
Abstract
This article evaluates whether we can use process-oriented theory to conduct comparative, historical social media research. There is a lack of theoretically informed approaches to studying recently digitized historical text with contemporary social media. This article argues that such perspectives are needed and extends Norbert Elias’ notions of ‘sociogenesis’ and ‘psychogenesis’ into data-driven research. Canonical process-oriented researchers such as Elias used mixed-methods approaches, including visual maps and quantitative surveys. By comparing 17th-century digitized diaries and 5 million digitized books from Google Books with contemporary tweet data, this study provides a successful case of comparing tweets with historical printed text at a big data scale. Moreover, quantitative methods are important to process-oriented methodologies and can be extended to big data empirical sources. An important finding is that there are similarities in the curation of everyday life in elite historical diaries and in more democratic forms of contemporary social media. Although accessibility and volume of content have changed over time from historical text to tweets, we found that there is a marked preference for certain words associated with communal sentiment over the centuries.
Keywords
Introduction
The use of new big data technologies has significantly contributed to computational innovations of social analyses of discourse. As Burgess and Matamoros-Fernández (2016: 5) argue, ‘plentiful traces [of …] rich, multimedia, social media data [are] opening up powerful new opportunities for digital media research’. Content analysis methods wherein word frequencies are studied to discuss patterns have potentially benefited from these types of methods. For scholars interested in historical corpora, digitalization projects have now enabled content analysis of historical text.
Until only recently, books from the 16th–19th century were not digitalized (Michel et al., 2011), and even if they were, it would have not been computationally possible to conduct quantitative analysis without supercomputer access. With the combination of accessible data collection methods and high-power processing within consumer-grade personal computers, new modes of large-scale content analysis have been made possible (Jacobs, 2009; Martin, 2012). Because more and more of our social communication is occurring within social media (Murthy, 2013), it makes it possible to compare historical and contemporary lexical patterns. The diverse and plentiful content in social media–Facebook updates, tweets, and check-ins–can be extracted and successfully compared to historical corpora.
There is an immediate sociological need for such comparisons. Specifically, social media writing continues to be marked in the popular press (and perhaps popular imagination) as a circus of emotions and an expression of some sort of degeneration into incivility and rudeness (CBS New York, 2013). 1 It is not uncommon to see journalists or cultural commentators’ remark on halcyon times prior to social media, where people pondered and reflected in their writing, as opposed to a culture of haste today which privileges sensationalizing over reflection. This has led some to ask whether social media has brought about ‘the end of reflection’ (Wayne, 2016). But how true is this? Indeed, it could be that even the most elite, reflective diary writers of the past share something in common with social media writers today. Forms of communication to document everyday experiences in a timely manner existed for centuries. Even 19th-century rural American diarists were writing entries on a daily basis (Motz, 1987).
Although the practice of autobiographical writing has varied over time, it, like other cultural practices, as Norbert Elias has argued, is part of a ‘process’ and ‘journey’, subject to continuities and discontinuities. However, it has traditionally been a challenge discerning textual continuities and discontinuities from one epoch to epoch. With large-scale digitalization projects, millions of historical volumes have been compared to discern macro-level ‘linguistic and cultural phenomena’ (Michel et al., 2011).
This article seeks to draw lines between historical and contemporary methods of recording everyday life–from the mundane to the remarkable. Diaries have historically been an important medium for this. Today, social media are increasingly used to document our everyday lives experiences. This study compares a sample of digitized historical diaries and tweets. This comparison allows us to not only innovate methods of comparing historical text with increasingly large volumes of contemporary social data but also provides new insights into the evolution of social communication over time. This provides us additional paths for shining light on contemporary, technologically mediated ‘curations’ of the self that are often considered ‘private and mundane practices’ (Berriman, 2014: 265). In addition, this approach allows us to examine whether egocentric publishing previously relegated to the elite are now manifested in more democratic publishing spaces.
This approach also provides mixed methods for others to emulate and extend this type of comparative, process-oriented mixed-methods historical work. Contemporary social media is not generally thought of as a media that can provide insights into larger sociohistorical trends. This article argues that we can directly benefit from studying social media and digitized historical text based on quantifiable linguistic patterns. In other words, this research uniquely provides evidence (along with novel methods) that we can successfully compare large corpora of contemporary social media and digitized historical text.
Ultimately, this study paves new directions in social media scholarship by arguing that understanding contemporary uses of social media can be benefited by historically informed comparative study. Findings such as the permanence of ‘good’ and ‘love’ in our everyday writing allow us not only to partially evaluate how much social communication has changed over time but also to trace continuities. Historically oriented approaches have been classically important to sociology, and this study specifically draws from Norbert Elias’ process-oriented approach that sees social production as part of an evolutionary process. By using data from the popular social media platform Twitter alongside Google n-gram data and a qualitative reading of digitalized 17th-century diaries, this article illustrates how our social communication has discursive similarities and differences over time.
A process-oriented approach to understanding tweets
Norbert Elias (1978) argues that social production is governed by an evolutionary process he terms ‘sociogenesis’. For Elias, sociogenesis tries to ‘balance choice and determinism or compulsion in the origins and development of concepts, social practices, and social structures’ (Dunning and Hughes, 2013: 81). Interrelated with these processes is his concept of ‘psychogenesis’, which involves psychological development and transformation, including personality and habitus (Elias, 1978; Sica, 1984). Put another way, psychogenesis reflects ‘what kind of person is produced by society’, and sociogenesis is a ‘reciprocal process by which individuals produce the society they wish to live in’ (Frank, 2010: 633). This reciprocal relationship means that sociogenesis and psychogenesis are, in many ways, two sides of the same coin. Fundamentally, this social/psychological framework is built around an understanding of the social as an understanding of relationships (Elias, 1978). Similarly, notions, such as power he argues, need to be understood from a relational perspective (Newton, 1999), and power is seen within a framework of power relations (Elias, 1978; Van Krieken, 1998).
Another aspect of Elias’ sociology is that he sees value in ‘trivial phenomena’. From his perspective, the trivial can produce insights into psychogenesis, the historical development of the psyche. Specifically, he has an interest in observing ‘affect control’ and ‘spheres of intimacy’ (Elias, 1978: 166) over time. This is useful for tracing links between notions such as shame and the banal. Elias was keen to understand norms, as evidenced by his work on manners. He was interested in the genesis of acceptable behavior. For example, Elias writes about ‘standard eating techniques in the Middle Ages’ and discerns a ‘structure of feeling’ and ‘an abundance of motivations and manners’ (Elias, 1978: 67). He also saw the construction of what is acceptable to be displayed publicly as part of a ‘sociohistorical process of centuries’ (Elias, 1978: 129). Moreover, from Elias’ point of view, this longue durée not only enables us to draw lines between norms today and in the past, but that it is important for us to do so. In the context of contemporary social media norms, understanding relevant sociohistorical processes is similarly fundamental.
One core contribution of Elias to sociology is his perspective of placing emphasis on the long-term changes in behavior, habitus, and power (a term also used by Bourdieu (1990) but somewhat differently). Scholarship on Twitter and social media more broadly lacks a long-term change model, instead usually focusing on analyses of relatively small segments of time ranging from several days to a year (e.g. Becker et al., 2011; Cheng et al., 2010; Davidov et al., 2010). From Elias’ (1978) perspective, sociality is an evolutionary process which is subject to histories of relations. Mennell and Goudsblom (in Elias and Stephen, 1998) observe that, for Elias, to understand social processes is to examine ‘very long-term processes’ that are continual. From a process-oriented perspective, the study of tweets should therefore be situated within these long-term processes.
This is not to say that Twitter is analogous to traditional diary writing per se. Specifically, everyday diary writing was elitist and private, while Twitter is relatively accessible and public. That being said, social media have not just sprung up. Part of their sociogenesis has involved sociohistorical processes that have involved people becoming more comfortable with sharing their personal thoughts in written form like diary writing did. Although diaries were historically shared posthumously, some diarists specifically wrote for an external audience, shared diaries with an intimate acquaintance, or designed them to be published while living (Steinitz, 2011: 81). Social media, on the other hand, is built for instant sharing. However, both involve documenting the mundane to the remarkable aspects of our everyday lives. A process-oriented view of social media does not focus on a finite start date per se but situates technological change as part of long-standing sociotechnical processes. These processes also have long-standing influences in terms of ‘psychogenesis’ or specifically our cognitive and emotional development as social media beings. Or reciprocally in terms of sociogenesis, we have–over time–produced a society that values public sharing of our everyday lives. For example, Lincoln and Robards (2017: 2) argue that Facebook ‘has become a key portal for users to document their everyday lives, and that their users were literally living out their lives on the site’. The goal is not simply to apply Elias in terms of a civilizing process but also to try to explore the journey of the process.
From this perspective, diary writing in previous epochs was part of a journey that included sociotechnical change such as the availability of accessible writing instrument technologies. In the same vein, contemporary tweets can be understood as connecting to historical strands originating in previous epochs. Ultimately, historical and contemporary media are relational. However, they do come from hugely varied social contexts, with early book publishing being the preserve of a homophilic elite and tweets representing a far greater socioeconomic diversity–perhaps serving as a somewhat democratic or, at least, everyday means of public communication.
Can we compare tweets with historical printed text?
Diaries and tweets are both life documents or as Plummer (2005) terms them ‘documents of life’. Contemporary social media, as Berriman (2014: 265) found, are used to document the ‘digital everyday’ and are often ‘mundane practices [… not] considered […] interesting enough to share with others’. Both types of media provide biographical insights into understanding individual stories and can be compared over the long term as part of a life document corpus. Some scholarship has begun to take a historical approach to studying Twitter data. Besides historically inspired theoretical accounts of Twitter (Murthy, 2012; Shoemaker and Reese, 2013; Standage, 2013), Humphreys et al. (2013) were the first to seriously explore Twitter data within a meaningful, historically informed context. Their study developed a coding scheme for tweets inspired from 18th- to 19th-century diaries and compared them to a random sample of tweets. They discovered that diaries during this time period ‘demonstrate remarkable resemblance to microblogs’ (Humphreys et al., 2013: 414) and that historical diarists shared mundane thoughts about their everyday lives, such as who they had visited, where they had been that day, and what they had done. Portable diaries were a transformative technological innovation in the 18th and 19th centuries. As Figure 1 illustrates, it is the ability to be ‘readily carried in the waistcoat pocket or purse’ (The Advancement of Learning, 1881: 1140) that changed the medium. Humphreys et al. (2013) argue that this sociotechnical change led to many short diary entries (akin to tweets).

De La Rue’s portable ‘Indelible Diary’ (The Advancement of Learning, 1881: 1140).
Some of the earliest diary entries found on Google Books (published in the 16th and 17th centuries) were more varied in length, given that they were written at a desk (usually at home). However, there are also many examples of short entries, even regarding major events. For example, the Bishop of London’s diary for 1632 had an entry on 11 February: ‘Monday night till Tuesday morning the great Fire upon London-Bridg [sic], Many Houses [sic] burnt down’ (Rushworth, 1680: 140).
The Google n-grams database derived from approximately 5 million books has been used widely in academic research (Graham et al., 2015), spawned by Michel et al.’s (2011) development of the field of ‘Culturomics’, ‘the application of high-throughput data collection and analysis to the study of human culture’. N-grams have been used widely to study patterns in large corpora of tweets (Barbosa and Feng, 2010; Ghiassi et al., 2013; Pak and Paroubek, 2010). Google’s n-grams have also been used to determine common words in published books within subject domains, and tweet corpora frequency has been studied for these selected n-grams (Uren and Dadzie, 2011).
Twitter has been compared with social communication in relation to early communication technologies such as the telegraph and telegram (Murthy, 2013; Silverman, 2010; Standage, 2013). This literature argues that modern social media forms such as Twitter should be understood within the context of historical broadcasting technologies that also ‘enable[d] the recursive exchange of information between humans in social relations’ (Fuchs, 2013: 43). Therefore, although comparative studies of tweets and historical text are emerging, there is a basis in the literature for further work in this area.
Methods
The largest book digitization project is Google Books with over 25 million volumes (Heyman, 2015). A byproduct of Google Books has been the extraction of n-grams, a ‘tuple of n words’ (Lakemeyer and Nebel, 2003: 276). More simply, an n-gram represents a sequence of n number of words (i.e. a unigram is one word, bigram is two words in sequence, and trigram is three words in sequence). The Google n-gram database specifically contains n-grams for words or phrases that have been derived from approximately 5 million published books from the 17th to 21st century. The Google n-gram database contains frequency counts for particular words or exact sequences of words from all books that have been scanned and contain character recognition. It works by users submitting queries to the database specifying a date range and word(s). The Google n-gram interface returns counts for these words by the specified time period. A limitation of the sample is that it only contains books selected by the Google Books digitization criteria (Graham et al., 2015: 10–12).
Because the Google n-gram data sets have been made public, social researchers have been able to develop and innovate their research methods and to compare historical data with contemporary forms of digitalized data. There is an established literature for using Google n-grams to inform studies of Twitter data. For example, Uren and Dadzie (2011) used Google n-grams as a baseline sample to discern scientific word frequency and compared this to collected English-language tweet data. Uren and Dadzie (2011) also found that scientific words that had multiple meanings, like ‘permafrost’, referred to coldness in general or to cultural products (e.g. a gaming server and designer iPhone case). Part of comparing tweets to Google n-grams involves scaling. Specifically, the raw frequency (sum) of tweets is going to be much higher than published books. Therefore, we need to compare relative proportions. This is something Gupta and Manning (2014) specifically did in terms of proportionately scaling tweet frequency to the frequency of unigrams (single words) in Google n-grams.
Twitter provides an Application Programming Interface (API) that allows for the collection of approximately 1% of all global tweets at any given time, known as Twitter’s Spritzer stream. For this study, 235 million tweets were collected from Twitter’s Streaming API between June and July 2013, with approximately 5 million tweets collected per day (Murthy and Bowman, 2014). These data were not restricted to any specific geographical location given known limitations with Twitter’s geolocated sample (i.e. generally less than 1% of tweets contain ‘structured geolocation information’ (Graham et al., 2014: 570)). N-gram frequency was calculated using the open-source statistical package, R. Basic bar charts, not entirely dissimilar to what is used by Google themselves in their n-gram platform, were used to visually compare Google n-gram frequency and tweet n-gram frequency.
The rationale for this approach was to start with diaries at the earliest time period available on Google Books in order to trace linguistic continuities and discontinuities. Although diaries from the 16th century were available, there were only a couple with optical character recognition applied to the digitized format and thus available in Google n-grams. This study therefore begins with the 17th-century text available in Google n-grams. For the sample of 17th-century diaries, Google Books was used to locate fully searchable English-language books with the keyword ‘diary’ from the 17th century. Results were filtered to only documents with full-text searchability. These search criteria yielded 40 results, given the scarcity of searchable 17th-century text. Of these, 18 were duplicates or not diaries or did not make any mention of any diary entries, resulting in a sample of 22. Although selected books did not have to be a diary to be included, they had to include text from at least one diary entry, though most had much more than that. A grounded theory approach (Strauss and Corbin, 1997) was used to identify common themes in documenting the everyday and what words were associated with these thematic areas. These word lists provided the basis for the selection criteria for the Google n-gram queries in Research Question 2 (see RQ2 in the following section).
Limitations
It should be noted that these diarists represent highly elite individuals like Samuel Pepys. The diaries of more ordinary individuals of this time are quite inaccessible compared to those from the 18th and 19th centuries. Graham et al. (2015: 10) argue that a limitation of the Google n-gram tool is that it ‘may only capture elite culture before the advent of accessible popular publishing’. The sample of diaries studied are majority British. 2 A technical limitation of the n-gram database is that, like all book digitization projects, poor optical character recognition can lead to pages of books or even entire volumes to not be machine readable (Graham et al., 2015: 10). That being said, an enormous corpus of machine-readable text was produced and outweighs optical character recognition limitations.
Another limitation of this study is that tweets generated by anyone (a varied demographic) are being compared to another medium (written diaries by elite individuals). Or put more generally, ‘Google NGrams may not be an ideal baseline for Twitter studies as it is known that social media differ in coverage from edited media’ (Uren and Dadzie, 2011). In addition, the diary writers being studied were British. Twitter users tweeting in English are, by far, not all native English speakers, nor British.
Research questions
The hypothesis of this study is that corpora of digitized historical text have some resemblance, connection, similarity or parallels with contemporary social media content. This draws from recent work that has found that communication on social media can be meaningfully compared with historical text (Humphreys et al., 2013; Wolf, 2015) and that quantitative methods of linguistic content analysis across multiple centuries of digitized text can be undertaken successfully (Michel et al., 2011).
RQ1. What types of content–including specific words, phrases, and thematic categories–were favored by historical diary writers to document everyday life? Diaries are designed to document everyday lived experiences from an ‘ego’ perspective. Do we see any patterns within the sample of digitized diaries with full optical character recognition in terms of word choice or topic areas? In addition, do historical diaries share any qualitative resemblance to tweets?
RQ2. Do historical printed books have similarities–in terms of word and phrases–with contemporary tweets? Digitized books (not broken down by any subject category) provide some reflection of dominant culture at the time (Michel et al., 2011). Of course, books are biased toward more elite writers. 3 Twitter users are far more diverse, although biases do exist in the user population (Blank, 2016; Sloan et al., 2015). Despite the large-scale demographic differences of these media, are there similarities and some of the types of words and phrases these two media have employed? Can we discern persistence of psychosocial themes (e.g. communal or agentic sentiment)?
Results
Lexical and thematic patterns in historical diaries (RQ1)
As mentioned previously, the 17th century is the earliest in terms of n-gram data that provides a sufficient sample of published books. In the case of the Google n-gram data, word and phrase usage in books published in the 17th century (vs the 18th, 19th, or 20th century) also reveals distinct lexical patterns (e.g. the use of the word ‘day’). Most historians have argued that the control of book publishing by the church and monarchy directly supported themes of love of God and King in printed matter of the time (Robertson, 2009). Dissenters in England were regularly fined or jailed. For example, Thomas Delaune (1684) and his family (wife and two kids) died in jail after he published A Plea for the Non-Conformists. A major agenda behind this was to combat fervent revolutionary sentiment of the time; 17th-century England (the Stuart dynasty) was the time of the Civil War and Revolution (1603–1714).
Before empirically comparing tweets and historical text, it was important to first get a qualitative feel of 17th-century text using a grounded theory approach (Glaser, 1998) to understand what themes and trends were prevalent. Diaries of the time–rather than the large and varied corpus of digitized 17th-century text–were studied. Indeed, part of the rationale for the Library of Congress to archive tweets was that they felt ‘Twitter forms part of the historical record of communication’, akin to historical personal letters and diaries (Campbell and Dulabahn, 2010: 275).
Of course, published 17th-century diaries do differ from tweets. Specifically, published diary writers of the time were elites and usually well known and either part of/well connected to the church and/or monarchy. For example, the Minister of Parliament Samuel Pepys (1898 [1660]) kept a diary which has become well known. Pepys makes clear his commitment to both church and monarchy in his diary. The digitally searchable part of his diary has 15 mentions of the word ‘love’. Most of these references regard ‘love and loyalty’ of the King to his subjects or the ‘Lord’s love’. Only one reference is of his wife’s love to him (‘While we were at play Mr. Cook brings me word of my wife [… and she] speaks very well of her love to me’ (Pepys, 1898 [1660]: 123)). There is only one mention of hate (in reference to Sir W. Pen about whom Pepys says, ‘I hate with all my heart for his base treacherous tricks’. In terms of gender, ‘him’ is mentioned over 100 times and ‘her’ is mentioned 79 times. Unsurprisingly, with a diary, I is mentioned over 100 times and you is mentioned 19 times (a difference of fivefold). Particularly striking is the difference in frequency in Pepys’ diary of the words ‘good’ and ‘bad’. The former occurs 86 times, while the latter occurs only 9 times. Crudely measured, Pepys is more than nine times more optimistic than he is pessimistic. Indeed, the majority of instances referring to ‘bad’ were in regard to bad weather.
Edmund Trench’s (1693) diary, on the other hand, is more personal and resembles the candid nature of tweets much more. He often discusses his daily happenings or health. For example, in an entry on 20 November 1684, Trench (1693: 65) writes, ‘my body had continued very crazy, Lungs sensibly heated and swell’d [sic] by the Catarrh’, and he goes on to say how his friends encouraged him to take the medicine he was prescribed, a ‘Milk variously prepar’d and mixt’ in a ‘strange’ manner. In the context of tweets, people often talk about their health (Murthy and Eldredge, 2016), and it is important to draw a line to historical instances of this. Indeed, the medical literature has argued that tweets can be read as a medical diary (Hemsley and Palmer, 2016; Parsons et al., 2015), potentially providing physicians with more accurate representations of patients’ health behaviors than their accounts in a doctor’s office. The diary of Lord Harrington (Fuller, 1684) offers many glimpses into his personal life. Harrington used his diary to ‘register his daily failings’, which, from his perspective, included being the unmarried last male of his ‘Honourable Family’ (Fuller, 1684: 835).
The diary of George Fox et al. (1832 [1694]) is typical of 17th-century English diaries in its references to church and monarchy. There are more than 100 mentions of the terms God and King in his diary. Interestingly, unlike Pepys’ diary, ‘I’ and ‘you’ are both mentioned more than 100 times. However, this is due to the fact that ‘you’ is used in the context of imploring one to follow God and Christian biblical teachings. Bad was mentioned 42 times and good was mentioned over 100 times. Although Fox’s diary entries often speak about religion, many entries chronicle everyday aspects of his life. For example, an entry from 1662 reads, ‘I staid [sic] not long at this time in London, but went into Essex, and so into the east, and to Norfolk, having great meetings’ (Fox et al., 1832 [1694]: 12). Like contemporary tweets, he chronicles what disturbed him during his daily life. An entry from 1663 reads, ‘Then leaving Tenterden we […] passed on through the country visiting friends and having great meetings, and all quiet and free from disturbance (except by some jangling baptists)’ (Fox et al., 1832 [1694]: 14; my emphasis). The trite reference to ‘jangling baptists’ bears strong resemblance to the types of tone seen in tweets–albeit with a different word choice.
The diary for the Archbishop of Canterbury in 1636 (Rushworth, 1680) includes many short entries, which describe the Archbishop’s musings and what he did that day. For example, his entry for 19 August 1636 read, ‘I was in great hazard of breaking my Right-Leg’ (Rushworth, 1680: 319). And a remarkably candid entry for 31 August 1636 read, ‘I dreamed marvelously that the King was offended with me, and would cast me off, and tell me no cause why’ (Rushworth, 1680: 319). Indeed, the Archbishop’s diary contained several entries regarding dreams. Many entries matter-of-factly conveyed who he had preached to, who had died, or where he had traveled to.
The diary of Philip Henry (Henry and Bates, 1797) resembled other diaries of the time, in that many entries were about religious conviction. In his cited diary entries, heaven is mentioned 36 times, hell is mentioned 3 times, good is mentioned over 100 times, bad is mentioned 13 times, evil is mentioned 19 times, and fear is mentioned 27 times. However, his diary also mentions more ‘banal’ occurrences such as workmen beginning the building of his house in 1657 (Henry and Bates, 1797: 23). The 17th-century books–even if they were diaries–reflected the dominant, patriarchal structure of English society and staunchly upheld the normative positions of the church and monarchy. Indeed, as Azman et al. (2010) note, contemporary social media is more like pamphleteering in the 17th century rather than books given the institutional stronghold the church and monarchy had over book publishing at the time. Or in sociological terms, print media content was part of larger macro-social structures dominated by church and monarchy. Indeed, William Caxton, thought to be the ‘founding father of English printing’, depended on the patronage of the ‘nobility and court of Edward IV’, and he printed ‘many volumes of the romances and poetry [… for the] literary amusement at the courts of Edward IV and Richard III’ (Feather, 2006: 15–16). Ultimately, this study finds that these types of everyday updates of daily life in 17th-century diary entries are akin to tweeting behaviors. Furthermore, there is evidence of lexical patterns among historical diarists–such as references to God, health, monarchy, family, and morality.
Comparing digitized historical text and tweets (RQ2)
Diary entries published in the 17th century studied in RQ1 cover a broad range of themes, including religion, politics, and daily life (what one had to eat or how one slept) (Pepys, 1898 [1660]; Woodforde and Beresford, 1999). One way to group these themes was through what social psychology refers to as differences between the use of ‘agentic’ and ‘communal’ words (Campbell et al., 2007). The former refers to more egocentric lexical choice (e.g., I and me), while the latter refers to more socially, communally geared words (e.g. they and you). English-language books published in the 17th century had new, distinctly creative linguistic uses of English (Bailey, 1992 [1991]). Although figures in this section do contain agentic and communal n-grams, the n-grams chosen to be studied were derived from the qualitative analysis of the selected 17th-century diaries.
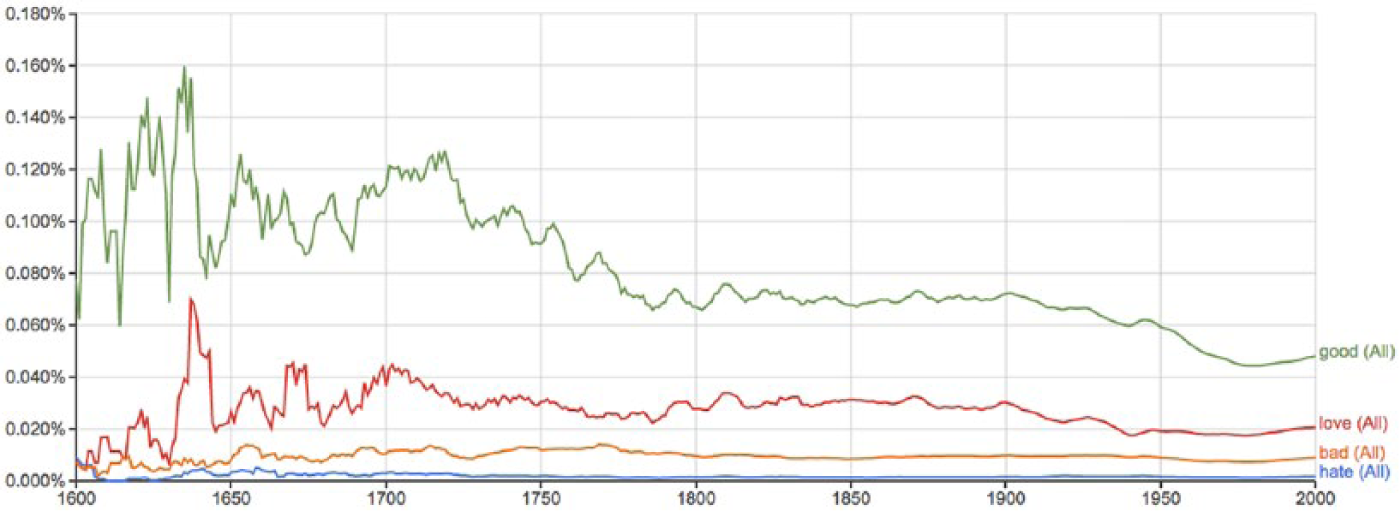
Using the lists of words derived from the 17th-century diaries in RQ1, the majority of English-language tweets with the word ‘lord’ refer to religion. However, the majority of tweets with the word ‘King’ refer to Michael Jackson (an effect of the data collection period) and are not royalty-related. What is interesting from these results is that the word ‘God’ is most frequent in the 17th-century text, as well as among the selected keywords in tweets. Of course, tweets with the word God are not, like the 17th century, usually religious (i.e. ‘oh my god’). However, it is interesting to see the continuity of certain words regardless of the–in this case, religious–disassociation of historical context. The use of God in Google’s n-gram corpus was also studied by Michel et al. (2011), who charted a steady decline in its usage since the 19th century (Figure 2 illustrates the same Google n-gram data they used). This highlights a particular linguistic journey attributable to both sociogenesis and psychogenesis, wherein changing attitudes to religion, for example, are part of a long-term historical evolution. Specifically, Elias saw broad social changes (i.e. the relationship between sociogenesis and psychogenesis) influencing the development of individual psychological outlooks. The decline of religion’s social influence therefore produces certain types of individual psychological outlooks (as part of psychogenesis) that can be collectively seen in this aggregation of individual tweeting patterns.
Google n-gram data. Interactive version available online. 4
But, interestingly, a key aspect of these results is a positivity both among historical diarists and contemporary Twitter users. In other words, social media are not generally a space of negativity as some popular press accounts argue (e.g. Woo, 2016). N-grams such as ‘love’ have historically been associated with feelings of communality, and terms such as ‘bad’ and ‘good’ have historically reflected negative and positive valences (Campbell et al., 2007). In the 17th century, as Figure 2 illustrates, good, love, bad, and hate are the most frequent in published books in that order. Figure 3 illustrates the frequency of these words in tweets. Interestingly, both the communal pair (love and good) and the negative valence pair (hate and bad) are flipped in frequency in the Google n-gram data (i.e. good is more frequent than love and bad more frequent than hate). Of note, in the Google n-gram data is that all four n-grams remain in the same rank and frequency for over 400 years (see Figure 2). However, this does not inherently indicate fundamental differences between the media of published books (rather than just diaries) and tweets. In the case of the word ‘love’, many tweets use the term sarcastically, highlighting some limitations of this method and similar quantitative methods (Bifet and Frank, 2010; Thelwall et al., 2011).
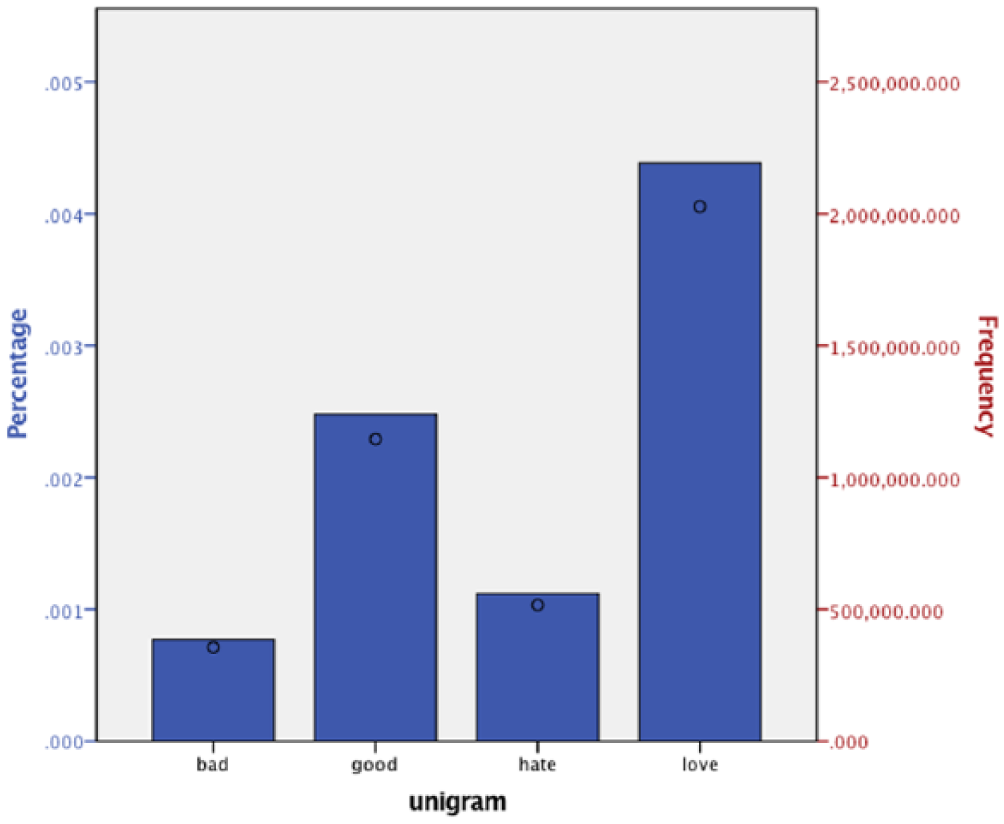
Mentions in collected Twitter data (by %). Circles represent frequency.
These results emphasize that comparing historical n-grams with contemporary tweet data also enables us to observe potential patterns of social solidarity, communality, and optimism. Seventeenth-century diary writers did have particularly optimistic worldviews and communal feelings, and there is some of this sentiment reflected in tweets today. These findings indicate both a historical positivity and a critique of overarching outlooks that frame social media as a dystopic space of depravity.
As Figure 4 indicates, ‘I’ was the most frequently used word in the 17th-century corpus of selected n-grams. This trend continues to the 21st century with usage starting to spike in the late 20th century. Again, popular accounts of social media position these platforms as overly egocentric. However, if we think of tweets as contemporary forms of autobiographical writing, the use of words such as ‘I’ was similarly employed among early diarists. Tweet n-gram frequencies (see Figure 5) and 21st-century Google n-gram frequencies (see Figure 4) have the same order of frequency. However, 17th-century n-grams are messier, with ‘you’ and ‘her’ changing places as the second most frequent at various times in the century. ‘Him’ also spikes in the earlier part of the 17th century.
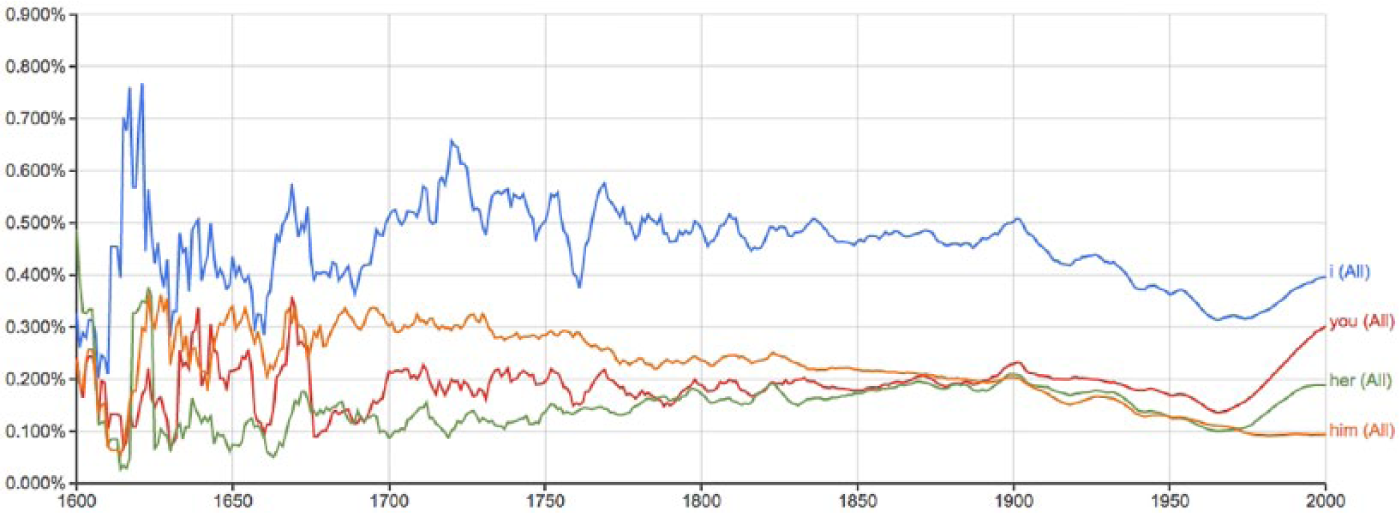
Google n-gram data. Interactive version available online. 5
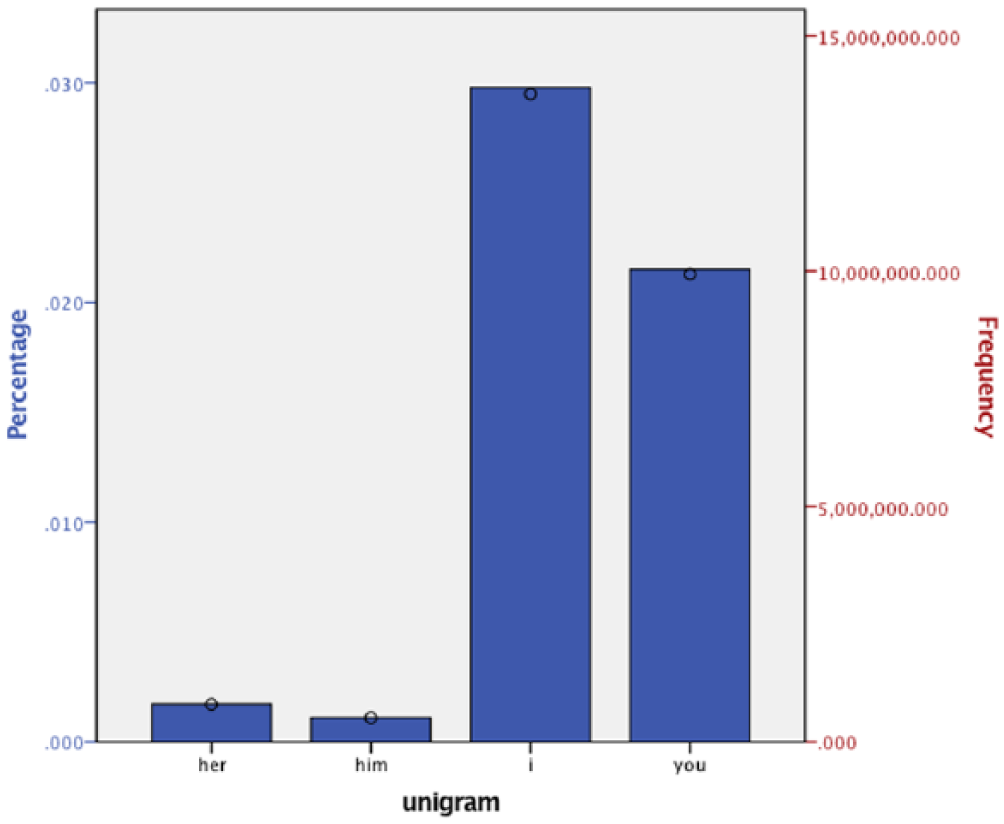
Mentions in collected Twitter data (by %). Circles represent frequency.
The high frequency of her is noteworthy as it reflects patriarchal social relations and the construction of women as needing salvation for their sins (Fletcher, 1995) or frail, as exemplified by frequent medical diagnoses of women as having ‘chlorosis’–a broad ranging condition encompassing headaches, anxiety, depression, body image issues, breathing difficulties, and insomnia (Perlick and Silverstein, 1994). Indeed, 17th-century women diarists were encouraged to write about their need for salvation, and diary writing was seen as ‘the core of a godly woman’s life’ (Fletcher, 1995: 354). In comparison, contemporary social media practices, though gendered (e.g. Pinterest), are not generally ascribed with such glowingly positive attributes.
Specifically, as Figure 6 illustrates, tweets have a preference toward mentioning ‘today’ rather than ‘time’ or ‘day’, whereas Figure 7 illustrates how books are less focused on the moment. Book publishing is, of course, far more reflective than the contemporaneous nature of tweets. However, it is important to see this in empirical data. Given that more and more social communication is taking place in social media, to see just how much ‘today’ has become important is fascinating. In the n-gram data in Figure 7, we see today just beginning to take off at the turn of the 20th century, making it a relatively modern temporal concept in the published text. This is important as it highlights how the accessibility of technology to talk about contemporaneous experiences, thoughts, and feelings has transformed our ability to publicly broadcast in the moment. This temporal argument is important in terms of what it may be indicating. Like all mediated communication, tweets are not de facto reflective but reflect perceptions. For example, Scannell (1989: 334) in his work on broadcasting argues that ‘It is not a reflection, a mirror of reality outside and beyond. It is one fundamental, scene, but, I noticed, constitutive component of contemporary reality for all’. Following Scannell, tweets are part of a ‘contemporary reality for all’, and they increasingly reflect a reality embedded in the present.
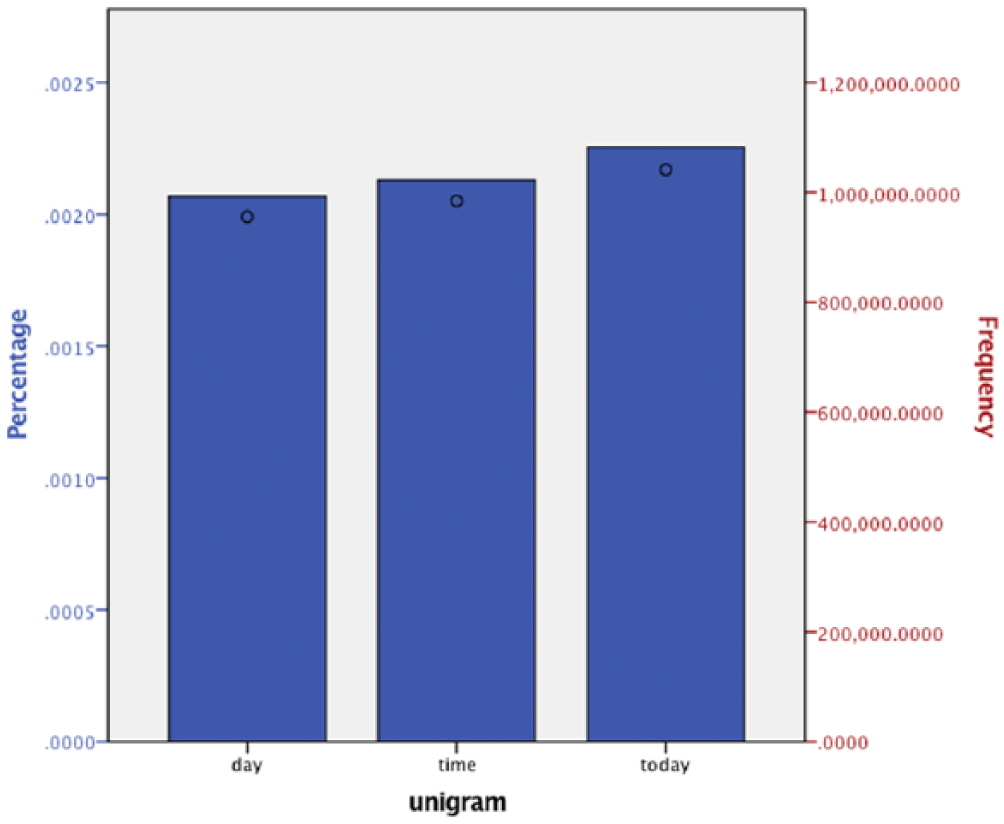
Mentions in collected Twitter data (by %). Circles represent frequency.
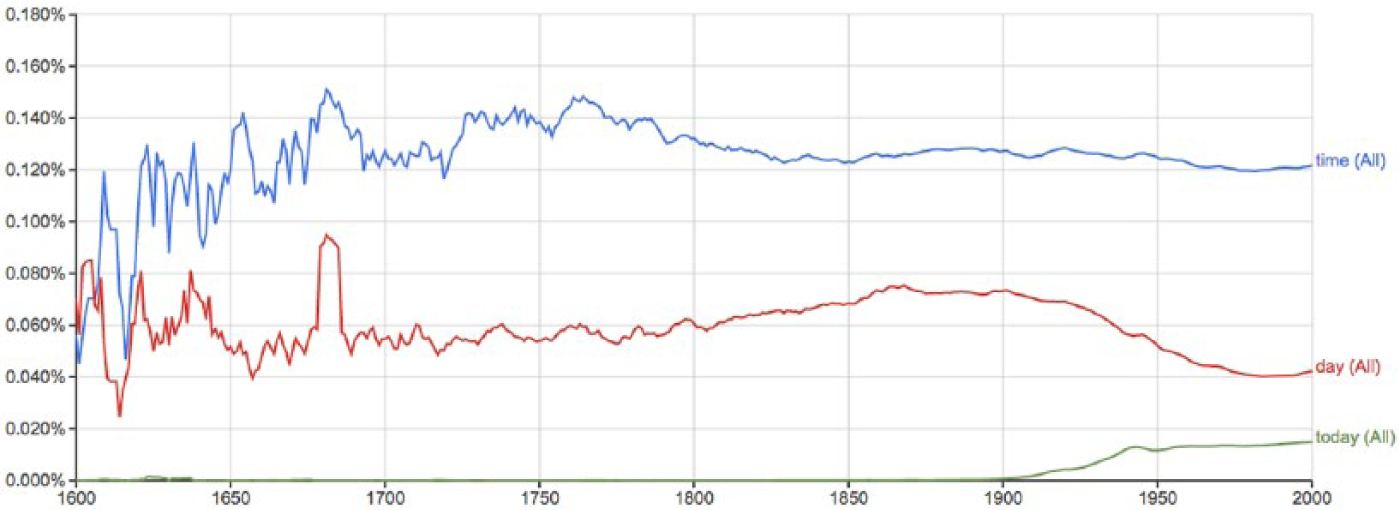
Google n-gram data. Interactive version available online. 6
Although a departure from studying n-grams common in 17th-century diaries, three popular trigrams (three word phrases or n-gram = 3) in tweets were compared between Google n-gram and tweet data. As Figure 8 illustrates, the three n-grams remain virtually nonexistent in the 17th century and only began gaining popularity in the mid-19th century (around 1850). The trigrams ‘If you want’, ‘I want to’, and ‘I love you’ are some of the most popular phrases in tweets today (Murthy, 2015) and their frequency is illustrated in Figure 9. This selection of n-grams provides evidence of how tweets display both strong communal feelings (e.g. ‘I love you’ and ‘if you want’) as well as agentic feelings (‘I want to’). Also, 17th-century expressions of love are far subtler. Recall Pepys’ diary entry mentioned previously, which refers to a third party conveying to Pepys his wife’s love (Pepys, 1898 [1660]), compared to the strong, direct nature of tweets (e.g. ‘OMG I love u 4 ever!!!!!!!’). Although this is just one set of observations, we can use such comparisons to ask questions of how, for example, expressing love might have changed from being communicated through an intermediary (in the case of Pepys) to direct communication (in the case of contemporary social media).
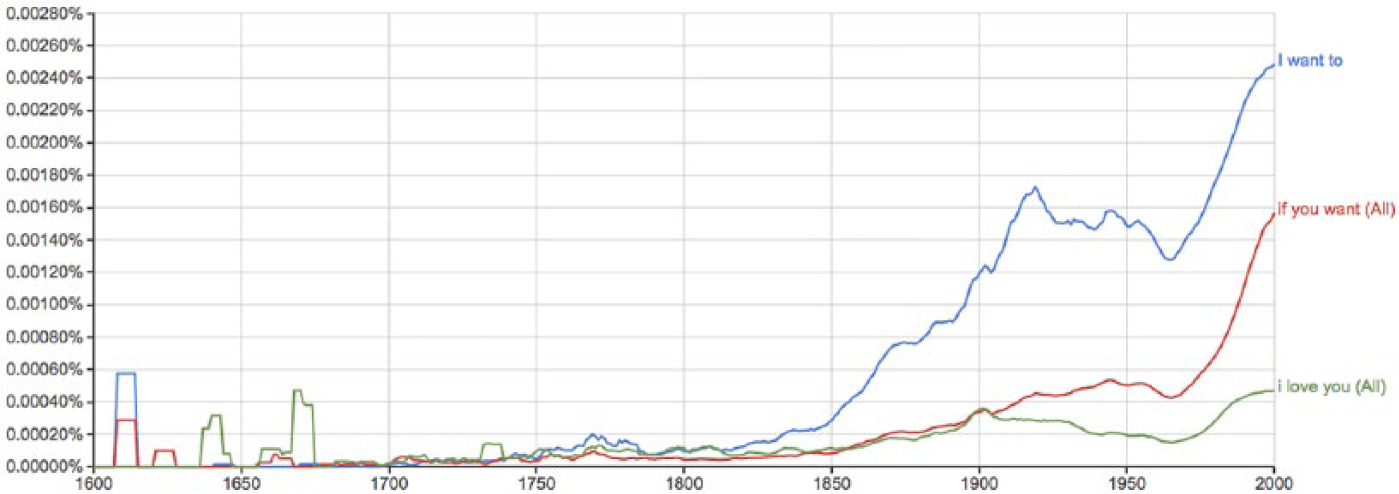
Google n-gram data. Interactive version available online. 7
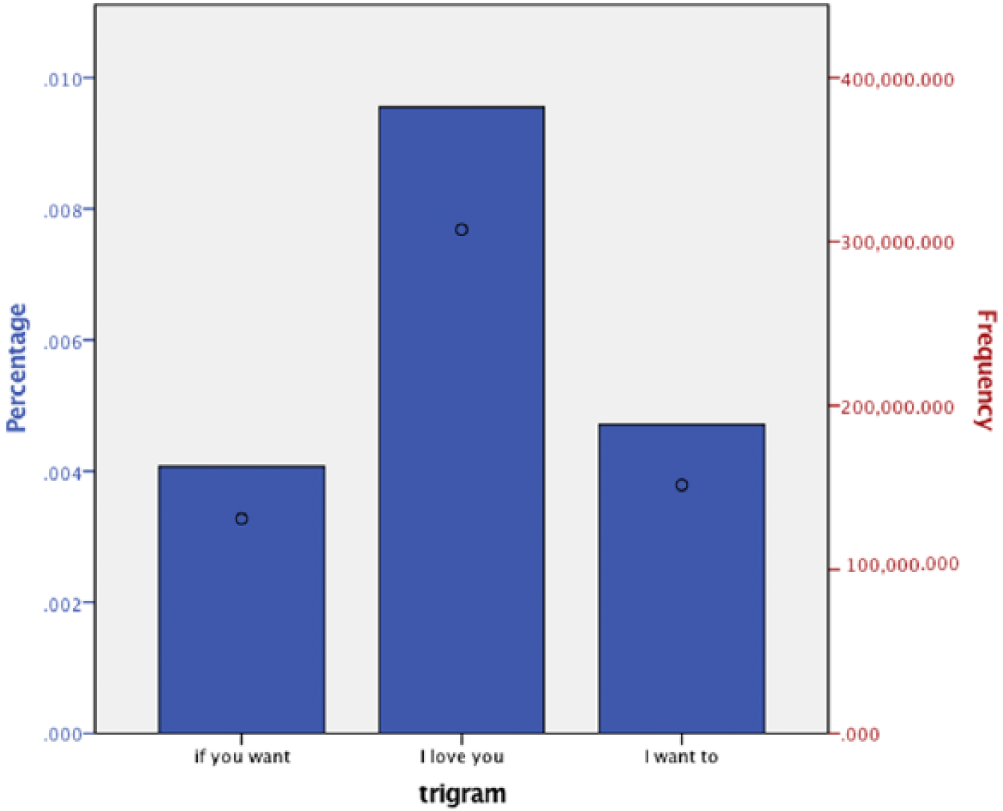
Mentions in collected Twitter data (by %). Circles represent frequency.
Figures 10 and 11 include many of the religiously oriented terms common in the studied 17th-century diary entries. God was only used in religious contexts in the 17th-century diary entries. Although the Archbishop of Canterbury is particularly interested in recording dreams, many other diarists discuss dreams in their diaries as well. Indeed, dream talk provided a sanctioned outlet in the 17th century for the exposure of anxieties, desires and fears (Sleeper-Smith, 1993). Interestingly, dream, hell, and heaven were all n-grams with the lowest frequency in Google n-grams data (see Figure 10), but hell, and dream are relatively frequent in tweets (see Figure 11). This difference, highlighted in Figure 10, alongside the qualitative study of historical diaries reveals that 17th-century diarists, in some ways, resembled tweeters today more than other writers of their time in terms of the frequency of these specific n-grams. The majority of tweets containing lord are related to religion (with most non-religious tweets referring to Lord of the Rings). This could be due to some strand of an identifiable notion of Christian religiosity that is traceable to 17th-century diarists, printed books, and tweets today. Viewing these results through the prism of Elias’ notions of sociogenesis and psychogenesis, we are able to see the development of conscience and habitus, following Mennell (2015), as long-term processes. These results importantly highlight that identifying meaningful historical strands is important to more comprehensive readings of contemporary social media. Furthermore, our results affirm RQ2, highlighting the existence of patterns, strands, and similarities between digitized historical text and contemporary social media.
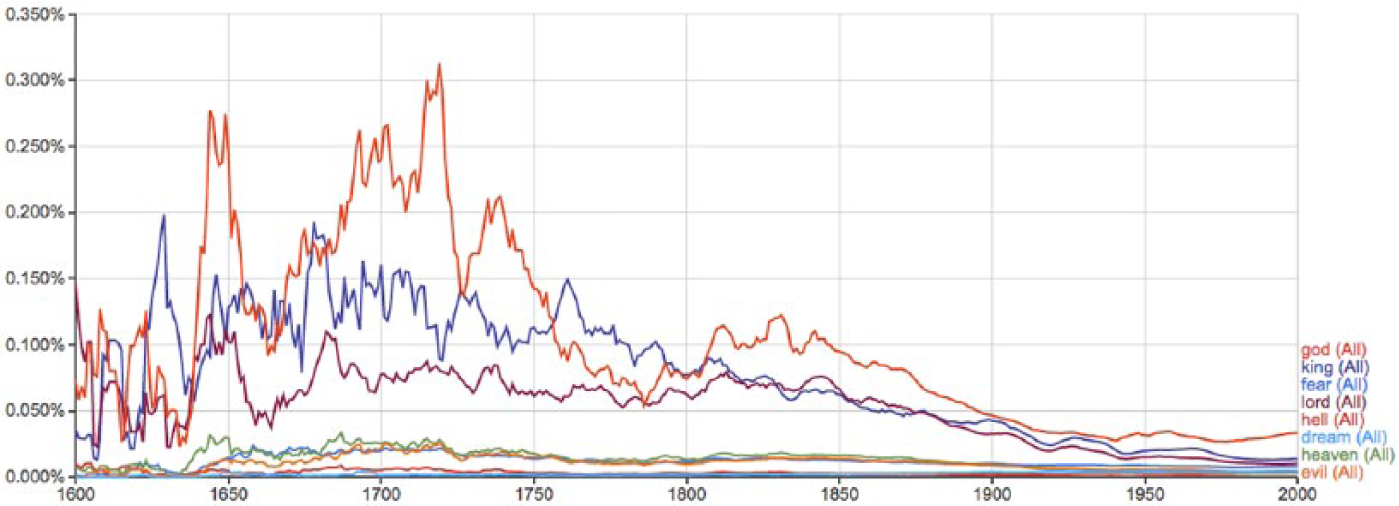
Google n-gram data. Interactive version available online. 8
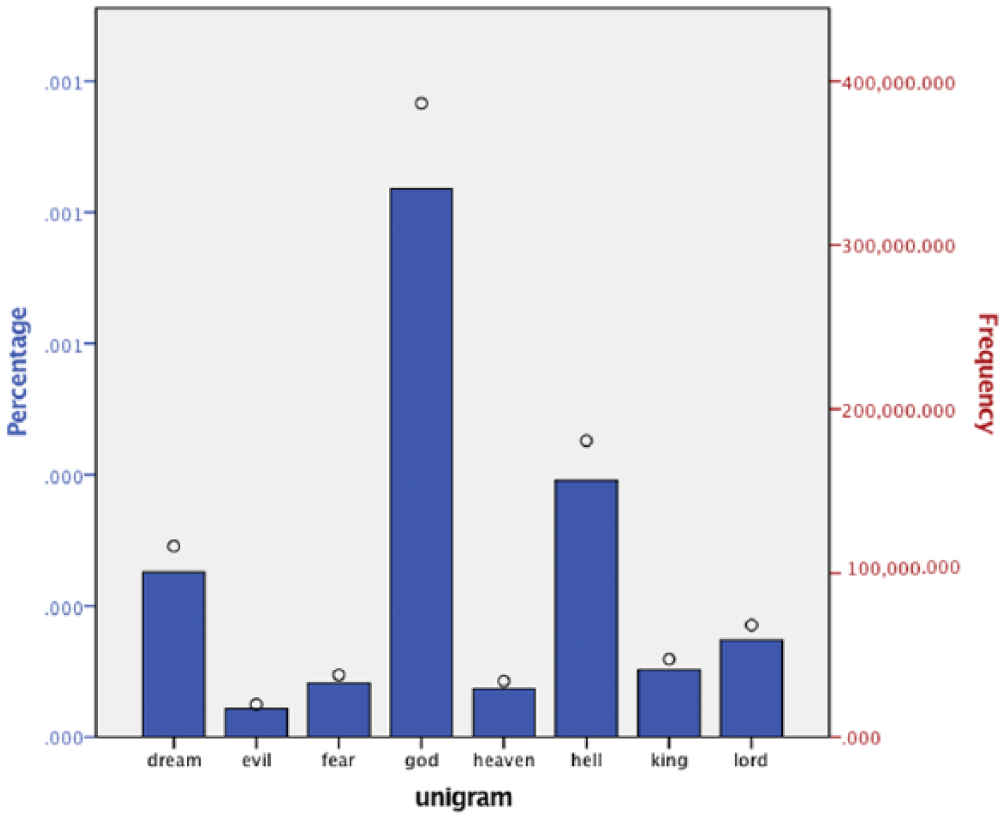
Mentions in collected Twitter data (by %). Circles represent frequency.
Discussion
Process-oriented methodologies place a strong emphasis on linking theory with empirical methods. However, in the digital age, this can sometimes be difficult to do. For example, much of our social lives increasingly occur online, and we leave behind an enormous digital footprint of trace data (Freelon, 2014). These data can be understood through a variety of empirical methods. The same can be said about the digital archiving of historical data. However, it is all too tempting to study these data without a clear theoretical framework. This article suggests that there is a journey or in Norbert Elias’ words, a genesis, from the ways in which historical diaries resonated with people of the time to Twitter today. Diary writing was the preserve of elites in the 17th-century and Pepys’ diary is testament to that. However, they represent an early media technology (i.e. portable writing instruments and bound diaries) for social sharing. Although elite in nature and generally publicly readable only posthumously, these diaries do provide some insights into continuation of language used to document the self. In this way, social media can be seen as born in the 21st century but are part of long-standing processes, both in terms of the written word and changes in media technology. These processes also had long-standing influences on what Elias terms ‘psychogenesis’ or specifically, our cognitive and emotional orientations. In the case of social media, our long-term cognitive and emotional histories are critical to understanding contemporary technology use.
Following Scannell (1989), social media have become part of public culture in ways that historical diaries do posthumously for their diarists. So, the sociogenesis taking place in some sense is the Eliasian civilizing process that has moved personal, intimate writing from the preserve of the elite to the everyday person via app-based social media. But these changes have led to social media, including Twitter, to be popularly perceived as ‘trivial’ and ‘banal’ (Ibrahim, 2015; Murthy, 2013). Although it is not always apparent why these labels continue to be applied, there is a need for ‘debanalizing Twitter’ and making it a serious, interdisciplinary object of study (Rogers, 2013). For Elias, the trivial can reveal insights into psychogenesis, the historical development of the psyche. This is useful for tracing links between media sharing and the banal. Put another way, social media sharing norms can be seen as part of ‘civilizing’ in the Eliasian sense. Just like Elias’ (1978) argument that eating with the right utensils was part of historical civilizing processes, social media use is governed by social negotiations that are influenced by social capital among other things. In this part of civilizing, social media also has the potential for community building, activism, and political engagement. But all these ‘civilizing’ forces have dark sides that can push toward a homogeneity of opinions that close down certain voices or opinions. For example, other work has explored how Twitter simultaneously acts as an ‘open-ended public sphere’ and a homogeneous/homophilic communitarian space (Colleoni et al., 2014: 327–328).
This study has sought to shed light on the ‘genesis’, as Elias puts it, of word usage in historical and contemporary media. This was done at both micro- and macro-levels. Although this study is not able to provide evidence of why people are using particular words on social media as part of their social sharing practices, an argument is made that some continuities in lexical choice exist between historical text and contemporary media that might be a product of the journey from private diaries published posthumously to the very public format of tweets. In addition, Twitter’s communicative framework is built on eliciting synchronous responses (i.e. users tweet and receive responses and re-tweets). This is in distinction to diaries in later epochs as well. Ultimately, seen from a process-oriented framework, our social communication has been partly ‘civilized’ into a more immediate response culture. Following Elias’ work on manners, a similar argument can be made that social sharing has always existed, but it is part of an always changing set of socially constructed processes, which have continuities and discontinuities. One of the continuities is agency. A key tension of contemporary social media is that it seems we are sharing more and more, and, as such, are more empowered. But what if our increased ability to share is itself part of larger macro-social structures of control (e.g. surveillance, targeted marketing, and behavior modification)? The perspective of this article is simultaneously macro and micro, by focusing on how we are collectively and individually negotiating social sharing. By drawing from Elias’ work on manners and his argument of the civilizing process, we can perhaps even discern a type of etiquette to social sharing on social media that is historically rooted linguistically. This provides us a useful context to understanding how terms from I/you/he/she to love/hate/god/hell are being deployed in contemporary social communication.
As Burgess and Matamoros-Fernández (2016: 5) highlight, the plentitude and richness of social media data not only open up opportunities but also present theoretical and empirical challenges and limitations. One of these challenges is the geographical location of Twitter users. The collected data are from tweets posted worldwide. Further work would benefit from comparing historical tweets with diaries and other accounts of everyday life specific to the location of those English-language diarists (e.g. the UK, USA, Canada, Australia, and New Zealand).
Conclusion
Big data analysis can reveal large, potentially recurrent macro-sociolinguistic trends. In the case of the 17th century, this was a time of great global change, colonial expansion, and deep changes to the British government, including strengthening of the Parliament and diminishing the power of the monarchy. Therefore, notions of agentic versus communal were particularly sharp. Today, we are witnessing major global change nationally and internationally (e.g. social movements in the Middle East, Brexit in the UK, and Donald Trump’s election in the USA). These factors impact and shape our social communication. This process-oriented sociological reading of both 17th-century diaries and tweet corpora using mixed-methods approaches provides a sociological view of linguistic evolution within the backdrop of historical continuities and discontinuities.
Following Norbert Elias’ (1978) argument that social processes should be studied over the longue durée, this article has drawn a line between historical text and contemporary tweets. In an age where social media analyses are often forced to be based on a short, fixed time (Burgess and Bruns, 2015), Elias’ framework emphasizes ‘the limitations of inquiries that concentrate on short-term intervals’ (Linklater and Mennell, 2010: 384). Although previous work such as Humphreys et al.’s (2013) approach of studying historical diaries alongside a small sample of tweets was an important start, there remains a gap in the literature in terms of comparing larger sets of data. This study seeks to fill this gap by comparing two media–historical books and tweets. By starting with a sample of historical diaries that were qualitatively studied, we were able to design a meaningful comparison between two very large corpora of text. This is done by counting n-grams, single or multiple co-occurrent words, that are found in historical diaries and contemporary social media. The historical data are derived from public data sets released by Google Books, and the social media data are derived from Twitter.
A key way in which this comparative approach was operationalized was through notions of the agentic and communal, concepts drawn from social psychology. This also better encapsulates Elias’ model of psychogenesis, which includes the impact of psyche and personality on social production. Interestingly, this study finds that the samples studied–17th-century digitalized diaries and tweets–indicate a preference for communal rather than agentic n-grams. For example, the n-grams good and love were frequently used in 17th-century Google n-grams and tweet n-grams today and are also n-grams associated with communal psychosocial sentiment (Campbell et al., 2007). That being said, the word ‘I’ is used in the early part of the 17th century (see Figure 5) at a much higher rate than any other subsequent time in the Google n-grams data, reflecting similarities to the agentic aspects of tweeting.
Diaries are seen as autobiographical accounts and have been studied as such. They are also mediated by writing instrument and paper. Changes in diary technology, such as the ability to write in the moment with portable bound diaries, shaped diary writing. Although the egocentric and individualistic side of Twitter is acknowledged by scholars, there remains a lack of thinking of social media as forms of autobiographical accounts that have developed from early forms of diary writing. Although they likely resemble earlier forms of mediated autobiographical accounts, attempts to compare the two are greatly lacking. This is partially due to not only the newness of social media but also the lack of appropriate research methods to undertake these types of research. With innovations in digital research methods, undertaking this type of research is particularly important.
A key part of this study has been to innovate digital social science research methods in sociology. Much work is being done in the digital humanities and beyond regarding analysis of tweets in relation to books and other archived digital documents. However, such work has generally been restricted to small samples of data. This study innovates and extends these methods by combining insights from comparative, process-oriented sociological methods, especially Elias’ models of sociogenesis and psychogenesis, with scalable computational content analysis methods. Being able to compare historical text with tweets in meaningful ways opens up new pathways of research. These extensions in comparative, historical methods provide insights to contemporary digital social researchers and archivists who are evaluating the future use of social media data in social research.
Footnotes
Acknowledgements
The author wishes to thank Alexander Gross and Sawyer Bowman for their assistance in Twitter trigram data extraction and Eeva Luhtakallio for her generous feedback on an earlier version of this article. The author also thanks Fumiya Onaka and participants of the Process-Oriented Social Research in Historical and Comparative Sociology session at the 2014 International Sociological Association Conference in Yokohama, Japan, for comments on a pilot version of this research. The author is also tremendously grateful to the anonymous peer reviewers for their invaluable comments and suggestions.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.