampled during the previous step. After a labeling pretest, the codebook can be revised to better fit the data if deemed necessary, including removing or adding categories to the aspect label set and adding representative examples from the target data. Once the codebook is fixed, the complete candidate sample can be manually annotated. Stances are coded on entire text sequences. Value references are coded as token spans. We recommend using annotation tools that particularly facilitate the task of sequence tagging and multiuser management, such as Label Studio (Tkachenko et al., 2025) or doccano (Nakayama et al., 2018). These open source tools provide intuitive user interfaces and can be configured to perform complex annotation tasks. At least two coders should code each argumentative unit in the first rounds to track inter-rater reliability (IRR). After each round, the IRR, such as Krippendorff's alpha or Cohen's kappa, should be determined to check whether the coders have developed a sufficient mutual understanding of the categories. For IRR calculation of Task B, we recommend using a relaxed metric that already considers overlapping or the presence of spans with a certain category in an augment unit as agreement instead of requiring perfect matches of coded spans. Disagreements and unclear cases can be marked during the process and discussed after each round to reach a consensus decision and further clarify the category definitions. While a mutual understanding of argument stance is relatively straightforward to establish, shaping a mutual understanding of more abstract aspect references can become quite cumbersome in the face of empirical data. Further, it is challenging to reliably annotate the beginnings and ends of text spans for aspect references. One rule of thumb is that the shortest possible substring that allows us to recognize the aspect should be coded.
For the first round(s), it can be expected that the IRR is too low and, therefore, the training data is too noisy and incoherent for a valid and reliable model. To achieve acceptable results, several rounds of codebook refinement and coder training can be necessary. For this, Step 2 can be repeated by extending the support training dataset with manually annotated target data where most annotators agree on the label decision. Barberá et al. (2021) state that annotating more data with experienced coders is preferred over coding fewer samples with multiple coders. Consequently, once the IRR reaches a satisfactory level (e.g., substantial agreement in terms of Cohen's κ > 0.6), the remaining label candidates can be coded by one coder per sample. The final ground truth datasets for the classification/ tagging task can be compiled from annotations with majority agreement from multiple coders during the first rounds, together with the single-coded examples from the last round. How many text units are necessary for a well-performing classifier depends mainly on the complexity of the categories and the heterogeneity of the target dataset. As a rule of thumb, we observed a saturating classification performance at about 100 examples per category in our transfer learning setups with PLMs and support datasets.
Step 4: Stance Detection and Aspect Sequence Tagging
The manually annotated data serves as input for training a text classification model for stance detection and a sequence tagging model for aspect text spans. Transformer-based models require almost no text preprocessing or feature extraction, which simplifies their application drastically compared to previous classifiers like SVM (cf. Hickman et al., 2022). For social media data, we recommend removing URLs. Genre-typical text characteristics such as @-mentions of fellow users and hashtags for flagging thematic content can be retained if they carry meaningful semantics for the classification task.
After preprocessing, the labeled datasets should be split into a train, dev, and test set of common sizes, such as 70%, 10%, and 20%. The dev set can be used to determine optimal hyperparameters for fine-tuning the PLM. 1 The selection of the best PLMs for a specific project mainly depends on the language of the target data and the computing capacities available to the researcher. The DeBERTaV3 model by Microsoft (He et al., 2023) or ModernBERT (Warner et al., 2025) would be a good choice for English-only datasets. For cross-language transfer, as in our example case (cf. Section 4), the multilingual version mDeBERTaV3 (Warner et al., 2025), the XLM-RoBERTa model (Conneau et al., 2020), or the multilingual version of ModernBERT would be suitable. Although one can expect moderate losses of classification accuracy due to cross-language transfer (cf. Lauscher et al., 2020), their overall performance would still be good enough to act as a prefilter for annotation candidates.
For training the final models for Task A and B, we recommend the multi-task learning paradigm, which simultaneously trains on the public argument mining support data and the newly annotated target data, as this latter dataset would generally be the smaller one. In this setup, the parameter weights of a single transformer base model are shared across multiple tasks. The base embedding model feeds multiple classifier heads placed as parallel final layers on top of it. The simultaneous training of different tasks not only feeds additional knowledge to the classifier but also serves as a regularization process to effectively prevent overfitting of the model to the target dataset. When predicting new data, one simply extracts the labels for the target task and discards the labels of the support tasks. Depending on the dataset sizes, it can be advised to use task-specific loss weights to put more emphasis on the target task during the training process. Standard metrics such as recall, precision, and the F1-score, or Matthew's correlation, should be used to evaluate the final classifier performance. F1-scores way below 70% usually require further optimization either through annotation of more training data and/or optimization of hyperparameters. Otherwise, there is an increased risk of spurious results in downstream tasks due to too much noise in the argument mining results. For the aspect sequence tagging task, Ruckdeschel and Wiedemann (2022) advised altering the evaluation scheme from the token to the sentence level since achieving a substantial overlap between ground truth spans and predicted spans is unnecessarily difficult. More important than an exact matching of the beginning and end of a text span is whether the automatic process correctly predicts the presence of an aspect category in an argument.
Step 5: Final Prediction and Analysis
The trained models for stance detection and aspect sequence tagging can be used in a final step to predict stances and aspects for the entire target dataset, resulting in a tabular data structure similar to the example presented in Table 2. This table can be augmented by the actual text spans for each identified aspect reference. Before further processing the argument mining results, they should undergo a careful validation process, as usually advised in computer-aided text analysis on big data sources (e.g., Sen et al., 2021; Tonidandel et al., 2018). Thankfully, checking for construct validity, content validity, discriminant, and external validity (Short et al., 2010) is a straightforward process due to the opportunity to closely read samples of texts classified as either pro- or con-arguments, to look at frequent text spans for distinct value references, and to research the backgrounds of the users or organizations they originate from.
Once researchers are confident that the results from the process are sufficiently valid and complete, any aggregation for descriptive statistics or statistical modeling of more complex relationships in the data can be performed. In longitudinal designs, such aggregations allow researchers to identify shifts in the distribution of predicted stance and aspect labels across time periods. Additional arbitrary variables can be added to enrich the dataset, such as grouping selected authors to organizations or entire societal fields. For individual organizations, for instance, one can observe the development of stances and aspect references over time. For characterizing organization–environment relationships, it can be interesting to contrast this measurement with approaches that seek to explain which specific aspects can predict stances in the entire data population and how this changes over time. With network analytic approaches, communities and central actors that push pro- and contra-stances, their connectivity and degree of polarization could be determined (cf. Haunss & Hollway, 2023). Depending on the data source, interaction patterns of organizations with stakeholders and other audiences can be investigated by looking at references to previous arguments in dialogical conversations.
Eventually, quantitative argument analysis should be accompanied by a close reading of data samples, for example, from different label combinations, time spans, or actor groups, to check for face validity. Going further into mixed-method research, the approach allows sampling representative example data points for standpoints, salient aspects, time periods, and arbitrary author groups based on the quantitative results. These subsets can be exported to specific data formats, such as REFI-QDA, for further qualitative processing in QDA software (Evers et al., 2020).
Organization–Environment Relationship of the Greens in the German Nuclear Energy Debate on Twitter
To demonstrate how argument mining contributes to the study of legitimization processes in organization–environment relationships, we perform a large-scale analysis of social media data about nuclear energy in Germany. First, we introduce the case study by briefly characterizing the course of the debate. Second, we highlight our theoretical foundation to investigate selected debate aspects with an organizational research perspective. Third, we describe how we conducted the five steps of the argument mining workflow and, finally, present key findings from our analysis.
The German Nuclear Energy Debate
The public debate on the issue of nuclear energy use is characterized by several sociologically interesting puzzles that can be investigated on different levels. For the period after the Fukushima incident in 2011, Haunss and Hollway (2023) describe a momentous macro-level shift in the German political discourse network that contributed to explaining the policy pivot of the government to shut down nuclear energy production as soon as possible. Studying the media discourse in the aftermath of the decision on a mesolevel, Bohn et al. (2026) find a “frame reversal” of the semantics of the security frame. Nuclear power has been presented as an incalculable security risk for around a decade before the phase-out decision. However, in the face of climate change debates, it is often framed as a solution to a newly emerging security problem (Bohn et al., 2026). Most recently, the year before the shutdown of the last remaining reactors in 2023, a heated debate about the future of the technology was pushed in German news media and the political sphere, driven, among others, by parties that previously supported the phase-out decision. In our exemplary study, we investigate how organized actors from politics discuss the topic on Twitter (now called X) with ordinary users in a longitudinal perspective. We collected around seven million tweets posted between 2010 and 2022. We use ABAM to observe shifts in pro- and contra-stances and value references over time. For single organizations, the method can reveal alignment and divergence between organizational values and their environment as one factor to study the success or failure of organizations to create legitimacy for their talk, decisions, and actions (cf. Brunsson, 2007).
Legitimation, Values, and Organizational Talk
For our purpose—introducing argument mining to organizational research—we employ the concept of organizational talk and its legitimizing potential in shaping organizational discourse (Brunsson, 2007, p. 26). We choose this approach because Brunsson stresses that organizational talk, decisions, and actions must be legitimized to different stakeholders. Organizations do not present themselves to their stakeholders in a static way, but engage in interactions with them and adapt if necessary (Besio & Meyer, 2022). For this interaction, rationalizing and challenging decisions by arguments play a crucial role.
A particularly valuable resource for studying organization–environment relationships is social media, where both organizations and external actors engage in public, unfiltered communication, expressing their viewpoints and values on specific issues. Social media thus serves both as a unidirectional channel for organizational messaging and as an interactive forum, enabling a dialogic exchange between organizations and their environment (Romenti et al., 2014). In this context, argument mining offers a powerful tool to systematically analyze how organizations position themselves on controversial topics, how their arguments evolve, and how they interact with external stakeholders.
As organizations do not operate outside of society, they must legitimize their actions and decisions to maintain societal acceptance and ensure their continuity (Brunsson, 1986, p. 165; Parsons, 1956). This legitimacy can be rooted in values, which, as “conceptions of the desirable” (Kluckhohn, 1951, p. 391), manifest in behavioral regularities through ideas, symbols, and moral norms that organizations are expected to act upon. While values are often described as enduring beliefs (Rokeach, 1973), they are not immutable and evolve due to factors such as cohort or period effects (Inglehart, 2015). This dynamic nature of values is reflected in organizational “talk” as a key mechanism for shaping perceptions and influencing subsequent decisions and actions (Brunsson, 2007, p. 99). By analyzing the arguments and values embedded as justifying aspects in this talk, ABAM can provide insights into how organizations construct legitimacy, adapt to societal expectations, and navigate evolving value systems.
For our case study, we focus on the posts of the German Green Party (Bündnis 90/Die Grünen) as well as on the public reactions from both party members and external users. This allows us to investigate how organizational talk positions the party issue-wise concerning other (political) organizations, how the party intends to create legitimacy for its political demands and decisions by value references, and whether and how its positions are accepted or contested by its environment.
Mining Arguments From Social Media Data
Data collection (Step 1): For our case study, we analyzed a corpus of 2.1 million German-language tweets posted on Twitter between 2010 and 2022. Tweets were collected via the Twitter Search API v2, 2 matching the ISO-language code “de” and at least one of the following key terms referring to German variants of the term nuclear energy and nuclear phase-out: Kernenergie*, Atomenergie*, Nuklearenergie*, Atomkraft*, Kernkraft*, Atomausstieg*, Atomverzicht*, where * indicates typical suffixes. In addition, we collected 4.7 million more tweets from complete conversation threads, that is, the tree-structured set of all replies to one original tweet, when threads contained at least two tweets with matching key terms (see Figure 2 for an example conversation). This is based on the assumption that such conversations presumably contain additional debate-relevant tweets that do not necessarily use one of our key terms. The collection of entire conversation threads allows for more complex analyses of argumentative dynamics than isolated tweets. For tweet text preprocessing, we remove URLs, the hashtag-symbol # (but not the tag itself), @-mentions of users, and emojis. As short messages from Twitter/X already represent a coherent unit ready for argument mining, we do not perform any text segmentation for the subsequent processes.
Target data adaptation (Step 2): To obtain candidates for manual annotation from our German-language target data and English-language support data, we utilize the multilingual transformer XLM-RoBERTa as a base model and fine-tune two variants based on previously published datasets. First, we fine-tune a stance classification model with the UKP SAM dataset. As training input, we create text pairs in the format “<issue>lt[SEP]<sentence>” together with the annotated stance label (pro, con, no stance). This way, the resulting model can predict stances for arbitrary topics with moderate accuracy. With this model, we predict stance label candidates for all the 2.1 million target tweets that contain key terms of the nuclear energy debate. Second, as a multiclass text classification task, we fine-tune an aspect tagging model with the AAC dataset. Since we expected a considerable overlap between aspect categories in the AAC dataset and our target value categories, we simply predicted the most likely category of the 12 aspect categories of the nuclear energy topic from the AAC dataset as a preliminary value label for each tweet for the first annotation round. From the label candidates, a random subset of 600 tweets predicted as “no stance” was sampled. For tweets predicted as either pro- or con-arguments about nuclear energy, we sampled another 100 tweets per preliminary aspect category. This resulted in an initial set of 1800 tweets for manual annotation, containing a significant share of argumentative tweets and a relatively balanced distribution of preliminary value labels as aspects.
Manual Annotation (Step 3): A close inspection of the preliminary value labels before the first coding round revealed that the aspect categories of the AAC dataset did not fully meet the concept of social values in our project. Thus, we slightly modified the aspect codebook by differentiating the existing categories more clearly and extending it from 12 to 17 categories (see Table 3). We started by annotating a 10% random subset of the label candidates with two coders using the open-source tool doccano. Since the IRR was only moderate for this first round, the disagreement for labels was discussed, and the code definitions were further refined. Manual annotations with agreements and consensus decisions after discussions were then used as additional support data in another iteration of the candidate sampling Step 2. This resulted in a new, slightly larger, and more accurate second set of 2,300 tweets (600 no-stance candidates and 100 candidates per 17 categories) for manual annotation. We coded distinct sub-samples of 200 random tweets per round for four rounds. After the fourth round, we reached an IRR of Cohen's Κ = 0.73 for the stance labels and Κ = 0.61 for the value labels, which is widely considered a substantial agreement level (Landis & Koch, 1977, p. 165). The final ground truth dataset contains 2,264 tweets (including 1,656 stance-taking tweets) and 3,074 value-tagged text spans (see Table 3 for dataset statistics and IRR scores).
Annotated Dataset Statistics.
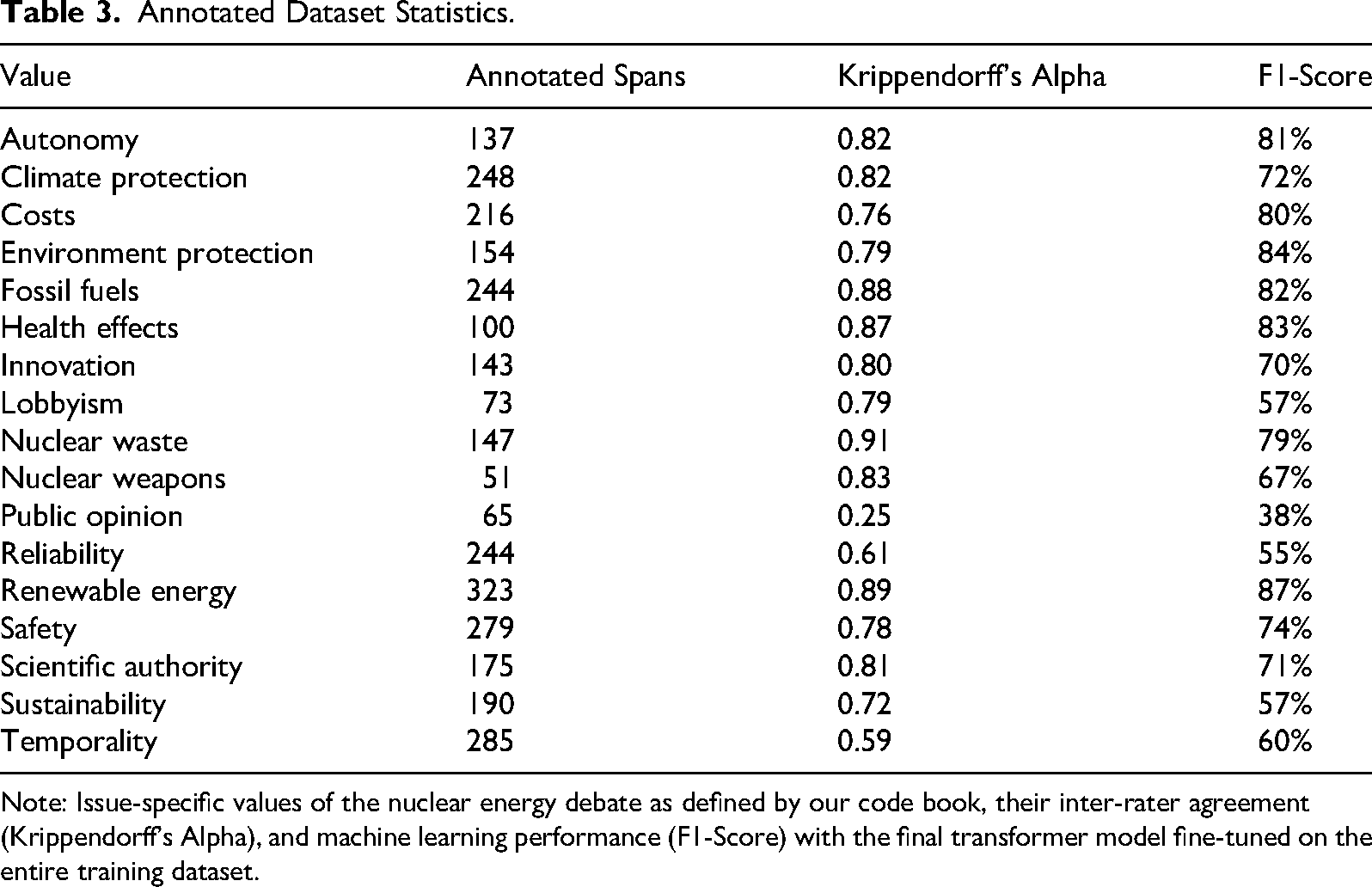
Note: Issue-specific values of the nuclear energy debate as defined by our code book, their inter-rater agreement (Krippendorff's Alpha), and machine learning performance (F1-Score) with the final transformer model fine-tuned on the entire training dataset.
Stance detection and aspect sequence tagging (Step 4): We fine-tuned a final XLM-RoBERTa model for stance detection with two multi-class classification tasks, the target task with our manually annotated data and the support task with the UKP SAM dataset. The model achieves a micro F1-score of 79% on the target data test set (pro 82%, con 77%, no stance 75%). For the aspect sequence tagging, we fine-tuned another XLM-RoBERTa model on the annotated target data together with partial data from the AAC dataset from the nuclear energy topic as a support task. Table 3 shows the classification performance for the individual values on the test set. The model achieved a micro F1-score of 73% (macro F1: 71%) on the target test set with individual value categories ranging from around 55% F1-score (lobbyism, sustainability, and reliability) to more than 80% (e.g., costs, health effects, and renewable energy). With only a 38% F1-score, “public opinion” could not be classified reliably as a value reference, mirroring the low inter-rater agreement during manual annotation. It will, therefore, not be taken into account for further analysis. While the overall result from this automatic argument mining step can be considered acceptable for further analysis, the three value categories with the lowest F1-scores must be handled cautiously during the final analysis. Conclusions drawn from measurements of these categories need particularly careful validation.
Final prediction and analysis (Step 5): With the final models for the two target tasks, we predict stances and value text spans for all 6.8 million tweets (keyword-matching tweets and their conversational thread contexts). From the original API result dataset, we used author information and the creation date of the tweets as metadata for the analysis. Additionally, we linked accounts of parliamentarians and organizations related to German political parties using an external resource, the database of public speakers by Schmidt et al. (2023), to allow for a closer inspection of the environment of political organizations in the social media debate.
Insights for the Organizational Perspective
We use the ABAM results in three final analyses to illustrate its potential for gaining complex insights: descriptive statistics to reveal the development of argument patterns over time, regression analysis to explain viewpoint changes through shifts in justification values, and interaction patterns of (counter-)argumentation between an organization and its environment. Thereby, we focus on “Bündnis 90/Die Grünen” as an example of a political organization. As we primarily focus on methodological opportunities, we limit ourselves to briefly highlighting key findings and refrain from further in-depth interpretations.
Surveying Stances in the Organizational Environment
The resurrection of the nuclear energy discourse in German media and politics in 2022 was accompanied and, as our data shows in Figure 3, already preceded by intense social media activities and a significantly increased polarization on the issue. As a first approach to the data, we conduct a descriptive statistical analysis of the pro- and contra-arguments to track the majority opinions and their shifts over time. The resulting temporal aggregates of predicted stance labels make shifts in majority positions directly visible in the data, which then can be related to external events or broader developments.
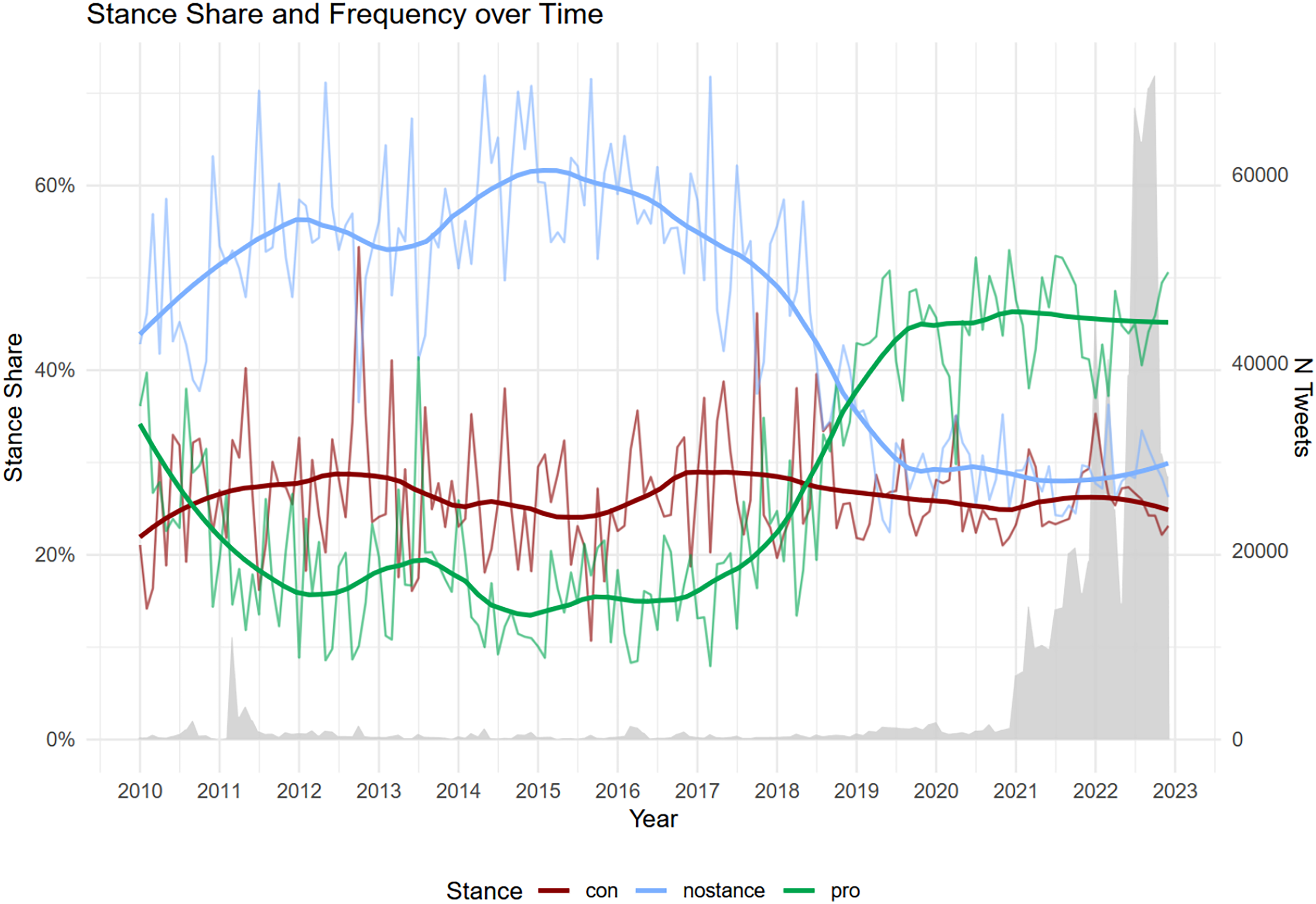
Longitudinal development of the nuclear energy debate.
This basic analysis already reveals highly intriguing developments that characterize the course of the debate. The tweet frequency graph in Figure 3 (gray area chart) highlights points of intensified debate in 2011, the year of the Fukushima nuclear disaster in Japan. Phasing out nuclear power was one of the primary goals of Germany's Green Party from the outset when it was founded in the early 1980s. After years of political struggle, even liberals and conservatives were ready to abandon nuclear power in light of the reactor catastrophe (cf. Haunss & Hollway, 2023). In the following years, shorter peaks in debate intensity can often be linked to events such as safety issues of single reactors and national or global discussions on future energy production in the context of climate change. The overall frequency of the debate has slowly but steadily increased since 2018, followed by a sharp surge in tweet activity from December 2020 onward. We hypothesize that much of the initial rise can be linked to growing protest movements against fossil fuel use in Germany's energy mix, such as “Ende Gelände,” which opposed new lignite mines, and “Fridays for Future,” which called for immediate climate action and organized its first global student strike in March 2019 (Marquardt, 2020). These protests sparked a broader societal debate about the future of Germany's energy production. The drastic increase in tweet activity from 2021 onward may also be partly influenced by the COVID-19 pandemic, which likely affected overall social media usage and, indirectly, specific topic trends.
When we contrast the frequency development with the development of pro-, contra-, and non-argumentative statements about nuclear energy, findings become even more intriguing. Over the study period, the analysis reveals two major shifts in the majority stances. The first occurred in 2011, when a slight pro-nuclear majority gave way to a consistent contra-majority, coinciding with the Fukushima disaster. This balance shifts again after 2017, as pro-nuclear arguments rise significantly, mainly at the expense of neutral statements, and form a clear pro-majority by mid-2018. Notably, the surge in activity from 2021 onward does not alter this distribution of argument stances. These patterns suggest an early polarization of the Twitter debate, likely driven by global climate policy discussions and related social controversies. Looking at the distribution of highly active accounts over time (not shown here) reveals that many new actors, primarily pro-nuclear and politically motivated, have entered the debate during the last years of the study period.
These findings illustrate the vital contribution that systematic observation of the environment can make for organizations, especially when operating in a specific issue area, as they must remain responsive to changing conditions (Brunsson, 1986; Luyckx & Janssens, 2016; Nyberg et al., 2020). The Green Party, for instance, which has long championed the phase-out of nuclear energy, could have benefited from an early warning that by 2018, they were no longer in line with the majority of social media on this issue.
Shifting Patterns of Value-Based Justifications
To advance organizational research, it is necessary to move beyond analyzing stance distributions and examine the underlying normative structures that give rise to argumentative positions. For organizations, it is essential not only to track shifts in public opinion on issues relevant to them but also to understand whether the underlying values they embody are changing and whether such changes could threaten the organization itself by eroding stakeholder support and societal legitimacy (Brunsson, 1986; Inglehart, 2015; Schwartz, 1992; Welzel, 2009). To address this, we examine the distribution of social values in relation to argumentative stances. Specifically, we ask to what extent references to specific values explain argumentative stances and how these relations change over time, potentially indicating broader shifts in societal value attribution.
We conduct a binary logistic regression analysis to examine the influence of referenced social values on argumentative stance. To capture temporal dynamics, we divide the dataset into three phases, informed by the descriptive statistical trends: the years 2011–2016, characterized by a clear contra-majority; 2017–2020, marked by contestation between pro- and contra-positions; and 2021–2022, during which a pro-stance stabilizes as the new hegemonic position in the Twitter discourse. As illustrated in Figure 4, the analysis reveals that roughly half of all argument aspects are strongly associated with either stance. Reactor safety and nuclear weapons emerge as key concerns for anti-nuclear arguments, while technological innovation and climate action are the strongest predictors of pro-nuclear positions. The dominance of specific values is linked to organizational pressure to conform and respond appropriately to environmental expectations. In 2011, for example, political organizations could not simply position themselves against reactor safety. Conversely, since 2017, it has become increasingly impossible to ignore the issue of climate protection in the debate on nuclear energy.
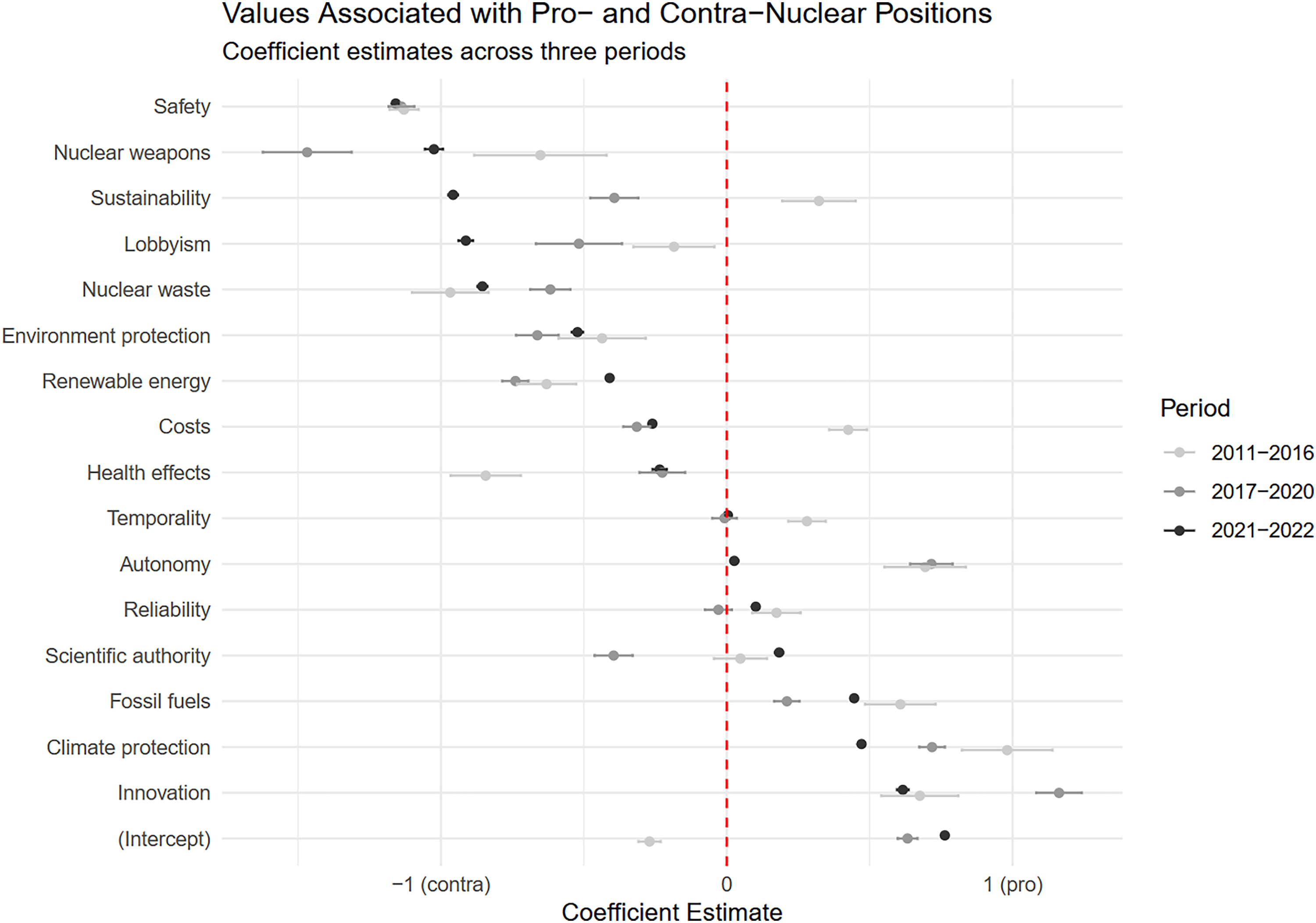
Logistic regression of argument stances and justifying values.
More insights emerge from significant coefficient shifts across the different phases. For example, references to sustainability initially supported pro-nuclear positions in the early debate but later transformed into a clear counter-argument. To some extent, this shift can be explained by the dispute about changes in the EU taxonomy that 2022 declared nuclear energy as a sustainable power source (cf. Egres & Sarlós, 2024). In Germany, this was heavily criticized by the government and became a heated debate on Twitter. Energy autonomy and independence from other countries remained a consistent component of pro-nuclear arguments throughout the entire period. A qualitative review suggests that recent contra-arguments emphasize the geopolitical risks of uranium imports, particularly from unreliable partners such as Russia. In contrast, health-related concerns, previously central to contra-arguments, have shifted to the point where they now support pro-nuclear stances, as nuclear power generation is no longer considered harmful due to technological advances.
Organizations need to observe how their values align with those of their environment and if the latter's values are suspected to change. The Green Party, for instance, justifies its anti-nuclear stance mainly with references to safety issues, high costs, and nuclear waste (cf. Figure 5), premises that are increasingly contested by pro-nuclear users and whose prevalence declined over the study period. In these cases, organizations must determine whether these shifts are strategically relevant, requiring adjustments in their communication with stakeholders or their environment, or even informing their internal decision-making processes.
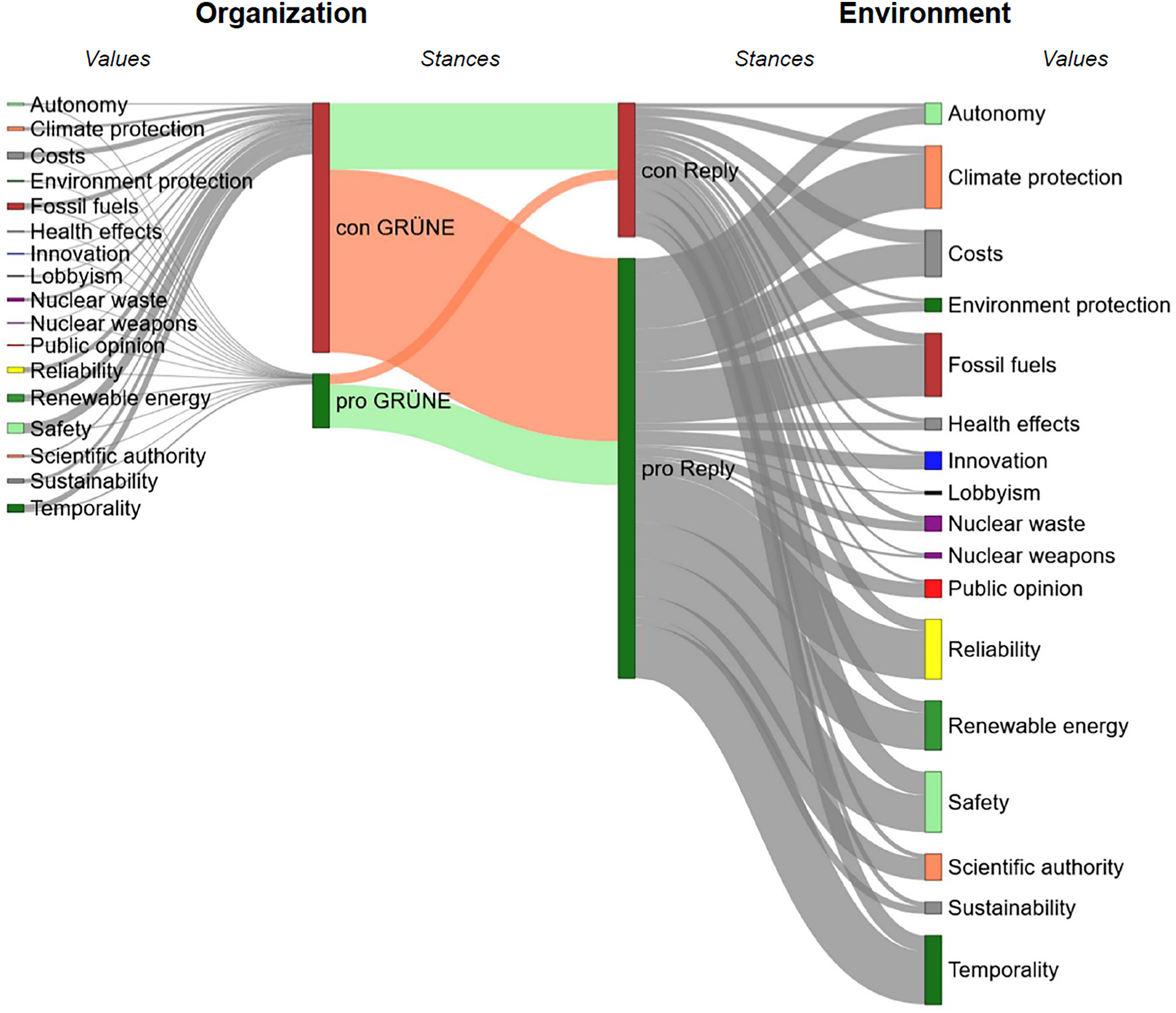
Sankey diagram of the stances and values of the Green Party and its commentators.
(Dis-)Alignment of Organizational Talk and Environmental Interaction
Before making strategic adjustments, organizations may first engage in dialogue with their environment to better assess the stability of prevailing stances and values. Social media provides a valuable window into such organization–environment interactions. Twitter/X accounts can be categorized based on their association with organizational entities to compare talk from organizations to stances and justifications in their environment.
We examine the argumentative interaction patterns of the Green Party with other users on the platform as an example. Figure 5 displays a subset of the discourse involving all Green Party accounts (left part), that is, party organizations and parliamentarians on the federal and national level, and users replying to their posts (right part) as a Sankey diagram. As expected, the Greens post a large majority of arguments against nuclear energy. More surprisingly, however, is the large share of pro-arguments by users counter-arguing the party's position. Vice versa, only a few pro-arguments uttered by Green Party accounts are attacked with counter-arguments and supported with significantly more pro-arguments instead. Focusing on the stances, most user posts in the discussion reject the critical stance against nuclear energy pushed by the Greens. A further look at the value references reveals informative differences between the two groups. While references to reactor safety and costs mainly justify the party's position, pro-leaning users often respond with references to climate change, fossil fuels, and reliability in their counter-arguments. The fact that climate change is mainly neglected in the Greens’ argumentation against nuclear energy, while it is, at the same time, highlighted by pro-nuclear users, is a salient and surprising pattern, considering climate protection and the transition away from fossil fuels being core values for the party. The patterns we find suggest a possible gap in the party's public communication, which eventually serves as an open gateway for the opinion shift during the study period. We argue that this partially explains why the Green Party and the anti-nuclear movement could not defend their hegemony on Twitter regarding the nuclear energy issue as soon as the climate issue began to take over the public agenda. Moreover, it complements findings from previous studies that determined a shift in the general news media coverage of nuclear energy from framing it as a security risk to a means of achieving climate security (Bohn et al., 2026).
Discussion
The exemplary study of the Green Party in the German nuclear energy debate demonstrates the analytical leverage that ABAM provides for organizational research. By tracing changes in argument stances, value references, and organization–environment interactions over time, the analysis revealed that shifting societal expectations did not affect the Greens’ organizational talk. Instead, the reframing of nuclear energy from a safety to a climate issue on Twitter produced increasing misalignments between the party's communication and its environment. This unnoticed divergence weakened the party's legitimacy on some of its core issues and ultimately undermined its role as a credible political representative of overall environmental interests in the eyes of many commentators. These findings underscore how ABAM enables the systematic observation of legitimacy dynamics as they unfold in public discourse. While qualitative approaches to the discourse most likely would have also identified the societal values that are referenced to justify different positions, they would have probably missed the patterns of shifting dominance during a certain time period, and the extent to which changing values contributed to it. However, the operationalization of aspects for argument mining is not restricted to (societal) values. Depending on the research question, other aspect types such as pointers to scientific evidence (e.g., studies, scholars and experts, or statistics) or references to laws and legal frameworks could be investigated, which may be more common in document types other than social media posts, but also play an essential role in organizational legitimization (Deephouse et al., 2017).
As arguments are communicative acts that constitute social reality, ABAM serves as an epistemic tool that makes those constitutive processes empirically observable at a large scale. Like manually conducted analyses of arguments, ABAM is based on a communication-centered ontology of argumentation and organizational talk. Its premise is that arguments are socially consequential acts of communication and justification through which organizations and their environments articulate, contest, and adjust their positions. It does not claim to know the intentions or personal attitudes of the creators of communication, nor does it claim to represent universal or factual truths. Instead, it replicates manual steps of analyzing arguments by encoding the interpretive knowledge gained from an empirical sample into a codebook, labeled training data, and machine learning models for different tasks.
As a text mining method, ABAM produces structured representations of argument components that are learned from recurring local patterns in training data and applied to empirical target data. By this, it extends qualitative approaches with a quantitative perspective on the data that allows for probabilistic and intersubjectively verifiable truth claims. Again, it is important to note that instead of interpreting the data on its own, the machine only seeks to replicate the human interpretations encoded in categorizations of the training data. The main advantage of scalability through automation is that we, for instance, can look for global patterns of longitudinal developments, assess the role of a wide range of discourse-shaping actors, or compare multiple cases. This can effectively prepare and inform subsequent interpretative analysis when integrated with social science methodologies, such as discourse analysis (Grant et al., 2001; 2004; Pandey & Pandey, 2019), (qualitative) content analysis (Duriau et al., 2007; Reger & Kincaid, 2021), or grounded theory (Nelson, 2020). Table 4 provides an overview of how these different methodologies can be informed by argument mining.
Positioning Argument Mining in Relation to Other Method(ologies)s.
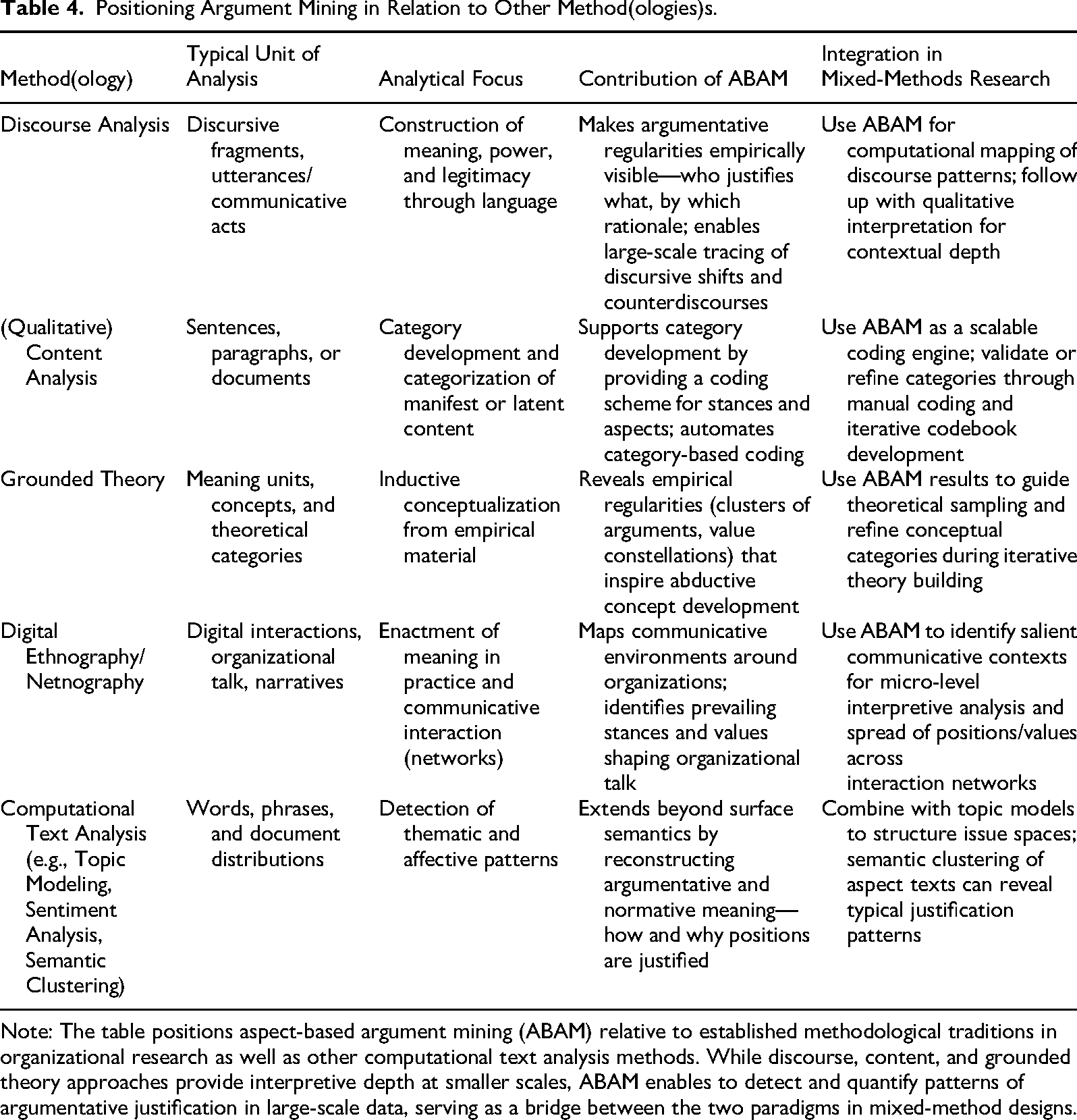
Note: The table positions aspect-based argument mining (ABAM) relative to established methodological traditions in organizational research as well as other computational text analysis methods. While discourse, content, and grounded theory approaches provide interpretive depth at smaller scales, ABAM enables to detect and quantify patterns of argumentative justification in large-scale data, serving as a bridge between the two paradigms in mixed-method designs.
With a discourse analysis perspective, for instance, ABAM enables the systematic tracing of argumentative patterns to describe the evolution of discourses and counterdiscourses over time, the identification of shifts in dominant positions, as well as monitoring social value references and actor coalitions that drive this development. For grounded theory, identified argument patterns can serve as an intermediate coding layer that facilitates theoretical sampling and concept development. Detected stances and aspects can be used as first-order codes to salient argumentative phenomena and, in the end, inform new theoretical constructs. For digital organizational ethnographies (cf. Akemu & Abdelnour, 2020; Yanow, 2012), ABAM can serve as a quantitative mapping of communicative environments, identifying which stances and legitimizing patterns circulate around an organization or policy. When integrated into mixed-method research designs, ABAM acts as a bridging tool between a quantitative perspective and interpretive methods. This allows for asking new questions (cf. Tonidandel et al., 2018) and offers new perspectives for theory building by combining the observation of statistical patterns of complex semantic concepts closely with the interpretative reconstruction of their meaning.
Furthermore, our case study has demonstrated how argument mining can be linked to a theoretical basis for researching organizational legitimacy. We believe that argument mining as a method can also be productively related to a variety of other theories. For example, there is the possibility of connecting recurring (prevalent) patterns of argumentation to organizational sensemaking processes (Weick et al., 2005). ABAM allows tracing how organizations and their environments construct, stabilize, and revise shared interpretations of contested issues over time, thereby offering an approach to empirically map sensemaking dynamics. Moreover, it is possible to capture organizational reasoning practices over longer periods of time for legitimation. This could be studied against the background of legitimation theories (e.g., Deephouse & Suchman, 2008; Luhmann, 1989) or in connection with neo-institutionalism (Meyer & Rowan, 1977) by providing a novel perspective on the coupling of organization and environment. This is true both in the sense that organizations reflect and adopt values from their environments (Besio & Meyer, 2022; Perkmann & Spicer, 2014; Risi et al., 2023) and in the sense that they discoursively contribute to shaping societal values and institutions (Chen et al., 2013). This last approach could also find resonance in approaches that stress the relevance of organizational rhetoric (Bohn et al., 2026; Boyd & Waymer, 2011; Ihlen & Heath, 2018) and impression management (Allen et al., 2026; Bolino et al., 2016). In particular, our approach could help understand the resonance of organizational attempts to shape values, attitudes, institutions, and even emotions. As another possible connection, we see the potential for the methodological operationalization of field theory and field analysis approaches (Bohn & Gümüsay, 2023; Wooten & Hoffman, 2017), particularly as a means to systematically describe complex stakeholder and organization–environment relationships in cross-level designs.
While the aforementioned possibilities for methodological integration and broad compatibility with established theories of organizational research are clear strengths of the approach, it also faces some limitations that can negatively impact its applicability and usefulness. First and foremost, ABAM requires a large amount of textual data containing substantial amounts of argumentative units. Compiling such a large dataset from diverse sources, such as organizational documents, traces of internal and public communication, protocols, or reports, can be challenging. As in our example case, social media is a rich and accessible source for studying an organization's environment. However, only this part of the environment that is actively participating in the discourse can be observed. The demographic characteristics and opinions of active German Twitter users in the nuclear energy debate, for instance, differ considerably from those of the overall German society. These limitations on the representativeness of the results need to be carefully considered during the interpretation of the results, as well as the fact that, in general, conclusions about causality based on correlation between independent and dependent variables in the data are hardly possible. Nevertheless, the focus on Twitter (now X) provides important insights because (representatives of) many important organizations use the platform to express their views, thereby significantly reflecting and shaping the public discourse. Second, the manual effort to annotate sufficiently large training datasets for the argument mining tasks is still considerably higher compared to data-driven methods such as topic modeling. PLMs and transfer learning from support datasets, as suggested in our workflow, have already reduced the necessary amount of manually annotated samples. A further reduction of efforts and simplification of the entire workflow can be expected through generative LLMs such as GPT-X or the Llama model family, which can identify argumentative structures via in-context learning (cf. Cabessa et al., 2025). While most recent LLMs achieve surprisingly accurate results for single argument mining tasks even without any training data, NLP studies show that fine-tuning of (smaller) LLMs still improves considerably upon their zero-shot performance (Cabessa et al., 2025). Moreover, as ABAM combines several tasks, results for each task need careful validation to mitigate error propagation throughout the workflow that could seriously harm the results of purely automatic end-to-end workflows (cf. Haunss & Blessing, 2025). At the same time, the feasibility of LLM-based argument mining is limited by computing resources when data collections comprising tens of thousands of document pages or millions of social media posts need to be processed. LLM queries that can easily take one or more seconds per given input may take weeks to process very large datasets, even on professional GPU servers. Currently, striving for the most accurate results possible while minimizing computational costs still favors fine-tuning smaller, BERT-like encoder models instead of switching the workflow entirely to generative LLMs. However, LLM-based classification can deliver a very good entry point for selecting smaller samples of argument candidates from the data that can be used for manual labeling, as described in Step 2 of our workflow (cf. Section 3). Third, as text classification in general, argument mining is not 100% accurate in determining arguments’ stances and value references. Generally, it must be accurate enough to validly detect significant patterns in the data in downstream tasks such as regression or network analysis. Ambiguous statements and linguistic phenomena such as irony and sarcasm, which frequently occur in social media posts, can pose a challenge (cf. Luyckx & Janssens, 2016, p. 1613). In cases when the reversal of argument stances due to sarcasm remains undetected, it decreases the accuracy of automated argument mining steps. As we noticed during our training data annotation, humans also struggle to detect these phenomena reliably, thus pointing to a more general methodical issue. Fortunately, careful validation of the results from individual workflow steps has demonstrated that state-of-the-art NLP models can be expected to perform sufficiently well most of the time.
Conclusion
In this article, we presented an argument mining workflow based on a combination of state-of-the-art NLP approaches adapted to the requirements of organization research. We further demonstrated the method's potential in an exemplary case study about the German nuclear energy debate on Twitter over 13 years. For the Green Party, a selected political organization with a vital interest in the issue, we showed (1) how argument mining provides an insightful analysis of prevailing argument patterns in its organizational environment, (2) how specific values essential to the organization contribute to the explanation of shifts of pro- and contra-stances in the debate over time, and (3) how value references in arguments can be compared to reveal alignment or divergence between the organization and its environment potentially affecting the organization's legitimacy. At this point, qualitative methods could be used for more in-depth analysis to produce further interpretative insights.
In summary, argument mining is particularly useful when researchers
want to analyze communicative legitimization strategies around (controversial) organizational talk, decisions, and actions, have a large corpus of relevant, textual data at hand that (potentially) contains a lot of arguments to extract, are interested in the relation of argumentative structures in documents or dialogical interaction, are interested in the longitudinal or cross-sectional comparisons of argumentation patterns across actors, organizations, or fields, want to extend qualitative analysis on argumentation with a quantitative perspective in a mixed-method design, and have the personnel and computational resources at hand to generate training data and fine-tune LLM-based text classification models.
Conversely, the method is less suitable for small sample sizes, texts with little argumentative content, or situations where the primary focus is on factual accuracy, thematic segmentation, or the author's intent in texts. If applied successfully, ABAM provides us with new information from large-scale analysis of organizational talk that, in the best sense of big data, allows for new questions to be asked. When applied to conversational data, for example, from social media or online forums, it provides a way to generate insights from the graph structure formed by reply relations of user comments—something that is rarely investigated in organizational research. Particularly, looking for the alignment or divergence of argumentative patterns of organizations in communicative interaction with different stakeholders provides us with a rich and valuable source to better explain and understand expectations placed on organizations compared to organizational behavior. The deeper semantic level that argument mining focuses on, compared to other computational approaches like topic modeling, is highly compatible with qualitative researchers’ ambition to gain a deeper understanding of their research subject. This way, ABAM is very well suited to serve as a quantitative part in mixed-method research designs. It can, for instance, contribute to theory development by linking prevalent and salient argument structures from large-scale data to qualitative reconstruction of their situated meanings based on representative samples. Beyond the illustrative case presented in this article, the approach applies to a wide range of research questions, including different issues, data sources, and theoretical frameworks related to the analysis of arguments. Although assembling suitable data and fine-tuning transformer models remains demanding, rapid advances in generative LLMs, especially their growing aptitude for stance detection and aspect categorization via in-context learning, are poised to make the method far more accessible and widely applicable. By bridging computational scalability with interpretive depth, ABAM offers organization researchers a powerful tool to study how organizations argue, adapt, and sustain legitimacy in increasingly digital communication environments.
Footnotes
Acknowledgments
We would like to thank Anna Skripchenko, Mattes Ruckdeschel, and the patient and meticulous reviewers for their contributions to the preparation and refinement of this article.
Funding
This work was funded by the Federal Ministry of Research, Technology and Space (BMFTR) as part of the project “FLACA: Few-shot learning for automated content analysis in communication science” (Project No. 16DKWN064B) and by the Deutsche Forschungsgemeinschaft (DFG) as part of the project “ReNEW: Rekursive Normenbildung in der Energiewende – Zum Wandel der Energieversorgung” (Project No. 442734315).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.