
Abstract
This article explores the tensions that arise in the evaluation of programs for the prevention of violent extremism (PVE), using Bourdieu’s theory of fields and frame analysis as analytical lenses. Based on qualitative data collected in nine Western countries, the study highlights how divergent field logics shape actors’ expectations, interpretations, and practices around evaluation. It identifies four central tensions—particularity vs harmonization, involvement vs independence, transparency vs confidentiality, and program vs practice evaluation—each reflecting structural and ethical dilemmas. Rather than viewing these tensions as obstacles, the article argues that they can become productive through processes of frame alignment, especially when evaluators act as mediators between fields. Although not exclusive to PVE, these challenges are intensified by the political sensitivity and ethical demands of this domain. The article concludes by emphasizing the need for relational competence, field awareness, and inclusive approaches in building meaningful and legitimate evaluations.
Introduction
The debate surrounding the evaluation of preventing violent extremism programs (PVE) programs is usually framed from a technical-methodological perspective, in which the main questions revolve around tools, procedures, and measurements, as well as the limitations of designs and indicators, the number and type of studies available, and the difficulties of attributing effects or demonstrating impact (Baruch et al., 2018; Bellasio et al., 2018; Feddes and Gallucci, 2015; Gielen, 2017; Hassan et al., 2021a, 2021b; Hirschi and Widmer, 2012; Madriaza et al., 2025; Mastroe and Szmania, 2016; Romaniuk, 2015; Sydes et al., 2023; Zeuthen, 2021). To reach this conclusion, the authors of these studies have based their analyses almost exclusively on reviews of the available evaluation literature and have rarely engaged with the actors directly involved in evaluation processes to understand why these challenges persist. As a result, the debate remains largely confined to the academic sphere and disconnected both from the real dynamics and constraints of evaluation practice and from the social, relational, and political dimensions of the evaluation process itself.
However, evaluation is not solely a methodological or conceptual issue, nor is it a process that concerns only researchers or evaluators. It is a socially situated practice that is influenced, on the one hand, by the political, institutional, historical, and social contexts in which it unfolds (Dahler-Larsen, 2012) and, on the other hand, by the divergent interests and expectations of the multiple actors involved (Patton, 2008). In this sense, the way in which a funder of a preventing violent extremism (PVE) program conceives evaluation—and the needs they project onto it—may differ significantly from how a practitioner interprets it based on their field experience. From this perspective, evaluation can be understood as a temporary encounter in which multiple logics, interests, and expectations converge regarding its meaning, its function, and its legitimacy (Verwoerd et al., 2021). In this encounter, divergences are not marginal: they are expressed in how problems are defined, which questions are prioritized, which procedures are deemed acceptable, what counts as valid evidence, and how findings can be used. Conceiving evaluation in this way implies recognizing, on the one hand, that it is a potential source of tension and conflict among these logics and, on the other, that it also constitutes a process through which they may enter into dialogue, acknowledging differences and building partial forms of shared understanding and legitimacy around procedures, findings, and their implications (Kunseler and Vasileiadou, 2016; Verwoerd et al., 2021). Thus, no actor is neutral, nor is the methodological process itself, since every evaluation involves selections, priorities, and decisions that privilege certain objectives, criteria, and audiences over others (Patton, 2008). The evaluation of PVE programs thus offers a particularly revealing space for observing how these tensions shape the evaluative process and influence the perceived utility and legitimacy of its results.
These ideas emerged within the context of a research project aimed at identifying the challenges of evaluating programs in this field through interviews with evaluators and practitioners from nine Western countries. This article examines the key tensions that arise from the coexistence of divergent logics in PVE evaluation. It also analyzes how actors navigate these tensions, and how they affect the perceived usefulness and legitimacy of evaluations. By tensions, we mean points of friction that emerge when divergent yet legitimate logics, specific to different fields of action, must coexist and be articulated within the evaluation process, forcing actors to make decisions and seek practical balances without definitive solutions. In this sense, these findings are analyzed in light of Bourdieu’s field theory (Bourdieu and Wacquant, 1992) and the frame analysis developed by Goffman (1974) and Snow et al. (1986).
Following Madriaza et al. (2025), this study uses the terms violent radicalization and violent extremism (VE) interchangeably, as well as prevention of violent radicalization and PVE, with the latter used consistently throughout the text. VE refers to ideologies or beliefs that justify the use of violence to achieve political, religious, social, or ideological goals. PVE programs seek to reduce risk factors that make individuals or groups more vulnerable to VE or recidivism. Evaluation is understood as “the systematic assessment of the design, implementation, or outcomes of an initiative intended for learning or informed decision-making” (Canadian Evaluation Society, 2025: 3; Poth et al., 2014).
What do we mean when we talk about the evaluation of PVE programs?
The literature on evaluation in this field has been dominated primarily by technical and methodological challenges (Bellasio et al., 2018; Madriaza et al., 2025; Mastroe and Szmania, 2016). Within this framework, the literature repeatedly identifies conceptual, design, and methodological implementation limitations. In particular, several authors point out that the absence of shared definitions of what constitutes “violent extremism,” and how to distinguish it from other social or political phenomena, hinders the construction of valid, comparable, and empirically robust indicators (Lindekilde, 2012; Mastroe and Szmania, 2016; Ris and Ernstorfer, 2017).
Added to this, as emphasized by Bellasio et al. (2018), are difficulties stemming from the inherent complexity of the field, in which programs often operate in contexts characterized by a low frequency of events of interest. This limits the statistical power of evaluations and complicates the measurement of outcomes. These conditions have, in some cases, led to the abandonment of initially planned experimental or quasi-experimental designs and to restrictions on the use of comparison groups, even in evaluations aimed at measuring impact (Schuurman and Bakker, 2016). This scarcity of cases is further compounded by restrictions on access to sensitive information—linked to judicial processes, national security considerations, or ethical standards in social services—which prevent evaluators from accessing complete, comparable, or longitudinal data (Hirschi and Widmer, 2012; Ris and Ernstorfer, 2017). Several authors also criticize the lack of systematization, coherence, and transparency in evaluation procedures: many evaluations rely on ad hoc methods, limit themselves to describing activities rather than analyzing outcomes, and omit key information on sampling, control of confounding variables, or data analysis techniques (Davey et al., 2019; Feddes and Gallucci, 2015; Marret et al., 2017).
Complementarily, the literature notes that many programs do not systematically integrate the knowledge generated by recent empirical research, nor are they designed on the basis of explicit theories of change. This creates a disconnect between the causal assumptions underlying the intervention and the methods used to evaluate it (Madriaza et al., 2022; Marret et al., 2017). As a result, a significant number of evaluations claim to measure impact but rely on indirect or intermediate indicators whose relationship to processes of radicalization or deradicalization is primarily theoretical and has not been empirically demonstrated (Madriaza et al., 2022).
The recurring problems identified in this literature—conceptual ambiguity, limited data, procedural weaknesses, and the weak connection between program design and evaluation strategies—may point not only to technical and methodological challenges but also to tensions embedded in the relationships among the stakeholders involved in evaluation. This, in turn, raises the question of whether these difficulties are shaped, at least in part, by the different positions, priorities, and interpretations of reality that actors bring to the evaluative process. The next section explores this issue through the broader literature on tensions in evaluation.
Tensions in the evaluation literature
The evaluation literature has shown that evaluative processes often unfold at the intersection of divergent logics, particularly when they involve multiple actors with different mandates, expectations, and criteria of legitimacy. One of the most recurrent tensions concerns the purpose of evaluation: it may be conceived either as a mechanism of accountability or as a tool for learning and programmatic improvement (Faling et al., 2024; Herbert, 2015; Reinertsen et al., 2022). When the donor’s perspective predominates, evaluation is primarily oriented toward accountability, requiring implementers to demonstrate the achievements attained (Faling et al., 2024; Herbert, 2015). In contrast, when evaluation is framed as an opportunity for learning, the emphasis shifts to identifying mistakes and areas for improvement—an approach often valued by practitioners themselves (Herbert, 2015). In the same vein, Poulin et al. (2000) distinguish between formal objectives, aimed at communicating results to external actors such as donors, and informal objectives, which focus on the internal needs of implementers and users. These orientations also influence the uses of evaluation, which tend to be more symbolic than substantive when they respond primarily to external demands (Kupiec et al., 2023; Raimondo, 2018).
These differences in purpose cannot be separated from the power relations that structure the evaluative process. Several studies show that donors, funding agencies, and other institutional actors often occupy dominant positions from which they define priorities and criteria for success, constraining the autonomy of evaluators and implementers (Emerson, 2020; Hanberger, 2022; Kupiec et al., 2023; Raimondo, 2018; Reinertsen et al., 2022; Sawadogo-Lewis et al., 2022; Van Tulder and Keen, 2018). In this regard, Hanberger (2022) emphasizes that evaluation can become a vehicle of “power over” other actors by determining which forms of knowledge, questions, and evidence are recognized as legitimate. Within this context, implementers frequently find themselves in a subordinate position, with limited space to incorporate contextual knowledge or promote genuine learning (Herbert, 2015).
More recently, this issue has been formulated in terms of paradoxes. Faling et al. (2024) define them as contradictory yet interdependent elements inherent to organizations that persist over time and resist definitive resolution. In the field of monitoring and evaluation, such paradoxes generate tensions in practice—that is, frictions that arise when actors and organizations attempt to respond simultaneously to opposing demands. Building on this approach, they identify five major paradoxes related to purpose, evaluator position, process permeability, method, and acceptance of results, showing that the tensions running through evaluation are not merely circumstantial but rather the practical manifestation of more structural contradictions.
Parallel to this, other studies have approached these tensions through the coexistence of divergent evaluation imaginaries. Drawing on Dahler-Larsen, Kunseler and Vasileiadou (2016) illustrate the coexistence of a modernist imaginary—associated with objectivity, measurement, and control—and a reflexive imaginary—linked to learning, participation, and complexity. Their analysis suggests that evaluative practice unfolds amid these coexisting logics, expanding the methodological repertoire but also generating tensions when innovative aspirations collide with institutionalized practices. Verwoerd et al. (2021) deepen this idea by showing that reflexive evaluation entails a constant negotiation between legitimacy and integrity—that is, between the need to meet dominant institutional expectations and the need to uphold reflexive and transformative principles. In both cases, the evaluator emerges as an intermediary who manages frictions (Kunseler and Vasileiadou, 2016) and performs alignment work between modernist and reflexive imaginaries (Verwoerd et al., 2021).
While the notion of tension used in this article is close to Faling et al.’s (2024) idea of paradox, it does not fully overlap with it. We agree that evaluation faces contradictory and persistent demands that may coexist within the same practice. However, we prefer to speak of tensions because our analysis draws on a theoretical tradition distinct from the management literature on paradoxical thinking and instead focuses on the concrete frictions that arise when actors situated in different positions and guided by different logics must define the aims, validity criteria, uses, and value of a specific evaluation. This perspective invites us to examine both the positions from which actors intervene and the broader frameworks through which evaluation acquires meaning and legitimacy. The following section proposes a conceptual scaffold for addressing this dual dimension.
From tensions between fields and imaginaries to the framing of divergences
From Bourdieu’s perspective, a field can be understood as a relatively autonomous social space governed by its own rules and logics, in which actors compete for resources and recognition (Bourdieu and Wacquant, 1992). This approach is particularly useful for the present study, as the evaluative process brings together actors from different fields. While the evaluator operates within the demands of the technical–scientific field, the practitioner acts from a logic oriented toward intervention, and the funder responds to political, economic, and administrative criteria. Each mobilizes specific sources of legitimacy and authority, such that evaluation becomes an interactional space among actors whose positions and logics of action do not necessarily converge. In this sense, relations between fields can generate tension, conflict, and misunderstandings (Shammas and Sandberg, 2016).
Superimposed onto this field logic is a second dimension intrinsic to evaluation itself: evaluation imaginaries, that is, the historically sedimented ways of understanding what evaluation is, what it is for, and what makes it legitimate (Dahler-Larsen, 2012). In ideal-typical terms, Dahler-Larsen distinguishes three major imaginaries: the imaginary of modernity, associated with progress, rationality, improvement, and control; the imaginary of reflexive modernity, linked to learning, deliberation, and plurality; and the imaginary of the audit society, centered on standardization, verifiability, risk management, and security. These imaginaries do not succeed one another linearly; rather, they can coexist and come into tension. Hence, evaluation appears as an arena in which two levels of tension intersect: that between actors situated in different fields, and that between divergent imaginaries regarding the purposes, procedures, and validity criteria of evaluation.
However, while the notions of field and imaginaries help clarify why evaluation is permeated by conflictual relations and divergent expectations, they offer fewer tools for analyzing how, in concrete interaction, actors negotiate these differences and construct partial forms of convergence. To address this dimension, it is useful to draw on the concept of framing. A frame “denotes ‘schemata of interpretation’ that enable individuals ‘to locate, perceive, identify, and label’ occurrences within their life space and the world at large” (Snow et al., 1986: 364). In this sense, evaluation imaginaries can be read as broad interpretive frames that shape how different groups understand and justify evaluation, but framing also captures how these schemes are actively mobilized and reconfigured by actors in practice (Snow and Benford, 1992).
This leads to the process of frame alignment, understood as the articulation of interpretive orientations that renders, at least partially, the interests, values, and goals of different actors compatible (Snow et al., 1986). Frame alignment has been an important lens for explaining why collaborative processes involving multiple stakeholders can fail or, conversely, become viable (Croteau and Hicks, 2003; Le Ber and Branzei, 2010; Madriaza, 2023; Vandenbussche et al., 2017; Zimmermann et al., 2021). Hence, the evaluative process can be understood not only as a space of confrontation among field logics and divergent imaginaries but also as a space in which actors attempt to frame, negotiate, and align their interpretations of evaluation. The challenge, then, lies in generating a sufficient degree of convergence to construct a shared understanding of the evaluative process.
Method
Participants
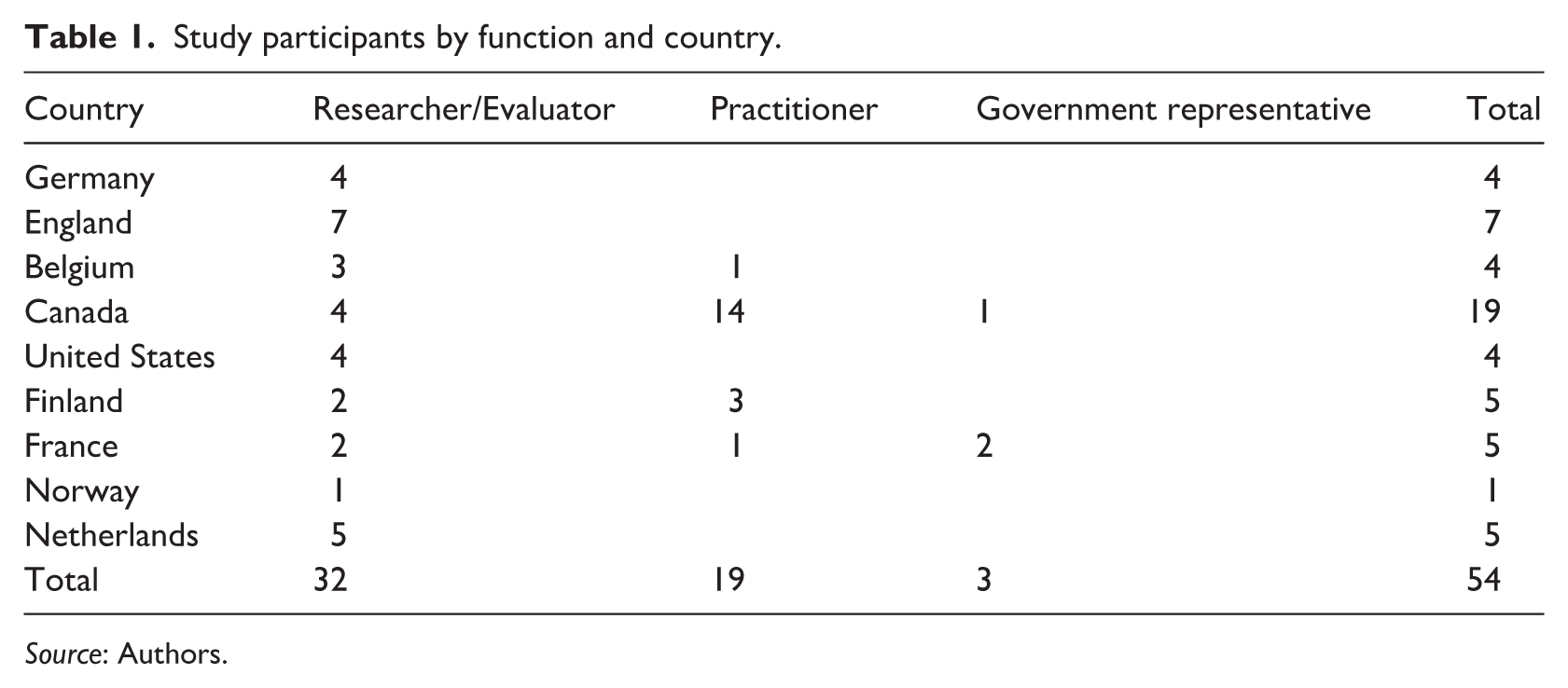
A total of 54 participants from nine countries were interviewed (see Table 1), divided into three groups:
32 researchers with experience in PVE program evaluation,
19 practitioners whose programs had been evaluated, and
3 government representatives.
The main inclusion criterion for participating in this study was that interviewees had experience in the evaluation of PVE programs, either as evaluators or as participants in an evaluation process.
Study participants by function and country.
Source: Authors.
Three strategies were used to identify participants:
a review of authors of evaluations of PVE programs, based on two previous systematic reviews of primary/secondary and tertiary prevention programs (Hassan et al., 2021a; Hassan et al., 2021b);
consultation with experts to identify relevant participants; and
the mapping of Canadian prevention programs conducted by CPN-PREV (Hassan et al., 2021c).
The latter explains the overrepresentation of participants from Canada, as the original scope of the study was focused on that national context. Based on this information, a preliminary list of researchers, practitioners, and government representatives was compiled.
Data collection
Data were collected through semi-structured interviews conducted both in person and remotely, including two research visits to Europe (England, France, and Belgium). In total, 40 interviews and one focus group were conducted. All data were transcribed and anonymized.
Data analysis
The researchers and research assistants conducted a descriptive thematic analysis of the anonymized data using NVIVO software. This process followed three coding phases (Saldaña, 2013):
First phase (initial coding): Data were organized into thematic categories based on the initial research questions: (a) general description of evaluation methods and procedures, (b) lessons learned from evaluations, (c) challenges and facilitating or hindering factors, (d) identified needs, and (e) recommendations.
Second phase (focused coding): The general themes were further developed by reorganizing the data into more specific categories using in vivo open coding to capture participants’ perspectives. During this phase, part of the analysis focused on identifying emerging subthemes within each of the overarching categories in which participants expressed divergent positions vis-à-vis other evaluation actors regarding this process.
Integration: Conceptual categories were analyzed in relation to the study’s research objectives and conceptual framework. Through this integration, the main tensions surrounding the evaluation of such programs were identified. In relation to the objectives of this publication, the emerging divergent positions identified in the previous phase were regrouped, resulting in the main tensions surrounding the evaluation of this type of program.
This process therefore entailed a complementary twofold exercise: first, the deconstruction of the information derived from the interviews, and second, the reconstruction of models based on that information, one of whose core axes corresponds to these tensions.
Findings: Four points of tension in the assessment process
As mentioned in the “Method” section, the results presented below correspond to the third level of analysis and focus on the points of tension identified when actors from different fields and logics seek, with varying degrees of success, to align their professional interpretive frameworks around evaluation. Given that most of the interviews were conducted with researchers/evaluators and practitioners, the tensions presented below mainly reflect the perspectives of these actors. When the viewpoints of funders or public officials appear, they largely correspond to reconstructions based on the perspectives of the other two groups and will not be considered in depth.
Four main tensions emerge from the analyzed data: particularity versus harmonization, involvement versus independence, transparency versus confidentiality, and program evaluation versus practice evaluation. Each of these tensions represents a pair of oppositional concepts, whose extremes should be understood as theoretical poles rather than absolute realities. In other words, they function as reference points along a continuum on which actors tend to position themselves. However, it is necessary to define these poles in opposition to understand the challenges involved in the encounter between these fields.
Particularity versus harmonization
Evaluation is immersed in a complex dilemma arising from the tension between, on the one hand, the professional practice field, where a contextual-responsiveness frame tends to approach each case as a singular, tailor-made reality, emphasizing the moment of intervention and adaptation to the particularities of the context, and, on the other hand, the evaluation/research field, where a comparability-and-attribution frame drives research and evaluation teams to seek patterns within the data in order to develop a broader view of the program. As one practitioner clearly put it: The evaluation aspect of things is very numerical and it’s like very quantitative, but it doesn’t really take the qualitative aspect of things [. . .] I don’t think necessarily that evaluation translates or correlates to the amount of work being done, it doesn’t take into account that, for instance, like these outreach workers and clinicians that I work with are bending day-in, day-out, right? They are driving clients at 8:00 pm in the night, they are with family members, they are the first point of contact for emergencies, right? They’ve become more than just outreach workers and clinicians, they’ve become a part of. . .that family’s essential ecology. Right? So, is that translated into evaluation? I would say if it is qualitative, then yes, but if it is quantitative, then no.
We are thus faced with the classic dilemma between the particular and the general, stemming from the inherent differences between the fields in which these actors operate and the frames that organize what each field recognizes as credible and valuable evidence. What emerges is a confrontation between two opposing logics of legitimacy: practitioners ground their legitimacy in the ability to navigate uncertainty and adapt each intervention to shifting contexts and singular needs—a skill considered indispensable—while evaluators base their authority on the identification of general patterns through rigorous methods that ensure the validity and reliability of results. As one evaluator explained, for example:
Yes, and I think if I would do it again, that will be another question: if I am to do it again, I will really try to get a control group to really say conclusively this works, to really get a good design . . .
As the first excerpt suggests, however, this pursuit of rigor can appear disconnected from practice when everyday work is not captured by conventional quantitative indicators. More broadly, this is where the particularity versus harmonization tension becomes concrete, unfolding into sub-dilemmas between rigor and flexibility, and between comparable designs aimed at causal attribution—often invoking “gold standard” experimental or quasi-experimental models such as control groups—and more adaptive approaches oriented to contextual fit and practical feasibility. The experimental design based on control groups makes this distance especially visible because it embodies the harmonization logic and thus operationalizes in this case the evaluation/research field’s frame of credibility: it standardizes exposure, produces comparability, and supports attribution. A practitioner describes this issue as follows:
[. . .] we can’t really run experiments, that we can’t have Control groups, like Control groups during the same time period. One for ethical reasons, we don’t want to like. . . ok, we want to make sure that all at-risk users see the advertisement, we don’t want to control the amount of it.
From a practitioner standpoint, this ethical concern is both valid and even essential: Why should only one specific group benefit when the intervention could potentially help all users at risk? On the other hand, for the evaluator or researcher accustomed to strict quantitative paradigms, it is evident that without a comparison group, it is virtually impossible to effectively assess the specific effects of a program, since such a group allows for the control of external variables that could influence the results.
Evaluation, however, can also become a point of convergence, that is, a point of frame alignment, when it can respond to and adapt to this shifting environment: That means accepting flexibility, accepting that there is a back-and-forth throughout the research, and that the practitioner team and the researcher will sometimes, as I said, sort of “pause” the research to look at a certain number of things or a portion of preliminary results (evaluator—free translation from French).
This convergence also becomes evident when the methodologies and procedures adopted resemble everyday practice and consider the concrete particularities of the local context, thereby translating the evaluation/research field’s demands for credibility into procedures that remain intelligible and acceptable within the practice field’s frame of contextual responsiveness. An evaluator noted the following:
Yeah, I mean I’m a big supporter practitioner-friendly, simple, qualitative. . . Yes, soft in works, not technical, you know, hyper rigorous [. . .] if that framework is not like full of readymade tools, it is fine, as long as there is enough insistence in taking the time to look at the contexts . . .
Ultimately, when evaluation moves away from the “gold standard” and demonstrates greater flexibility, humanity, and closeness to what is local, specific, and dynamic, it becomes a genuine meeting ground between researchers and practitioners because it makes partial compatibility possible between two field-based frames of legitimacy. Considering this complex reality, a crucial question arises for those conducting evaluations: Should evaluation primarily and necessarily respond to the specific needs of the program being assessed, even at the risk of complicating comparison and limiting the utility and transferability of its results to other contexts? Or should it prioritize comparability through a harmonized approach that can be applied across various contexts, even if this means sacrificing the specific particularities of each situation?
An evaluator summed it up as follows:
[One barrier] we are trying to overcome with a project (. . .) [is] this assumption that every locality is different and you cannot really use one model, you cannot lie to another locality (. . .) The reality is if you work with the CVE preventors in these localities, you find a lot of similarities.
Involvement versus independence
This tension between particularity and harmonization leads to another fundamental issue related to the position occupied by the evaluator or researcher during the evaluation process—both in relation to the team implementing the evaluated program and to the funding body. In this context, the evaluator’s independence emerges as a key ethical principle, whose importance lies in ensuring an objective perspective or, at the very least, maintaining a proper critical distance from the program under analysis in line with an independence-and-critical-distance frame dominant in the evaluation field. As one evaluator noted: “I don’t know who is truly independent, but in any case, the goal is to be as independent as possible” (free translation from French). From this perspective, only an evaluation conducted by someone sufficiently independent and external to the program can safeguard against potential biases. Evaluator independence thus becomes a fundamental condition—indeed, a red line that must not be crossed in evaluation practice. Nevertheless, threats to this independence frequently arise in a domain that is subject to significant political pressures. One evaluator shared their experience in relation to a funding agency:
But we actually had a more difficult time [. . .] with our funders, because they kind of wanted us to keep some things out of the report because it would reflect poorly on some of their counterparts. And we made it clear that that’s the last thing we would do because it would amount to censorship.
Independence from the funder is generally valued by the interviewed actors, who consider any form of external interference in the evaluation process unacceptable. However, from the perspective of intervention, this independence can paradoxically produce a bias that limits the depth and reach of the evaluation. This limitation stems from the risk of adopting an excessively distant stance, overlooking the internal reality and operational particularities of the program being evaluated—a critique that reflects a proximity-and-situated-knowledge frame anchored in the practice field. One practitioner illustrates this issue clearly: To design an evaluation tool, you need to understand how the system works. Maybe what I’m saying goes against the norm, but I, for instance, wouldn’t go evaluate a bricklayer without knowing anything about masonry, or without understanding what they’re building, and for what purpose . . . (free translation from French).
From this point of view, a fully external perspective risks missing key elements related to the complexity inherent to professional practice field—complexity that arises precisely from its adaptation to the specific contexts of intervention. Thus, the kind of independence that is legitimate and necessary within the professional logic of the evaluation field may be perceived as a lack of legitimacy from the perspective of the practice domain, as it is disconnected from in-depth, on-the-ground knowledge and the real problems experienced in day-to-day implementation. In contrast, for professionals working within the program, an evaluation built from an internal perspective carries intrinsic legitimacy, as it is grounded in direct knowledge and lived field experience. One practitioner expresses it as follows when describing an internal evaluation process: Pretty good, because it was an internal process and we were a very small team of three or four people, you see. And so we were quite close, and really the approach was a shared one. That means I would explain my need. . . I would explain the kind of tool I wanted to develop to address that need, and then I’d ask them how they could contribute to it . . . (free translation from French)
This tension between independence and involvement helps to explain, at least in part, the mistrust that some practitioners express toward external researchers and evaluators, as well as the perceived gap between the two professional field. One evaluator explains: Yes, to some extent, and for some people it’s understandable, because unfortunately there are a lot of evaluations that. . . to be open, are not worth for. There are no recommendations. It is a like a “so what” [. . .], it did cost money and it did consume resources, and it might have distracted from the original mission. And at the end, some researchers write a report and then that’s it. The end of the story. So, people are right to be skeptical about evaluation.
This mistrust has direct implications for how the value of external evaluation is perceived. It is often seen as a secondary task, low in priority, and offering little tangible benefit to the day-to-day work of the professionals involved. Instead, it tends to be viewed as an added operational burden in contexts already marked by significant constraints on time, resources, and availability.
In response to this challenge, some researchers and evaluators seek to align these opposing frames, adopting the opposite stance, as one interview participant clearly stated: “building up trust with people is important before you can do anything . . ..” This trust requires going beyond the traditional external role of the evaluator, establishing direct relationships with the actors involved in everyday practice. That is, alignment in this case involves sacrificing an absolute form of independence in order to incorporate elements belonging to the practice field’s frame—proximity, direct knowledge, and so on. In this dimension, social competencies become critically important within the evaluation process, as another evaluator pointed out: “I know she is fantastic at networking, and maybe her more personal approach worked far better.”
As part of this frame alignment, the evaluation process is enriched through the establishment of an open and ongoing dialogue with all the actors involved, which makes it possible to obtain more authentic, accurate, and contextualized information. Some evaluators, for instance, choose to facilitate regular meetings and offer early feedback on preliminary findings, as one of them explained:
. . . we always had these 1 on 1 interviews but then we had a general meeting with everyone involved to share our findings. This was intended to show them that we were sharing with them and to give them the opportunity to call out mistakes.
In other cases, a direct involvement and a strong commitment to the people engaged in the evaluated practice is prioritized, as another interviewee clearly expressed:
and we accepted this challenge because at the end of the day we could have gone ahead and built this entire project without anybody’s input, that’s governments are like that; “just go ahead and develop a project and tell people to come to it” and I refuse to do that because ultimately if you want to develop a tool, I want it to be used by the people that I developed with and for. Because like you know teachers are inundated with big charades, and tools and how to do this and how to spot that, they don’t need another lecture, right? They don’t need another workshop, so yeah, so I think it was hard, but it was hard on purpose.
However, this strategy entails, as mentioned, partially sacrificing the evaluative independence that comes from the distance and neutrality associated with a fully external evaluation. Such an approach carries the risk of introducing certain biases that may affect the validity of the findings and, as a result, may not fully and fairly reflect the activities carried out within the evaluated program. Striking the right balance between these two dimensions is therefore extraordinarily complex, as another interviewed evaluator acknowledged:
Yes, may be clearly . . . be aware of the role that you have as a researcher, and that it is inevitable that in some way it will influence the results of the study if you do qualitative research, probably if you do quantitative as well if you work closely with the program workers. There is always going to be some kind . . . there will always be a tendency to uphold good communication with them and good relations while still aiming to be honest and critical and managing the balance between those two can be very tricky.
Program or practice evaluation
The second tension leads us to a third point of divergence, which emerges through two distinct conceptions of evaluation: on the one hand, program evaluation, and on the other, practice evaluation. Although it presents elements similar to the preceding tension, it is important to note that the divergence here does not primarily concern the evaluator’s relative distance from the program and its actors, which may (or may not), depending on the field position adopted, enable a judicious assessment of the program as a whole. Rather, it concerns what is considered the appropriate purpose of evaluation and the consequences that may follow: evaluating programs as an ensemble of organizational actions versus evaluating practice as situated professional work within the care relationship. A practitioner highlights this difference as follows: “I think there are several levels—evaluating programs, evaluating the practitioners or professionals who deliver the services and programs” (free translation from French.) Program evaluation thus represents the traditional frame of understanding evaluation, insofar as it seeks to assess the program as a whole, an approach that is coherent and legitimate within the professional field of researchers, evaluators, and, of course, funding bodies. However, an evaluation that does not address the everyday, routine practices carried out by practitioners can also be perceived as incomplete in the practice field: I think that shows a certain quality of support and a level of trust we were able to build with a setting (. . .) and to see that it had positive effects within that setting itself. I believe that if practitioners are not involved, it would be a shame not to find a way within the methodology to also include this kind of data, in order to assess not only the various impacts. (practitioner, free translation from French)
From the practitioner’s field, evaluation may therefore become more meaningful when it incorporates elements of practice evaluation, that is, when it does not only assess the program as a whole but also attends to the specificity and complexity of the care relationship and everyday work. This, however, can be extremely complex and time-consuming for an evaluator, while also potentially generating resistance from the practitioners themselves. One evaluator reflected on this:
Sure, well, I mean, innately with some people there was clearly some hesitance to speak with an outside party. It’s all very sensitive work, in general probation work, especially with these types of clients, so they didn’t want any outsiders looking on their fingers so to speak.
Evaluating practices also means evaluating the quality of the professional as an individual, and therefore, it can become a source of anxiety: I try to put myself in the shoes of those being evaluated; I can understand that there is a certain discomfort in being assessed, because, you know, even though we are professionals, this kind of work remains subjective (. . .) I can understand that some people might be afraid, thinking that the person themselves is being evaluated. (. . .) I think it can definitely be a source of anxiety. (practitioner, free translation from French)
Considering this tension, a related sub-dilemma arises: the evaluator is expected to manage two difficult-to-reconcile demands. On the one hand, they are asked to provide a detailed and close evaluation that enables an understanding of the specific reality of everyday work (practice evaluation); on the other, they are expected to maintain enough distance to avoid creating discomfort or anxiety among the professionals involved. This dilemma requires the evaluator to adopt a particularly reflective and sensitive stance toward the ethical and practical challenges posed by such evaluations. As one practitioner put it: “It seems to me that this is a process that can be quite emotionally taxing to go through, and so it demands a lot of delicacy and humility—that feels really important” (free translation from French). The demand expressed by this practitioner illustrates precisely the dilemma in which evaluators find themselves: they are being asked to perform two nearly opposing roles at the same time—that of an external, objective, and detached judge (typical of program evaluation), and that of a sensitive and supportive companion (typical of practice evaluation). This latter expectation is clearly reflected in a practitioner’s remark: “I think what would be relevant in the evaluation is to link it with some form of support.” (free translation from French).
Evaluation could thus end up becoming, unintentionally, a hybrid between a traditional evaluation function and a form of personalized clinical supervision. This contradiction clearly reflects how two distinct—even opposing—logics coexist within the evaluative field, highlighting why conducting evaluations in these contexts is especially complex.
Transparency vs confidentiality/trust/protection
The strength of an evaluation depends on the quality of the information collected and, crucially, on the level of access granted to it. While this criterion is fundamental to any evaluative exercise, it becomes far less evident in the field of preventing VE. Evaluators and researchers often lament the lack of primary data, the questionable quality of what is available, and the difficulties in accessing it. As one evaluator stated: “There is a desperate need for more data.” The highly sensitive nature of this subject—both from political and security perspectives—contributes to this scarcity. Another evaluator cautioned: “People . . . are sensitive about this topic.” This creates a tension between the demand for transparency and reliable data on the part of researchers and evaluators, and the need to protect such information by those responsible for its management. Here, the evaluation/research field’s transparency-and-accountability frame encounters an intervention-field protection frame, in which confidentiality, trust, and protection are understood as intertwined manifestations of an ethics of care and harm prevention. From the intervention field, this second pole takes on a different meaning, rooted in diametrically opposed concerns: data protection is about safeguarding the individual receiving support, and thereby preserving the care relationship based on mutual trust. From this standpoint, evaluation—with its constant demand for transparency—could be experienced as an ethical threat to the intervention process. The following practitioner illustrates this point in terms of threats to user confidentiality:
So, you know, for example, if I were to go on my balcony today and (. . .) [I] put up an Atomwaffen flag and start yelling like “sieg heil” and it made the news and I was charged for something and then I went in a CVE program in the city, when they were reporting that data it would probably be pretty clear to whoever was looking at it that it might be like, “Oh yeah, you know, that 27 year old guy from October 2018 is the person in this program”.
Thus, from the practitioner’s field, an evaluation that overlooks these elements entails a double risk. On the one hand, it threatens the care relationship by breaking the bond of trust that is essential to effective intervention; on the other, it can directly harm the individual involved. Stigmatization, in fact, constitutes a recurring challenge, as illustrated by the following observation:
Jack brought up privacy issues. That’s another huge one for us. Especially when we’re dealing with partnerships with different people, how important partnerships are. But then, the sharing of information is not always easy. That’s not necessarily part of the evaluation side of things, but it’s part of the challenge, I guess, in doing this kind of work. I can’t think of, well, there’s probably one worse label to give somebody than a terrorist.
Stigmatization, however, does not affect only individuals; it also extends to communities that have been subjected to discriminatory policies and practices simply by virtue of belonging to them—particularly Muslim communities in Western countries:
(. . .) here the challenge is that people are very very sensitive, even about terminologies, like the term radicalization, the perception about this term is exclusively used for Muslim communities, right? So, don’t even use the term, imagine the outcome of the evaluation, right? So, you have to be very very careful about the language and the terminologies and the way you prepare the narrative and the communication and the messaging so that when we have the outcome report, it doesn’t stigmatize any particular demographic or any particular race or gender or ethnicity.
Total transparency in evaluation methods and the detailed publication of results—pillars of the evaluator’s legitimacy frame—can paradoxically undermine the very efforts carried out during the intervention itself. Some actors therefore point to the need for a more context-sensitive form of transparency (e.g. careful language, narrative, and messaging) as a potential way of partially aligning evaluation requirements with the protection frame, especially when dissemination risks stigma or re-identification. The challenge, as in other dimensions, lies in bringing evaluation closer to the ethics of intervention—something practitioners describe as a more human practice. One evaluator summarized this tension as follows:
In this case, how do you avoid criminalizing, stigmatizing, putting people, clients as a guinea pig because it is easy to do that, and I think in our case we really grappled with that (. . .) the ethics of this is that, at the end of the day, we have to be mindful that we are working with people and our subjects are not the only people talking about, because everybody in the equation becomes a guinea pig and that is really hard.
Discussion
As noted previously in the evaluation literature, the findings show that evaluation is far from being a purely technical exercise; rather, it takes shape as a space of interaction where practical rationalities from different social fields converge—and often collide. This helps explain why what one actor considers relevant or necessary may appear secondary, or even problematic, to another. As illustrated in the findings, for instance, while an evaluator may require full access to information to ensure the validity of the analysis, a frontline professional might perceive that demand as a threat to the trust-based relationship with users. In this sense, evaluation cannot be conceived as a uniform or easily generalizable process, since each actor operates within specific interpretive and legitimacy frameworks shaped by their field of affiliation and professional trajectory.
These differences influence not only the content and design of the evaluation but also the very interpretation of its usefulness and legitimacy. Evaluation thus becomes a setting where we must negotiate not only methods and objectives but also preconceived notions about what evaluation is, what it is for, and which outcomes are valuable. In other words, it becomes a process of framing. One of our aims was precisely to identify forms of this framing process, particularly in terms of alignment. However, the findings allow us to address this objective unevenly. Where alignment appeared most clearly, it primarily took the form of adjustments driven by evaluators rather than reciprocal transformations among all actors. This was particularly evident in two cases. First, in the tension between particularity and harmonization, evaluators adapted methods and procedures to better match the contextual demands of the practice field. Second, in the tension between involvement and independence, they invested in relational work and trust-building to reduce skepticism while still maintaining a degree of critical distance. By contrast, in the tensions relating to transparency and protection, or to program and practice evaluation, alignment appears more as a possibility suggested by participants’ accounts or as an avenue to be explored than as a clearly observed empirical result. In that sense, our findings show more strongly the coexistence of divergent frames than the effective processes through which those frames become stably articulated.
Despite these uneven findings, the indications of alignment we identified suggest that this process of negotiation, more than the mere implementation of rigorous methodological protocols, influences whether an evaluation may be perceived as legitimate, relevant, and useful by the actors involved, and it provides clues as to how this process might unfold in some cases. Frame alignment, in this sense, does not occur spontaneously or automatically; it requires active work of mutual recognition and translation across professional languages. In this context, as Verwoerd et al. (2021) and Kunseler and Vasileiadou (2016) note, the evaluator assumes a key role as an intermediary, navigator, or interface between different fields and logics, so that evaluative logic becomes comprehensible, legitimate, and meaningful for actors operating with different interpretive frames. In our material, this “interface” role appears above all in concrete practices such as building trusting relationships, providing iterative feedback on results, or choosing methods that try to remain rigorous while still being acceptable to practitioners. Conversely, retreating exclusively into the logics of the methodological field may result in strong legitimacy within that field, but with limited resonance or practical relevance for those who implement or fund programs. In such cases, technique ceases to be a bridge and becomes a barrier. Translation, however, does not mean diluting methodological standards; rather, it involves intelligently adapting them to diverse contexts, so they do not become an obstacle to the framing process. The challenge for the evaluator is therefore considerable: they must perform this mediating role without losing sight of the minimum requirements of methodological quality.
The framing process may be facilitated by the gray areas created by actors’ and organizations’ multiple affiliations across social fields. This points to a limitation of the present analysis, which, as noted at the outset of the results section, emphasized theoretical poles rather than concrete realities. In practice, even when guided by a dominant field logic, actors and organizations cannot be understood as exclusive representatives of that logic. A single actor may simultaneously operate across multiple fields, as noted by Atkinson (2023), which creates the potential to articulate diverse—and at times even contradictory—frames. Many practitioners, for example, receive basic training in research and program evaluation, which can broaden their sensitivity to the rationalities and expectations of that field, fostering a certain permeability between approaches. Likewise, it is important to recognize that actors within the same field do not necessarily share homogeneous views on issues such as evaluation. This complexity is also reflected at the organizational level. A single institution can be shaped by—and even host—coexisting field logics. For instance, the administrative logic typical of funding bodies is also present in prevention programs, which must demonstrate efficient resource management. Many organizations working in the field of PVE also include a strong research component, which may make practitioners more attuned to the challenges posed by other professional approaches (Hassan et al., 2021c). Funders are not solely concerned with the efficient allocation of resources; they also seek effective public action that addresses the social problem of VE in a meaningful way. In this sense, conflicts do not arise from the actors or organizations themselves, but from the field logics that guide their practices and from the frames through which they view evaluation. As a result, tensions are not limited to interactions between different organizations or actors; they can also surface within a single institution attempting to conduct an internal evaluation.
One final aspect to consider is the specificity that program evaluation in the field of PVE acquires in comparison with evaluations conducted in other contexts. Many of the tensions previously discussed—such as the opposition between particularity and harmonization, or between evaluator independence and involvement—also appear in other types of evaluations (Faling et al., 2024). In this sense, the elements explored in this section can be considered relevant across a range of evaluative processes. However, the evaluation of PVE initiatives introduces certain nuances that, while not exclusive to this domain, tend to intensify conflicts that may be less decisive in other settings. For example, the dilemma between transparency and confidentiality takes on particular significance when evaluations involve sensitive data related to national security or the risk of further stigmatizing already vulnerable communities. Similarly, the need to preserve trust between practitioners and participants becomes especially delicate in environments shaped by processes of radicalization, suspicion, or state surveillance. These particularities do not preclude comparison with other evaluative contexts, but they do underscore the importance of approaching PVE program evaluation with a specific ethical and political sensitivity. This sensitivity must acknowledge both the common ground shared with other fields and the unique risks and challenges posed by this type of intervention. In this sense, rather than claiming absolute exceptionalism for PVE evaluation, the goal is to identify key tension points that can inform and guide more conscious and context-sensitive evaluation practices in this domain.
This study has several limitations that also point to relevant avenues for future research. A first key limitation concerns the composition of the sample, which overrepresents researchers and evaluators, while the perspectives of other central stakeholders—particularly government actors, funders, and program beneficiaries—are largely absent. In many cases, views on decision-makers had to be inferred from other participants’ accounts. More systematically incorporating these perspectives would be essential to identify additional forms of tension that emerge in evaluation processes and to better understand how such tensions are managed or remain unresolved.
A second major limitation relates to geographic scope. All participants were based in Western countries despite the fact that a substantial share of PVE programs and evaluations are implemented in non-Western contexts. Extending research beyond Western settings is therefore critical. In such contexts, tensions may be shaped by distinct institutional arrangements, power asymmetries, and local constraints. This is particularly relevant in regions such as Africa, where PVE initiatives often overlap with development and humanitarian programs and are largely funded by Western donors. Comparative research across national and regional contexts would allow for a more fine-grained understanding of how evaluative tensions emerge and are negotiated under different field configurations. 1 In addition, because most of the practitioners interviewed were based in Canada while many researchers and evaluators came from other countries, the study is better positioned to analyze perceived divergences between frames associated with different fields than to observe sustained processes of alignment in shared work settings.
Finally, as with all qualitative research, the findings are also shaped by the subjective interpretations of both participants and researchers. Nevertheless, the diversity of perspectives included allows for the identification of meaningful patterns in the tensions that structure evaluation processes. Future research would benefit from designs that observe evaluation in action—for example, through ethnographic or longitudinal approaches to multi-actor evaluative processes—which would make it possible to document more directly the interaction between frames, attempts at alignment, and also the dynamics of competition between fields.
Conclusion
This article aimed to analyze the tensions that arise from the coexistence of divergent professional logics in the evaluation of programs to prevent VE, as well as how actors manage these tensions and how they influence the perceived usefulness and legitimacy of evaluations. The findings were interpreted in light of Bourdieu’s field theory (1995) and frame analysis as developed by Goffman (1974) and Snow et al. (1986). The analysis highlights three main elements. First, four key tensions were identified, reflecting frictions between actors associated with the fields of action from which they interpret evaluation. Second, evaluation emerges not as a purely technical exercise, but as a relational process that requires coordination and negotiation among divergent perspectives. Third, while these divergences often generate persistent tensions, our material suggests that partial and uneven forms of articulation may sometimes be possible, most often through evaluator-led adjustments rather than reciprocal transformations among all parties. Finally, the evaluator may be called upon to act as an interface or translator across field logics, but this role is neither guaranteed nor cost-free, and it must be pursued without compromising independence or generating role confusion.
Footnotes
Ethical considerations
This study was approved by the Research Ethics Committee of the Faculty of Arts, Humanities and Social Sciences at the Université de Sherbrooke (ethical approval number: 2019-2381).
Consent to participate
Written informed consent was obtained from all participants involved in the study.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Community Resilience Fund of Public Safety Canada. The opinions expressed in this article are solely those of the authors and do not necessarily reflect those of the funding organizations.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.