
Abstract
The study examines whether there is any difference between the effects of a reading–writing integrated task and comprehensive corrective feedback (CF) on English as a foreign language (EFL) learners’ writing development, and whether the input language in the integrated task makes a difference in L2 writing development over time and the language accuracy of the writing resulting from the integrated task. It also explores the possible relationships among language, content alignment and language accuracy and the relationship between language alignment and content alignment. To this end, a quasi-experimental study was conducted to assess participants’ L2 writing development based on a pretest–posttest–delayed-posttest design implemented in four intact EFL freshman classes. Four groups were created: an English-reading–English-writing (EE) group, a Chinese-reading–English-writing (CE) group, a comprehensive CF group, and a control group, which engaged solely in writing practice. The results demonstrated that (1) the EE and CF groups outperformed the control and CE groups on the posttest and outscored the control group on the delayed posttest with respect to language, although there were no significant differences among the three experimental groups in overall, content, and organization scores; (2) the input language of the integrated reading–writing task had a significant effect on language accuracy in the resulting essays; and (3) there was no significant correlation between content alignment and language accuracy for the CE group, whereas for the EE group, a significant positive correlation was observed not only between content and language alignment, on the one hand, and language accuracy, on the other hand, but also between content alignment and language alignment.
Keywords
I Introduction
The integration of language comprehension and production is receiving increasing attention from researchers in diverse fields, such as second language writing, psycholinguistics, second language assessment, and second language acquisition (SLA). For example, Pickering and Garrod (2004) argued from the perspective of psycholinguistics that interlocutors align at linguistic, situational, or general knowledge levels in dialogue. This contention implies that the integration of comprehension and production can prompt the representation of the less competent speaker to align with that of the more competent, correct speaker. Similarly, the efficient route to second language (L2) learning as proposed recently by Wang (2011) accentuates the integration of comprehension and production during interaction. Inspired by this idea, Wang (2012) further advanced the reading–writing continuation task to improve L2 learning, with learners completing an unfinished story. Wang maintained that tasks build creative use of language on imitation and expedite L2 learners’ use of newly encountered linguistic forms. This task particularly appeals to foreign language learners because foreign language learning is typified by an abundance of opportunities for written interaction but a paucity of oral interaction opportunities.
Notwithstanding its theoretical promise, little research is geared toward the integration of comprehension and production during oral interaction, and even less has been directed towards written communication as exemplified by reading–writing integrated tasks. In fact, a certain number of studies in the field of second language writing have compared the writing processes or products between writing-only tasks and reading/listening integrated writing tasks (e.g. Cumming et al., 2005; Plakans, 2008). The latter are in many ways similar to the continuation task and are thus deemed interchangeable in the present study. Cumming et al. (2005) noted that the products derived from independent and integrated reading/listening-writing tasks differed significantly in a number of discourse features, including lexical complexity, syntactic complexity, rhetoric, and pragmatics. With a focus on the writing process, Plakans (2008) reported that integrated reading–writing tasks elicited a more interactive process for some writers, whereas writing-only tasks called for more initial but less online planning, and that test-takers demonstrated a preference for the former. Most recently, Wang and Wang (2014) conducted a study involving a reading–writing continuation task to determine whether language alignment occurred as part of the task and whether language alignment bore on language accuracy in L2 learners’ writing. They compared the error rates of two groups: one in which the English version of a reading story was continued, and the other in which the Chinese version of the story was continued. The study found that the language adopted in the reading passage affected the alignment in language, which then influenced the error rate of the written products. These studies offered insights into integrated writing tasks. Nevertheless, none of them investigated the learning potential of integrated writing tasks by adopting a pretest–posttest–delayed-posttest design with a control group, whereas Wang and Wang (2014) accentuated this need. Therefore, one aim of the current study is to employ a more rigorous experimental approach to explore the learning potential of reading–writing integrated tasks in connection with English as a foreign language (EFL) writing development.
In the field of second language writing, considerable research attention has also been given to written corrective feedback (CF). However, to the best of our knowledge, no study compares the efficacy of integrated writing tasks with that of comprehensive CF in L2 writing. Accordingly, research comparing models and recasts in written form is greatly warranted on two counts. One is theoretical in that studies of this sort are informative on the issue of theoretical import. That is, such research would be helpful in resolving the theoretical conflict between Truscott (1996, 1999, 2004, 2007) and Ferris (2003, 2004) regarding the utility of written CF in SLA. Truscott makes a strong case that CF is ineffective and even harmful on both practical and theoretical grounds. The practical concern relates to both teachers and learners because teachers might not be capable of properly and consistently proffering feedback and students might not be able or willing to make use of this feedback. The theoretical concern stems from important insights of SLA theories (for more details, see Van Beuningen et al., 2012). The detractor, Ferris (2004), in contrast, advocates for the use of written CF in L2 writing, averring that supportive evidence has been amassed from various lines of research, including SLA research, L2 writing research, and student survey research. The current evidence appears to favour the latter (e.g. Sheen et al., 2009; Van Beuningen et al., 2012). The second justification is pedagogical in that written CF, although well received in L2 writing instruction, is time-consuming for and demanding of teachers. Therefore, if we could identify a more easily implemented approach, such as a reading–writing integrated task, that is superior or at least equivalent to written CF, it would be well received by L2 writing teachers. Accordingly, the current study fills this gap by determining whether a reading–writing integrated task, for which models are proffered, outperforms comprehensive CF, which is the written equivalent to oral recasts (Sheen, 2010), in which all linguistic errors in L2 learners’ writing are corrected. The determinations are based on overall and component scores, namely, scores for content, organization, and language/style.
The field of psycholinguistics and L2 research has witnessed a growing interest in the alignment of language use over the past few years (Wang & Wang, 2014). The aforementioned psycholinguistic conception of alignment is that in dialogue, the interlocutors become aligned at many levels, including the linguistic level, situational level, and level of general knowledge, and that one level of alignment can enhance other levels of alignment and that, conversely, the blocking of alignment at one level may induce blocking at other levels (Pickering & Garrod, 2006). For example, if one interlocutor uses the word chef, then the other interlocutor is more likely to use chef rather than cook; however, if the former opts for cook, then the latter will very likely follow suit and also use the term cook (Garrod & Anderson, 1987), which instantiates language alignment in dialogue. By extension, Wang and Wang (2014) strongly argue that in reading–writing integrated tasks, L2 learners tend to align in aspects of language and content-based situation models, and that alignment in content might facilitate alignment in language or vice versa.
In the fields of second language writing and assessment and SLA, some researchers have noted the use of source texts by L2 learners during integrated writing tasks (e.g. Plakans & Gebril, 2012, 2013; Wang & Wang, 2014; Weigle & Parker, 2012). Plakans and Gebril (2012) observed that this source use serves functions as varied as affecting writers’ opinions about the topic, proffering ideas on the topic, buttressing writers’ positions, and serving as a language repository. Plakans and Gebril (2013) examined how source text use predicts participant writing performance in a reading–listening–writing integrated task. The results of a hierarchical linear regression analysis indicated that the source text features accounted for 55% of the variance in scores on the task. Most recently, Wang and Wang (2014), in the only study known to us, considered whether an integrated task led to language alignment between reading passages and the resulting written products and, if this alignment occurred, how it affected the written products. The results clearly indicated that learners performing the English-to-English continuation task aligned with the English passage with respect to words and sentences such that the error rates for their written products were considerably lower than those of their counterparts performing the Chinese-to-English continuation task. This finding substantiated Wang and Wang’s hypothesis that error counts index language alignment between input and output. For example, the noun diamond is more likely to take its plural form in the former task because the plural form is used exclusively in the English passage, but is likely to manifest itself in its singular form in the latter task because no target language is provided.
The above three studies are informative with respect to alignment in integrated writing tasks. However, several limitations must be acknowledged. For example, only a few studies analysed both language and content alignment in such integrated tasks. Next, although Wang and Wang (2014) examined the impact of language alignment on language accuracy in the written products of an integrated task, the relationship between content alignment and language accuracy remains unexplored. Finally, whereas Wang and Wang (2014) contended that one level of alignment would enhance other levels based on Pickering and Garrod (2004, 2006), to the best of our knowledge, no empirical study has been designed thus far to verify this contention. However, a more fine-grained analysis of content and language alignment in integrated tasks would be helpful in explaining and supporting the short- and long-term effects of these tasks on L2 writing development.
Therefore, another objective of the current study is to explore L2 learners’ language and content alignment during such integrated tasks and to examine how this alignment is affected by the input language by proffering two types of integrated tasks: (1) reading an English argumentative essay and writing an English argumentative essay, and (2) reading a Chinese translation of that English essay and writing an English argumentative essay. More important, the present study aims to elucidate the potential relationship between content and language alignment, on the one hand, and language accuracy, on the other hand, and the relationship between content alignment and language alignment during the integrated tasks.
The limited research base and theoretical controversy prompt the present study to consider the following questions:
Is there a difference among the three experimental groups in terms of their effects on the overall writing scores and three component scores?
Do the essays resulting from the two types of integrated tasks differ in language accuracy? What is the possible relationship between the alignment in content and language and language accuracy in the essays resulting from the two types of integrated tasks? What is the possible relationship between language alignment and content alignment for the English-reading–English-writing (EE) group?
II Methods
1 Design and participants
The current study adopted a quasi-experimental design with a pretest, treatment, posttest, and delayed posttest. The 120 participants were from four intact classes of first-year non-English majors at a college in China, and all were native Chinese. Before entering college, they had studied English for 6 to 8 years; however, none had ever been abroad. Of the participants, 78 were female, and ages ranged from 17 to 19. At the onset of the experiment, the participants’ English scores on the national matriculation examination (NME) were collected and were assumed to represent their language proficiency at the time of the experiment, which was conducted shortly after they took the NME. Their NME scores placed them at the intermediate proficiency level of English learners. At the time of the investigation, the participants were taking a compulsory 100-minute English class twice a week, in which the prevailing teaching method was the integration of the traditional focus-on-forms method and the communicative teaching method. The four intact classes were randomly assigned to one of three experimental groups and a control group, each with 30 participants. The experimental groups participated in two treatment sessions between the pretest and the posttest, whereas the control group only took part in writing practices and tests. The posttest was completed during the week after the second treatment session, and the delayed posttest was conducted two weeks after the posttest. During each testing session, an impromptu writing test was administered to detect potential improvement in the participants’ writing ability. The design of the study is schematized in Figure 1.
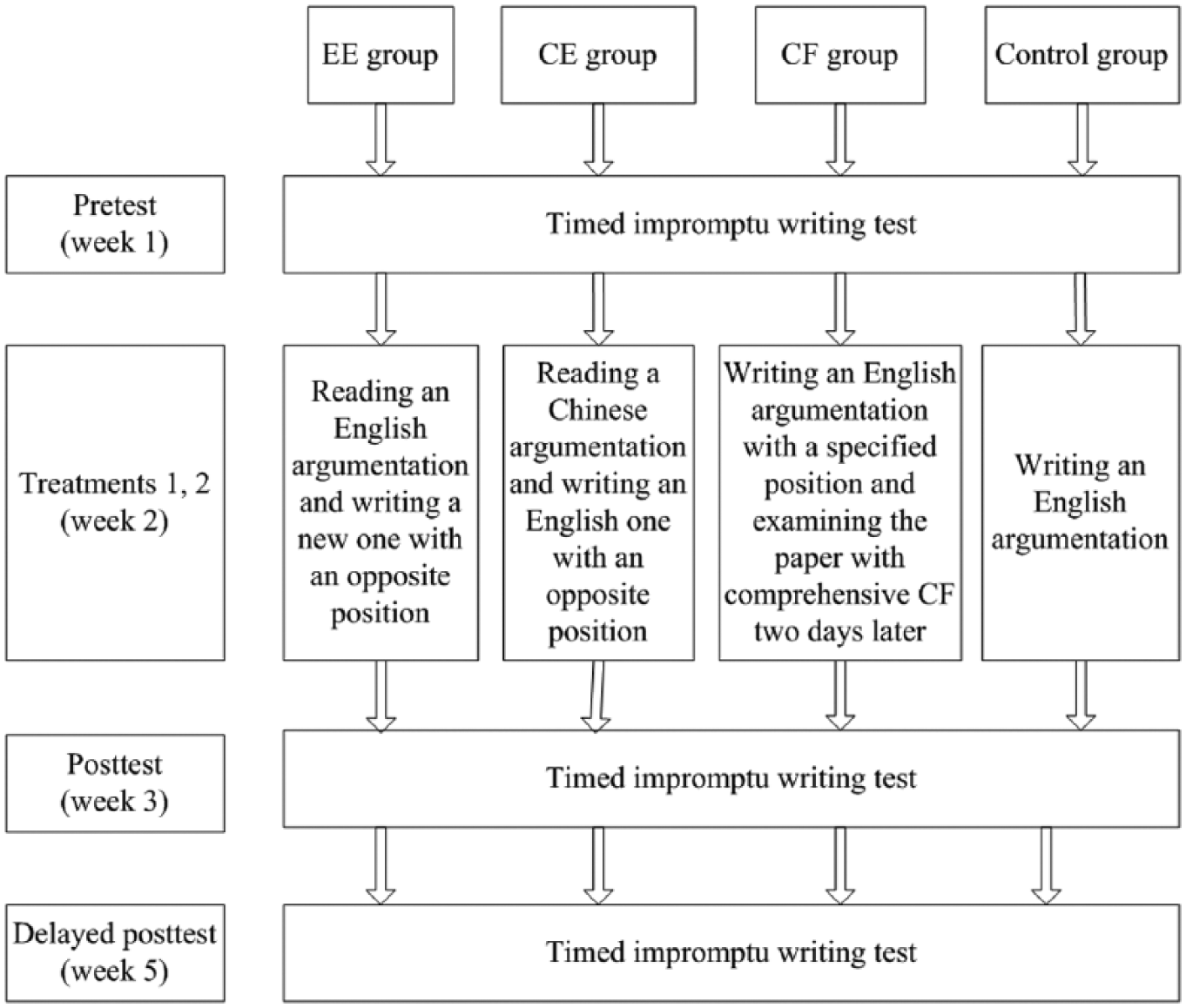
Design of the study.
2 Treatment
Two topics for treatment tasks were selected after consulting with many English teachers working with students of the same population as the participants. The topics were mistakes and law, both of which effectively held the participants’ interest and elicited clear positions for argumentation. The two topics were piloted with 30 students from a comparable population to determine the time allotment and assess the clarity of the instructions. The pilot study required the participants in the EE group to underline the words they found difficult to understand. On the basis of their responses, a word list consisting of the 6 most frequently noted difficult words together with their Chinese translations was proffered after the reading passage to both integrated groups and after instruction to the CF group. It was determined that 70 minutes should be allocated for each writing task, and the instructions specified that participants in the two integrated task groups should incorporate any appropriate information or ideas from the reading passage in relation to content, organization and language, and that the essays would be evaluated according to these three aspects. For the comprehensive CF group, the 70 minutes consisted of 50 minutes for the initial writing and 20 minutes for feedback review, thus ensuring that time was kept constant across the three experimental groups during the treatments.
The participants attended two separate sessions, three days apart. During the first session, the EE group was instructed to read one English argumentative essay of slightly more than 400 words, which promoted a certain view. The group was then instructed to write a new argumentative essay that supported the opposing view to that presented in the article. In contrast to the EE group, the Chinese-reading–English-writing (CE) group was required to read the Chinese version of the English argumentative essay before writing their argumentative essay in English. Both groups were encouraged in the instructions to incorporate what appeared in the reading passages as much as possible, including organization, ideas, and linguistic forms. To ensure the comparability of the different treatments, the CF group was instructed to write about the same topic from the same position as the other experimental groups. That is, they were to write an argumentative essay that presented the opposing view of that espoused in the reading passage. The researcher identified all linguistic errors (including grammatical errors, errors concerning word use, and spelling errors) by underlining them and writing the correct forms above the errors. Two days later, the participants’ writing together with the comprehensive CF on their writing were returned, and the participants were then given approximately 20 minutes to carefully review the corrective comments. During these 20 minutes, the participants were to read the corrected writing and review each corrected error. At the end of this period, the writing was collected again by the researcher.
During the second session, the participants in the specific groups went through the same procedure as that of the previous session, although they were given another writing task, namely, writing an argumentative essay from a specific perspective. The instructions for the treatment tasks in the first session are presented in Supplementary data 1.
3 Assessment tasks and scoring
Three comparable versions of timed impromptu writing tests were developed to assess the degree of advancement that the participants demonstrated in their writing ability (Supplementary data 2). The three writing tasks were piloted with 30 Chinese EFL learners from a comparable population. A one-way repeated ANOVA was conducted to ascertain that there were no significant differences among the versions (F(2, 58) = 1.161,p = .320, η2 = .038). To preclude the possibility that the three versions of the writing tasks presented differing levels of difficulty for the participants in the main study, the tasks were counterbalanced for each group in each testing session. During each testing session, the participants, irrespective of their group assignment, were asked to write, in a 60-minute period, an argumentative essay of 200 to 300 words in which they either defended or refuted a particular view. Their essays were scored using an analytical rating scale borrowed from Kobayashi and Rinnert (1992) because such analytic ratings could offer greater insight into the similarities and differences among the effects of the different treatment conditions than could holistic ratings. The ratings consisted of assessments on a 5-point scale for each of 11 analytical subcomponents, which constituted the three main components (Supplementary data 2). The overall score and the three component scores were tallied separately and functioned as the dependent variables for the study.
Two experienced EFL writing teachers were responsible for scoring the essays, and a third rater was used to resolve disagreements. The Pearson correlation coefficients of the two raters’ scores for the three components (content, organization, and language) ranged from .88, .90, and .86, respectively. The final scores were the average of the two raters’ scores.
4 Coding
a Alignment coding
For the two integrated experimental groups, the alignment between the participants’ essays and the source passages was examined with respect to two factors, namely, content and language. All the coding was performed on the first integrated writing task due to logistic limits. It was imperative to code the alignment separately for each of the two factors.
Regarding content, T-units in the body of the participants’ essays were first identified and were then subjected to further discrimination between T-units derived from the source passage and those originating from the participants’ original thoughts, following Plakans and Gebril’s (2013) methodology. T-units are defined by Hunt (1977) as ‘a single main clause (or independent clause) plus whatever other subordinate clauses or non-clauses are attached to, or embedded within, that one main clause’ (p. 93). In this particular analysis, aligned/borrowed T-units were operationalized as T-units in both the reading passage and the participants’ essays that were similar to or directly opposite each other in terms of meaning. The rationale for including the semantically square opposite T-unit was that such ideas were very likely inspired by the reading passage. It should be noted that for both integrated experimental groups, aligned T-units were identified between the English reading passage and the participants’ essays. This decision further allowed for easy comparison between these two groups in connection with content alignment and was justified by the fact that the Chinese reading passage was an accurate translation of the English reading passage. One reason why the analysis of content alignment was confined to the body of the essay was that the preliminary analysis of the entire essay indicated that both the introductions and the conclusions were consistently aligned with the reading passage for both integrated groups. Consequently, because the coding of these sections contributed little new information, it was decided to ignore these sections and focus only on the body of the essay. Furthermore, because the task asked the participants to argue the opposite position of that presented in the reading, the body of the essay contained more important content that did the introduction and conclusion. Two raters marked borrowed T-units from the source passage for each essay. Rater agreement was verified for each T-unit in the pilot study of 20 essays, with a satisfactory agreement rating of 89, and for the contested T-units, a third rater was employed to resolve disagreements. In the present study, the inter-rater correlation coefficient was .90.
The next step was to rank the borrowed T-units from 1 to 4 in terms of importance in the source passage, reflecting the specificity of ideas in the T-units, as done by Plakans and Gebril (2013). This ranking was performed because the importance of source text ideas affects writing performance (Plakans & Gebril, 2013). Specifically, the main argument of the entire essay received a score of 4, sub-arguments received a score of 3, supporting details and examples received a score of 2, and minor details received a score of 1. The rankings fell into a continuum of specificity from more general to more specific. The same two raters ranked the level of importance of the T-units from the first English source passage, and the final rankings were determined based on their agreement, yielding an inter-rater correlation coefficient of .94. The rank scores of all the borrowed T-units were totalled for each essay and then converted into a proportion for analysis by first dividing that total score by the total number of T-units in the body of the essay and multiplying the resultant score by 10, which indicates the importance score of the borrowed T-units per 10 T-units. A 10 T-unit ratio was used because the body of the participants’ essays contained, on average, approximately 10 T-units. One sample appears in Supplementary data 3.
Regarding linguistic alignment, word strings of 3+ words were targeted. That is, the coders manually identified strings of 3+ words in essays when they were traceable to the source text. According to Cumming et al. (2005), the length of three words neither over- nor under-identifies the exact source use. After the strings were identified, the number of aligned words was tallied and further totalled for each essay. This totalled number was transformed into a proportion by first dividing it by the total number of words and then multiplying the resultant number by 200, thus indicating the frequency of borrowed words per 200 words. One sample appears in Supplementary data 4.
b Linguistic accuracy coding
The essays derived from the first treatment task by the two integrated groups were coded for linguistic errors. The researcher was responsible for coding all the essays, and the entire process was blind. Another assistant recoded 10% of the data, resulting in an inter-rater reliability of .99. As practised in past studies on written CF (e.g. Van Beuningen, De Jong, & Kuiken, 2012), an error ratio was calculated to index overall accuracy, namely, [number of linguistic errors/total number of words] × 100.
III Results
1 Comparisons of the four groups
The first research question examined whether the three experimental groups differed significantly in terms of the overall score and the three component scores (i.e. content, organization, and language). Tables 1–4 include the descriptive statistics for the overall writing score and the three component scores for all four groups over the three testing periods. To establish the comparability of the groups at the onset of the study, one-way ANOVAs were performed on the overall score and the three component scores of the pretest and the NME scores for English. The results revealed no initial group differences in overall writing, F(3, 116) = .457, p = .713, η2 = .012; content, F(3, 116) = .642, p = .589, η2 = .016; organization, F(3, 116) = .815, p = .488, η2 = .021; language F(3, 116) = .739, p = .531, η2 = .019; or English language proficiency, F(3, 116) = 2.179, p = .094, η2 = .053.
Descriptive statistics for overall writing score by condition and session.
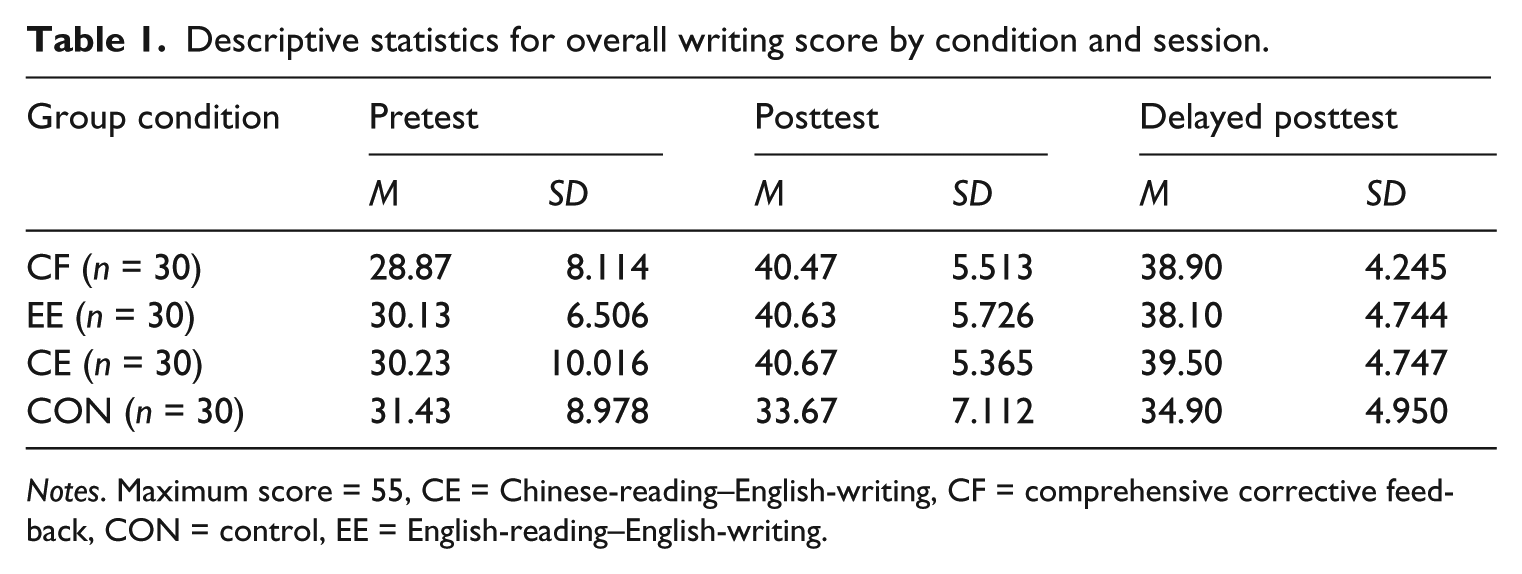
Notes. Maximum score = 55, CE = Chinese-reading–English-writing, CF = comprehensive corrective feedback, CON = control, EE = English-reading–English-writing.
Descriptive statistics for content score by condition and session.
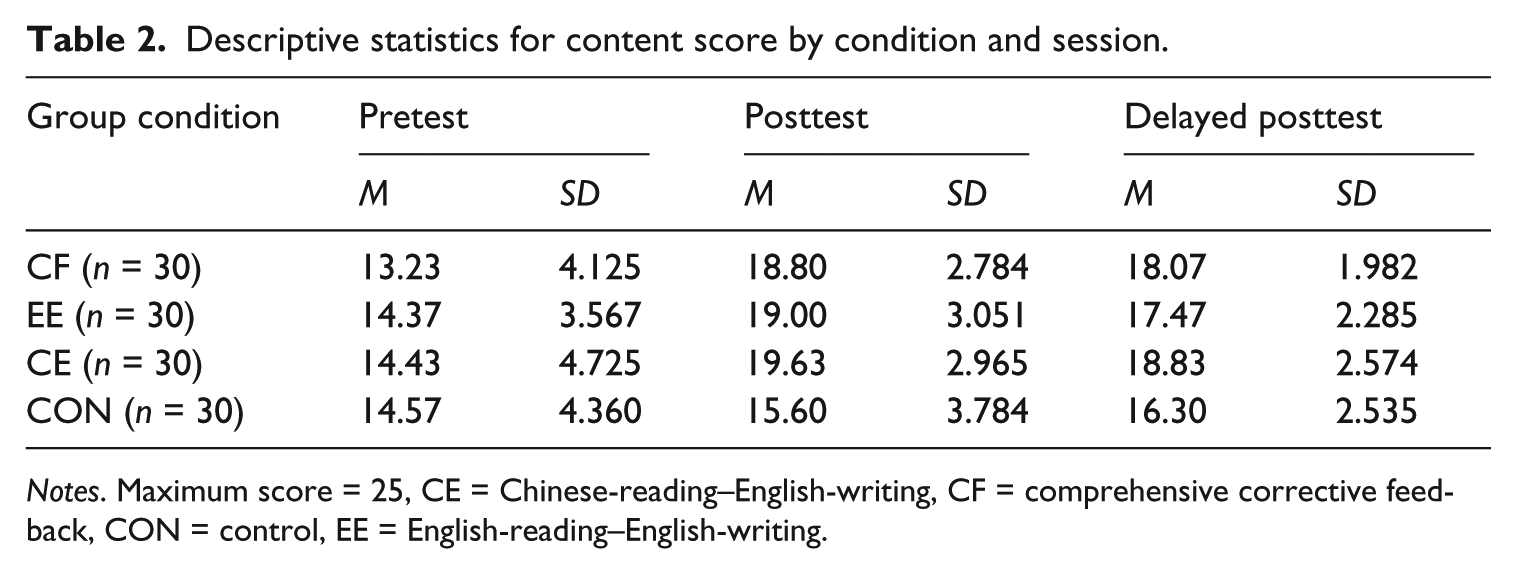
Notes. Maximum score = 25, CE = Chinese-reading–English-writing, CF = comprehensive corrective feedback, CON = control, EE = English-reading–English-writing.
Descriptive statistics for organization score by condition and session.
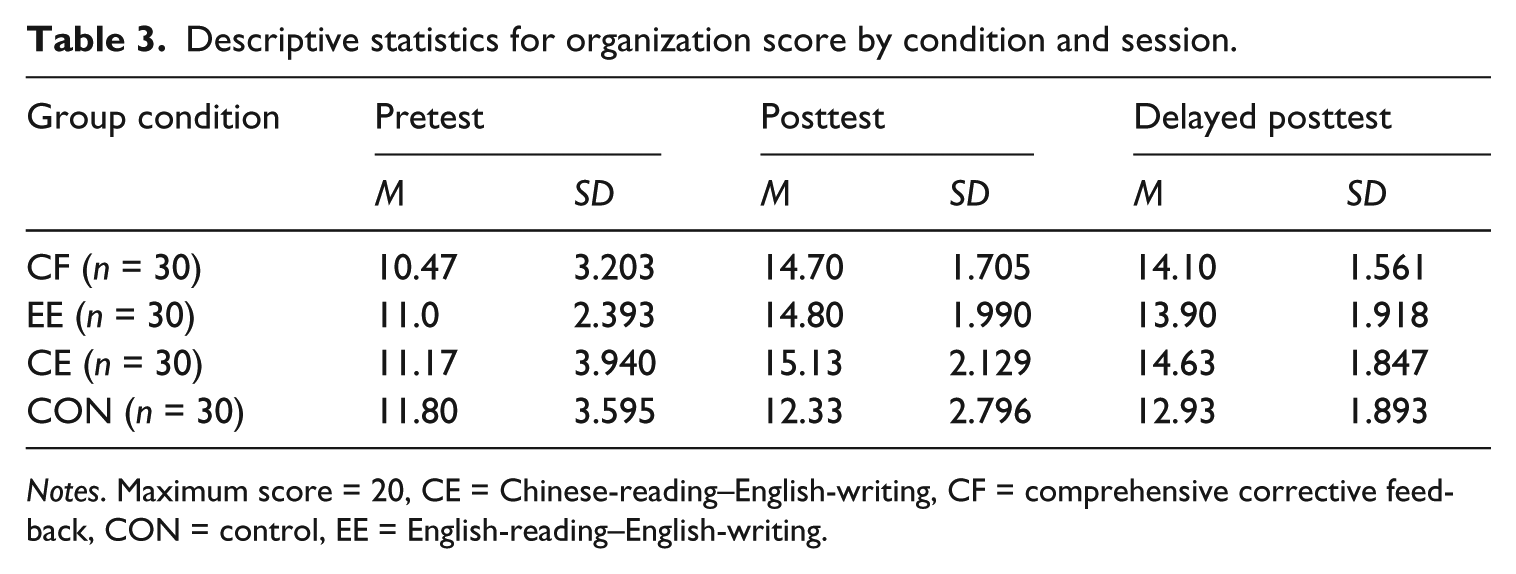
Notes. Maximum score = 20, CE = Chinese-reading–English-writing, CF = comprehensive corrective feedback, CON = control, EE = English-reading–English-writing.
Descriptive statistics for language score by condition and session.
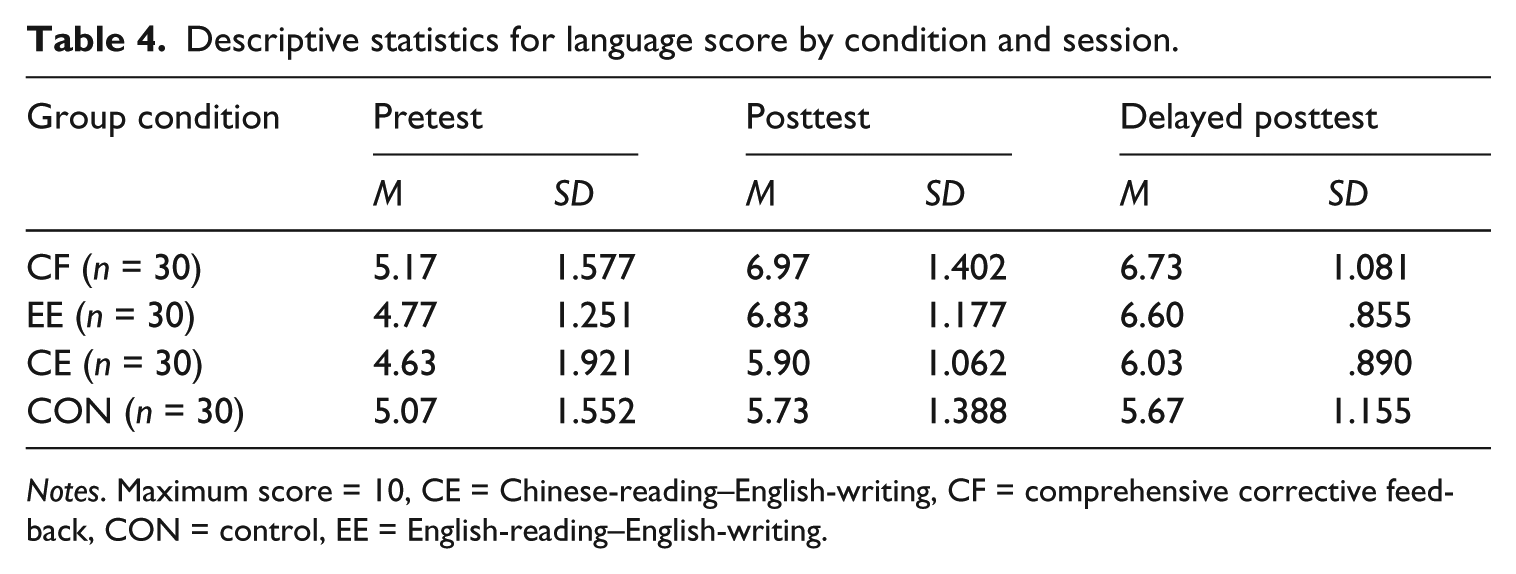
Notes. Maximum score = 10, CE = Chinese-reading–English-writing, CF = comprehensive corrective feedback, CON = control, EE = English-reading–English-writing.
The results of the mixed two-way ANOVA on the overall writing score showed a significant main effect for group (F(3, 116) = 2.876, p = .039, η2 = .069) and time (F(1.754, 203.460) = 100.650, p = .000, η2 = .465) and also a significant interaction between group and time (F(5.262, 203.460) = 5.570, p = .000, η2 = .126). To statistically examine the differences between pairs of groups, one-way ANOVAs with the posthoc comparisons were conducted on the posttest and the delayed posttest, revealing significant differences among the groups on both the posttest (F(3, 116) = 10.091, p = .000, η2 = .207) and the delayed posttest (F(3, 116) = 5.751, p = .001, η2 = .129). More specifically, the three experimental groups outperformed the control group on the posttest (p = 0 in all cases), and the CF and CE groups exhibited significantly better writing performance than did the control group on the delayed posttest (p = 0 in all cases). Additionally, the difference between the EE group and the control group on the delayed posttest approached significance (p = .055). However, the three experimental groups were not distinct from each other on either of the posttests (p = 1 in all cases).
Four one-way repeated measures ANOVAs showed that the control group did not demonstrate significant progress over time (F(2, 58) = 2.787, p = .070, η2 = .088), whereas all three experimental groups did: the CF group (F(2, 58) = 45.977, p = .000, η2 = .613); the EE group (F(2, 58) = 48.792, p = .000, η2 = .627); and the CE group (F(1.672, 48.474) = 32.436, p = .000, η2 = .528). Particularly for the CF and CE groups, the gains between the pretest and the posttest (p = .000 for both) and between the pretest and the delayed posttest (p = .000 for both) were significant, although the learners failed to progress significantly from the posttest to the delayed posttest (p = .486; p = .862, respectively). With respect to the EE group, all the pairwise differences were significant as follows: between the pretest and posttest p = .000, between the pretest and delayed posttest p = .000, and between the posttest and delayed test p = .016.
In short, in terms of overall score, the three experimental groups not only exhibited significantly better performances than did the control group but also demonstrated significant progress over time. However, no significant differences were detected among the three experimental groups.
The effects of the distinct treatments on the three component scores – content, organization, and language – were then analysed to determine whether the effects were disguised by the overall score.
The results of the mixed two-way ANOVA on the content score revealed a significant main effect for group (F(3, 116) = 3.792, p = .012, η2 = .089) and time (F(1.835, 212.900) = 82.254, p = .000, η2 = .415), and a significant interaction between group and time (F(5.506, 212.900) = 4.988, p = .000, η2 = .114). One-way ANOVAs with the posthoc comparisons were run on the posttest and the delayed posttest. It was determined that in the posttest, the three experimental groups significantly outperformed the control group (p < .05 in all cases), whereas the experimental groups themselves were indistinguishable from each other (p = 1 in all cases). In the delayed posttest, despite no significant differences among the three experimental groups (p > .10 in all cases), only the CF and CE groups exhibited significantly better performance than the control group (p < .05 in all cases).
Regarding the score for organization, a slightly different pattern was observed. The mixed two-way ANOVA revealed a significant main effect for time (F(1.701, 197.322) = 78.615, p = .000, η2 = .404) and also a significant interaction between group and time (F(5.103, 197.322) = 5.306, p = .000, η2 = .121) but no significant main effect for group (F(3, 116) = 2.553, p = .059, η2 = .062). To examine the differences between pairs of groups, one-way ANOVAs with the posthoc comparisons were performed on the posttest and the delayed posttest. The analyses revealed that on the posttest, the three experimental groups were significantly superior to the control group (p = .000 in all cases), whereas the three groups themselves did not differ significantly from each other (p = 1 in all cases), and that in the delayed posttest, only the CE group outscored the control group (p = .002), while the three experimental groups still failed to differ significantly from each other (p > .700 in all cases).
With respect to the language score, the mixed two-way ANOVA revealed a significant main effect for group (F(3, 116) = 5.129, p = .002, η2 = .117) and for time (F(2, 232) = 66.864, p = .000, η2 = .366), and a significant interaction between group and time (F(6, 232) = 2.955, p = .008, η2 = .071). A one-way ANOVA with the posthoc comparisons on the posttest identified significant differences between the CF and EE groups, on the one hand, and the CE and control groups, on the other hand (p < .005 in all cases), but found no significant differences within the first two groups or the last two groups (p > .900 in all cases). The results of the one-way ANOVA with the posthoc comparisons on the delayed posttest indicated that despite there being no significant difference between the CF and EE groups (p = 1), the former outscored both the CE group (p = .047) and the control group (p = .000), whereas the latter only outperformed the control group (p = .003). Moreover, the difference between the CE and control groups did not reach statistical significance (p = .957).
Taken together, with respect to content and organization, all three groups were superior to the control group on the posttest, whereas the CE group performed better on the delayed test and was the only group to perform better than the control group on both tests. In contrast, with respect to language, the EE group did not pale in comparison to the CF group because both performed better than the CE and control groups. Furthermore, the two did not differ significantly from each other.
2 Input language, content alignment, language alignment, and language accuracy
The second question investigated whether the essays resulting from the two types of integrated tasks differed in language accuracy, the possible relationship between content and language alignment, on the one hand, and language accuracy, on the other hand, for the CE and EE groups, and the relationship between language alignment and content alignment for the EE group. Although each participant in each integration group performed two integrated tasks, to minimize the demands of the research, the following analysis involved only the first integrated task. The results are presented in the following section.
a Effects of input language on language accuracy
The descriptive statistics for language accuracy, itemized by group assignment, are displayed in Table 5. As evidenced in the table, the mean frequencies of linguistic errors for the EE and CE groups were 4.90 and 9.67 per 100 words, respectively. To ascertain whether the two groups differed significantly, an independent sample t test was conducted on language accuracy. The findings reveal that the EE group committed significantly fewer errors than did the CE group (t = −7.655, df = 58, p = .000).
Descriptive statistics for language accuracy by group condition.
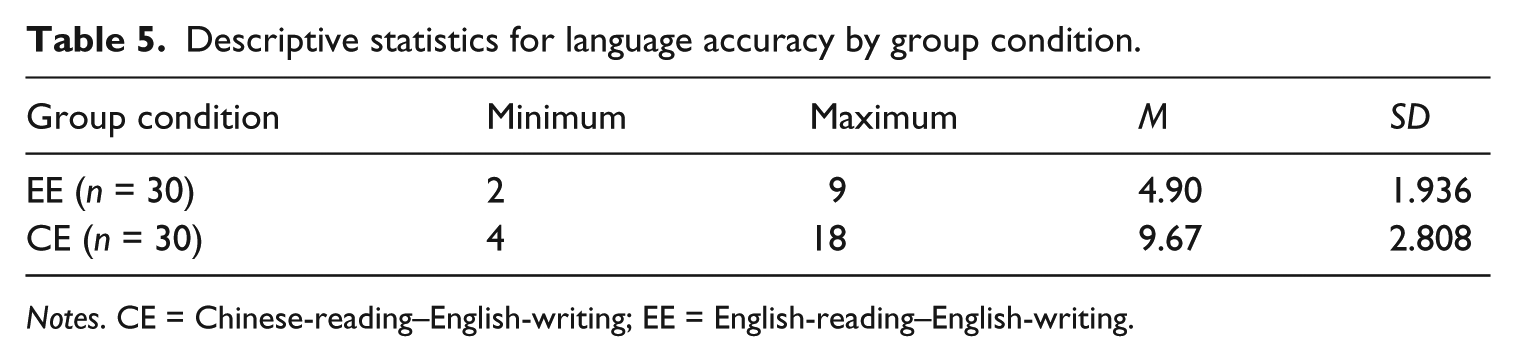
Notes. CE = Chinese-reading–English-writing; EE = English-reading–English-writing.
b The relationships among content, language alignment, and language accuracy, and between content alignment and language alignment
Tables 6 and 7 summarize the descriptive statistics of content and linguistic alignment for the integrated groups. Regarding content alignment, 20 of 30 participants in the EE group exhibited content alignment in that they borrowed T-units from the original English reading text. Similarly, 15 of 30 participants in the CE group borrowed T-units from the corresponding Chinese reading text. To further examine the relationship between content alignment and language accuracy, two Spearman correlational analyses were performed for the two experimental groups 1 . The results indicate that content alignment ratings were negatively associated with the error rate for the EE group, r = –.415, p = .023, whereas no such relationship was observed for the CE group, r = .246, p = .191. Thus, for the EE group, the more important T-units the participant borrowed from the original reading passage, the fewer mistakes the participant was likely to make. However, the same did not hold for the CE group.
Descriptive statistics for content alignment by group condition.

Notes. CE = Chinese-reading–English-writing; EE = English-reading–English-writing.
Descriptive statistics for linguistic alignment of the EE group.

Note. EE = English-reading–English-writing.
With respect to language alignment, all 30 participants exhibited language alignment in that they all borrowed word strings of 3+ words from the original English reading text. These analyses revolved around the EE group because no English was proffered to the CE group. A Pearson correlational analysis was performed for the EE group, revealing that the error rate negatively correlated with language alignment, r = –.410, p = .024. That is to say, for the EE group, the more word strings the participant borrowed from the original reading composition, the less likely the participant was to make mistakes. Another Spearman correlational analysis run between content alignment and language alignment found a positive association between the two, r = .611, p = .000, with the implication that the more important T-unit alignment the EE group participants incorporated in their integration task, the greater their degree of language alignment tended to be.
IV Discussion
1 Comparisons of the four groups
The first research question sought to determine whether there were significant differences among the three experimental groups with respect to the overall score and three component scores. It was determined that the overall score and the content and organization scores failed to distinguish among the three experimental groups over time. However, with respect to language, significant differences were detected between the EE and CF groups, on the one hand, and the control and CE groups, on the other hand, on the posttest, and between the EE and CF groups, on the one hand, and the control group, on the other hand, on the delayed posttest. Additionally, the difference between the CF and EE groups did not reach statistical significance on either of the posttests, and the CF group rather than the EE group outperformed the CE group on the delayed posttest.
The finding that both the CF and EE groups, which were indistinguishable from each other, were superior to the CE and control groups in terms of language supports Ferris’ position regarding written CF, while it contradicts Truscott’s claim. It also lends credence to Wang’s (2011, 2012) advocacy of reading and writing continuation tasks. The finding that the CF group outperformed the control group regarding language offers compelling evidence that written CF is effective in improving language accuracy. The explanation for this finding may be found in Carroll’s (2001) autonomous induction theory, which claims that to be effective, CF must direct learners’ attention to the errors that they have made. As strongly argued by Sheen (2010), written CF is explicit in nature, thus suggesting that it is likely to be noticed by learners and will thus lead to improved performance on the posttests.
The EE group exhibited a significantly better performance than the control group in terms of language, which attests to the strength of the integrated reading–writing task. Such tasks lead the learner to align with the correct and appropriate language in the reading passage, which thus results in lower error rates in the integrated writing, as confirmed by Wang and Wang (2014). Given that both the posttest and the delayed test involved argumentative writing, it is highly possible that some words and sentence patterns utilized in the integrated treatment tasks were useful on the posttests. Moreover, the usage-based theories inform us that token frequency determines the degree of entrenchment and the accessibility of certain expressions (Tomasello, 2003). In other words, the more we use certain expressions, the more likely those expressions are to be used in the future. This idea suggests that the correct and appropriate expressions and sentence patterns used by the participants in the treatment might be extended to the posttests, which accordingly resulted in a higher language quality on the posttests. Close scrutiny of several participants’ posttests and delayed posttest essays affirmed this theory. For example, the phrase ‘in sum’ was used in the concluding paragraph by one participant across the integrated task and the posttests, while no such summarizing word was contained in the concluding paragraph of the pretest. In another, more illustrative example, on the pretest, the participants tended to use the phrase, ‘I agree/disagree this view’, while on the posttests, the phrase was more often written correctly as ‘I agree/disagree with this view’.
In sharp contrast, the CE group was inferior not only to the EE group but also to the CF group in terms of language, which could be accounted for by the absence of language alignment because no target language input was available to the CE group. Even worse, the Chinese language input might have induced more L1-transfer errors in that some word-for-word translations might have been used in the integrated treatment task and then extended to the posttests. An examination of some participants’ essays proved this to the case. For example, the aforementioned ‘I agree/disagree with this view’ statements, as observed in the essays of the EE group, were incorrectly written as ‘I agree/disagree this view’, ‘I’m very agreed’, or ‘I am disagree the view’ in the essays of the CE group, which were in no sense appropriate.
In regard to organization and content, although the performances of the three experimental groups were superior to that of the control group on the posttest, the differences among the three experimental groups were negligible. Unlike language use, knowledge of organization is easy for learners to grasp and apply in their writing. Given that prior to the experiment, the participants had learned the organizational pattern of argumentative writing, that the treatment tasks given to both the EE and CE groups offered the model concerning organization irrespective of the input language used, and that the comprehensive linguistic CF might raise participants’ metalinguistic awareness such that knowledge concerning organization might be activated at the same time, the three experimental groups were not distinct from each other but outperformed the control group in the short term. This effect was maintained in the long term as revealed by the descriptive statistics, although the EE and CF groups could not be differentiated from the control group. With respect to content, no significant differences among the three experimental groups are traceable to the fact that the two integrated groups were proffered the same content regardless of the language used. Furthermore, CF given to the CF group, although focusing on language, may also have influenced content, as argued by Wang and Wang (2014), who contend that alignment at the level of language may facilitate the alignment of content. In other words, the three types of treatment may have equally influenced the content of the posttest. This effect was also maintained on the delayed posttest, although there was no significant difference between the EE group and the control group.
This finding has important pedagogical implications. While the EE task did not pale in comparison to that of the CF but was more easily implemented, it has great potential to be utilized in L2 writing classrooms and be embraced by both L2 writing teachers and students. First, as emphasized by Ferris (1996, 2010), most L2 writing teachers are unable to offer comprehensive CF due to limited time, patience, and expertise and thus consider providing CF to be one of the most time-consuming and exhausting parts of their work. Second, as noted by Wang and Wang (2014), the foreign language learning setting is characterized by a paucity of interactions with native speakers of the target language such that integrated tasks can readily serve as a surrogate for oral interaction, which instantiates the intimate coupling of comprehension and production but can cause increased anxiety for L2 learners.
2 Input language, content alignment, language alignment, and language accuracy
The second question addresses whether the essays resulting from the two types of integrated tasks differed in language accuracy and explores the possible relationship between content and language alignment, on the one hand, and language accuracy, on the other hand, for the CE and EE groups and the relationship between language alignment and content alignment for the EE group. It was found that the input language exerted a significant effect on language accuracy such that the EE group exhibited significantly higher language accuracy than did the CE group. Additionally, no significant correlation was observed between content alignment and language accuracy for the CE group, whereas for the EE group, a significant positive correlation was detected between content and language alignment, on the one hand, and language accuracy, on the other, and between content alignment and language alignment.
The finding that the input language in the integrated task had a significant effect on the language accuracy of the resulting essays illuminates the role of language alignment in L2 writing development. The previous reasoning presupposed that for the EE group, the target language was available such that the correct and appropriate language in the reading text was incorporated into the participants’ writing. This presupposition was then borne out by the finding that all 30 participants in the EE group manifested language alignment. Such language alignment ineluctably constrained the occurrence of errors. In sharp contrast, for the CE group, because Chinese was used, the participants not only did not have access to the target language but also turned to Chinese for help, thereby producing many L1 transfer errors.
When the relationship between content and language alignment on the one hand and language accuracy on the other hand was examined, a difference was again observed between the two groups. For the CE group, no correlation was found between content alignment and language accuracy. This finding was conceivable given that content alignment could not facilitate language alignment due to the absence of the target language in the reading text. Thus, with the lack of language alignment, language accuracy could not be enhanced. A different picture was presented with respect to the EE group in that a positive correlation existed not only among content, language alignment, and language accuracy but also between content alignment and language alignment. This finding is consistent with the contention of Wang and Wang (2014), built on that of Pickering and Garrod (2004); that is, one level of alignment during a reading–writing integrated task can promote alignment at another level. With respect to the EE group, content alignment could facilitate language alignment, which, in turn, would contribute to language accuracy.
V Conclusions
This study has advanced existing research on written CF and reading–writing integrated tasks by comparing the effect of comprehensive written CF and positive input manifested in integrated tasks and by investigating the long-term effects of integrated tasks more rigorously. The results indicate that in terms of language, the EE and CF groups exhibited significantly better performance than the control group over time, with the CF group performing slightly better than the EE group. This result occurred because although both significantly outscored the CE group on the posttest, only the former performed better than the CE group on the delayed test. Aside from the aforementioned differences, the three experimental groups were indistinguishable from each other with respect to overall, content, and organization scores.
The present study has also advanced the line of research on alignment in integrated writing tasks, not only because it considered both content alignment and language alignment but also because, for the first time, the relationships among input language, content and language alignment, and language accuracy were examined more systematically. The findings indicate that the input language of the integrated tasks had a significant effect on language accuracy and that for the CE group, there was no significant correlation between content alignment and language accuracy, while for the EE group, a positive significant correlation was observed not only between content and language alignment, on the one hand, and language accuracy, on the other hand, but also between content alignment and language alignment.
The findings are insightful in that they clarify the controversy involving CF in written communication and enrich our understanding of alignment in L2 writing development. Nevertheless, several qualifications must be considered. Because the participants were exclusively Chinese EFL learners, it remains unknown whether the same applies to L2 learners with other L1 backgrounds. Thus, the generalizability of the findings is uncertain. Furthermore, because we have only considered content and language alignment in the integrated tasks, organization alignment during such tasks is a topic for future research. An additional factor relates to the genre of the writing task. Because the current study focused on argumentation, evidence on other types of writing is lacking and therefore is called for to achieve further clarification.
Footnotes
Supplementary data 1
Treatment materials for the experimental groups.
Supplementary data 2
Supplementary data 3
Supplementary data 4
Acknowledgements
The author thanks the two anonymous reviewers for their helpful comments on the earlier versions of the article, and all students who participated in the study.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a grant from the Science and Technology Department of Shaanxi Provincial Government of China (2013KRM2-07), and a grant from Xi’an University of Finance and Economics, China (13xcj31).