
Abstract
This mixed-methods study examined the impact of integrating generative artificial intelligence (GenAI) into English as a foreign language (EFL) writing classes on students’ writing performance and affective responses. Nearly 100 Chinese students from four parallel International English Language Testing System (IELTS) writing classes in a university foundation program participated in a 9-week trial, with half assigned to an experimental group and half to a control group. Both groups received theme-based instructions on IELTS Writing Task 2 through a three-stage writing process, while the experimental group also engaged with Kimi, a widely used GenAI chatbot in China, during and after class. Unlike previous studies, this research targeted lower-intermediate learners and aimed to offer a more nuanced understanding of GenAI’s role by employing natural language processing (NLP)-based evaluations and linear mixed-effect models in the quantitative analysis. The pretest and posttest results showed that GenAI-assisted instruction did not significantly improve students’ writing performance except in syntactic complexity. The questionnaire and interview data, however, indicated that this approach positively influenced learners’ motivation, engagement, and self-efficacy. Further analysis suggested that the discrepancy between students’ improvements in writing performance and their reported affective gains may be attributed to limited learner agency, a lack of teacher support outside class, and misalignment between their English proficiency levels, cognitive readiness, and GenAI’s affordances. The study concludes with implications for second-language writing instruction and directions for future research.
I Introduction
The recent emergence of generative artificial intelligence (GenAI) tools such as ChatGPT is reshaping second-language (L2) writing education (Praphan & Praphan, 2023), offering new possibilities to support the structural, dialogical, and linguistic dimensions of student writing through roles such as virtual assistant and automated evaluator (Su et al., 2023). In response, a growing body of research has begun to investigate the effectiveness of GenAI in L2 writing classrooms. While findings generally suggest that GenAI-assisted instruction can enhance writing performance and improve learners’ affective experiences (see Section II.3), questions remain regarding the generalizability of these results. This is due to contextual variation in L2 learning environments (Wu, 2024) and methodological limitations in prior studies.
This study contributes to this line of inquiry by examining the effects of GenAI-assisted instruction on lower-intermediate English as a foreign language (EFL) students’ International English Language Testing System (IELTS) writing performance and affective factors in a university foundation program. In particular, we investigate whether changes in students’ writing performance align with their reported affective responses, and explore potential factors underlying any observed discrepancies. Distinct from previous studies, we adopt mixed-effects modeling and assess students’ writing performance through a combination of expert ratings and natural language processing (NLP)-based evaluations. By doing so, we aim to enrich our understanding of GenAI’s efficacy in diverse EFL pedagogical settings and inform more effective integration of GenAI in L2 writing classrooms.
II Literature review
1 AI and mediated L2 development
Within the Vygotskian sociocultural tradition, L2 development is viewed as a mediated process, shaped by interaction, guidance, and the use of tools within a learner’s zone of proximal development (ZPD). One influential framework that builds on this idea is mediated development or mediated learning experience (Feuerstein et al., 1980), which posits that human cognitive abilities are not static but can be enhanced through intentional and contingent mediation. Lantolf and Thorne (2006) and Van Lier (2010) extended this perspective to the L2 context, emphasizing that L2 development is mediated through social interaction and collaborative engagement within the learning environment.
Over time, language education has increasingly incorporated technology as a mediation, from mobile-assisted language learning, which emphasizes personalized instruction, to synchronous computer-mediated communication that facilitates peer interaction and virtual reality environments that simulate immersive language experiences (Mohsen et al., 2024). This in turn is reshaping our cognitive structures for language learning (Warschauer, 2002). The rise of AI has introduced new forms of technological mediation in L2 education, fundamentally altering the learning ecology. Whereas teachers have traditionally served as the primary mediator scaffolding students’ linguistic and cognitive development, AI now interacts with L2 learners in increasingly sophisticated ways, reconfiguring the traditional teacher–learner dynamic into an increasingly triadic mediation model (Fryer & Carpenter, 2006). In spite of this, many language educators still believe that as education coevolves with new technologies, “teachers remain a keystone species in this human-nonhuman relational ecology” (Thorne, 2024, p. 572).
2 Affective factors, learner agency and L2 development
Research has increasingly highlighted the psychological dimensions of L2 acquisition, emphasizing the crucial role of affective factors such as learners’ attitudes, perceptions, self-beliefs, and motivation 1 (Wesely, 2012; see also Papi, 2022 for a focus on L2 writing). When negative emotions are mitigated and a supportive psychological state is established, learners are more likely to exercise agency in their language learning. Defined as an individual’s will and capacity to act, learner agency entails autonomous, self-regulated, and goal-directed learning behaviors. When agency is fully activated, learners not only take greater ownership of their progress but are also better equipped to overcome challenges and make sustained gains in language proficiency (Gao, 2010).
However, learner agency is a complex and dynamic construct. It is shaped not only by affective experiences but also by learners’ actual competencies, self-regulatory capacity and the affordances present in specific learning settings (Mercer, 2011). Moreover, it is “a relationship that is constantly co-constructed and renegotiated with those around the individual and with the society at large” (Pavlenko & Lantolf, 2001, p. 148). As such, the relationship between affective factors and learning outcomes is not always linear or predictable. As Wesely (2012, p. 103) notes, “scholars should embrace when a relationship [between learner attitudes, perceptions, and beliefs to outcomes] is not found when expected and they should allow themselves to explore and interpret the reasons.”
3 Existing studies on effects of GenAI-assisted EFL writing instruction
Since the advent of ChatGPT, a growing body of research has explored the effects of ChatGPT-assisted instruction on undergraduate EFL writing outcomes and/or learners’ affective experiences. Yan (2023), for instance, conducted interviews with eight EFL undergraduates following a 1-week ChatGPT-supported practicum, highlighting the tool’s affordances and pedagogical potential. Similarly, a qualitative study by Karataş et al. (2024) of 13 EFL students suggested that ChatGPT positively influences students’ learning experiences, particularly in writing, grammar, and vocabulary acquisition, while also enhancing their motivation and engagement due to its accessibility and versatility. Using questionnaires with a large sample of EFL undergraduates, Huang and Mizumoto (2024) found that ChatGPT’s integration can improve intrinsic motivation and writing self-efficacy, provided structured guidance is available to manage issues such as plagiarism. Combining quantitative and qualitative analysis, Song and Song (2023) reported that EFL university students who received ChatGPT-assisted instruction demonstrated significant improvements in both writing performance and motivation compared to the control-group students. Ghafouri et al. (2024) also found that learners in the experimental group significantly outperformed the control group in IELTS-style writing task scores after a 10-week ChatGPT-based writing instruction protocol. In a similar vein, Aladini et al. (2025) examined a large sample of intermediate EFL learners and found that those engaged in self-directed AI-based writing tasks not only achieved higher writing scores than the control group but also demonstrated greater growth in mindfulness.
While these studies suggest promising benefits of GenAI in L2 writing instruction, several research gaps remain. First, despite encouraging findings, potential publication bias may exist (Wu, 2024), particularly given the current enthusiasm surrounding GenAI; therefore, more conceptual or constructive replications (Marsden et al., 2018) across diverse educational contexts are needed to further test the generalizability of these findings under different conditions. Second, existing quantitative analysis fail to take individual learner differences into account. While some studies controlled for initial proficiency levels by comparing pretest scores between experimental and control groups, heterogeneity still exists within these groups. Standard statistical methods such as t-tests or analysis of variance (ANOVA) may overlook the effect of individual differences in postintervention outcomes (Cunnings, 2012). Third, existing studies rely solely on subjective assessments of writing quality, without incorporating objective linguistic analyses. While rubric-based human rating remains essential for assessing students’ L2 output (Xi, 2017), exclusive use of this approach may introduce researcher bias and compromise the validity of posttest evaluations. It was in response to these gaps that we conducted the current study. Before detailing our study, however, a brief review of L2 writing assessment is necessary.
4 Assessing L2 writing performance
Evaluating writing performance is essential for determining the effectiveness of AI-assisted instruction in L2 contexts. Traditional rubric-based assessments, while common, are subject to rater variability and often overlook fine-grained linguistic features. In response, researchers have increasingly adopted automated, data-driven approaches. The widely used complexity–accuracy–fluency (CAF) framework (Housen & Kuiken, 2009; Norris & Ortega, 2009) captures key dimensions of proficiency and aligns well with NLP-based metrics.
Complexity in L2 writing includes syntactic and lexical dimensions. Syntactic complexity is often operationalized through the length of syntactic units such as sentences, clauses, and T-units, or the proportions of various fine-grained syntactic structures (Lu, 2011). Lexical complexity or richness, on the other hand, consists of lexical diversity, typically measured as the proportion of unique words to total words, and lexical sophistication, often quantified by the relative frequency with which L2 writers’ lexis appears in the target language (Johnson, 2017; Lu, 2012). Fluency is typically measured as total word count within a set time (Plakans et al., 2019). Accuracy, the ability to produce error-free language, is gauged through error-free units, weighted T-units, error counts, or holistic ratings (Polio & Shea, 2014). While GenAI has shown promise for automated accuracy assessment (Mizumoto et al., 2024), it still relies primarily on human judgment for precision.
It is worth noting, however, writing is not only about linguistic form but also communicative effectiveness. Xi (2017) noted that while linguistic features inform rater judgments, overall communicative effect often weighs more heavily. Kuiken and Vedder (2014) similarly found that raters prioritize content, argumentation, organization, and comprehensibility over formal features. Thus, combining human ratings with objective measures offers a more valid assessment, balancing communicative insight with reliability and granularity.
5 The present study
The present study was carried out in a university-level English foundation program, where lower-intermediate EFL learners received GenAI-assisted IELTS writing instruction over a 9-week period, whereas their peers in the control group were taught using the same syllabus without GenAI support. Specifically, we aim to address the following research questions.
Is GenAI-assisted writing instruction more effective in improving lower-intermediate EFL learners’ linguistic complexity, fluency, accuracy, and communicative adequacy in argumentative essays compared to traditional writing instruction?
To what extent does GenAI-assisted writing instruction influence lower- intermediate EFL learners’ perceived affective responses, i.e., their attitudes, motivation, and self-efficacy?
Do lower-intermediate EFL students’ writing improvements align with their perceived affective responses? If not, what factors might account for the discrepancy?
III Method
1 Research setting and participants
The study took place in four parallel IELTS writing classes within the foundation stage of a joint program between a Shanghai-based higher education institute and several overseas universities. After 2 years of study in China, students apply to complete their degrees in Australia or the UK, where admission is based on their grade point average (GPA) and IELTS scores (typically requiring a 6.0–6.5 overall band).
In the first semester, students take an 18-week IELTS course covering all four modules, with midterm and final exams contributing to their GPA. For this study, four writing classes, taught by the two authors, were selected. The 9-week intervention began after the midterm exam. Two classes formed the experimental group and two the control group. To minimize instructor bias, each teacher was assigned one class in each condition (Table 1).
Overview of the participating classes.
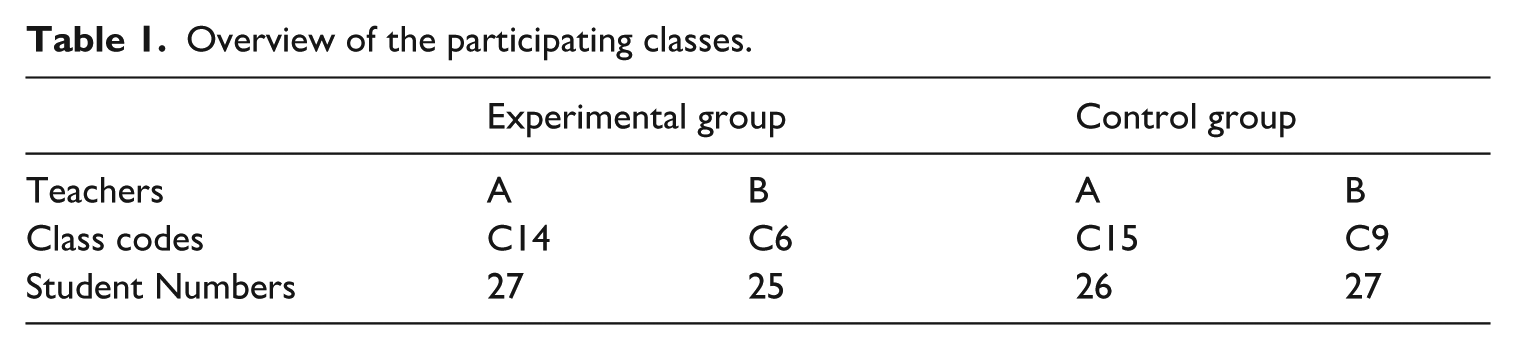
Each class had 25–27 students and met twice weekly for 90-minute sessions. At the start of the program, all students took an in-house English proficiency test modeled on the IELTS listening and reading sections. Although individual scores varied, class averages were similar (approximately 5.0 out of 9.0 on the IELTS scale), indicating lower-intermediate proficiency.
2 Writing instruction
During the 9-week research period, both experimental and control groups received theme-based instructions on IELTS Writing Task 2 through a mix of lectures and task-based activities, including individual work, pair exercises, and small group collaboration. The only difference was that the experimental group used GenAI assistance during and after class. Both groups were assigned the same homework on class-related writing topics and each student handed in one essay every 2 weeks. Teachers provided individual written feedback on submitted essays, and a 20-minute feedback session with reflection and discussion was held biweekly for all classes. To ensure instructional parity, no extra after-class individual tutoring was provided to either group, and the two instructors jointly reviewed the teaching plan before each session.
Specifically, students in the experimental classes engaged with Kimi, a widely used free GenAI chatbot in China, at three stages of the writing process, broadly aligning with the first three phases of the protocol proposed by Su et al. (2023). In the idea generation stage, students generated argumentation outlines for a given topic through peer or group discussion and subsequently interacted with Kimi to refine and strengthen their ideas. In the evidence development stage, depending on the time constraints, each student drafted one or two supporting paragraphs, or the entire body section, either in Chinese or English; Kimi was then consulted to evaluate the relevance and effectiveness of the supporting details (with the focus on evidence only, not language). In the proofreading stage, students first revised their English draft, or translated their version from Chinese to English, and then used Kimi to enhance linguistic accuracy, sophistication, and textual coherence. After class, they were assigned additional Kimi-assisted practice on theme-related topics. For submitted essays, however, they were asked to consult Kimi only after submission, allowing them to compare and reflect on both sources of feedback.
Two points are especially worth noting here. First, as most of our students had limited experience in utilizing GenAI chatbots for IELTS writing, the instructors prepared a set of prompt templates, tailored to the three main IELTS Writing Task 2 question types and aligned with these students’ desired target IELTS writing scores (typically 6.5), to guide their interaction with Kimi throughout the writing process. To make them more accessible, the prompts were designed in Chinese, the students’ native language (see Appendix 1). Figure 1 partially illustrates a student’s interaction with Kimi at the evidence development stage of the writing process for the IELTS-style topic “It is better for children to use smartphones for learning than for entertainment. Do you agree or disagree?” In this instance, Kimi pointed out issues such as self-contradiction in the argument and the weakness of using “smartphones create distractions” as evidence, noting that distraction may show smartphones are unsuitable for learning but does not establish why they would be better suited for entertainment. Second, the instructors conducted regular in-session checks to ensure that students adhered to the teaching protocol and used Kimi strictly as a support resource rather than as a substitute for their own idea generation and writing. Meanwhile, as the instructor circulated around the classroom, ad hoc support was provided to individual students, including guiding them in formulating follow-up questions to Kimi. This was necessary because some students were slow to grasp the purpose of the template prompts and struggled to adapt them fully to the assigned topic, while others remained uncertain why their supporting evidence was judged as a poor fit despite Kimi’s explanations, or were confused by Kimi’s suggested revisions to specific words or sentence structures. For example, in the case shown in Figure 1, the student sought the instructor’s clarification because Kimi’s feedback was too complex for him to comprehend. The instructor then guided the student through Kimi’s comments, helping him understand that his argument could be strengthened by explaining why smartphones easily distract learners during study (a point missing from Kimi’s feedback in fact), and, in the next paragraph, by elaborating on why smartphones may be particularly well suited for entertainment, as Kimi had indicated.

Part of a student’s interaction with Kimi for evidence development following the prompting template.
Students in the control classes followed the same three-stage protocol but received only teacher guidance instead of GenAI assistance. Due to time constraints, the instructors selectively commented on student responses at each stage. After class, they practiced independently on the same set of theme-related topics assigned to the experimental classes and each submitted one essay every 2 weeks. This design ensured that both groups were exposed to identical writing content while differing only in the type of support received.
3 Procedure and instruments
This study employed paper-based tests modeled on IELTS Academic Writing Task 2 to assess students’ writing performance before and after the instructional intervention. The pretest and posttest prompts were thematically related but distinct to evaluate transfer of learning beyond rote memorization. The topic of the pretest, administered during the midterm exam, was “Some people believe that social media has had a positive impact on mental health, while others argue that it has caused mental health problems. Discuss both views and give your own opinion.” The topic of the posttest, conducted as part of the final exam, was “Social media has become a center for spreading false information. What are the causes of this problem, and how can it be addressed?” Both essays had a 250-word target and a 40-minute time limit.
At the end of the program, students in the experimental group completed a brief questionnaire in Chinese anonymously (see Appendix 2 for the English translation), administered via Wenjuanxing, a widely used online survey platform in China. The survey included three parts: (1) students’ perceived affective responses (attitudes, motivation, self-efficacy); (2) challenges they felt in using Kimi for IELTS writing practice; and (3) their perceived behavioral change. The questionnaire was partially informed by previous studies (Huang & Mizumoto, 2024; Meniado et al., 2024) and reviewed by two external experts. Two things should be noted. First, out of the same concern as Liu and Reinders (2025) about response fatigue, the questionnaire was intentionally kept short to ensure that our students had the patience to complete it attentively, as previous research has shown that single-item measures can, in certain contexts, yield validity comparable to multi-item scales (Gogol et al., 2014). Second, the section addressing the challenges that students felt in using Kimi was based on the students’ informal feedback provided to the instructors during the intervention and two pilot interviews.
In addition, after two pilot interviews, semi-structured interviews (see Appendix 3) were conducted with 11 students from the experimental group to gain deeper insights into their learning experiences. Interviews were held in Chinese via Tencent Meeting, lasted 20–30 minutes, and were recorded with the participants’ consent.
4 Measures and quantitative data collection
For a more accurate evaluation of improvements in students’ writing performance, we combined NLP-based linguistic analyses with rubric-based human ratings for both pretest and posttest essays in the control and the experimental groups (Table 2).
Measures of students’ writing performance.
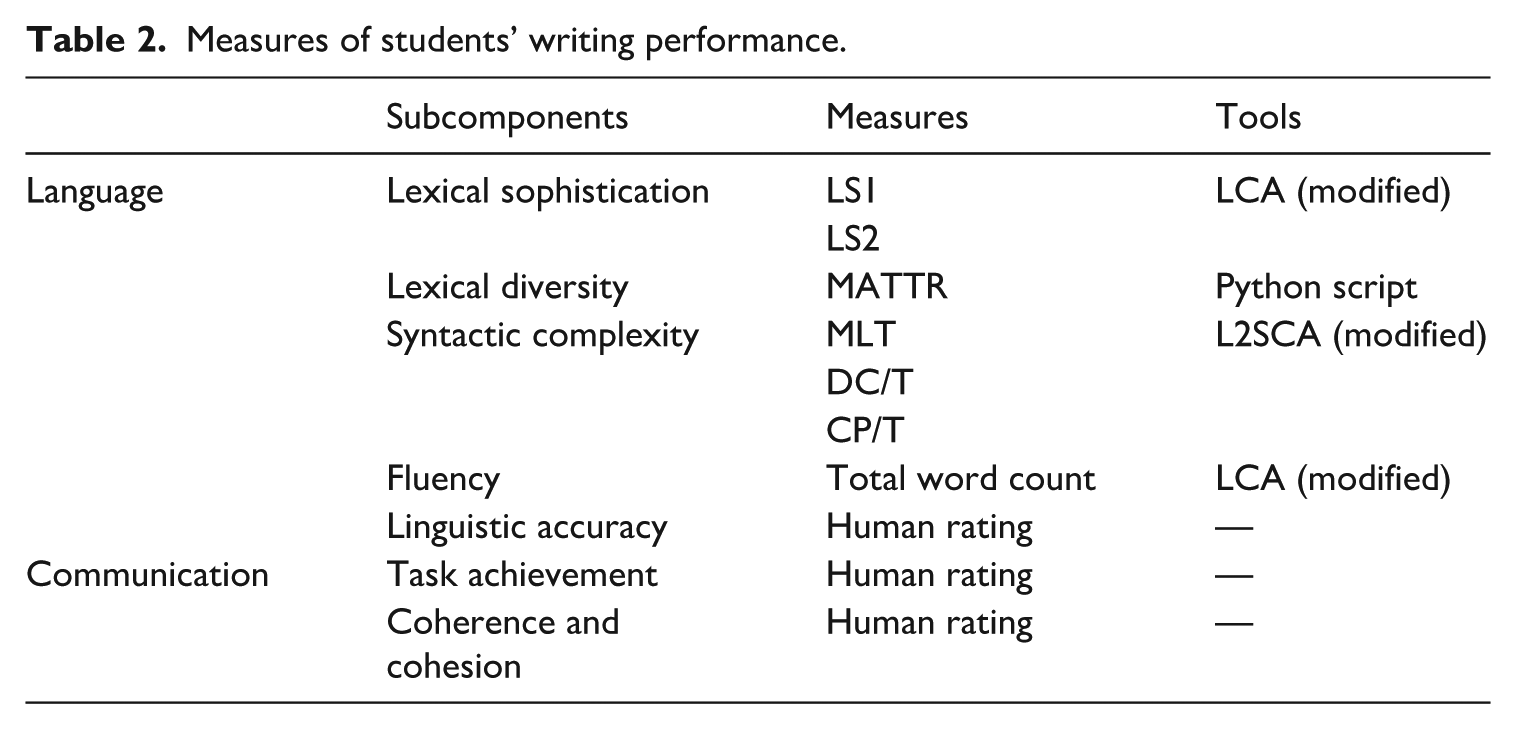
All essays were first transcribed into Word documents by a postgraduate student in applied linguistics, with all apparent spelling mistakes corrected to avoid skewing NLP indices. The Word versions were then converted to .txt files and their lexical sophistication, syntactic complexity, and fluency (i.e., the number of words per text) were analyzed with a modified version of the Lexical Complexity Analyzer (LCA) (Lu, 2012) and the L2 Syntactic Complexity Analyzer (L2SCA) (Lu, 2011) run with SpaCy (Spring & Johnson, 2022), which offers superior tagging and parsing compared with older taggers and parsers (Kyle & Eguchi, 2024).
For lexical sophistication, we chose LS1 (the number of sophisticated words divided by the number of lexical words) and LS2 (the number of sophisticated word types divided by the total number of word types), excluding verb-specific indices (VS1, CVS1, and VS2), which are less valid for short texts (Yang et al., 2023).
To avoid redundancy, syntactic complexity was measured using mean length of T-units (MLT), dependent clauses per T-unit (DC/T), and coordinate phrases per T-unit (CP/T), following Chan et al. (2015). We also excluded structure-specific indices (e.g., complex nominals), which show lower reliability than measures for higher-level units (Polio & Yoon, 2018); besides, our students’ English proficiency level would have made them even more problematic.
Lexical diversity, which also falls under lexical complexity, was assessed using moving-average type-token ratio (MATTR), a robust measure least affected by text lengths and ideal for short texts such as those in our study (Zenker & Kyle, 2021). Since it is not available in LCA, we calculated it separately with custom Python scripts.
Due to the high frequency of linguistic errors in our students’ essays, we adopted a holistic measure of linguistic accuracy rather than human-coded error analysis. We created an IELTS-style accuracy scale (see Supplemental Material, Part 1) based on prior research (Polio & Shea, 2014; Xie, 2019) and our teaching experience. A pilot rating of 20 essays confirmed interrater reliability, after which all essays were rated independently, yielding a reliability of .727.
To assess higher-order communicative adequacy, i.e., content, structure, and coherence, we applied IELTS subscales for Task achievement and Coherence and cohesion (see Supplemental Material, Parts 2 and 3). The former addressed relevance and completeness of content, and the latter logical structure and flow. We independently rated the essays after an initial consultation, achieving an interrater reliability of .709 and .656 respectively.
5 Data analysis
We used linear mixed-effects (LME) models in R to examine changes in L2 writing performance between pretests and posttests across the experimental and control groups. LME models are well-suited for tracking L2 development over time and accounting for random effects such as individual variation (Cunnings, 2012). In our models, fixed effects included group (experimental versus control) and time (pretest versus posttest), while random effects captured individual differences: an important but often overlooked factor in prior GenAI-assisted writing research. Although we initially considered including teacher as a random effect, a singular fit issue suggested near-zero variance, indicating that this factor added no meaningful explanatory power. As a result, we opted for simpler, more robust models to analyze all subcomponents of students’ writing performance: model <- lmer(Performance Measures ~ Time*Group + (1|Student)), where “Time*Group” represents the fixed effects of time, group, and their interaction, “(1|Student)” accounts for individual differences in students’ baseline writing performance (random intercept). For each model, we report both marginal R² (R²m; variance explained by fixed effects) and conditional R² (R²c; variance explained by both fixed and random effects).
Three additional considerations should be noted. First, texts shorter than 100 words were removed from analysis (the shortest included text was 133 words), as such brevity could compromise the validity of automated linguistic measures (Garner et al., 2019). Second, while LME models allow for missing values, we chose to exclude students who missed either the pretest or posttest or whose essays were removed due to their extreme short lengths, given the modest sample size. Finally, as LME models assume normally distributed residuals, we applied logit, log, or square root transformations to dependent variables to approximate normality as closely as possible (Fox & Weisberg, 2019).
For the survey results, we calculated the means and standard deviations of the students’ responses to each question. For the qualitative data, thematic analysis was used to identify patterns in students’ interview transcripts. After an initial discussion, we independently coded three transcripts using an inductive approach. We then compared and refined the coded themes, resolving any differences through mutual agreement. We each subsequently coded four of the remaining eight transcripts. Representative excerpts were jointly selected to illustrate each theme.
IV Findings
1 Comparisons of writing performance
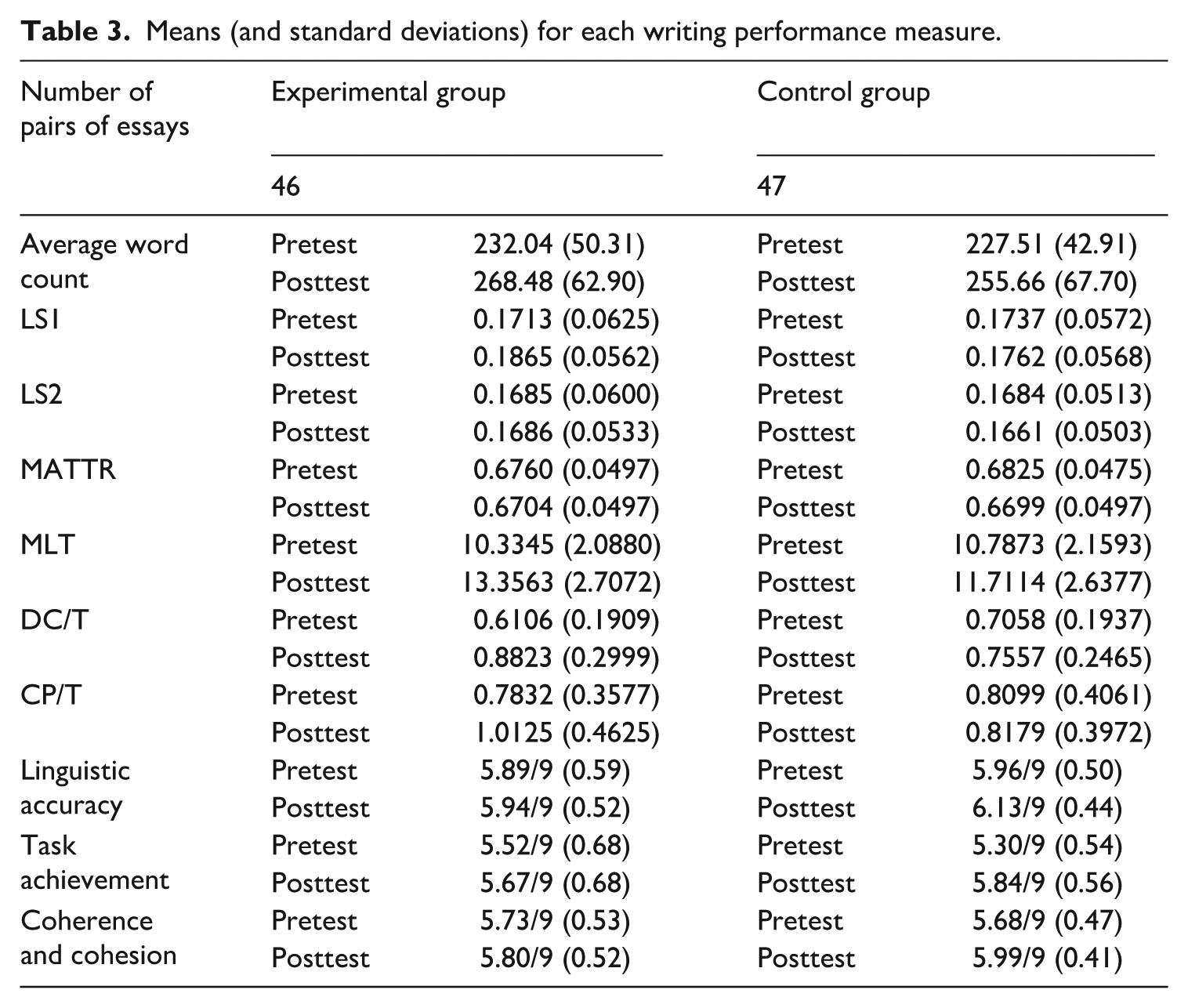
Table 3 gives the descriptive statistics for the pretest and posttest performance measures of the experimental group and the control group. Tables 4 –7 present the LME results for word count, MLT, DC/T, and CP/T, respectively. For word count, the model showed a significant main effect of time, but the interaction between time and group was not significant. Regarding MLT, in addition to the significant effect of time, the interaction between time and group also showed significant effect: on average, the experimental group increased by about 0.11 units more than the control group from the pretest to the posttest. For DC/T, although there was no significant effect of time, significant effect still existed of the interaction between time and group. For CP/T, the interaction between time and group showed marginally significant effect (p = .054). It is also important to note that the fixed effects accounted for a small proportion of the variance explained by these models, which themselves explained less than half of the total variance, as indicated by the values of R2m and R2c.
Means (and standard deviations) for each writing performance measure.
LME fixed effects for word count (square root transformed).
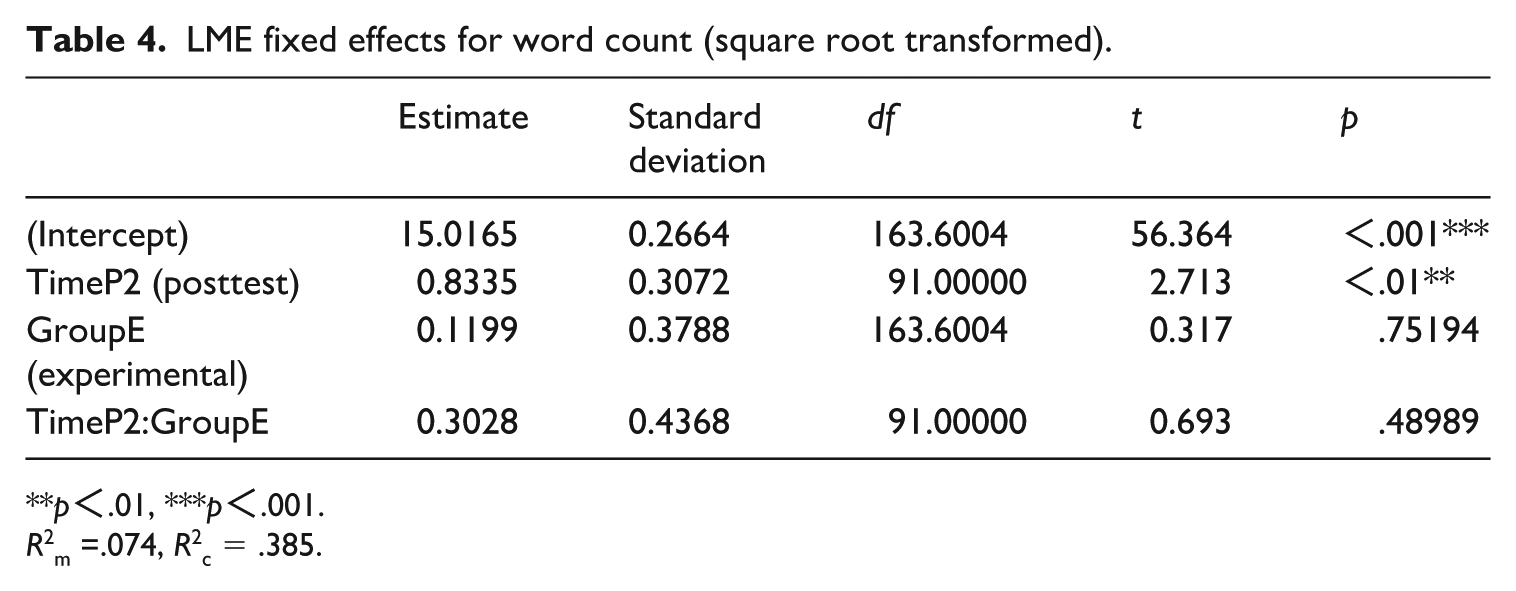
**p<.01, ***p<.001.
R2m =.074, R2c = .385.
LME fixed effects for MLT (log transformed).
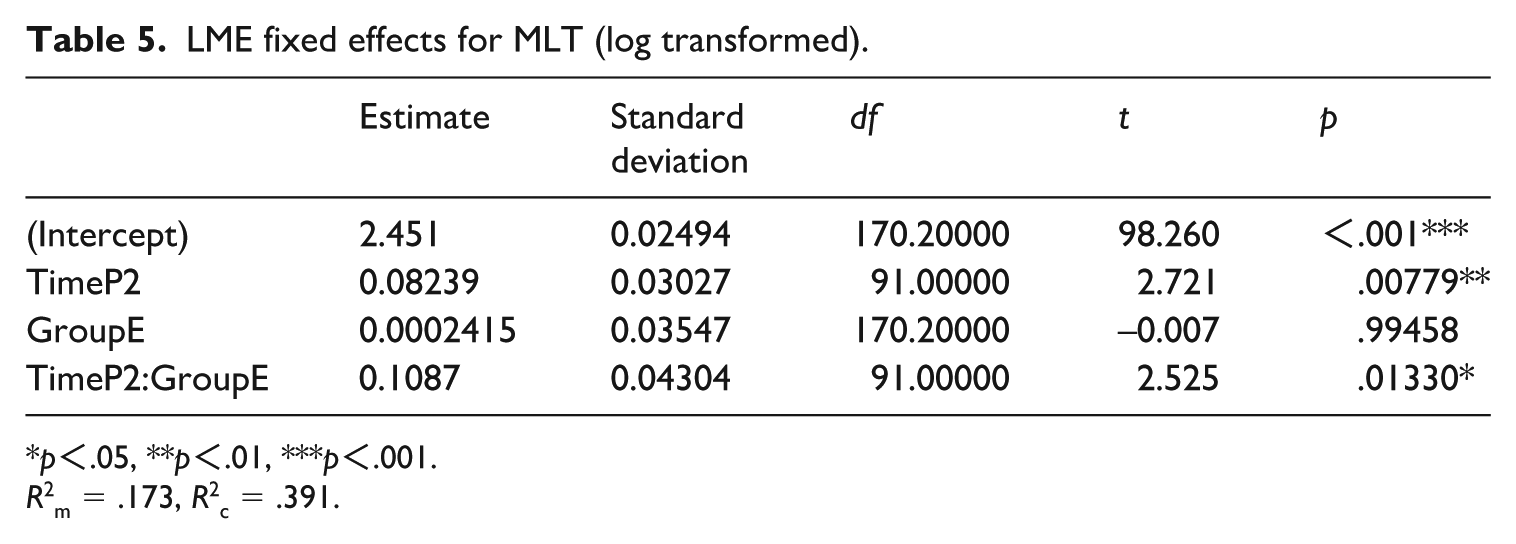
p<.05, **p<.01, ***p<.001.
R2m = .173, R2c = .391.
LME fixed effects for DC/T (log transformed).
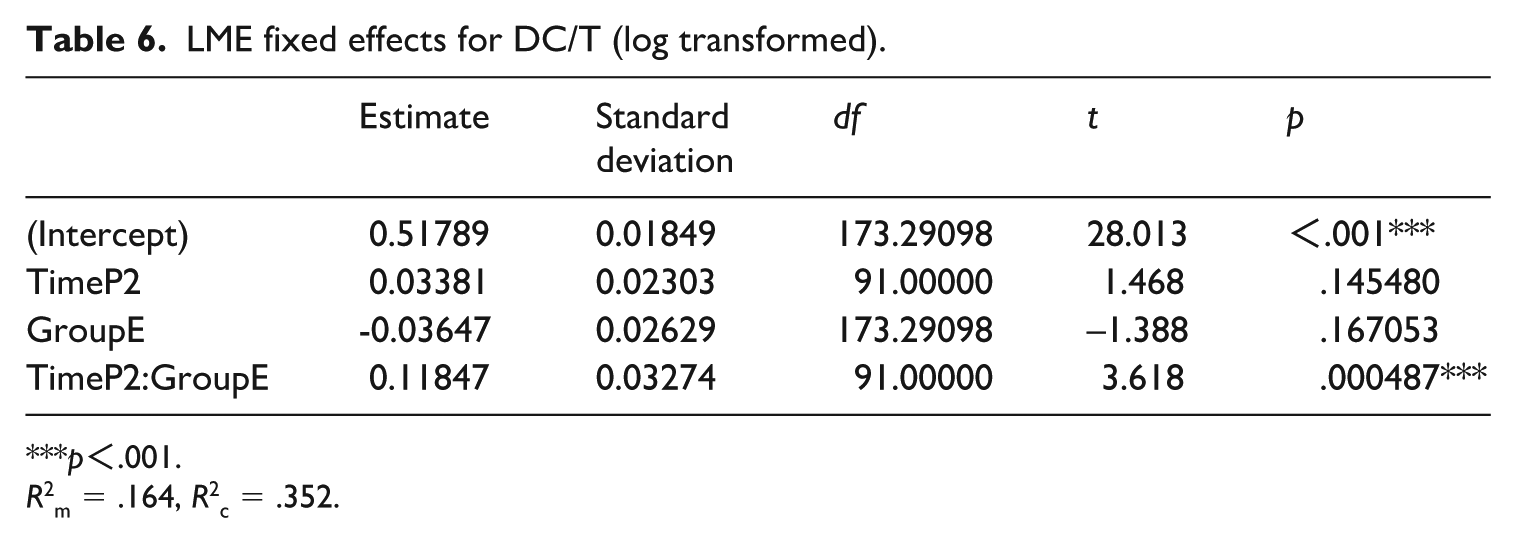
***p<.001.
R2m = .164, R2c = .352.
LME fixed effects for CP/T (log transformed).
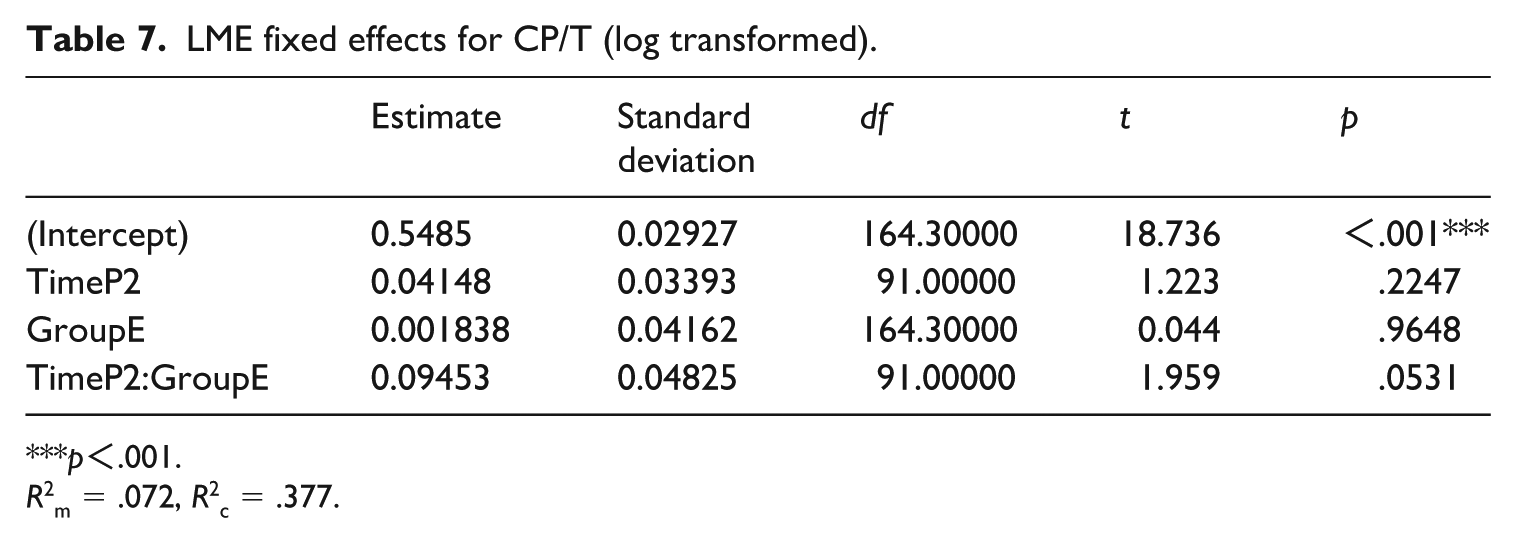
***p<.001.
R2m = .072, R2c = .377.
A summary of the LME models for the other writing performance measures is provided in Tables 1–6 of the Supplemental Material (Part 4), where no significant effect of the interaction between time and group was found on any of these measures.
2 Results of the questionnaire
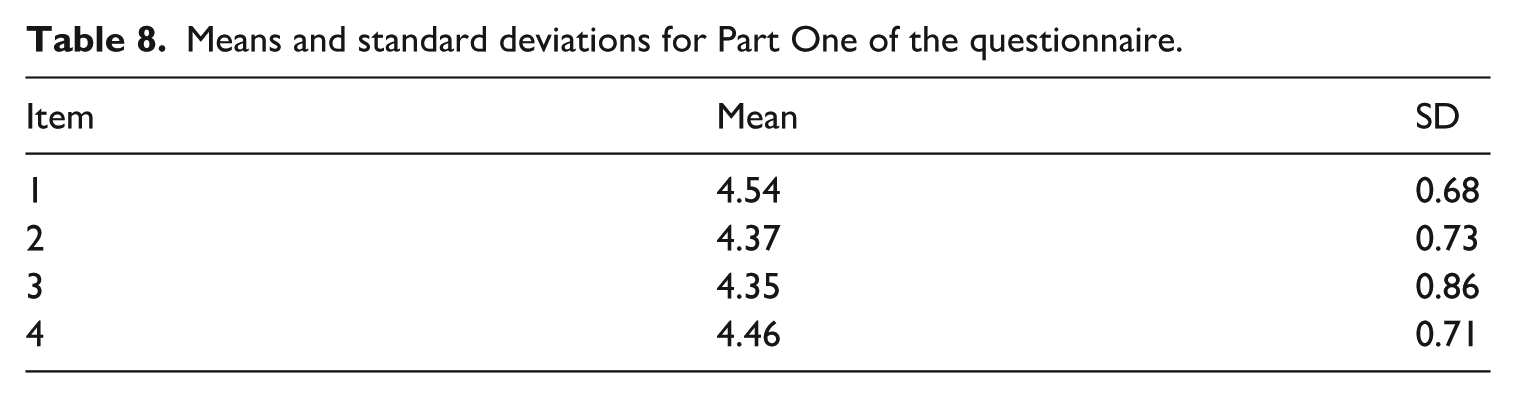
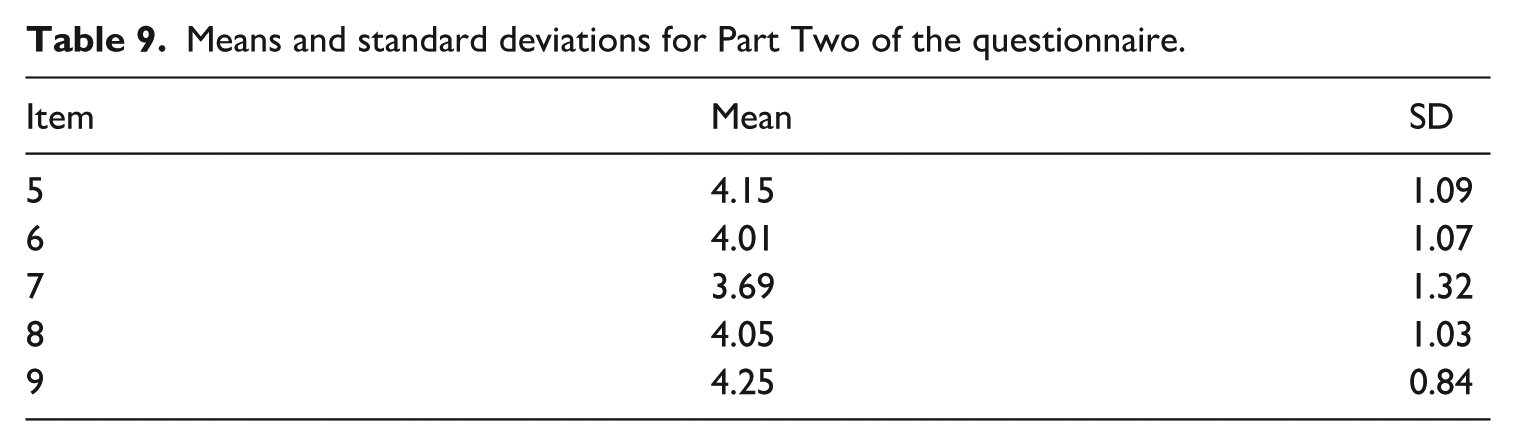
Table 8 presents the results for the first part of the questionnaire, showing that students in the experimental group generally exhibited positive affective responses to Kimi-mediated IELTS writing instruction. Table 9 lists the responses to the second part, indicating general agreement with the statements regarding the challenges of Kimi-assisted writing instruction. The lowest mean was for Q7, suggesting students were relatively less concerned about expressing needs when interacting with AI. For the final part of the questionnaire (item 10), however, the mean score was 3.28 (standard deviation [SD] = 0.82), the lowest of all 10 items.
Means and standard deviations for Part One of the questionnaire.
Means and standard deviations for Part Two of the questionnaire.
3 Themes in the interviews
Through thematic analysis of the 11 semi-structured interviews, six major themes emerged, revealing how the participants perceived and experienced the GenAI-assisted IELTS writing instruction.
a Theme 1: Positive effects of GenAI on writing development and learning experience
Participants widely acknowledged Kimi’s role in improving their writing through structural support and timely, personalized feedback. Many also reported an enhanced learning experience and a greater sense of achievement. “AI can point out my grammatical errors and suggest much better ways of expression, which I will deliberately use in my next writing. This increased my confidence and I found the class more targeted than before.” (S1)
b Theme 2: Irreplaceable role of teachers
Participants recognized the irreplaceable role of teachers in constructing systematic knowledge frameworks, fostering critical thinking, offering more useful input and feedback, and giving emotional support during the writing process. “My teacher provided more comprehensible input which helped me organize my idea with consideration of not only language skills, argument reasoning but also humanity experiences.” (S10)
c Theme 3: Overdependence on GenAI
Some participants were aware of the risk of overdependence on GenAI. They noted that frequent use of AI-generated content could diminish their agency to think independently, particularly when facing time pressure for assignments. “AI can give you everything. I don’t have much self-control. For after-class assignments, I just couldn’t resist the temptation to use AI to generate content without much thinking, even though I know it’s not right.” (S2)
d Theme 4: Limitations of GenAI in catering to students’ competence levels
Some participants noted a tendency for GenAI to produce template-based responses that did not align with their language proficiency and cognitive abilities. “I think the content provided by AI wasn’t very helpful to me. I often couldn’t understand what it gave me. For some arguments it created, I didn’t even know what to write about.” (S6)
e Theme 5: Hope for more teacher guidance after class
Some participants expressed a desire for more teacher support on how to effectively use GenAI. In particular, they felt they needed teacher assistance for after-class activities in order to make the most use of GenAI tools. “I even had some trouble following what the teacher told us to do with AI in class. The teacher encouraged us to make more use of AI in after-class practice, but I was at loss about what I was supposed to do.” (S8)
f Theme 6: Future learning strategies
Many participants tended to view AI as an intelligent learning assistant rather than a substitute, maintaining an open mind to explore new models of human–machine collaborative learning. “I will continue to use AI to identify and fill my knowledge gaps, but I think I need to insist on independently completing the first draft to have my own training and I have to be selective and critical with AI stuff.” (S5)
V Discussion
Our research findings indicate that GenAI-assisted writing instruction did not significantly enhance lower-intermediate EFL learners’ performance on IELTS Writing Task 2 except for syntactic complexity (RQ1), although it did positively influence their perceived affective responses (RQ2). Thus, our students’ writing improvements did not align well with their perceived affective gains (the first part of RQ3). Interestingly, these results parallel the findings of Zheng and Yu (2018)’s pre-AI research, which reported that low-proficiency EFL students displayed positive affective engagement with teacher written corrective feedback, while their behavioral and cognitive engagement remained limited and superficial. In this section, we discuss our findings in relation to previous studies, and explore the factors that may explain this discrepancy (the second part of RQ3).
Consistent with most prior research (Aladini et al., 2025; Huang & Mizumoto, 2024; Karataş et al., 2024; Song & Song, 2023), our participants reported increased motivation, engagement, and self-efficacy. This was evidenced in the responses to the first section of the questionnaire and reinforced by qualitative insights from student interviewees. However, our results regarding students’ actual writing improvements, as measured by both NLP-based linguistic analysis and human rubric-based ratings, differ from many previous studies. Whereas Yan (2023), Song and Song (2023), Ghafouri et al. (2024), and Aladini et al. (2025) reported significant gains in both overall writing quality and its subcomponents for students receiving GenAI-supported instruction, our study found significantly greater improvement only in syntactic complexity. No significant between-group differences were observed in lexical complexity, linguistic accuracy, or communicative adequacy. The only study that partially corroborates this aspect of our findings is Escalante et al. (2023), who found that students receiving feedback from ChatGPT did not achieve significantly higher posttest essay scores than those receiving feedback from a human tutor.
From our point of view, the mismatch between our students’ learning outcomes and their perceived affective gains may stem from several factors. First, unlike subjects in most other studies, our participants were foundation program students in China, many of whom had failed to achieve their desired results in gaokao, China’s national college entrance examination, and viewed enrolment in a foreign university through a foundation program as a viable alternative. Socioculturally, these students generally had weaker study habits, lower self-regulatory capacity, and limited peer support or mutual encouragement. As Lund (2013) observed, while young students can quickly learn to operate new technological tools, teacher presence is still crucial for language learning to happen. Although our students reported positive emotions in general after Kimi-assisted writing instruction, many still struggled to sustain self-directed study outside class due to low self-discipline and a lack of teacher supervision (see Themes 3 and 5 in Section IV.3). This is also reflected in responses to Items 6 and 10 of the questionnaire. Alternatively, their positive perceptions may have stemmed from a “novelty effect” (Fryer et al., 2017), which may have temporarily enhanced their affective responses without leading to sustained behavioral change. While some students may have found themselves more involved during class, they likely did not invest sufficient or serious effort especially outside class to actively engage in an active learning process (see Theme 3 in Section IV.3). Another interviewee (S9) made the same point indirectly, “AI alone can't make you improve instantly. Just reading a few AI-generated samples won't necessarily lead to progress. I think it's more important to memorize, practice and review on your own.”
Second, our students’ relatively low language proficiency and limited cognitive readiness may have impeded the full exercise of their learner agency. Our students generally had a lower English proficiency compared with participants in many previous studies, and some of Kimi’s output may have still exceeded their ZPD despite the specification of their proficiency levels in the prompts. When GenAI-generated content surpasses learners’ current level of language competence, it becomes difficult for them to notice linguistic features that are different from their own and to make meaningful improvements (Pack & Maloney, 2024). As reflected in Items 8 and 9 of the questionnaire, some students found that Kimi failed to generate content suited to their proficiency level, and it was difficult for them to internalize the output (see Theme 4 in Section IV.3). This concern was echoed by an interviewee (S4), “Often, the content that AI provided was too difficult for me. When I asked it to give me some simpler content, as you instructed, what it gave me was simple but far too short; when I asked it to meet the word limit, it became too difficult for me again.” 2 Beyond language proficiency, limited cognitive skills may have also constrained some students’ ability to engage effectively with GenAI’s affordances. The amount and complexity of the information provided by Kimi sometimes overwhelmed them, given their limited skills and experience in negotiating with GenAI chatbots. One interviewee (S11) captured this difficulty succinctly, “Sometimes AI’s comments and suggestions are too difficult, and there are so many of them and so lengthy that I don’t really feel like going through them closely.”
Third, the writing topic of the posttest essay may have also contributed to the discrepancy. Research has shown that topic familiarity does appear to impact EFL students’ writing performance (Kessler et al., 2021). The prompts for both the pretest and posttest were well within students’ experience. In particular, for the posttest topic (false information on social media), students likely had much to say regardless of the affordances provided by GenAI. If a related but unfamiliar topic had been covered in class, students who had received GenAI support might have had more to draw upon. Interestingly, in the interview, one student (S9) expressed doubt that GenAI would have helped him even if an unfamiliar topic had been covered in class. He said, “I wouldn’t have recalled the outline and evidence generated by GenAI in that case because the issue behind the topic was far beyond my understanding. I know what I already know, but I still don’t know what is beyond me.” This further suggests that GenAI’s affordances may be limited when students’ cognitive abilities are insufficient, as mentioned in the previous paragraph.
In spite of this, the observed significant increase in syntactic complexity for the experimental group following GenAI-assisted writing instruction, i.e., MLT, DC/T, and, marginally, CP/T, suggests that GenAI may facilitate the production of more varied and elaborate sentence structures on the part of EFL learners. One possible reason is that students in GenAI-assisted writing class are exposed to the output that featured complex syntactic constructions more frequently, as GenAI can easily generate a wider range of diverse sentence structures than fixed sample essays provided by human instructors. This frequency effect likely enables students to incidentally pick up and incorporate such structures into their own writing. However, while the experimental-group students experimented with more complex structures, they may not have truly internalized the grammatical rules governing them. Their linguistic accuracy ratings in the posttest did not differ significantly from those in the pretest. This is not surprising, as complexity typically develops before accuracy in L2 writing (Verspoor et al., 2012). In our case, this could also be ascribed to the fact that frequency alone is not a sufficient explanation for acquisition (Ellis, 2002). Language production demands robust knowledge internalization, a process requiring both time and concentrated cognitive reinforcement (Yang & Chen, 2025); without fully activating their learner agency, our students may not have engaged in deliberate practice necessary for consolidating their understanding.
These points are further supported by the fact that students in the experimental group failed to show significantly greater improvements in lexical complexity. We had anticipated that their posttest essays might exhibit greater lexical sophistication and/or diversity; however, this was not the case. In Marzuki et al. (2023), which examined EFL teachers’ reflections on the effect of AI tools on student writing, one teacher voiced concerns that GenAI-mediated instruction might lead students to use more advanced words without fully understanding their context or connotations, which could lead to awkward or excessively formal writing. Our study, however, found that students were not able to convert this incidental, implicit lexical inputs from GenAI into active usage within the constraints of a time-limited essay test. One of our interviewees (S11) remarked, “When I’m writing an essay during an exam and the time is tight, it feels like all the important words I’ve learned suddenly slip my mind, and I can only use the words I already know.” What may explain the discrepancy between the experimental students’ improvements in lexical and syntactic performance is that students may have encountered certain syntactic structures more frequently than specific lexical items: while vocabulary tends to be topic-dependent, syntactic patterns recur across a wide range of topics, thus providing relatively more opportunities for reinforcement.
One final point worth mentioning is that although no significant differences were observed in the means of any of the seven measures for the pretest essays across the four classes, within-group variation was still evident (Table 3), an outcome not uncommon in many L2 educational settings. In fact, the smaller proportion of pretest–posttest variance accounted for by the fixed effects than by the random effects in our LME models indicates that even if GenAI-assisted instruction had some effect on lower-intermediate EFL students’ writing proficiency, its effect varied considerably across individual students. This highlights the need to further examine the role of individual differences within seemingly ergodic ensembles (Lowie & Verspoor, 2019) in moderating the effectiveness of GenAI-assisted L2 writing instruction.
VI Conclusion
As GenAI is now assuming an unprecedented mediating role in language education, it is crucial for frontline L2 writing teachers to “map out the digital terrain” (Darvin & Hafner, 2022) and reflect on the integration of these tools into writing classrooms. This involves assessing their effect on learning outcomes, identifying their potential benefits and challenges, and, in particular, “illuminating what factors might be contributing to success or failure in working AI writing tools” (Godwin-Jones, 2022, p. 15).
Conducted in a distinct educational context, an IELTS writing course within a university-level foundation program for lower-intermediate EFL students, this study attempted to address research gaps using NLP tools and LME models. Regarding RQ1, in contrast to many previous studies, we found that GenAI-assisted (Kimi in this case) IELTS writing instruction did not significantly enhance our EFL learners’ writing performance except for syntactic complexity. For RQ2, consistent with prior research, the instruction appeared to positively influence learners’ perceived affective responses. As for RQ3, a clear mismatch emerged between students’ actual writing improvements and their reported affective gains. Factors such as limited learner agency, a lack of teacher support outside class, and misalignment between learners’ L2 proficiency, cognitive levels, and GenAI’s affordances, among others, may have contributed to this discrepancy.
Although the study focused solely on Kimi, given the similar underlying mechanisms of GenAI chatbots, the findings have relevance beyond this specific tool and offer several implications for L2 writing instruction and suggestions for future research. First, the effect of incorporating GenAI tools into writing classrooms is not as clear-cut as previous studies suggest; variability in educational contexts and learner populations may significantly affect outcomes. Second, the efficacy of GenAI mediation in writing class varies considerably across individual students. This variability adds nuance to its impact, and unpacking this complexity with the idiodynamic method (MacIntyre & Ducker, 2022) may be an important direction for future research. Third, the seemingly almost unanimous conclusion that GenAI-assisted writing instruction boosts students’ affective responses may only tell part of the story. While students generally report affective gains, these perceptions do not necessarily translate into sustained learner agency or significant improvements in their overall writing performance, as also shown in pre-AI studies of teacher written corrective feedback, where language accuracy gains were limited (Zheng & Yu, 2018). Future research could explore to what extent such responses evolve into genuine agency or simply reflect a novelty effect, and whether extended exposure to GenAI affordances is necessary to achieve more meaningful learning gains. Finally, our findings tentatively suggest that GenAI-mediated L2 writing instruction may not be suitable for all learners, particularly those with lower L2 proficiency or cognitive readiness. As Warschauer et al. (2023, p. 5) caution, “any use of AI-based tools in writing instruction should be introduced in a balanced and age-and level-appropriate manner.” In such cases, teachers may need to implement additional reinforcement activities and rigorous compliance check mechanisms to ensure that they make the most of GenAI assistance.
Despite the above-mentioned findings and implications, this study is not without limitations. One is that large portions of the variance were not explained by the LME models (as indicated by R2c), suggesting that additional unmeasured factors may have been at work. Future research, in addition to the suggestions outlined here, should consider exploring more covariates or adopting more detailed, longitudinal designs to better capture the effects of GenAI-assisted instruction on the complex nature of L2 writing proficiency. Another limitation, as one reviewer pointed out, is that the questionnaire responses were analyzed only at the aggregate level. Because the survey was administered anonymously, we could not link individual students’ affective responses directly to their writing performance gains. Future studies could refine the survey and incorporate some of the survey data as covariates in LME models, in order to examine a subtler alignment between individual learners’ writing improvements and their affective responses. This again underscores the importance of focusing on the role of individual differences in the effect of GenAI-assisted L2 writing instruction.
Supplemental Material
sj-pdf-1-ltr-10.1177_13621688251397724 – Supplemental material for Generative AI in EFL writing instruction for lower-intermediate learners: Do perceived affective gains translate to improved performance?
Supplemental material, sj-pdf-1-ltr-10.1177_13621688251397724 for Generative AI in EFL writing instruction for lower-intermediate learners: Do perceived affective gains translate to improved performance? by Yi Chen and Jia Chen in Language Teaching Research
Footnotes
Appendix 1: Prompt templates
Here we provide prompt templates provided to the students during the three stages of the writing process.

| Stage | Prompt templates (Chinese original and English translation) |
|---|---|
| Idea generation | Type I ( “agree or not agree”) [Chinese original] 我是一位雅思考生,我的目标是大作文考到6.5分。你能帮我给下面的作文题目列出一个含有四个主体段落(开头与结尾段除外)的应答大纲吗?只需段落中心句的内容,无需具体支持细节。作文题目是:. . . To what extent do you agree? [English translation] I am an IELTS test taker, and my goal is to achieve a 6.5 in the Writing Task 2. Could you help me outline a response with four body paragraphs a (excluding the introduction and the conclusion) for the following essay question? I only need the main point for each paragraph, without specific supporting details. The essay topic is: . . . To what extent do you agree? b Type II ( “discuss both views) [Chinese original] 我是一位雅思考生,我的目标是大作文考到6.5分。你能帮我给下面的作文题目列出一个含有两个主体段落(开头与结尾段除外)的应答大纲吗?每个主体段落由三个分论点构成,只需论点内容,无需具体支持细节。作文题目是 . . . Discuss both points of view and present your own opinion. [English translation] I am an IELTS test taker, and my goal is to achieve a 6.5 in the Writing Task 2. Could you help me outline a response with two body paragraphs (excluding the introduction and the conclusion) for the following essay question? Each body paragraph should consist of three main arguments. I only need the main points, without specific supporting details. The essay topic is: . . . Discuss both points of view and present your own opinion. Type III (“causes/implications & solutions” ) [Chinese original] 我是一位雅思考生,我的目标是大作文考到6.5分。你能帮我给下面的作文题目列出一个含有两个主体段落(开头与结尾段除外)的应答大纲吗?分析原因部分由三个原因构成,解决方案也要由三个构成,只需论点内容,无需具体支持细节。题目是 . . . What are the causes of this issue and how can it be solved? [English translation] I am an IELTS test taker, and my goal is to achieve a 6.5 in the Writing Task 2. Can you help me outline a response with two body paragraphs (excluding the introduction and the conclusion) for the following essay question? The analysis of reasons should include three causes, and the solutions should also consist of three parts. I only need the main points, without specific supporting details. The essay topic is: . . . What are the causes of this issue and how can it be solved? |
| Evidence development | [Chinese original] 我是一位雅思考生,我的目标是大作文考到6.5分。下面是我根据这一雅思大作文题目(在此填入具体题目)对主体段落/主体段落中的一段进行的细节扩充。我的观点是赞同/不赞同,在此简要明确你的观点。请帮我看一下每段/这段的论证是否合理?你无需关注语言,只需关注证据本身。. . .观点+具体拓展. . . [English translation] I am an IELTS test taker, and my goal is to achieve a 6.5 in the Writing Task 2. Below is my detailed expansion of the body paragraphs or one body paragraph for this IELTS essay question (insert specific topic here). My position is to agree/disagree, and restate it very briefly here. c Could you please check whether the reasoning has any problems? You don’t need to focus on the language, only on the evidence provided. . . . main point + expanded evidence . . . |
| Proofreading | Step 1 [Chinese original] 下面是我根据这一雅思大作文题目(在此填入具体题目)所写的主体段落/主体段落中一段的初稿,我的目标是考到6.5分,请帮我纠正其中的用词和语法错误,并改进段落内句子的衔接,或进行其他方面的修改,以达到我的考分目标。. . .段落或整体初稿. . . [English translation] I am an IELTS test taker aiming for a band 6.5 in the Writing Task 2. Below is my initial draft of the body paragraphs / one body paragraph based on this IELTS essay question (insert specific topic here). Please help me correct any word choice and grammatical errors, and improve the coherence and cohesion between sentences within the paragraph, and make any other necessary revisions to achieve my target score. . . .one body paragraph or full body paragraphs draft. . . Step 2 [Chinese original] 请提供一个可以达到7-7.5分的版本,并请具体说明和上面给我修改的版本的差别,以便我进行比较。 [English translation] Please provide a version that could achieve a band score of 7 or 7.5, and please specify the differences from the revised version you provided me above, so that I can make a comparison. |
Typically, two to three well-developed body paragraphs are sufficient for this question type, and for the other two types, two main points for each body paragraph usually suffice. However, to provide students with a broader range of illustrative examples, the prompt for this instance was designed to elicit more points than would normally be required.
The exact wording of the IELTS Writing Task 2 prompt may vary for each of the three question types. Accordingly, the prompt template used for student interaction with Kimi may be adjusted slightly to match each case.
This part (My position is to agree/disagree, and restate it very briefly here) only applies to the “agree or not agree” question type.
Appendix 2: The Questionnaire
Participants responded to the following items on a 5-point Likert scale, where 1 = strongly disagree and 5 = strongly agree.
Appendix 3: Semi-structured Interview Questions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the Fundamental Research Funds for the Central Universities of China.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.