
Abstract
Supported by decades of research on praise and its effect on student behaviors, we developed the Behavior-Specific Praise–Observation Tool (BSP-OT) to measure characteristics of effective praise. We evaluated interrater reliability of the BSP-OT to measure praise specificity, contingency, and variety using intraclass correlation (ICC) and Cohen’s kappa statistics. In addition, we assessed usefulness and practicality of the tool with social validity measures. Four raters with experience in praise research completed a survey and coded videos (n = 14) of teachers in authentic situations delivering praise. Overall assessment indicated strong reliability between raters with ICC(2, k) of .80: 95% confidence interval (CI) = [0.77, 0.83], F(269, 19906) = 5.1, p < .001, and mean kappa score of .91. Furthermore, high social validity ratings suggest the BSP-OT is a valuable contribution to the field concerning praise research and teacher development. The process of developing the BSP-OT and study findings are presented, with a discussion of implications and suggestions for future research.
Keywords
Researchers have studied the effects of praise on students with disabilities for decades (e.g., Gable & Shores, 1980; Hall et al., 1968; Markelz et al., 2019; Sutherland et al., 2000). Unfortunately, the long history of praise research limits the methodological quality of many studies included in systematic reviews to determine whether teacher praise is an evidence-based practice (Moore et al., 2019). However, empirical evidence repeatedly demonstrates positive effects of praise on a range of academic and behavioral outcomes, including increased student time on task, decreased inappropriate behaviors, and reduced student tardiness (Royer et al., 2019). Furthermore, praise has been associated with positive classroom environments and improved teacher–student relationships (Conroy et al., 2009; Reinke et al., 2013). But not all praise is deemed equally effective. Over the years, effective functional and topographical characteristics of praise have emerged from research.
Characteristics of Effective Praise
Specificity
The literature classifies praise into two broad categories, general and behavior specific. General praise (GP) consists of brief and ambiguous statements, such as “Great job, Annie,” or “Nice work, Kevin.” GP can deliver positive affirmation to a student; however, it does not clearly communicate why the student received affirmation. Behavior-specific praise (BSP) consists of a behavioral description with positive affirmation to clarify which observed behavior the teacher is acknowledging. Examples of BSP include “Excellent job waiting patiently for me to call on you, Sarah,” or “I love how Jenny and Jon are working quietly together, great job!” These examples demonstrate how BSP provides explicit feedback on student performance while also communicating expectations to other students in the classroom. According to Hirn and Scott (2014), student feedback involves specific actions by the teacher to indicate success or failure in response to student behavior (academic or social), which acts a positive affirmation of success that is delivered in the form of positive praise. There is a consensus that BSP is more functionally effective than GP given that specific feedback is a greater reinforcer (Brophy, 1981a, 1981b; Cooper et al., 2019; Skinner, 1953). However, there are other characteristics of praise, besides specificity, that researchers have identified as important to praise’s efficacy; yet, those characteristics have not been empirically investigated.
Contingency
Researchers of praise identified praise contingency as another important functional characteristic of effective praise (Brophy, 1981a; Floress et al., 2017). Contingent praise is when an affirmative statement follows the occurrence of desired behaviors. For example, Sarah raises her hand quietly and waits for the teacher to call on her. The teacher delivers contingent praise by saying, “Thank you for raising your hand quietly, Sarah.” Noncontingent praise would be if Sarah raised her hand but was calling out, and the teacher said, “Thank you for raising your hand quietly, Sarah.” In both examples, the teacher delivers BSP; however, contingent praise is more effective in reinforcing desirable behaviors because the delivery of positive reinforcement is only delivered when the behavior occurs. Noncontingent praise communicates to Sarah that she can raise her hand, call out, and still receive praise.
In addition, contingent praise should immediately follow the behavior given the importance of reinforcement immediacy. Reinforcement delay can diminish intended effects because the behavior temporally closest to the presentation of the reinforcer will be strengthened by its presentation (Cooper et al., 2019). In other words, if the delivery of praise is delayed and another behavior occurs, a teacher may inadvertently reinforce a nontarget behavior.
Given the importance of contingent praise, we reviewed the literature to identify studies where BSP or GP were dependent variables and whether contingency was measured (see Table 1). Out of 38 studies, 16 studies mentioned contingency (or a concept synonymous with contingency) in the praise definition. For example, Hawkins and Heflin (2011) defined BSP as “contingent verbal praise given by the teacher that specified the desired behavior for which the student was being praised” (p. 100). Although contingency was mentioned in 16 studies, no study empirically examined whether praise statements were contingent or not. Meaning, participants might have used noncontingent praise statements; yet, those data were not reported in results. Although contingent praise is deemed more effective than noncontingent, the absence of data differentiating between contingent and noncontingent praise is concerning and leaves a gap in the literature on characteristics of praise.
Characteristics of Praise Studies.
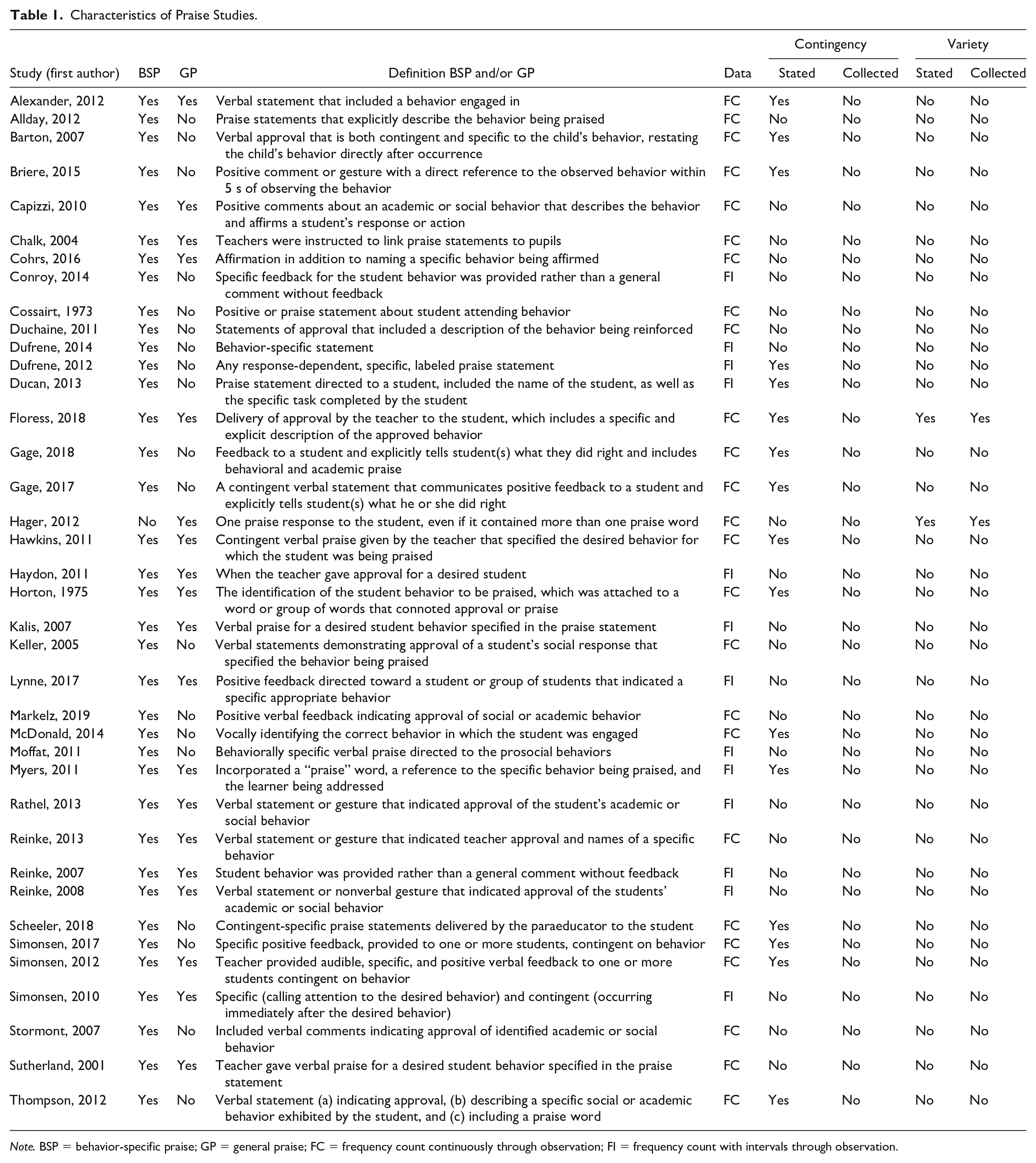
Note. BSP = behavior-specific praise; GP = general praise; FC = frequency count continuously through observation; FI = frequency count with intervals through observation.
Variety
A third characteristic, praise variety, is a topographical characteristic of effective praise. The efficacy of praise variety is grounded in research about the quality of reinforcer (Cooper et al., 2019). A stronger reinforcer will more likely affect behavior. Habituation of a reinforcer is when a reinforcer decreases in strength following repeated delivery of that reinforcer (Thompson & Spencer, 1966). A student who hears “good job” repeatedly may habituate to that praise statement and find it not as reinforcing. Therefore, a teacher who uses a variety of praise statements (e.g., excellent, awesome, great) may increase the novelty of praise, capturing the attention of the student, and increase the strength of reinforcement.
Out of our review, two studies mentioned and measured variety of praise (Floress & Beschta, 2018; Hager, 2012). Floress and Beschta discussed “diverse praise” and identified eight categories: (a) work/job, (b) adjective, (c) effort, (d) compliance/appreciation, (e) gesture, (f) tangible, (g) physical, and (h) miscellaneous. Although the authors identified eight categories, they coded praise variety based on the behavior targeted. For example, if the observed teacher had a total of three BSP statements, including “Thank you Johnny for sitting”; “Johnny, you are doing a great job sitting”; and “I like how you helped your neighbor,” the first two statements were counted as one praise variety because both targeted the behavior “sitting.” Therefore, the teacher had a total of two praise variety statements for this observation.
Hager (2012) measured praise variety by differences in the adjective used. For example, “great job paying attention” and “awesome job paying attention” counted as two praise variety statements. Some researchers have investigated the effects of praise on academic behaviors (e.g., Kirby & Shields, 1972); however, a majority of student outcome measures center on increasing appropriate behaviors (e.g., Rathel et al., 2014). It seems appropriate that on-task behaviors are targeted for improvement, given the challenges teachers report managing student behavior (Reinke et al., 2011) and the salience of teacher praise to affect student outcomes (Gage & MacSuga-Gage, 2017). Although, praise statements can vary across multiple categories as identified by Floress and Beschta (2018), adjective or descriptive variety may be the best method to enhance the novelty of praise when targeting a specific behavior. For example, if a student’s behavior support plan identifies a specific behavior for improvement (e.g., staying in one’s seat), the teacher will want to praise the student when that behavior occurs: “Great job staying in your seat, Dylan” or “Dylan, I appreciate how hard you are working and staying in your seat.” Using a variety of descriptive statements may maintain the novelty of those praise statements and increase their efficacy.
Data Collection of Praise
Frequency counts are the overwhelming data collection procedure for praise statements (see Table 1). With frequency counts, researchers have recorded specificity of praise (i.e., BSP or GP) and usually report as rate per minute or overall totals. One reason for simple frequency counts of praise (by interval or continuous count) is likely due to the nature of praise data collection. An observer needs to be present in a classroom for live observations, or a video recording is needed to observe praise delivery. The more characteristics of praise measured, the more complex the data collection procedure becomes. To date, an observational tool designed to easily measure multiple characteristics of praise has not been validated. We believe the field of teacher development needs an observation tool that measures functional and topographical characteristics of praise.
Purpose of Study and Research Questions
Although research on praise documents the importance of contingency and variety (e.g., Floress et al., 2017; Simonsen et al., 2017), explicit measurements of such characteristics are lacking. Researchers of praise would benefit from more accurate measurements to inform the field of teacher development on whether certain characteristics contribute differently to praise efficacy. The purpose of this study, therefore, was to examine the reliability of the Behavior-Specific Praise–Observation Tool (BSP-OT) so that the field of teacher development can utilize a precise tool for measuring effective praise. We explicitly aimed to measure praise specificity, contingency, and variety. The following two research questions guided our analyses:
Method
BSP-OT Development and Use
The training packet is located in the supplemental material and includes an introduction to the BSP-OT, definitions and examples, scoring procedures, and a completed BSP-OT example. Table 2 highlights each dimension of the tool. Based on our desire to capture multiple components of praise, we designed the BSP-OT to be practical for live observations and adaptable to accommodate individual observational needs (e.g., duration of intervals or total duration of observation). Within the BSP-OT, one can find lettered rows and numbered intervals to help observers maintain accurate data collection, while also allowing for easy interobserver agreement (IOA) calculations.
Descriptions of the Dimensions in the Observation Tool.
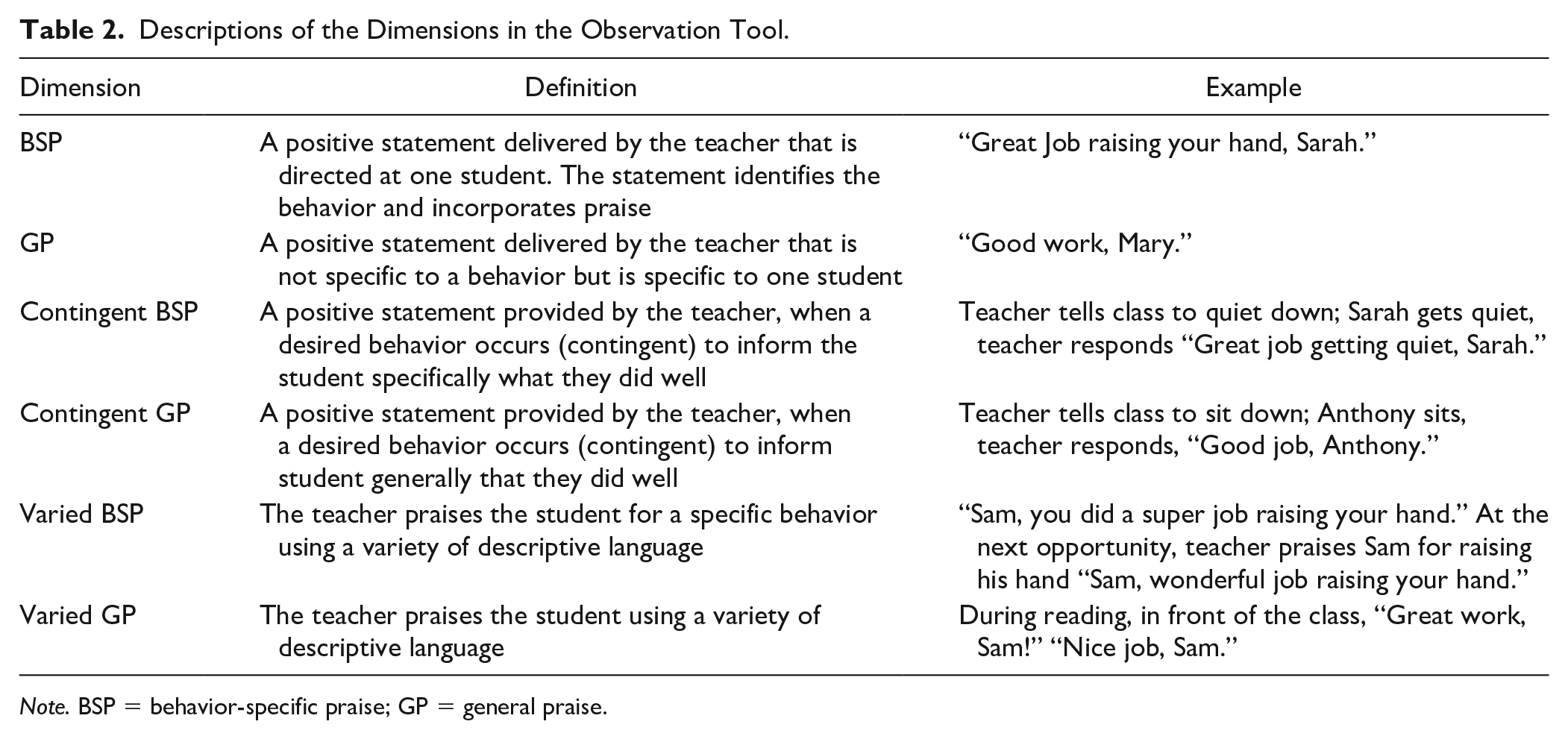
Note. BSP = behavior-specific praise; GP = general praise.
The BSP-OT relies on the use of a frequency within interval technique for data collection. When using frequency within intervals, the total length of the observation is divided into smaller intervals, and each observer records the number of praise statements along with the characteristics of those statements made during each interval. Frequency within intervals was selected for the BSP-OT because it lends itself to more rigorous reliability analysis (e.g., Cohen’s κ) to evaluate the ratio of variability between scores of the same behavior (Kottner & Streiner, 2011). Agreement procedures such as simple agreement or total count IOA (Cooper et al., 2019) point to the question of whether scores are identical, similar, or the degree to which they differ (Kottner & Streiner, 2011) and may be less rigorous than reliability (Shoukri, 2010).
At the beginning of an observation, the observer starts in row A, Interval (column) 1. Following Interval 1, the observer moves across row A to Interval 2, then 3, then down to row B, Interval 1, and so on. The duration of interval is predetermined by the observer. We set interval lengths for this reliability assessment to 20 s. It is important to set an interval that is not too short (e.g., 5 s) because the intervals will pass too quickly and not allow enough time to record data. In contrast, an interval that is long (e.g., 5 min) will allow too much time to pass and potentially result in too many praise statements recorded per interval, thus losing the benefit of interval agreement.
It is also necessary for the observer to have an audio, tactile, or visual prompt device that is set to the interval duration to indicate the beginning of each interval. Observers will need to know when one interval ends and another begins. If or when the observed teacher delivers a praise statement, the observer marks whether the statement was BSP or GP in the “specificity” row with a simple tally mark. The observer then immediately moves down to the “contingency” row and records with another tally mark whether the statement was contingent on student behavior. If not, the observer leaves the contingency block blank. Then, the observer immediately writes the adjective or descriptive word of the praise statement in the “variety” row (e.g., “awesome”).
For example, the teacher says, “Great job raising your hand, Ashley.” The observer marks a tally in the BSP box because a specific behavior was praised. The observer saw that Ashley was in fact raising her hand, so the statement is recorded as contingent. Then, the observer writes “great” in the variety row because the descriptive word in the praise statement was “great.” As another example, the teacher says, “Good job, Matt.” The observer marks a tally in the GP box because the praise statement was general and not specific. The observer knows Matt is supposed to be working on his math assignment, but he is talking with his neighbor, so the observer leaves the contingency block blank because the praise statement was not contingent on him doing a good job. Finally, the observer writes “good” in the variety row.
The observer will continue this procedure to data collecting praise specificity, contingency, and variety throughout the predetermined duration of the total observation. The BSP-OT summary sheet allows the observer to record notes and calculate contingent and varied percentages for BSP and GP. These data can then be reported to the teacher to assist in their development in delivering effective praise.
For the purpose of this investigation, we limited the BSP-OT to be used between one teacher and one target student. An observer needs to see a student to determine whether a praise statement is contingent or not. Knowing that we videotaped lessons, and that our raters would not be able to see the entire class, including all students, we instructed the raters to only code praise statements delivered to the target student. In addition, if a praise statement started in one interval but ended in the next interval, we instructed our raters to record that praise statement in the interval that it started in.
Materials
We recorded 16 videos between four teachers in authentic elementary classroom settings. Each video was 15 min in length. Prior reliability studies have found that reliable and generalizable estimates of BSP can be measured using at least 15-min observations (Gage et al., 2014). Two of the videos were used during rater training, whereas the other 14 videos were used for interrater and intrarater analysis. The videos were recorded using an iPad and Swivl (Franklin et al., 2018). Each teacher wore the Swivl lanyard to capture audio; however, the Swivl was locked in position to remain on the target student. The videos were uploaded to a secure university-affiliated, cloud-based account.
Three members of our research team created a master BSP-OT for each of the 16 videos. The master BSP-OT was created to represent an accurate data sheet that each of the raters’ data sheets would be compared with for reliability. The three researchers independently watched and scored the videos, and then compared data sheets. Any disagreements throughout the BSP-OT were discussed until instances were resolved, and 100% agreement was obtained.
Survey Instrument
We designed the social validity survey to measure expert opinion on the practicality of the BSP-OT. We used a Likert-type scale to assess the following questions pertaining to the BSP-OT: (a) How practical was it to use the BSP-OT? (b) How important is contingency when delivering praise? and (c) How important is variety when delivering praise? In addition to assessing expert opinion on the practicality of the BSP-OT, we sought to obtain expert opinions on the BSP-OT itself and how we might improve the tool. We asked four open-ended question to that end: (a) How do you think the BSP-OT would be useful for BSP research? (b) What did you like about the BSP-OT? (c) Was there anything about the BSP-OT you did not like? and (d) How would you improve the BSP-OT?
Data Analysis
To answer our first research question, we conducted a series of interrater reliability via two measures: Cohen’s kappa and intraclass correlation (ICC). Both statistical methods are used to measure the degree of reliability between raters and the set standard as a way to assess reliability.
ICC was used to measure the amount of agreement and disagreement on overall assessment and between categories: BSP, GP, contingency, and variety. ICCs are used in studies with two or more coders with nominal, categorical, interval, or ratio scores (Gisev et al., 2013). ICC goes a step further than common interrater reliability by incorporating a magnitude of agreement versus “all or nothing” agreement (e.g., Cohen’s κ, Fleiss’ κ, Light’s κ; Hallgren, 2012). Cited cutoffs for ratings of reliability based on ICC values are less than .40 = poor agreement, values between .40 and .59 = fair agreement, between .60 and .74 = good agreement, and values between .75 and 1.0 = excellent agreement (Cicchetti, 1994). ICC is commonly used in determining interrater agreement for coding data reliability (Bandalos, 2018), and has been used as a means of validating observation assessments (Kilgus et al., 2016).
For ICC reliability, BSP, GP, contingency, and variety were calculated between the master code and the raters as a group, individually between one rater and the master code, and finally, between each of the raters. All variables (BSP, GP, contingency, and variety) were scored and rated based on a continuous interval to compare raters with the master copy in degree of accuracy. For variety coding, raters’ adjectives were recoded as either in agreement or disagreement to the master copies. For example, if the master copy recorded “good’ in the varied box—as in the teacher said “good job”—and the rater also recorded “good” in the varied box, that instance would be an agreement. If the master copy recorded “good” but the rater recorded “great”—as in “great job” instead of “good job”—that instance would be a disagreement.
Kappa was used to measure each rater to the set standards (master copies) individually for BSP, GP, and overall. We included kappa reliability because future users of the BSP-OT will most likely only have two coders, thereby making kappa an appropriate reliability measure. Kappas were analyzed where scores less than zero indicated no agreement, .01 to .20 as none to slight, .21 to .40 as fair, .41 to .60 as moderate, .61 to .80 as substantial, and .81 to 1.00 as almost perfect agreement (Gisev et al., 2013).
To answer our second research question, we descriptively analyzed Likert-type scale items with averages and ranges. Open-ended responses were analyzed for themes. The small sample of raters and open-ended questions allowed us to present rater responses’ verbatim in the “Results” section.
Rater Recruitment and Training
Given the novelty of the BSP-OT, we wanted experts in BSP to serve as raters and provide feedback for our social validity data. We, therefore, personally reached out and recruited four raters. We considered the rater as an expert in BSP if they had two or more peer-reviewed empirical publications where BSP was a dependent variable. After initially agreeing to code, one expert rater was unable to complete the training due to prior commitments and withdrew. We then recruited another rater who had one peer-reviewed publication on BSP. We considered this rater as a quasi-expert on BSP.
Rater trainings occurred asynchronously by the first author with video conferencing. Training consisted of three sessions. Session 1 lasted approximately 40 min and was an introduction to the BSP-OT. A procedural reliability checklist for Training 1 entailed 13 items. During this session, the first author reviewed the BSP-OT training packet and coding procedures. Dimension definitions and examples were given, and raters had the opportunity to ask questions for clarification. At the end of Training Session 1, raters were told how to access the first training video. Raters then coded the first training video independently. Across Training Session 1, 100% procedural reliability was obtained.
The purpose of the second training session was to review raters’ scores and discuss disagreements. A procedural reliability checklist for Training Session 2 consisted of five items. Training Session 2 lasted approximately 30 min. The first author reviewed the coded BSP-OT for Video 1 interval by interval. Any disagreement by a rater was discussed until the rater understood the cause of error and felt comfortable moving forward. Procedural reliability for Training Session 2 was 100% across raters.
For the third training session, raters were given access to a second training video and instructed to code the video independently. This time, raters scanned a copy of their coded sheets to the research team who conducted an ICC analyses between their score sheet and the master score sheet to analyze the degree of agreement. We set ICC cutoffs as greater than or equal to .75 to represent excellent values of rater agreement (cf. Cicchetti, 1994). Procedural reliability for the third training session entailed three items: (a) raters code training video independently; (b) raters score .75 or above, and if below .75, raters receive corrective feedback and practice coding video again; and (c) raters access 14 videos to code.
Three out of four raters achieved acceptable ICC reliability on their first attempt on the training video (Rater 1 with .86, Rater 3 with .93, Rater 4 with .91). During the second training video, Rater 2 began coding all BSP statements (i.e., class wide) rather than just those delivered toward the target student. Once the research team identified this error, the rater was reminded to code only praise statements delivered toward the target student. The rater then recoded the second training video and obtained an acceptable level of reliability (Rater 2 with .83). Reliability between all raters on the training video consisted of high reliability with an ICC of .84: 95% confidence interval (CI) = [0.81, 0.87], F(269, 1076) = 27, p < .001. Procedural reliability for Training Session 3 was 100%. After each rater demonstrated acceptable reliability for the training video, they were given access to the 14 videos for coding (15 min each; 210 min total). Once completed, each rater mailed their completed BSP-OT data sheets back to the research team for analysis.
Results
ICC Reliability
Reliability was analyzed based on praise specificity (i.e., BSP, GP) with a .75 cutoff score for ICC. Contingency and variety of praise variables were examined as subcomponents of BSP and GP categories (see Table 3). A high degree of ICC reliability was found between raters for all measurements of BSP. The average measure of ICC was .78 with a 95% CI = [0.72, 0.83], F(134, 9916) = 4.8, p < .001. GP represented a higher degree of reliability for all measurements with an ICC of .81, F(134, 9916) = 5.3, p <.001. The lowest reliable variable for BSP was contingency at .77, 95% CI = [0.69, 0.84], F(44, 3256) = 4.6, p < .001. GP held a greater range in reliability compared with BSP individual variables. The lowest reliable variable of GP was also contingency with .80, 95% CI = [0.71, 0.86], F(44, 3256) = 5.1, p < .001, and its highest was GP with .91, 95% CI = [0.72, 0.88], F(44, 3256) = 5.3, p < .001. Reliability among variables appears to support strong evidence of interrater agreement with regard to the variables.
Reliability of Variables in the Observation Tool.
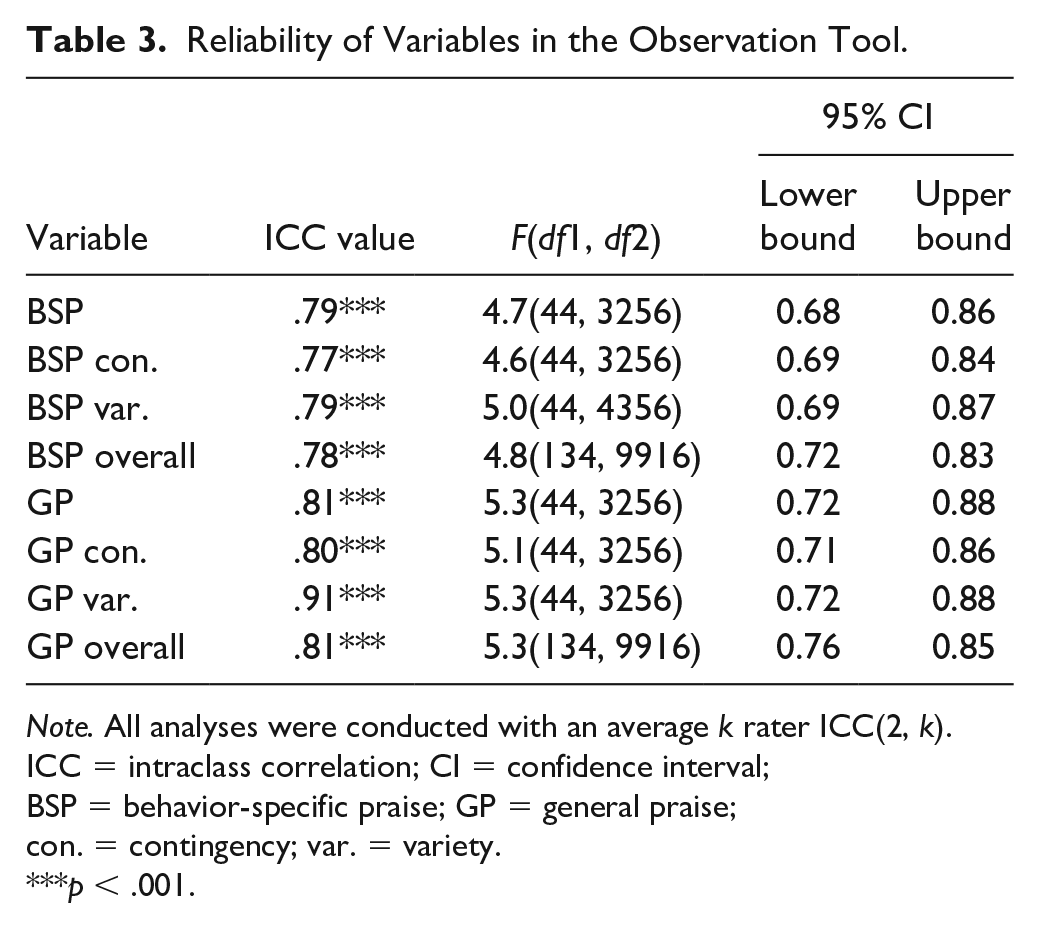
Note. All analyses were conducted with an average k rater ICC(2, k). ICC = intraclass correlation; CI = confidence interval; BSP = behavior-specific praise; GP = general praise; con. = contingency; var. = variety.
p < .001.
There was also strong reliability between all videos rated and the master copy with ICC(2, k) of .80, 95% CI = [0.77, 0.83], F(269, 19906) = 5.1, p < .001. All but four videos did not meet the established cut score for good reliability videos: A, E, F, and K (see Table 4). The lowest reliability in videos were between Video A and the master copy, with a .71 reliability score, 95% CI = [0.67, 0.75], F(269, 1076) = 13, p < .001. The highest reliability of videos was between Video C and the master copy, with .95 reliability score, 95% CI = [0.94, 0.95], F(269, 1076) = 23, p < .001.
Reliability of Videos of Teachers Delivering Praise.
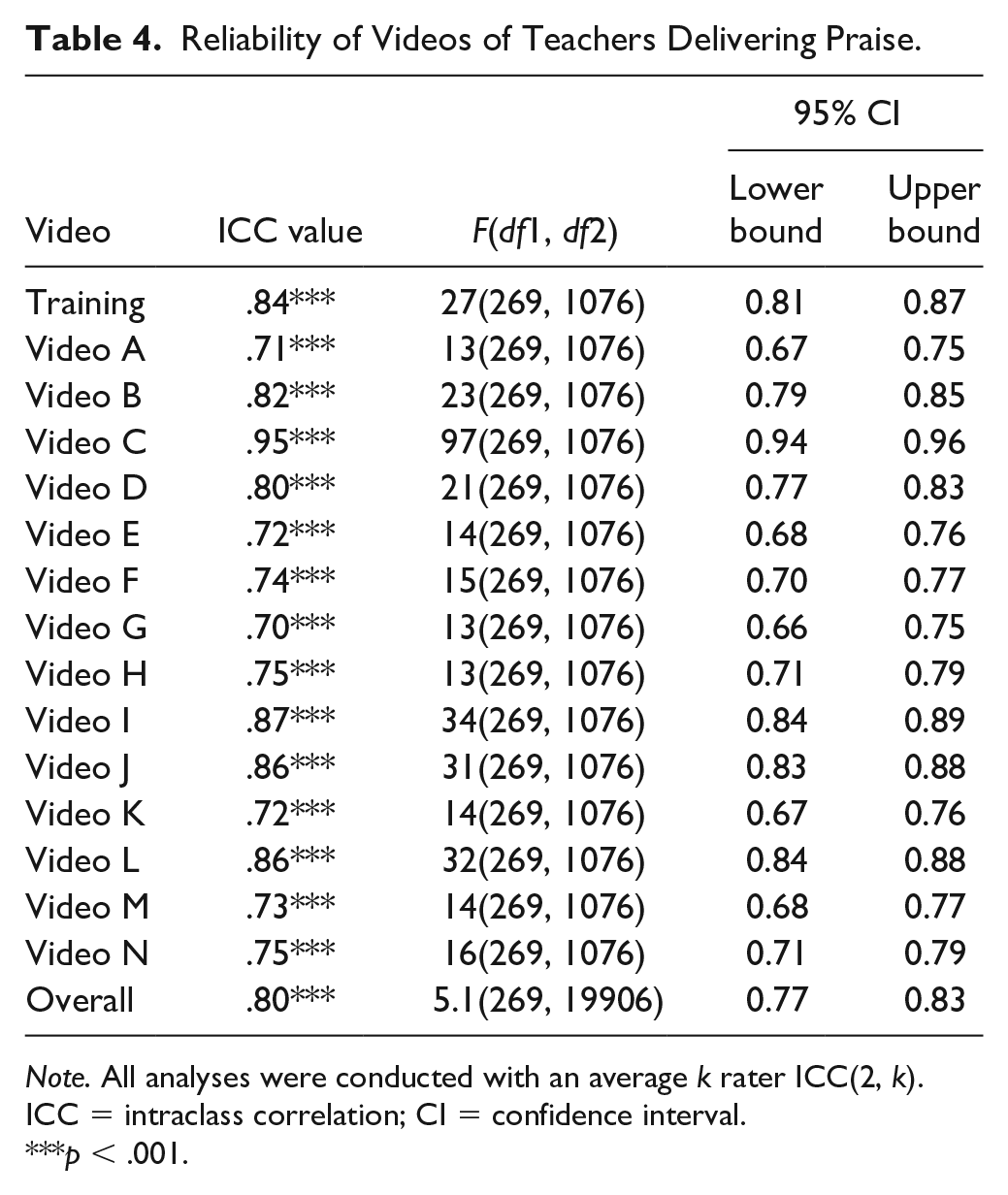
Note. All analyses were conducted with an average k rater ICC(2, k). ICC = intraclass correlation; CI = confidence interval.
p < .001.
Kappa Reliability
A very high degree of kappa reliability was found between each rater and the set standards (see Table 5). All CIs were at or above 0.8, indicating no issue between individual raters and the master copies. Overall, Rater 1 obtained near perfect agreement, κ = .88, 95% CI = [0.86, 0.90], p < .001. Rater 2 obtained near perfect agreement, κ = .92, 95% CI = [0.90, 0.93], p < .001. Rater 3 obtained near perfect agreement, κ = .92, 95% CI = [0.92, 0.94], p < .001. Rater 4 obtained near perfect agreement, κ = .91, 95% CI = [0.93, 0.93], p < .001.
Kappa Rater Agreement for Raters and Set of Standards.
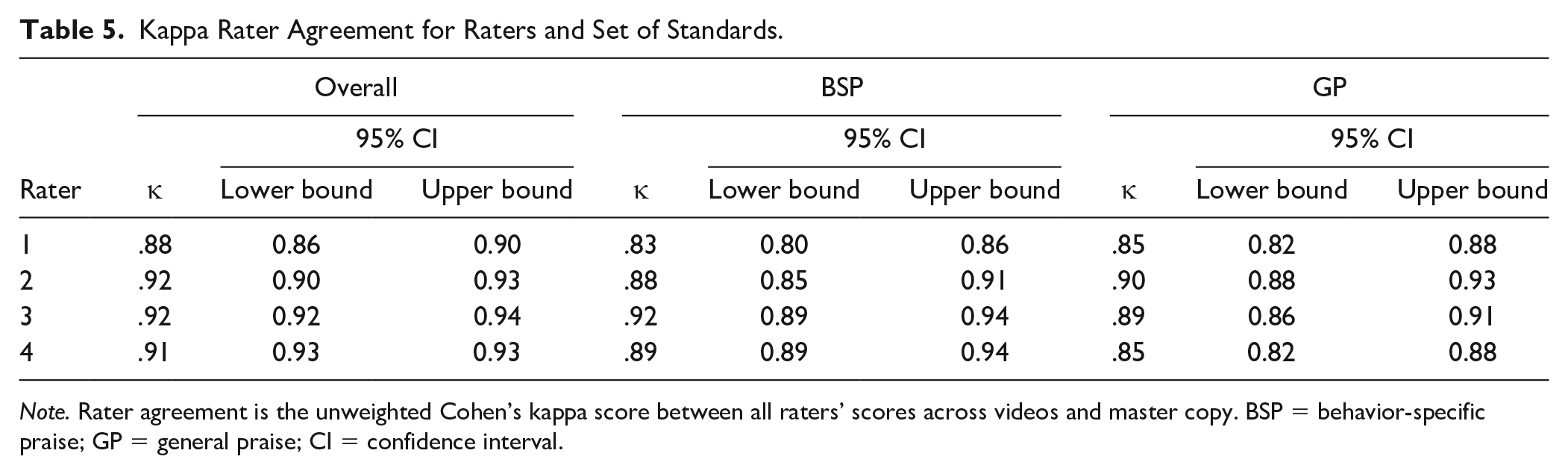
Note. Rater agreement is the unweighted Cohen’s kappa score between all raters’ scores across videos and master copy. BSP = behavior-specific praise; GP = general praise; CI = confidence interval.
Social Validity Results
Raters indicated that the BSP-OT is a practical and effective tool for measuring praise (M = 4.5). Pertaining to the importance of praise being contingent on student behavior, the majority of raters reported that the contingent delivery of praise is important (M = 4.75). Raters were also asked their opinion on the importance of varying praise statements. All raters noted that variety when delivering praise is important (M = 5.5). Mean and range results for the three Likert-type scale items dealing with the practicality of the BSP-OT can be found in Table 6.
Survey Quantitative Results Regarding the BSP-OT.

Note. Mean and range of responses to quantitative survey items using a Likert-type scale (6 = very important, 5 = important, 4 = somewhat important, 3 = somewhat not important, 2 = not important, 1 = not at all important). BSP-OT = Behavior-Specific Praise–Observation Tool.
We also sought feedback on the BSP-OT itself by asking four open-ended survey items to our raters. The first open-ended question presented to the raters was, “How do you think the BSP-OT would be useful for BSP research?” Responses were predominantly positive. For example, one rater stated, “I think the tool is very useful for research, because there is nothing out that really measures BSP.” However, one rater was not convinced that the tool is unique beyond other operationally defined approaches to counting the frequency of BSP. Second, we asked, “What did you like about the BSP-OT?” There was some variety in responses to this question; however, two raters mentioned they appreciated that the BSP-OT parsed out if praise was actually contingent. Next, we asked, “Was there anything about the BSP-OT you did not like?” Again, the responses to this question varied. One rater did not like having to turn the page on the BSP-OT. Another rater mentioned the challenge of writing down the various praise statements when the teachers praised a lot. Finally, we asked, “How would you improve the BSP-OT?” Raters mentioned altering the layout of the BSP-OT to be on one page and to provide additional space to write verbatim responses/notes. See Table 7 for a full report of open-ended survey responses.
Survey Qualitative Results by Rater for the BSP-OT.
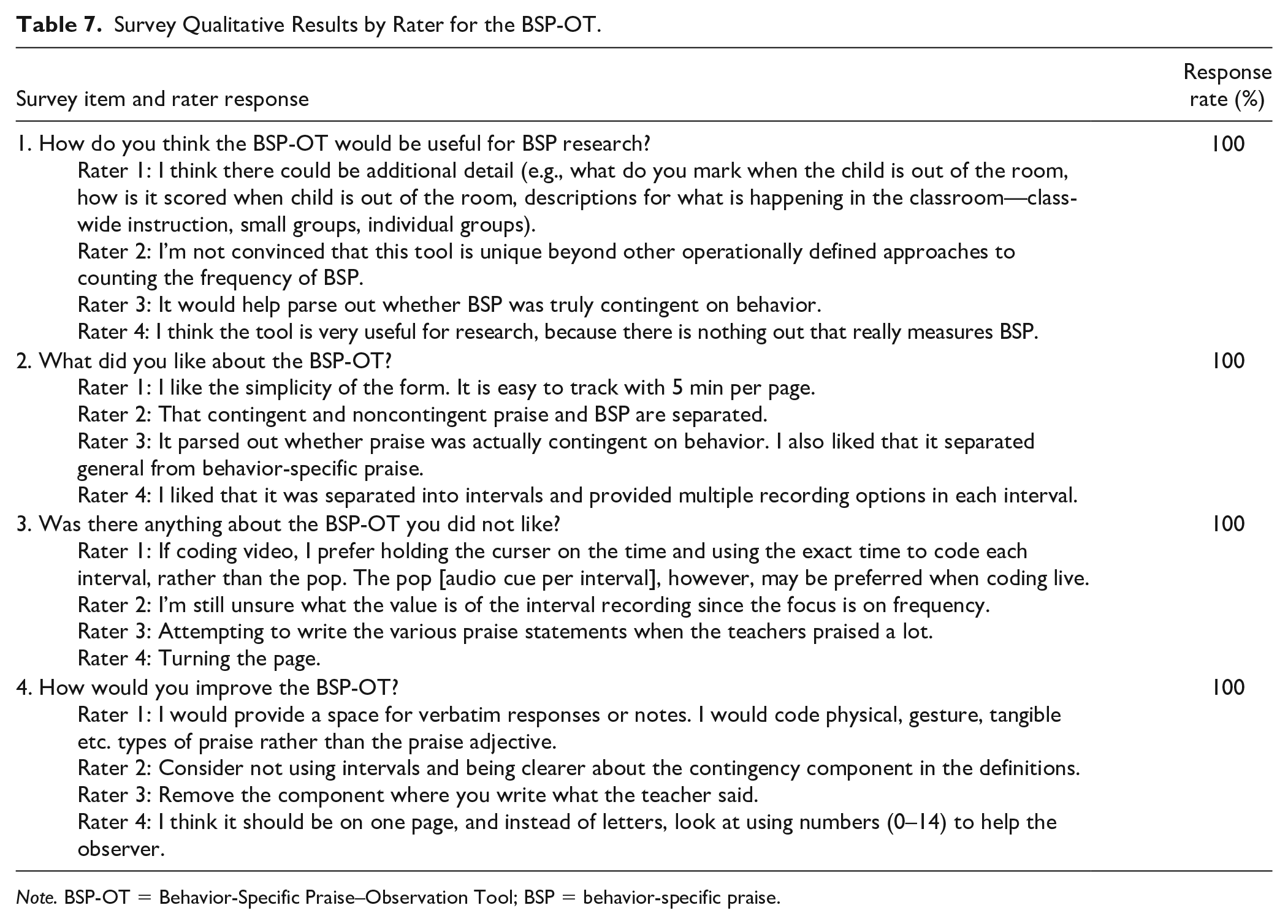
Note. BSP-OT = Behavior-Specific Praise–Observation Tool; BSP = behavior-specific praise.
Discussion
The purpose of our investigation was to examine reliability of the BSP-OT and its practicality for research. To do so, we asked two research questions: (a) Is the BSP-OT a reliable tool to measure specificity, contingency, and variety of praise? and (b) What is the social validity of the BSP-OT tool for measuring praise? Results indicate the BSP-OT is both a reliable and practical tool for measuring characteristics of praise.
Reliability of the BSP-OT
Direct observation procedures should be designed to allow for accurate (i.e., valid) and consistent (i.e., reliable) measurement of behavior (Hintze, 2005). In recent years, there have been a number of studies evaluating teachers’ use of BSP. To date, researchers have primarily relied on frequency counts to measure teachers’ use of BSP (see Table 1). Frequency data allow for crude estimates of agreement. The BSP-OT is designed to serve as a measurement tool for researchers, supervisors, or clinicians to reliably measure teachers’ use of praise and important characteristics of praise (i.e., specificity, contingency, variety). The use of frequency within interval coding provides a more sensitive measure to evaluate teachers’ use of praise. In addition, interval coding permits more stringent reliability procedures (e.g., κ) for future research reliability of praise.
The findings from this study indicate acceptable ICC scores across variables (i.e., specificity, contingency, variety) and videos. High kappa scores suggest that raters were able to measure accurate data compared with the master copies. These findings are an encouraging step in developing a tool that measures characteristics of praise accurately and consistently. Furthermore, acceptable reliability scores and social validity data lend support to the BSP-OT being used in the field by researchers investigating praise, those supporting in-service teachers’ use of praise, and student teaching supervisors in programs looking to increase their students’ use of effective praise for proactive classroom management.
Universal guidelines for praise are still developing. A general rule for the rate of teacher praise is around six to 10 praise statements per 15 min (Sutherland et al., 2002); yet, little research has explored too little versus too much praise. And, as we have discussed, specific, contingent, and variable praise is likely more effective than not. But apart from general guidelines, specific quantification recommendations are lacking. Because the BSP-OT enables quantification of praise characteristics as percentages, the tool will allow future investigation into measuring and manipulating those characteristics to determine benchmark ratings (e.g., poor, fair, good, excellent). We can infer that 100% variable praise is better than 15%, or 90% contingent praise is better than 20%, but until empirical manipulation of praise characteristics occurs, inferences are all we have. An exploration focusing on the influence of praise contingency and variety is needed to formulate suggested guidelines (e.g., >80%).
Practicality of the BSP-OT
In addition to developing a tool to research the characteristics of praise, our second goal in developing the BSP-OT was to provide an observation sheet for interventionists, or teacher trainers, to use when assisting with teacher development. After analyzing raters’ responses, it appears the BSP-OT was deemed practical and useful; however, there are challenges in designing a tool that accommodates a variety of research needs and teacher observation applications. Most of the critiques from the raters centered on logistical aspects of using the BSP-OT such as turning the page or interval recording. We agree that a simple frequency count, or conversion to rate per minute, of praise is easier than interval recording and may be sufficient for teacher professional development; however, researchers examining praise will benefit from interval recording procedures. Although the BSP-OT is designed for individualization by future users, we remind readers that we used 20-s interval lengths; therefore, deviation from this standard may affect reliability scores.
Another critique from the raters was writing the praise adjective during high frequencies of praise statements. During the development of the BSP-OT, we also found this to be challenging. One solution to this issue may involve developing abbreviations for praise adjectives, which would prevent the need to write out the entire word. A second solution may be to create a permanent product (i.e., video recording) of the observation as an ex post facto method of data collection. There are several benefits to permanent products including making measurements more accurate, complete, and continuous, to facilitate diligent IOA (Cooper et al., 2019). However, there are also challenges in securing video recordings such as privacy issues and technology logistics, which may not be necessary for nonresearch purposes. The tension between developing a tool that satisfies both research and authentic teacher development applications has been highlighted in our process of developing the BSP-OT. We encourage researchers of praise and teacher development to continue refining our efforts in providing a reliable and practical tool for measuring characteristics of praise.
Limitations and Future Research
In the following paragraphs, we outline three limitations of this research and direction for future research. The first limitation was that raters did not use the BSP-OT in a controlled setting or authentic situation. Raters coded videos with the BSP-OT at their convenience on personal computers; therefore, we are unable to account for numerous extraneous variables that might have affected coding performance (e.g., time of day, number of videos coded in one sitting, setting distractions). Although, the videos were recordings of teachers in authentic situations, we are unable to generalize our reliability findings to raters using the BSP-OT in live authentic situations. Future research should, therefore, examine the reliability of the BSP-OT by raters conducting live observations. In doing so, additional strengths and weakness of the tool in the field may emerge.
The second limitation was that the fourth expert rater had to drop from the study due to competing responsibilities. We replaced the expert rater with a quasi-expert who had one publication focusing on BSP. Future research should investigate the reliability and practicality of the BSP-OT across numerous raters with varying degrees of experience to assess the generalizability of our findings.
The third limitation to our study was that student data collection did not occur. The true measure of praise effectiveness is a positive change in student behavior (Markelz et al., 2019). Increasing effective characteristics of praise is meaningless unless student behavior improves. Therefore, future research should explore the addition of a student data collection component to the BSP-OT. A momentary time sampling procedure for student data could be easily added as an additional row with interval recording. Future research would need to investigate whether the addition of this coding procedure reduces reliability and practicality.
Implications
In general, research indicates BSP is an effective and efficient strategy to facilitate behavior change in students (Moore et al., 2019). However, a tool for measuring functional and topographical characteristics (i.e., specificity, contingency, variety) of praise is needed to examine the affect various praise characteristics have on student behavior. In addition, a practical tool may allow for interventionists or student–teacher supervisors to provide specific feedback on praise characteristics to develop teacher’s use of effective praise. Based on the results of our research, we suggest the following:
When measuring praise, researchers, university supervisors, and mentors/coaches should examine characteristics of praise during observations.
The BSP-OT is useful for parsing out important characteristics of praise and would be helpful when conducting research and during professional learning with teachers.
Statistical analysis of coded videos by expert raters suggests the BSP-OT is a reliable tool for measuring praise characteristics.
Researchers use the BSP-OT to measure and manipulate characteristics of praise to identify normative guidelines and standards of praise efficacy.
Conclusion
To our knowledge, the BSP-OT is the first tool that attempts to measure characteristics of praise beyond specificity. Given the historical scope of research on praise (Floress et al., 2017) and continuous concerns of classroom management (Westling, 2010), we believe further analysis into praise efficacy is warranted. We hope that the development and reliability findings of this study propel researchers to use and refine the BSP-OT to enhance practices of effective praise for the betterment of student outcomes.
Supplemental Material
Behavior_Specific_Praise_Observation_Tool_Coding_Manual_Supplementary_File – Supplemental material for Reliability Assessment of an Observation Tool to Measure Praise Characteristics
Supplemental material, Behavior_Specific_Praise_Observation_Tool_Coding_Manual_Supplementary_File for Reliability Assessment of an Observation Tool to Measure Praise Characteristics by Andrew M. Markelz, Benjamin S. Riden, Kimberly A. Zoder-Martell, Joseph E. Miller and Sarah J. Bolinger in Journal of Positive Behavior Interventions
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.