
Abstract
Purpose
The aim of the study is to improve the accuracy of age related macular degeneration (AMD) disease in its earlier phases with proposed Capsule Network (CapsNet) architecture trained on speckle noise reduced spectral domain optical coherence tomography (SD-OCT) images based on an optimized Bayesian non-local mean (OBNLM) filter augmentation techniques.
Methods
A total of 726 local SD-OCT images were collected and labelled as 159 drusen, 145 dry AMD, 156 wet AMD and 266 normal. Region of interest (ROI) was identified. Speckle noise in SD-OCT images were reduced based on OBNLM filter. The processed images were fed to proposed CapsNet architecture to clasify SD-OCT images. Accuracy rates were calculated in both public and local dataset.
Results
Accuracy rate of local SD-OCT image dataset classification was achieved to a value of 96.39% after performing data augmentation and speckle noise reduction with OBNLM. The performance of proposed CapsNet was also evaluated on the public Kaggle dataset under the same processing procedures and the accuracy rate was calculated as 98.07%. The sensitivity and specificity rates were 96.72% and 99.98%, respectively.
Conclusions
The classification success of proposed CapsNet may be improved with robust pre-processing steps like; determination of ROI and denoised SD-OCT images based on OBNLM. These impactful image preprocessing steps yielded higher accuracy rates for determining different types of AMD including its precursor lesion on the both local and public dataset with proposed CapsNet architecture.
Introduction
Age related macular degeneration (AMD) is one of the common cause of visual loss in elderly and the number of patients are expanding rapidly with aging.1,2 AMD is clinically staged in early, intermediate and late phases. Late AMD further categorized into wet and dry according to the presence of neovascularization.1,2 According to some researchers early AMD detection is based on the identification of drusen.3–5 Discovery of AMD in its beginning phases is significant for good visual prognostic outcome, and the differential identification among dry and wet AMD is additionally basic for proper treatment and burden of disease severity.6,7 Thanks to the new era optical coherence tomography (OCT) technology with axial resolutions of 5 µm, small drusen are now more easily to be visualized and differentiated from exudates.8,9 Automatic AMD segmentation using spectral domain optical coherence tomography (SD-OCT) has become an active area of investigation since it provides a better view for doctors to examine the status of the retina. 10
Artificial intelligence (AI) has arrived in ophthalmology owing to its focus on image-based diagnostics. The highly organized structures of the retinal tissue are an ideal target for implementing AI to support ophthalmologists in their clinical work hours on a daily basis. 11 Convolutional neural networks (CNNs) (mostly commonly used deep learning algorithm) have been used for the automated AMD grading from fundus images and interpreting and segmenting OCT images.12–14 However deep learning requires relatively big datasets during training process which, in fact, is not an easy task to overcome in medical image analyses field. Data augmentation is one of the alternative techniques to reduce over fitting, in case of inadequate dataset. There are numerous data augmentation approaches defined for different image classification problems, such as translation, rotation, mirroring or scaling of target and reducing noise.15,16 As far as we know this is the first study that used to augment a dataset using speckle noise reduction17,18 based on an optimized Bayesian non-local mean filter (OBNLM) in OCT images. Hinton et al. built up a capsule network that can learn positional relations among images utilizing cases. 19 Capsule networks can achieve better performance than existing CNNs on the small size and noised dataset. 19 But there is still a need to modify the capsule network for increasing accuracy. In this study our modified capsule network model was proposed to classify different types of AMD lesions affecting the same region of the retina from OCT images with the use of our local deidentified dataset. For sake of comparision, the same CapsNet architecture and preprocessing operation were applied to the publicly available Kaggle (https://www.kaggle.com/paultimothymooney/kermany2018) dataset.
Methods
Study design
Medical records of patients aged 50 years and over with drusen, dry AMD (dAMD) and wet AMD (wAMD) were retrospectively reviewed. Patients who had preceeding retinal surgeries and preexisting ocular diseases other than AMD including visually disturbing cataract formation were excluded. In order to select a normal control; the medical records of early stage of glaucoma patients who had been screened for ganglion cell count were reviewed.
The study was affirmed by the Ethical Committee of the Institutional Review Board (2019–14/52) and adhered to Good Clinical Practice rules and the principles of the Declaration of Helsinki.
OCT imaging protocol
At least one horizontal cross sectional B-scan image of the diagnosis significant lesion sites from macula region was selected from the Topcon 3D SD-OCT and Spectralis SD-OCT devices’ screen display. All pictures were downloaded in a standard.jpg format as denoted in operating instructions. The images were preprocessed to identify and then eliminate any finding in the data that might hinder generating a model, such as cross-segment lines, scales, and matrices.
OCT image dataset
Four classes (drusen, wAMD, dAMD and normal) were created and labelled by two experienced ophthalmologists (ARCC, EB), a sample of collected OCT images in these classes were shown in Figure 1. Image size was measured as 791 × 1172 pixels.

Demonstration of OCT images of the different groups. (a) Normal (b) Drusen (c) dAMD (d) wAMD.
OCT image preprocessing and ROI selection
An ideal image fix is one that contains the entirety of the significant anatomical structures, includes the focal point of the fovea and avoids superfluous tissues, which may hamper the classification result. Determination of ROI increase classification accuracy of deep neural networks by reducing unnecessary components in an image (Figure 2).

(a) Original optical coherence tomography image (b) and its correspondent ROI.
Determination of ROI was established in MATLAB environment (MATLAB; MathWorks, Natick, MA, USA).
First, the 2D cross sectional OCT image was selected from the en-face OCT image that crossed the centre of the fovea. In that 2D cross sectional OCT image, ROI was identified. As SMD in all phases begun in the deepest layers of the retina, the centre of the OCT images was determined on the deepest layers of the retina. Finally the size of ROI was selected as 301 × 501 pixel for each image. Then each ROI was re-sized to 64 × 64 using linear interpolation to feed our proposed capsule network.
Noise reduction & data augmentation with optimized Bayesian Non-local mean (OBNLM) filter
In the current study, the OBNLM method was adapted to original OCT images (Figure 3(a)) with a smoothing parameter of 8 (h = 8) and a value of 7 for search area size (W = 7) was devoted to provide a more clear dataset. The denoised image was shown in Figure 3(b), after the amount of noise (Figure 3(c)) that was removed using the OBNLM filter.

(a) Original optical coherence tomography image (b) denoised optical coherence tomography image by OBNLM method with smoothing parameter (h = 8) and search area size (W = 7) and (c) corresponding residual image.
Determination of noise reduction was also established in MATLAB environment (MATLAB; MathWorks, Natick, MA, USA).
Our proposed capsule network architecture
The original capsule network was implemented to classify MNIST dataset. It has one layer of convolution, two layers of capsules and three fully connected layers to classify images. Details can be found elsewhere. 20
In our proposed capsule network we made various changes in order to increase the accuracy rate of capsule network architecture. First, the number of primary capsules was increased. In this way, the learning of discriminative features was improved. Additionally, two convolution layers were cascaded before the capsule layer, which could also improve accuracy by creating more complex image coding before feeding it into the capsule layer. Two cascading convolution layers were applied and each of the image patches was convolved with different sized kernels to obtain feature maps. Two hundred fifty-six size 11 × 11 feature maps, were generated by the first convolution layer with a stride (S) size of 2, with valid padding (P) and the spatial dimension was reduced to 123 × 123. The legitimate padding includes no zero padding, so it covers just the substantial information, excluding misleadingly produced zeros. Yield of the principal convolution layer was allowed to the subsequent convolution layer as contribution to extricate valuable low level features. At this stage 256 size 7 × 7 feature maps were obtained with the parameters S = 2. The next layer is a primary capsule layer, which generated 64 8-D capsules using 9 × 9 kernels with S = 2. The final capsule layer included 4 capsules, referred as “Class Capsules”, one for each type of OCT image. The dimension of these capsules was 16. The decoder element included three fully connected layers with 512, 1024 and 4096 neurons, respectively. The number of neurons in the last fully connected layer was the same as the number of pixels in the input image, because the goal was to minimize the sum of squared differences between input and reconstructed images. Figures 4 and 5 presented the proposed network architecture.
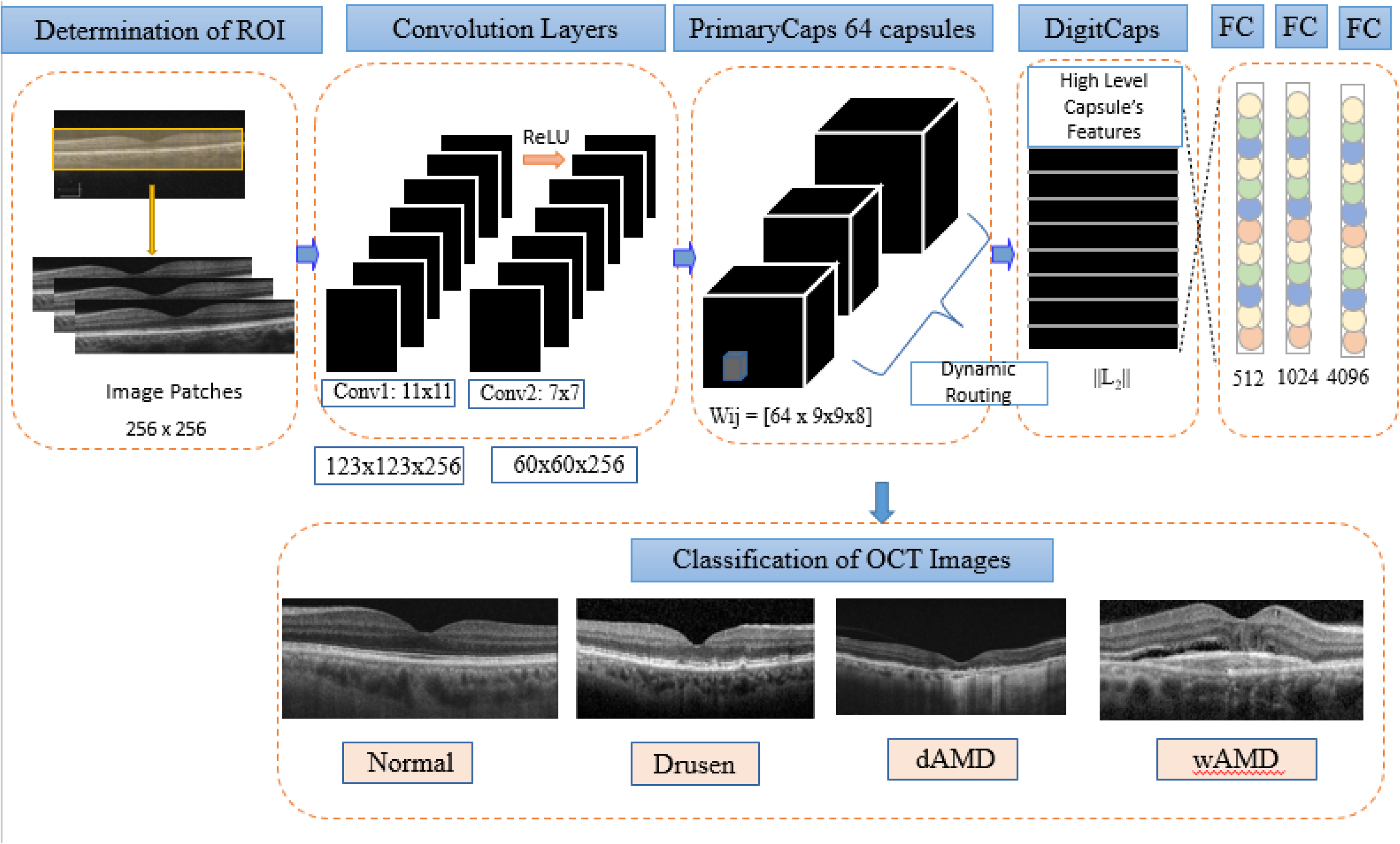
The proposed Capsule network architecture for classification of different types of AMD and Normal OCT images.
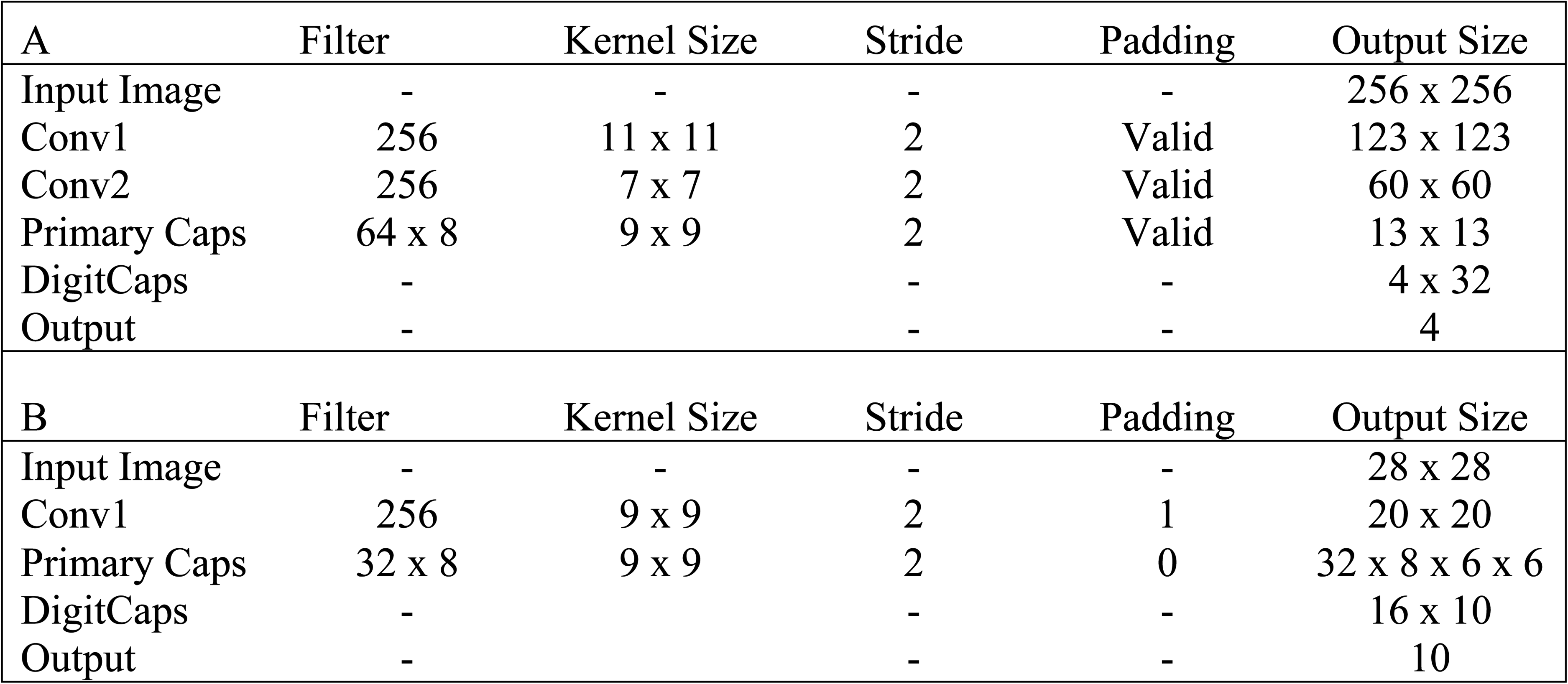
Proposed CapsNet and original CapsNet architectures were given in parts A and B respectively.
Results
A total of 726 SD-OCT images were available for analysis. 159 images were labelled as Drusen, 156 were labelled as wAMD, 145 were labelled as dAMD images and 266 images were devoid of any AMD features and labelled as normal.
Different CapsNet architectures were implemented with TensorFlow using a stochastic optimization model of the Adam algorithm on a workstation with Intel Core i7-6700 at 3.4 GHz, and 16 GB of RAM with Nvidia Tesla k40 GPU. It was trained 180 epochs with a batch size of 40 images with learning rate of 0.01. 21 Dropout was only added to the fully connected layers with the probability of 0.4 in order to prevent over-fitting and reduce error. Success rates of different CapsNet configurations were evaluated and the best CapsNet configuration was selected to classify AMD types.
The proposed CapsNet was evaluated with 3 different approaches: First, the CapsNet was fed with our original dataset. The success rate of our classification system was higher (94.57%) with the original baseline architecture of CapsNet designed for the MNIST dataset (90.50%). Certain components of the baseline MNIST CapsNet model were changed to extract discriminative features: Increasing the number of primary capsules and convolution layers before the capsule layer improved classification (When two convolution layer with 256 size of 11 × 11 and 7 × 7 feature maps were used and the number of primary capsules was increased, the overall accuracy of our system was increased to 94.57%).
In the second step, the same proposed CapsNet configuration was evaluated with the denoised dataset based on OBNLM method and the accuracy rate increased to 95.86% from 94.57%. Image denoising increased the classification success of the proposed CapsNet architecture, most probably due to elimination of the negative effect of speckle noise on the learning capability of the CapsNet.
In the final step; we have augmented denoised dataset based on OBNLM method with rotation, translation and mirror. The accuracy rate of the proposed CapsNet was increased to 96.39% from 94.57% on the augmented denoised dataset.
At this final step of configuration; the accuracy rate of the subgroups for wAMD, dAMD, drusen and normal were 95.54%, 96.43%, 94.57% and 100%, respectively. The overall success rate of our proposed CapsNet model was 96.39%, which was still higher than the original MNIST CapsNet (90.50%) as demonstared in Table 1.
The overall accuracy rate of proposed CapsNet architecture on our denoised local dataset .

We tested our proposed CapsNet architecture with public Kaggle dataset for comparison. This dataset was reachable online at https://www.kaggle.com/paultimothymooney/kermany2018 website. So we labelled test dataset into two subgroups as Testlocal, and Testpublic. First our proposed CapsNet model was evaluated with original ROI images in our local dataset and the public Kaggle dataset and in both dataset groups the overall accuracy rates were 94.57% and 97.25%, respectively. In the second step, our proposed CapsNet model was fed with denoised images using the OBNLM method and evaluated both with our local dataset and the public Kaggle dataset and in both dataset groups the overall accuracy rates were increased to 96.39% and 98.07%, respectively.
In subgroup analysis we further tested our proposed CapsNet model using public Kaggle dataset and the rates of accuracy for the groups of wAMD, dAMD, drusen and normal were; 98.25%, 97.4%, 96.42% and 100%, respectively. More detailed results were shown as confusion matrix in Table 2.
The overall accuracy rate of proposed CapsNet architecture on denoised public Kaggle Dataset.

The accuracy rates of different methods for the classification of different OCT images with our local dataset and public Kaggle dataset were summarized in Table 3.
The accuracy rates of different methods for the classification of OCT images.

In both datasets, it was observed that the classification success of the proposed CapsNet architecture were increased after determining the ROI and performing the noise reduction with OBNLM method.
We have seen the difference between original OCT image and its correspondent reconstructed images (Figure 6). We can observe that normal and dAMD images are reconstructed better than the drusen OCT images.
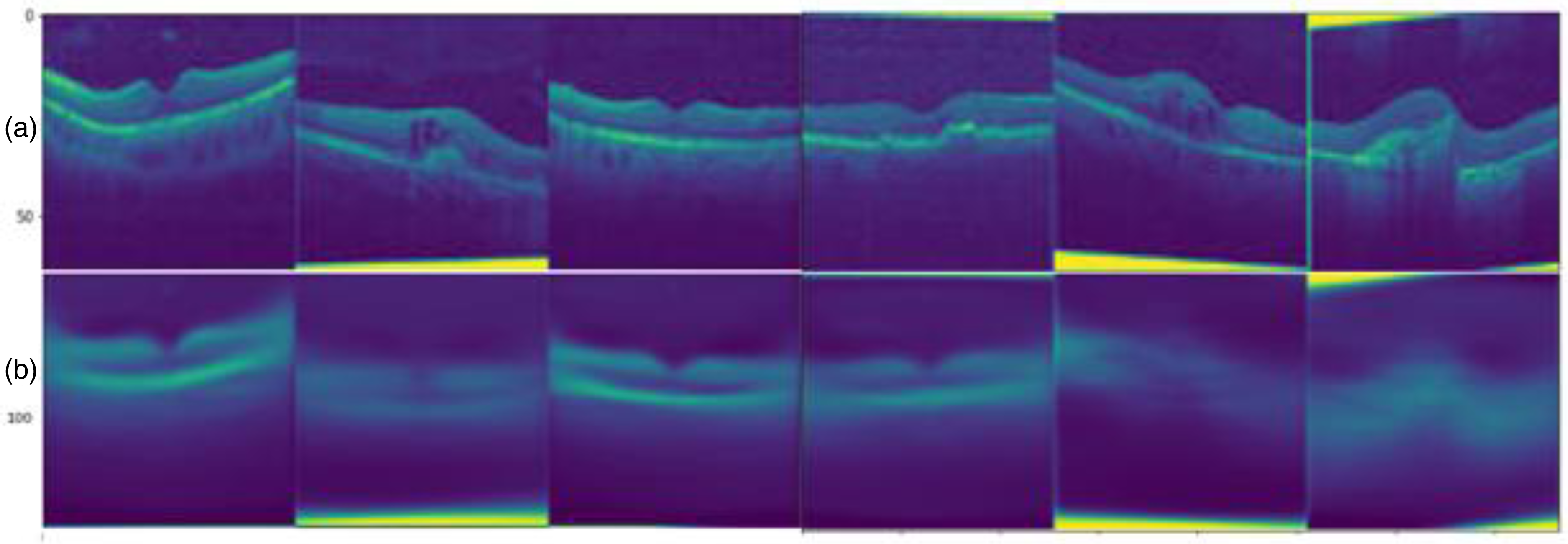
(a) Original optical coherence tomography image (b) and their reconstructed images based on proposed capsule network architecture.
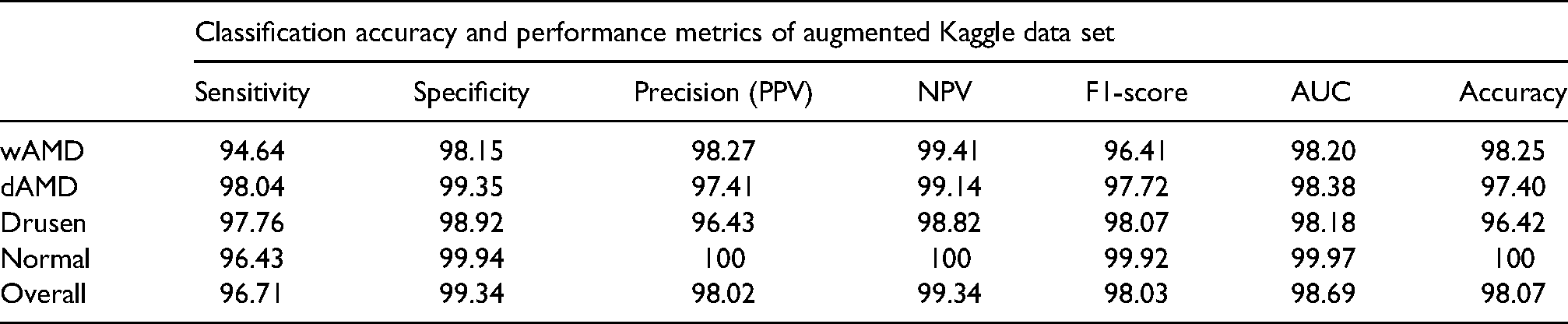
The sensitivity (true positive rate) and specificity rates (true negative rate) among with positive predictive value (PPV) and negative predictive value (NPV) are very important measures to confirm the power and validity of the Computer Aided Diagnostic (CAD) system in the clinical setting. The sensitivity and specificity rates among with PPV and NPV were calculated both for local data set and public Kaggle dataset and were found as 96.66%, 98.88%, 96.60% and 98.89% for local dataset and 96.71%, 99.34%, 98.02% and 99.34% for public Kaggle dataset, respectively. These results for subgroups were all summarized in Tables 4 and 5.
The sensitivity, specificity, PPV, NPV, F-1 score and AUC rate along with Accurcy rates of proposed CapsNet architecture on denoised local dataset.

The sensitivity, specificity, PPV, NPV, F-1 score and AUC rate along with Accurcy rates of proposed CapsNet architecture on public Kaggle dataset.
Discussion
Recent advances in deep learning methods have expanded the point of view of the clinical experts on expected utilization of AI-driven devices. In ophthalmology, automatic assessment of fundus photos and OCT images to identify AMD from DME and / or other macular diseases has been accounted recently.22–28 However there is not such a study that identified AMD with its subgroups solely. Herein we developed a deep-learning based diagnostic tool using CapsNet algorithm to detect and differentiate dry AMD and wet AMD with its precursor lesion of drusen using SD-OCT images. To the best of our knowledge; our proposed CapsNet algorithm represents the first application for diagnosis of different types of AMD from its precursor lesion of drusen in a local database.
One important aspect of increasing the success of result was the image quality. It can be increased with using a denoising technique.29,30 The reduction of non-significant information in the dataset might have a positive effect on the recognition system's ability. It has to be always considered that preservation of the critical anatomical information during noise reduction (denoising) is mandatory. OBNLM method allows us to preserve robust texture and shape feature while eliminating speckle noise that present in OCT images. In our study with the use of this procedure; the accuracy rate of the proposed CapsNet was increased to 95.86% from 94.57% on denoised dataset based on OBNLM method. There is not such a study that used this unique imaging preprocessing step in OCT images. We also applied the same preprocessing steps on the augmented Kaggle dataset. The classification accuracy rate was also increased to 98.07% which is higher than the result stated in Kermany et al. (96.6%) that also used Kaggle dataset. 31 So this preprocessing step not only increased the accuracy rate in our local dataset and also increased the machine learned more accurately with public Kaggle dataset.
Another important aspect of our study is related to the determination of ROI before training of proposed CapsNet architecture. The main contribution of our study is feeding the CapsNet with denoised OCT images which solely containing the retinal layers. The accuracy rate of the CAD system was increased to 98.07%, which is greater than the result reported by Kermany et al. (96.6%). 31 Determination of ROI in terms of removing unnecessary parts of the OCT image and elimination of negative effect of speckle noise with OBLNM method provide to learn better robust feature and resulted with higher accuracy values on both local dataset and public Kaggle dataset. In Alqudah's study, 32 double density wavelet transform-based adaptive thresholding technique 33 was applied for noise reduction in OCT images. That method unfortunately removes edge discriminating features. OBNLM is more successful method than wavelet transformation based noise reduction in terms of preserving discriminative features like edge information of the image.33,34
There is one study that constructed a CNN architecture for the diagnosis of various retinal disease affecting different retina layers with the use of OCT images. It was trained and tested using a huge dataset of containing 136,187 images. It was found an accuracy rate of 98.1%. In that paper there are 15 layers including 4 convolutional, 4, batch normalization, 3 max pooling layers. 32 However we can reach the same accuracy (98.1%) with using Kaggle dataset containing half of the images with our proposed CapsNet architecture that only includes 2 cascading convolutional layers. By changing the hierarchical organization of the Capsule Network or the number of the convolution layers, the ability of the system can be increased in order to reach the desired goal. So instead of increasing the convolutional layers, which ended up with extra costs and extra time to conduct, we herein reached the same ratio of accuracy during classification of various AMD lesions with a less complex network.
During the training phase of a deep learning study, a large amount of data is required to test an algorithm. One strategy tending to for an absence of huge data in a given image is to use data from a similar dataset, a method known as transfer learning. In literature there were different studies using transfer learning in data from different SD-OCT databases. Karri et al. used transfer learning with GoggleNet CNN with 10.000 OCT images and they found a 96% of accuracy. 23 Srinivasan et al. also used transfer learning with Inception ResNet V2 CNN in 113.397 OCT images in 4 classes but they reached an accuracy level of 86%. 35 Ji et al. also used transfer learning with more layered Inception V3 CNN in 1680 OCT images and they reached 98% accuracy. 36 It seems that the accuracy increased but the amount of time that was spent during learning was increased and unfortunately it ended with high-cost and more complex architectures. In order to prevent this we proposed image preprocessing (proper selection of ROI and image speckle denoising) and more importantly a new architecture (modified Capsule network) to reach the same level of accuracy (98.07%). Another study by Fang et al. conducted iterative fusion CNN for classification of 84.484 OCT images recently and reached 87.3% accuracy, which is less than the value we get from our local dataset (96.39%). 37
There is only one recent study in ophthalmology by Tsuji et al. that we have come in touch using CapsNet models instead of using CNN, however they again used transfer learning which increased the amount of processing time and the cost They proposed a CapsNet with adding five more convolutional layers to the original CapsNet architecture for improving the accuracy rate of their CAD system. 38 They classified OCT images using public Kaggle dataset (https://www.kaggle.com/paultimothymooney/kermany2018) with more complex (including 6 convolutional layers) highly costed proposed CapsNet system without applying image preprocessing. They did not use any data augmentation process and they relied on public dataset, however we have used and tested our proposed CapsNet architecture with a total of 726 local 3D-OCT images. We have decreased convolution layers to two in our proposed CapsNet architecture in addition to perform speckle noise elimination and determination of ROI and reached very similar accuracy rates. As stated in Tables 1 and 2 our proposed capsule network performed in 100% accuracy in terms of discriminating normal images from the rest of pathologies.
Our study had one important limitation which is related to the spectrum of retinal diseases that we did not study. We rejected bad quality pictures and patients who had other retinal diseases. Consequently, it is indistinct whether our outcomes can be applied to general population. Thus this is our preliminary study and we initially aimed to test our proposed capule network with these unique image preprocessing techniques in more limited spectra of diseae however we are still working to extend the indication list with more complicated retinal diseases. Herein we aimed to show even just a clinic can develop its deep learning algorithm and train it with using these augmentation techniques.
In conclusion, this proposed capsule network architecture with two cascading convolution layers and add-on proposed innovative means of data augmentation with speckle noise reduction using the OBNLM method offered a solution for the training problem of CapsNet when there is a less amount and noisy training data set. A deep learning-based algorithm with image augmentation recognized AMD disease with high accuracy, less costly and more precisely during the assessment of OCT images.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.