
Abstract
Based on an original bibliometric analysis, this article examines three decades of Evaluation’s publications, mapping the key conversations and debates that have shaped the journal. Using a network analysis of cross-citations and a systematic review of the journal’s authorship, we identify eight clusters of closely interconnected articles that represent central thematic areas: ‘evaluative complexity’, ‘theory-based evaluation’, ‘realist evaluation’, ‘dialogue in evaluation’, ‘evaluation use’, ‘evaluation systems’, ‘politics of evaluation’ and ‘accountability’. We detail the content of each cluster, highlighting key authors and specific subtopics, and trace the intellectual exchanges both within and across these thematic boundaries. Our findings reveal a broad conceptual shift over time, in which early emphasis on evaluation use and dialogue has given way to growing interest in evaluation systems and capacity, theory-based approaches and complexity. In sum, we offer a cross-cutting perspective on some of the evolving debates that have shaped the European evaluation community over the long term.
Introduction
This is to be an international journal with strong European roots but with a commitment to encourage dialogue between European, Scandinavian, Northern American, Asian, Australasian and other existing and emergent evaluation communities. The journal will seek to build bridges between different domains and traditions of evaluation and in particular address issues of common concern across these domains and traditions – highlighting comparative experience and possibilities for mutual learning and convergence. The journal will seek to advance theoretical and methodological understandings of evaluation in the context of evaluation policy and practice and to locate evaluation policy and practice within wider theoretical and methodological debates. It will also provide a communication channel for professional societies and associations that wish to use it. The journal will provide a forum for scholarly exchange open to contributions from across the social sciences, economics and related disciplines and especially welcomes multidisciplinary, interdisciplinary and issue-based contributions. (Stern, 1995)
Back in July 1995, the very first editorial of Evaluation pledged to ‘encourage dialogue between [. . .] existing and emergent evaluation communities’, to ‘provide a forum for scholarly exchange’ and a ‘communication channel for professional societies and associations’. While acknowledging the diversity of evaluation domains and traditions, the idea was to ‘build bridges between’ them, around ‘issues of common concern’ (Stern, 1995). This editorial set the tone for what Evaluation – the discipline, the practice and the journal – should be a crossroads rather than a one-way avenue.
Given this initial manifesto, how has the journal fared since then? To what extent has Evaluation been a place for conversations and not for people talking to themselves only? Were some bridges built around issues of common concerns? This question is not entirely new to Evaluation, which already published a retrospective issue for its 20th anniversary (Stern et al., 2015). The editors used this opportunity to reflect on the fault lines in evaluative thinking and practice at the time, noting the then-growing importance of the ill-defined notions of ‘complexity’ or ‘theory’ or the fast-declining enthusiasm for counterfactual evaluations.
This article offers a different perspective. To mark the 30th anniversary of the journal, we applied a bibliometric approach to the Evaluation corpus, with a view to identify ‘conversations’ between authors and articles. In its most simple version, ‘Bibliometrics is the quantitative study of physical published units, or of bibliographic units, or of the surrogates for either’ (Broadus, 1987). Bibliometrics are used in the sociology of science to map ‘research fronts’, dominating and declining concepts or vivid controversies within scientific communities (De Solla Price, 2011; Mejia et al., 2021; Shibata et al., 2011). As Latour (1987) reminds us, scientific knowledge is not only a matter of (un)stable social communities, but also an infrastructure of (inter)citations that can signal belonging, keep arguments ‘in reserve’, or ‘attack’ other parts of the network in time of controversies. Breaking down and scrutinising the cross-referencing of papers in a subfield of knowledge then gives precious hints on its general structure and its evolution. Bibliometrics also help to characterise the social stratification of science and professional knowledge (Bourdieu, 1984; Cole and Cole, 1981), by investigating the ‘who’ and ‘where’ of a network, its core and its periphery, its social and institutional drivers, and so on.
This potential may explain the success of bibliometric analyses not only in the sociology of scientific (sub)fields, but also for the study of single journals, which increasingly publish studies on their own content, usually on anniversaries (Anyi et al., 2009; Tiew, 1997). This type of analysis helps to understand a journal’s identity, its contribution to a field or a set of fields, its most common corresponding journals (by co-citations), the disciplinary and institutional roots of its authors and the main discussion objects – which may be theories, concepts, practices, and so on.
The bibliometric analysis carried out in this article addresses the following question: What are the main conversations, if any, that have taken place within the Evaluation journal in the past 30 years? To answer this question, we constructed a network composed of the direct citations between articles published in the journal and identified clusters of articles based on the density and strength of the links between articles. The first section presents the methodological approach employed and the second describes the main clusters that emerged from the analysis. Some of them are explored in more detail, based on the actual content of the articles. The point, in this case, is to verify whether direct citations actually translate into an actual conversation, that is, an exchange of ideas between authors within the journal. The article ends up with a discussion of the findings and a conclusion.
Methodology
The analysis presented in this article is based on the premise that groups of articles frequently citing each other (referred to as ‘clusters’) can serve as a quantitative approximation of intellectual conversation. To identify whether such clusters existed, we constructed a direct citation network, where each node is an article published in the journal, and each edge represents a citation of an article of the journal by another. Such process was viewed as a way to identify configurations of articles without relying on the priors or experience of this paper’s authors. This experience, however, was then used by the authors to make sense of the content and assess whether a substantive conversation could indeed be observed (section 2).
To build the direct citation network, a list of 982 ‘bibliographic units’ published in Evaluation between 1 January 1995 and 1 October 2024 was retrieved using the Scopus database 1 . To ensure that the network reflected academic exchanges, we excluded two sets of ‘units’:
Editorials, presidential editorials, forewords and editors’ notes (n = 107) systematically cite all articles in a given issue, generating citation patterns that differ fundamentally from the selective references that authors include in their papers. Their removal helps isolating the latter patterns 2 .
French-language abstracts (n = 23), ‘news from the community’ (n = 13) as well as other less popular formats are hosted by the journal, but are not academic articles and usually do not include any reference to other articles. They are therefore of limited value to identify substantive connections.
The remaining 823 academic articles form the dataset used to build the citation network.
External citations
Scopus provides a ‘cited by’ indicator for each article, which measures the number of times it has been referred to by articles published in the journals and book series covered by Scopus. On average, the articles published in the journal are cited 25 times 3 , the most cited one being an article by Yin (2013), ‘Validity and generalisation in future case study evaluations’, cited 919 times. It is followed by Rogers’ (2008) ‘Using programme theory to evaluate complicated and complex aspects of interventions’, cited 619 times. However, on average, older articles do not tend to be cited more. Rather, the articles which tend to be cited more often were published between 2000 and 2016 – two thirds are cited between 26 and 40 times; 80 articles have never been cited 4 .
Two Python 5 scripts were then developed to retrieve the bibliographic references of each article using the CROSSREF Application programming interface (API)6,7. Using the Digital Object Identifier (DOI) of each of these articles, an adjacency matrix was generated to map cross-citations between Evaluation articles. In addition, the number of references to articles published in other journals in the field of evaluation was extracted to estimate whether conversations are mostly happening within the journal or extend beyond it. The prefixes of the DOI addresses were used to identify citations of articles published in the American Journal of Evaluation (AJE), the Canadian Journal of Programme Evaluation/La revue canadienne d’évaluation de programme (CJPE), the Evaluation Journal of Australasia (EJA), Evaluation and Programme Planning (EPP), the Journal of MultiDisciplinary Evaluation (JMDE) and New Directions for Evaluation (NDE) 8 . However, it was not easily feasible to retrieve the number of times articles published in Evaluation were cited in these journals.
The outputs of both scripts above show that 698 articles either cite or are cited by at least one other article of the journal (85%). Of these, 352 both cite and are cited by other articles within the journal. This leaves 125 articles outside of the citation network (Figure 1 below). Specifically, 166 articles are cited by others in the journal but do not cite any other article within it, while 180 articles cite other articles but are not cited by any. Looking at the citations of articles published in other evaluation journals, it appears that the 352 articles that both cite and are cited in Evaluation also overwhelmingly cite articles in other evaluation journals (74%), while only 21% of the articles that neither cite nor are cited within the journal mention articles published in other evaluation journals.
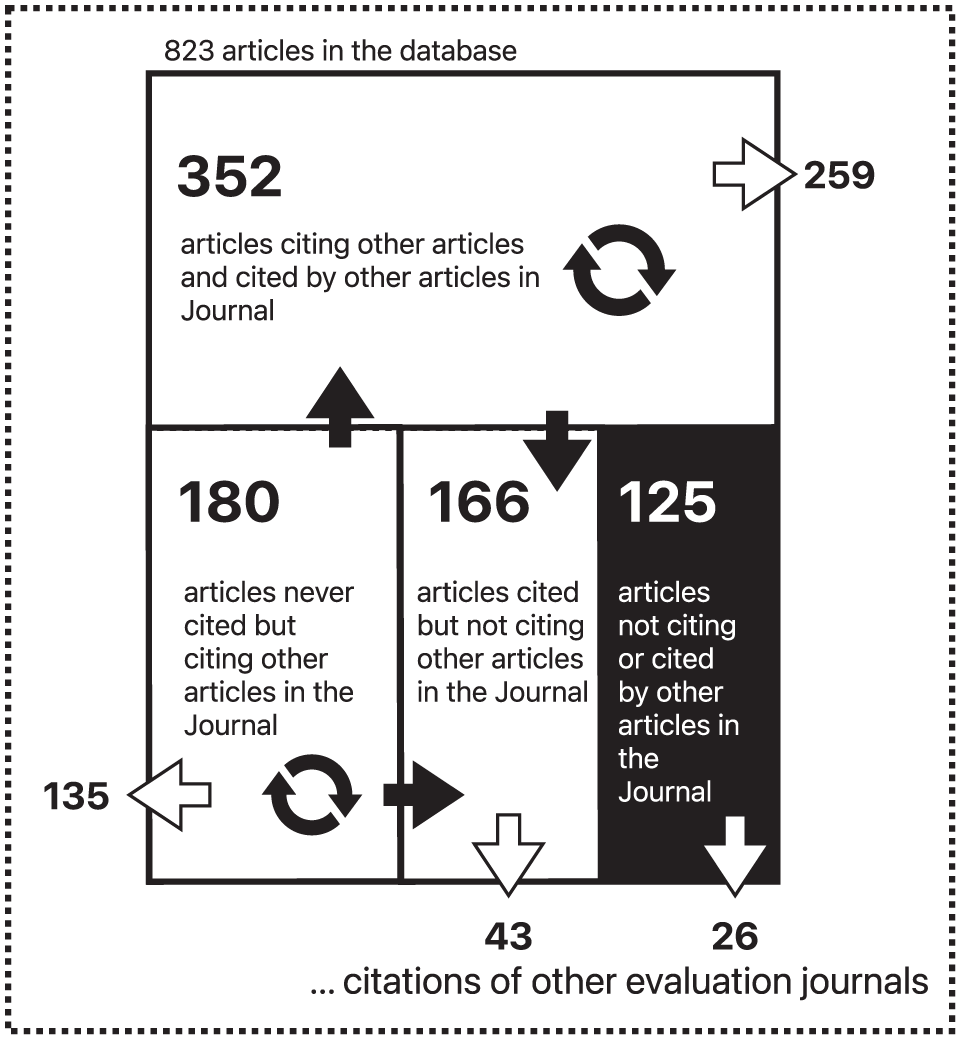
Citations by articles in the Evaluation journal.
On average, articles in the corpus are cited by 2.5 other articles within the journal (4 times when excluding the articles which are neither cited by other articles in the journal, nor cite others). This value is directly correlated with the publication date: between 1995 and 2018, the average ranges from 2 to 5 citations (including never cited articles) but then falls at 1 or below after 2019. Focusing on articles cited at least once according to Scopus (n = 743), citations from Evaluation account for 15% of their total citations on average, and even a quarter or more for 20% of them. 31% of those articles, however, were never cited by other articles published in Evaluation.
Initially, the number of Evaluation articles cited in the journal was low, reflecting the limited pool of articles to cite from. It then mostly varied between 2 and 4 between 2003 and 2013, increasing to 3 to 5 citations since then. On average, the total number of inward and outward citations is 5.1 (6.8 when excluding the articles which are never cited nor cite others). It was generally lower before 2001 and since then ranged mostly between 5 and 8. Since 2022, this number has declined, probably because the most recently published articles have not been cited yet.
In total, 117 articles (17% of the articles cited or being cited) are connected at least 10 times to other articles in the journal. Among these, 43 articles are cited at least 10 times by other articles of the journal (in-degree), and 35 articles cite other articles of the journal 10 times or more (out-degree).
Who publishes in Evaluation?
Whereas this paper does not focus on the social stratification of Evaluation, a few facts regarding the journal’s authorship are worth mentioning. The affiliations of 1,327 individual authors who published in the journal were retrieved from the Scopus database 9 . 70% declared a primary affiliation with a university, a college or a research centre (public or private) at the time of publication. This contrasts with the smaller number of consultants (n = 80), international organisations officials (n = 34) or officials of the European Union (n = 9). While this information is clearly limited (as many professional evaluators combine an academic affiliation with private practice or an administrative role), it nonetheless shows that Evaluation’s authorship claims for the most part an academic identity.
Second, and based on the address of the affiliation organisation 10 , the journal’s authorship appeared predominantly located in the United Kingdom at the time of writing (n = 438 authors for 612 signed pieces, 33%, see Figure 2 below). Authors from the Anglo-American world (Australia, Canada, New Zealand, South Africa and the United States) represent an additional 22%. Finally, 465 authors (35%) were located in other Continental European countries, with a quarter of these based in The Netherlands, and another quarter in Nordic countries. Notably, Evaluation is recognised as the journal of choice of Nordic evaluation scholars (Nielsen and Winther, 2014). Lacking reliable information about the size of national evaluation communities, these figures might reflect a range of factors beyond geographic distribution, such as language considerations, or the existence of an evaluation field in the national academic landscape 11 .
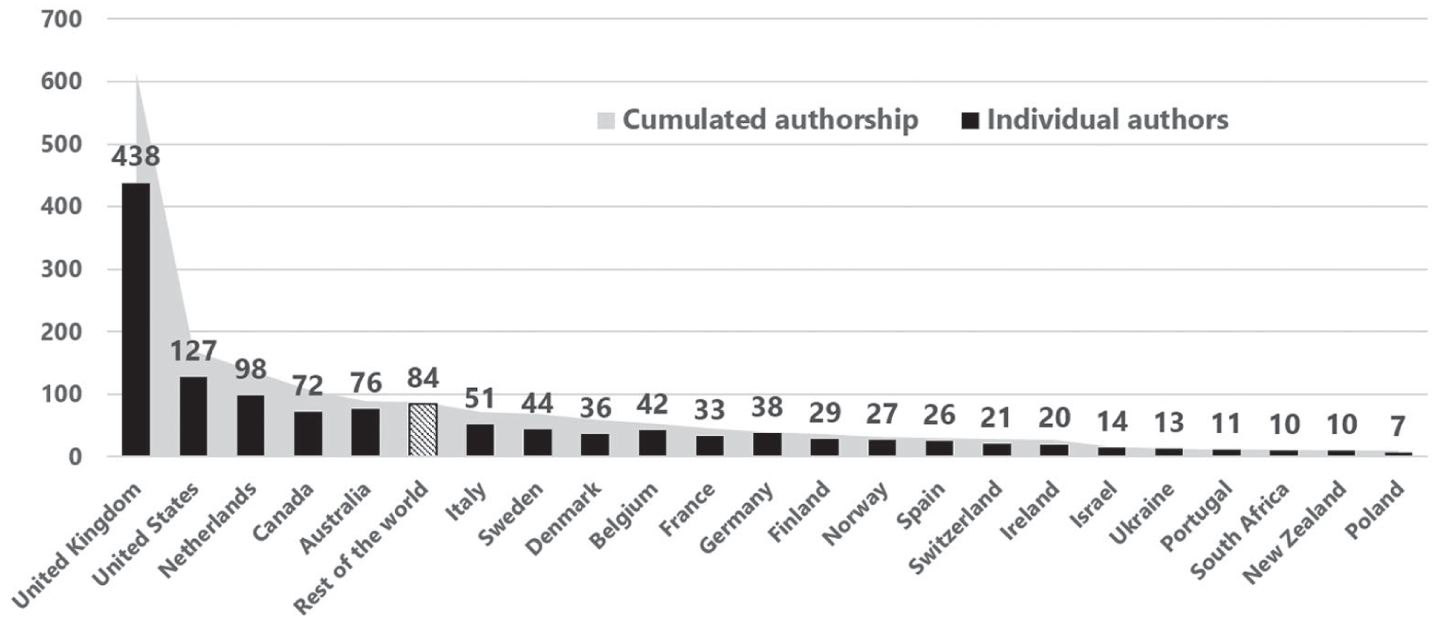
Evaluation’s cumulated authorship and individual authors by country of institution, 1995–2024. 12
The matrix was then imported into Gephi 13 to visualise the directed citation network for Evaluation and identify clusters. Using Gephi’s ‘modularity’ module (Blondel et al., 2008), 14 clusters were identified. The largest cluster contains 118 articles and the three smallest, 2. The average size is 47 articles. To refine this algorithmic output, we calculated two metrics for each cluster: the total number of connections (degrees) and the average number of connections per article. The first calculation shows that the number of degrees varies widely, from 2 to 772. The clusters are much closer, however, in terms of the average number of degrees per article, ranging from 5 to 6, with a standard deviation of 1.5 (excluding the 3 clusters containing only 2 articles).
Figure 3 below presents a visualisation of the direct citation network for Evaluation articles which cited or are cited by at least one other article in the journal 14 . The layout is oriented by the total number of in- and out-degrees, to which the node size is proportional. The colour coding highlights the main clusters identified in the analysis, which are discussed in the next section. Figure 4 presents a trimmed down version, displaying only those articles that were cited, or cited by at least 10 other articles in the journal.
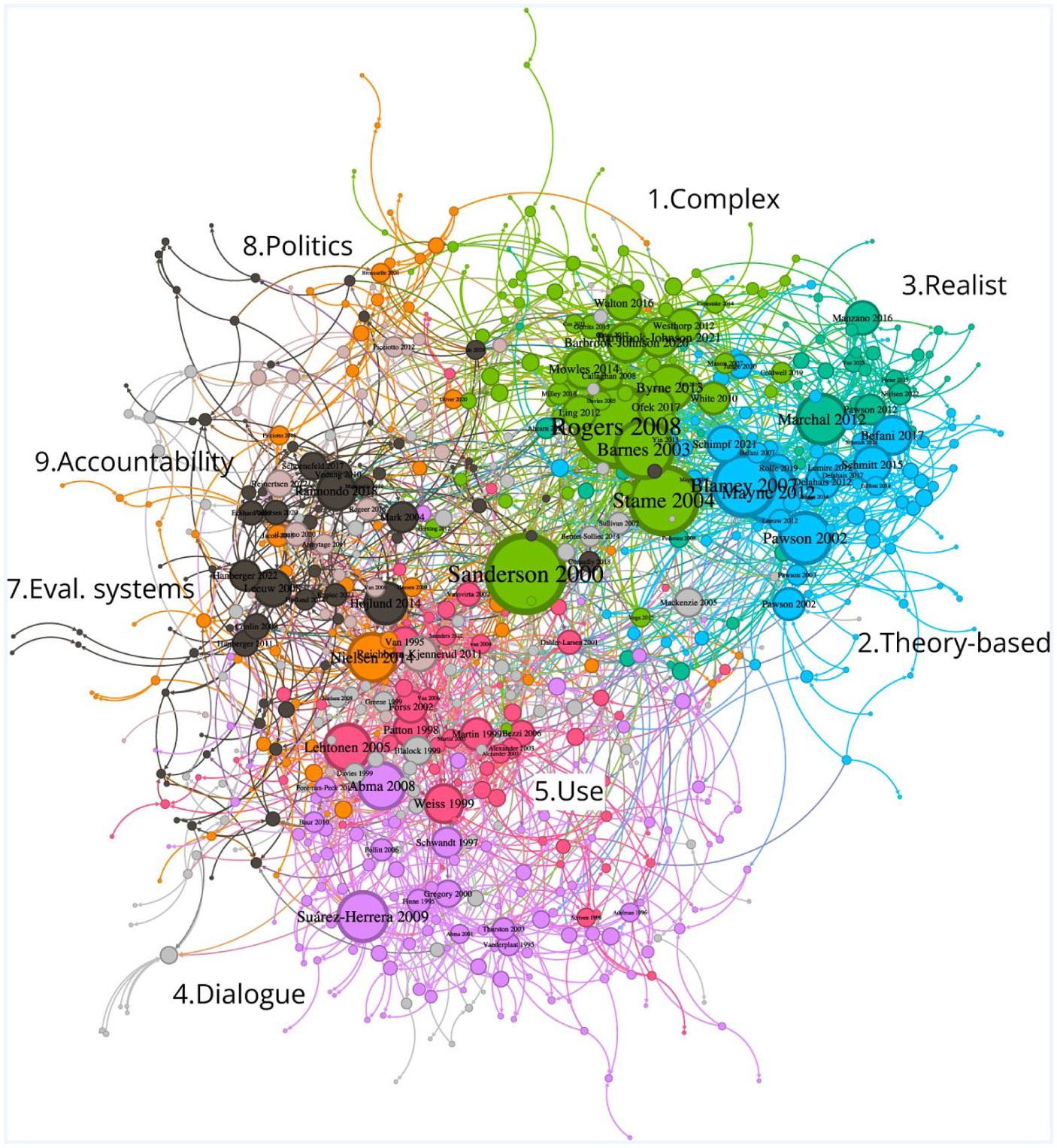
The direct citation network of Evaluation (1995–2024).
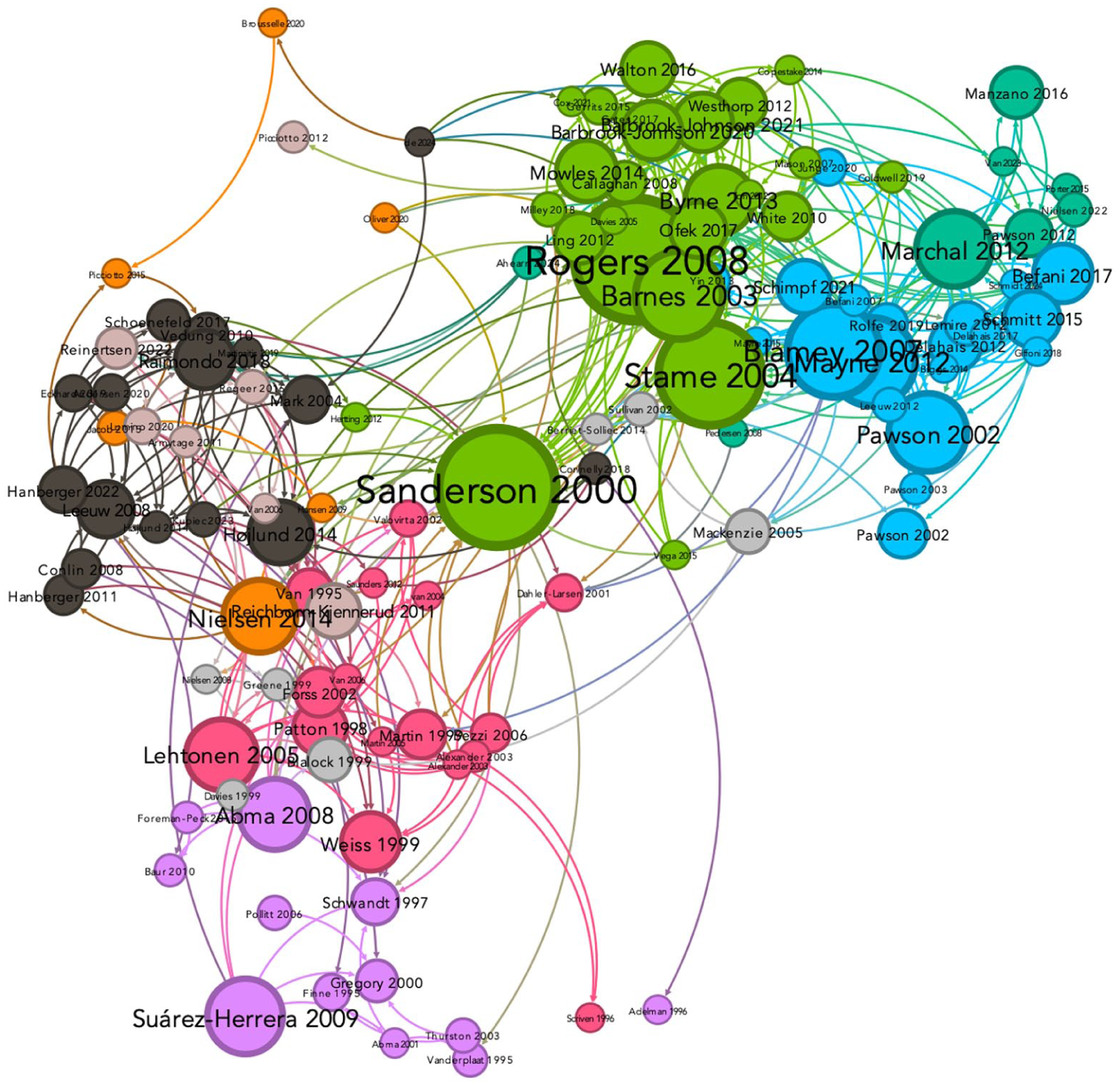
Trimmed down view including only authors with at least 10 in or out-citations.
Clusters description
This section describes the eight main clusters identified in the network analysis. Together, these clusters typically represent between 60% and 90% of the articles published each year (72% in total). Each cluster is named and briefly described in quantitative terms. ‘Core’ articles in each cluster were identified by crossing two criteria: their total number of connections to the corpus (total degree) and a ratio of citations by other Evaluation articles (in-degree) 50% higher than the number of Evaluation articles they cite (out-degree).
In the 2015 20th anniversary issue of the journal, Leeuw and Donaldson (2015) published a synthesis – or, in their own words, ‘an impressionistic picture, mainly qualitative, of how ‘theory’ has featured in past issues of this journal’. They came with two typologies: one which considers the ‘theories of policy makers, stakeholders and evaluators underlying their professional work in making policies and doing evaluations’; and a second, which is about ‘scientific theories capable of contextualising and explaining the consequences of policies, programmes and evaluators’ actions’.
The first three clusters that are discussed below are largely related to the first typology, and in particular to theory-based evaluation. Leeuw and Donaldson noted that the debate in the 2000s and early 2010s involved ‘articles [which] set themselves the goal to find and understand mechanisms and contexts of policies and programmes [or] to test the [Theory of Change/Programme Theory] (ToC/PT) or to compare programme theories with other (programme) theories’, and articles which criticise ‘the linear logic of most PT/ToC approaches’. The authors also pointed at other challenges, such as ‘who should reconstruct the programme theory’, the relationship to inductivism and deductivism, or the notion of context and its influence on the expected outcomes. They also mentioned possible solutions to these challenges, which might be approaches – mainly realist evaluation but also systems concepts or complexity theory– mixing methods, or using novel ones such as network analysis, process tracing, Qualitative Comparative Analysis (QCA), participatory approaches and so on.
Leeuw and Donaldson did not specify which articles correspond to this typology. This hinders our ability to verify alignment with the clusters identified in the bibliometric analysis. Most of the articles in the three first clusters were published in the 2010s and early 2020s, which means that their synthesis came midway through the ‘theory-based wave’ in the journal. The sections below describe the discussions that happened in these clusters, focusing on what happened since the last journal decennial anniversary.
Evaluating the complex (89 articles, 772 cumulative citations – in green)
Most articles in this cluster were published between 2012 and 2021 (n = 58). However, the articles most frequently cited by other articles in the journal precede this period. These are the already mentioned article by Rogers (2008), ‘Using programme theory to evaluate complicated and complex aspects of interventions’; Stame’s (2004) ‘Theory-Based Evaluation and Types of Complexity’; Sanderson’s (2000) ‘Evaluation in Complex Policy systems’; and finally, Barnes et al.’s (2003) ‘Evidence, Understanding and Complexity: Evaluation in Non-Linear Systems’.
Leeuw and Donaldson had already identified ‘complexity’ as an emerging theme in evaluation theory. Complexity is indeed evoked in 57 article titles out of 89 15 . But what is ‘complex’ in this body of articles is actually different things: it can be the policy context or the governance, as in the article of Sanderson; or the evaluation object and its underlying theory of change, as explored by Rogers and Stame. Rogers builds on the typology of simple, complicated and complex systems as conceptualised by Glouberman and Zimmerman (2004) and suggests ways to use programme theories to evaluate these. Stame, meanwhile, calls on the idea of a ‘black box’ in programme intervention logic, and explains how theory can be used to open the box: ‘For Chen and Rossi, good theories should substitute for no theory; for Weiss, better theories should substitute bad ones; for Pawson and Tilley, theories become good thanks to what actors do about them’.
Articles published in the 2010s tend to emphasise the use of a complexity lens to investigate programmes. Those articles support thinking in terms of systems (a term mentioned in 37 titles). Some articles combine several of these perspectives, such as Byrne’s (2013) ‘Evaluating complex social interventions in a complex world’ and Westhorp’s (2012) ‘Using complexity-consistent theory for evaluating complex systems’. These papers discuss various theoretical frameworks, approaches (theory-based, mixed-methods, ‘inductive and quasi-experimental’, realist, reflexive) and tools, such as social network analysis or participatory system mapping. The group also includes a strong practical component – how to deal with complexity in real-life evaluations? – as well as case studies, as in Ling’s (2012) ‘Evaluating complex and unfolding interventions in real time’.
The articles that were published in the last 10 years have continued to explore the nexus between complex systems and policies, theories of change and participatory approaches, especially in areas such as health, education, or international development, as well as some of the methods that can be used in this context. Several articles have played an important role in structuring this group by systematically referring to other articles in this cluster. These are in particular an article by Ofek (2017) about evaluation users’ preference in terms of complexity-aware approaches, and two articles by Barbrook-Johnson and Penn (2020) and Barbrook-Johnson et al (2021), respectively, on the understanding of complexity by evaluators and on the application of participatory system mappings to two real-world cases.
In general, this body of articles, especially the most quoted ones, cite more articles published in the Evaluation journal than in the six other journals combined, which hint at a conversation that is followed primarily in this journal.
Theory-based impact evaluation (87 articles, 627 cumulative citations – in blue)
These articles were primarily published in the 2010s. Their common thread is the use of theories in evaluation (56 titles), and especially in evaluating complex interventions and in introducing new causal approaches to do so. This explains why this cluster is very strongly connected with the ‘complexity’ cluster. The most cited article of the journal (as per Scopus cite-by indicator) is in this group. This is Yin’s (2013) ‘Validity and generalization in future case study evaluations’. However, this article is not frequently cited in the journal itself.
Twelve of the articles in this corpus explicitly discuss realist evaluation, realist synthesis or the use of realist principles in evaluation, and there is also a specific cluster for realist evaluation, which is presented below. The discussion on realist evaluation preceded that on other approaches, and started in the 2000s with two of the most central articles in this collection: ‘Theories of Change and Realistic Evaluation: Peas in a Pod or Apples and Oranges?’ (Blamey and Mackenzie, 2007) and ‘Evidence-based Policy: The Promise of ‘Realist Synthesis’’ (Pawson, 2002). The former is cited in the Complexity, Theory-based and Realist clusters, while the latter is cited in the last two and is one of the most cited papers of the journal (as per Scopus cite-by indicator).
Leeuw and Donaldson had principally identified realist evaluation as a solution to the challenges of theory-based evaluation. However, many other possibilities have been discussed within this cluster over the years. It includes for instance a discussion on Contribution analysis (14 articles), which started with a special issue published in 2012, and in particular Mayne’s (2012) article ‘Contribution analysis: Coming of age?’. This special issue was itself the coda to a years-long conversation between Mayne and other authors such as Jacques Toulemonde, Erika Wimbush, Frans Leeuw and Sebastian Lemire. Subsequent articles built on these foundations, applying contribution analysis to capacity-building interventions, health, small & medium enterprise policy, research and other fields.
Other approaches discussed in this cluster comprise Process tracing, which was already nascent in the 2000s and really emerged in 2015 with articles by Befani and Stedman-Bryce (2017) or Schmitt and Beach (2015); QCA and configurational approaches 16 (5 articles), with several articles by Befani (2013); Befani et al. (2007); and the use of case studies (5 articles). Some articles, such as those of Delahais and Toulemonde (2017) and Delahais and Lacouette-Fougère (2019), discuss several of these approaches together.
Realist evaluation (45 articles, 278 cumulative citations – in dark green)
Realist evaluation (along with broader theory-based or theory-driven qualitative research) constitutes its own distinctive cluster. Leeuw and Donaldson had already noted ‘that the single most frequent “type” of evaluation referred to in this journal is from the “realist” school; only exceeded by the frequency of reference to Ray Pawson and Nick Tilley!’ (Stern et al., 2015). While this cluster is strongly connected to the ‘complex’ and ‘theory-based’ clusters, it is also distinct due to its high level of internal connectivity. This group is nearly as old as the journal itself, with the first article in the series being Julnes et al.’s (1998) review of Pawson and Tilley’s (1997) book, Realistic Evaluation. Since then, this cluster has been in constant expansion: 7 articles in the 2000s, 17 in the 2010s, and 18 in the 2020s, while at the same time the number of articles on realist evaluation outside the journal literally exploded (Lemire et al., 2020). This is the reason why this group of articles is also much more connected to other evaluation journals, especially AJE and NDE, and also, although this is not visible from our data, with public health (see, for example, Marchal et al., 2012).
This cluster includes a diverse range of contributions, such as theoretical and ontological articles (Pawson, 2016; Porter, 2015) but also many case studies and practical articles. These articles discuss concepts and constructs of realist evaluation such as context-mechanism-outcome configurations (De Souza, 2013; Pawson and Manzano-Santaella, 2012), or the use of methods or tools in the context of realist evaluation (Manzano, 2016).
Dialogue (118 articles, 607 cumulative citations – in purple)
The first three clusters above are strongly interconnected. To some extent, they represent subfields in a broader discussion about (theory-based) evaluation and complexity. In contrast, the other clusters are quite far from this conversation. They also tend to be more distinct from each other and more delineated in time, though complexity is a common thread in several of them.
This ‘dialogue’ cluster is significant in size, with 118 articles about “dialogue” (30 occurrences in the title or keywords), “participation” (28), and to a lesser extent “empowerment” (11) and “democracy” (9). The discussion, however, was mostly active in the 1990s and 2000s, with 90 per cent of the articles in this cluster published in this period. One of the early discussions in this group is between Tineke Abma, Jennifer Greene, Ove Karlsson, Katherine Ryan, Thomas Schwandt and Guy Widdershoven (18 articles), which took place between 1996 and 2001. It culminated in a panel discussion at a European Evaluation Society (EES) gathering in which they explored questions such as What is your concept of dialogue? Why do you think dialogue is important for evaluation, especially for programme evaluation in the public sector and civil society? During an evaluation, what are the essential characteristics of a meaningful dialogue? Who participates? What do they talk about? What is the evaluator’s role? What prior value commitments or facilitating conditions are necessary? What are desired outcomes? What are the most important cautions we should take when conducting a more dialogical evaluation and finally, how ‘good’ are the dialogues we conduct, and what in fact constitutes ‘good’ dialogue? (Abma et al., 2001)
Other themes, such as participation, democracy or empowerment partly build on this foundational ‘dialogue on dialogue’, but also re-emerge regularly with a new perspective. For instance, in the 2000s, articles about participation adopted a critical stance and were concerned with conflict, distrust or power dynamics, and the role of the evaluator in dealing with these. In the last decade, this theme is still present, but the focus has shifted to more practical aspects, such as managing dialogue, relying on narratives or leveraging digital technology to enhance youth participation. The question of learning from participatory or dialogical evaluation is also a lingering theme, from Finne et al.’s (1995) ‘Trailing Research: A Model for Useful Program Evaluation’ to Suárez-Herrera et al.’s (2009) ‘Critical Connections between Participatory Evaluation, Organizational Learning and Intentional Change in Pluralistic Organizations’ – the former being largely cited in Evaluation, while the second is mostly quoted in American journals. In recent years, part of the discussion on participation has shifted towards the complexity and theory-based spheres, for example, in terms of including stakeholders in the development of a theory or a (systemic) causal mapping.
Use of evaluation (68 articles, 464 cumulative citations – in pink)
These articles were predominantly published between 1998 and 2007. They discuss ‘the use and usability of evaluations’ (Saunders, 2012) and offer two distinct perspectives on the topic. The first focuses on the role of ‘pro-active evaluators’ (Boaz and Hayden, 2002) and their efforts to make the evaluation design and process facilitative of use. A prominent article in this group is a conference address by Michael Patton (1998), in which he presents ‘process use’, which he had introduced the year before in an update to his book, Utilisation-focused evaluation (Patton, 1997). Process use is defined ‘as relating to and being indicated by individual changes in thinking and behaving that occur among those involved in evaluation as a result of the learning that occurs during the evaluation process’. Fostering use therefore means using evaluation and evaluative thinking to support these changes. Through this work, Patton closed the hiatus between practitioners’ common knowledge that ‘much that is useful [. . .] takes place during the evaluation process, [and] the literature on the utilization of evaluation, however, [which] mostly refers to lessons learned and recommendations implemented after the evaluation’ (Forss et al., 2002). Several subsequent articles sought to document these process uses (see, for example, Forss et al., 2002; Rebolloso et al., 2005; Valovirta, 2002).
The second perspective adopts a policy-oriented standpoint and features for instance addresses from Eleonor Chelimsky (1997) and Carol Weiss (1999). The latter’s speech at the 1999 EES Conference in Rome primarily frames evaluation as an ‘enlightenment’ process. Weiss situates evaluation within a much broader and more complex context, where ‘policy does not take shape at a single place and with a limited set of characters [. . .] If policy had to wait on the arrival of definitive knowledge, it would be a very long wait indeed, and political actors are used to making do with whatever is known, or believed’. She identifies the many obstacles and conditions affecting the use of evaluations, discusses ‘the channels through which evaluation travels’ and highlights the role of intermediaries in bringing evaluation knowledge to policy makers. Like Patton’s work, Weiss’s ideas have been influential, but it is difficult to trace back this influence to this specific article, given that both authors have discussed these topics in numerous publications. Still, 12 articles in this cluster cite Weiss’s Evaluation articles, for instance as a way to acknowledge that ‘the policy and decision-making process is anything but rational’, or to highlight the organisational realities in which evaluations are carried out (Perrin, 2002). Questions of organisational learning and the ways to integrate evaluation into public sector/programme management are also explored in several articles, such as Peter Van der Knaap’s (2000) article on ‘Performance Management and Policy Evaluation in the Netherlands’.
Evaluation published another influential article on use, by Mark and Henry (2004). ‘The Mechanisms and Outcomes of Evaluation Influence’ takes a different perspective on the question by considering the underlying theory of change of evaluation influence. With its ‘three levels of analysis (individual, interpersonal and collective), each with four kinds of processes (general influence, attitudinal, motivational and behavioural)’, it also combines the perspectives of Patton’s, Weiss’s and others. However, when this article was published, the discussion of use in Evaluation had largely faded. While this article is frequently cited in the journal, it is primarily referenced in the cluster on evaluation systems, which, in a sense, continues the discussion on use in different ways.
Evaluation systems (77 articles, 456 cumulative citations – in black)
This corpus includes articles published between 1996 and 2024. It is distinctive in that, while the average number of articles published every year within this cluster is limited (2.5), the flow has remained steady since the journal’s creation. The titles and keywords for these articles largely mention ‘evaluation systems’ (17 occurrences) but also evaluation functions, evaluation capacity or the institutionalisation of evaluation. In practice, the cluster includes many case studies of evaluation systems and challenges in institutionalising evaluation (the bureaucracy, the connection with politics), especially in Northern Europe and in international organisations.
An influential article in this cluster is Leeuw and Furubo’s (2008) ‘Evaluation systems: What are they and why study them?’. Building upon the International Atlas of Evaluation (Furubo et al., 2002), they provide an ‘overview of evaluation systems to be found in (mainly western) countries and in organizations such as the World Bank’. The article introduces a typology of evaluation systems, with different purposes, features and underlying logic, including performance monitoring; performance audit, inspection and oversight; (quasi-)experimental evaluations and evidence-based policy; accreditation; and monitoring and evaluation. Leeuw and Furubo insist that these systems need to be understood in their context rather than as abstract procedures. They also challenge common misconceptions, such as the belief that these systems always produce useful information. In reality, they may instead produce ‘routinised information’ that ‘confirms rather than questions policies’, rendering it ‘of little relevance for fundamental reassessments’. This article was cited by articles whose objective was either to improve understanding or to critique specific systems, and by articles that discuss the tensions between accountability and learning. Of specific interest are case study articles questioning the use and influence of some of these systems, such as the European Commission (Højlund, 2014) or the World Bank (e.g. Raimondo, 2018). These effectively connect with the subgroup of the ‘evaluation use’ cluster which is concerned with organisational learning.
Another frequently cited paper in this cluster is by Vedung (2010). In this article, he presents ‘Four Waves of Evaluation Diffusion’: scientific, dialogue-oriented, neo-liberal and evidence-based, each of which ‘[having] deposited sediments which form present-day evaluative activities’. The wave metaphor allows to consider different timelines of diffusion in different countries. Similar to Leeuw and Furubo, Vedung hardly cites other articles in the journal, with most of his references drawn from books. However, his article has been widely cited by Nordic authors, who notably refer to his brief application of the waves to the Swedish case.
The politics of evaluation (70 articles, 323 cumulative citations – in orange)
This group of articles is notable for its size, but it is also very loose and deeply intertwined with almost all other clusters (Evaluation systems, Complexity, Theory-based evaluation, Dialogue and Use). It is not always easy to identify a common thread, though evaluation as a political activity and evaluation in policy-making are more central themes here than in other clusters.
This cluster notably encompasses discussions of institutionalisation, as with Jacob et al.’s (2015) article ‘The institutionalisation of evaluation matters: Updating the International Atlas of Evaluation 10 years later’; evidence-based policy making and the role of systematic reviews in it (Hansen and Rieper, 2009; Shadish et al., 2005); democratic evaluation (Picciotto, 2015), ‘Evaluation of and for democracy’ (Hanberger, 2006); and finally the ethical responsibility of evaluators, with articles by Schwandt (2018), Mathison (2018) or more recently Brousselle and McDavid (2020).
A strong connecting force within this cluster is the Nordic origin of many of its authors, whose articles are cited in the recapitulating paper ‘A Nordic evaluation tradition? A look at the peer-reviewed evaluation literature’ (Nielsen and Winther, 2014). However, even when this article is removed, a cluster persists.
Accountability (35 articles, 211 cumulative citations – in light brown)
The last significant cluster explores the notion and function of accountability – or rather its troubled relationship or ‘unresolved tension’ (Armytage, 2011) with the neighbouring concept of ‘learning’. Since the mid-2000s, this cluster has maintained a small but steady stream of publications, largely reflecting conversations in the field of international development, where the pressure for accountability – on both grantees and donors – is particularly strong (Benjamin, 2008). But this cluster also includes contributions on performance auditing and the role of Supreme audit institutions (e.g. courts of auditors and auditing boards), for which accountability of executive bodies to the public and its representatives has been an historical raison d’être.
The authors in this cluster were particularly interested in the conditions under which accountability – understood as the formalised production of feedback and knowledge – can serve as a lever for policy and community improvement through learning. As put in a seminal paper by Van Der Meer and Edelenbos (2006), this intertwining is not without contradictions: the contemporary fragmentation of the policy process dissolves the former top-down policy responsibility between many actors, whereas the claims of policy responsiveness or flexibility (typically linked with learning) can clash with the expectations of coherence or stability of ‘accountable’ policy-making. A successful coupling between accountability and learning, they argue, may occur if the evaluators create an emulation around the evaluation process. Subsequent papers have echoed the idea that accountability is becoming less hierarchical, more networked and multiple (Benjamin, 2008; Lehtonen, 2014).
Similar to the ‘evaluation systems’ cluster (to which it is connected through Leeuw and Furubo and their epigons), the counterproductive nature of formalism and reporting is often put forward. In a reflective piece on international development in the age of results-based management (RBM), Lauren Kogen argued that many international organisations conflate accountability and learning. These organisations assume that an increased collection and display of results will automatically result in collective learning (Kogen, 2018). In response, Robert Picciotto reasserted the value of accountability frameworks, as they favour collective learning and are eventually ‘the two sides of the same coin’ (Picciotto, 2018).
The other salient theme in this cluster is the relation (or frontier) between control, (performance) audit and evaluation. Reichborn-Kjennerud and Johnsen (2011), for instance, documented how auditors conduct performance audit, offering a chance to clarify the distinction in the thinking or posture between auditors and evaluators. Their work also illustrates the potential collision between accountability and learning, as seen in the case of Norwegian public auditors who refused to consider information related to the ‘cooperation’ created by an urban renewal programme as they deemed this notion too vague or too difficult to measure in unquestionable terms. As these auditors sought to embody impartiality and authoritativeness, they distanced themselves from any kind of statement that would have appeared overly interpretative. In a subsequent article, Reichborn-Kjennerud (2014) explained how Norwegian public auditors were more and more prone to engage directly with ministries to increase the readership and usefulness of their reports, effectively acting as governmental ‘managing consultants’. Both cases underscore the balance that auditors must strike between ‘independence and responsiveness’ (Lonsdale, 2008) as well as the ‘hybrid activity’ that audit has become.
Other conversations in evaluation
Though they are not discussed in depth in this article, there are plenty of other themes discussed in the journal. Some of the ‘smaller conversations’ that can be observed discuss topics such as the evaluation of European policies; the evaluation of science, innovation and technology policies; ethics; the evaluation profession; or evaluation capacity. Other articles in our corpus do not appear as ‘conversations’ for the lack of connections with other articles in the journal. But they can be part of discussions that are happening in other journals, such as culturally responsive or gender-responsive or feminist evaluation. The uncited papers can also be regarded as solitary ‘echoes’ of wider conversations, as most of the 80 uncited papers within our sample are case studies, conference proceedings or summaries of specific institutions’ perspectives (e.g. The World Bank, the OECD or national ministries).
Discussion
In this final section, we synthesise what is learned from the analysis, before taking a more critical view about the cluster analysis and its value added for better understanding the debates happening in the evaluation sphere.
A longitudinal view on the journal’s conversation
In the 20th anniversary special issue of the Evaluation journal, the editors had identified two main topics for an additional overview: complexity (Gerrits and Verweij, 2015) and theory (Leeuw and Donaldson, 2015). Ten years later, these two subjects are still largely at the forefront of conversations. However, there are also parallel conversations that are happening, some of them being as old as the journal itself, while others were once prominent but are now much less significant. Figure 5 illustrates this, by showing the percentage of papers published each year according to their respective cluster.
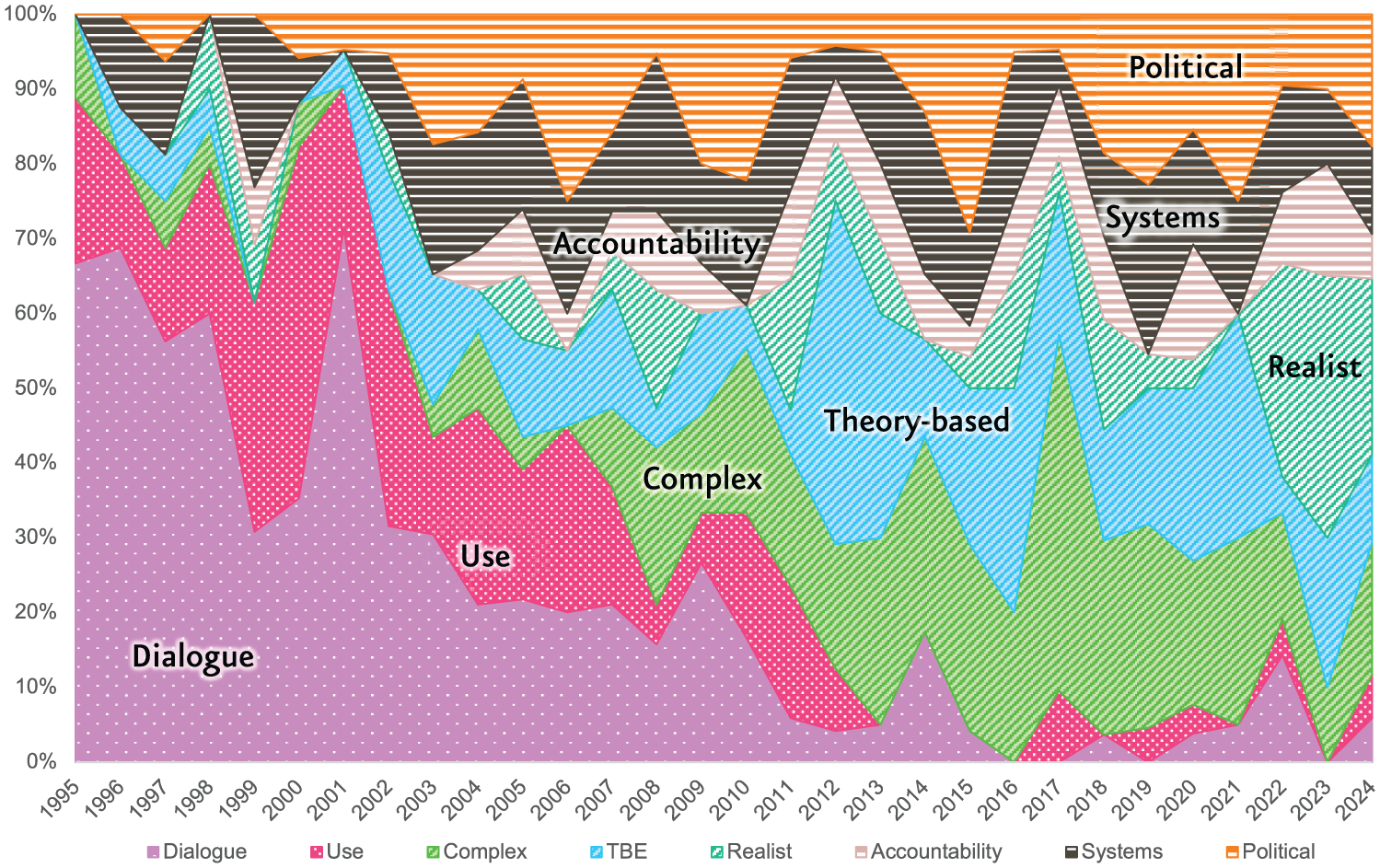
Proportion of articles published each year according to their cluster.
From dialogue and use to theory and complexity
In its early years, the journal seemed first and foremost interested with the consolidation of evaluation as a core intermediation practice in contemporary politics, as clearly reflected in the prominence of the ‘dialogue’ and ‘use’ clusters. Authors were concerned about the political and social performance of their activity and urged the then flourishing independent evaluations to build bridges and go beyond bureaucratical and mono-methodological approaches. However, these issues became less salient in the journal after 2000: They might have migrated to other journals, been reframed with new lexicons and research problems, or they may have run out of steam more globally.
Perhaps the most striking turn in Evaluation, however, has been a methodological one. At first a small share of the journal’s activity, papers on methods, grew in importance from the late 2000s onwards. This growth was driven by reflections on theory-based and realist evaluations, which ended up amounting to more than a third of publications in the Journal’s last decade. This rise in methodological focus was tightly coupled with the conversation on complexity. It comes as no surprise that this shift was partly, and sometimes implicitly, an answer to the parallel exaltation of experimental and quasi-experimental evaluation methods in many international contexts. While Evaluation was in no way closed to such approaches, its role in the scholarly debate appeared to be counterbalancing, as its authors advocated for encompassing the plurality of worldviews on policy-making through adapted and diverse methodological approaches.
Shifting debates
Conversations have also evolved or merged over time, depending on the authors involved, or new perspectives taken on similar themes. An example is the discussion on use, which moved from a debate framed by the long-standing conversation between people such as Weiss and Patton, to a conversation on evaluation systems and their influence. 20 out of 68 articles (29%) in the ‘Evaluation systems’ cluster refer to at least one article of the cluster on use, and Mark and Henry’s (2004) article on the mechanisms of evaluation influence was automatically classified as part of the ‘Evaluation systems’ cluster due to its high level of citation in this group. This shift marks a reflective and critical turn in Evaluation, as the general tone seemed to switch from enthusiasm and voluntarism to a more sceptical outlook.
By the mid-2000s, the more classical concept of ‘utilisation’ had been reframed as a broader (non)-‘influence’ on the policy process, blending with other sources of information or policy feedbacks. Evaluation was no longer considered solely as a virtuous mechanism to improve welfare, but as something that could be routinised or weaponised. This shift translated into grounded case studies or reviews of the effects of evaluation ‘in context’. This discussion also intersects with a neighbouring one, focused on accountability and its (im)possible combination with the learning and improvement functions of evaluation. The dialogue on accountability has notably been fed by observations from the world of international development, where the top-down control role of evaluation has historically been prominent.
Conversations can also change within a same cluster. This is particularly evident in the ‘complexity’ and ‘theory-based evaluation’ clusters. Though these two themes were already important ten years ago, they have also mutated. The complexity cluster, for instance, has moved towards a system-informed perspective, while the theory-based cluster has progressively incorporated a range of approaches that can be used in complex settings. Similarly, in the ‘dialogue’ cluster, the initial discussion between people like Schwandt, Abma and others had largely concluded by the end of the 1990s, giving way to new themes such as stakeholder participation.
Added value and limitations in a clustering analysis
Conversations or themes?
In this article, we have made the assumptions that cross-citations between articles are evidence of ongoing conversations. Our definition of ‘conversations’ is broad and includes debates on common themes. However, clusters as such are not enough to infer an actual debate, nor do they always reflect ‘themes’ in the evaluation literature. This is demonstrated by taking a list of articles which discuss ‘evaluation capacity’ and ‘institutionalisation’ 17 , and identifying the network of citations within. Among these 38 articles, 36 are cited at least once by another paper in the journal, but only 19 cite each other (Figure 6). In fact, ‘capacity’ and ‘institutionalisation’ could be described as transversal themes, cutting across most of the clusters above. But it is also a fragmented topic, which faces definitional challenges. Typically, a recent ‘integrative review’ of evaluation capacity building mentioned only one article in Evaluation (Bourgeois et al., 2023).
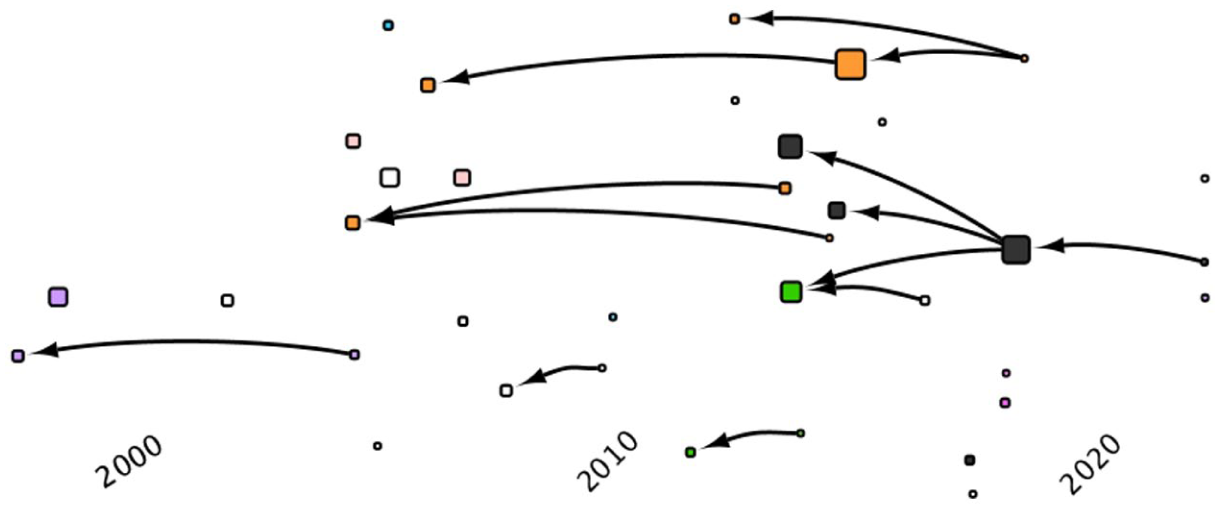
Cross-citations within an evaluation theme.
Similarly, the discussion about complexity in the journal extends far beyond the ‘complexity’ cluster. Articles which mention complexity and systems now routinely represent between a quarter and a third of all articles published annually (Figure 7). However, authors in the journal have approached this topic from different angles. Some, like Rogers and Stame, have focused on the complexity of evaluation objects (complex systems of change, interventions, causal relationships, unexpected effects, etc.) and how the evaluation scope (in terms of intervention, but also timescale, places, people, etc.) influences the evaluation process (Woolcock, 2013). Others have been more interested in how evaluation could deal with this complexity, using distinctive programme theories and social science theories as already discussed, but also complexity theory and systems thinking (Hummelbrunner, 2011; Westhorp, 2012). A distinctive feature of Evaluation is how it has hosted many articles on complexity-aware approaches and tools (‘Theory-based’ cluster) and exploring how these can be made more robust (Apgar et al., 2024; Yin, 2013). And finally, some have focused on the complexity of the evaluation context and its position in the systems that it evaluates. This is evident in how the discussion on use has merged with the discussion on evaluation systems, as described above, as in long-standing exchanges about the role and posture of evaluators (e.g. Finne et al., 1995; Gates, 2017).
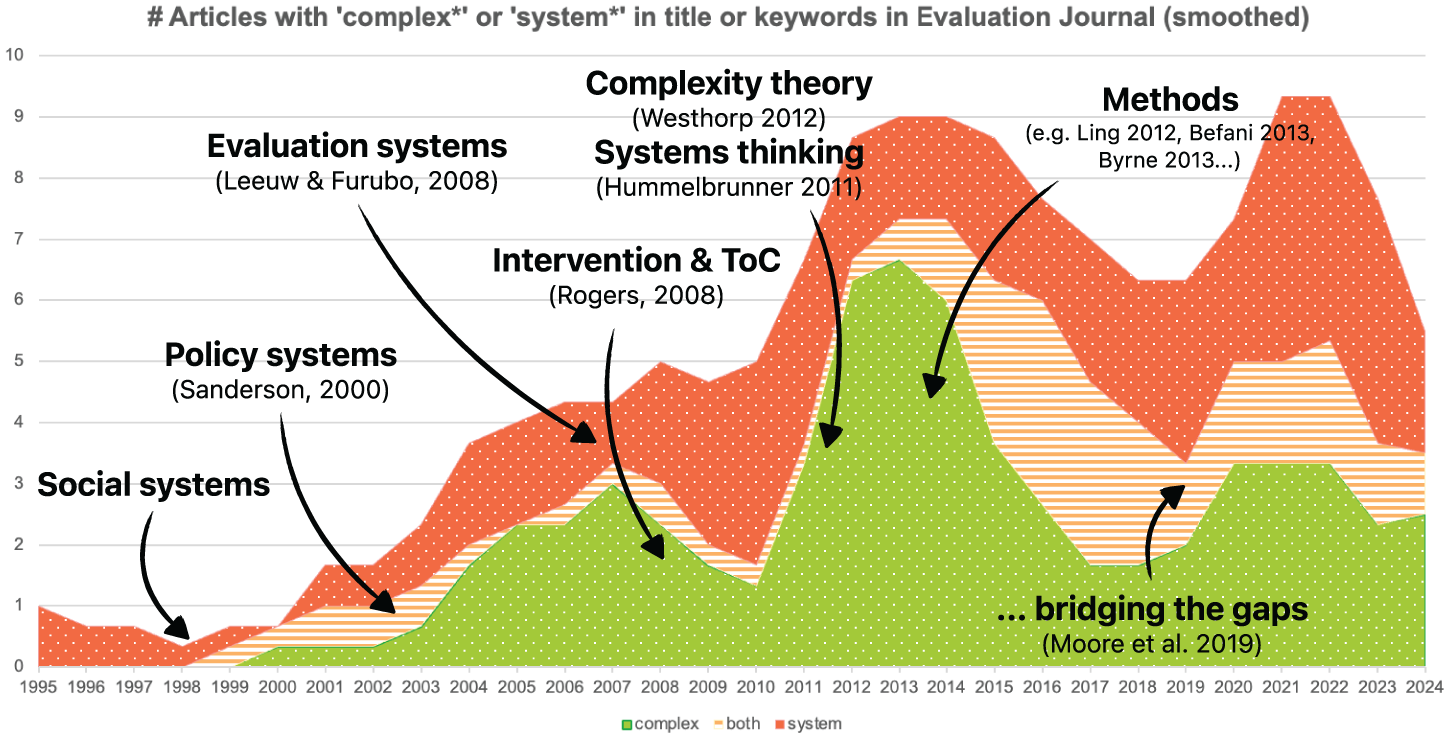
Number of articles with ‘complex*’ or ‘system*’ in title or keywords in Evaluation (smoothed).
Conversely, the orange ‘political’ cluster is an interesting example that shows connections between themes (institutionalisation, evidence-based policy-making, democracy, ethical responsibility) which may not have been tangible without looking at connections.
Ghosts haunting the cluster
The data set used in this article is limited to articles from the Evaluation journal and neither includes articles in other journals nor other publications such as books or reports. To some extent, the mapping of conversations in the journal is haunted with these ‘ghost’ publications, which possibly connect the dots between some articles or clusters within a broader conversation. A typical example is Contribution analysis, which has been discussed equally in Evaluation and in the CJPE.
We ran complementary analyses to give a sense of the journal’s broader echo. Using Scopus, we analysed the citations of the 20 most-cited articles from Evaluation, which account for around 30% of the journal’s total citations by other sources (6,597/22,482) as of July 2025. While evaluation-focused outlets (such as the CJPE or the AJE) are among the top-citers of Evaluation, they rank behind health and medical journals (such as the British Medical Journal or the BMC Health Research), which account for more than a third of the sources citing Evaluation. Political science or public administration journals (such as the Public Management Review) rank third, with only a tenth of the articles citing Evaluation, while environmental and sustainability studies rank fourth (6%). This pattern may be due to the nature of the top-cited articles in Evaluation, which primarily address methodological and epistemological issues (such as validity or realist evaluation). The proposed solutions are then applied in medical or public health case studies.
Expanding our analysis to all of Evaluation’s articles using Scopus’ survey tools, we found a consistent distribution of citing sources 18 , with Social sciences at large (including evaluation) amounting to 35.9% of the citations of Evaluation articles, followed by Health (14%), Business and management (13%) and Economics (5%). Interestingly, these proportions closely match the inbound citations of Evaluation, which implies that the bulk of the journal’s readership and cross-disciplinary conversation lie at the intersection between social, health and management sciences 19 . Conversely, a myriad of sub-networks of citations by policy or disciplinary specialisation seem to exist at the margins and would deserve further investigation in the future.
Similarly, books may play an important role in pursuing the evaluative conversations of the journal. In these two recent examples, Evaluation is central to the conversation, with other journals being less represented:
Changing Bureaucracies (Perrin and Tyrrell, 2021) includes 23 citations of 20 articles of the journal, 14 citations of the AJE and 5 citations of the CJPE. Most of these articles are part of the ‘evaluation systems’ cluster.
Theories of Change in Reality (Koleros et al., 2024) includes 24 citations of 20 articles of the journal, vs 15 citations of 13 articles of the AJE and 14 citations of 9 articles of the CJPE. Most of these articles are in the ‘theory-based’ cluster.
Finally, there is only limited evidence of direct exchanges outside of the clusters, except in a few cases. Pawson, typically, was called directly at least four times (Astbury, 2013; Kaehne, 2018, 2021; Porter, 2015), and responded at least once (Pawson 2016), but he is more the exception than the rule. Some papers or special issues are actually the results of conversations that happened as part of networks such as INTEVAL, in conferences such as those hosted by the EES, or more informally. Examples include the special issues on Contribution analysis; ‘Policy evaluation for a complex world’; or the COP26, as well as papers such as ‘Dialogue on Dialogue’ (Abma et al., 2001).
The special issues stemming from the EES conferences are particularly telling. Each contains a curated selection of articles that resonate with the eight clusters, such as public dialogue, organisational systems, causal inference, and so on. It is one of several echoes of a broader European conversation, which is reflected in the journal insofar as its editors and authors are also active members of the European and national evaluation societies. The clustering exercise also hints at existing communities who interact through the journal, such as realist evaluators, the Nordic evaluation community, British academics trained in systems, or scholars hosted in British institutions working on aid. In these cases, Evaluation enables more than it triggers a conversation.
Citation patterns
Finally, cluster analysis is particularly sensitive to ‘citation patterns’ which don’t have much to do with an actual conversation and rather reflect individual or social practices in the evaluation field. We identify four of these patterns here:
Ritualistic citation: some authors are cited almost automatically when mentioning certain concepts. Weiss and Patton, for instance, are very often cited in relationship to use in our corpus, but often without any specific engagement with the content of their work. To some extent, these ‘ritual’ papers are not part of the debate anymore: they have become part of the background.
Anchoring citations: authors may cite an article to position themselves in a certain discussion, especially when this discussion is emergent and the literature is scant. This does not always mean that they fully align with the cited works, but rather that previous references lend credibility to their original contribution. A case in point is Sanderson’s article ‘Evaluation in Complex Systems’, which was the first in the journal to combine ‘evaluation’ and ‘complex’ in its title. Many articles which followed and wanted to discuss complexity went on to cite this article, even when their understanding of complexity differed significantly from Sanderson’s.
Self-citation: authors tend to cite their own work, even when this work is only partially related to the conversation. With prolific authors, this may lead to connections between different groups of articles that are not representing a conversation – or only one with oneself. This pattern is evident, for instance, in the cluster on ‘Use’.
Synthesis: periodically, papers emerge that summarise research on a given topic, either to support a case study or before engaging in a new direction. Introductions of special issues sometimes play this role too, as in the CECAN special issue (Barbrook-Johnson et al., 2021). Such papers are likely to be referenced by subsequent articles. The articles in the ‘complexity’ and ‘evaluation systems’ clusters are typically connected through these sorts of papers.
We do not wish to convey the idea that these patterns would necessarily obfuscate or distort the ‘true nature’ of scholarly conversations. On the contrary, rituals and anchors help readers recognise shared references, while synthesis is a good way to leverage the ‘reservoir of knowledge’ (Hanney et al., 2004) in pursuing a conversation. These patterns must however be considered when analysing conversations and making sense of them.
Conclusion
In this article, we have aimed to provide a fresh perspective on 30 years of publications in Evaluation. Using a bibliometric approach, we uncovered eight clusters of articles characterised by high levels of cross-citation and analysed their content to map the themes of the intellectual conversations happening in the journal, and how they have evolved. This approach proved useful in revealing connections between seemingly disparate topics. On the contrary, it highlighted fragmentation within supposedly consistent themes in the evaluation debate. Of course, evaluative conversations are not confined to a single journal; nor are they limited to the evaluation sphere! We are conscious that this article may generate frustration: How do the themes identified in Evaluation compare to those found in other evaluation journals? Does the journal’s content merely reflect global trends, or has it helped shape them – e.g. on complexity or theory-based evaluation? Do conversations migrate from a journal to another and why? Can we identify similar themes being discussed in different ways in different journals – as might be the case for use or capacity? Alas, these are questions we must leave to future research. Our hope is in opening this new field of investigation, and perhaps trigger a new conversation across journals.
Reviewing three decades of Evaluation, we were struck by the longevity of many conversations. Mutatis mutandis, many of the debates that started at the turn of the millennium are still relevant today, although the terminology, the framing and concepts have evolved and refined. Typically, the conversations on use and dialogue, which were central to the journal’s early years, appeared to fade at the beginning of the 2000s. Or did they? In fact, these themes are still being discussed today, albeit embedded within broader discussions of ‘evaluation systems’ or the ‘political’ perspective on evaluation. In the meantime, complexity and theory-based evaluation have progressively become the ‘signature’ of the journal, permeating discussions throughout Evaluation. As in Vedung’s (2010) article on evaluation diffusion, the conversations in this journal are like waves: they ebb and flow, their intensity varies, they are never the same, and they leave sediments for future discussants. Indeed, there is potential to revisit this accumulated material through contemporary perspectives, concepts, and practices, and to learn from it as we move forward.
Footnotes
Acknowledgements
The authors thank the long-standing collaborators of the journal and other experts in the evaluation field that commented – and helped to improve – this article.
Author note
One of the authors serves on the Editorial Board of Evaluation.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.