
Abstract
Purpose
To evaluate the appropriateness and readability of the responses generated by ChatGPT-4 and Bing Chat to frequently asked questions about glaucoma.
Method
Thirty-four questions were generated for this study. Each question was directed three times to a fresh ChatGPT-4 and Bing Chat interface. The obtained responses were categorised by two glaucoma specialists in terms of their appropriateness. Accuracy of the responses was evaluated using the Structure of the Observed Learning Outcome (SOLO) taxonomy. Readability of the responses was assessed using Flesch Reading Ease (FRE), Flesch Kincaid Grade Level (FKGL), Coleman-Liau Index (CLI), Simple Measure of Gobbledygook (SMOG), and Gunning- Fog Index (GFI).
Results
The percentage of appropriate responses was 88.2% (30/34) and 79.2% (27/34) in ChatGPT-4 and Bing Chat, respectively. Both the ChatGPT-4 and Bing Chat interfaces provided at least one inappropriate response to 1 of the 34 questions. The SOLO test results for ChatGPT-3.5 and Bing Chat were 3.86 ± 0.41 and 3.70 ± 0.52, respectively. No statistically significant difference in performance was observed between both LLMs (p = 0.101). The mean count of words used when generating responses was 316.5 (± 85.1) and 61.6 (± 25.8) in ChatGPT-4 and Bing Chat, respectively (p < 0.05). According to FRE scores, the generated responses were suitable for only 4.5% and 33% of U.S. adults in ChatGPT-4 and Bing Chat, respectively (p < 0.05).
Conclusions
ChatGPT-4 and Bing Chat consistently provided appropriate responses to the questions. Both LLMs had low readability scores, but ChatGPT-4 provided more difficult responses in terms of readability.
Introduction
Internet usage for medical information is rapidly increasing worldwide, and its accessibility is becoming easier. 1 The findings of the Pew Research Center reveal that one in three American adults use Internet as a valuable resource for medical inquiries, and a significant 72% of Internet users actively seek out information on medical issues. 2 Artificial intelligence (AI) is a field of computer science dedicated to developing intelligent machines capable of emulating human-like thinking and actions. 3 large language models (LLM) have gained widespread popularity in the AI field and have been seamlessly integrated into publicly available chatbots, including ChatGPT (by OpenAI, California, US), Bing Chat (by Microsoft Corporation, Washington, US), and Google Bard (Google LLC, California, US). 4 These chatbots mimic human interaction and generate intelligent-sounding responses to user prompts.
Glaucoma stands as one of the leading causes of acquired blindness, and a considerable number of glaucoma patients do not exhibit any glaucoma-related symptoms. 5 Considering this situation, patients may have difficulty understanding the severity of the disease and the importance of treatment adherence. In addition, glaucoma is a disease that often requires long-term treatment. 6 Due to these reasons, glaucoma patients and their relatives frequently use the internet as an information source. However, the evaluation of the accessible online material in ophthalmology has shown that information regarding glaucoma is generally insufficient and difficult to comprehend due to its low quality and readability. 7 In this study, the appropriateness and readability of the responses given by ChatGPT-4 (released in March 2023) with improved performance and higher reliability, and Bing Chat models to frequently asked questions by the patients about glaucoma were evaluated.
Method
The study was Institutional Review Board (IRB) exempt as no patient-level data were used. This study was conducted in July 2023 using ChatGPT-4 and Bing Chat. Thirty-four questions were designed in consultation with clinicians and sourced from the top 10 unsponsored websites on Google for the keywords ‘frequently asked questions about glaucoma’. These questions encompassed various aspects, including the definition of the disease, its types, risk factors, prevalence, impact on the vision, prevention, visual recovery, medical and surgical treatment options, as well as potential side effects of glaucoma drugs. A total of 34 questions were queried in the fresh ChatGPT-4 and Bing Chat online interfaces, with each question repeated three times to account for potential variations in responses due to the nature of LLMs. Each set of recorded responses for all questions was thoroughly reviewed by two independent glaucoma specialists (OK and GD). They evaluated and graded the answers based on their clinical experience, categorising them as ‘appropriate’, ‘inappropriate’, or ‘incomplete’. An appropriate response was characterised as a correct answer that closely aligned with the recommendations the reviewer would typically provide to the patients. Conversely, an inappropriate response was considered either inaccurate or deviating from the reviewer's clinical recommendations. Lastly, an incomplete response was defined as one that was relevant and accurate but lacked sufficient information to be considered comprehensive. When the categorisations, as decided by specialists, were the same for all three answers to the same question, we used that evaluation as our final appropriateness category. However, when there was a discrepancy between at least two answers to the same repeated question, the set of answers was considered ‘incoherent’. In instances where we encountered different categorisation by two reviewers, we sought the opinion of a third glaucoma specialist (DAT) as an independent adjudicator.
Additionally, the accuracy of the responses was assessed using the Structure of the Observed Learning Outcome (SOLO) taxonomy by third expert. This framework is recognised for its robust, research-based methodology within the sphere of educational research. 8 The SOLO taxonomy itself comprises five distinct structural levels: prestructural, unistructural, multistructural, relational, and extended abstract. These levels categorise learning outcomes with increasing complexity. In assessment contexts, these levels are typically assigned a numerical score ranging from 1 (prestructural) to 5 (extended abstract). 8
All responses were transformed into plain text, and any irrelevant content, including legends and references, was removed. The analysis was conducted in the readability application, Readable (https://app.readable.com/text/)9, using five readability formulas: Flesch Reading Ease (FRE), Flesch Kincaid Grade Level (FKGL), Coleman-Liau Index (CLI), Simple Measure of Gobbledygook (SMOG), and Gunning- Fog Index (GFI). The FRE and FKGL are formulas that utilise the average sentence length in words and the average number of syllables per 100 words for their evaluation, but they have different weighting factors. The FRE score is a numerical value ranging from 1 to 100, with higher scores indicating better readability. A score between 70 to 80 is equivalent to a school grade 8 in terms of readability. This means that text should be fairly easy for the average adult to read. 9 The scale of the FKGL ranges from 0 to 18, and this score is a number that corresponds with a U.S. grade level. 8 In other words, an increase in value, contrary to the FRE score, indicates a decrease in readability. The result is a number that corresponds with a U.S. grade level. The GFI formula produces a grade level between 0 and 20, estimating the required education level to comprehend the text. A Gunning-Fox score of 6 indicates that the text is easily readable for sixth-grade students.9,10 The SMOG Index is determined by tallying every polysyllabic word in sections containing 10 sentences each, placed at the beginning, middle, and end of the text in question.11,12 Unlike the other readability formulas, the CLI does not consider the number of syllables. Instead, it bases its assessment on the average number of letters and sentences per 100 words.9,13 The SMOG Index and CLI are particularly useful in healthcare and for the evaluation of medical documents. 9 The FKGL, CLI, SMOG and GFI indexes use a scale based on the education level needed to understand the text. A score lower than 6 is considered to be at a 6th-grade reading level, and a score of 17 or above is regarded as a collage graduate, and the text intended for the general public should target a grade level of around 8.9,10
Statistical analysis
Statistical analysis was performed using SPSS, version 25.0, for Windows (SPSS Inc., Chicago, IL, USA). The data are presented as mean values, standard deviations, and percentages. A chi-square test and the Mann-Whitney U test were used to analyse the categorisation results of the responses between two LLMs. The Kolmogorov- Smirnov test was used to evaluate the normality of numerical data. The Mann-Whitney U test was applied to analyse the data that exhibited a non-normal distribution, and the independent sample t- test was applied for the data with a normal distribution to evaluate the significance of differences between the readability scores in LLMs. A p-value of less than 0.05 was considered statistically significant.
Results
When each question is asked three times in the system, a total of 102 questions were directed to the ChatGPT-4 and Bing Chat online interfaces for evaluation. The categorisation results from the two independent reviewers showed a 98% (100/102) agreement. All questions directed to LLMs and categorised gradings by reviewers are presented in Table 1.
Appropriateness of the responses generated by ChatGPT-4 and Bing Chat.
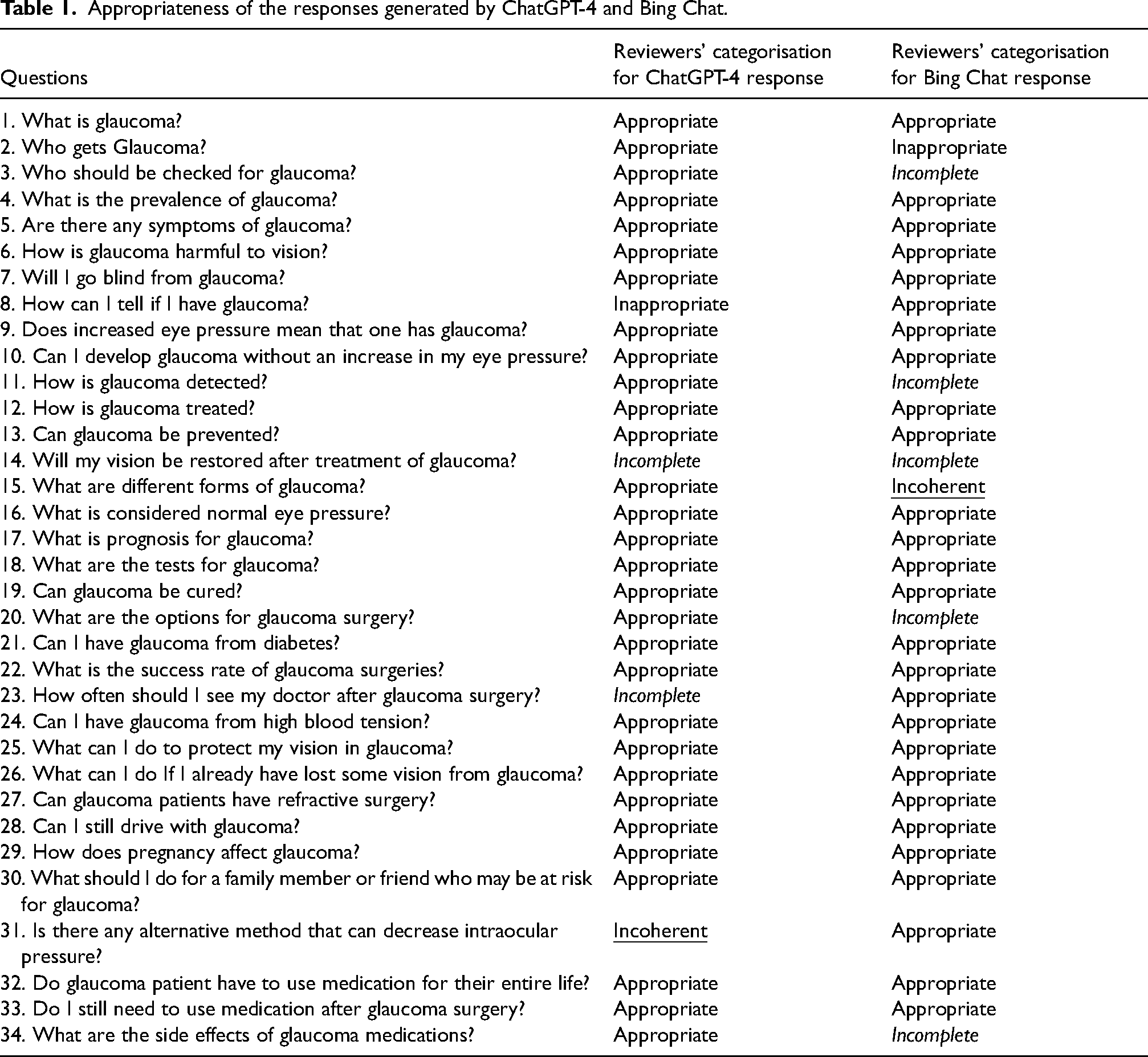
The ChatGPT-4 provided appropriate answers to all three repeated questions in 88% (30/34). Appropriate Bing Chat responses to repeated questions were 82% (28/34). This difference between the two LLMs was not statistically significant (p > 0.05). Among the total of 102 (34*3) responses, the ChatGPT-4 provided appropriate answers in 93 instances, while the Bing Chat's appropriate answers amounted to 89 (p > 0.05).
The ratio of at least one inappropriate response was 3% (1/34) in both ChatGPT-4 and Bing Chat online interfaces. The inappropriate response in ChatGPT-4 (question 8) was about the awareness of the disease in a glaucoma patient, while Bing Chat's inappropriate response (question 2) was about the patients at risk for glaucoma. Answers were incomplete at least once in %6 (2/34) and 12% (4/34) of ChatGPT-4 and Bing Chat responses, respectively. Incoherent answers were identified in two (2/34) of the questions in ChatGPT-4. Among these, answers to question 8 received one inappropriate and two appropriate categories from reviewers, whereas answers to question 31 received one appropriate and two incomplete categories. Similarly, in Bing Chat, incoherent responses were given to two of the 34 questions The responses to questions 2 in Bing Chat was categorised as inappropriate once and appropriate twice and question 15 was categorised as appropriate twice and incomplete once (Table 2).
The SOLO test results for the chatbots ChatGPT-3.5 and Bing Chat were 3.86 ± 0.41 and 3.70 ± 0.52, respectively. There was no statistically significant difference between LLMs (p = 0.101). According to the SOLO test results, both LLMs predominantly provided responses that, on average, approached the Relational category for questions pertaining to KRS.
The mean word counts in responses were 316.5 (± 85.1) and 61.6 (± 25.8) in ChatGPT-4 and Bing Chat, respectively. This difference was statistically significant (p < 0.001). The mean results for FRE, FKGL, CLI, SMOG, and GFI of responses obtained with ChatGPT-4 were 28.8, 13.5, 14.9, 16.5, and 18.4, respectively. In contrast, the mean FRE, FKGL, CLI, SMOG, and GFI scores obtained with Bing Chat were 43.8, 10.9, 12.4, 14.6, and 17.1, respectively (Table 3). The FRE in Chat GPT was statistically significantly lower, and the other readability scores were statistically significantly higher compared to Bing Chat (p < 0.05).
The categorisation distribution of unique and repeated responses.

NA: Not available.
Readability scores of ChatGPT-4 and Bing Chat responses.

*: Independent Sample Test, **: Mann-Whitney U Test.
Discussion
The use of AI technologies has become even more popular, especially with the introduction of ChatGPT. 14 Despites their widespread popularity and adeptness in generating user responses, they are not without limitations. These limitations could manifest as potential inaccuracies, biases, or responses that might be deemed inappropriate. 15 Due to these factors, it is crucial for us to remain cognizant of the accuracy and reliability of the generated responses for the users, as they will function as novel educational resources for patients. Moreover, LLMs do not have specific requirements for readability for patients, potentially introducing an additional limitation in their utility for medical conditions. In the present study, we aimed to evaluate the appropriateness and readability of the responses generated by ChatGPT-4 and Bing Chat for prompts related to ‘frequently asked questions about glaucoma’.
The number of people with glaucoma is increasing rapidly, and it is a chronic condition requiring lifelong management. 16 Patients often turn to the internet, particularly AI chatbots like ChatGPT and Bing Chat, to seek information about prognosis, treatment options, and alternatives. This trend highlights the growing reliance on AI for health information and the need for accurate and reliable information to be readily available.17–19
In a previous study, the technical quality and readability of the information were evaluated for the top 150 websites on a Google search using the keywords glaucoma, high intraocular pressure, and high eye pressure, and this study showed that institutional websites received higher scores, but the majority of the websites had low quality. 20 Another study evaluated the outcomes of medical website searches which conducted using the keyword ‘glaucoma’, and they showed that these medical materials are generally either unsuitable or only insufficient for use. 7 In the present study, LLMs provided a considerable number of appropriate responses to frequently asked questions about glaucoma, the percentage of appropriate responses in ChatGPT-4 and Bing Chat was 88.2% and 79.4%, respectively. Patients are not always able to ask the physicians everything they wonder about their disease, or the physicians cannot provide full, detailed information due to time constraints. Meanwhile, with improved accessibility and ease of use, patients are increasingly visiting websites for comprehensive information about their disease-related curiosities. Considering the rates of appropriate responses provided by ChatGPT-4 and Bing Chat to ‘frequently asked questions about glaucoma’, the utilisation of AI-powered websites by patients is also expected to increase steadily.
Over time, AI may derive its knowledge from previous AI summaries, leading to the repetition and amplification of errors. This phenomenon is also known as the “echo chamber effect. 21 ” Despite our efforts to mitigate this by using fresh applications and repeatedly asking questions to avoid influence from previous answers, this effect may still persist. To minimise this issue, it would be beneficial to regularly update chatbots to refresh their information, have them supervised by human experts, and present the acquired knowledge more transparently. Although both LLMs in this study produced inappropriate responses to the given prompts one time, a positive feature was their inclination to provide non-committal advice, such as recommending a visit to an ophthalmologist, rather than presenting their responses as incontrovertible facts. Additionally, we made an effort not to ask leading questions to the chatbots, but LLMs are susceptible to biases, may produce inaccurate or misleading outputs, and exhibit a lack of transparency regarding their training data, processes, and decision-making methodologies. Consequently, users should critically evaluate and independently verify information obtained from chatbots by consulting credible external sources such as their ophthalmologist.
Readability quantifies the ease with which a given text can be read, and the readability formulas typically consider factors such as sentence length, syllable density, and word familiarity as components of their calculations. 8 It is not only the appropriateness of the responses provided by AI models, but also the comprehensibility of these appropriate answers by the patients that is important. In this study, the readability scores of ChatGPT-4 and Bing Chat responses were evaluated using five different formulas, including Flesch Reading Ease (FRE), Flesch Kincaid Grade Level (FKGL), Coleman-Liau Index (CLI), Simple Measure of Gobbledygook (SMOG), and Gunning- Fog Index (GFI). The mean FRE score of ChatGPT-4 responses was between 10 and 30, indicating that the readability of the text is very difficult, and that this text is suitable for only 4.5% of U.S. adults. 22 The mean FRE score of Bing Chat responses was 43.8 (±14.7), indicating a difficult level of readability, and these responses were appropriate for 33% of U.S. adults. 22 GFI and SMOG results indicated that the reader requires to have at least a college graduation level to read the ChatGPT-4 and Bing Chat answers in our study. 13 The readability levels of the two LLMs were not easy; however, the answers of ChatGPT-4 were significantly longer, and they were more difficult in terms of readability compared to those generated by Bing Chat.
Chatbots can enhance the readability of their responses by using simple, familiar language and avoiding technical jargon. 23 They can keep sentences short and direct, making the information easier to digest. Breaking down content into short paragraphs and using bullet points or lists to organise complex ideas can also help. Additionally, LLMs can use headings and subheadings to guide users through the content, making it more scannable. Incorporating visuals like images and charts to illustrate key points can further aid understanding. Summarising key concepts and offering content in various formats, such as text, audio, and video, can cater to different user preferences and needs, ensuring the information is accessible to a wider audience. 23
Bing Chat typically offers attribution through direct contextual links in most responses, whereas ChatGPT does not automatically provide attribution. Chat GPT has a knowledge database that needs to be updated regularly, and this database can use both predatory and reputable journal articles without distinction. 24 In this study, patients’ frequently asked questions were directed to LLMs; however, a similar ratio of appropriate responses might not be obtained for a more specific and scientific content in ophthalmology.
The limitations of this study are that we directed a limited number of questions about glaucoma to ChatGPT-4 and Bing Chat. As a result, we do not know how the other LLMs and ChatGPT versions perform on our questions or the response quality and readability of ChatGP-4 and Bing Chat on another ophthalmic topic remain unknown. We did not categorise the questions directed to LLMs when evaluating the grading and readability results. Despite the reviewers’ high agreement (98%) in evaluating the appropriateness of the responses, we used a subjective grading system in the present study. Additionally, due to ChatGPT's lack of references for the generated responses, we could not use validated criteria such as DISCERN, QUEST, and Sandvik's General Quality Criteria for the evaluation of health information. Further studies with a larger number of questions that are evaluated with objective criteria are needed to assess the utility of ChatGPT versions and other LLMs for general information about glaucoma and other ophthalmic conditions.
In conclusion, ChatGPT-4 and Bing Chat provided highly appropriate responses to frequently asked questions about glaucoma. Despite the high appropriateness of the responses, the readability scores were low for a layperson. ChatGPT-4 provided longer responses for each question, and the readability of the ChatGPT responses were harder than those generated by Bing Chat. Artificial intelligence technologies are continuously evolving resources and should generate responses, especially on health-related topics, that have better readability.
Footnotes
Data availability
The data utilised to support the findings of the present study have been incorporated within the article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.