
Abstract
Second language (L2) listening skills play an important role in both content- and language-focused academic success; however, provision of L2 listening-related pedagogy may be lacking or unsuitable in many contexts. Difficulties transposing research derived knowledge about listening processes to appropriate pedagogy arise because it can be difficult to monitor learners’ L2 listening activities, much research uses group-based data which can be difficult to extrapolate to individual needs, and comprehension and related factors are often measured using static metrics. For educators, situated, learner-centric accounts of listening processes, difficulties, and related responses may enable more appropriate listening-related pedagogy; therefore, this study used idiodynamic methodology to capture the dynamic nature of listening comprehension and to elicit rich accounts of learners’ experiences as they watched English medium instruction (EMI)-situated presentations. The data provides evidence of previously-uncaptured comprehension-related volatility during a single presentation, and different comprehension patterns across presentations and between learners. Idiodynamic methodology further allowed the researcher to pinpoint which listening difficulties – e.g. top-down, bottom-up, knowledge- and vocabulary-related – impacted which learner at any specific moment of the presentations. These results can help provide targeted L2 provision in language and EMI programs, and give guidance to EMI providers as to the level-appropriateness of their programs.
Keywords
I Introduction
English as a medium of instruction (EMI), which is defined as ‘The use of the English language to teach academic subjects in countries or jurisdictions where the first language (L1) of the majority of the population is not English’ (Dearden, 2014, p. 2), has become a global phenomenon (see Macaro et al., 2018; Murata, 2018). In such an environment, successful academic and linguistic development is dependent on learners developing sufficient second language (L2) listening skills to follow teacher directions, understand lecture content, and understand peer- and instructor-generated content across a wide variety of class types.
It has, however, been reported that L2 listening skills are undertaught (Vandergrift & Goh, 2012) and/or suffer from a restricted focus on either a product-orientated approach (Siegel, 2014) or on top-down focused instruction (Siegel & Siegel, 2015).Top-down approaches use pre-existing mental schema to develop meaningful inferences from an aural text; however, Swan and Walter (2017) argue that teaching these skills does little to augment L2 listening ability as they already exist in the L1. Similarly, product-orientated approaches have been criticized for repeatedly testing learners’ listening ability without teaching listening skills (Brown, 1986; Kaur, 2017; Sheerin, 1987).
Difficulties in developing appropriately targeted L2 listening pedagogy may stem from a combination of the ‘invisible’ and complex interaction of multiple listening processes, difficulties in measuring comprehension and related factors as they change throughout the duration of an aural text, and difficulties in extrapolating relevant advice from group-based empirical research to individual learners. Therefore, to help develop appropriately focused listening pedagogy, this research uses idiodynamic methodology to uncover the complex and dynamic nature of learners’ listening-related difficulties and their associated responses while watching their peers’ EMI graduation thesis presentations.
II Literature review
1 Difficulties in EMI education
EMI seemingly offers pedagogical efficiency by simultaneously providing learners with academic content and opportunities to acquire English (Brinton, Snow & Wesche, 2003; Coleman, 2006; Smit & Dafouz, 2012). The efficacy and effectiveness of EMI, however, remains unproven. While Macaro et al. (2018) reported that worries about language proficiency are noted by both students and teachers in many contexts around the world, Galloway, Kriukow & Numajiri (2017) found students around the globe struggling with topic comprehension, longer times to complete courses, increased dropout rates, and reduced motivation related to comprehension difficulties in EMI courses. In the Japanese context, Chapple (2015) reported high dropout rates for students enrolling in an EMI program, while Chapple (2015) and Uchihara and Harada (2018) noted that students had to resort to a wide range of compensation methods, such as borrowing notes from international students and making audio recordings of lessons, to make up for English-related difficulties.
Further empirical data support teachers’ and students’ concerns about language proficiency. Li (2018) found that English competence was the strongest predictor of academic success in a Chinese university’s bilingual early childhood education program. Similarly, a study by Xie and Curle (2020) found a strong relationship between business English proficiency and students’ end-of-term scores for an EMI marketing course in a separate Chinese institution. In the Japanese university context, Rose et al. (2019) found that English language proficiency and academic English skills were statistically significant predictors of academic success in EMI.
Of the 4 major English skills domains, aiding learners to develop proficient L2 listening skills, both inside and outside of EMI contexts, should be a high priority for educators (Rubin, 1994; Turan Öztürk & Tekin, 2020). In EMI, successful academic and linguistic development is dependent on learners developing sufficient L2 listening skills to follow teacher directions, understand academic content, and understand peer- and instructor-generated utterances across a wide variety of class types. Furthermore, good listening skills are considered to facilitate the development of other L2 skills (Candlin, 2013; Rost, 2002; Vandergrift, 2007); in this regard, Uchihara and Harada (2018) found that Japanese EMI students with higher scores on an aural vocabulary recognition test tended to participate more, while those with lower scores encountered difficulties participating in discussion activities.
Listening difficulties, however, extend beyond learners’ own proficiency. Difficulties in comprehending lectures and following teacher directions may be impeded by variations in teacher pronunciation/accents (Hellekjær, 2010), use of unknown technical vocabulary (Chan, 2015; Uchihara & Harada, 2018), and the need to delineate nonlinear, spontaneous, or non-topical comments (Siegel, 2020).
2 Difficulties in teaching listening
The multifaceted and complex nature of listening is apparent in its definition; Vandergrift (n.d.) paraphrases Rost (2002, pp. 2–3) in describing listening as: . . . a process of receiving what the speaker actually says (receptive orientation); constructing and representing meaning (constructive orientation); negotiating meaning with the speaker and responding (collaborative orientation); and, creating meaning through involvement, imagination and empathy (transformative orientation).
For L2 instructors, two key models of listening processes are top-down processing (TDP) and bottom-up processing (BUP), which are considered to be complementary and concurrently occurring (Buck, 2001; Helgesen & Brown, 2007; Rost, 1990). TDP describes how listeners use prior knowledge of (e.g. topic, genre, culture) ‘to build a conceptual framework’ (Vandergrift, 2004, p. 4) of what they are listening to. For BUP, listeners focus on linguistic features, delineating sounds and words for semantic meaning and/or grammatical features before combining them to create meaning.
Given the dual role of EMI to both promote English acquisition and further content-based knowledge, EMI-focused listening takes on a broad definition, covering the targeted development of L2 listening proficiency (both BUP and TDP), and listening to acquire language while simultaneously learning content-focused skills and knowledge.
It has, however, been reported that L2 listening skills are poorly taught (Berne, 2004), or undertaught (Vandergrift & Goh, 2012), and/or suffer from a restricted focus on a product-orientated approach (Siegel, 2014) or on top-down focused instruction (Siegel & Siegel, 2015).Top-down approaches use pre-existing mental schema to develop meaningful inferences from an aural text, such as predicting aural-text content from its title and source of origin; however, Swan and Walter (2017) argue that teaching these skills does little to augment L2 listening ability as they already exist in the L1. Similarly, product-orientated approaches have been criticized for repeatedly testing learners’ listening ability without teaching listening skills (Brown, 1986; Kaur, 2017; Sheerin, 1987).
Various factors may contribute to the pedagogical limitations described. First, learners’ listening processes and efforts are invisible to the observer and are not easily recorded in writing or by audio/video. Second, listening is complex. Receptive listening skills, such as top-down and bottom-up processing, must be supported by a variety of learner capabilities, including L2 vocabulary knowledge, auditory discrimination ability, metacognitive awareness of listening efforts, and working memory capacity (Vandergrift & Baker, 2015). Additionally, particularly in EMI, learners must engage a range of active skills; for example, deciding what content to pay attention to, and translating aural and visual information into notes or action. Third, listening relevant factors and comprehension measurements are examined as discrete, static phenomenon when listening is a dynamic and multisensory experience; for example, lecture comprehension research has employed quizzes or tests (Gallien, Hotho & Staines, 2000), quantity of notes taken during lectures (Airey & Linder, 2006), survey (Siegel, 2020), and transcript marking (Littlemore, 2001) to measure comprehension. These approaches, however, do not account for variations in comprehension across the length of an aural text. Moreover, static measurements of comprehension cannot not link specific factors that impact comprehension to changes in a learner’s comprehension at any given time. Fourth, the ergodicity problem (Lowie & Verspoor, 2018) means that it can be difficult to predict or interpret an individual’s situated behaviours based on the results of group-based studies. For example, examinations of the impact of anxiety on working memory using questionnaires and physiological data (Angelidis et al., 2019) can inform about the negative impact of anxiety on cognitive functioning; however, anxiety may have multiple iterations (e.g. classroom vs. test anxiety) and will manifest, become aroused, become debilitating, and be overcome differently for each individual. Furthermore, research capturing learners’ listening proficiency development between pre- and post-comprehension tests (e.g. Graham, Santos & Vanderplank, 2008) or strategic responses to perceived listening difficulties (Namaziandost et al., 2019) use group-research based questionnaires, which neither acknowledge individuals’ experiences of (and responses to) listening difficulties nor consider learners’ ongoing paths of L2 development. As such, complementing knowledge derived from large-scale studies with rich descriptions of individual learners’ behaviors, thoughts, and emotions in specific situations may help teachers and researchers draw particular relevance from research to their own contexts.
3 A CDST approach to listening
In response to the difficulties mentioned above, second language acquisition researchers have turned to complex dynamic systems theory (CDST, Larsen-Freeman & Cameron, 2008) to understand learning processes; however, there are, currently, relatively few listening comprehension-focused CDST-grounded studies. CDST acknowledges that language proficiency and language supporting affective, cognitive, and social subsystems are constantly changing overtime, that ALL variables impact all other variables, that systems have unpredictable future states, and that minor variations in subsystems may potentially lead to highly divergent outcomes (de Bot, Lowie & Verspoor, 2007). Thus, a CDST approach to listening comprehension may help educators gain a learner-focused perspective of listening processes that facilitates the adaptation of listening research findings to the classroom and lecture hall.
The need for individual-level research is underlined by Lowie and Verspoor’s (2018) 46-week examination of 22 Dutch students’ writing development in which apparently similar students showed different longitudinal learning trajectories. Examinations of individuals and their differences, however, are complicated by the fact that research often describes learner characteristics/differences (LDs) as discrete items when, in fact, they are ‘ambiguous composites of multiple factors’ (Ehrman, Leaver & Oxford, 2003, p. 325). Furthermore, these ambiguously defined composites may interact multilaterally; for example, motivation to listen to a text may wax and wane in relation to topic interest and comprehension of the text-at-hand, and vice versa. The paths of these interactions and the relative weight of influence of various factors may fluctuate over time (see, for example, Jiang and Dewaele, 2015), while the timescales at which various factors are measured may reveal differing patterns of variability (MacIntyre, 2007).
Accommodating these difficulties, CDST-grounded research has explicated the situated, interrelated, complex, and dynamic nature of L2 development (e.g. Larsen-Freeman, 2006; Spoelman & Verspoor, 2010), and of learner differences (e.g. Dörnyei, MacIntyre & Henry, 2015; Ducker, 2020) and behaviours (Ducker, 2021, 2022) that impact learning outcomes. CDST indicates that systems, such as learners’ L2 development, (1) are constantly changing; (2) consist of completely interrelated variables, i.e. all variables impact all other variables; (3) are, with the state of some systems, highly dependent on prior states; (4) and, are highly unpredictable with minor variations in subsystems potentially leading to highly divergent outcomes for similar combinations of factors (de Bot et al., 2007).
Beyond a small number of longitudinal studies that have examined variability of listening proficiency and strategy use (Chang & Zhang, 2021; Dong, 2016; Graham et al., 2008; Peters, 1999), little listening-focused CDST-grounded research exists. Graham et al. (2008) investigated strategy use before and after a six-month period amongst French as an L2 (FL2) students. Participants’ strategy use remained stable; however, the limited measurements (twice) of strategy use may account for this lack in variation. Peters (1999) examined listening comprehension and strategy use of twelve Canadian FL2 students at monthly intervals for 10 months using talk aloud protocols. Between a pre- and post-test, the study found 27% average increases in listening comprehension for a higher proficiency group and 30% average increases for a lower proficiency group; both these gains coincided with falling rates of strategy use. Dong (2016) examined the complex and dynamic development of a Chinese postgraduate student’s listening comprehension performance and strategy use across a 40-week period, including a 13-week strategy training intervention. Increasing proficiency coincided with an initial increase in overall metacognitive strategy use followed by lower, stable metacognitive strategy use. More specifically, the participant reported fluctuating use of unknown strategies but stability concerning use of familiar strategies while listening performance followed an alternating path of regression followed by progression. Similar to Peters (1999), decreasing use of strategies coincided with increasing rates of comprehension. Alternating paths of listening-proficiency progression were also reported in a 3-and-a half-year-long study of three Chinese students of English as a foreign language (EFL) by Chang and Zhang (2021) with outside influences, such as familial relationships, vacations, and English-related career opportunities, influencing each participant’s development differently.
With regards to the current study’s purpose of improving L2 classroom and EMI listening pedagogy, the above studies (Chang & Zhang, 2021; Dong, 2016; Graham et al., 2008; Peters, 1999) do not uncover the detailed information required to impact classroom practices because (a) they do not occur in classroom settings, (b) discuss longitudinal (bi-weekly/monthly) strategy development which evades detailed descriptions of learners’ immediate strategy use required to overcome difficulties encountered in aural texts, (c) do not attend to the BUP- and TDP-needs of learners, and (d) use static measurements of listening comprehension which ignore the second-by-second dynamicity of listening processes. Therefore, a situated, moment-by-moment investigation of L2 learners’ listening difficulties in an EMI classroom is warranted.
III The study
1 Research questions
To examine the CDST nature of listening comprehension in an EMI activity, the following research questions were investigated:
Research question 1: What patterns of perceived comprehension do learners’ report during an EMI listening activity?
Research question 2: What phenomena impacted the ebb and flow of learners’ perceived listening comprehension levels?
Research question 3: How did learners respond to the phenomena that impacted their perceived listening comprehension?
2 Contextualized data collection
To capture various phenomena relating to learners’ lived-in experiences of EMI classes, data was initially collected during a classroom event. Large numbers of students that are not streamlined by language proficiency or content knowledge may partake in the same EMI classes; therefore, variations in learners’ linguistic proficiency and background knowledge, disparities in content difficulty, and differentiation in attending supporting language classes were all incorporated into the study.
3 Research setting
Data collection took place during and after the graduation thesis presentation sessions of an intercultural communication EMI seminar class at a small Japanese university. Seminars are small group classes (maximum 10 students) for third- and fourth-grade students with the curriculum designed at the discretion of the individual instructor. The target seminar class is the only EMI seminar class at the institution. It has no language-proficiency requirements for entry. Prior to entering the EMI seminar class, learners have the option of attending two related lectures in their second year.
In the 3rd year, the seminar curriculum is made up of a series of coordinated data collection and data presentation activities that cover a range of topics (e.g. world view, cultural dimensions, identity formation, cultural hegemony, facial expressions) with the students practicing a range of data collection techniques, including interviews, questionnaires, ethnography, literature surveys, laboratory-type tests, and analyses of various media. Fourth-year students are required to write and present a research thesis in order to graduate. The thesis topic is of their choosing, and the presentation is given in a 20-minute format of: hook > background > research questions > results and analysis > discussion > Q&A.
Ten presentations were held with the first presentation from the morning session and the afternoon session selected as sources for data collection, creating a roughly 3-hour gap between the first and second target presentations. To demonstrate variability over longer time periods, and highlight that linguistic proficiency does not necessarily improve as students progress in their studies, data were collected twice with a one-year gap between first and second data collection days.
4 Aural texts
All presenters’ L1 was Japanese; however, Presenter 2 had spent the previous year living in Malaysia and had developed a Malaysian-English accent. Presentation 1 (P1) compared Japanese interns’ and overseas interns’ attitudes towards workplace values using a questionnaire to over 150 participants. Presentation 2 (P2) reported on Malaysian university students’ motivation to study either Japanese or Korean using a questionnaire to 89 participants. The following year, Presentation 3 (P3) reported on the oppression and identity development of three minority Ainu culture people in Japan’s northern island of Hokkaido using semi-structured interviews. Presentation 4 (P4) compared technical differences between American-made and Japanese-made horror movies through an analysis of the on-screen features of the movies. Transcripts are provided in Supplementary File One.
The variable nature of each presentation is described in Table 1 with vocabulary levels checked against the JACET 8000 word list, an educational vocabulary list for Japanese learners of English, using a word-level-checker provided by Aoyama Gakuin University (Someya, 2006). The unknown words column in Table 1 appears to be overweighted; however, it includes many items that the audience would have been expected to know, such as technical items taught in the seminar classes, names of Japanese cities and people, and culturally bound items (i.e. from Japanese culture). While 80% to 90% of the words of each presentation fell in the lower bands (L1–L4), in a study of 104 conference presentations by Dang (2022), knowledge of the 3,000 most frequent items on the Academic Spoken Word List would give a listener 96.84% coverage; this indicates that the lexical challenge of the current presentations was not inconsiderable.
Presentation data.
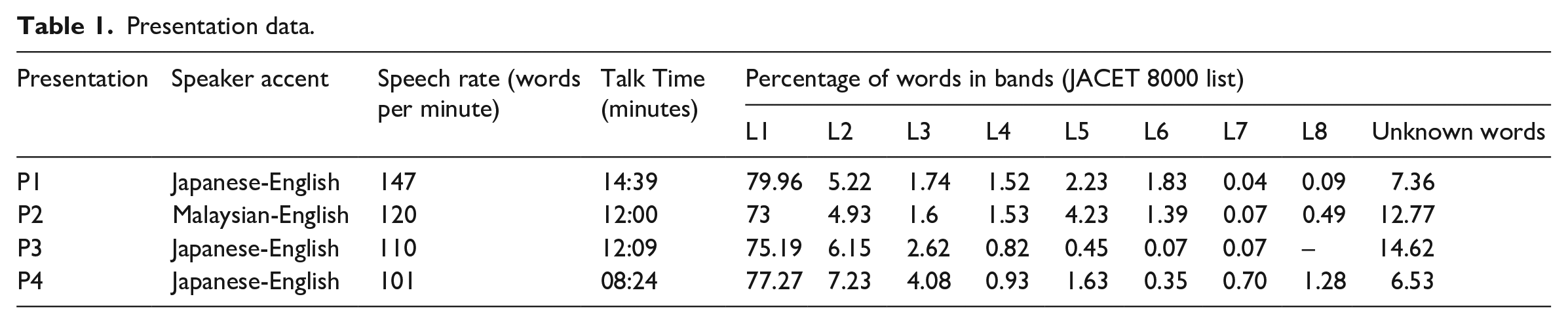
The average speech rate for a lecture delivered in British English has been reported as 173 words per minute (wpm) with a range of 125–247 wpm in the corpora used (Wang, 2021). P2 approached and P1 crossed the lower threshold described therein, while P3 and P4 were slower. Concerning topic knowledge, P1 and P3 reported on topics that had featured in the related EMI-lecture series and the seminar classes, while P2 and P4 reported on non-curriculum-related topics.
5 Research participants
Volunteer research participants were sourced from incoming and existing seminar students. At the time of the first round of data collection, three students were at the end of their 3rd year of study and were beginning to think about planning their own graduation thesis projects; in year two of this study, they would also be presenting their own research. Two students were at the end of their 2nd year of study and were preparing to join the seminar class. They had contrasting levels of linguistic proficiency,1,2 as could be expected in many EMI settings (Querol-Julián & Crawford-Camiciottoli, 2019). Participant data is shown in Table 2. Students were given a 2,000-yen gift card for their research participation on both days that they attended interviews (total 4,000-yen).
Participants.
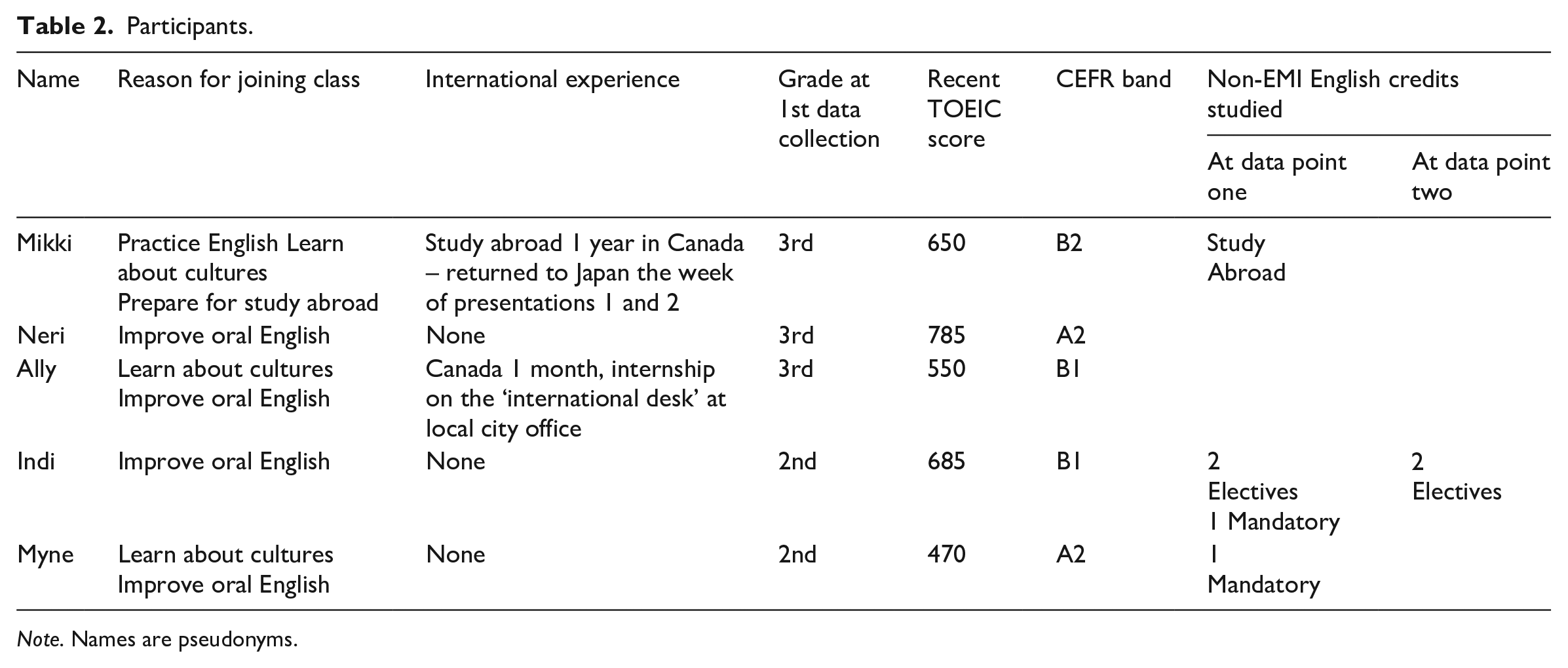
Note. Names are pseudonyms.
6 Data collection tools
a Idiodynamic software
Idiodynamic methodology was designed to capture the volatility and stability of learner differences over short timescales (see MacIntyre & Ducker, 2022). It involves the use of a specially designed software, 3 shown in Figure 1, to capture a research participant’s quantitative ratings of a target construct (e.g. confidence) while watching a video playback of a learning-related event. The steps of idiodynamic methodology are: video record an event > confirm what is to be rated > watch the video and rate > carry out a stimulated recall interview to elicit commentary about the ratings > ask follow-up questions. This is, potentially, its first application in L2 listening comprehension-focused research, particularly with regards to EMI-focused listening.
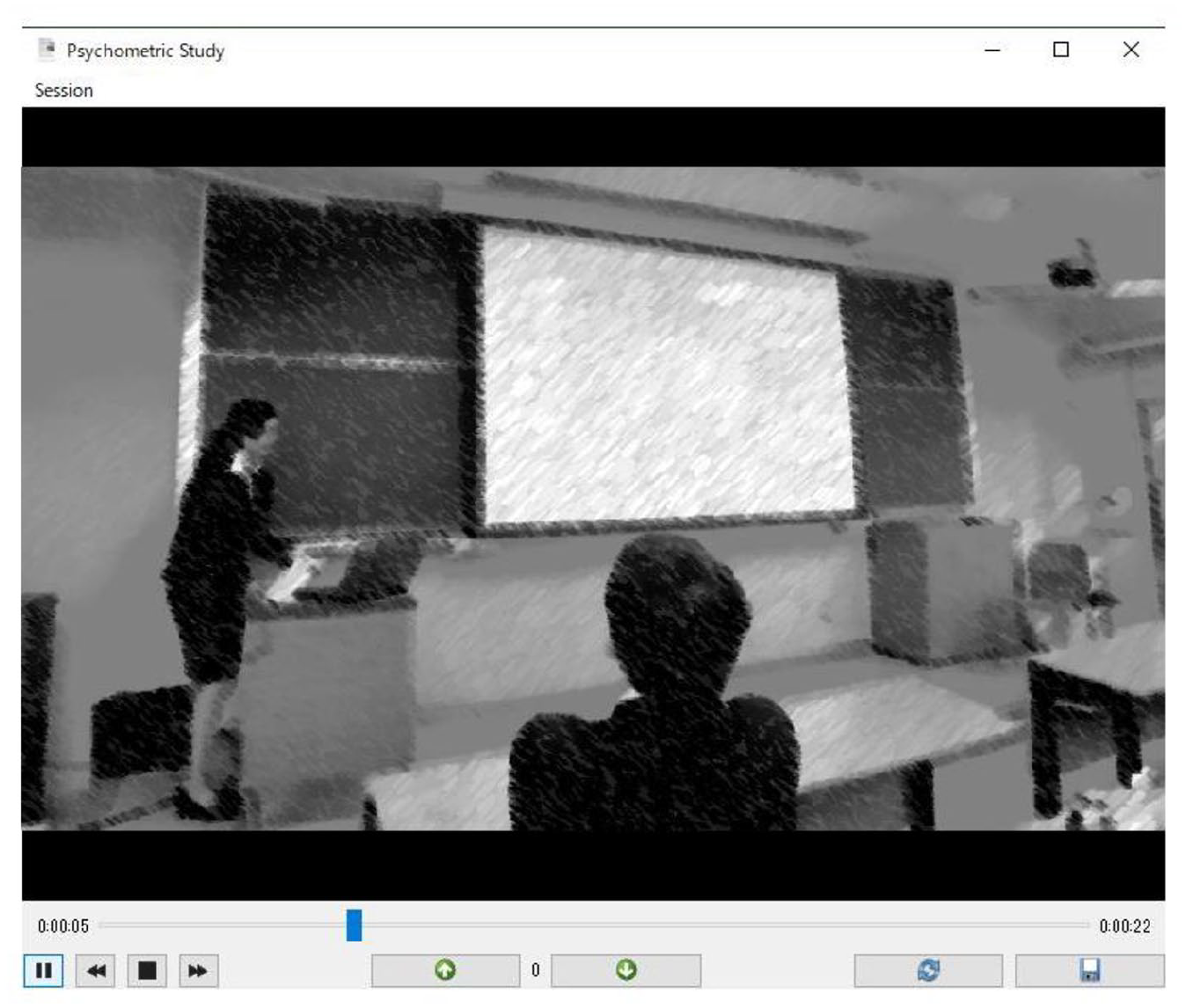
Idiodynamic video player.
Participants manually increase or decrease the score by clicking the up/down buttons on the video player using their mouse. The software records every input a participant makes. When the participant wishes to maintain the current score, they are required to hold the mouse button in the ‘click’ position. To encourage the user to continually monitor their input, the software has a return-to-zero-score function if the button is not clicked or held after a 2.5 second delay. Once the rating session is completed, the participant’s ratings and time-stamp data are returned in a Microsoft Excel table and chart. As a retrospective methodology, the use of idiodynamic methodology is time sensitive with recalls best carried out within 48 hours of the event-under-examination (see Gass & Mackey, 2000).
b Comprehension test
In order to juxtapose the learners’ idiodynamic comprehension ratings with static measurements of listening comprehension, a comprehension quiz was prepared. Given the time-sensitive nature of the study, the researcher wrote the comprehension tests in English while watching each presentation. Due to the variable length and range of content in the presentations, the number of questions written also varied. As soon as the presentations finished, these were typed up and printed, ready for the beginning of the idiodynamic- and stimulated recall interview sessions.
During the stimulated recall session, quiz scores could also be used to guide further questioning when (for example) a high rating coincided with an incorrect quiz score. After data collection, a blank set of these questions (Appendix 1) and the presentation videos were checked by two English teaching colleagues (one who has experience of EMI) to ensure that the questions matched the presentation content. Inappropriate questions were discarded at this stage, regardless of whether the participants had answered the question(s).
7 Data collection procedures
Presentation viewing and recording took place on two separate graduation presentation days, a year apart, using presentations by two cohorts of students graduating in consecutive years from the intercultural communication seminar class. In year one of the study (presentation one and two) and year two of the study (presentation three and four) the same steps for the idiodynamic method were carried out, as shown in Figure 2.

Idiodynamic procedures individually completed by each research participant.
a Step one: Video recording
For participants, presentations represented an (unofficial) benchmark for the academic and English proficiency standards required to complete the EMI course and stood as a model of a graduation presentation. Furthermore, the data collection techniques and topical knowledge described in the presentations held relevance for future study. On presentation days, a video camera was placed amongst the audience seating to capture a student-point-of-view recording of the presentations, as shown in Figure 1.
For future study and to aid the processing and recall of content (Siegel, 2018; Tsai & Wu, 2010), attending students took notes. These were submitted to the teacher for review but, due to a global lack of clarity in evaluating notes (see Siegel et al., 2020), were not graded.
b Step two: Comprehension quiz
Individual interviews were held within 36 hours of the live presentations with data elicitation for presentation one and two carried out consecutively. As presentation content could not be completely known until the live presentation, comprehension quizzes were administered at the beginning of each recall session (e.g. quiz one prior to the recall session for P1, quiz two prior to the recall session for P2); thereby, the quiz helped the participants remember the live presentation prior to the recall activity. Participants were informed that they could choose to respond to the quiz in either Japanese or English with oral translation provided if required. Responses were immediately graded by the researcher to be used in the following steps. Post-interviews, responses were confirmed by the previously-mentioned contributing teachers.
c Step three: Idiodynamic recall
Participant(s) viewed the video recordings of the presentation using the idiodynamic player. Bilingual English and Japanese instructions were as follows: ‘We teachers and lecturers want to make our lessons easy to understand, so you can learn as much knowledge as possible from us. To help us make better lectures and lessons, we need to know what makes it difficult or easy for students to understand lessons; for example, if we speak too fast, we need to know this so we can speak more slowly. Therefore, I want you to watch two of the presentations that you saw today/yesterday and use the up and down buttons to rate how much of the presentation you could understand at that time. Please remember this research is not related to your grades in anyway; and the more you can tell me, the more I can help teachers improve lectures to make them easy to understand for everyone.’ To capture how participants operationalized comprehension, limited guidance concerning interpretation of the scale (i.e. 0 = I understand nothing; +10 = I completely understand) was given.
d Step four: Stimulated recall
Upon completion of the ratings, the raw data was downloaded from the idiodynamic software and opened in Excel, see Figure 3, to guide a stimulated recall interview. Comments were elicited in three ways. First, when the participant reported zero or changing scores, they were asked (e.g.) ‘Why did you report no score here?’ or ‘Your score went down/up here, can you explain why?’ with further prompts added, such as: ‘So what did you do then?’ or ‘How did you try to understand what was happening at that time?’ Second, when ratings scores diverged from quiz scores, participants were informed that ‘Your quiz score shows a right/wrong answer, but your ratings are high/low, so they don’t match. What do you think the presenter was saying at this time?’. Third, participants were also instructed that they could stop the video at any time they felt they had anything interesting or useful to add.
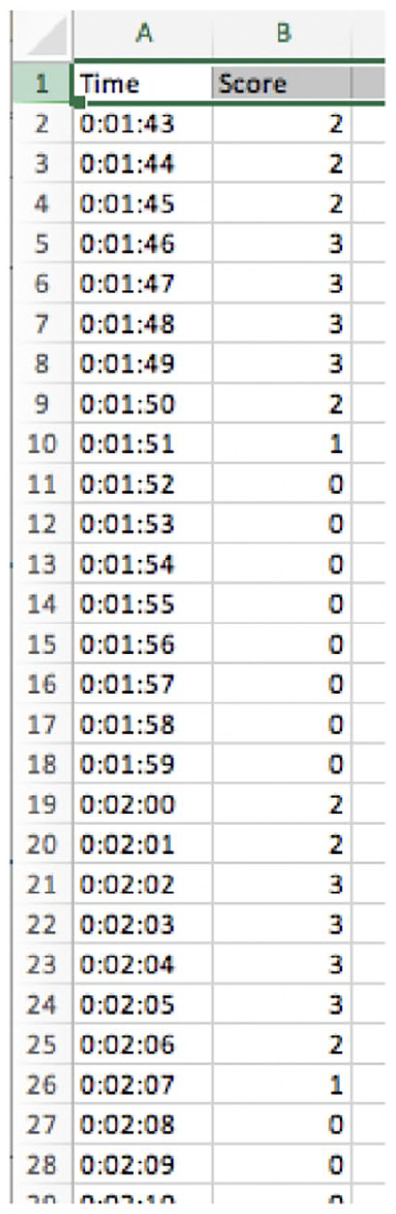
Raw idiodynamic data.
As the students wished to improve their English abilities, interviews were initiated in English; however, at the first instance of communication difficulty, participants were informed they could use Japanese at their discretion. Post-hoc translation was completed by myself 4 (the researcher) and checked by a Japanese-L1 English teacher colleague with any discrepant items resolved through mutual discussion.
Unknown or difficult sections of the presentation were repeated at a slower pace to check if the speech rate and/or accent of the presenter had caused difficulties for the participant in parsing the audio stream. If the participant still could not discern the meaning of the relevant section of the presentation, the relevant presentation section was translated into Japanese to check if the interviewee’s grammatical/lexical knowledge had impacted their comprehension. Finally, if the participant could still not understand the relevant section, the relevance of that section to the overall meaning of the presentation was explicated; this would help identify if topic knowledge and/or technical information had hindered the participant’s efforts to build up a mental schema of the relevant section of the presentation.
Re-watching and receiving explanations of the presentations allowed participants to learn new language items (e.g. Mikki, P1, ‘precise’; Neri, P1, ‘corporate’) and content (Neri, P2, soft power). This process led participants to report noticing improved comprehension during the interviews, e.g. Ally, P2, ‘At that time, I didn’t understand that question’s contents, but now (during the interview) I understand’; and Neri, P2, ‘I understood it this time, but originally, I didn’t understand.’ These occurrences indicate that the participants distinguished between their comprehension during the live presentation and the new interpretations they developed while re-watching the videos.
Field notes were taken during the idiodynamic recall and stimulated recall sessions.
e Step five: Transcription and data triangulation
The data set consisted of (a) transcriptions and original videos of the presentations, (b) timestamp and (c) idiodynamic ratings data, (d) stimulated recall interview data, and (e) field notes. The first stage of analysis was carried out during the interviews as field notes would help with later organization of data (Saldaña, 2013). Similarly, further familiarization and early analysis of the data was possible while transcribing and translating interview data (Wong & Waring, 2010).
The next stage of analysis was to align the time stamp, idiodynamic ratings, presentation transcript, and interview comments for each presentation in the downloaded Excel sheet in a time-locked manner, so they were matched to the second of the presentation in which they were reported by the participant. The two previously-mentioned English teachers checked the alignment of the timestamp and presentation content by watching 5 randomly chosen sections of Presentations A and B while reading the second-by-second transcriptions. When necessary, the data was transcribed again until the researcher and both teachers were satisfied the transcriptions was accurately aligned to +/– 0.5 seconds per row. The data set was thus:
column A = timestamp;
columns B – F = participants’ ratings;
column G = stage of the presentation;
column H = second-by-second transcription of presentation;
columns I – M = respective comments by participants.
An example of this data preparation can be seen in Figure 4.
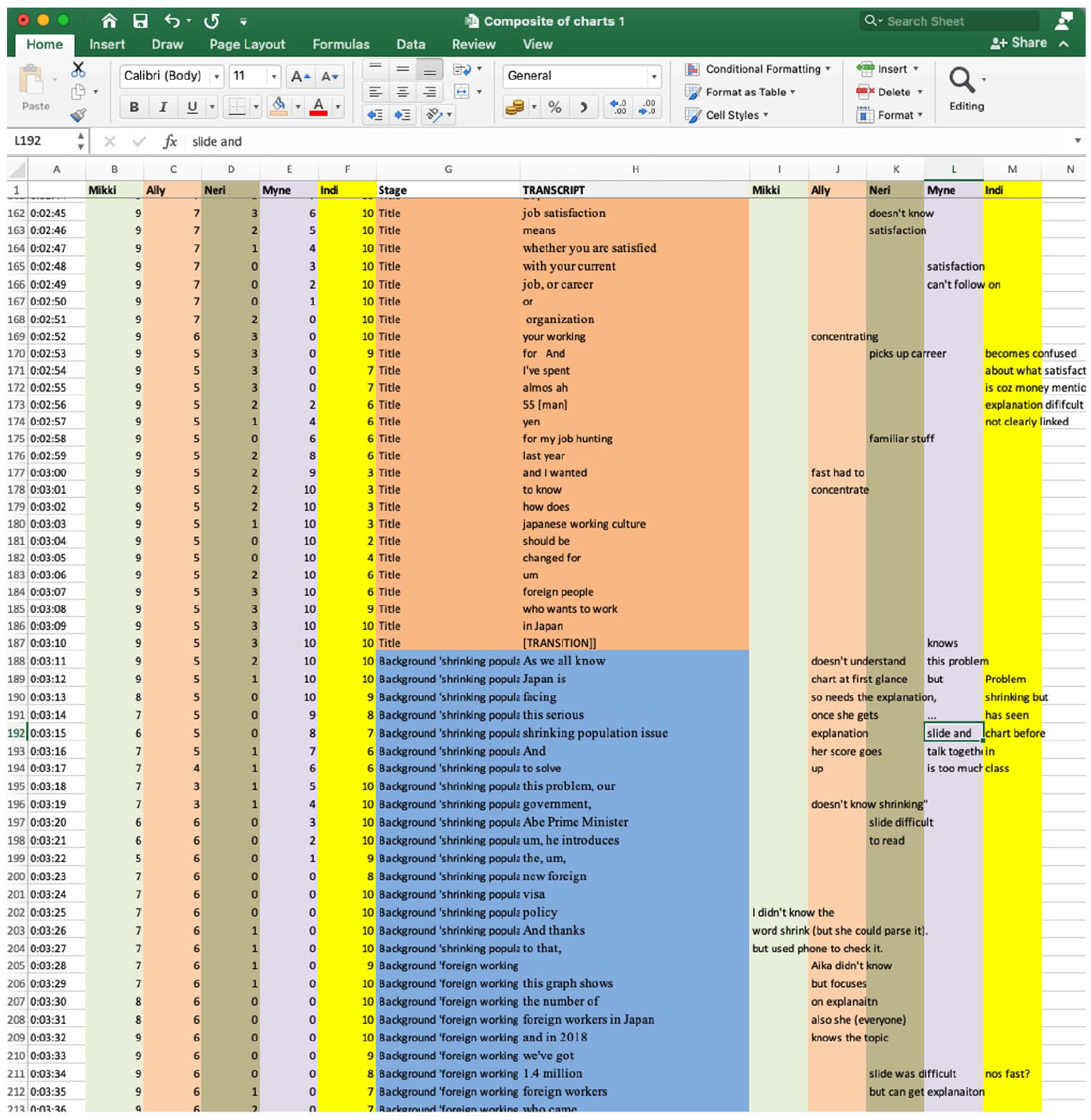
Excerpt of triangulated data for presentation one.
During the idiodynamic recall, there may have been a slight time-lag between viewing the video and inputting ratings; however, this may have been offset by the fact that participants were watching the presentation for the second time and could recall/predict what was going to happen next in the video. The accuracy of the ratings can be discerned by examining row 192, column H, ‘shrinking population’, in Figure 4. All participants reported difficulty with this section, with the vocabulary item ‘shrinking’ identified by Mikki and Indi as the main source of difficulty; both participants’ scores begin to decrease in row 190.
f Step six: Follow-up questions
Further questions become relevant during the analysis and writing-up of the data, so the researcher followed-up with participants by email; the questions were ‘Do you feel your listening proficiency has developed in the last year?’ and ‘Do you have a recent TOEIC/TOEFL score? When was this score achieved?’.
8 Coding
Initial deductive coding (Ellis & Barkhuizen, 2005) for research question 2 was based on Rost and Wilson’s (2013) active listening pedagogical framework, codes were:
a. affective: e.g. anxiety, motivation, etc;
b. top-down: focusing on the development of mental schema of the texts;
c. bottom-up: attending to, identifying, and processing components of an audio signal;
d. interactive: efforts to use peers and surrounding stakeholders (e.g. teachers) as resources; and
e. autonomous: conscious learning efforts (strategies).
During coding it became necessary to add further codes in an inductive manner (Ellis & Barkhuizen, 2005). These codes were:
a. knowledge-related issues;
b. lexical difficulties (vocabulary/grammar);
c. difficulties related to the visual/multimodal aspect of presentations; and
d. numeracy difficulties.
As new codes were derived from the data, it became necessary to revisit the previously-examined data in a recursive manner to check that items pertaining to the new codes had not been missed.
After coding, it became evident that some items were foregrounded as difficulties, while other items were described as resources (knowledge) and skills (strategies) that learners employed to enhanced their comprehension. The codes were, therefore, divided into two categories: (a) comprehension difficulties responding to research question 2 and (b) comprehension enhancing phenomena responding to research question 3. Then, the transcriptions were checked again, particularly in an inductive manner, to identify comprehension enhancing knowledge types and strategies that had previously been unnoticed. Using the codes and categories described above, the full data set was independently re-coded by the two previously-mentioned English teaching colleagues; finally, any discrepant items were discussed until agreement could be found.
IV Results and analysis
1 Examining comprehension and ratings
A Qualitative description of ratings
As the ratings data provide an innovate alternative to static measurements of comprehension (e.g. quizzes/tests, quantity of notes, or surveys), examples of qualitative descriptions of ratings data may help the reader clarify what ratings actually mean and provide insights into how EMI listening comprehension is experienced by learners in the classroom/lecture hall. Therefore, the second-by-second transcription of P1 was examined to find examples of ratings 0–10 supported by the research participants’ corresponding explanations. These are displayed in Table 3. These descriptions indicate that comprehension is highly nuanced with multiple iterations.
Iterations of comprehension.

Note. The bold, underlined rating indicates the maximum or minimum rating recorded for the passage under discussion.
Additionally, the multilevel nature of comprehension should be acknowledged. For example, in P1, the following exchange highlights how comprehension can be both high and low at the same time:
When she asked do you know monochromic and polychromic your score was 10?
I understood the question.
I see, I see, but you didn’t know the answer?
Correct.
Further examples can be found in Table 3 where the ratings for 5, 6, and 7 were impacted by not knowing one vocabulary item, yet relatively elevated comprehension levels were returned. On one level, comprehension of the item may be binary (e.g. I understand/know or I don’t understand/know); however, the impact this momentary difficulty may have on (level two) longer sections of a presentation (e.g. 5, 10, or 15 seconds) may vary greatly.
B Comparison of ratings and comprehension quiz scores
Using the second-by-second transcription of the presentations (see Figure 4), sections pertaining to items on the comprehension quizzes were identified (i.e. for P1, information pertaining to comprehension question 1 was presented between 02:21–02:40). Then, each participants’ corresponding ratings (i.e. between 02:21–02:40) were noted down. Table 4, shows the participants’ comprehension quiz scores and the related ratings for P1. Scores were marked as ‘10’ = correct; ‘0’ = incorrect; and ‘5’ = approximated some of the necessary information. In the rating column, a single score indicates that the ratings were constant during that section of the presentation. Multiple ratings indicate variable ratings; for example, ‘Mikki Question 2’ returns 9,5,7, indicating that the ratings fell from 9 to 5 and then rose to 7 during the relevant section. Complete ratings and quiz scores for P2, P3, and P4 are provided in Supplementary File Two.
Quiz scores and ratings for P1.
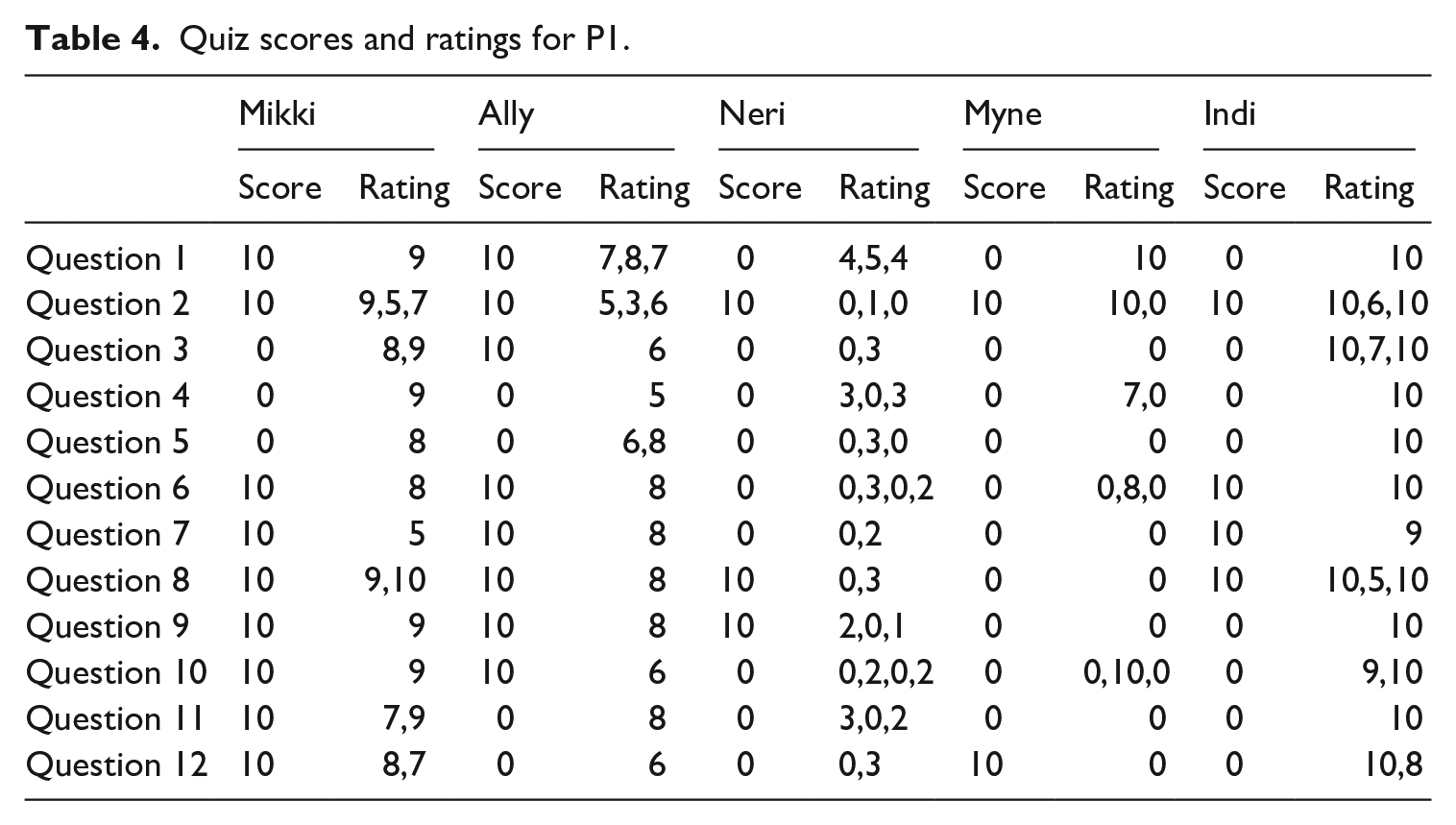
The argument that dynamic measures of comprehension may be a valuable alternative to static measurements of comprehension, such as listening tests, are supported by junctures when quiz scores and ratings did not match. For example, Ally, Question 2 (score 10; rating 5,3,6) reported that full listening comprehension was not required to intuit the correct answer. Additionally, the answer to the question may play out over a matter of a few seconds or many tens of seconds, indicating that some questions may place greater demands on learners’ resources than others. Furthermore, Myne had problems responding to some of the questions as the words uttered by the presenter ‘didn’t match the words in the question’, indicating she could not manipulate what she heard into useable language and content. Finally, in some cases, learners forgot the information. In addition to revealing how static and dynamic measurements of comprehension may differ, these issues also highlight potential difficulties that may occur when developing tests that attend to both L2 development and content mastery.
2 Research question 1: Patterns of perceived comprehension
To describe the dynamic nature of the participants’ perceived comprehension, the idiodynamic ratings and the automatically produced ratings charts were examined. Participants’ mean and mode ratings for each presentation were calculated in Excel. Comparing these mean and mode score across the participants gives an approximation of which participants understood which presentation better. The number of inclines and declines in each chart were also counted, and the resulting number was divided by the number of minutes the presentation lasted. This gives a score described as Volatility per Minute (VpM), which gives an indication of how (un)stable perceived comprehension was for each participant during each presentation.
Charts for two participants, one who reported decreased mean and mode ratings (Mikki) and one who reported increased mean and mode ratings (Neri) across the first and second data collection days (i.e. year one and year two), are reported. Overall, it can be said that the idiodynamic ratings charts show (a) the ebb and flow of perceived comprehension across a single text, (b) learner differentiation in reaction to the same texts, and (c) individuals’ variable perceived comprehension levels across different texts, which had all previously been undetected.
For P1, Mikki (Table 5) returned high mean (7.8) and mode (9) ratings indicating few perceived comprehension difficulties while low volatility (VpM = 2) reflected stability in her perception of her comprehension. For P2, Mikki returned similarly elevated mean (8.1) and mode (9) scores with lower volatility (0.99 VpM) compared to P1. These ratings, in conjunction with relatively high quiz scores (P1 = 75%: P2 = 91%), indicate that Mikki’s listening proficiency matched the linguistic and content-focused challenge provided by the presentations.
Mikki’s ratings.
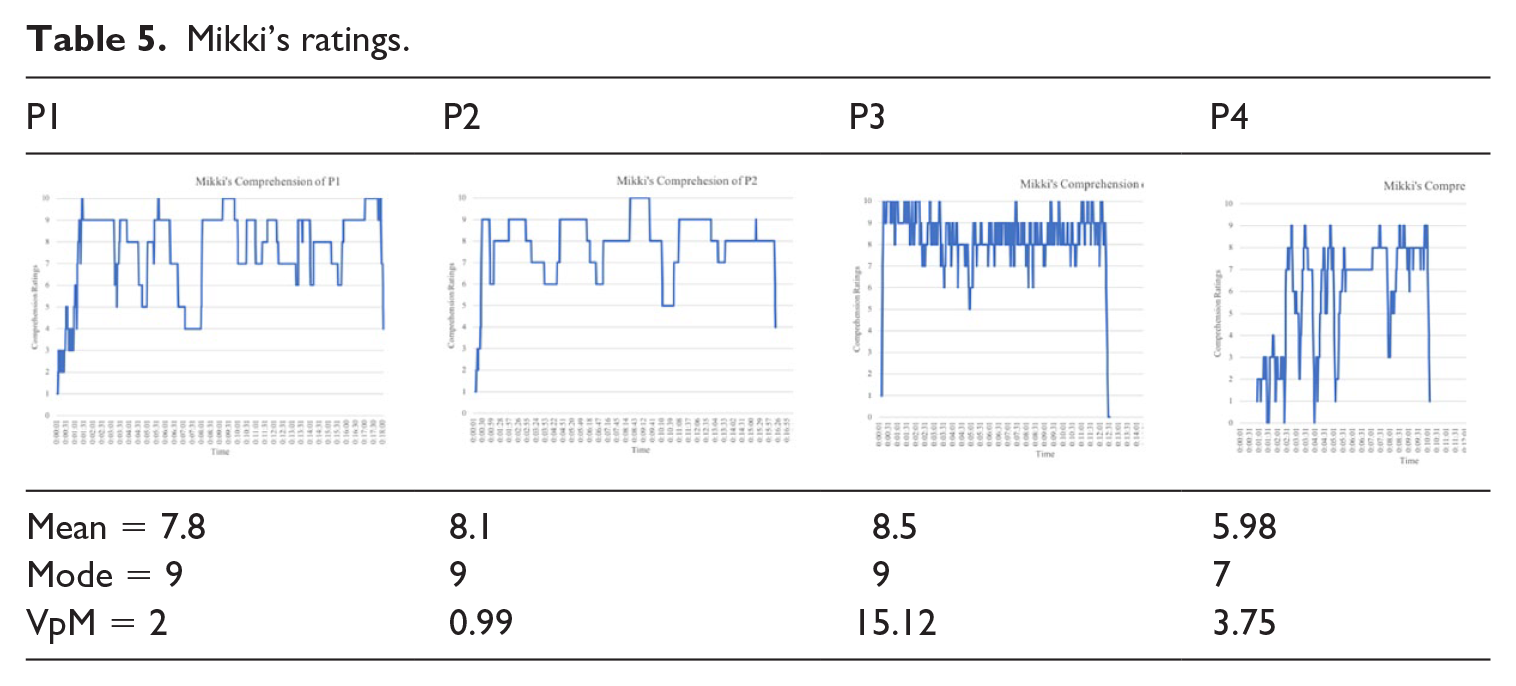
A year later, Mikki’s perceived comprehension ratings for P3 were still high, mean (8.5) and mode (9); however, she reported much greater volatility with 15.12 VpM. Finally, Mikki’s ratings for P4 (mean 5.98 and mode 7) combined with greater volatility (VpM = 3.75) indicated lower comprehension levels than for P1 and P2. Presentation content and delivery cannot account for the decline in Mikki’s ratings, as P3 and P4 had slower speech rates and (as shown in Table 1) there are no clear differences in the levels of vocabulary reported across all the presentations; furthermore, Neri returned improved ratings for P4 compared to P1 and P2. Accordingly, Mikki explained, during her interview, that the frightening nature of video clips used in the introduction interfered with her concentration and comprehension throughout P4.
Compared to Mikki, Neri reported increased ratings between year one and two, as shown in Table 6. Concerning P1, Neri returned low mean (0.8) and mode (0) scores in combination with relatively high volatility (VpM = 5.95), indicating notable listening comprehension difficulties, which matched her low quiz ratings (P1, 25%). Neri then reported slightly improved ratings for P2 with her mean rating increasing to 1.7 and VpM (5.58) decreasing slightly. In addition to a mode score of zero and low quiz ratings (P2, 18.2%), these scores indicate ongoing listening difficulties whereby she could not discern much of either presentation’s content.
Neri’s ratings.
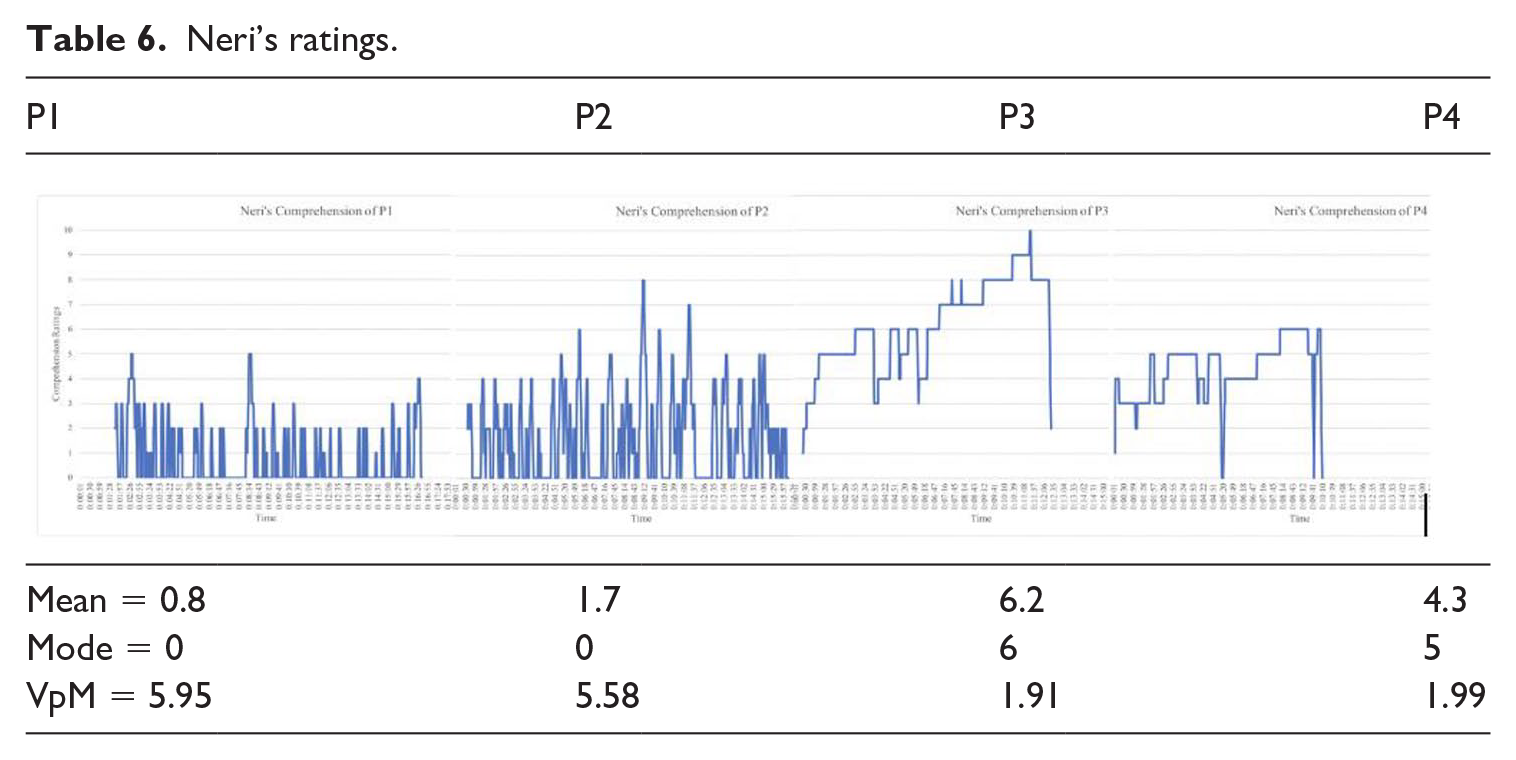
The following year, Neri reported much improved ratings. For P3, Neri’s mean and mode scores increased to 6.2 and 6 respectively. Volatility decreased to 1.91 VpM, and she returned a quiz score of 68.8%. In combination with ratings for P4, (mean 4.3, mode 5, VpM 1.99, and 54.6% quiz score) it appears that Neri’s listening proficiency in year two matched the challenges posed by the presentations more closely than in year 1.
Another feature of the charts is the speed at which participants could get a ‘full grasp’ of the presentation content. For example, for Mikki P1 and P4, and for Neri P3, ratings increased in a stepped manner, indicated that the participants’ comprehension gradually increased as the presentation unfolded and the listeners built a mental schema of the content. Conversely, Mikki’s ratings for P2 and P3 return high scores immediately; for P2, Mikki indicated that this was because she had previewed the title of the presentation on an online social network service (SNS) poster; and for P3, this may have been because (as reported by all the participants) the topic of Japan’s indigenous Ainu population is taught in many schools in Japan.
3 Research question 2: Factors impacting comprehension
This section discusses the first category of codes, comprehension difficulties, which respond to research question 2. Examples of coding are presented in Appendix 2. In the following reports, stable or volatile ratings pertaining to the phenomena under discussion are shown in brackets, e.g., (Ratings 8,7,6).
Affective difficulties could be triggered by presentation content; for example, in P2, all students reported difficulties and a lack of interest triggered by the word ‘history’. Mikki (Ratings 8,7,6) noted: ‘I’m not good at learning history and, personally, I didn’t like the history, so my concentration is getting down.’ Affective difficulties also arose from non-content-related issues, such as listening-related confidence, as reported by Neri (R0) at the beginning of P1: ‘I thought the presentation will begin, “oh no!” That’s all.’
Top-down like problems arose when learners were able to completely discern the English utterances but could not connect the parts of the presentation, or could not discern the meaning of items from the context, or could not discern the speaker’s intentions. In P3, Ally (R6,5,4) could not discern the speaker’s intentions in trying to compare indigenous Ainu culture to Japanese culture of that time: ‘She said, “no agriculture”. Why she said like this? Maybe she expect they do agriculture? . . . . . . but I couldn’t understand why she said (no agriculture).’ Furthermore, a lack of knowledge could render top-down listening processes, such as predicting, more difficult. When watching P4 (horror movies), Mikki (R8,2) discerned the meaning of the slide’s title ‘The Way of Performance’ but, not tending to watch horror movies, she had no frame of reference to help her predict what would be described in the following section: ‘I can understand the title of the slide, but I have no idea what she will talk about.’
Bottom-up like problems refers to difficulties the learners had in discerning sounds and words. Difficulties included ‘The speed increased, so I can’t pick up what she says’ (Myne, P2, R0), and external background noises meaning that ‘I couldn’t hear her voice’ (Ally, P3, R8,0). In such cases, the word ‘pick up’ is a literal translation of two Japanese pictographic symbols, the first 聞く ‘to listen’ and the second 取る ‘to take’ or ‘to pick up’. Additionally, learners reported mishearing known words; for example, Ally (R6,4) described the following about P3: ‘I heard “forest lover”. What is “forest lover”? When I heard the explanation, I could understand “forced labour”.’ Furthermore, all students commented on the quality of the presentations’ audio stream. Indi described this problem in P3 as: ‘her voice is GunyaGunya (lit. flabby not sharp and clear), so her pronunciation is difficult for me. The words I can’t pick them up.’ Other difficulties included:
Presenter 4’s flat intonation 5 made word identification difficult (reported by Indi).
Presenter 2’s accent was difficult for Ally and Indi.
The room for presentations 3 and 4 had poor acoustics (Mikki).
Audio quality could change during a presentation, as well. In P2, Indi noted that the presenter spoke more quietly and more casually when responding to audience questions, and Myne (P2) described how speech rate increased when the presenter announced transitions to upcoming slides.
Interactive difficulties were mainly caused by topic knowledge difficulties (e.g. Neri, P1, R0, monochromic vs. polychromic tendencies), which restricted students’ ability to discuss the items at hand. During P1, however, Mikki (R4) also noted that the person next to her was ‘speaking a lot with her friend’ meaning Mikki could not join in, indicating an interactive problem that students may encounter if they do not have acquaintances nearby.
Knowledge-related problems occurred when learners had forgotten items that had previously been taught in the lecture series. Commonly, this included a range of theories pertaining to the topic of intercultural communication, such as high- and low-context communication differences (Hall & Hall, 1990), and monochromic vs. polychromic tendencies (see Lindquist and Kaufman-Scarborough, 2007); but it could also include skills-based knowledge, such as the use of Likert-types scale based on frequency, ‘daily’, ‘sometimes’, ‘never’. The used of these scales in P2 coincided with falls in ratings for Mikki (R8,5), Indi (R10,6), and Myne (R10,0). Additionally, students’ previously-assumed knowledge could clash with information taught in the presentations. For example, Ally (P3, R7,4) noted confusion concerning a historical map of Japan that depicted the historical extent of the indigenous Ainu people’s settlements: ‘I thought Ainu people was originally from this area. So, what is that (map) for? Who were (on) the island?’
Visual aids and the multimodal nature of presentations could also be problematic. Sometimes, ‘the font was too small’ (Neri, P1, R0,2,0; Myne, P3, R10,0), or slides carried too much information: ‘So many questions are there, so, what is this?’ (Mikki, P1, R9,7). Moreover, Myne struggled when ‘the words don’t match the power point’ (P3, R10,0). Finally, the speed at which the presentation progressed could be problematic, Neri (P1, R3,0) noted that ‘as I was reading it, she started to speak, and she speaks so fast I couldn’t pick it up. So, I was desperately reading it to keep up.’
Lexical difficulties commonly referred to vocabulary that learners could identify but did not know the meaning of: shrink, productivity, promotion, limitation, job satisfaction, GDP, corporate, perception, submission, appeasement, excluded, clown, unconscious, obedience, and so on. Occasionally, grammatical constructions clouded comprehension when all the words were known; for example, ‘the longer you stay at the company, the more pay you get’ caused confusion for Neri (P1, R1,0,1).
Numeracy difficulties were reported by Myne (P3). These included translating numbers from English to Japanese (R10,0): ‘I had a long time to understand the number in English, so the score is down’, and twice being unable to decipher the Arabic numerals in simple pie charts that depicted 4 conditions (R10,0 both cases).
Three caveats concerning the identification of difficulties should be noted. First, while learners usually foregrounded a single aspect of listening as a difficulty, successful listening requires that multiple processes are constantly engaged (see, for example, Vandergrift and Baker, 2015). Sometimes this interrelatedness was explicated by students. For example, in P4, the presenter described that: ‘You can know that one of the characters died from the scene, by the showing of white flowers placed at the incident site. Therefore, this reflects high context culture because this needs a knowledge of flowers as an offering for this person.’ Indi (R10,9) was unable to aurally discern the word ‘flowers’, seemingly a bottom-up like difficulty; however, Indi also reported confusion because no flowers were easily visible on the accompanying slide. The lack of visual confirmation apparently impacted Indi’s ability to develop a schema concerning the white flowers, a seemingly top-down like difficulty.
Second, various listening difficulties could occur consecutively. In P1, Neri (R3,0,2,0) encountered a problem with the multimodal nature of the presentation. She did not have time to read the question, ‘Promotion should be based on output and measurable results instead of length of service’. When the presenter informed the audience that the participants in her study mainly responded ‘disagree’, the lack of time to read caused Neri a top-down like difficulty as ‘I couldn’t read the question, so I can’t understand what is “no”.’
Third, even similar difficulties could create differing depths and/or lengths of impact on comprehension. In P1, Mikki reported troubles with the words ‘shrink’ (R9,5 with 5 lasting only 1 second), ‘productivity’ (R8,6 with 6 lasting 10 seconds), followed by ‘GDP’ (R6,5 with 5 lasting 16 seconds), ‘promotion’ (R10,7 with 7 lasting 28 seconds), and finally ‘precise’ (R9,7 with 7 lasting 57 seconds). The length and depth of impact may depend on how central to the meaning of that section the word was, if and how the word was explicated or paraphrased, if and how the learner compensated, etc.
a Difficulties by presentation
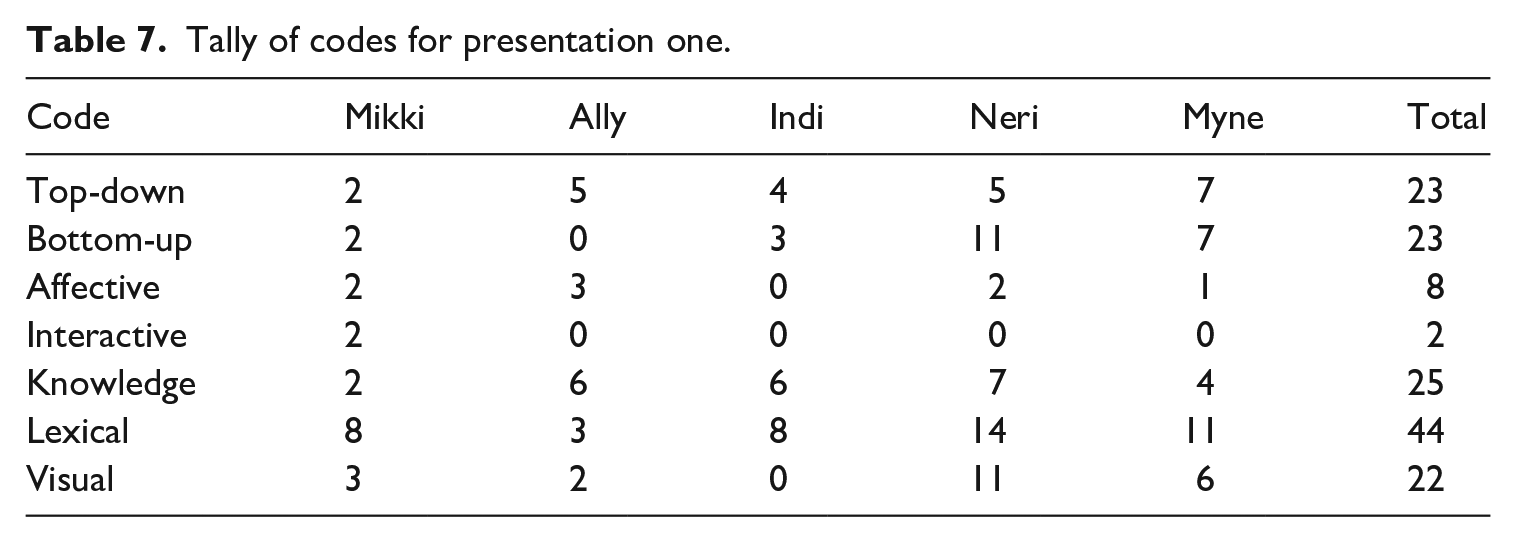
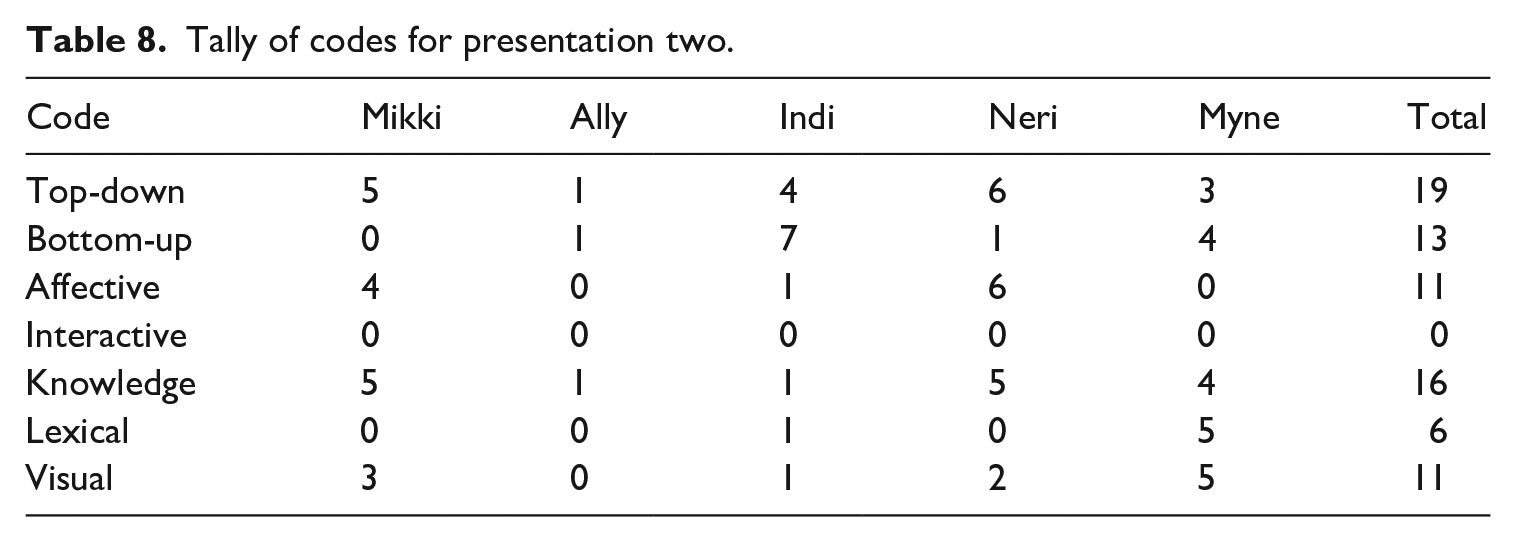
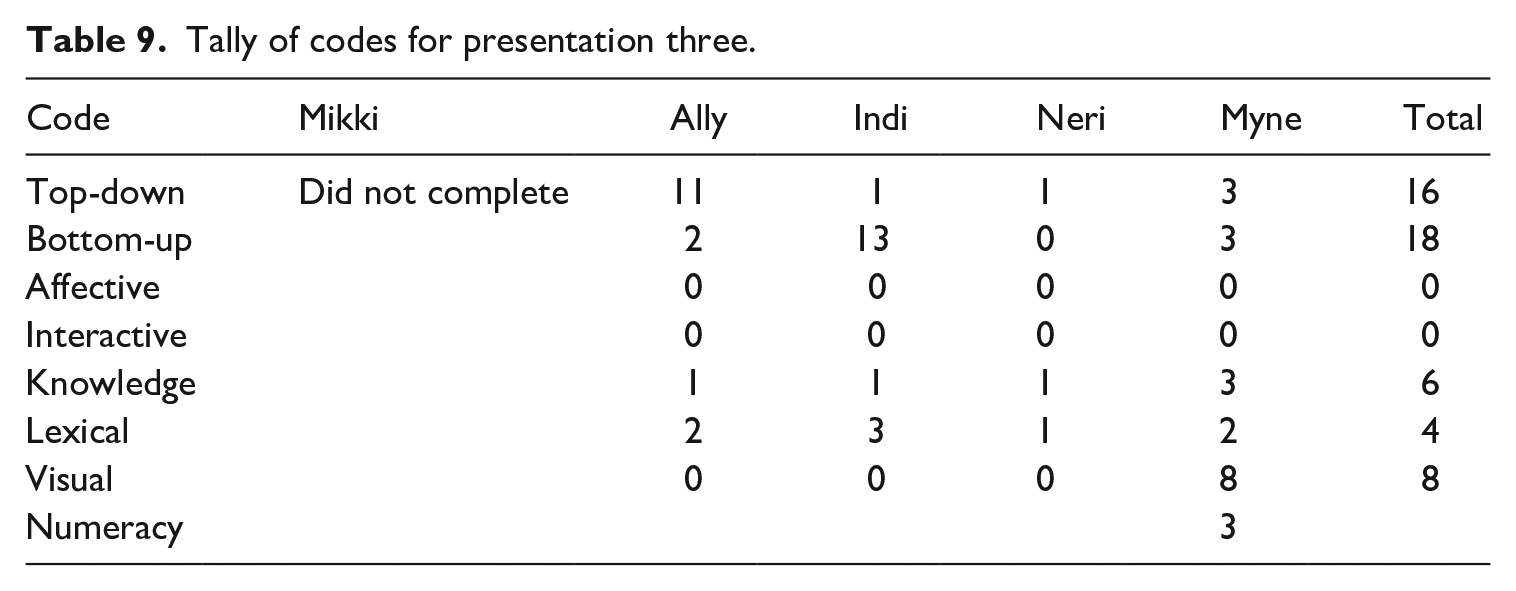
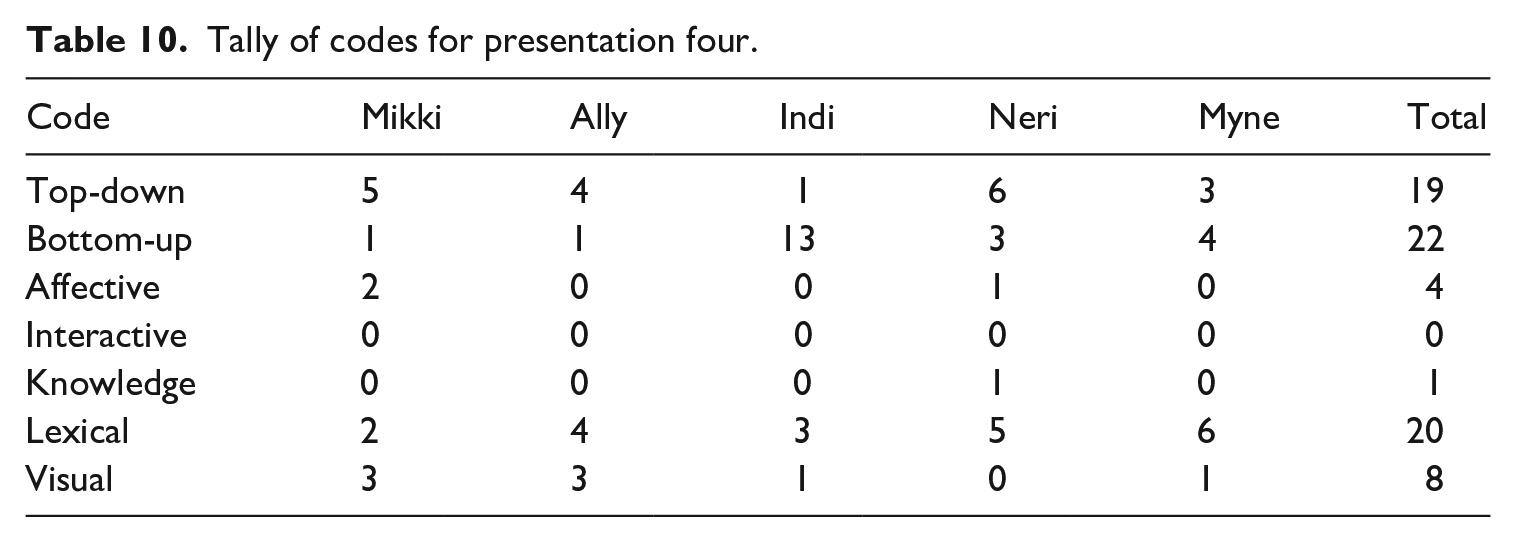
Once items had been coded, the number of items pertaining to each code were counted for each participant across each presentation. The number of difficulties reported by the learners for each presentation are presented in Tables 7–10, showing that each presentation posed different problems to the learners. For example, in P1 (Table 7) the stand out difficulties were lexical items (reported 44 times). This was followed by an almost equal number of reports of difficulties relating to knowledge (25 times), top-down like difficulties (23 times), bottom-up like difficulties (23 times), and problems relating to the multimodal/visual nature of the presentations (22 times). Notwithstanding the difference in presentation length, these differences can be compared to P2 (Table 8), whereby the standout problem related to top-down like difficulties (reported 19 times in total) which is similar in number but not in ranking to P1. Conversely, lexical difficulties were only reported as a difficulty a total of 6 times for P2, meaning they were the second least important difficulty across the presentation. While it can be concluded that P1 contained more unknown words than P2, this data contradicts the information concerning lexical difficulty reported in Table 1.
Tally of codes for presentation one.
Tally of codes for presentation two.
Tally of codes for presentation three.
Tally of codes for presentation four.
b Difficulties by learners
Using the same tables, idiosyncratic difficulties can also be examined and reported. For example, in P1 (Table 7), Mikki was the only participant to report interactive difficulties as she was not sitting next to her friends. In both P3 (Table 9) and P4 (Table 10), Indi reported a much higher number of bottom-up like processing difficulties (13 for both) compared to her peers. This was reflected in her comments about the audio stream in P3: ‘her words are not clear’, and that Presenter 4 had flat intonation. 5 Concerning P3 and P4, similar difficulties were not reported by her peers.
c Examining charts to identify common areas of difficulty
Ratings charts also provided a way to identify common areas of difficulty, which are represented by coinciding troughs/falls in ratings by multiple learners. For ease of reading, ratings charts are presented in two groups: higher proficiency, which is characterized by higher ratings that sometimes drop/fall (Figure 5); and lower proficiency, which is characterized by low ratings that sometimes spike (Figure 6). In Figure 5, there is a trough between 06:48 and 08:00 for the three listeners, Mikki (9,4), Ally (6,0), and Indi (10,9). On Figure 6, lower proficiency learners, a coinciding trough (R0) for both learners occurs between 07:20 to 08:00. Examining the transcriptions (see Figure 4) revealed that this trough was caused by a lack of knowledge concerning the technical items ‘polychromic’ and ‘monochromic’ tendencies, which the presenter encouraged the audience to discuss with each other; Indi’s less pronounced reaction (Figure 5) was accounted for by the person next to her explaining it.
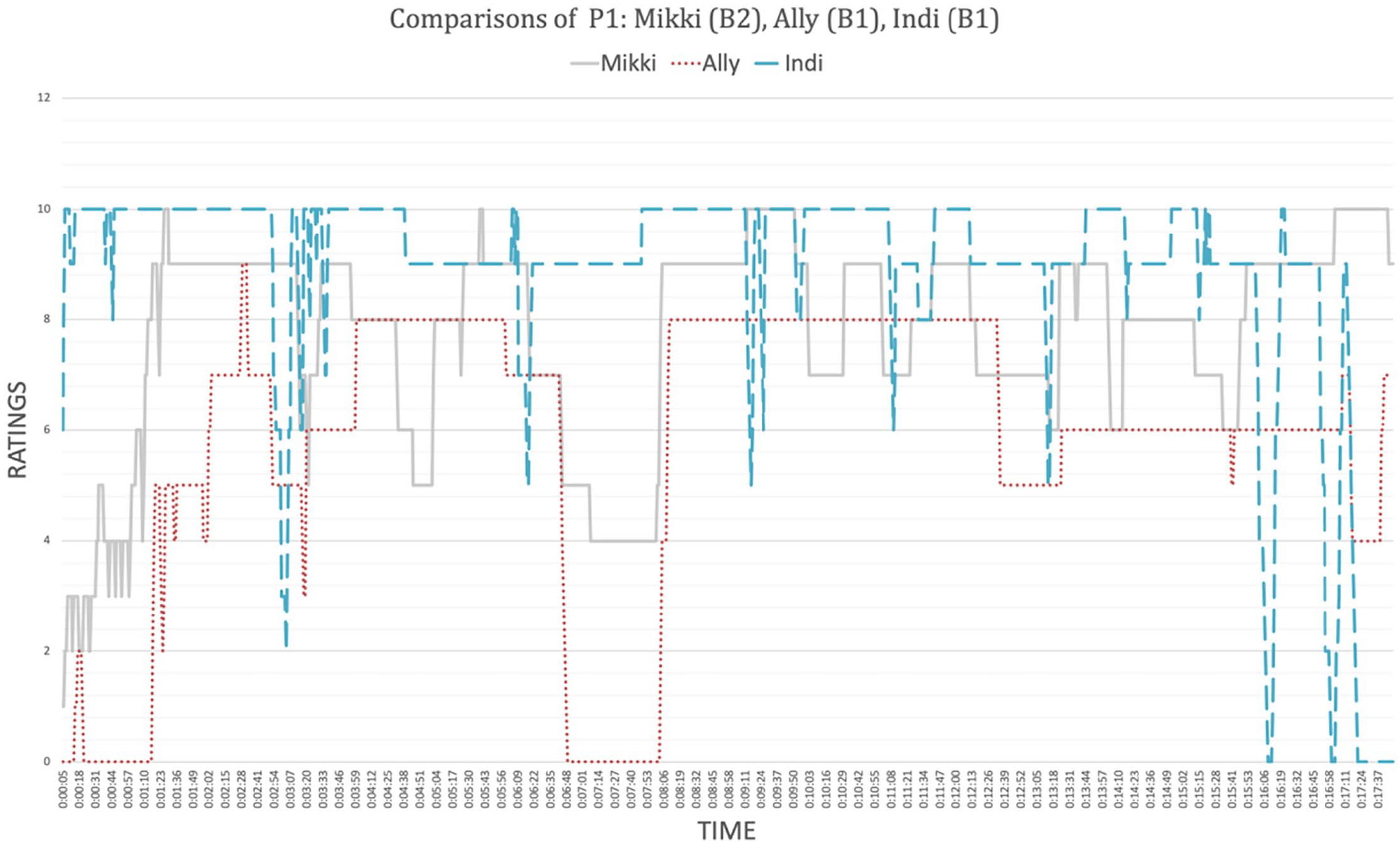
Higher proficiency ratings for P1.
Lower proficiency ratings for P1.
A similar coinciding drop in scores occurred in P2, when the presenter introduced the ‘history’ section of the presentation; and in P4, when the presenter explicated 6 key items in the literature section which were used to describe her results. Further examination of the transcriptions indicated that the use of the word ‘enemy’ as a synonym for the central item of horror movies’ ‘ghosts’ or ‘monsters’ caused difficulty.
4 Research question 3: Responding to difficulties
Sections IV.4.a and IV.4.b discuss the second category of codes, comprehension enhancing phenomena, which respond to research question 3. Two key factors were reported as enabling better comprehension: engaging knowledge and strategy use. In some cases, knowledge-based resources automatically enabled comprehension but, at other times, the participants had to use various strategies in association with this knowledge to enable comprehension.
a Responding to difficulties by engaging knowledge
Examples of coding relating to knowledge are presented in Appendix 3.
Technical knowledge was derived from the associated lectures and seminar classes. This knowledge included (A) subject-specific theories and technical items; (B) charts describing various social phenomena, such as declining birthrates; and (C) pictures used in the lecture series to exemplify ideas/theories. Concerning (A) subject-specific theories and technical items, a set of intercultural communication-based topics, such as those developed by Hofstede (2001), were reported as causing difficulties for most participants in P1; however, Neri reported familiarity with multiple items such as ‘long- vs. short-term orientation’ and ‘high power distance and low power distance’. Mention of these items led to small peaks in her charts (R0,2,0) without any clear recourse to additional strategy implementation. Similarly, Indi noted that during P1, the presenter used (B) charts that the teacher had previously used in the associated lectures series, thus, at these junctures her score could be easily maintained at R10. Moreover, in P1 the presenter used (C) the same pictures (acquired through a Google search) that the lecturer had used during the associated lecture series, which helped Indi remember the idea from the lecture; consequently, her ratings increased (R9,10).
General knowledge could be expected to be known by both learners and teachers. This knowledge included (D) topics taught to the wider population at junior and senior high school level; (E) inferential information that is culturally based or widely disseminated in social media, news media, and print press; and (F) culturally shared items. The former, (D), included mention of Japan’s role in WW2; this momentary mention enabled Neri’s score to rise (R0,4,0). Similarly, in P3, a description of the Japanese government’s (historic) spread into the northern areas of the Japanese archipelago had been previously taught to Ally, enabling her score to increase (R3,8). Such knowledge could also impact overall presentation comprehension; for example, Ally, Myne, Indi, and Neri reported that they had previous knowledge of the indigenous Ainu population in the north of Japan, described in P3, which they reported making this presentation easier to understand than P4. Concerning (E), inferential knowledge, the word ‘GDP’ in P1 caused problems for multiple learners; however, when Mikki encountered this word, she recalled having seeing it in the newspaper. She knew it relates to the economic situation and could approximate that high GDP is considered a positive phenomenon; consequently, her score remained constant (R6). Also in P1, multiple students found ‘the problem of long working hours in Japan’ easy to discern as it was a widely understood phenomenon with jumps in scores for Myne (R0,8) and (Neri R0,3) not requiring any clearly foregrounded strategy use. Finally, (F) refers to cultural items that learners might be expected to know. Some referred to cultural items specific to Japan, such as the celebration of the Japanese Tanabata festival that Presenter 2 shared with her students in Malaysia. Some items were more cross-cultural; for example, in P4 the presenter used an image of a man holding a white flag to signify ‘submission or appeasement’, which Neri (R5) reported understanding while Mikki (R7,0) did not.
Knowledge concerning presentation discourse included knowledge of (G) overall presentation organization, (H) intra-slide discourse structure, and (I) presenting techniques, all of which enabled students to listen strategically. Concerning (G), in P1, Ally (R 0,7) reported that she could identify the personal story the presenter told as a ‘hook’, which was designed to raise the interest of the audience and set the scene for the presentation. Similarly, in P3, Neri identified a question about the physical appearance of a legally Japanese but ethnically and racially indigenous Ainu person as a hook (R0,4), and Mikki identified the showing of movie clips at the beginning of P4 (R0,3) as ‘useful hooks’. The relationship of a hook to the presentation content is not always explicit, and awareness of the presenter’s intentions may help reduce listener uncertainty and cognitive load. Similarly, during each presentation, the presenter described their research process. Familiarity with the structure of the presentations helped participants identify that the speaker was elucidating the research process, even if the listeners could not clearly discern the words being spoken or read the full content of the slide being used at that time. In addition, some of the participants showed that they could use their awareness of (H) the normal intra-slide discourse structure (each slide explicates a topic/key result followed by an explanation and an example) in a strategic way. For example, throughout P1 and onwards, Mikki frequently described how she knew that it was normal to not fully understand the initial key point of a slide and that a key strategy of hers was to wait calmly for the explanation; in such cases, her ratings score would remain unchanged (other difficulties aside) from the beginning of a particular slide while she processed the explanation. Such behaviours were also apparent in Neri’s listening efforts during P3 and P4 when she returned much improved ratings and frequently described ‘understanding from the explanation’. Finally, concerning the use of presentation techniques (I), some learners were able to discern various tactics presenters used to draw attention to key data. For example, in P2, Mikki noted that ‘she (presenter) highlighted the pink line, so it is easy to understand what she said.’ Conversely, in P3, the presenter used an Ainu language word, written in red and highlighted to differentiate it from the English words, to explicate the childhood experiences of a research participant. Ally, however, was unable to discern the distinction from the surrounding text and assumed it was an English word she did not know, and her score fell (R4,0).
Personal knowledge and experiences also impacted scores positively (in juxtaposition to Section IV.3, knowledge-related difficulties in comprehension). When participants’ (J) real life experiences coincided with claims/ideas made by the presenter, scores peaked above the current rating. In P1, the presenter’s description of overseas students’ negative expectations of working in a Japanese company aligned with Ally’s recent experience: ‘I agree with her because my friends are living in [city where university is located] and study some engineer something. So, I asked them same question, but they said that same answer . . .’; accordingly, Ally’s score peaked (R7,9). In the same way, Mikki’s (R7,9) experience of watching a horror movie with her friend agreed with the analysis provided by the presenter in P3.
Previewed information (K), enabled Mikki’s high comprehension (R9) from the beginning of P2. Mikki had previewed the presentation title on an SNS poster and, combined with her personal knowledge of the presenter’s background (they are in the same school sports club), she was able to report a high rating from the very beginning of the presentation. This bears clear relevance to the idea that students should view the syllabus and complete any prerequisite reading(s) before lectures.
b Responding to difficulties with knowledge-independent strategies
Participants also reported employing strategies that were not directly founded on the use of knowledge. Examples of coding are included in Appendix 4.
Concentration was under the control of the listener. For example, Mikki (R9) described having high concentration at the beginning of P1 as it was the first presentation of the day; however, as the presentation drew to a close, Mikki allowed her concentration to drop (R8,6) because she thought the presentation was finishing, only to have to refocus when she realized that the speaker had not finished (R6,8,10). Similarly, as Presenter 2 described the history of overseas Japanese language education, Mikki (R9,6) noted that ‘I didn’t like the history, so my concentration was getting down.’
Guessing could be applied to overall comprehension and specific items. Concerning the latter, an English derived-from-Korean loan-word, hallyu, was used in P2, and Mikki’s comprehension fell (R7,6). In response, Mikki drew comparison with a similar Japanese word, hanryu, which Myne (R10,9) also correctly guessed. Guessing also related to discerning the speaker’s overall intentions rather than understanding a single item; for example, during P1, when a large number of items featured on a slide and the font size was too small to read quickly, Mikki approximated that the slide elucidated the research process (R9,7).
Directing focus was necessary when what was being said and the words on the screen did not match perfectly or when the quantity of visual and audio content did not allow for simultaneous reading and listening. At such junctures, listeners had to decide on which input to focus on. In P1, Neri described focusing on speech more than reading the slides (R1,0,3) in order to understand the explanation of Japan’s (then) current visa policy for overseas workers. Adjusting focus depended on reacting very quickly to differently nuanced input. In P1, Mikki approximated that the researcher was explaining the research processes (R9,7) and concentrated on listening when the slide held too much written content in too-small-a-font-to-read. Conversely, in P4 (R5,2), when the same problem occurred, Mikki noted that she found the size of the font too small but focused on reading because ‘. . . she showed these sentences. So, I think this is the important for her. So, I try to (read them).’ Discerning such nuanced differences in real time should be considered an important listening skill.
Waiting to engage bottom-up processes as a strategy is differentiated from ‘waiting for an explanation’ (see IV.4.a., Knowledge concerning presentation discourse). In P1 and P2, Neri frequently reported zero comprehension (R0) over stretches of 10s of seconds. In order to cope with these stretches, she reported that ‘Just I want to understand so I’m listening, but I just can’t; so let’s get through this bit and move onto the next point that I can pick up.’ At this juncture, it should be noted that motivational issues were not mentioned by any of the participants. When Neri was asked why she did not just give up and stop listening during the moments that she did not understand, she reported that ‘Just I want to listen, I want to understand.’ This may indicate that interest and motivation are key benefits of studying in the EMI context; Neri did not take any optional electives in English, yet she had committed to 2 years of potentially very difficult study that her graduation (and future career) depended on her successfully completing.
Translating was reported by Myne, who relied on direct translation of both oral and visual content while also ‘thinking about what it all means’ rather than listening and understanding in English. This can be compared to (a) Mikki describing listening for the general meaning of the presentations but not focusing on individual words; and (b) Neri, who reported trying to pick out individual words that she could understand.
Thinking was reported by Mikki on three occasions (R8,10; R10,8; R8,5) during P2. On each occasion, this ‘thinking’ related to Mikki processing (top-down like) results explicated by the presenter and supported by pie charts. In each case, Mikki had to concurrently read the pie charts, listening to the oral explanation, and think.
Imagining was reported by both Neri and Mikki. Both participants described being attracted to the hook used by Presenter 2, which described her experience of living in Malaysia, and teaching Japanese language and culture. In response, both listeners reported using their imagination with divergent outcomes. Neri used her imagination to enhance her understanding of the speaker’s experiences and intentions (R0,4); however, Mikki’s ratings dropped (R9,8,9) because she imagined what life was like for the presenter in Malaysia and became distracted.
Predicting was not directly mentioned as a strategy by the learners; however, in P4, Mikki reported that the novelty of the topic left her unable to predict the content of four separate slides from their titles and the coordinated speaker’s transitional comments (R3,0,3; R3,0; R6,2; R8,3), which indicated her widespread use of this strategy during presentations.
Researching occurred both during and after presentations. In P1, Mikki (R9,5,9) checked the meaning of ‘shrinking’ on her smartphone while continuing to focus on the presentation. Conversely, in P1, Ally reported not understanding key technical items, ‘monochromic’ and ‘polychromic’, so ‘I came home and read the books’. This strategy, however, was not open to all, as Myne noted that ‘I suppose I should look things up, but I don’t know what the words are, so I can’t remember them to look them up.’
V Discussion and implications
1 Discussion
In response to the need for proficient listening skills to succeed in EMI and frequent reports of inappropriate or insufficient listening-focused pedagogical practices, this study examined learners’ situated, moment-to-moment listening difficulties and their associated responses from a CDST perspective. The study was expected to help resolve four difficulties when examining listening, namely (a) the opacity of learners’ listening processes, (b) the complexity of listening related processes and factors, (c) that variations in learners’ behaviours (and changes in proficiency levels) may be obscured by using static measurements of comprehension, and (d) that the paths of each learners’ development may diverge from the results reported in group-based studies.
With regards to (a), (c), and (d), ratings charts described (1) within-learner dynamism of perceived comprehension across a single text, (2) idiosyncratic reactions to the same texts, and (3) differentiation in levels of perceived comprehension across different texts. In this regard, these charts confirm the value of examining L2 processes at different timescales (MacIntyre, 2007) as they show differentiation compared to CDST-grounded, longitudinal studies over greater (bi-weekly or monthly) timescales, such as those by Dong (2016) and Chang and Zhang (2021). Furthermore, the above idiosyncrasies, dynamism, and differentiation across learners and texts is unaccounted for in currently published group-based listening proficiency and/or listening strategies research (e.g. Namaziandost et al., 2019; Vandergrift and Baker, 2015).
The ratings charts are complemented by situated accounts of factors that influenced the ratings. For example, Mikki’s ratings for P1 and P2 appear similar; however, her interview data revealed the varied challenges that each aural text posed, which she then responded to in myriad, unpredictable ways. Concerning textual differences, in P1 Mikki was challenged by unknown key vocabulary but overcame difficulties thanks to her awareness of presentation discourse; however, during P2 Mikki required a different response (i.e. thinking) to understanding research protocols, such as Likert scales and data presented in numerical charts. Concerning learner differences, Mikki struggled with forgotten lesson content in P1, while her own concentration caused problems in P2. Said idiosyncratic difficulties and responses cannot be accounted for in group-based research, such as listening focused research that elicits strategy use with questionnaires (e.g. Graham et al., 2008; Namaziandost et al., 2019), or in longitudinal studies that make use of diaries (e.g. Chang & Zhang, 2021; Dong, 2016) as these do not describe in moment-to-moment detail the nuances of listening challenges learners face nor the corresponding strategies learners employ in response.
In addition to the dynamism described in the charts, the stimulated recalls also highlight the interconnectedness of multiple factors in a system (see De Bot et al., 2007), such as those described by (Vandergrift & Baker, 2015). For example, accounting for the improvements in perceived comprehension reported by Neri between year one and year two (see Table 6) requires acknowledging the combination of more sympathetic delivery of aural texts (speech rate and length are reported in Table 1), prior topical knowledge (Neri was familiar with the topic of P3 and somewhat familiar with the topic of P4), improved understanding of discourse structures (having completed a further year of study involving her own intensive presentation practice), lower listening anxiety, and perhaps improved bottom-up-processing; all of which potentially aided her top-down processing efforts and implementation of listening strategies. This highlights a strength and weakness of this study. Describing these factors’ interrelatedness complements studies that describe factors discretely (e.g. Angelidis et al., 2019; Graham et al., 2008). Conversely, situated descriptions of difficulties were usually limited to those foregrounded in the learners’ minds at that time; for example, in P3 Neri articulated that her minimum rating was because ‘I didn’t know this word’ and her highest rating attributed to ‘it was interesting’. Lexical difficulty and topic interest are predicated on the convergence of all the interrelated factors mentioned above; however, in-situ, it was not usually possible for the learner to concurrently detect multiple factors.
Sometimes, multiple factors were identified as impacting listeners at the same time; for example, in P4, Indi (R10,9) was concurrently unable to aurally discern the word ‘flowers’ (BU-like difficulty), but she also lacked the clear visual support as the flowers the presenter had announced were not clear in the picture, which confused her. This was a seemingly top-down like difficulty. Similarly, in P1, Mikki (R9,7) heard the comment ‘precise instructions’, which featured four times in the section, as ‘pré-cee-size instructions’. Not knowing the word ‘precise’ can be attributed as a lexical difficulty; however, this also contributed to Mikki being unable to discern the sounds exactly as they were pronounced in the presentation, a bottom-up like difficulty. Modern L2 listening pedagogy has been criticized for being limited to top-down (Siegel, 2014) or product-orientated approaches (Kaur, 2017); however, this study clarifies that learners must concurrently and consecutively engage a range of listening processes.
Complexity was also present in the fluid accounts of phenomena impacting learners’ perceived comprehension, which could be tracked throughout a presentation. For example, in P4, Neri first reported affective issues because she was waiting to present; she then reported top-down processing difficulties in that she could not discern why the presenter had chosen the specific movie clips that were shown; these top-down difficulties were followed by bottom-up processing difficulties during the presenter’s explication of the movie clips, which Neri countered with her knowledge of presentation discourse structures; finally, Neri reported improved comprehension as she found commonalities between the presenter’s research findings and her own experiences. CDST theory states that the current state of a system is dependent on its prior states (De Bot et al., 2007); however, further examination of CDST-related listening processes would reveal whether there is (a) cumulative and/or discrete effect(s) for each of those difficulties described by (e.g.) Neri in P4.
A further aspect of CDST is that the interplay and interdependence of factors can lead to highly divergent outcomes (De Bot et al., 2007). Sometimes learners described the same difficulty, but this could result in converging or diverging outcomes. Relating to convergence, both Mikki and Neri struggled with the topic knowledge and large quantities of written text at the same juncture during P1, in response, they both returned falling ratings but were able to approximate the meaning of P1’s methodology section. Concerning divergence, the same learners both reported interest in P2’s hook; however, while Mikki lost concentration and reported falling scores, Neri reported improved concentration and improved ratings. Convergence and divergence of responses warrants further investigation; for example, Littlemore et al., (2011) reported that learners identified idioms as a source of difficulty when reading lecture transcripts, indicating that idioms should be avoided. The effect the use of idioms has when the text is delivered aurally, however, is unclear; learners may compensate and maintain comprehension levels, view difficulties as affordances for learning, or lose comprehension/concentration. A greater understanding of how individual learners react to similar difficulties may, therefore, inform future aural text design.
Finally, the authentic nature of the listening texts used in this study highlighted the within-text variability of the message being imparted, which much L2 listening research (Chang & Zhang, 2021; Dong, 2016; Graham et al., 2008; Namaziandost et al., 2019) somewhat overlooks. This may have two impacts. First, while comprehension is impacted by learner differences, such as L2 vocabulary knowledge, auditory discrimination ability, metacognitive awareness of listening efforts, and working memory capacity (Vandergrift & Baker, 2015), comprehension is also function of the way the message is conveyed; to wit, the intelligibility and comprehensibility of aural texts are variable. In many cases, however, such variability is not described and uniformity of aural text difficulty is assumed. Second, as per this study, many listening resources depend on the coordination of multiple sources of information (e.g. visual aids and shared knowledge between the speaker and the listener) but these multiple semiotics and their varying impacts may be ignored or be obscured in many studies.
2 Implications for pedagogy
These results reveal the kind of learner training that would benefit each learner; for example, in P1 and P2, Neri reported many periods of zero comprehension caused by bottom-up and lexical type difficulties. To cope with this level of listening challenge, Neri would benefit from bottom-up skills focused training and general vocabulary building. Mikki, on the other hand, reported mainly lexical issues which did not unduly impact her comprehension of presentations P1 and P2; Mikki may, therefore, benefit from academic vocabulary-focused pedagogy.
Education providers may use these results to improve pedagogy in three ways. First, by asking ‘What kind of learning processes are learners expected to undergo during the course of study?’, educators can devise curricula focusing on different stages of listening development. It may be posited that learners pass through three broad and overlapping phases of listening comprehension development. Phase one would predominantly focus on developing basic L2 listening proficiency. During phase one, learners will encounter mostly bottom-up type difficulties (see, for example, Table 6, Neri P1 and P2; Table 7, Neri; and Figure 6). Phase two would have a greater focus on learners listening to learn language. This phase would be defined by learners encountering a range of difficulties and challenges (see, for example, the problems reported in Table 7 by Mikki and Ally) as they cope with new linguistic items while listening to aural texts. Phase three would focus more on learners listening to acquire content knowledge. Phase three would be defined by learners encountering mainly top-down like challenges as they construct meaning and develop new content knowledge and content-related skills (see, for example, the problems reported in Table 9 by Ally).
Second, learners may be matched to classes that suit their particular needs. For example, profiles shown in Table 6, Neri P3 and P4, indicate a listener developing a clearer understanding of the aural text as it progresses. Matched with reports of the learner encountering more top-down like difficulties and fewer bottom-up like difficulties (Tables 9 and 10) it appears that the student is ready for content-focused study in phase 3 of a listening or EMI curriculum, contingent on the text difficulty. In the current study, however, while all participants cited ‘improving English’ as a key reason for joining the course, only one participant chose to study additional English language credits. This indicates that the learners saw the EMI course as an alternative to traditional language studying methods. Framed this way, the key benefits of EMI for the participants were increased English exposure and motivation to continue to be exposed to the language. Accordingly, many of this study’s participants may have expected or hoped to encounter a wide range of language development challenges (phase two) rather than expecting to solely learn a range of content (phase three).
Third, instead of asking ‘What listening skills should be taught to students?’ educators can ask ‘How can differing types of instruction (e.g. bottom-up, top-down, strategy-instruction) be matched to learner needs?’ For example, in Table 6, Neri P1 and P2, and Figure 6, Neri’s ratings frequently dropped to zero. In such cases, content-focused education providers could reduce the difficulty (e.g. by reducing the speech rate and lexical difficulty) of the texts used, while language-support focused educators could encourage the learner to develop greater bottom-up listening proficiency.
Concerning content-focused instruction, a range of manageable lecture delivery issues were described, including font size, quantity of text on a slide, vocabulary selection, speech rate, etc. Additionally, learners frequently reported forgetting content-related knowledge and having difficulty with technical skills (e.g. reading charts and understanding Likert-type scales) that had previously featured in the seminar classes. A glossary of key terms or frequent review quizzes may alleviate difficulties arising therewith; however, as the items had been previously taught, planners should establish with whom (instructor or learner) lies the responsibility for retaining previously-taught items. Additionally, culturally bound knowledge was essential for learners to develop an understanding of the presentations. It may be common for learners and educators to have cultural-, linguistic-, and age-gaps. Accordingly, it may be beneficial to have student assistants preview lecture content to ensure relevant items fall within the general knowledge boundaries of the target audience.
When developing listening-focused education, providers of pedagogy should also acknowledge the following points:
Learners will struggle with differing quality of audio streams, such as speech rate, accent, room acoustics, etc.
As EMI-lecturers may come from many backgrounds, institutions should not use mono-accented tests (e.g. TOEIC/TOEFL) as measures of learners’ listening proficiency.
Culturally familiar materials and materials that feature previously-covered knowledge may help novice learners focus specifically on bottom-up type difficulties before commencing training with materials that cover novel topics that put greater emphasis on learners’ top-down processing faculties.
An understanding of the discourse patterns and associated communication techniques of relevant genres of aural text (e.g. lecture, discussion, presentation) may enable more strategic listening behaviours.
Listeners must learn to respond to the visual aspects of lecture comprehension as well as the aural aspects.
Listening strategies need to be employed concurrently and/or consecutively not discretely.
None of the participants asked for help, more time, or a better explanations during the presentations. Learner training should include an awareness that learners in many situations are within their rights to ask the teacher/speaker (e.g.) ‘Sorry, could you speaker more slowly, please’ or ‘Can you show that slide for longer please?’
Gaps between quiz scores and ratings highlighted the need for (a) training in creating assessments that differentiate between language and content items, and (b) learner training in responding to said assessments.
Mikki’s falling ratings between year one and year two indicate that steps must be taken to ensure students’ language proficiency is maintained across the length of a course of study.
VI Limitations and future study
Concerning generalizability, varying genres of academic aural text (e.g. presentation, discussion, lecture, laboratory explanation, etc.) have different discourse features, which must be taken into account when extrapolating the findings of this study to other contexts. In addition, readers must acknowledge that EMI instructors’ linguistic proficiency, accent, depth of topic knowledge, and extent of experience (see Dearden, 2014; Macaro et al., 2018) vary from context to context. Concerning idiodynamic methodology, time delay and learners’ interpretations of events were key concerns in the procedures for this study, including that fact that the comprehension quiz results may have been impacted by learners forgetting items before attending the interviews. Further validation of idiodynamic methodology with (e.g.) standardized comprehension tests and/or summaries of aural text content would strengthen the claims of this study. Furthermore, learners’ accounts of difficulties and listening processes were limited to those foregrounded in their minds at that time of first exposure to the text, hence, findings using this methodology should be seen to complement current listening-focused knowledge rather than seeking to replace it.
In addition to providing situated accounts of learners’ difficulties in EMI-focused listening, this study provided a novel way of capturing the volatility and complex nuances of listening comprehension. Such variations in comprehension may not be captured by other measures of comprehension, e.g. quizzes or surveys. Idiodynamic ratings may be further calibrated with qualitative descriptions of comprehension (such as those in Table 3) to enable a new approach to studying L2 listening-related pedagogy and comprehension; for example, controlled studies may examine how (e.g.) varied speech rates impact overall comprehension across various proficiency levels. Moreover, in the current study, limited guidance on interpreting ratings and no instruction on listening strategies or processes was given to avoid biasing learners’ responses. Future studies could develop a clear scale allowing for more reliable comparisons of ratings and/or pre-teach examples of listening processes, strategies, and difficulties to elicit a greater depth and range of learner experiences.
There are also potential pedagogical uses for idiodynamic methodology; for example, difficult sections of commonly used texts (e.g. lecture content or how-to-do videos) could be identified by learners and then be revised or simplified by instructors. Similarly, for listening skills instruction, challenging sections of aural texts might be identified and turned into affordances for listening skills development. Furthermore, educators with smaller numbers in their classes could use it as a diagnostic tool to identify individual learner’s listening-focused needs, such as focusing on top-down or bottom-up processes, or vocabulary. Finally, the data showed that learners’ responses to commonly-encountered-difficulties differed. Educators may wish to use these points of divergence as a pedagogical tool by having learners compare the ways in which they perceived and responded to certain difficulties, as described by Ducker (2021).
VII Conclusions
As implementation of EMI spreads around the globe, development of good listening skills is crucial for both content- and language-focused academic success. In many cases, however, listening skills may be undertaught or unsuited to learners’ needs. Difficulties in preparing effective listening pedagogy include the opaque nature of listening processes, the complex interrelatedness of listening-related factors, the ergodicity problem, and the use of static metrics to measure a dynamic process. In response, this CDST-grounded study applied idiodynamic methodology to collect data concerning five learners’ listening processes as they watch EMI-situated graduation presentations.
The results showed students returning a dynamic range of ratings for their listening comprehension. These ratings showing (a) that perceived comprehension ebbs and flows across a single text, (b) how learners differed in their reaction to the same texts, and (c) how individuals’ comprehension levels differ across different texts, which had all previously been undetected in L2 listening research. The ratings also provided a dynamic alternative to static measurements of comprehension, such as quizzes or surveys. Additionally, learners’ situated accounts of listening-related difficulties, and the knowledge-related and knowledge-independent strategies they employed to overcome these difficulties could be pinpointed to exact phenomena in the presentations. These accounts revealed when multiple difficulties coincided or ran concurrently, and when multiple resources and strategies had to be engaged in tandem to overcome said difficulties; thus, giving a clearer, situated description of the CDST properties of learners’ listening comprehension processes.
In addition to complementing a range of studies that have examined strategy use (Graham et al., 2008; Namaziandost et al., 2019), longitudinal changes in listening proficiency (Chang & Zhang, 2021; Dong, 2016; Graham et al., 2008), and studies that have explicated the multiple underlying processes of L2 listening (Vandergrift & Baker, 2015), the findings from this study may help EMI and language program developers understand learners’ needs better and, accordingly, develop appropriate listening curricula that target learners’ level-specific needs. Furthermore, with direct reference to EMI programs, the findings of this study may help instructors improve lecture delivery and provide useful heuristics for educators working to develop learners’ L2 English listening proficiency.
Supplemental Material
sj-docx-1-ltr-10.1177_13621688221124439 – Supplemental material for A situated examination of the complex dynamic nature of L2 listening in EMI
Supplemental material, sj-docx-1-ltr-10.1177_13621688221124439 for A situated examination of the complex dynamic nature of L2 listening in EMI by Nathan Thomas Ducker in Language Teaching Research
Supplemental Material
sj-docx-2-ltr-10.1177_13621688221124439 – Supplemental material for A situated examination of the complex dynamic nature of L2 listening in EMI
Supplemental material, sj-docx-2-ltr-10.1177_13621688221124439 for A situated examination of the complex dynamic nature of L2 listening in EMI by Nathan Thomas Ducker in Language Teaching Research
Footnotes
Appendix 1
Appendix 2
Appendix 3
Appendix 4
Acknowledgements
The author would like to thank all the students without whom the study could not exist, his colleagues for their invaluable assistance, and the anonymous peer reviewers for their insightful advice.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.