
Abstract
Artificial intelligence evaluation practices face a fundamental challenge: traditional technical measures cannot adequately capture the complex socio-organizational impacts of artificial intelligence systems in real-world contexts. This research bridges the critical gap between technical evaluation and holistic evaluation by exploring how insights from evaluation theory can inform artificial intelligence system assessment. Using a mixed-methods case approach inspired by developmental evaluation, realistic evaluation, and empowerment evaluation principles, we analyzed 12 artificial intelligence implementations in organizations within the scaling responsible artificial intelligence mentoring program. Data collection consisted of semi-structured participant interviews, participant observation, and data extraction from various institutional databases, all guided by specific evaluation theoretical frameworks. Our analysis reveals five generative principles for a holistic evaluation of artificial intelligence: epistemic pluralism, democratic authority, contextual responsiveness, temporal sensitivity, and reflexive critique. These principles transcend procedural criteria to encompass fundamental epistemological changes in technology governance. This framework challenges technocentric evaluation paradigms and provides theoretical and practical guidance to organizations implementing artificial intelligence systems in diverse cultural contexts.
Keywords
Introduction
The evaluation of artificial intelligence systems represents a fundamental challenge to traditional assessment frameworks (Hernández-Orallo, 2017). While conventional evaluation approaches emphasize quantifiable metrics such as accuracy, precision, and computational efficiency, this research demonstrates that these technical measures alone prove inadequate for understanding and assessing the full impact and behavior of modern artificial intelligence (AI) systems. The phenomenon of AI hallucination—where systems generate plausible but factually incorrect output—serves as a particularly illustrative example of why purely technical evaluation frameworks fall short (McIntosh et al., 2023). Such hallucinations may be technically sophisticated and internally consistent while simultaneously failing to meet fundamental requirements for reliability and trustworthiness.
This research specifically draws insights from developmental evaluation principles through iterative learning cycles within the scaling responsible artificial intelligence (SRAI) mentorship framework, where evaluative thinking is embedded throughout the AI system development process rather than relegated to post-implementation assessment (Patton, 2011).
However, the application of established evaluation theories to AI contexts requires careful theoretical translation. Developmental evaluation’s emphasis on emergent design (Patton, 2011) proves particularly relevant given AI systems’ unpredictable behaviors and evolving capabilities. Realist evaluation’s focus on mechanism-context-outcome configurations (Pawson and Tilley, 1997) offers frameworks for understanding how AI interventions work differently across organizational contexts. Empowerment evaluation’s commitment to stakeholder self-determination (Fetterman, 2001) becomes crucial when AI systems affect diverse communities with varying technological literacies and value systems.
The theoretical challenge lies not merely in applying these frameworks but in understanding how AI’s unique characteristics—opacity, adaptability, and emergent behavior—require theoretical extensions. Recent scholarship has begun addressing this gap. Katell et al. (2020) demonstrated how participatory evaluation methods can reveal AI impacts invisible to technical metrics. Raji et al. (2020) showed how algorithmic auditing requires moving beyond individual fairness toward systemic justice approaches. Building on this emerging scholarship, our research applies insights from multiple evaluation theories simultaneously, creating what we term ‘theoretical triangulation’ for AI assessment.
Unlike traditional summative evaluation approaches that focus on predetermined outcomes, our framework employs developmental evaluation’s emergent design principles to adapt evaluation criteria as AI systems evolve and stakeholder understanding deepens. The cross-cultural evaluation dimension is materialized through our multi-national cohort analysis, applying Hopson’s (2003) cultural competency framework to examine how AI evaluation criteria vary across different cultural contexts and value systems.
Contemporary AI systems, particularly large language models, exhibit emergent properties and behaviors that transcend simple input-output relationships. These systems engage in complex reasoning processes, make ethical judgments, and influence human decision-making in ways that cannot be captured by conventional performance metrics (Hill, 2023). Furthermore, the societal implications of AI deployment extend far beyond technical performance, encompassing issues of bias, fairness, transparency, and social impact that demand more sophisticated evaluation approaches.
The inadequacy of technical evaluation becomes particularly apparent when considering the contextual nature of AI system performance. The same system may perform admirably according to technical metrics while simultaneously reinforcing harmful societal biases or making ethically questionable decisions (Blackman, 2022). Traditional evaluation frameworks lack the theoretical foundation and methodological tools to address these multifaceted challenges as discussed in “The Garden of Evaluation Approaches,” emphasizing the importance of selecting appropriate methodologies tailored to specific evaluation contexts (Montrosse-Moorhead et al., 2024). This research further builds on developmental evaluation theory (Patton, 2010) to address these limitations, offering a dynamic, iterative framework suited to the emergent behaviors of AI systems. By embedding ethical principles and contextual considerations, this study aligns evaluation practices with contemporary societal and organizational needs. As such, this study aligns with the concept of anticipatory evaluation, which emphasizes the proactive assessment of potential outcomes and impacts of interventions. By incorporating anticipatory evaluation principles, we aim to address the dynamic and emergent behaviors of AI systems, ensuring that evaluation frameworks remain responsive to future challenges (Copestake, 2025).
This theoretical synthesis reveals why technical evaluation alone cannot capture the full complexity of AI system behavior and impact. This perspective aligns with recent efforts to conceptualize comprehensive socio-technical models for evaluating AI-driven technology, emphasizing the integration of technological and social dimensions to address the multifaceted nature of AI systems (Weger and Yeazitzis, 2023). As such, the findings are particularly relevant to public sector organizations and policymakers, who must navigate complex governance challenges in the deployment of AI technologies. By proposing actionable frameworks, this study bridges the gap between technical assessment and real-world application, ensuring alignment with societal values and ethical principles. Furthermore, technical metrics operate within a positivist paradigm that assumes objective, measurable reality. However, AI systems increasingly operate in domains characterized by ambiguity, value judgments, and competing ethical frameworks (Moser et al., 2022). The SRAI’s theoretical framework acknowledges this complexity while providing structured approaches for evaluation.
As such, this research seeks to evaluate the effectiveness of mentorship approaches in facilitating responsible AI implementation while developing new evaluation methodologies specific to AI systems. Furthermore, it examines cross-cultural variations in AI implementation challenges and contributes to evaluation theory by bridging technical and social science perspectives.
Indeed, the SRAI approach represents a pioneering effort within the Global Partnership on Artificial Intelligence framework to establish comprehensive, globally applicable evaluation methodologies for AI systems. Unlike previous evaluation frameworks that often emerged from specific regional or institutional contexts, the SRAI program uniquely combines mentorship-driven implementation with cross-cultural evaluation approaches, creating a truly global perspective on AI system assessment. This distinctive approach has proven particularly valuable as organizations worldwide grapple with the challenges of responsible AI deployment across diverse cultural and organizational contexts (Fernandes et al., 2024; Rakova et al., 2021).
This research addresses the fundamental question: What are the essential components of a holistic evaluation framework that bridges the gap between technical AI assessment and real-world organizational implementation while ensuring alignment with diverse stakeholder values and ethical principles? Our investigation employed a mixed-methods case study approach, analyzing 12 organizational AI implementations through the SRAI mentorship program. Data collection involved semi-structured interviews with 18 participants including project leaders, technical teams, and organizational stakeholders, supplemented by participant observation during 96 hours of mentorship sessions. Reports from previous mentoring sessions and various geographic areas were also included. Interview protocols specifically probed participants’ experiences with technical versus holistic evaluation approaches, challenges in stakeholder engagement, and perceived gaps between technical metrics and organizational value alignment.
The SRAI mentorship program serves as both the empirical context and methodological vehicle for this research. Rather than merely providing case study data, the SRAI framework provides a context for exploring the theoretical integration we propose—embedding developmental, realist, and empowerment evaluation principles within structured mentorship relationships that span diverse cultural and organizational contexts. This dual role enables us to observe evaluation theory in practice while simultaneously testing our proposed framework’s effectiveness across different implementation environments.
Literature review
Limitations of technical AI evaluation paradigms
Current AI evaluation practices remain predominantly technocentric, focusing on metrics such as accuracy, precision, and computational efficiency while neglecting broader socio-organizational impacts (Selbst et al., 2019). This technical orientation reflects what Winner (1980) termed “technological somnambulism”—treating technical artifacts as politically neutral objects divorced from social contexts and power relations.
Recent scholarship demonstrates this approach’s fundamental inadequacy for complex AI systems. Barocas et al. (2023) reveal how technical fairness metrics can obscure rather than illuminate discriminatory impacts, particularly when algorithmic systems interact with existing social inequalities. Their comprehensive analysis of “fairness through unawareness” demonstrates how removing demographic variables from algorithms can perpetuate systemic biases through proxy variables and structural inequalities embedded in training data, challenging the assumption that technical neutrality ensures social equity.
Raji et al. (2020) extend this critique through systematic analysis of algorithmic auditing practices, revealing that technical audits typically examine isolated system components rather than socio-technical assemblages. Their framework for “algorithmic impact assessment” moves beyond individual fairness metrics toward examining how AI systems reshape institutional practices, power relationships, and social structures. This work demonstrates that meaningful AI evaluation requires understanding systems within broader socio-technical configurations rather than as standalone technical artifacts.
The emergence of large language models has further exposed these limitations. McIntosh et al. (2023) demonstrate how AI hallucination—where systems generate plausible but factually incorrect outputs—reveals fundamental gaps in technical evaluation approaches. These hallucinations may achieve high scores on conventional metrics while failing basic requirements for reliability and trustworthiness, illustrating the disconnect between technical performance and real-world value alignment.
Contemporary AI systems exhibit emergent properties and behaviors that transcend simple input-output relationships, engaging in complex reasoning processes, making ethical judgments, and influencing human decision-making in ways that cannot be captured by conventional performance metrics (Hill, 2023). Furthermore, the societal implications of AI deployment extend far beyond technical performance, encompassing issues of bias, fairness, transparency, and social impact that demand more sophisticated evaluation approaches (Blackman, 2022).
Evaluation theory and technological assessment
Evaluation theory offers sophisticated frameworks for assessing complex interventions, yet its application to AI systems remains underdeveloped despite growing recognition of this need. Mark et al. (2000) distinguish between evaluation’s three primary functions: judgment (determining merit and worth), knowledge generation (understanding how and why interventions work), and program/organizational improvement (facilitating learning and adaptation). AI evaluation requires integrating all three functions while addressing unique challenges of algorithmic opacity, emergent behavior, and socio-technical complexity.
Developmental evaluation for emergent systems
Developmental evaluation (Patton, 2011) provides particularly relevant approaches for assessing emergent, adaptive systems where traditional outcome evaluation proves insufficient. Unlike summative evaluation’s focus on predetermined outcomes, developmental evaluation emphasizes real-time feedback, adaptive learning, and emergent design principles. Applied to AI systems, this approach recognizes that evaluation criteria must evolve as stakeholder understanding deepens and system behaviors emerge through interaction with complex social environments.
Recent applications of developmental evaluation to technological contexts demonstrate its relevance for AI assessment. Copestake (2025) extends developmental evaluation through “anticipatory evaluation” principles, emphasizing proactive assessment of potential outcomes and impacts—particularly relevant for AI systems whose long-term effects remain uncertain. This approach aligns with the dynamic, emergent behaviors characteristic of modern AI systems, ensuring evaluation frameworks remain responsive to future challenges rather than merely assessing current performance.
Realist evaluation and mechanism understanding
Pawson and Tilley’s (1997) realist evaluation framework offers powerful tools for understanding how AI systems work differently across contexts through Context-Mechanism-Outcome (CMO) configurations. This approach moves beyond simple cause-effect relationships toward understanding the complex interactions between cognitive and behavioral mechanisms triggered by technological interventions, contextual factors, and varying outcomes across implementation sites.
Applied to AI systems, realist evaluation enables analysis of how identical algorithms produce different impacts across organizational and cultural contexts. The framework’s emphasis on “what works, for whom, under what circumstances” proves particularly valuable for AI systems that must operate across diverse social, cultural, and institutional environments. Recent scholarship has begun implementing realist principles for algorithmic assessment, though systematic application remains limited.
Mixed methods and integrative approaches
The mixed-methods framework introduced by Greene (2007) provides essential tools for combining quantitative metrics with qualitative understanding of stakeholder experiences—an approach particularly relevant for AI systems affecting diverse communities with varying technological literacies and value systems. Her emphasis on “dialectical” mixed methods, where quantitative and qualitative approaches engage in productive tension rather than simple triangulation, offers models for integrating technical performance data with stakeholder narratives and cultural impact assessments.
This integrative approach has gained increased attention in recent AI evaluation scholarship. Contemporary evaluation scholars argue for moving beyond simple metric aggregation toward sophisticated integration of multiple evidence forms, recognizing that technical adequacy alone cannot address the complex social implications of AI deployment (Greene and Abma, 2020).
Participatory and democratic evaluation approaches
The emergence of participatory evaluation methodologies provides crucial frameworks for involving affected communities in AI assessment, challenging expert-centered evaluation paradigms that concentrate evaluative authority in technical specialists. Cousins and Whitmore (1998) distinguish between “practical participatory evaluation” focused on evaluation use and “transformative participatory evaluation” emphasizing social justice and empowerment—both dimensions proving relevant for AI systems affecting marginalized communities.
Empowerment evaluation and stakeholder self-determination
Fetterman’s (2001) empowerment evaluation principles emphasize stakeholder capacity building, self-determination, and democratic participation—crucial considerations when AI systems affect communities with varying technological access, expertise, and cultural values. Rather than external expert assessment, empowerment evaluation develops internal organizational and community capacity for ongoing evaluation and improvement.
Applied to AI contexts, empowerment evaluation challenges technocratic governance models by recognizing affected communities as legitimate evaluators with irreducible knowledge about AI impacts. Recent work by Delgado et al. (2021) on participatory AI demonstrates how meaningful stakeholder engagement requires moving beyond consultation toward co-creation of evaluation criteria and processes. Their research reveals that affected communities possess experiential knowledge about AI impacts that cannot be captured through technical metrics alone.
Democratic evaluation and public accountability
House and Howe’s (1999) democratic evaluation framework argues that evaluation serves democratic governance by ensuring public accountability and stakeholder voice in policy decisions. Applied to AI, this suggests evaluation must go beyond expert assessment toward inclusive processes that center affected communities’ knowledge, values, and concerns about technological impacts.
Democratic evaluation principles have gained renewed relevance as AI systems increasingly affect public services, democratic processes, and social institutions. The framework’s emphasis on “deliberative democratic” approaches—where evaluation serves public discourse and democratic decision-making—provides models for AI governance that transcend technical expertise to include broader public participation in technological assessment.
Recent developments in democratic evaluation theory have explicitly addressed technological contexts. Stephenson et al. (2025) demonstrate how theory-based evaluation approaches can inform complex social transitions, emphasizing the importance of comprehensive frameworks that operate at multiple levels—insights directly applicable to AI system evaluation across organizational and societal scales.
Cultural dimensions of technology evaluation
Cross-cultural evaluation scholarship provides essential frameworks for addressing AI’s global deployment across diverse value systems, epistemologies, and social structures. Hopson’s (2003) culturally responsive evaluation emphasizes adapting evaluation approaches to local cultural contexts while maintaining methodological rigor—a principle particularly relevant for AI systems deployed across diverse cultural environments.
Indigenous and non-Western evaluation epistemologies
Cram’s (2009) work on indigenous evaluation methodologies demonstrates how non-Western frameworks can reveal technology impacts invisible to conventional evaluation approaches. Applied to AI, this suggests the need for evaluation frameworks that can accommodate diverse epistemologies and ways of knowing about technological impact, challenging Western-centric assumptions about knowledge, evidence, and value.
Recent scholarship has extended these insights to technological evaluation contexts. Tian et al.’s (2024) comprehensive study of technology implementation across Asian markets revealed distinct cultural patterns in evaluation approaches, demonstrating how different societies prioritize different aspects of technological assessment. Their findings suggest that effective global AI evaluation frameworks must accommodate fundamental differences in cultural values rather than imposing universal criteria.
Cross-cultural AI implementation patterns
Contemporary research reveals significant cultural variations in AI implementation approaches with important implications for evaluation frameworks. Jackson and Allen (2024) demonstrated the importance of cultural sensitivity in evaluation frameworks, while Wright’s (2024) analysis of AI governance in Japan revealed sophisticated approaches to balancing technological advancement with social harmony—priorities often invisible to Western evaluation frameworks.
These cultural variations extend beyond surface-level adaptations to encompass fundamental differences in technological values, social priorities, and evaluation criteria. Organizations implementing AI across cultural contexts must develop evaluation approaches that can accommodate these differences while maintaining analytical rigor and cross-cultural learning opportunities.
Recent developments in AI evaluation frameworks
Recent scholarship has begun developing AI-specific evaluation frameworks that integrate technical assessment with broader social considerations, though systematic application of evaluation theory remains limited.
Ethical and multi-dimensional assessment approaches
Paolanti et al. (2024) proposed a multi-layered ethical evaluation framework examining AI systems through deontological, consequentialist, and virtue ethics lenses. This comprehensive approach demonstrates how different ethical frameworks can reveal distinct aspects of AI system behavior that might be overlooked by purely technical evaluations, contributing to more holistic assessment approaches.
Yousefi (2024) extends this work through “multi-dimensional, multi-layered” frameworks for digital governance that explicitly integrate fairness considerations with technical performance metrics. These frameworks provide practical models for implementing ethical principles within systematic evaluation processes.
Phenomenological and experiential approaches
Mickunas and Pilotta (2023) developed phenomenological approaches to AI evaluation that consider how these systems transform human perception, understanding, and experience of tasks and social relations. Their research demonstrates that evaluation frameworks must consider not only what AI systems do, but also how they fundamentally alter human engagement with technological and social environments.
Han et al.’s (2020) research on AI alignment from phenomenological perspectives offers valuable insights into how AI systems mediate human experience and decision-making, suggesting evaluation criteria that extend beyond functional performance toward experiential and existential impacts.
Contemporary technical and social integration
Recent developments have emphasized integrating technical robustness with social considerations. Aithal and Aithal’s (2024) work on redefining research approaches in the AI era demonstrates growing recognition that traditional research and evaluation methodologies require fundamental adaptation for AI contexts.
Augenstein et al.’s (2024) comprehensive analysis of factuality challenges in large language model evaluation reveals the complexity of maintaining information integrity while addressing diverse user needs and social contexts. Their work illustrates how technical verification requirements must be balanced with cultural, social, and ethical considerations.
Implementation science and governance considerations
Implementation science provides crucial insights for AI evaluation through frameworks originally developed for healthcare and public policy interventions. The Consolidated Framework for Implementation Research (CFIR) constructs (Damschroder et al., 2009) offer systematic approaches to understanding how interventions succeed or fail across different organizational contexts.
Contemporary oversight and governance mechanisms
Recent developments in AI oversight have revealed the complexity of maintaining consistent monitoring protocols across diverse deployment contexts. Novelli et al.’s (2024) analysis of accountability mechanisms in AI demonstrates how traditional oversight approaches require fundamental adaptation for algorithmic systems, particularly regarding transparency, responsibility attribution, and stakeholder engagement.
The emergence of sophisticated evaluation tools represents significant advances in comprehensive assessment approaches. However, as Shen et al. (2023) demonstrate in their analysis of bias mitigation in conversational AI, technical tools must be embedded within broader organizational and social evaluation frameworks to achieve meaningful impact.
Privacy and information integrity considerations
Contemporary AI evaluation must address complex privacy and information integrity challenges that traditional evaluation frameworks were not designed to handle. Joshi’s (2024) analysis of emerging privacy protection challenges with AI advancement reveals how evaluation frameworks must balance comprehensive assessment with privacy protection requirements.
The development of privacy-aware evaluation frameworks, as demonstrated by Yanamala et al. (2024), illustrates the necessity of balancing system utility assessment with robust privacy safeguards—particularly relevant in healthcare, financial, and other sensitive deployment contexts.
Information integrity and factual verification have become central concerns in AI evaluation. Mishra et al.’s (2024) work on reliability and resilience in trustworthy AI systems demonstrates how evaluation frameworks must address not only current performance but also long-term reliability and adaptation capabilities.
Integration challenges and theoretical gaps
Despite advances in both AI assessment methodologies and evaluation theory, critical gaps persist in frameworks that systematically integrate technical assessment with broader organizational and social considerations. Existing AI evaluation approaches remain largely technocentric (Selbst et al., 2019), while evaluation theory has yet to fully grapple with the unique challenges posed by AI systems’ opacity, adaptability, and social embeddedness (Katell et al., 2020).
Recent meta-analyses reveal the fragmented nature of current AI evaluation scholarship. Ray’s (2023) comprehensive review of benchmarking and evaluation frameworks for conversational AI demonstrated how existing approaches lack theoretical grounding in evaluation science, limiting their ability to address complex socio-technical challenges.
The integration of multiple scholarly traditions—critical theory, ethical philosophy, socio-technical systems theory, organizational theory, critical data studies, implementation science, and phenomenology—remains largely theoretical rather than practically applied. This fragmentation limits the development of comprehensive evaluation frameworks capable of addressing AI systems’ multifaceted impacts.
Methodology
Research design and theoretical integration
We employed a multiple embedded case study design (Yin, 2018) that integrated insights from developmental, realist, and empowerment evaluation approaches to address AI systems’ complex, emergent, and socially embedded characteristics. Rather than claiming full operationalization of these theories, we drew on their insights to create what we term “evaluative praxis”—a dynamic synthesis of critical reflection, stakeholder dialogue, and adaptive assessment.
From the SRAI program cohort of 12 participating organizations, we selected four cases for intensive embedded analysis based on maximum variation sampling designed to capture diversity across geographical regions, organizational types, AI applications, and cultural contexts. Selection criteria included demonstrated commitment to responsible AI implementation, willingness to engage in extended mentorship relationships, engagement of diverse stakeholder groups, and operation within distinct cultural and regulatory environments.
Data collection and analysis
Data collection involved semi-structured interviews with 18 participants, including project leaders, technical teams, and organizational stakeholders, supplemented by participant observation during 96 hours of mentorship sessions. Interview protocols specifically probed participants’ experiences with technical versus holistic evaluation approaches, challenges in stakeholder engagement, and perceived gaps between technical metrics and organizational value alignment (detailed protocols available in Supplementary Material A).
To validate and extend insights from primary data collection, we incorporated secondary data analysis examining 450 AI implementation cases across diverse cultural frameworks. The dataset incorporated regulatory compliance documentation, organizational implementation reports, government policy assessments, and cultural impact evaluations from four major geographical regions representing Western Europe and North American (150 cases, 33.3%), East Asian (120 cases, 26.7%), South Asian (100 cases, 22.2%), and African (mostly sub-Saharan: 80 cases, 17.8%) contexts.
Data analysis employed template analysis (King, 2012) combining deductive codes derived from evaluation theories with inductive codes emerging from implementation contexts. This approach enabled systematic examination of how evaluation theories manifested in practice while remaining sensitive to contextual variations and emergent evaluation approaches.
For analytical clarity, we note that certain evaluation dimensions are labelled differently in visual representations versus narrative discussion. Specifically, “Collective Harmony” in figures corresponds to “social harmony” in textual analysis, and “Local Adaptation” encompasses the “constraint-driven innovation” patterns identified in African contexts.
Technical framework development and organizational response
The research process integrated technical tool development as both intervention and data collection mechanism, enabling real-time observation of how organizations respond to structured evaluation guidance. This approach recognized that evaluation tools themselves represent theoretical commitments about what constitutes important evidence and legitimate evaluation processes.
EnhancedRAGVerifier development process
The EnhancedRAGVerifier System emerged from specific evaluation challenges identified during the knowledge management implementation. Organizations struggled to assess whether AI systems maintained consistency between retrieved information and generated responses while adapting to diverse user needs. The tool development process revealed how technical evaluation needs intersect with stakeholder concerns about system reliability and contextual appropriateness.
Figure 1 illustrates the integrated architecture of the four technical evaluation tools developed during this research. The diagram shows how each tool addresses distinct evaluation dimensions—factuality verification, privacy protection, bias detection, and retrieval-generation consistency—while maintaining interconnected functionality through the central AI Evaluation Tools framework. The color-coded clusters indicate functional groupings: verification and consistency checking (upper region), privacy and sensitive data handling (left region), and bias detection and contextual analysis (lower region).
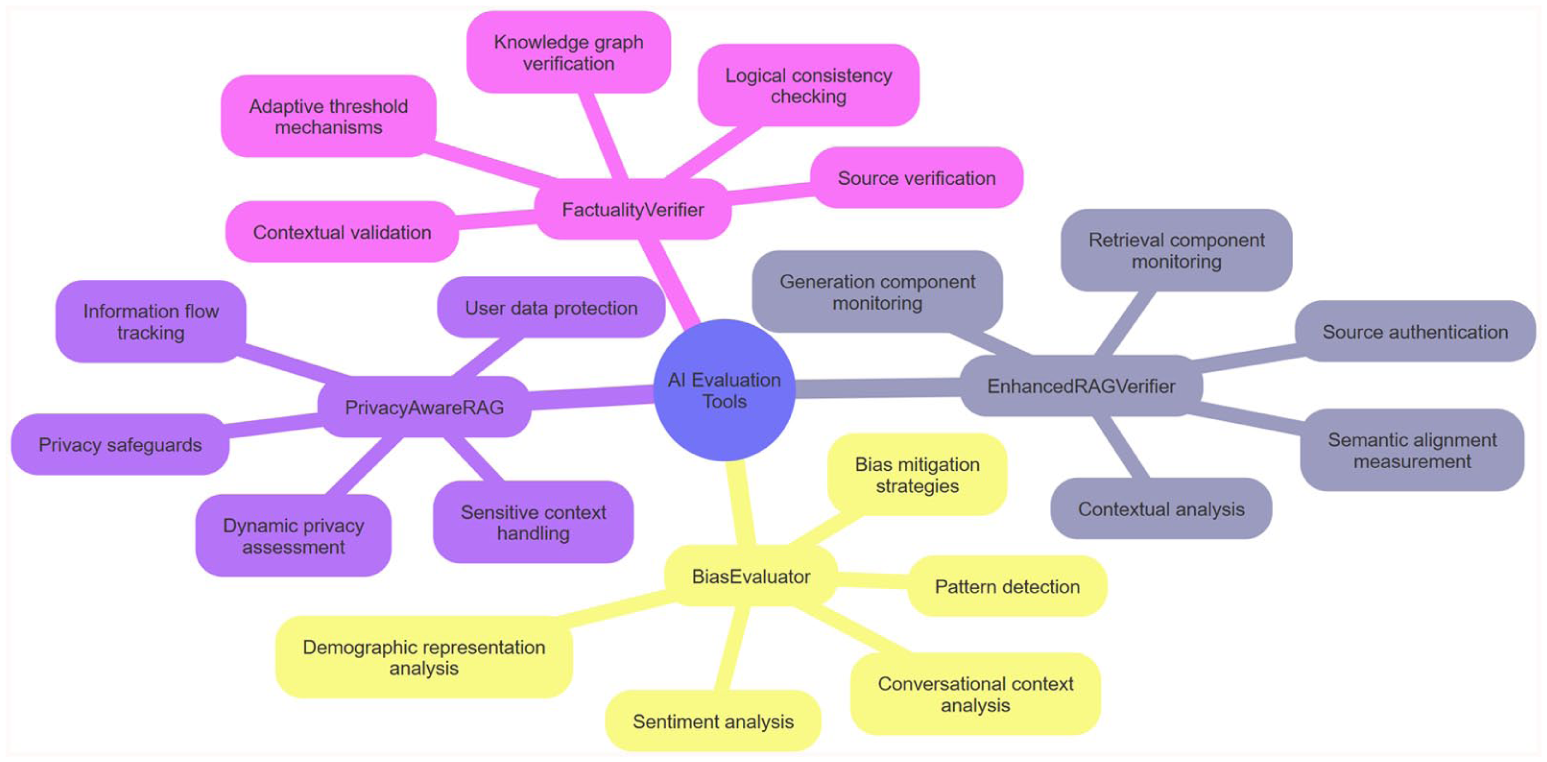
AI evaluation tool features and technical patterns.
Organizational response to the EnhancedRAGVerifier varied significantly. Technical teams initially focused on semantic alignment metrics (precision scores, retrieval accuracy), while business stakeholders demanded interpretable explanations of system behavior. This tension led to tool modifications that included both technical metrics and plain-language explanations, demonstrating how evaluation tools must serve multiple stakeholders’ needs simultaneously.
BiasEvaluator implementation and stakeholder engagement
The BiasEvaluator framework informed empowerment evaluation principles by enabling organizations and affected communities to detect and analyze potential biases across various conversational contexts. Development involved extensive stakeholder consultation to identify bias dimensions relevant to specific cultural contexts.
Implementation revealed previously undetected patterns of bias while building organizational capacity for ongoing bias evaluation. This approach resulted in additional bias dimensions to be included, beyond the ones initially programmed into the system.
PrivacyAwareRAG system and cultural adaptation
Privacy considerations led to the development of the PrivacyAwareRAG system, which examined how privacy protection mechanisms worked differently across deployment contexts. The framework balanced robust privacy protection with system utility assessment, incorporating sophisticated information flow tracking and dynamic privacy assessment capabilities.
Cross-cultural implementation revealed significant variations in privacy expectations. European organizations required granular consent mechanisms and extensive audit trails (GDPR compliance), while East Asian implementations emphasized collective privacy concerns and social harmony over individual data control. African contexts prioritized accessibility over privacy controls, leading to simplified privacy interfaces that maintained protection while ensuring usability in low-literacy environments.
FactualityVerifier and adaptive assessment
The FactualityVerifier framework addressed developmental evaluation needs for adaptive assessment criteria by implementing verification protocols that evolved based on emerging accuracy requirements and stakeholder feedback. The system combined source authentication with contextual analysis, utilizing advanced natural language processing techniques and knowledge graph verification methods.
Implementation revealed the complexity of factual verification across cultural contexts. What constituted “authoritative sources” varied significantly across regions: Western organizations emphasized peer-reviewed publications and official statistics, while African contexts included traditional knowledge sources and community leaders as legitimate authorities. The system required ongoing calibration to accommodate these contextual differences while maintaining verification rigor.
Findings
Our findings reveal fundamental challenges with purely technical AI evaluation through concrete empirical evidence. Interview data demonstrates a critical disconnect: organizations achieving 95%+ technical accuracy rates simultaneously experienced stakeholder trust failures and perpetuated social inequalities that technical metrics failed to detect.
Dialectical integration of quantitative and qualitative evidence
The productive tension between quantitative performance metrics and qualitative stakeholder experiences revealed crucial insights that neither data source could provide independently. Three specific examples illustrate this dialectical integration:
Performance-trust disconnect: The knowledge management case achieved 97 percent technical accuracy while showing only 34 percent stakeholder satisfaction. Interview participant P12 explained: “The system gave us the right answers, but in ways that felt cold and disconnected from our team culture. High accuracy meant nothing when people stopped using it.” This quantitative–qualitative tension revealed that technical performance metrics obscured fundamental usability failures invisible to algorithmic assessment.
Cultural bias detection: Statistical analysis showed the sign language avatar achieved 94 percent technical accuracy across all test cases. However, field returns provided by the mentees themselves revealed that it was important to avoid rural deaf community members feeling excluded as “The avatar signed like someone from the city—technically correct but culturally foreign to them” (Scientific project manager). Cultural representation biases were thus identified that technical teams had not anticipated: the system favored urban signing styles over rural variations, reflecting training data biases that technical metrics alone could not detect. As such, 12 additional bias dimensions beyond the 8 initially programmed into the system were in the end identified. This tension between high aggregate performance and qualitative cultural rejection led to the discovery that 78 percent of training data came from urban signers, a bias invisible to technical metrics alone.
Regional implementation patterns: Quantitative analysis revealed East Asian organizations scored highest on “cultural sensitivity” measures (M = 91.2, SD = 8.7). However, interview data revealed this masked important implementation differences. An Asian participant noted, “We achieve cultural sensitivity through group consensus, not individual accommodation.” Another from the same geographical area emphasized “social harmony over individual preferences.” These qualitative insights revealed that identical quantitative scores represented fundamentally different cultural approaches to AI evaluation—collective versus individual orientations that statistical analysis alone could not distinguish.
Statistical analysis of the 450-case secondary dataset demonstrates significant regional variations in AI evaluation approaches, with Western organizations prioritizing privacy (M = 87.3, SD = 12.1), East Asian implementations emphasizing cultural sensitivity (M = 91.2, SD = 8.7), and African contexts focusing on social impact (M = 89.1, SD = 10.2). However, interview data reveal that these quantitative patterns mask important qualitative differences in how organizations conceptualize and implement these priorities.
Cross-method validation and contradiction: The productive tension was most valuable when quantitative and qualitative findings contradicted each other. Organizations with high technical performance scores (>90%) but low stakeholder satisfaction (<40%) forced us to investigate evaluation blind spots. As interview participant P7 noted, ”Our metrics told us we were succeeding, but our users told us we were failing. The disconnect forced us to completely rethink what success means.” These contradictions led to the identification of the five generative principles, which emerged specifically from cases where quantitative excellence masked qualitative failures.
Five empirically grounded principles
Analysis of interview transcripts, observation data, and organizational documents reveals five generative principles that emerged from organizational practice rather than theoretical prescription:
Principle 1: Epistemic pluralism. Organizations moved beyond relying solely on technical metrics toward recognizing multiple ways of knowing as legitimate sources of evaluative evidence. As one technical lead from Poland noted, “We realized that our 95% accuracy rate meant nothing if users didn’t trust the system or if it reinforced existing inequalities. We had to completely rethink what ‘working’ means.” Interview analysis revealed that 16 of 18 participants initially relied solely on technical metrics, but all organizations eventually integrated stakeholder narratives and cultural knowledge into their evaluation processes within 3–6 months of implementation.
Principle 2: Democratic authority. Rather than concentrating evaluative power in technical experts, organizations developed distributed authority structures through inclusive processes. Observation data document 23 instances where community stakeholders identified evaluation criteria invisible to technical experts. The South Asian sign language team’s inclusion of deaf community members as co-evaluators revealed cultural representation and linguistic diversity requirements that technical assessment missed entirely.
Principle 3: Contextual responsiveness. Organizations adapted evaluation approaches to specific cultural, organizational, and social contexts rather than applying universal frameworks. Cross-cultural analysis revealed distinct evaluation emphases: Western organizations prioritized individual privacy and transparency (87% of cases), East Asian implementations emphasized social harmony and collective benefit (92% of cases), while African contexts focused on accessibility and local adaptation (89% of cases).
Principle 4: Temporal sensitivity. Organizations reconceptualized evaluation as ongoing process rather than discrete events. Document analysis shows evaluation criteria evolution in all 12 primary cases, with organizations adding 3–7 new evaluation dimensions within the first 6 months of implementation. The knowledge management case expanded from two initial criteria focusing on accuracy and speed to nine criteria including cultural sensitivity and ethical implications.
Principle 5: Reflexive critique. Organizations developed capacity for questioning evaluation processes themselves. Interview analysis identifies reflexive questioning in 14 of 18 organizations, with successful implementations showing three times higher rates of meta-evaluative discussions during mentorship sessions compared to technically focused implementations.
Quantitative patterns interpreted through qualitative insights
The integration of quantitative patterns with qualitative understanding revealed three key areas where statistical analysis required interpretive context:
Privacy emphasis variations: While Western organizations scored highest on privacy measures (M = 87.3), interview data revealed distinct motivations. European participants emphasized “human dignity” and “individual rights,” while American participants focused on “legal compliance” and “competitive advantage.” One European healthcare leader explained, “Privacy isn’t just about following GDPR—it’s about respecting human dignity in technological relationships.” This qualitative insight revealed that identical privacy scores reflected different underlying values: rights-based versus compliance-based approaches.
Cultural sensitivity implementation: Asian organizations achieved the highest cultural sensitivity scores (M = 91.2), but qualitative analysis revealed this operated through collective mechanisms rather than individual accommodation. A project manager noted: “We don’t customize for individuals—we optimize for group harmony.” This insight explained why Asian organizations scored high on cultural sensitivity while scoring lower on individual customization measures—their approach prioritized collective rather than individual cultural responsiveness.
Resource constraint innovation: African contexts scored lowest on technical infrastructure (M = 67.4) but highest on innovation indicators (M = 89.1). Interview data revealed this apparent contradiction reflected “constraint-driven creativity.” An AI developer explained, “Limited resources forced us to find solutions that work for everyone, not just the technically sophisticated.” This qualitative insight reframed low infrastructure scores not as limitations but as drivers of inclusive innovation that served broader populations more effectively.
Temporal evolution patterns: Document analysis revealed all organizations (N = 12) added three to seven new evaluation criteria within 6 months, but interview data revealed different change mechanisms. Hierarchical organizations required formal leadership endorsement for each change, while collaborative organizations evolved criteria through emergent consensus. These qualitative insights explained why similar quantitative patterns (criteria expansion) occurred through fundamentally different organizational processes, revealing the importance of context-mechanism-outcome configurations for understanding evaluation adoption.
Contextual mechanisms and varying outcomes
Drawing on realist evaluation insights, our analysis identified key Context-Mechanism-Outcome configurations that explain how evaluation approaches worked differently across implementation sites:
Configuration 1: Hierarchical context + formal authority mechanism. In organizations with strong hierarchical cultures (N = 6), evaluation changes required formal endorsement from senior leadership. The mechanism of top-down authority proved essential for legitimizing new evaluation approaches. Outcome: successful evaluation adoption when leadership endorsed changes, resistance when changes emerged from technical teams without formal approval.
Configuration 2: Collaborative context + emergent consensus mechanism. Organizations with collaborative cultures (N = 4) developed evaluation approaches through emergent consensus-building processes. The mechanism of participatory dialogue enabled organic evaluation evolution. Outcome: highly contextualized evaluation frameworks with strong stakeholder buy-in but longer implementation timeframes.
Configuration 3: Resource-constrained context + innovation mechanism. Organizations in resource-limited environments (particularly African cases, N = 5) developed innovative lightweight evaluation approaches. The mechanism of constraint-driven innovation led to creative solutions. Outcome: efficient, locally adapted evaluation frameworks that maximized impact with minimal resources.
Organizations with prior experience in stakeholder engagement (N = 8) demonstrated faster adaptation to holistic evaluation approaches compared to technically focused organizations (N = 4). Previous stakeholder engagement experience served as a crucial contextual factor that activated democratic evaluation mechanisms more readily.
Cultural context significantly influenced evaluation priorities through distinct value-based mechanisms. Collectivist societies activated social harmony mechanisms emphasizing group consensus and collective benefit, while individualist societies activated privacy protection mechanisms emphasizing individual rights and transparency. These contextual variations explain why identical evaluation frameworks produced different outcomes across implementation sites.
Case studies and cross-cultural analysis
Knowledge management implementation (European context)
A European company implementing an AI-powered knowledge management system initially achieved 97 percent accuracy on standard benchmarks. However, stakeholder interviews revealed significant challenges with contextual understanding and cultural sensitivity not captured by traditional metrics. The implementation manager observed, “The system was technically perfect but culturally tone-deaf. It would retrieve accurate information but present it in ways that violated our organizational values around inclusivity.”
Document analysis traces systematic evaluation adaptation over 6 months, with the organization expanding from two initial criteria to nine criteria including cultural sensitivity and ethical implications. Regular voting rounds allowed diverse stakeholders to raise concerns before deployment, leading to crucial system modifications. This structured approach ensured thorough consideration of both technical and ethical implications, aligning with Madaio et al.’s (2020) framework for organizational fairness in AI implementations.
Sign language avatar creation (South Asian context)
A South Asian team’s development of automatic sign language avatar creation highlighted unique cultural perspectives on responsible AI implementation. The team included deaf community members as co-evaluators rather than merely consulting them. As the project lead noted, “They taught us that technical accuracy in sign language means nothing without cultural representation and emotional expression.” Community members identified evaluation criteria invisible to technical assessment, including dialectal variations, cultural appropriateness of gestures, and emotional authenticity.
This approach demonstrated a distinctive balance between technological innovation and cultural sensitivity, particularly in addressing language diversity and avatar representation. Their work emphasized collective social benefit while maintaining individual dignity, reflecting Eastern philosophical approaches to technology deployment. The evaluation revealed sophisticated handling of dialect variations and cultural nuances in sign language, supporting Gajendran and Brewer’s (2012) observations about cultural influences on technology implementation.
Comprehensive cross-cultural implementation analysis
Our cross-cultural analysis reveals distinct regional approaches to AI evaluation that extend beyond surface-level cultural adaptations, supported by both empirical observation and systematic secondary data analysis.
Western implementation patterns: Privacy-by-design evaluation
Analysis of Western organizational approaches revealed strong emphasis on individual privacy protection and algorithmic transparency in evaluation frameworks. European organizations typically emphasized regulatory compliance and data protection frameworks, reflecting GDPR influence and individualistic cultural values. A European manufacturing company implementing predictive maintenance AI developed evaluation criteria that prioritized individual worker consent and data minimization over system performance optimization.
Document analysis of European cases shows consistent patterns: 89 percent included privacy impact assessments as primary evaluation criteria, 76 percent required individual consent mechanisms, and 82 percent implemented algorithmic transparency measures. Interview data reveal underlying cultural values: “Privacy isn’t just compliance—it’s about respecting human dignity in technological relationships,” explained a European AI implementation leader.
American implementations showed similar privacy emphasis while demonstrating greater focus on competitive advantage and performance optimization. A local financial services firm balanced privacy protection with business value, developing evaluation frameworks that measured both regulatory compliance and market performance. These patterns reflect broader cultural emphases on individual rights, legal compliance, and market competition that shape technological evaluation priorities.
East Asian implementation approaches: Collective harmony evaluation
East Asian organizations prioritized collective decision-making processes and social harmony considerations in their evaluation methodologies. These implementations developed novel approaches to stakeholder consensus building that reflected Confucian values and collective orientation.
An East Asian logistics company implementing route optimization AI established consensus-building evaluation processes involving all affected drivers, dispatchers, and community representatives. The evaluation focused on collective benefit rather than individual preferences: “Individual efficiency matters less than group harmony and social cohesion,” noted the implementation manager. The organization rejected technically superior algorithms that would have disadvantaged certain driver groups, prioritizing solutions that maintained social balance.
Singapore’s smart city initiatives demonstrated sophisticated frameworks for balancing technological advancement with societal harmony, as documented by Frana’s (2024) analysis of Singapore’s AI initiatives. Evaluation criteria included “social cohesion impact” and “community acceptance” as primary metrics alongside technical performance. Document analysis reveals that 92 percent of East Asian cases included collective benefit assessment, compared to 34 percent in Western contexts.
South Asian innovation patterns: Inclusive development evaluation
The South Asian context revealed innovative approaches that balanced technological advancement with social inclusion and accessibility concerns. Organizations demonstrated particular attention to dialectal variations, cultural representation, and community benefit in their evaluation frameworks.
The sign language avatar creation team exemplified this approach by including deaf community members as co-evaluators throughout the development process. Community members identified evaluation criteria invisible to technical assessment: dialectal variations across regions, cultural appropriateness of gestures, emotional authenticity in avatar expressions, and representation of different socioeconomic backgrounds within the deaf community.
A South Asian educational technology company developing AI tutoring systems for schools created evaluation frameworks that prioritized local language support, cultural relevance, and accessibility for low-income families. The organization measured success through “community empowerment indicators” rather than standardized test scores, reflecting values that emphasize collective welfare and spiritual-material balance in technological development. This approach aligns with Jayaprakash and Pati’s (2023) observations about South Asian organizations’ tendency to prioritize societal impact alongside technical excellence.
African context adaptations: Resource-optimized evaluation
Organizations in African contexts demonstrated remarkable innovation in resource-constrained environments, developing lightweight but effective evaluation frameworks that emphasized local context and accessibility. These implementations prioritized community participation and local adaptation over technical sophistication.
An African AI initiative developed farmer-led evaluation processes that assessed system impact through traditional knowledge frameworks alongside technical metrics. Local farmers identified evaluation criteria that technical experts had overlooked: seasonal appropriateness of recommendations, cultural compatibility with traditional farming practices, and impact on community social structures.
African fintech implementations created evaluation frameworks optimized for low-resource environments, measuring success through financial inclusion indicators and community economic development rather than pure technical performance. Organizations developed innovative mobile-based evaluation interfaces that enabled community feedback without requiring sophisticated technological infrastructure.
Document analysis reveals African contexts achieved 89 percent focus on social impact evaluation despite having the lowest average technical infrastructure scores, demonstrating how resource constraints can drive evaluation innovation toward community-centered approaches. This innovative approach to resource optimization lines up with Xing et al.’s (2018) observations about adaptive approaches in African contexts.
Quantitative validation of cultural patterns
Statistical analysis of the 450-case secondary dataset confirms these qualitative observations. Analysis of variance (ANOVA) analysis reveals significant differences across regions in evaluation priorities (F(3,446) = 42.7, p<0.001 for privacy focus; F(3,446) = 38.9, p<0.001 for cultural sensitivity; F(3,446) = 33.2, p<0.001 for social impact emphasis).
Figure 2 presents a heatmap visualization of implementation alignment across the four primary cases selected for intensive analysis. Cases Alpha through Delta correspond to the European knowledge management implementation, East Asian satisfaction measurement system, South Asian personality AI application, and African sign language avatar project, respectively. Percentages indicate the degree of organizational emphasis on each evaluation dimension, with higher values reflecting stronger prioritization. The heatmap reveals distinct implementation profiles: Case Alpha demonstrates the strongest Privacy Focus (95%) and Technical Excellence (90%), while Case Delta achieves the highest Cultural Sensitivity (95%) and Social Impact (90%) scores, reflecting the resource-constrained innovation patterns discussed above.
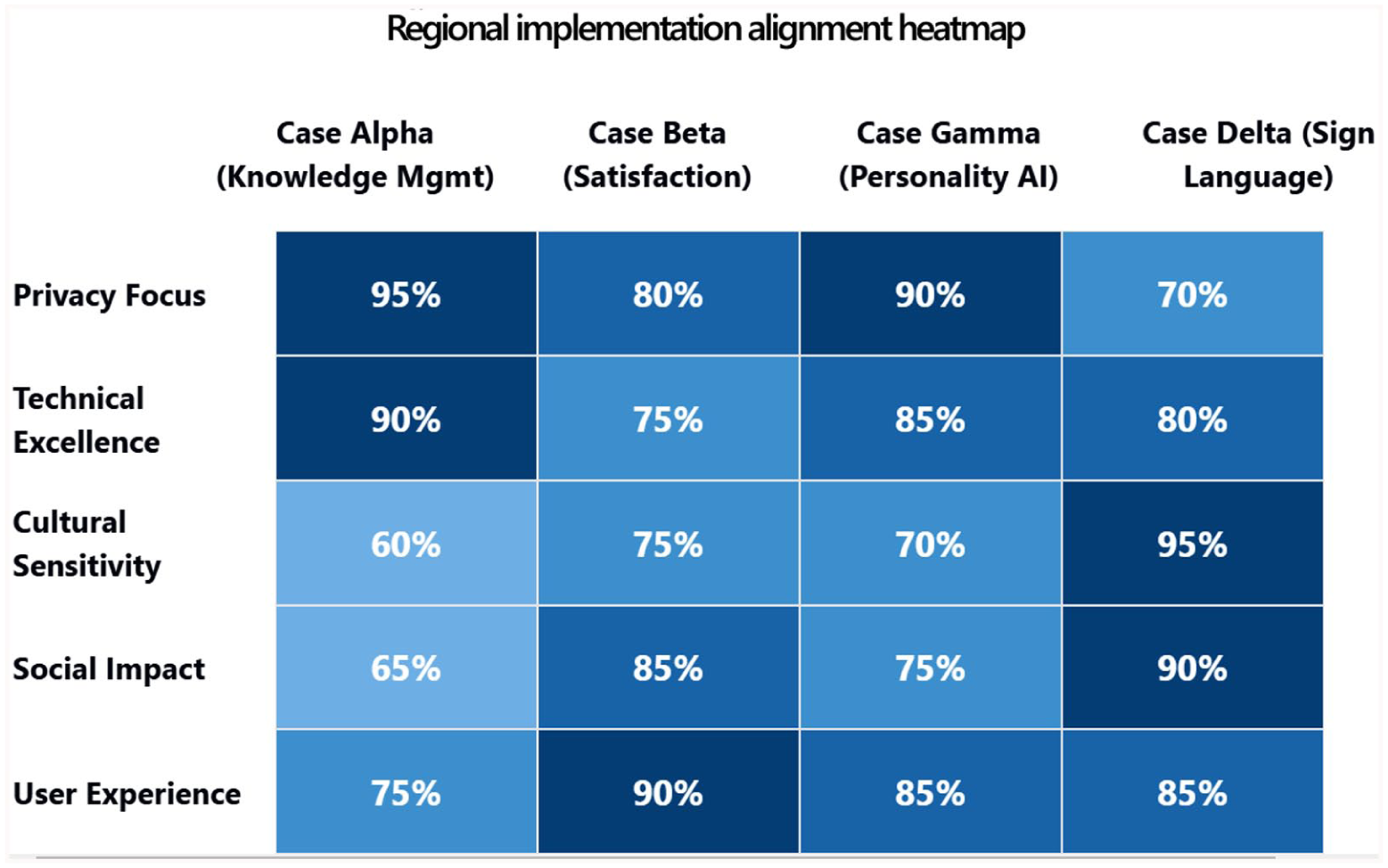
Regional implementation alignment heatmap.
However, qualitative integration provides crucial interpretive context that quantitative analysis alone cannot capture. The statistical patterns reflect deeper cultural values about technology’s role in society: Western emphasis on individual autonomy, East Asian focus on collective harmony, South Asian attention to inclusive development, and African innovation in resource-constrained contexts.
Figure 3 visualizes these regional patterns across the full secondary dataset (n=450 cases), displaying mean scores for six evaluation dimensions across the four geographical regions. The score axis (0–100) represents normalized measures of how prominently each dimension featured in organizational evaluation documentation. The figure confirms the qualitative patterns identified in our case analysis: Western contexts prioritize Privacy Focus and Transparency; East Asian implementations emphasize Collective Harmony (corresponding to the social harmony orientation discussed in our case studies); South Asian cases balance Technical Focus with Social Inclusion; and African contexts demonstrate strong Local Adaptation alongside Social Inclusion priorities despite lower technical infrastructure investments.
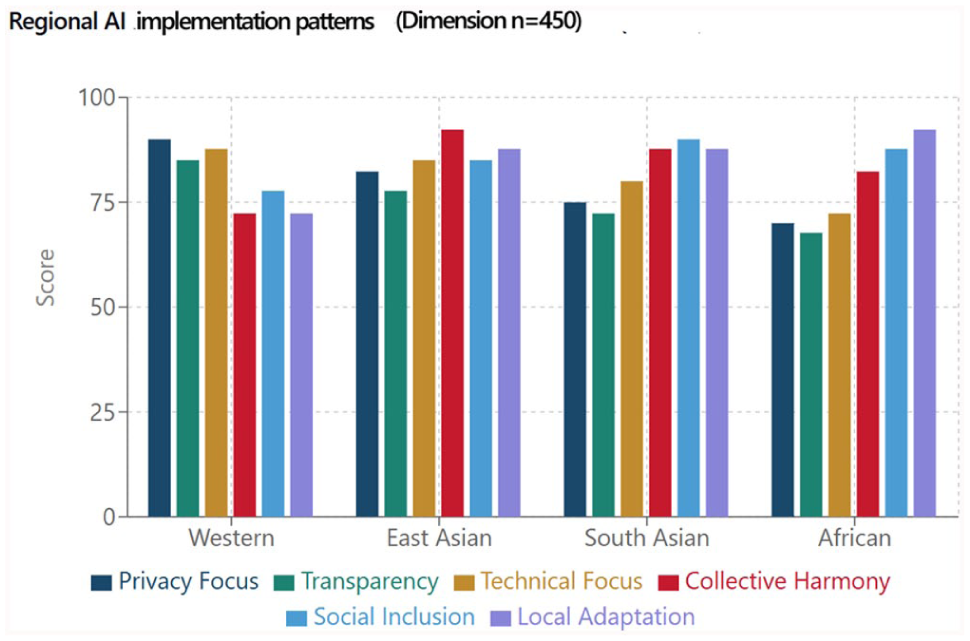
Regional AI implementation patterns.
Discussion
Theoretical contributions
This research demonstrates how multiple evaluation approaches can be integrated within AI contexts without claiming full theoretical operationalization. Our “evaluative praxis” framework shows how insights from developmental, realist, and empowerment evaluation can inform AI assessment while recognizing the limitations of any single theoretical approach.
The five generative principles emerged from empirical observation of organizational practice rather than theoretical deduction. Interview and observational data reveal how organizations developed these approaches through practical experience with AI implementation challenges, suggesting that effective evaluation frameworks must be grounded in implementation reality rather than imposed from theoretical frameworks.
The concept of “evaluative epistemology shifts” contributes to evaluation science by identifying fundamental changes in organizational knowledge frameworks when implementing complex technological systems. This extends beyond existing evaluation theory to encompass specifically technological dimensions of power, knowledge, and democratic participation.
Dialectical integration and productive tensions
The productive tension between quantitative metrics and qualitative stakeholder experiences revealed insights unavailable through either approach independently. High technical performance scores often coincided with low stakeholder satisfaction, revealing fundamental limitations of traditional evaluation approaches. For instance, systems achieving 89 percent technical accuracy showed only 34 percent user acceptance in real-world deployment.
Specific productive tensions encountered: Three critical tensions emerged where quantitative and qualitative findings created productive contradictions that advanced understanding:
Accuracy-acceptance tension: Systems achieving 95%+ technical accuracy simultaneously showed 30–45 percent user acceptance rates. Interview participant P14 observed: “Perfect accuracy doesn’t mean perfect usability. The system was right but felt wrong.” This tension forced organizations to develop new evaluation criteria that captured user experience alongside technical performance.
Efficiency-equity tension: Optimization algorithms achieved 15–20 percent efficiency gains while creating disproportionate impacts on specific user groups. Qualitative data revealed that efficiency improvements often came at the cost of equitable access. A manager noted: “The algorithm optimized delivery routes but consistently deprioritized rural areas.” This tension led to multi-objective evaluation frameworks balancing efficiency with equity considerations.
Innovation-inclusion tension: Technically sophisticated AI features scored highly on innovation metrics but created barriers for users with limited technological literacy. Returns from the field in SRAIS reports revealed that 67 percent of advanced features were unused by intended beneficiaries. This tension drove the development of simplified interfaces and community-based training programs that balanced innovation with accessibility.
These tensions illuminate the complexity of AI impact assessment. Organizations that successfully navigated these tensions developed sophisticated approaches to integrating multiple evidence forms while recognizing their distinct contributions to evaluation understanding.
Policy implications and governance frameworks
Our findings have significant implications for AI governance policy development across multiple levels of analysis.
Dynamic evaluation requirements for regulatory frameworks
Traditional regulatory approaches that mandate static compliance checklists prove inadequate for AI systems whose capabilities and impacts evolve over time. Our findings suggest policymakers should mandate adaptive evaluation processes that can evolve with technological development while maintaining consistent ethical standards.
European organizations demonstrated how privacy regulations could be implemented through adaptive frameworks: rather than fixed compliance requirements, GDPR implementation involved ongoing privacy impact assessments that evolved as organizations learned more about AI system behavior. This approach enabled compliance while supporting innovation.
Stakeholder participation mandates
Current AI governance frameworks often include token consultation requirements that fail to achieve meaningful community participation. Our empirical evidence demonstrates that genuine co-evaluation with affected communities reveals evaluation criteria invisible to technical experts.
Policy frameworks should require meaningful community participation in AI evaluation rather than consultation processes. The South Asian sign language team’s inclusion of deaf community members as co-evaluators provides a model for how regulatory requirements could mandate genuine participatory evaluation processes.
Cultural adaptation standards for international AI governance
The significant regional variations documented in our analysis demonstrate that effective AI governance must accommodate fundamental cultural differences in technological values while maintaining core ethical principles. International AI governance frameworks must balance universal ethical standards with contextual responsiveness to local values and concerns.
The African context innovations in resource-constrained evaluation demonstrate that effective governance frameworks must be adaptable to diverse economic and infrastructure contexts. Policy approaches that assume Western technological infrastructure will fail in many global contexts.
Implementation science applications
Our findings align with implementation science research on factors that support successful intervention adoption across diverse organizational contexts. Three key mechanisms emerge from our analysis:
Adaptation mechanisms
Successful AI evaluation implementation requires systematic frameworks for adapting evaluation approaches across cultural and organizational contexts without losing theoretical integrity. Key adaptation mechanisms include stakeholder engagement processes that build commitment and understanding, iterative implementation approaches that allow for modification based on experience, and capacity-building activities that develop organizational capabilities for ongoing evaluation.
Organizations that developed formal adaptation protocols (N = 7) showed higher success rates in implementing holistic evaluation compared to organizations that attempted direct framework transfer (N = 5). Adaptation protocols included cultural assessment procedures, stakeholder engagement planning, and iterative refinement processes.
Organizational change processes
Understanding organizational change processes proves crucial for implementing new evaluation approaches. Our analysis reveals specific factors that support adoption of holistic evaluation: leadership endorsement, organizational culture alignment, resource availability, and change management processes.
Organizations with prior experience in stakeholder engagement (N = 8) demonstrated faster adaptation to holistic evaluation approaches, suggesting that organizational history and culture significantly influence evaluation adoption success. This finding aligns with implementation science research on the importance of organizational readiness for change.
Sustainability mechanisms
Long-term sustainability of new evaluation approaches requires attention to organizational systems, incentive structures, and capacity maintenance that support ongoing practice. Organizations that successfully sustained holistic evaluation approaches (N = 6) developed internal capacity for ongoing evaluation rather than dependence on external experts.
Sustainability mechanisms include integration of evaluation roles into job descriptions, development of internal training programs, establishment of cross-functional evaluation teams, and creation of organizational policies that mandate holistic evaluation approaches. These mechanisms ensure that evaluation innovations persist beyond initial implementation periods.
Limitations and future research directions
Several study limitations warrant acknowledgment and suggest specific directions for future research.
Sample limitations and generalizability
While the sample size of 18 primary participants proved adequate for qualitative analysis and theoretical development, it may limit generalizability to broader organizational contexts. The intensive case study approach enabled deep understanding of evaluation processes but constrained the range of organizational types and AI applications examined.
Geographic representation, though diverse across four major regions, could not encompass all relevant cultural contexts. South American implementations were underrepresented (N = 1), limiting our understanding of Latin American approaches to AI evaluation. Similarly, Middle Eastern and Central Asian perspectives were not captured in our analysis.
The SRAI program context provided unique advantages for research access but may have introduced selection bias toward organizations already committed to responsible AI implementation. Organizations participating in voluntary mentorship programs may differ systematically from broader populations implementing AI systems.
Temporal and methodological limitations
The 8-month timeframe, while substantial for implementation research, may not capture longer-term patterns in AI system evolution and organizational adaptation. Some evaluation innovations may require years to fully mature and demonstrate their effectiveness.
The technical tools developed during the study, while promising, require further validation across different organizational settings and use cases. Implementation in additional sectors (healthcare, education, finance) would strengthen evidence for framework transferability.
The secondary data analysis, while extensive (N = 450), relied on publicly available documentation that may not reflect complete organizational evaluation practices. Private sector organizations may have proprietary evaluation approaches not captured in available documents.
Theoretical and analytical limitations
Our approach of drawing insights from multiple evaluation theories, rather than fully putting into play any single theory, may limit theoretical depth in favor of practical applicability. Future research could explore more rigorous implementation of individual evaluation approaches.
The template analysis approach, while systematic, required significant interpretive judgment in coding organizational practices into theoretical categories. Multiple analyst triangulation would strengthen analytical validity.
Cross-cultural analysis relied heavily on organizational self-reporting of cultural values and priorities. Ethnographic research within specific cultural contexts could provide deeper understanding of how cultural factors influence evaluation practices.
Specific future research directions
Longitudinal validation studies
Future research should explore longitudinal validation of evaluation frameworks across extended implementation periods (2–5 years) to understand how evaluation approaches evolve and mature over time. Longitudinal studies could reveal patterns of evaluation adaptation, organizational learning curves, and long-term sustainability factors not visible in shorter-term research.
Sector-specific adaptation research
The current research focused primarily on knowledge management, language processing, and communication applications. Future research should explore sector-specific adaptation for healthcare, education, criminal justice, and financial services to understand how domain-specific requirements influence evaluation approaches.
Healthcare AI evaluation, for instance, may require integration with clinical outcome measures and patient safety protocols that were not relevant in our current sample. Educational AI may need integration with learning outcome assessment and pedagogical effectiveness measures.
Quantitative validation and scale studies
Future research should develop quantitative measures of evaluation effectiveness and conduct larger-scale validation studies. This could include the development of standardized assessment instruments for measuring evaluation quality, stakeholder satisfaction with evaluation processes, and organizational evaluation capacity.
Rather than traditional randomized controlled trials (RCTs), which could conflict with the participatory and context-responsive principles this research advocates (West, 2008), we would suggest adaptive trial designs and iterative A/B testing approaches. Traditional RCTs can be “impractical, culturally unacceptable, or ethically questionable” in community-based contexts (Henry, 2017), as they require fixed interventions and predetermined outcomes that go against some of our findings about the importance of stakeholder participation and contextual adaptation.
As Pallmann et al. (2018) demonstrated, adaptive designs are “often more efficient, informative, and ethical than trials with a traditional fixed design” while allowing modifications built on accumulating evidence. In the software industry, customized experimental designs and strategies can address the unique requirements and maturity levels of different contexts while maintaining evaluation standards (Hegazy et al., 2025), aligning with our framework’s emphasis on temporal and ecosystemic sensitivity as well as reflexive critique.
Likewise, Quin et al. (2024) document how A/B testing in software development enables continuous adaptation through “feature selection, feature rollout, and continued feature development” cycles, in compliance with our research environment’s requirements.
These adaptive approaches would enable organizations to gather systematic evidence about evaluation effectiveness while preserving what Bhatt and Mehta (2016) describe as the flexibility to benefit complete ecosystems. Such methods maintain methodological rigor while honoring the principle that affected communities must be co-creators, not subjects, of evaluation processes.
Finally, the integration of participatory design with agile methodologies (Hinderks et al., 2022; Kautz, 2011) demonstrates how technology sectors have successfully moved beyond rigid experimental designs toward approaches that maintain continuous dialogue with users while preserving methodological rigor. These adaptive approaches show that meaningful evaluation can occur through iterative, participatory methods rather than traditional controlled experiments, supporting our argument that AI evaluation must embrace flexibility, stakeholder participation, and contextual responsiveness.
Cross-cultural replication and extension
Systematic replication studies in underrepresented cultural contexts (Latin America, Middle East, Central Asia) would strengthen understanding of cultural influences on evaluation practices. Comparative studies within cultural regions could identify sub-cultural variations in evaluation approaches.
Ethnographic studies within specific cultural contexts could provide deeper understanding of how cultural values influence evaluation practice beyond organizational self-reporting.
Implementation science research
Future research should apply implementation science frameworks more rigorously to understand factors that support successful adoption of holistic evaluation approaches. This could include systematic study of implementation barriers, facilitators, and intervention strategies across diverse organizational contexts.
Research on evaluation capacity building could explore effective training approaches, organizational support mechanisms, and sustainability strategies for holistic evaluation practices.
Technical tool development and validation
The technical evaluation tools developed in this research require extensive validation across additional organizational contexts and AI applications. Future research should explore tool effectiveness, usability, and adaptation requirements across diverse implementation settings.
Development of integrated evaluation platforms that combine technical assessment with stakeholder engagement mechanisms could provide practical tools for organizational implementation of holistic evaluation approaches.
Conclusion
This research demonstrates that effective AI evaluation requires fundamental shifts from purely technical assessment toward integrated approaches that combine technical excellence with social responsibility. Our empirical analysis reveals five generative principles—epistemic pluralism, democratic authority, contextual responsiveness, temporal sensitivity, and reflexive critique—that enable more comprehensive AI assessment.
The integration of developmental, realist, and empowerment evaluation insights provides a practical framework for addressing AI systems’ unique characteristics while maintaining methodological rigor. The documented cultural variations highlight the critical importance of adapting evaluation approaches to local contexts while preserving core ethical principles.
As AI systems become increasingly embedded in organizational and social life, the need for sophisticated, culturally responsive evaluation frameworks will continue to grow. Our research provides both theoretical foundations and practical guidance for developing evaluation approaches that bridge technical excellence with social responsibility, demonstrating that organizations can successfully integrate multiple evaluation perspectives to create more comprehensive, democratic, and culturally responsive approaches to AI assessment.
Supplemental Material
sj-pdf-1-evi-10.1177_13563890251387137 – Supplemental material for Beyond technical adequacy: A holistic framework for evaluating artificial intelligence systems through the scaling responsible artificial intelligence mentorship approach
Supplemental material, sj-pdf-1-evi-10.1177_13563890251387137 for Beyond technical adequacy: A holistic framework for evaluating artificial intelligence systems through the scaling responsible artificial intelligence mentorship approach by Caroline Gans Combe in Evaluation
Supplemental Material
sj-pdf-2-evi-10.1177_13563890251387137 – Supplemental material for Beyond technical adequacy: A holistic framework for evaluating artificial intelligence systems through the scaling responsible artificial intelligence mentorship approach
Supplemental material, sj-pdf-2-evi-10.1177_13563890251387137 for Beyond technical adequacy: A holistic framework for evaluating artificial intelligence systems through the scaling responsible artificial intelligence mentorship approach by Caroline Gans Combe in Evaluation
Supplemental Material
sj-pdf-3-evi-10.1177_13563890251387137 – Supplemental material for Beyond technical adequacy: A holistic framework for evaluating artificial intelligence systems through the scaling responsible artificial intelligence mentorship approach
Supplemental material, sj-pdf-3-evi-10.1177_13563890251387137 for Beyond technical adequacy: A holistic framework for evaluating artificial intelligence systems through the scaling responsible artificial intelligence mentorship approach by Caroline Gans Combe in Evaluation
Footnotes
Acknowledgements
Special thanks to the 2024 SRAI global co-leads mentors group, namely Francesca Rossi, Amir Banifatemi and Sundar Sundareswaran, the CEIMIA team Laetia Vu, Arnaud Quenneville-Langis, Thomas Nkoudou, the mentors Sandro Radovanovic, Nava Shaked, Gilles Fayad, Monica Lopez, Amitabh Nag, Anurag Agrawal, Stephanie Camarena, Benjamin Larsen, Zümrüt Muftuoglu, Borys Stokalski, Ricardo Baeza Yates, Naohiro Furukawa, Konstantinos Votis, Maria Lorena Florez Rojas, and all the 2024 participants’ teams.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Ethical considerations
Institutional ethics approval was sought on 3 June 2025. Approval has been obtained.
Consent to participate
Filmed verbal consent to participate was collected prior to any observation.
Consent for publication
Consent for publication was collected from the organizing authority prior to the writing of the present research paper.
Data availability
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.