
Abstract
Background/Objectives:
Characterizing spinal cord multiple sclerosis (MS) lesions in MRI is critical for diagnosis, monitoring, and treatment evaluation. However, current automated approaches for lesion detection and segmentation are typically designed for specific MRI contrasts or acquisition sites, limiting their generalizability in real-world clinical settings where imaging protocols vary widely. This work proposes a robust multi-site, multi-contrast segmentation framework for spinal cord lesions.
Methods:
The segmentation model was trained and evaluated on a large-scale dataset comprising 4428 annotated images from 1849 persons with MS across 23 imaging centers, encompassing six MRI contrasts (T1w, T2w, T2*w, PSIR, STIR, and UNIT1) acquired at 1.5 tesla (T), 3 T, and 7 T.
Results:
Likert-type assessment performed by neuroradiologist ratings demonstrated superior generalization of the model compared to existing contrast-specific pipelines (p < 0.01). Additional experiments evaluated robustness across spinal levels, acquisition resolutions, binarization thresholds, and quantitative evaluation on external labeled datasets.
Conclusions:
The proposed model can achieve accurate and reliable spinal cord MS lesion segmentation across heterogeneous MRI data, addressing a key barrier to clinical translation. The model is available in the Spinal Cord Toolbox v7.2 and higher.
Introduction
Context
Multiple sclerosis (MS) is the leading cause of non-traumatic neurological disability in young adults, with increasing global prevalence. 1 While research has historically focused on brain lesions, spinal cord (SC) lesions, particularly in the cervical region, disrupt motor and sensory pathways and strongly correlate with disability progression. 2
Magnetic resonance imaging (MRI) is central to MS diagnosis and monitoring, underpinning the McDonald criteria and their revisions.3 –5 Beyond lesion count, lesion segmentation provides precise volumetric and spatial information that maps lesions to specific anatomical structures (like the corticospinal tract), enabling better prediction of motor outcomes through structure-function analysis.6 –8
A wide range of MRI sequences, including T1w, T2w, T2*w, STIR, PSIR, and MP2RAGE, performed at various magnetic field strengths from different manufacturers, are used to visualize MS lesions. 9 However, SC imaging remains technically challenging due to its small size, deformability, and susceptibility to magnetic field inhomogeneities. 10 Despite recent harmonization efforts and international guidelines,11 –14 adoption of those guidelines remains very uneven for SC imaging in MS, and lesion appearance continues to vary across contrasts.
These challenges highlight the need for a robust, generalizable model that can automatically segment SC MS lesions across diverse imaging conditions.
Related works
While automated segmentation of MS lesions in the brain has been extensively studied for over two decades,15 –18 SC lesion segmentation remains comparatively underexplored.
The advent of convolutional neural networks (CNNs) marked a paradigm shift in automated brain MS lesion segmentation, with U-Net and its variants establishing state-of-the-art performance19 –23 and becoming the de facto standard.16,24 Despite the growing interest in transformer-based architectures, CNNs remain particularly well suited for medical imaging tasks due to their strong spatial inductive biases, computational efficiency, and robustness in data-limited regimes.
In contrast, only a limited number of SC-specific methods have been proposed, many of which are not publicly available25,26 or require advanced technical expertise, 27 limiting their clinical adoption. Moreover, most existing approaches are tailored to specific MRI contrasts and do not generalize well across acquisition protocols. For instance, sct_deepseg_lesion 28 has been developed and validated for T2w and T2*w images, while other variants have been proposed for PSIR and STIR, 29 MP2RAGE, 30 or axial T2w scans. 31
Existing methods are predominantly based on CNNs, often derived from U-Net or its optimized implementation, such as the nnU-Net framework. Gros et al. 28 combined three U-Nets for centerline detection, cord segmentation, and lesion delineation on T2w and T2*w scans. More recently, U-Net pipelines optimized with nnU-Net were proposed for MP2RAGE, PSIR, and STIR sequences,29,30 while Karthik et al. 31 developed a region-based nnU-Net model, explicitly restricting predictions to the SC. Another recent study 25 featured segmentation on dual-contrast inputs; however, the lack of code or model availability has limited reproducibility and widespread adoption.
A major challenge in SC lesion segmentation models lies in the variability of manual annotations, where inter- and intra-rater variability is substantial for small or ambiguous lesions. This variability is further amplified in the SC compared to the brain due to lower lesion conspicuity and image artifacts.25,26,28 Such inconsistencies produce noisy ground truth labels that impair model training as deep learning models may learn rater-specific biases rather than lesion-specific features. 32 Evaluation itself is also hindered by noisy annotations, as standard metrics computed against imperfect ground truth labels may not fully reflect the true performance of segmentation models. To mitigate this limitation, complementary evaluation strategies such as blind expert evaluation of predicted segmentations—as we do here with the Likert-type assessment—can provide a more reliable assessment of clinical plausibility.
In this study, we introduce the first segmentation model explicitly designed to operate reliably across a broad spectrum of contrasts. Model performances are assessed using both quantitative segmentation metrics and expert neuroradiologist reviews, ensuring clinical relevance. Rather than aiming for uniform performance across all MRI contrasts, this work focuses on developing a single segmentation model that generalizes robustly across heterogeneous acquisition protocols and contrasts, reflecting real-world clinical variability.
Methods
Data
Experiments were conducted on a large-scale, heterogeneous multi-site SC MRI dataset (Figure 1). The dataset comprises 4428 annotated images acquired from 1849 unique participants across 23 imaging centers, spanning a wide range of acquisition protocols and scanner configurations. Table 1 lists relevant acquisition parameters for each site. The dataset included images acquired on GE, Siemens or Philips MRI systems, at 1.5 T, 3 T or 7 T, using six distinct MRI contrasts: T2w (n = 3060), T2*w (n = 548), PSIR (n = 363), UNIT1 (reconstructed uniform image from MP2RAGE sequence, n = 343), STIR (n = 92), and T1w (n = 22), and spans 2D axial (n = 2895), 2D sagittal (n = 1160), and 3D (n = 373) acquisition planes. Proton-density weighted imaging was excluded because of the poor lesion contrast. The field-of-view coverage varied across sites (brain and upper SC, or SC only). Image resolution exhibited high variability, with an average (± standard deviation) of 1.10 ± 1.13 × 0.51 ± 0.24 × 3.27 ± 1.95 mm3 reported in “RPI-” orientation (Right→Left, Posterior→Anterior, Inferior→Superior), and pixel dimensions ranging from 0.19 mm to 11.92 mm, including inter-slice gap.
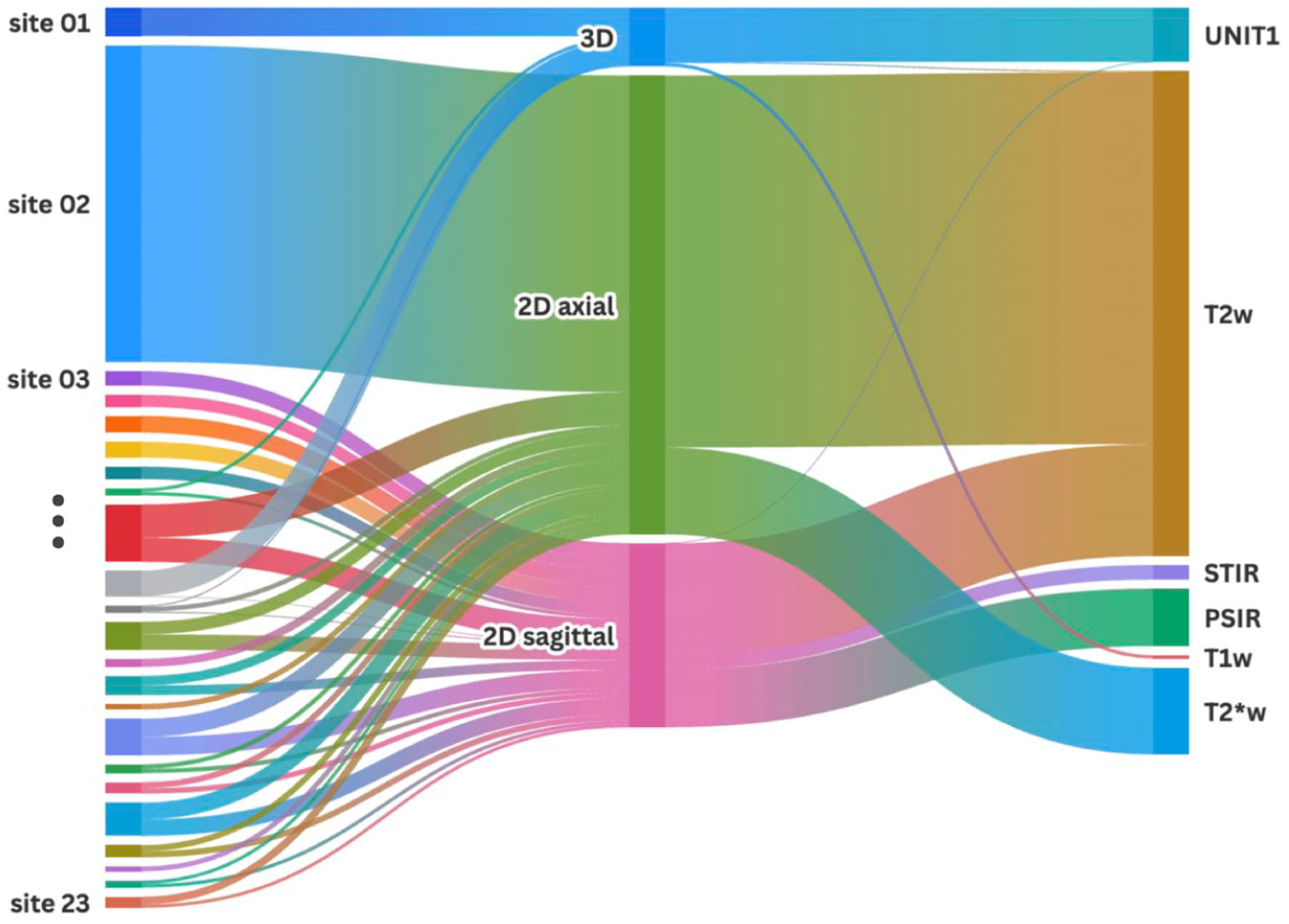
Sankey diagram of annotated MRI scans across clinical sites. Line thickness is associated with the number of scans.
MRI dataset characteristics across projects/sites, contrasts, acquisitions, orientations, resolutions, participants, and field strength.

AMU: Aix-Marseille Université. Basel: University of Basel. BWH: Brigham and Women’s Hospital. CanProCo (n = 5 sites): Canadian Prospective Cohort Study for People Living with MS [33]. IRCCS: IRCCS San Raffaele Scientific Institute. Karolinska: Karolinska University Hospital. MGH: Massachusetts General Hospital. NIH: National Institutes of Health. NYU: NYU Langone Medical Center. OFSEP-Lyon: Observatoire Français de la Sclérose en Plaques—Lyon. OFSEP-Montpellier: Observatoire Français de la Sclérose en Plaques—Montpellier. Rennes: Centre hospitalier universitaire de Rennes. TUM: Technical University of Munich. UCL: University College London. UCSF: University of California San Francisco. Vanderbilt: Vanderbilt University Institute of Imaging Science. Tiantan: Beijing Tiantan Hospital, Capital Medical University. Mayo: Mayo Clinic College of Medicine and Science. UMass: University of Massachusetts Memorial Medical Center.
Lesions were segmented manually at each site and data were organized according to a standard (more details about raters’ expertise, segmentation methods, and dataset aggregation can be found in Supplemental Appendix A).
In addition, we also had access to a collection of 2291 unannotated images originating from three independent cohorts (Table 1). These images were used to qualitatively assess the generalization capability of the segmentation model in real-world out-of-distribution clinical data. However, since no lesion segmentations were available for these sites, they could not be included in the quantitative evaluation of model performance.
Model architecture and training
Several deep learning models were benchmarked on our multi-site dataset, and pretrained weights were used when available: Attention U-Net, 33 STUNet, 34 MultiTalent, 35 MedNeXt, 36 and various nnU-Net architectures. 37 Among these architectures, the best-performing model was a 3D Residual Encoder U-Net (ResEnc), trained within the nnUNetv2 framework. 37 The architecture used the nnUNetPlannerResEncL template with an input patch size of 192 × 192 × 192 voxels, with resampled isotropic resolution of 1.0 × 1.0 × 1.0 mm3.
Images were randomly partitioned into training (n = 3925), test (n = 433), and external validation (n = 70) subsets. The dataset was partitioned at the subject level to ensure subject independence between training and test sets, while maintaining the original contrast distribution across both subsets. The external validation set consisted of one separate dataset which was not seen during training or validation. Training was performed using a fivefold cross-validation scheme with an 80%/20% train/validation split in each fold. A small batch size of two was used to maximize generalization and prevent overfitting, consistent with findings from prior work. 38 The loss function was the combination of Dice and Cross-Entropy without label smoothing (DiceCELoss). Standard data augmentation from the nnU-Net framework was used. More details can be found in Supplemental Appendix B.
Evaluation
Model performance was assessed on two distinct subsets: (i) an internal test set comprising 10% of each dataset (n = 433), and (ii) an external test set composed of an entirely independent dataset not seen during training (n = 70). The internal test set included six MRI contrasts: PSIR (n = 36), STIR (n = 7), T1w (n = 3), T2*w (n = 57), T2w (n = 295), and UNIT1 (n = 35), while the external set included T2*w (n = 22) and T2w (n = 48) acquisitions. For each input, the final segmentation was generated by averaging the binary predictions obtained from the five cross-validation folds, followed by binarization using a fixed threshold of 0.5, which corresponds to the cut-off for partial volume effect.
Quantitative evaluation of segmentation quality employed both voxel-wise and lesion-wise metrics.
The proposed model was compared to established segmentation pipelines tailored to specific MRI contrasts: (i) sct_deepseg_lesion, 28 which supports sagittal T2w (flag “-c t2”), axial T2w (flag “-c t2_ax”) and axial T2*w (flag “-c t2s”) contrasts, (ii) sct_deepseg lesion_ms_mp2rage, adapted to MP2RAGE UNIT1 acquisitions, 30 and (iii) sct_deepseg lesion_ms_axial_t2, recently proposed for axial T2w images. 31
A complementary qualitative evaluation was conducted by selecting a panel of 8 neuroradiologists who reviewed a subset of 40 randomly selected images from the internal test set (~9%), scoring the quality of the segmentation masks produced by the model as well as the manual segmentation, using a 5-point Likert-type scale (1: very poor, 5: excellent). Manual segmentation and model prediction were anonymized to limit evaluation bias. Inter-rater agreement was also quantified (see details in Supplemental Appendix C).
Model performance along the SC was computed per intervertebral disks in Supplemental Appendix D alongside the prevalence of each disk level and the average lesion total volume. The robustness of the model across spatial resolution and post-processing experiments were also investigated in Supplemental Appendix E and F, respectively.
To assess the generalizability of the model, unlabeled scans from independent sites were passed through the model (“Un-annotated data” in Table 1). The resulting predictions were inspected to evaluate segmentation plausibility and overall robustness on acquisition protocols unseen during training.
Results
Qualitative examples of predicted lesion segmentations
Figure 2 presents examples of predicted lesion segmentations. In some instances, manual annotations appear to underestimate lesion boundaries, whereas the model predictions provide a more complete delineation (e.g. MP2RAGE-UNIT1). The PSIR example illustrates the intrinsic ambiguity in lesion interpretation, where the same hyperintense region could be segmented either as several smaller lesions or as a single larger confluent lesion.

Qualitative examples of SC lesion segmentation across different MRI contrasts and orientations.
Figure 3 shows examples of predicted segmentations on unannotated MRI scans, illustrating generalization to unseen acquisition protocols. Across diverse sites, field strengths, and contrasts, the model produced reliable segmentations.

Representative examples of SC lesion segmentations across MRI scans from unannotated dataset.
Model performance
Quantitative evaluation of the model demonstrated robust segmentation performance across datasets (see Table 2). On the internal test set, the model achieved a mean Dice score of 0.63, while lesion-wise evaluation yielded an L-F1-score of 0.71. On the external test set, the model achieved an L-F1-score of 0.80, confirming its ability to generalize across independent data. Importantly, L-Recall remained consistently high (>0.80 across all sets), indicating that the model rarely missed lesions. In contrast, precision values were lower, especially on the test set (L-PPV = 0.76), reflecting a tendency toward over-detection. The relatively large standard deviations across metrics underscore the challenges posed by SC imaging (heterogeneity of acquisition parameters, motion artifacts, etc.) and inter-rater variability in manual annotations.
Voxel-wise and lesion-wise performance of the proposed segmentation model. Performance is reported on the train set (n = 3925), test set (n = 433), and external test set (n = 70).

Evaluation is done on both voxel-wise metrics (Dice score) and lesion-wise metrics (recall, positive predictive value (PPV), and F1-score).
Table 3 shows the robustness of the model across MRI contrasts. Among the most represented contrasts, T2w and UNIT1 images achieved the highest Dice scores, with 0.75 on the training set and 0.64 on the test set for T2w, and 0.77 and 0.67 for UNIT1. Conversely, underrepresented contrasts such as T1w (n = 19 in training) exhibited markedly lower performance, with Dice dropping to 0.42 on the test set. Intermediate performances were obtained for PSIR and T2*w acquisitions, although with higher variability. Notably, despite the limited number of cases, STIR images yielded a relatively high Dice score on the test set, which can be explained by the similarity of T2w and STIR contrasts.
Dice score per MRI contrast.

Performance is reported on the train, test, and external test sets for each available sequence.
Performance across MRI contrasts should be interpreted in light of the strong imbalance in contrast representation within the dataset. While T2w and T2*w acquisitions dominate the training and evaluation sets, several underrepresented contrasts, including UNIT1 and STIR, still achieved competitive performance, suggesting that the model captures contrast-invariant lesion characteristics rather than relying on contrast-specific cues.
Comparison to baseline methods
The proposed model consistently outperformed existing methods across all evaluated metrics (see Table 4). On the test set, our model achieved a mean Dice score of 0.63 ± 0.34, compared to 0.36 ± 0.37 for sct_deepseg T2w_ax, 0.48 ± 0.40 for sct_deepseg MP2RAGE, and 0.23 ± 0.38 for sct_deepseg_lesion. Comparable trends were observed for L-Recall, L-PPV, and L-F1-score. Specifically, L-Recall remained high (0.81 ± 0.31) while maintaining balanced L-PPV (0.76 ± 0.37), resulting in a superior L-F1-score (0.71 ± 0.36) relative to all baseline approaches. These findings indicate that the model provides substantial improvements in both voxel-wise and lesion-wise detection compared with existing contrast-specific segmentation strategies.
Quantitative comparison with existing segmentation methods on voxel-wise metrics (Dice) and lesion-wise metrics (L-Recall, L-PPV, and L-F1-score) reported for both training (A) and testing sets (B).

The top line indicates the method names and the contrasts for which they were designed, listed in parentheses. The proposed model consistently outperforms contrast-specific methods in both train and test data. † indicates significant differences (p < 0.01). ↑ Higher score is better.
Table 5 compares model performance across MRI contrasts. The proposed model performed better than existing methods on all contrasts, even on contrasts for which existing models had been specifically trained on.
Dice score per MRI contrast for our model and existing segmentation methods, reported on training and testing sets.

The top line indicates the method names and the contrasts for which they were designed, listed in parentheses. The proposed model consistently achieves higher Dice across contrasts, even outperforming baseline models on their specific contrast.
Likert-type grading by expert neuroradiologists
Figure 4 shows the comparative evaluation of Likert-type scores between manual and predicted segmentations. Global comparison showed a significant difference (p = 0.01, Wilcoxon signed-rank test) between manual (3.38 ± 1.28) and predicted segmentation (3.58 ± 1.09). For most raters, no significant difference was observed between scores assigned to predicted segmentations and manual annotations. Exceptions were noted for rater 7, who assigned significantly higher scores to the predicted vs the manual segmentations (4.33 vs 3.77, p = 0.01). In addition to an overall higher mean score, the variance of Likert-type ratings was lower for predicted segmentations, suggesting greater consistency across raters in their assessment of model outputs. Rater Kappa agreement was also investigated in Supplemental Appendix C.

Violin plot of Likert-type scores comparing manual and predicted segmentations across six raters.
Soft segmentation
Soft predictions provide voxel-wise probability estimates of model uncertainty and partial volume, enabling clinicians to select either more exhaustive or more conservative segmentations depending on the clinical context. 39 As illustrated in Figure 5, soft segmentations preserve finer boundary details and highlight subtle lesion regions that are not captured by binary predictions. In clinical settings, soft segmentations could also be used to compute more precise volumes, particularly at the boundaries of the lesions where binary segmentation does not account for partial volume effects.

Visual comparison of manual segmentation, predicted soft segmentation and predicted binary segmentation on sagittal T2w, sagittal PSIR and axial T2w (from top to bottom).
Discussion
This study introduces a multi-contrast deep learning model for SC MS lesion segmentation. Unlike prior approaches tailored to specific acquisition protocols, the proposed framework was trained and validated on a uniquely diverse multi-site dataset (n = 23) encompassing six MRI contrasts and acquired on various manufacturers. This design enabled the model to demonstrate strong generalizability and to achieve state-of-the-art performance for SC MS lesion segmentation.
Dataset considerations
The multi-site nature of the dataset presents both opportunities and limitations. A major challenge arises from the strong imbalance in MRI contrast distributions: while T2w dominates clinical practice, newer sequences such as PSIR, STIR, and MP2RAGE remain underrepresented, influencing model learning and performance. Regarding the external test set, further experimentation is necessary to evaluate the model’s performance on a broader range of contrasts, particularly those currently underrepresented within the training dataset.
Beyond considerations of model performance, the dataset used in the current study can shed additional light on the best MR contrasts to use for lesion detection. For example, computing metrics such as lesion-to-background contrast and inter-rater variability could inform current efforts in standardizing spinal cord imaging protocols.12,14 Specifically, small confluent lesions tend to lead to high rater variability as they can be interpreted as many small lesions or a larger confluent lesion. Also, highly anisotropic (such as STIR or PSIR in our study) made interpretation more complex compared to isotropic acquisitions (UNIT1 in our study), leading to more variable interpretations. The latter could explain the relatively high performance of the model compared to the relatively small amount of UNIT1 scans.
Furthermore, the absence of a unified segmentation protocol across sites posed additional challenges. While the variability in ground truth labels negatively impacted model performance, 40 it also represented the “real world” variability in ground truth labels and allowed the model to learn an average of site-specific annotation biases.
Proton-density weighted imaging was a priori excluded from this work. Lesion boundaries were extremely difficult to delineate due to the subtle contrast between abnormal and healthy tissue. Including such data would have compromised the performance of the model.
Although the vast majority of the dataset consists of 3 T acquisitions, the model design and evaluation confer robustness to variations in spatial resolution and image quality. This suggests that the proposed model should perform well on other field strengths (1.5 T and 7 T), although it remains to be further tested extensively.
Model training strategies and performances
The results of this study indicate that a relatively simple architecture, when combined with a well-engineered training pipeline such as nnU-Net, can achieve superior performance compared to more recent state-of-the-art models. 41
To mitigate the class imbalance between lesion and non-lesion voxels, we investigated an alternative strategy involving training exclusively on volumes containing lesions. Although this approach increased L-Recall, it came at the cost of reduced L-PPV, ultimately lowering overall performance.
An additional consideration is whether developing models across all imaging modalities is necessary, given that some contrasts provide superior lesion sensitivity.42,43 Although these comparisons are to some extent dependent on factors other than the pulse sequence, our findings indicate that, by leveraging complementary contrasts and larger, more heterogeneous datasets, a multimodal framework enhances generalization and reduces modality-specific biases.
To enhance model robustness and generalizability, various training configurations were tested. Aggressive data augmentation, such as done by, 44 facilitated faster performance improvements during early training epochs, but showed performance plateauing slightly below that of standard data augmentation, while increasing training time by a factor of three to four. Batch sampling strategies, such as those done in, 45 designed to up-weight underrepresented modalities, did not enhance segmentation accuracy and may have inadvertently promoted overfitting by imposing unrealistic class distributions.
Qualitative inspection of segmentation results revealed persisting challenges in lesion delineation. In particular, raters and models alike struggled with whether to delineate boundaries as one large lesion or several smaller ones. Variable visualization of the central canal in the SC further complicated interpretation, as it could easily be mistaken for a lesion (see the orange arrow in the PSIR image of Figure 2). This ambiguity becomes particularly problematic in longitudinal analyses, where lesion “fusion” may confound clinical interpretation of lesion growth or stability.
Performance remained skewed toward contrasts with higher representation in the training data, although strong performance was still achieved for the relatively lower-represented UNIT1 scans. The external test set only contained T2w and T2*w scans. Consequently, broader validation will require subsequent external testing on underrepresented contrasts. High variability in performance was observed, which can be attributed to multiple factors, including variability in manual annotations, image artifacts, and partial volume effects. When comparing our model to baseline tools, it is important to note that prior methods were trained on subsets of both training and test data, potentially inflating their performance.
Importantly, moderate Dice scores are expected due to high inter- and intra-rater variability. Walsh et al. 26 demonstrated that even expert raters achieve median voxel-wise Dice scores below 0.5 when evaluated against a senior expert-adjudicated ground truth. In this context, very high Dice values would likely indicate overfitting to a specific rater style rather than improved clinical validity. The performance reported here should therefore be interpreted relative to known human variability rather than absolute segmentation accuracy.
Evaluation metrics
The choice of evaluation strategy in SC MS lesion segmentation remains a debated issue as the most used metric, Dice score, is not suited for small object segmentation with high boundary uncertainty. 46 The 10% IoU threshold to match predictions with reference lesions is somewhat arbitrary, but no consensus exists within the community regarding this threshold. While the Free-response Receiver Operating Characteristic (FROC) may provide a more clinically meaningful assessment of detection performance, it relies on lesion-level probability estimates, which are not produced by the current framework.
The Likert-type ratings were used to provide an independent, expert-based qualitative assessment of clinical acceptability of the predicted segmentations relative to manual annotations. This evaluation aimed to assess perceived segmentation quality and consistency, complementing quantitative metrics that are known to be sensitive to annotation variability in spinal cord lesions. Likert-type evaluations by expert neuroradiologists showed that predicted segmentations were perceived as comparable, or in some cases slightly superior, to manual annotations. This reinforces the clinical relevance of the predictions, showing that despite quantitative metrics being relatively modest, the outputs achieve a level of quality acceptable to experts. Furthermore, Likert-type scores showed reduced variability for predicted vs manual segmentations. This reduced variability could indicate that the automated segmentations may exhibit more uniform quality and clearer lesion delineation, contributing to improved inter-rater agreement compared to manual annotations. Nevertheless, potential bias cannot be excluded, as raters might occasionally recognize the source of the segmentation, which could have influenced their evaluations.
Overall, this tool could contribute to improved detection and quantification of lesions in the spinal cord. As demonstrated in other studies, 25 expert evaluations are improved when incorporating model prediction. Furthermore, this tool could mitigate variability in scan interpretation, as it is not subject to inter-rater variability and exhibits robustness across contrasts.
Supplemental Material
sj-docx-1-msj-10.1177_13524585261427333 – Supplemental material for Generalizable spinal cord multiple sclerosis lesion segmentation across MRI contrasts, protocols, and centers
Supplemental material, sj-docx-1-msj-10.1177_13524585261427333 for Generalizable spinal cord multiple sclerosis lesion segmentation across MRI contrasts, protocols, and centers by Pierre-Louis Benveniste, Laurent Létourneau-Guillon, David Araujo, Lydia Chougar, Dumitru Fetco, Masaaki Hori, Kouhei Kamiya, Steven Messina, Charidimos Tsagkas, Bertrand Audoin, Rohit Bakshi, Elise Bannier, Daniel Blezek, Jean-Christophe Brisset, Virginie Callot, Erik Charlson, Michelle Chen, Olga Ciccarelli, Sarah Demortière, Gilles Edan, Massimo Filippi, Tobias Granberg, Cristina Granziera, Christopher C. Hemond, B. Mark Keegan, Anne Kerbrat, Jan Kirschke, Shannon Kolind, Pierre Labauge, Lisa Eunyoung Lee, Yaou Liu, Caterina Mainero, Julian McGinnis, Nilser Laines Medina, Mark Mühlau, Govind Nair, Kristin P. O’Grady, Jiwon Oh, Russell Ouellette, Alexandre Prat, Daniel S. Reich, Maria A. Rocca, Timothy M. Shepherd, Seth A. Smith, Leszek Stawiarz, Jason Talbott, Roger Tam, Shahamat Tauhid, Anthony Traboulsee, Constantina Andrada Treaba, Paola Valsasina, Zachary Vavasour, Marios Yiannakas, Hervé Lombaert and Julien Cohen-Adad in Multiple Sclerosis Journal
Footnotes
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Laurent Létourneau-Guillon is supported by a Fonds de Recherche Quebec Sante (FRQ-S)/Fondation de L’Association des Radiologistes du Quebec (FARQ) Junior 1 salary award (![]() ). Shannon Kolind has received grant support or consulting fees from AbbVie, Biogen, Roche, and Sanofi-Genzyme. B. Mark Keegan: consulting from Moderna, EMD Serono, Tr1X Inc, and book royalties from Oxford University Press. Daniel S. Reich—research funding from Abata and Sanofi. Massimo Filippi is Editor-in-Chief of the Journal of Neurology, Associate Editor of Human Brain Mapping, Neurological Sciences, and Radiology; received compensation for consulting services from Alexion, Almirall, Biogen, Merck, Novartis, Roche, Sanofi; speaking activities from Bayer, Biogen, Celgene, Chiesi Italia SpA, Eli Lilly, Genzyme, Janssen, Merck-Serono, Neopharmed Gentili, Novartis, Novo Nordisk, Roche, Sanofi, Takeda, and TEVA; participation in Advisory Boards for Alexion, Biogen, Bristol-Myers Squibb, Merck, Novartis, Roche, Sanofi, Sanofi-Aventis, Sanofi-Genzyme, Takeda; scientific direction of educational events for Biogen, Merck, Roche, Celgene, Bristol-Myers Squibb, Lilly, Novartis, Sanofi-Genzyme; he receives research support from Biogen Idec, Merck-Serono, Novartis, Roche, the Italian Ministry of Health, the Italian Ministry of University and Research, and Fondazione Italiana Sclerosi Multipla. Maria A. Rocca received consulting fees from Biogen, Bristol-Myers Squibb, Roche, and speaker honoraria from Alexion, Biogen, Bristol-Myers Squibb, Celgene, Horizon Therapeutics Italy, Merck-Serono SpA, Mitsubishi-Tanabe Pharma, Neuraxpharm, Novartis, Roche, Sandoz, and Sanofi. She receives research support from the MS Society of Canada, the Italian Ministry of Health, the Italian Ministry of University and Research, and Fondazione Italiana Sclerosi Multipla. She is an Associate Editor for Multiple Sclerosis and Related Disorders, and Associate Co-Editor for Europe and Africa for Multiple Sclerosis Journal. O. Ciccarelli is an NIHR Research Professor (RP-2017-08-ST2-004); she has been a member of an independent DSMB for Novartis; she acted as a consultant for Merck, Biogen, and Lundbeck; she is Deputy Editor of Neurology®, for which she receives an honorarium; and has received research grant support from the MS Society of Great Britain and Northern Ireland, the NIHR UCLH Biomedical Research Centre, the Rosetree Trust, the National MS Society, and the NIHR-HTA. All other authors report no relevant disclosures. Tobias Granberg—Awardee of the Grant for Multiple Sclerosis Innovation (GMSI) funded by Merck. Dr. Bakshi has received speaking honoraria from EMD Serono, advisory board consulting fees from Sanofi, and research support from Novartis. Constantina Andrada Treaba has received research support from Genentech. Kristin O’Grady—Dr. O’Grady’s research is supported in part by the National Multiple Sclerosis Society under award number JF-2306-41540. The authors not mentioned in this section declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
). Shannon Kolind has received grant support or consulting fees from AbbVie, Biogen, Roche, and Sanofi-Genzyme. B. Mark Keegan: consulting from Moderna, EMD Serono, Tr1X Inc, and book royalties from Oxford University Press. Daniel S. Reich—research funding from Abata and Sanofi. Massimo Filippi is Editor-in-Chief of the Journal of Neurology, Associate Editor of Human Brain Mapping, Neurological Sciences, and Radiology; received compensation for consulting services from Alexion, Almirall, Biogen, Merck, Novartis, Roche, Sanofi; speaking activities from Bayer, Biogen, Celgene, Chiesi Italia SpA, Eli Lilly, Genzyme, Janssen, Merck-Serono, Neopharmed Gentili, Novartis, Novo Nordisk, Roche, Sanofi, Takeda, and TEVA; participation in Advisory Boards for Alexion, Biogen, Bristol-Myers Squibb, Merck, Novartis, Roche, Sanofi, Sanofi-Aventis, Sanofi-Genzyme, Takeda; scientific direction of educational events for Biogen, Merck, Roche, Celgene, Bristol-Myers Squibb, Lilly, Novartis, Sanofi-Genzyme; he receives research support from Biogen Idec, Merck-Serono, Novartis, Roche, the Italian Ministry of Health, the Italian Ministry of University and Research, and Fondazione Italiana Sclerosi Multipla. Maria A. Rocca received consulting fees from Biogen, Bristol-Myers Squibb, Roche, and speaker honoraria from Alexion, Biogen, Bristol-Myers Squibb, Celgene, Horizon Therapeutics Italy, Merck-Serono SpA, Mitsubishi-Tanabe Pharma, Neuraxpharm, Novartis, Roche, Sandoz, and Sanofi. She receives research support from the MS Society of Canada, the Italian Ministry of Health, the Italian Ministry of University and Research, and Fondazione Italiana Sclerosi Multipla. She is an Associate Editor for Multiple Sclerosis and Related Disorders, and Associate Co-Editor for Europe and Africa for Multiple Sclerosis Journal. O. Ciccarelli is an NIHR Research Professor (RP-2017-08-ST2-004); she has been a member of an independent DSMB for Novartis; she acted as a consultant for Merck, Biogen, and Lundbeck; she is Deputy Editor of Neurology®, for which she receives an honorarium; and has received research grant support from the MS Society of Great Britain and Northern Ireland, the NIHR UCLH Biomedical Research Centre, the Rosetree Trust, the National MS Society, and the NIHR-HTA. All other authors report no relevant disclosures. Tobias Granberg—Awardee of the Grant for Multiple Sclerosis Innovation (GMSI) funded by Merck. Dr. Bakshi has received speaking honoraria from EMD Serono, advisory board consulting fees from Sanofi, and research support from Novartis. Constantina Andrada Treaba has received research support from Genentech. Kristin O’Grady—Dr. O’Grady’s research is supported in part by the National Multiple Sclerosis Society under award number JF-2306-41540. The authors not mentioned in this section declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was funded by the Canada Research Chair in Quantitative Magnetic Resonance Imaging [CRC-2020-00179], the Canadian Institute of Health Research [PJT-190258, PJT-203803], the Canada Foundation for Innovation [32454, 34824], the Fonds de Recherche du Québec—Santé [322736, 324636], the Natural Sciences and Engineering Research Council of Canada [RGPIN-2019-07244], the Canada First Research Excellence Fund (IVADO and TransMedTech), the Courtois NeuroMod project, the Quebec BioImaging Network [5886, 35450], INSPIRED (Spinal Research, UK; Wings for Life, Austria; Craig H. Neilsen Foundation, USA), Mila—Tech Transfer Funding Program. This research is supported in part by the FRQNT Strategic Clusters Program (Center UNIQUE—Centre de recherche Neuro-IA du Québec) and Canada Research Chair in Shape Analysis in Medical Imaging. These works were supported by a grant from the Fonds de recherche du Québec (![]() ). This research was supported in part by the Intramural Research Program of the National Institutes of Health (NIH). The contributions of the NIH authors are considered Works of the United States Government. The findings and conclusions presented in this paper are those of the authors and do not necessarily reflect the views of the NIH or the U.S. Department of Health and Human Services. CanProCo funders: MS Canada, Biogen Canada, Brain Canada Foundation, Hoffmann-La Roche Limited, and Government of Alberta.
). This research was supported in part by the Intramural Research Program of the National Institutes of Health (NIH). The contributions of the NIH authors are considered Works of the United States Government. The findings and conclusions presented in this paper are those of the authors and do not necessarily reflect the views of the NIH or the U.S. Department of Health and Human Services. CanProCo funders: MS Canada, Biogen Canada, Brain Canada Foundation, Hoffmann-La Roche Limited, and Government of Alberta.
Ethical Considerations
Data acquisition and storage at each site were authorized by the local IRB. Data were then aggregated at the managing site, under Polytechnique Montréal’s IRB (CER-2324-26-D).
Consent to Participate
Research participants in their respective imaging sites signed a consent form as per the local IRB regulations.
Consent for Publication
Not applicable.
ORCID iDs
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.