
Abstract
Processing morphemic elements is one of the most difficult parts of second language acquisition (DeKeyser, 2005; Larsen-Freeman, 2010). This difficulty gains prominence when second language (L2) learners must perform under time pressure, and difficulties arise in using grammatical knowledge. To solve the problem, the current study used the tenets of multimedia learning theory (Mayer, 2005) to help L2 learners’ reconstruct multiclausal sentences. This theory assumes that limitations in cognitive capacity are reduced when information is given to learners both visually and aurally. Given this assumption, the current study examined whether pictorial information helps L2 learners process morphemic elements in multiclausal sentences presented aurally. Thirty-two learners of Japanese engaged in elicited imitation both with and without pictorial support. The results revealed that the learners performed significantly better with pictorial support, lending support to multimedia learning theory for L2 learners’ processing of morphemic elements. However, a limited effect of pictorial support was found for the processing of an element that the L2 learners had learned recently, and that was in sentence-final position, suggesting that these types of items are difficult to automatize regardless of cognitive support.
I Introduction
Morphology is one of the most difficult areas of grammar for learners of a second language (L2) to acquire (DeKeyser, 2005), with the acquisition of inflectional morphemes in particular posing many difficulties for L2 learners (Larsen-Freeman, 2010). Larsen-Freeman described L2 learners’ problems in production, such as ‘morphological omissions, commissions, and substitutions of one allomorph for another’ (p. 221). Problems involved in processing and producing inflectional morphemes are most typically observed during spontaneous production and timed tasks. L2 learners’ difficulty in sentence processing under time pressure may reflect their underdeveloped procedural knowledge. DeKeyser (2009) defines procedural knowledge as knowledge of how to do something, which includes applying morphological rules to verbs. It has been argued that procedural knowledge is closely tied to automaticity, which is characterized as rapid, spontaneous and devoid of cognitive effort (Levelt, 1989; Segalowitz & Hulstijn, 2005). Jiang (2007) refers to linguistic knowledge that is readily available in spontaneous communication as integrated knowledge. In his definition, integrated knowledge reflects changes in mental representation. As learners continue to learn, new linguistic knowledge is integrated with learners’ existing knowledge and, thus, learners with integrated knowledge can apply rules during processing without conscious effort. According to Levelt (1989), sentence formulation entails lexical, grammatical, morphological and phonological encoding. However, attending to these multiple properties of language under time pressure is difficult, given that human attentional capacity is limited (Levelt, 1989; Segalowitz & Hulstijn, 2005; VanPatten, 2002, 2004). For L2 learners whose integrated knowledge is still developing, retrieving multiple properties of the target language may be demanding, so some properties may be left unattended. Studies have indicated that L2 learners’ processing of morphemic elements is particularly vulnerable under time pressure (Ellis, Loewen, & Erlam, 2006; Jiang, 2007; Lardiere, 1998; Prévost & White, 2000).
Previously, some researchers in the field of educational psychology have sought solutions for problems associated with processing information in real time, and they have argued that visual support associated with aural information enhanced learners’ recall (e.g. Mayer 2005; Penney 1989). Their arguments are based on the assumption that information is processed through visual and auditory paths, and humans’ cognitive capacity within a single resource is limited. Based on these premises, Mayer (2005) proposed a multimedia learning theory that claims that optimal learning takes place when learners can build connections between aurally and visually presented information with support from relevant prior knowledge. Research evidence to support the effect of providing information in different modalities has accumulated over the past decades (Frick, 1984; Martin, 1980; Moreno & Mayer, 1999; Mousavi, Low, & Sweller, 1995) and, more recently, L2-related studies have examined the effects of multimedia support for learning unfamiliar words (Jones, 2004; Jones & Plass, 2002; Plass, Chun, Mayer, & Leutner, 2003). The current study, which is based on a multimedia learning theory of L2 learners’ sentence processing, examined whether visual presentation promotes retrieval of morphemic elements included in multiclausal sentences. Issues related to on-line processing, such as integrated knowledge (Jiang, 2007) and phenomena that are thought to be caused by limited cognitive capacity, are discussed in the following section.
II Literature review
1 Automaticity and development of L2 linguistic knowledge
The acquisition of automaticity in sentence processing can be viewed as cognitive development. Segalowitz and Hulstijn (2005) argued that automaticity involves cognitive changes and increased proficiency in the L2 and that it should be distinguished from a mere speeded-up performance. Jiang (2007) also argued that automatic performance improves as L2 learners integrate existing and newly obtained knowledge. He defined knowledge that is obtained in this process as integrated knowledge and argued that linguistic items can be processed without attention as learners integrate various types of knowledge. However, not all linguistic items are eventually automatized (DeKeyser, 2009). Omission and/or erroneous production of morphemic elements under time pressure is a recognized problem (Ellis, Loewen, & Erlam, 2006; West, 2012). Limited attentional capacity may explain why morphology remains problematic for L2 learners. The L2 literature widely acknowledges that learners’ attentional resources are primarily allocated to lexical items during processing due to limitations in cognitive resources (VanPatten, 2002, 2004). A meta-analysis of English morpheme acquisition conducted by Zobl and Liceras (1994) showed that L2 learners acquire lexical items before functional items, and free morphemes before bound morphemes. Likewise, a meta-analysis of L2 learners’ listening skills by Johnston and Doughty (2007) revealed a developmental shift from semantic to syntactic cues in performing listening tasks. These meta-analyses indicate that low-level L2 learners attend to semantic items before functional ones when processing, and consequently, functional items are less likely to be processed. For L2 Japanese learners, suffixes known as connective particles are a problematic morpheme. The function of connective particles is to connect clauses in the same way as conjunctions, but connective particles are bound morphemes attached to a verb, an adjective or a copula, and they are located at the end of a clause because Japanese is a SOV language (Mori, 1999). For low-level L2 Japanese learners, selecting an appropriate connective particle while considering its function and grammatical rules is cognitively taxing, and this may limit their use of connective particles during free production (Kondo, 2004; Yamauchi 2009).
Jiang (2007) argued that three types of knowledge sources may lead to automatic processing: learners’ first language (L1), input and interaction, and explicit knowledge obtained from instruction. Given his argument, enhancing automaticity for an item without a counterpart in the learner’s L1 would be difficult, particularly for an item that has been the subject of recent instruction (and not otherwise known to the learner). For most classroom L2 learners, building solid knowledge for an item with an unfamiliar function may be difficult to accomplish considering the time that is available during classroom activities. An influence on learners’ spontaneous productions due to the time since linguistic items were introduced to L2 learners was reported by Mine (2007) and Yamauchi (2009). Both studies analysed the KY corpus (Yamauchi, 2009) that is based on Oral Proficiency Interviews and revealed that the order in which connective particles appeared in novice to intermediate learners’ data closely resembles the order in which the connective particles are introduced in most elementary Japanese textbooks. However, no such trend was found in higher-proficiency L2 learners’ production, in which the instructional sequence of connective particles was indistinguishable. These analyses support Jiang’s (2007) argument that knowledge integration is incremental and gradual; that is, integrating knowledge of recently introduced connective particles is challenging for low-level L2 learners, so the particles are not automatically processed or produced. Research on the effect of instructional duration for new L2 words has shown an effect of longer instructional time for L2 learners’ successful sentence repetition (Rast & Dommergues, 2003).
2 Influence of location of an item for sentence processing and production
The location of an item within a sentence also interacts with cognitive capacity in processing. The literature indicates that both L1 and L2 speakers experience difficulty in holding all elements in memory when hearing a long sound string. In tasks in which participants are prompted to repeat a sound string, the participants tend to repeat the middle part inaccurately; this phenomenon is known as the serial order effect (Bley-Vroman & Chaudron, 1994; Lewandowsky & Murdock, 1989). This effect can be graphically depicted by a skewed U-shaped line: The beginning of the line is the highest, reflecting the highest percentage correct (at the beginning of the sentence); the center of the line is the lowest, corresponding to the part that is difficult to recall correctly (in the middle of the sentence); and the end is also low (representing the end of the sentence), but higher than the center. The same grammatical item may be processed differently depending on its position in a sentence due to learners experiencing the serial order effect (Bley-Vroman & Chaudron, 1994). In a second language acquisition (SLA) study, Spitze and Fischer (1981) confirmed this phenomenon in ESL (English as a second langauge) learners’ recall of sound strings, with the results indicating that a sentence-medial item was the most difficult to recall. Among five sets of lists that the learners were asked to reconstruct, a random list resulted in the most serious serial order effect, while the effect was least for regular sentences, suggesting that the recall of medial elements may become more difficult when lexical cohesion among items is weak. An influence of location may explain difficulties in processing Japanese verbs with suffixes. The difficulty in recalling an item when a suffix is attached is a recognized phenomenon, known as the suffix effect, and is observed when a suffix is attached near the end of a verbal stimulus (Penney, 1989). Penney argues that this problem may be caused by a loss of cognitive resources towards the end of a verbal stimulus during processing. Normally, an item at the end of such a stimulus is relatively easy to recall, as explained by the serial order effect. However, when a suffix is attached to an item located at or near the end of a stimulus, allocating cognitive resources becomes more difficult because the item loses distinctiveness because it is no longer at the end of a stimulus with its suffix and, furthermore, cognitive resources have probably been consumed to process the preceding items. This mechanism may account for difficulty in processing Japanese connective particles, given their default position at the end of a clause.
3 The effect of multimedia learning for processing and storage of verbal information
Researchers in the field of educational psychology have investigated the effect of providing multiple cognitive aids to enhance verbal memory, with the basic claim that the efficiency of storing information in memory increases when information is provided via both visual and phonological paths (Mayer, 2001, 2005; Penney, 1989). Mayer (2005) proposed a multimedia learning theory to explain the mechanism of memory in learning based on three assumptions: dual-channel, limited-capacity and active processing. Mayer uses the term ‘dual channel’ to indicate the use of both visual and auditory paths in processing. He claims that humans possess two separate paths, where visual information in the form of pictures or printed text is processed through the visual path, whereas sounds are processed through the auditory path. Particularly significant in this separate-path assumption is the convertibility of information processed via the visual and auditory paths. With this conversion mechanism, learners may be able to utilize the auditory path while looking at printed text by mentally converting text to sounds without hearing any physical sounds and, likewise, learners may activate the visual path by mentally converting auditory information to visual images. The second assumption, limited capacity, refers to humans’ limitations in processing via a single path, so that information is better processed and held in memory if it is processed both visually and auditory. The third assumption, active processing, is that integration of information separately processed through either the visual or auditory path occurs in working memory when learners actively select relevant information and relate it to prior knowledge. According to Mayer, the implementation of multimedia learning results in better retention and application of prior knowledge to solve new problems. This multimedia learning theory coincides well with the working memory model (Baddeley, 1986) in assuming that memory storage consists of visual and audio components, with each component having a limited capacity, and that visually and auditorily processed information together contribute to working memory. Multimedia learning theory is also relevant in regard to modality effects (Penney, 1989), which refers to the increased short-term memory available when information is presented in both auditory and visual modes. Penney argues that auditorily presented items are stored in the acoustic code, and that visually presented items are retained in the phonological code and a visual code. Learners can retrieve phonological information from texts without physical sounds, so visually presented information can be stored in the phonological code, which is similar to the conversion mechanism described in multimedia learning theory. The effect of multimedia learning has been tested in educational contexts, for example, in a study conducted by Moreno and Mayer (1999). Learners in different multimedia-support groups saw animations relevant to a lecture while reading or hearing a lecture about meteorology, with their learning evaluated using free verbal recall, guided recall and multiple-choice questions about the content. The results revealed that the groups that received auditory narration with visual support outperformed the groups that received all information visually, lending support to the claim that learners recall information better from visual and auditory modes together.
In the L2 field, Mayer’s (2001, 2005) multimedia learning theory has been used to promote vocabulary acquisition (Altarriba & Knickerbocker, 2011; Jones, 2004; Jones & Plass, 2002), listening comprehension (Jones & Plass, 2002) and reading comprehension (Plass, Chun, Mayer, & Leutner, 2003). Jones and Plass (2002) examined whether multimedia annotations enhance L2 learners’ vocabulary acquisition of novel words and listening comprehension in French. The results revealed that the learners who were given both pictorial and written annotations performed the best, and no significant difference was found between the groups that were given only pictorial or written annotations. Multimedia annotation was also found effective in reading comprehension in German (Plass, Chun, Mayer & Leutner, 2003), and the best annotation type was the combination of a text translation of the word and a photograph or short video clip. These studies indicate that multiple annotations are more beneficial for L2 learners than singular annotations; however, an increased variety of annotations does not always enhance the effect of multimedia learning. Jones (2004) found no significant difference between the test performances of L2 French learners who were given only written annotation in the L1 and those who were given both written and pictorial annotations. If L2 learners can mentally convert visually presented written text to sound as Mayer (2005) and Penney (1989) argue, written text alone may allow L2 learners to establish both visual and auditory paths. Altarriba and Knickerbocker (2011) found that an English translation condition was more facilitative than a picture condition in a lexical decision task for L1 speakers of English learning novel L2 Spanish words, arguing that some L1 English speakers recognized phonemes that are similar to native English phonemes and utilized this orthographic information to create an auditory store to learn the novel L2 Spanish words. One condition that may allow L2 learners to mentally convert text to audio is an orthographic similarity between the L1 and L2 (Altarriba & Knickerbocker, 2011; Jones, 2004).
Multimedia learning theory (Mayer, 2001; 2005) assumes a limited cognitive capacity, and if multimedia learning is effective in helping learners overcome this limitation, problems in processing sentence-medial or sentence-final items from auditory input could be alleviated by presenting these items visually. In a study of the effect of providing visual support for L2 sentence processing by Yuan, Woltz and Zheng (2010), EFL learners saw translations of key words briefly in their L1, Mandarin, when they heard sentences in their L2 and made a decision about the validity of the sentences. The translations were provided for one word in either sentence-initial or sentence-final positions or for one word in each position, but all translations disappeared immediately before the learners heard a target word. In the study, translations were facilitative for words in sentence-initial position, but not for words near the ends of sentences. The authors concluded that visual information for sentence-final words loses its facilitation effect after learners’ cognitive resources are exhausted by retrieving sentence-initial words. However, the limited contribution of visual support in their study may be due to the way in which the visual translations were presented. In their study, visual support was provided for one or two words, and when two visuals were used they were presented sequentially. According to Penney (1989), sequential presentation of visual information is not as facilitative of recall as simultaneous presentation. Penney’s meta-analysis of visual and auditory processing reports that humans are better at associating visually presented items when they are presented simultaneously as opposed to sequentially. If so, to better assist L2 learners’ sentence processing, visuals should be provided simultaneously for all lexical items representing a sentence, rather than providing a visual for one lexical item alone or providing two visuals for two lexical items sequentially as Yuan, Woltz and Zheng (2010) did. Whether simultaneous presentation of visuals may reduce difficulty in processing sentence-medial or sentence-final items needs further scrutiny.
III The present study
The main objective of the present study is to test the effect of pictorial support on L2 learners’ reconstructions of morphemic elements from auditory input, with particular interest in treating problems that stem from limited cognitive capacity, such as the serial order effect and difficulty in processing recently introduced items. The current study used connective particles as target morphemic elements. They are similar to inflectional morphemes in that they are functional bound morphemes, carry little semantic information and require the application of morphological rules. In Japanese, a SOV language, a variety of verb suffixes is used at the end of clauses. The default verb suffix is -masu, which marks the end of a sentence and expresses formality (Makino & Tsutsui, 1986). Connective particles are suffixes attached to verbs, adjectives and copulas to connect clauses, and thus play a major role in creating discourse coherence (Mori, 1999). The following example indicates the use of connective particles in a multiclausal sentence, and these particles are underlined.
Kooen ni it = After (I) go to a park and play tennis, (I’ll) go home and take a shower.
To investigate the serial order effect, the target items are included in different locations: the first, second and third clauses of multiclausal sentences as indicated in the above sentence. The following predictions were made on the basis of multimedia learning theory (Mayer, 2005) as well as findings from previous studies that investigated sentence processing.
L2 learners of Japanese will reconstruct all morphemic elements better under the pictorial support condition than the no-pictorial support condition, as multimedia learning theory predicts that learners can integrate verbal information efficiently in a condition that information is processed via both the visual and auditory paths.
Although the learners will perform better with pictorial support, they will suffer from the serial order effect; an item in sentence-medial or sentence-final position will be more difficult to reconstruct than an item in sentence-initial position.
Reconstruction of a recently introduced item will remain problematic because L2 learners may not have received enough input and instruction to integrate knowledge to the point of automatization (Jiang, 2007). Therefore, the learners’ successful reconstruction of the target items will differ depending on the time since the morpheme was introduced to the learners in class.
IV Methodology
1 Participants
Thirty-two learners of Japanese, 22 men and 10 women, aged 18–25, participated in the study. They were enrolled in a second-year Japanese course in a public university in the USA, and none of them had been in Japan for more than six months. The data were collected during their fourth semester of Japanese, in which five hours of Japanese instruction was provided each week. All of the participants were native speakers of English.
2 Target items
Three types of morphemic elements were selected to test the hypothesis that the L2 learners’ processing of morphemic elements would be affected by the time since the learners had been introduced to them in class. The target morphemic elements were the connective particles -te, -tari and -tara, shown in Table 1, and all of them were introduced to the learners during their regular Japanese classes. As shown in Table 1, among the target items, the item that was introduced to the learners most recently was -tara, and it was expected to be the most difficult to process, whereas -te was expected to be the least difficult because the learners had had the most time to integrate it into their language systems. Verbs must be conjugated when connective particles are attached. L2 learners’ processing of connective particles involves knowing the type of verb and applying the correct conjugation rules. Table 2 indicates examples of conjugated verbs proceeding connective particles. There are no clear morphemic boundaries in Japanese verbs (Klafehn, 2003). However, L2 learners are usually instructed to memorize verb types, pay attention to verb endings, and apply conjugation rules according to verb types and subcategories. A study that investigated Japanese nonce verb conjugations by L1 speakers and L2 learners revealed that L2 learners’ ability to conjugate verbs was considerably superior to that of L1 speakers (Klafehn, 2003), suggesting that explicitly instructed rules help L2 learners conjugate verbs appropriately. The three connective particles require the same conjugation rules, so the difficulty in conjugation was controlled.
Connective particles included in test sentences.

Types of verbs used in test sentences.

Note. * The conjugation of iku (‘to go’) is exceptional because it does not follow the rule of other verbs that end with -ku. ** -te, -tari, and -tara change to their voiced allomorphs -de, -dari, and -dara, respectively, if the plain form of the preceding verbs end with -mu, -bu, or -gu. *** Japanese has two irregular verbs su-ru (‘to do’) and ku-ru (‘to come’). Usually L2 learners are instructed to memorize conjugated forms of irregular verbs.
3 Sentence types
Table 3 shows the test sentences used as stimuli. To examine the research question asking whether the L2 learners process the same connective particle differently depending on its position it was necessary to position the target connective particles in sentence-initial, -medial or -final positions. Thus, the target items were included in the first, second and third clauses of multiclausal sentences, representing sentence-initial, -medial and -final positions, respectively. As a result of locating each type of connective particle in different positions while maintaining grammaticality, five types of sentences were created as stimuli. Ideally, all test sentences should have an equal number of target connective particles across different locations; however, this implementation was difficult due to grammatical constraints. For instance, inserting -te or -tara between -tari clauses makes sentences illogical and incomprehensible. The current study prioritized the use of grammatical and comprehensible sentences over controlled yet ungrammatical sentences.
Examples of five types of test sentences.

The lexical items used in the experiment were selected from the vocabulary in the textbook that had been introduced during the learners’ first year of Japanese. These vocabulary items frequently appeared in the textbook and during class. The lexical items were randomized such that the learners could not expect a particular lexical item in a particular structure or in a particular location within a sentence. In addition, no vocabulary item was used more than once in a single sentence, and no item appeared more than three times within the same sentence type, with the exceptions of suru (to do), iku (to go) and kaeru (to go home). These verbs were in various positions within the sentences to prevent the learners from making associations among these verbs, connective particles and their sentence positions.
4 Procedure
The learners engaged in elicited imitation individually in a small room in a language laboratory. Prior to the task, the following instructions were displayed on the computer screen: ‘You are asked to repeat the 120 sentences you will hear as precisely as you can. Request a short break when you get tired. You are free to skip any part or any sentence.’ The learners were also instructed to count to three before repeating. This implementation was to preclude the learners’ use of echoic memory (Cowan, 1993). All of the learners engaged in the task both with and without pictorial support. The entire session consisted of six blocks of the following types: five types of test sentences with pictures, five types of test sentences without pictures, five distracters with pictures, and five distracters without pictures. All of the sentences were randomized, while sentences with pictures and without pictures were interspersed. The learners were given five distracter sentences for practice prior to starting the elicited imitation task. The researcher controlled the entire session to ensure that the learners listened to each sentence only once. In the pictorial support condition, a picture corresponding to the digitally recorded sound of the clause appeared on the screen, and the following clause was added to the right of the previous picture within 0.5 seconds. All four pictures (Appendix 1) remained on the screen until the participant finished repeating the entire sentence. This presentation of pictures is in accord with Penney’s (1989) claim that visual presentation is effective for recall when simultaneously presented. As shown in the Appendix 1, four pictures represent the lexical information of each clause, but they are not directly linked to any of the connective particles, so the connective particles used in the test sentences were not recoverable from the pictures. For the purpose of the current study, the role of pictorial information needed to be restricted to assisting the learners’ automatic processing. To prevent the learners from creating a sentence on their own by viewing the pictures on the screen, the researcher moved to the next sentence immediately after the learner finished repeating a sentence or paused longer than two seconds. 1 Any parts reconstructed after a two-second pause were removed from the analysis. Prior to the main study, a pilot test was conducted to test the appropriateness of the procedures, and it was found that two seconds was reasonably long for the L2 learners to retrieve a given test sentence. However, disallowing a pause longer than two seconds imposed time pressure on the learners in repetition. All of the pictures were pretested for usability prior to the study. The pretesting involved graduate students identifying the activity that each picture represented, and any pictures that were not identified accurately were removed and replaced until at least three people correctly identified them.
5 Analysis
The reconstructed sentences were transcribed and analysed to identify (1) whether the L2 learners processed the connective particles differently depending on their location and (2) whether the learners’ reconstructions of the connective particles differed depending on the time since they were introduced in class. One point was assigned when a learner reconstructed a connective particle at its original position. No points were given when a learner replaced the original connective particle with another, even if a substitution did not cause ungrammaticality. A total of 180 measurements were taken for each learner (= 2 pictorial conditions × 5 sentence types × 3 locations × 6 trials). Two raters separately transcribed and scored 20% of the data with 97.8% agreement, and discrepancies were resolved by a third rater. After the two raters discussed the causes of the discrepancies, the first rater transcribed and scored the entire set. To analyse the influence of location, the learners’ reconstruction scores were categorized by clause location. Thus, each clause location included a total of 30 (= 5 sentence types × 6 trials) connective particles consisting of mixed types. To address the question regarding the time since a morpheme was introduced to the learners, the learners’ reconstruction scores were categorized by type of connective particle, namely, -te, -tari and -tara, which had been introduced at different times in the instructional sequence. The total number of each connective particle included in all stimuli was 42 (7 -te × 6 trials), 24 (4 -tari × 6 trials) and 24 (4 -tara × 6 trials) in each pictorial condition.
V Results
Analyses by location and type of connective particle were conducted separately by using two-way repeated-measures ANOVAs. In the cases where Mauchly’s test indicated that the assumption of sphericity had been violated, the degrees of freedom were corrected using the Greenhouse–Geisser estimate of sphericity. To report effect sizes, Cohen’s d was used to measure the magnitude of the effect of visual support. Effects are considered small if d ≤ 0.20, medium if 0.20 < d < 0.80 and large if 0.80 ≤ d (Cohen, 1988). Partial eta squared was used to indicate the magnitude of the effect of location and type of connective particles. According to Cohen (1988), effect size is considered small if η2; ≤ .0099, medium if .0588 ≤ η2 ≤ .1379 and large if η2 is above .1379.
1 Effects of pictorial support and location
Table 4 shows descriptive statistics of the learners’ reconstruction scores by location. The two repeated-measures variables are pictures (with or without) and the location of the connective particles, with three levels representing the first, second and third clauses. There were significant effects for picture with a large effect size, F(1, 31) = 175.61, p < .001, η2 p = .850, and for location with a large effect size, F(1.40, 43.51) = 20.293, p < .001, η2 p = .396. The interaction for picture × location was also significant with a medium effect size, F(1.56, 48.31) = 3.725, p = .041, η2 p = .107. A Bonferroni post-hoc test revealed that there was no significant difference in the students’ success in reconstructing the connective particles in the first and second clauses, p = .120, but that those in the second clause were reconstructed significantly better than those in the third clause, p < .001. Therefore, the learners’ difficulty in retrieving multiclausal sentences started beyond the second clause. A large effect of pictorial support was found for all locations. The largest was for the third clause, t(31) = 9.53, p < .001, d = 1.42, followed by the second clause, t(31) = 10.66, p < .001, d = 1.304, and the first clause, t(31) = 9.06, p < .001, d = 1.011.
Descriptive statistics of the learners’ production of connective particles by location.
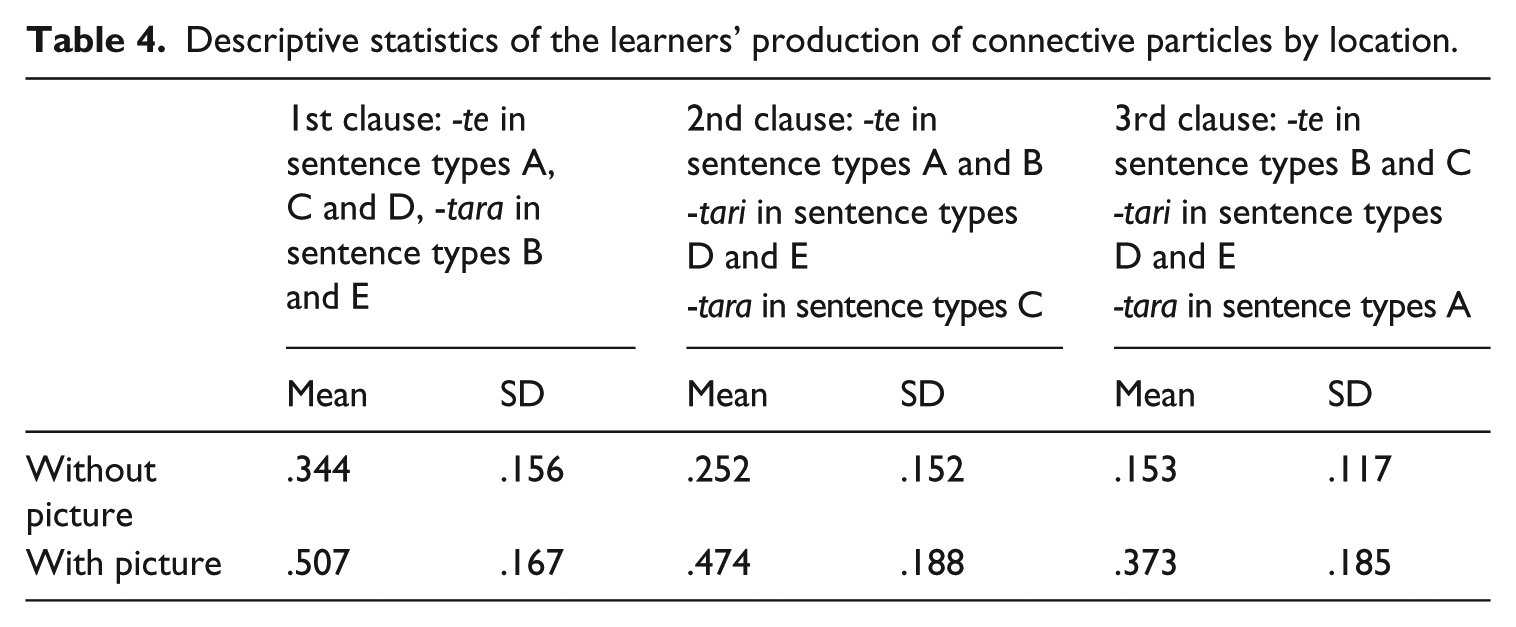
The results confirmed the hypothesis for pictorial support by showing a significant improvement in the learners’ reconstruction in all locations, with the largest effect in sentence-final position. The hypothesis regarding the influence of location was partly confirmed. As predicted, the learners had more difficulty reconstructing connective particles in sentence-final position than ones in sentence-initial position; however, no difference was found between sentence-initial and -medial positions (see Figure 1).
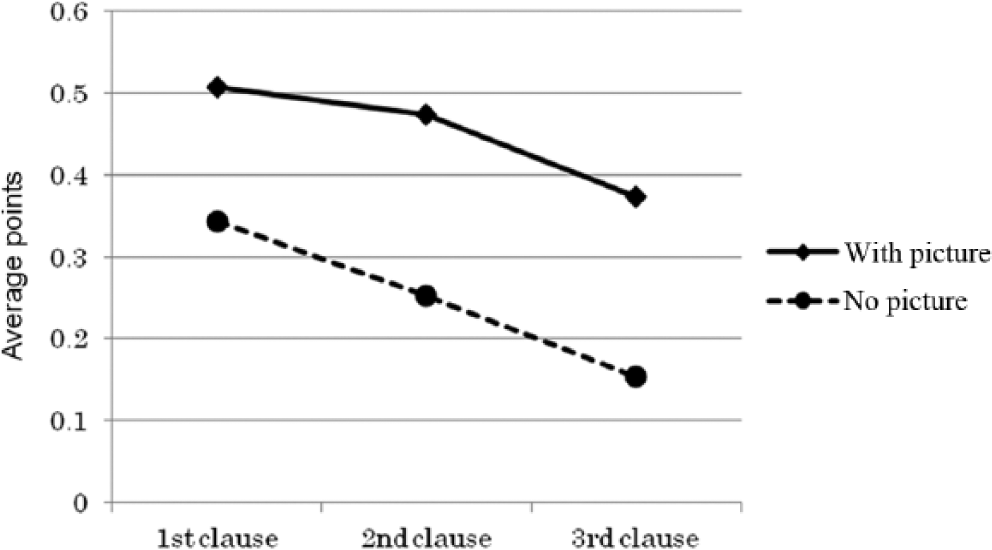
Reconstructed connective particles by location.
2 Effect of pictorial support and time since a morpheme was introduced to the learners
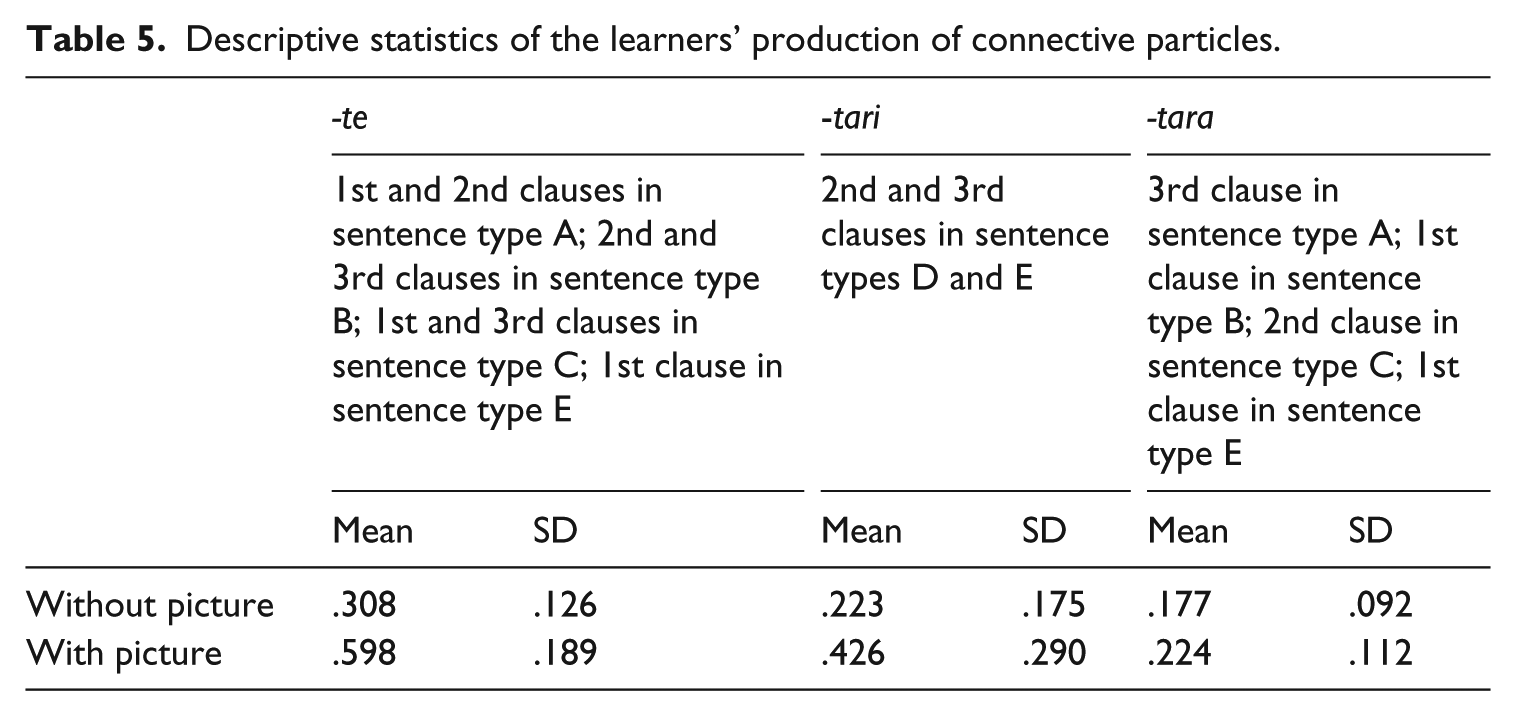
Descriptive statistics of the learners’ reconstruction scores are shown in Table 5. The two repeated-measures variables are pictures (with or without) and the connective particles -te, -tari and -tara, which were introduced to the learners at different times in class. The results revealed significant main effects for picture, F(1, 31) = 147.37, p < .001, η2 p = .826, and for connective particles, F(1.49, 46.29) = 31.89, p < .001, η2 p = .507. The picture × connective particles interaction was significant as well, F(2, 62) = 28.10, p < .001, η2 p = .475. A Bonferroni post-hoc test showed a significant difference between the reconstruction of -te and -tari, p = .003, -tari and -tara, p = .005, and -te and -tara, p < .001. The effect size of pictorial support was large for -te, t = 12.42, p < .001, d = 1.80, and -tari, t = 6.66, p < .001, d =.85, and medium for -tara, t = 2.96, p = .006, d = .47. As predicted, the learners’ processing of connective particles improved under the pictorial support condition regardless of type, but the effect of pictorial support was smaller for more recently introduced items (see Figure 2).
Descriptive statistics of the learners’ production of connective particles.
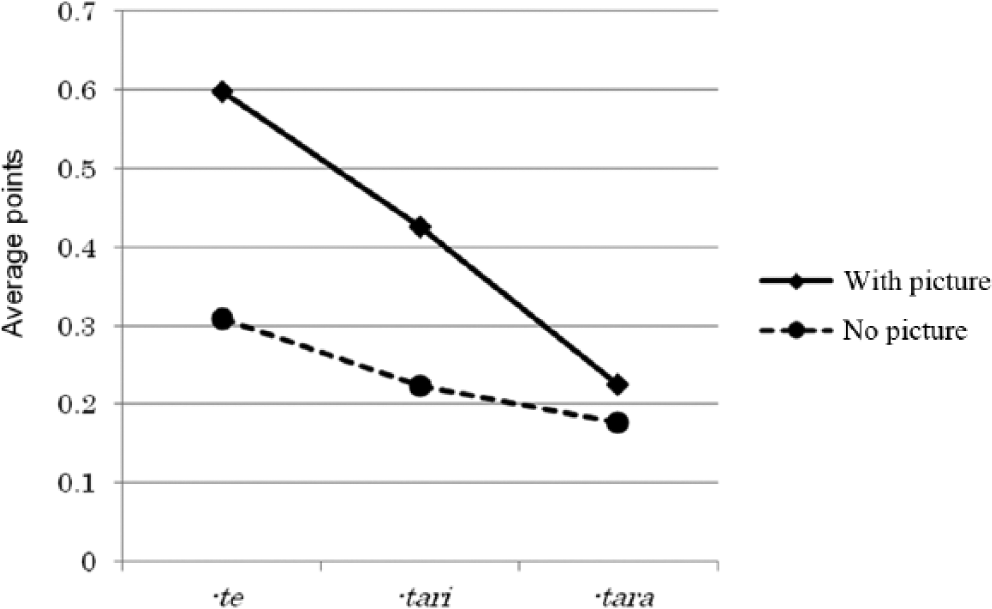
Reconstructed connective particles representing the time since a morpheme was introduced to the learners.
VI Discussion
The results of present study support the multimedia learning theory (Mayer, 2001, 2005) claims that learners are better able to attend to input and integrate it in a condition in which they receive input through both visual and auditory paths. One may argue that the visuals were used to assist the L2 learners’ production, not sentence processing, in a way that allowed the learners to extract semantic information from the pictures. However, the present study claims that pictorial information assisted the integration of visually and auditorily processed input with the help of previous linguistic knowledge, as multimedia learning theory claims. The pictures used in the current study did not specify the grammatical items that were used to connect the clauses, so the learners had to figure out the target morphemic elements solely from the auditory input and their own previous knowledge. Thus, the primary role of the pictorial information in the current study was to support the processing of sentences, in addition to the production of morphemic elements. Without pictorial information, the L2 learners might have exhausted their cognitive resources before processing morphemic elements due to their preference for semantic over grammatical information (VanPatten, 2002, 2004). The L2 learners’ improved performance with pictorial support reflects the premise of Mayer’s multimedia learning theory that information is better processed when it is presented both visually and auditorily.
The third research question concerned the effect of pictorial support for reconstructing items that had been introduced to the learners at different times. As hypothesized, the effect of pictorial support was the largest for the reconstruction of the connective particle -te, and this may reflect the learners’ longer learning experience with it in class than with the other two target morphemes. The learners’ performance may be interpreted as follows: an item for which they have received a larger amount of input is better processed with reference to their own previous knowledge. This tendency found in the current study is in accord with the assumption that input and interaction contribute to knowledge integration (Jiang, 2007). A particularly important finding of the current study, which has not been fully discussed in Mayer’s multimedia learning theory (2001, 2005), is the limited role of visual support. The effect was smallest for the item that had been introduced to the learners most recently (approximately half a semester prior to the test), suggesting that items that are not part of integrated knowledge are less accurately retrieved even under a condition where the L2 learners’ cognitive burden is reduced. The smaller pictorial effect for processing more recently introduced morphemic items is probably due to underdeveloped explicit knowledge and insufficient input, both of which are necessary sources for knowledge integration (Jiang, 2007). The results of the current study indicate that pictures do not compensate for a lack of input nor a lack of the knowledge that is necessary for automatic processing.
As found in previous studies, the current study also showed that processing items in final position is more difficult than processing items in initial or medial positions (Bley-Vroman & Chaudron, 1994; Lewandowsky & Murdock, 1989; Spitze & Fischer, 1981). Unlike the findings of Yuan, Woltz and Zheng (2010), visuals in the current study contributed to improvement in the L2 learners’ processing of sentence-final items. The results also support Penney’s (1989) claim that simultaneously presented visuals are facilitative of verbal recall. However, though the learners’ reconstruction was enhanced by visuals in all locations, the reconstruction of connective particles in the third clause was still worse than those in the first and second clauses, suggesting that the suffix effect persists even when verbal information is provided both visually and auditorily.
VII Limitations and future research
The current study demonstrated the overall trend that the time since a morpheme was introduced in class influenced the learners’ reconstruction of the target morphemic elements regardless of pictorial support. However, it remains unclear whether the high accuracy rate of -te can be also attributed to its higher frequency in the stimuli. As a result of prioritizing the use of grammatical sentences, unequal numbers of the target connective particles were used in each clause to create logical sentences, and this unbalanced distribution might have created differences in the success of retrieving -te. According to N. Ellis (2002), frequency is a major factor for language processing, so the learners in the current study might have benefited from the higher frequency of -te used in the stimuli. Another study that uses artificial grammatical items to control the distribution of target items may be necessary to better interpret the influence of location and input frequency for multiclausal sentence reconstruction.
It may be useful to examine whether the Japanese phonetic alphabet, kana, facilitates L2 learners’ sentence processing, as kana can provide both visual and phonological information. 2 According to multimedia learning theory (Mayer, 2001, 2005), written text can be used to create an auditory path if learners can mentally convert letters to sound. Though written text facilitated L1 English speakers’ listening comprehension in French (Jones, 2004) and vocabulary learning in Spanish (Altarriba & Knickerbocker, 2011), the Japanese phonetic alphabet may not facilitate creating an auditory path for L2 learners, considering the dissimilar orthographic systems of Japanese and English. Conversion in a dissimilar orthography to sounds and/or obtaining semantic information by looking at dissimilar orthography during a timed task is potentially cognitively taxing for L2 learners, so a tradeoff may be involved between the cost of decoding characters and the benefit of simultaneously obtaining visual and auditory information. Investigating the use of dissimilar orthographic systems may shed more light on the mechanism of providing dual paths for processing.
Footnotes
Appendix
Examples of test sentences with pictures.
| kooen ni itte | tenisu o shitara | uchi ni kaette | shawaa o abimasu |
|---|---|---|---|
| After (I) go to a park and play tennis (I) go home and take a shower. | |||
| uchi ni kaettara hon o yondari inu to asondari shimasu* | |||
| When (I) go home (I’ll) do things such as read books, play with (my) dog, etc. | |||
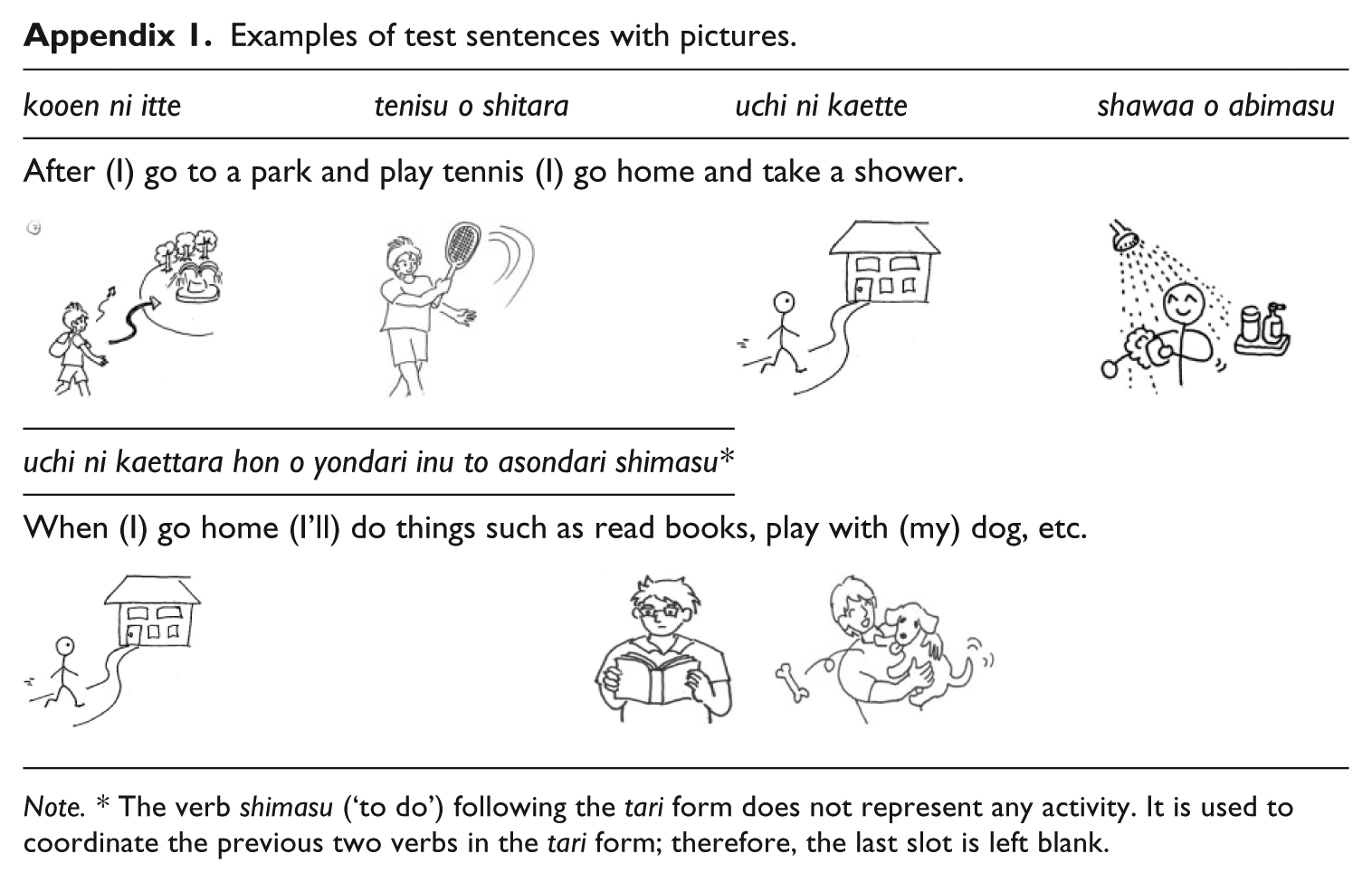
Note. * The verb shimasu (‘to do’) following the tari form does not represent any activity. It is used to coordinate the previous two verbs in the tari form; therefore, the last slot is left blank.
Acknowledgements
I am grateful to Dr Chris Sheppard of Waseda University for his generous and invaluable advice on the statistical analysis of data in this article. I also would like to thank two anonymous reviewers for their constructive suggestions and comments.
Declaration of Conflicting Interest
The author declares that there is no conflict of interest.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.